

Population Game-Assisted Multi-Agent Reinforcement Learning Method for Dynamic Multi-Vehicle Route Selection


Abstract
:1. Introduction
- A Period-Stage-Round Route Selection Model (PSRRSM) is introduced to precisely address the Nash equilibrium by dividing vehicle populations at each intersection. It uses a multi-stage game strategy to coordinate the determination of optimal routes for multiple vehicles.
- The Period Learning Algorithm for Route Selection (PLA-RS) uses population game data from PSRRSM to help road agents learn more quickly, improving the accuracy and efficiency of dynamic route selection for vehicles. Importantly, the PLA-RS takes into account multifaceted travel costs in its considerations.
- The Vehicle Multi-stage Population Game Algorithm (VMPGA) is crafted to furnish game decisions for vehicles at each intersection in the Period Learning Algorithm for Route Selection (PLA-RS). It plays a crucial role in substantially optimizing vehicle routes and enhancing coordination capabilities, serving as an informative source for PLA-RS.
2. Related Works
3. Period-Stage-Round Route Selection Model
3.1. Problem Model
3.2. Utility Calculation
4. Period Learning Algorithm for Route Selection
4.1. Method Architecture
- N: The number of agents, which corresponds to the number of roads. Agent is also known as road agent . .
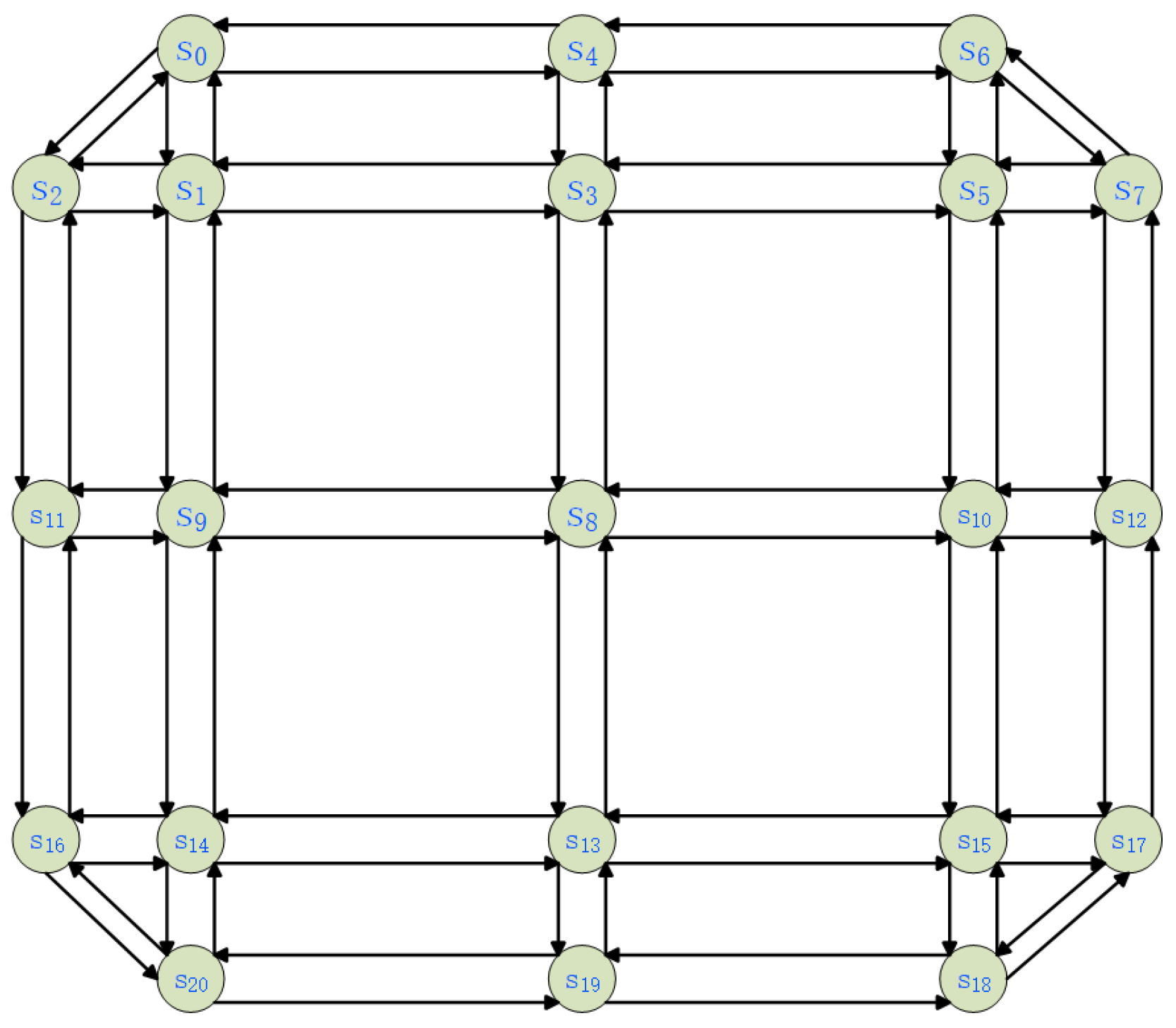
- S and O: The observation of agent is the vector consisting of the number of vehicles of all neighbouring edges, where the edges . is the set of edge ’s neighbouring edges. The set of neighbouring edges is defined as follows:In Figure 2, the set of neighbouring edges of is . The neighbouring edges of an edge include itself. ’s observation state at the ltth time step is denoted by . The joint state is a matrix consisting of the observations of all agents.
- A: The action of agent at time step is defined as the proportion of strategy selection for the vehicle contained in the corresponding edge . In this algorithm, there exists online action and target action , where the former is generated by the agent, and the latter is the action that the agent needs to learn, and also the proportion of the strategy that the vehicle actually executes. In different periods of this algorithm, the relationship between and is different. In period 1, the Agent does not generate and converts the Nash equilibrium generated by the game to ; in period 2, the agent’s actor network generates , which is used to optimize the initial strategies of the vehicles in order to improve the convergence rate of the game, but the used for learning is still converted from the Nash equilibrium; in period 3, , and the vehicle directly executes the strategy given by the agent.Distribution of actions: convert from proportional to integer according to the number of vehicles on edge . Following the pairing principle, when vehicle v participates in the game at intersection , if the off edge chosen by satisfies , then , . When the remaining vehicles cannot be matched with the remaining strategies, a random distribution is performed. Distribution is complete when all go to zero.
- R: The reward of agent at time step is defined as the opposite of the sum of travel costs of the vehicles included in the corresponding edge , i.e., .
- : Decay factor that determines the importance of the rewards obtained from one learning. As time progresses, the importance of rewards produced later decreases.
4.2. Period Learning Algorithm for Route Selection Implementation
4.2.1. Vehicle Multi-Stage Population Game Algorithm
| Algorithm 1 VMPGA (Vehicle Multi-stage Population Game Algorithm) |
| Input: urban road network , intersection for gaming , decision unit , maximum of stage number B, number of rounds per stage T |
| Output: Nash equilibrium or a set of mixed strategies when the stage number reaches B |
|
4.2.2. Road Multi-Agent Deep Reinforcement Learning Algorithm
| Algorithm 2 PLA-RS (Period Learning Algorithm for Route Selection) |
| Input: Online actions for each agent , Learning times of agents, sample size , learning times boundaries , for dividing the period |
| Output: Target action of each agent |
| 1: for do |
| 2: for do |
| 3: generates observation |
| 4: end for |
| 5: if then |
| 6: Randomly initialize the mixing strategies for all enter edge vehicles |
| 7: else |
| 8: for do generates the online action , which is distributed to the corresponding edge ’s vehicles |
| 9: end for |
| 10: end if |
| 11: if then |
| 12: The VMPGA is run to derive the equilibrium solution |
| 13: for do |
| 14: Generate from |
| 15: end for |
| 16: else |
| 17: for do |
| 18: |
| 19: end for |
| 20: end if |
| 21: end for |
| 22: All vehicles execute the pure strategies corresponding to the mixed strategies |
| 23: for do |
| 24: for do |
| 25: generates observation |
| 26: calculates reward according to vehicle payoffs |
| 27: saves into the replay buffer D |
| 28: end for |
| 29: end for |
| 30: if then |
| 31: for do |
| 32: for do |
| 33: samples samples from replay buffer D |
| 34: carry out learning and update target network parameters |
| 35: end for |
| 36: end for |
| 37: end if |
| 38: Learning times increase, |
5. Experiments
5.1. Experiments in the Artificial Road Network
5.1.1. Experimental Conditions
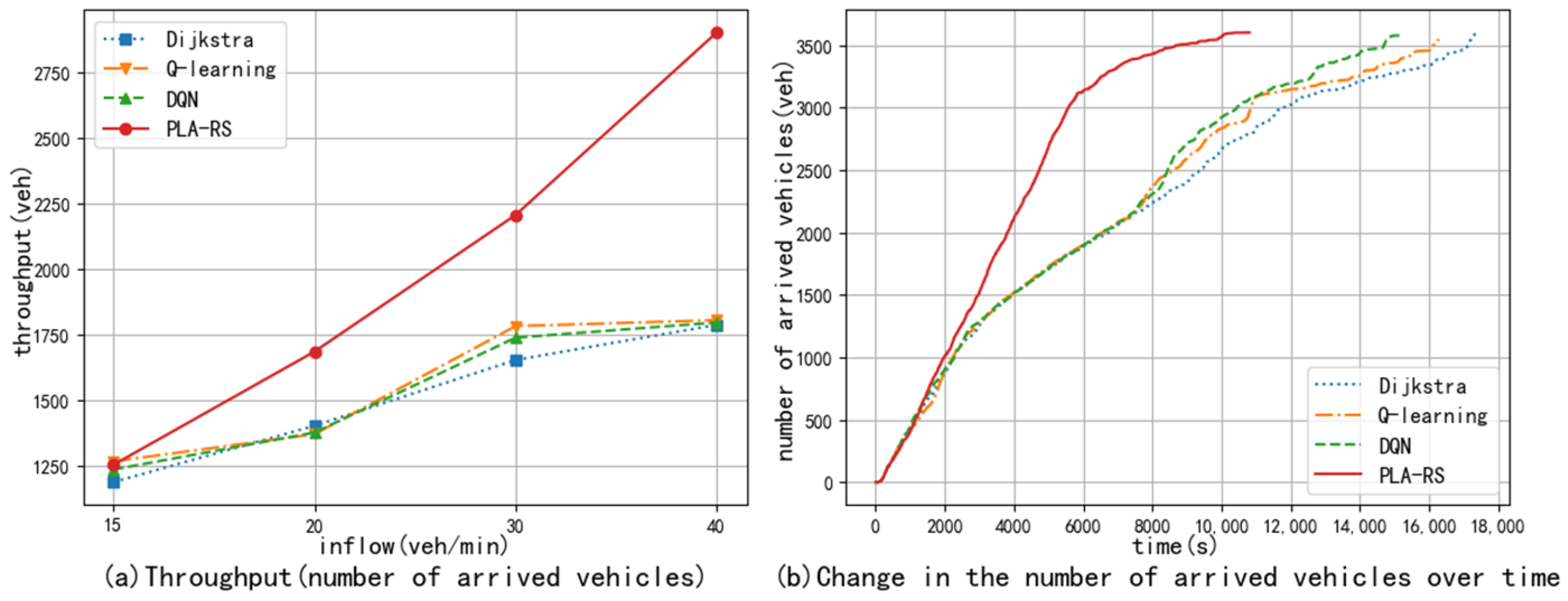
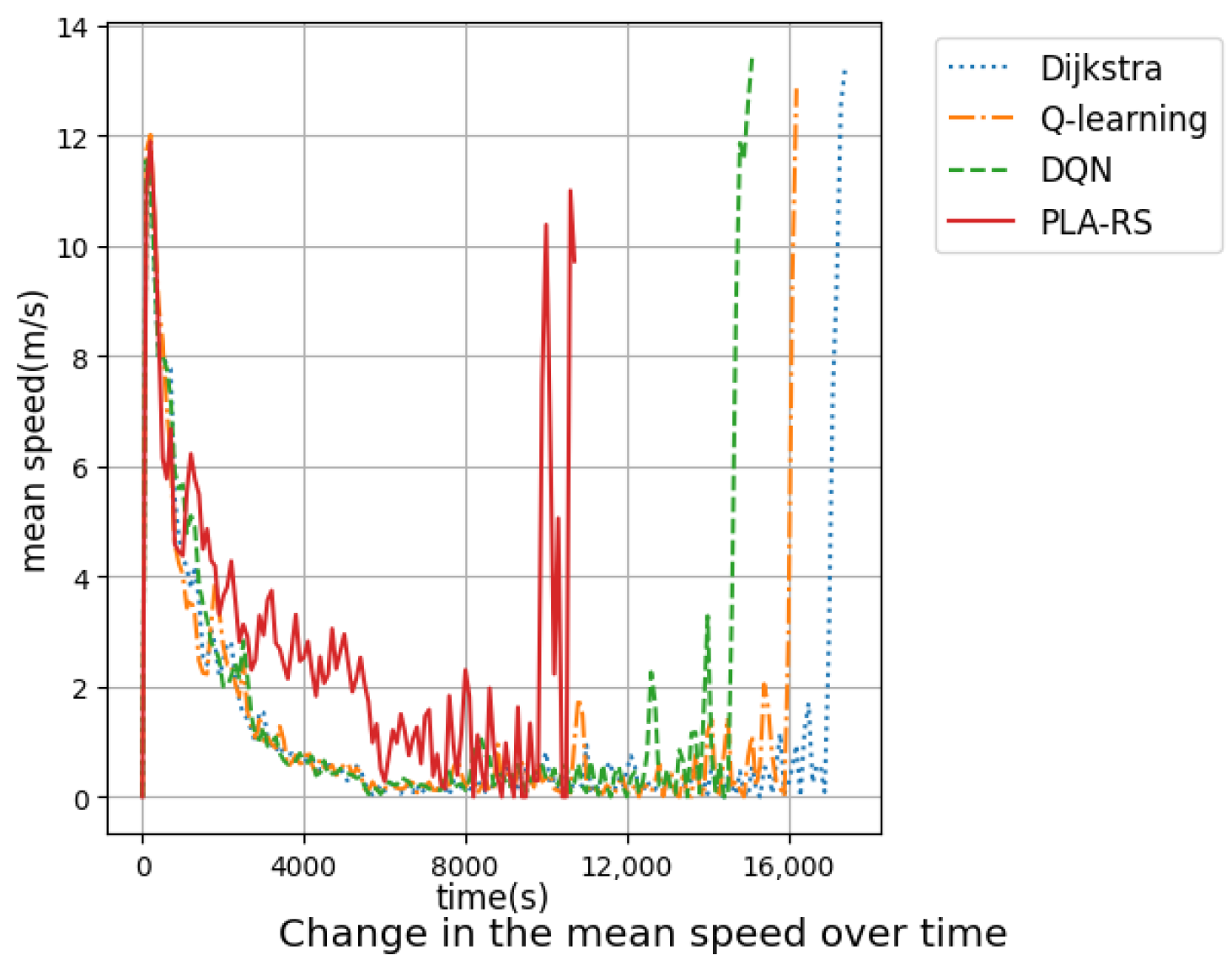
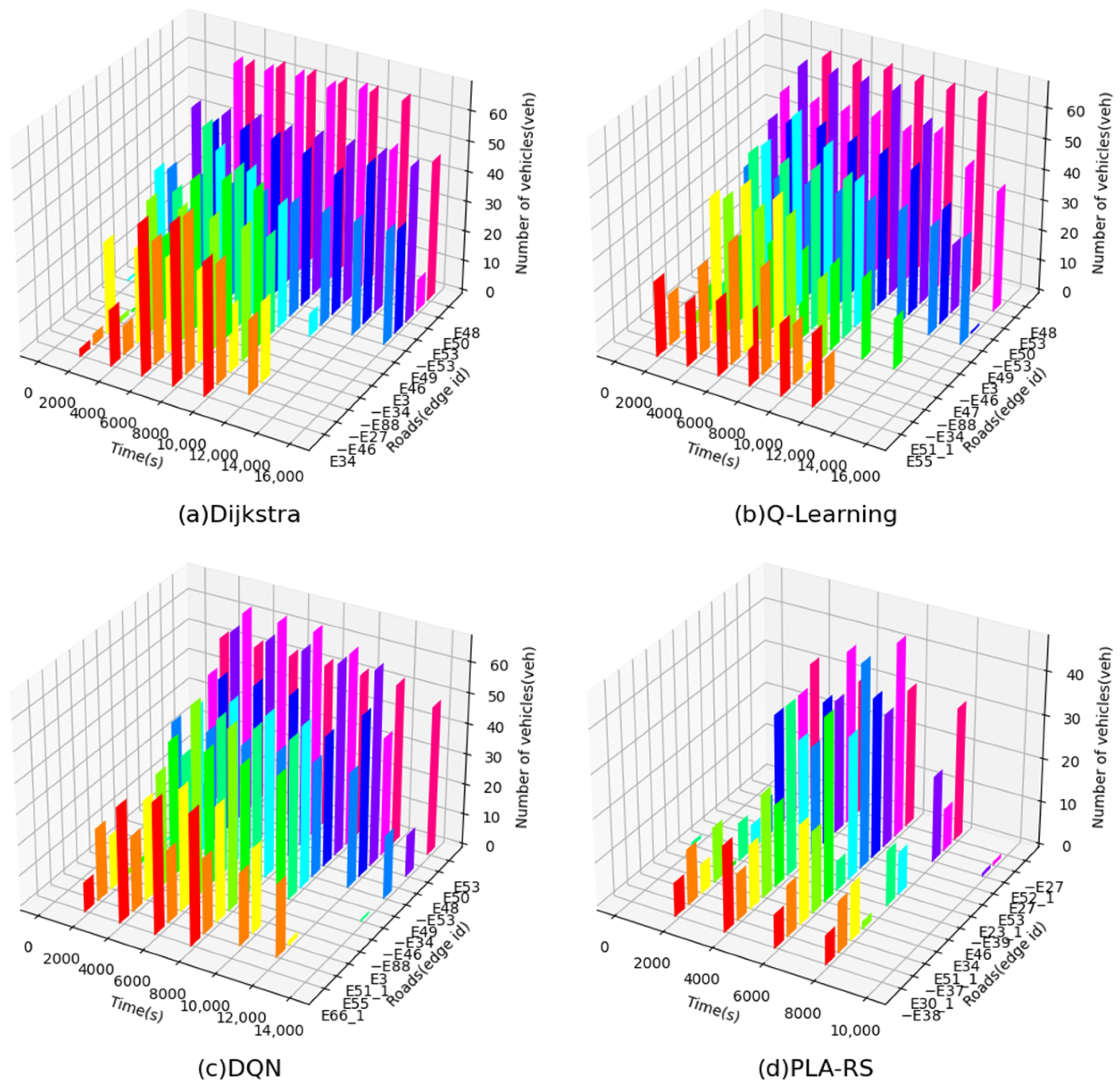
5.1.2. Experimental Results and Analysis
5.2. Experiments in the Real Road Network
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SUMO | Simulation of Urban MObility |
| MARL | Multi-Agent Reinforcement Learning |
| PSRRSM | Period-Stage-Round Route Selection Model |
| PLA-RS | Period Learning Algorithm for Route Selection |
| VMPGA | Vehicle Multi-stage Population Game Algorithm |
References
- Akhtar, M.; Moridpour, S. A review of traffic congestion prediction using artificial intelligence. J. Adv. Transp. 2021, 2021, 8878011. [Google Scholar] [CrossRef]
- Ližbetin, J.; Stopka, O. Proposal of a Roundabout Solution within a Particular Traffic Operation. Open Eng. 2016, 6, 441–445. [Google Scholar] [CrossRef]
- Akcelik, R.; Maher, M. Route control of traffic in urban road networks: Review and principles. Transp. Res. 1977, 11, 15–24. [Google Scholar] [CrossRef]
- Zhu, D.-D.; Sun, J.-Q. A new algorithm based on Dijkstra for vehicle path planning considering intersection attribute. IEEE Access 2021, 9, 19761–19775. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X. Application of improved A* algorithm in customized bus path planning. Comput. Sci. Appl. 2020, 10, 21–28. [Google Scholar]
- Wang, S.; Lin, F.; Wang, T.; Zhao, Y.; Zang, L.; Deng, Y. Autonomous vehicle path planning based on driver characteristics identification and improved artificial potential field. In Proceedings of the Actuators, Basel, Switzerland, 8 February 2022; p. 52. [Google Scholar]
- Li, Q.; Xu, Y.; Bu, S.; Yang, J. Smart vehicle path planning based on modified PRM algorithm. Sensors 2022, 22, 6581. [Google Scholar] [CrossRef]
- Shi, Y.; Li, Q.; Bu, S.; Yang, J.; Zhu, L. Research on intelligent vehicle path planning based on rapidly-exploring random tree. Math. Probl. Eng. 2020, 2020, 5910503. [Google Scholar] [CrossRef]
- Ahmed, Z.H.; Hameed, A.S.; Mutar, M.L. Hybrid Genetic Algorithms for the Asymmetric Distance-Constrained Vehicle Routing Problem. Math. Probl. Eng. 2022, 2022, 2435002. [Google Scholar] [CrossRef]
- Miao, C.; Chen, G.; Yan, C.; Wu, Y. Path planning optimization of indoor mobile robot based on adaptive ant colony algorithm. Comput. Ind. Eng. 2021, 156, 107230. [Google Scholar] [CrossRef]
- Lu, E.; Xu, L.; Li, Y.; Ma, Z.; Tang, Z.; Luo, C. A novel particle swarm optimization with improved learning strategies and its application to vehicle path planning. Math. Probl. Eng. 2019, 2019, 9367093. [Google Scholar] [CrossRef]
- Li, X.; Zhou, J.; Pedrycz, W. Linking granular computing, big data and decision making: A case study in urban path planning. Soft Comput. 2020, 24, 7435–7450. [Google Scholar] [CrossRef]
- Tang, C.; Hu, W.; Hu, S.; Stettler, M.E. Urban traffic route guidance method with high adaptive learning ability under diverse traffic scenarios. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2956–2968. [Google Scholar] [CrossRef]
- Lu, J.; Li, J.; Yuan, Q.; Chen, B. A multi-vehicle cooperative routing method based on evolutionary game theory. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 987–994. [Google Scholar]
- Ge, Q.; Han, K.; Liu, X. Matching and routing for shared autonomous vehicles in congestible network. Transp. Res. Part Logist. Transp. Rev. 2021, 156, 102513. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, Z.; Ge, H.; Cheng, R. An extended macro model accounting for the driver’s timid and aggressive attributions and bounded rationality. Physica A 2020, 540, 122988. [Google Scholar] [CrossRef]
- Konda, V.; Tsitsiklis, J. Actor-critic algorithms. In Advances in Neural Information Processing Systems 12; MIT Press: Cambridge, MA, USA, 1999; p. 12. [Google Scholar]
- Misztal, W. The impact of perturbation mechanisms on the operation of the swap heuristic. Arch. Motoryz. 2019, 86, 27–39. [Google Scholar] [CrossRef]
- Šedivý, J.; Čejka, J.; Guchenko, M. Possible application of solver optimization module for solving single-circuit transport problems. LOGI–Sci. J. Transp. Logist. 2020, 11, 78–87. [Google Scholar] [CrossRef]
- Stopka, O. Modelling distribution routes in city logistics by applying operations research methods. Promet 2022, 34, 739–754. [Google Scholar] [CrossRef]
- Paisarnvirosrak, N.; Rungrueang, P. Firefly Algorithm with Tabu Search to Solve the Vehicle Routing Problem with Minimized Fuel Emissions: Case Study of Canned Fruits Transport. LOGI–Sci. J. Transp. Logist. 2023, 14, 263–274. [Google Scholar] [CrossRef]
- Zhang, L.; Khalgui, M.; Li, Z.; Zhang, Y. Fairness concern-based coordinated vehicle route guidance using an asymmetrical congestion game. IET Intell. Transp. Syst. 2022, 16, 1236–1248. [Google Scholar] [CrossRef]
- Banjanovic-Mehmedovic, L.; Halilovic, E.; Bosankic, I.; Kantardzic, M.; Kasapovic, S. Autonomous vehicle-to-vehicle (v2v) decision making in roundabout using game theory. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 292–298. [Google Scholar] [CrossRef]
- Lin, K.; Li, C.; Fortino, G.; Rodrigues, J.J. Vehicle route selection based on game evolution in social internet of vehicles. IEEE Internet Things J. 2018, 5, 2423–2430. [Google Scholar] [CrossRef]
- Tai, T.S.; Yeung, C.H. Adaptive strategies for route selection en-route in transportation networks. Chin. J. Phys. 2022, 77, 712–720. [Google Scholar] [CrossRef]
- Tanimoto, J.; Nakamura, K. Social dilemma structure hidden behind traffic flow with route selection. Physica A 2016, 459, 92–99. [Google Scholar] [CrossRef]
- Zolfpour-Arokhlo, M.; Selamat, A.; Hashim, S.Z.M.; Afkhami, H. Modeling of route planning system based on Q value-based dynamic programming with multi-agent reinforcement learning algorithms. Eng. Appl. Artif. Intell. 2014, 29, 163–177. [Google Scholar] [CrossRef]
- Li, S.; Xu, X.; Zuo, L. Dynamic path planning of a mobile robot with improved Q-learning algorithm. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 409–414. [Google Scholar]
- Liu, S.; Tong, X. Urban transportation path planning based on reinforcement learning. J. Comput. Appl. 2021, 41, 185–190. [Google Scholar]
- Zhou, M.; Jin, J.; Zhang, W.; Qin, Z.; Jiao, Y.; Wang, C.; Wu, G.; Yu, Y.; Ye, J. Multi-agent reinforcement learning for order-dispatching via order-vehicle distribution matching. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2645–2653. [Google Scholar]
- Alshehri, M.; Reyes, N.; Barczak, A. Evolving Meta-Level Reasoning with Reinforcement Learning and A* for Coordinated Multi-Agent Path-planning. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, Auckland, New Zealand, 9–13 May 2020; pp. 1744–1746. [Google Scholar]
- Nazari, M.; Oroojlooy, A.; Snyder, L.; Takác, M. Reinforcement learning for solving the vehicle routing problem. In Proceedings of the Advances in Neural Information Processing Systems 31, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Li, J.; Ma, Y.; Gao, R.; Cao, Z.; Lim, A.; Song, W.; Zhang, J. Deep reinforcement learning for solving the heterogeneous capacitated vehicle routing problem. IEEE Trans. Cybern. 2021, 52, 13572–13585. [Google Scholar] [CrossRef] [PubMed]
- Nai, W.; Yang, Z.; Lin, D.; Li, D.; Xing, Y. A Vehicle Path Planning Algorithm Based on Mixed Policy Gradient Actor-Critic Model with Random Escape Term and Filter Optimization. J. Math. 2022, 2022, 3679145. [Google Scholar] [CrossRef]
- Albaba, B.M.; Yildiz, Y. Driver modeling through deep reinforcement learning and behavioral game theory. IEEE Trans. Control Syst. Technol. 2021, 30, 885–892. [Google Scholar] [CrossRef]
- Li, Z.; Su, S.; Jin, X.; Xia, M.; Chen, Q.; Yamashita, K. Stochastic and distributed optimal energy management of active distribution network with integrated office buildings. CSEE J. Power Energy Syst. 2022, 10, 504–517. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Instruction | Value |
|---|---|---|
| Time step. | 60 s | |
| Road capacity. | ||
| B | Maximum stage number of the game. | 4 |
| T | Number of rounds per stage. | 100 |
| Exploration probabilities for mixed strategies. | 0.35 | |
| Weights of each of the sub-costs of travel cost. | 0.7599, 0.05, 0.0001, 0.09, 0.1 | |
| Replay buffer capacity. | 3125 | |
| Sample size. | 256 | |
| Period transformation step boundary 1. | 256 | |
| Period transformation step boundary 2. | 3125 | |
| Exploration probability of agents’ choice of actions. | 0.1 | |
| Attenuation factor. | 0.95 | |
| Learning rate (actors). | 0.0001 | |
| Learning rate (critics). | 0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, L.; Cai, Y. Population Game-Assisted Multi-Agent Reinforcement Learning Method for Dynamic Multi-Vehicle Route Selection. Electronics 2024, 13, 1555. https://doi.org/10.3390/electronics13081555
Yan L, Cai Y. Population Game-Assisted Multi-Agent Reinforcement Learning Method for Dynamic Multi-Vehicle Route Selection. Electronics. 2024; 13(8):1555. https://doi.org/10.3390/electronics13081555
Chicago/Turabian StyleYan, Liping, and Yu Cai. 2024. "Population Game-Assisted Multi-Agent Reinforcement Learning Method for Dynamic Multi-Vehicle Route Selection" Electronics 13, no. 8: 1555. https://doi.org/10.3390/electronics13081555
APA StyleYan, L., & Cai, Y. (2024). Population Game-Assisted Multi-Agent Reinforcement Learning Method for Dynamic Multi-Vehicle Route Selection. Electronics, 13(8), 1555. https://doi.org/10.3390/electronics13081555