


Using Data Augmentation to Improve the Accuracy of Blood Pressure Measurement Based on Photoplethysmography

 , ,
, ,
Abstract
:1. Introduction
- 1.
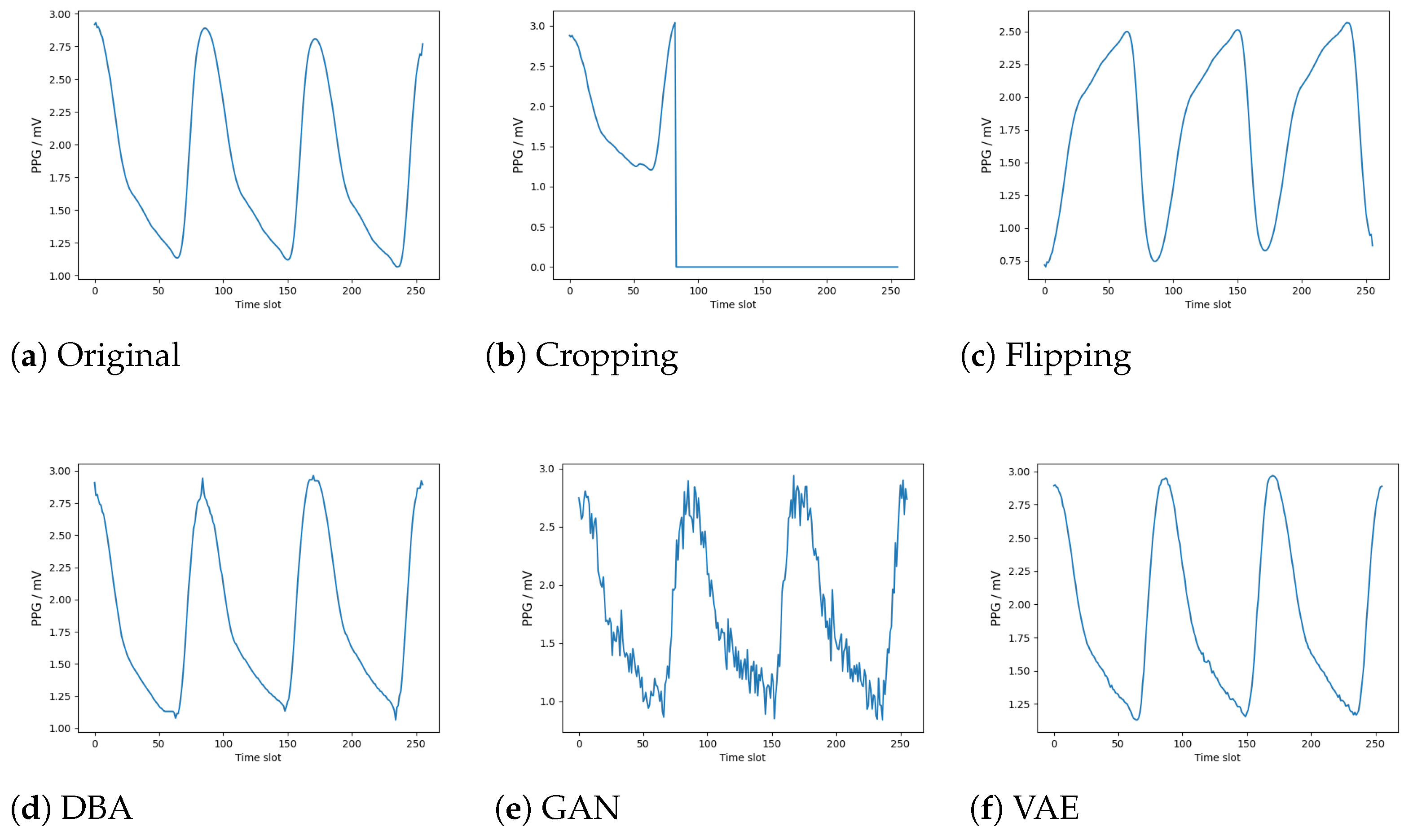
- In order to improve the accuracy of BP measurement based on few-show PPG data, we design five PPG data augmentation methods: flipping, cropping, DTW barycentric averaging (DBA), generative adversarial network (GAN) and variational auto-encoder (VAE). Each method can generate synthetic PPG data to expand the size of dataset.
- 2.
- We design a data-driven model applying position encoding (PE), a convolutional neural network (CNN) and a gated recurrent unit (GRU) network to fully utilize the sequence information in PPG. The well-trained model end-to-end outputs BP values based on PPG data as inputs, thus realizing cuff-less BP measurement.
- 3.
- We perform valid experiments based on a MIMIC II dataset. Results show that VAE improves the measurement accuracy most significantly. PE–CNN–GRU after PPG data augmentation performs well in cuff-less BP measurement compared to existing works.
2. Data Preparation
2.1. Detection of Artifacts in PPG
2.2. Formation of PPG-BP Samples
3. Data Augmentation of PPG
3.1. Cropping and Flipping
3.2. DTW Barycentric Averaging
3.3. Generative Adversarial Network
3.4. Variational Auto-Encoder
4. Blood Pressure Measurement Based on PE–CNN–GRU Model
4.1. Position Encoding
4.2. The Receptive Field of CNN
4.3. The Architecture of PE–CNN–GRU Model
5. Numerical Results and Performance Analysis
5.1. Dataset Description
5.2. Performance of Data Augmentation Methods
5.3. Performance Comparison of PE–CNN–GRU
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mancia, G.; Sega, R.; Milesi, C.; Cessna, G.; Zanchetti, A.A. Blood-pressure control in the hypertensive population. Lancet 1997, 349, 454–457. [Google Scholar] [CrossRef] [PubMed]
- SPRINT Research Group. A randomized trial of intensive versus standard blood-pressure control. New Engl. J. Med. 2015, 373, 2103–2116. [Google Scholar] [CrossRef] [PubMed]
- Sebald, D.J.; Bahr, D.E.; Kahn, A.R. Narrowband auscultatory blood pressure measurement. IEEE Trans. Biomed. Eng. 2002, 49, 1038–1044. [Google Scholar] [CrossRef] [PubMed]
- Sapinski, A. Standard algorithm of blood-pressure measurement by the oscillometric method. Med. Biol. Eng. Comput. 1992, 30, 671. [Google Scholar] [CrossRef] [PubMed]
- Avolio, A.; Butlin, M.; Walsh, A. Arterial blood pressure measurement and pulse wave analysis—Their role in enhancing cardiovascular assessment. Physiol. Meas. 2010, 31, R1–R47. [Google Scholar] [CrossRef] [PubMed]
- El-Hajj, C.; Kyriacou, P.A. Cuffless blood pressure estimation from PPG signals and its derivatives using deep learning models. Biomed. Signal Process. Control 2021, 70, 102984. [Google Scholar] [CrossRef]
- Elgendi, M.; Fletcher, R.; Liang, Y.; Howard, N.; Lovell, N.H.; Abbott, D.; Lim, K.; Ward, R. The use of photoplethysmography for assessing hypertension. NPJ Digit. Med. 2019, 2, 60. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wang, Z. A hybrid model for blood pressure prediction from a PPG signal based on MIV and GA-BP neural network. In Proceedings of the 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017. [Google Scholar]
- El-Hajj, C.; Kyriacou, P.A. Cuffless and continuous blood pressure estimation from PPG signals using recurrent neural networks. In Proceedings of the 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020. [Google Scholar]
- Samimi, H.; Dajani, H.R. A PPG-based calibration-free cuffless blood pressure estimation method using cardiovascular dynamics. Sensors 2023, 23, 4145. [Google Scholar] [CrossRef] [PubMed]
- Paviglianiti, A.; Randazzo, V.; Villata, S.; Cirrincione, G.; Pasero, E. A comparison of deep learning techniques for arterial blood pressure prediction. Cogn. Comput. 2022, 14, 1689–1710. [Google Scholar] [CrossRef]
- Qin, K.; Huang, W.; Zhang, T. Deep generative model with domain adversarial training for predicting arterial blood pressure waveform from photoplethysmogram signal. Biomed. Signal Process. Control 2021, 70, 102972. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Mahmud, S.; Chowdhury, M.E.H.; Khandakar, A.; Salman Khan, M.; Ayari, M.A.; Tahir, A.M.; Rahman, M.S. PPG2ABP: Translating photoplethysmogram (PPG) signals to arterial blood pressure (ABP) waveforms. Bioengineering 2022, 9, 692. [Google Scholar] [CrossRef]
- Mehrabadi, M.; Aqajari, S.; Zargari, A.; Dutt, N.; Rahmani, A. Novel blood pressure waveform reconstruction from photoplethysmography using cycle generative adversarial networks. In Proceedings of the 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Glasgow, Scotland, 11–15 July 2022. [Google Scholar]
- Chu, Y.; Tang, K.; Hsu, Y.; Huang, T.; Wang, D.; Li, W.; Savitz, S.; Jiang, X.; Shams, S. Non-invasive arterial blood pressure measurement and SpO2 estimation using PPG signal: A deep learning framework. BMC Med. Inform. Decis. Mak. 2023, 3, 131. [Google Scholar] [CrossRef] [PubMed]
- Mou, H.; Yu, J. Transfer learning with DWT based clustering for blood pressure estimation of multiple patients. J. Comput. Sci. 2022, 64, 101865. [Google Scholar] [CrossRef]
- Mou, H.; Yu, J. CNN-LSTM Prediction Method for Blood Pressure Based on Pulse Wave. Electronics 2021, 10, 1664. [Google Scholar] [CrossRef]
- Moody, G.; Mark, R. A database to support development and evaluation of intelligent intensive care monitoring. In Computers in Cardiology; IEEE: Indianapolis, IN, USA, 1996. [Google Scholar]
- Saeed, M.; Villarroel, M.; Reisner, A.; Clifford, G.; Lehman, L.W.; Moody, G.; Mark, R.G. Multiparameter intelligent monitoring in intensive care II (MIMIC-II): A public-access intensive care unit database. Crit. Care Med. 2011, 39, 952. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.; Pollard, T.; Mark, R. MIMIC-III Clinical Database (Version 1.4). Available online: https://physionet.org/content/mimiciii/1.4/ (accessed on 28 November 2023).
- Moody, B.; Hao, S.; Gow, B.; Pollard, T.; Zong, W.; Mark, R. MIMIC-IV Waveform Database (Version 0.1.0). Available online: https://physionet.org/content/mimic4wdb/0.1.0/ (accessed on 28 November 2023).
- Shorten, C.; Khoshgoftaar, T. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Cui, X.; Goel, V.; Kingsbury, B. Data augmentation for deep neural network acoustic modeling. IEEE/ACM Trans. Audio Speech, Lang. Process. 2015, 23, 1469–1477. [Google Scholar]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2022, arXiv:2002.12478. [Google Scholar]
- Iwana, B.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]
- Gao, J.; Song, X.; Wen, Q.; Wang, P.; Sun, L.; Xu, H. Robusttad: Robust time series anomaly detection via decomposition and convolutional neural networks. arXiv 2021, arXiv:2002.09545. [Google Scholar]
- Kiyasseh, D.; Tadesse, G.; Thwaites, L.; Zhu, T.; Clifton, D. PlethAugment: GAN-based PPG augmentation for medical diagnosis in low-resource settings. IEEE J. Biomed. Health Inform. 2020, 24, 3226–3235. [Google Scholar] [CrossRef] [PubMed]
- Ding, C.; Xiao, R.; Do, D.; Lee, D.; Lee, R.; Kalantarian, S.; Hu, X. Log-spectral matching gan: Ppg-based atrial fibrillation detection can be enhanced by gan-based data augmentation with integration of spectral loss. IEEE J. Biomed. Health Inform. 2023, 27, 1331–1341. [Google Scholar] [CrossRef]
- Mazumder, O.; Banerjee, R.; Roy, D.; Bhattacharya, S.; Ghose, A.; Sinha, A. Synthetic PPG signal generation to improve coronary artery disease classification: Study with physical model of cardiovascular system. IEEE J. Biomed. Health Inform. 2022, 26, 2136–2146. [Google Scholar] [CrossRef] [PubMed]
- Bandara, K.; Hewamalage, H.; Liu, Y.; Kang, Y.; Bergmeir, C. Improving the accuracy of global forecasting models using time series data augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Hu, H.; Tang, M.; Bai, C. Datsing: Data augmented time series forecasting with adversarial domain adaptation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, Ireland, 19–23 October 2020. [Google Scholar]
- Song, K.; Park, T.; Chang, J. Novel data augmentation employing multivariate gaussian distribution for neural network-based blood pressure estimation. Appl. Sci. 2021, 11, 3923. [Google Scholar] [CrossRef]
- Wu, B.; Chiu, L.; Wu, Y.; Lai, C.; Chu, P. Contactless blood pressure measurement via remote photoplethysmography with synthetic data generation using generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Kachuee, M.; Kiani, M.; Mohammadzade, H.; Shabany, M. Cuff-Less Blood Pressure Estimation Data Set. Available online: https://archive.ics.uci.edu/dataset/340/cuff+less+blood+pressure+estimation (accessed on 4 December 2023).
- Majeed, I.A.; Jos, S.; Arora, R.; Choi, K.; Bae, S. Motion Artifact Removal of Photoplethysmogram (PPG) Signal. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019. [Google Scholar]
- He, W.; Ye, Y.; Lu, L.; Cheng, Y.; Li, Y.; Wang, Z. Robust heart rate monitoring for quasi-periodic motions by wrist-type PPG signals. IEEE J. Biomed. Health Inform. 2020, 24, 636–648. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Mohseni, P.; Kilgore, K.; Najafizadeh, L. Cuff-less blood pressure estimation from photoplethysmography via visibility graph and transfer learning. IEEE J. Biomed. Health Inform. 2021, 26, 2075–2085. [Google Scholar] [CrossRef] [PubMed]
- Mariani, G.; Scheidegger, F.; Istrate, R.; Bekas, C.; Malossi, C. Bagan: Data augmentation with balancing gan. arXiv 2018, arXiv:1803.09655. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jin, R.; Wu, M.; Wu, K.; Gao, K.; Chen, Z.; Li, X. Position Encoding Based Convolutional Neural Networks for Machine Remaining Useful Life Prediction. IEEE/CAA J. Autom. Sin. 2022, 9, 1427–1439. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chemla, D.; Millasseau, S. A systematic review of invasive, high-fidelity pressure studies documenting the amplification of blood pressure from the aorta to the brachial and radial arteries. J. Clin. Monit. Comput. 2021, 35, 1245–1252. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Layer | Dimension | Activation |
|---|---|---|---|
| Generator | Input | 256 | - |
| FC1 | 128 | LeakyReLU | |
| BN1 | - | - | |
| FC2 | 128 | LeakyReLU | |
| BN2 | - | - | |
| FC3 | 256 | - | |
| Discriminator | Input | 256 | - |
| FC1 | 512 | LeakyReLU | |
| BN1 | - | - | |
| FC2 | 256 | LeakyReLU | |
| BN2 | - | - | |
| FC3 | 1 | Sigmoid |
| Network | Layer | Dimension | Activation |
|---|---|---|---|
| Encoder | Input | 256 | - |
| FC1 | 128 | ReLU | |
| Latent Space | FC1 | 64 | - |
| FC2 | 64 | - | |
| Sampling | 64 | - | |
| Decoder | Input | 64 | - |
| FC1 | 128 | ReLU | |
| FC2 | 256 | Sigmoid |
| Method | MAE | RMSE | ME ± SD |
|---|---|---|---|
| Origin | 4.68 | 8.86 | 0.60 ± 8.84 |
| Cropping | 4.29 | 9.00 | 0.51 ± 8.99 |
| Flipping | 4.91 | 9.12 | 0.40 ± 9.11 |
| DBA | 4.21 | 8.67 | 0.84 ± 8.63 |
| GAN | 5.21 | 10.12 | 1.41 ± 10.02 |
| VAE | 3.80 | 8.36 | 0.48 ± 8.35 |
| Method | MAE | RMSE | ME ± SD |
|---|---|---|---|
| Origin | 2.52 | 4.33 | 0.12 ± 4.32 |
| Cropping | 2.31 | 4.02 | 0.00 ± 4.02 |
| Flipping | 2.68 | 4.34 | 0.48 ± 4.31 |
| DBA | 2.28 | 4.13 | 0.15 ± 4.13 |
| GAN | 2.73 | 4.65 | 0.10 ± 4.65 |
| VAE | 2.02 | 3.88 | 0.15 ± 3.88 |
| Method | SBP | DBP | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | ME ± SD | MAE | RMSE | ME ± SD | |
| ANN [10] | 7.41 | N/A | −4.02 ± 10.40 | 3.32 | N/A | −0.31 ± 4.89 |
| ResNet + LSTM [11] | 4.87 | 10.02 | 0.06 ± 10.02 | 2.48 | 4.70 | −0.08 ± 4.70 |
| RDAE [12] | 8.84 | 13.00 | 4.20 ± 12.31 | 4.76 | 6.58 | −0.14 ± 6.58 |
| PPG2ABP [13] | 11.57 | 15.50 | 8.77 ± 12.78 | 5.62 | 7.57 | −2.88 ± 7.00 |
| Cycle GAN [14] | 2.89 | 5.18 | 0.67 ± 4.52 | 3.22 | 4.82 | 1.78 ± 4.67 |
| Transformer [15] | 2.41 | 2.72 | −0.037 ± 2.72 | 1.31 | 1.77 | 0.029 ± 1.77 |
| CNN-GRU [16] | 5.95 | 11.19 | −0.05 ± 11.19 | 2.81 | 4.90 | 0.24 ± 4.90 |
| PE–CNN–GRU | 3.80 | 8.36 | 0.48 ± 8.35 | 2.02 | 3.88 | 0.15 ± 3.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mou, H.; Li, C.; Zhou, H.; Zhang, D.; Wang, W.; Yu, J.; Tian, J. Using Data Augmentation to Improve the Accuracy of Blood Pressure Measurement Based on Photoplethysmography. Electronics 2024, 13, 1599. https://doi.org/10.3390/electronics13081599
Mou H, Li C, Zhou H, Zhang D, Wang W, Yu J, Tian J. Using Data Augmentation to Improve the Accuracy of Blood Pressure Measurement Based on Photoplethysmography. Electronics. 2024; 13(8):1599. https://doi.org/10.3390/electronics13081599
Chicago/Turabian StyleMou, Hanlin, Congjian Li, Haoran Zhou, Daobing Zhang, Wensheng Wang, Junsheng Yu, and Jing Tian. 2024. "Using Data Augmentation to Improve the Accuracy of Blood Pressure Measurement Based on Photoplethysmography" Electronics 13, no. 8: 1599. https://doi.org/10.3390/electronics13081599
APA StyleMou, H., Li, C., Zhou, H., Zhang, D., Wang, W., Yu, J., & Tian, J. (2024). Using Data Augmentation to Improve the Accuracy of Blood Pressure Measurement Based on Photoplethysmography. Electronics, 13(8), 1599. https://doi.org/10.3390/electronics13081599