
Optimizing Network Service Continuity with Quality-Driven Resource Migration


Abstract
:1. Introduction
- Quality-guided migration timing decision: QD-RMS introduces a Service Migration Index () for the holistic evaluation of node service quality, aiding in the prediction of migration propensities. This index amalgamates crucial indicators like the average distance between users and base stations, service throughput, and node resource utilization. Continual monitoring allows QD-RMS to proactively discern the necessity for service migration, facilitating an immediate assessment of service status. Upon the hitting or surpassing a dynamic threshold, the system interprets this as an indicator of deteriorating service quality, thereby initiating the migration process and adaptively recalibrating the threshold to align with current node conditions. If the remains below this threshold, the service shifts into a dormant state, pending subsequent evaluation. This approach preemptively triggers migration to avert significant service quality decline, effectively stabilizing service quality levels and curtailing both service downtime and the duration required for migration.
- Optimize the load through Pareto optimality theory: QD-RMS starts by merging node resources and task loads to evaluate the load status of potential migration nodes, leading to the development of a multi-objective optimization model. This model, utilizing Pareto optimality theory, gauges the load quality of these nodes and is efficiently resolved through the simulated annealing algorithm, facilitating the identification of superior candidate nodes promptly. Distinct from conventional load balancing methods, QD-RMS accentuates the compatibility of resources between tasks and nodes, thereby circumventing the selection of nodes at the brink of resource saturation, minimizing overload risks, and fostering a more sophisticated load-balancing regime.
- Effective experimental validation: Comprehensive empirical tests were carried out on QD-RMS to assess its effectiveness in real-world applications, particularly in terms of service quality and maximum task capacity at nodes. By simulating four different service requests on a virtual machine platform, we compared the performance of QD-RMS with that of conventional reference strategies in service migration, illustrating their service quality in comparative graphs. The results highlighted QD-RMS’s significant advantage in maintaining service quality, evidenced by more stable service performance and smaller fluctuation ranges. Additionally, the load-balancing performance of QD-RMS was evaluated, with experimental data confirming that, under similar hardware configurations, QD-RMS improved the maximum task capacity by approximately 20% compared to traditional load-balancing algorithms.
2. Related Work
3. Preliminaries
3.1. Service Migration
- Service continuity: If a user moves to another location, the services associated with that user must remain available.
- Service mobility: Services must be capable of being migrated to new servers when needed.
- User state mobility: The data associated with user services must be moved along with the services.
- System context: This includes any information related to computing and communication systems.
- User context: This refers to any context information associated with user characteristics.
- Environmental context: This encompasses any context information related to the physical environment, excluding system and user context.
- Temporal context: This defines any context information related to time.
3.2. Load Balancing
- Random Algorithm: Random algorithms distribute incoming requests by selecting servers at random. These methods do not account for the server’s load or response metrics, relying solely on random selection.
- Round Robin Algorithm: Requests are distributed to servers in a sequential, rotating order. Despite its simplicity, it does not account for performance differences between servers, which can lead to inefficient resource allocation.
- Least Connection Algorithm: Requests are assigned based on the current number of connections to each server, aiming for balanced task distribution. However, this can still result in unbalanced resource utilization when server performance varies significantly.
3.3. Pareto Optimality
4. Methodology
4.1. Active Migration Timing Based on Service Quality
4.1.1. Service Migration Index
4.1.2. Service Monitoring
- Counter: An incrementing counter used for tracking request counts, task completion counts, and similar metrics.
- Gauge: A metric that can take on arbitrary values, suitable for metrics like CPU utilization, memory usage, and other numerical data.
- Histogram: Categorizes a set of observations into multiple bins and exposes the number of bins and the respective observation value ranges.
- Summary: An extension of Histogram that aggregates data (sums, counts) and provides metrics like mean and sample standard deviation.
- Node Exporter: For Linux/Unix systems, providing data on CPU, disk, network, memory, and more.
- Blackbox Exporter: For probing network ports, HTTP, DNS, ICMP, and other network services to assess service statuses.
- Redis Exporter: For monitoring the performance of Redis databases and exporting metric data to Prometheus.
4.1.3. Active Migration Process
- Index Monitoring Module: This module monitors the status of applications on service nodes using monitoring software. It calculates the Service Migration Index in real-time based on relevant parameters and compares it with the migration threshold to determine the migration trend for the service. The primary objective of the monitoring program is to monitor and compute parameters. As shown in Algorithm 1, this module calculates the real-time by continuously collecting data on the current service’s resource utilization, the average distance of all session users, and the total throughput of all session instances Q. If the is less than the set threshold (SMI-T) for the current round, the system will sleep for a period before resuming the process. If the is greater than or equal to the SMI-T threshold, the service status is changed to migration mode, the loop is terminated, and the service migration module is invoked.
| Algorithm 1 Index monitoring |
| Input: Application , Resource weight W, Threshold SMI-T Output: Application state app_status app_status while app_status do if SMI-T then Wait some time else /*Application enters migration state*/ end if end while run Service migration return |
- 2.
- Service Migration Module: Initially, all session instances within the service are scanned and sorted based on the distance of each user from the nodes, and users are sequentially moved to a migration queue for migrating instances starting with users farthest from the nodes. This process continues until the drops below the migration threshold, at which point migration stops. During this process, violations by migrating users are monitored and recorded. The service migration program primarily selects session instances for migration based on the . It iterates through all current session instances, calculates the distance of each user from the service nodes, adds this information to a distance queue, and then proceeds to migrate users in order of their distance from the service nodes until the falls below the set threshold (SMI-T), at which point the loop stops, and the threshold update module is called. Algorithm 2 demonstrates the procedure of a service migration.
| Algorithm 2 Service migration |
| Input: Application , Service migration index Output: otal number of service violations while SMI-T do for all do Sort migration /* Calculate the maximum number of violation incidents about */ if then end if end for end while run Threshold updating return |
- 3.
- Threshold Updating Module: This module compares the product of distance and average waiting delay with a predefined base value to evaluate the reasonableness of the threshold. A violation value of 0 indicates an appropriately set threshold for migration in the current context, and a slight random increase in the threshold can enhance the utilization of service nodes. If the violation value is greater than 0, it signifies that the threshold set is too high, causing multiple violations by the time the reaches the threshold. In such cases, a small random decrease in the threshold is necessary. The threshold update program first calculates the current migration round for the service. If the migration rounds are relatively low, such as equal to or less than 5, the SMI-T is randomly adjusted based on violations, with the adjustment value correlated to the violation severity. For higher migration rounds, the module takes the SMI-T and average waiting delay into account, using the method of least squares to fit a function. The computation determines the maximum value of the independent variable for which the fitted function equals 0, providing a new SMI-T value. The threshold update strategy is shown in Algorithm 3.
| Algorithm 3 Threshold updating |
| Input: Application , Distance D, Average waiting delay , Migration round , Total number of service violations Output: updated threshold SMI-T if then if then SMI-T increase small random number else SMI-T descend small random number end if else /*Using least squares method for function fitting*/ end if /*Calculating the maximum value of the independent variable when the fitted function f equals 0*/ SMI-T return SMI-T |
4.2. Node Selection Algorithm Based on Load Balancing
4.2.1. Resource-Based Load Balancing
4.2.2. Task-Based Load Balancing
4.2.3. Migration Node Selection Algorithm Based on Task-Resource Matching
| Algorithm 4 Comprehensive screening of Pareto optimal nodes |
| Input: Server nodes ID, User demand resource vector Output: Set of servers that achieves Pareto optimality for do Calculate the resource balance degree after server i accepts the task Calculate the load balancing degree after server i accepts the task end for for do for do if () and () then Replace node i with node y Record the serial number of node i end if end for Delete all recorded nodes from n end for |
| Algorithm 5 Simulated annealing searches for Pareto optimal nodes |
| Input: Serialized server nodes ID, User demand resource vector Output: Set of servers that achieves Pareto optimality for do Calculate the resource balance degree after server i accepts the task Calculate the load balancing degree after server i accepts the task Perform range perturbation to generate new solutions Calculate the degree of equilibrium if then Accept and record new optimal else Accept with a certain probability according to metropolis guidelines end if Iterate for multiple times Terminate gradually according to annealing temperature end for |
5. Evaluation
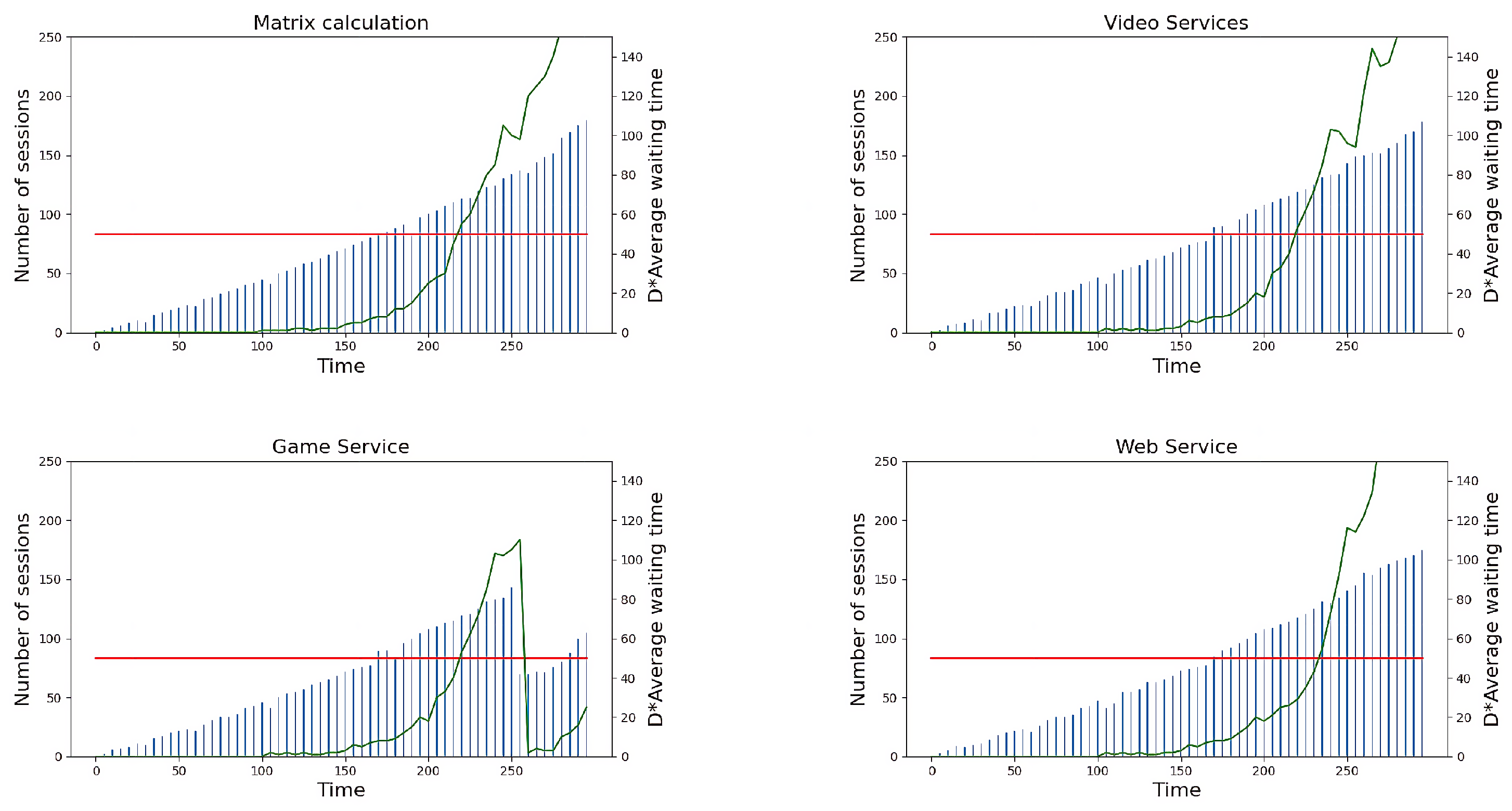
5.1. Active Migration Based on Service Quality
5.2. Migration Node Selection for Task-Resource Matching
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, J. Cyberspace Endogenous Safety and Security. Engineering 2022, 15, 179–185. [Google Scholar] [CrossRef]
- Tan, K.H.; Lim, H.S.; Diong, K.S. Modelling and Predicting Quality-of-Experience of Online Gaming Users in 5G Networks. Int. J. Technol. 2022, 13, 1035–1044. [Google Scholar] [CrossRef]
- Lu, H.; Li, M.; Zhang, Y. Research on optimization method of computer network service quality based on feature matching algorithm. Proc. J. Phys. Conf. Ser. 2021, 1982, 012005. [Google Scholar] [CrossRef]
- Flora, J. Improving the security of microservice systems by detecting and tolerating intrusions. In Proceedings of the 2020 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Coimbra, Portugal, 12–15 October 2020; pp. 131–134. [Google Scholar]
- Wang, Z.; Jiang, D.; Wang, F.; Lv, Z.; Nowak, R. A polymorphic heterogeneous security architecture for edge-enabled smart grids. Sustain. Cities Soc. 2021, 67, 102661. [Google Scholar] [CrossRef]
- Kang, R.; He, F.; Oki, E. Virtual network function allocation in service function chains using backups with availability schedule. IEEE Trans. Netw. Serv. Manag. 2021, 18, 4294–4310. [Google Scholar] [CrossRef]
- Zhao, J.; Dai, M.; Xia, Y.; Ma, Y.; He, M.; Peng, K.; Li, J.; Li, F.; Fu, X. FRSM: A Novel Fault-Tolerant Approach for Redundant-Path-Enabled Service Migration in Mobile Edge Computing. In Proceedings of the International Conference on Web Services; Springer: Cham, Switzerland, 2022; pp. 1–12. [Google Scholar]
- Ma, Y.; Dai, M.; Shao, S.; Xia, Y.; Li, F.; Shen, Y.; Li, J.; Li, Y.; Peng, H. A Performance and Reliability-Guaranteed Predictive Approach to Service Migration Path Selection in Mobile Computing. IEEE Internet Things J. 2023, 10, 17977–17987. [Google Scholar] [CrossRef]
- Kulshrestha, S.; Patel, S. An efficient host overload detection algorithm for cloud data center based on exponential weighted moving average. Int. J. Commun. Syst. 2021, 34, e4708. [Google Scholar] [CrossRef]
- Yang, L.; Yang, D.; Cao, J.; Sahni, Y.; Xu, X. QoS Guaranteed Resource Allocation for Live Virtual Machine Migration in Edge Clouds. IEEE Access 2020, 8, 78441–78451. [Google Scholar] [CrossRef]
- Velrajan, S.; Sharmila, V. QoS Aware Service Migration in Multi access Edge Compute Using Closed Loop Adaptive Particle Swarm Optimization Algorithm. J. Netw. Syst. Manag. 2023, 31, 17. [Google Scholar] [CrossRef]
- Chen, X.; Bi, Y.; Chen, X.; Zhao, H.; Cheng, N.; Li, F.; Cheng, W. Dynamic Service Migration and Request Routing for Microservice in Multicell Mobile-Edge Computing. IEEE Internet Things J. 2022, 9, 13126–13143. [Google Scholar] [CrossRef]
- Bozkaya, E. Digital twin-assisted and mobility-aware service migration in Mobile Edge Computing. Comput. Netw. 2023, 231, 109798. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.; Zhou, A.; Guo, Y.; Wang, S. Service migration in mobile edge computing: A deep reinforcement learning approach. Int. J. Commun. Syst. 2023, 36, e4413. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, Y.; Lok, T.M.; Huang, K. Multi-Cell Mobile Edge Computing: Joint Service Migration and Resource Allocation. IEEE Trans. Wirel. Commun. 2021, 20, 5898–5912. [Google Scholar] [CrossRef]
- Kim, T.; Chen, S.; Im, U.; Zhang, X.; Ha, S.; Joe-Wong, C. MoDEMS: Optimizing Edge Computing Migrations for User Mobility. IEEE J. Sel. Areas Commun. 2023, 41, 675–689. [Google Scholar] [CrossRef]
- Xu, Y.; Zheng, Z.; Liu, X.; Yao, A.; Li, X. Three-way decisions based service migration strategy in mobile edge computing. Inf. Sci. 2022, 609, 533–547. [Google Scholar] [CrossRef]
- Le, V.T.; Ioini, E.; Barzegar, H.R.; Pahl, C. Trust Management For Service Migration Multi-access Edge Computing environments. Comput. Commun. 2022, 194, 167–179. [Google Scholar] [CrossRef]
- Li, C.; Zhu, L.; Li, W.; Luo, Y. Joint edge caching and dynamic service migration in SDN based mobile edge computing. J. Netw. Comput. Appl. 2021, 177, 102966. [Google Scholar] [CrossRef]
- Du, A.; Jia, J.; Chen, J.; Guo, L.; Wang, X. Online two-timescale service placement for time-sensitive applications in MEC-assisted network: A TMAGRL approach. Comput. Netw. 2024, 244, 110339. [Google Scholar] [CrossRef]
- Tuli, S.; Casale, G.; Jennings, N.R. PreGAN: Preemptive Migration Prediction Network for Proactive Fault-Tolerant Edge Computing. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 670–679. [Google Scholar]
- Dai, X.; Xiao, Z.; Jiang, H.; Alazab, M.; Lui, J.C.S.; Dustdar, S.; Liu, J. Task Co-Offloading for D2D-Assisted Mobile Edge Computing in Industrial Internet of Things. IEEE Trans. Ind. Inform. 2023, 19, 480–490. [Google Scholar] [CrossRef]
- Moon, S.; Lim, Y. Task Migration with Partitioning for Load Balancing in Collaborative Edge Computing. Appl. Sci. 2022, 12, 1168. [Google Scholar] [CrossRef]
- Zhao, P.; Tao, J.; Rauf, A.; Jia, F.; Xu, L. Load balancing for energy-harvesting mobile edge computing. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2021, 104, 336–342. [Google Scholar] [CrossRef]
- Liu, D.; Hafid, A.; Khoukhi, L. Workload Balancing in Mobile Edge Computing for Internet of Things: A Population Game Approach. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1726–1739. [Google Scholar] [CrossRef]
- Song, S.; Ma, S.; Zhao, J.; Yang, F.; Zhai, L. Cost-efficient multi-service task offloading scheduling for mobile edge computing. Appl. Intell. 2022, 52, 4028–4040. [Google Scholar] [CrossRef]
- Liu, L.; Chan, S.; Han, G.; Guizani, M.; Bandai, M. Performance modeling of representative load sharing schemes for clustered servers in multiaccess edge computing. IEEE Internet Things J. 2018, 6, 4880–4888. [Google Scholar] [CrossRef]
- Abedin, S.F.; Bairagi, A.K.; Munir, M.S.; Tran, N.H.; Hong, C.S. Fog load balancing for massive machine type communications: A game and transport theoretic approach. IEEE Access 2018, 7, 4204–4218. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
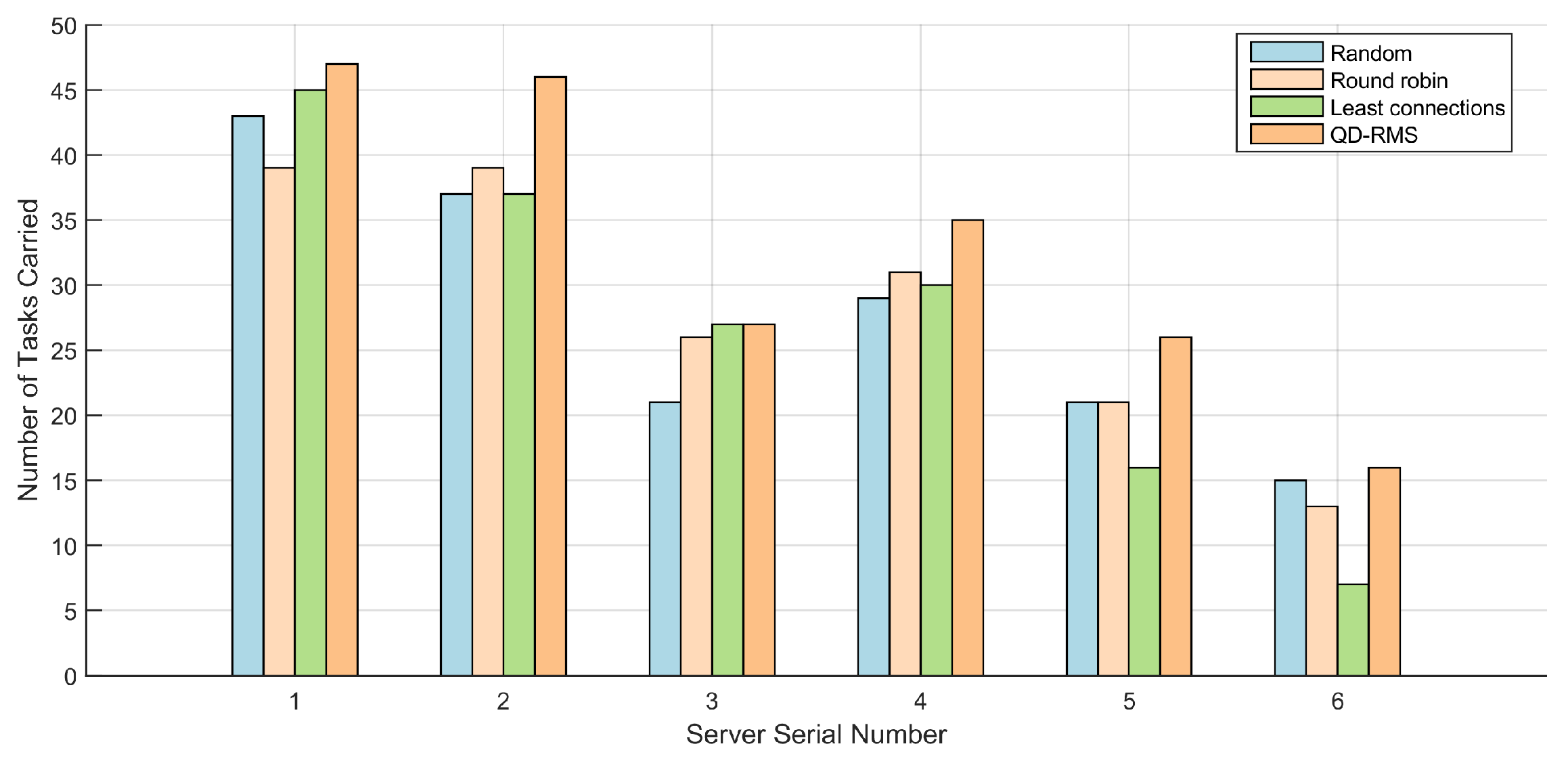{kind=link}
{kind=link}
{kind=link}
| Active Migration | Passive Migration | |
|---|---|---|
| Service node status during migration | Running | Suspended |
| Factors affecting the timing of migration | Quality of users and status of service node | Availability of services |
| Purpose of migration | Ensure high-quality services | Ensure continuous services |
| Data | Collection Method | Collection Cycle |
|---|---|---|
| Throughput (queries_per_second) | Exposing exporter | 1 (s) |
| CPU Utilization (node_cpu_seconds_total) | Exposing exporter | 1 (s) |
| Memory Utilization (node_memory_MemTotal_bytes) | Exposing exporter | 1 (s) |
| Storage Utilization (node_disk_io_time_second) | Exposing exporter | 1 (s) |
| Network Activity (node_netstat_Tcp_(Active|Passive)Opens) | Exposing exporter | 1 (s) |
| Average user session distance | Provided by base station | Determined by base station |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Song, Y.; Jiang, Y.; Zhang, M. Optimizing Network Service Continuity with Quality-Driven Resource Migration. Electronics 2024, 13, 1666. https://doi.org/10.3390/electronics13091666
Chen C, Song Y, Jiang Y, Zhang M. Optimizing Network Service Continuity with Quality-Driven Resource Migration. Electronics. 2024; 13(9):1666. https://doi.org/10.3390/electronics13091666
Chicago/Turabian StyleChen, Chaofan, Yubo Song, Yu Jiang, and Mingming Zhang. 2024. "Optimizing Network Service Continuity with Quality-Driven Resource Migration" Electronics 13, no. 9: 1666. https://doi.org/10.3390/electronics13091666
APA StyleChen, C., Song, Y., Jiang, Y., & Zhang, M. (2024). Optimizing Network Service Continuity with Quality-Driven Resource Migration. Electronics, 13(9), 1666. https://doi.org/10.3390/electronics13091666