
An Enhanced Hidden Markov Model for Map-Matching in Pedestrian Navigation


Abstract
:1. Introduction
- Persistent map-matching errors due to the large localization error in the initial phase of navigation;
- Lack of handling the state of open field traversal.
2. Related Works
3. Preliminaries
3.1. Map-Matching Problem
3.2. HMM Methods for Map-Matching
3.2.1. Emission Probability Distribution
3.2.2. Initial State Probability Distribution
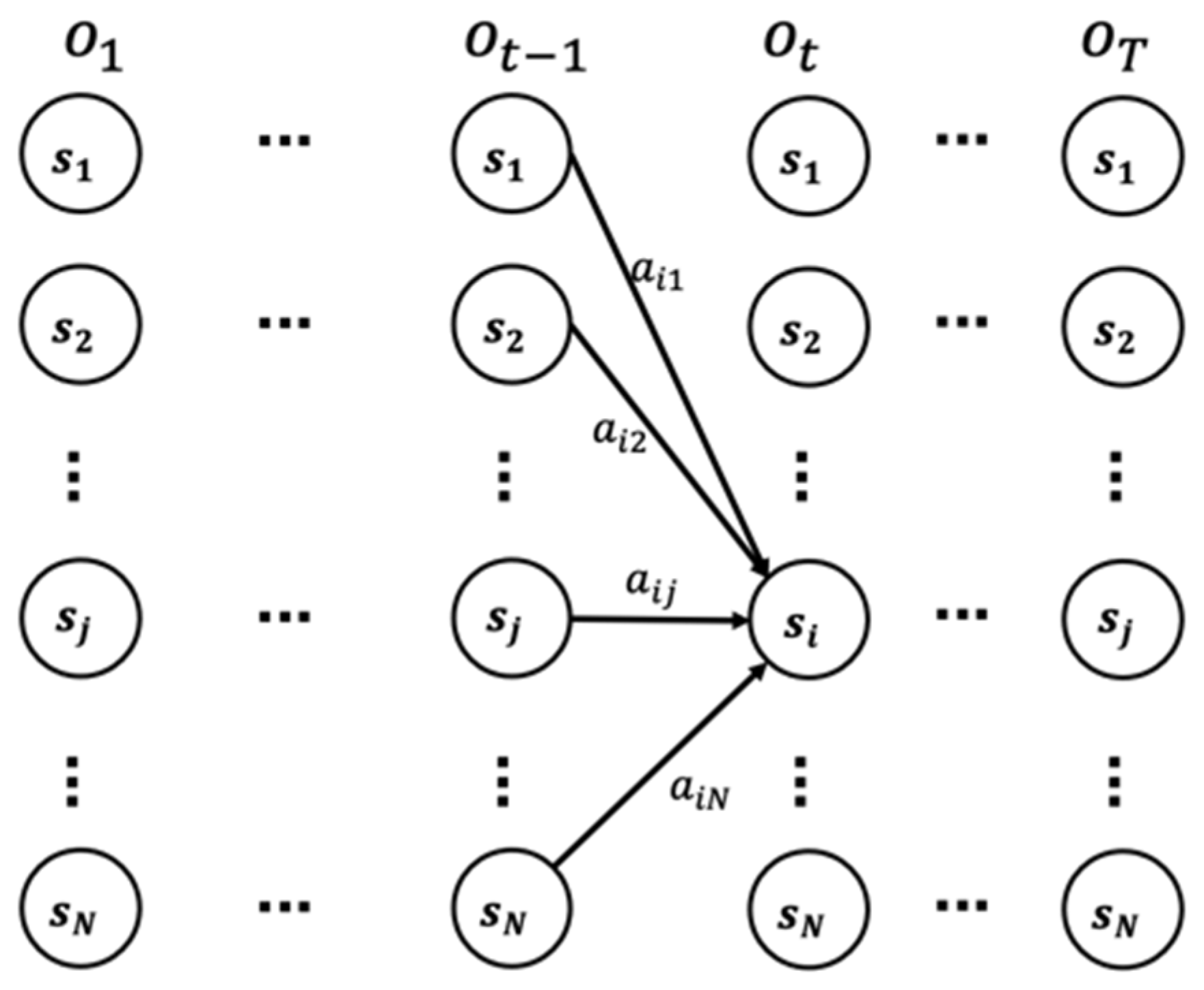
3.2.3. Transition Probability Distribution
3.3. Viterbi Algorithm
- (1)
- Initialization. Initialize the algorithm by assigning initial values for the first hidden state based on the initial probability distribution and emission probability distribution.
- (2)
- Recursion. Iteratively compute the probabilities of all possible hidden state sequences up to a given GPS measurement .
- (3)
- Termination. Identify the final state by finding the sequence that maximizes the probability.
- (4)
- Backtracking. Trace back through the sequence to determine the most likely path of hidden states that led to the identified final hidden state.
- (5)
- Return the optimal hidden state sequence.
- (6)
- is the maximum probability of producing observation sequence when moving along a hidden state sequence and getting into state .
4. The Enhanced HMM for Map-Matching
4.1. Problem Statements
4.2. EHMM-P
4.2.1. Probability Distributions of the Initial States
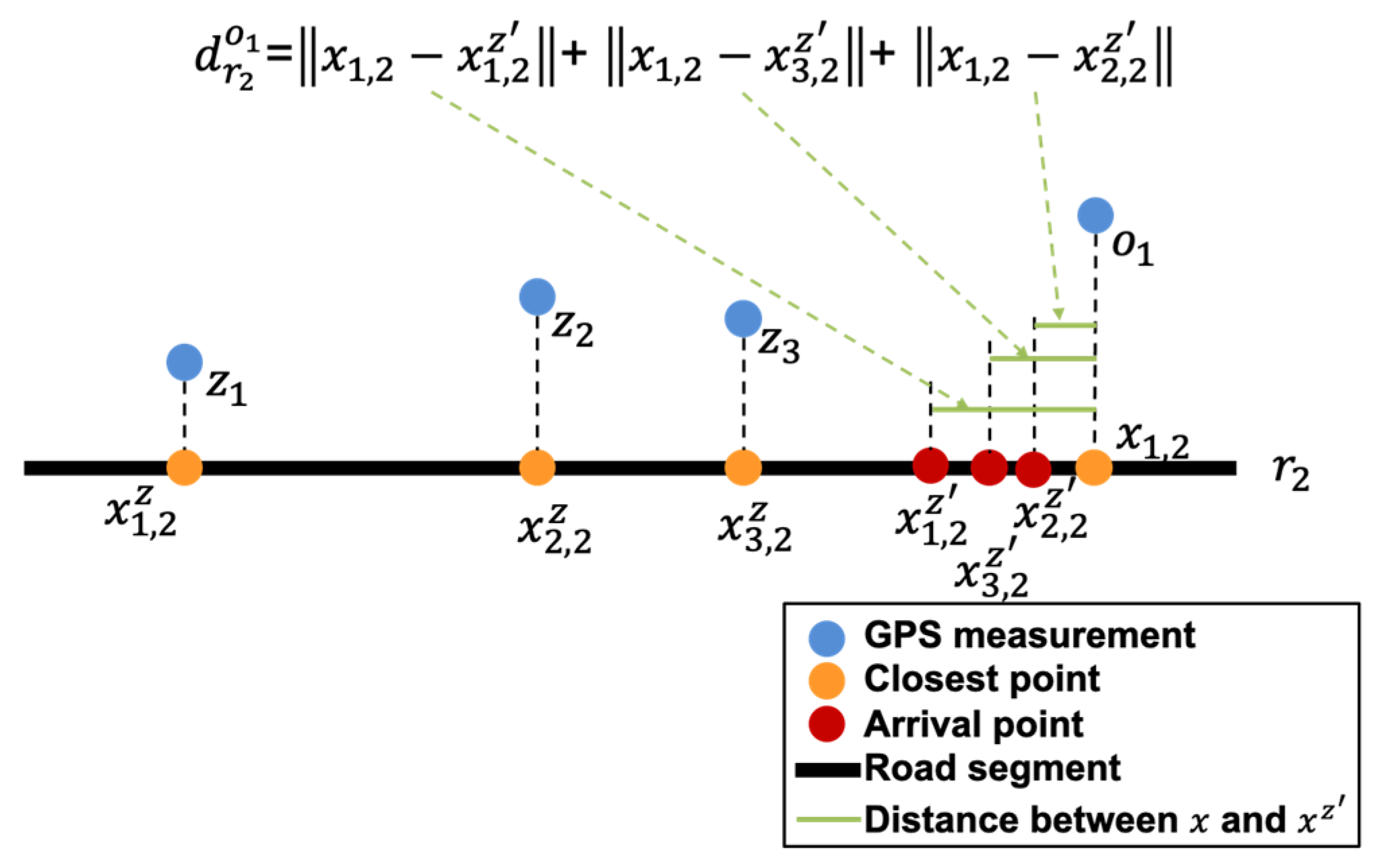
4.2.2. Emission and Transition Probability Distributions
Emission Probability Distribution
Transition Probability Distribution
- (1)
- Distance Difference
- (2)
- Direction Difference
- (3)
- Position Difference
4.2.3. Algorithm
| Algorithm 1 EHMM-P |
| Inputs: GPS trajectory ; Road network Outputs: Matched road segments and open-field trajectory 1. Initialization: For each do 2. 3. For each do 4. For each and do 5. Recursion: 6. Termination: 7. Backtracking: For do 8. Initialize and as empty lists 9. For in do 10. If is a road segment do 11. 12. Else 13. Return and |
4.2.4. Trajectory Prediction in Open-Fields Based on Human Mobility Patterns
5. Experiments
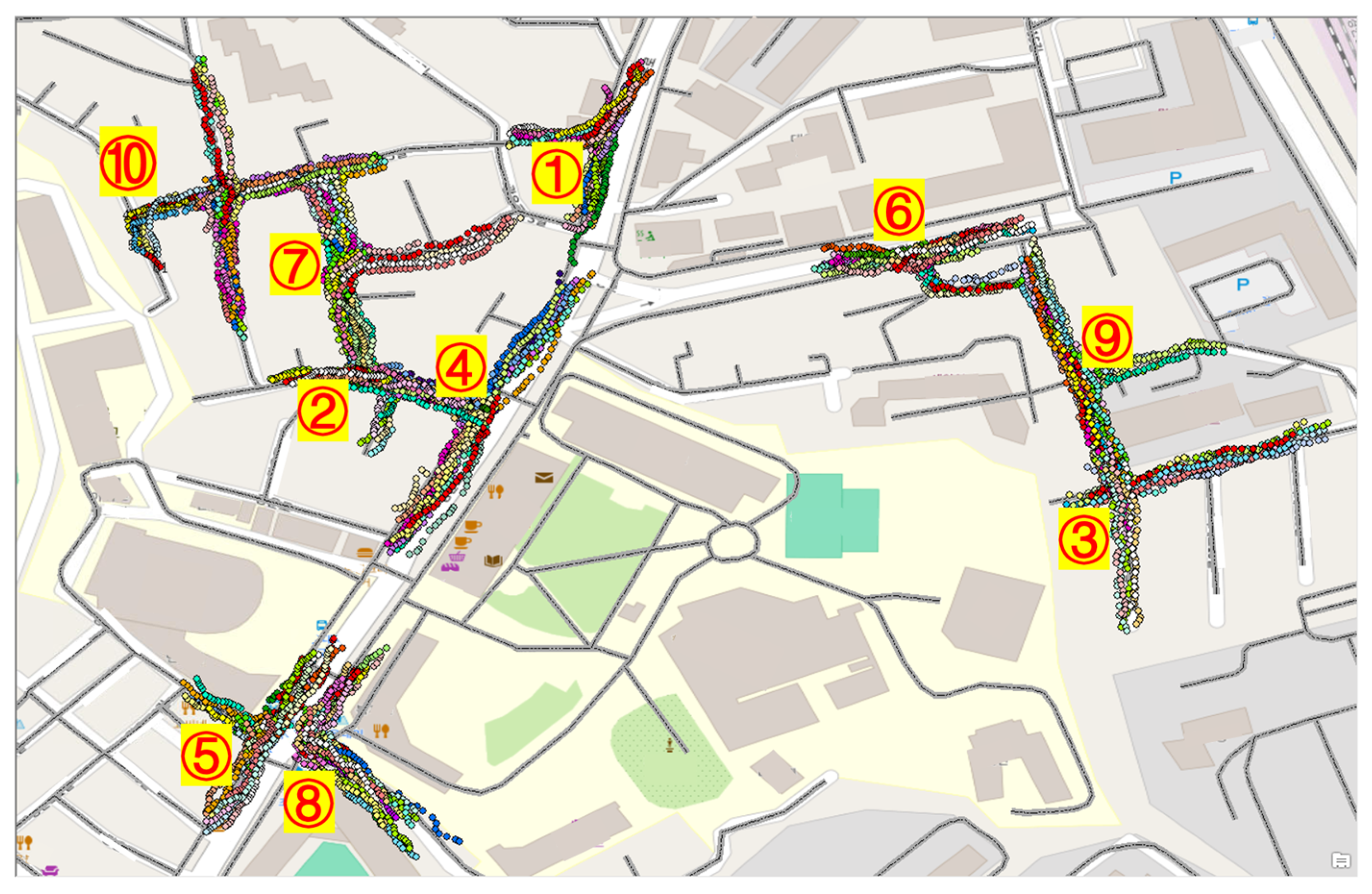
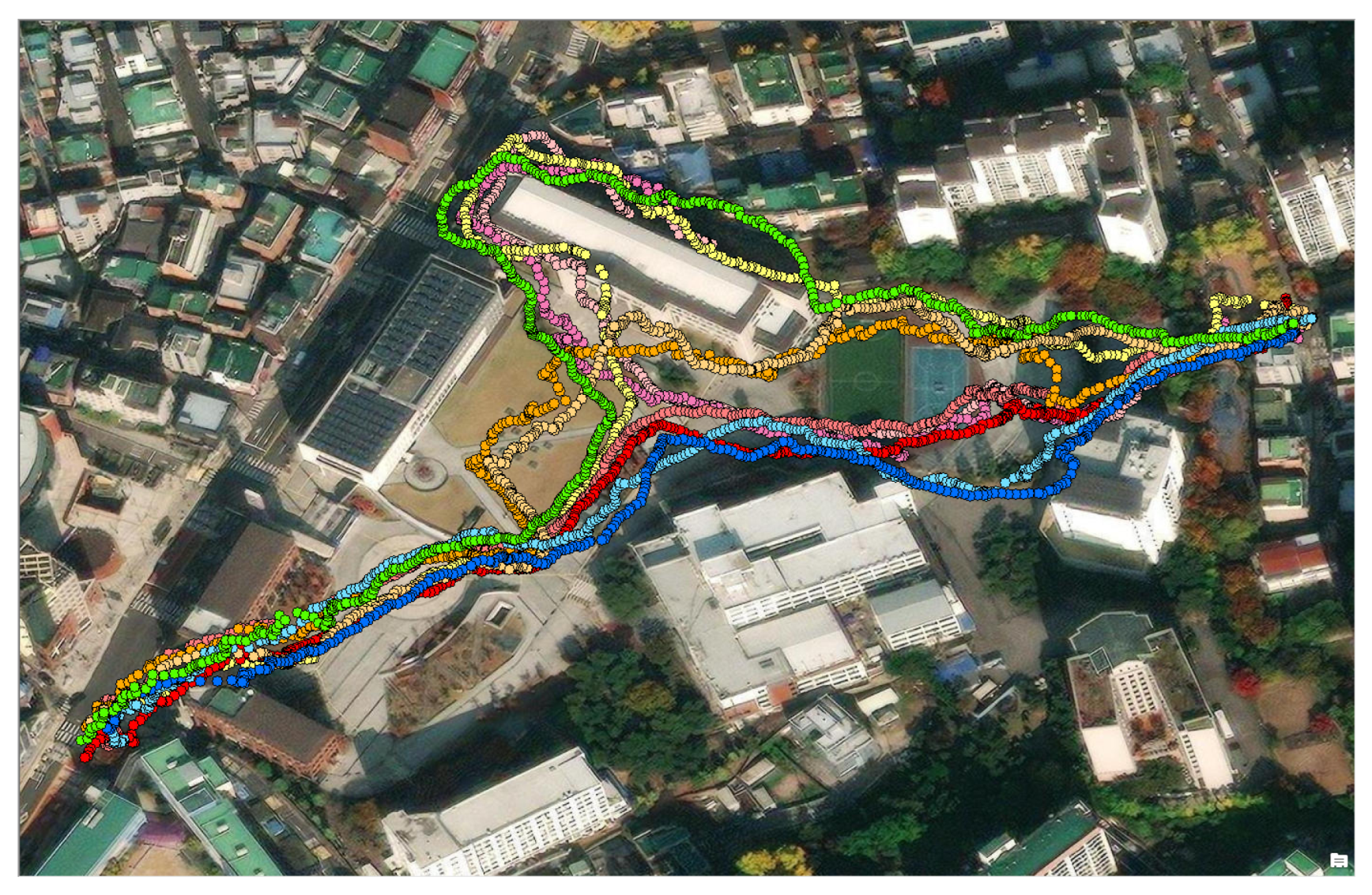
5.1. Data Collection and Data Preprocessing
5.2. Results and Discussion
- A.
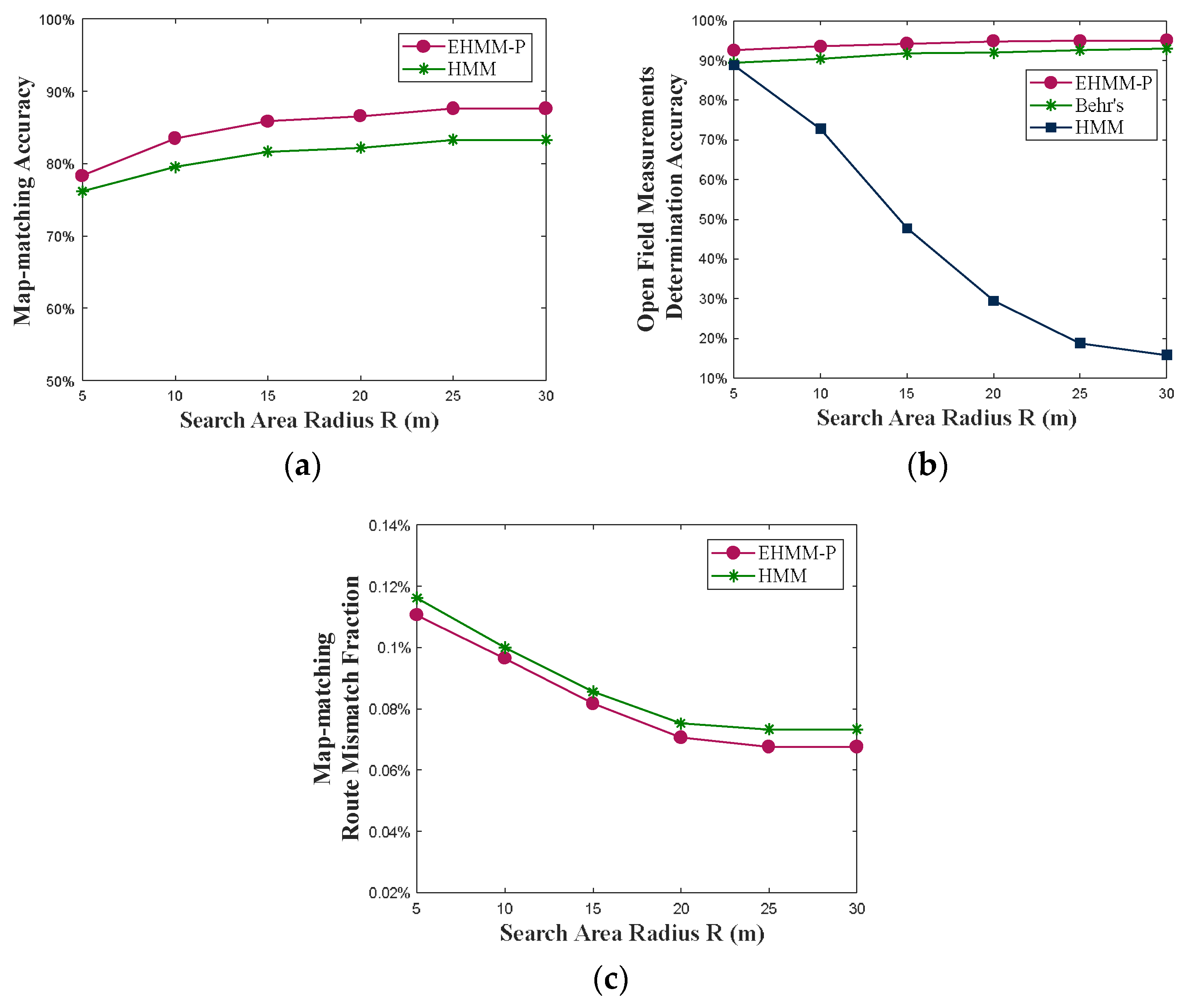
- Performance Evaluation of Proposed Method for Initial Map-Matching
- B.
- Performance Evaluation of Map-matching
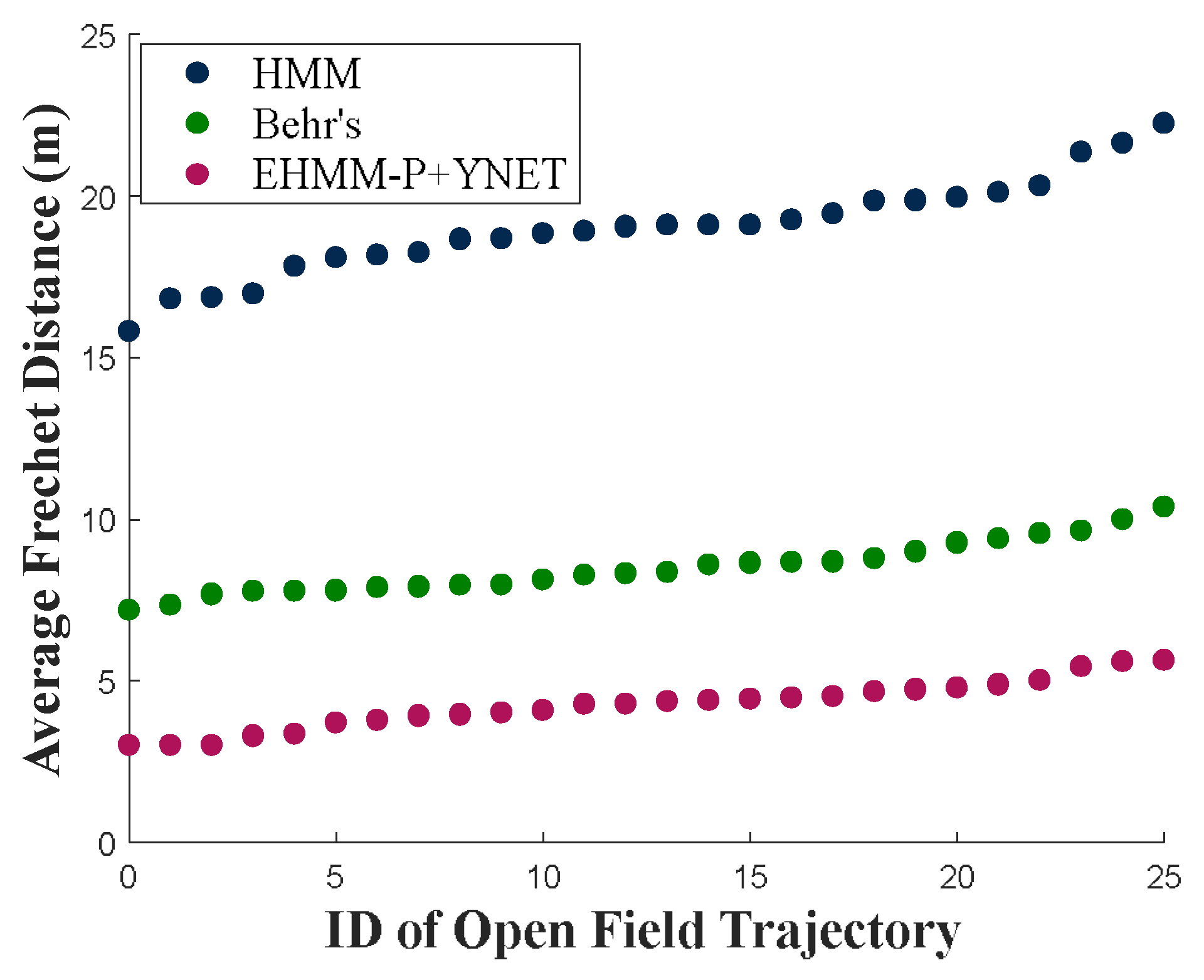
- C.
- Human Behavior-Based Trajectory Prediction in Open-fields
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Siriaraya, P.; Wang, Y.; Zhang, Y.; Wakamiya, S.; Jeszenszky, P.; Kawai, Y.; Jatowt, A. Beyond the shortest route: A survey on quality-aware route navigation for pedestrians. IEEE Access 2020, 8, 135569–135590. [Google Scholar] [CrossRef]
- Kim, Y.H.; Choi, M.J.; Kim, E.J.; Song, J.W. Magnetic-map-matching-aided pedestrian navigation using outlier mitigation based on multiple sensors and roughness weighting. Sensors 2019, 19, 4782. [Google Scholar] [CrossRef]
- Bang, Y.; Kim, J.; Yu, K. An Improved Map-Matching Technique Based on the Frechet Distance Approach for Pedestrian Navigation Services. Sensors 2016, 16, 1768. [Google Scholar] [CrossRef]
- Hashemi, M.; Karimi, H.A. A weight-based map-matching algorithm for vehicle navigation in complex urban networks. J. Intell. Transp. Syst. 2016, 20, 573–590. [Google Scholar] [CrossRef]
- Maaref, M.; Kassas, Z.M. Ground vehicle navigation in GNSS-challenged environments using signals of opportunity and a closed-loop map-matching approach. IEEE Trans. Intell. Transp. Syst. 2019, 21, 2723–2738. [Google Scholar] [CrossRef]
- Lai, C.; Zhang, M.; Cao, J.; Zheng, D. SPIR: A secure and privacy-preserving incentive scheme for reliable real-time map updates. IEEE Internet Things J. 2019, 7, 416–428. [Google Scholar] [CrossRef]
- An, Q.; Feng, Z.; Chen, S.; Huang, K. A green self-adaptive approach for online map matching. IEEE Access 2018, 6, 51456–51469. [Google Scholar] [CrossRef]
- Ahmed, M.; Karagiorgou, S.; Pfoser, D.; Wenk, C. A comparison and evaluation of map construction algorithms using vehicle tracking data. GeoInformatica 2015, 19, 601–632. [Google Scholar] [CrossRef]
- Ding, Z.; Yang, B.; Guting, R.H.; Li, Y. Network-Matched Trajectory-Based Moving-Object Database: Models and Applications. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1918–1928. [Google Scholar] [CrossRef]
- Priambodo, B.; Ahmad, A.; Kadir, R.A. Predicting Traffic Flow Propagation Based on Congestion at Neighbouring Roads Using Hidden Markov Model. IEEE Access 2021, 9, 85933–85946. [Google Scholar] [CrossRef]
- Chen, Z.; Jiang, Y.; Sun, D. Discrimination and prediction of traffic congestion states of urban road network based on spatio-temporal correlation. IEEE Access 2019, 8, 3330–3342. [Google Scholar] [CrossRef]
- Wei, X.; Li, J.; Feng, K.; Zhang, D.; Li, P.; Zhao, L.; Jiao, Y. A Mixed Optimization Method Based on Adaptive Kalman Filter and Wavelet Neural Network for INS/GPS During GPS Outages. IEEE Access 2021, 9, 47875–47886. [Google Scholar] [CrossRef]
- Newson, P.; Krumm, J. Hidden Markov map matching through noise and sparseness. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4–6 November 2009; pp. 336–343. [Google Scholar]
- Forney, G.D. The Viterbi algorithm. Proc. IEEE 1973, 61, 268–278. [Google Scholar] [CrossRef]
- Abdallah, F.; Nassreddine, G.; Denoeux, T. A Multiple-Hypothesis Map-Matching Method Suitable for Weighted and Box-Shaped State Estimation for Localization. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1495–1510. [Google Scholar] [CrossRef]
- Chambers, E.; Fasy, B.T.; Wang, Y.; Wenk, C. Map-matching using shortest paths. ACM Trans. Spat. Algorithms Syst. (TSAS) 2020, 6, 1–17. [Google Scholar] [CrossRef]
- Liu, X.; Liu, K.; Li, M.; Lu, F. A ST-CRF map-matching method for low-frequency floating car data. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1241–1254. [Google Scholar] [CrossRef]
- Alrassy, P.; Jang, J.; Smyth, A.W. OBD-Data-Assisted Cost-Based Map-Matching Algorithm for Low-Sampled Telematics Data in Urban Environments. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12094–12107. [Google Scholar] [CrossRef]
- Huang, Z.; Qiao, S.; Han, N.; Yuan, C.; Song, X.; Xiao, Y. Survey on vehicle map matching techniques. CAAI Trans. Intell. Technol. 2021, 6, 55–71. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, B. A Hidden Markov Model-Based Map Matching Algorithm for Low Sampling Rate Trajectory Data. IEEE Access 2019, 7, 178235–178245. [Google Scholar] [CrossRef]
- Hansson, A.; Korsberg, E.; Maghsood, R.; Nordén, E. Lane-level map matching based on HMM. IEEE Trans. Intell. Veh. 2021, 6, 430–439. [Google Scholar] [CrossRef]
- Choi, K.; Suhr, K.; Jung, J.H.G. Map-Matching-Based Cascade Landmark Detection and Vehicle Localization. IEEE Access 2019, 7, 127874–127894. [Google Scholar] [CrossRef]
- Lee, Y.J.; Suhr, J.K.; Jung, H.G. Map Matching-Based Driving Lane Recognition for Low-Cost Precise Vehicle Positioning on Highways. IEEE Access 2021, 9, 42192–42205. [Google Scholar] [CrossRef]
- Ma, S.; Lee, H. Improving positioning accuracy based on self-organizing map (SOM) and inter-vehicular communication. Trans. Emerg. Telecommun. Technol. 2019, 30, e3733. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, M.; Xiao, Z.; Zhou, L.; Zhou, J. Adaptable Map Matching Using PF-net for Pedestrian Indoor Localization. IEEE Commun. Lett. 2020, 24, 1437–1440. [Google Scholar] [CrossRef]
- Ren, M.; Karimi, H.A. Movement pattern recognition assisted map matching for pedestrian/wheelchair navigation. J. Navig. 2012, 65, 617–633. [Google Scholar] [CrossRef]
- Jagadeesh, G.R.; Srikanthan, T. Online Map-Matching of Noisy and Sparse Location Data with Hidden Markov and Route Choice Models. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2423–2434. [Google Scholar] [CrossRef]
- Goh, C.Y.; Dauwels, J.; Mitrovic, N.; Asif, M.T.; Oran, A.; Jaillet, P. Online map-matching based on hidden markov model for real-time traffic sensing applications. In Proceedings of the 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 776–781. [Google Scholar]
- Osogami, T.; Raymond, R. Map matching with inverse reinforcement learning. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2547–2553. [Google Scholar]
- Chao, P.; Hua, W.; Mao, R.; Xu, J.; Zhou, X. A survey and quantitative study on map inference algorithms from gps trajectories. IEEE Trans. Knowl. Data Eng. 2020, 34, 15–28. [Google Scholar] [CrossRef]
- Shen, Z.; Du, W.; Zhao, X.; Zou, J. DMM: Fast map matching for cellular data. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London, UK, 21–25 September 2020; pp. 1–14. [Google Scholar]
- Perttula, A.; Leppäkoski, H.; Kirkko-Jaakkola, M.; Davidson, P.; Collin, J.; Takala, J. Distributed Indoor Positioning System with Inertial Measurements and Map Matching. IEEE Trans. Instrum. Meas. 2014, 63, 2682–2695. [Google Scholar] [CrossRef]
- Zampella, F.; Ruiz, A.R.J.; Granja, F.S. Indoor Positioning Using Efficient Map Matching, RSS Measurements, and an Improved Motion Model. IEEE Trans. Veh. Technol. 2015, 64, 1304–1317. [Google Scholar] [CrossRef]
- Zhong, Y. HMM Map Matching for Trajectories in City Areas with Multipath Errors. Master’s Thesis, Eindhoven University of Technology, Eindhoven, The Netherlands, 2021. [Google Scholar]
- Behr, T.; van Dijk, T.C.; Forsch, A.; Haunert, J.H.; Storandt, S. Map Matching for Semi-Restricted Trajectories. In Proceedings of the 11th International Conference on Geographic Information Science (GIScience 2021), Online, 27–30 September 2021. [Google Scholar]
- Boissonnat, J.-D.; Devillers, O.; Teillaud, M.; Yvinec, M. Triangulations in CGAL. In Proceedings of the 16th Annual Symposium on Computational Geometry, Hong Kong, China, 12–14 June 2000; pp. 11–18. [Google Scholar]
- Sasaki, Y.; Yu, J.; Ishikawa, Y. Road Segment Interpolation for Incomplete Road Data. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 February–2 March 2019; pp. 1–8. [Google Scholar]
- Ding, X.; Fan, H.; Gong, J. Towards generating network of bikeways from Mapillary data. Comput. Environ. Urban Syst. 2021, 88, 101632. [Google Scholar] [CrossRef]
- Fu, X.; Zhang, J.X.; Zhang, Y. An Online Map Matching Algorithm Based on Second-Order Hidden Markov Model. J. Adv. Transp. 2021, 2021, 9993860. [Google Scholar] [CrossRef]
- Salnikov, V.; Schaub, M.T.; Lambiotte, R. Using higher-order Markov models to reveal flow-based communities in networks. Sci. Rep. 2016, 6, 23194. [Google Scholar] [CrossRef] [PubMed]
- Koller, H.; Widhalm, P.; Dragaschnig, M.; Graser, A. Fast hidden Markov model map-matching for sparse and noisy trajectories. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2557–2561. [Google Scholar]
- Mangalam, K.; An, Y.; Girase, H.; Malik, J. From goals waypoints & paths to long term human trajectory forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 15233–15242. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| GPS measurement | |
| Road segment | |
| Open-field hidden state | |
| The set of hidden states | |
| The probability of the optimal state sequence | |
| The end state of the optimal state sequence | |
| The standard deviation of GPS measurements | |
| The parameter of the exponential distribution | |
| -th road segment within the search area | |
| Matched road segment sequence | |
| Matched open-field sequence |
| Path ID | No. of GPS Measurements | No. of Open-Field GPS Measurements |
|---|---|---|
| 1 | 910 | 317 |
| 2 | 794 | 320 |
| 3 | 1442 | 641 |
| 4 | 917 | 489 |
| 5 | 767 | 374 |
| Total | 4830 | 2141 |
| Method | HMM | Behr’s Method | EHMM-P |
|---|---|---|---|
| Reduced Error (m) | 1.02 | 2.35 | 4.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, S.; Wang, P.; Lee, H. An Enhanced Hidden Markov Model for Map-Matching in Pedestrian Navigation. Electronics 2024, 13, 1685. https://doi.org/10.3390/electronics13091685
Ma S, Wang P, Lee H. An Enhanced Hidden Markov Model for Map-Matching in Pedestrian Navigation. Electronics. 2024; 13(9):1685. https://doi.org/10.3390/electronics13091685
Chicago/Turabian StyleMa, Shengjie, Pei Wang, and Hyukjoon Lee. 2024. "An Enhanced Hidden Markov Model for Map-Matching in Pedestrian Navigation" Electronics 13, no. 9: 1685. https://doi.org/10.3390/electronics13091685
APA StyleMa, S., Wang, P., & Lee, H. (2024). An Enhanced Hidden Markov Model for Map-Matching in Pedestrian Navigation. Electronics, 13(9), 1685. https://doi.org/10.3390/electronics13091685