Hardware Considerations for Tensor Implementation and Analysis Using the Field Programmable Gate Array



Abstract
:1. Introduction
2. Algorithms for Tensor Analysis
2.1. Introduction
2.2. Tensors as Algebraic Objects
2.3. Machine Learning, Deep Learning, and Tensors
2.4. Tensor Hardware
2.5. Contribution of this Paper
- A general approach to inner and outer product, n dimensional, 0 ≤ n;
- a general approach relative to scalar operations other than + and ×; and
- a demonstration of how the design enables speed-up for Kronecker Products
2.6. The Kronecker Family of Algorithms
3. Memory Considerations for Tensor Analysis
3.1. Introduction
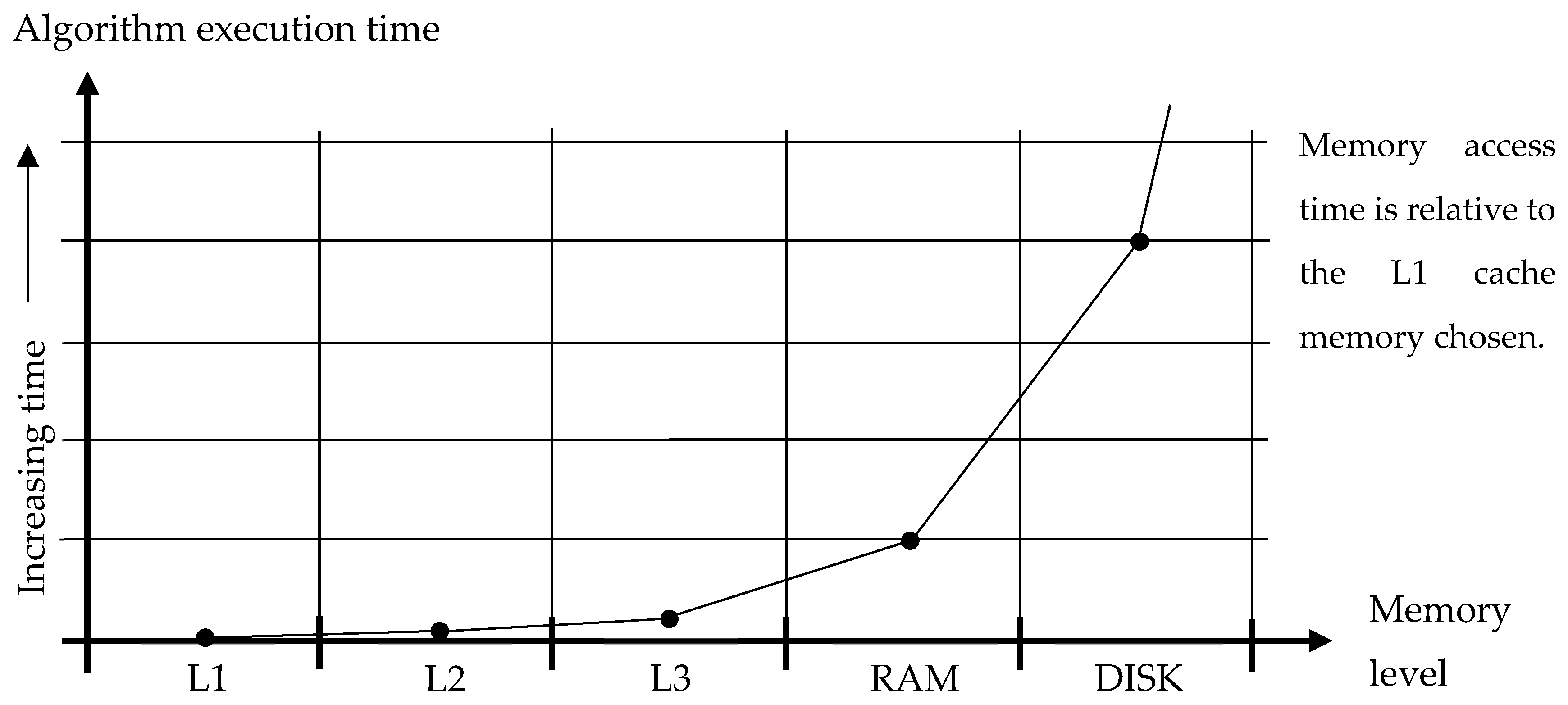
3.2. Computer Memory Access
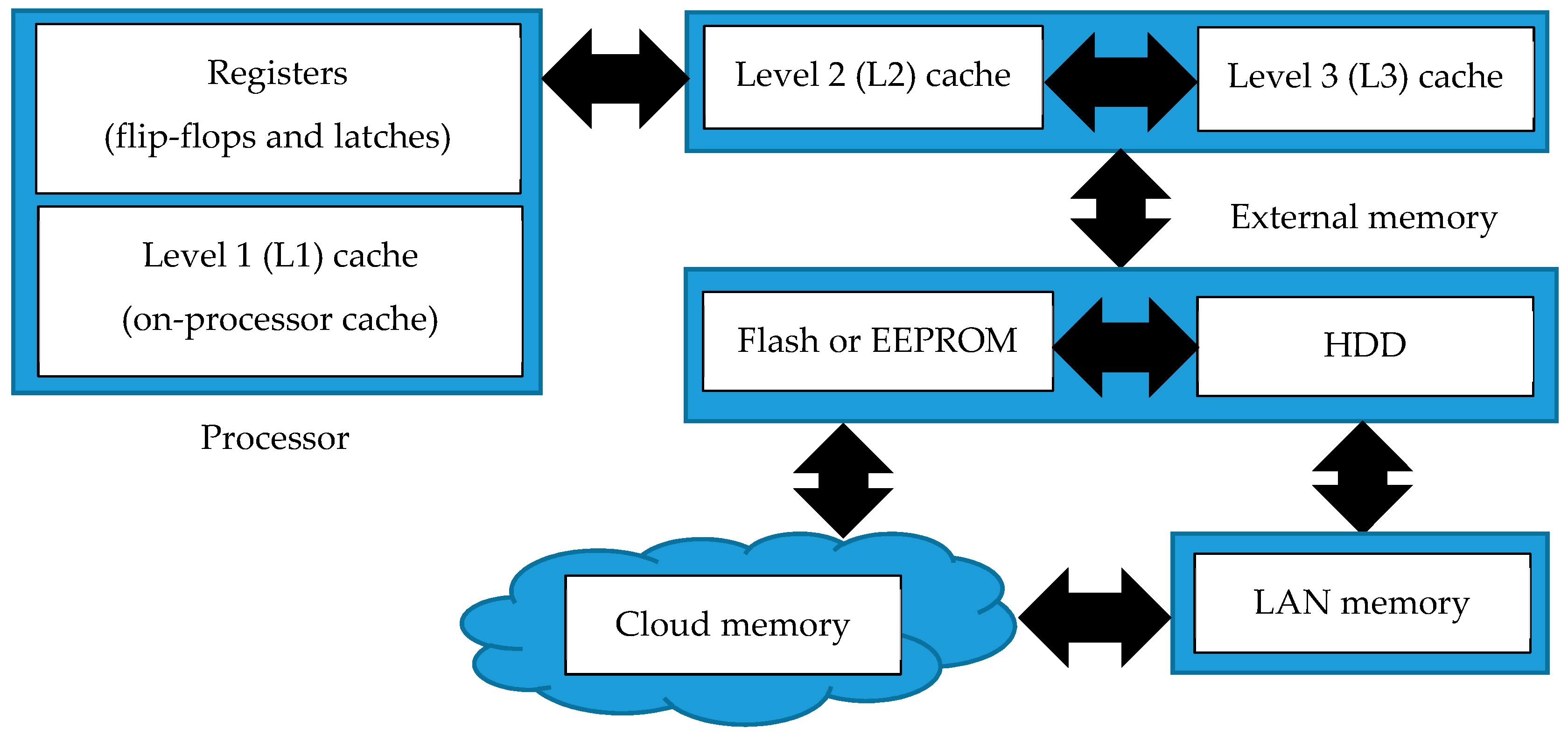
3.3. Cache Memory: Memory Types and Caches in a Typical Processor System
3.4. Cache Misses and Implications
3.5. Cost Functions for Memory Access
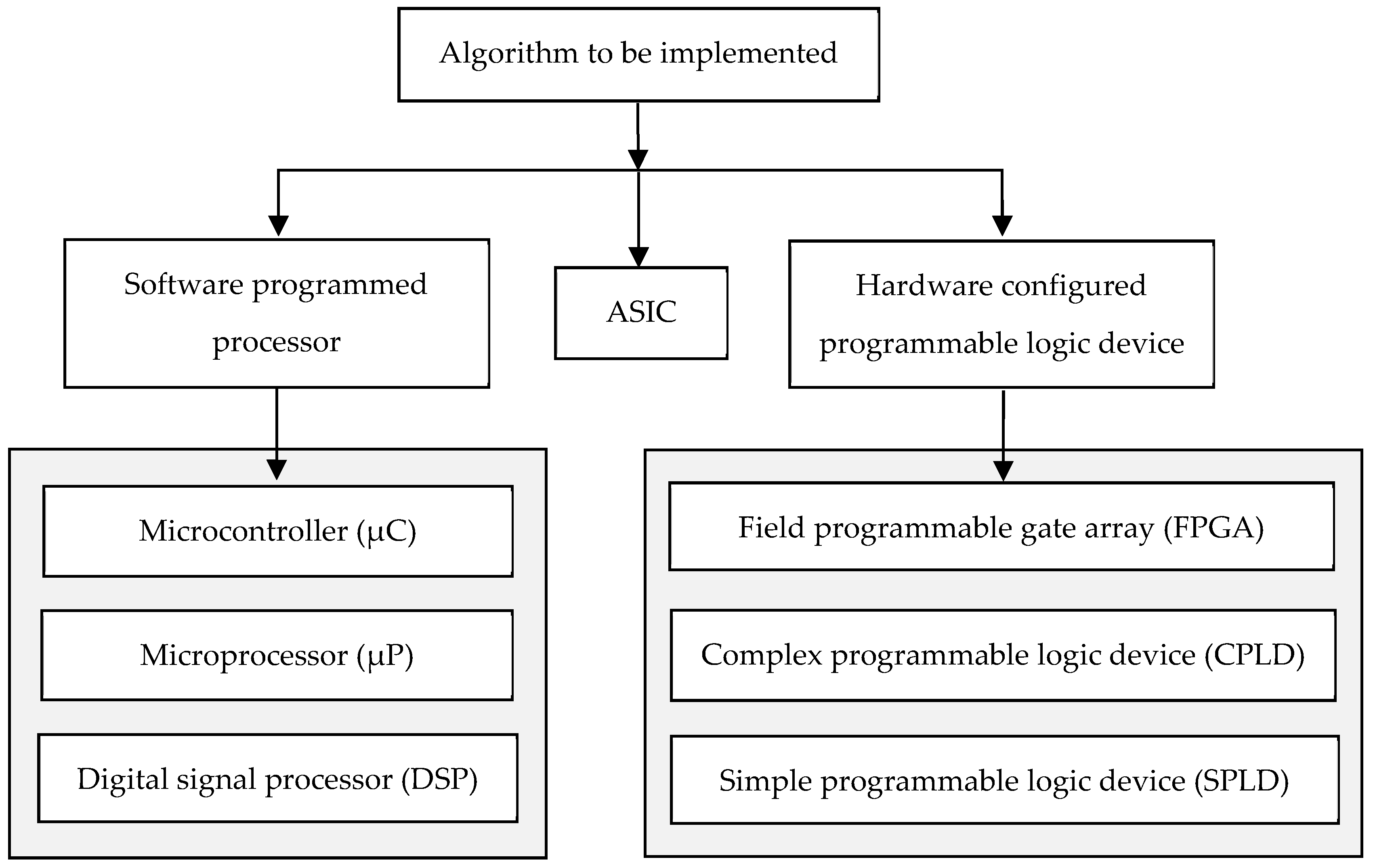
4. The Field Programmable Gate Array (FPGA)
4.1. Introduction
4.2. Programmable Logic Devices (PLDs)
4.3. Hardware Functionality within the FPGA
- Volatile memory: When data are stored within the memory, the data are retained in the memory whilst the memory is connected to a power supply. Once the power supply has been removed, then the contents of the memory (the data) are lost. The early FPGAs utilized volatile SRAM based memory.
- Non-volatile memory: When data are stored within the memory, the data are retained in the memory even when the power supply has been removed. Specific FPGAs available today utilize Flash memory for holding the configuration.
5. Inner and Outer Product Implementation in Hardware Using the FPGA Case Study
5.1. Introduction
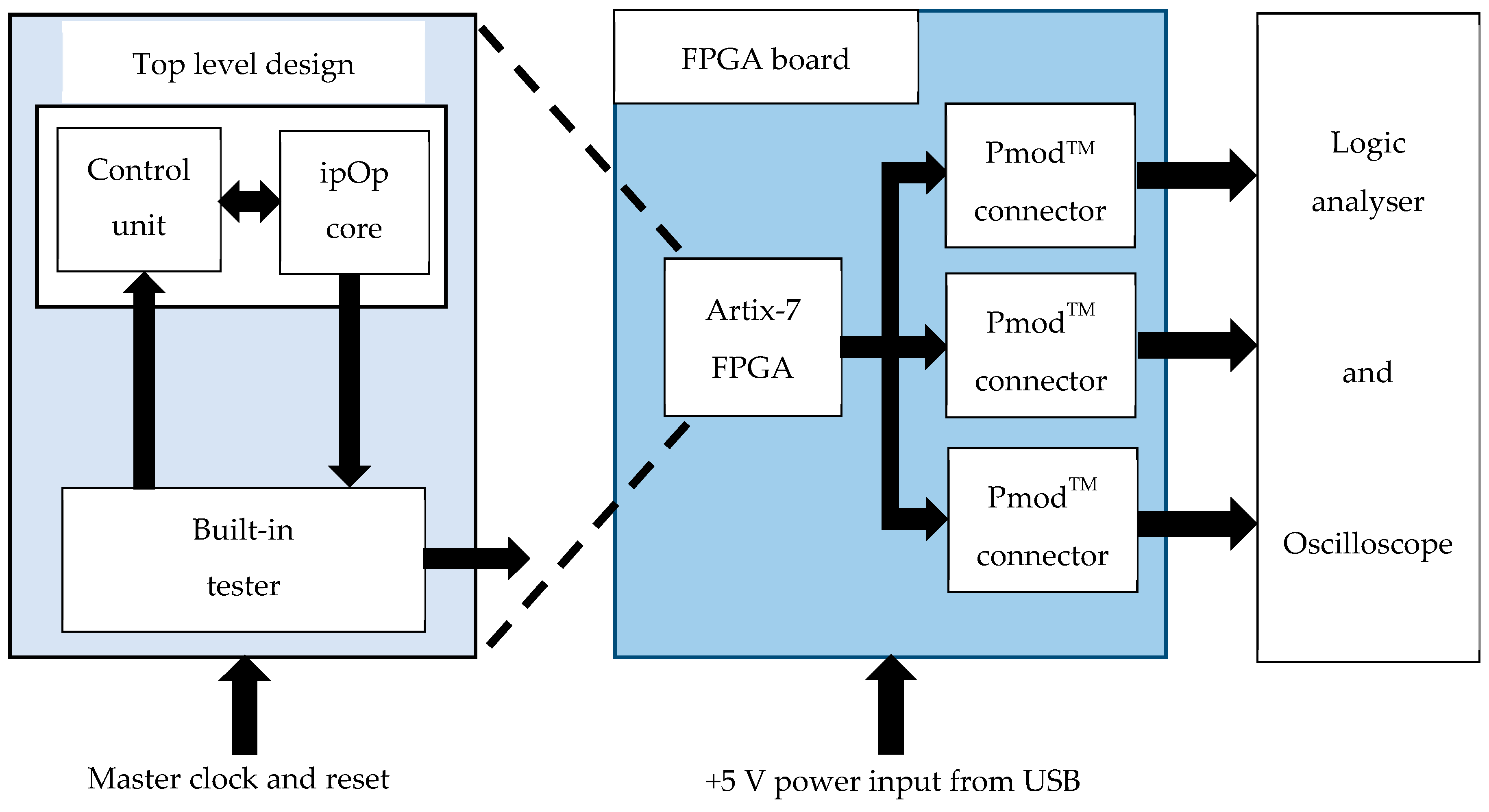
- The development board used provided hardware resources that were useful for project work, such as the 100 MHz clock, external memory, switches, push buttons, light emitting diodes (LEDs), expansion connectors, LAN connection, and a universal serial bus (USB) interface for FPGA configuration and runtime serial I/O.
- The development board was physically compact and could be readily integrated into an enclosure for mobility purposes and operated from a battery rather than powered through the USB +5 V power.
- The Artix-7 FPGA provided adequate internal resources and I/O for the work undertaken and external resources could be readily added via the expansion connectors if required.
- For memory implementation, the FPGA can use the internal look-up tables (LUTs) as distributed memory for small memories, can use internal BRAM (Block RAM) for larger memories, and external volatile/non-volatile memories connected to the I/O.
- For computation requirements, the FPGA allows for both fixed-point and floating-point arithmetic operations to be implemented.
- For an embedded processor based approach, the MicroBlaze CPU can be instantiated within the FPGA for software based implementations.
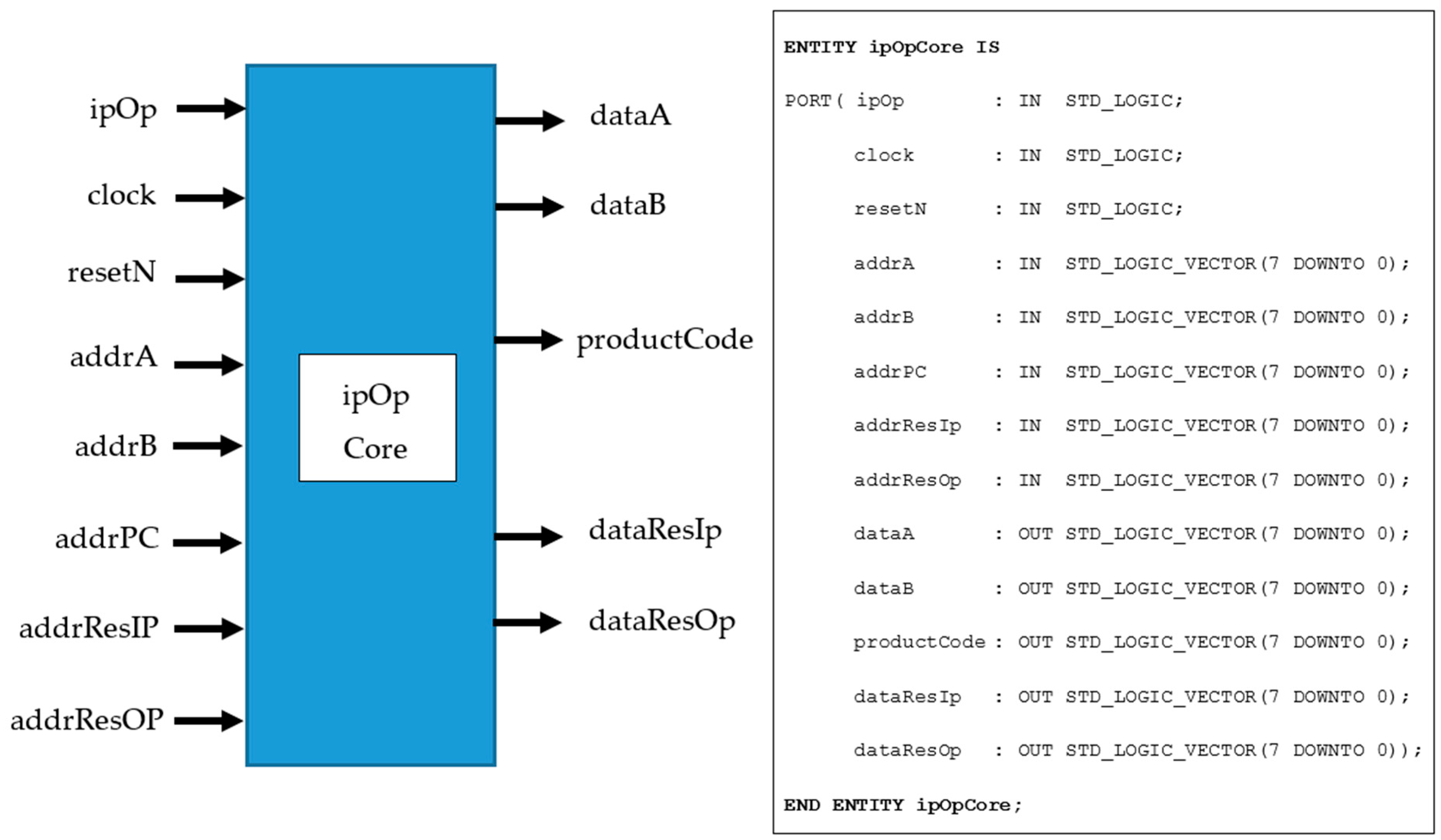
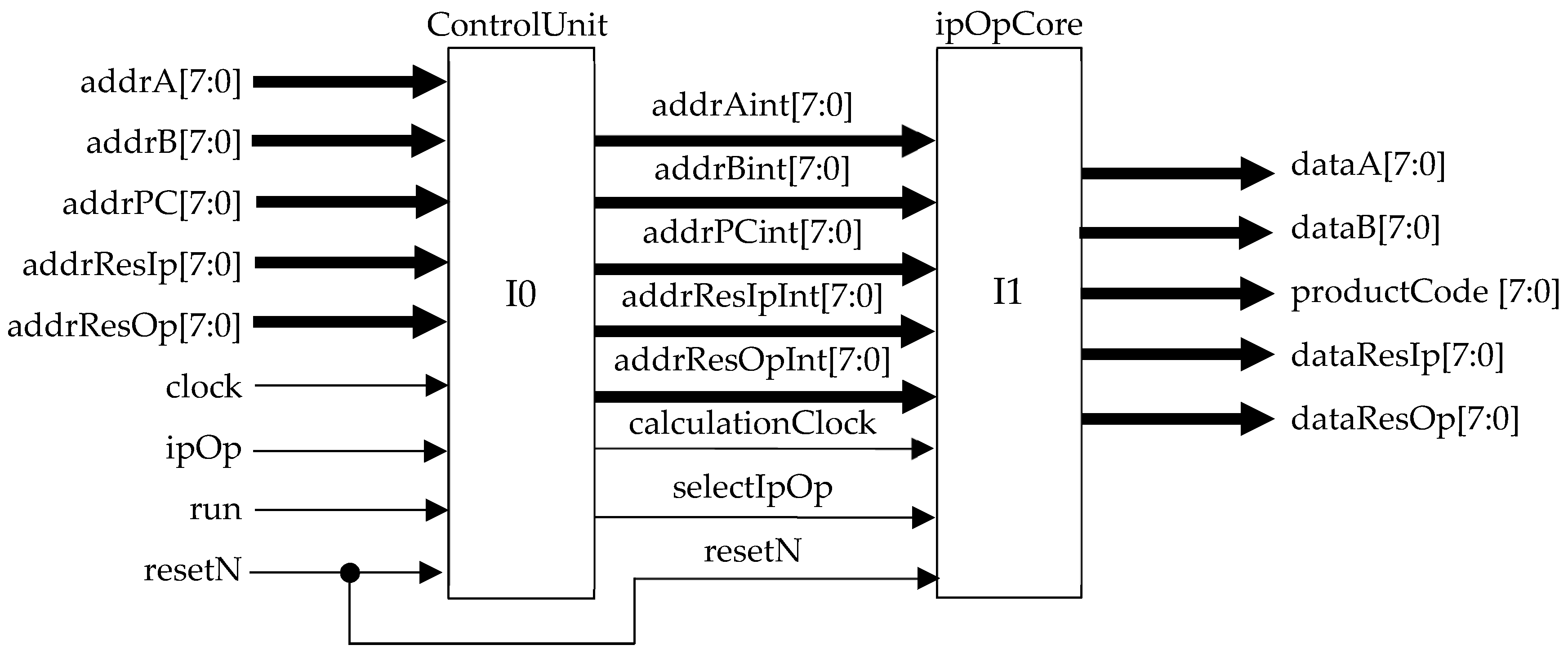
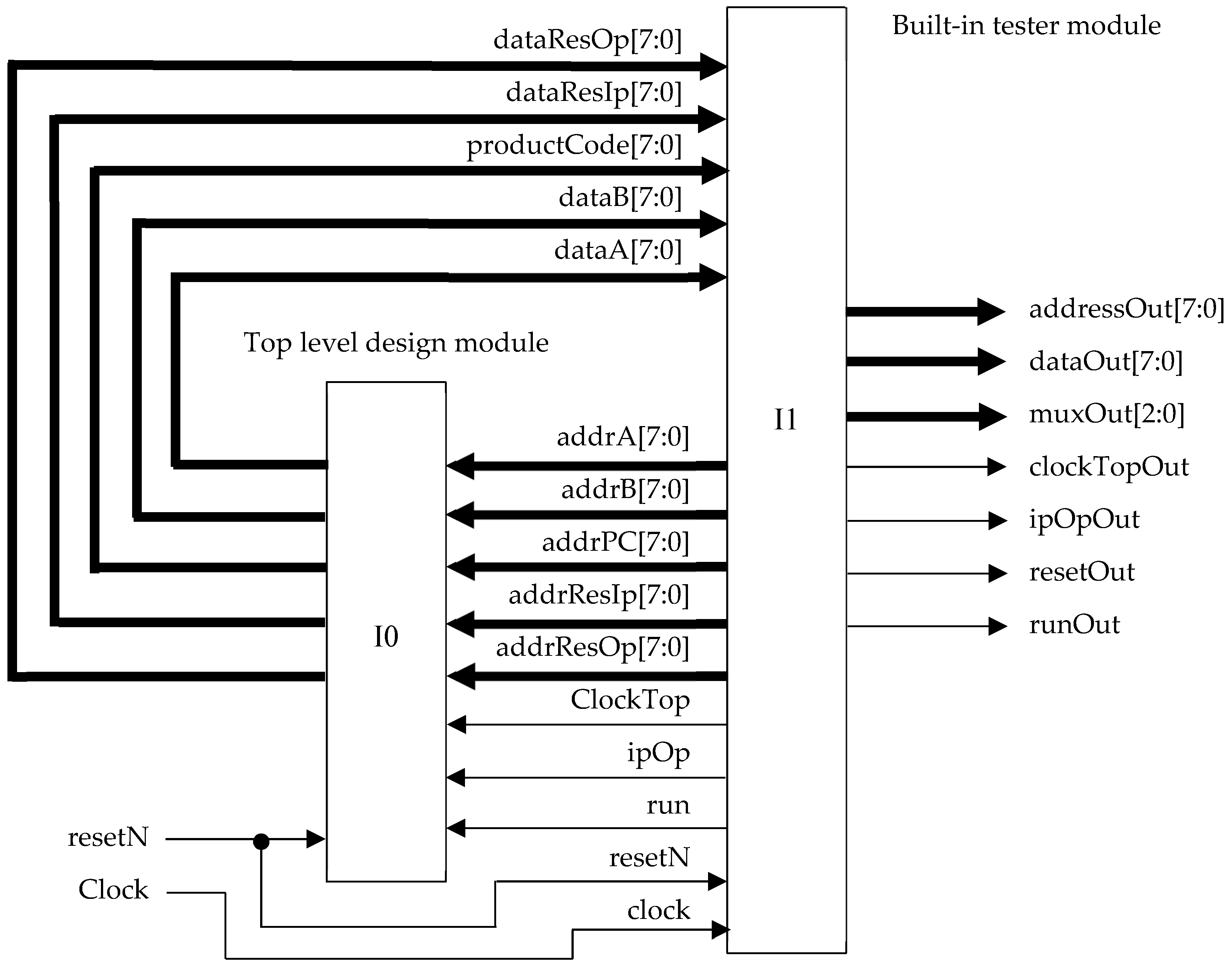
| ipOp | User to select whether the inner or outer product is to be performed. |
| clock | Master clock (100 MHz). |
| resetN | Master, asynchronous active low reset. |
| addrA | Array A address for reading array contents (input tensor A). |
| addrB | Array B address for reading array contents (input tensor B). |
| addrPC | Array PC address for reading array contents (product code array). |
| addrResIp | Address of inner product for reading array contents (output tensor IP). |
| addrResOp | Address of outer product for reading array contents (output tensor OP). |
| dataA | Array A data element being accessed (for test purposes only). |
| dataB | Array B data element being accessed (for test purposes only). |
| productCode | Input array size and shape information for algorithm operation. |
| dataResIp | Inner product result array (Serial read-out). |
| dataResOp | Outer product result array contents (serial readout). |
5.2. Design Approach and Target FPGA
- How to model the arrays for early-stage evaluation work and how to map the arrays to hardware in the FPGA.
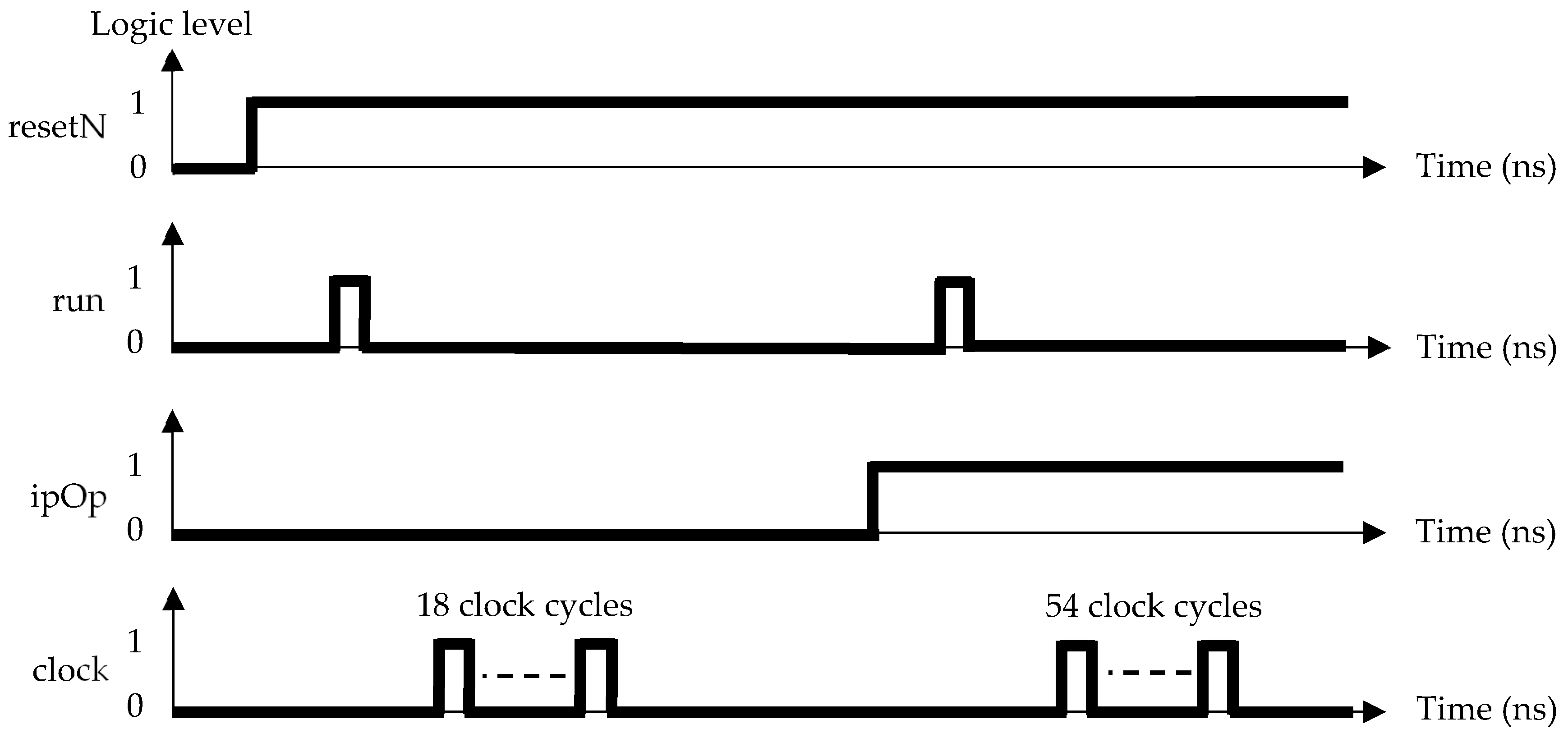
- How to design the algorithm to meet timing constraints, such as maximum processing time, number of clock cycles required, hardware size considerations, and the potential clock frequency, with the hardware once it is configured within the FPGA.
TYPE array_1by4 IS ARRAY (0 TO 3) OF INTEGER; TYPE array_1by6 IS ARRAY (0 TO 5) OF INTEGER; TYPE array_1by9 IS ARRAY (0 TO 8) OF INTEGER; TYPE array_1by36 IS ARRAY (0 TO 35) OF INTEGER; TYPE array_1by54 IS ARRAY (0 TO 53) OF INTEGER; CONSTANT arrayA : array_1by9 := (0, 1, 2, 3, 4, 5, 6, 7, 8); CONSTANT arrayB : array_1by6 := (0, 1, 2, 3, 4, 5); SIGNAL arrayResultIp : array_1by6 := (0, 0, 0, 0, 0, 0); SIGNAL arrayResultOp : array_1by54 := (0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0);
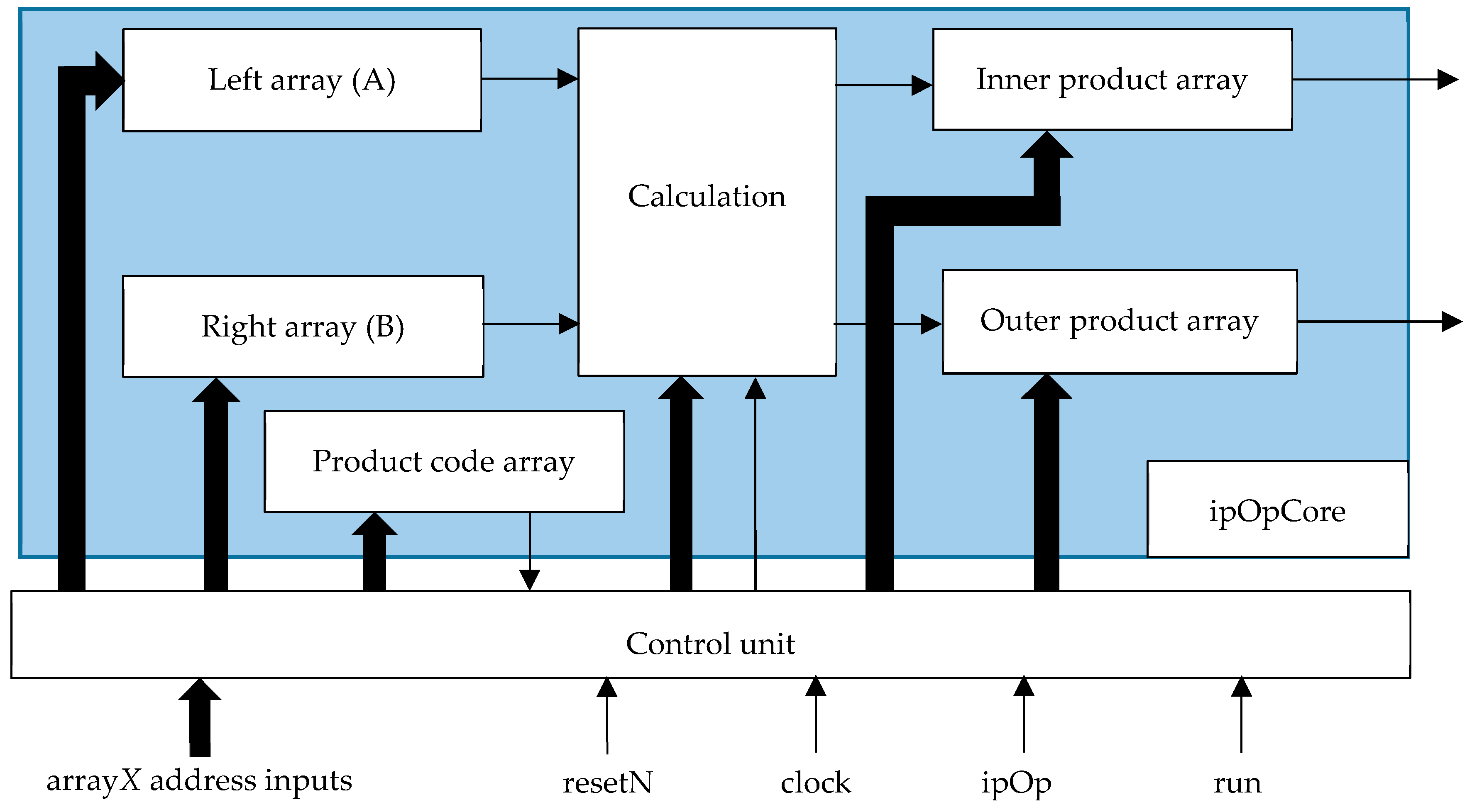
5.3. System Architecture
| ipOp | User to select whether the inner or outer product is to be performed; |
| clock | Master clock (100 MHz); |
| resetN | Master, asynchronous active low reset; and |
| run | Initiate a computation run (0-1-0 pulse) |
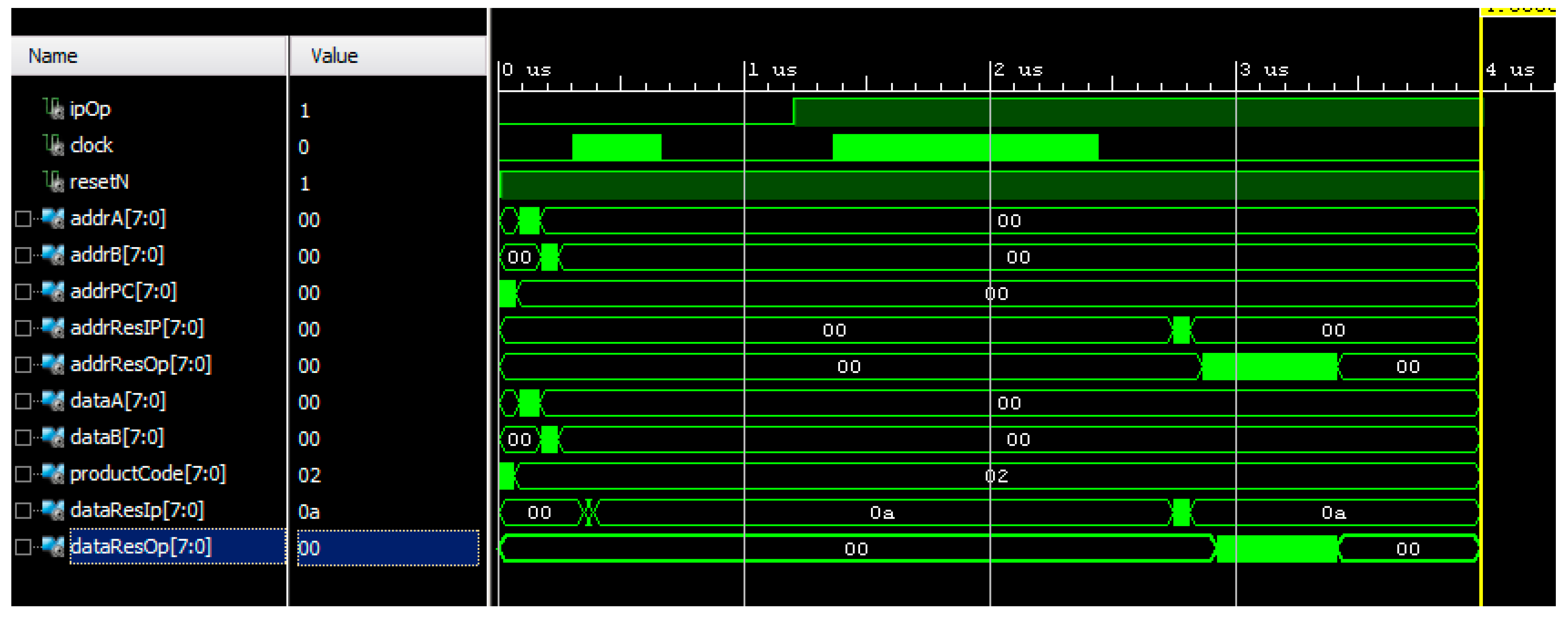
5.4. Design Simulation
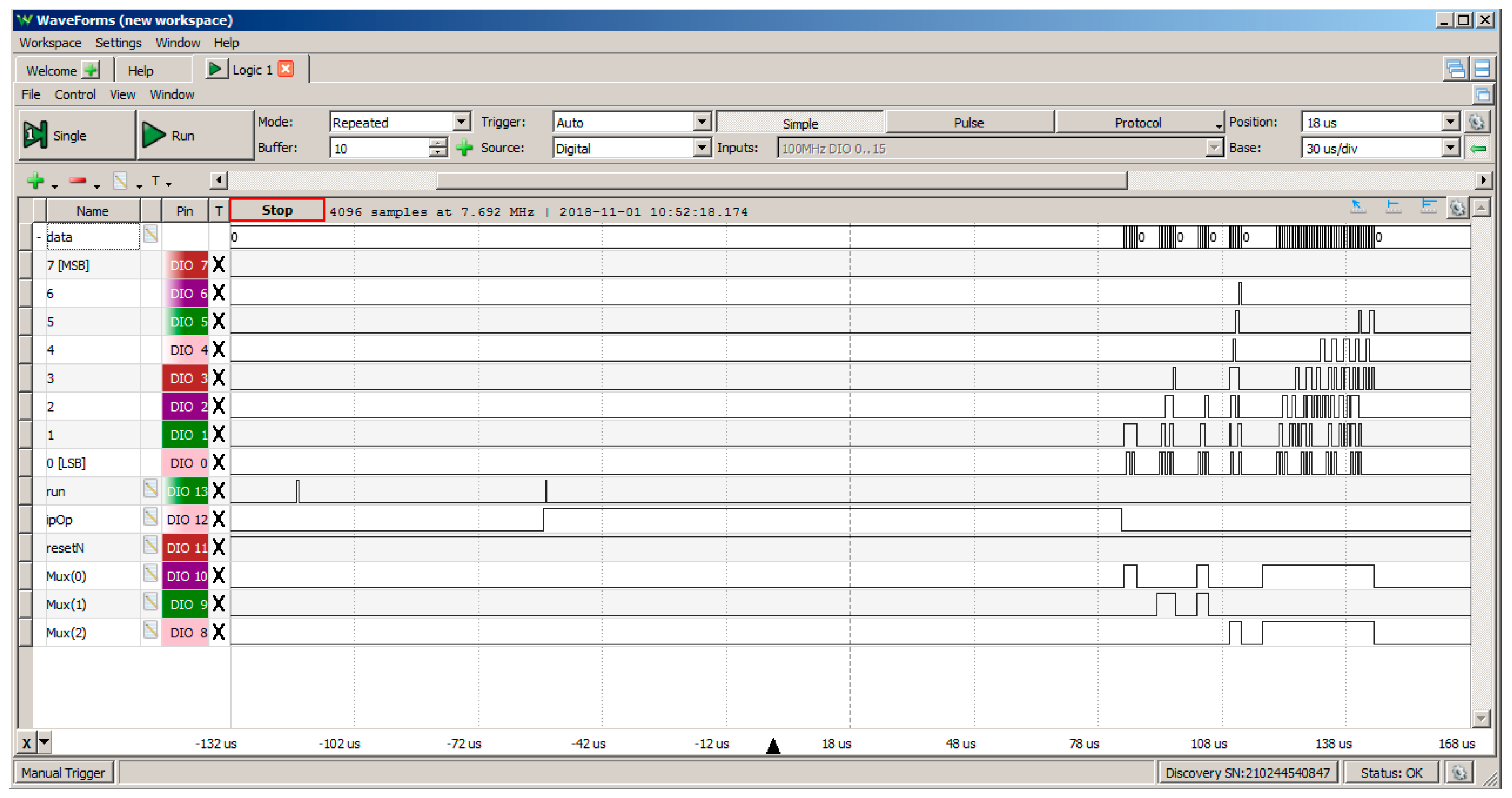
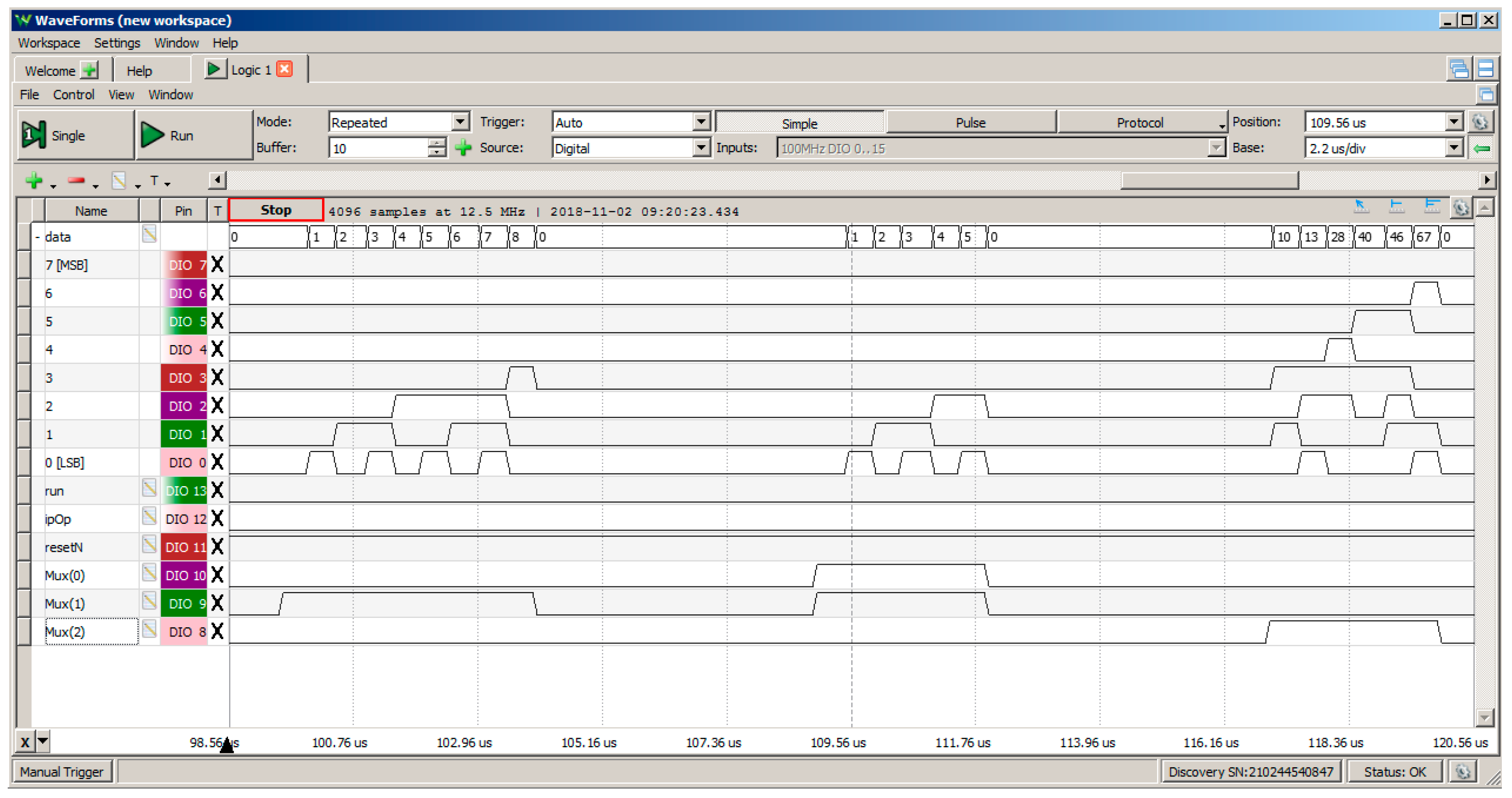
5.5. Hardware Test Set-Up
5.6. Design Implementation Considerations
- The computation module.
- The control module. The control module was required to receive control signals from an external system and transform these to internal control signals for the computation module.
- The memory module.
- The algorithm module.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Earley, S. Analytics, Machine Learning, and the Internet of Things. IT Prof. 2015, 17, 10–13. [Google Scholar] [CrossRef]
- Corneanu, C.A.; Simón, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-Related Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xilinx®. FPGA Leadership across Multiple Process Nodes. Available online: https://www.xilinx.com/products/silicon-devices/fpga.html (accessed on 9 October 2018).
- Xilinx®. Homepage. Available online: https://www.xilinx.com/ (accessed on 9 October 2018).
- Xilinx®. Artix-7 FPGA Family. Available online: https://www.xilinx.com/products/silicon-devices/fpga/artix-7.html (accessed on 9 October 2018).
- Daniel Fleisch. A Student’s Guide to Vectors and Tensors; Cambridge University Press: Cambridge, UK, 2011; ISBN-10 0521171903, ISBN-13 978-0521171908. [Google Scholar]
- Institute of Electrical and Electronics Engineers. IEEE Std 1076-2008—IEEE Standard VHDL Language Reference Manual; IEEE: New York, NY, USA, 2009; ISBN 978-0-7381-6853-1, ISBN 978-0-7381-6854-8. [Google Scholar]
- Kindratenko, V.; Trancoso, P. Trends in High Performance Computing. Comput. Sci. Eng. 2011, 13, 92–95. [Google Scholar] [CrossRef]
- Lane, N.D.; Bhattacharya, S.; Mathur, A.; Georgiev, P.; Forlivesi, C.; Kawsar, F. Squeezing Deep Learning into Mobile and Embedded Devices. IEEE Pervasive Comput. 2017, 16, 82–88. [Google Scholar] [CrossRef]
- Mullin, L.; Raynolds, J. Scalable, Portable, Verifiable Kronecker Products on Multi-scale Computers. In Constraint Programming and Decision Making. Studies in Computational Intelligence; Ceberio, M., Kreinovich, V., Eds.; Springer: Cham, Switzerland, 2014; Volume 539. [Google Scholar]
- Gustafson, J.; Mullin, L. Tensors Come of Age: Why the AI Revolution Will Help HPC. 2017. Available online: https://www.hpcwire.com/2017/11/13/tensors-come-age-ai-revolution-will-help-hpc/ (accessed on 9 October 2018).
- Workshop Report: Future Directions in Tensor Based Computation and Modeling. 2009. Available online: https://www.researchgate.net/publication/270566449_Workshop_Report_Future_Directions_in_Tensor-Based_Computation_and_Modeling (accessed on 9 October 2018).
- Tensor Computing for Internet of Things (IoT). 2016. Available online: http://drops.dagstuhl.de/opus/volltexte/2016/6691/ (accessed on 9 October 2018).
- Python.org, Python. Available online: https://www.python.org/ (accessed on 9 October 2018).
- TensorflowTM. Available online: https://www.tensorflow.org/ (accessed on 9 October 2018).
- Pytorch. Available online: https://pytorch.org/ (accessed on 9 October 2018).
- Keras. Available online: https://en.wikipedia.org/wiki/Keras (accessed on 9 October 2018).
- Apache MxNet. Available online: https://mxnet.apache.org/ (accessed on 9 October 2018).
- Microsoft Cognitive Toolkit (MTK). Available online: https://www.microsoft.com/en-us/cognitive-toolkit/ (accessed on 9 October 2018).
- CAFFE: Deep Learning Framework. Available online: http://caffe.berkeleyvision.org/ (accessed on 9 October 2018).
- DeepLearning4J. Available online: https://deeplearning4j.org/ (accessed on 9 October 2018).
- Chainer. Available online: https://chainer.org/ (accessed on 9 October 2018).
- Google, Cloud TPU. Available online: https://cloud.google.com/tpu/ (accessed on 9 October 2018).
- Lenore, M.; Mullin, R. A Mathematics of Arrays. Ph.D. Thesis, Syracuse University, Syracuse, NY, USA, 1988. [Google Scholar]
- Mullin, L.; Raynolds, J. Conformal Computing: Algebraically connecting the hardware/software boundary using a uniform approach to high-performance computation for software and hardware. arXiv. 2018. Available online: https://arxiv.org/pdf/0803.2386.pdf (accessed on 1 November 2018).
- Institute of Electrical and Electronics Engineers. IEEE Std 1364™-2005 (Revision of IEEE Std 1364-2001), IEEE Standard for Verilog® Hardware Description Language; IEEE: New York, NY, USA, 2006; ISBN 0-7381-4850-4, ISBN 0-7381-4851-2. [Google Scholar]
- Ong, Y.S.; Grout, I.; Lewis, E.; Mohammed, W. Plastic optical fibre sensor system design using the field programmable gate array. In Selected Topics on Optical Fiber Technologies and Applications; IntechOpen: Rijeka, Croatia, 2018; pp. 125–151. ISBN 978-953-51-3813-6. [Google Scholar]
- Dou, Y.; Vassiliadis, S.; Kuzmanov, G.K.; Gaydadjiev, G.N. 64 bit Floating-point FPGA Matrix Multiplication. In Proceedings of the 2005 ACM/SIGDA 13th International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 20–22 February 2005. [Google Scholar] [CrossRef]
- Amira, A.; Bouridane, A.; Milligan, P. Accelerating Matrix Product on Reconfigurable Hardware for Signal Processing. In Field-Programmable Logic and Applications, Proceedings of the 11th International Conference, FPL 2001, Belfast, UK, 27–29 August 2001; Lecture Notes in Computer Science; Brebner, G., Woods, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 101–111, ISBN 978-3-540-42499-4 (print), ISBN 978-3-540-44687-3 (online). [Google Scholar]
- Hurst, S.L. VLSI Testing—Digital and Mixed Analogue/Digital Techniques; The Institution of Engineering and Technology: London, UK, 1998; pp. 241–242. ISBN 0-85296-901-5. [Google Scholar]
- Digilent®. Analog Discovery. Available online: https://reference.digilentinc.com/reference/instrumentation/analog-discovery/start?redirect=1 (accessed on 1 November 2018).
- Digilent®. Waveforms. Available online: https://reference.digilentinc.com/reference/software/waveforms/waveforms-3/start (accessed on 1 November 2018).
- Nvidia. Nvidia Tensor Cores. Available online: https://www.nvidia.com/en-us/data-center/tensorcore/ (accessed on 1 November 2018).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank. | Mathematical Entity | Example Realization in Python Code |
|---|---|---|
| 0 | Scalar (magnitude only) | A = 1 |
| 1 | Vector (magnitude and direction) | B = [0,1,2] |
| 2 | Matrix (two dimensions) | C = [[0,1,2], [3,4,5], [6,7,8]] |
| 3 | Cube (three dimensions) | D = [[[0,1,2], [3,4,5]], [[6,7,8], [9,10,11]]] |
| n | n dimensions | … |
| Vendor | FPGA | SPLD/CPLD | Company Homepage |
|---|---|---|---|
| Xilinx® | Virtex, Kintex, Artix and Spartan | CoolRunner-II, XA CoolRunner-II and XC9500XL | https://wwwxilinxcom/ |
| Intel® | Stratix, Arria, MAX, Cyclone and Enpirion | --- | https://wwwintelcom/content/www/us/en/fpga/deviceshtml |
| Atmel Corporation (Microchip) | AT40Kxx family FPGA | ATF15xx ATF25xx, ATF75xx CPLD families and ATF16xx, ATF22xx SPLD families | https://wwwmicrochipcom/ |
| Lattice Semiconductor | ECP, MachX and iCE FPGA families | ispMACH CPLD family | http://wwwlatticesemicom/ |
| Microsemi | PolarFire, IGLOO, IGLOO2, ProASIC3, Fusion and Rad-Tolerant FPGA families | --- | https://wwwmicrosemicom/product-directory/fpga-soc/1638-fpgas |
| Item | Use | Number Used |
|---|---|---|
| Package pin | Input | 44 |
| Output | 40 | |
| Design synthesis results | ||
| Post-synthesis I/O | Inputs | 23 * |
| Outputs | 40 | |
| Slice LUTs | Total used | 454 |
| LUT as logic | 442 | |
| LUT as memory (distributed RAM) | 12 | |
| Slice registers | Total used | 217 |
| Slice register as flip-flop | 217 | |
| Other logic | Clock buffer | 2 |
| Design implementation results | ||
| Post-implementation I/O | Inputs | 23 |
| Outputs | 40 | |
| Slice LUTs | Total used | 391 |
| LUT as logic | 379 | |
| LUT as memory (distributed RAM) | 12 | |
| Slice registers | Total used | 217 |
| Slice register as flip-flop | 217 | |
| Other logic | Clock buffer | 2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grout, I.; Mullin, L. Hardware Considerations for Tensor Implementation and Analysis Using the Field Programmable Gate Array. Electronics 2018, 7, 320. https://doi.org/10.3390/electronics7110320
Grout I, Mullin L. Hardware Considerations for Tensor Implementation and Analysis Using the Field Programmable Gate Array. Electronics. 2018; 7(11):320. https://doi.org/10.3390/electronics7110320
Chicago/Turabian StyleGrout, Ian, and Lenore Mullin. 2018. "Hardware Considerations for Tensor Implementation and Analysis Using the Field Programmable Gate Array" Electronics 7, no. 11: 320. https://doi.org/10.3390/electronics7110320
APA StyleGrout, I., & Mullin, L. (2018). Hardware Considerations for Tensor Implementation and Analysis Using the Field Programmable Gate Array. Electronics, 7(11), 320. https://doi.org/10.3390/electronics7110320