1. Introduction
Unmanned aerial vehicles (UAVs) are non-manned aircraft that are operated by radio remote control equipment or a self-contained program control device. Drones have wide applicability in military and civilian areas because they have advantages of simple and practical structure, convenient and flexible operation, and low cost. Furthermore, users do not have to worry about casualties that drones may cause. They are widely used in military missions such as tactical reconnaissance and territorial surveillance, target positioning, and so on. In civil use, drones can be used for field monitoring, meteorological exploration, highway inspection, etc. With the popularization and wide application of drones in military and civilian fields, drones’ safety issues must be considered. Relevant data show that the number of failures in the recycling process of drones accounts for more than 80% of the total number of failures of drones. Therefore, research on the safe landing and recovery of drones has become an urgent task.
However, due to the complex application environment of drones (especially in the context of war), drones’ landing research needs to consider many factors and versatility, with improved practicality. To be more specific, the main challenges cover the following points: (1) Autonomous control without GPS signal. The anti-jamming capability of GPS is extremely weak. If the on-board GPS signal receiver of drones malfunctions due to electronic interference, drones will lose their navigation and positioning function, and thereby fail to land safely. In the natural state, GPS signals can be easily interfered. The influencing factors are mainly divided into four categories: (a) weather factors and sunspots may reduce signal strength, but generally do not affect positioning; (b) electromagnetic interference, radio, and strong magnetic fields all generate different levels of interference; (c) GPS signals will decrease under shelters, such as buildings, vehicles, insulation paper, trees, and metal components; and (d) high-rise buildings and dense high-rise buildings will affect GPS signals. Therefore, it is very important to study the autonomous positioning and flight control of drones without GPS signals; (2) Passive landing in an emergency. Since the drone’s compensation mechanism does not allow the failed drone to continue flying for a long time, it should begin to select a site for emergency landing. Although this is a helpless move, it is also an important measure to prevent the drone from falling into densely populated areas. The Federal Aviation Administration of the United States believes that, in the future, drones must not only guarantee their own secure flight, but also have the ability to interact safely with a variety of aircraft in their airspace in the event of an emergency. Such regulations still assume the ability of drones to maintain communication between the air and ground during emergencies. In fact, when some more serious failures occur, a drone is likely to completely lose contact with the ground. At that point, drones’ abilities to autonomously plan routes, autonomously search for landing sites, and autonomously land become the last resort to save themselves; (3) Autonomous landing in an unknown environment. In the military field or in disaster relief situations, the place where drones need to perform tasks is mostly an unknown environment or a variegated environment. It is essential that drones can choose landing sites with proper strategies and land safely.
To address these problems, researchers have made their contributions to drones’ autonomous flight and secure landing. Jung et al. [
1] propose a four-rotor drone guided landing algorithm. This paper presents a framework for the utilization of low-cost sensors for precise landing in moving targets. Based on the previous paper, authors in [
2] describes the tracking guidance for autonomous drone landing and the vision-based detection of the marker on a moving vehicle with a real-time image processing system. Falanga et al. [
3] presents a quadrotor system capable of autonomously landing on a moving platform using only onboard sensing and computing. This paper relies on computer vision algorithms, multi-sensor fusion for localization of the robot, detection and motion estimation of the moving platform, and path planning for fully autonomous navigation. Authors in [
4,
5] propose drone landing technology by identifying a sign and then landing the drone on the marker. Therefore, the drone needs to place the landing mark in the landing area before landfall. Vlantis et al. [
6] studies the problem of landing a quadrotor on an inclined moving platform. The aerial robot employs a forward-looking on-board camera to detect and observe the landing platform, which is carried by a mobile robot moving independently on an inclined surface. Kim et al. [
7] propose a vision-based target following and landing system for a quadrotor vehicle on a moving platform. The system employs a vision-based landing site detection and locating algorithm using an omnidirectional lens. Measurements from the omnidirectional camera are combined with a proper dynamic model in order to estimate the position and velocity of the moving platform. Forster et al. [
8] proposes a resource-efficient system for real-time three-dimensional terrain reconstruction and landing spot detection for micro aerial vehicles. This paper uses the semi-Direct monocular visual odometry (SVO) algorithm to extract the key points to create the terrain map. However, SVO is a visual odometer based on the semi-direct method, which inherits some drawbacks of the direct method and discards optimization and loop detection. Authors in [
9] propose a fixed-wing drone landing method based on optical guidance, using the ground landing guidance system to optically guide the landing. A measuring camera is arranged on both sides of the runway, and a marker light is installed in front of the drone, and the drone is spatially positioned by binocular stereo vision. This method has many outstanding advantages, being a self-contained system with high measurement accuracy that is low-cost and has low power consumption. Furthermore, it is less susceptible to interference without time accumulation errors. However, it is a ground guidance system and is not suitable for fully-autonomous landing of quadrotor UAVs in emergencies and unknown environments.
Despite the above, these methods have their own drawbacks and limitations: (1) most existing methods focus on landing the drone on a marker; and (2) some methods use model-based approaches to deal with missing visual information. Alternative solutions are realized with the use of additional sensors attached to landing area. Among many, these sensors include inertial measurement units (IMUs), GPS receivers, or infrared markers; and (3) previous research has only been able to accomplish landing in a given environment. Additionally, GPS [
7,
10,
11,
12] or motion capture systems [
13,
14] are often used for state estimation, either only while patrolling or throughout the entire task. Conversely, this paper relies only on visual–inertial odometry for state estimation. These approaches do not work in many cases, such as an emergency landing of a UAV or landing in a stricken area. There are also many emergency situations during the flight of UAVs, such as low battery power, machine malfunctions, or some unexpected conditions where drones need to be landed in unmarked areas. Therefore, we need UAVs to be able to land autonomously in unstructured and natural environments.
In order to land in unknown environments, our approach is to use visual landing technology. The simultaneous localization and mapping (SLAM) algorithm is a hotspot of robot and computer vision research, and is considered as one of the key technologies for automatic navigation in unknown environments. In 2007, Professor Davison presented MonoSLAM [
15], which is the first real-time monocular vision SLAM system. MonoSLAM was designed to expand the Kalman filter for the back-end, tracking very sparse feature points. Parallel tracking and mapping (PTAM) [
16] is a well-known single-SLAM algorithm that proposes and implements the tracking and mapping into two separate thread modules, and greatly improves the efficiency of the algorithm so that the algorithm can run in real time. PTAM combined with augmented reality (AR) is used in augmented reality software. Nevertheless, it also has its own limitations. For example, it can only be applied in a relatively small working environment. Forster et al. propose a semi-direct monocular visual odometry (SVO) based on a semi-direct method [
17]. It uses pixel brightness to estimate pose, resulting in the ability to maintain pixel-level precision in high-frame-rate video. However, SVO abandons the optimization and loop detection part in order to improve speed and make the system lightweight, which results in increased calculation error and inaccurate posture estimation under a long running time, and the loss is not easy to reposition. LSD-SLAM (large-scale direct monocular SLAM) [
18] is an algorithm based on features and direct methods, proposed by Engel et al. It applies the direct method to semi-dense monocular SLAM, which can realize semi-dense scene reconstruction on a CPU. Since LSD-SLAM uses direct methods to track, it also inherits the disadvantages of direct methods. For example, LSD-SLAM is very sensitive to the intrinsic camera parameters and exposure, and it fails very easily in the process of fast motion. Mur-Artal et al. propose a feature-based monolithic SLAM system, ORB_SLAM2 [
19], which can be applied to all scenes in real-time. The algorithm is divided into four modules: tracking, building, relocating, and closed-loop detection. The system is divided into three separate threads, which can successfully track and build a map. With the advent of the new sensor event-based camera, many SLAM studies based on event cameras [
20,
21] have emerged in recent years. However, the event-based camera is expensive and has a low spatial resolution, which limits the performance of the application.
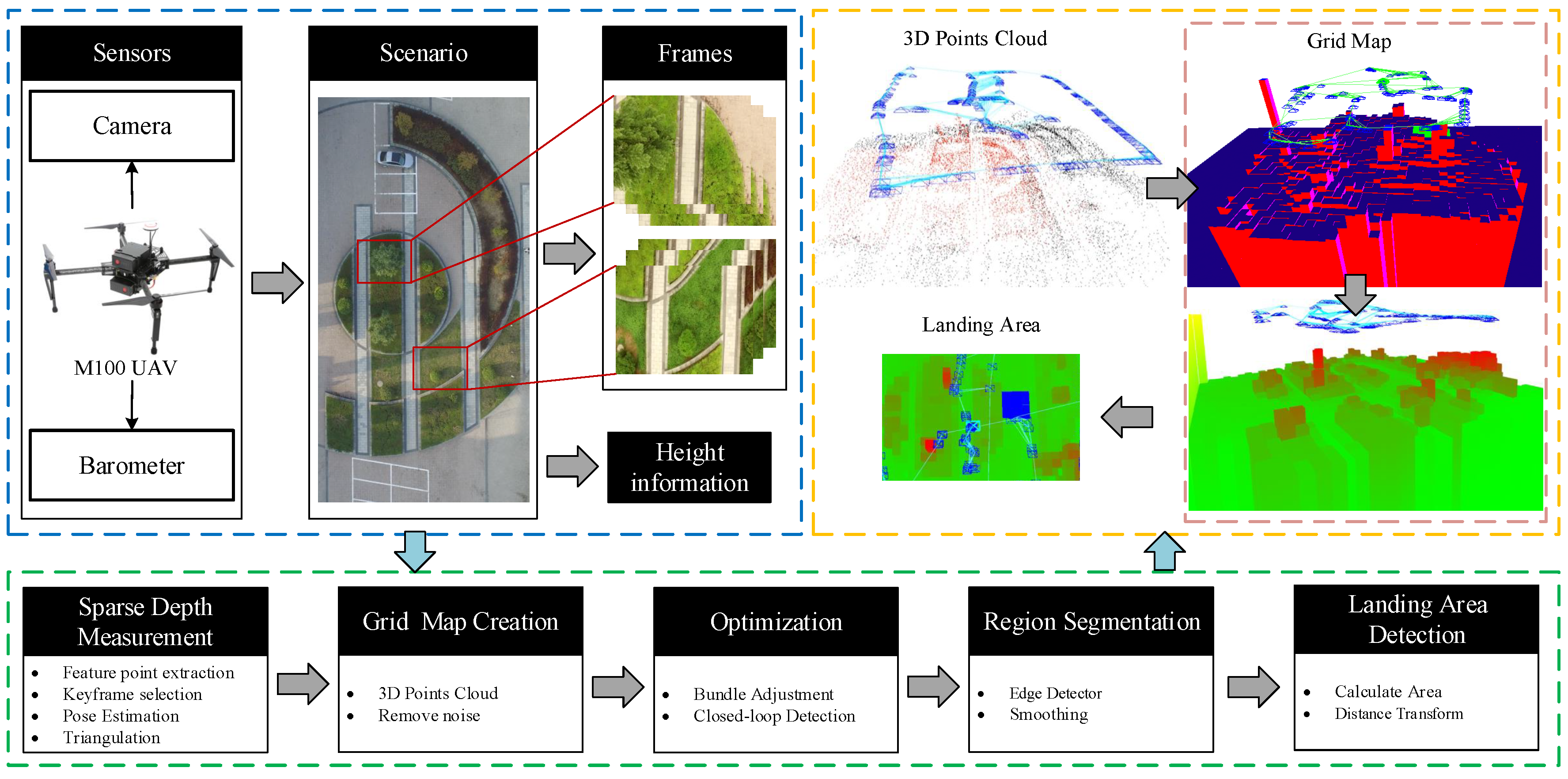
In this paper, a vision-based UAV landing method is used. With the help of optical equipment and image recognition technology, the UAV is capable of autonomously identifying the landing zone and reconstructing three-dimensional terrain to accomplish automatic return and route planning. Before preparing for an autonomous landing, the drones scan the scene, analyze the appropriate location, and initiate an autonomous calibration of the initial landing site. Then, it carries out autonomous route planning for this point. When the appropriate landing path is calculated, the autonomous landing control mode is automatically switched on and the proper solution is adopted to approach the landing site. After reaching the landing field along with a correct landing route, it starts the descent mode. As drones continue to decline, the control system systematically identifies information such as altitude change rate and pose of the drone, and adjusts the altitude of the drone at any time until it lands in a predetermined landing zone. As shown in
Figure 1, the experiments were performed in multiple scenarios. The results of the experiments show that the environmental awareness and the landing area selection have high robustness and real-time performance.
When an airport fails to receive a control signal in some case (e.g., system failure or signal interference), the ability to land at the airport with a good strategy and land safely will greatly reduce the damage of the unmanned drone to the ground personnel. Advanced autonomous visual landing control technology can avoid the danger of drones facing emergency landings. With the use of optical and other detection equipment, the autonomous sensing capabilities of drones will be greatly improved, and evasion will be implemented before ground controllers are put in danger. An anti-collision algorithm that takes both safety and economy into consideration will automatically re-plan the route after the UAV has implemented collision avoidance maneuvers to continue the task.
This method can be applied not only to the passive landing of drones in complex scenarios or in emergency situations and the active landing of drones, but also to many areas such as the automatic driving of unmanned vehicles, augmented reality, and the autonomous positioning of robots.
The main contributions of this work can be summarized as follows:
This paper proposes and implements the vision-based drone autonomous landing system in an unstructured environment. By combining existing technologies, they are improved to better meet the requirements of the system proposed herein.
This paper proposes a novel map representation approach that combines three-dimensional features and a mid-pass filter. Each visible feature is converted into a grid map by utilizing the mid-pass filter to remove noise that is too high and too low in each grid. After constructing a grid map, feature points of different heights can be visualized as grids of different heights.
This paper recommends a region segmentation to detect the edge of different-height grid areas. It smooths the areas with the same height based on a mean shift algorithm. An edge detector is used to identify obstacles and flat areas. By region segmentation, the speed and accuracy of the subsequent landing area selection are substantially improved.
Based on a grid map and region segmentation, we present a visual landing technology to explore a suitable landing area for drones in emergencies and unknown environments. Furthermore, with the pose calculated by SLAM, drones can autonomously fulfill path planning and implement landing. To evaluate the proposed algorithm, we apply it in multiple sets of real scenes. Experimental results demonstrate that the proposed method achieves encouraging results.
The remainder of this paper is organized as follows. In
Section 2, we propose a UAV autonomous landing approach based on monocular visual SLAM. The experimental results are presented in
Section 3. Finally, we conclude the paper in
Section 4.
2. The Approach
An overview of the proposed algorithm for the detection of landing sites is shown in
Figure 2. When the drone begins the landing procedure, the approach can estimate the position and posture of the drone, build the grid map of the environment, and select the most suitable area for landing via the filtering algorithm. A selecting landing area and vision navigation method is demonstrated, which uses SLAM to estimate the current pose of the drone.
This paper establishes a three-dimensional point cloud map of the environment by visual SLAM. Then, a two-dimensional grid map is set up by the three-dimensional point cloud of the feature points proposed by the SLAM algorithm. The height of each grid is calculated by projecting the map points of the graph into the corresponding grids. Then, the mean shift-based image segmentation algorithm is used to smooth the height of the grid map, divide the obstacles and ground, and combine the highly similar image blocks together. By calculating the space distance between the landing area and the obstacle, the algorithm selects the region which is the farthest from the obstacle as the filtered landing area. In this way, a suitable area for UAV landing is selected. The UAV finally lands on the safe area by following the descent program.
2.1. Sparse Depth Measurement
The camera pose is forwarded to the on-board computer, which associates the camera pose with the corresponding images based on the pre-calibrated camera. These camera pose estimates are used as priors in the bundle adjustment if an area is marked as a potential landing spot. Additionally, feature tracks are generated by the provided framerate. The ORB (oriented FAST and rotated BRIEF) [
22] feature tracker is used to generate coarse depth measurements for region tracking in unknown terrain and in the bundle adjustment of the backend thread. The ORB feature tracker is made up of the oriented FAST (Features from Accelerated Segment Test) [
23] corner detector, which detects corners with a description of scale and rotation, and BRIEF (Binary Robust Independent Elementary Features) [
24], an efficient feature point descriptor.
Monocular vision SLAM is a feature-based system that can be applied to all scenes in real time. The algorithm divides the algorithm into four modules: tracking, building, relocating, and closed-loop detection. It divides the system into three separate threads, which can track well and build a map. The ORB_SLAM2 [
19] algorithm can guarantee the global consistency of trajectory and map through its optimization and closed-loop detection. If the camera returns to the same scene as before, the algorithm can optimize posture and map by conducting closed-loop detection.
If the scene is a plane, or is approximated as a plane, or when the parallax is small, the motion estimation can be done by homography. The motion is restored by the basic matrix F in a non-planar scene with large parallax. Although the camera is facing the ground, the data captured by the drone may involve rugged terrain. The basic matrix F indicates the relationship between any two images of the same scene that constrains where the projection of points from the scene can occur in both images. At the same time, in order to improve the robustness of the system, the basic matrix F and the homography matrix H are estimated at the same time when the real data always contains some noise. The homography matrix H describes the mapping relation between two images of the same planar surface in space. Then, the smaller one is chosen as the motion estimation matrix by comparing the weight projection error. The method in the ORB_SLAM2 algorithm is to calculate the value and select the corresponding model according to the worth.
- (1)
Extract reference frame and current frame features , and then match features between two frames . If the number of matching features are not enough, the reference frame is reset.
- (2)
Calculate the homography matrix
H:
, and then calculate the fundamental matrix
F:
,
, where
K is the internal matrix of the camera and
E is the essential matrix. The essential matrix
E can be seen as a precursor to the fundamental matrix, and its relationship with
F is as above. The degrees of freedom of the homography matrix is 8, which can be computed by four pairs of matching features. The fundamental matrix
F can be calculated by the classical eight-point-algorithm [
25]. It is unavoidable that there is a large number of mismatches in feature matching, and we use random sampling consistency (RANSAC) to solve them.
- (3)
Restore motion from the fundamental matrix F or the homography matrix H.
We can get the motion
of the camera by the polar constraint. The depth information of the map points can be estimated by the motion of the camera by triangulation.
,
are set to represent the coordinates after the features are normalized on two frames,
where
,
represent the depth of two-frame features,
are the three-dimensional coordinates of the current frame and reference frame features, and
comprised of rotation matrix
R and translation matrix
t is the transformation matrix of the first graph to the second graph.
However, when solving the pose of the camera, because of the scale equivalence of the essential matrix E itself, there is also a scale equivalence of the t, R obtained by decomposing E. The normal method is to normalize the scale of t, which leads directly to the scale uncertainty of monocular vision. For t, after it is multiplied by an arbitrary constant, the polar constraint is always established. In order to solve this scale uncertainty, we compared the height information measured by the barometer with the flight altitude calculated by the SLAM system to obtain the scale factor.
The Matrice M100 comes with a barometer module. The barometer is based on the experimental principle of Evangelista Torricelli for measuring atmospheric pressure. Most of the aircraft’s altitude measurement is achieved through a barometer, and GPS-equipped aircraft also generally have a barometer as a backup. For every 12 m of height raised, the mercury column is lowered by about 1 millimeter, so the height of the aircraft when it is flying in the air can be measured. In the experimental scenario, the drone’s flying height is usually no more than 30 m, so the error of the height measured by the barometer is not very large and satisfies the experimental requirements. The experiment in this article has the feature that the monocular visual SLAM application environment is oriented to the ground. In addition, the camera ZENMUSE X3 (DJI, Shenzhen, China) used in the experiment has a PTZ (Pan/Tilt/Zoom) self-balancing function, which can ensure that the camera maintains its ground-facing state. A PTZ camera is a camera that supports all-around (up, down, left, and right) movement and lens zoom control. Because of the scale problem of monocular vision SLAM and the characteristics of the experiments in this paper, the height information obtained by the barometer measurement is sufficient to restore the SLAM scale factor on the
z-axis:
where
represents the height difference in the
z-axis measured by monocular visual SLAM,
represents the height variation in world coordinate system, and
s represents the scale factor. The value of
s can be calculated by replacing
with the height variation measured by a barometer. It is thus possible to continue to obtain true height information by scaling the visual pose.
After the success of the map initialization, PNP (Perspective-N-Point) is used to transform the three-dimensional motion into two-dimensional point pairs. Therefore, the position posture of the current frame can be obtained by using a PNP solution to calculate the three-dimensional motion to two-dimensional points by using the three-dimensional map point P in the reference frame and the two-dimensional keypoints p on the current frame.
Given a three-dimensional map point set
P and two-dimensional matching on the set of points
p, we can calculate the pose by minimizing the re-projection error pose:
The error is obtained by comparing the pixel coordinates (i.e., the observed projected position) with the position of the three-dimensional point projected according to the currently-estimated pose. This error is called the re-projection error. We minimize the re-projection error of the matching point by constantly optimizing the pose in order to obtain the optimal camera pose.
For each frame, when the map is initialized, the system estimates the position of the current frame in accordance with the previous frame. Hence, with successful tracking, it is relatively easy to get the posture information of each frame.
However, a sparse feature point map does not meet the requirements of the screening landing area. Thus, it is imperative to integrate other methods to optimize the map.
2.2. Grid Map Creation
First of all, as shown in
Figure 3, we divide the plane into small grids. The size of the grid can be adjusted according to the actual situation. Then, the SLAM algorithm is applied to calculate the three-dimensional location of feature point in the world coordinate system and the pose of each key frame. Then, we will convert the three-dimensional point clout into a two-dimensional grid map. Furthermore, this article sets the point to be projected into the grid only when it is observed by multiple frames. If it is observed by merely one frame, the point will not be projected into the grid, which can avoid points that are noise. Thus, each grid has a pile of two-dimensional points with the height information. There is one final step needed to determine which grids are suitable for drones to land on based on these points.
First, we define the height of each grid:
where
represents the map points in the grid
, and the map points
and
represent the maximum and minimum values in the grid. The highest and lowest points in the grid are removed, and then the mean of the map points is computed to assign the value to the grid height
.
The following formula defines whether the grid is suitable for landing:
where
is the height value of the map point
on the two-dimensional grid map and
represents the height of the grid
in the grid coordinates.
r is the radius of the search, and is adjusted according to the size of the UAV. Through traversal of each grid, the drone can search for the landing area. Grids that do not have a projection point are regarded as unreliable and marked as non-landing areas. Finally, the threshold of the formula
is set according to the actual application to determine the grid suitable for the UAV landing, and at the same time the grid is marked out.
2.3. Pose and Map Optimization
There will be errors when the camera is calibrated and tracked, so it is necessary to do some optimization after the pose estimation. The estimate of the pose is obtained by tracking frames. By using this estimate as an initial value, we can model the optimization problem as a least-squares graph optimization problem and then use g2o (General Graph Optimization) [
26] to optimize poses and maps. Even after optimization, there will be errors, and these tracking errors will continue to accumulate, which may lead to an increasingly growing rear frame pose estimation error, and eventually deviate from reality. Thus, long-term estimates of the results will be unreliable. Considering this, closed-loop testing, which is related to the correctness of estimated trajectory and maps after a long time, is particularly important.
Because the pose of key frames is estimated based on the previous reference frame, the error will be accumulated and result in increasingly inaccurate posture estimates. Therefore, we optimize the position and orientation using a closed-loop detection. When the camera captures the previously captured image, we can correct the position of the camera by detecting the similarity between the images. Closed-loop detection can be achieved through the word pocket model DBow3 [
27]. DBoW3 is an open source C++ library for indexing and converting images into a bag-of-word representation. It implements a hierarchical tree for approximating nearest neighbours in the image feature space and creating a visual vocabulary. DBoW3 also implements an image database with inverted and direct files to index images and enabling quick queries and feature comparisons.
Feature extraction: select features based on the data set and then describe them to form feature data. For example, the sift key points in the image are detected, and then the feature descriptor is calculated to generate a 128-dimensional feature vector;
Learning the word bag: merge all of the processed feature data. Then, the feature words are divided into several classes by means of clustering. We set the number of these classes, and each class is equivalent to a visual word;
Use of a visual bag to quantify the image features: each image consists of many visual words. It can use statistical word frequency histograms to indicate which category an image belongs to.
With the dictionary, given any feature, the corresponding word can be found by looking up the dictionary tree layer-by-layer. When the new key frame is inserted, the distribution of the image in the word list or the histogram can be computed. This allows us to use the text search algorithm TF-IDF (term frequency-inverse document frequency) [
28] and the approach in [
29] to calculate the similarity between the two images. After detecting the closed loop, BA (bundle adjustment) is used to optimize some of the previous reference frames.
2.4. Region Segmentation-Based Landing Area Detection
It is necessary to divide the map according to the height before the screening of the landing area suitable for the UAV. The grid map of precise region segmentation based on height is helpful to improve the speed and accuracy of the subsequent landing area selection. In this paper, a method based on image segmentation to divide the height region of the grid map is proposed. This section introduces the algorithm flow in detail.
According to the experimental requirements, an image segmentation method based on mean shift [
30] is used to segment the mesh map. In accordance with image segmentation based on the mean shift principle, the grid map obtained in the second chapter is smoothed and divided. Firstly, the size of the grid map and the height of each grid are input. Each grid is regarded as the smallest unit. Secondly, the mean shift algorithm is used to cluster the height of the grid to determine the total number of categories and the center of each category. Then, using these statistics as input, the final division of the grid map via the mean shift algorithm is obtained. Specific steps are shown in Algorithm 1.
| Algorithm 1 Image Segmentation-Based Grid Map Partitioning Algorithm. |
| Input: grid map |
| 1: use the mean shift algorithm to smooth the created grid map. For each grid, initialize , . |
| 2: while modulus point non-convergence do |
| 3: calculate |
| 4: |
| 5: end while |
| 6: the grid map is smoothed with mean shift, and the convergence result is stored in , |
| 7: for do |
| 8: if grid space distance < && height distance < then |
| 9: divided into different categories |
| 10: end if |
| 11: end for |
| Output: for each grid ⋯, the category logo . |
After clustering the grid map, the ground condition without a priori environment information can be obtained. Therefore, the system gains understanding of the height distribution of the ground and the obstacle information to a certain extent, and is able to select an area suitable for the UAV to land. Then, the world coordinates in this district can be output to guide the landing of the UAV. Due to the skewing that may occur during the drone’s landing, the UAV landing point needs to avoid obstacles in order to ensure a safe of landing. For the grid map, the algorithm sets the districts of all the altitude, except the landing height H, as obstacles. After districts with matching height and area are selected, it is necessary to calculate the integrated distance between the districts and all the obstacles. Specific steps are shown in Algorithm 2.
| Algorithm 2 Choose the Best Landing Spot. |
| Input: the previous grid height categories , the appropriate landing height H, the appropriate landing area S. |
| 1: for grid categories do |
| 2: if the height h of && the area then |
| 3: add grid to the landing zone candidate set and number |
| 4: else |
| 5: add grid to the obstacle set and number |
| 6: end if |
| 7: end for |
| 8: for the landing zone candidate set do |
| 9: for the obstacle set do |
| 10: calculate the distance of each area from each obstacle ; that is, the distance from the candidate area to the nearest edge of the obstacle area. |
| 11: calculate the overall distance of each area from all obstacles. |
| 12: end for |
| 13: end for |
| Output: The area with the largest is the landing point, which makes it possible to stay away from existing obstacles. |
The appropriate landing height H is selected from the previous grid height categories and the appropriate landing area S is set according to the size of the UAV. Then, the system can determine the best landing location through these two screening approaches.
3. Experiments
3.1. Experimental Platform
This paper chose the commercial UAV DJI Matrice 100 (M100) as a platform for the data acquisition offline processing stage and the UAV autonomous real-time control stage experiment. It includes a flight controller, power system, barometer module, GPS module, and other modules. This paper used the monocular camera, ZENMUSE X3, as a visual sensor to carry out the experimental data collection. The small ZENMUSE X3 monocular camera can guarantee high-quality video during high-speed movement with its wide-angle fixed focus lens, powerful performance, a shooting screen without distortion, and clear images. At the same time, we used the camera’s PTZ self-balancing function to make the camera face the ground. We also used the barometer module on the UAV to measure the flight altitude for the monocular SLAM scale correction. In this paper, the image data resolution was
. The experimental configuration environment was an Intel Core i7-8700K
[email protected] GHz processor, 16.0 GB memory, and 64-bit operating system.
If the camera used does not have a PTZ self-balancing function, the height difference on the z-axis cannot be used directly when restoring the scale factor. In the calculation of the scale factor stage, the aircraft only moves in height, and the difference in the three-dimensional space of the pose in this time period is calculated to replace the difference in the z-axis. In addition, during the initial phase of the aircraft, it is necessary to ensure that the camera is parallel to the ground. After this, the PTZ self-balancing function no longer affects system functionality.
The experimental platform interacted with the M100 through the image acquisition card and the wireless serial port to simulate the on-board processing, as shown in
Figure 4. The laptop captured the image stream taken by the drone in real-time through the image capture card, and sent the control command to the drone in real-time through the wireless serial port.
3.2. Real-Time Control Experiments
In
Section 2, we can get the key frame data of monocular image sequence processing, and obtain the UAV pose information and the three-dimensional point cloud data according to the visual SLAM system. Then, we convert the three-dimensional point cloud into a two-dimensional grid. Next, the image segmentation algorithm based on mean shift is used to deal with the two-dimensional grid map. Finally, the two-dimensional grid map is filtered and the appropriate landing area is obtained.
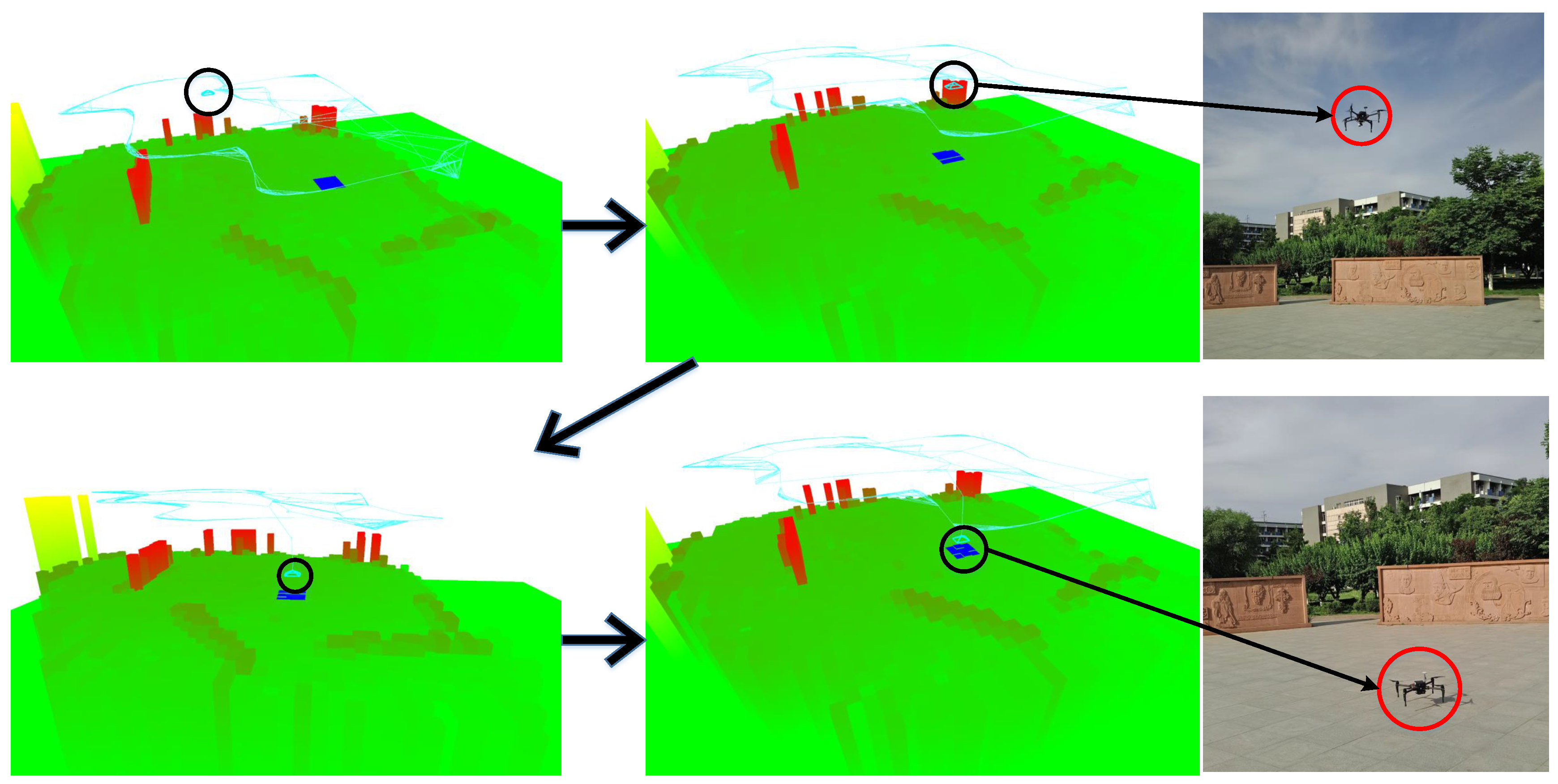
At the beginning of the experiment, we first turned on the computer and started the program. The drone flew over the scene and began to simulate entering the fault state. It was necessary to start the autonomous landing procedure. The startup program controlled the drone to scan the landing environment. When the UAV started the data acquisition, the first step is to initialize. At the initial location, the aircraft pose must have a translation instead of a rotation change. In order to reduce the error of the pose information and the 3D point cloud data estimated by the SLAM system, after completing the initialization, the UAV started the closed-loop flight, followed by some closed loops of smaller radius. By forming a closed loop, the construction and pose estimation results are optimized. The candidate landing area is selected from within the construction result. The drone moved to the top of the candidate area with the shortest path, and focused on the candidate landing area (i.e., movement with small displacement). Finally, if the program still confirmed that the area was the final landing area, the landing mode was started. Otherwise, the candidate area was re-determined and scanned.
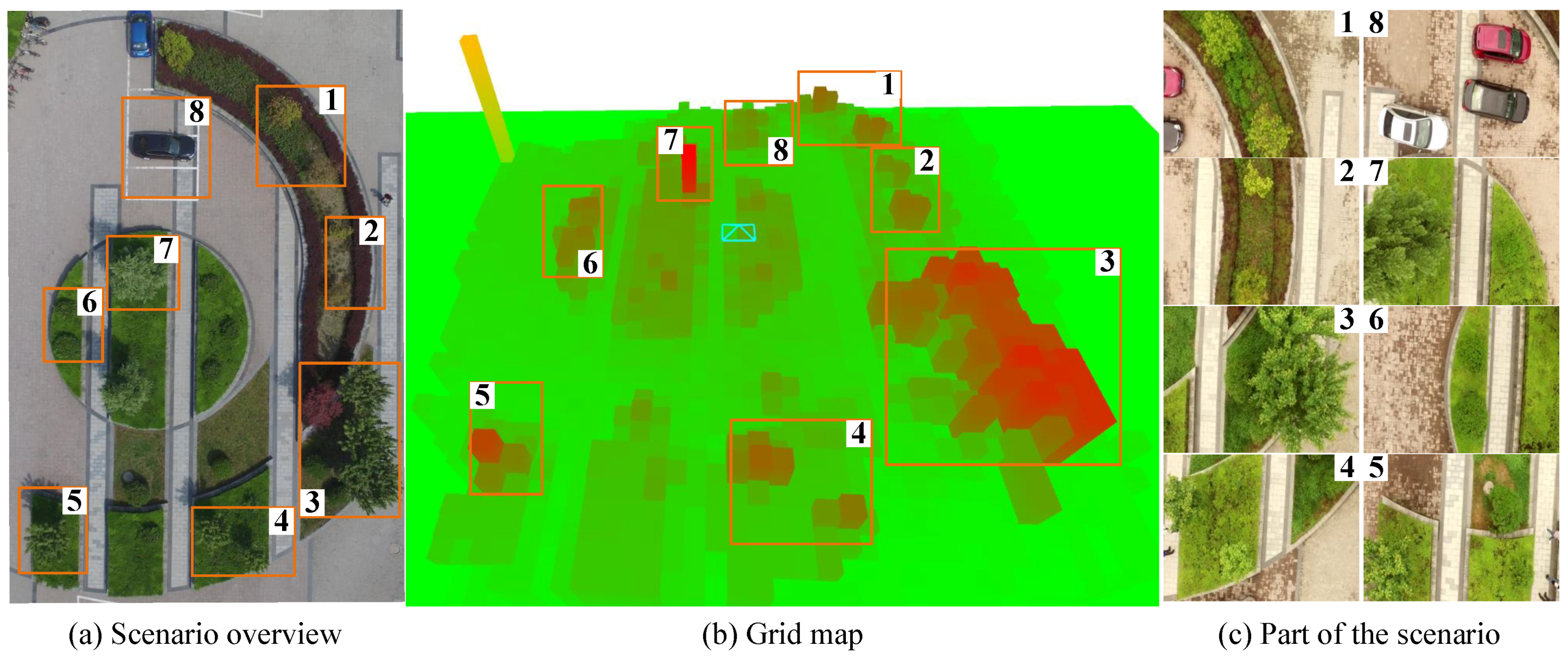
Figure 5 shows the creation of a two-dimensional height grid map and the specific meaning of each part of the grid map. The color represents the depth of the map. Green represents the lowest point, red represents the highest point, and the middle height is represented by a gradient color. Dark blue indicates a suitable landing site. Light blue indicates the flight path of the drone. The experimental scene is a circular flower bed surrounded by large semi-circular flower beds. There are three cars parked in front of the flower bed. There are big trees, shrubs and weeds on the circular flower beds and the semicircular flower beds on the periphery. The other half of the flower bed is an empty square which is suitable for landing.
In order to prove the accuracy of the proposed UAV autonomous landing system, we carried out a real-time control experiment of UAV autonomous landing. The landing trajectory and the specific process are shown in
Figure 6. It presents our study of the UAV autonomous landing area screening and the entire implementation process of the UAV autonomous landing system. When the UAV was ready to land, flight control switched from normal flight to autonomous landing. The autonomous landing system was started. Then, the system was initialized and the flight began. After the initialization was completed, the pose was estimated, and the closed-loop flight was carried out. Then, the area to be measured was screened. After the selection of the UAV landing area, it began to fall on the selected area.
3.3. Landing Area Detection in Multi-Scenario
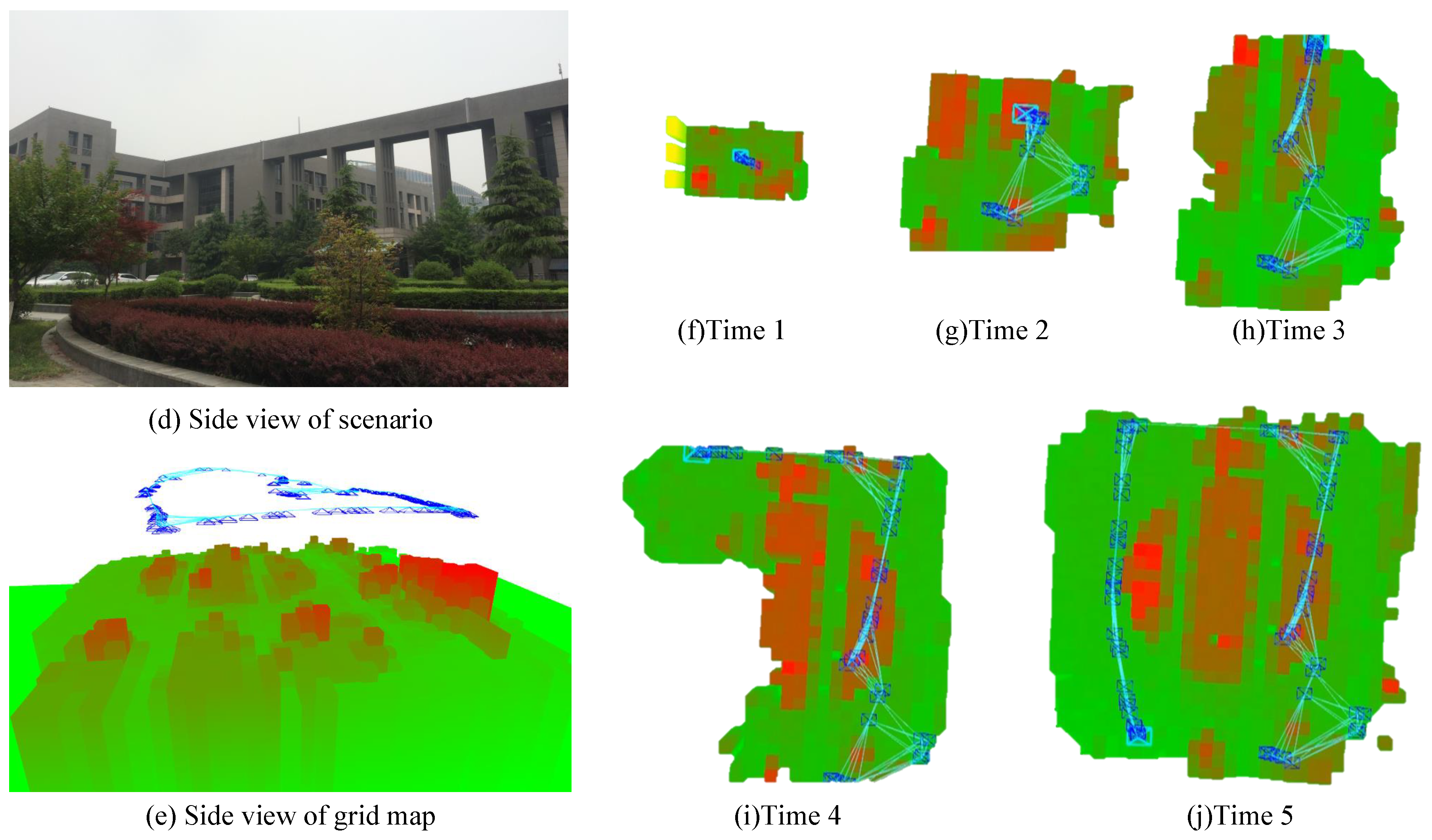
In this paper, several groups of data experiments and analysis were conducted. Five sets among the experimental results are shown in
Figure 7. All experimental data were collected from the Northwestern Polytechnical University Chang’an campus. The first scene was a small forest with a suitable landing zone in the middle. The scene for the second set of data acquisition was a gentle slope. Surrounded by trees, a larger humanoid sculpture was located in the middle of the slope. The front part of the slope was relatively flat and suitable for landing. Several trees and shrubs were scattered in the third scene. The middle of the scene was flat and suitable for landing. The scene of the fourth set of data collection was a square with five highly-visible obstacles evenly distributed within it. Three of the obstacles were carved walls, while the others were long stone benches. The middle area of the square was flat and suitable for landing, without any obstacles.
Figure 7 shows the specific experimental locations and experimental results of the proposed method. The robustness of the proposed system is demonstrated by experimental results in different conditions. The characteristics of the four experimental sites in
Figure 7 are different and they simulate different actual application environments.
Scenarios 1, 2, and 3 were experiments simulating field environments. Scenario 1 simulated a forest landscape, with a large areas of trees. There was only a small piece of land suitable for landing in the middle, which our method chose. Scenario 2 simulated wild hillside and boulders. The system chose the flat ground between the hillside and the flat land and avoided obstacles well. Scenario 3 simulated a farm field. Although the shrub area was relatively flat, our method chose a flatter grassland. Scenario 4 simulated the urban environment with regular tall buildings and flat squares. There were even and obvious obstacles distributed in Scenario 4, and the experimental results can be intuitively understood. The landing site selected by our algorithm had the largest integrated distance and was located in the center of the five obstacles.
Take scenario 1 as an example. The drone has a flying height of 20 m. The entire landing process took 1 min and 52 s. Firstly, the drone scans the scene and builds a map. However, due to the high flying height, high scene complexity and the existence of many empty areas (area with large height differences but small areas), the sparse point cloud map constructed by monocular SLAM can not meet the requirements for detecting the landing area of drones. At this point, the grid map proposed in this paper shows its practicality. Based on the three-dimensional point cloud map, the grid map expands the space, fills in the area around the feature point, and realizes the perception of the overall environment. Only in the presence of a coherent flat area, the drone can land. All the revised parts are shown by blue font in the revision.
Experiments showed that, although the three-dimensional point cloud of visual SLAM was estimated to be sparse, the two-dimensional height grid map reconstructed supplied excellent scene information. The map was accurate enough to meet the needs of UAV landing. In various simulation environments and simulation field experiments, the landing sites selected by the proposed method were the safest places in the scenes, and the drone landed accurately in these areas.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








