EE-TCAM: An Energy-Efficient SRAM-Based TCAM on FPGA


Abstract
:1. Introduction
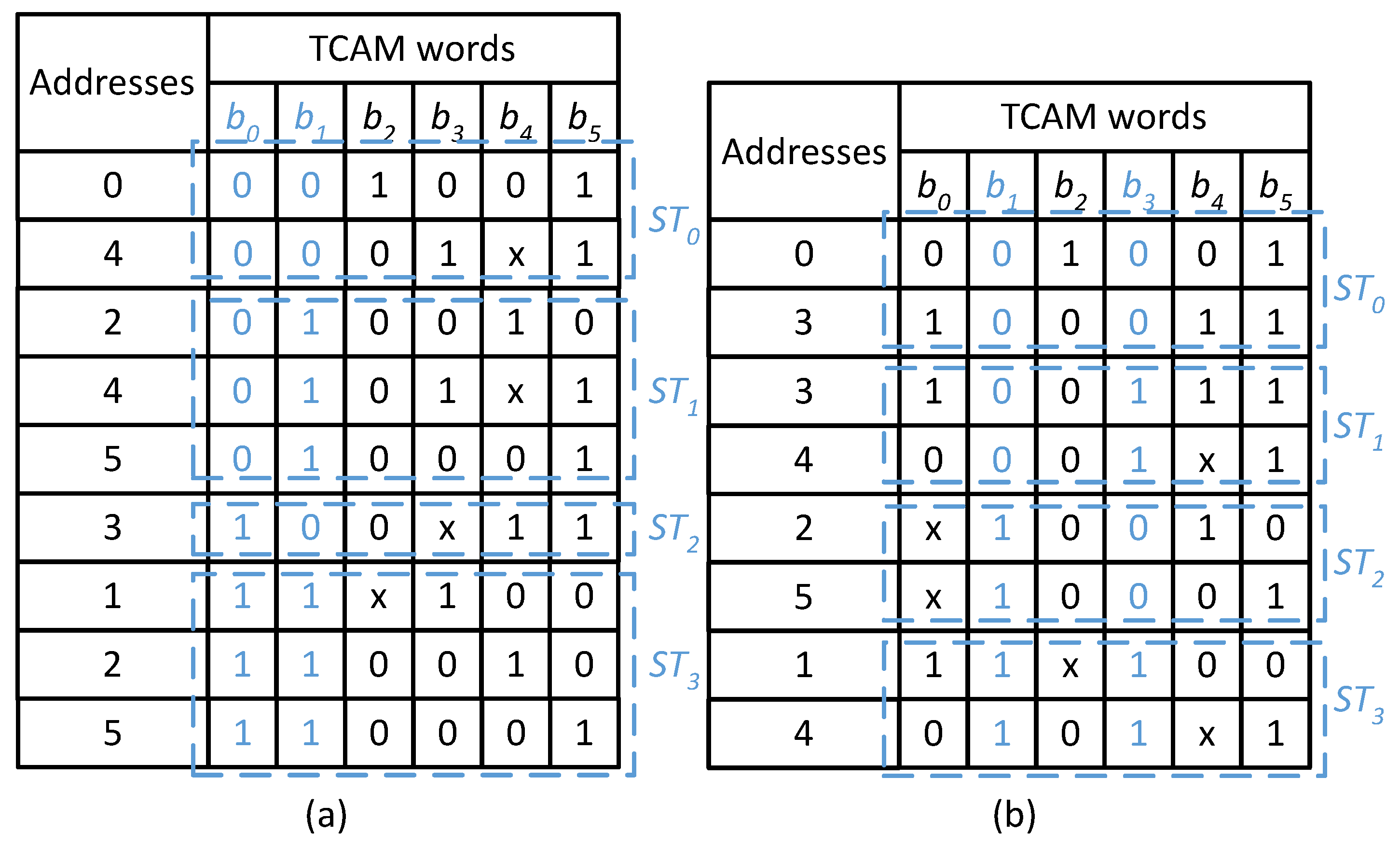
- A TCAM table classification scheme is proposed to create several balanced-size groups of TCAM words. (Section 3.1)
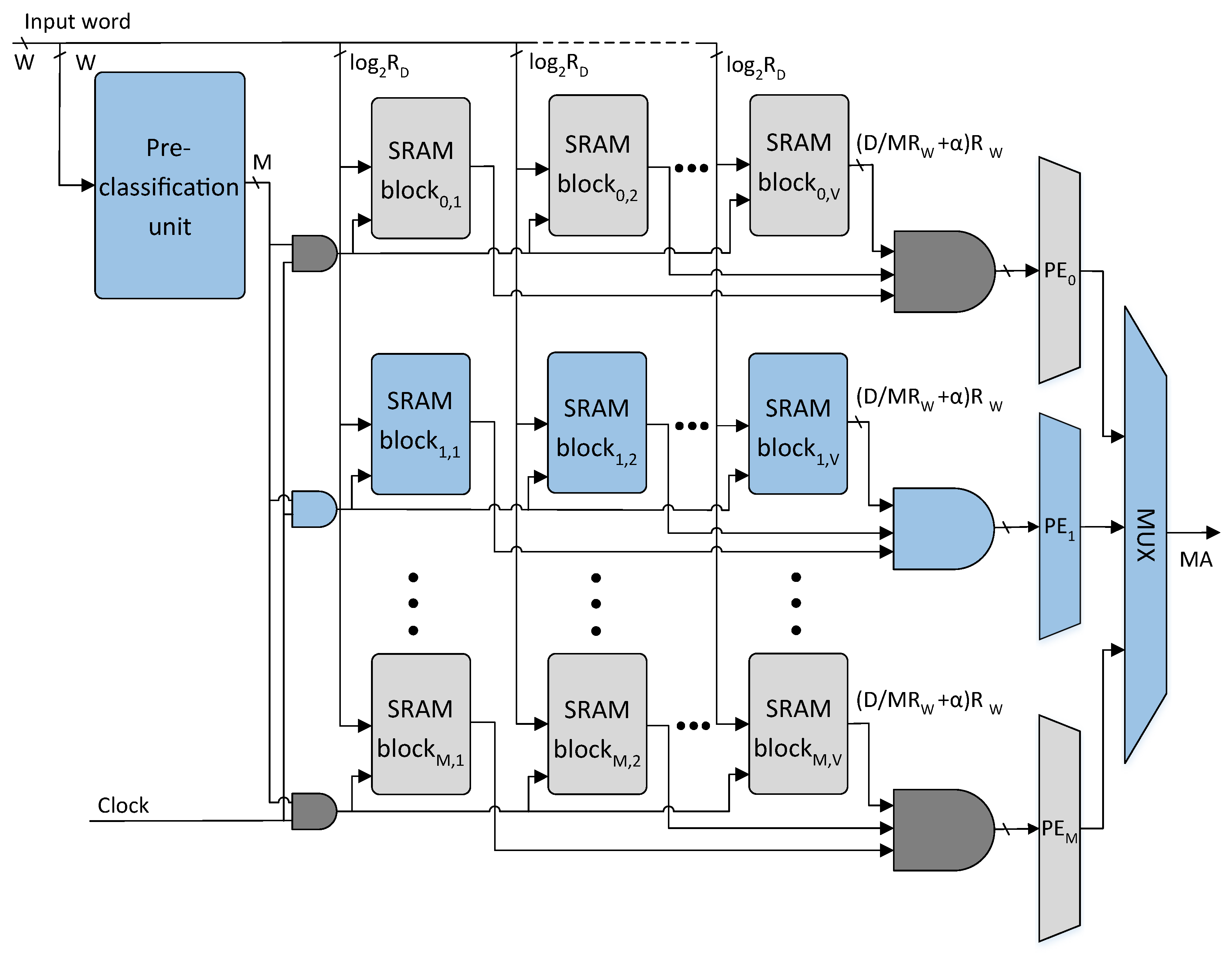
- To the best of our knowledge, this is the first pre-classifier-based architecture for SRAM-based TCAM design, which achieves a considerable reduction in power consumption. (Section 3.2)
- The proposed design is implemented on a state-of-the-art FPGA. The proposed design is compared in detail with the existing FPGA realizations of TCAM with respect to power consumption per performance. Compared to prior work, our architecture exhibits at least 3× lower power consumption per performance. (Section 4)
- The trade-off details between the number of TCAM sub-tables M and the power consumption and throughput performance of the proposed design are presented. (Section 4.2)
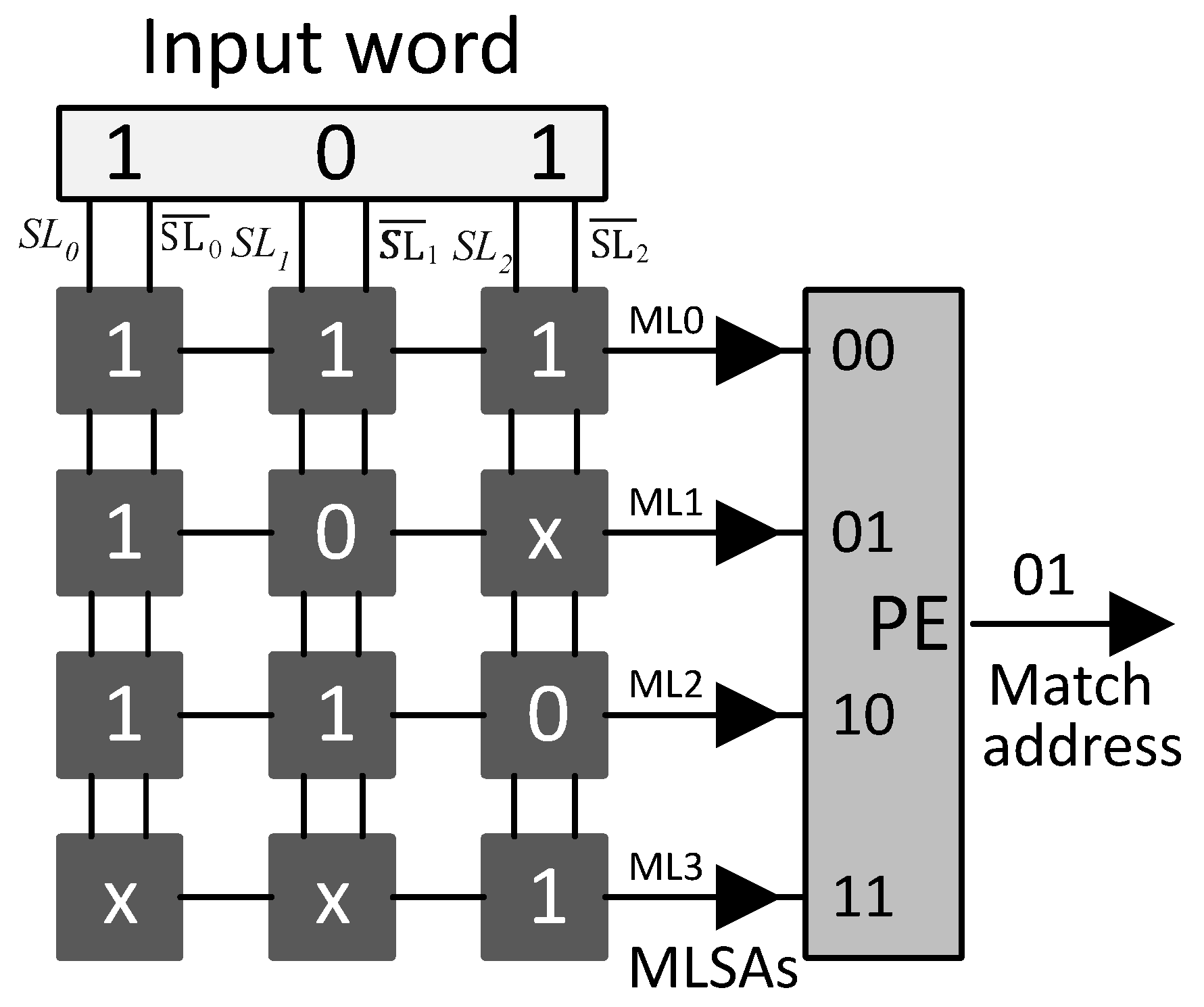
2. Related Work
3. Proposed Classification Scheme and Architecture
3.1. Proposed Classification Scheme for TCAM Table
| Algorithm 1 Algorithm for the classification of the TCAM table into M sub-tables. |
|
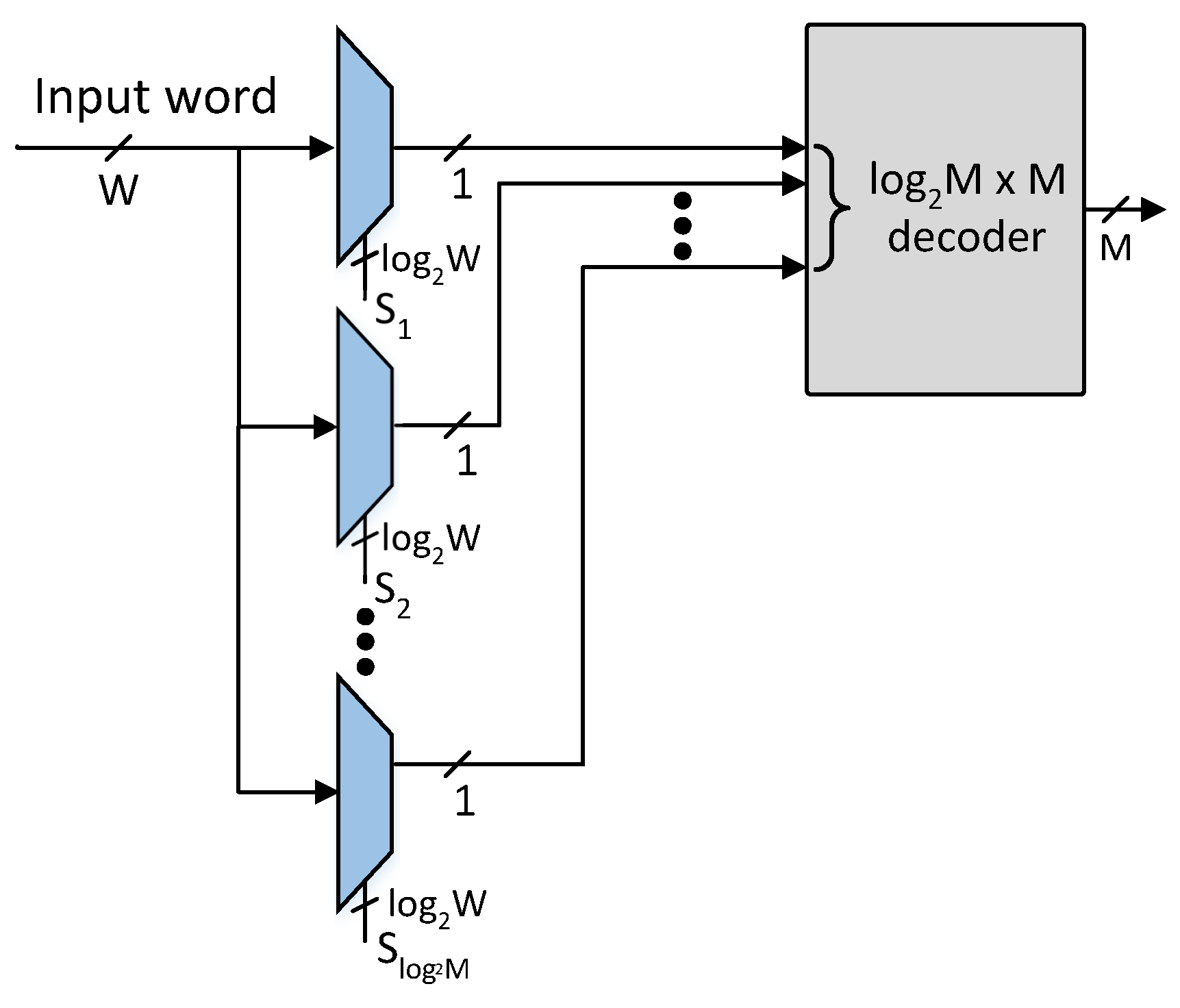
3.2. Proposed Architecture
3.3. Update Operation
4. FPGA Implementation Results & Performance Evaluation
4.1. Scalability of EE-TCAM
4.2. Trade-Off between the Number of TCAM Sub-Tables (M) and Performance
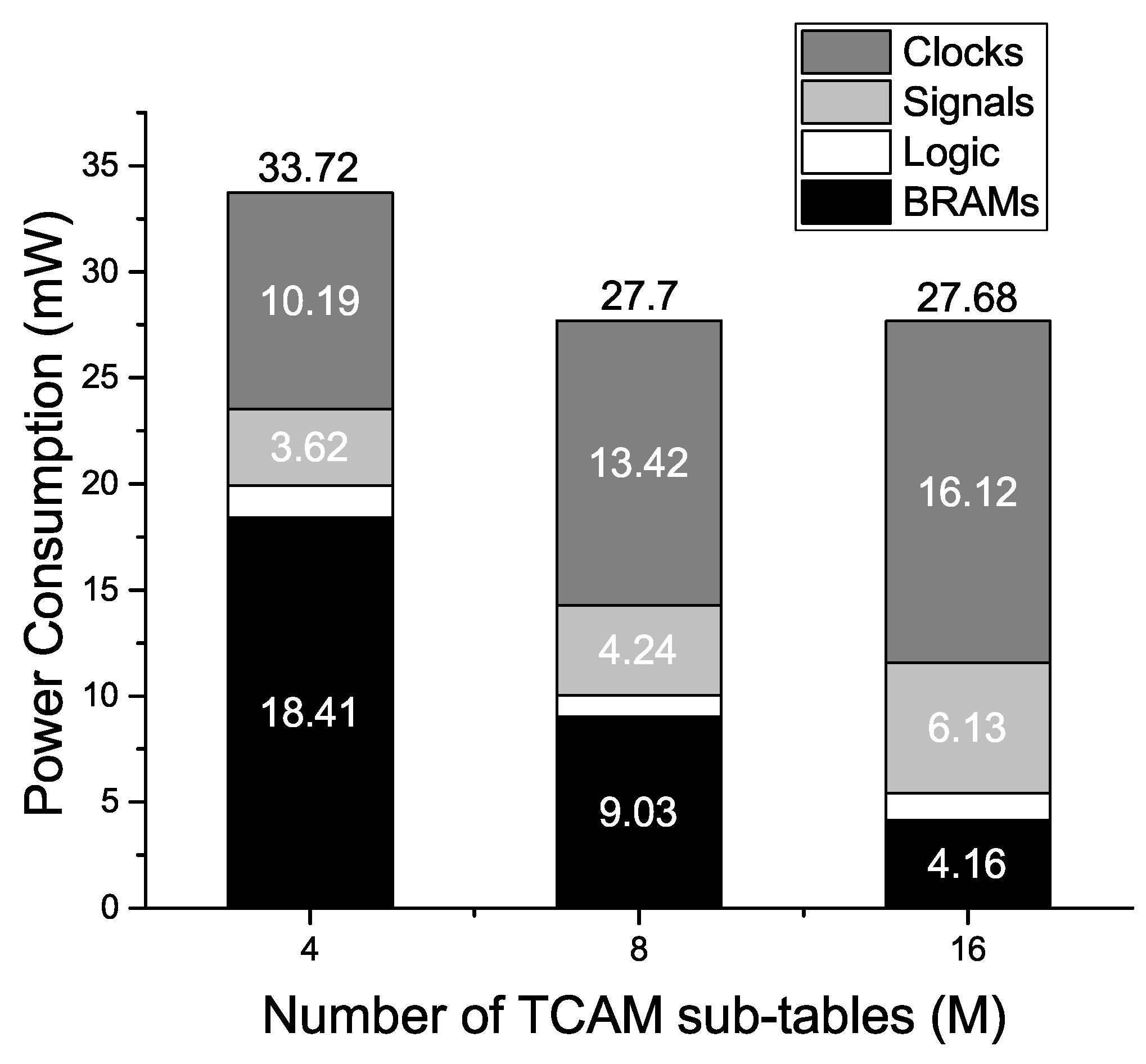
4.3. Power Consumption
4.4. Power Consumption per Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Etzel, K. Answering IPv6 Lookup Challenges; Technical Article; Cypress Semiconductor Corporation: San Jose, CA, USA, 2004. [Google Scholar]
- Taylor, D.E. Survey and taxonomy of packet classification techniques. ACM Comput. Surv. (CSUR) 2005, 37, 238–275. [Google Scholar] [CrossRef]
- Haigh, J.R.; Clark, L.T. High performance set associative translation lookaside buffers for low power microprocessors. Integr. VLSI J. 2008, 41, 509–523. [Google Scholar] [CrossRef]
- Karam, R.; Puri, R.; Ghosh, S.; Bhunia, S. Emerging trends in design and applications of memory-based computing and content-addressable memories. Proc. IEEE 2015, 103, 1311–1330. [Google Scholar] [CrossRef]
- Nguyen, X.T.; Hoang, T.T.; Nguyen, H.T.; Inoue, K.; Pham, C.K. An FPGA-Based Hardware Accelerator for Energy-Efficient Bitmap Index Creation. IEEE Access 2018, 6, 16046–16059. [Google Scholar] [CrossRef]
- Chang, M.F.; Lin, C.C.; Lee, A.; Chiang, Y.N.; Kuo, C.C.; Yang, G.H.; Tsai, H.J.; Chen, T.F.; Sheu, S.S. A 3T1R nonvolatile TCAM using MLC ReRAM for frequent-off instant-on filters in IoT and big-data processing. IEEE J. Solid-State Circuits 2017, 52, 1664–1679. [Google Scholar] [CrossRef]
- Tsai, H.J.; Yang, K.H.; Peng, Y.C.; Lin, C.C.; Tsao, Y.H.; Chang, M.F.; Chen, T.F. Energy-efficient TCAM search engine design using priority-decision in memory technology. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 962–973. [Google Scholar] [CrossRef]
- Mujahid, O.; Ullah, Z.; Mahmood, H.; Hafeez, A. Fast Pattern Recognition Through an LBP Driven CAM on FPGA. IEEE Access 2018, 6, 39525–39531. [Google Scholar] [CrossRef]
- Lin, K.J.; Wu, C.W. A low-power CAM design for LZ data compression. IEEE Trans. Comput. 2000, 49, 1139–1145. [Google Scholar]
- Agrawal, B.; Sherwood, T. Modeling TCAM power for next generation network devices. In Proceedings of the 2006 IEEE International Symposium on Performance Analysis of Systems and Software, Austin, TX, USA, 19–21 March 2006; pp. 120–129. [Google Scholar] [Green Version]
- Lambiri, C.; Senior staff architect IDT. Private communication, 2008.
- Akhbarizadeh, M.J.; Nourani, M.; Vijayasarathi, D.S.; Balsara, T. A nonredundant ternary CAM circuit for network search engines. IEEE Trans. Very Large Scale Integr. Syst. 2006, 14, 268–278. [Google Scholar] [CrossRef] [Green Version]
- Jiang, W. Scalable ternary content addressable memory implementation using FPGAs. In Proceedings of the Ninth ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), San Jose, CA, USA, 21–22 October 2013; pp. 71–82. [Google Scholar]
- Jiang, W.; Prasanna, V.K. Parallel IP lookup using multiple SRAM-based pipelines. In Proceedings of the IEEE International Symposium on Parallel and Distributed Processing (IPDPS 2008), Miami, FL, USA, 14–18 April 2008; pp. 1–14. [Google Scholar]
- Xilinx. Virtex-6 FPGA Memory Resources User Guide. Available online: http://www.xilinx.com (accessed on 15 July 2018).
- Alfke, P. Creative Uses of Block RAM; White Paper: Virtex and Spartan FPGA Families; Xilinx: San Jose, CA, USA, 2008. [Google Scholar]
- Qian, Z.; Margala, M. Low power RAM-based hierarchical CAM on FPGA. In Proceedings of the 2014 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 8–10 December 2014; pp. 1–4. [Google Scholar]
- Somasundaram, M. Circuits to Generate a Sequential Index for an Input Number in a Pre-Defined List of Numbers. U.S. Patent 7,155,563, 26 December 2006. [Google Scholar]
- Cho, S.; Martin, J.; Xu, R.; Hammoud, M.; Melhem, R. CA-RAM: A High-Performance Memory Substrate for Search-Intensive Applications. In Proceedings of the IEEE International Symposium on Performance Analysis of Systems Software, (ISPASS 2007), San Jose, CA, USA, 25–27 April 2007; pp. 230–241. [Google Scholar] [CrossRef]
- Locke, K. Parameterizable content-addressable memory. In Xilinx Application Note XAPP1151; Xilinx: San Jose, CA, USA, 2011. [Google Scholar]
- Jiang, W.; Prasanna, V.K. Large-scale wire-speed packet classification on FPGAs. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2009; pp. 219–228. [Google Scholar]
- Ahmed, A.; Park, K.; Baeg, S. Resource-Efficient SRAM-Based Ternary Content Addressable Memory. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 1583–1587. [Google Scholar] [CrossRef]
- Ullah, Z.; Ilgon, K.; Baeg, S. Hybrid partitioned SRAM-based ternary content addressable memory. IEEE Trans. Circuits Syst. I Regul. Pap. 2012, 59, 2969–2979. [Google Scholar] [CrossRef]
- Ullah, Z.; Jaiswal, M.K.; Cheung, R.C. Z-TCAM: An SRAM-based architecture for TCAM. IEEE Trans. Very Large Scale Integr. Syst. 2015, 23, 402–406. [Google Scholar] [CrossRef]
- Ullah, Z.; Jaiswal, M.; Cheung, R. E-TCAM: An Efficient SRAM-Based Architecture for TCAM. Circuits Syst. Signal Process. 2014, 33, 3123–3144. [Google Scholar] [CrossRef]
- Ullah, Z.; Jaiswal, M.K.; Cheung, R.C.C.; So, H.K.H. UE-TCAM: An ultra efficient SRAM-based TCAM. In Proceedings of the 2015 IEEE Region 10 Conference (TENCON 2015), Macau, China, 1–4 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Ullah, I.; Ullah, Z.; Lee, J.A. Efficient TCAM Design Based on Multipumping-Enabled Multiported SRAM on FPGA. IEEE Access 2018, 6, 19940–19947. [Google Scholar] [CrossRef]
- Wang, Z.; Che, H.; Kumar, M.; Das, S.K. CoPTUA: Consistent policy table update algorithm for TCAM without locking. IEEE Trans. Comput. 2004, 53, 1602–1614. [Google Scholar] [CrossRef]
- Shah, D.; Gupta, P. Fast incremental updates on Ternary-CAMs for routing lookups and packet classification. In Proceedings of the Hot Interconnects, Stanford, CA, USA, 16–18 August 2000. [Google Scholar]
- Shah, D.; Gupta, P. Fast updating algorithms for TCAM. IEEE Micro 2001, 21, 36–47. [Google Scholar] [CrossRef]
- Syed, F.; Ullah, Z.; Jaiswal, M.K. Fast Content Updating Algorithm for an SRAM based TCAM on FPGA. IEEE Embed. Syst. Lett. 2017, 10, 73–76. [Google Scholar] [CrossRef]
- Xilinx. Xilinx Xpower Analyzer. Available online: http://www.xilinx.com (accessed on 15 July 2018).
- Nakahara, H.; Sasao, T.; Iwamoto, H.; Matsuura, M. LUT Cascades Based on Edge-Valued Multi-Valued Decision Diagrams: Application to Packet Classification. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 73–86. [Google Scholar] [CrossRef]
- Chen, O.C.; Sheen, R.B. A power-efficient wide-range phase-locked loop. IEEE J. Solid-State Circuits 2002, 37, 51–62. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| D | Depth of TCAM table |
| W | Width of TCAM table |
| Depth of the configured SRAM blocks | |
| Width of the configured SRAM blocks | |
| Address bits of the configured SRAM blocks | |
| M | Number of TCAM sub-tables/Rows of the SRAM blocks in architecture |
| V | Number of SRAM blocks in each row of the proposed architecture |
| Address | TCAM Words |
|---|---|
| 0 | 001001 |
| 1 | 11x100 |
| 2 | x10010 |
| 3 | 100x11 |
| 4 | 0x01x1 |
| 5 | x10001 |
| Proposed Design Cases | Slice Registers | LUTs | BRAMs |
|---|---|---|---|
| EE-TCAM-I [M = 4] | 652 | 1535 | 32 |
| EE-TCAM-II [M = 8] | 687 | 1455 | 32 |
| EE-TCAM-III [M = 16] | 712 | 1419 | 32 |
| No. of TCAM | TCAM Depth | 256 | 512 | 1024 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Sub-Tables | TCAM Width | 36 | 54 | 72 | 36 | 54 | 72 | 36 | 54 | 72 |
| Memory utilization (b) | ||||||||||
| 576 | 864 | 1152 | 1152 | 1728 | 2304 | 2304 | 3456 | 4608 | ||
| 576 | 864 | 1152 | 1152 | 1728 | 2304 | 2304 | 3456 | 4608 | ||
| 1152 | 1728 | 2304 | 1152 | 1728 | 2304 | 2304 | 3456 | 4608 | ||
| Clock rate (MHz) | ||||||||||
| 326 | 313 | 299 | 276 | 260 | 243 | 264 | 252 | 233 | ||
| 338 | 323 | 308 | 321 | 306 | 261 | 297 | 272 | 246 | ||
| 346 | 335 | 317 | 336 | 316 | 270 | 310 | 293 | 251 | ||
| Power consumption () | ||||||||||
| 26.3 | 37.3 | 55.2 | 33.7 | 52.9 | 70 | 62 | 89.1 | 134 | ||
| 23.6 | 36.8 | 51.3 | 27.7 | 50.3 | 64.5 | 36.1 | 59.1 | 80 | ||
| 32.1 | 54.2 | 72.7 | 27.7 | 47.9 | 61.4 | 30.9 | 55.5 | 72.1 | ||
| Architecture | FPGA | TCAM Size | Speed | AM/L (a) | Throughput | Power | PC/P (b) |
|---|---|---|---|---|---|---|---|
| (D × W) | (MHz) | (Gb/s) | (mW) | ||||
| Locke [20] | Virtex-6 | 512 × 36 | 166 | 2304 | 5.8 | 253 | 85 |
| Qian [17] | Virtex-6 | 504 × 180 | 133 | 5040 | 23.4 | 2548 | 216 |
| REST [22] | Kintex-7 | 72 × 28 | 35 (50) | 36 | 1.4 | 161 (113) | 2329 |
| HP-TCAM [23] | Virtex-6 | 512 × 36 | 118 | 2016 | 4.2 | 188 | 89 |
| Z-TCAM [24] | Virtex-6 | 512 × 36 | 159 | 1440 | 5.6 | 109 | 38 |
| E-TCAM [25] | Virtex-6 | 512 × 36 | 164 | 1440 | 5.8 | 91 | 31 |
| UE-TCAM [26] | Virtex-6 | 512 × 36 | 202 | 1152 | 7.1 | 78 | 21 |
| Jiang [13] | Virtex-7 | 1024 × 150 | 97 (139) | 9792 | 20.4 | 4587 (3211) | 315 |
| EE-TCAM-I | Virtex-6 | 512 × 36 | 276 | 288 | 9.7 | 33.72 | 6.8 |
| EE-TCAM-II | Virtex-6 | 512 × 36 | 321 | 144 | 11.3 | 27.7 | 4.8 |
| EE-TCAM-III | Virtex-6 | 512 × 36 | 336 | 72 | 11.8 | 27.68 | 4.6 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, I.; Ullah, Z.; Lee, J.-A. EE-TCAM: An Energy-Efficient SRAM-Based TCAM on FPGA. Electronics 2018, 7, 186. https://doi.org/10.3390/electronics7090186
Ullah I, Ullah Z, Lee J-A. EE-TCAM: An Energy-Efficient SRAM-Based TCAM on FPGA. Electronics. 2018; 7(9):186. https://doi.org/10.3390/electronics7090186
Chicago/Turabian StyleUllah, Inayat, Zahid Ullah, and Jeong-A Lee. 2018. "EE-TCAM: An Energy-Efficient SRAM-Based TCAM on FPGA" Electronics 7, no. 9: 186. https://doi.org/10.3390/electronics7090186
APA StyleUllah, I., Ullah, Z., & Lee, J. -A. (2018). EE-TCAM: An Energy-Efficient SRAM-Based TCAM on FPGA. Electronics, 7(9), 186. https://doi.org/10.3390/electronics7090186