Approximate CPU Design for IoT End-Devices with Learning Capabilities



Abstract
:1. Introduction
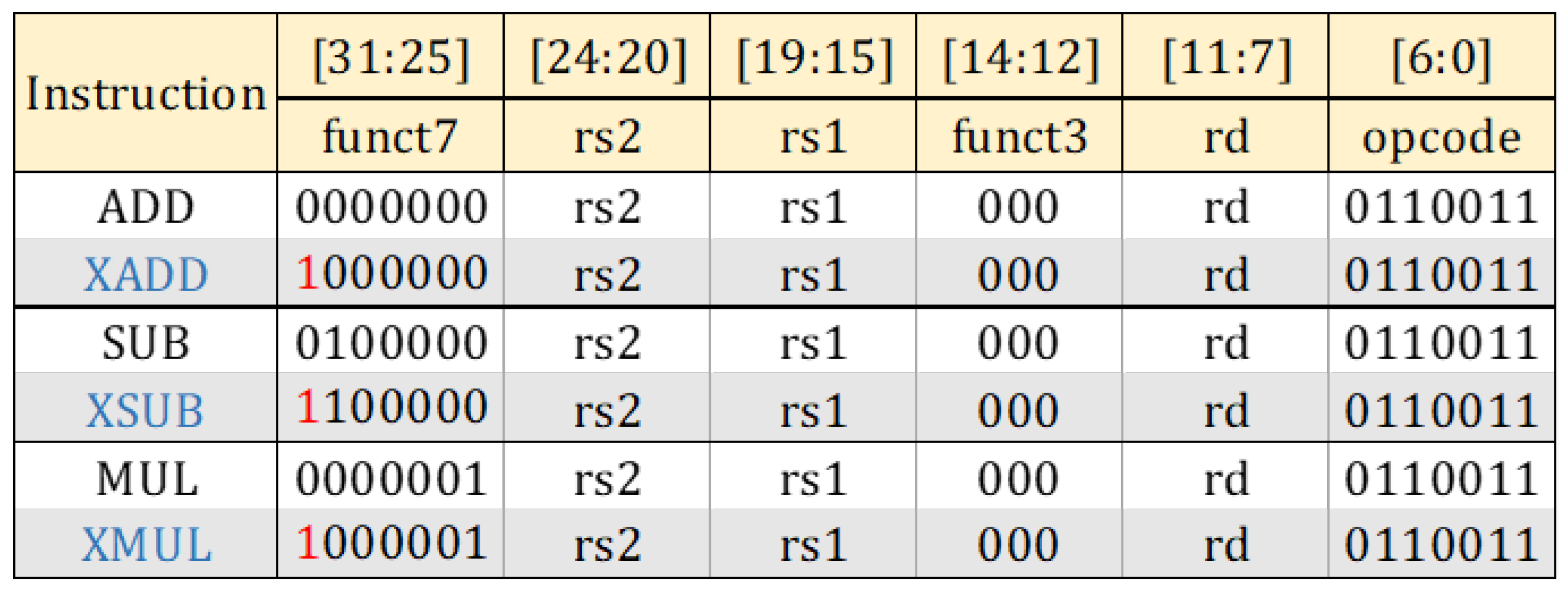
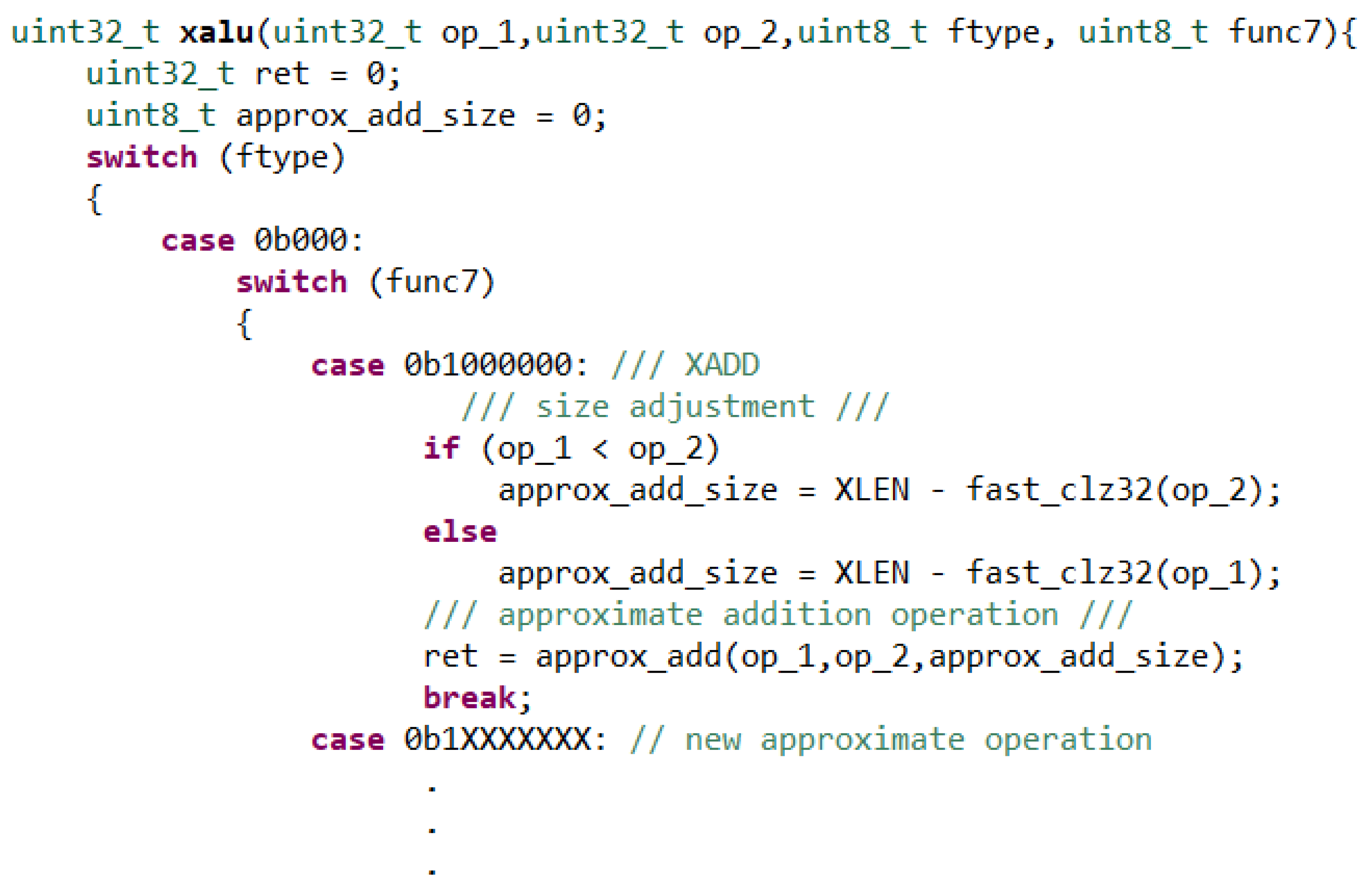
- In machine learning, the majority of operations are addition (ADD), subtraction (SUB) and multiplication (MUL). In our processor, we extend base 32-bit Reduced Instruction Set Computer-V (RISC-V) Instruction Set Architecture ISA [15] only with XADD, XSUB and XMUL for approximate addition, subtraction and multiplication, respectively (Section 3.1). Code pieces that can benefit from approximate instructions are handled via the plug-in that we developed for GCC compiler [16] (Section 4.1).
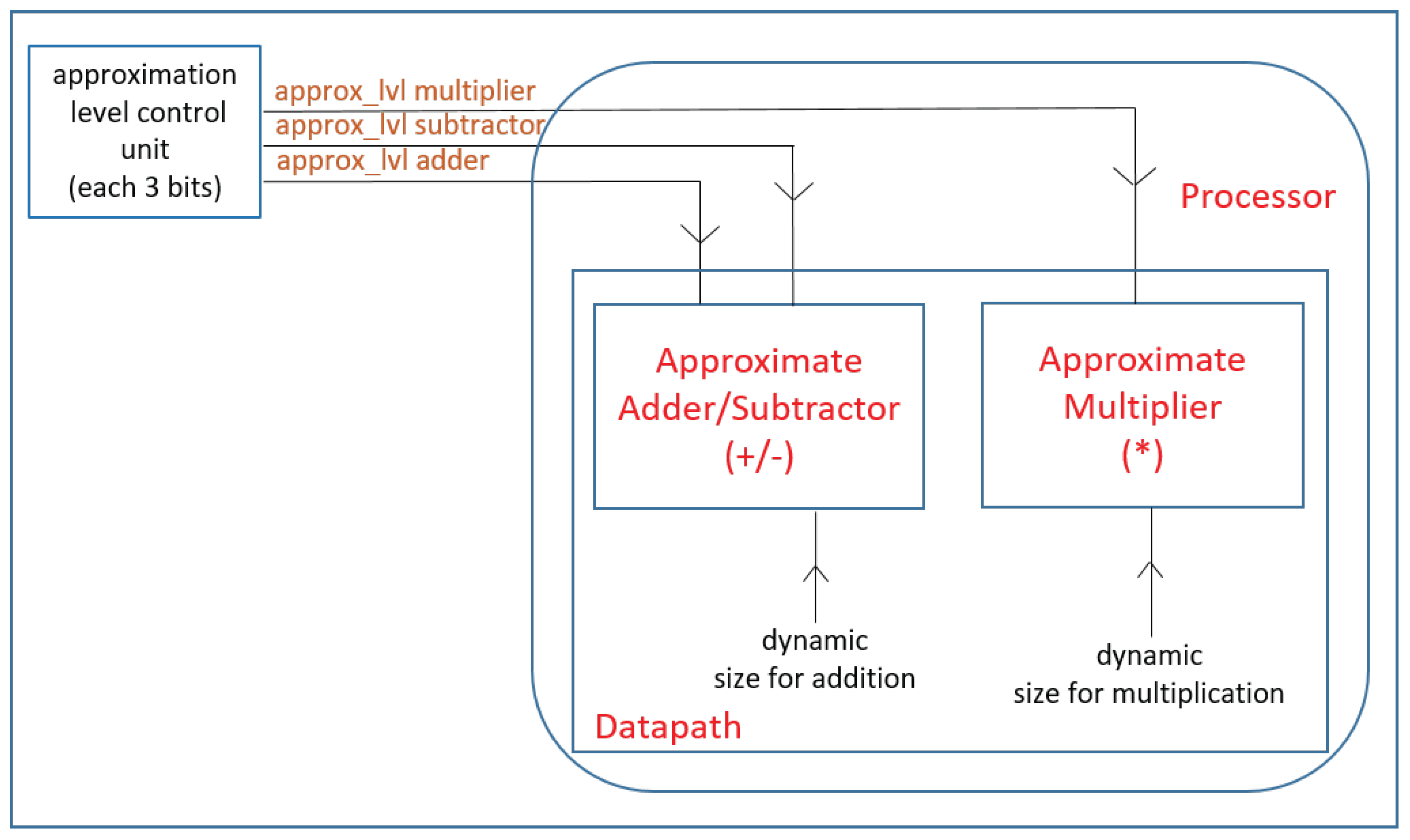
- We propose a coarse-grain control mechanism for setting accuracy of approximate operations during run-time. In our proposal, number of control signals is minimized by setting each control signal to activate a group of bits. To achieve this, we design a parallel-prefix adder and a wallace tree multiplier. We present three approximation levels to control the accuracy of the computations (Section 3.2).
- To reduce the power consumption, we adjust the size of the operands of the approximate operators dynamically at the data-path. Since approximate operators are faster than the exact ones, dynamic sizing does not deteriorate the performance (Section 3.2.1).
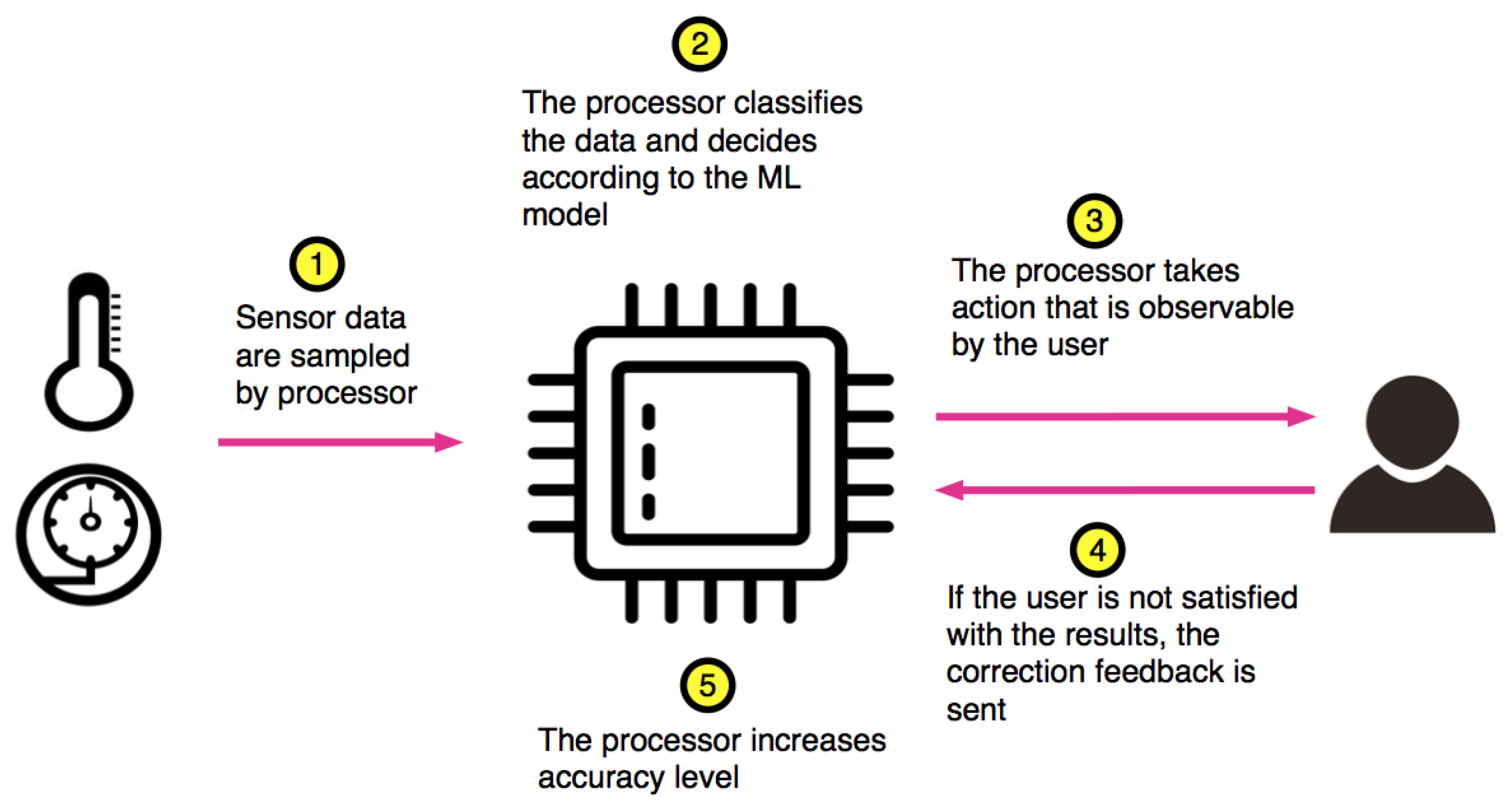
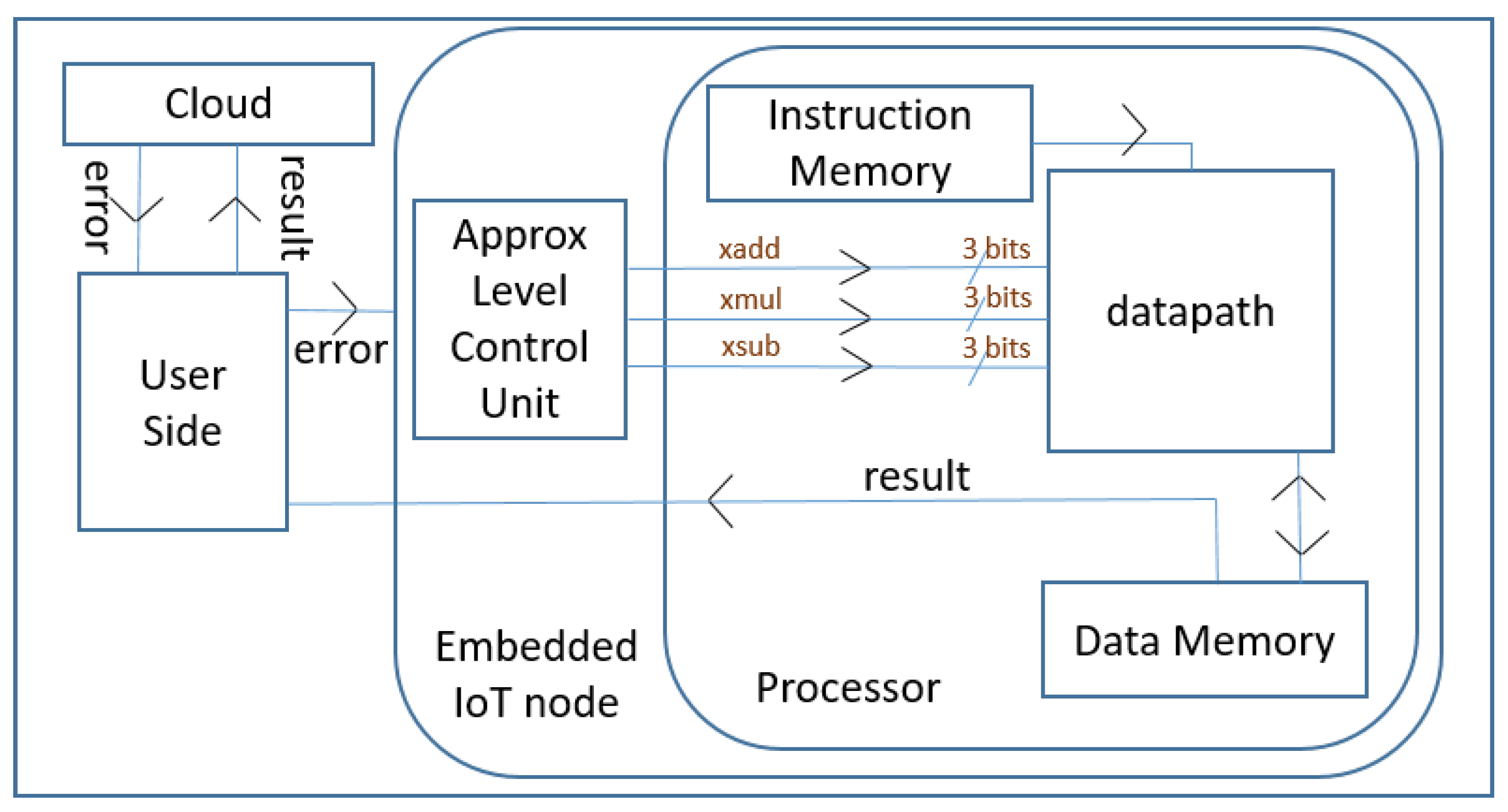
- For monitoring quality of the decisions resulting from the ML algorithms running on our approximate processor, we rely on the interaction of the IoT device with the IoT user or other constituents of IoT ecosystem (Section 2.3).
2. Related Works
2.1. Approximate Processors
2.2. Circuit-Level Approximate Computing
2.3. Dynamic Accuracy Control
2.4. IoT Applications
3. Core Description
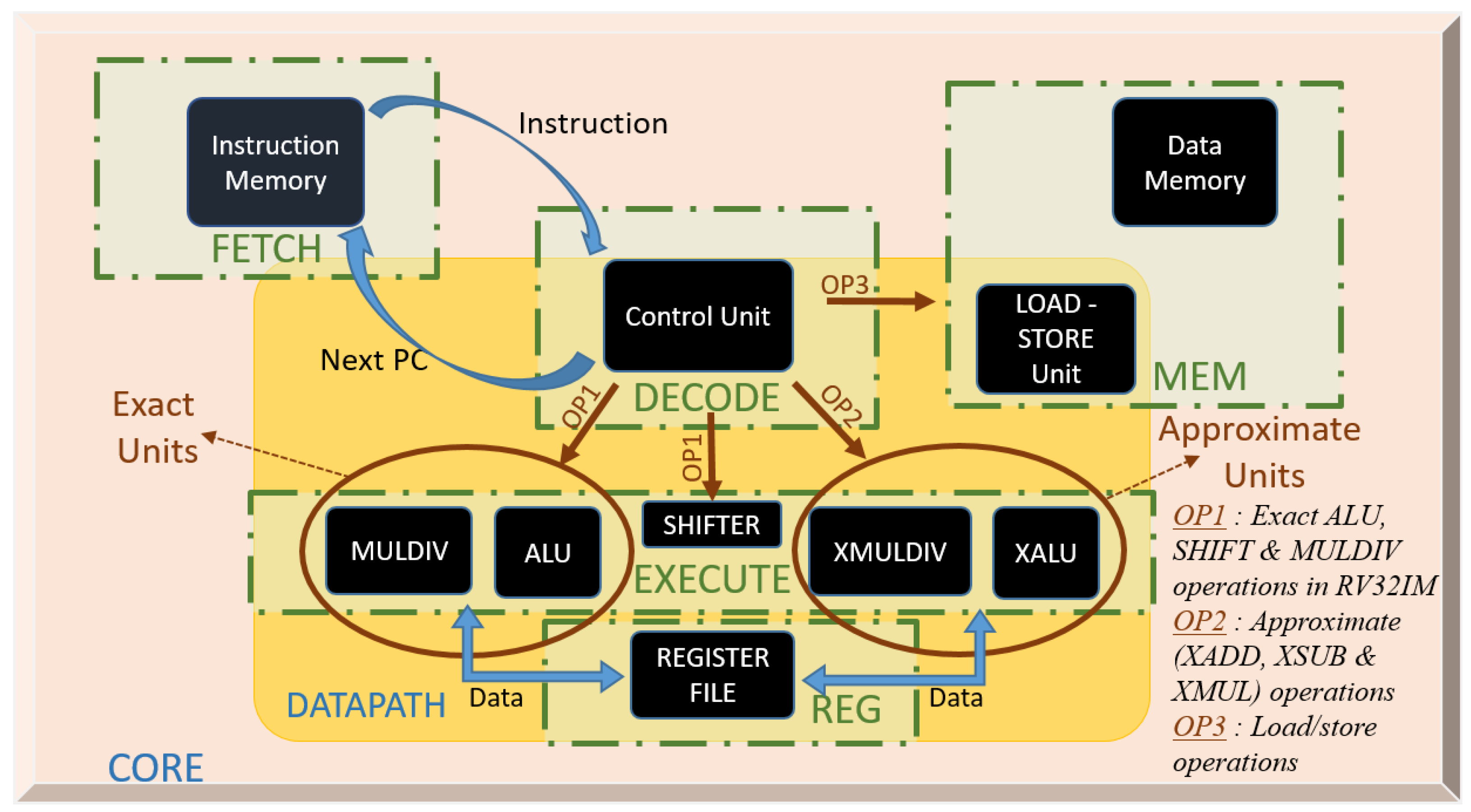
3.1. General Description of the Core
3.2. Approximate Units
3.2.1. Dynamic Sizing
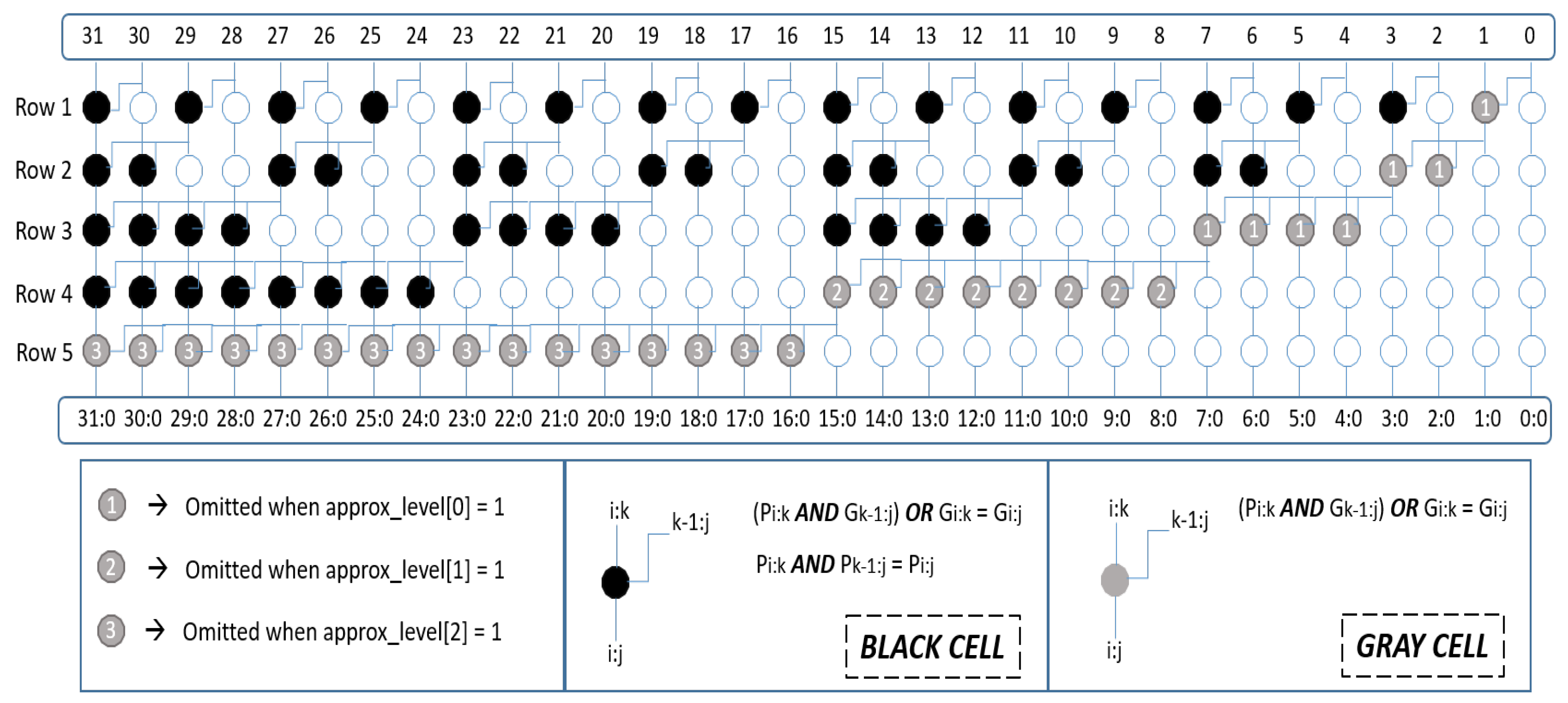
3.2.2. Approximate Adder/Subtractor
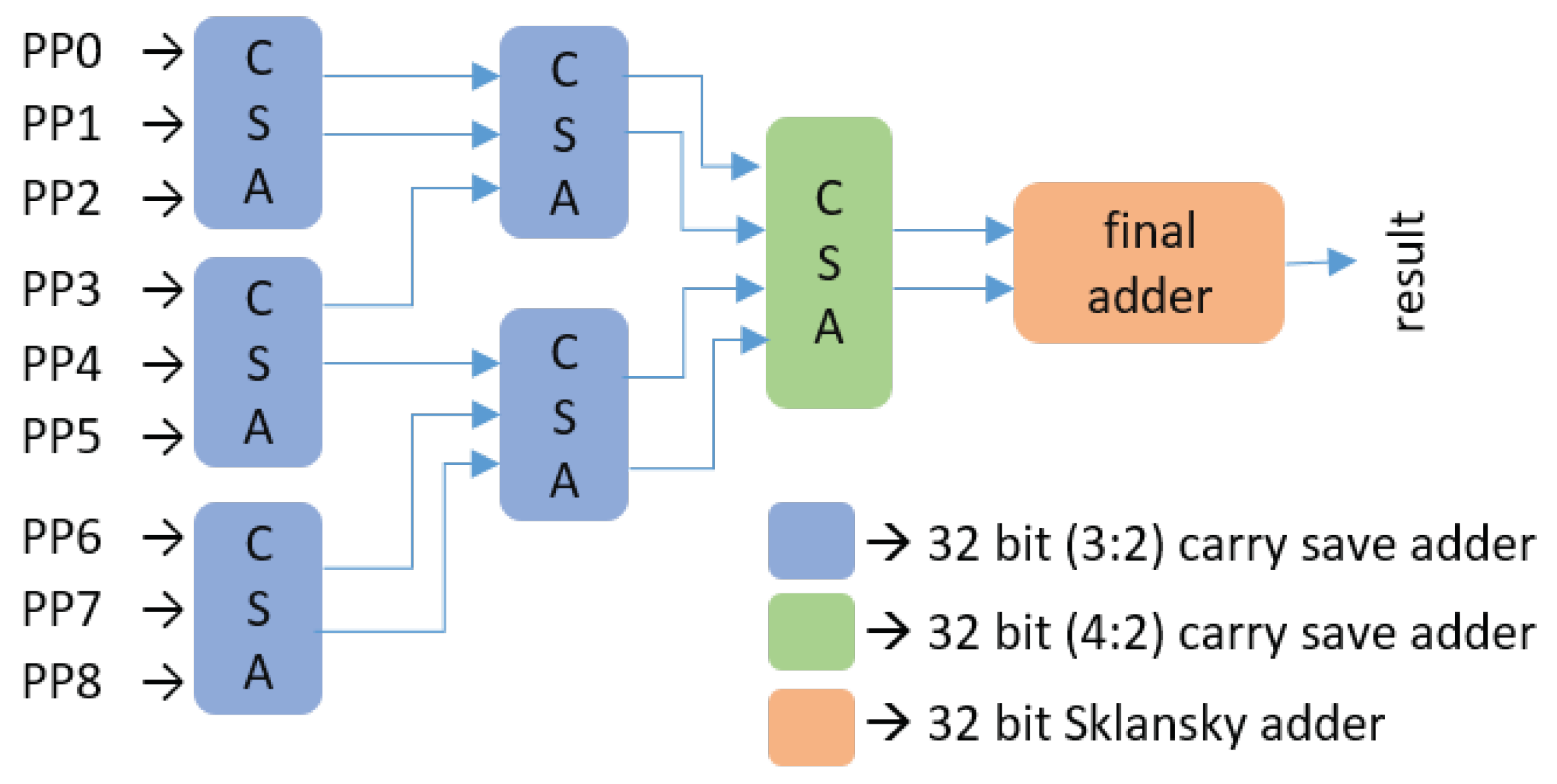
3.2.3. Approximate Multiplier
4. Experiments
4.1. Experimental Setup
4.2. Datasets and Algorithms
4.3. Approximate Regions in the Codes
4.4. Experiments
4.4.1. Dynamic Sizing
4.4.2. Approximate Addition/Subtraction and Exact Multiplication
4.4.3. Exact Addition/Subtraction and Approximate Multiplication
4.4.4. Approximate Addition and Approximate Multiplication
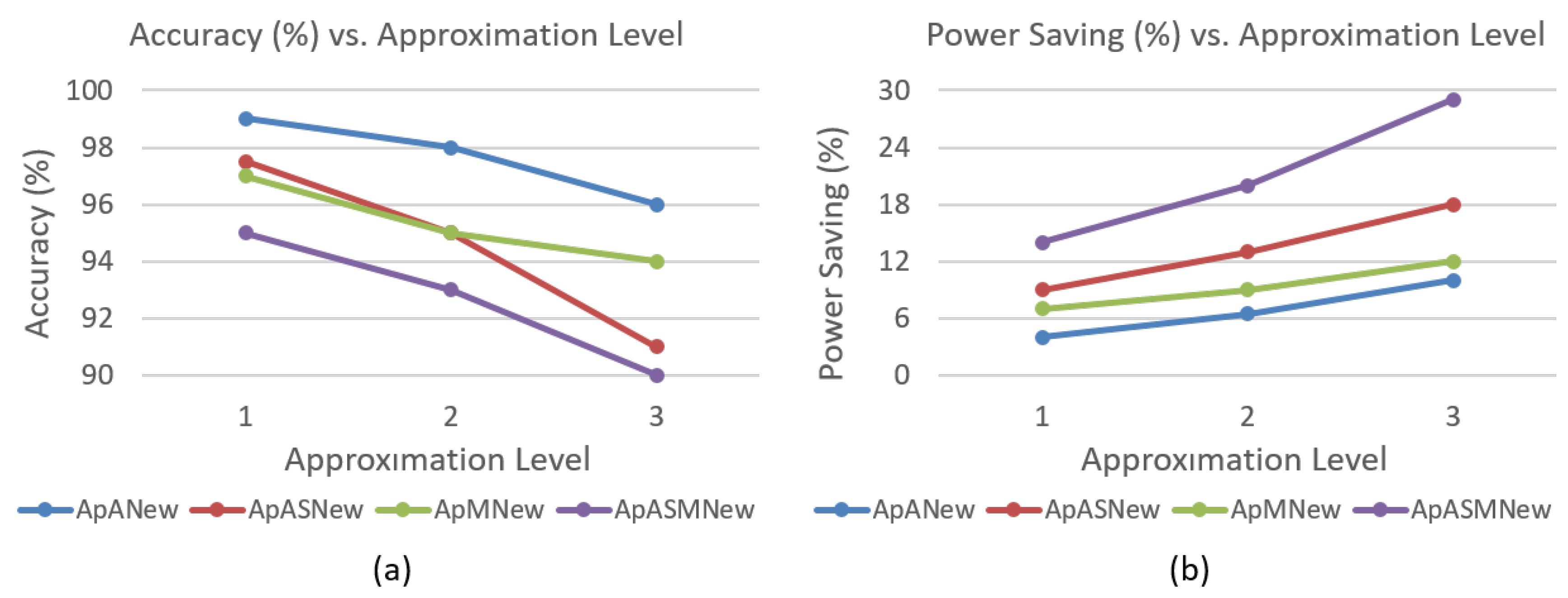
4.4.5. Approximation Level Modification at Run-time
5. Discussions
5.1. ASIC Implementation of the Proposed System
5.2. Bit-Truncation in the Approximate Blocks
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lueth, K.L. State of the IoT 2018: Number of IoT Devices Now at 7B—Market Accelerating. Available online: https://iot-analytics.com/state-of-the-iot-update-q1-q2-2018-number-of-iot-devices-now-7b/ (accessed on 23 December 2019).
- La, Q.D.; Ngo, M.V.; Dinh, T.Q.; Quek, T.Q.; Shin, H. Enabling intelligence in fog computing to achieve energy and latency reduction. Digit. Commun. Netw. 2019, 5, 3–9. [Google Scholar] [CrossRef]
- Su, M.Y. Using clustering to improve the KNN-based classifiers for online anomaly network traffic identification. J. Netw. Comput. Appl. 2011, 34, 722–730. [Google Scholar] [CrossRef]
- Doshi, R.; Apthorpe, N.; Feamster, N. Machine Learning DDoS Detection for Consumer Internet of Things Devices. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 29–35. [Google Scholar] [CrossRef] [Green Version]
- Siewert, S. Real-time Embedded Components and Systems; Cengage Learning: Boston, MA, USA, 2006. [Google Scholar]
- Leon, V.; Zervakis, G.; Xydis, S.; Soudris, D.; Pekmestzi, K. Walking through the Energy-Error Pareto Frontier of Approximate Multipliers. IEEE Micro 2018, 38, 40–49. [Google Scholar] [CrossRef]
- Lee, J.; Stanley, M.; Spanias, A.; Tepedelenlioglu, C. Integrating machine learning in embedded sensor systems for Internet-of-Things applications. In Proceedings of the 2016 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Limassol, Cyprus, 12–14 December 2016; pp. 290–294. [Google Scholar] [CrossRef]
- Chen, C.; Choi, J.; Gopalakrishnan, K.; Srinivasan, V.; Venkataramani, S. Exploiting approximate computing for deep learning acceleration. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 821–826. [Google Scholar] [CrossRef]
- Venkataramani, S.; Chippa, V.K.; Chakradhar, S.T.; Roy, K.; Raghunathan, A. Quality programmable vector processors for approximate computing. In Proceedings of the 2013 46th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Davis, CA, USA, 7–11 December 2013; pp. 1–12. [Google Scholar]
- Henry, G.G.; Parks, T.; Hooker, R.E. Processor That Performs Approximate Computing Instructions. U.S. Patent 9 389 863 B2, 12 July 2016. [Google Scholar]
- Agarwal, V.; Patil, R.A.; Patki, A.B. Architectural Considerations for Next Generation IoT Processors. IEEE Syst. J. 2019, 13, 2906–2917. [Google Scholar] [CrossRef]
- Esmaeilzadeh, H.; Sampson, A.; Ceze, L.; Burger, D. Architecture Support for Disciplined Approximate Programming. In Proceedings of the Seventeenth International Conference on Architectural Support for Programming Languages and Operating Systems, London, UK, 3–7 March 2012; ACM: New York, NY, USA, 2012; pp. 301–312. [Google Scholar] [CrossRef]
- Yesil, S.; Akturk, I.; Karpuzcu, U.R. Toward Dynamic Precision Scaling. IEEE Micro 2018, 38, 30–39. [Google Scholar] [CrossRef]
- Liu, Z.; Yazdanbakhsh, A.; Park, T.; Esmaeilzadeh, H.; Kim, N.S. SiMul: An Algorithm-Driven Approximate Multiplier Design for Machine Learning. IEEE Micro 2018, 38, 50–59. [Google Scholar] [CrossRef]
- RISC-V. Available online: https://riscv.org (accessed on 23 December 2019).
- RISC-V. RISC-V GCC. Available online: https://github.com/riscv/riscv-gcc (accessed on 18 March 2018).
- Chen, Y.; Yang, X.; Qiao, F.; Han, J.; Wei, Q.; Yang, H. A Multi-accuracy-Level Approximate Memory Architecture Based on Data Significance Analysis. In Proceedings of the 2016 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, PA, USA, 11–13 July 2016; pp. 385–390. [Google Scholar] [CrossRef]
- Sampson, A.; Dietl, W.; Fortuna, E.; Gnanapragasam, D.; Ceze, L.; Grossman, D. EnerJ: Approximate Data Types for Safe and General Low-power Computation. SIGPLAN Not. 2011, 46, 164–174. [Google Scholar] [CrossRef]
- Balasubramanian, P.; Maskell, D.L. Hardware Optimized and Error Reduced Approximate Adder. Electronics 2019, 8, 1212. [Google Scholar] [CrossRef] [Green Version]
- Shafique, M.; Ahmad, W.; Hafiz, R.; Henkel, J. A low latency generic accuracy configurable adder. In Proceedings of the 2015 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 June 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Kahng, A.B.; Kang, S. Accuracy-configurable adder for approximate arithmetic designs. In Proceedings of the DAC Design Automation Conference 2012, San Francisco, CA, USA, 3–7 June 2012; pp. 820–825. [Google Scholar] [CrossRef] [Green Version]
- Yezerla, S.K.; Rajendra Naik, B. Design and estimation of delay, power and area for Parallel prefix adders. In Proceedings of the 2014 Recent Advances in Engineering and Computational Sciences (RAECS), Chandigarh, India, 6–8 March 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Macedo, M.; Soares, L.; Silveira, B.; Diniz, C.M.; da Costa, E.A.C. Exploring the use of parallel prefix adder topologies into approximate adder circuits. In Proceedings of the 2017 24th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Batumi, Georgia, 5–8 December 2017; pp. 298–301. [Google Scholar] [CrossRef]
- Moons, B.; Verhelst, M. DVAS: Dynamic Voltage Accuracy Scaling for increased energy-efficiency in approximate computing. In Proceedings of the 2015 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Rome, Italy, 22–24 July 2015; pp. 237–242. [Google Scholar] [CrossRef]
- Pagliari, D.J.; Poncino, M. Application-Driven Synthesis of Energy-Efficient Reconfigurable-Precision Operators. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Alsouda, Y.; Pllana, S.; Kurti, A. A Machine Learning Driven IoT Solution for Noise Classification in Smart Cities. arXiv 2018, arXiv:1809.00238. [Google Scholar]
- Viegas, E.; Santin, A.O.; França, A.; Jasinski, R.; Pedroni, V.A.; Oliveira, L.S. Towards an Energy-Efficient Anomaly-Based Intrusion Detection Engine for Embedded Systems. IEEE Trans. Comput. 2017, 66, 163–177. [Google Scholar] [CrossRef]
- Yu, Z. Big Data Clustering Analysis Algorithm for Internet of Things Based on K-Means. Int. J. Distrib. Syst. Technol. 2019, 10, 1–12. [Google Scholar] [CrossRef]
- Suarez, J.; Salcedo, A. ID3 and k-means Based Methodology for Internet of Things Device Classification. In Proceedings of the 2017 International Conference on Mechatronics, Electronics and Automotive Engineering (ICMEAE), Cuernavaca, Mexico, 21–24 November 2017; pp. 129–133. [Google Scholar] [CrossRef]
- Moon, J.; Kum, S.; Lee, S. A Heterogeneous IoT Data Analysis Framework with Collaboration of Edge-Cloud Computing: Focusing on Indoor PM10 and PM2.5 Status Prediction. Sensors 2019, 19, 3038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, J.; Eom, D.S. Offloading and Transmission Strategies for IoT Edge Devices and Networks. Sensors 2019, 19, 835. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, G.; Primmer, J.; Zhang, Z. Rapid Generation of High-Quality RISC-V Processors from Functional Instruction Set Specifications. In Proceedings of the 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Rokicki, S.; Pala, D.; Paturel, J.; Sentieys, O. What You Simulate Is What You Synthesize: Designing a Processor Core from C++ Specifications. In Proceedings of the ICCAD 2019—38th IEEE/ACM International Conference on Computer-Aided Design, Westminster, CO, USA, 2 October 2019; pp. 1–8. [Google Scholar]
- Tolba, M.F.; Madian, A.H.; Radwan, A.G. FPGA realization of ALU for mobile GPU. In Proceedings of the 2016 3rd International Conference on Advances in Computational Tools for Engineering Applications (ACTEA), Beirut, Lebanon, 13–15 July 2016; pp. 16–20. [Google Scholar] [CrossRef]
- Introducing Vhdl/Verilog Code to Vivado HLS. Available online: https://forums.xilinx.com/t5/High-Level-Synthesis-HLS/Introducing-vhdl-verilog-code-to-Vivado-HLS/td-p/890586 (accessed on 23 December 2019).
- Sklansky, J. Conditional-Sum Addition Logic. IRE Trans. Electron. Comput. 1960, EC-9, 226–231. [Google Scholar] [CrossRef]
- Macsorley, O.L. High-Speed Arithmetic in Binary Computers. Proc. IRE 1961, 49, 67–91. [Google Scholar] [CrossRef]
- Esposito, D.; Strollo, A.G.M.; Napoli, E.; Caro, D.D.; Petra, N. Approximate Multipliers Based on New Approximate Compressors. IEEE Trans. Circuits Syst. I: Regul. Pap. 2018, 65, 4169–4182. [Google Scholar] [CrossRef]
- GCC Online Docs: GIMPLE. Available online: https://gcc.gnu.org/onlinedocs/gccint/GIMPLE.html#GIMPLE (accessed on 25 November 2019).
- RISC-V Binutils. Available online: https://github.com/riscv/riscv-binutils-gdb (accessed on 25 November 2019).
- GNU-AS Machine Specific Features: RISC-V Instruction Formats. Available online: https://embarc.org/man-pages/as/RISC_002dV_002dFormats.html#RISC_002dV_002dFormats (accessed on 25 November 2019).
- RISC-V GNU Compiler Toolchain. Available online: https://github.com/riscv/riscv-gnu-toolchain (accessed on 25 November 2019).
- Dua, D.; Graff, C. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 23 March 2019).
- Prabakaran, B.S.; Rehman, S.; Hanif, M.A.; Ullah, S.; Mazaheri, G.; Kumar, A.; Shafique, M. DeMAS: An efficient design methodology for building approximate adders for FPGA-based systems. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 917–920. [Google Scholar] [CrossRef]
- Ullah, S.; Murthy, S.S.; Kumar, A. SMApproxLib: Library of FPGA-based Approximate Multipliers. In Proceedings of the 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Utilization | Available | Utilization (%) |
|---|---|---|---|
| LUT | 1725 | 53,200 | 3.24 |
| LUTRAM | 2 | 17,400 | 0.01 |
| FF | 938 | 106,400 | 0.88 |
| DSP | 6 | 220 | 2.72 |
| Datasets | # of Test Points | # of Attributes | # of Class | max. Bit-Length |
|---|---|---|---|---|
| Wifi Localization Data Short Version | 200 | 7 | 4 | 8 |
| Wifi Localization Data Long Version | 2000 | 7 | 4 | 8 |
| Robot Sensor Data Short Version | 200 | 4 | 4 | 16 |
| Robot Sensor Data Long Version | 2000 | 4 | 4 | 16 |
| Banknote Authorization Data | 300 | 4 | 2 | 16 |
| KNN | KM | ANN | ||||
|---|---|---|---|---|---|---|
| Approximate Design Name | Avg. Power Saving (%) | Max. Power Saving (%) | Avg. Power Saving (%) | Max. Power Saving (%) | Avg. Power Saving (%) | Max. Power Saving (%) |
| ApANew | 3.1 | 5.2 | 2.1 | 2.9 | 1.8 | 2.5 |
| ApMNew | 4.5 | 7.6 | 4 | 5.2 | 4.9 | 6.5 |
| ApAMNew | 8.2 | 12.8 | 5.8 | 7.9 | 7.3 | 10.1 |
| KNN | KM | ANN | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Approximate Design Name | Avg. Accuracy (%) | Avg. Power Saving (%) | Max. Power Saving (%) | Avg. Accuracy (%) | Avg. Power Saving (%) | Max. Power Saving (%) | Avg. Accuracy (%) | Avg. Power Saving (%) | Max. Power Saving (%) |
| ApA1 | 99 | 4.3 | 6.7 | 97.6 | 3.8 | 5.2 | 91.6 | 5.5 | 7.9 |
| ApA2 | 90.8 | 8.2 | 12.1 | 92.4 | 6.2 | 8 | 87.4 | 8.9 | 10.4 |
| ApANew | 98 | 9.8 | 13.7 | 97.9 | 9.3 | 12.5 | 94.8 | 11.7 | 14.3 |
| ApASNew | 92 | 19.5 | 24.1 | 94.3 | 18.5 | 23.5 | - | - | - |
| ApM1 | 89.2 | 7.8 | 11.5 | 88.8 | 8.9 | 12.5 | 86.4 | 8.5 | 10.5 |
| ApM2 | 88.5 | 8.7 | 12.1 | 87.4 | 10.1 | 13.2 | 85 | 9.2 | 13.1 |
| ApMNew | 95 | 13.1 | 17.9 | 95.6 | 14.1 | 17.7 | 92 | 14.7 | 17.8 |
| ApAM1 | 87.6 | 11.3 | 16.2 | 86.1 | 11.1 | 14.5 | 84.2 | 12.7 | 15.2 |
| ApAM2 | 86.5 | 16.1 | 20.2 | 84.2 | 14.9 | 19.8 | 82.3 | 16.7 | 20.8 |
| ApAMNew | 93 | 22.1 | 27.5 | 94 | 21.5 | 27.6 | 90.2 | 23.4 | 29.8 |
| ApASMNew | 90 | 31.7 | 40.3 | 91.8 | 30.6 | 35.2 | - | - | - |
| Approximate Module | LUT Amount | Area Overhead on the Core (%) |
|---|---|---|
| ApA1 | 58 | 2.2 |
| ApA2 | 52 | 2 |
| ApANew | 95 | 3.5 |
| ApASNew | 95 | 3.5 |
| ApM1 | 227 | 8.4 |
| ApM2 | 235 | 8.7 |
| ApMNew | 250 | 9.3 |
| ApAM1 | 285 | 10.6 |
| ApAM2 | 287 | 10.7 |
| ApAMNew | 345 | 12.8 |
| ApASMNew | 345 | 12.8 |
| Approximate Module | Average Power Saving | Area Overhead on the Core (%) |
|---|---|---|
| ApANew | 7.7 | 2.3 |
| ApASNew | 12.3 | 2.3 |
| ApMNew | 11.6 | 6.2 |
| ApAMNew | 17.3 | 8.5 |
| ApASMNew | 23.1 | 8.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taştan, İ.; Karaca, M.; Yurdakul, A. Approximate CPU Design for IoT End-Devices with Learning Capabilities. Electronics 2020, 9, 125. https://doi.org/10.3390/electronics9010125
Taştan İ, Karaca M, Yurdakul A. Approximate CPU Design for IoT End-Devices with Learning Capabilities. Electronics. 2020; 9(1):125. https://doi.org/10.3390/electronics9010125
Chicago/Turabian StyleTaştan, İbrahim, Mahmut Karaca, and Arda Yurdakul. 2020. "Approximate CPU Design for IoT End-Devices with Learning Capabilities" Electronics 9, no. 1: 125. https://doi.org/10.3390/electronics9010125
APA StyleTaştan, İ., Karaca, M., & Yurdakul, A. (2020). Approximate CPU Design for IoT End-Devices with Learning Capabilities. Electronics, 9(1), 125. https://doi.org/10.3390/electronics9010125