Detecting and Localizing Anomalies in Container Clusters Using Markov Models



Abstract
:1. Introduction
2. Related Work
3. Hierarchical Hidden Markov Model (HHMM) for Anomaly Detection in Container Clusters
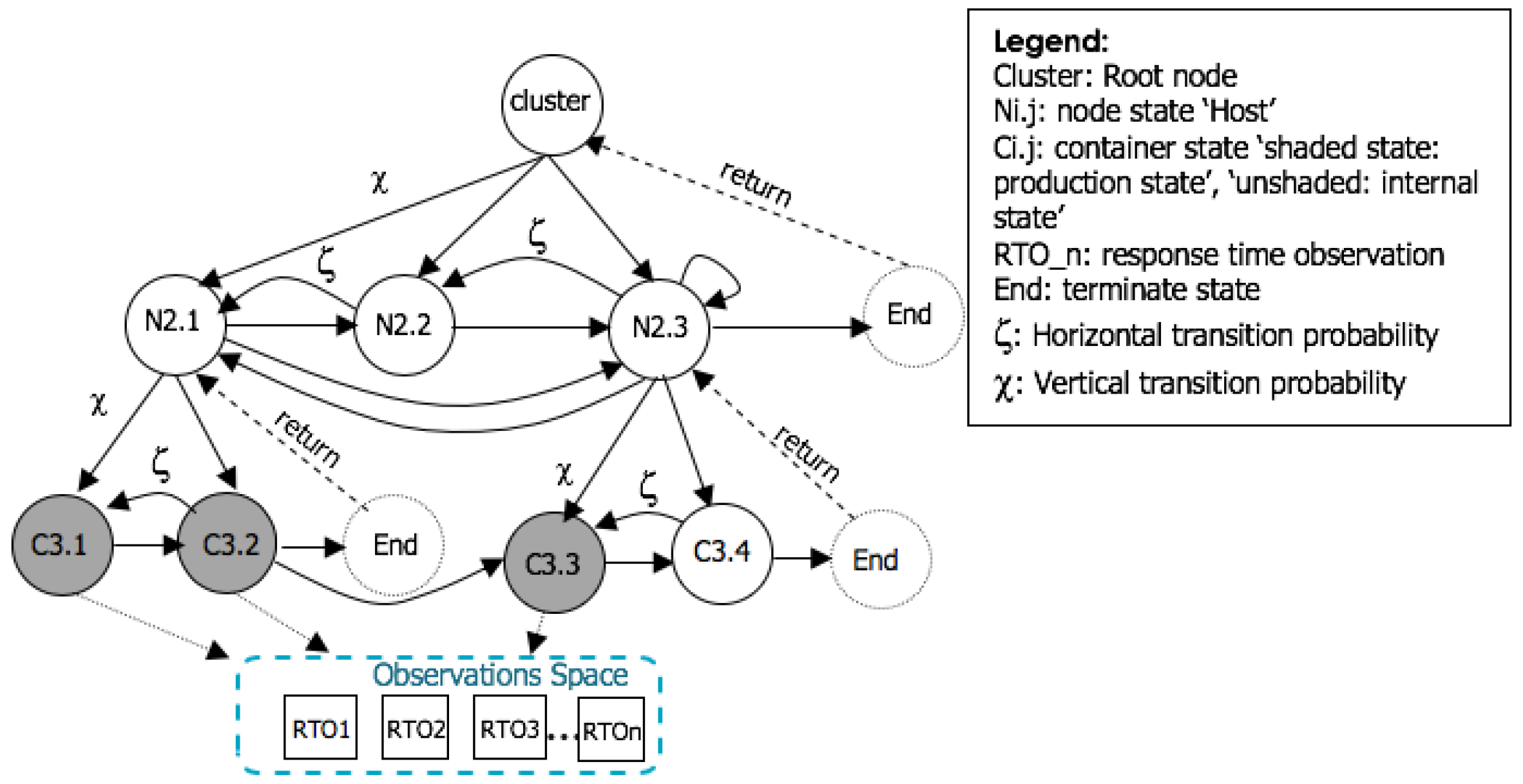
3.1. HHMM Basic Structure and Definition
- Calculating the likelihood of a sequence of observations: given a HHMM and its parameter set, find the probability of a sequence of observations to be generated by the model. The first problem can be used to determine which of the trained model is most likely when a training observation sequence is given. In our performance analysis case of containerized-cluster environment, given the previous observations of the containers, the model detects the anomalous behaviour. To achieve this step, the model is designed to adjust and optimize its parameters.
- Finding the most probable state sequence: given the HHMM, its parameter set, and an observation sequence, find the state sequence that is most likely to generate the observation (finding out the hidden path of anomalous observation). In our case, we apply the model to track the sequence of anomalous behaviour in the system. At this problem, number of different observations should be applied to the model to refine its parameters. At this stage, we use the Viterbi algorithm.
- Estimating the parameters of a model: given the structure of the HHMM and its observation sequences, find the most probable parameter set of the model. The third problem deals with the model training. In our case, once the model has been thoroughly optimized, we train the model with historical and runtime data to perform detection and tracking enhancement. The Baum-Welch algorithm is used to train the model.
3.2. Customizing HHMM for Anomaly Detection in Container Clusters
- Cluster: which is the root state in the model. It is responsible for controlling nodes and containers, which are the states. A cluster consists of at least two nodes and multiple containers.
- Nodes, i.e., resources that offer capacity to its containers such as Memory and CPU. The main job of the node is to perform requests to its underlying substates, which are the containers in our case. The system may contain one or multiple nodes belongs to one cluster. In our HHMM, nodes are substates, and they may be internal states, if they do not emit any observation. In case a node emits an observation, it is considered a production state. In such situation, a production state cannot have substates as it is considered a leaf in the hierarchy.
- Containers, i.e., lightweight virtualized execution units that can run an application in an isolated environment. One or multiple containers can run on the same node and share its resources. As specified in the node, a container is considered an internal state if it does not emit any observation. Otherwise, it is considered a production state.
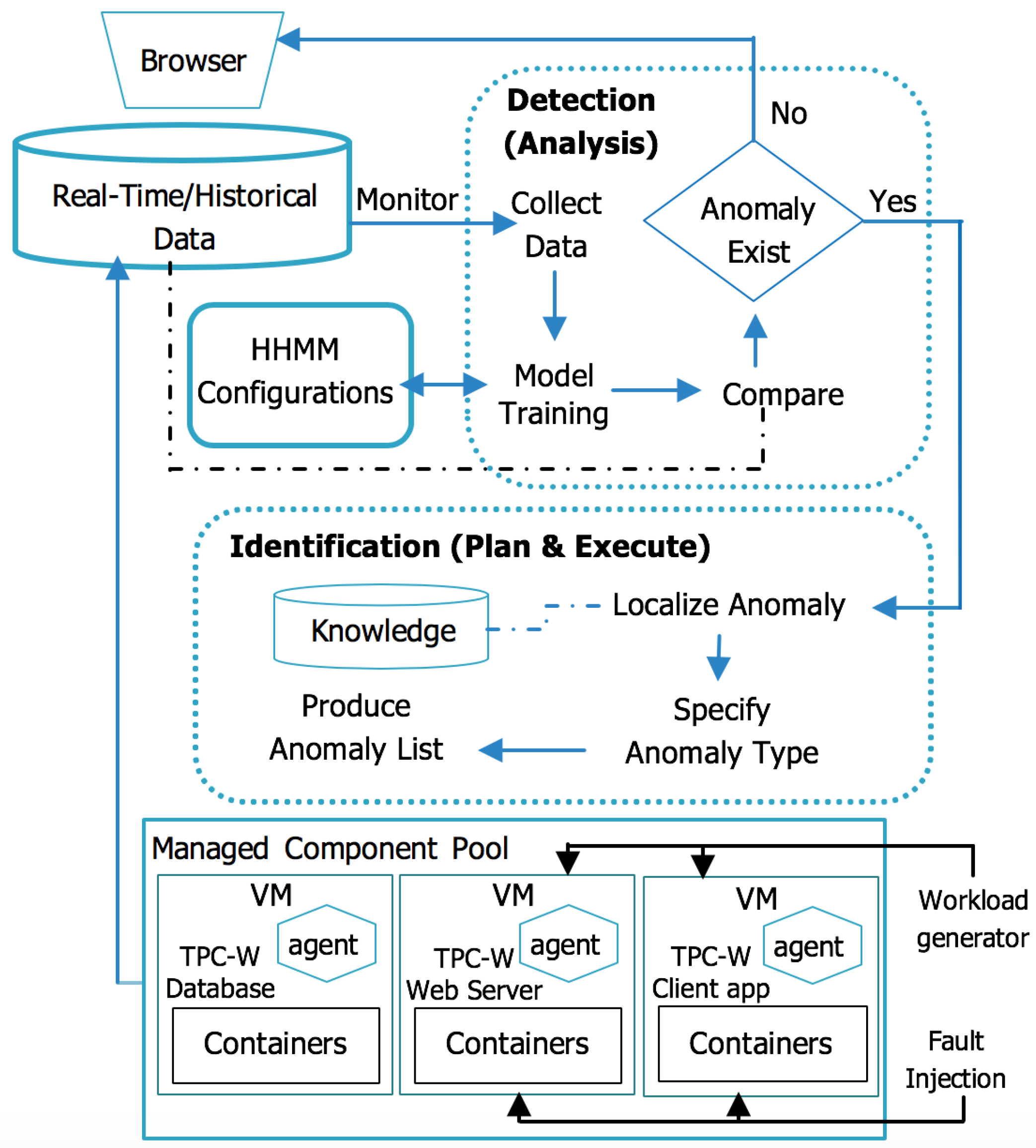
4. An Anomaly Detection and Identification Framework
- Monitor: collects data about components and resources for later analysis. Data is gathered from an agent that is installed on each node. We use the spearman rank correlation to capture the existence of anomalous behaviour.
- Analysis: once data is collected, we built HHMMs for the system as shown in Figure 1 to provide a high level of performance over the entire detection space. At this stage, a HHMM detects the existence of anomalous behaviour.
- Plan and Execute: when the HHMM detects an anomaly, it tracks its path and identifies its type.
- Knowledge: a repository with different anomaly cases that occur at different levels. Such cases are used by the plan and execute stage to aid in identifying the type of the detected anomaly.
4.1. Anomaly Cases
- Case 1.1 Container Overload (Self-Dependency): a container enters into a self-load loop because it is heavily loaded with requests or has limited resources. This load results in low container response time. This case may apply for one or multiple containers with no communication.
- Case 1.2 Container Sibling Overload (Inter-Container Dependency): an overloaded container may indirectly affect other dependent containers at the same node. For example, has an application that almost consumes its whole resources. When it communicates with and is overloaded, then will go into underload because and share resources of the same node.
- Case 1.3 Container Neighbour Overload (External Container Dependency): happens if one or more communicating containers at different nodes are overloaded. For example, shows low response time once is overloaded as depends on , and depends on to complete user requests. Thus, a longer response time occurs for those containers.
- Case 2.1 Node Overload (Self-dependency): node overload happens when a node has low capacity, many jobs waiting to be processed, or network problems occur. For example, has limited capacity, which causes an overload at container level for and .
- Case 2.2 Node Overload (Inter-Node Dependency):an overloaded node may indirectly affect other nodes in the same cluster. This may cause low response time observed at node level, which slows the whole operation of a cluster because of the communication between the two nodes assuming that and share the resource of the same cluster ’physical server’. Thus, when shows a heavier load, it would affect the performance of .
4.2. Anomaly Detection and Identification Mechanism
4.2.1. Anomaly Monitoring
| Algorithm 1 Check Performance Degradation |
1: Initialization:
array to store interval in minutes 3: Begin 4: ; 5: ; 6: while do 7: ; 8: ; 9: end while 10: ; 11: ; 12: End 13: Output: return |
4.2.2. Anomaly Detection and Identification: Analysis and Execute
| Algorithm 2 Detection-Identification Algorithm | |
1: Initialization:
4: Initialize HHMM: 5: if then 6: initialize HHMM parameters; 7: else 8: initialize HHMM parameters with the last updated values; 9: end if 10: Training HHMM 11: Detection 12: do | |
| 13: ; | ▹ run Baum-Welch algorithm |
| 14: ; | ▹ update all Baum-Welch parameters |
| 15: ; | ▹ sotre updated values in , , |
| 16: ; | ▹ increase the model iteration number |
| 17: while 18: ; 19: Identification 20: ; 21: ; 22: for each r in do 23: for each c in do 24: if ( AND AND ) then 25: case ← Container Sibling Overloaded (Inter Container Dependency); 26: else if ( AND AND ) then 27: case ← Container Overloaded (Self-Dependency); 28: else if ( AND AND ) then 29: case ← Container Neighbor Overloaded (External Container Dependency); 30: else if ( AND AND ) then 31: case ← Inter Node Dependency; 32: else 33: case ← Node Overload (Self-dependency); 34: end if | |
| 35: ; | ▹ increment c |
| 36: end for 37: ; | |
| 38: ; | ▹ increment r |
| 39: end for 40: End 41: Output: case, path | |
5. Evaluation
5.1. Experimental Set-Up
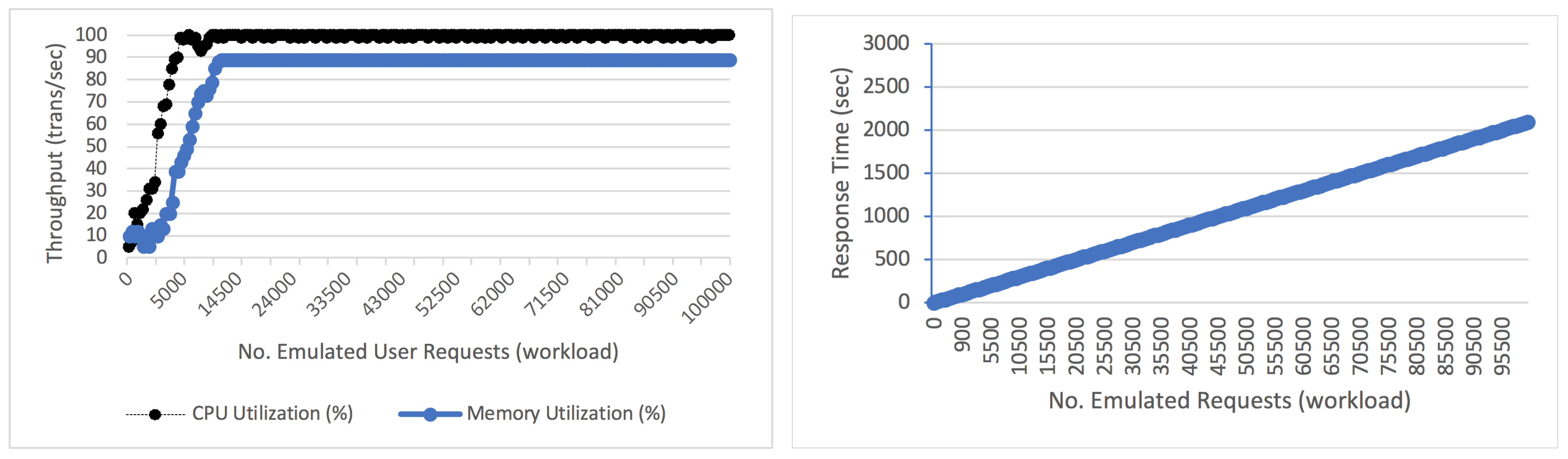
5.2. Anomaly Injection and Workload Contention Scenarios
5.2.1. Resource Exhaustion
| Algorithm 3 Anomaly Injection Algorithm at Container Level |
1: Input:
3: for each do 4: for each do 5: for each do 6: InjectAnomaly(, , ); 7: ; 8: end for 9: end for 10: end for 11: End 12: Output: , at |
| Algorithm 4 Anomaly Injection Algorithm at Node Level |
1: Input:
3: for each do 4: for each do 5: InjectAnomaly(, , ); 6: ; 7: end for 8: end for 9: End 10: Output: , at , |
5.2.2. Workload Contention
5.3. Detection and Identification of Anomaly Scenarios
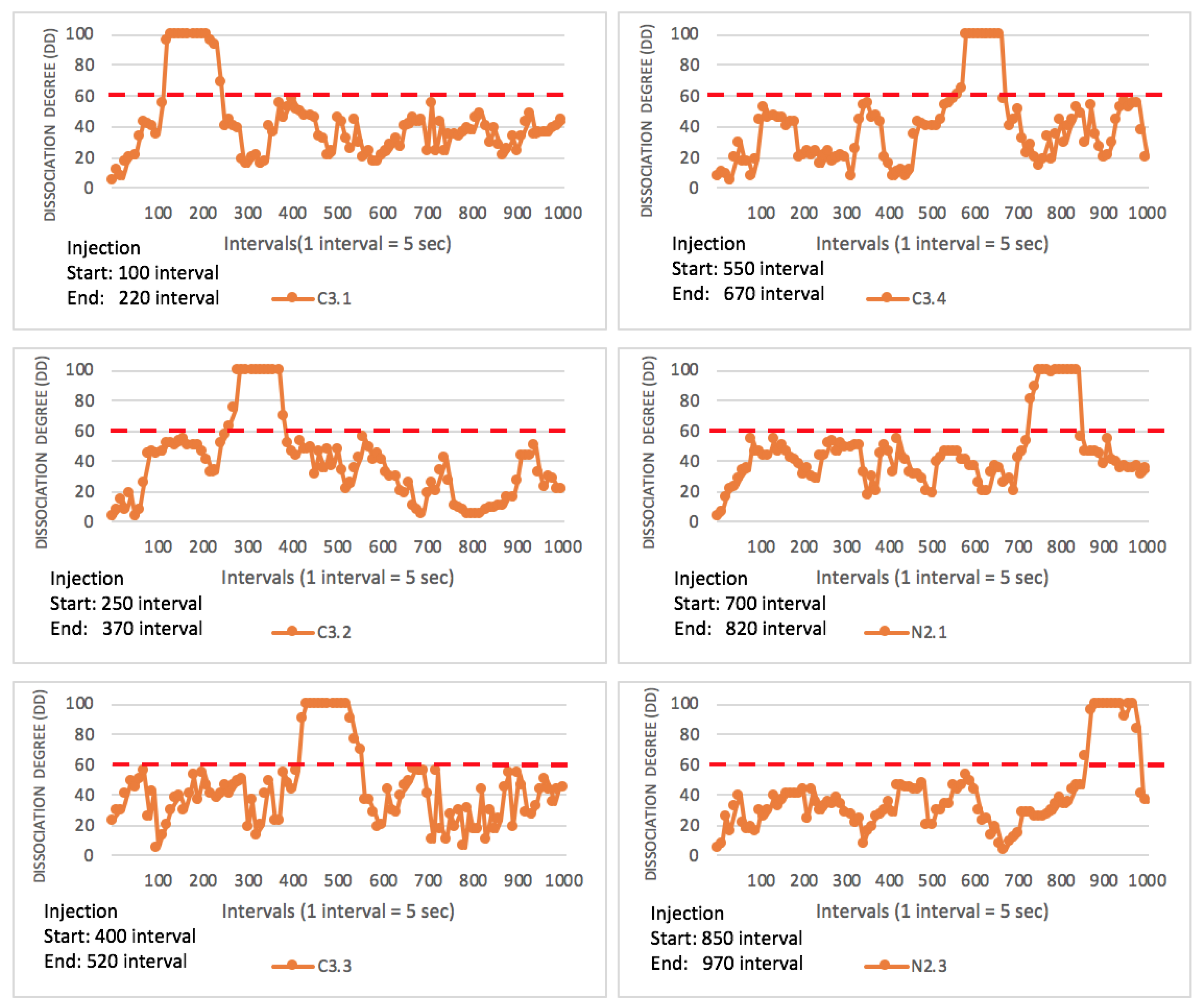
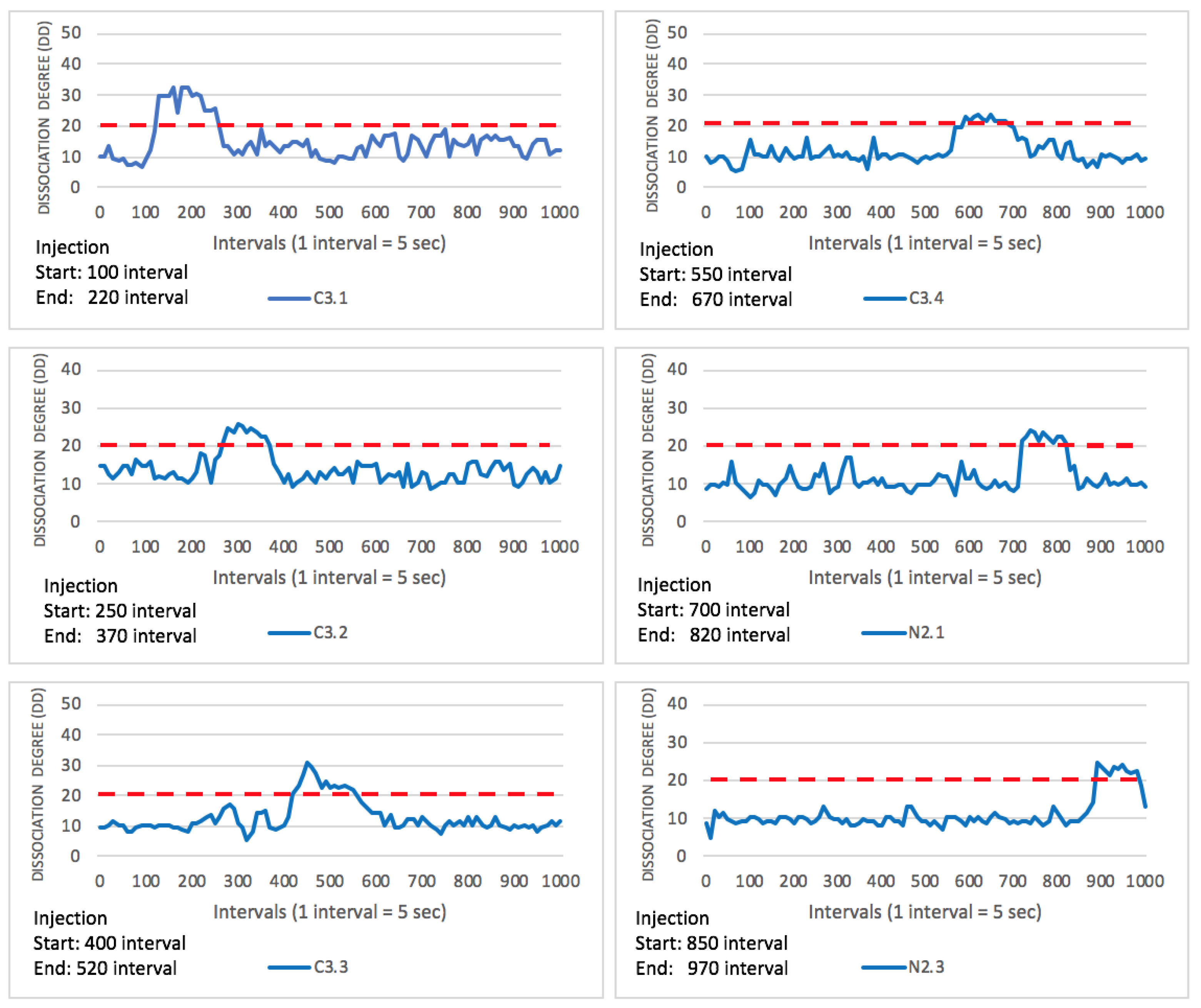
5.3.1. System-Level Injection
5.3.2. Component-Level Injection
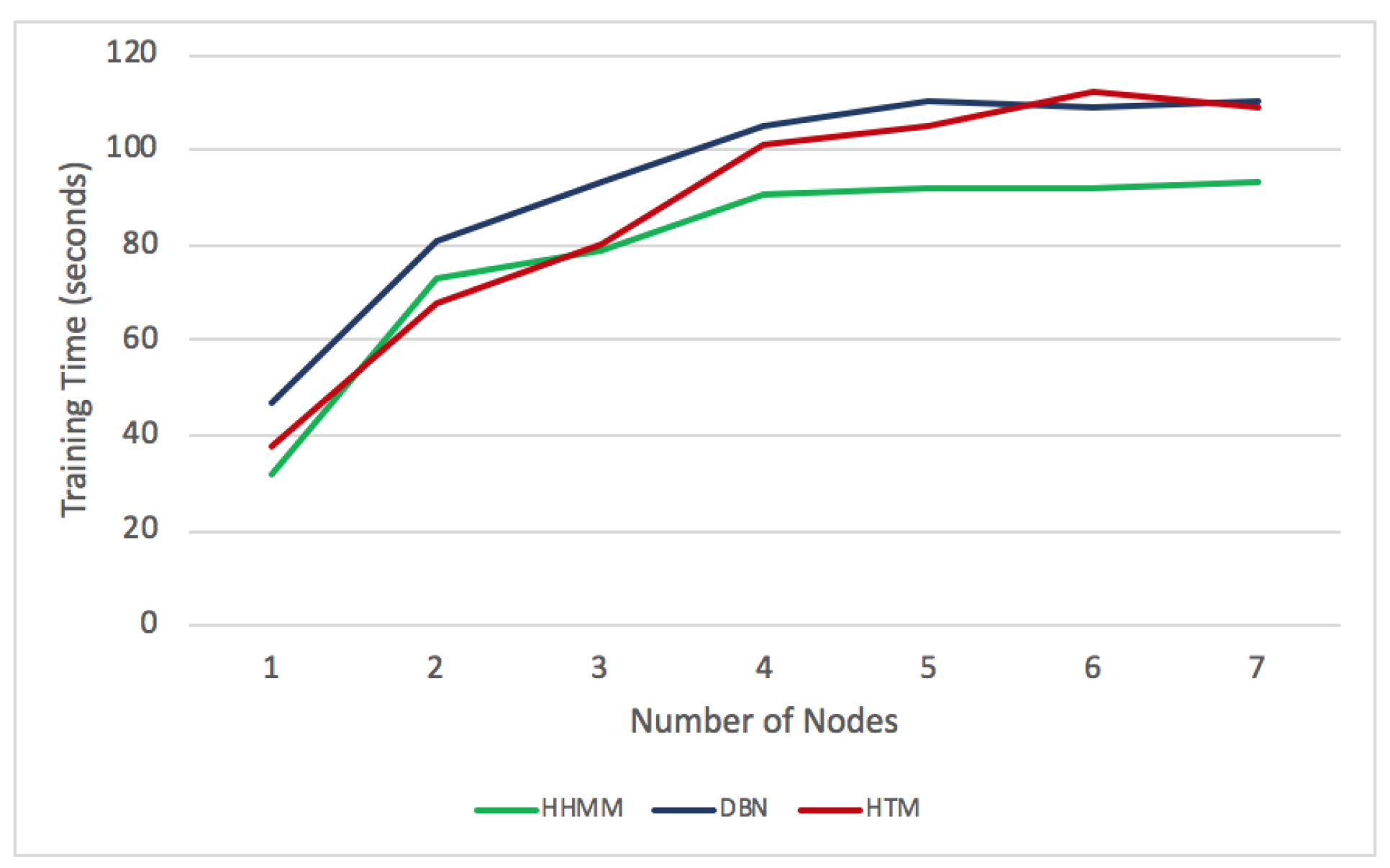
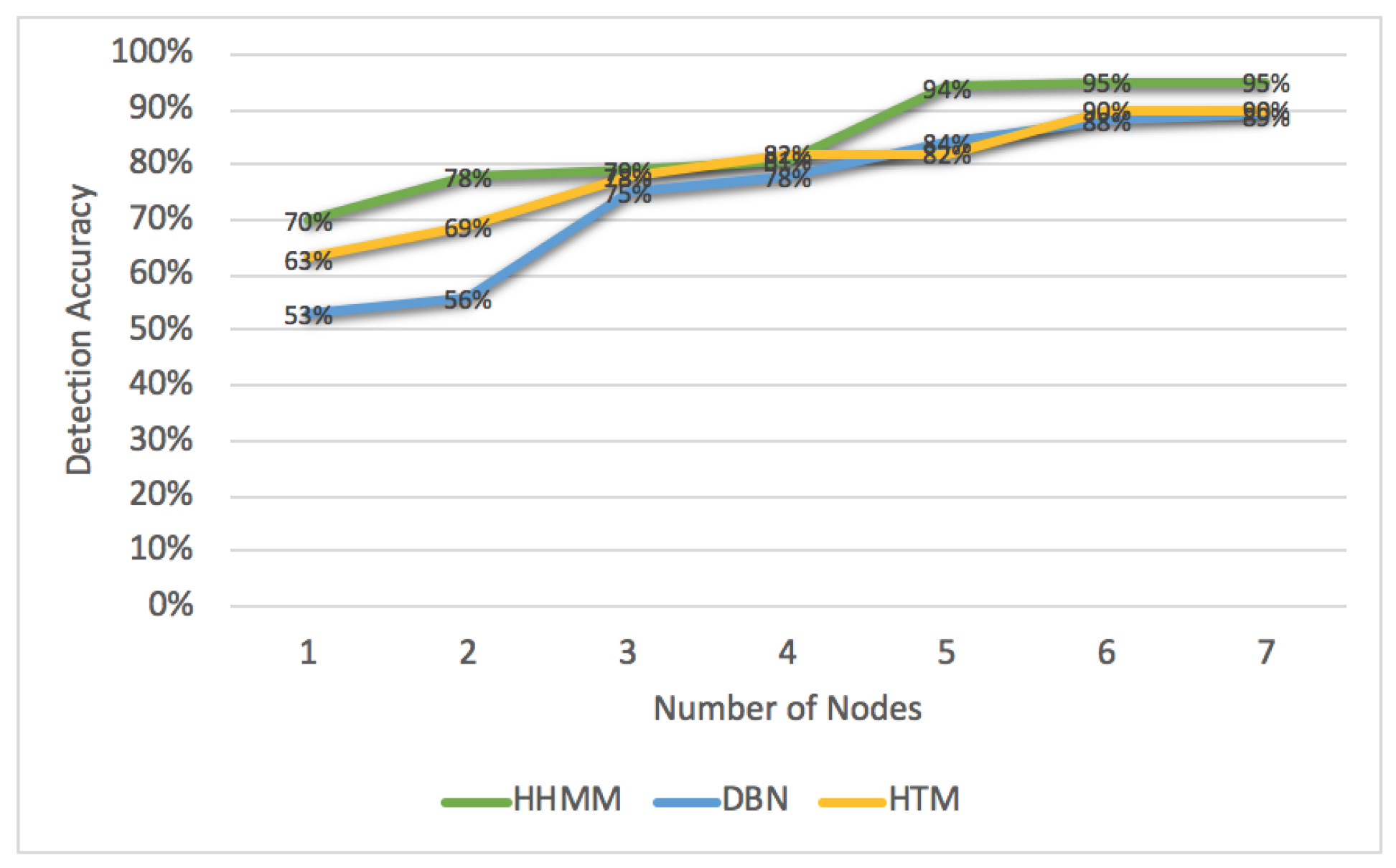
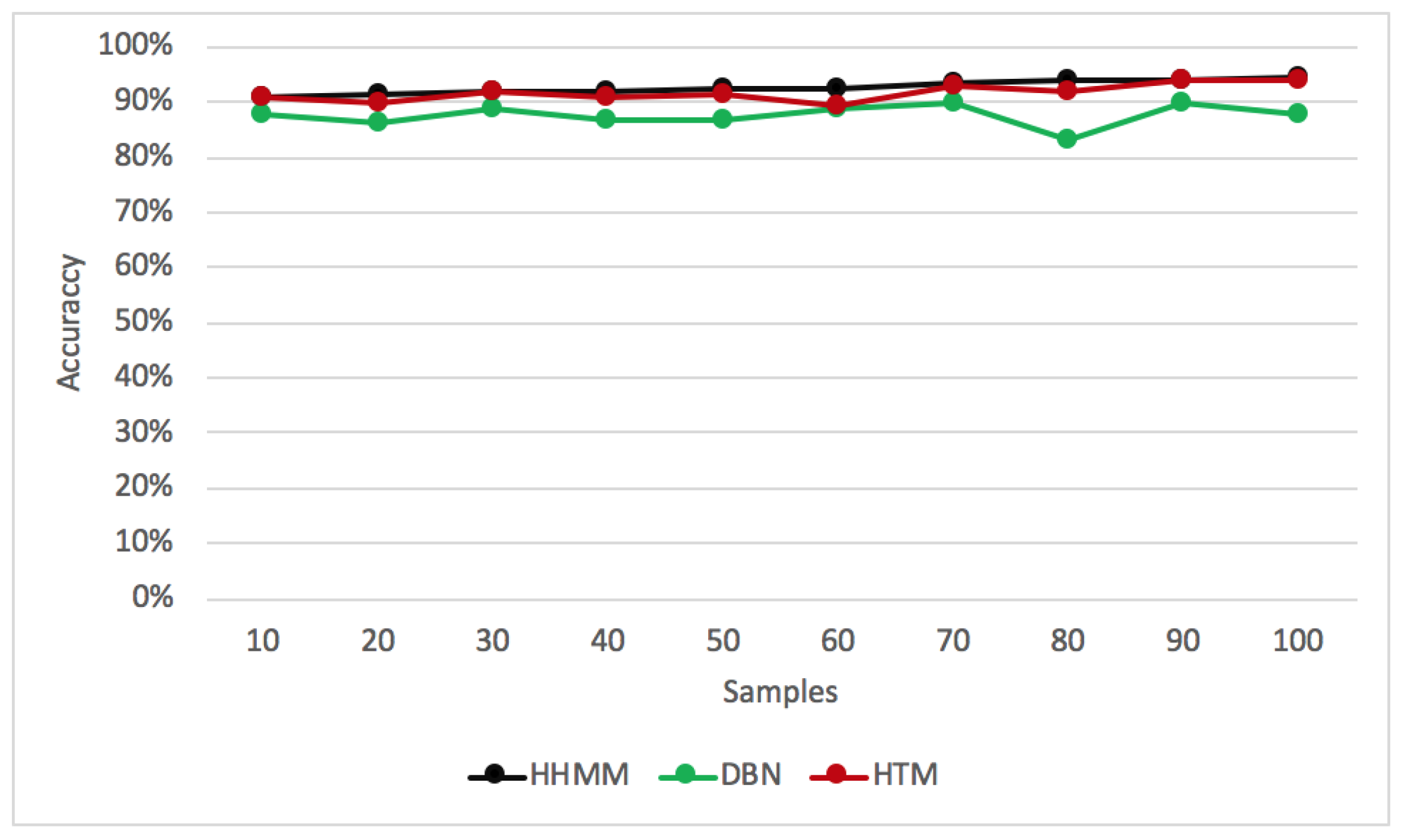
5.4. A Comparative Evaluation of Anomaly Detection and Identification
5.4.1. The Assessment of Anomaly Detection
- Precision is the ratio of correctly detected anomaly to the sum of correctly and incorrectly detected anomalies. High precision indicates the model correctly detects anomalous behaviour.
- Recall measures the completeness of correctly detected anomalies to the total number of detected anomalies that are actually defective. Higher recall indicates that fewer anomaly cases are undetected.
- F1-score measures the detection accuracy. It considers both precision and recall of the detection to compute the F1-score with values from [0–1]. The higher the value, the better the result.
- False Alarm Rate (FAR) is the number of normal components, which have been detected as anomalous (values in [0–1]). A lower FAR value indicates the model effectively detects anomalies.
5.4.2. The Assessment of Anomaly Identification
- Accuracy of Identification (AI): measures the completeness of the correctly identified anomalies with respect to the total number of anomalies in a given dataset. The higher the value, the more correct the identification made by the model.
- Number of Correctly Identified Anomaly (CIA): It is the percentage of correct identified anomalies (NCIA) out of the total set of identifications, which is the number of correct Identification (NCIA) + the number of incorrect Identifications (NICI)). A higher value indicates the model is correctly identified anomalous component.
- Number of Incorrectly Identified Anomaly (IIA): is the percentage of identified components that represent an anomaly, but are misidentified as normal by the model. A lower value indicates that the model correctly identified anomalous components.
- False Alarm Rate (FAR): is the number of normal identified components, which have been misclassified as anomalous by the model.
5.5. Comparison with Other Monitoring Tools
5.6. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| HMM | Hidden Markov Model |
| HHMM | Hierarchical Hidden Markov Model |
| MAPE-K | Monitor Analysis Plan Execute - Knowledge |
| DD | Dissociation Degree |
| DBN | Dynamic Bayesian Network |
| HTM | Hierarchical Temporal Memory |
| IIA | Incorrect Identified Anomaly |
| CIA | Correct Identified Anomaly |
| NCIA | Number of Correct Identification Anomaly |
| NICI | Number of Incorrect Identification |
| FAR | False Alarm Rate |
| DIL | Detection and Identification Latency |
References
- Pahl, C.; Jamshidi, P.; Zimmermann, O. Architectural principles for cloud software. ACM Trans. Internet Technol. (TOIT) 2018, 18, 17. [Google Scholar] [CrossRef]
- Taibi, D.; Lenarduzzi, V.; Pahl, C. Architecture Patterns for a Microservice Architectural Style. In Communications in Computer and Information Science; Springer: New York, NY, USA, 2019. [Google Scholar]
- Taibi, D.; Lenarduzzi, V.; Pahl, C. Architectural Patterns for Microservices: A Systematic Mapping Study. In Proceedings of the CLOSER Conference, Madeira, Portugal, 19–21 March 2018; pp. 221–232. [Google Scholar]
- Jamshidi, P.; Pahl, C.; Mendonca, N.C. Managing uncertainty in autonomic cloud elasticity controllers. IEEE Cloud Comput. 2016, 3, 50–60. [Google Scholar] [CrossRef]
- Mendonca, N.C.; Jamshidi, P.; Garlan, D.; Pahl, C. Developing Self-Adaptive Microservice Systems: Challenges and Directions. IEEE Softw. 2020. [Google Scholar] [CrossRef] [Green Version]
- Gow, R.; Rabhi, F.A.; Venugopal, S. Anomaly detection in complex real world application systems. IEEE Trans. Netw. Serv. Manag. 2018, 15, 83–96. [Google Scholar] [CrossRef]
- Alcaraz, J.; Kaaniche, M.; Sauvanaud, C. Anomaly Detection in Cloud Applications: Internship Report. Machine Learning [cs.LG]. 2016. hal-01406168. Available online: https://hal.laas.fr/hal-01406168 (accessed on 15 December 2019).
- Du, Q.; Xie, T.; He, Y. Anomaly Detection and Diagnosis for Container-Based Microservices with Performance Monitoring. In Proceedings of the International Conference on Algorithms and Architectures for Parallel Processing, Guangzhou, China, 15–17 November 2018; pp. 560–572. [Google Scholar]
- Wang, T.; Xu, J.; Zhang, W.; Gu, Z.; Zhong, H. Self-adaptive cloud monitoring with online anomaly detection. Future Gener. Comput. Syst. 2018, 80, 89–101. [Google Scholar] [CrossRef]
- Düllmann, T.F. Performance Anomaly Detection in Microservice Architectures under Continuous Change. Master’s Thesis, University of Stuttgart, Stuttgart, Germany, 2016. [Google Scholar]
- Wert, A. Performance Problem Diagnostics by Systematic Experimentation. Ph.D. Thesis, KIT, Karlsruhe, Germany, 2015. [Google Scholar]
- Barford, P.; Duffield, N.; Ron, A.; Sommers, J. Network performance anomaly detection and localization. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 1377–1385. [Google Scholar] [CrossRef] [Green Version]
- Pahl, C.; Brogi, A.; Soldani, J.; Jamshidi, P. Cloud container technologies: A state-of-the-art review. IEEE Trans. Cloud Comput. 2018, 7, 677–692. [Google Scholar] [CrossRef]
- Lawrence, H.; Dinh, G.H.; Williams, A.; Ball, B. Container Monitoring and Management. 2018. Available online: https://docs.broadcom.com/docs/container-monitoring-ebook (accessed on 15 December 2019).
- Taylor, T. 6 Container Performance KPIs You Should Be Tracking to Ensure DevOps Success. 2018. Available online: https://www.devopsdigest.com/6-container-performance-kpis-you-should-be-tracking-to-ensure-devops-success (accessed on 15 December 2019).
- Fine, S.; Singer, Y.; Tishby, N. The hierarchical hidden markov model: Analysis and applications. Mach. Learn. 1998, 32, 41–62. [Google Scholar] [CrossRef] [Green Version]
- Sorkunlu, N.; Chandola, V.; Patra, A. Tracking system behavior from resource usage data. In Proceedings of the IEEE International Conference on Cluster Computing, ICCC, Honolulu, HI, USA, 5–8 September 2017; Volume 2017, pp. 410–418. [Google Scholar] [CrossRef]
- Agrawal, B.; Wiktorski, T.; Rong, C. Adaptive anomaly detection in cloud using robust and scalable principal component analysis. In Proceedings of the 2016 15th International Symposium on Parallel and Distributed Computing (ISPDC), Fuzhou, China, 8–10 July 2016; pp. 100–106. [Google Scholar] [CrossRef]
- Magalhães, J.P. Self-Healing Techniques for Web-Based Applications. Ph.D. Thesis, University of Coimbra, Coimbra, Portugal, 2013. [Google Scholar]
- Kozhirbayev, Z.; Sinnott, R.O. A performance comparison of container-based technologies for the Cloud. Future Gener. Comput. Syst. 2017, 68, 175–182. [Google Scholar] [CrossRef]
- Peiris, M.; Hill, J.H.; Thelin, J.; Bykov, S.; Kliot, G.; Konig, C. PAD: Performance anomaly detection in multi-server distributed systems. In Proceedings of the 2014 IEEE 7th International Conference on Cloud Computing, Anchorage, AK, USA, 27 June–2 July 2014; Volume 7, pp. 769–776. [Google Scholar] [CrossRef]
- Sukhwani, H. A Survey of Anomaly Detection Techniques and Hidden Markov Model. Int. J. Comput. Appl. 2014, 93, 26–31. [Google Scholar] [CrossRef]
- Ge, N.; Nakajima, S.; Pantel, M. Online diagnosis of accidental faults for real-time embedded systems using a hidden markov model. Simulation 2016, 91, 851–868. [Google Scholar] [CrossRef] [Green Version]
- Brogi, G. Real-Time Detection of Advanced Persistent Threats Using Information Flow Tracking and Hidden Markov Models. Ph.D. Thesis, Conservatoire National des Arts et Métiers, Paris, France, 2018. [Google Scholar]
- Samir, A.; Pahl, C. A Controller Architecture for Anomaly Detection, Root Cause Analysis and Self-Adaptation for Cluster Architectures. In Proceedings of the International Conference on Adaptive and Self-Adaptive Systems and Applications, Venice, Italy, 5–9 May 2019; pp. 75–83. [Google Scholar]
- Samir, A.; Pahl, C. Self-Adaptive Healing for Containerized Cluster Architectures with Hidden Markov Models. In Proceedings of the 2019 Fourth International Conference on Fog and Mobile Edge Computing (FMEC), Rome, Italy, 10–13 June 2019. [Google Scholar]
- Samir, A.; Pahl, C. Detecting and Predicting Anomalies for Edge Cluster Environments using Hidden Markov Models. In Proceedings of the Fourth IEEE International Conference on Fog and Mobile Edge Computing, Rome, Italy, 10–13 June 2019; pp. 21–28. [Google Scholar]
- Chis, T. Sliding hidden markov model for evaluating discrete data. In European Workshop on Performance Engineering; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Bachiega, N.G.; Souza, P.S.; Bruschi, S.M.; De Souza, S.D.R. Container-based performance evaluation: A survey and challenges. In Proceedings of the 2018 IEEE International Conference on Cloud Engineering, IC2E 2018, Orlando, FL, USA, 17–20 April 2018; pp. 398–403. [Google Scholar] [CrossRef]
- La Rosa, A. Docker Monitoring: Challenges Introduced by Containers and Microservices. 2018. Available online: https://pandorafms.com/blog/docker-monitoring/ (accessed on 15 December 2019).
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Elasticity in cloud computing: State of the art and research challenges. IEEE Trans. Serv. Comput. 2017, 11, 430–447. [Google Scholar] [CrossRef] [Green Version]
- Spearman’s Rank Correlation Coefficient Rs and Probability (p) Value Calculator; Barcelona Field Studies Centre: Barcelona, Spain, 2019.
- Josefsson, T. Root-Cause Analysis Through Machine Learning in the Cloud. Master’s Thesis, Upsala Univ., Uppsala, Sweden, 2017. [Google Scholar]
- Markham, K. Simple Guide to Confusion Matrix Terminology 2014. Available online: https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/ (accessed on 15 December 2019).
- Pahl, C.; El Ioini, N.; Helmer, S.; Lee, B. An architecture pattern for trusted orchestration in IoT edge clouds. In Proceedings of the Third International Conference on Fog and Mobile Edge Computing, FMEC, Barcelona, Spain, 23–26 April 2018; pp. 63–70. [Google Scholar]
- Scolati, R.; Fronza, I.; El Ioini, N.; Samir, A.; Pahl, C. A Containerized Big Data Streaming Architecture for Edge Cloud Computing on Clustered Single-Board Devices. In Proceedings of the 10th International Conference on Cloud Computing and Services Science, Prague, Czech Republic, 7–9 May 2020; pp. 68–80. [Google Scholar]
- Von Leon, D.; Miori, L.; Sanin, J.; El Ioini, N.; Helmer, S.; Pahl, C. A performance exploration of architectural options for a middleware for decentralised lightweight edge cloud architectures. In Proceedings of the CLOSER Conference, Madeira, Portugal, 19–21 March 2018. [Google Scholar]
- Von Leon, D.; Miori, L.; Sanin, J.; El Ioini, N.; Helmer, S.; Pahl, C. A Lightweight Container Middleware for Edge Cloud Architectures. In Fog and Edge Computing: Principles and Paradigms; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019; pp. 145–170. [Google Scholar]
- Pahl, C. An ontology for software component matching. In Proceedings of the International Conference on Fundamental Approaches to Software Engineering, Warsaw, Poland, 7–11 April 2003; pp. 6–21. [Google Scholar]
- Pahl, C. Layered ontological modelling for web service-oriented model-driven architecture. In Proceedings of the European Conference on Model Driven Architecture—Foundations and Applications, Nuremberg, Germany, 7–10 November 2005. [Google Scholar]
- Javed, M.; Abgaz, Y.M.; Pahl, C. Ontology change management and identification of change patterns. J. Data Semant. 2013, 2, 119–143. [Google Scholar] [CrossRef] [Green Version]
- Kenny, C.; Pahl, C. Automated tutoring for a database skills training environment. In Proceedings of the ACM SIGCSE Symposium 2005, St.Louis, MO, USA, 23–27 February 2005; pp. 58–64. [Google Scholar]
- Murray, S.; Ryan, J.; Pahl, C. A tool-mediated cognitive apprenticeship approach for a computer engineering course. In Proceedings of the 3rd IEEE International Conference on Advanced Technologies, Athens, Greece, 9–11 July 2003; pp. 2–6. [Google Scholar]
- Pahl, C.; Barrett, R.; Kenny, C. Supporting active database learning and training through interactive multimedia. ACM SIGCSE Bull. 2004, 36, 27–31. [Google Scholar] [CrossRef]
- Lei, X.; Pahl, C.; Donnellan, D. An evaluation technique for content interaction in web-based teaching and learning environments. In Proceedings of the 3rd IEEE International Conference on Advanced Technologies, Athens, Greece, 9–11 July 2003; pp. 294–295. [Google Scholar]
- Melia, M.; Pahl, C. Constraint-based validation of adaptive e-learning courseware. IEEE Trans. Learn. Technol. 2009, 2, 37–49. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric Name | Description |
|---|---|
| CPU Usage | CPU utilization for each container and node |
| CPU Request | CPU request in millicores |
| Resource Saturation | The amount of work a CPU/memory cannot serve and waiting in queue |
| Memory Usage | Occupied memory of the container |
| Memory Request | Memory request in bytes |
| Node CPU Capacity | Total CPU capacity of cluster nodes |
| Node Memory Capacity | Total memory capacity of cluster nodes |
| Components | Settings |
|---|---|
| CPU | 2.7GH_z Intel Cores i5 |
| Disk Space | 1TB |
| Memory | 8 GB DDR3 |
| Operating System | MacOS |
| Application | R |
| Dataset | TPC-W benchmark |
| Components | Settings |
|---|---|
| Number of Nodes | 3 |
| Container no. | 4 |
| Number of CPUs | 3 |
| HD | 512 GB |
| RAM | 2 GB |
| Guest OS | Linux |
| Orchestration Tool | Docker and Kubernetes |
| Parameter Name | Description | Value |
|---|---|---|
| EB | Emulate a client by sending and receiving requests | rbe.EBTPCW1Factory |
| CUST | Generate random number of customers | 15,000 |
| Ramp-up | Time between sending requests | 600 s |
| ITEM | Number of items in database | 100,000 |
| Number of Requests | Number of requests generated per second | 30–100,000 request/s |
| Resource | Fault Type | Fault Description | Injection Operation |
|---|---|---|---|
| CPU | CPU hog | Consume all CPU cycles for a container | Employing infinite loops that consumes all CPU cycle |
| Memory | Memory leak | Exhausts a container memory | Injected anomalies to utilize all memory capacity |
| Workload | Workload Contention | Generate increasing number of requests that saturate the component resources | Emulate user requests using Remote Browser Emulators in TPC-W benchmark |
| Components | Injection Time (Interval) | Detection Time (Interval) | Detection Period (Interval) |
|---|---|---|---|
| C3.1 | 100 | 140 | 40 |
| C3.2 | 250 | 340 | 90 |
| C3.3 | 400 | 460 | 60 |
| C3.4 | 550 | 620 | 70 |
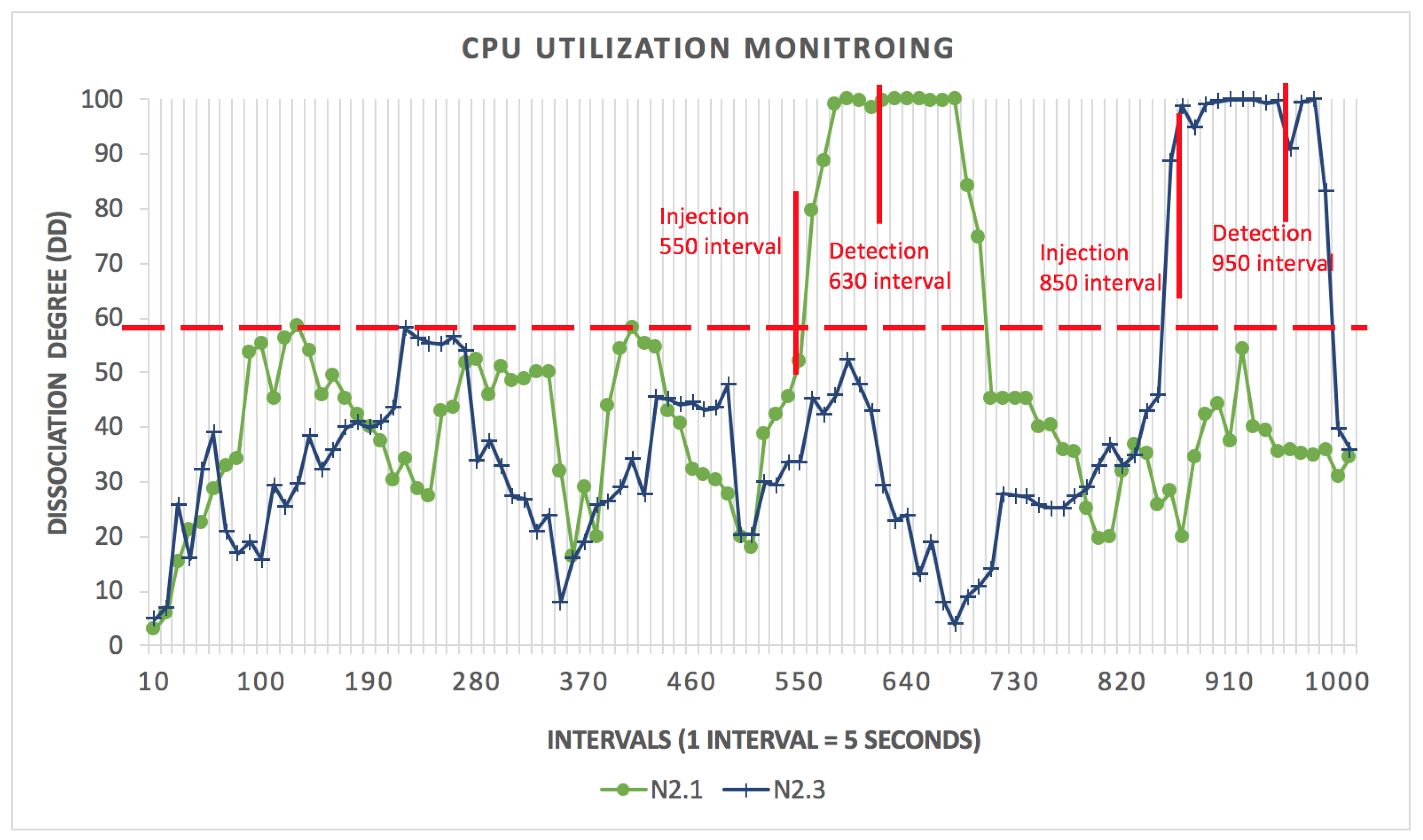
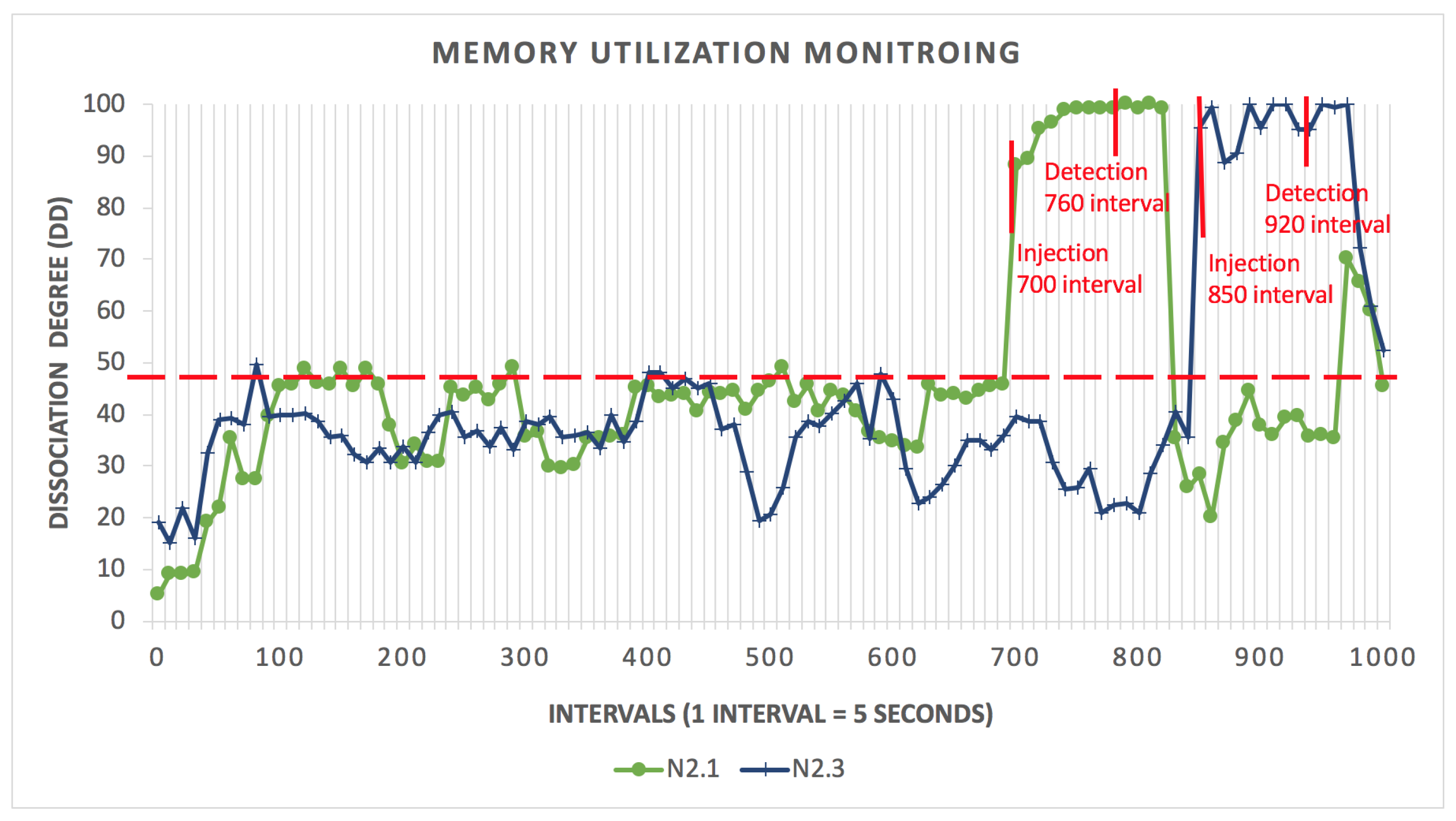
| N2.1 | 700 | 760 | 60 |
| N2.3 | 850 | 950 | 100 |
| Components | Injection Time (Interval) | Detection Time (Interval) | Detection Period (Interval) |
|---|---|---|---|
| C3.1 | 100 | 140 | 40 |
| C3.2 | 250 | 320 | 70 |
| C3.3 | 400 | 490 | 90 |
| C3.4 | 550 | 650 | 100 |
| N2.1 | 700 | 760 | 60 |
| N2.3 | 850 | 950 | 100 |
| Datasets | Metrics | HHMM | DBN | HTM |
|---|---|---|---|---|
| A = 650 | Precision | 0.95 | 0.94 | 0.95 |
| Recall | 0.96 | 0.96 | 0.95 | |
| F1-score | 0.95 | 0.95 | 0.95 | |
| FAR | 0.19 | 0.21 | 0.28 | |
| B = 861 | Precision | 0.96 | 0.91 | 0.95 |
| Recall | 0.94 | 0.84 | 0.91 | |
| F1-score | 0.95 | 0.87 | 0.93 | |
| FAR | 0.27 | 0.46 | 0.31 | |
| C = 1511 | Precision | 0.87 | 0.64 | 0.87 |
| Recall | 0.93 | 0.83 | 0.94 | |
| F1-score | 0.90 | 0.72 | 0.90 | |
| FAR | 0.31 | 0.47 | 0.33 |
| Metrics | HHMM | DBN | HTM |
|---|---|---|---|
| AI | 0.94 | 0.84 | 0.94 |
| CIA | 94.73% | 87.67% | 93.94% |
| IIA | 4.56% | 12.33% | 6.07% |
| FAR | 0.12 | 0.26 | 0.17 |
| Anomaly Behaviour | Zabbix | Dynatrace | Framework |
|---|---|---|---|
| CPU Hog | 410 | 408 | 398 |
| Memory Leak | 520 | 522 | 515 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samir, A.; Pahl, C. Detecting and Localizing Anomalies in Container Clusters Using Markov Models. Electronics 2020, 9, 64. https://doi.org/10.3390/electronics9010064
Samir A, Pahl C. Detecting and Localizing Anomalies in Container Clusters Using Markov Models. Electronics. 2020; 9(1):64. https://doi.org/10.3390/electronics9010064
Chicago/Turabian StyleSamir, Areeg, and Claus Pahl. 2020. "Detecting and Localizing Anomalies in Container Clusters Using Markov Models" Electronics 9, no. 1: 64. https://doi.org/10.3390/electronics9010064
APA StyleSamir, A., & Pahl, C. (2020). Detecting and Localizing Anomalies in Container Clusters Using Markov Models. Electronics, 9(1), 64. https://doi.org/10.3390/electronics9010064