1. Introduction
With the rapid development of computer network technology, the Internet is a part of people’s everyday lives, and it has been widely used in various fields such as the economy, military, education, and so on. Internet is a double-edged sword similar to some other technology: it promotes the rapid development of the social economy on one hand, but it brings unprecedented challenges on the other hand. Malware traffic refers to the malicious part in network traffic, including network attacks, business attacks, malicious crawlers, etc. In the open environment of the Internet, malware traffic has become a new criminal tool that not only seriously affects the stability of the Internet, it also causes economic losses and even seriously threatens national security [
1]. According to Computer Economics, financial loss due to malware attack has grown from
$3.3 billion in 1997 to
$13.3 billion in 2006. Recently in 2016, two WannaCry ransomware attacks crippled the computers of more than 150 countries, causing financial damage to different organizations. In 2016, Cybersecurity Ventures3 estimated that the total damage due to malware attacks was
$3 trillion in 2015, and it is expected to reach
$6 trillion by 2021 [
2]. Network traffic contains a lot of valuable information, as it is the most basic component of transmission and interaction in cyberspace. It is of great significance to enhance network stability, improve anti attack ability, and maintain information security by detecting and intercepting malware traffic in time.
Traditional traffic classification methods can be divided into four categories: port-based, deep packet inspection (DPI)-based, statistical-based, and behavior-based [
3]. The accuracy of port-based methods is low. DPI-based methods can not process encrypted traffic and have high computational complexity. Most research studies focus on statistical-based methods and behavior-based methods, both of which are based on the idea of machine learning. These two methods do not need to check the port or analyze the traffic, they are also applicable to encrypted traffic, and the complexity of the calculations is relatively low. However, there is the same problem in the two methods: it is too difficult to design proper feature sets that can accurately reflect the characteristics of different traffic; meanwhile, the quality of the feature sets directly affects the classification performance.
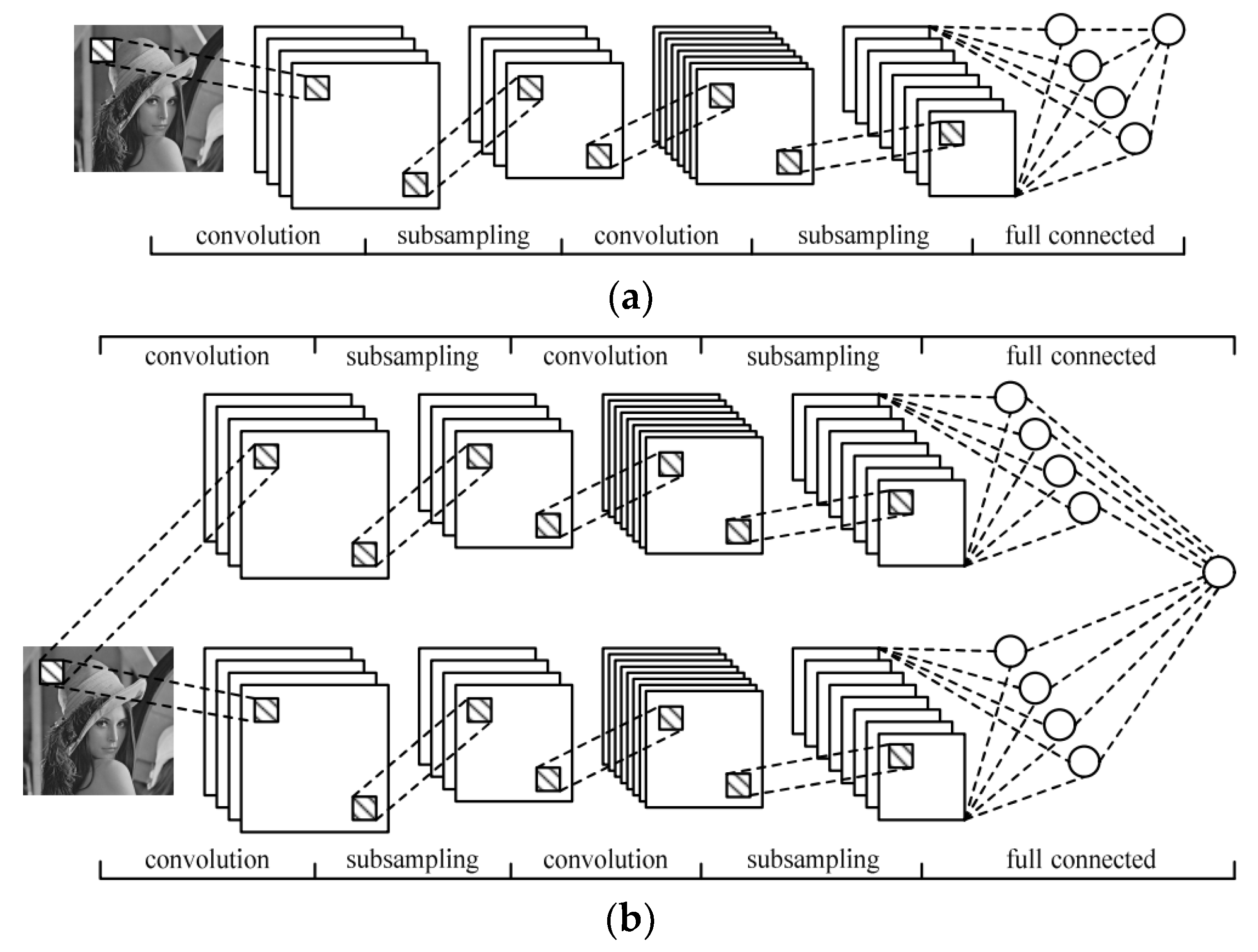
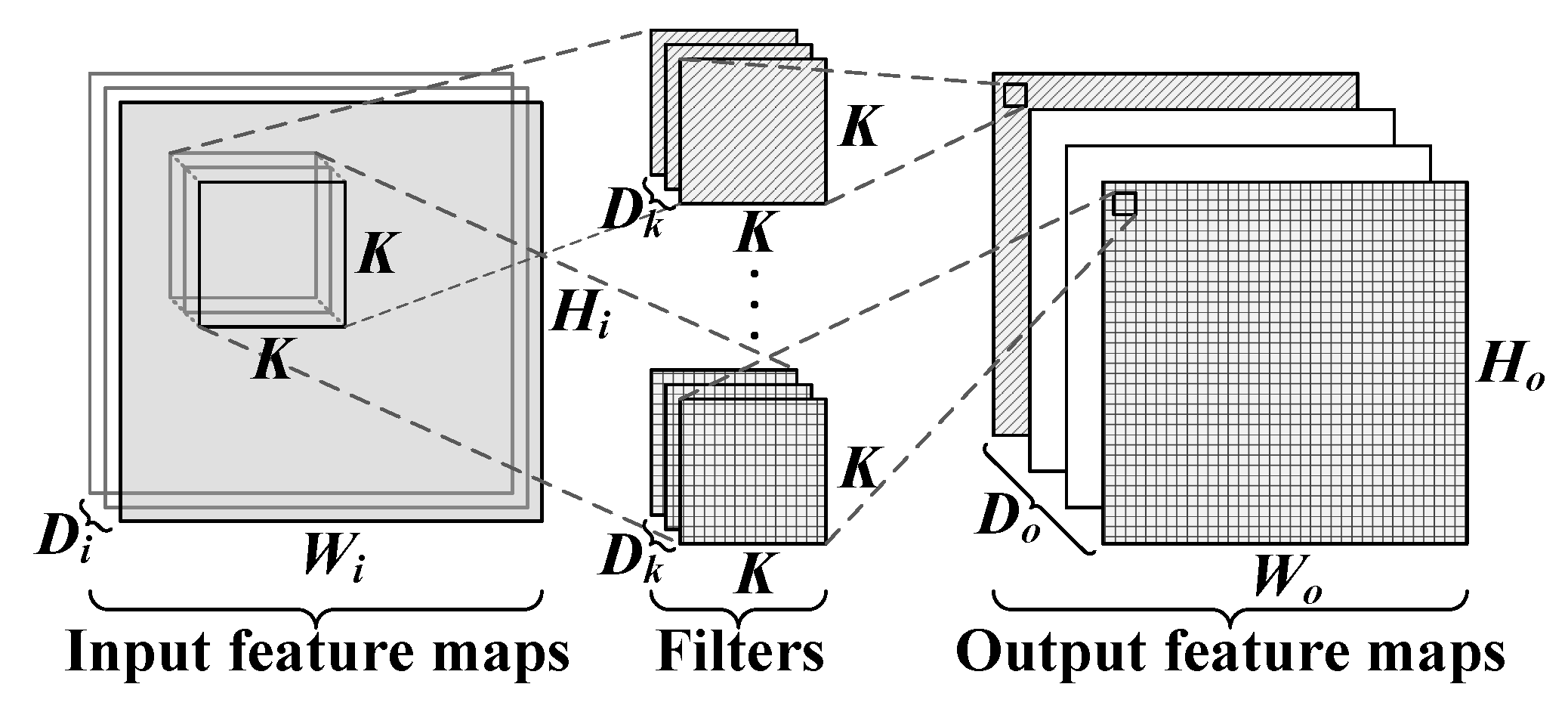
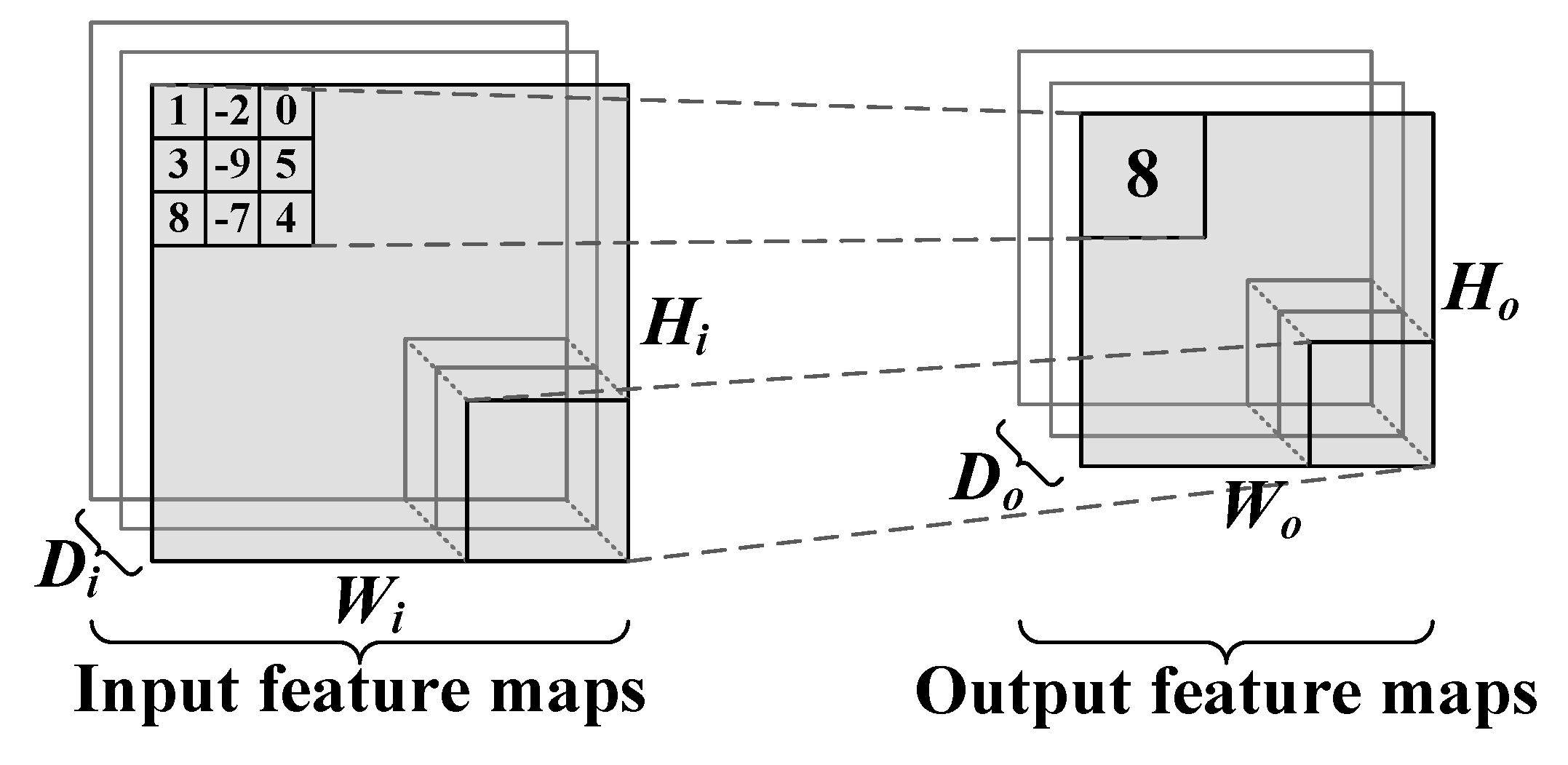
Representation learning is a new rapidly developing machine learning approach in recent years that automatically learns features from raw data and to a certain extent has solved the problem of hand-designing features [
4]. Especially, the deep learning method, which is a typical approach of representation learning, has achieved very good performance in many domains including image classification and speech recognition [
5,
6]. Deep learning is a kind of machine learning technology that is an extension of representation learning; it was proposed by Geoffrey Hinton in 2006 [
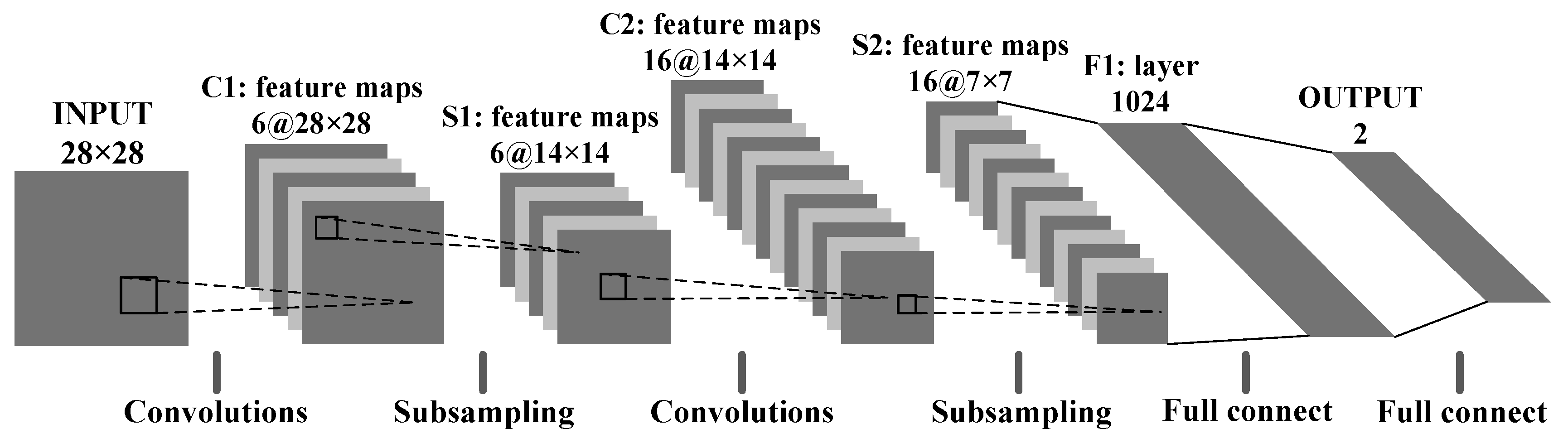
7]. The convolutional neural networks (CNNs) model is one of many deep learning architectures. In the last two years, the CNNs model has become one of the research hotspots because of its good performance in image classification and object detection. Traffic characteristics can be automatically learned from the original data by using CNNs [
8]. There is no need to manually extract features from traffic; instead, CNNs take raw traffic data as images, so as to avoid the problems of designing proper feature sets. The CNNs model can be used to perform image classification, which is a common task for CNNs [
9]. Finally, the goal of malware traffic classification was achieved.
However, with the development of CNNs, the number of hidden layers in the neural network have gradually increased, and the number of parameters has also become larger. As a result, computation and power consumption increase further, which limits the application of CNNs-based malware traffic classification in portable devices. Therefore, research studies on the hardware acceleration of CNNs-based malware traffic classification are necessary.
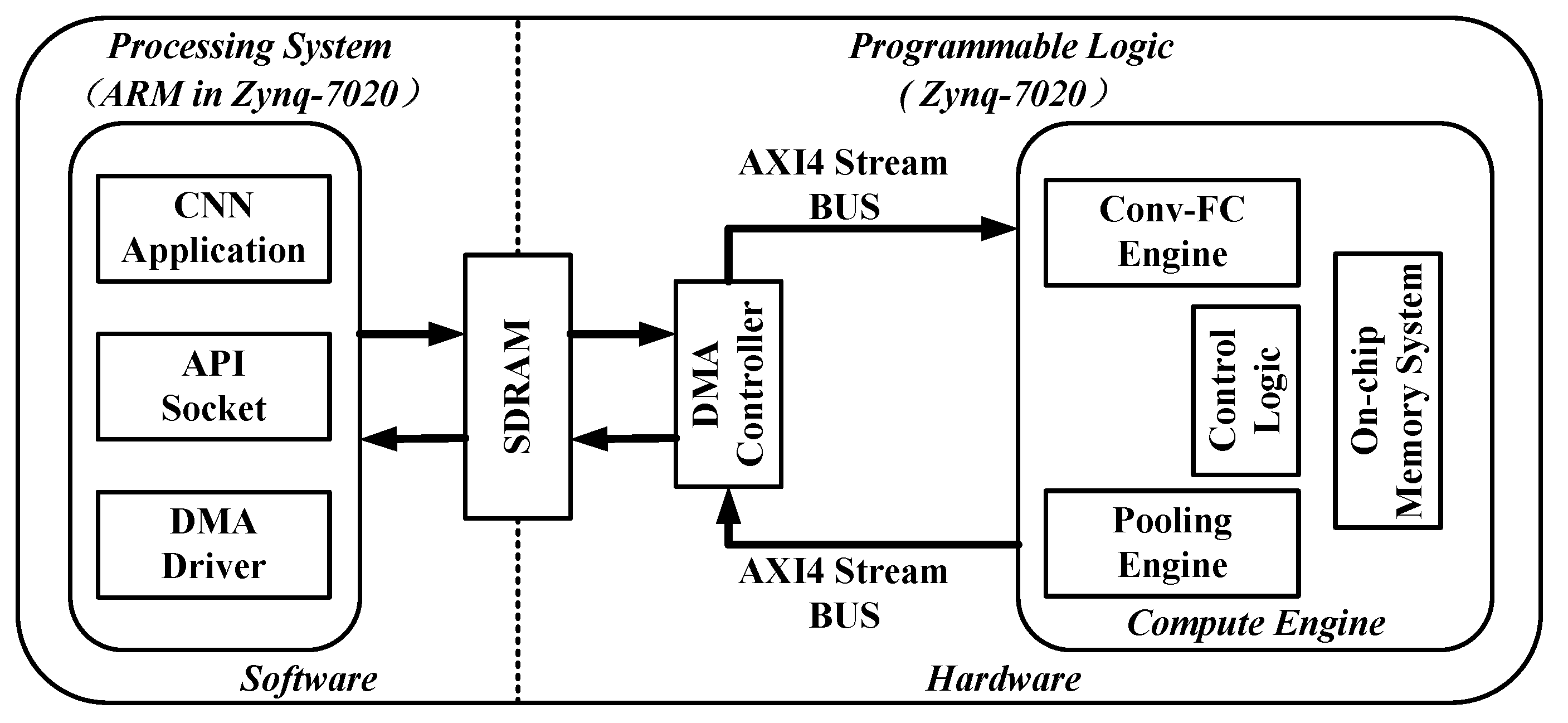
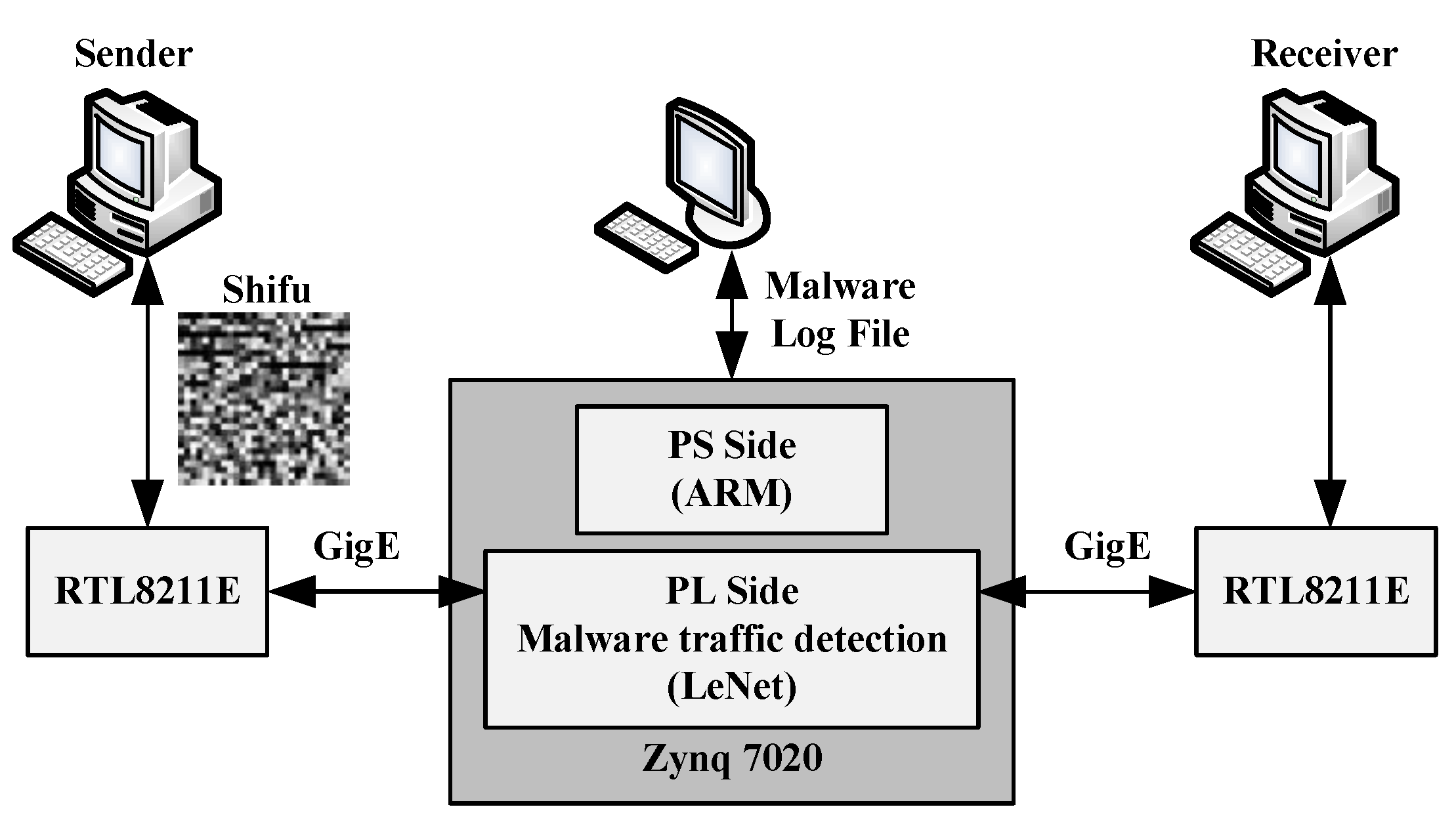
Considering the problems above, CNNs-based methods are constructed to evaluate their ability for malware traffic classification, and a field programmable gate array (FPGA) accelerator for CNNs-based malware traffic classification is designed. Our contributions are as follows:
- (1)
The approach presented in this paper neither relies on feature engineering nor on experts’ knowledge of the domain, avoiding the problems of designing proper feature set.
- (2)
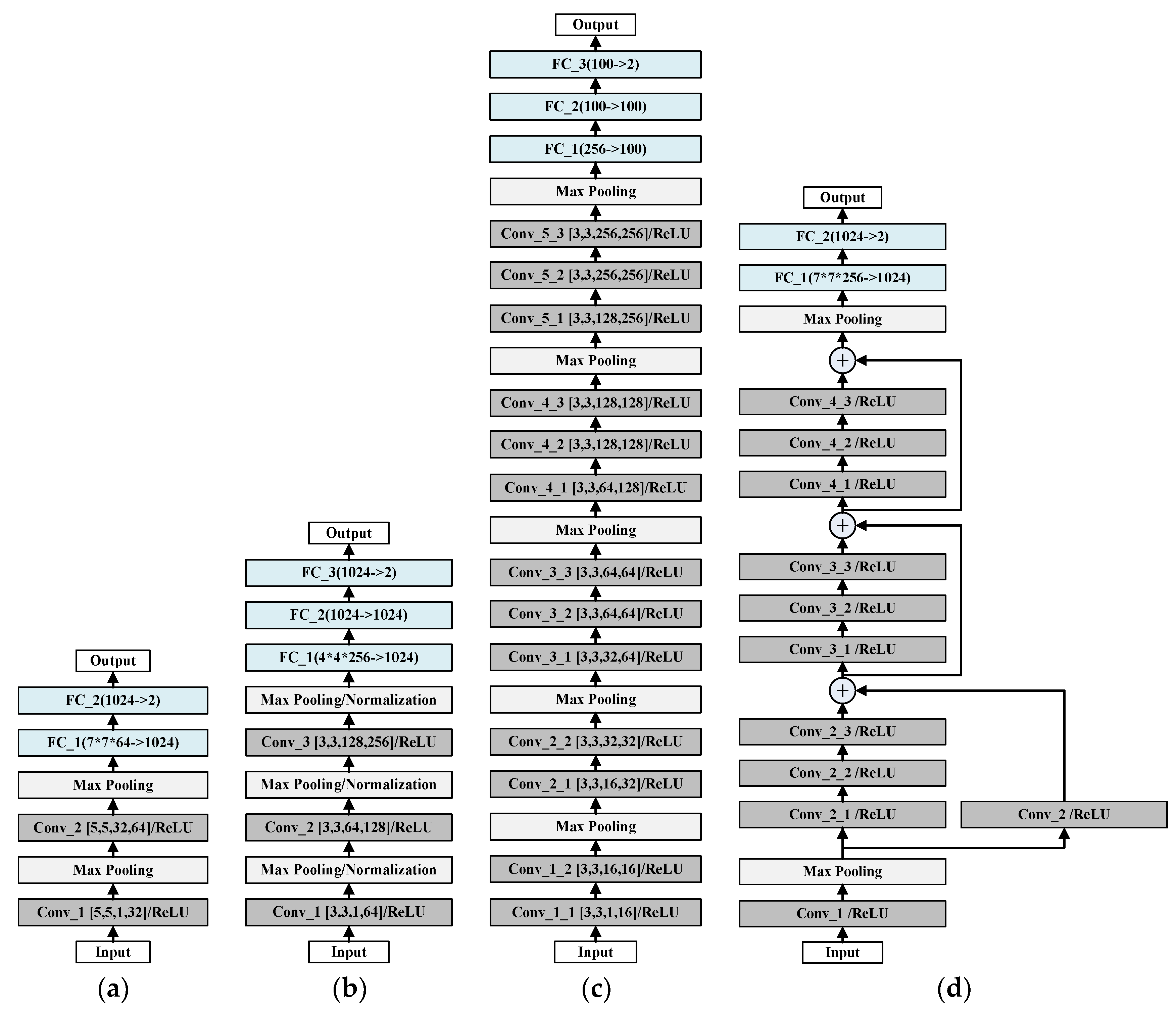
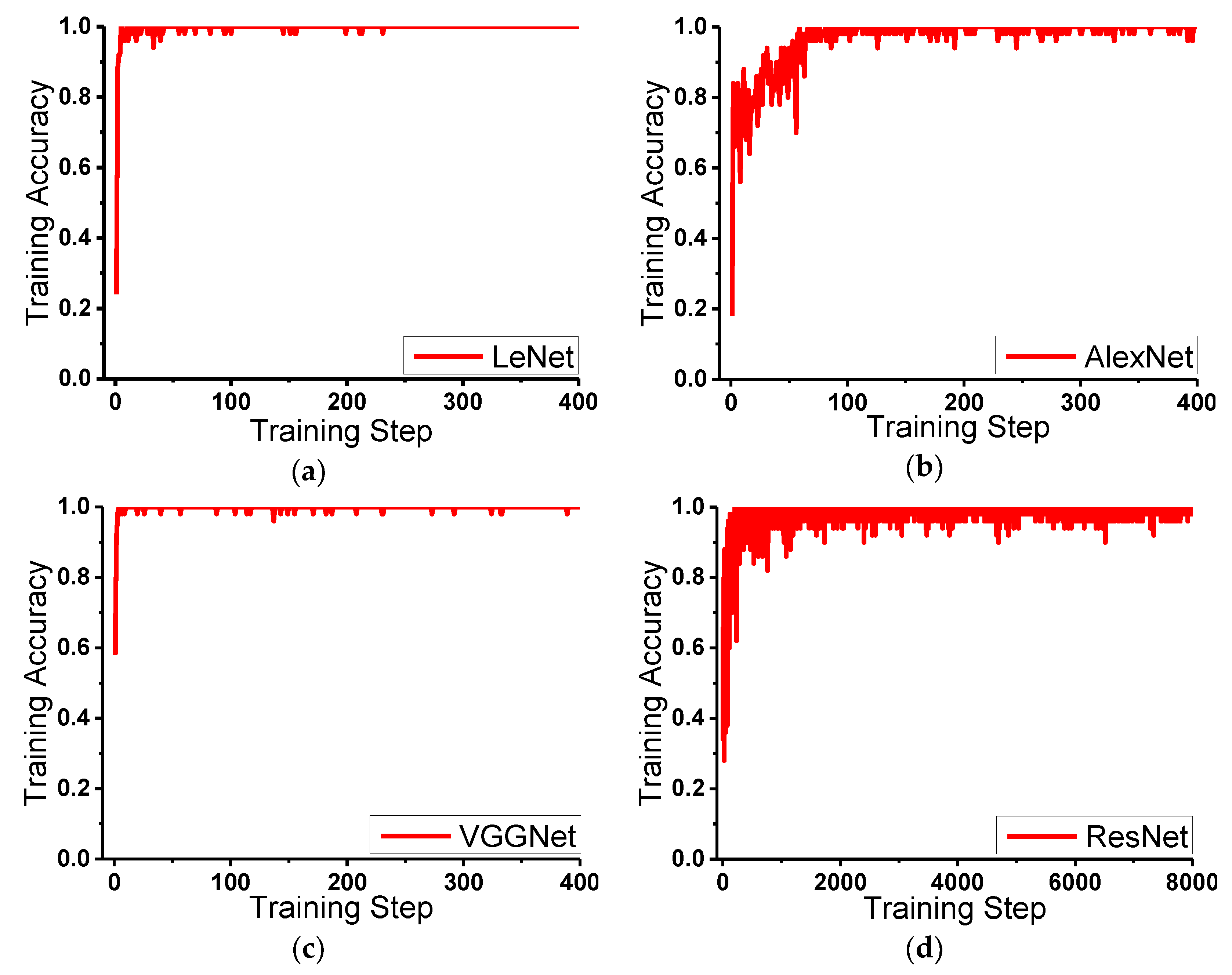
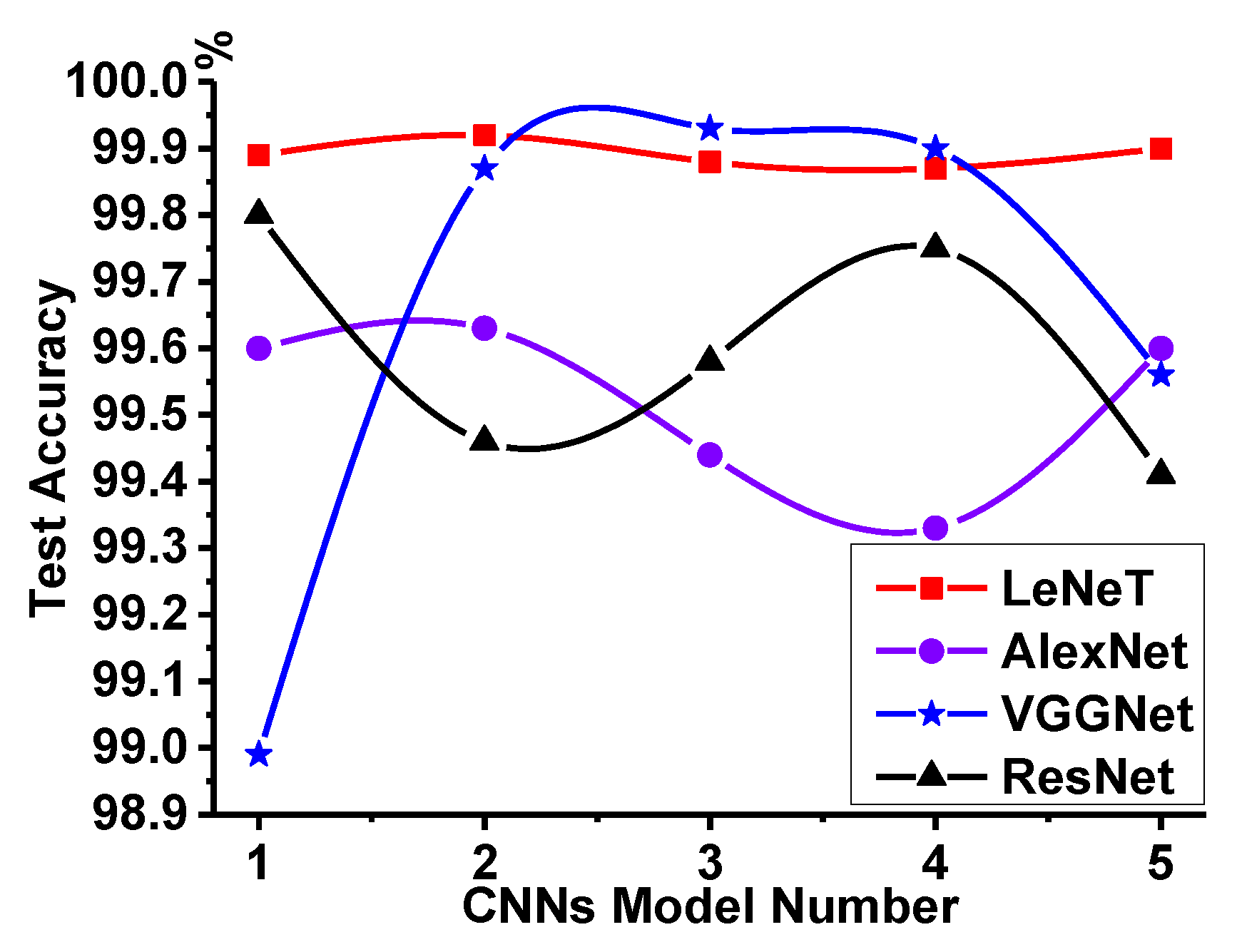
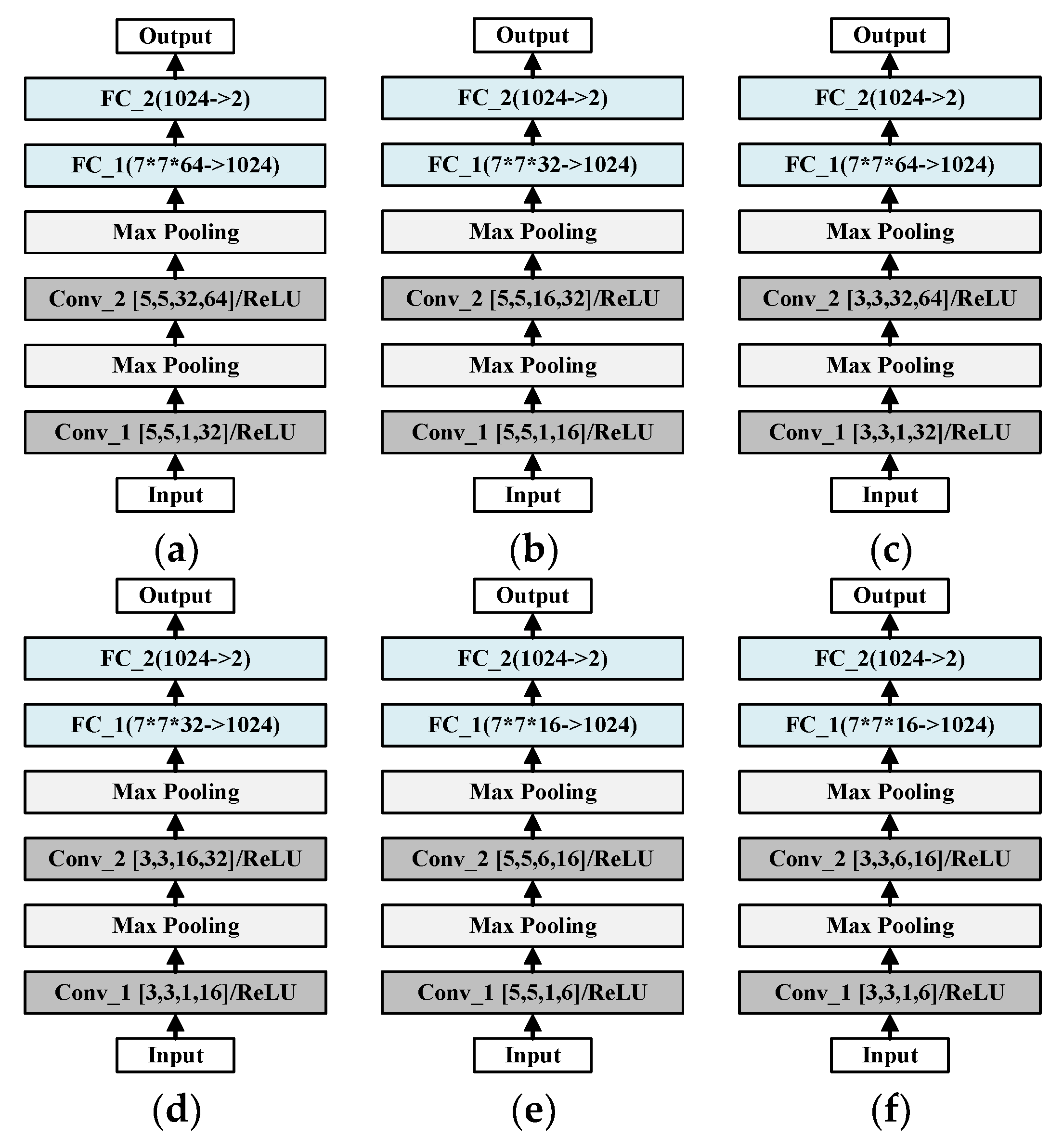
Experiments and comparisons of LeNet, AlexNet, VGGNet, and ResNet have been carried out to evaluate their classification ability, and LeNet is found good and stable. The final average accuracy of LeNet is 99.77%, which meets the practical application standard.
- (3)
A reconfigurable FPGA acceleration framework is proposed, which loses only 0.01% of classification accuracy from 99.78% to 99.77%, and each traffic image can be classified in 18.97 us.
- (4)
A software framework is designed to interact with the underlying hardware logic and also provides a convenient user interface for the fast deployment of CNNs applications.
- (5)
A typical application of the accelerator is constructed. The whole system is evaluated on an MZ7XB board, and the throughput can reach up to 411.83 Mbps.
This paper is organized as follows.
Section 2 lists the related work of malware traffic classification.
Section 3 shows the background for CNNs and network traffic preprocessing. Different CNNs are constructed and trained to evaluate their performance in
Section 4. The hardware design is shown in
Section 5, which describes the overall structure of the FPGA accelerator for CNNs-based malware traffic classification. The results and analysis are discussed in
Section 6.
Section 7 provides the concluding remarks.
2. Related Work
The port-based and DPI-based methods have been relatively mature in the industry, and the related work mainly focuses on how to accurately extract mapping rules and improve performance. The accuracy of port-based methods is low; as Dreger elaborated in his paper, the port-based traffic recognition only gives less than 70% accuracy, although it is fast and simple [
10]. Finsterbusch et al. summarized the current main DPI-based traffic classification methods [
11], but as mentioned above, DPI-based methods can not process encrypted traffic and have high computational complexity.
The classic machine learning approach of traffic classification includes statistical-based and behavior-based methods, which have attracted a lot of research in academia, and related works have mainly focused on how to choose a better feature set. Dhote et al. provided a survey on the feature selection techniques of Internet traffic classification [
3].
There are a few research studies about CNNs-based traffic classification now. Gao et al. proposed a malware traffic classification method using deep belief networks [
12]. Javaid et al. proposed a malware traffic identification method using sparse auto encoder [
13]. They both used deep learning and applied it to the design of network-based intrusion detection systems. However, there is a similar problem in both studies above in that they used hand-designed flow feature datasets as input data: KDD CUP1999 and NSL-KDD, respectively [
14]. Unfortunately, these two studies give up the biggest advantage of CNNs, which is that CNNs can learn features directly from the raw data. The successful application of deep learning in image classification and speech recognition fully proved this.
Wang proposed a stacked auto-encoder-based network protocol identification method using raw traffic data and achieved high accuracy [
15]. Traffic classification and protocol identification are very similar tasks. Therefore, it is reasonable to presume that deep learning methods can achieve good performance in malware traffic classification tasks, which is one of the motivations of this paper.
With the development of mobile communication technology, the Internet is a part of people’s daily lives. Embedded devices such as mobile phones generate huge amounts of traffic in our daily life. The effective deployment of lightweight CNNs applications in embedded terminals has become an urgent problem to be solved. It is important to reduce power consumption and the computation of CNNs in portable devices. By integrating a hardware accelerator for CNNs-based malware traffic classification in portable devices, not only can the central processing unit (CPU) resources be released, the energy consumption can be reduced and secure real-time data transmission can be effectively guaranteed as well, which is another motivation of this paper.
7. Conclusions
In this paper, four CNNs are used to classify malware traffic and normal traffic. Through experiments and comparisons, it is found that LeNet has good and stable classification ability for malware traffic and normal traffic. There is no need to hand-design the traffic feature sets beforehand. The raw traffic data are the direct input data of the traffic classifier, and the classifier can learn features automatically.
Meanwhile, an FPGA accelerator for CNN-based malware traffic classification is designed. As a result, the CNN accelerator implemented on FPGA loses only 0.01% of classification accuracy from 99.78% to 99.77%. It can classify each traffic image from the training and test dataset in 18.97 μs under the clock frequency of 150 MHz, which is 6.2 times faster than F-CNN, 42.2 times faster than Intel Xeon E5-2680, and 7.04 times faster than NVIDIA Tesla K20X. The implementation keeps the balance between resource occupancy and computation speed, which makes it possible to deploy CNN-based malware traffic classification in portable devices. The throughput of the typical application system designed in this paper can reach 411.83 Mbps.
Through the research and application in this paper, we can quickly train a CNN model for malware traffic classification from the raw traffic within a couple of hours in the actual application scenario, which can effectively resist malware traffic attacks from hackers to a large extent. By integrating a hardware accelerator for CNN-based malware traffic classification in portable devices, not only can the CPU resources be released and the energy consumption reduced, but secure and real-time data transmission can be effectively guaranteed as well.
In the future, in order to further improve the bandwidth to meet the communication requirements of the gigabit network, a multi-core parallel acceleration scheme can be adopted. In addition, four int4 multiplication operations can be implemented in each dsp48e1; therefore, the model can be further quantified to implement more calculations in each clock cycle. Thirdly, in order to meet the requirements of low power consumption and light weight in portable devices, LeNet was chosen to be implemented on FPGA for the hardware acceleration of malware traffic classification. However, other CNNs can also be applied on the FPGA acceleration platform in this paper, which can explore the feasibility of hardware acceleration for other anomaly detections later. At the same time, BNN is also very attractive. These research directions will be further carried out in the future.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
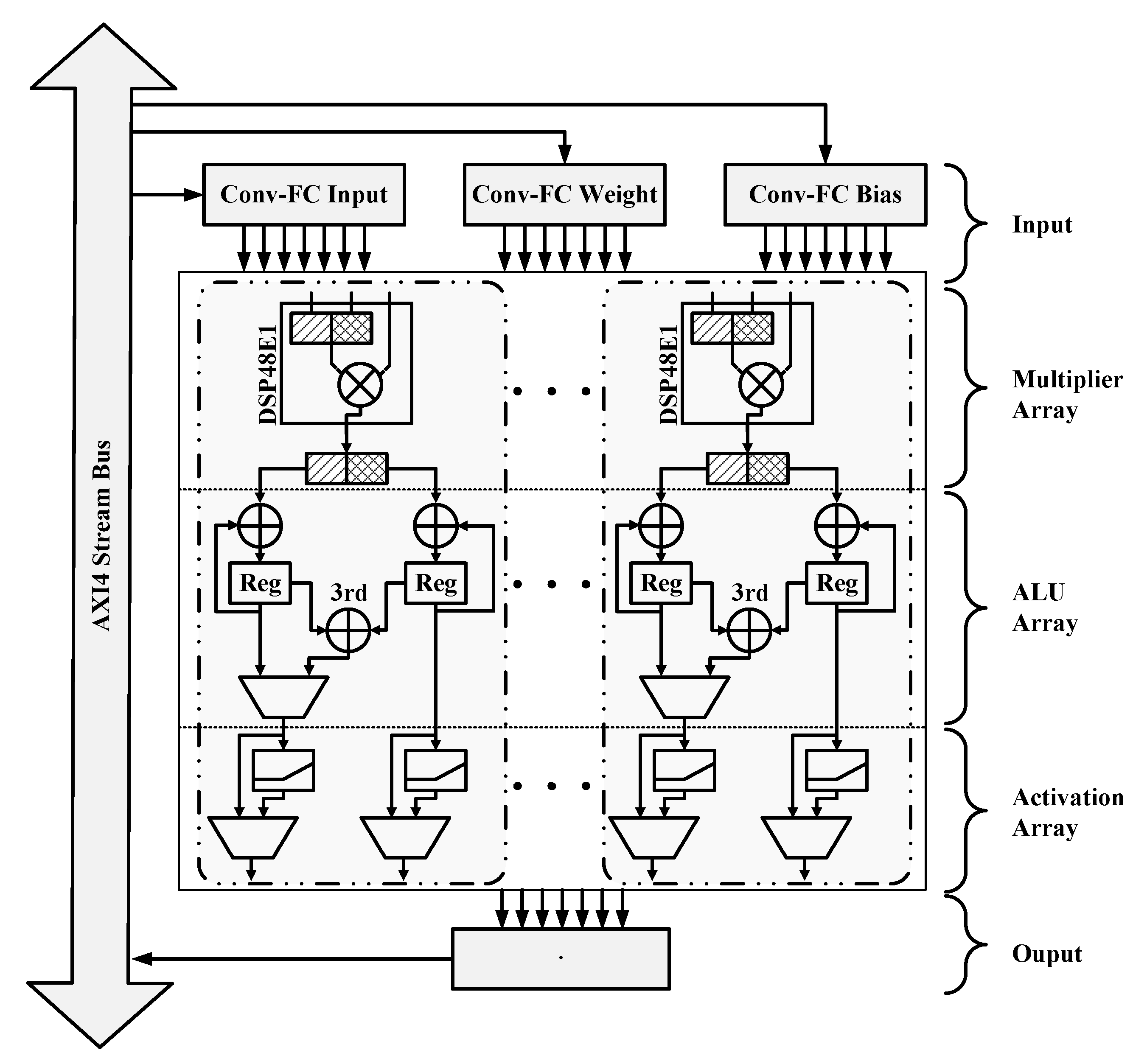{kind=link}
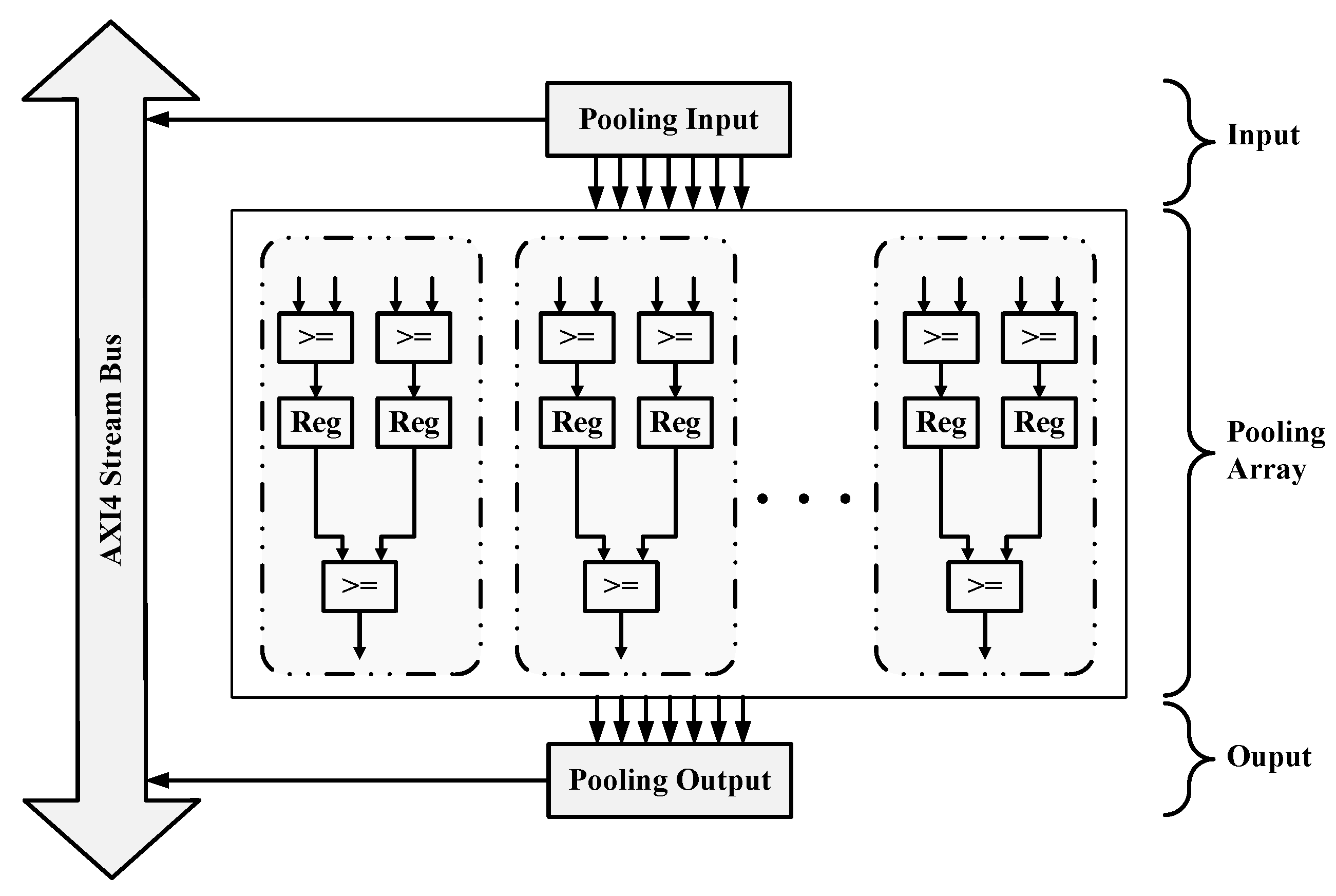{kind=link}
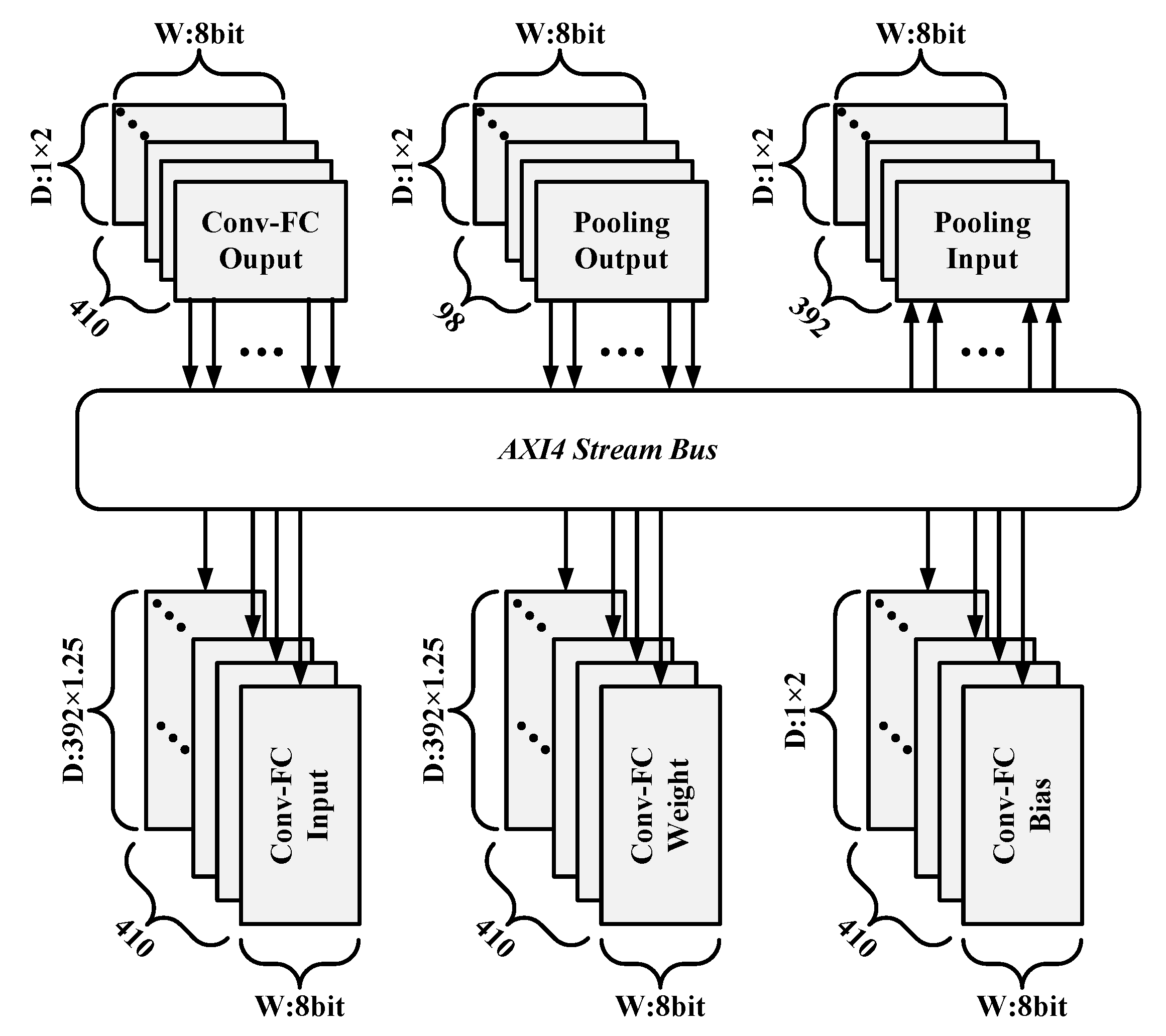{kind=link}
{kind=link}
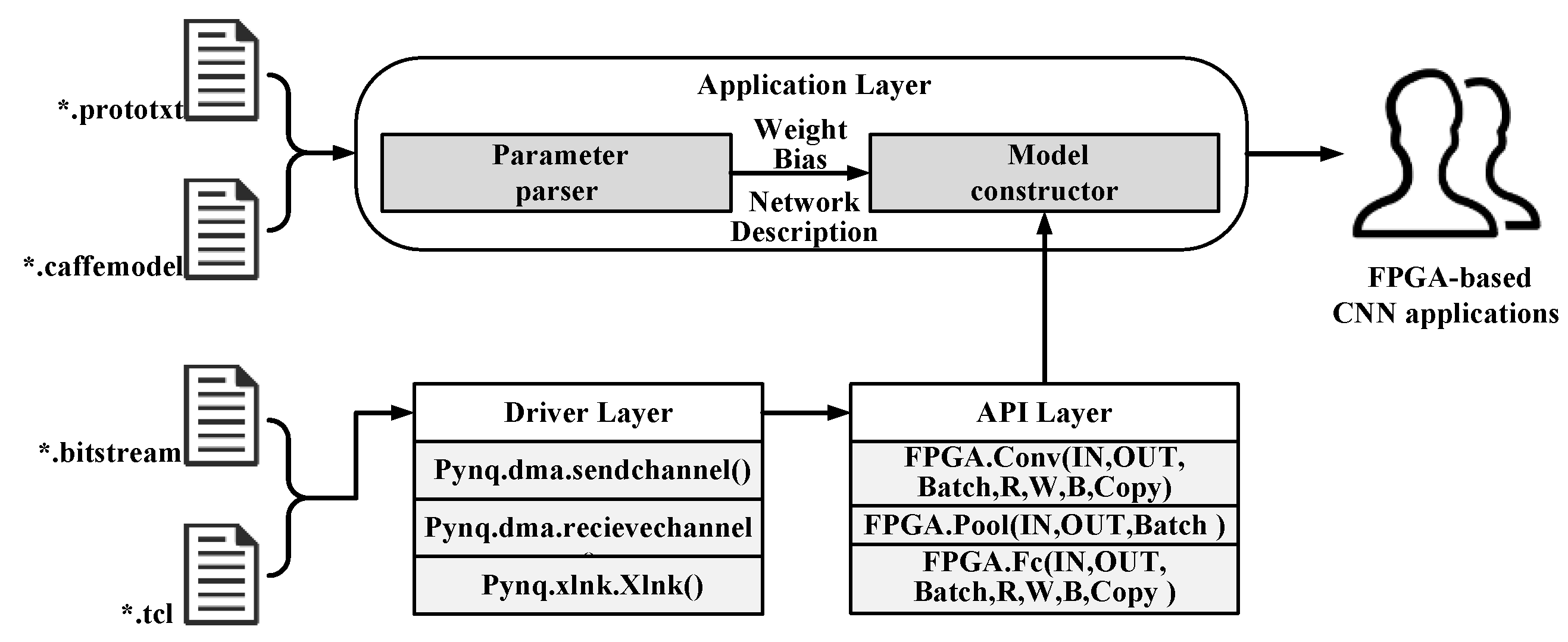{kind=link}
{kind=link}
{kind=link}
{kind=link}