1. Introduction
Access control is the basic element of security systems answerable to assess if a user can be allowed to operate in a specific way on a certain application. It can guarantee more privacy and confidentiality. According to Brandeis and Warren’s study [
1], privacy can be defined as “the right to be left alone”. The stipulation of security can necessitate the security of sensitive data, services, or tools by assuring that only authorised people have access to it. Biometric systems provide numerous solutions in the field of security.
The word biometrics is derived from a combination of Greek words: “bio means life” and “metrics means to measure”. The aim of biometric systems is to identify, verify, or authenticate a person’s identity based on behavioral or physical characteristics. The possible application based on biometric modalities is access control, criminal recognition or verification, airport boarding, log-in for mobile or computers, digital multimedia rights, authentication, and voice mail security. Several biometric modalities have been investigated in the last decade such as iris, face, fingerprint, palm-print, gait, and auditory perception responses.
Within the previous few years, biometric applications for web security and web control access have been developed based on the physical and behavioral features of humans. What lies ahead is a huge task of protection of sensitive and confidential information in this digitised era. Access to one’s account information on the internet is traditionally secured by the help of usernames and passwords or pins [
2].
These methods cannot be trusted in the sense that they are unable to detect an intruder who has acquired the requested information for verification [
3]. The password-based access system can easily be spoofed. Spoofing is the phenomenon by which namely persons who pretend to be others gain illegal access to preserved data, services, or facilities. Biometric approaches, such as anti-intrusion and anti-spoofing are being used for securing the confidential data related to an individual or to an organization that is vulnerable to spoofing attacks.
2. Related Work
2.1. Non-Biometric Approaches for Web Access Control
Among web access approaches, usernames and passwords are mostly used to limit/grant access to the contents of a website [
4]. Most of the organizations have restricted webpages. Those who want access first need a centralised and authentic login allocated by the administration.
In a web-based application, controlling access is the basic element of the design. Systems assign certificates such as kerberos ticket [
5] or an X.509 certificate [
6] which are issued to a user for verification to authorise him/her access to a specific webpage. Kerberos is a computer network authentication protocol that operates based on tickets to acknowledge nodes interacting across nonsecure channels to confirm their identity of an individual in a protected fashion, while the X.509 certificate system is used for many internet browsers to secure the protocol of the webpage and it contains a self-identity or signed trusted certificate for security. These kinds of systems have not yet achieved a wide range of appreciation, and it fails to provide compatibility between administrative domains.
Several approaches have been proposed for web control access and intrusion detection [
7,
8]. An existing approach is used to detect intrusion attacks in the apache web server; it is a strong and responsive intrusion detection system, which is known as Generic Authorization and Access-control Application Program interface (GAA-API). API is a collection of functions and modes, allowing the production of applications that enter the characteristics or data of an application, operating system, application, or related services. GAA-API is a form of simple API for intrusion detection: it generates a HyperText Transfer Protocol (HTTP) request right after it checks whether the request represents a threat, and then it will be permit access. GAA-API has the ability to respond quickly in real time for a suspected intrusion attack [
7].
For the online intrusion detection system, Adaboost is used in the first approach with decision stumps (a decision stump is a decision tree with a root node and two leaf nodes, and it is built for each feature component of the network connection data), and online Gaussian mixture models (GMMs) are the second approach as weak classifier. Adaboost is a famous machine-learning algorithm, and it can be used in combination with other machine-learning algorithms to enhance performance. It corrects the mistakes made by weak classifiers and overcomes the problem of over-fitting. The combination is built by using an algorithm based on particle swarm optimization (PSO) and support vector machines (SVMs). A distribution intrusion detection framework is proposed as a local parameterised detection model wherein each node of the online Adaboost algorithm performs separately [
8].
Indeed, many intrusion blocker softwares are available in order to crack the existing control access systems. Each intrusion scheme is designed for a specific control access system, and they lack the capability to adjust to new ones. However, as there are often new intrusion schemes, we cannot rely completely on the existing control access designs.
2.2. Biometric Approaches for Web Control Access
Biometrics has been proposed as one of the solutions to solve intrusion problems. The field of biometrics has become a user-friendly technology as it also provides an alternative approach for personal verification. Biometric technologies such as fingerprints, facial recognition, and retinal scans produce accurate and unique identifiers. The identification using such modalities are reliable [
9,
10,
11].
Physical Biometrics for web control access: fingerprint and face verification became very popular by replacing pins and passwords. Thus, it provides a secure verification for critical websites such as e-banking and official email. A database is created containing the usernames and fingerprint impressions. A user inputs their username and the fingerprint impression. If there is a match, the user is granted access to the webpage; otherwise, the access is denied [
12]. There is always a problem that exists when having a minor cut on the finger, which may affect the results [
13].
Other biometric approaches for web control access are designed using facial features. The face recognition system is based on the ability of the technique used to match patterns to identify faces. A real-world application has also been proposed by Facebook. A dataset of nearly 60,000 face images was used for evaluation using face recognition algorithms. For instance, it has been reported that some algorithms using Support Vector Machines (SVMs) provides the highest accuracy of 65% and is said to be more efficient [
14]. Using characteristics of the whole face for automatic identification is a difficult task because of the variances caused by different facial expressions such as hairstyle, camera angles, head position, lightning conditions, etc. Other limitations can be caused by the wide range of camera scales and the lighting environments.
Iris recognition can also be used to access web control. It has a highly detailed and unique pattern that remains constant for decades. Another property of the iris that it cannot be damaged or modified unless a forger creates an artificial eye of the same structure. Weak infrared/visible light is sent through the pupil of the eye in order to scan the structure of the iris. This technique is accurate and effective but also very invasive and uncomfortable [
15]. An advantage of this approach is that it can capture the pattern of the iris even if the user is several feet away.
Behaviorial biometrics for web control access: In human behavioral features, voice can be used for identification. Several web-based access control systems have been designed for automatic identification of a person through voice. Voice traits can allow identification of gender, age, and language without providing any previous information to the system [
16]. It can also be used for unwanted or irrelevant telephone call filtering and detection of answering machines. Voice biometric technology is mostly used by call center companies for fraud and theft detection [
17]. In another technique, the user has to speak a set of sentences to the speaker, which are then used as identity markers along with a smartcard. The user inserts his/her smartcard into the slot and then speaks to the PC through a microphone. The speech pattern is compared with the stored data in the system through the smartcard, and then access is granted if they match [
18].
Similar to a hand-written signature, keystrokes dynamics has some neurophysical impression which can be utilised to identify an individual. The time-lapse between keystrokes normally shows a unique timing pattern, which can be used as a feature to identify an individual. For identification and verification, an individual has to generate a reference profile through their keyboard. Then, a test person can take a test and compare their profile with the existing one. If the difference is large between the two profiles, the access to the system is denied [
13].
3. Motivations
The information rendering from the environment through different senses is known as perception. Human receives and perceives sounds through the auditory system. Thus, auditory perception is the ability of the auditory system to receive and render sound waves of different audible frequencies transmitted through the air or any other source of the sound. The auditory perception response varies with age, such as, when age increases, the highest audible range of frequency decreases, which leads to hearing loss. Hearing loss occurs due to the damage of hair cells inside our auditory system [
19,
20,
21,
22]. There is a correlation between auditory perception and age [
23,
24,
25,
26]. It is stated in the literature that humans have the tolerance for hearing a sound of 12 Hz under supportive conditions [
22] and that from 20 Hz to 20,000 Hz is a commonly declared range of human hearing [
23,
24,
25]. The highest audible frequency is 17,000 Hz at the age of 18 years, while at the age of 30 years, it decreases to 15,000 Hz.
Research in the field of age estimation through auditory perception responses has been introduced for the first time in 2017 [
27]. In this paper, we present a more accurate and advanced study about the correlation between age and auditory perception. We also propose a web control access filter called BiometricAccessFilter. BiometricAccessFilter has the ability to limit the access of adults to the virtual world of kids and which can help to prevent child sexual abuse in an ever-evolving online sphere. Thus, we are focusing on two objectives in this work:
Human age estimation using auditory perception: different regression models are built to find the best one with the highest accuracy for age verification based on the auditory perception.
Web access filter application: we proposed an application of age estimation using auditory perception. It controls the access of the user according to its estimated age. This proposed web filter can prevent adults from accessing children web applications.
The rest of the paper is organized as follows: In
Section 4, we proposed auditory perception-based methods for studying the correlation between age and auditory perception. Based on this study, we developed a specific web application to prevent adults from accessing children’s contents and their web environment. In
Section 5, the results and the evaluations of the proposed approaches are discussed. In the
Section 6, we propose the integration of the proposed method in a web application. Finally, in the last
Section 7, we conclude this work and propose a set of perspectives of this work.
4. Materials and Methods
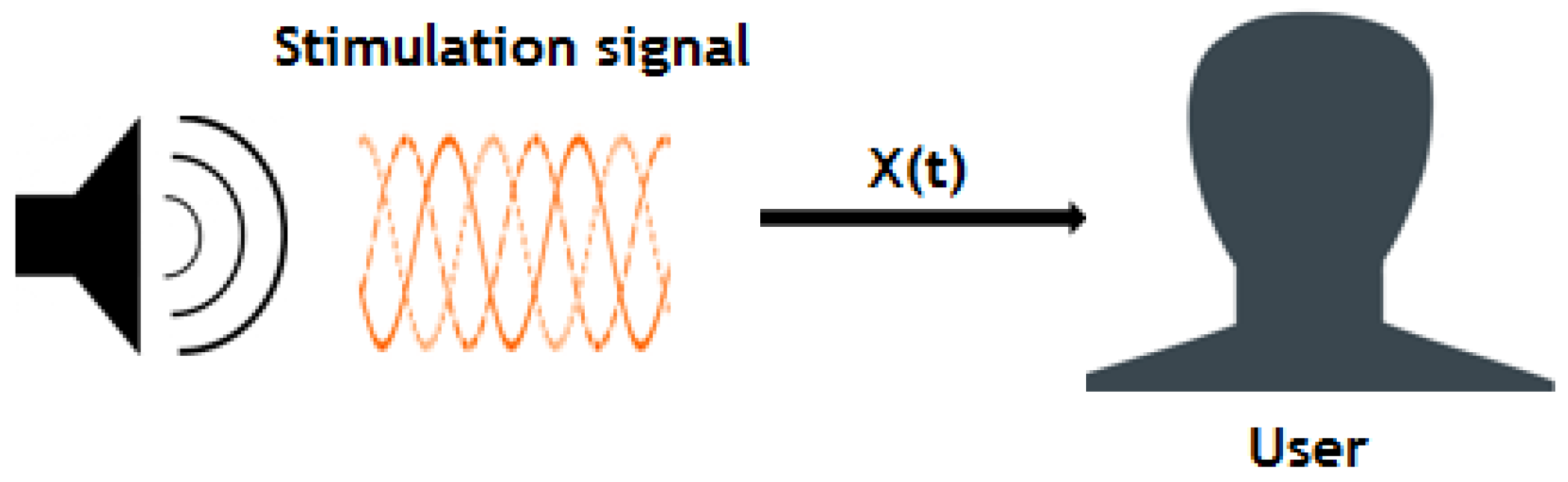
The diagram of bilateral acoustical stimulation is shown in
Figure 1. First, the auditory system is stimulated using a dynamic frequency sound (characterized by a constant change) and a test person has to interact with the system through their keyboard when a sound is heard. The corresponding frequencies of the user feedbacks are saved (
Section 4.1). Using the result of the tests, the regression model should verify the age of the volunteer. Access is accepted by the web application if the volunteer is below or equal to 18 years old; else, access is denied (
Section 4.2).
4.1. Protocol of Stimulation
The human auditory system is stimulated by generating dynamic sound waves, according to the following model:
where
stands for sound amplitude,
t stands for time,
is the initialization frequency, and
stands for the increasing/decreasing frequency speed [
9].
In this experiment, the stimulation duration of
t is set to 20 s. The system demands a real-time interaction, as shown in
Figure 2. A dynamic frequency sound is generated. Each volunteer should react to the system while he/she stops hearing the sound or starts hearing the sound. Basically, there are two tests conducted for the stimulation:
first test of stimulation: the sound is generated in an increasing manner from lower frequency (20 Hz) to higher frequency (20,000 Hz). The volunteer ends the first test (e.g., keyboard action) once no sound is perceived,
second test of stimulation: a second stimulation is triggered automatically once the volunteer completes the first mode action. In this case, the sound is generated by decreasing the frequency from the higher frequency (20,000 Hz) to the lower frequency (20 Hz). The volunteer ends the second test once the sound is perceived.
The average of the two test frequencies has been calculated. A feature vector bringing together the frequency of the first test, the frequency of the second test, and the average of two frequencies is created.
4.2. Age Estimation Based on the Auditory Perception
The second part of this work concerns the age estimation of the two auditory perceived responses. For that, a regression model has been presented in order to estimate the age of a volunteer.
Several regression methods are examined to determine that the valid approach is chosen for age estimation through the auditory system responses. They are the Regression Forest (RF) [
28], the Support Vector Regression (SVR) [
29,
30], Artificial Neural Networks (ANNs) regression [
31], and Adaboost. For all the stated regression models, 10-fold cross-validation technique has been used.
Support Vector Machine (SVM) was originally proposed by Boser, Guyon, and Vapnik in 1992 [
29,
30]. SVMs construct a set of hyperplanes that maximize the separation, or margin, between samples of the different classes. The sets to discriminate could not be linearly separable in their original space. Thus, it was proposed that the original finite-dimensional space be mapped into a much higher-dimensional space, presumably making the separation easier in that space. Several transformations or kernel functions are evaluated. Multiple values for gamma and cost has been tested (
and
). The best results were achieved with radial kernel,
, and
.
Random Forest (RF) was proposed by Leo Breiman in 2001 [
28]. RF is a set of larger decision trees that are created on a bootstrap sample of the training data by using a random selection of variable subsets. Every tree of the forest then votes to determine the sample’s class, and a majority vote makes the final decision. The RF classifier is built with recommended values by Breiman for the number of decision trees, which is equal to 500 and the number of features used to split the node in the decision tree growing process denoted by Mtry. It is fixed to
, which is quite close also to the recommended value by Breiman (
, where p is the feature vector size; p in our experiment is 3).
Artificial Neural Networks (ANNs) illustrate the initial neural network model using the least-squares method to calculate the weights that are then used for calculating the activation function. The proposed approach is that the transformed samples have a common structure of sparsity in each class, unlike other methods. The least-square regression model imposes an interclass sparsity restriction that significantly reduces the sample margins of the same class, whereas samples from different classes will show an increase. Such variables support the way regression is transformed more compactly and discriminated, thus producing better results than others [
31].
Stratified k-fold cross-validation is performed using Support Vector Regression (SVR) and Regression Forest (RF) models with k = 10. Cross-validation is a technique to evaluate predictive models by partitioning the original sample into a training set to train the model and a test set to evaluate it [
32,
33,
34]. To optimize the parameters of the algorithms, loops of cross-validation are used by further splitting each of the ten original training datasets into smaller training datasets and validation datasets. For every combination of the parameters of the classifiers, cross-validation performance is computed and then the best performing parameters inside the loop are chosen. Then, regression with the best parameters is applied to the original testing dataset. The SVR model is tuned with specific parameters such as the radial kernel, gamma with the best value of 2, and cost value of 10.
5. Experiments and Results
In this section, the required conditions are explained; then, the process of dataset collection and analysis discrimination of the two age groups is briefly explained. Finally, the results of age estimation are provided.
5.1. Condition of the Experiment
To asses our system, Dell precision COREi7 M4700 is used. The calculated distance for a volunteer from a computer to take the test in order to access the system is 12 inches. The generated sound has an intensity of 95 db, and the duration is equal to 20 s.
5.2. Dataset Collection
In this experiment, 201 volunteers from different ages and genders participated to create the dataset. To complete one test, a volunteer needs around 2 min. The number of volunteers for two age groups are quite balanced, as shown in
Table 1.
The collected datasets is then subdivided into two age groups. As shown in
Table 1, a volunteer belongs to the following groups:
Child: if the volunteer conducting the experiment is less than or equal to 18 years old,
Adult: if the volunteer conducting the experiment is more than 18 years old.
Both groups are almost balanced: For the child groups from 6 years to 18 years, 41 male and 59 female volunteers participated. In total, we have 100 samples for the child group. In the adult group from 19 years to 65 years, 68 males and 23 females were sampled. In total, 101 samples were obtained for the adult group.
5.3. Dimentionality Reduction of the Auditory Perception Responses
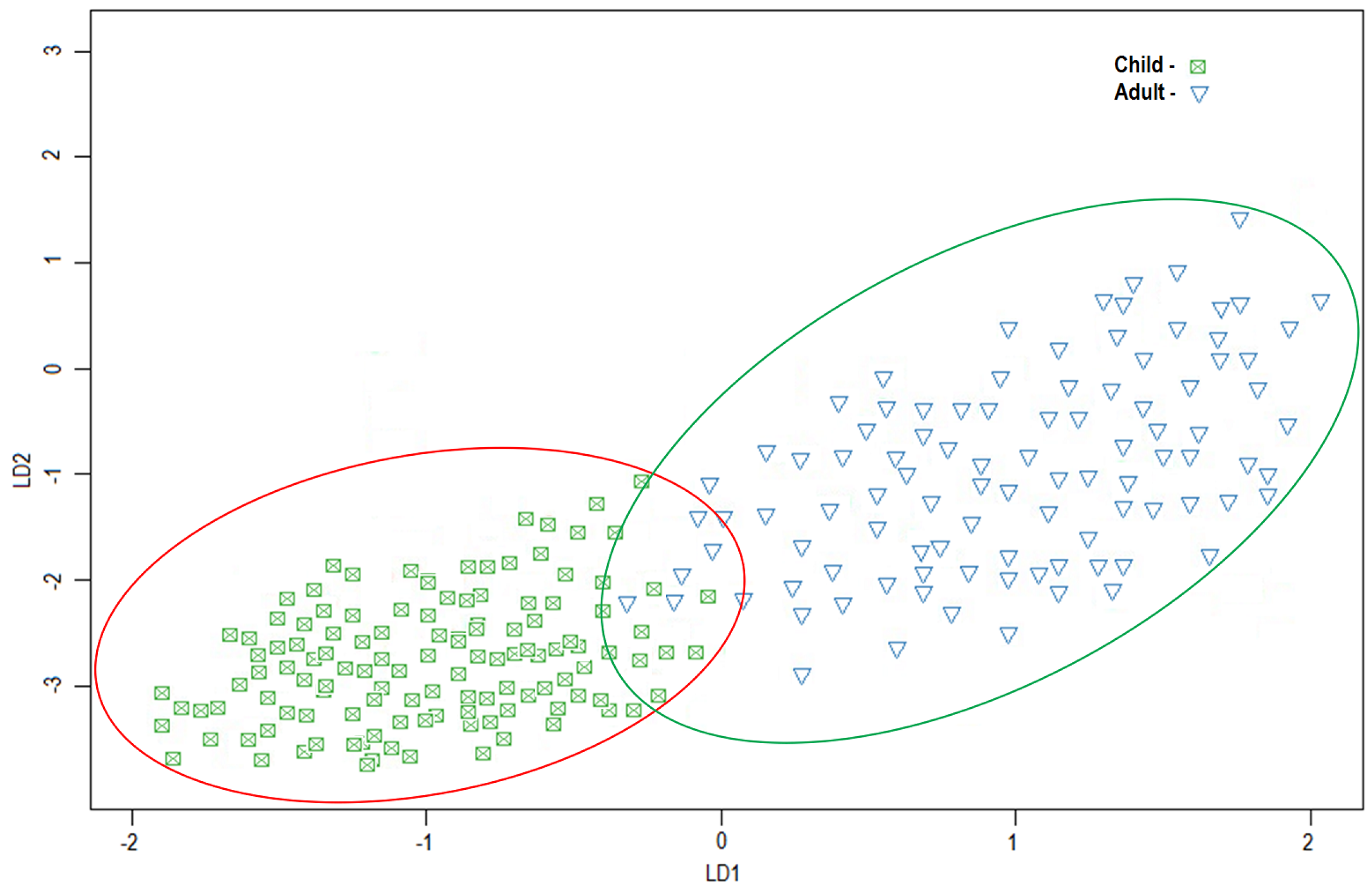
A technique of dimentionality reduction is used to explore auditory perception in a linear discriminant space. Linear Discriminant Analysis (LDA) is used [
35]. The ratio of within-class variance to the between-class variance is maximized with the objective of reducing the variation of the data in the same class and of increasing the separation between classes. Therefore, among the classes, solid boundaries are built to make it a linear classifier. It is performed on subsets of conditions using three features that correspond to three frequencies (the registered frequency from the first test, the registered frequency from the second test, and the average of the two frequencies). The samples are projected on the two first linear discriminant axes (LD1 and LD2). The projected data are presented in
Figure 3. In fact, there is a few points overlapping between the two classes, but in general, the dataset is pretty separable. This good separation shows that the auditory perception responses is highly correlated to the age, and the age group of person can be identified from its auditory perception responses.
5.4. Quantification of the Separability Between the Two Age Groups
After the statistical analysis, univariate analysis is applied into the dataset divided into two age groups. By using univariate
t-tests, the samples of the two age groups show variability by considering average frequencies. In order to testify the statistical significance of the evidence, a
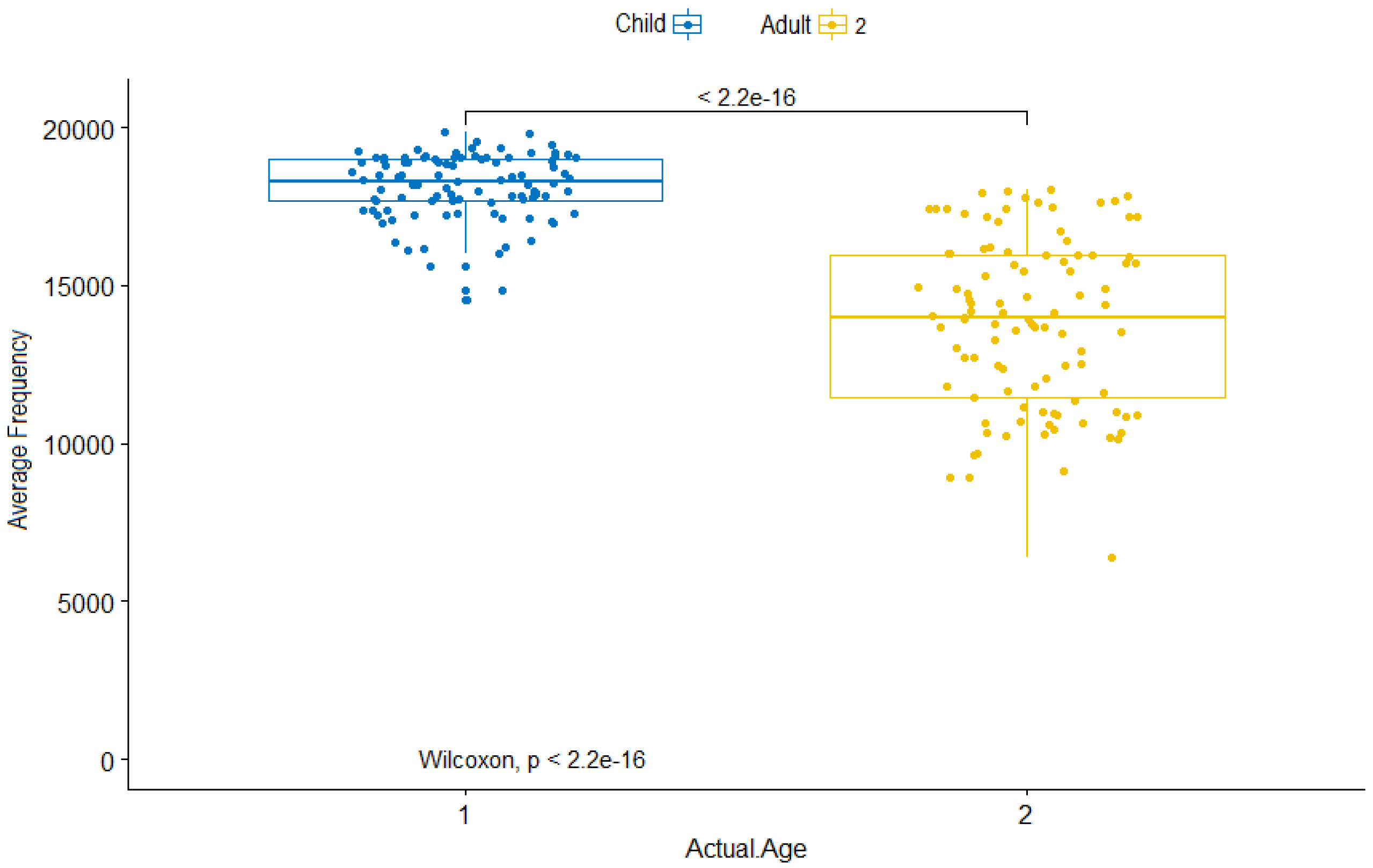
t-test is proposed based on the null hypothesis. Likewise, it calculates the differences among the variables in a dataset. A detailed interpretation to discriminate the two age groups is presented using boxplot as shown in
Figure 4. The boxplots display variation in samples of the age groups and point out the intra- and interclass variability or correlation.
The p-value between the two age groups are inferior to . Consequently, the two age groups are very different and discriminate according to the audible frequencies of the volunteers. The distribution of the adult age group is a little spread out; it means there is big variability inside this group. Some samples can be misclassified despite the outliers samples; the p-value is a matter of fact indicating that there is a big discrimination and separation between the adult and child age groups. Thus, auditory perception maybe used for age estimation of a person.
5.5. Classification of Adult and Child Age Groups
In this section, the classification of the auditory perception into two groups is performed using Support Vector Machine (SVM), Random Forest (RF), Adaboost, Linear discriminant Analysis (LDA), and Neural Network (ANNs) classifiers. Tenfold cross-validation technique is used for all the classification approaches. The final calculated classification rate is shown in
Table 2. To conclude, there is an obvious separability between the two age groups. Comparing the classification accuracy of the different classifiers, RF shows the best accuracy of 95% for two age groups. The confusion matrix using the RF classifier into two age groups is shown in
Table 3. The most misclassified samples come from the child group, and it means that it is easier to recognize an adult than a child. Thus, the web filter proposed in this paper could easily recognize an adult and could prevent access to children’s applications.
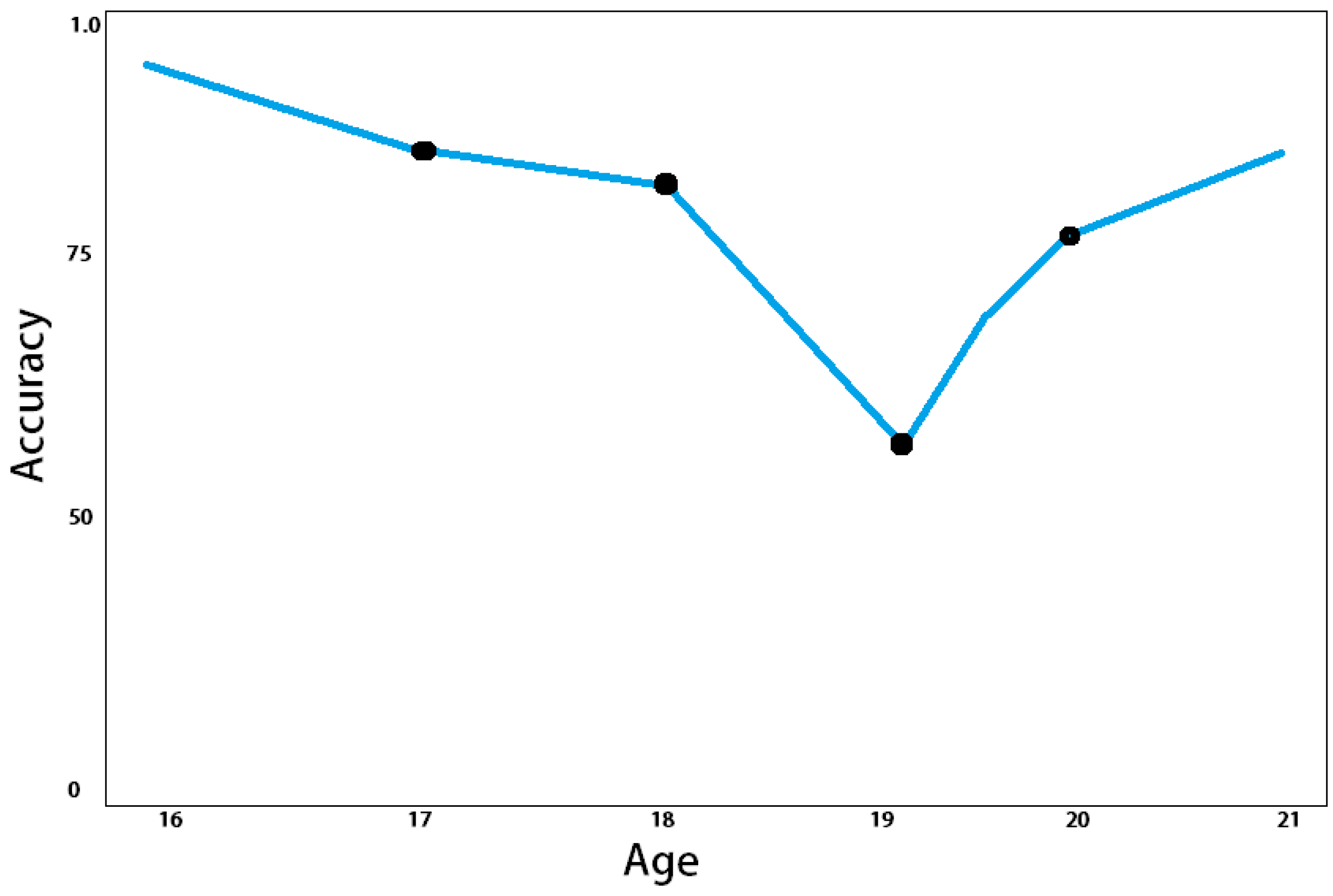
Classification of Six Age Groups
To test the performance of our proposed system, six age groups are chosen that have nearly similar auditory perception responses. The classification performances for the age range of 16–21 years are shown in
Figure 5. For this experiment, 17 subjects conducted the test with 10 repetitions. The classification rate for all subjects (16, 17, and 19–21) using random forest classifier shows acceptable results as compared to the subjects of 18 years old. The performance of the system for the subjects of age 18 years is nearly 65%.
5.6. Age Estimation Based on the Auditory Perception
The performances of the regression analysis for age estimation using Regression Forest (RF), Support Vector Regression (SVR), Adaboost, and Artificial Neural Network (ANNs) is summarized in
Table 4. RF regression using 10-fold cross-validation shows the best rate of efficiency of 97% and the smallest root mean square of error (RMSE) of 2.6 years. The resultant model is stable, the spread out of the estimated ages from their average value is small, and it is represented using the variance that corresponds to 8.71 years and the standard deviation of 2.95 years. All the other regression models show lower accuracy as compared to RF for our proposed dataset, such as SVM shows an RMSE value of 7.25 years, Adaboost shows 9.31 and ANNs shows 11.17 years. Therefore, the proposed regression model using RF in 10-fold cross-validation is the most accurate approach for age estimation using auditory perception.
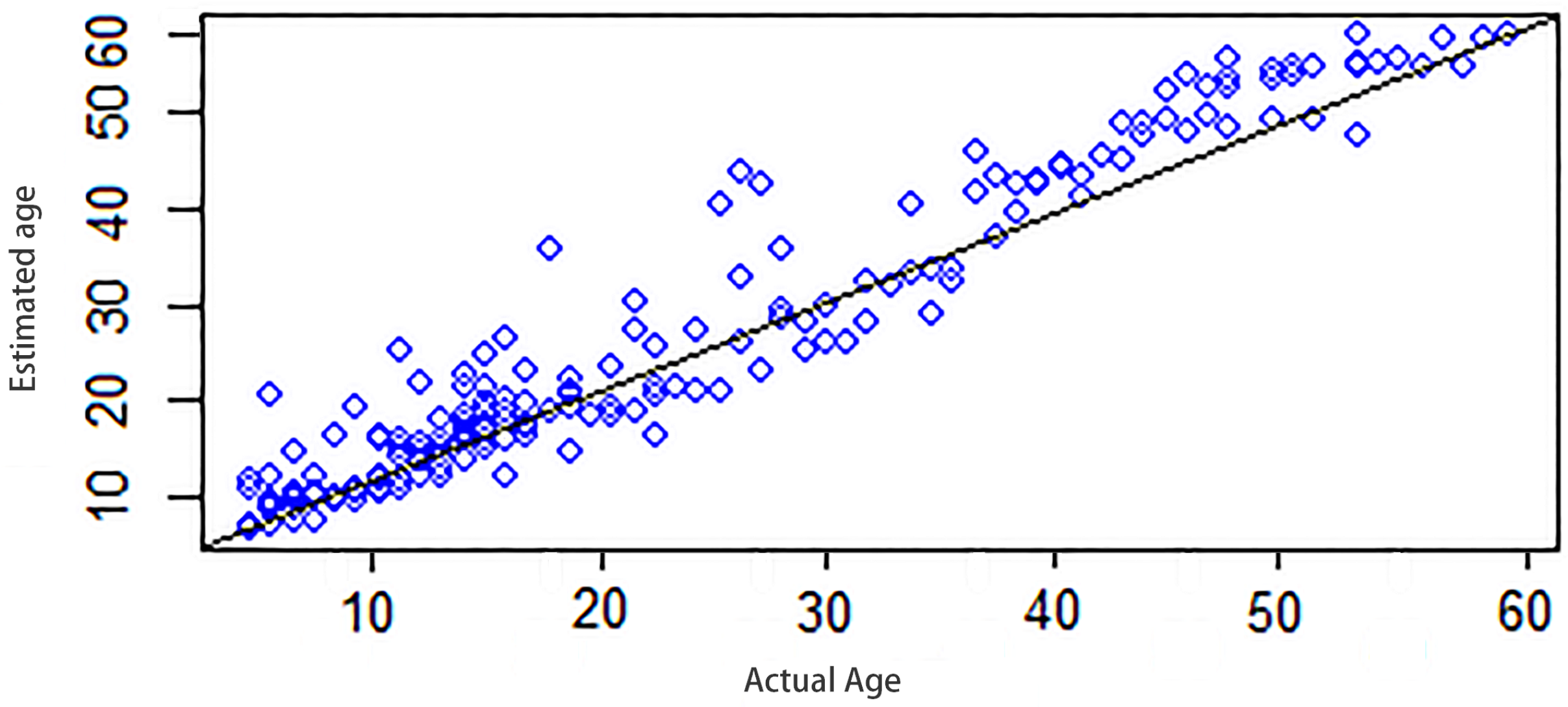
The age of the child group is estimated more accurately than the adult group, as shown in
Figure 6. The difference between actual age of a volunteer and the estimated age the for child group is much less compared to the adult group, while the mean error value for age estimation is 2.95 years.
The scatter plot of the known actual verses predicted age and overlay of line y = x are shown in
Figure 6. If the model predicts the age perfectly, then all the data points would lie on this line. There are only a few outliers that do not fit well on the line, with a few years of difference. It can be seen that, below 20 years, the data points lie perfectly on the line. Therefore, our approach is able to predict the age of a child with high accuracy.
5.7. Objective Performance Evaluation
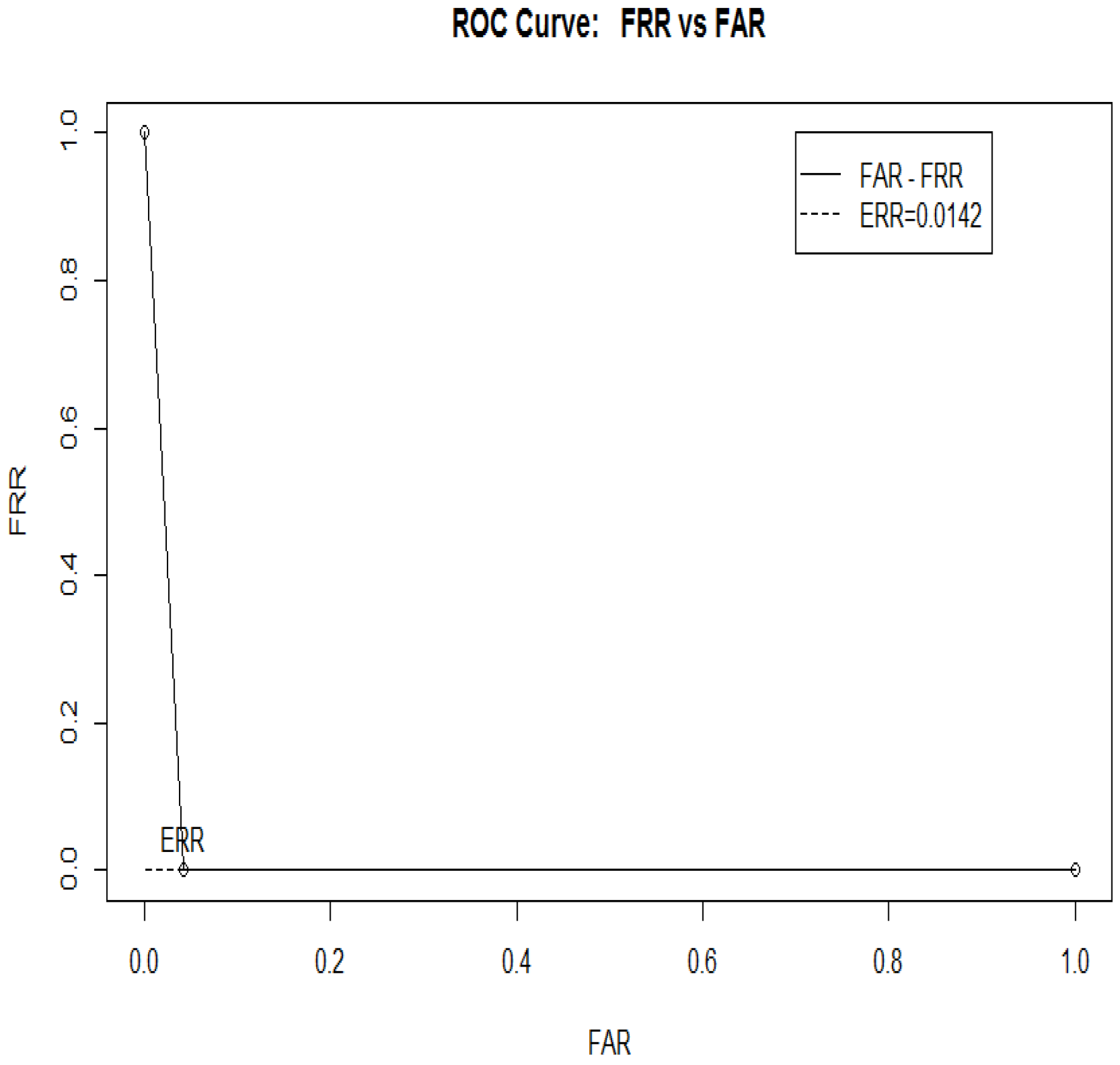
The objective evaluation shows how much the results and the references are determined as the same person by using auditory perception. To evaluate the performance of the system, volunteers of different ages and genders have tested our designed system. For real-time evaluation, the regression model trains the model with the reference database and tests the model with a volunteer’s data that does not exist in the database of the system. This evaluation checks the likelihood that the volunteer belongs to the same age class, and then, the similarity is evaluated based on the accuracy and the thresholds. While handling a biometric system, objective evaluation techniques are based on two factors: the FAR (False Acceptance Rate), which is calculated as a fragment of impostor scores overshooting the threshold, and the FRR (False Rejection Rate), which is calculated as a fragment of genuine scores falling below the threshold. There is no admissible way to determine if a system with a lower FAR and a higher FRR value performs better than a system with a higher FAR and a lower FRR. Therefore, the equal error rate (EER) of a system can be used. The more minor the value of EER, the better the performance of the system. The ROC (Receiver Operating Characteristic) curve is created in order to choose the prime threshold; we obtain 113 genuine scores and three impostor scores through some volunteers of different ages and genders. By considering the definition of FAR and FRR, the value of EER can easily be calculated. The ROC curve for our proposed model after testing is shown in
Figure 7. It is concluded that the system’s performance is quite satisfying; hence, the EER is 1.4%. However, it is obvious that the performance can be affected by changing the standardized parameters (distance from the computer, using headphones or speaker, and sound intensity), and hearing loss is also a factor that can affect the results.
6. BiometricAccessFilter-Based Web Application
The auditory perception responses encode biometric information about the age of a person and considering these encoded information; a robust regression model is designed which is able to estimate the forensic age according. Many applications have been developed on the proposed approach of human age estimation based on auditory perception responses such as detection of hearing loss [
36] and a web access filtering system called BiometricAccessFilter. A web application which uses Algorithm 1, for web access control is available (
http://iilyas.com/).
| Algorithm 1: Biometric control access filter. |
| | Result: Access Verification
Access = false;
login = Enter_ login()
Age ←
while Access == false &
age ← ≤ 18 do
|
| ![Electronics 09 00361 i001]() | (20, 20000);
if then
![Electronics 09 00361 i002]() ; ;
else
![Electronics 09 00361 i002]() ; ;
end |
| end
|
In
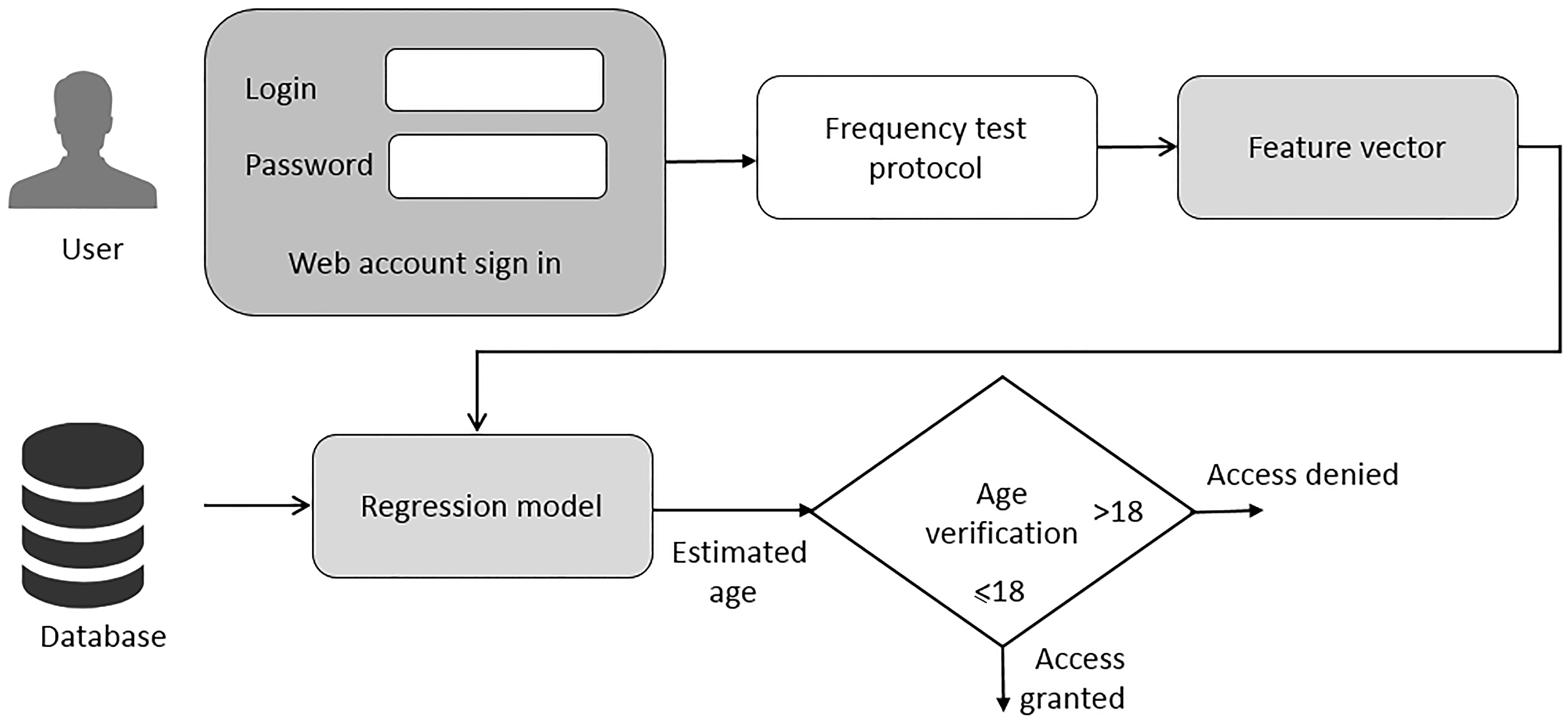
Figure 8, it is explained how a user can create an account on our online web interface. It requires some data to be inserted manually such as email address, name, and password. After successful creation of an account, on the login page, an age verification step is presented to give access rights to users less than 18 years old. The subject takes the test by listening to the sound and by pressing the “enter key” when they stop hearing the sound, while for the second test, the subject should press the “enter key” when the start hearing the sound. The corresponding frequency is registered in the databases. The regression model is used to predict and estimate the age of the subject. If the estimated age of the subject is higher than 18 years, then the access will be denied, and if his/her age is lower or equal to 18 years, the account will be created for further use.
BiometricAccessFilter can limit the access of adults to the virtual world of kids and can prevent child abuse or harassment. With this web application, we hope to change the practise and to introduce new ways of developing more secure web applications using smart biometric approaches. Consequently, forensic biometrics can help in a wide range of applications in cyber crime detection. It can overcome the loopholes of traditional anonymous identification systems.
Our designed system is much stronger and secure than the existing web access control systems. Besides, our system requires a smart interactive way of cooperation with the user. Moreover, our system is robust compared to the traditional modalities for verification system.
Our proposed system is still vulnerable to spoof attacks such as a spoof attacker fooling the system:
An old subject can impersonate themself as a young one just by finishing the experiment with a high-frequency in the first test and by responding after some seconds in the second test of the experiment.
A young subject can impersonate themself as an old one by finishing the first test with a lower-frequency and by responding with a higher delay for the second test.
In order to enhance the performance of the proposed BiometricAccessFilter system, we designed an anti-spoofing system based on auditory perception responses. The system based on auditory perception responses has shown promising results with an EER value of 5.5% under spoof attacks [
37].
7. Conclusions and Future Work
In this paper, we presented BiometricAccessFilter, which is a completely new approach for access control systems. It is based on auditory perception. It is proved that the proposed system can limit the access of users within certain age groups and that regression forest is the most accurate for age estimation. A robust regression model is also built, and it has an accuracy rate of 97.04% and a root mean square of error of 4.17 years. The EER value is 1.4%.
In the future, we are planning to develop a more sophisticated system that is equipped with an anti-spoofing system. The database will be developed in new machine learning, and deep learning approaches will be considered to better performance. As a new perspective, we will demonstrate replacing CAPTCHA using auditory perception responses.
Author Contributions
Conceptualization, M.I.; Methodology, M.I.; Supervision, A.O. and A.N.-A.; Visualization, M.I.; Writing—original draft, M.I.; Writing—review & editing, R.F., A.O. and A.N.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Warren, S.D.; Brandeis, L.D. The right to privacy. Harv. Law Rev. 1890, 4, 193–220. [Google Scholar] [CrossRef]
- Galbally, J.; Coisel, I.; Sanchez, I. A new multimodal approach for password strength estimation—Part II: Experimental Evaluation. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1167–1179. [Google Scholar] [CrossRef]
- Prabhakar, S.; Pankanti, S.; Jain, A.K. Biometrics Recognition: Security and privacy concern. IEEE Trans. Inf. Forensics Secur. 2017, 1, 33–42. [Google Scholar] [CrossRef]
- Fu, K.; Sit, E.; Smith, K.; Feamster, N. Dos and don’ts of client authentication on the web. In Proceedings of the 10th USENIX Security Symposium, Washington, DC, USA, 13–17 August 2001. [Google Scholar]
- Kornievskaia, O.; Honeyman, P.; Doster, B.; Coffman, K. Kerberized credential translation: A solution to web access control. In Proceedings of the 10th USENIX Security Symposium, Washington, DC, USA, 13–17 August 2001. [Google Scholar]
- International Telecommunications Union. ITU-T Recommendation X.509: The Directory: Authentication Framework; Technical Report X.509; ITU: Geneva, Switzerland, 1997. [Google Scholar]
- Ryutov, T.; Neuman, C.; Dongho, K.; Li, Z. Integrated access control and intrusion detection for Web servers. IEEE Trans. Parallel Distrib. Syst. 2003, 14, 841–850. [Google Scholar] [CrossRef]
- Hu, W.; Gao, J.; Wang, Y.; Wu, O.; Maybank, S. Online Adaboost-Based Parameterized Methods for Dynamic Distributed Network Intrusion Detection. IEEE Trans.Cybern 2014, 44, 66–82. [Google Scholar] [PubMed] [Green Version]
- Hu, B.; Jin, Y.; Liu, J.; Liu, J.; Wang, Y.; Chen, C. Construction of Interactive Service Software Based on Internet Security. In Proceedings of the 2017 3rd International Conference on Information Management (ICIM), Chengdu, China, 21–23 April 2017. [Google Scholar] [CrossRef]
- Dong, B.; Mi, J.X. Trimmed sparse coding for robust face recognition. Electron. Lett. 2017, 53, 1473–1475. [Google Scholar] [CrossRef]
- Czajka, A.; Bowyer, K.W.; Krumdick, M.; VidalMata, R.G. Recognition of Image-Orientation-Based Iris Spoofing. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2184–2196. [Google Scholar] [CrossRef]
- Pura, M.L. User Authentication to a Web Site Using Fingerprints; Henri Coanda: Brasov, Romania, 2014; p. 347. [Google Scholar]
- Jain, A.K.; Flynn, P.; Ross, A.A. (Eds.) Handbook of Biometrics; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Becker, B.C.; Ortiz, E.G. Evaluation of face recognition techniques for application to facebook. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face & Gesture Recognition, Amsterdam, The Netherlands, 17–19 September 2008. [Google Scholar]
- Miller, B. Vital signs of identity [biometrics]. IEEE Spectr. 1994, 31, 22–30. [Google Scholar] [CrossRef]
- Li, W.; Kim, D.J.; Kim, C.H.; Hong, K.S. Voice-Based Recognition System for Non-Semantics Information by Language and Gender. In Proceedings of the 2010 Third International Symposium on Electronic Commerce and Security, Guangzhou, China, 29–31 July 2010; pp. 84–88. [Google Scholar]
- Reynolds, D.A. An overview of automatic speaker recognition technology. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; pp. 4072–4075. [Google Scholar]
- Feustel, T.C.; Glemboski, M.A.; Ordun, M.R.; Velius, G.A.; Weinstein, S.B. Speaker Verification System Using Integrated Circuit Cards. U.S. Patent No. 4,827,518, 2 May 1989. [Google Scholar]
- Stockwell, C.W.; Ades, H.W.; Engström, H. XCVII patterns of hair cell damage after intense auditory stimulation. Ann. Otol. Rhinol. Laryngol. Suppl. 2017, 78, 1144–1168. [Google Scholar] [CrossRef] [PubMed]
- Manley, G.A.; van Dijk, P. Frequency selectivity of the human cochlea: Suppression tuning of spontaneous otoacoustic emissions. Hear Res. 2016, 336, 53–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paolis, A.D.; Bikson, M.; Nelson, J.T.; de Ru, J.A.; Packe, M.; Cardoso, L. Analytical and numerical modeling of the hearing system: Advances towards the assessment of hearing damage. Hear Res. 2017, 349, 111–128. [Google Scholar] [CrossRef] [PubMed]
- De Sá, L.C.; De Lima, M.; Tomita, S.; Frota, S.M.; Santos, G.A.; Garcia, T.R. Analysis of high frequency auditory thresholds in individuals aged between 18 and 29 years with no ontological complaints. Rev. Bras. Otorrinolaringol. 2007, 73, 2. [Google Scholar]
- Zwicker, E. Subdivision of the audible frequency range into critical bands (frequenzgruppen). J. Acoust. Soc. Am. 1961, 33, 248. [Google Scholar] [CrossRef]
- Stuart, R.; Howell, P. Signals and Systems for Speech and Hearing, 2nd ed.; Peter Howell: London, UK, 2011; p. 163. [Google Scholar]
- Rossing, T. Springer Handbook of Acoustics, 1st ed.; Springer: Berlin, Germany, 2007; pp. 747–748. [Google Scholar]
- Ilyas, M.; Othmani, A.; Nait-ali, A. Age Estimation Using Sound Stimulation as a Hidden Biometrics Approach. In Hidden Biometrics; Springer: Singapore, 2020; pp. 113–125. [Google Scholar]
- Ilyas, M.; Othmani, A.; Nait-Ali, A. Human age estimation using auditory system through dynamic frequency sound. In Proceedings of the IEEE 2nd International Conference on Bio-engineering for Smart Technologies (BioSMART), Paris, France, 30 August–1 September 2017. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2011, 45, 123–140. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the fifth annual workshop on Computational learning theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Wen, J.; Xu, Y.; Li, Z.; Ma, Z.; Xu, Y. Inter-class sparsity based discriminative least square regression. Neural Networks 2018, 102, 36–47. [Google Scholar] [CrossRef] [PubMed]
- Guyon, I.; Saffari, A.; Dror, G.; Cawley, G. Model selection: beyond the bayesian–frequentist divide. JMLR 2010, 11, 61–87. [Google Scholar]
- Anguita, D.; Ridella, G.A.S.; Sterpi, D. K-fold cross validation for error rate estimate in support vector machines. In Proceedings of the 2009 International Conference on Data Mining, Las Vegas, NV, USA, 13–16 July 2009; pp. 291–297. [Google Scholar]
- Dietterich, T.G. Approximate statistical tests for comparing supervised classification learning algorithms. Neural Comput. 1998, 10, 1895–1923. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Ilyas, M.; Othmani, A.; Nait-Ali, A. Prediction of hearing loss based on auditory perception: A preliminary study. In International Workshop on PRedictive Intelligence In MEdicine; Springer: Cham, Switzerland, 2018; pp. 34–41. [Google Scholar]
- Ilyas, M.; Othmani, A.; Fournier, R.; Nait-ali, A. Auditory Perception Based Anti-Spoofing System for Human Age Verification. Electronics 2019, 8, 1313. [Google Scholar] [CrossRef] [Green Version]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).




 ;
;








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}