1. Introduction
Selenium (
https://www.selenium.dev/) is an open-source framework mainly used for testing web applications. It enables the impersonation of users interacting with browsers such as Chrome, Firefox, Edge, or Opera in an automated manner. Nowadays, it is considered the de facto framework to develop end-to-end tests for web applications and supports a multi-million dollar industry [
1]. A recent study about software testing by Cerioli et al. identifies Selenium as the most valuable testing framework nowadays, followed by JUnit and Cucumber [
2].
Software ecosystems are collections of actors interacting with a shared market underpinned by a common technological background [
3]. Specifically, the Selenium ecosystem, target of the study, comprises the Selenium framework and other projects, libraries, and other actors. Selenium is a relevant testing framework due to the valuable contribution of its root projects (WebDriver, Grid, IDE), and for the contributions of a significant number of related projects and initiatives around them. This article presents the results of a descriptive survey carried out to analyze the status quo of Selenium and its ecosystem. A total of 72 participants from 24 countries completed this survey in 2019. The results reveal how practitioners use Selenium in terms of main features, test development, System Under Test (SUT), test infrastructure, testing frameworks, community, and personal experience. In light of the results, we provide some hints about future challenges around Selenium.
The remainder of this paper is structured as follows.
Section 2 provides a comprehensive review of the main features of the Selenium family (WebDriver, Grid, and IDE) and the related work.
Section 3 presents the design of the descriptive survey aimed to analyze the Selenium ecosystem.
Section 4 presents the results of this survey, and then
Section 5 provides a discussion and validity analysis of these results. Finally,
Section 6 summarizes some conclusions and possible future directions for this piece of research.
2. Background
Selenium was first released as open-source by Jason Huggins and Paul Hammant in 2004 while working in ThoughtWorks. They chose the name “Selenium” as a counterpoint to an existing testing framework developed by Hewlett-Packard called Mercury. In the opinion of Huggins, Selenium should be the testing framework that overcomes the limitations of Mercury. The idea behind the name is that “Selenium is a key mineral which protects the body from Mercury toxicity”.
The initial version of Selenium (now known as Selenium Core) allowed to interact with web applications impersonating users by opening URLs, following links (by simulating clicks on them), enter text on forms, and so forth, in an automated fashion. Selenium Core is a JavaScript library that interprets operations called Selenese commands. These commands are encoded as an HTML table composed by three parts:
Command: an action done in the browser. For example, opening a URL or clicking on a link.
Target: the locator which identifies the HTML element referred by the command. For example, the attribute id of a given element.
Value: data required by the command. For example, the text entered in a web form.
Huggins and Hammant introduced a scripting layer to Selenium Core, creating a new Selenium project called
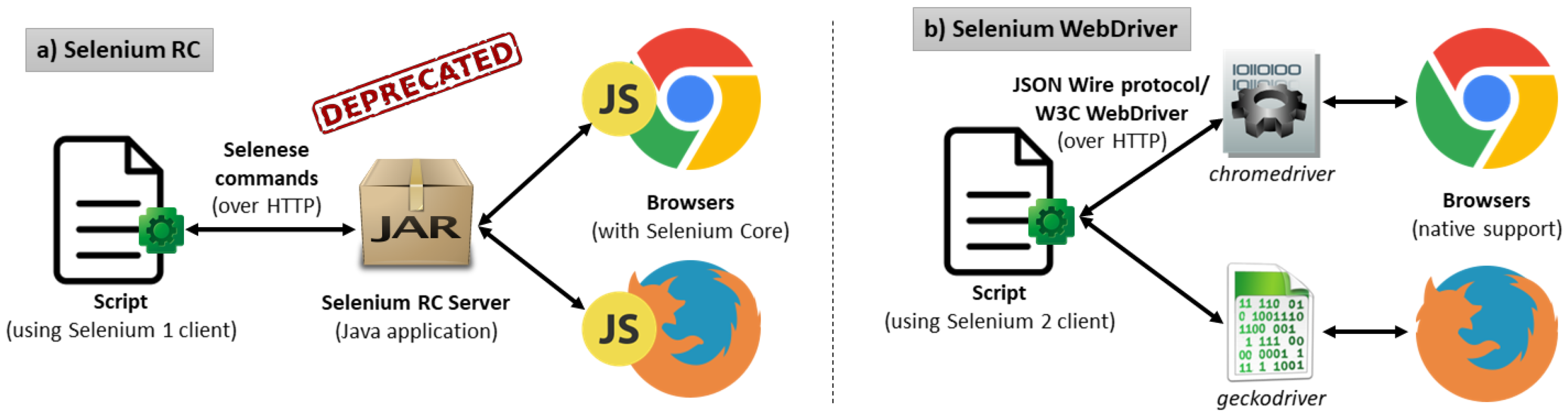
Remote Control (RC). As depicted in
Figure 1a, Selenium RC follows a client-server architecture. Selenium scripts using a binding language (such as Java, Perl, Python, Ruby, C#, or PHP) act as clients, sending Selenese commands to an intermediate HTTP proxy called Selenium RC server. This server launches web browsers on demand, injecting the Selenium Core JavaScript library in the SUT to carry out the automation through Selenese commands. To avoid same-origin policy issues (for example, when testing a public website), the Selenium RC Server masks the SUT under the same local URL of the injected Selenium Core library. This approach allows practitioners to create automated end-to-end tests for web applications using different programming languages.
Although Selenium RC was a game-changer in the browser automation space, it had significant limitations. Since JavaScript was the base technology to support automated web interactions, different actions could not be performed, for example, file upload and download, or pop-ups and dialogs handling, to name a few. Moreover, the Selenium RC Server introduces a considerable overhead which impacts in the final performance of the test. For these reasons, Simon Stewart at ThoughtWorks developed a new tool called
Selenium WebDriver, first released in 2008. From a functional point of view, WebDriver is equivalent to RC, that is, it allows the control of browsers from scripts using different language bindings [
4]. Nevertheless, its architecture is entirely different. To overcome the limitation of automating through JavaScript, WebDriver drives browsers using their native automation support. To that aim, a new component between the language binding and the browser needs to be introduced. This component is called the driver. The driver is a platform-dependent binary file that implements the native support for automating a web browser. For instance, this driver is named
chromedriver in Chrome or
geckodriver in Firefox (see
Figure 1b). The communication between the Selenium client and the driver is done with JSON messages over HTTP using the so-called JSON Wire Protocol. This mechanism, proposed initially by the Selenium team, has been standardized in the W3C WebDriver recommendation [
5]. Nowadays, Selenium WebDriver is also known as “Selenium 2”, while Selenium RC and Core are known as “Selenium 1”, and its use is discouraged in favor of WebDriver.
Another relevant project of the Selenium family is
Selenium Grid. Philippe Hanrigou developed this project in 2008. We can see it as an extension of Selenium WebDriver since it allows testers to drive web browsers hosted on remote machines in parallel. As illustrated in
Figure 2, there may be several nodes (each running on different operating systems and with different browsers) in the Selenium Grid architecture. The Selenium Hub is a server that keeps track of the nodes and proxies requests to them from Selenium scripts.
The last project of the Selenium portfolio is called the
Selenium IDE. In 2006, Shinya Kasatani wrapped the Selenium Core into a Firefox plugin called Selenium IDE. Selenium IDE provides the ability to record, edit, and playback Selenium scripts. As of version 55 of Firefox (released on 2017), the original Firefox plugin mechanism implemented in Firefox (based on XPI modules) migrated to the W3C Browser Extension specification [
6]. As a result, the Selenium IDE stopped working. To solve this problem, the Selenium team rewrote the IDE component as Chrome and Firefox extensions using the Browser Extensions API [
6]. Moreover, at the time of this writing, Selenium IDE is being ported to Electron. Electron is an open-source framework that allows the development of desktop applications based on Chromium and Node.js [
7].
2.1. Related Work
This paper belongs to the test automation space. In this arena, we can find a relevant number of existing contributions in the literature. For instance, Rafi et al. present a systematic literature review about the benefits and limitations of automated software testing [
8]. According to this work, the main advantages of test automation are reusability, repeatability, and effort saved in test executions. As counterparts, test automation requires investing high costs to implement and maintain test cases. Besides, staff training is also perceived as problematic. Other contributions report the status of test automation following different approaches. For example, Kasurinen et al. present an industrial study aimed to identify the factors that affect the state of test automation in various types of organizations [
9]. In this work, test automation is identified as a critical aspect to secure product features. However, high implementation and maintenance costs are recognized as limiting issues. The limited availability of test automation tools and test infrastructure costs causes additional problems. These results are aligned with the contribution of Bures and Miroslav [
10]. This work also identifies the maintenance of test scripts as a limiting point for the efficiency of test automation processes.
Focusing on the specific domain of Selenium, we find a large number of contributions in the literature. For example, the SmartDriver project is an extension of Selenium WebDriver based on the separation of different aspects of the test automation in separate concerns: technical elements related to the user interface and test logic and business aspects associated with the application under test [
11]. Leotta et al. propose Pesto, a tool for migrating Selenium WebDriver test suites towards Sikuli [
12]. Selenium WebDriver is sometimes referred to as a second-generation automation framework for web applications since the location strategies are based on the DOM (Document Object Model) of web pages. On the other side, Sikuli is a third-generation tool since it uses image recognition techniques to identify web elements [
13]. This technique can be convenient for those cases where the DOM-based approach is not possible (e.g., Google Maps automated testing). Another tool of the Selenium ecosystem is Selenium-Jupiter, an JUnit 5 extension for Selenium providing seamless integration with Docker. References [
14,
15] show how to use Selenium-Jupiter to implement automated tests aimed to evaluate the Quality of Experience (QoE) of real-time communication using web browsers (WebRTC) [
16].
Maintainability problems are also reported in the Selenium literature. The modification and evolution of a web application might break existing Selenium tests. For instance, this could happen when the layout of a web page changes, and Selenium tests coupled to the original layout remain unaltered. When this occurs, repairing the broken tests is usually a time-consuming manual task. In this arena, Christophe et al. present a study about the prevalence of Selenium tests. This work tries to understand the maintenance effort of existing Selenium tests as long as the SUT evolves. Authors claim to identify the elements of a test that are most prone to change: constants (frequently in locator expressions to retrieve web elements) and assertions (statements to check the expected outcomes) [
17]. Bures et al. propose a tool called TestOptimizer aimed to identify potentially reusable objects in automated test scripts [
18]. This tool carries static analysis in test scripts (such as Selenium WebDriver tests) to seek reusable subroutines. In this line, Stocco et al. investigate the benefits of the page objects pattern to improve the maintainability of Selenium tests with Apogen, a tool for the automatic generation of these objects [
19].
In other related publications, we find contributions comparing Selenium with other alternatives. For instance, Kuutila presented a literature review on Selenium and Watir, identifying differences in the performance using different configurations in these testing tools [
20]. We find another example in Reference [
21], in which Kaur and Gupta provides a comparative study of Selenium, Quick Test Professional (QTP), and TestComplete in terms of usability and effectiveness.
Finally, we find the most straightforward reference to the target of this paper, that is, the Selenium ecosystem, in the official documentation (
https://www.selenium.dev/ecosystem/). This information captures existing tools which use Selenium WebDriver as its main component, namely:
Browser drivers: such as chromedriver for Chrome, or geckodriver for Firefox.
Additional language bindings: Go, Haskell, PHP, R, Dart, among others.
Frameworks: WebDriverIO, Capybara, Selenide, FluentLenium, among others.
To the best of our knowledge, there are no further sources that analyze the Selenium ecosystem as a whole. We interpret this fact as an indicator of the need for the present article.
3. Survey Design
The way to conduct an investigation is often known as a research approach [
22]. Glass et al. identified three types of research approaches in the computing field (composed by Computer Science, Software Engineering, and Information Systems), namely Reference [
23]:
Descriptive: aimed to explain the characteristics of a phenomenon under study.
Evaluative: aimed to assess some effort in a deductive, interpretative, or critical manner.
Formulative: aimed to propose a solution to a problem.
We use a descriptive research approach to get the current snapshot of Selenium and its ecosystem. To that aim, we use an online questionnaire implemented with Google Forms to gather information from the Selenium community. We launched the survey just before the beginning of SeleniumConf Tokyo (
https://conf.selenium.jp/) in April 2019. At that time, the stable version was Selenium 3, and during that conference, the first alpha release of Selenium 4 was made public.
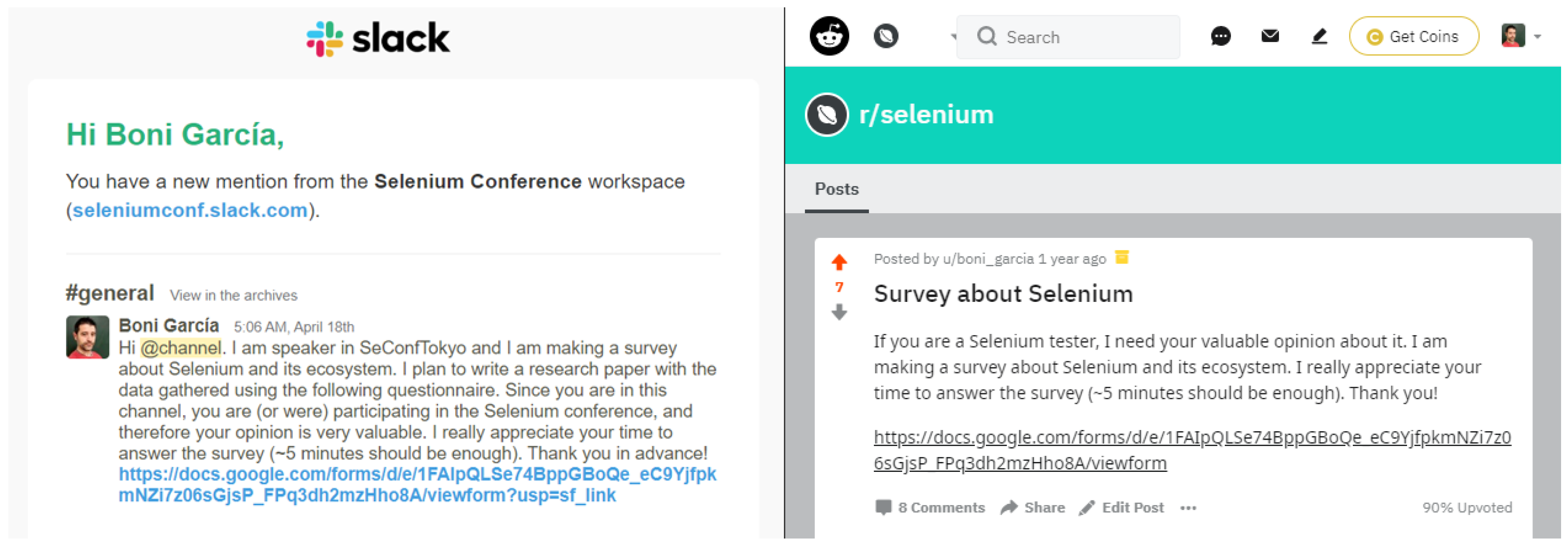
We employed two different ways to recruit participants for the survey. First, we used the general channel of the SeleniumConf Slack workspace (
https://seleniumconf.slack.com/). Participants in this channel are former or future participants in SeleniumConf. Therefore, the potential respondents coming from this workspace are likely to be experts (or at least quite interested) in Selenium. The left part of
Figure 3 shows the message posted on this Slack channel. To reach a wider audience, we also ask for participation in the survey in the Selenium Reddit community (
https://www.reddit.com/r/selenium/). People participating in this community show a proactive interest in Selenium, and therefore, their opinion can also be valuable for the survey. The right part of
Figure 3 shows the message posted on the Selenium Reddit community.
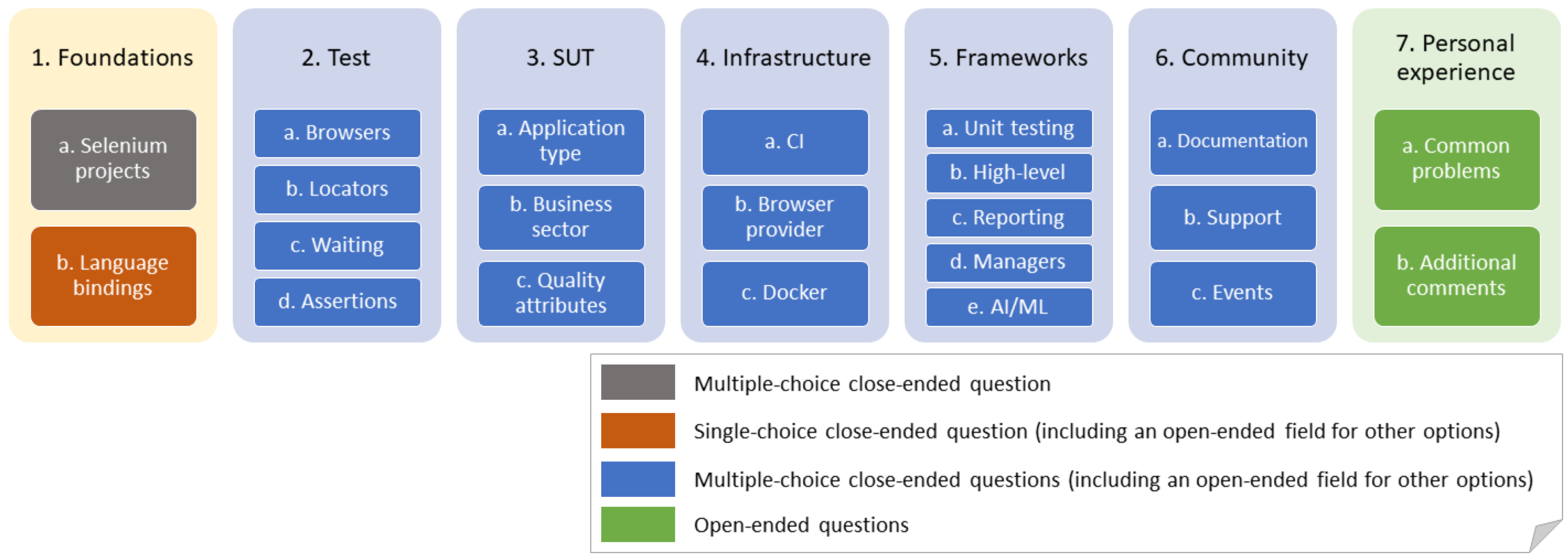
As illustrated in
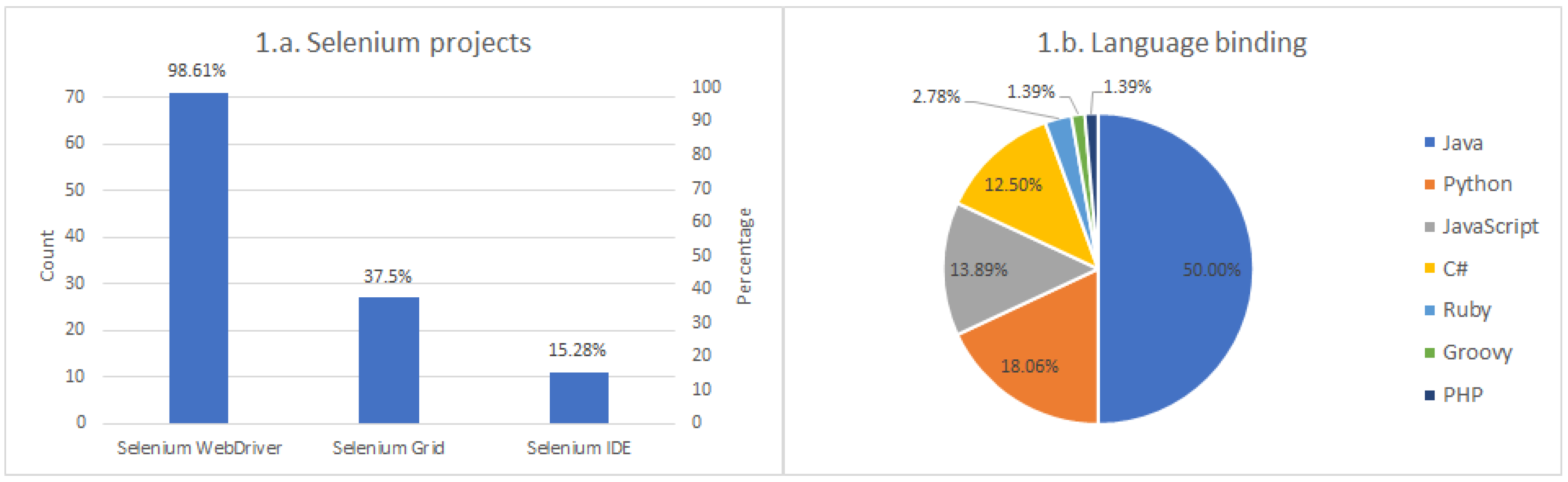
Figure 4, the structure of the survey contains seven different sections. We labeled the first section as “Foundations” in this diagram, and it is about the core features of Selenium (i.e., essential aspects of Selenium) used by the community. This section contains two questions. First, we ask the participants to chose which project of the official Selenium family (i.e., WebDriver, Grid, IDE) use. This question is a multiple-choice close-ended question [
24]. In other words, respondents can choose one or more answers to this question. The second question in this section is about the language bindings, that is, the programming language in which Selenium scripts are developed. The possible answers to this question are the officially supported languages for Selenium, that is, Ruby, Java, JavaScript, Python, C#, or JavaScript (
https://www.selenium.dev/downloads/), and also other language bindings supported by the community, such as PHP or Dart among others. Even though developers can use different language bindings, this question is designed to be a single-choice close-ended. In other words, participants can choose one and only one of the answers. This constraint aims to get a reference of the preferred language and use this number to calculate usage quotas of additional features of Selenium relative to the language binding.
As depicted in
Figure 4, the rest of the questions available from sections two to six, are of the same type: multiple-choice close-ended questions (including an open-ended field for other options). These questions provide a list of possible answers (which can be selected or not by respondents) and an additional field for alternatives. This format aims to simplify the survey filling by participants while providing additional possibilities (the “other” field) to complement the answers with custom choices.
The second section, labeled as “Test” in
Figure 4, is about the design and implementation of the end-to-end tests developed with Selenium. This section aims to discover how participants develop Selenium tests by analyzing the following aspects:
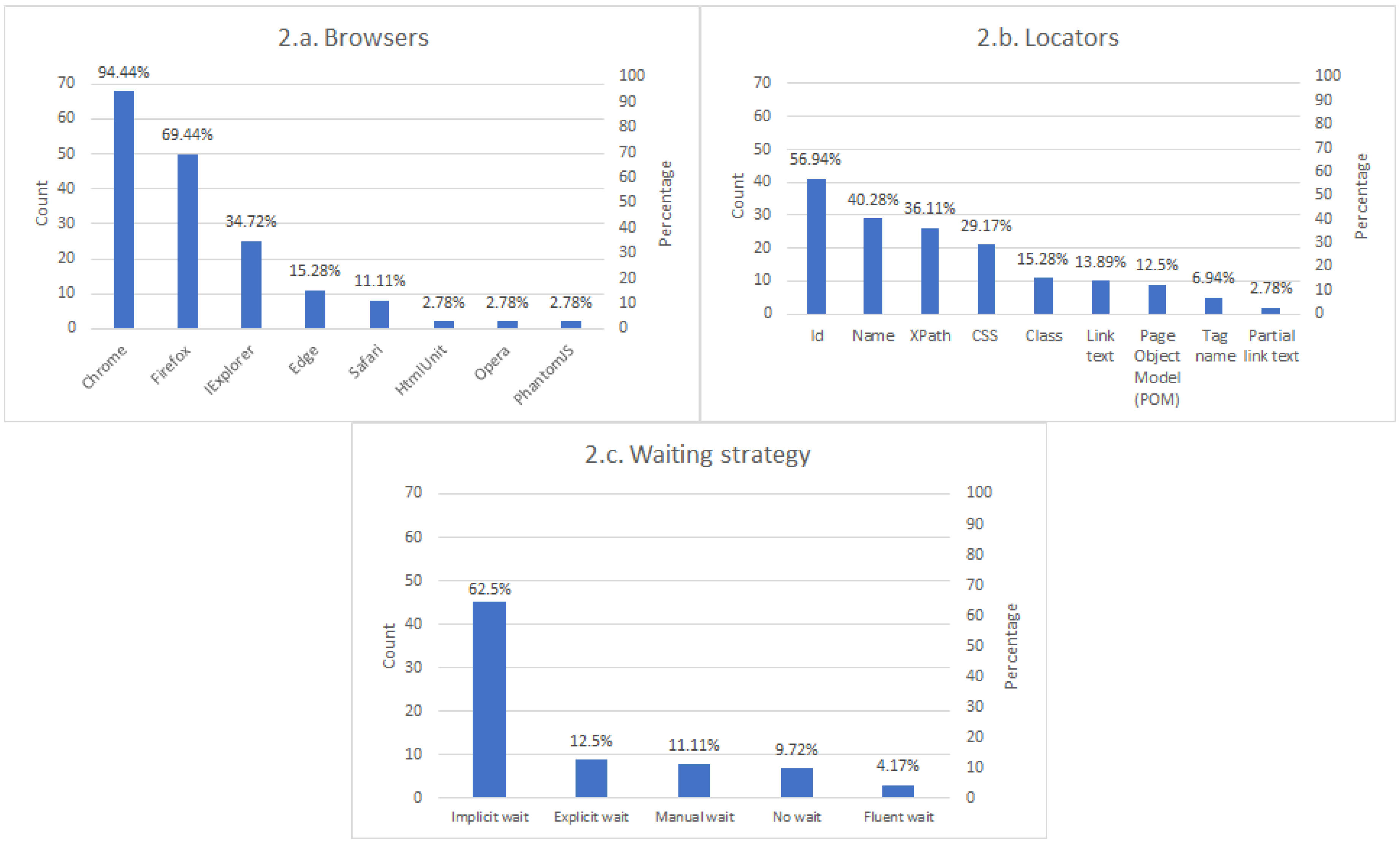
Browsers selected to be driven automatically through Selenium, such as Chrome, Firefox, Opera, Edge, among others.
Locator strategy. A locator is an abstraction used in the Selenium API to identify web elements in Selenium. There are different strategies available in the Selenium API: by attribute id, by attribute name, by link text, by partial link text, by a given tag name, by the attribute class, by a CSS (Cascading Style Sheets) selector, or by XPath [
25]. In addition to these methods, there is a complementary technique to locate web elements called the Page Object Model (POM). POM is a design pattern in which developers can model web pages using an object-oriented class to ease test maintenance and reduce code duplication [
26]. These page objects internally also use the aforementioned DOM-based locators (by id, name, and so for). We specifically ask if users use POM because it is the best practice to help make more robust tests.
Waiting strategy. The load time of the different elements on a web page might be variable. To handle this dynamic interaction, Selenium implements different waiting strategies. There are two main types of waits in Selenium. On the one hand, the so-called implicit waits tell Selenium WebDriver to wait a certain amount of time before raising an exception. On the other hand, explicit waits wait a given timeout to a given expected condition. Moreover, there is a type of explicit condition called fluent waits, which allows setting additional parameters such as the polling time and the exception raised [
27].
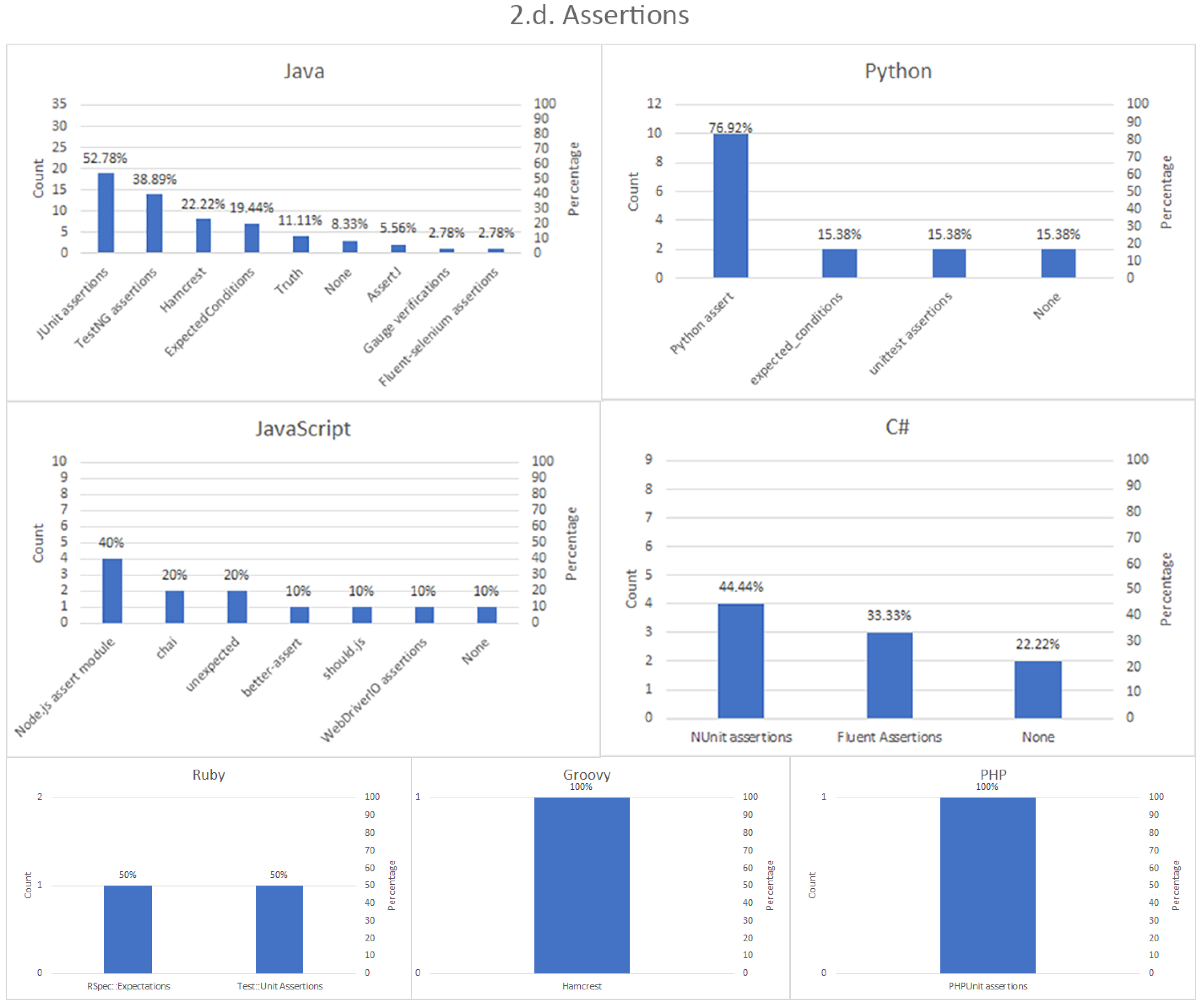
Assertion strategy. Tests are supposed to exercise a SUT to verify whether or not a given feature is as expected, and so, an essential part of tests are the assertions. Assertions are predicates in which the expected results (test oracle) are compared to the actual outcome from the SUT [
28]. The strategy for this assessment can be heterogeneous in Selenium, and for that reason, this part of the survey investigates this relevant point.
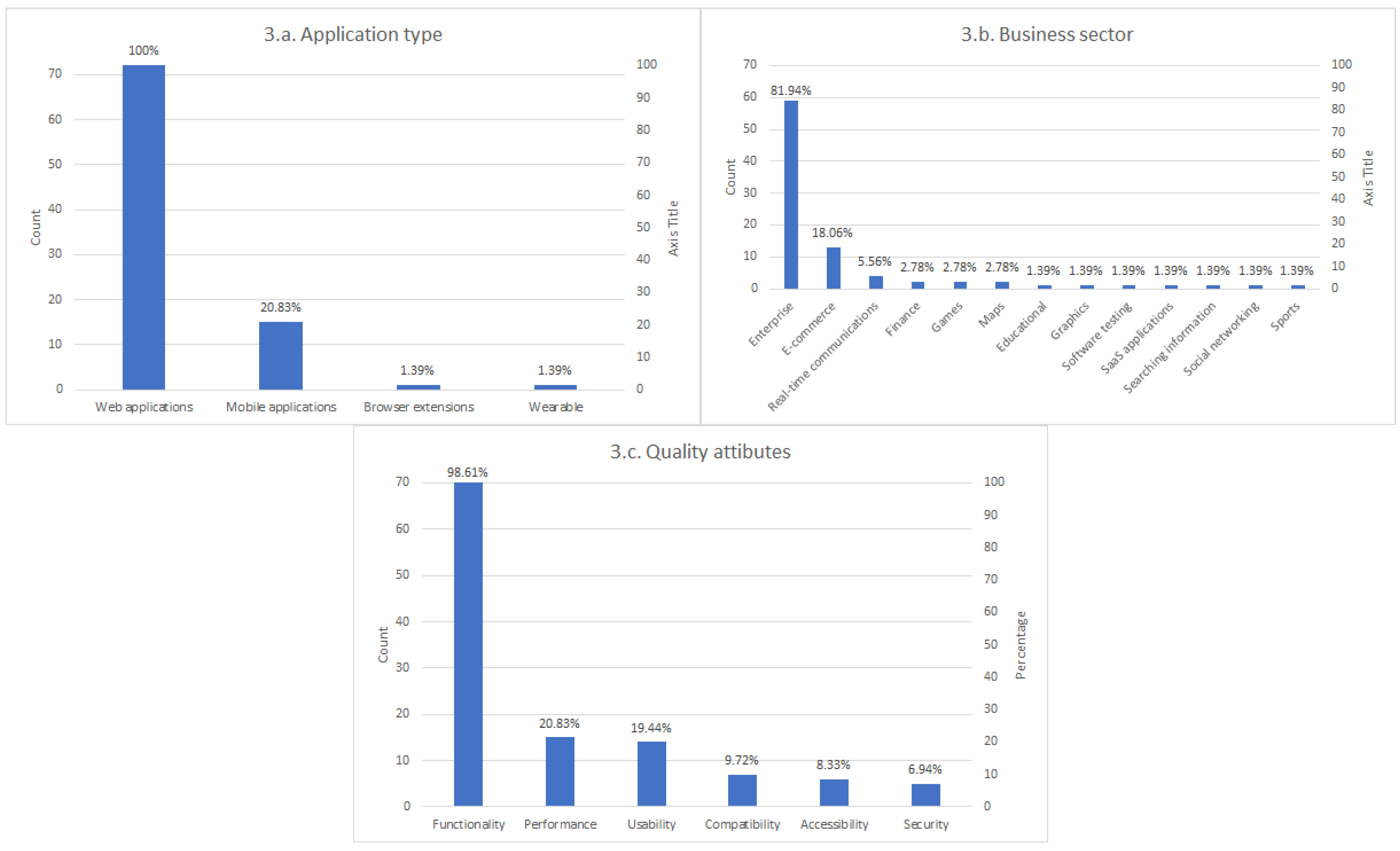
The next part of the survey is labeled as “SUT” in
Figure 4. This part first surveys the nature of the application tested with Selenium. Although the answer to this question seems pretty obvious since Selenium is a test framework for web applications, we ask the participants this question to evaluate if other application types are also assessed (for instance, mobile apps, when also using Appium). In the next question, we ask about the business sector in which the participants catalog their SUT, such as enterprise applications, e-commerce, or gaming, to name a few. Moreover, we ask the participants to inform about the quality attributes verified with Selenium, for example, functionality, performance, compatibility, usability, accessibility, or other non-functional properties [
29].
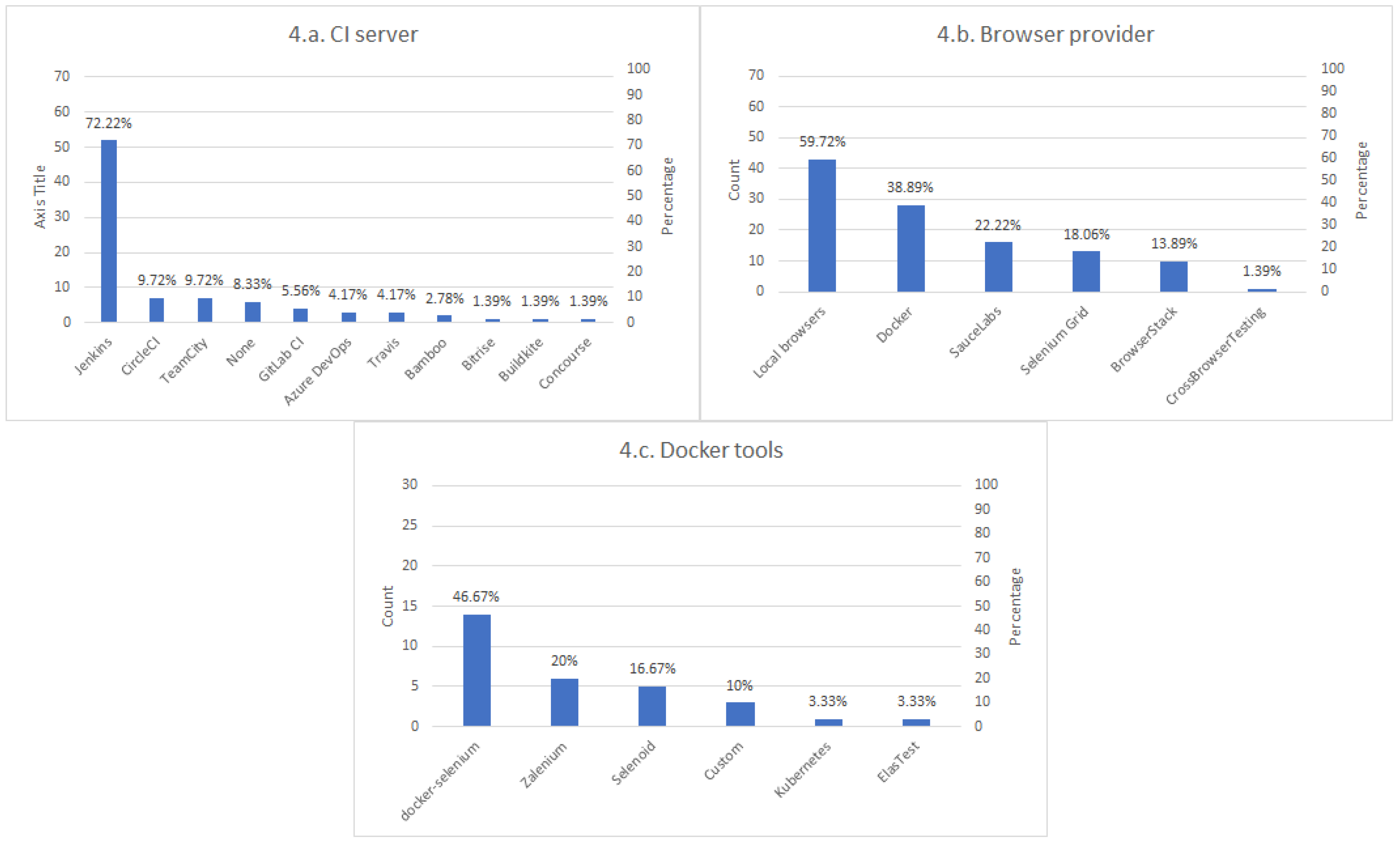
The fourth group of questions of the survey concerns to test infrastructure and contains three items. This first question asks the participants for the Continous Integration (CI) server used to execute Selenium tests. The second question surveys about the browser provider, that is, the source of the browsers. Possible answers to this question include the use of local browsers (installed in the machine running the test), remote browsers (accessed using Selenium Grid), browsers in Docker containers, or use of services that provide on-demand browsers, such as SauceLabs or BrowserStack, among others. To conclude this section, we included an additional question regarding the Docker tools used with Selenium.
The fifth part, “Frameworks”, is about complementary tools to Selenium. This part explores existing frameworks, libraries, and other utilities used in conjunction with Selenium, grouped into different categories:
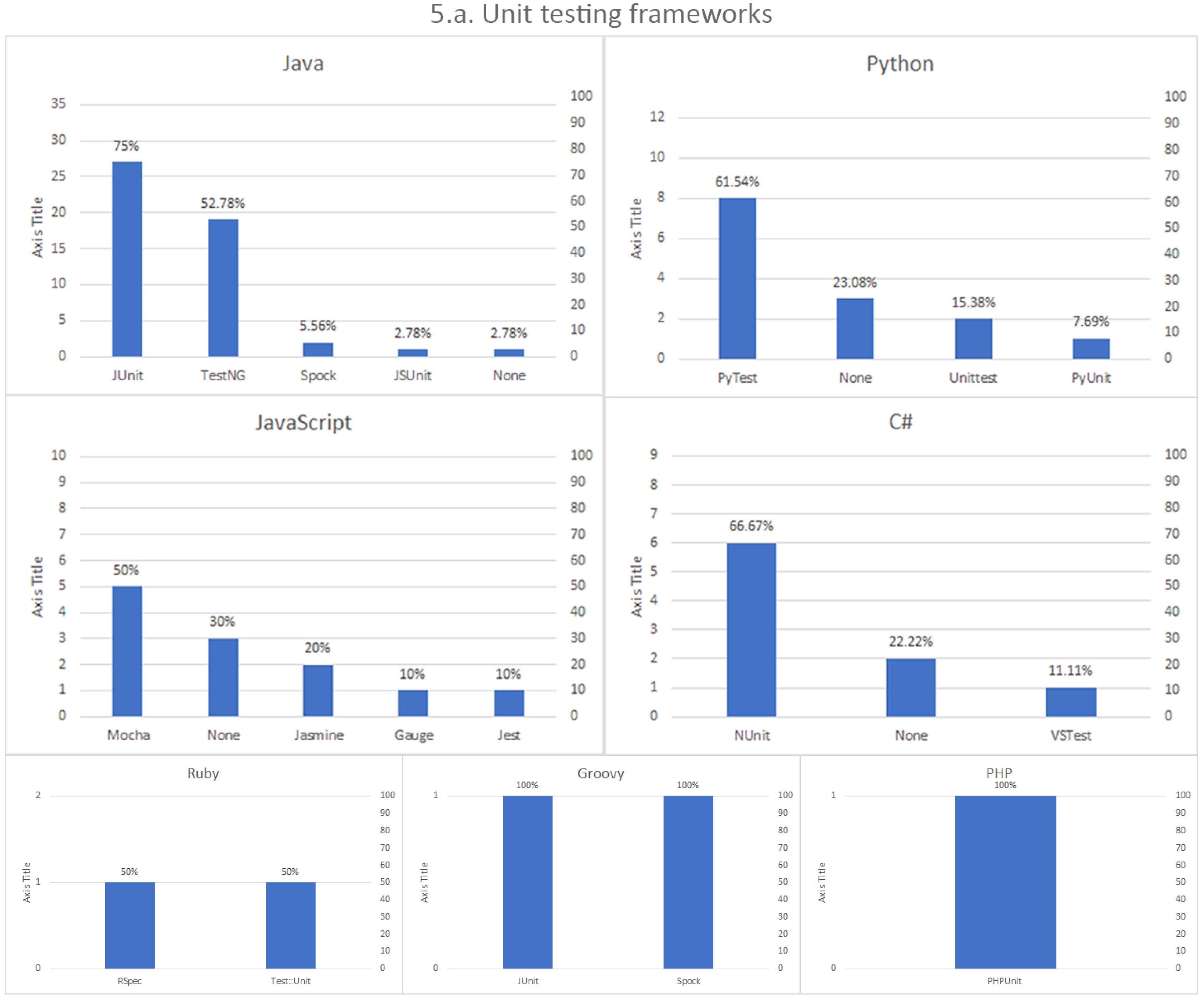
Unit testing frameworks. Although Selenium can be used as a standalone framework (for example, when making web scrapping to gather data from websites [
30]), it is a common practice to embed a Selenium script inside a unit test. This way, the execution of the Selenium logic results in a test verdict (pass or fail). Examples of typical unit testing frameworks are JUnit, TestNG, or Jasmine, among others.
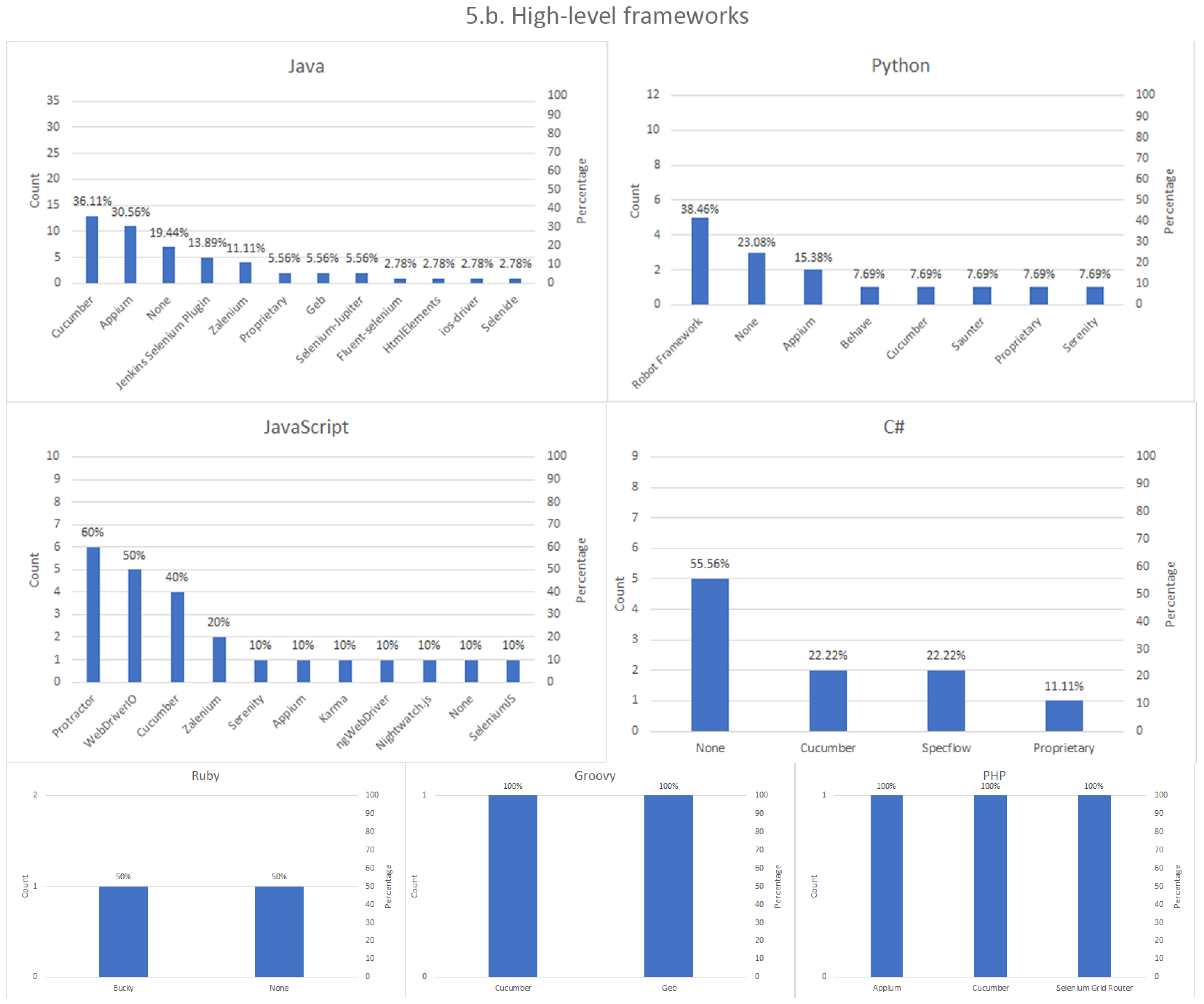
High-level testing frameworks. Selenium is sometimes used in conjunction with additional frameworks that wrap, enhance, or complement its built-in features. Examples of these frameworks are, for example, Cucumber, Protractor, or WebDriverIO, among others.
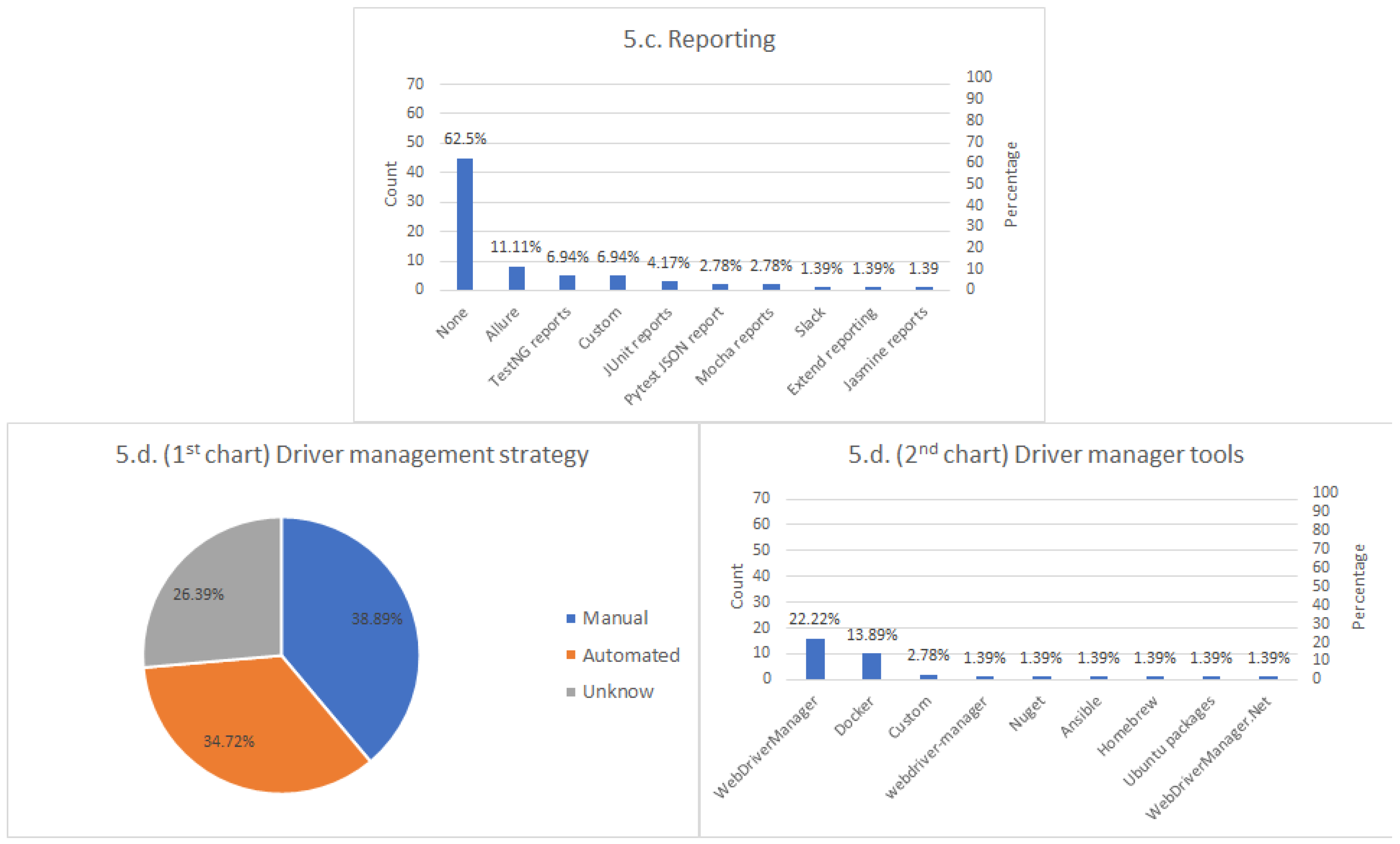
Reporting tools. Test reports are pieces of information in which the results of a test suite are documented. These reports can be critical to try to find the underlying cause of some failure. This part explores the mechanisms used to report Selenium tests by practitioners.
Driver managers. As explained in
Section 2, Selenium WebDriver requires a platform-dependent binary file called driver (e.g.,
chromedriver when using Chrome or
geckodriver when using Firefox) to drive the browser. We find different tools to automate the management of these drivers in the Selenium ecosystem, the so-called driver managers. This question investigates the actual usage of these tools in the community.
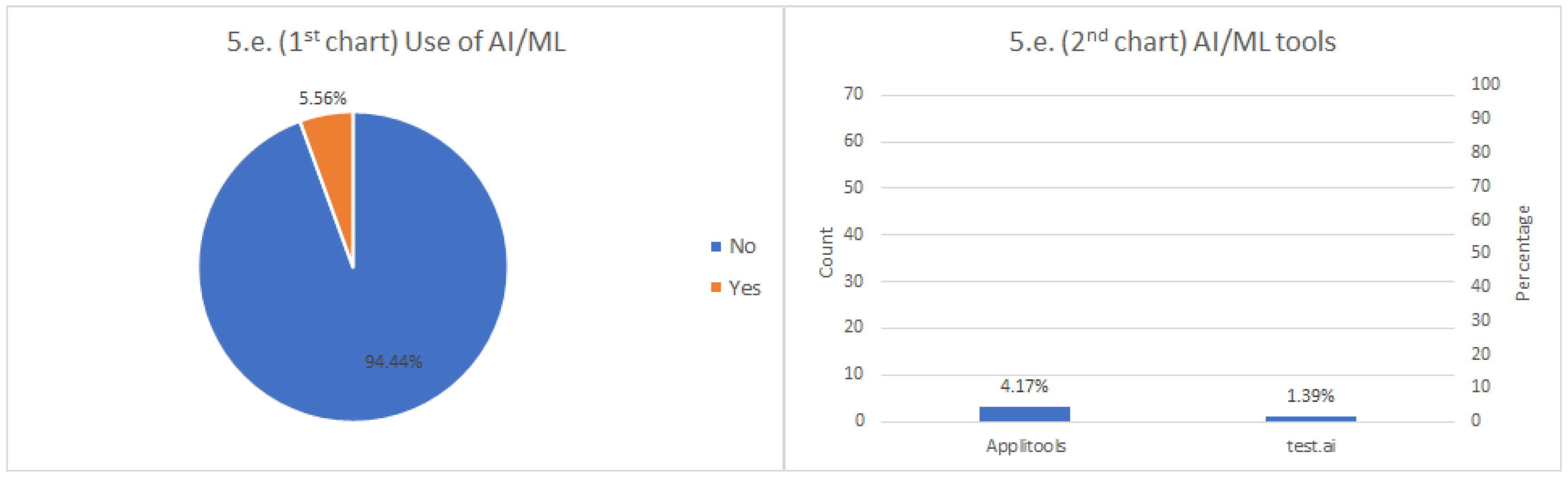
Framework based on Artificial Intelligence (AI) or Machine Learning (ML) approaches. AI/ML techniques promise to revolutionize the testing practice in the next years [
31]. We include a specific question about it to estimate the usage of these techniques in the Selenium space.
The sixth section of the survey comprises aspects related to the Selenium community. The first question is about the preferred sources of information to learn and keep updated about Selenium (i.e., documentation). The second question surveys about the most convenient ways to obtain support about Selenium from the community. The last item of this section asks the participant to report relevant events related to Selenium, such as SeleniumConf or the Selenium Groups.
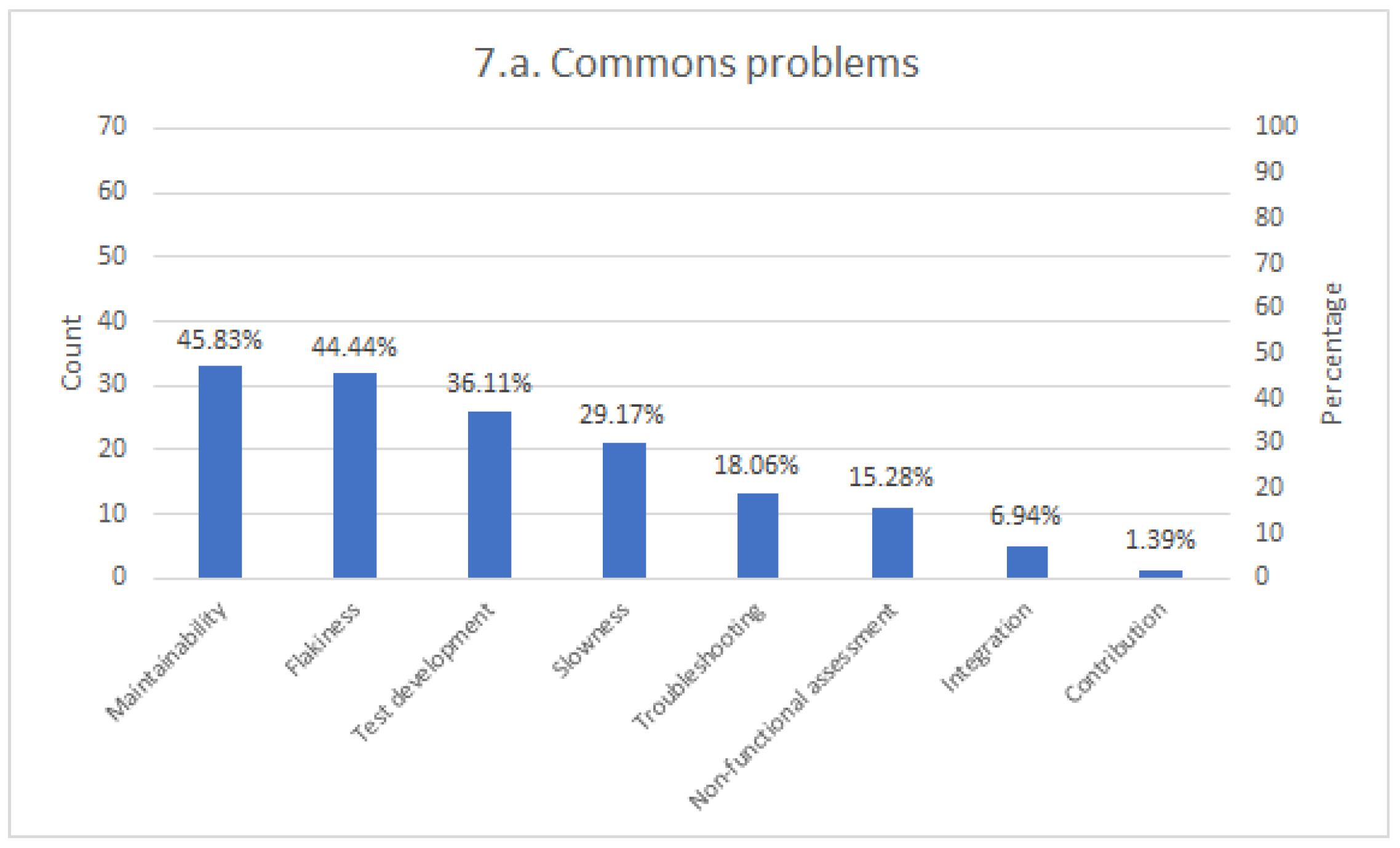
The last part of the survey contains open-ended questions about the participants’ experience with Selenium. We ask them to use their own words (in English) using a text area to answer these questions. First, we ask about the common problems related to the development and operation with Selenium. This question aims to discover the main issues that Selenium testers face, such as maintainability or flakiness, among other potential problems. To conclude, this survey contains another open-ended question to report personal opinions or further comments about the Selenium ecosystem.
5. Discussion
This section analyses the results of the survey. Regarding the Selenium projects, the first conclusion we can draw is that Selenium WebDriver is undeniably the heart of Selenium since almost all Selenium users utilize it. Regarding language binding, there is a preference for Java. In a second-tier, we find Python and JavaScript.
Regarding browsers, Chrome is the browser used for almost every Selenium tester, followed by Firefox. Surprisingly, the third browser in terms of Selenium automation is Internet Explorer, selected by 34.72% of the participants. Even though it is a deprecated browser nowadays, it seems it is still in use by the community. This fact can be related to the results of the SUT. There is a clear preference for testing the functional features of enterprise web applications. Internet Explorer was the dominant browser years ago, and it seems it is still in use in legacy Windows systems. All in all, practitioners need to ensure that Explorer still supports their applications, and Selenium is the selected tool to carry out this verification process.
Regarding infrastructure, there is a clear preference to use Jenkins as a CI server. Then, we find that the usage of local browsers is the preferred option. Nevertheless, we can see that Docker is also very relevant to Selenium. As explained in the next section, we can see another proof of the importance of Docker in Selenium in the features of the next version of Selenium Grid.
We interpret the diversity in the answers for several aspects studied by the survey as a health symptom of the Selenium ecosystem. First, the number of high-level frameworks based in Selenium is remarkable. This figure is a clear indicator of the success of Selenium as the germ to further technologies, such as Appium, Zalenium, or Robot Framework, to name a few. Moreover, we find other frameworks that are used in conjunction with Selenium to extend their original features. In this arena, Cucumber is a relevant actor, since the BDD approach used in Cucumber tests, can be used to implement end-to-end tests to assess web applications with Selenium.
Analyzing the results of the frameworks section, we can also identify potential weaknesses in the Selenium ecosystem, first, regarding reporting tools. In this domain, most of the respondents declared not using any reporting tool. A plausible explanation is that the plain output provided by the unit testing frameworks (i.e., red/green reports and error traces) is sufficient for most of the projects. Nevertheless, this fact might also be an indicator of a lack of comprehensive specific reporting tools for Selenium. This view is reinforced by the fact that some respondents reported that it is a challenge to troubleshoot problems when tests fail. Proper reporting tools could bring visibility over the whole test infrastructure. In this arena, Allure (the second choice in light of results) might be a candidate to fulfill this need, since it can be used from different binding languages in Selenium. Another improvement point is the use of driver managers. A relevant percentage of respondents declared to manage driver manually, which in the long run, might cause maintainability and test development problems. Tools like WebDriverManager and other managers promise to solve this problem, but it seems the usage of this kind of helper utility is not wide-spread yet. Finally, although the use of AI/ML techniques promises to revolutionize the testing arena, at the time of this writing, there is still limited adoption of such methods (only Applitools and test.ai were reported in the survey).
We can get some conclusions from the numbers about the community. Regarding the documentation, it is remarkable that the two preferred options are online tutorials and blogs. These options are, in general, maintained by the community. Again, this is an indicator or the interest in Selenium. This fact is endorsed by support results, in which another community-based solution, StackOverflow, is the preferred option to get support about Selenium. Regarding the events, the most significant events are the official conference (SeleniumConf) and Meetup. Nevertheless, it is interesting to discover that other events, not oriented explicitly to Selenium but for Quality Assurance (QA) and testing (such as TestBash or SauceCon), are also identified as related to Selenium.
Concerning the common problems of Selenium, the first group of difficulties is about the maintainability of Selenium tests. As introduced in
Section 2.1, maintainability is a well-known issue in test automation in general and Selenium in particular. Nevertheless, this problem should not be a stopper in the adoption of test automation since the maintenance cost of automated tests is proved to provide a positive return on investment compared to manual testing [
34]. When coming to Selenium, the maintenance and evolution of end-to-end tests (especially large-scale suites), to be efficient, requires the adoption of appropriate techniques and best practices [
35]. To this aim, the adoption of design patterns in the test codebase is recommended. The test patterns proposed by Meszaros (such as the delegated test method setup or customs assertions, to name a few) can enhance the quality of the xUnit tests that embed the Selenium logic [
36]. Then, and specific to Selenium, the usage of page objects is a well-known mechanism to improve the reusability, maintainability, and readability of Selenium tests. According to Leotta et al., the adoption of POM in Selenium tests contributes to significant effort reduction: maintenance time is reduced in a factor of 3, and lines of code (LOCs) to repair tests is reduced in a factor of 8 [
26]. The fact that maintainability is the first category of problems pointed out by almost half of the surveyed people is in line with our finding that few respondents use page objects to model their web page interactions. In light of the evidence reported in previous literature, we think that the adoption of POM could drastically increase the reliability of Selenium tests. To ease the adoption of POM, Selenium WebDriver provides a page factory utility set [
37]. Within the scope of POM, we find another pattern called Screenplay, which is the application of the SOLID design principles to page objects. The Screenplay pattern uses actors, tasks, and goals to define tests in business terms rather than interactions with the SUT [
38].
The locator strategy in Selenium tests is also reported as a possible cause of maintainability issues. We consider that practitioners need to be aware of this potential problem to prevent it, designing a coordinated plan between the front-end and testing teams aimed to ease and maintain the testability during the project lifecycle. In this regard, different strategies can be adopted. For instance, Leotta et al. investigate the LOC modified and the time required to evolve Selenium WebDriver tests when using different locator strategies. Although not conclusive, this work reported fewer maintenance efforts when using id locators in conjunction with link text compared to XPath [
32]. The automatic generation of locator strategies has also been reported in the literature to avoid fragility in Selenium tests. For example, Reference [
39] proposes an algorithm called ROBULA (ROBUst Locator Algorithm) to automatically generated locators based on XPath. This algorithm iteratively searches in the DOM nodes until the element of interest is found. To improve the reliability of this approach, the authors of this work propose a multi-locator strategy that selects the best locator among different candidates produced by different algorithms [
40].
Another very relevant common problem detected is the unreliability of some tests, often known as flaky. Generally speaking, the first step to fix a flaky test is to discover the cause. There are different causes of non-deterministic tests in Selenium, including fragile location strategies, inconsistent assertions, or incorrect wait strategies. Again, we think that using the POM model together with robust waiting and location strategies could increase the reliability of flaky tests. Regarding waiting strategies, as we saw, that there is a preference for implicit waits. Nevertheless, several users declared no using wait strategies or manual waits. Depending on the hardware and the SUT, this fact might lead to flaky tests [
41]. Regarding troubleshooting, observability tools like the ELK (ElasticSearch, Logstash, and Kibana) stack [
42] or ElasTest (
https://elastest.io/) [
43] could help alleviate this problem.
5.1. Evolution of Selenium and Alternatives
The immediate future of Selenium is version 4, in alpha at the time of this writing. Selenium 4 brings new features for all the core project of Selenium. A key point in Selenium WebDriver 4 is the full adoption of the standard W3C WebDriver (
https://www.w3.org/TR/webdriver/) specification as the only way to automate browsers. In other words, the communication between Selenium and a browser driver is entirely standard as of Selenium WebDriver 4. This adoption is expected to bring stability to the browser automation through Selenium since a standards committee maintains the automation aspects which browser vendors should adopt. Another new feature in Selenium WebDriver 4 is the introduction of relative locators, that is, the capability to find nearby other elements or the exposure of the DevTools API for Chromium-based drivers (continue reading this section for further details about DevTools). Version 4 also brings novelties to the rest of the official Selenium family. When coming to the Selenium Grid project, the Selenium server (hub) performance and its user interface are highly improved in the new version. Besides, Selenium Grid incorporates native Docker support for nodes and supports GraphQL for making queries. Regarding Selenium IDE, the next version includes a Comand-Line Interface (CLI) runner, and the ability to specify different locator strategies when exporting test cases. Last but not least, the official Selenium documentation has been renewed.
To conclude, we consider it is interesting to review alternatives to Selenium in the browser automation arena. A relevant project to be considered is Puppeteer (
https://pptr.dev/), a Node.js library created by Google that allows controlling browsers based on the Blink rendering engine (i.e., Chrome, Chromium, Edge, or Opera) over the DevTools Protocol. DevTools is a set of developer tools built directly into Blink-based browsers. DevTools allows editing web pages on-the-fly, debugging CSS and JavaScript, or analyzing load performance, among other features. The DevTools Protocol (
https://chromedevtools.github.io/devtools-protocol/) is a protocol based on JSON-RPC messages, which allows instrumenting, inspecting, debugging, and profiling Blink-based browsers.
Playwright (
https://playwright.dev/) is also a Node.js library for browser automation created by Microsoft. The Playwright team is made up of ex-Googlers who previously worked developing Puppeteer. We can say that Playwright is a newcomer in the browser automation space since the first public release of Playwright was in January 2020. Although the API of Playwright and Puppeteer are quite similar, internally, both tools are quite different. One of the most significant differences between Playwright and Puppeteer is cross-browser support. In addition to Chromium-based browsers, Playwright can drive WebKit (the browser engine for Safari) and Firefox. To implement this cross-browser support, Playwright is shipped with patched versions of WebKit and Firefox in which their debugging protocols are extended to support remote capabilities through the Playwright API.
Cypress (
https://www.cypress.io/) is another Node.js framework that allows implementing end-to-end tests using a sandbox environment based on JavaScript following a client-server architecture. Tests on Cypress runs inside the browser, and therefore the waits for web elements are automatically managed by Cypress. The limitations of Cypress are the lack of cross browsing (for example, Safari is not supported) and same-origin constraints (i.e., to visit URLs with different protocol and host in the same test).
Sikuli (
http://www.sikulix.com/) is a tool to automate the interaction within a desktop environment from Windows, Mac, or Linux/Unix. It uses image recognization based on OpenCV to identify GUI components [
44]. It supports several scripting languages, including Python, Ruby, JavaScript, Robot Framework text-scripts, and Java-aware scripting (e.g., Jython, JRuby, Scala, or Clojure).
5.2. Threats to Validity
We discuss the main threats to the validity of our research following commonly accepted techniques described in Reference [
45]. This way, we analyze the construct, internal, and external validity.
We carried out a careful design of our questionnaire using high-level dimensions of the Selenium ecosystem to minimize threats in the construct. For the shake of completeness, we include the “other” field to allow custom answers in many of the questions. Finally, and before launching the survey, we did a thorough review of the questionnaire with the help of several experts in testing with Selenium.
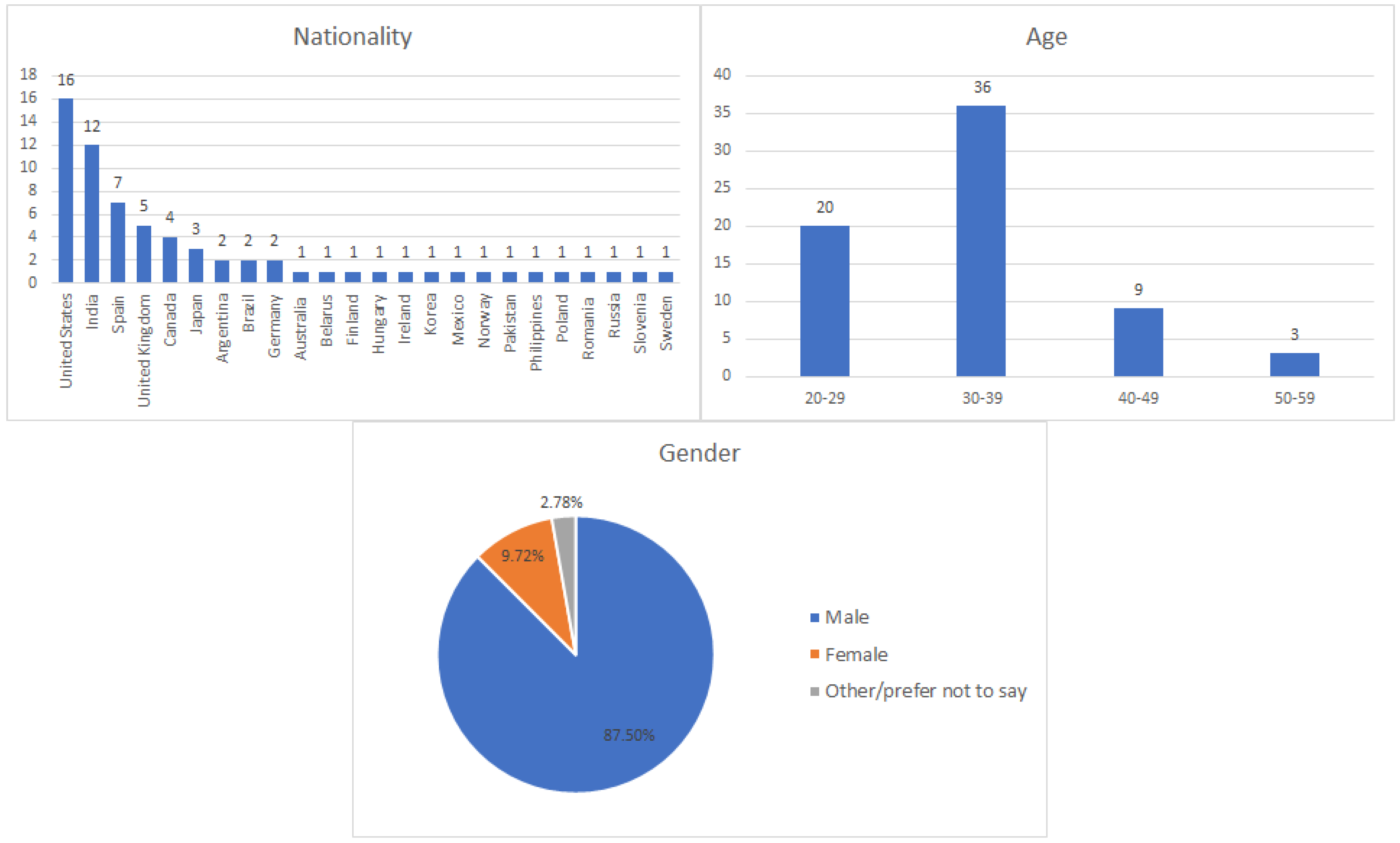
Internal validity is the extend in which the design of the experiment avoids introducing bias into the measurement. To enhance our internal validity, we tried to avoid any selection bias by enabling the Selenium community to answer the questionnaire freely. This strategy was successful, given the number and spectrum of participants in terms of age and nationality. The risk of statistical effects in the outcome (for non-language-specific questions) is low since 72 participants completed the questionnaire, which is a significant population for this kind of survey.
External validity refers to the extent to which the results can be generalized. In this regard, the main threat comes from a lack of statistical significance. We designed the survey to get a snapshot of the Selenium ecosystem, but no hypotheses were defined at the beginning of the process. This fact, together with the low rate of some language bindings (e.g., C#, Ruby, Groovy, and PHP), poses a generalizability problem.
6. Conclusions
The Selenium framework (made up of the projects WebDriver, Grid, and IDE) is considered by many as the de facto standard for end-to-end web testing. It has come a long way since its inception in 2004. Nowadays, the Selenium ecosystem comprises a wide range of variety of other frameworks, tools, and approaches available around the root Selenium projects.
This paper presents an effort to investigate the Selenium ecosystem. To this aim, we launched to the Selenium community a descriptive survey in 2019. In the light of results, we can see that the average Selenium tester uses Selenium WebDriver and Jenkins to drive Chrome automatically and assess the functional features of enterprise web applications. Nevertheless, in addition to this common usage, we check there is a wide variety of other elements in the Selenium ecosystem, including assertion libraries or high-level frameworks (for example, Appium or Cucumber). Besides, we discovered that Docker is already a relevant actor in Selenium. However, there is still room to generalize the use of additional parts of the ecosystem, such as driver managers (e.g., WebDriverManager) or reporting tools (e.g., Allure). The adoption of AI/ML approaches (e.g., Applitools) is still at an early stage.
We believe the results presented in this paper help to provide a deeper understanding of the development of end-to-end tests with Selenium and the relationship with its ecosystem. Nevertheless, there are still open challenges that deserve further attention. In particular, we think that the reported problems related to Selenium might outline future research directions in the browser automation space. To this aim, additional effort should be made to identify the root causes of the commons problems related to Selenium tests. In this arena, future research might help to determine the relationship of the identified problems (such as maintainability, flakiness, or troubleshooting) with specific aspects, such as the use of design patterns (e.g., POM), waiting and location strategies, or the adoption of observability mechanisms.
Finally, another aspect that might drive further research is the assessment of non-functional attributes with Selenium. Although Selenium is a framework mostly used for functional testing, our survey reveals that some practitioners also carry out non-functional testing with it. We think that future investigations about how to perform, for example, security, usability, or accessibility assessment with Selenium, might reveal novel approaches in the end-to-end testing domain.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















