Speech Enhancement Based on Fusion of Both Magnitude/Phase-Aware Features and Targets


Abstract
:1. Introduction
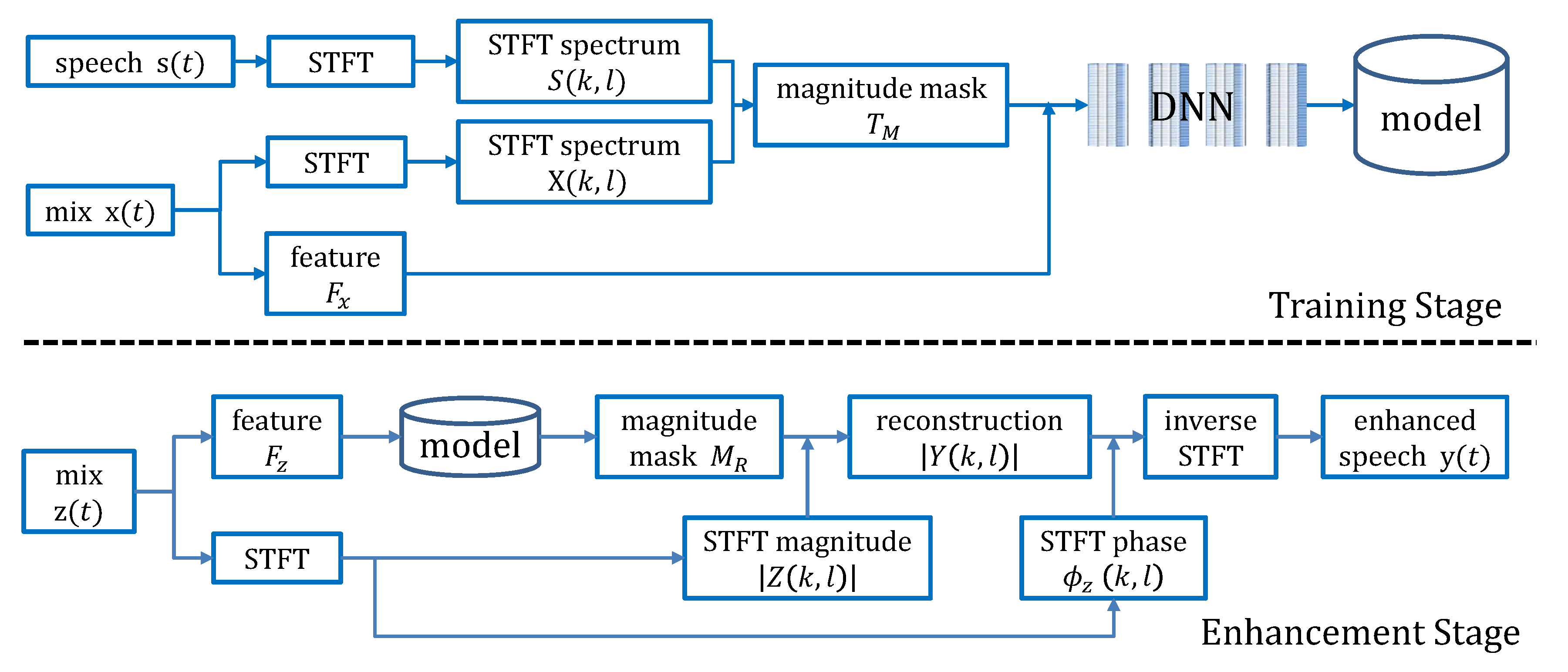
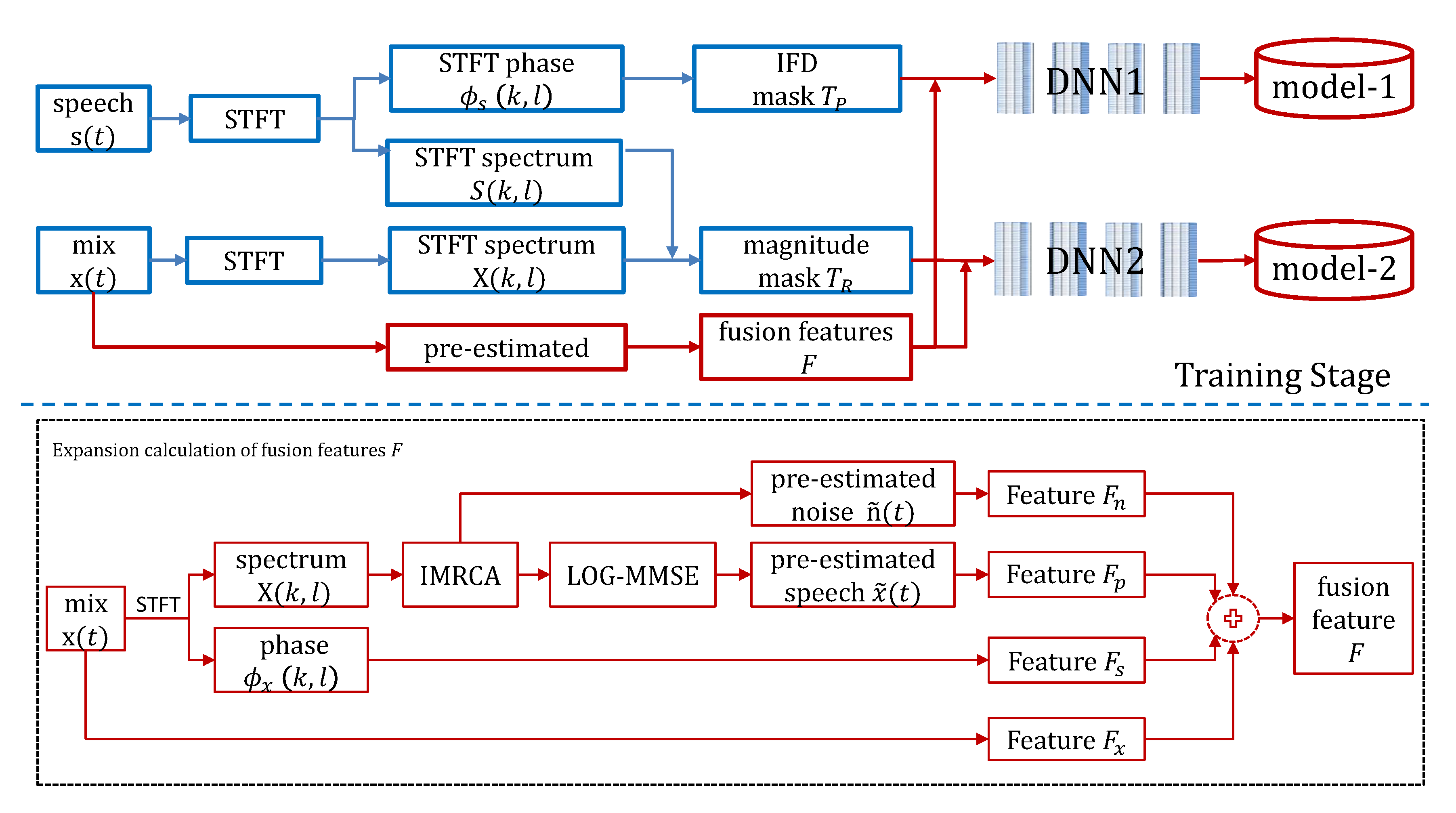
2. Proposed Method
2.1. Pre-Estimation of Noise and Speech
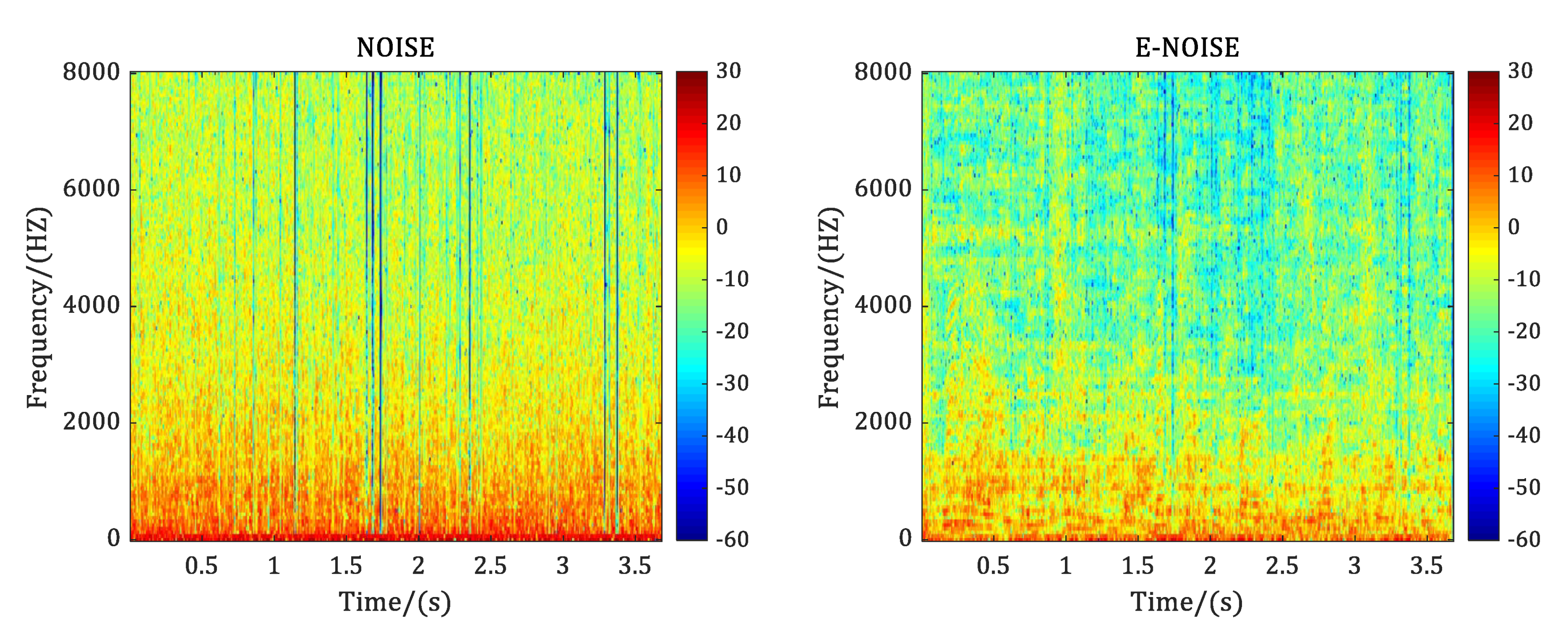
2.1.1. Noise Estimation
2.1.2. Speech Estimation
2.2. Feature Fusion
2.3. Training Target
2.4. Network Structure and Training Strategy
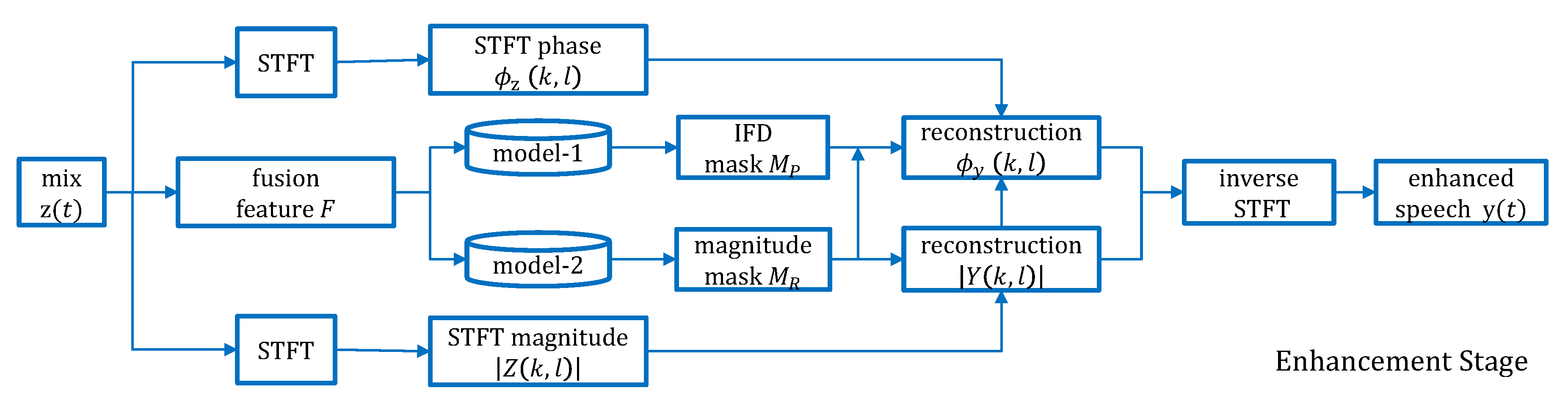
2.5. Speech Enhancement
3. Experimental Data, Comparison Methods and Evaluation Metric
3.1. Experimental Data
3.2. Comparison Methods
3.3. Evaluation Metrics
4. Experiments and Analysis
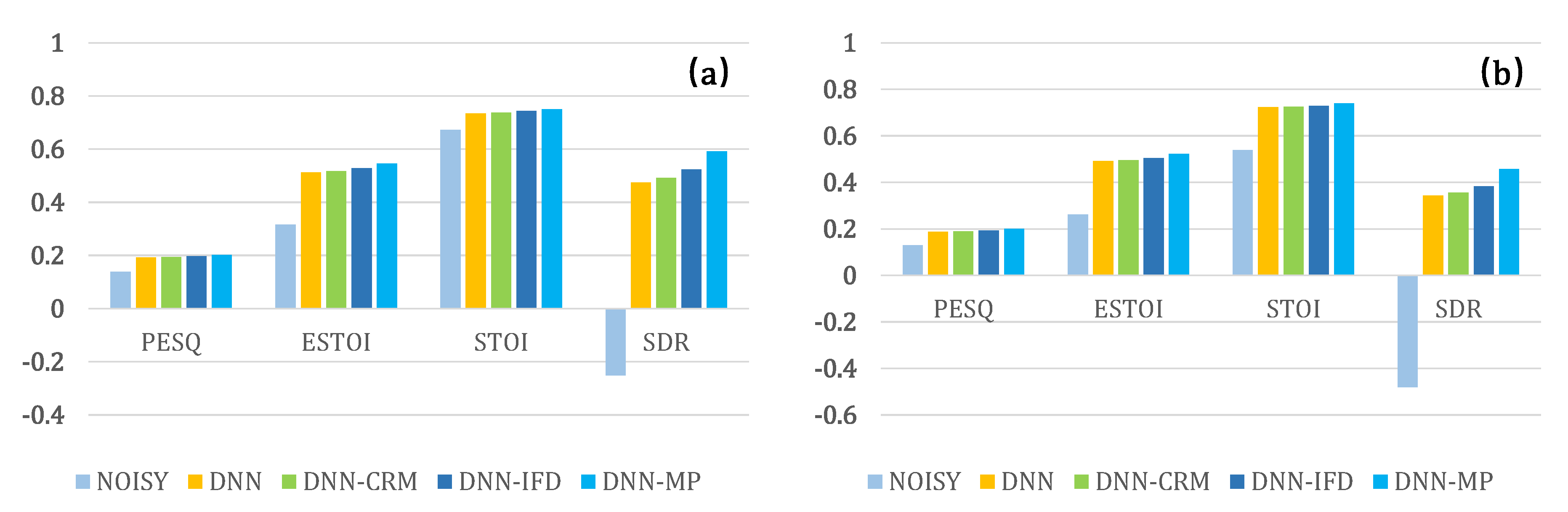
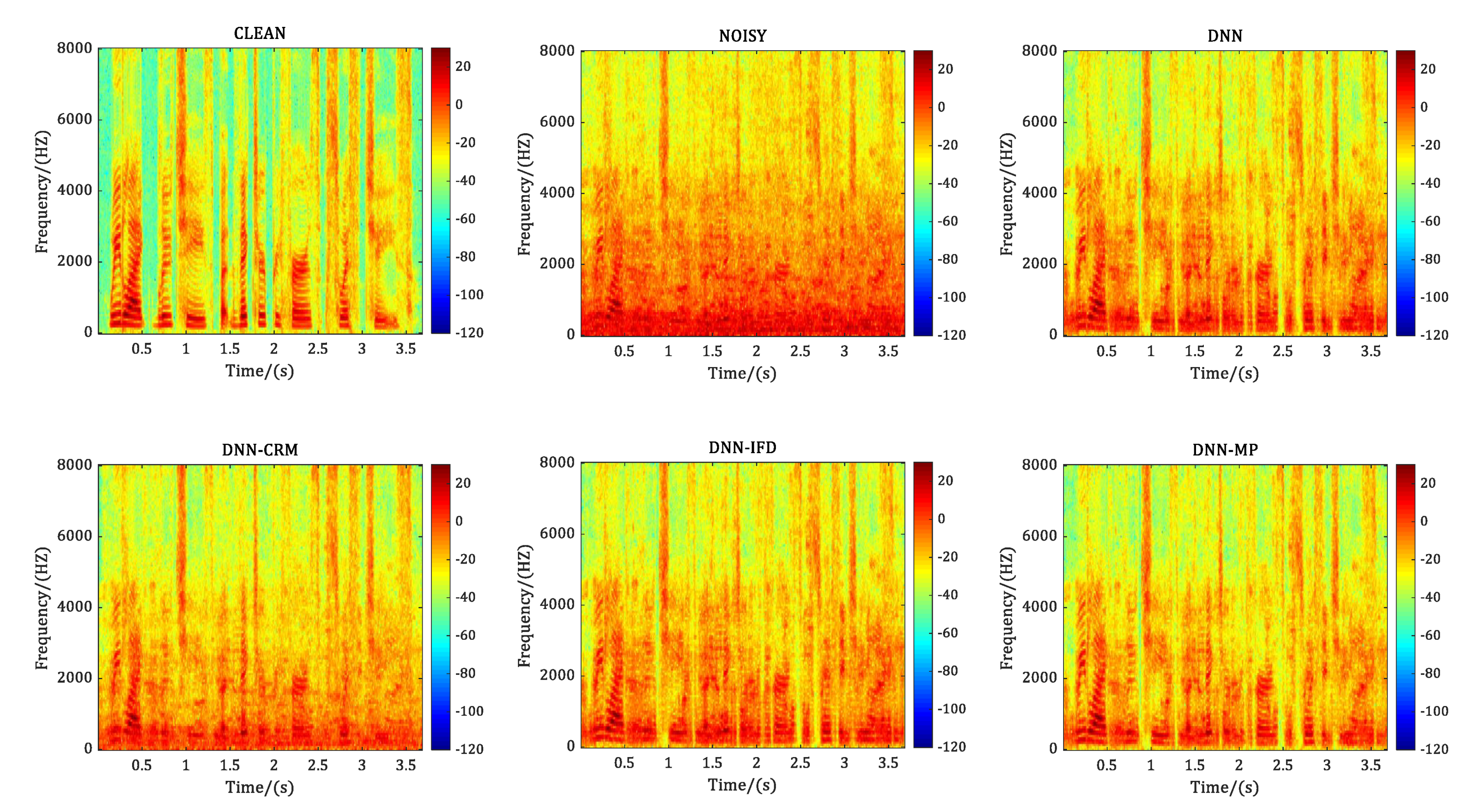
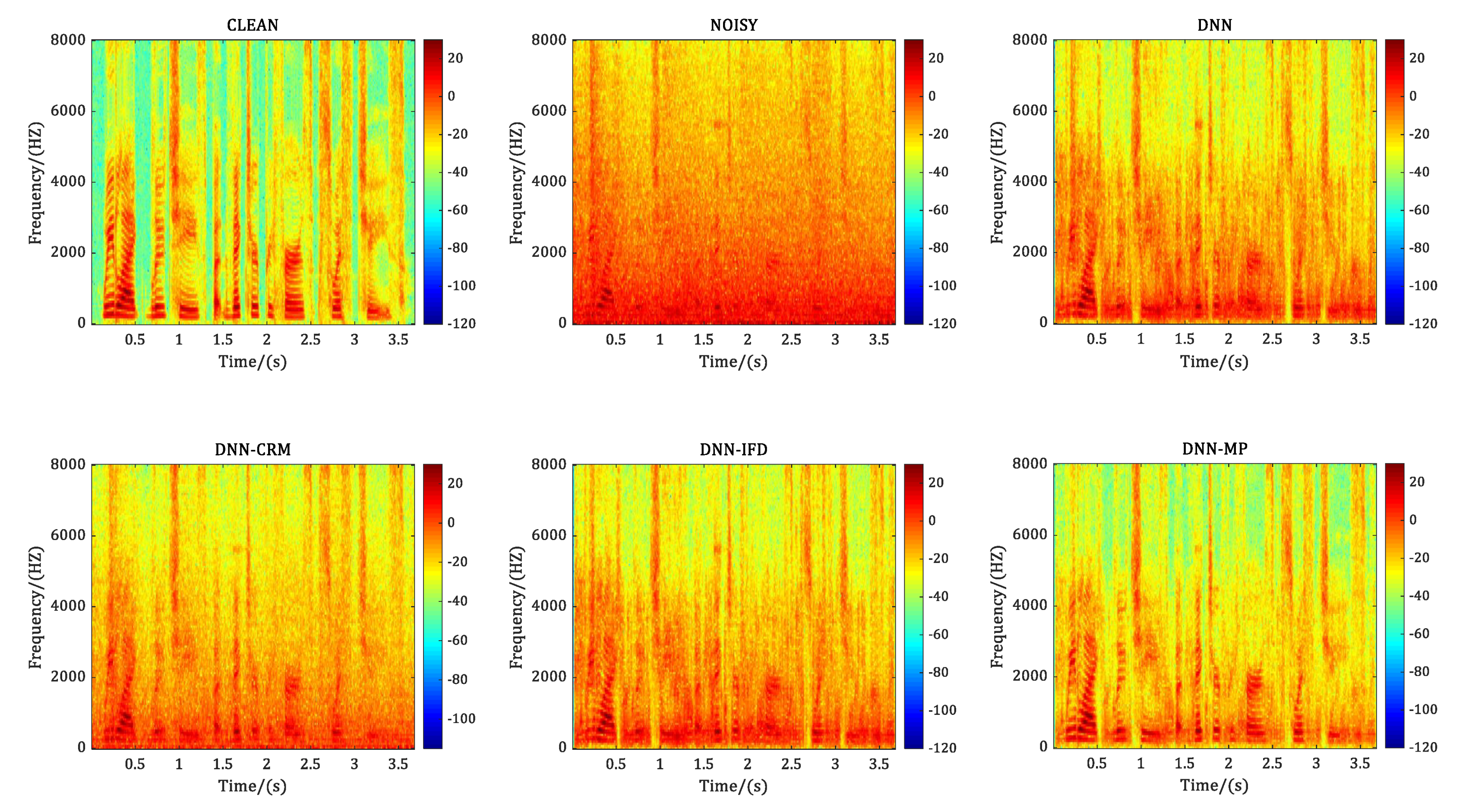
4.1. Experiment 1: Speech Enhancement Performance Comparison
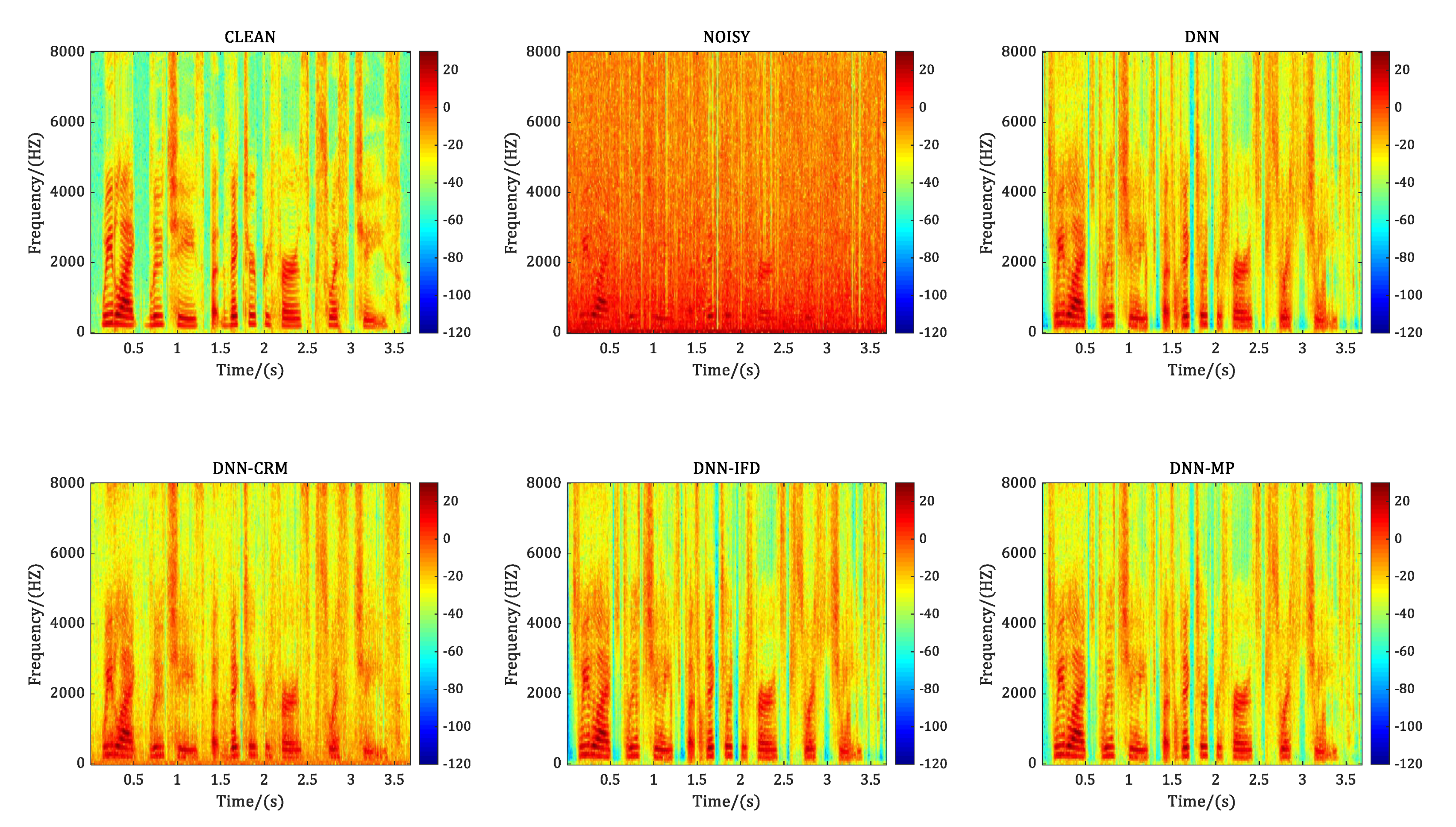
4.2. Experiment 2: Generalization Ability Evaluation on Unseen Noise
4.3. Experiment 3: Ablation Study
4.4. Experiment 4: Subjective Test by Human Listeners
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Liu, H.; Zheng, C.; Li, X. Spectral subtraction based on two-stage spectral estimation and modified cepstrum thresholding. Appl. Acoust. 2013, 74, 450–458. [Google Scholar] [CrossRef]
- Scalart, P. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; Volume 2, pp. 629–632. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef] [Green Version]
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Djendi, M.; Bendoumia, R. Improved subband-forward algorithm for acoustic noise reduction and speech quality enhancement. Appl. Soft Comput. 2016, 42, 132–143. [Google Scholar] [CrossRef]
- Ephraim, Y.; Van Trees, H.L. A signal subspace approach for speech enhancement. IEEE Trans. Speech Audio Process. 1995, 3, 251–266. [Google Scholar] [CrossRef]
- Elmaleh, K.H.; Kabal, P. Comparison of voice activity detection algorithms for wireless personal communications systems. In Proceedings of the CCECE’97. Canadian Conference on Electrical and Computer Engineering. Engineering Innovation: Voyage of Discovery. Conference Proceedings, Saint Johns, NL, Canada, 25–28 May 1997; Volume 2, pp. 470–473. [Google Scholar]
- Tucker, R. Voice activity detection using a periodicity measure. Commun. Speech Vision IEE Proc. I 1992, 139, 377–380. [Google Scholar] [CrossRef]
- Cohen, I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging. IEEE Trans. Speech Audio Process. 2003, 11, 466–475. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, D. Towards scaling up classification-based speech separation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1381–1390. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.H.; Jo, Q.H.; Kim, D.K.; Kim, N.S. Global soft decision employing support vector machine for speech enhancement. IEEE Signal Process. Lett. 2008, 16, 57–60. [Google Scholar] [CrossRef]
- Narayanan, A.; Wang, D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process. Lett. 2013, 21, 65–68. [Google Scholar] [CrossRef]
- Weninger, F.; Eyben, F.; Schuller, B. Single-channel speech separation with memory-enhanced recurrent neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3709–3713. [Google Scholar]
- Weninger, F.; Hershey, J.R.; Le Roux, J.; Schuller, B. Discriminatively trained recurrent neural networks for single-channel speech separation. In Proceedings of the 2014 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Atlanta, GA, USA, 3–5 December 2014; pp. 577–581. [Google Scholar]
- Du, J.; Tu, Y.; Dai, L.R.; Lee, C.H. A regression approach to single-channel speech separation via high-resolution deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1424–1437. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Wang, Q.; Du, J.; Dai, L.R.; Lee, C.H. A multiobjective learning and ensembling approach to high- performance speech enhancement with compact neural network architectures. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2018, 26, 1181–1193. [Google Scholar] [CrossRef]
- Zhang, X.L.; Wang, D. A deep ensemble learning method for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2016, 24, 967–977. [Google Scholar] [CrossRef]
- Brown, G.J.; Wang, D. Separation of speech by computational auditory scene analysis. In Speech Enhancement; Springer: New York, NY, USA, 2005; pp. 371–402. [Google Scholar]
- Srinivasan, S.; Roman, N.; Wang, D. Binary and ratio time-frequency masks for robust speech recognition. Speech Commun. 2006, 48, 1486–1501. [Google Scholar] [CrossRef]
- Liang, S.; Liu, W.; Jiang, W.; Xue, W. The optimal ratio time-frequency mask for speech separation in terms of the signal-to-noise ratio. J. Acoust. Soc. Am. 2013, 134, EL452–EL458. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Narayanan, A.; Wang, D. On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef] [Green Version]
- Bao, F.; Abdulla, W.H.; Bao, F.; Abdulla, W.H. A New Ratio Mask Representation for CASA-Based Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. (TASLP) 2019, 27, 7–19. [Google Scholar] [CrossRef]
- Zheng, N.; Zhang, X.L. Phase-aware speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 27, 63–76. [Google Scholar] [CrossRef]
- Stark, A.P.; Paliwal, K.K. Speech analysis using instantaneous frequency deviation. In Proceedings of the Ninth Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008. [Google Scholar]
- Wang, Y.; Han, K.; Wang, D. Exploring monaural features for classification-based speech segregation. IEEE Trans. Audio Speech Lang. Process. 2012, 21, 270–279. [Google Scholar] [CrossRef] [Green Version]
- Kim, G.; Lu, Y.; Hu, Y.; Loizou, P.C. An algorithm that improves speech intelligibility in noise for normal-hearing listeners. J. Acoust. Soc. Am. 2009, 126, 1486–1494. [Google Scholar] [CrossRef] [Green Version]
- Hermansky, H.; Morgan, N. RASTA processing of speech. IEEE Trans. Speech Audio Process. 1994, 2, 578–589. [Google Scholar] [CrossRef] [Green Version]
- Shao, Y.; Wang, D. Robust speaker identification using auditory features and computational auditory scene analysis. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 1589–1592. [Google Scholar]
- Shao, Y.; Jin, Z.; Wang, D.; Srinivasan, S. An auditory-based feature for robust speech recognition. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 4625–4628. [Google Scholar]
- Paliwal, K.; Wójcicki, K.; Shannon, B. The importance of phase in speech enhancement. Speech Commun. 2011, 53, 465–494. [Google Scholar] [CrossRef]
- Mowlaee, P.; Saeidi, R.; Stylianou, Y. Advances in phase-aware signal processing in speech communication. Speech Commun. 2016, 81, 1–29. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon Tech. Rep. N. 1993, 93, 27403. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 443–445. [Google Scholar] [CrossRef]
- Cohen, I. On the decision-directed estimation approach of Ephraim and Malah. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, pp. 1–293. [Google Scholar]
- Loizou, P.C. Speech enhancement based on perceptually motivated Bayesian estimators of the magnitude spectrum. IEEE Trans. Speech Audio Process. 2005, 13, 857–869. [Google Scholar] [CrossRef]
- Friedman, D. Instantaneous-frequency distribution vs. time: An interpretation of the phase structure of speech. In Proceedings of the ICASSP’85. IEEE International Conference on Acoustics, Speech, and Signal Processing, Tampa, FL, USA, 26–29 April 1985; Volume 10, pp. 1121–1124. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time– frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Jensen, J.; Taal, C.H. An algorithm for predicting the intelligibility of speech masked by modulated noise maskers. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 2009–2022. [Google Scholar] [CrossRef]
- Vincent, E.; Gribonval, R.; Févotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
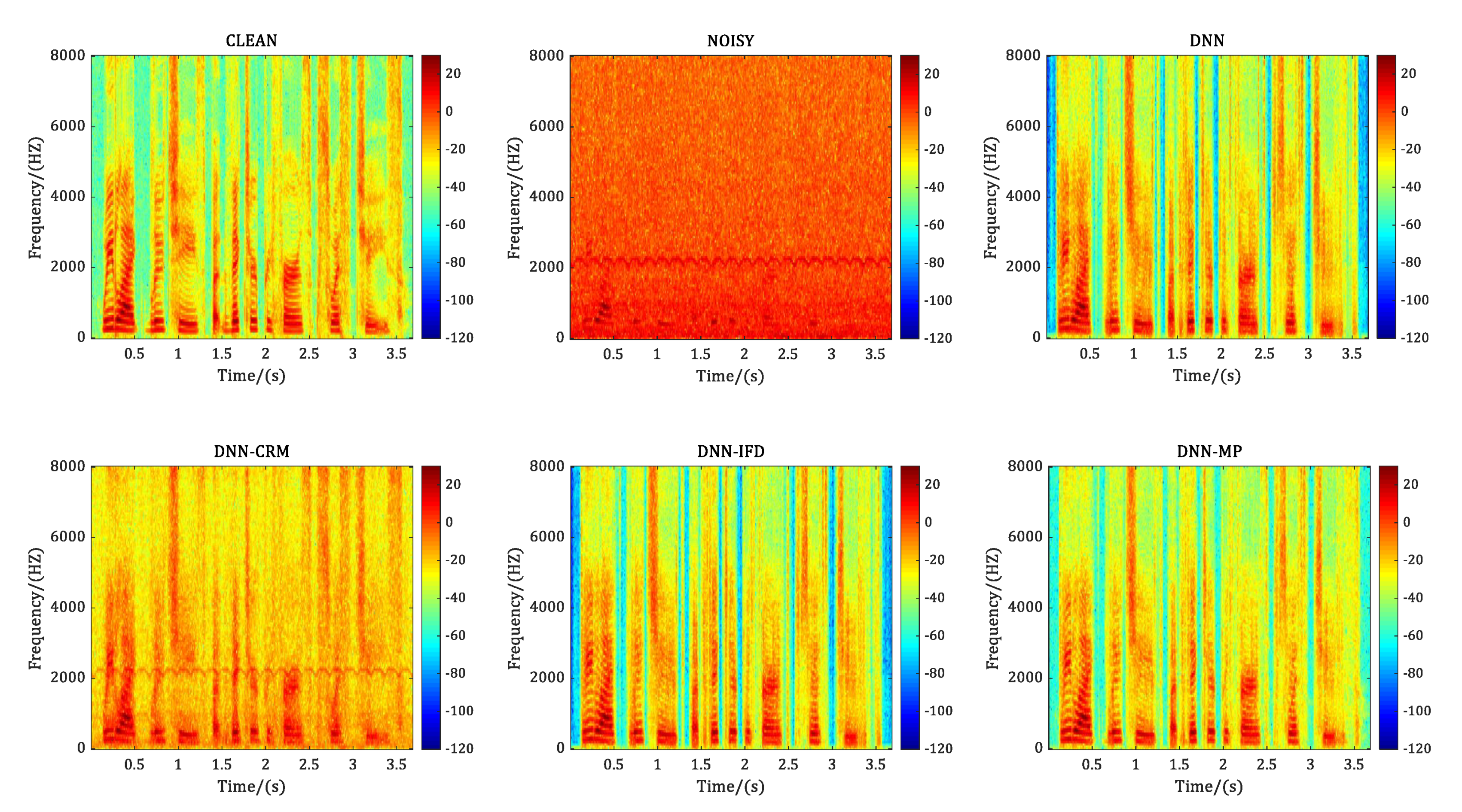{kind=link}
| SNR | Method | Babble | Factory1 | Factory2 | Buccaneer1 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PESQ | ESTOI | STOI | SDR | PESQ | ESTOI | STOI | SDR | PESQ | ESTOI | STOI | SDR | PESQ | ESTOI | STOI | SDR | ||
| NOISY | 1.42 | 0.273 | 0.547 | −4.81 | 1.29 | 0.254 | 0.534 | −4.80 | 1.31 | 0.293 | 0.548 | −4.81 | 1.19 | 0.226 | 0.526 | −4.81 | |
| DNN | 1.62 | 0.419 | 0.643 | 0.35 | 1.70 | 0.427 | 0.671 | 2.41 | 2.13 | 0.591 | 0.798 | 5.94 | 2.08 | 0.529 | 0.779 | 5.00 | |
| −5 dB | DNN-CRM | 1.63 | 0.420 | 0.645 | 0.40 | 1.71 | 0.431 | 0.675 | 2.52 | 2.14 | 0.596 | 0.801 | 6.13 | 2.10 | 0.534 | 0.783 | 5.19 |
| DNN-IFD | 1.64 | 0.425 | 0.646 | 0.54 | 1.74 | 0.442 | 0.682 | 2.94 | 2.21 | 0.606 | 0.806 | 6.31 | 2.14 | 0.542 | 0.785 | 5.53 | |
| DNN-MP | 1.75 | 0.455 | 0.662 | 1.41 | 1.83 | 0.460 | 0.688 | 3.55 | 2.27 | 0.621 | 0.815 | 7.18 | 2.22 | 0.561 | 0.792 | 6.18 | |
| NOISY | 1.55 | 0.319 | 0.596 | −2.85 | 1.42 | 0.308 | 0.580 | −2.85 | 1.45 | 0.345 | 0.600 | −2.86 | 1.30 | 0.275 | 0.571 | −2.86 | |
| DNN | 1.81 | 0.483 | 0.703 | 2.43 | 1.87 | 0.495 | 0.724 | 4.31 | 2.28 | 0.638 | 0.827 | 7.36 | 2.24 | 0.583 | 0.808 | 6.35 | |
| −3 dB | DNN-CRM | 1.82 | 0.488 | 0.707 | 2.55 | 1.89 | 0.502 | 0.728 | 4.46 | 2.30 | 0.646 | 0.832 | 7.55 | 2.26 | 0.595 | 0.810 | 6.67 |
| DNN-IFD | 1.84 | 0.495 | 0.709 | 2.71 | 1.93 | 0.510 | 0.731 | 4.75 | 2.35 | 0.651 | 0.835 | 7.81 | 2.31 | 0.601 | 0.812 | 6.91 | |
| DNN-MP | 1.93 | 0.503 | 0.714 | 3.57 | 1.97 | 0.529 | 0.737 | 5.32 | 2.41 | 0.663 | 0.844 | 8.07 | 2.34 | 0.619 | 0.819 | 7.54 | |
| NOISY | 1.74 | 0.397 | 0.665 | 0.10 | 1.62 | 0.385 | 0.653 | 0.10 | 1.67 | 0.431 | 0.676 | 0.10 | 1.49 | 0.358 | 0.644 | 0.10 | |
| DNN | 2.08 | 0.581 | 0.781 | 5.43 | 1.87 | 0.495 | 0.724 | 4.31 | 2.50 | 0.704 | 0.864 | 9.46 | 2.48 | 0.659 | 0.847 | 8.35 | |
| 0 dB | DNN-CRM | 2.10 | 0.589 | 0.785 | 5.58 | 1.88 | 0.507 | 0.729 | 4.77 | 2.52 | 0.711 | 0.870 | 9.66 | 2.50 | 0.667 | 0.851 | 8.62 |
| DNN-IFD | 2.14 | 0.592 | 0.789 | 5.82 | 1.93 | 0.512 | 0.732 | 4.82 | 2.59 | 0.723 | 0.873 | 9.83 | 2.56 | 0.675 | 0.855 | 8.78 | |
| DNN-MP | 2.23 | 0.610 | 0.806 | 6.71 | 2.03 | 0.531 | 0.740 | 5.64 | 2.65 | 0.739 | 0.883 | 10.74 | 2.66 | 0.686 | 0.859 | 9.14 | |
| PESQ | ESTOI | STOI | SDR | |
|---|---|---|---|---|
| DNN | 1.19 | 0.182 | 0.607 | −3.69 |
| DNN-CRM | 1.26 | 0.201 | 0.631 | −0.637 |
| DNN-IFD | 1.34 | 0.245 | 0.653 | −0.829 |
| DNN-MP | 1.37 | 0.249 | 0.661 | 1.37 |
| PESQ | ESTOI | STOI | SDR | |
|---|---|---|---|---|
| DNN-MP | 2.22 | 0.561 | 0.792 | 6.18 |
| 2.21 | 0.561 | 0.790 | 6.21 | |
| 2.17 | 0.557 | 0.788 | 5.81 | |
| 2.15 | 0.550 | 0.787 | 5.79 | |
| 2.16 | 0.556 | 0.787 | 5.82 | |
| 2.15 | 0.549 | 0.786 | 5.80 | |
| 2.12 | 0.542 | 0.783 | 5.61 |
| PESQ | ESTOI | STOI | SDR | |
|---|---|---|---|---|
| NOISY | 1.19 | 0.226 | 0.526 | −4.81 |
| DNN-M | 2.13 | 0.544 | 0.783 | 5.46 |
| DNN-MP | 2.22 | 0.561 | 0.792 | 6.18 |
| 24 | 28 | 36 | 74 | 136 | 155 | 163 | 172 | 179 | 207 | 234 | 235 | 239 | 267 | 306 | 321 | 377 | 391 | 398 | 400 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ∆ | ∆ | ∆ | ◊ | ∆ | ∆ | ◊ | ∆ | ◊ | ◊ | ∆ | ∆ | ◊ | ◊ |
| S2 | ∆ | ◊ | ∆ | ∆ | ∆ | ∆ | ◊ | ∆ | ◊ | ◊ | ∆ | ∆ | ∆ | ◊ | ∆ | ◊ | ∆ | ∆ | ∆ | ∆ |
| S3 | ∆ | ◊ | ∆ | ◊ | ∆ | ☐ | ◊ | ◊ | ∆ | ∆ | ◊ | ∆ | ◊ | ◊ | ◊ | ∆ | ∆ | ◊ | ∆ | ∆ |
| S4 | ☐ | ☐ | ∆ | ☐ | ☐ | ◊ | ◊ | ◊ | ☐ | ◊ | ☐ | ☐ | ☐ | ◊ | ♡ | ◊ | ☐ | ◊ | ♡ | ◊ |
| S5 | ∆ | ◊ | ◊ | ◊ | ∆ | ∆ | ∆ | ☐ | ∆ | ◊ | ∆ | ∆ | ◊ | ∆ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ |
| S6 | ◊ | ◊ | ∆ | ◊ | ∆ | ◊ | ∆ | ☐ | ◊ | ∆ | ∆ | ∆ | ◊ | ◊ | ◊ | ◊ | ◊ | ∆ | ∆ | ∆ |
| S7 | ☐ | ☐ | ∆ | ∆ | ☐ | ∆ | ∆ | ☐ | ∆ | ∆ | ∆ | ∆ | ◊ | ∆ | ∆ | ☐ | ∆ | ☐ | ☐ | ∆ |
| S8 | ◊ | ◊ | ◊ | ☐ | ☐ | ◊ | ☐ | ◊ | ☐ | ☐ | ☐ | ☐ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ☐ | ◊ |
| S9 | ☐ | ☐ | ☐ | ◊ | ☐ | ☐ | ☐ | ◊ | ◊ | ☐ | ☐ | ☐ | ☐ | ☐ | ◊ | ◊ | ◊ | ☐ | ◊ | ☐ |
| S10 | ◊ | ☐ | ☐ | ☐ | ∆ | ☐ | ◊ | ∆ | ☐ | ☐ | ◊ | ∆ | ∆ | ☐ | ☐ | ☐ | ☐ | ∆ | ◊ | ☐ |
| S11 | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ◊ | ☐ | ☐ | ☐ | ◊ | ☐ | ∆ | ◊ | ☐ | ☐ | ♡ | ♡ | ♡ |
| S12 | ♡ | ☐ | ☐ | ◊ | ♡ | ☐ | ◊ | ◊ | ☐ | ◊ | ♡ | ♡ | ☐ | ◊ | ♡ | ☐ | ◊ | ☐ | ☐ | ◊ |
| S13 | ☐ | ☐ | ◊ | ∆ | ∆ | ∆ | ☐ | ◊ | ◊ | ∆ | ∆ | ☐ | ∆ | ◊ | ∆ | ◊ | ∆ | ∆ | ∆ | ☐ |
| S14 | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ∆ | ◊ | ◊ | ∆ | ◊ | ∆ | ◊ | ◊ | ◊ | ∆ | ◊ | ∆ | ◊ |
| S15 | ◊ | ◊ | ∆ | ☐ | ♡ | ∆ | ◊ | ☐ | ∆ | ◊ | ∆ | ◊ | ∆ | ∆ | ∆ | ◊ | ∆ | ∆ | ◊ | ∆ |
| S16 | ☐ | ◊ | ◊ | ◊ | ◊ | ☐ | ◊ | ☐ | ◊ | ◊ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ |
| S17 | ☐ | ☐ | ◊ | ☐ | ☐ | ☐ | ◊ | ♡ | ◊ | ☐ | ☐ | ♡ | ☐ | ☐ | ☐ | ☐ | ◊ | ☐ | ◊ | ☐ |
| S18 | ◊ | ☐ | ◊ | ◊ | ◊ | ☐ | ☐ | ◊ | ◊ | ◊ | ☐ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ |
| S19 | ☐ | ☐ | ◊ | ◊ | ☐ | ☐ | ☐ | ◊ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ |
| S20 | ◊ | ◊ | ☐ | ∆ | ∆ | ☐ | ◊ | ☐ | ♡ | ◊ | ∆ | ♡ | ☐ | ☐ | ◊ | ☐ | ☐ | ☐ | ◊ | ∆ |
| S21 | ☐ | ☐ | ◊ | ☐ | ∆ | ☐ | ∆ | ☐ | ☐ | ☐ | ∆ | ∆ | ◊ | ∆ | ☐ | ☐ | ∆ | ∆ | ∆ | ☐ |
| S22 | ♡ | ∆ | ∆ | ☐ | ♡ | ♡ | ∆ | ∆ | ◊ | ♡ | ♡ | ∆ | ♡ | ♡ | ∆ | ♡ | ∆ | ♡ | ∆ | ∆ |
| S23 | ☐ | ◊ | ☐ | ☐ | ◊ | ☐ | ☐ | ☐ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ☐ | ◊ | ☐ | ◊ |
| S24 | ◊ | ◊ | ☐ | ◊ | ☐ | ☐ | ☐ | ☐ | ◊ | ☐ | ∆ | ∆ | ◊ | ☐ | ∆ | ☐ | ☐ | ☐ | ☐ | ♡ |
| S25 | ☐ | ◊ | ☐ | ∆ | ◊ | ∆ | ☐ | ☐ | ♡ | ☐ | ☐ | ☐ | ☐ | ◊ | ☐ | ☐ | ☐ | ☐ | ☐ | ☐ |
| S26 | ◊ | ☐ | ◊ | ☐ | ◊ | ☐ | ♡ | ◊ | ∆ | ♡ | ∆ | ∆ | ∆ | ◊ | ◊ | ◊ | ☐ | ∆ | ∆ | ♡ |
| S27 | ☐ | ◊ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ∆ | ◊ |
| S28 | ∆ | ∆ | ∆ | ∆ | ♡ | ∆ | ∆ | ∆ | ♡ | ◊ | ♡ | ♡ | ∆ | ♡ | ♡ | ♡ | ♡ | ◊ | ∆ | ∆ |
| S29 | ∆ | ☐ | ☐ | ∆ | ☐ | ☐ | ∆ | ∆ | ∆ | ☐ | ∆ | ☐ | ∆ | ∆ | ☐ | ∆ | ∆ | ☐ | ∆ | ∆ |
| S30 | ∆ | ∆ | ∆ | ∆ | ☐ | ∆ | ∆ | ☐ | ☐ | ∆ | ∆ | ☐ | ☐ | ∆ | ☐ | ☐ | ∆ | ∆ | ∆ | ∆ |
| S31 | ◊ | ☐ | ☐ | ◊ | ☐ | ◊ | ☐ | ◊ | ◊ | ☐ | ☐ | ☐ | ☐ | ◊ | ☐ | ◊ | ☐ | ◊ | ◊ | ♡ |
| S32 | ◊ | ◊ | ∆ | ☐ | ∆ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ | ☐ | ◊ | ∆ | ∆ | ◊ | ☐ | ∆ | ☐ | ◊ |
| S33 | ◊ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ☐ | ◊ | ◊ | ◊ |
| S34 | ∆ | ☐ | ∆ | ◊ | ☐ | ☐ | ∆ | ◊ | ◊ | ∆ | ☐ | ◊ | ☐ | ∆ | ◊ | ☐ | ∆ | ☐ | ◊ | ◊ |
| S35 | ◊ | ◊ | ◊ | ◊ | ☐ | ☐ | ☐ | ◊ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ | ◊ |
| S36 | ∆ | ◊ | ◊ | ◊ | ∆ | ◊ | ☐ | ◊ | ☐ | ◊ | ◊ | ☐ | ◊ | ☐ | ◊ | ◊ | ◊ | ◊ | ☐ | ☐ |
| 24 | 28 | 36 | 74 | 136 | 155 | 163 | 172 | 179 | 207 | 234 | 235 | 239 | 267 | 306 | 321 | 377 | 391 | 398 | 400 | Sum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DNN | 2 | 0 | 0 | 0 | 4 | 1 | 1 | 1 | 3 | 2 | 3 | 4 | 1 | 2 | 3 | 2 | 1 | 2 | 2 | 4 | 38 |
| DNN-CRM | 9 | 4 | 13 | 10 | 12 | 10 | 8 | 8 | 8 | 7 | 15 | 13 | 9 | 11 | 8 | 3 | 13 | 11 | 12 | 11 | 193 |
| DNN-IFD | 11 | 15 | 10 | 10 | 12 | 17 | 15 | 11 | 10 | 12 | 10 | 13 | 12 | 8 | 9 | 12 | 12 | 9 | 9 | 8 | 225 |
| DNN-MP | 14 | 17 | 13 | 16 | 8 | 8 | 12 | 16 | 15 | 15 | 8 | 7 | 14 | 15 | 16 | 19 | 10 | 14 | 13 | 14 | 264 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lang, H.; Yang, J. Speech Enhancement Based on Fusion of Both Magnitude/Phase-Aware Features and Targets. Electronics 2020, 9, 1125. https://doi.org/10.3390/electronics9071125
Lang H, Yang J. Speech Enhancement Based on Fusion of Both Magnitude/Phase-Aware Features and Targets. Electronics. 2020; 9(7):1125. https://doi.org/10.3390/electronics9071125
Chicago/Turabian StyleLang, Haitao, and Jie Yang. 2020. "Speech Enhancement Based on Fusion of Both Magnitude/Phase-Aware Features and Targets" Electronics 9, no. 7: 1125. https://doi.org/10.3390/electronics9071125
APA StyleLang, H., & Yang, J. (2020). Speech Enhancement Based on Fusion of Both Magnitude/Phase-Aware Features and Targets. Electronics, 9(7), 1125. https://doi.org/10.3390/electronics9071125