1. Introduction
Cloud computing has provided numerous features such as on-demand services, resilience to security attacks, and ubiquity to many fields in enterprise networks [
1,
2,
3]. Usually, Small and Medium Enterprises (SMEs) put their workload on the cloud, and it is estimated that 83% of total business will be on cloud reaching up to
$411 billion of market value [
4]. Security and privacy of data have always been the ever-growing and prime issue in cloud computing models and services. In 2018, the Massachusetts Institute of Technology (MIT) forecast that the ransomware would be the prevalent cyber threat in cloud computing [
5]. In the cloud environment, the logs are the first and significant piece of evidence for digital forensic investigations. To secure the log data in cloud storage, the existing cloud logging schemes use encryption; thus, the validity of logs becomes uncertain in the presence of an adversary and a malicious Cloud Service Provider (CSP) [
6].
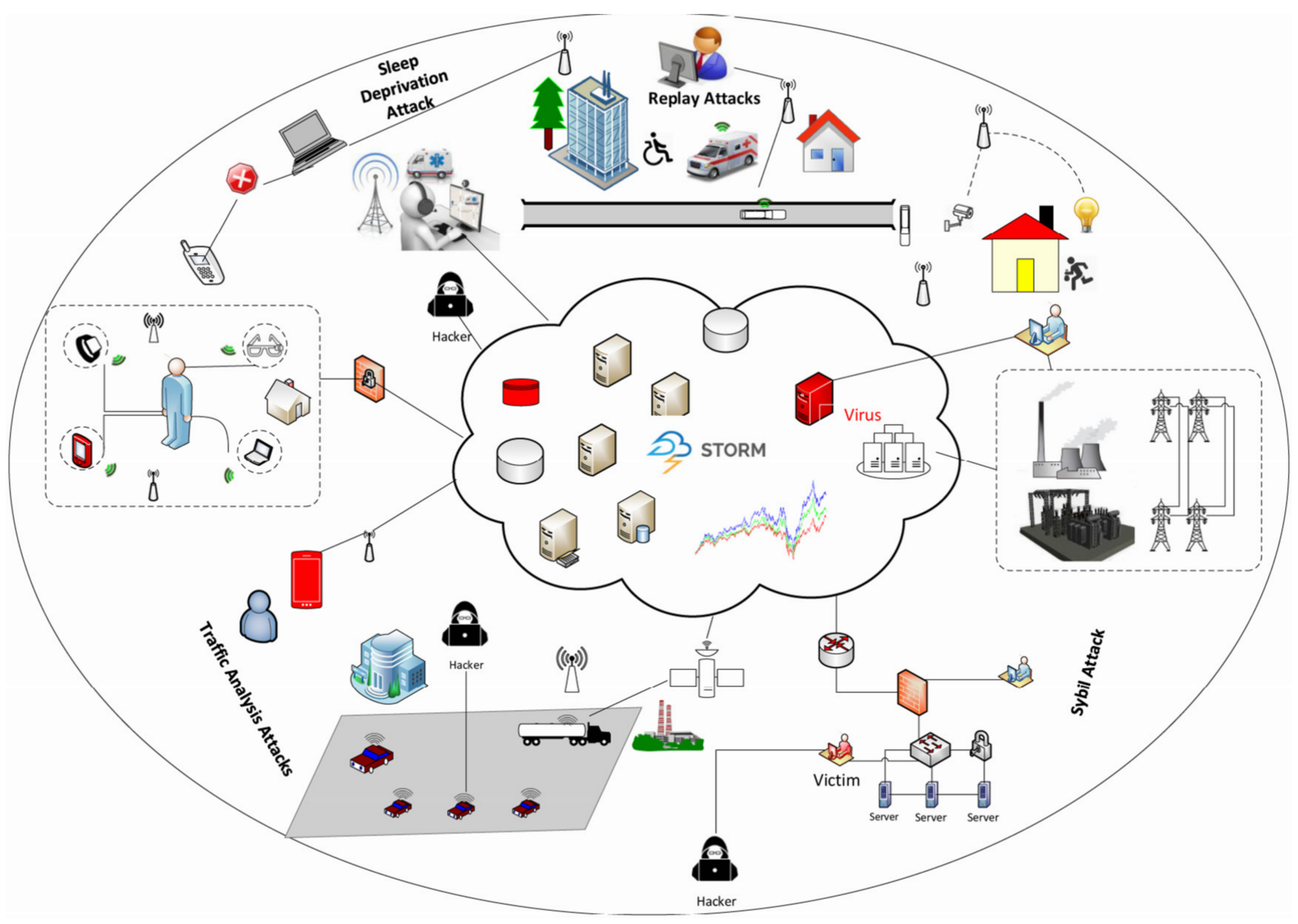
The ubiquity, smartness, and communication abilities of the Internet of Things (IoT) devices coupled with cloud, provide tremendous assistance in healthcare, industrial control systems, smart homes, and transportation [
7,
8,
9]. As signposted by CISCO, the estimation of IoT revenue will be approximately
$14.4 trillion between 2013 to 2022. On the other hand, security and privacy threats such as disruption of IoT networks, Denial of Service (DoS) attacks, and traffic analysis attacks are the main problems in the digital investigation in a cyber-crime scene [
10,
11]. An illustration of security trepidation in IoT-based smart environments as shown in
Figure 1.
Cloud-connected IoT edge nodes are fragile on security management as they are geographically distributed from the cloud, which makes it easy for an adversary to launch an attack and remove the logs [
12,
13]. Moreover, edge nodes are not energy efficient and have potential problems for continuous log collection and preservation [
14]. For instance, malicious users, attackers, edge-nodes, and the attacks of the rogue gateway and the rogue data center may be disguised as regular fogs between the data center and the users [
15,
16]. In May 2018, an IoT system with routers, surveillance cameras, and digital video recorders was disabled for four days after an attempt was made to hinder the service. There are many intrusion attempts at these service endpoints and the processing of forensic data are critical for ensuring the protection of endpoints and for resolving protection accidents.
Digital forensics has become more relevant in the fog cloud because fog nodes and edge nodes are targeted [
17]. As a consequence, digital experts need a fog-cloud forensic data collection method, as attackers capture, exploit and remove the fog nodes, boundary nodes and the computers, rendering the processing of forensic data from fog nodes impossible [
18]. Furthermore, the data of IoT devices are updating with time and, if a crime occurs using these devices, the attacker always intends to remove the traces of logs that are sent to virtual machines in clouds [
19,
20]. Therefore, a logging scheme is required to collect log data without CSP cooperation.
In case of a crime, sometimes it is not possible to separate and shut down the victim device and to carry it to the evidence extraction laboratory as it is done in traditional digital forensic scenes in which the investigator gets the equipment to obtain evidence [
21]. Consider an example in which an attack is launched on an IoT device, the device is forcefully shut down and the volatile data of forensic significance are lost and there is no way to reconstruct the incident. Therefore, IoT forensics need to collect and retain useful knowledge for forensic purposes proactively. This will improve the forensic capability of the environment and will reduce the cost of incident responses [
11]. Logging applications must define and solve these issues in fog-cloud environments.
Recently, the fog-cloud computing paradigm has been proposed, which offers different tools that focus on the advantages of fog computation [
22]. In one of the top 10 strategic technical developments in 2018, Gartner has classified “fog cloud” as “fog driven”. The implementation of the fog cloud model demands more efforts to upgrade the network, expand network availability, increase network efficiency, and get services closer to the consumer in a cost-effective manner [
23]. Customer facilities are less safe and less efficient in the edge-cloud than the cloud structures. The reason is that a fog node is more user-appropriate than the edge-cloud.
Fog computing expands the computing and storing properties of cloud computing for the network edge which is a reasonable solution that provides low-latency via computational offloading. To avoid delay in edge cloud network communication, fog assisted IoT network is used to assign the tasks. This is done through computation offloading which lessen the load of the core network [
24,
25]. Moreover, it delivers short delay services, particularly for those computation-exhaustive and delay-sensitive jobs. Conversely, fog nodes also face constrained computing resources paralleled to the cloud. Therefore, fog node auxiliary offloads the task complexity to the cloud to attain supplementary computing resources. This mutually enhances the computing and communication resources in fog edge and cloud nodes [
26,
27].
Nonetheless, considering that the fog-enabled cloud edge security and privacy design and specifications have not been described explicitly, it is recommended that a fog enabled cloud framework should be used for security services before the deployment of the forensic logging mechanism [
28]. Unlike a traditional cloud provider, fog-cloud systems are provided with fog nodes.
The following theoretical situation can demonstrate the particular problem that we anticipate to solve: An IoT edge node connects directly to the cloud and send its statistics for analytics. The attacker launches an attack to edge device for two purposes: (i) compromise the edge device and use it as a bridge to get into the cloud and launch a bigger attack; (ii) delete the log information of edge device or make it dead so none of the digital assets can be retrieved for forensics reincarnation.
In this research, we propose a Proactive Forensics in IoT, Privacy-Aware Log-preservation Architecture in Fog-enabled-cloud using Holochain and Containerization Technologies (PLAF). The proposed architecture introduced the holistic log preservation scheme which ensures the security and privacy of logs generated by IoT devices by considering the features of the fog-cloud. The salient features of the proposed PLAF are; Log preservation via ensuring log integrity, log verifiability, log provenance, and temper resistance, Privacy preservation automation through automated log collection and Tackling multi-stakeholder problem via assuring ownership non-repudiation and trust admissibility. All the aforementioned features are incorporated into the three-layered architecture of PLAF that are; Layer 1: Dedicated for Log generation and collection Layer; Layer 2: Performs log preservation task at fog level and Layer 3: Secure enclave at the cloud to securely store logs data and preserve proof of past logs. We have implemented the test-bed comprising of these three layers using different state-of-the-art technologies, which are: C&C (command and control) bots for autonomous log collection, Docker containers to orchestrate the IoT microservices, and Holochain for preservation.
Our Contributions
We propose an architecture for continuous log collection and preservation for IoT devices in a fog enabled cloud environment for proactive forensic aware logging. Moreover, the proposed PLAF architecture performs the forensic aware logging and considers automated, secure, and privacy concerned distributed edge node log collection in fog-cloud by tackling the multi-stakeholder collusion problem. The contributions to the proposed scheme are as follows:
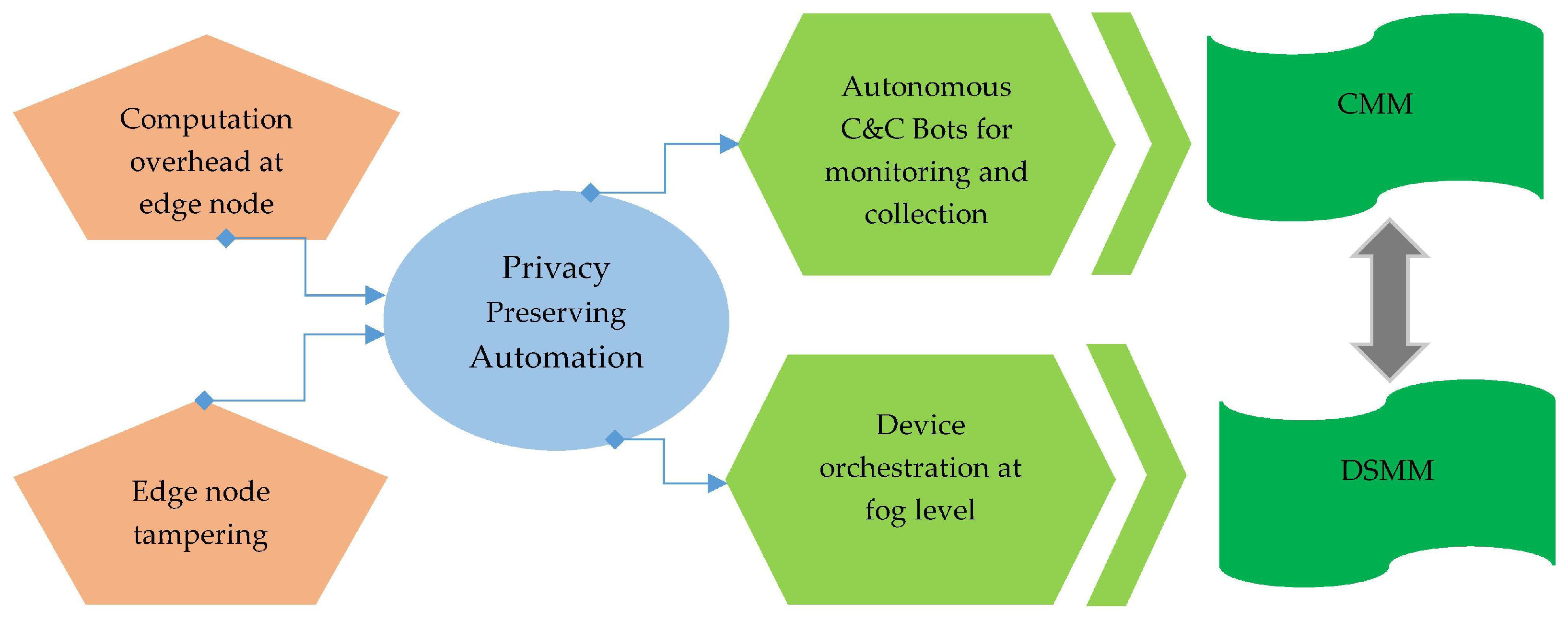
Privacy-Preserving Automation: For continuous and automated log collection, we used non-malicious botnets at fog level which provides the Privacy-Preserving Automation for IoT environment.
Proof of past log (PPL) preservation at fog level via Holochain: Preserving log integrity, privacy, provenance trust admissibility via Holochain distributed network instead of blockchain which is a more power-consuming approach.
Secure session management and log storage for log validation and verification are done via SSL mutual authentication with curve25519 and Paillier homomorphic encryption, respectively.
The organization of the paper is as follows:
Section 2 discusses related work and background studies;
Section 3 defines the threat model and threat scenarios,
Section 4 demonstrates the proposed PLAF architecture,
Section 7 concludes the paper and outlines plans for future work.
2. Related Work
The existing research proposes many solutions such as web-based management console and read-only API to secure logs for the reliable and efficient forensic process. However, the proposed schemes do not ensure the integrity and confidentiality when CSP is not trustworthy. Some other schemes provided the integrity privacy of preserved logs from the external attacker but failed to provide integrity and confidentiality when the logger itself is untrustworthy or a malicious user. The inevitability of honest and reliable log in the digital investigation is crucial. These issues have been investigated by the researchers in different dimensions.
Logging is a continuous process that keeps a record of each event occurred in the framework. This includes both the equipment and the programming part where numerous records are alluded to as log documents. The reason for log documents varies due to the nature of the product and the application that creates the occasions. Despite adaptation to non-critical failure, logs are a fundamental part of security control and advanced investigations as they can help the associations to identify incidents, security infringement, and noxious exercises.
A log securing scheme is given in [
29] which depends on the security logs in the operating system. They used eucalyptus to set up their cloud environment and snort for IP tracing. They examine the performance of eucalyptus components after launching a DDoS attack on the cloud storage using the virtual machines that reside in cloud storage. As a result, they successfully identified the IP of attacking machines, the locks requested by the attacker, and the type of browser used. A management module called a cloud forensic module was implemented in the cloud infrastructure. The purpose of this module is to connect with the kernel, for example, a system call provides access to the network stack and virtual file system to obtain the logs of the machine. The limitation in his work is that the privacy and availability of the required logs haven’t been validated [
30].
The problem is the infrastructure layer needs modification so Ref. [
31] provides a secure logging scheme for cloud infrastructure. The main feature of this work is to provide access logs such as network process logs of read-only API through CSP. Another scheme was proposed in [
32] and implemented in FROST; however, this scheme failed to show how to protect the integrity and privacy of users log such as instigators and CSP. Another game based logging scheme was presented in [
33] which states a use-case based game. This game-based approach is dependent on the model of the business and logging the security. This research proposed to generate the logs based on the following attributes such as timestamp, user ID, session ID, application ID, severity, and categorization of the morgue.
Variants of bloom filter technique are used in peer to peer networks and are presented in [
34] for log integrity verification. The work presented in [
35] automatically collects and preserves the logs. It also uses non-malicious botnets as-a-service in the cloud layer with no modification in cloud infrastructure. A proactive cloud-based cross-reference framework is presented in [
36] to verify the integrity of logs. A model is presented in [
37] to minimize forensic evidence analysis time in the cloud environment through MapReduce. Another Blockchain-based secure logging framework is analyzed in [
38] which provides cloud level integrity checking as storage. Forensic aware ecosystem for IoT termed as FAIoT is proposed in [
39] which delivers physical device information in a virtual system for preservation, provenance, and integrity.
Zowoad et al. [
40] proposed RESTful APIs to guarantee secrecy and minimize the potential for tampering using Proof of Past Log (PPL). For convenient and proficient proof examination, Kebande et al. proposed a Cloud Forensic Readiness Proof Analysis System that uses appropriate equipment in the cloud environment through MapReduce [
41]. The framework contains modules including forensic database and Forensic MapReduce Task (FMT) modules. FMT recovers the potential advanced proof through the MapReduce process, including criminology logs, virtual pictures, and hypervisor mistake logs. All these logs are then placed in the forensic database.
Cloud log assuring soundness and secrecy(CLASS) is proposed in [
42] which ensures maintenance of logs in the cloud through deviated encryption. McCabe et al. produced PPL using Rabin’s fingerprint strategy and blossom channel [
43]. Blockchain-based log preservation is also offered in their proposed scheme. It utilized the unchanging property of blockchain to guarantee the classification and integrity of cloud logs and proposed secure logging-as-an administration in the cloud environment. The plan includes steps such as extraction of logs from a virtual environment; formation of scrambled log passages for each log using open key encryption; and capacity of encoded log sections on the Blockchain.
An open verification model through Blockchain to guarantee the integrity of logs in the cloud is proposed in [
44] using an outsider reviewer. The authors used homomorphic and single direction hash capacities to create the labels for log passages and Merkel tree structure for capacity. Another scheme named Probe-IoT ensures the confidentiality, anonymity, and non-repudiation of publicly available pieces of evidence by using a digital ledger [
45].
Harvesting and preserving forensically useful data from smart environments is presented as IoT-Dots in [
46]. A holistic overview of normal and malicious behavior in log collection [
47]. A fog based IoT reediness forensic framework is presented [
48]. eCLASS proposed a distributed network log storage and a verification mechanism of edge nodes [
24].
Table 1 provides the comparison of related techniques on the bases of adversarial model assumptions, security features, and limitations.
After the detailed analysis of the existing literature on secure logging in a cloud-based environment for IoT and other network environments, we yielded that most of the solutions use Blockchain, RSA, and open key encryption to secure logs in the cloud environment. It is important to note that there is a problem and that is when we need to collect the logs of a smart environment which is multi-hop from the cloud and when the log integrity is threatened, the network latency is tremendously increased during the log sending. Therefore, there is a need for an architecture that preserves the log privacy, provenance, and confidentiality along with scalability of edge node integration in an efficient fashion. The subsequent sections provide the detail of proposed scheme based on discovered solutions along with threat model and security requirements [
49,
50].
4. Proposed Architecture PLAF
We proposed a holistic architecture that addresses the main issues in our findings and implements the related security requirements in the proposed architecture PLAF. The main idea of PLAF is: “Automated and secure log collection and preservation of smart environment logs from distributed edge nodes in fog enabled cloud environment”. To securely preserve and transfer logs from IoT devices to cloud while considering the task offloading and delay sensitivity, we assisted the architecture of PLAF by intervening fog layer amid the IoT and cloud layer.
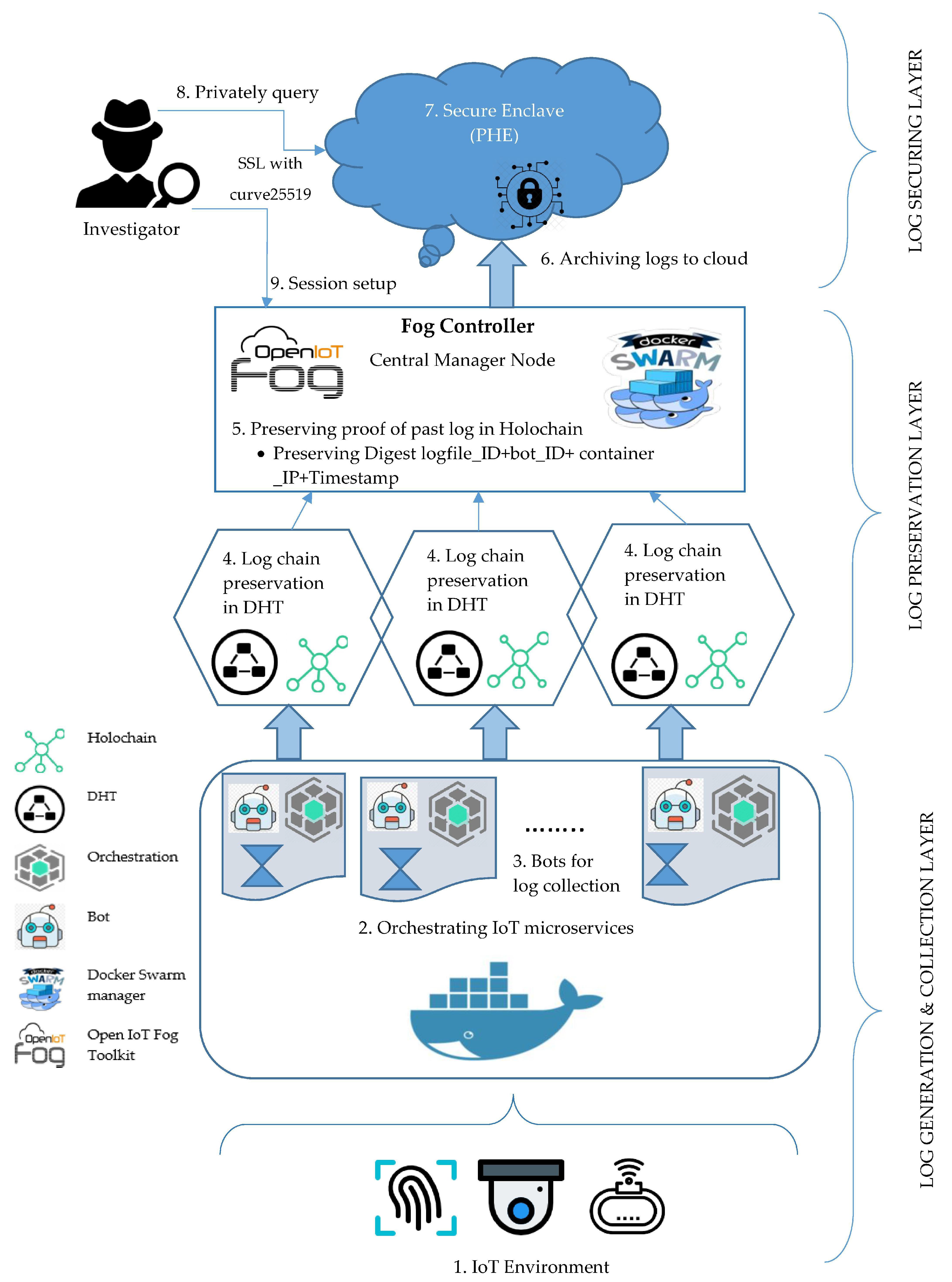
Fog computing lessens the cloud connotation by dint of pre-processing information generated by the sensors and further IoT devices. The logging and pre-processing in PLAF is performed at fog node and governed by fog node controller to offload the tasks of the edge layer. Conversely, fog node only collects and preserves the PPLs in dedicated format and transfer to the cloud log storage for further secure log archiving and log verification operations. All of the three layers offers different security controls for log secrecy and privacy to tackle multi-stakeholder issue and log alteration. In the following section, all three of the layers are described in detail. All of the operations and information flow of PLAF architecture are given in
Figure 7 and described in the steps below:
Create an IoT environment.
Initiate Docker Swarm Management Module (DSMM) and Central Management Module (CMM) for the placement and orchestration of IoT microservice using docker swarm manager at fog worker node.
Placement of bots in a container beside the microservice to collect logs.
Initiate the Data Preservation Module (DPM) for log preservation at fog worker nodes via Holochain and send all the Proof of Past Logs (PPL) to the central manager node.
Fog controller node administrates the DSMM, CMM, and DPM. In addition, prepare the PPL to transfer from the central manager node to cloud log storage.
Archiving the logs from fog node controller to cloud log storage.
Secure the logs at Cloud Log Storage (CLS) via Piallier Homomorphic Encryption (PHE).
Investigator initiates the secure session to privately query the logs for forensic investigation via SSL with curve25519 mutual authentication.
Then, for validating the logs at CLS, secure sessions are established amid fog node and investigator to get PPLs and verify log integrity.
PLAF is comprised of three layers which are: Log generation and collection Layer, Log Preservation Layer, and Log Archiving layer. The security threats that are described in the threat model are addressed in these three layers of PLAF by implementing the security requirements, which are ownership non-repudiation, trust admissibility, temper resistance, log integrity, log verifiability, provenance of PPLs, and privacy-preserving Automation. The mapping of threats and corresponding security features align with essential security requirements in different layers of PLAF are elaborated and discussed in
Table 3. The details of all activities performed with protocol-specific information in the three layers are illustrated in activity diagram of PLAF, see
Figure 8. The overview of three layers of PLAF is described below:
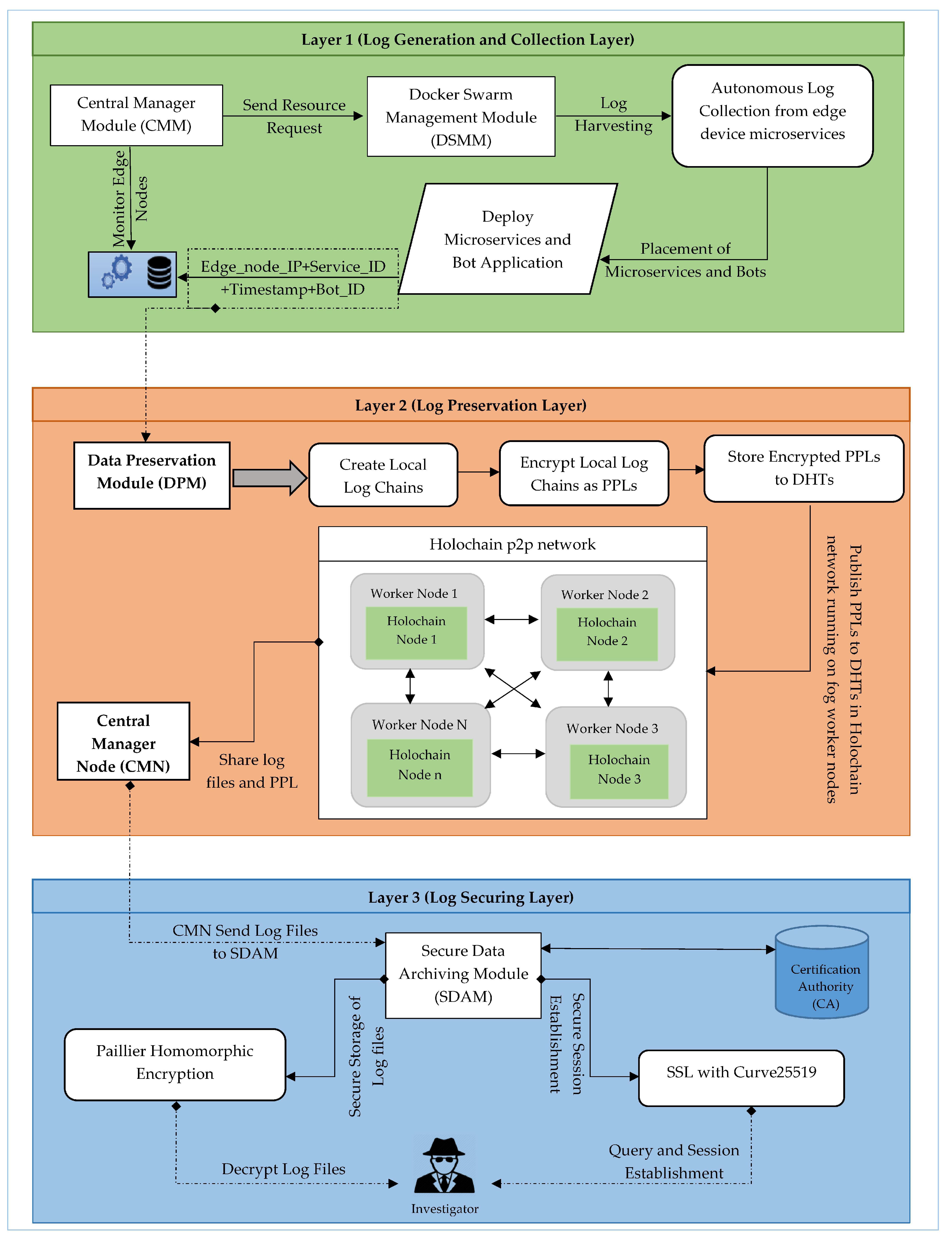
Log Generation and Collection Layer: This layer offers the log harvesting and collection, The orchestration of IoT microservices is continuous Integration of new arrivals performed. In addition, it provides the autonomous log collection generated by IoT devices via C&c bots which are placed in the container of microservice. This layer includes two modules DSMM and CMM for privacy-preserving automation.
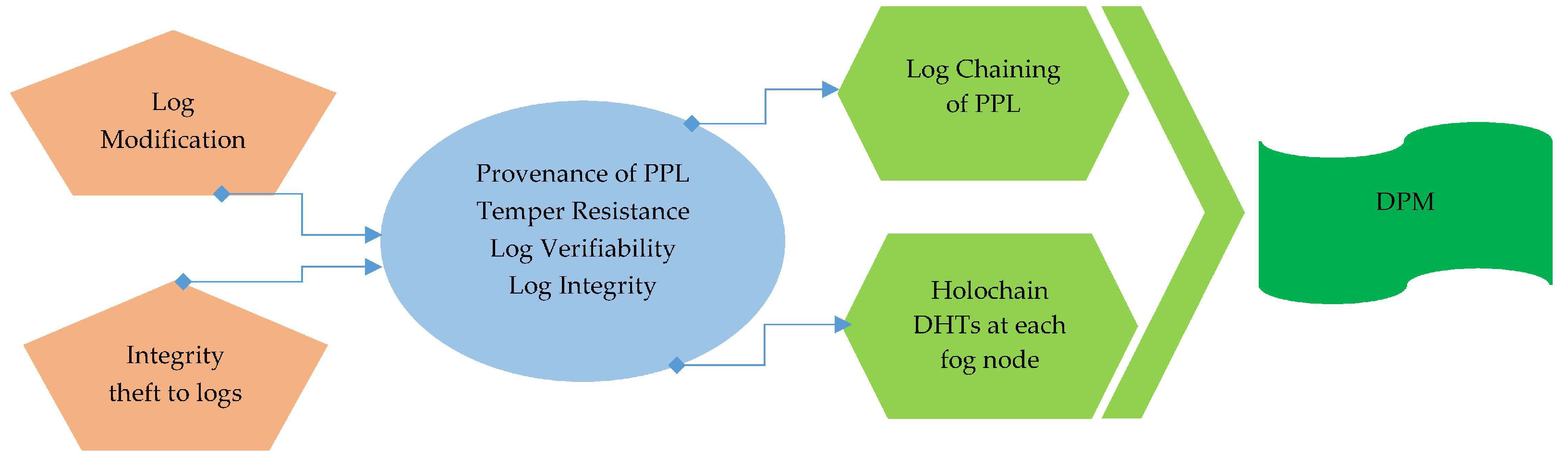
Log Preservation Layer: Secure Log preservation and generation of Proof-of-past logs is achieved in this layer. We used Holochain to perform the log Preservation in fog nodes. DPM is the module of this layer to generate PPL.
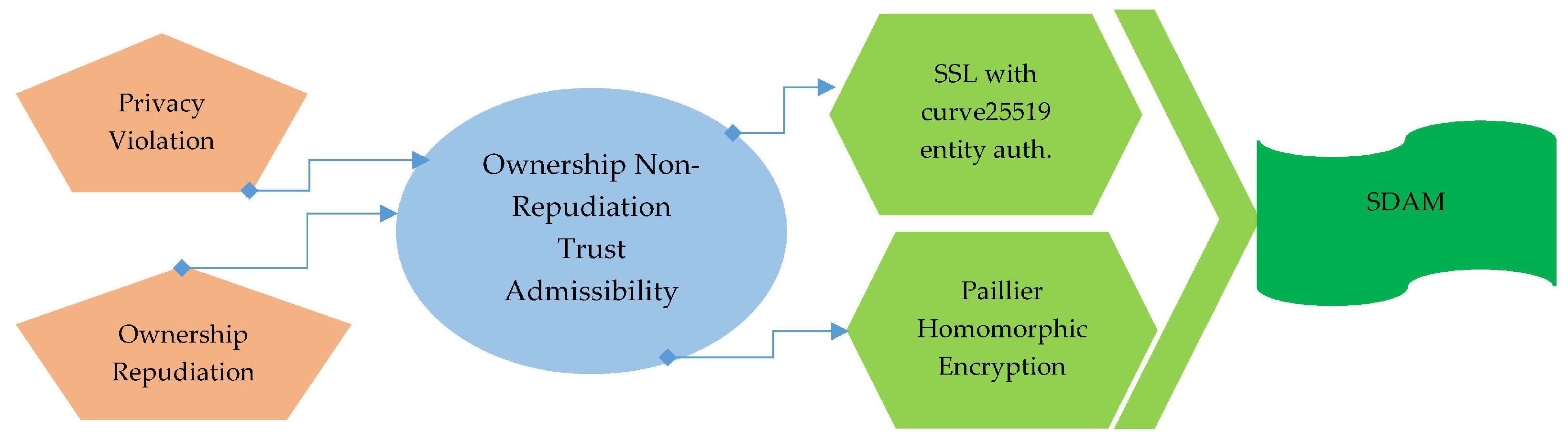
Log Archiving Layer: Secure log Storage and secure session establishments for querying the log from storage are performed here. Logs are stored here via Paillier Homomorphic Encryption and SSL with curve25519 is used for secure session establishment for querying. Two aforementioned operations are performed via SDM.
4.1. Log Generation and Collection Layer (Layer One)
This is the first driving part of the architecture where the logs are harvested and sent to the next layer of the PLAF. This layer performs the log generation and collection mechanism and these two operations are administered by DSMM and CMM. The DSMM administrates the other container worker nodes along with CMM. Both the CMM and DSM run on a fog node controller so having a central fog node controller provides the functionality to get the fine-grained control of running services in terms of both orchestration and monitoring. Other fog nodes called worker fog nodes run the app-containers and device microservices along with automated log collection bots.
To understand the DSMM and CMM operation, we illustrate an example. An Xbee-Stick is a connected IoT device node, after its connection, CMM is notified and the ZigBee application is started as swarm worker node and map the device in swarm cluster. CMM sends the notification to Docker swarm orchestration service to create the containerized microservices of a respective node based on the requirement of IoT devices such as Xbee-Stick. The app-container of IoT device node downloads the Docker image of respective microservices and starts. Following these two, DSMM and CMM of Layer one are discussed.
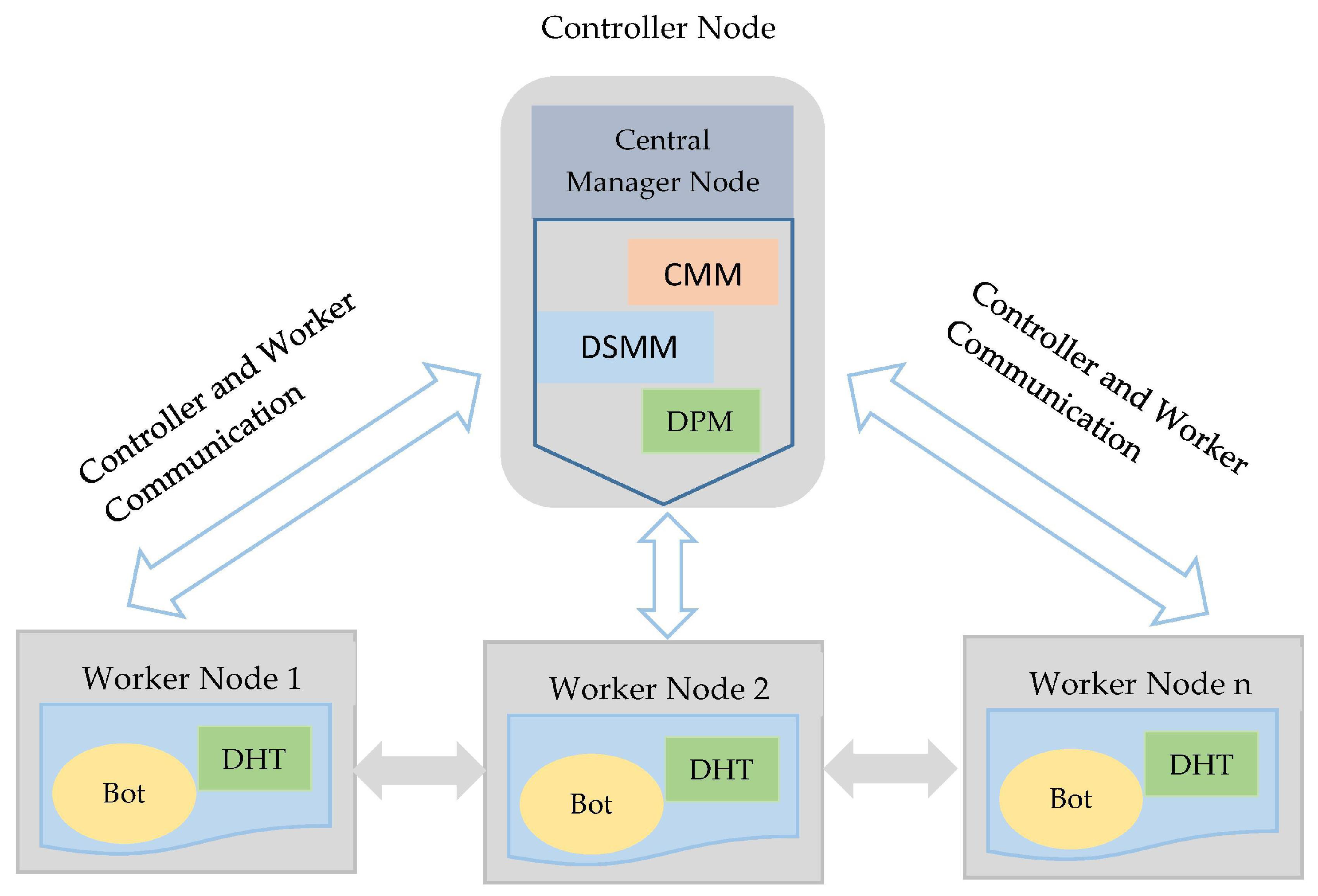
Figure 9 provides the placement of CMM and DSMM in the controller node and their communication with worker nodes. We can see in
Figure 9 that the central manager node communicates with the fog worker nodes in a back and forth manner. This is an illustration of layer two mechanisms where manager nodes send commands to worker node and receive their responses from them as well.
4.1.1. Central Management Module (CMM)
We developed the OpenIoTFog Central Manager Module (CMM) which runs beside Docker Swarm Manager (DSM). The edge devices orchestrated in containers at fog worker nods may require some software packages for computing and data storage capabilities. Therefore, we deployed CMM to monitor the resource requirement of edge device microservice running in a container and inform the DSMM about updates in terms of software packages and resource allocation. The orchestration or virtualization of microservices is established in the context of the OpenIoTFog toolkit [
53]. CMM manages and executes the service functionalities of each via following four operations which are: monitoring the health of fog node by and its resources (CPU, Storage, memory); providing the glimpse of “things” connected to manager; detecting the changes and autonomously execute commands on connected devices; and managing the access control of the device to the container for provisioning the swarm services.
4.1.2. Docker Swarm Service Manager Module (DSMM)
DSMM takes the information from edge devices from CMM in terms of resource requirements for scalable and continuous device integration. We used the Docker container orchestration tool for IoT microservice orchestration. Docker container technology shrinks the application overhead in deployment at fog node and utilizes the device resources and delivers application scalability. The Docker container orchestration environment is the best choice for IoT ecosystem orchestration, where the first layer of PLAF deploys, creates, starts, and stops the microservices running in a container or whole container. We built IoT microservices as a series of separately built, modified, and escalated microservices with autonomous log collecting bots. That microservice is used as an individual container and CPU, bandwidth, RAM, and storage specifications are specified as a resource necessity for each microservice.
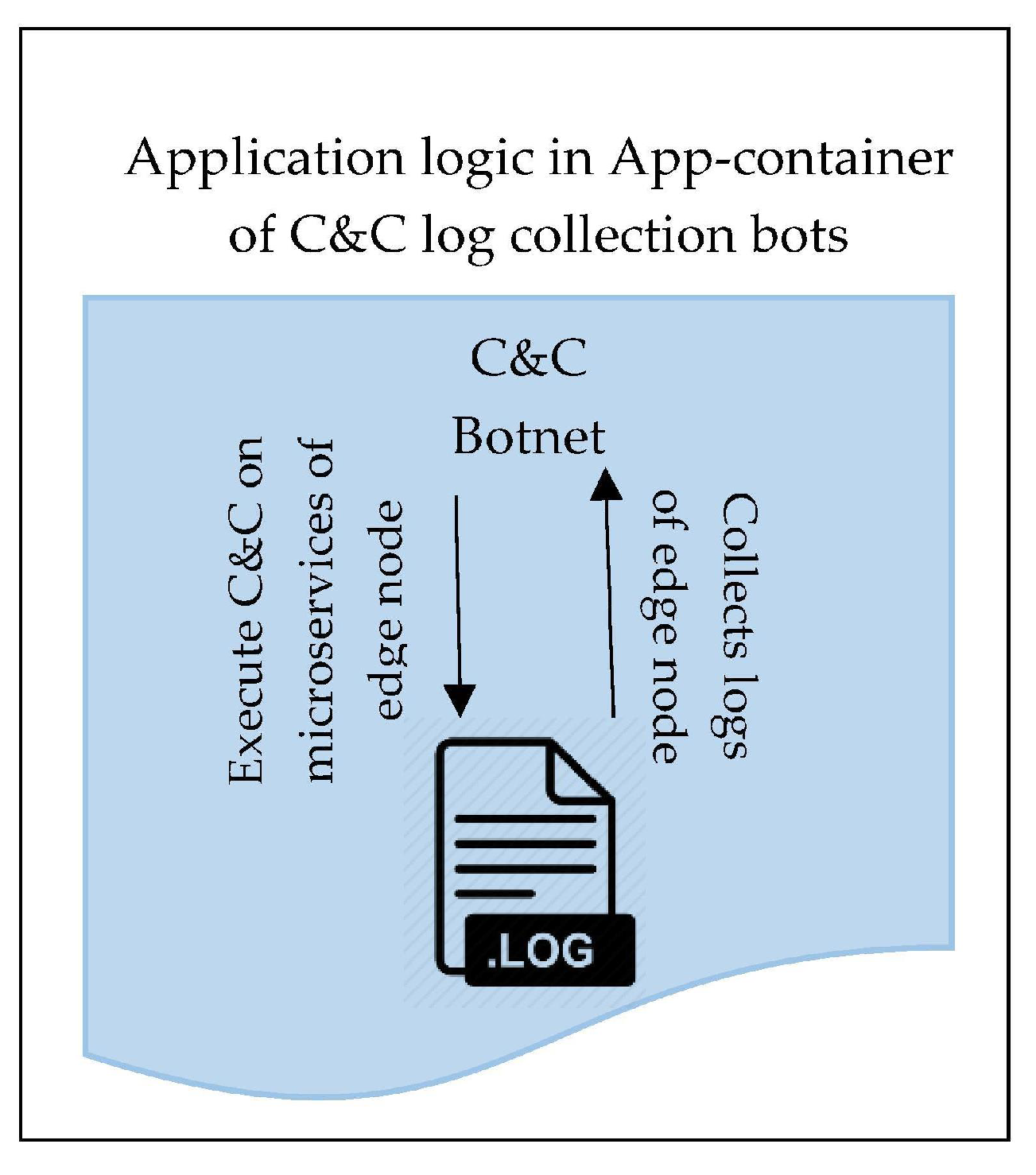
The other application of DSMM provides autonomous log collection via automated C&C bots other than the microservice orchestration. The principal purpose of placing automated bots besides the microservice is that the first layer of PLAF is capable of autonomously capturing the logs in a container environment. To collect the logs autonomously in such a way that the intervention of an outsider is avoided, the automated bots are deployed in the respective IoT device container running at fog worker node. These bots are the inspiration of malicious bots that works on the phenomenon of C&C (command and control) to collect desired information automatically. These automated bots are the automated command and control Python scripts, which collects the microservices application logs of the corresponding container in which they are running.
DSMM deploys the C&C bots besides the microservice in the container of edge device running on the fog worker node. To collect the log from IoT microservice, bots gather the stored logs in a specific directory provided on edge device microservice application. Logs are kept in storage in a predefined format along with the service information for forensics. Equation (
1) provides the digest of information format harvested in the microservice of the edge device. These bots are assigned with nonce identifiers so that the corresponding logs must be identified separately. This will also be useful in making information digest during the log preservation chain.
Figure 10 provides the inside view of bots working in containers along with microservices.
4.2. Log Preservation Layer (Layer Two)
The importance of preserving digital information is to make sure that none of the malicious entity can perform modification and tempering to digital assets generated by layer one. In this layer, the aforementioned objective is achieved by preserving the integrity of logs and generating secure PPLs that builds resistance to tempering and provides log verifiability as well. This layer provides crucial safeguarding mechanisms to ensure log integrity, temper resistance, log verifiability, and provenance.
To ensure all the aforesaid security requirements, the proposed architecture PLAF provides a holistic solution that is secure and scalable at once which can easily be executed on a fog node even comprises of a Raspberry-Pi. In layer two, the Data Preservation Module (DPM) is deployed on a fog node controller to perform log preservation via Holochain for secure, scalable, and robust logs preservation. DPM runs beside the CMM and DSM at fog node controller as shown in
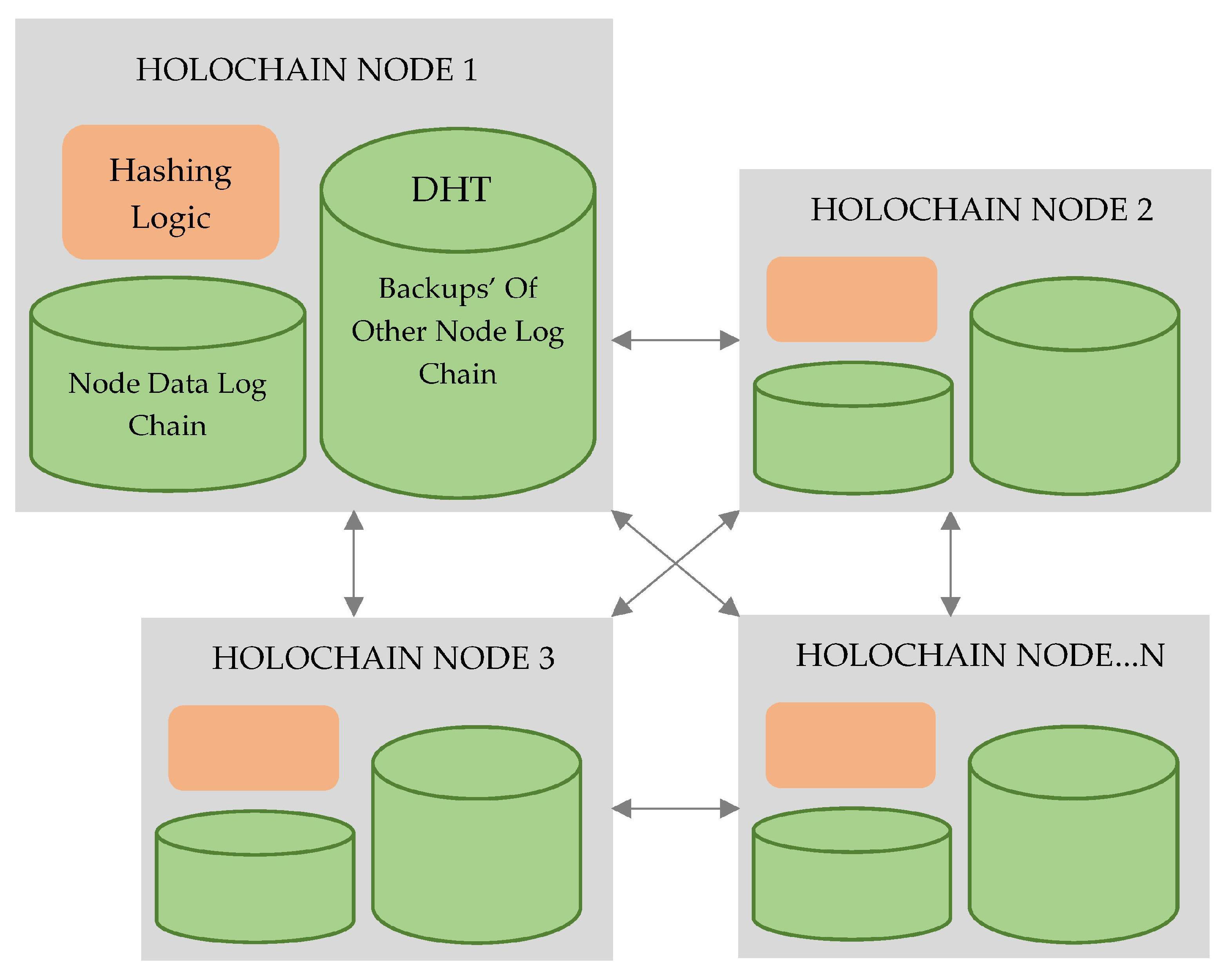
Figure 9. In layer two, DPM sends the request to fog worker nodes and receives the responses from them. These worker nodes run the instances of Holochain nodes. These Holochain nodes manage the DHTs of log metadata. Following the details about fog worker and controller nodes executing the DPM, module procedures are given.
4.2.1. Data Preservation Module (DPM)
This module governs log data preservation to ensure log integrity, privacy, and peer-to-peer data sharing via Holochain. Holochain used for secure and scalable log preservation schemes which establish the peer-to-peer network communication of all Holochain nodes distributed among fog worker nodes. The following sections describe the Holochain technology and different operations executed by Holochain at fog worker node [
54,
55].
4.2.2. Holochain
Holochain offers an agent-centric and relativistic environment to create the underlying validity of data. Holochain guarantees data integrity for distributed applications by carefully collecting data from the local immutable chain of each fog node. This effectively allows for an update to conventional double accounting with the use of cryptographic signatures as accounts are linked to unchanging chains. Each node manages its local transaction chain in this double-entry accounting system instead of a global coins leader as in Blockchain.
Holochain does not waste computing power as it is wasted in Blockchain because it is not dependent on some kind of global leader consensus. Moreover, Holochain is not dependent on the references to the proof-of-work, the proof-of-stake, or leading selection algorithms to ensure the data integrity for peer-to-peer applications.
This means that each balance of a fog worker node is stored on its chain, and when two fog worker nodes are transacted, they only have to test the background of their counter-party to make sure that they have credits. Third-party authorization or consensus is not needed in this case.
Figure 11 illustrates the peer-to-peer validation mechanism of Holochain for privacy preservation in distributed fog worker nodes.
4.2.3. Creating Log Chains as Proof of Past Logs
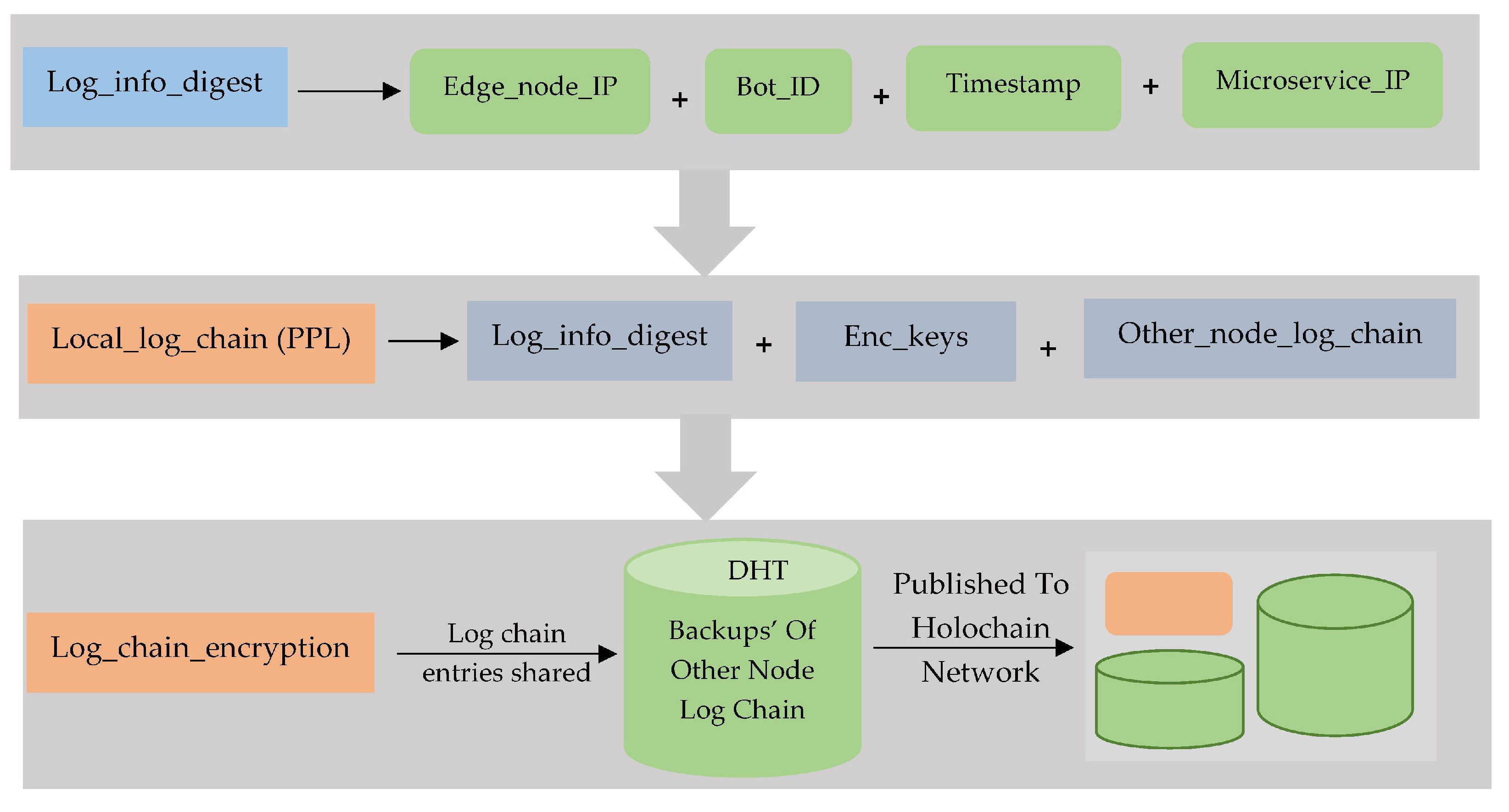
The fog worker node receives the edge nodes logs from automated bots and builds the log info digest. Log info digest comprises of some attributes which are log_file_ID, bot_ID, container_IP, and timestamp. These log info digests being stored at local storage of respective fog worker node along with their private keys and peer node log chain ID. Finally, all of the fog nodes stores their respective encrypted local log chains.
Figure 12 illustrates the procedure of the digest building of local log chains.
4.2.4. Distributed Hash Tables (DHTs)
Fog worker logs the local backup of log info digest and then exchanges its local log chain to the peer network fog worker node. In DHTs, a single key that will be “IP:Port” of that node with the SHA-1 algorithm will be allocated to each node. A node may construct a DHT ring and other nodes may join the ring through the IP:Port of this node. When a node enters or joins a ring, some threads are created to ensure correct entries in a finger table. The successor and predecessor fog nodes share and acknowledge the local log chain of each other. There is a list of successors with “R” entries in each node. This list is used when a successor node leaves the ring, and the next node in the successor list will automatically be assigned as the successor to it. A growing node periodically asks the successor and predecessor to remember that they remained in the ring. If no acknowledgment is earned, the ring is left and stabilization is carried out accordingly. Every node maintains a map to store pairs of the key values. When a key is accessed, a single ID is often allocated and stored in a node whose ID is only greater than the ID of that key. If a node again leaves the ring, it gets all the keys from its successor.
4.2.5. Log Archiving Layer (Layer Three)
In this layer, all of the collected logs are securely stored at CLS. This layer affects the session authentication when log retrieval is requested and secure storage of logs as well. The aforementioned operations are executed under the Secure Data Archiving Module (SDAM). These stored logs can be used for testimonial in the court of law, in the recreation of footprints and for threat intelligence analytics. SDAM performs two following operations of log securing and secure session establishment.
Under the considered system model and security requirements for secure and incremental log storage, our goal is to propose a security and privacy-aware storage scheme based on homomorphic encryption in the cloud. The cloud storage is susceptible to side-channel attacks, fake information injection attacks, and data forgery attacks. To prohibit previously mentioned threats in the multi-tenant and black-box nature of the cloud, we used a Partial homomorphic encryption mechanism based Paillier Homomorphic Encryption (PHE) scheme for privacy and security of logs. The purpose of using PHE is to attain the privacy and security of logs in cloud storage while the continuous updates of logs from the fog node controller. PHE is fast and provides additive operations upon logs file increment in cloud storage and also provides semantics security [
56].
The public and private keys of CLS are directly stored in the premises of the law enforcement agencies to avoid any kind of conspiracy. There are three main steps involved in this scheme namely Key generation, Encryption, and Decryption. The underlying steps in each of these steps are explained as follows; in the key generation step, the public (encryption) and private (decryption) are generated and stored; in step two, the computation performs on encrypted data, in step three, decryption of both plain text is performed via private keys, this phase is only done at the agent’s machine.
Figure 13 provides a simple explanation of PHE working in the context of log storage. The benefit of using PHE is that, even if the attacker intercepts the communication between layer two and layer three, she cannot obtain the sensitive information belongs to logs.
Whenever the investigating entity makes requests to fetch and validate the integrity logs from CLS, a secure session is initiated amid entity, cloud, and fog node controller. These sessions are authenticated by SSL (Secure Socket Layer) using curve25519 as a cryptographic protocol for mutual authentication. The SSL with curve25519 cryptographic protocol offers better security with faster performance compared to RSA, it is compact, and uses only 68 characters compared to RSA 3072 that has 544 characters. RSA is the most widely used public-key algorithm for SSH keys. However, compared to curve25519, it is slower and even considered not safe if it is generated with the key smaller than 2048-bit length [
57].
The well-thought-out mutual authentication mechanism executes by SDAM in the following steps; the first session of authentication is established among investigators and CLS. When the investigator is verified as a legitimate entity at the CLS verification point, it will be able to request the PPL from the fog node controller via the same authentication scheme used at the cloud level. After this phase of entity authentication, the CLS regenerates the tokens and certificates specifically for the fog node controller. This mutual entity public-key authentication process is presented in
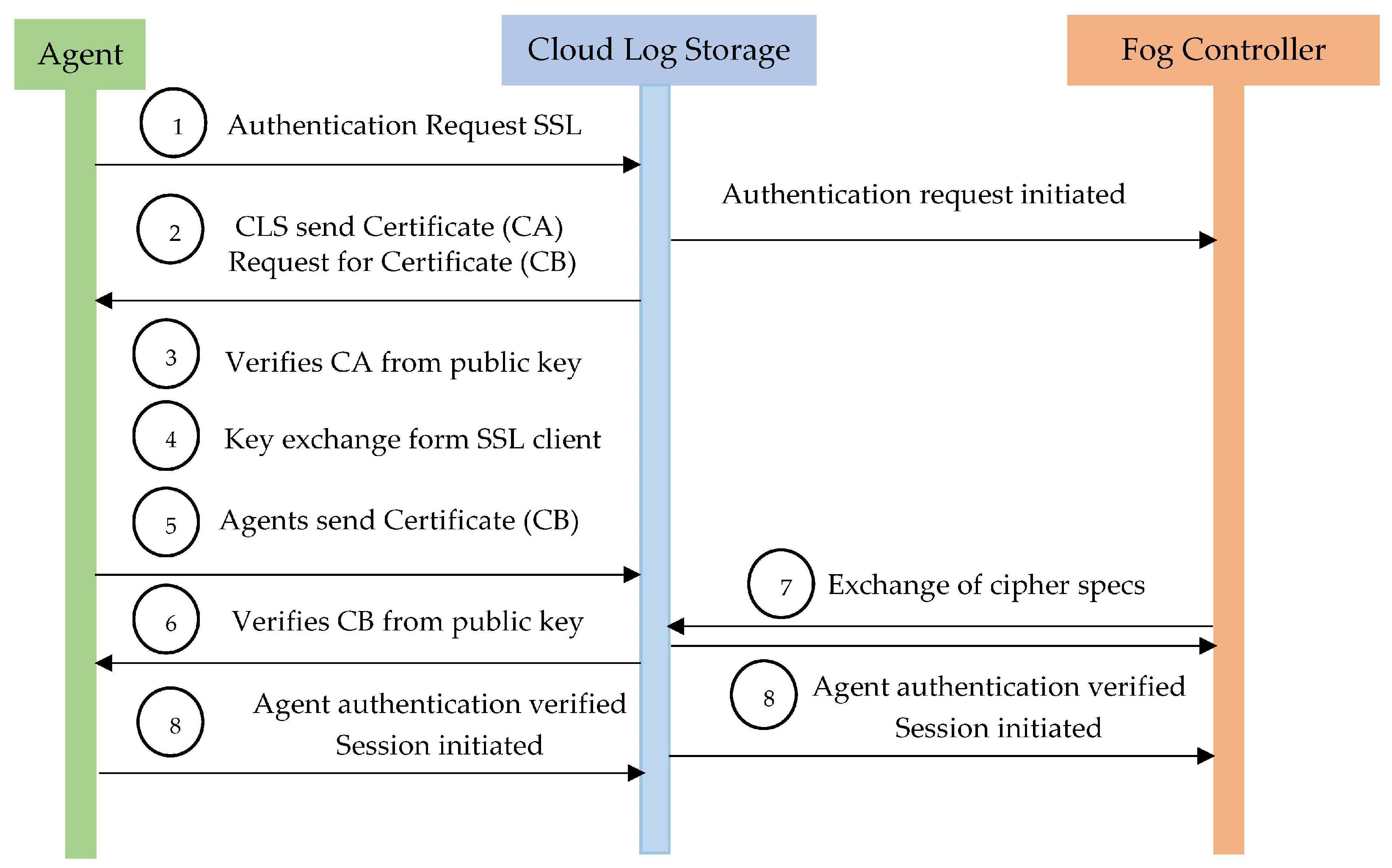
Figure 13. In two-way SSL authentication, the SSL client (agent) verifies the identity of the SSL server (CLS), and the SSL server (CLS) verifies the identity of the SSL client (agent). The mutual authentication scheme provides in
Figure 14 works in subsequent steps;
SSL client (agent) sends a secure connection request to CLS
CLS reply with its certificate (CA) and request for agent certificate (CB)
Agent verifies the certificate (CA)
Key exchange from SSL client (agent) side
Agent sends its certificate (CB) signed by its private key
CLS receives and verifies the certificate (CB) from public keys of agent
Exchange of cipher specs at both SSL client and server-side and fog node controller
Secure session initiated.
After the session begins to initiate, the agent gets the encrypted logs and decrypted them on its machine. Here, the third phase of PHE occurs and log validation as well.
5. Performance Evaluation and Security Analysis
This section explains the implementation details, performance evaluation, and security analysis of PLAF. The performance analysis is performed based on stress testing and log preservation processing analysis. In security analysis, the formal log integrity verification and validation are performed. In addition, the comparison of PLAF with existing literature is provided.
5.1. Implementation
To implement a prototype environment, the technical PLAF specifications for the host machine are Ubuntu 20.04 LTS system with 16 GB RAM, and a Core i7 Processor. We used the OpenStack cloud platform to host a fog node controller and the Docker swarm management console is used to orchestrate IoT services in fog node; C&C scripts are written in Python to fetch and collect the logs automatically. For the verification of the log hash chain based scheme, Holochain rust API is implemented to create the PPL. To achieve the confidentiality of data, we used PHE for encryption. The authentication of the user is achieved through SSL with curve25519 for mutual entity authentication. The real-time testbed is implemented using IoT devices, the OpenStack cloud platform, and a Raspberry Pi. This testbed is cross-verified from the given threat model and also the simulation results are compared with existing literature. In the following steps, the testbed is described.
Step 1: Layer one is implemented in this phase where different logs of IoT environment are generated and collected. We used different IoT devices such as IP cameras, fingerprint scanners, and Wi-Fi enabled devices to get the logs. In the second phase of layer one simulation, the orchestration of IoT device node microservices was performed via the Docker swarm platform for continuous integration and privacy-preserving automation. In the Docker swarm environment, different containers are deployed to orchestrate microservices of IoT devices. For continuous and autonomous log collection, the C&C bots application was deployed in the container of each microservice. These automated bots are actually the Python script which uses the C&C mechanism to get the logs continuously. Each bot has a unique ID which is allotted via a nonce key so no malicious bot can access the container.
Step 2: Layer two which is a log proof preservation layer has been instigated in step two of implementation. This step is performed at fog node layer PLAF. We used a Raspberry Pi as a fog node because our adopted preservation scheme can easily run on less resource fog nodes. We used Holochain container-API written in rust for log preservation in different fog nodes. We used the OpenStack cloud platform to simulate the fog node controller which governs the phenomenon of Docker swarm management, fog node monitoring, and DHTs management of different fog nodes. In fog node controller, monitoring of the following modules was implemented; DSMM for microservice orchestration, OpenIoTFog agent (CMM) to monitor the health of IoT devices, data preservation module to effect Holochain mechanism and secure migration of log from fog to cloud.
Step 3: Secure log archiving is deployed in dedicated cloud log storage and is created in the cloud platform. We used Paillier Homomorphic Encryption to secure the log storage and private keys are directly stored in the respective monitoring agent server. SSL with curve25519 for mutual authentication is used for entity authentication when the session is established at CLS and fog node.
5.2. Performance Analysis
This section provides the evaluation of securing logs in PLAF. Fast data processing and data integrity checking are critical because it aims to collect log data in fog enabled cloud environments. Furthermore, the minimal computational power and overhead at fog node have to be calculated during log preservation. The efficiency is measured using four success metrics: fog node automation processing, stress testing of bot running in container besides microservices, privacy preservation processing, and log validation analysis.
5.2.1. Use Case
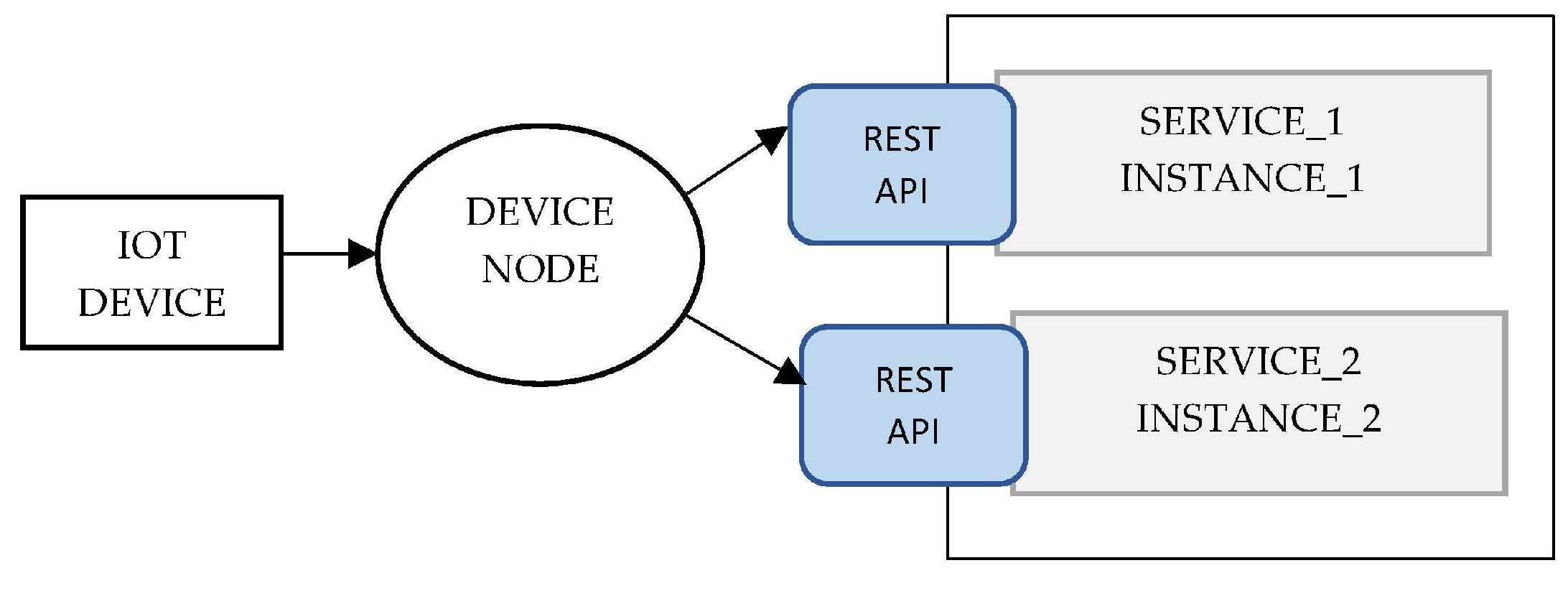
We built a testbed workload of IoT scenarios to evaluate the efficiency of PLAF. The testbed is modeled on the IoT application environment based on microservices which automatically collects data and sends it to the fog node. There are situations in which a fog node has to be attached physically to the computers. Applications also require access to other resources than CPU, memory, and storage, and serial ports. When requirements for containers are created by DSMM, together the DSMM and CMM ensure that the required resource container is available. When an IoT device connects to the PLAF environment, the requested IoT microservices are placed in the container as shown in
Figure 15. The containerized program will also be designed for that particular fog node. The DSMM must facilitate this form of container positioning and CMM must be conscious of the robustness of the device.
5.2.2. Fog Level Privacy Automation Processing and Testing
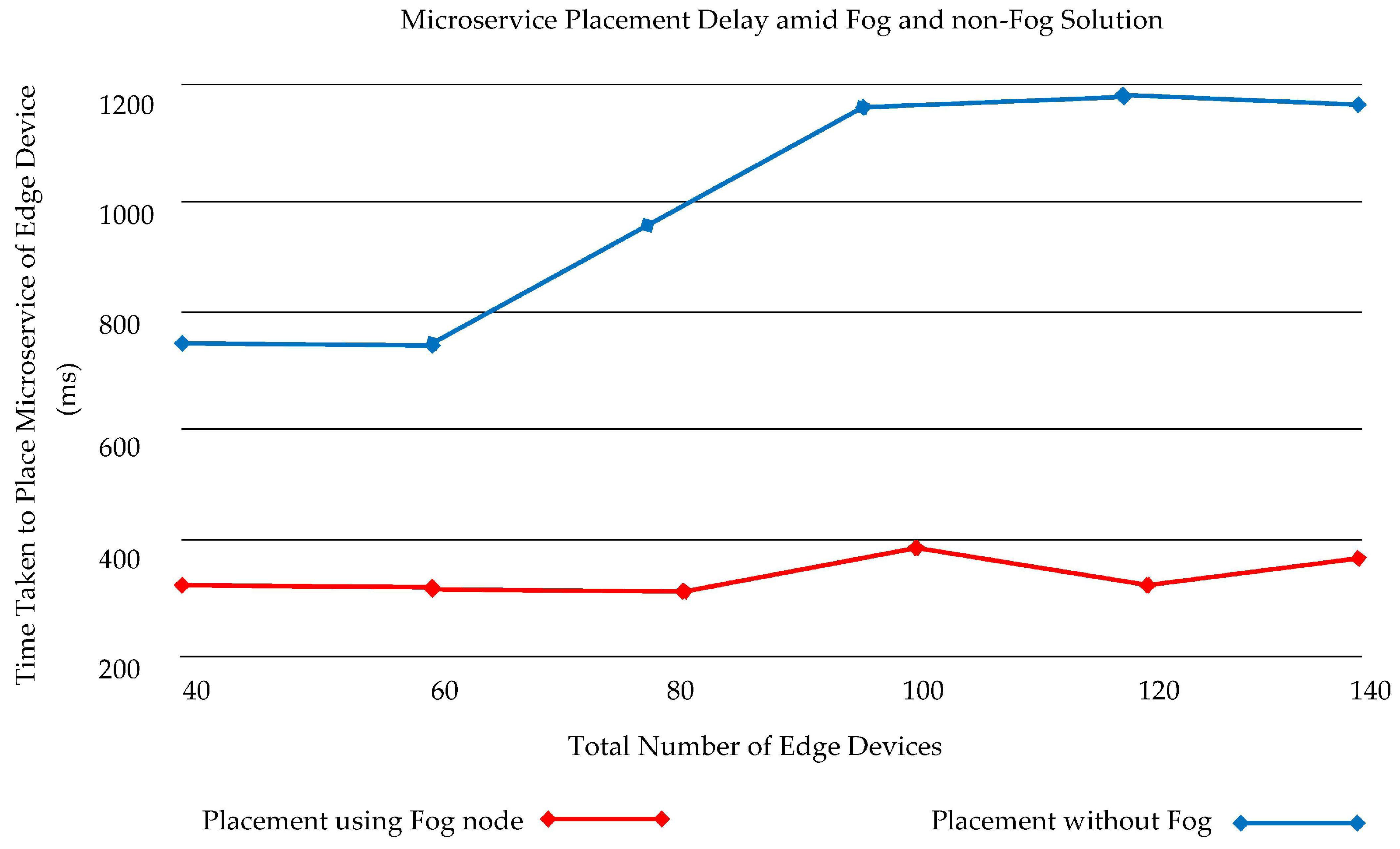
A resource-constrained computer such as a Raspberry Pi is used as a fog node. The DSMM must be able to automatically identify and connect the fog node to the cluster, and only the required program packages are included in this node. In terms of latency and network utilization of the device after deployment, we have tested our scenario with microservices utilizing the autonomous bots and contrasted it with a cloud-based application. The placement methodology is tested based on the time required in the placement of microservices in the fog layer and the cloud. The details are presented in
Figure 16.
5.2.3. Stress Testing of Bots and Containers
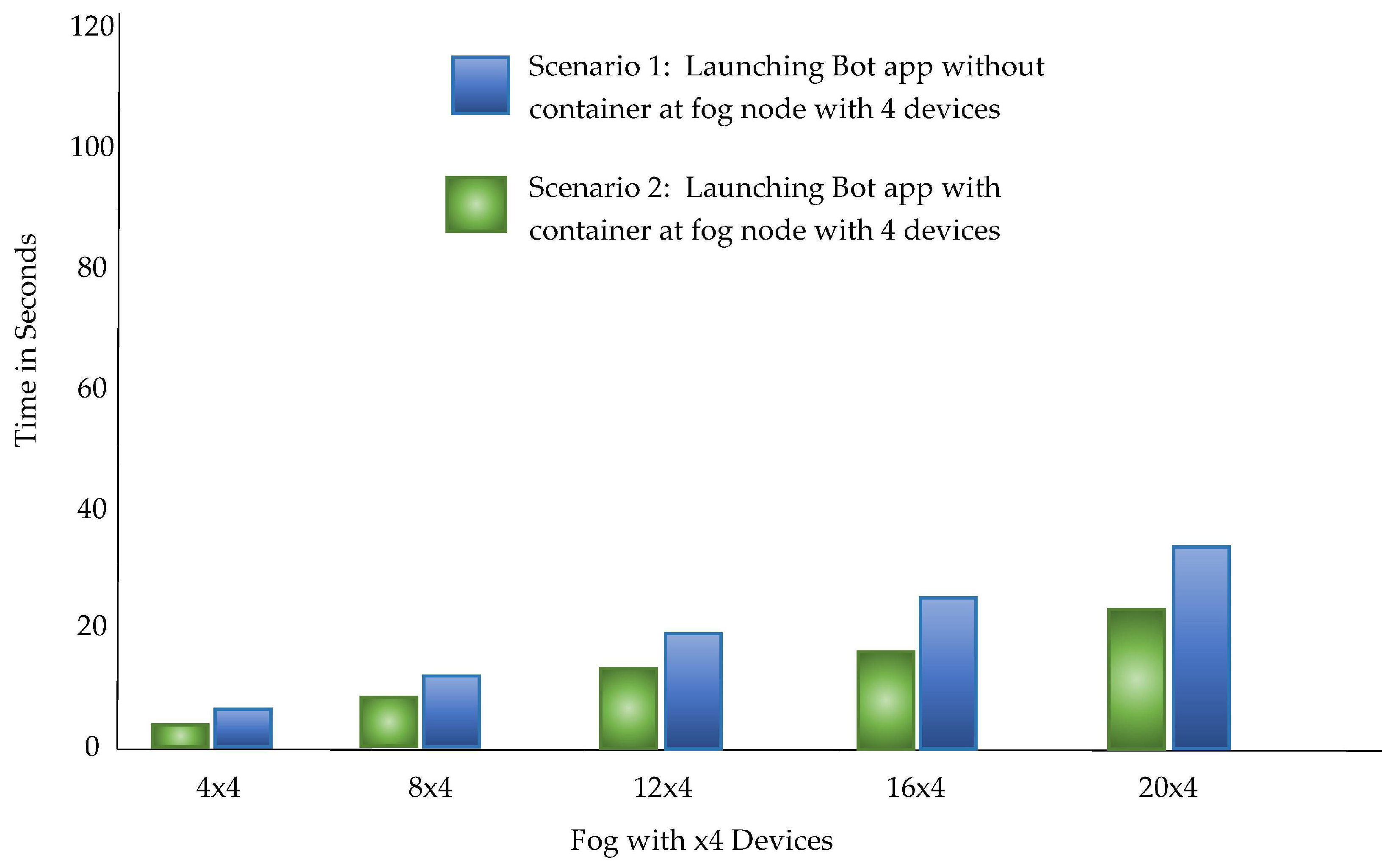
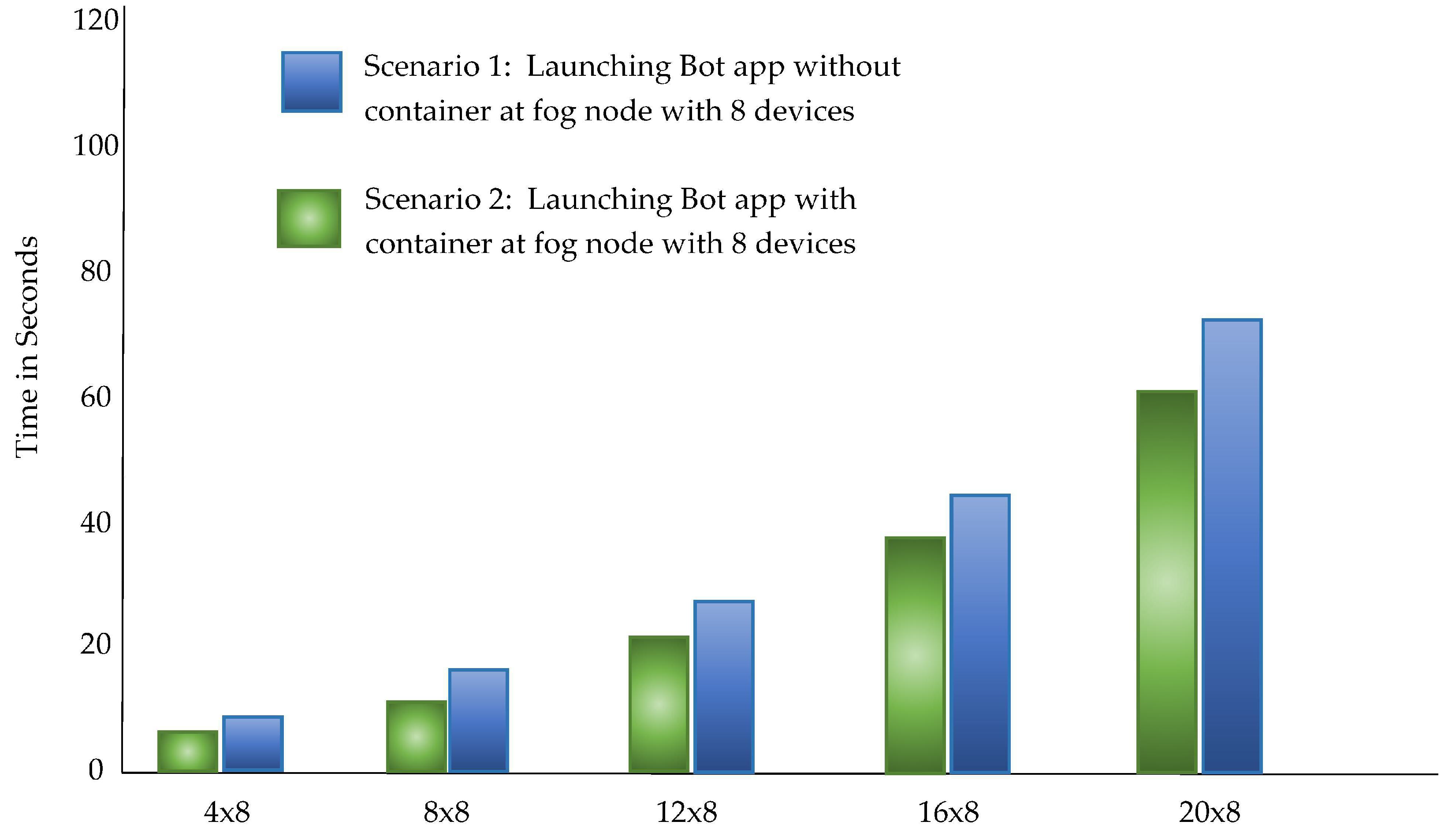
The proposed architecture PLAF aims to automate the deployment of the bots in the fog environment which is composed of heterogeneous fog nodes with fewer resources. Therefore, the log harvesting mechanism of PLAF has been evaluated using two scenarios. Scenario 1: In the first scenario, the ZigBee devices were launched with bot application directly running on the host operating system, The time required to reach the ZigBee application is evaluated.
Scenario 2: In the second scenario, we did the calculations in a Docker container while executing the isolated bot program. Finally, in the containers, all gateways and bot applications were running together. The cycle has been replicated twenty times. Docker Containers have observed an overall overhead of about 0.039 sec. The confidence interval for both the scenarios is 95.7%.
The statistics provided in
Table 4 demonstrate the outcomes of observations of two scenarios. We used a stress testing method for Linux where -c, -m, -io are all CPU, memory, I/O workload generator. Note that this lag is only noticed when the device is first accessed. The more stress exerted on the PLAF in the simulations, the more time it takes to launch the (Xbee) program. It was observed that, initially, the latency in usage is milliseconds of stress tests. This interruption takes place only once before the program begins and does not create additional overhead in this situation of the Docker container.
In our experiments, we have increased and decreased the number of sensors in the fog layer to evaluate the performance. We also experimented with the deployment of more edge devices attached to each fog node and additionally allocated a few more resources.
Table 5 specifies the criteria of simulation for a minimal period to start a container and microservices in the architecture of PLAF.
Figure 17 and
Figure 18 provide the delay computed after increasing the number of IoT devices and the placement of microservices in them.
5.2.4. Log Preservation Processing Analysis
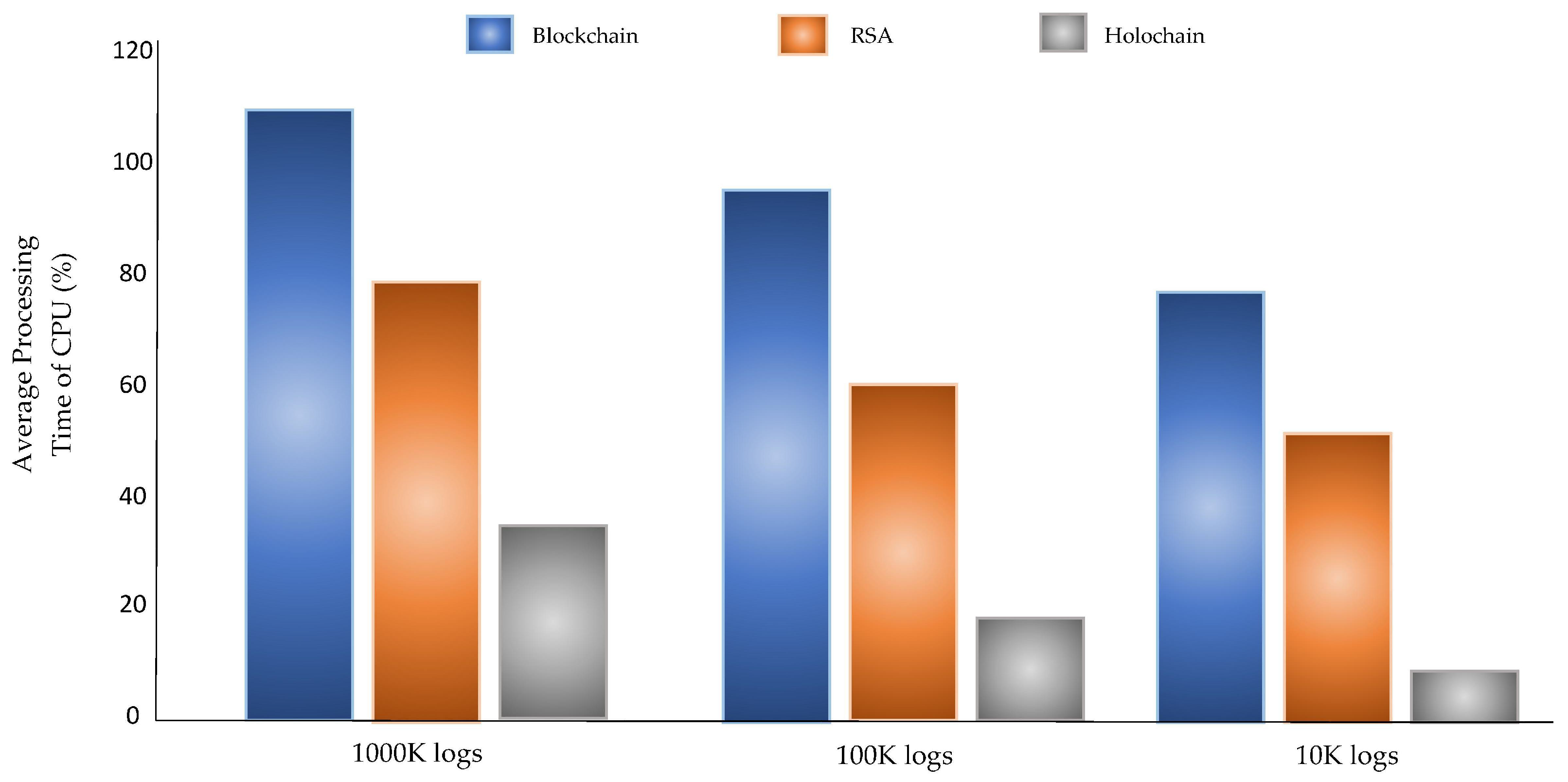
As previously described, the proposed architecture PLAF applies a Holochain mechanism for the preservation of logs at distributed fog nodes. We compare the PPL preservation performance in terms of CPU resources for the RSA, Blockchain, and Holochain. We used 10, 100, and 1000 KB of the log files with 200 log entries each. The log preservation duration in fog node is shown in
Figure 19, which describes that the log protection using Holochain was found to be better than the blockchain and RSA encryption.
5.2.5. Secure Log Storage Processing Analyses
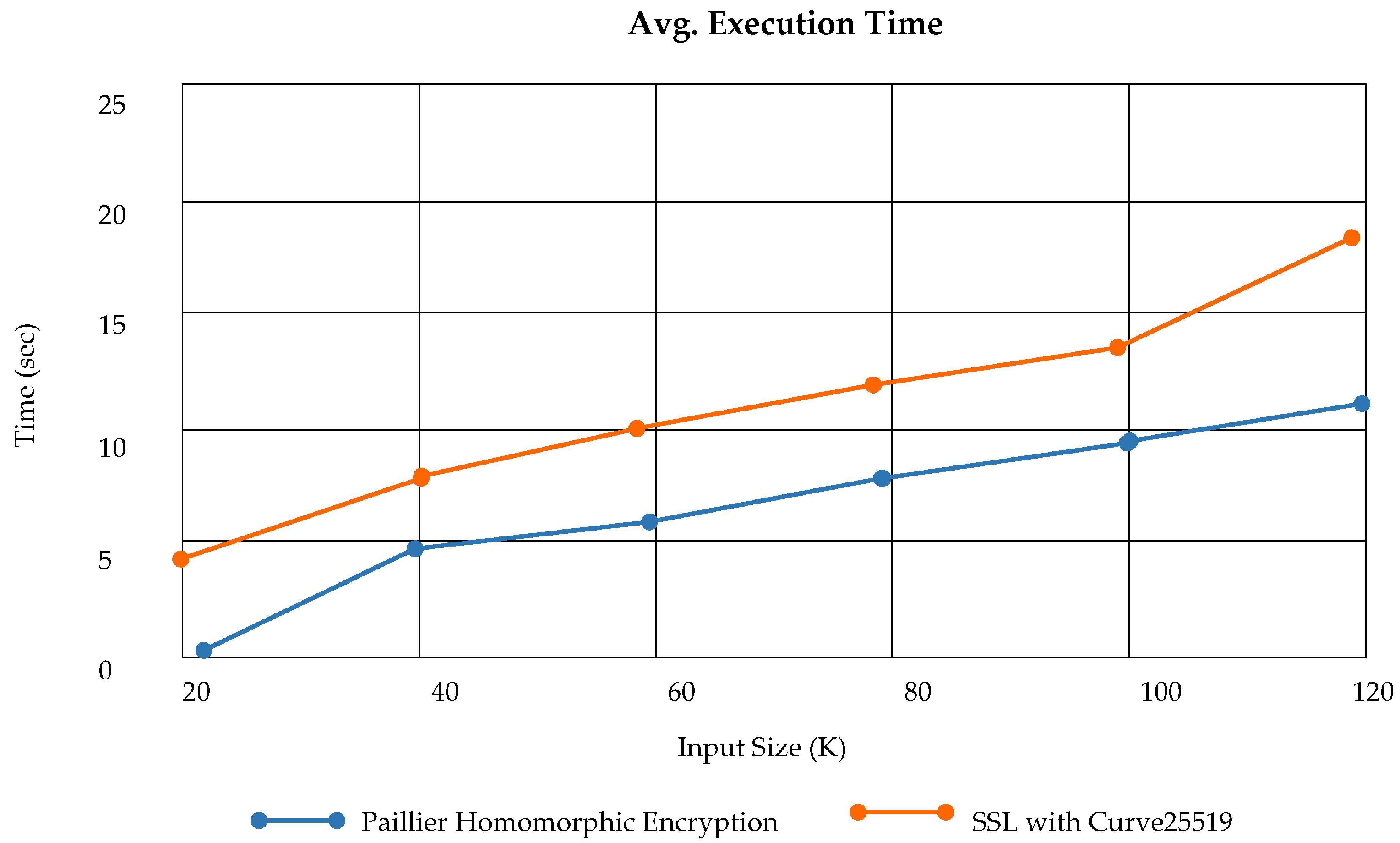
PLAF stores the actual log data at the third layer of architecture via PHE (Paillier Homomorphic Encryption) and provides the secure session establishment for log retrieval as well. We have analyzed the privacy-aware secure log storage at CLS and the time taken to perform the incremental addition. The analysis of average time execution for PHE to execute incrementally is illustrated in
Figure 20. Time taken to perform mutual authentication via SSL certificates using curve25519 is also shown in
Figure 20.
5.2.6. Performance Validation of PPL Processing
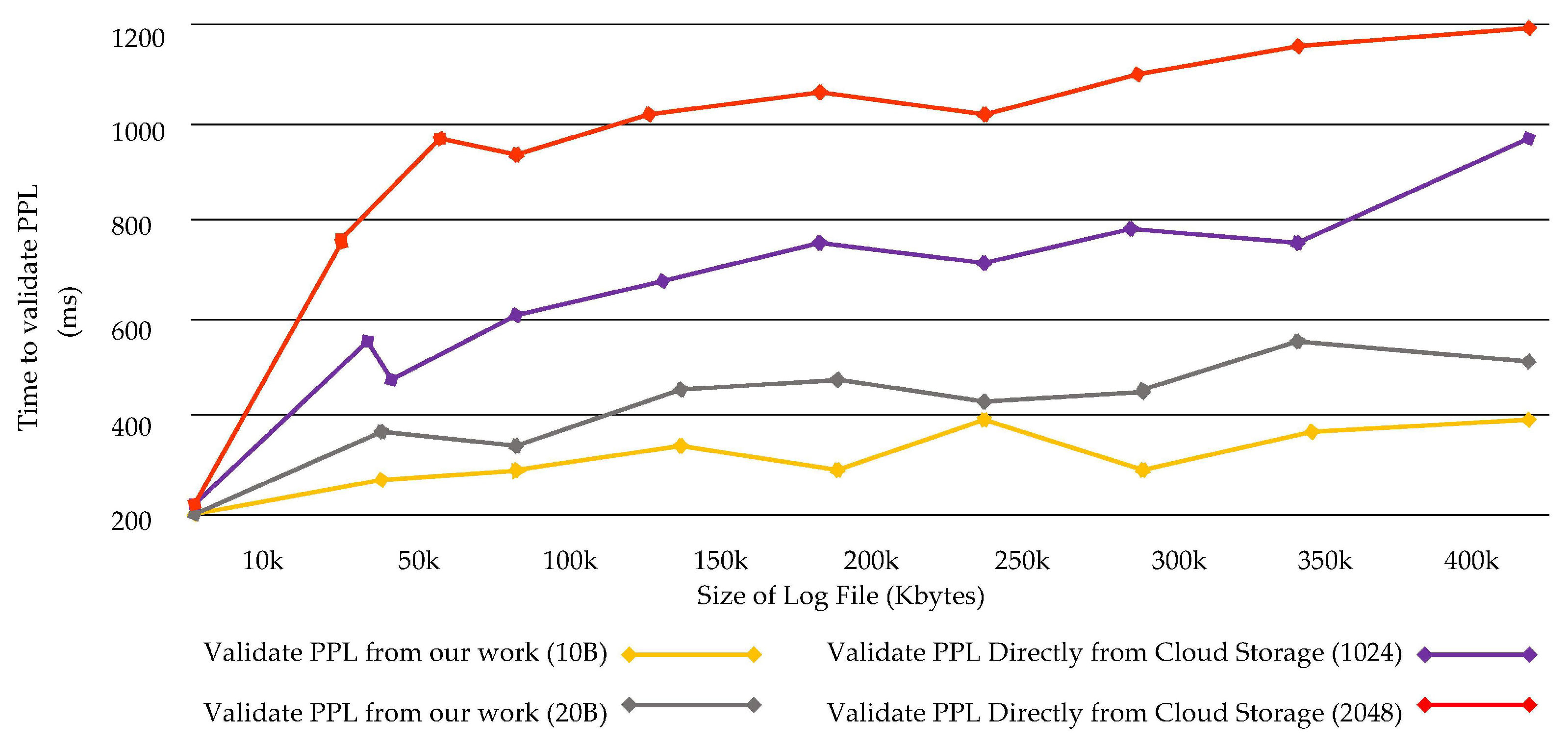
Only the data created by geo-distributed sensors in cloud location is sent to a central cloud that is multi-hops from the edge of the network, Because all data produced are submitted to the cloud, the number of data streams through the central network arises, significantly increasing the network jamming. Due to these reasons, proof of past logs fetching services deployed in the cloud is recovered and validated considerably late. In addition, data size increases when encrypting and decrypting the data. Encrypting cloud logs is approximately three times expensive and larger files take more storage and time to validate them. In PLAF, the size of the log data during validation is not increased during the performance testing of the validation processing.
Figure 21 provides the time consumed to validate the PPL in two scenarios: (i); fetching and validating the PPL from fog node; (ii) fetching and validating the PPL directly from the cloud.
5.2.7. Computing Resource Allocation Trade-Offs
This work proposes a new log preservation architecture named PLAF offering many security aspects for log preservation in an automated manner. On the other hand, it also affects some computational trade-offs in terms of CPU and memory utilization. in this section, these trade-offs and computational costs are presented and elaborated.
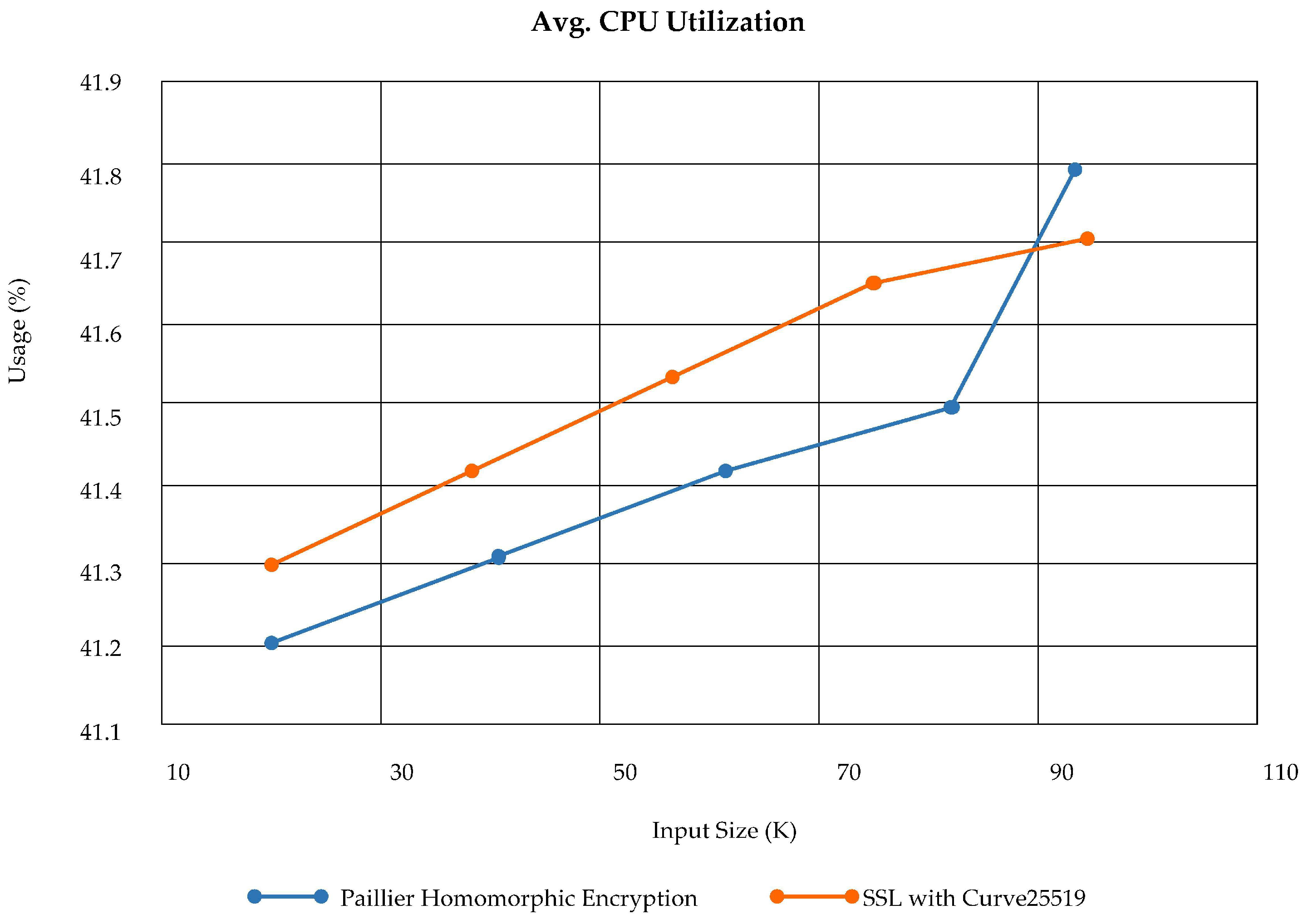
CPU Utilization: The CPU utilization during experimentation and simulations were compared. The average CPU utilization for secure log storage using PHE and session establishment via SSL on log size from 10-120KB log size is given in
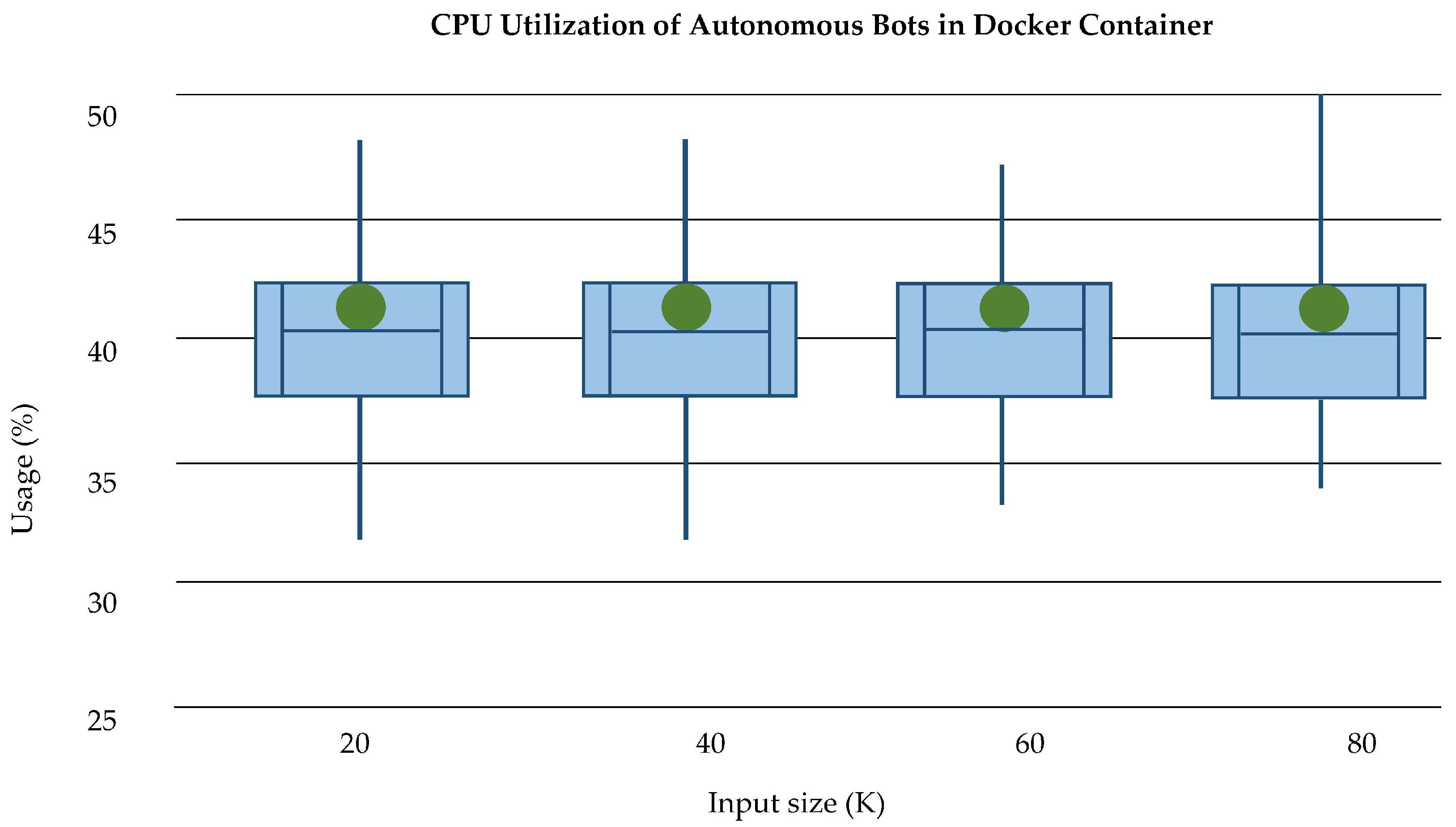
Figure 22. We can see that at the cloud layer the average CPU utilization is approximately 40% of total CPU, which is an overhead. The CPU utilization at the fog level has also been analyzed based on the usage of Docker containers and automated bots for log collection. We have independently and separately analyzed the total CPU usage of Docker containers in fog nodes which is shown in
Figure 23. As the Bots are running continuously in containers, they thus create an additional overhead in a container environment; in
Figure 24, it is shown that the presence of bots in containers seeks more CPU usage.
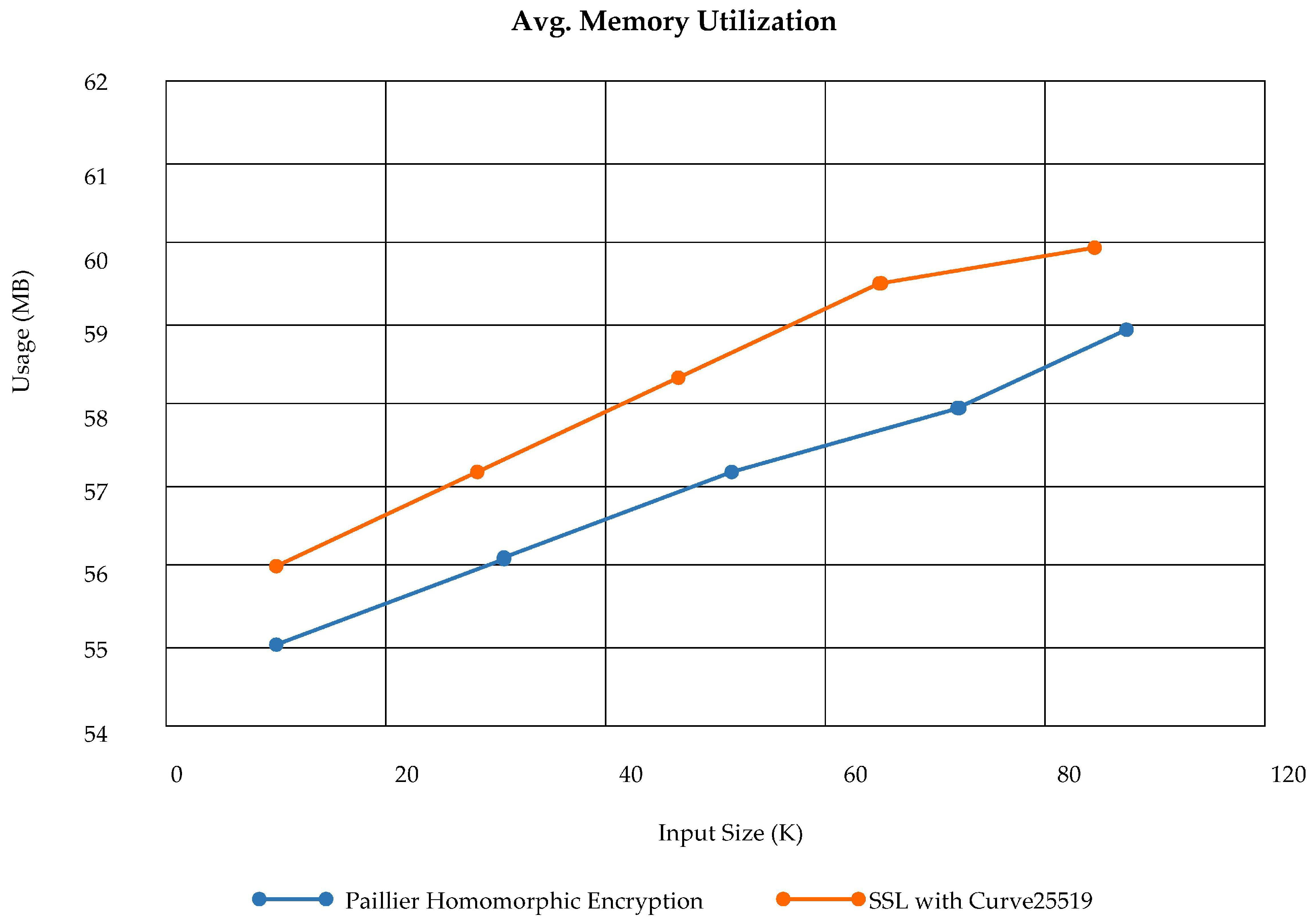
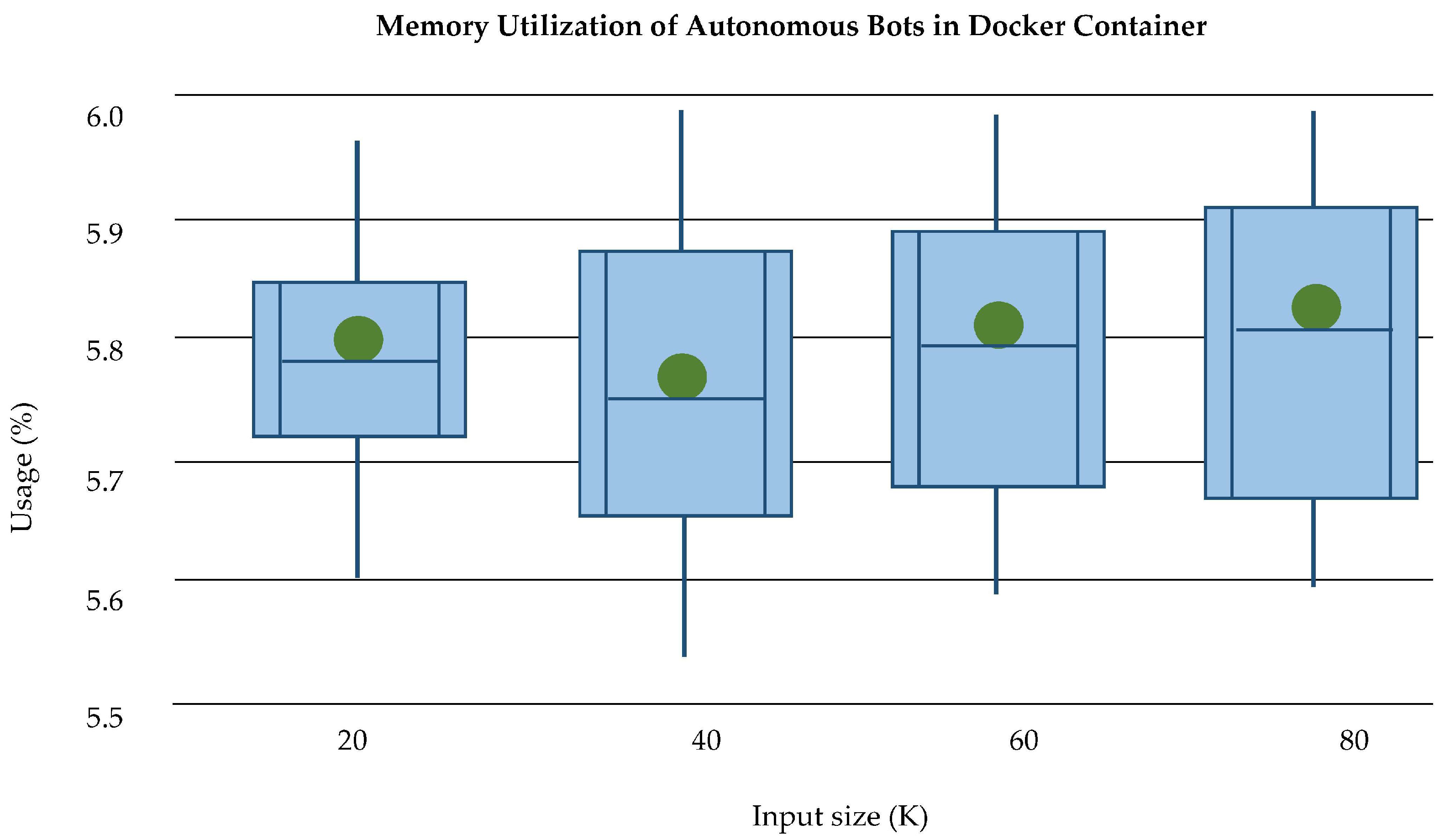
Memory Utilization: The memory utilization of docker container without bots is very low as shown in
Figure 25. As the data size increases after the deployment of bots, it requires more memory allocation than containers. The memory allocation of containers and bots has separately analyzed and described in
Figure 26. The average memory utilization at the third layer of PLAF of log size up to 120 K shows that PHE and SSL both use memory with a minimum difference, which can be seen in
Figure 27.
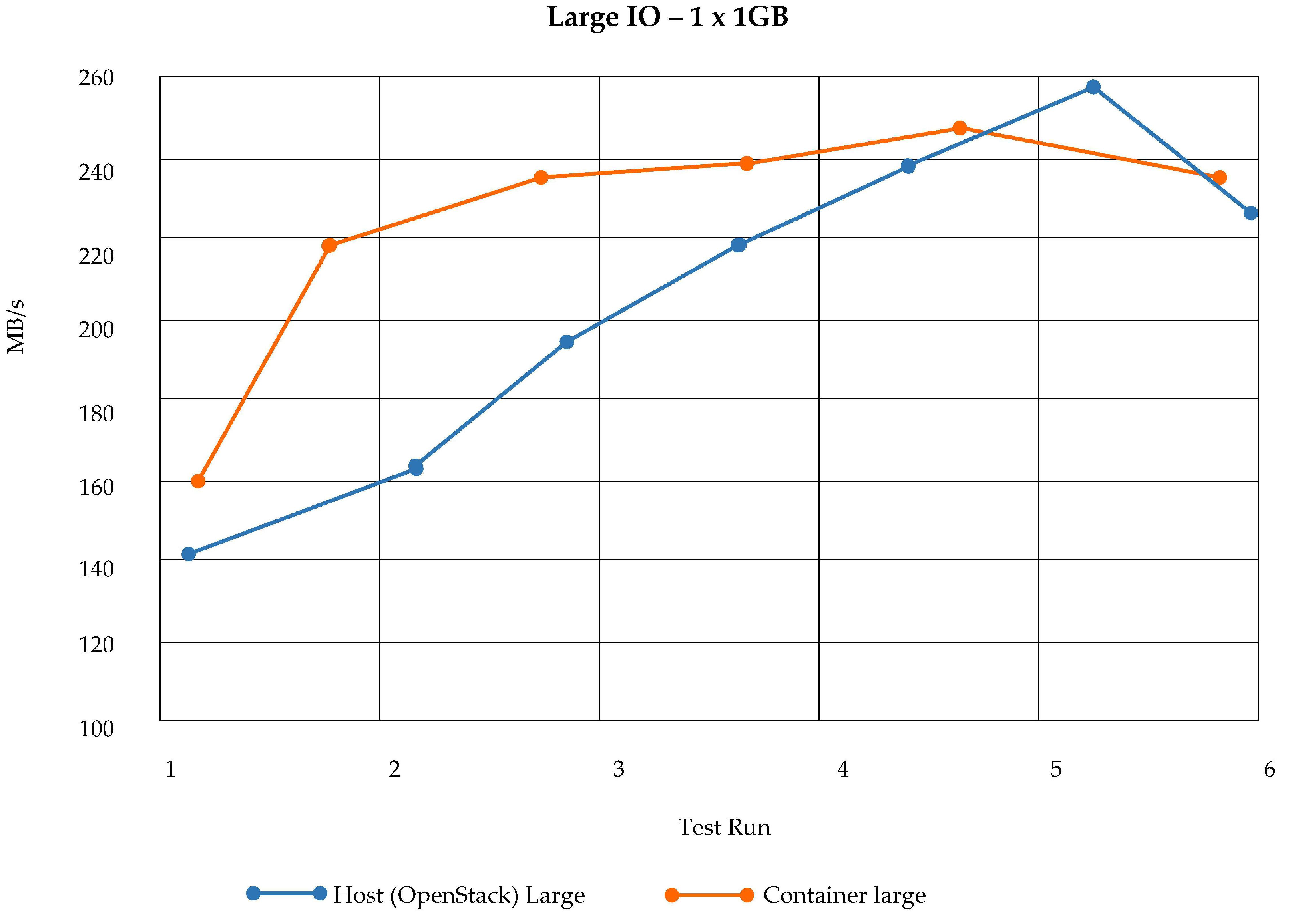
Complexity of Using Docker Containers in OpenStack: We have demonstrated the CPU and memory utilization of Docker containers and bots. Here, the resource usage terms of RAM of a docker container in a fog node controller are presented, which is an OpenStack cloud virtual machine. To build a fog node controller, we have used a virtual machine with the following specifications: Quad-core processor, 32 GB RAM, and 75 GB of storage. To test the docker usage according to OpenStack VM image specifications, we have executed two tests, which are resource complexity analysis on a large Host and resource complexity analysis on a small host. Results of testing using a large Host (OpenStack) shows that we can deploy a large number of containers, which means that a fog node controller must be equipped with maximum resource allocation. This phenomenon is shown in
Figure 28.
Conversely, the deployment of a small host (OpenStack) shows that the inverse results as compared to a large host. We can conclude here that a docker container doesn’t use many resources but is adaptable to host machine resources. The results of small host usage are shown in
Figure 29.
5.3. Security Analysis
PLAF is designed for all the security attributes discussed previously and can address the issues in the existing literature. We summarize the limitations in existing schemes and explain how PLAF tackle these.
In the case of a typical cloud attack incident, an agent demands the CSP for a log database for integrity-based validation as forensic evidence. If log validity is not checked, it cannot be accepted and is not credibly acceptable as forensic evidence. However, PLAF guarantees log integrity, log verification, provenance, trust admissibility, temper resistance, ownership non-repudiation, and privacy-preserving automation using Holochain to check the log integrity over a distributed network of hash table at a fog level. We have performed and analyzed the security comparison of PLAF with all the existing literature techniques addressed in
Section 2. From the analysis of literature, we have comprehended the essential security requirements for privacy and security-aware log preservation. The scrutinized security requirements were as follows; Ownership Non-Repudiation, Trust admissibility, the provenance of PPL, Temper Resistance, Log Integrity, Log Verifiability, and Privacy-Preservation Automation.
PLAF acquires all the aforementioned security requirements and can defeat each aspect of the threat model given in
Section 3. A comprehensive comparison of PLAF with the existing literature is provided in
Table 6. The essential security requirements are placed in columns; therefore, we aimed to comprehensively analyze the gains of PLAF with a lack of existing literature. The tick and cross signs indicate the presence and absence of security requirements. The security comparison in
Table 6 describes the novice contributions offered by PLAF that outperform with all other existing work. In addition,
Table 6 provides the security comparison in the context of essential scrutinized security requirements for log preservation. It can be observed that PLAF provides the following distinctions over existing techniques which are used for the securing of logs in the CLS, which is described in the following points:
Independent autonomous forensic log collection framework assisted via automated bots.
Previous workers secure the log data through data encryption and deception methods but heavily rely on their respective CSPs. PLAF incorporates the automation of edge node log collection, which provides integrity and privacy management.
Logging scheme that incorporates the security of edge nodes logs into the account.
PLAF is formulated to hash the log chain and proof for log replication in such a way that log modification could be supervised throughout the log verification process.
Preventing the log compromise due to collusion between the owner CSP, the customer, and the investigators.
Because all CSPs have encrypted database and PPL data, there is no possible way to avoid or check the involvement between owners, investigators, and CSPs with DB and the PPL records. However, in PLAF, the log chains of all DHTs cannot be modified from distributed fog nodes because it shares encrypted and distributed log chains with other network fog nodes.
5.3.1. Log Integrity Verification
In the case of an accident affecting classic cloud protection, a forensic authority first needs an integrity-based report from CSP for the processing of technical evidence and the interpretation of records. If the validity of the documents is not proven, they are not legitimately accurate and cannot be regarded as forensic evidence. Moreover, PLAF preserves the log integrity with the hash function of log chain digest and tests the accuracy logs using a distributed storage network of Holochain.
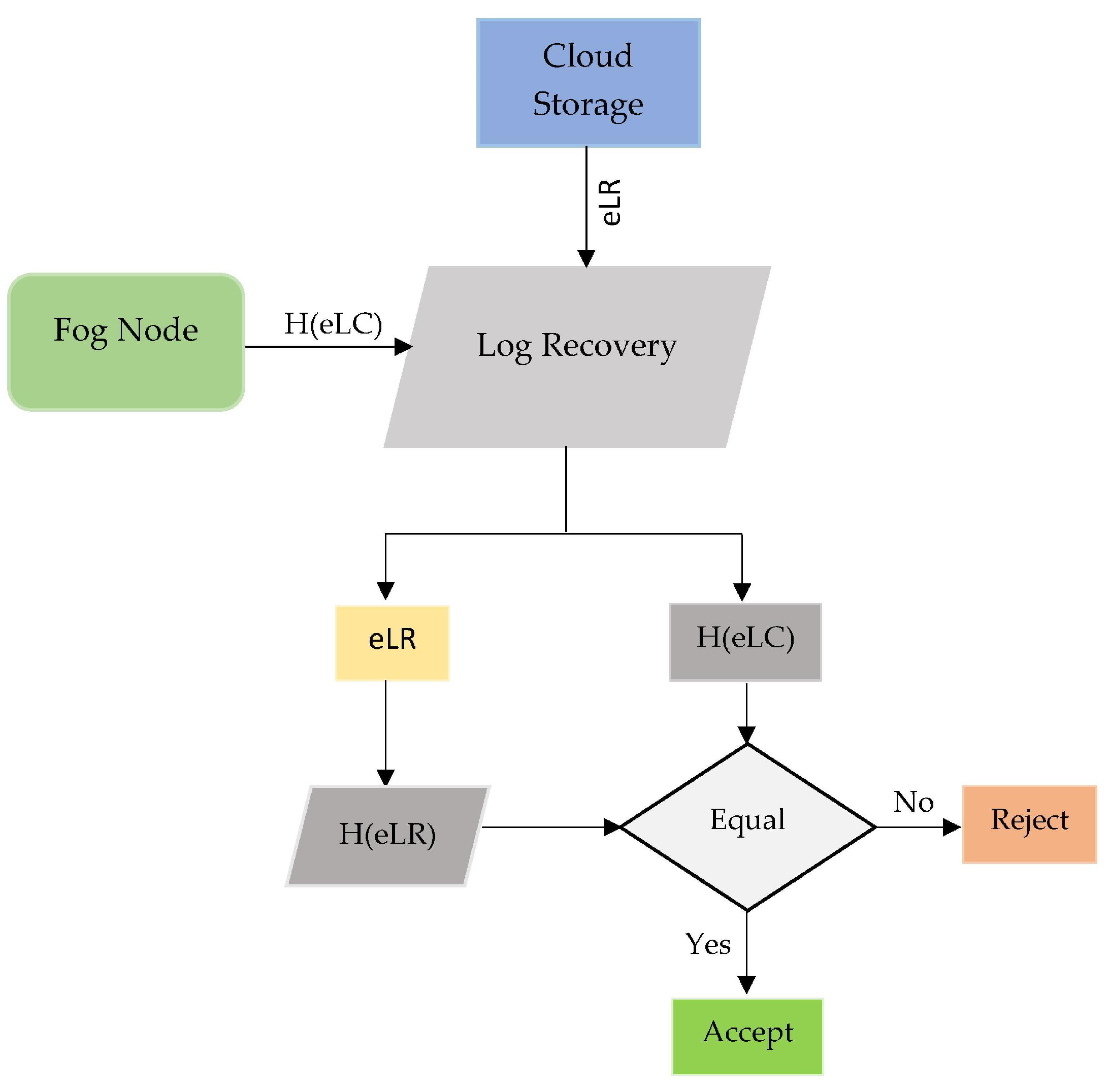
Fog nodes create log chain hash values Hashes of encrypted log chain (H(eLC)) to ensure the log integrity.
Figure 30 describes how to log data from cloud and fog nodes can be verified for integrity. The investigators collect distributed log digest data and recover the log data using log chain validation to verify the validity of the log data. As the cloud storage data recovered comprises of encrypted log record (eLR)) and Hash of Log chain (H(eLR)), the collected (H(eLC)) data chain from fog node is pondered to see whether they match (H(eLR)). The validity of integrity will be validated if both information complements each other.
5.3.2. Log Chain Validation
To ensure the correct order of each log file, we used Precision Time Protocol (ptp) to sync the same time. PLAF provides the accurate sync up time among fog nodes of log digest via PTP. The Precision Time Protocol (PTP) implementation [
58] has ensured synchronization between clocks from all fog nodes. Furthermore, it should be noted that, before updating the log digest, the end-to-end time synchronization is achieved. This method permits the timestamps to be shared with fog worker nodes that can verify if the timestamp is altered or not. It also prohibits the tempered timestamp addition and publication.
Log Validation algorithm (LVA) with time complexity is the timestamp sharing and comparison method as described in Algorithm 1. Timestamp comparison is done to validate the correct order of log files. The input variables are: TBI (timestamp block identifier), PathGTB
(Path identifier of groups of all timestamp block), and MTID (Multi-timestamp path identifiers). LVA works on two phases, which are timestamp generation and sharing, and timestamp blocks for comparison or validation.
| Algorithm 1: Log Validation Algorithm (LVA) |
![Electronics 09 01172 i001]() |
The first phase of LVA generates TID (timestamp identifiers) using Bot_ID, Timestamp, logfile_ID. BTID (block of timestamps) used to publish these Timestamps to investigators. BTID is composed of TID and PathGTB of all identifiers.
Log validation and comparison is done in phase two of LVA. Here, the correct orderings of all timestamp are compared to published BTIDs in a while loop. This phase provides information about log validation by confirming the order of timestamps. If the order and given timestamp is equal to timestamp under comparison, then it is declared as SAFE otherwise tempted:
We calculated the time and space complexity of both phases of LVA. The time complexity of phase one and two is described as in Equation (
2), which shows
T(
n) = each fog node(timestamp blocks generation) + (timestamp comparison). The space complexity of phase one and two is
O(
n) = each edge node(timestamp blocks generation) + (timestamp comparison) as given in Equation (
3).
6. Discussion
Investigating various logs such as process logs and network logs plays a vital role in computer forensics. Collecting logs from a cloud is a challenging task due to the black-box nature and the multi-tenant cloud models, which can impinge on consumer privacy when accumulating logs. Moreover, the shifting paradigm of cloud computing toward fog computing brought new challenges for digital forensics. Smart nodes are more susceptible to security threats and with less computing resources, making this impossible to gather logs.
This work proposed a forensic aware logging architecture for security and privacy-aware log autonomous log preservation in fog enabled cloud federations. We also considered the secured and privacy concerned distributed edge node log collection by tackling the multi-stakeholder collusion problem. To address the problem domain of PLAF, we also compared the security requirements with the threat model and analyzed the required security controls. Based on scrutinized security controls, we have designed the security requirements via Secure Tropos methodology.
PLAF offers the seven essential security requirements needed against some security threats which are privacy violation, owner repudiation, log modification integrity theft, edge node tempering, and computation overhead at edge level. The following are the addressed security requirements: Ownership Non-Repudiation, Trust admissibility, provenance of PPL, Temper Resistance, Log Integrity, Log Verifiability, and Privacy Preservation Automation. PLAF architecture is comprised of three layers to mitigate the above-mentioned threats and affect the security requirements. The first layer provides privacy preservation automation to avoid edge level threats. The second layer mitigates the log integrity and privacy threats by implementing the Holochain distributed network that is not acquainted with existing Blockchain technology, which is a power-consuming approach. Ownership repudiation, privacy violation issues, and multi-stakeholder issues are dulled at the third layer of PLAF via Paillier Homomorphic Encryption for secure storage and SSL with curve25519 mutual authentication, respectively.

 ,
, 
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}