REVERT: A Network Failure Recovery Method for Data Center Networks

Abstract
:1. Introduction
1.1. Motivation
1.2. Our Proposal
1.3. Contributions
- Except recovering the switches failures and failures of links between switches, how to recover the failures of links between the switches and servers is also considered in this work.
- The REVERT, which contains a failure preprocessing method, a data structure, a server cluster agent and a routing path calculation method, is proposed to recover network failures in SDDCNs, especially the failures of links between the switches and servers.
- REVERT has been implemented based on the RYU controller. Meanwhile, the performance of REVERT has been evaluated utilizing Mininet, in terms of ability of recovering the above three kinds of network failures, recover time, link utilization and load balance degree.
2. Related Work
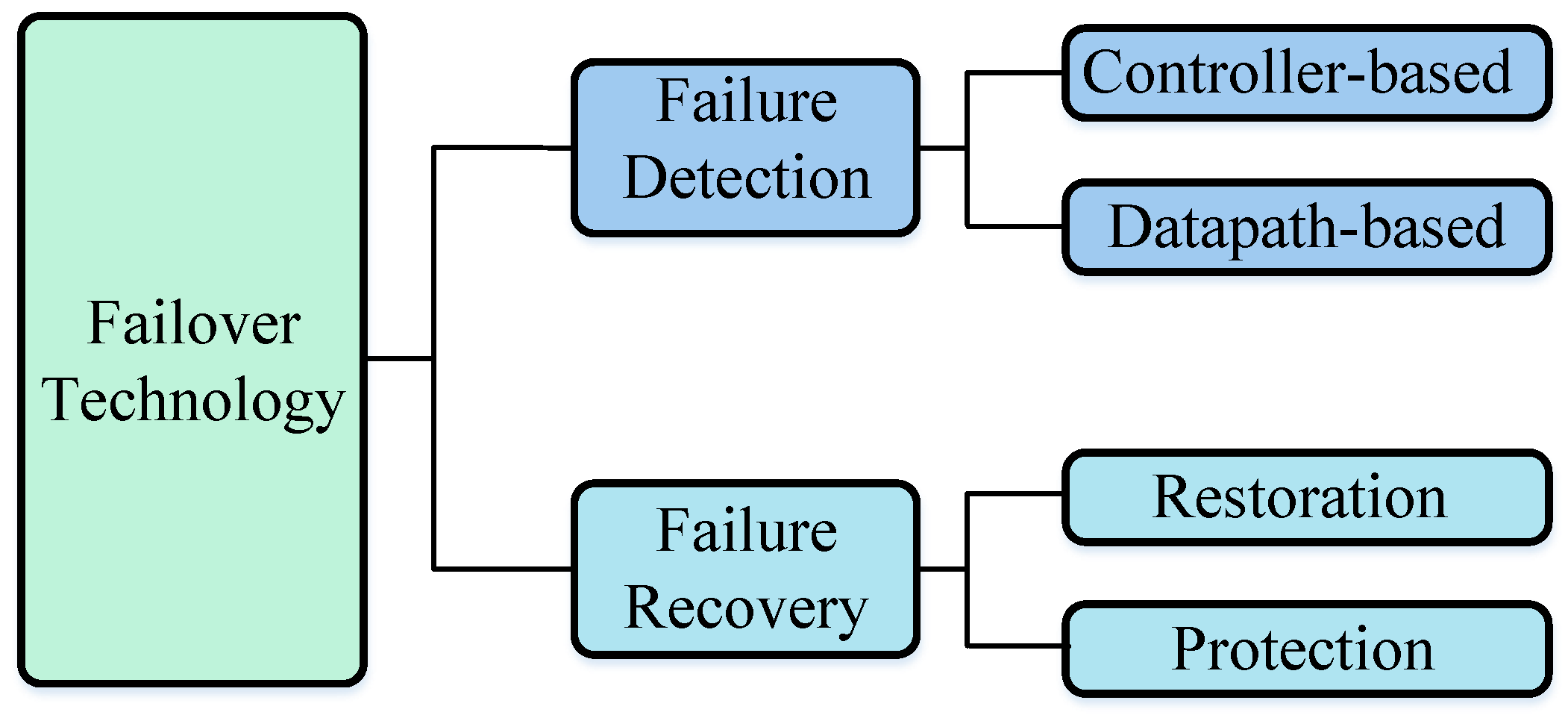
2.1. Failure Detection
2.2. Failure Recovery
3. REVERT: A Network Failure Recovery Method for SDDCNs
3.1. Detailed Design of REVERT
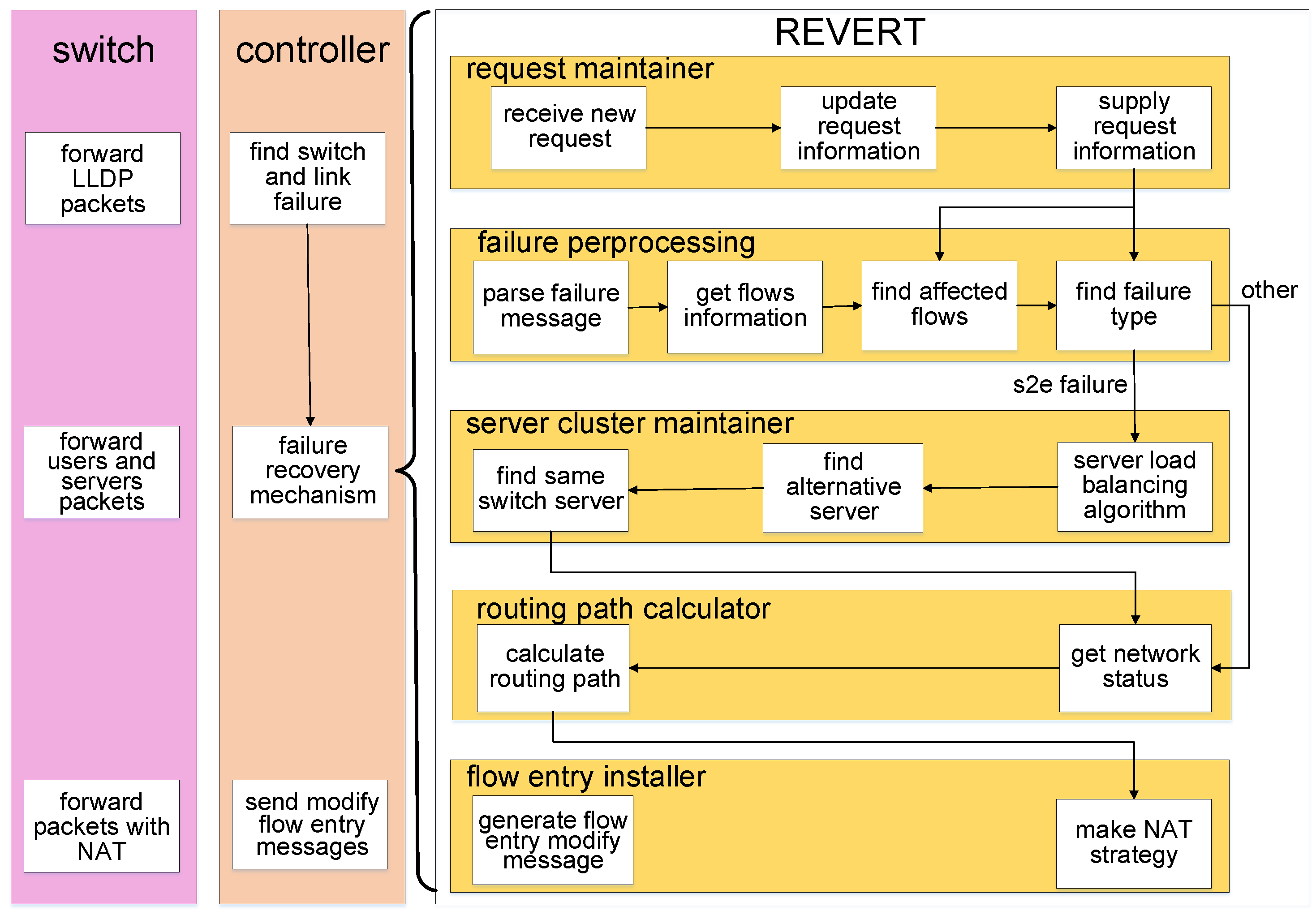
3.1.1. Overall Architecture of REVERT
3.1.2. Recovering Network Failures
3.1.3. Storing Information and Finding Affected Flows
| Algorithm 1: Recovering network failures |
| Input: failure message |
Output: recover affected flows
|
| Algorithm 2: Storing information |
| Input: routing path message , alternative server , affected flow |
| Output: store and update related information in , |
|
3.1.4. Selecting Alternative Routing Paths
| Algorithm 3: Routing algorithm based on GA. |
| Input:, source address src_ip and destination address dst_ip. |
Output: routing path
|
4. Evaluation
4.1. Evaluation Metrics
4.1.1. Recovery Time
4.1.2. Link Usage and Load Balancing Degree
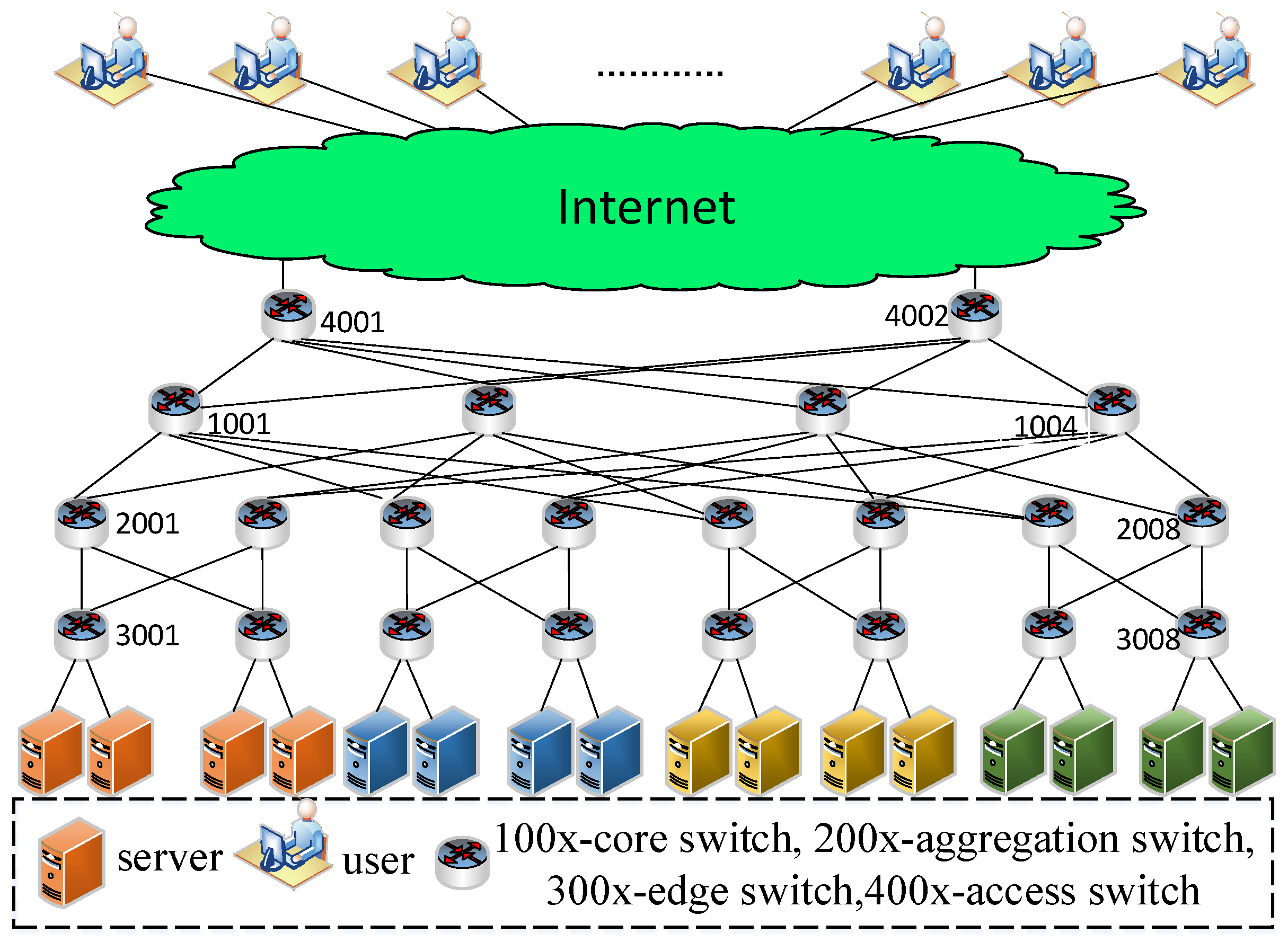
4.2. Simulation Setting
4.3. Evaluation Results
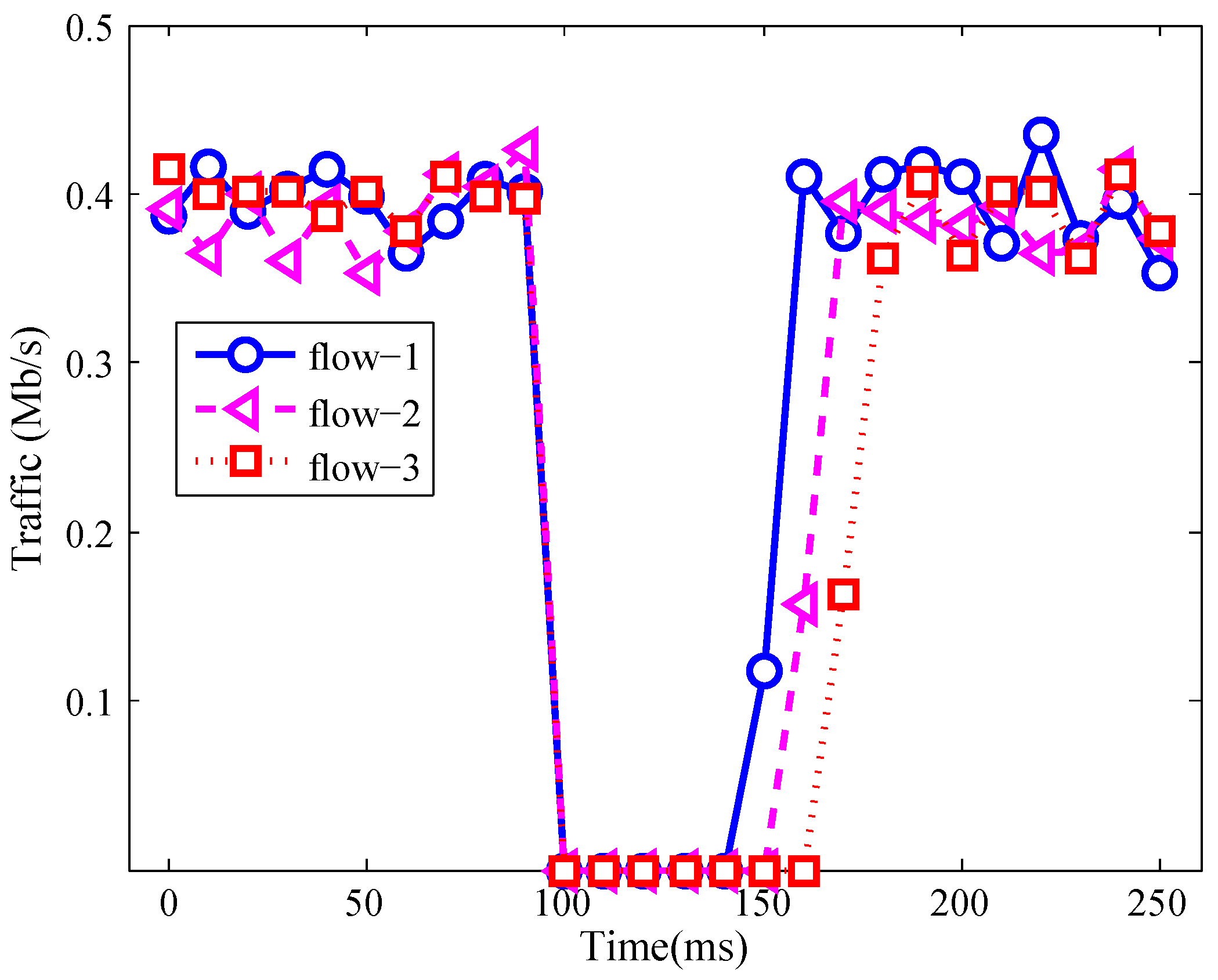
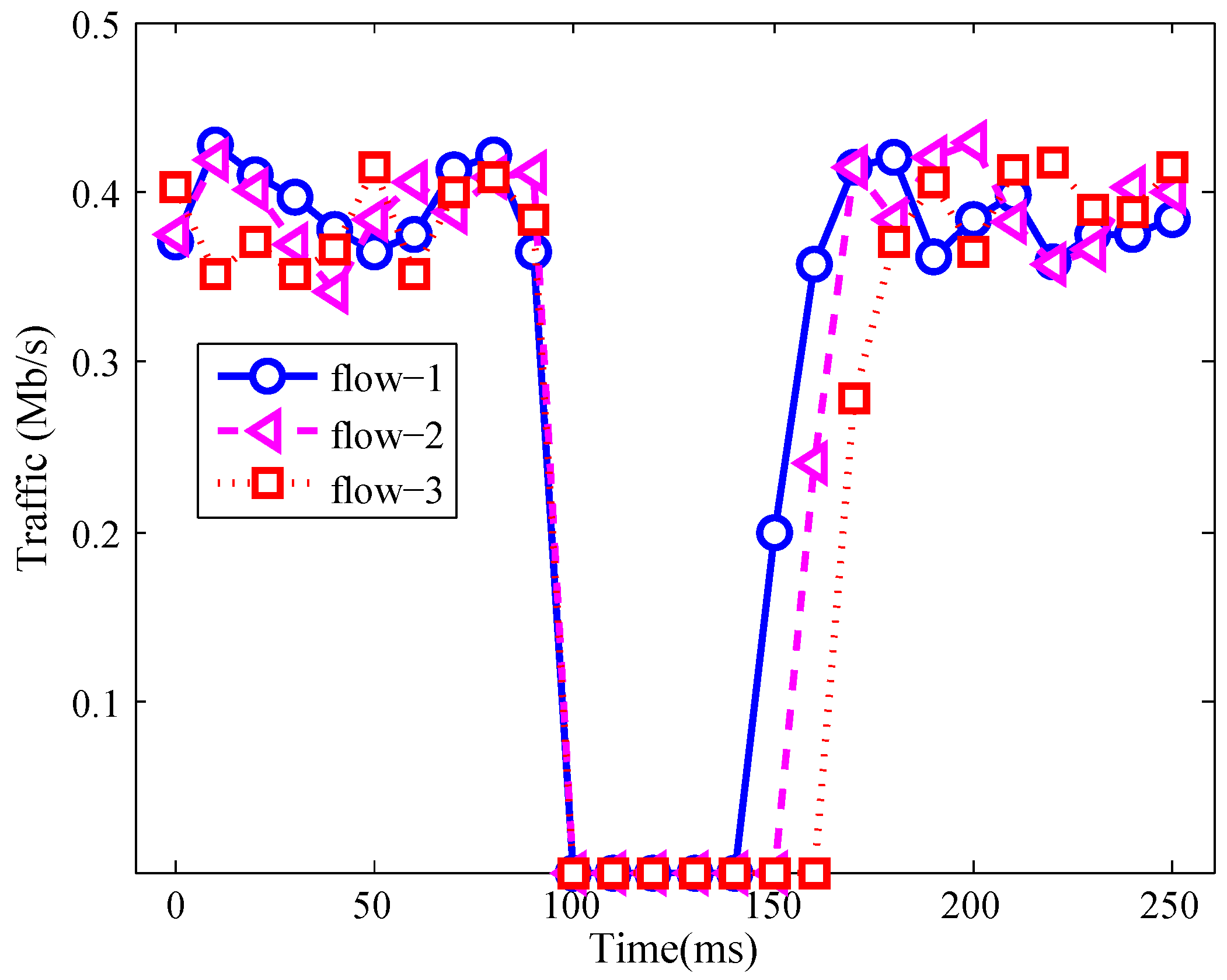
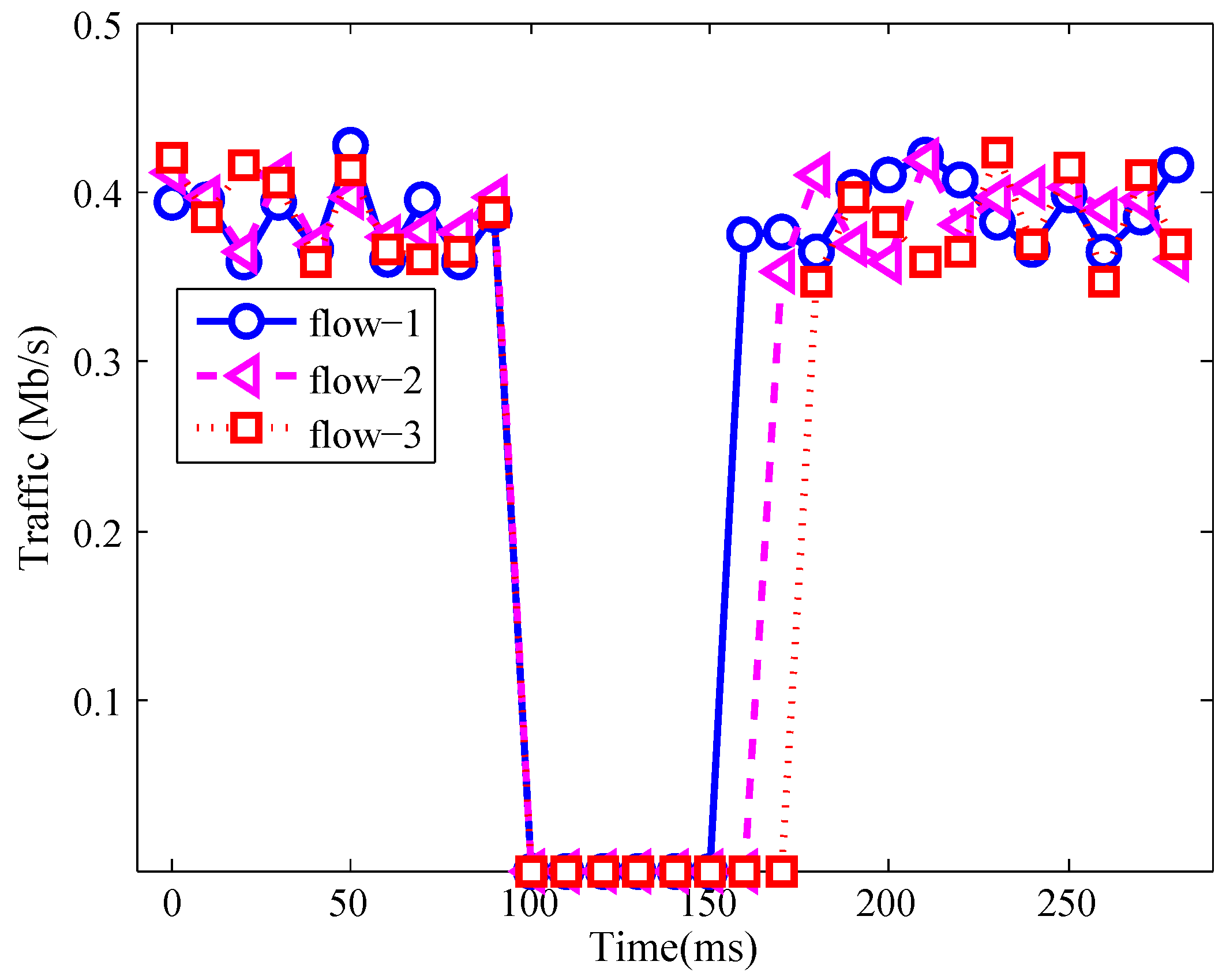
4.3.1. Ability of Recovering Three Kinds of Network Failures
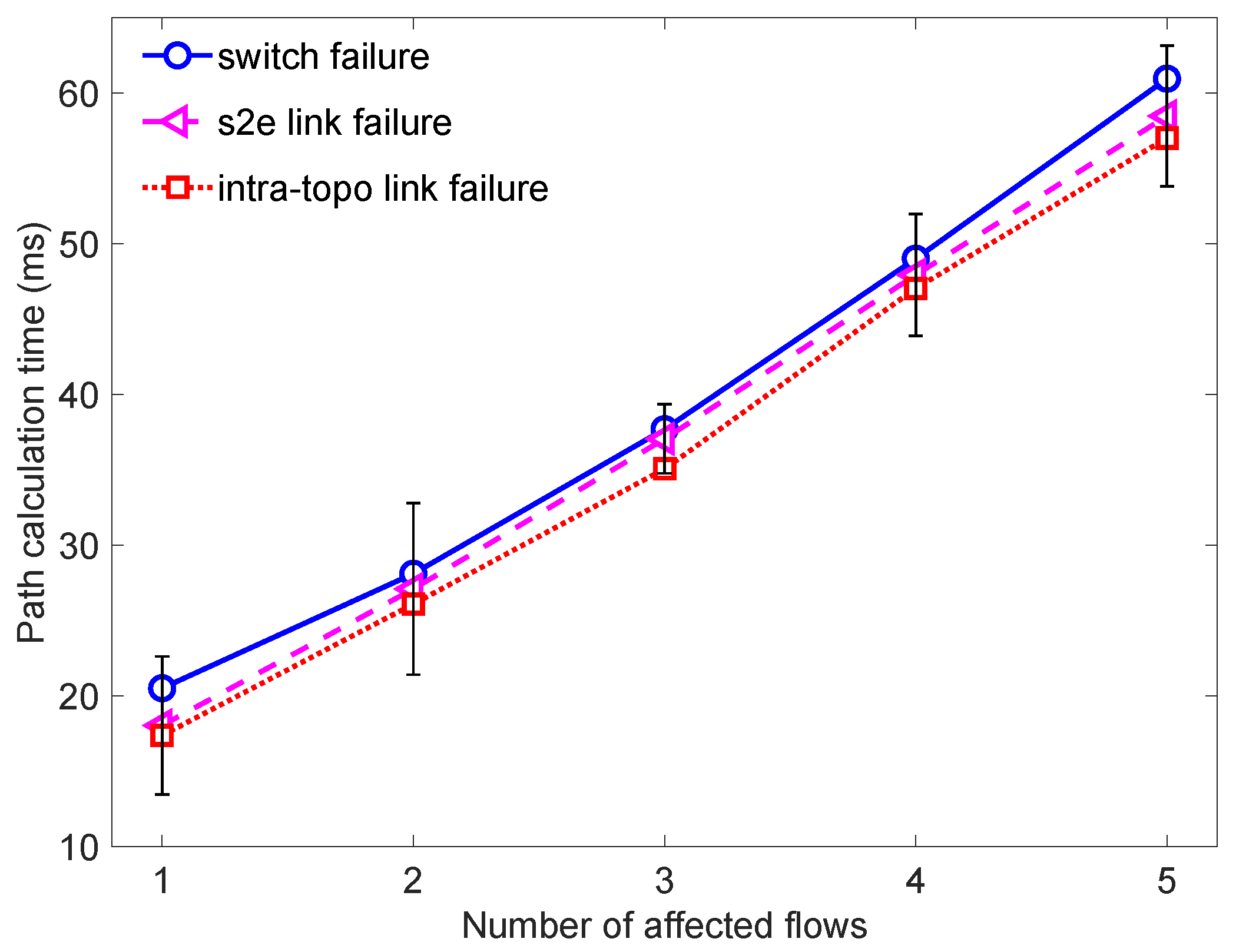
4.3.2. Recover Time
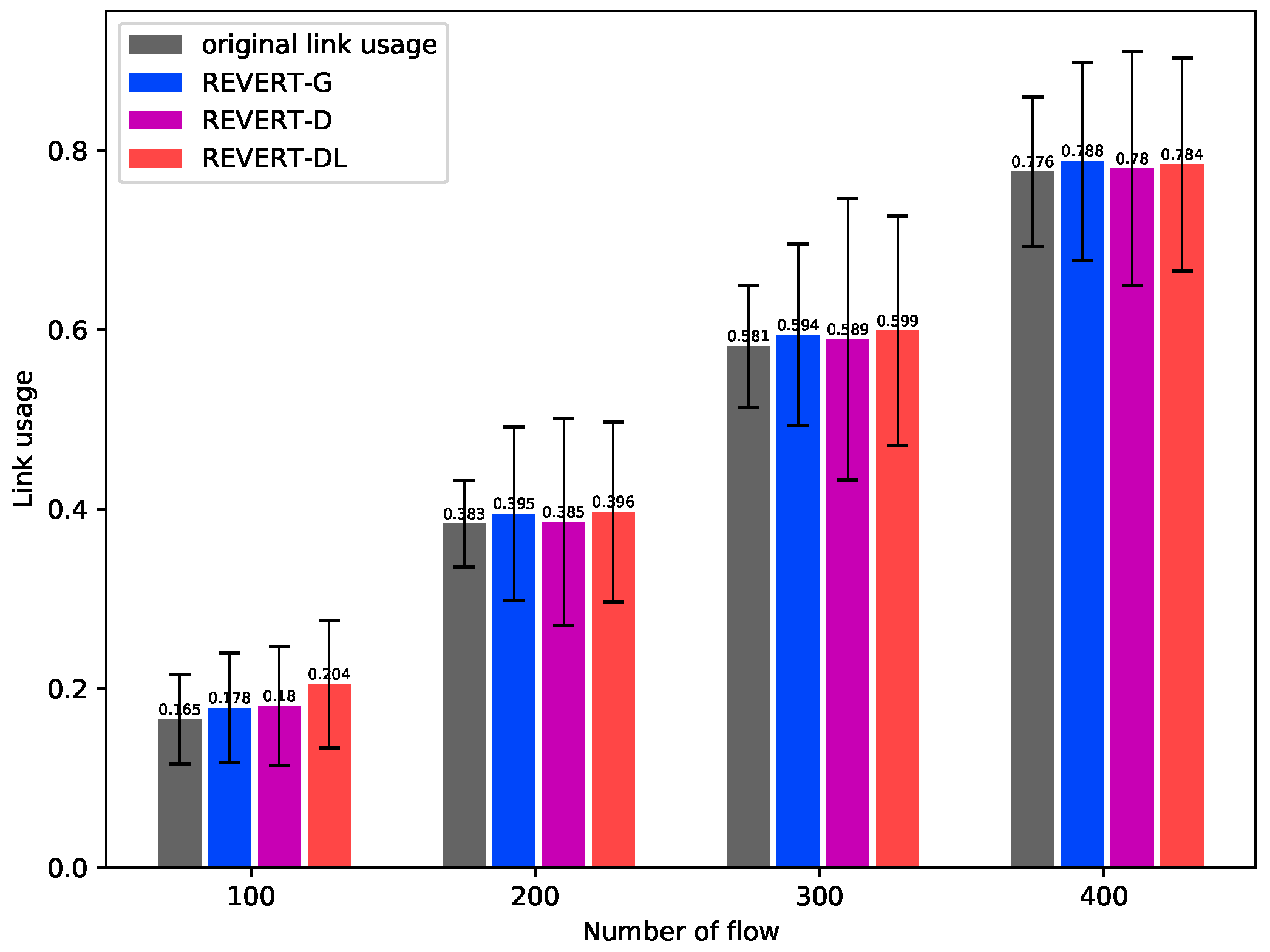
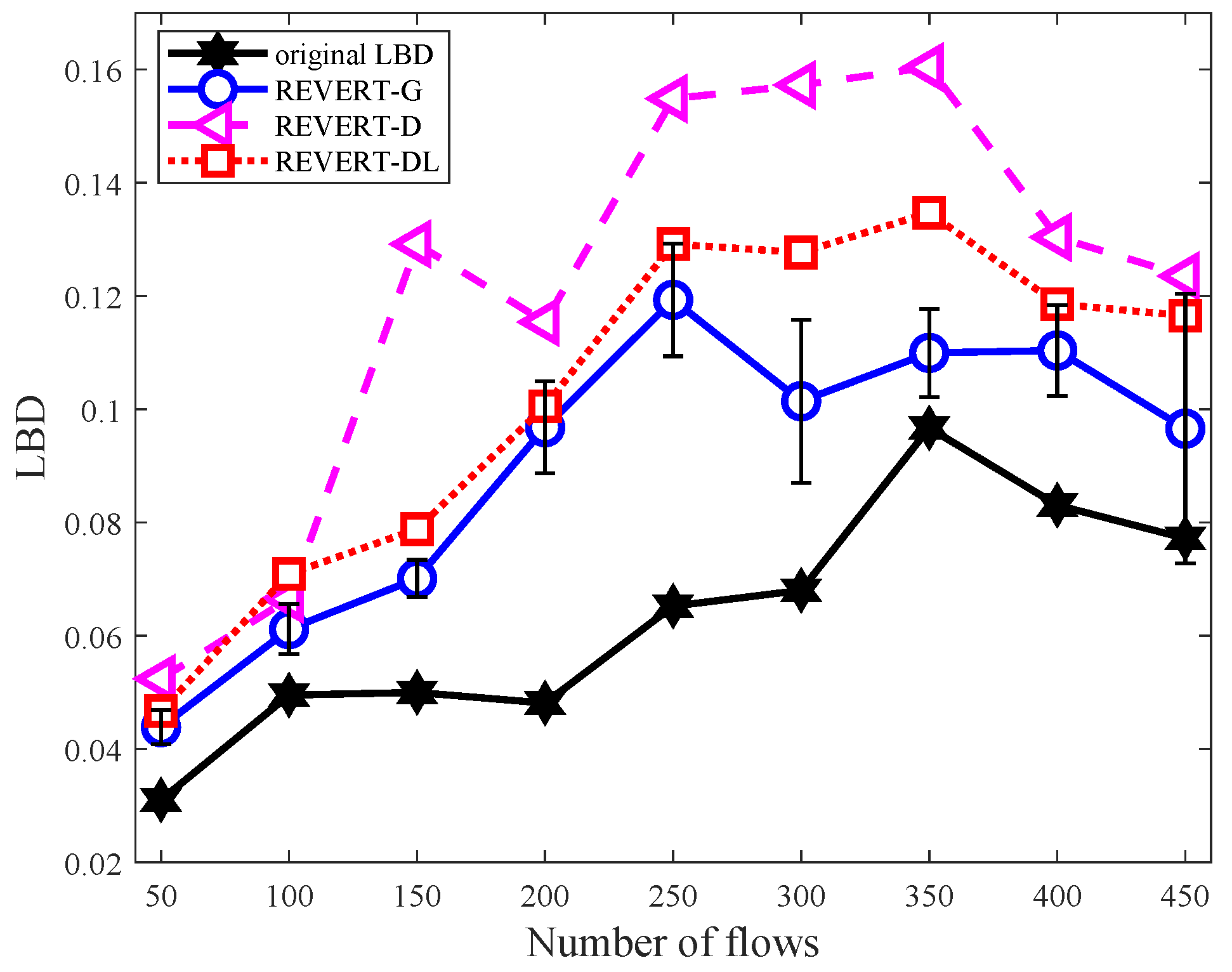
4.3.3. Link Usage and Load Balance Degree
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Di, S.; Kondo, D.; Cappello, F. Characterizing cloud applications on a Google data center. In Proceedings of the 2013 42nd International Conference on Parallel Processing, Lyon, France, 1–4 October 2013; pp. 468–473. [Google Scholar]
- Dehury, C.K.; Sahoo, P.K. Failure Aware Semi-Centralized Virtual Network Embedding in Cloud Computing Fat-Tree Data Center Networks. IEEE Trans. Cloud Comput. 2020. [Google Scholar] [CrossRef]
- Marahatta, A.; Wang, Y.; Zhang, F.; Kumar, A.; Tyagi, S.K.S.; Liu, Z. Energy-Aware Fault-Tolerant Dynamic Task Scheduling Scheme for Virtualized Cloud Data Centers. Mob. Netw. Appl. 2019, 24, 1063–1077. [Google Scholar] [CrossRef]
- Zhang, M.; Mysore, R.N.; Supittayapornpong, S.; Govindan, R. Understanding lifecycle management complexity of datacenter topologies. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’19), Boston, MA, USA, 26–28 February 2019; pp. 235–254. [Google Scholar]
- Sun, G.; Zhou, R.; Sun, J.; Yu, H.; Vasilakos, A.V. Energy-efficient provisioning for service function chains to support delay-sensitive applications in network function virtualization. IEEE Internet Things J. 2020, 7, 6116–6131. [Google Scholar] [CrossRef]
- Wang, S.; Bi, J.; Wu, J.; Vasilakos, A.V.; Fan, Q. VNE-TD: A virtual network embedding algorithm based on temporal-difference learning. Comput. Netw. 2019, 161, 251–263. [Google Scholar] [CrossRef]
- Tank, G.P.; Dixit, A.; Vellanki, A.; Annapurna, D. Software-Defined Networking: The New Norm for Networks. Available online: https://www.opennetworking.org/images/stories/downloads/sdn-resources/white-papers/wp-sdn-newnorm.pdf (accessed on 27 May 2020).
- Bao, X.; Liang, H.; Liu, Y.; Zhang, F. A Stochastic Game Approach for Collaborative Beamforming in SDN-Based Energy Harvesting Wireless Sensor Networks. IEEE Internet Things J. 2019, 6, 9583–9595. [Google Scholar] [CrossRef]
- Jain, S.; Kumar, A.; Mandal, S.; Ong, J.; Poutievski, L.; Singh, A.; Venkata, S.; Wanderer, J.; Zhou, J.; Zhu, M.; et al. B4: Experience with a globally-deployed software defined WAN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 3–14. [Google Scholar] [CrossRef]
- Cui, Y.; Yan, L.; Li, S.; Xing, H.; Pan, W.; Zhu, Z.; Zheng, X. SD-Anti-DDoS: Fast and efficient DDoS defense in software-defined networks. J. Netw. Comput. Appl. 2016, 68, 65–79. [Google Scholar] [CrossRef]
- Lee, S.S.W.; Li, K.Y.; Chan, K.Y.; Lai, G.H.; Chung, Y.C. Path layout planning and software based fast failure detection in survivable OpenFlow networks. In Proceedings of the 2014 10th International Conference on the Design of Reliable Communication Networks (DRCN), Ghent, Belgium, 1–3 April 2014; pp. 1–8. [Google Scholar]
- Rehman, A.U.; Aguiar, R.L.; Barraca, J.P. Fault-Tolerance in the Scope of Software-Defined Networking (SDN). IEEE Access 2019, 7, 124474–124490. [Google Scholar] [CrossRef]
- Feng, S.X.; Wang, Y.; Zhong, X.X.; Zong, J.R.; Qiu, X.S.; Guo, S.Y. A Ring-based Single-link Failure Recovery Approach in SDN Data Plane. In Proceedings of the 2018 IEEE/IFIP Network Operations and Management Symposium (NOMS 2018), Taipei, Taiwan, 23–27 April 2018; pp. 1–8. [Google Scholar]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. In-band control, queuing, and failure recovery functionalities for OpenFlow. IEEE Netw. 2016, 30, 106–112. [Google Scholar] [CrossRef] [Green Version]
- Ramos, R.M.; Martinello, M.; Rothenberg, C.E. Slickflow: Resilient source routing in data center networks unlocked by openflow. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks ((LCN), Sydney, Australia, 21–24 October 2013; pp. 606–613. [Google Scholar]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. OpenFlow: Meeting carrier-grade recovery requirements. Comput. Commun. 2013, 36, 656–665. [Google Scholar] [CrossRef]
- Sgambelluri, A.; Giorgetti, A.; Cugini, F.; Paolucci, F.; Castoldi, P. OpenFlow-based segment protection in Ethernet networks. J. Opt. Commun. Netw. 2013, 5, 1066–1075. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, Y.; He, Q.; Yu, J.; Guo, S. Backup-resource based failure recovery approach in SDN data plane. In Proceedings of the 2016 18th Asia-Pacific Network Operations and Management Symposium (APNOMS), Kanazawa, Japan, 5–7 October 2016; pp. 1–6. [Google Scholar]
- Tomassilli, A.; Di Lena, G.; Giroire, F.; Tahiri, I.; Saucez, D.; Perennes, S.; Turletti, T.; Sadykov, R.; Vanderbeck, F.; Lac, C. Poster: Design of survivable SDN/NFV-enabled networks with bandwidth-optimal failure recovery. In Proceedings of the 2019 IFIP Networking Conference (IFIP Networking), Warsaw, Poland, 20–22 May 2019. [Google Scholar]
- Chu, C.Y.; Xi, K.; Luo, M.; Jonathan Chao, H. Congestion-aware single link failure recovery in hybrid SDN networks. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; pp. 1086–1094. [Google Scholar]
- Li, J.; Hyun, J.H.; Yoo, J.H.; Baik, S.; Won-Ki Hong, J. Scalable failover method for data center networks using OpenFlow. In Proceedings of the 2014 IEEE Network Operations and Management Symposium (NOMS), Krakow, Poland, 5–9 May 2014; pp. 1–6. [Google Scholar]
- Kempf, J.; Bellagamba, E.; Kern, A.; Jocha, G.; Takacs, A.; Sköldström, P. Scalable fault management for OpenFlow. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 6606–6610. [Google Scholar]
- Van Adrichem, N.L.M.; van Asten, B.J.; Kuipers, F.A. Fast recovery in software-defined networks. In Proceedings of the 2014 Third European Workshop on Software Defined Networks, Budapest, Hungary, 1–3 September 2014; pp. 61–66. [Google Scholar]
- Achleitner, S.; Bartolini, N.; He, T.; La Porta, T.; Tootaghaj, D.Z. Fast Network Configuration in Software Defined Networking. IEEE Trans. Netw. Serv. Manag. 2018, 15, 1249–1263. [Google Scholar] [CrossRef]
- Xu, A.; Bi, J.; Zhang, B.; Xu, T.; Wu, J. USTR: A High-Performance Traffic Engineering Approach for the Failed Link. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1–8. [Google Scholar]
- Borokhovich, M.; Schiff, L.; Schmid, S. Provable data plane connectivity with local fast failover: Introducing openflow graph algorithms. In Proceedings of the 3rd Workshop Hot Topics Software Defined Networking (HotSDN), Chicago, IL, USA, 22 August 2014; pp. 121–126. [Google Scholar]
- Geng, H.; Yao, J.; Zhang, Y. Single Failure Routing Protection Algorithm in the Hybrid SDN Network. Comput. Mater. Contin. 2020, 64, 665–679. [Google Scholar] [CrossRef]
- Nguyen, K.; Minh, Q.T.; Yamada, S. A software-defined networking approach for disaster-resilient WANs. In Proceedings of the 2013 22nd International Conference on Computer Communication and Networks (ICCCN), Nassau, Bahamas, 30 July–2 August 2013; pp. 1–5. [Google Scholar]
- Kim, H.; Schlansker, M.; Santos, J.R.; Tourrilhes, J.; Turner, Y.; Feamster, N. Coronet: Fault tolerance for software defined networks. In Proceedings of the 2012 20th IEEE International Conference on Network Protocols (ICNP), Austin, TX, USA, 30 October–2 November 2012; pp. 1–2. [Google Scholar]
- Kitsuwan, N.; Slyne, F.; McGettrick, S.; Payne, D.; Ruffini, M. A Europe-wide demonstration of fast network restoration with OpenFlow. IEICE Commun. Express 2014, 3, 275–280. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Enabling fast failure recovery in OpenFlow networks. In Proceedings of the 2011 8th International Workshop on the Design of Reliable Communication Networks (DRCN), Krakow, Poland, 10–12 October 2011; pp. 164–171. [Google Scholar]
- Astaneh, S.A.; Heydari, S.S. Optimization of SDN flow operations in multi-failure restoration scenarios. IEEE Tran. Netw. Serv. Manag. 2016, 13, 421–432. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Fast failure recovery for in-band OpenFlow networks. In Proceedings of the 2013 9th International Conference on the Design of Reliable Communication Networks (DRCN), Budapest, Hungary, 4–7 March 2013; pp. 52–59. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Type | Technique | Application Scenarios | Contribution | Limitation |
|---|---|---|---|---|---|
| [19] | Protection | ILP; column generation | hybrid SDN network | It precomputes a set of rerouting paths while satisfies the service function chain requirements. | When recovering the network failures, the current network traffic statistics information is not considered. |
| [20] | Restoration | heuristic algorithm; optimization problem; rerouting | hybrid SDN network | It can recover network failures in hybrid SDN networks, by reroute the traffic on the failed link through rerouting paths. | It needs to periodically calculate rerouting paths, no matter whether a link failure occurs. |
| [21] | Restoration | connectivity matrix table; local optimal method; uplink and downlink separation | SDN network | It can recover the network failure using a connectivity matrix table and a local optimal method, where the port has least load will be chosen as the recover out port. | A static value has been chosen to collect the traffic statistic information. When calculating the rerouting path, only the traffic load is considered. |
| [26] | Restoration | modulo strategy; DFS; BFS | SDN network | It provides modulo strategy, DFS- and BFS-based routing algorithms used to recover the network failure. | No implementation and evaluation have been given in this work. |
| [27] | Restoration | 0-1 ILP; greedy algorithm | hybrid SDN network | Network failures are recovered by forwarding the affected packets to SDN switches. | The load balance is not considered when calculating rerouting paths. |
| This paper | Restoration | failure preprocess; failure classify; server cluster | SDN network | Except recovering the switch failure and failure of link between switches, it can also recover the failures of links between the switches and servers. | It is designed for SDN network, which means that it can not work in hybrid SDN network. |
| Notations | Definition |
|---|---|
| G | Network topology |
| V | A set of switches |
| E | A set of links |
| S | A set of servers |
| The ith switch | |
| The link between node and | |
| The ith server | |
| A set of links among switches | |
| A set of links connect switches and servers | |
| The cost of link | |
| The unit price of link | |
| The bandwidth required by the affected kth request | |
| The load rate of link | |
| The currently used bandwidth of link | |
| The total bandwidth of link |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Y.; Qian, Q.; Shen, G.; Guo, C.; Li, S. REVERT: A Network Failure Recovery Method for Data Center Networks. Electronics 2020, 9, 1187. https://doi.org/10.3390/electronics9081187
Cui Y, Qian Q, Shen G, Guo C, Li S. REVERT: A Network Failure Recovery Method for Data Center Networks. Electronics. 2020; 9(8):1187. https://doi.org/10.3390/electronics9081187
Chicago/Turabian StyleCui, Yunhe, Qing Qian, Guowei Shen, Chun Guo, and Saifei Li. 2020. "REVERT: A Network Failure Recovery Method for Data Center Networks" Electronics 9, no. 8: 1187. https://doi.org/10.3390/electronics9081187
APA StyleCui, Y., Qian, Q., Shen, G., Guo, C., & Li, S. (2020). REVERT: A Network Failure Recovery Method for Data Center Networks. Electronics, 9(8), 1187. https://doi.org/10.3390/electronics9081187