1. Introduction
The number of processing cores integrated into multiprocessor system-on-chips (MPSoCs) has increased rapidly, and conventional shared or multiple channel on-chip buses are no longer suitable as interconnect modules. Consequently, network-on-chips (NoCs) have become a crucial component for the overall system performance to provide parallelism and scalability. The design of NoCs typically requires the satisfaction of multiple conflicting constraints, including minimizing packet latency, reducing the router area, and lowering communication energy overheads [
1]. MPSoC systems are employed in many applications, such as networking, signal processing, general purpose, and deep neural networks, to meet the growing functional demands. The NoC, therefore, must be sufficiently flexible to support a wide range of on-chip communication scenarios and quality-of-service (QoS) requirements.
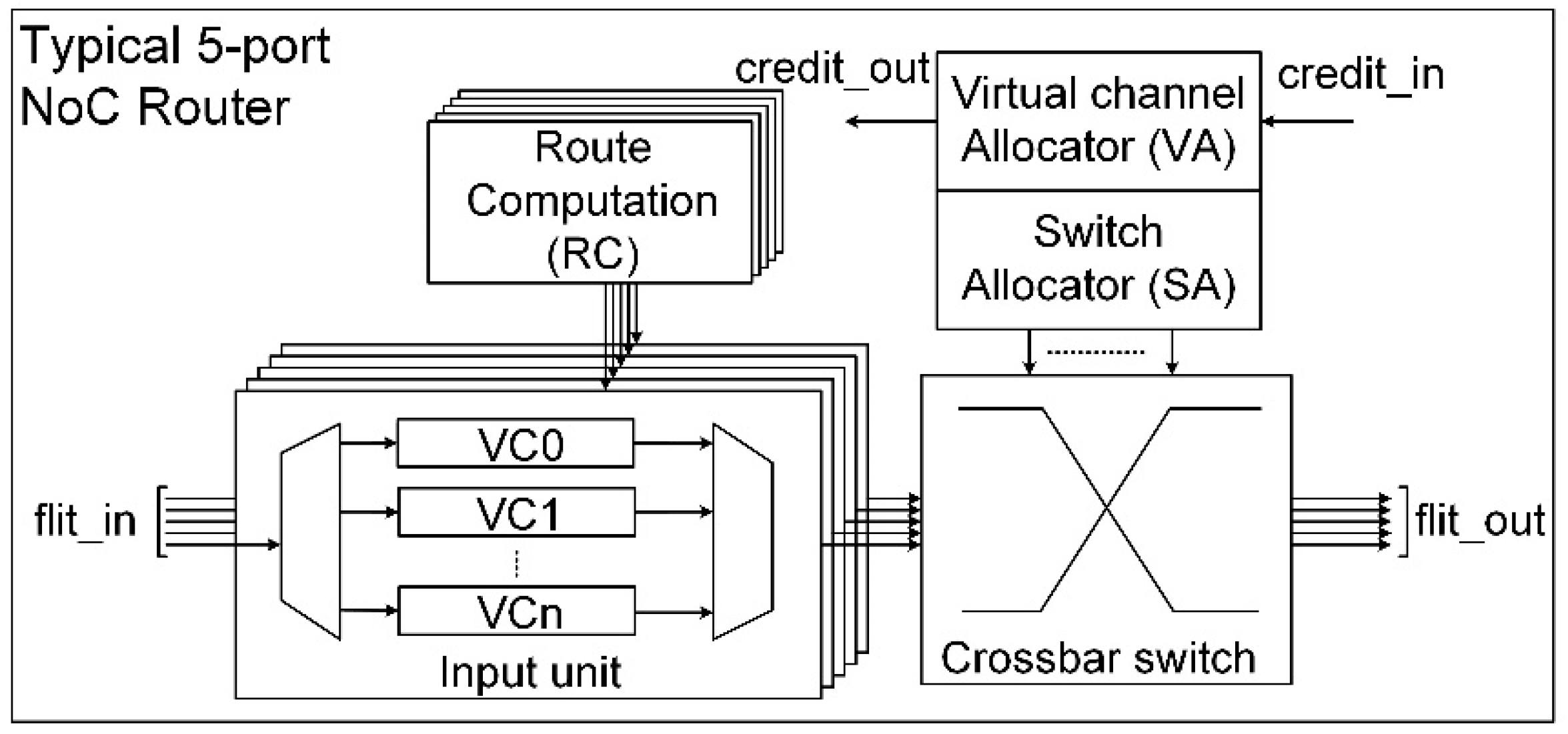
Conventional NoCs consist of five-port routers, to which only one local core can be attached per router [
2,
3,
4]. A flit passes through a router to the next hop after five stages of the routing process: route computation (RC), virtual channel allocator (VA), switch allocator (SA), switch traversal (ST), and link traversal (LT). Each input port of the router is equipped with collections of buffers referred to as virtual channels (VCs), which make the router complex. Although the VCs can improve the saturated bandwidth of the network, they do not increase the actual router bandwidth; rather than increasing the physical channels of the router, they incur a larger area overhead [
5]. Therefore, many multiport NoCs have employed 7-, 9-, 10-, or 11-port routers, which increase the physical channels of the router, and therefore, increase the maximum number of flits concurrently delivered through a router [
5,
6,
7].
There are two types of transactions that support the QoS in NoCs—guaranteed throughput (GT) and best effort (BE) traffic; further, GT is often given higher priority than BE [
8]. The network must meet the throughput and latency requirements of the GT traffic communications over a finite time interval between sources and destinations, while it attempts to forward packets of the BE traffic to destinations whenever possible, without satisfying any constraints. The two basic approaches in NoC designs to make the QoS support possible are reserved connections (hard guarantee) and prioritized routings (soft guarantee) [
9]. The soft guarantee, which is based on packet switching with multiple VCs, is usually employed. The hard guarantee, where the GT packets are never blocked by the BE packets, is obtained by circuit switching, where routing resources of an entire routing path from the source to destination need to be reserved. Most NoCs provide the BE service based on wormhole packet switching because of its efficient bandwidth utilization and high throughput [
2,
3,
4].
Wang and Bagherzadeh [
7] proposed a QoS-aware and congestion-aware multiport router architecture that exploits adaptive routing and multiple parallel buffers to provide the QoS for differentiated service classes with reasonable implementation costs compared with those of conventional NoCs. Their experimental results demonstrated that sharing routing resources (e.g., parallel buffers), as the network load increases for both BE and GT traffic, achieves better performance in latency and resource utilization than the reserved resource approach. Carara et al. [
5] proposed a 10-port NoC that duplicates the physical channels of the conventional router and provides various QoSs. However, the QoS may be affected when there are conflicts among high-priority traffic flows for the same routing paths, incurring high implementation costs because of the complex QoS control mechanism and the doubled number of ports. Ruaro et al. [
10] proposed a duplicated channel NoC that tracks the communication performance at runtime to dynamically change between the circuit and packet switching techniques according to the application requirements. Although this reduces the number of deadline violations for soft guaranteed services, it does not completely address this issue and QoS control is still complex. Dorai et al. [
11] proposed an NoC with double physical planes to support multimedia applications by controlling the traffic injection of four service levels. All the above mentioned NoCs were designed with fixed topologies and complicated router structures, which not only are difficult to apply in diverse traffic patterns but also consume a large chip area.
Because NoCs often consume a large portion (up to 40%) of the total chip power [
12], power efficiency is also an important aspect that needs to be carefully considered. Existing studies have stated that buffers are the most dominant factors, contributing at least 50%, for both the area and power in the conventional 5-port NoC (NoC5) [
13,
14]. This percentage increases significantly in multiport NoCs. Therefore, it is necessary to reduce the buffer amount as much as possible without significantly degrading the performance.
In this study, we propose a flexible and simplified NoC architecture, referred to as the unified system network architecture (USNA), which consists of routers and linkers that are used to configure various network topologies with various traffic patterns depending on the application. The architecture can also provide an acceptable soft guarantee at a very low cost. The router has multiple ports on which processor cores or linkers can be attached; the linker, which determines the operation types of the network, connects two adjacent routers, and can be register-sliced, a set of VCs, or a combination of both. The USNA provides flexibility for network configurations, so that system designers can easily customize the network in accordance with applications during the designing process. Additionally, a communication channel with zero latency can be established between the adjacent ports without the arbitration of a router. By allowing more than one local core per router, the network size can be reduced, which reduces the average routing distance, or the network size can be extended for the same number of local cores, where some routers can be configured as fully connecting components for communication-centric applications. Various USNA configurations have been simulated and analyzed to observe their effects on network performance under uniform random traffic and implementation costs. Additionally, the performance of the USNA is compared with that of other NoCs.
3. USNA Architecture
The USNA consists of routers and linkers. The number of ports per router can be flexibly configured, and either a local core or a linker can be attached to each port in a plug-and-play manner. The linker is used to connect the routers, and the local core is a computing unit. The number of local cores and link channels (linker) per router can be adjusted independently, depending on the application, whereas the conventional NoC can attach only one local core to the designated port. The USNA network, therefore, can be constructed in regular or customized topologies according to various application requirements. The topology defines possible routing paths through which a packet can be routed to reach its destination, which significantly affects the network performance and implementation costs. For example, one router can be eliminated without any performance degradation if the other router has two local cores, and a high communication bandwidth is not required. The behaviors at the interfaces between the router and local core and between the router and linker are similar, indicating that the local cores and linkers can be attached to any of the ports of the router.
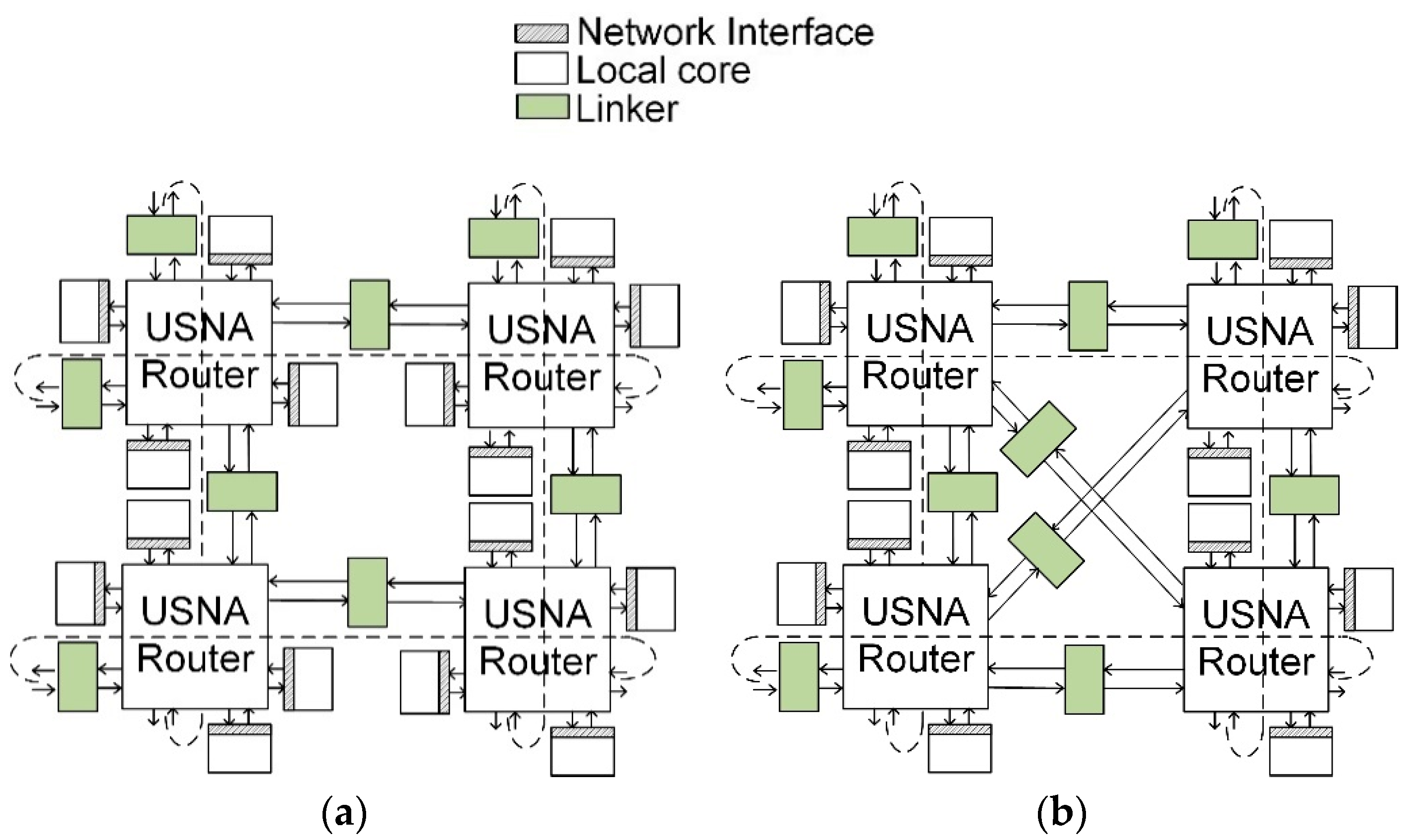
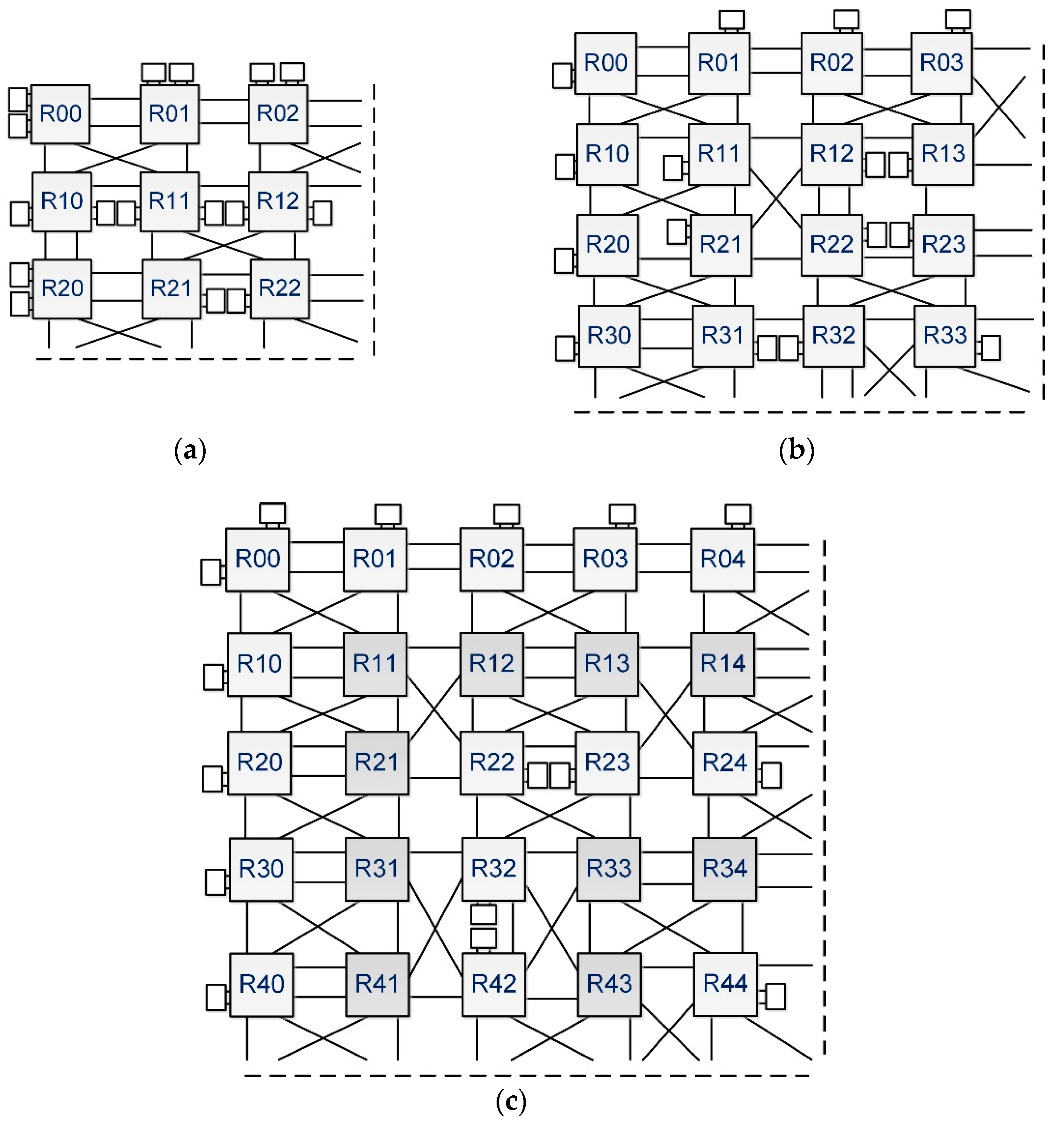
Figure 2 shows examples of 2 × 2 torus USNA network configurations with 16 and 12 local cores. Each router in
Figure 2a has four local cores and linkers, respectively, and the system has four routers. If a higher communication bandwidth is desired, two linkers can replace four local cores, and can be positioned as horizontal, vertical, or diagonal links, depending on the traffic patterns, as shown in
Figure 2b, where the linkers are placed in diagonal links.
3.1. Router Architecture
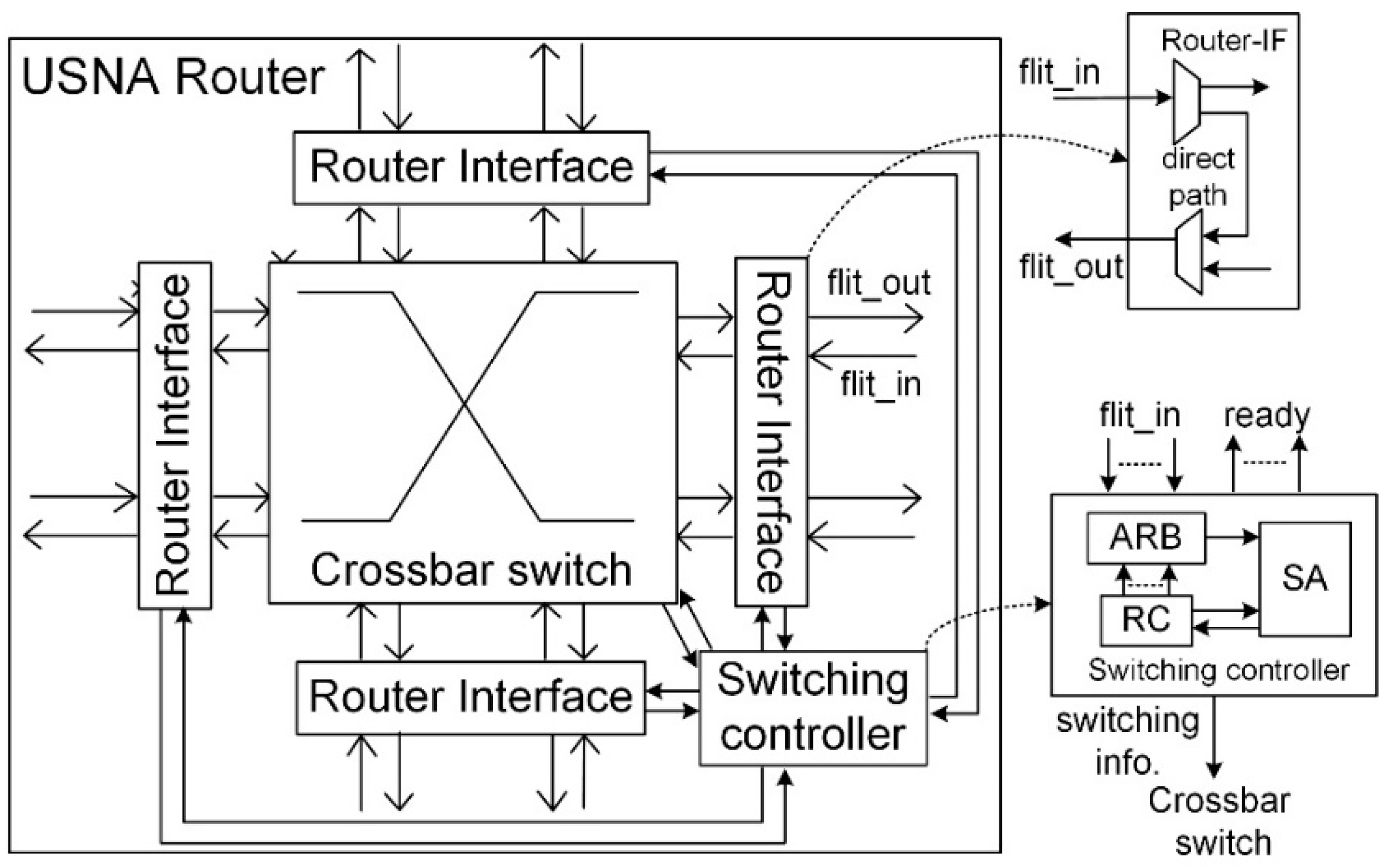
The 8-port USNA router is composed of router interfaces (router-IF), a switching controller, and a crossbar switch, as shown in
Figure 3. The port of the router can hold either a local core or a linker, and the neighboring ports, which are connected to the same routing interface, can be routed directly without the switching controller. When a new packet arrives at the router (indicated by a head flit), the router interface checks if it requires “direct routing”; this is extended from the “direct routing” process used in a system network architecture (SNA) [
15]. It is established inside the router interface between two ports without disturbing the switch controller. In other words, the packet can be delivered to another port through the direct path so that the router controller can handle the remaining packets. The direct routing is made in the same cycle as that when the packet arrives. If the router interface holds two linkers that do not connect the same pair of routers and the direct routing is made, the packet bypasses the router and arrives at the next router in a single cycle, which results in simultaneously transferring the packet by two hops.
If direct routing is not established, the router interface sends a routing request signal to the switching controller for “local routing”. The switching controller consists of an arbiter (ARB), an RC, and SA. The ARB chooses the highest priority head flit among the incoming ones to service every cycle in a round-robin manner. Rather than implementing an output ARB for each output port as in the conventional NoC, only one input ARB is employed at the arbitration stage for hardware simplicity. The lower priority packets may need to wait one or a few more cycles for servicing, even in the absence of conflicts of using routing resources among them. However, this does not significantly affect the network performance because the probability of concurrent multiple head flit arrivals is quite low, especially for long packet traffics. The RC then selects the available output ports after checking the statuses of the output ports issued by the SA. The arbitration stage selects the packets with the higher priorities among the packets whose output ports are available, thus, reducing the number of idle cycles in the routing process. The SA collects the information of the winner at the arbitration stage and schedules the channel formation of the crossbar switch at the next cycle. Additionally, the SA also monitors the end of the packet (the tail flit) to properly issue the statuses of the output ports to the RC. To solve the conflict at the router interface caused by the local and direct routing, higher priority is assigned to the local routing because the channel allocated to it becomes idle until the router interface releases the direct routing. However, the direct routing for the GT traffic has higher priority than the local routing for the BE traffic. A simple switching controller is implemented in this study to form one channel in a cycle and gives higher priority to the GT packets to support the QoS. This substantially reduces the implementation cost; however, it may slightly increase communication latencies when the injection rate is very high. The complexity of the crossbar switch is reduced due to the direct routing. For example, the crossbar switch of an 8-port router has the complexity of a 7-port router.
3.2. Linker
A linker connects routers and determines the packet transfer type. It can be configured as a single register slicer or piled VCs, depending on its application.
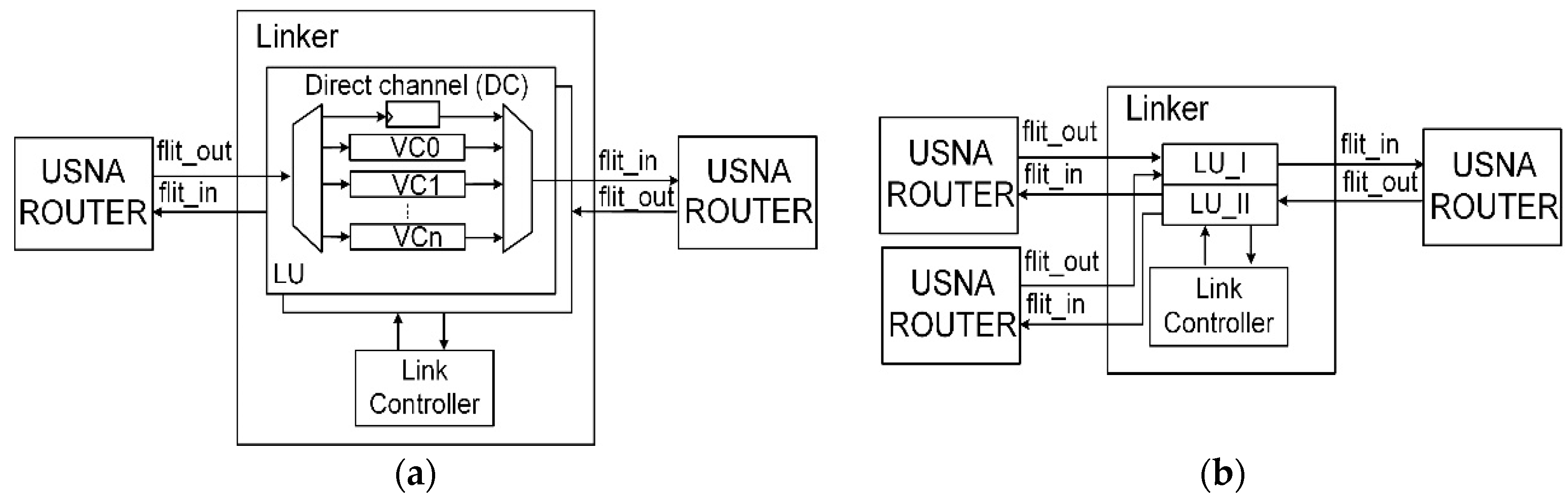
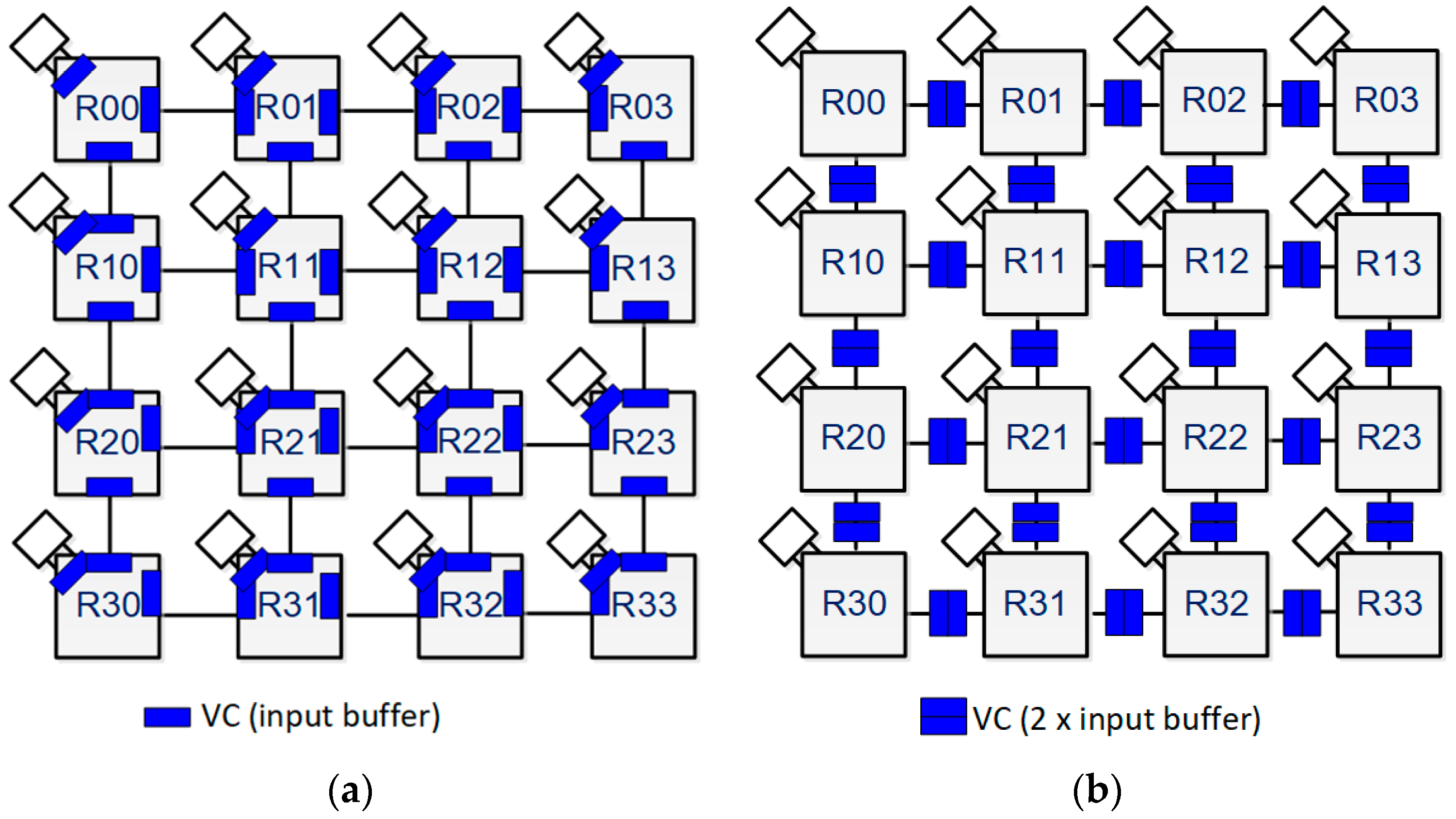
Figure 4a shows a linker with multiple VCs, and a single direct channel, which is a single register slicer used for the GT traffic. The area overhead dominated by the VC buffers is reduced in the USNA, as the injection port buffers are removed. The buffers located inside the linkers play a similar role to the input buffers in the conventional router. By moving these buffers to the linkers, we aim to modularize the design of the USNA for ease of configuration. Additionally, one row and one column of linkers can be removed from the mesh topologies, which further reduces the area overhead caused by the VCs. For example, a 4 × 4 mesh topology with the conventional NoC includes at least 64 (=3 × 4 + 4 × 8 + 5 × 4) sets of VCs, whereas that with the 5-port USNA router includes 24 (=2 × 3 × 4) sets of VCs, as shown in
Figure 5. The injection ports have higher priorities than the linker ports, such that the packets are not blocked at the source’s queue. The packets then wait in the linkers for the next hop’s routing.
The routers receive and send packets simultaneously through the linkers, which include two linking units (LUs) for both directions and a link controller, as shown in
Figure 4. Although the linker normally connects two routers, it may connect three routers when it has three ports, as illustrated in
Figure 4b. Because the router in the USNA can have multiple local cores, it can have an orphan port that is not paired with a port of another router. A three-port linker can accommodate the orphan port. It has two types of linking units: LU-I with two inbound channels and one outbound channel, and LU-II with one inbound channel and two outbound channels. The LU-I receives packets from two routers and sends them to a router, and the LU-II receives packets from a router and sends them to the router that gives the first grant signal. Two-port linkers are considered in this study. The linker is a unique feature of the USNA compared with the conventional NoCs.
3.3. Routing Rules for Deadlock Avoidance
We propose an adaptive turn restriction routing algorithm by modifying the West-first routing [
16] to exploit the advantages of the diagonal links and guarantee deadlock avoidance. The West-first algorithm is based on networks with horizontal and vertical links, and prevents creating cycling routing paths formed by 90-degree turns to avoid deadlocks. The proposed “modified West-first” routing algorithm prevents creating cycling routing paths including diagonal links because the USNA allows diagonal links. It consists of two rules: rule 1 is inherited from the West-first algorithm and rule 2 is added to the proposed algorithm as shown below. The turns that cause cyclic acquisition are prohibited according to the following rules:
Rule 1: 90-degree turns are restricted to West-first.
Rule 2: If a routing pair (source, destination) is located at the same row or column, forwarding a packet through the corresponding diagonal link is prohibited. For example, if a router forwarded a packet to a neighboring router on the right located on the same row, the possible routing paths would be the East, South, or North links; alternatively, the South–East and North–East links would be prohibited for routing in such a case.
The pseudo-code of the modified West-first routing algorithm is shown in Algorithm 1. The port list in the brackets represents the checking order to determine the final output port after taking into account the port status from left to right. For example, at the second If branch, the possible output ports can be the East (E), North (N), or South (S) port if the packet targets a destination core located in the East region. The East output port is checked first and is available for use if its port status is not busy. Otherwise, the North output port is the next candidate and the final one is the South output port. Diagonal links shorten the routing distance if communications are made between a pair of routers located at both a different column and different row. Specifically, the diagonal link is always prioritized for routing over the horizontal and vertical linkers if a packet targets the northwest, southwest, northeast, and southeast regions.
| Algorithm 1 Pseudo-code of the modified West-first routing algorithm. Modified West-First Routing Algorithm |
| 1. Input: cur_X, des_X, cur_Y, des_Y // coordinates of current and destination routers |
| 2. Input: port_busy // statuses of output ports |
| 3. Output: des_port // desired output port |
| 3. Begin |
| 5. Xoffset = des_X − ur_X |
| 6. Yoffset = des_Y − cur_Y |
| 7. If (Xoffset = 0) And (Yoffset = 0) Then des_port = {local} //local port |
| 8. ElseIf (Xoffset > 0) And (Yoffset = 0) Then des_port = {E, N, S} //east region |
| 9. ElseIf (Xoffset < 0) And (Yoffset = 0) Then des_port = {W} //west region |
| 10. ElseIf (Xoffset = 0) And (Yoffset > 0) Then des_port = {S, W, E} //south region |
| 11. ElseIf (Xoffset = 0) And (Yoffset < 0) Then des_port = {N, W, E} //north region |
| 12. ElseIf (Xoffset < 0) And (Yoffset < 0) Then des_port = {NW-diagonal, W} // northwest region |
| 13. ElseIf (Xoffset < 0) And (Yoffset > 0) Then des_port = {SW-diagonal, W} // southwest region |
| 14. ElseIf (Xoffset > 0) And (Yoffset < 0) Then des_port = {NE-diagonal, E, N} // northeast region |
| 15. Else des_port = {SE-diagonal, E, S} // southeast region |
| 16. End |
3.4. GT/BE Traffic Support in USNA
The USNA provides the soft guarantee by supporting the GT/BE traffic in the routers and linkers. The router interface analyzes the head flit to extract the QoS information and generate the routing request signal. The QoS information represents up to 16 priority levels, including the normal (or BE) packet, and the number of levels can be modified during implementation. Systems with the two-level QoS support (GT/BE) are considered in this study because most conventional NoCs support GT and BE traffic. At the arbitration stage, the switching controller gives higher priority to the packet with a higher QoS level.
The linker supports the QoS traffic when it has VCs. The structure of the linkers depends on the application operations. Each VC can be assigned to a GT packet only or shared by both the GT and BE packet. A dedicated VC is occupied by GT packets only and is idle when there are none. A shared VC can be occupied by either GT or BE packets. Networks with dedicated VCs provide higher performance for the GT traffic but incur a higher implementation cost because more VCs are usually included. The linker may include a direct channel with a single register for the GT packet, as shown in
Figure 4a. The channel is reserved for the GT packet, and the linker processes the packet in the direct channel with the highest priority. The direct channel, which further increases the performance for the GT traffic when the VCs are full, can be implemented at a very low cost.
Additionally, the linker provides preemptive mechanisms that further improve the network performance. When a GT packet arrives at a linker, the linker takes the channel request token from the BE packet and initiates the channel request for the GT packet, unless a BE packet in the shared VCs has already obtained a grant at the next hop’s arbitration. The GT packet may be blocked by a BE packet that has already occupied the physical channel. If another GT packet occupies the VC and it does not obtain a grant signal, the linker alternatively gives the request token to the GT packets in the VCs to prevent a long waiting time. On the other hand, the BE packets stored in the VCs are processed in order of arrival. However, the linker may process a new packet first if one of the old packets do not obtain a grant signal. Particularly, when the current packet fails in obtaining the grant signal, the linker passes the request token to the next BE packet in a round-robin manner to reduce the overall waiting cycles. In the USNA, because the multiport router design would provide more alternative routing paths, BE packets can travel through longer routing paths without starvation.
3.5. Comparison of USNA with Conventional Multiport NoCs
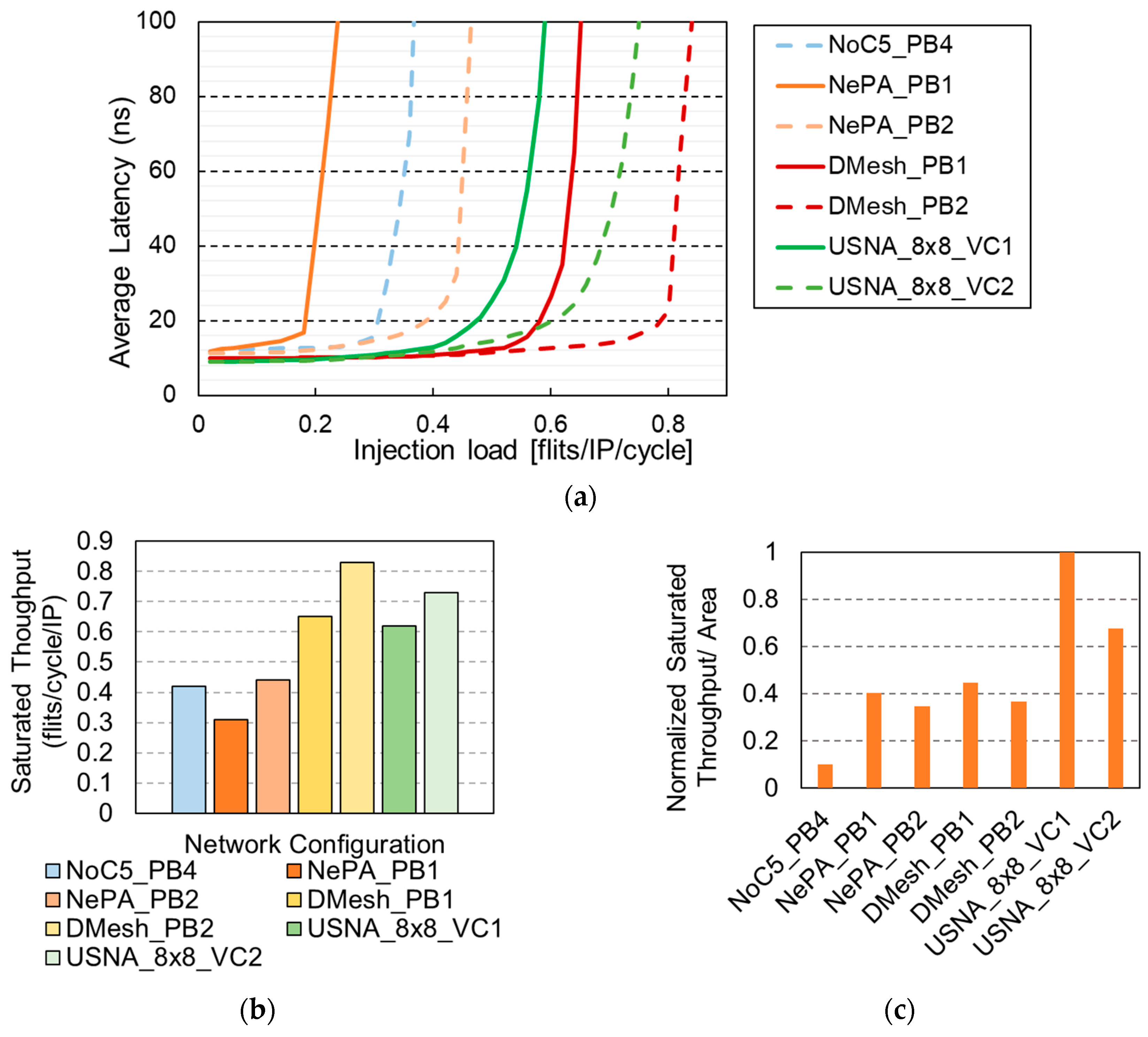
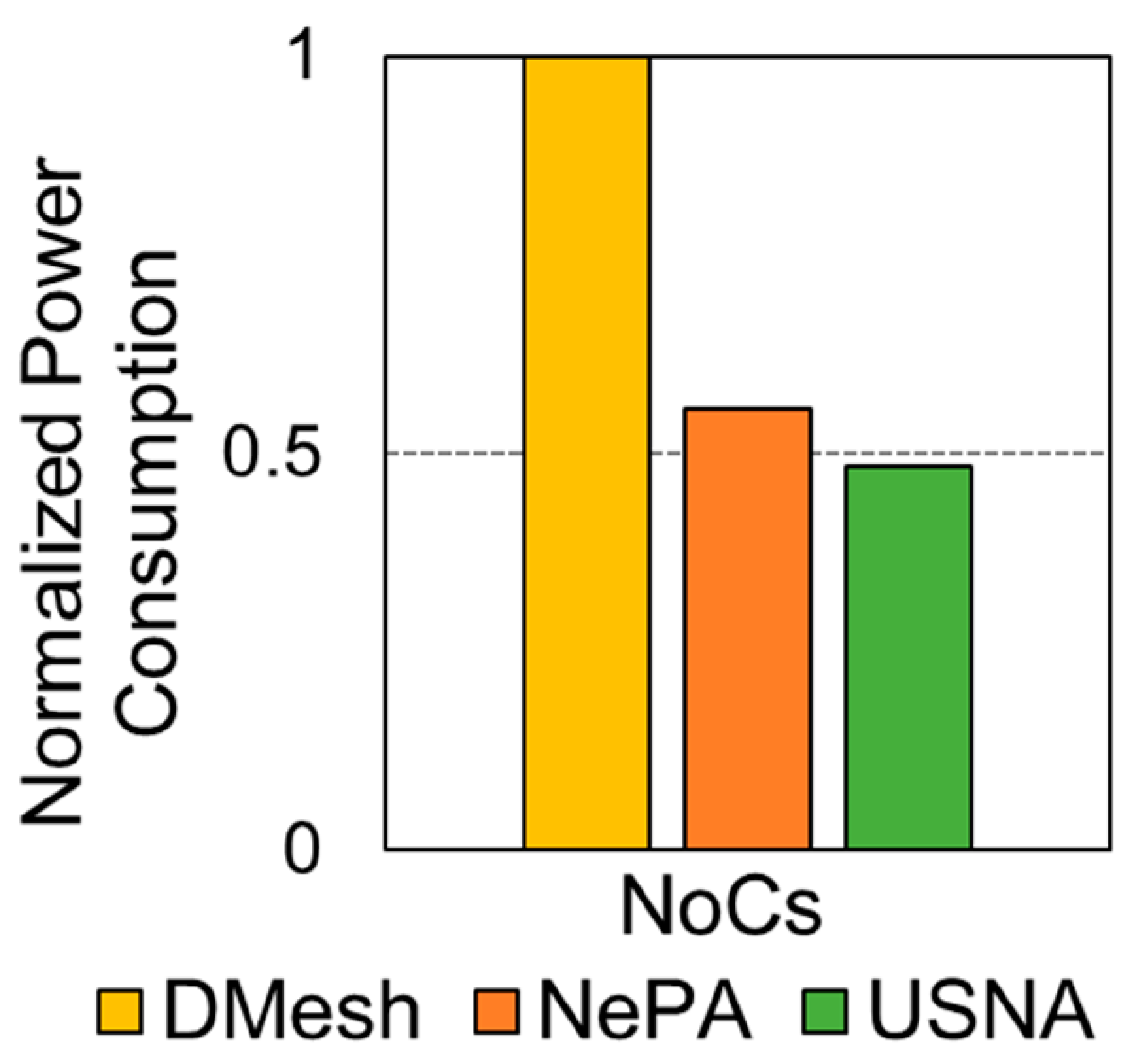
Table 1 shows the comparison results between the USNA and the other multiport NoCs mentioned above. The other NoCs are designed with a fixed topology (e.g., 2D mesh), which limits their adaptations to diverse traffic applications, especially to those requiring customized network shapes and non-uniform traffic patterns. The USNA enables a flexible network configuration using routers with a variable number of ports, local cores, and connections with other routers. The routers are connected using linkers with a register slicing physical channel or VCs. Although the USNA router has a larger crossbar size than others except the DMesh, the area overhead of the USNA router is lower because it does not have the input buffers and employs a simple routing algorithm. Owing to the modular architecture, the USNA network can be designed with various combinations of routers and linkers. In this study, to reduce the hardware complexity, the router was designed to issue one grant signal per cycle for the local routing. However, by taking advantage of the direct routing, the maximum number of simultaneous routings is five for each cycle. Because more than one local core can be attached to a router, it is possible to design a system using a smaller number of USNA routers, which lowers the hardware complexity of the USNA network in comparison with the conventional NoCs.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}