Particle Swarm Optimization—An Adaptation for the Control of Robotic Swarms


Abstract
:1. Introduction
1.1. PSO in Swarm Robotics
- 1.
- As recognized by Hereford et al [17], the particles in PSO are assumed to be physically unconstrained (i.e., unconstrained velocity and acceleration); an assumption that does not hold for physical robots.
- 2.
- The control of the robots, and the updating of the robots’ states, are performed asynchronously. The rate at which the velocity is updated depends on the speed of robot control system. Therefore, changing the loop delay of a controller will result in different characteristics of the physical system, even if the PSO parameters used remain the same.
- 3.
- PSO assumes an immutable environment. That is because PSO does not consider if the cost (fitness) of past locations might change with time. This is clearly incompatible to real-world robotic applications where both the state of the source and the environment can change.
- 4.
- It is impossible for the swarm to know the location of a source before a particle has passed directly over it, this is incompatible with collision avoidance.
2. Particle Swarm Optimization Theory
2.1. Parameter Tuning
2.2. Introduction to RPSO
2.2.1. Dynamic Velocity Control
3. Particle Swarm Optimization in Swarm Robotics
3.1. Adaptation of PSO for Swarm Robotics
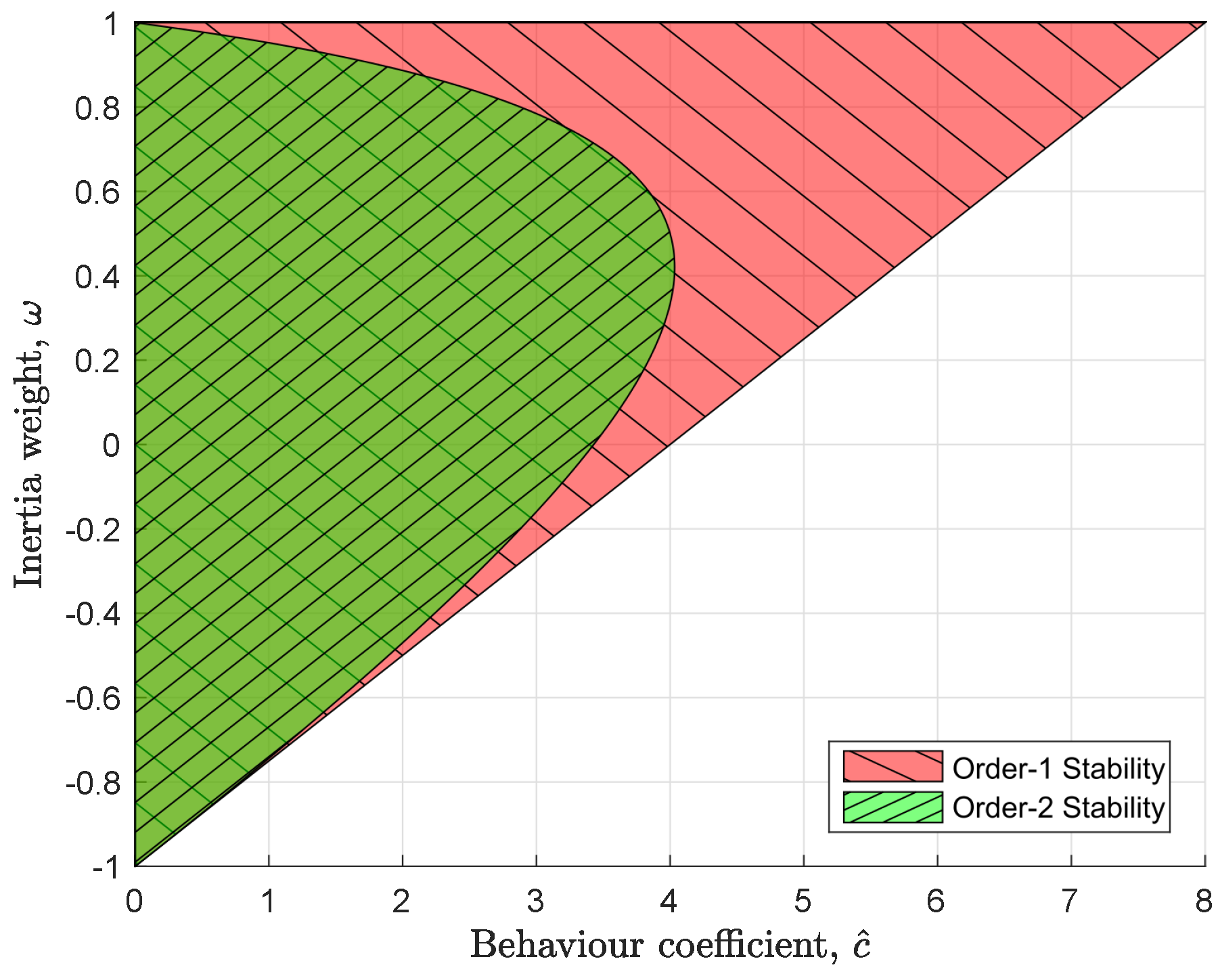
3.2. Updated Parameter Tuning Stability Criteria
3.3. Control of Velocity and Acceleration
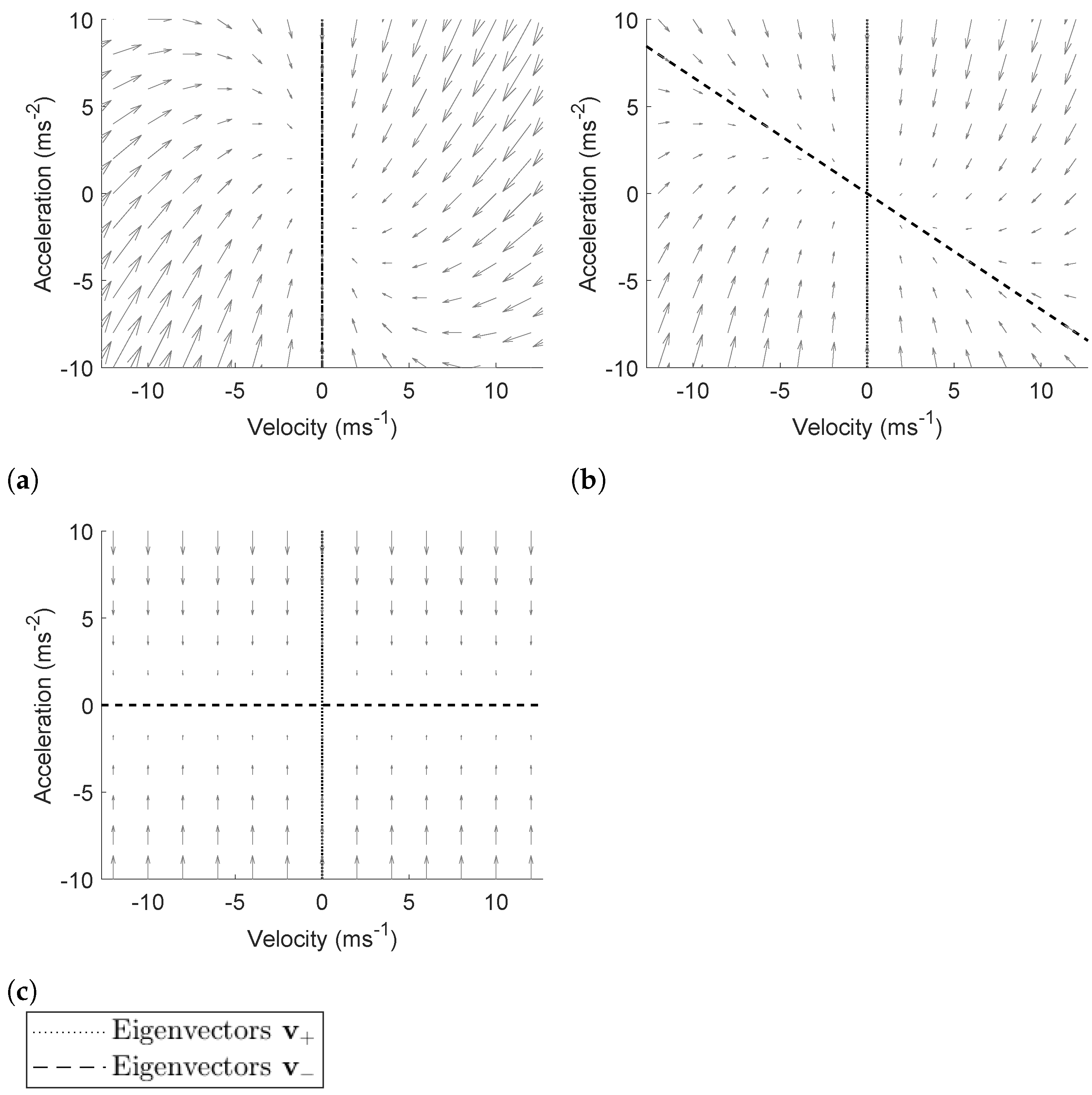
3.3.1. State Model
3.3.2. State Space Analysis
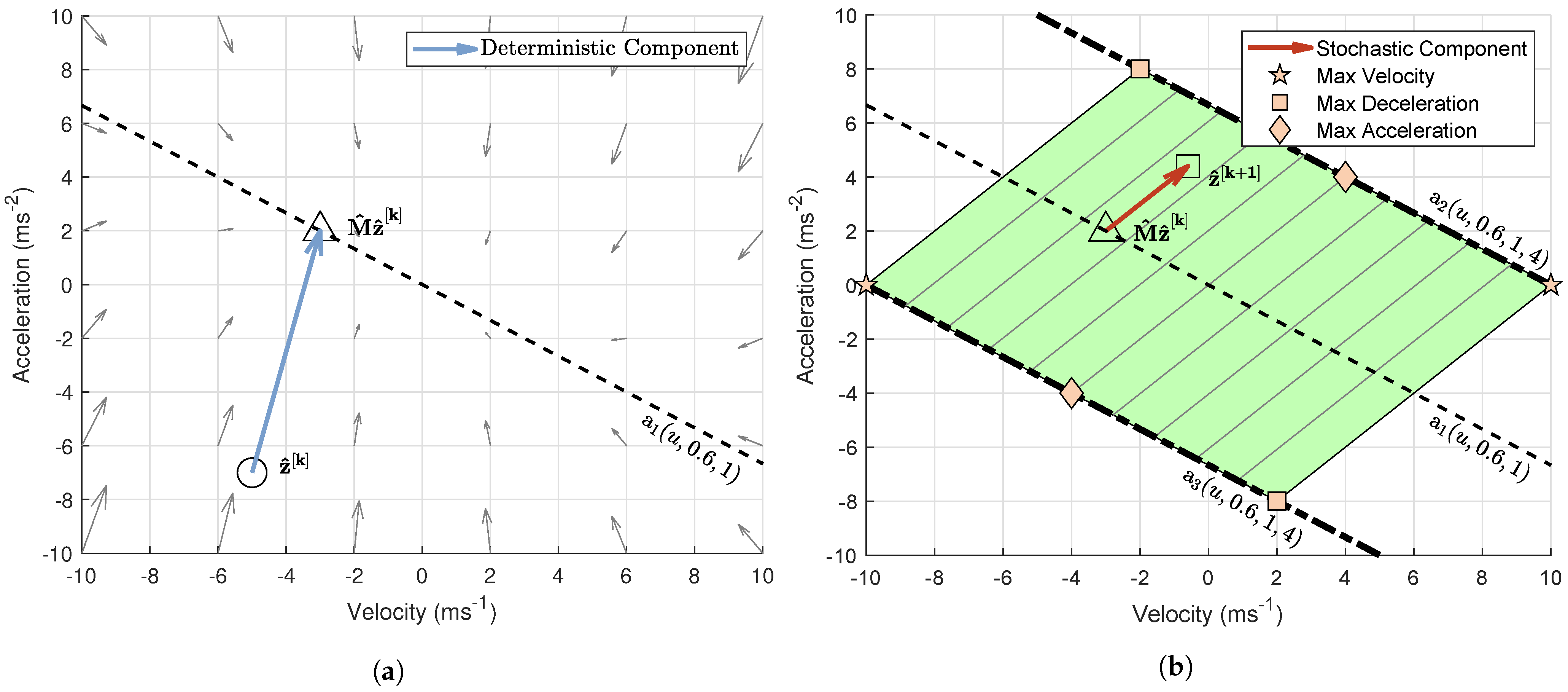
3.3.3. Derivation of Extreme Cases
3.4. Generalized Adapted PSO
3.5. Guidelines
- Identify the controller loop delay: needs to be large enough to accommodate the time delay introduced by computationally expensive tasks and communications between robots.
- Identify U: The desired maximum speed of the robot. It must be made sure that this does not exceed the actual maximum speed that the robot can achieve.
- Calculate either or : The desired maximum acceleration or deceleration using (33). It must be made sure that they do not exceed the actual maximum acceleration or deceleration that the robot can achieve.
- Calculate and : Use (31) and (32) respectively.
- Ensure that and satisfy the criteria of (16): If not, then a faster controller is required (i.e., smaller )
- Select appropriate values for , , …, : The sum of the individual coefficients must satisfy (37).
4. Application to a Real-World System
4.1. Implementation of Dynamic Velocity Control
- Set the desired maximum speed .
- Using (33), calculate the desired maximum acceleration .
- Using (31), .
- Using , calculate and based on the desired ratio .
- Set the desired maximum speed .
- Using (33), calculate the desired maximum acceleration . Please note that needs to be the same as in the previous step, in order to result in the same value for as described in (34).
- Using (31), .
- Finally, .
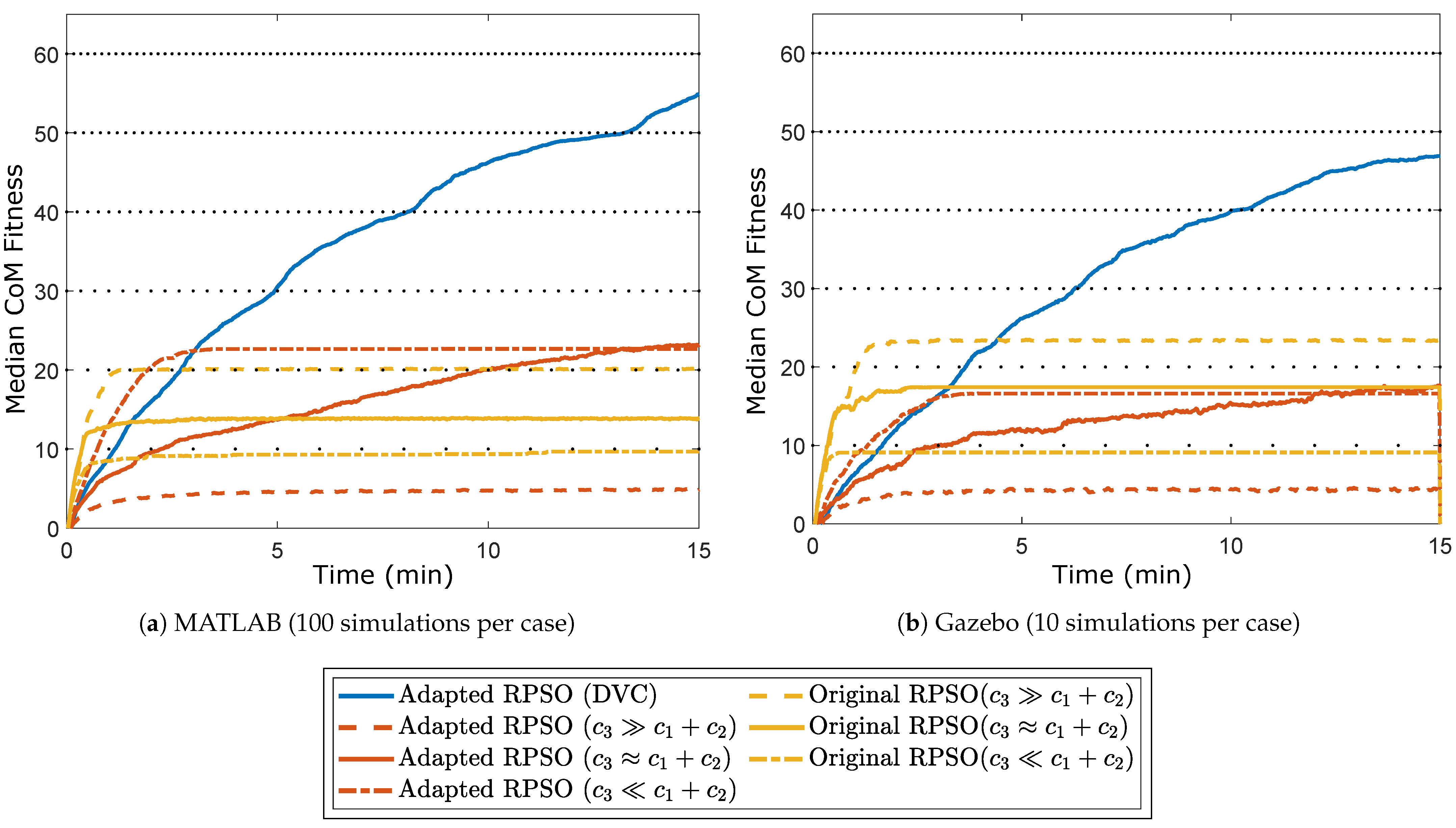
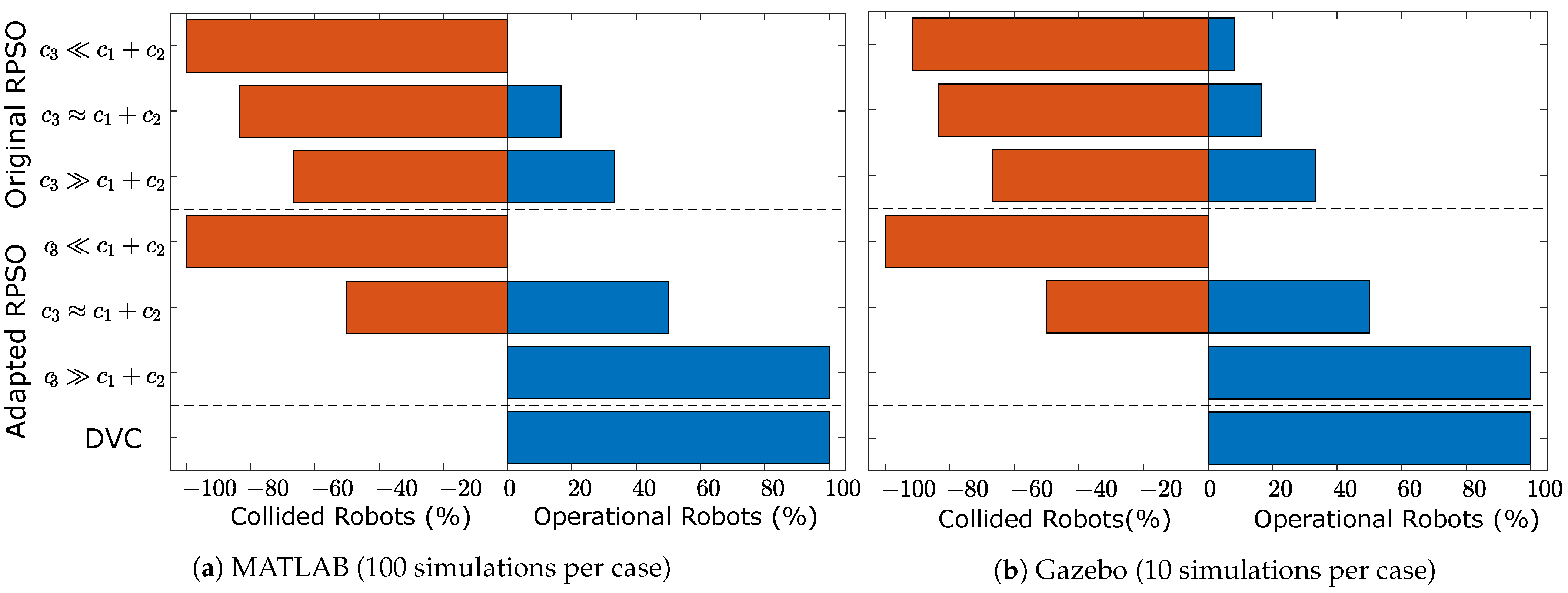
5. Results
- The original RPSO algorithm described by (9) with constant parameters.
- The adapted RPSO algorithm described by (38) with constant parameters.
- The adapted RPSO algorithm described by (38) with DVC.
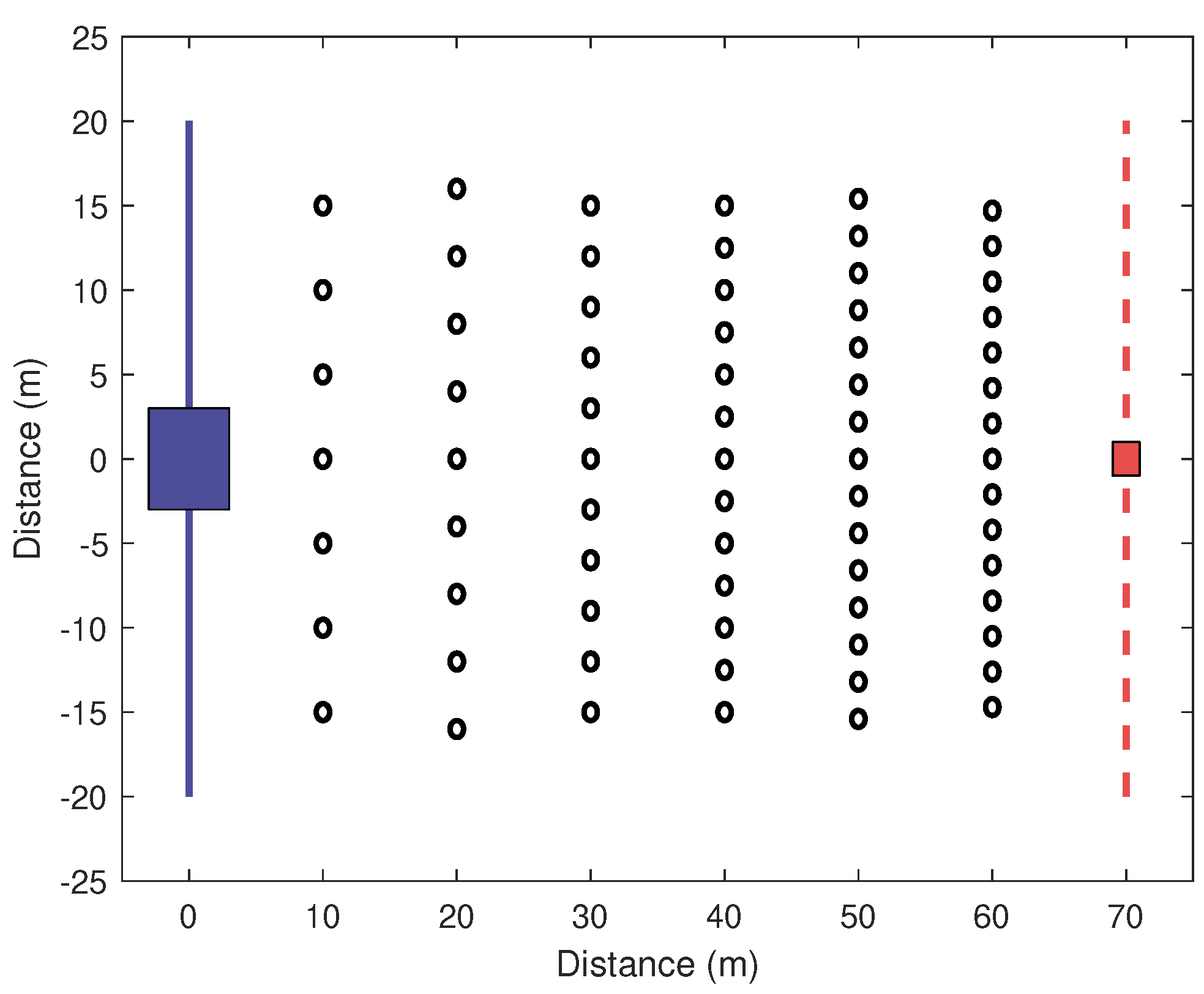
5.1. World and Robot Description
5.1.1. Original RPSO with Constant Values
5.1.2. Adapted RPSO with Constant Values
5.1.3. Adapted RPSO with DVC
5.2. MATLAB Simulations
5.3. Gazebo Simulations
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Lemma 1
Appendix A.1. Lemma 2
Appendix A.2. Theorem 1
Appendix A.3. Theorem 2
References
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Parsopoulos, K.E.; Vrahatis, M.N. Particle Swarm Optimization and Intelligence: Advances and Applications; Information Science Publishing (IGI Global): London, UK, 2010. [Google Scholar]
- Liu, C.; Chu, Y.; Wang, L.; Zhang, Y. Application and the parameter tuning of ADRC based on BFO-PSO algorithm. In Proceedings of the 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; pp. 3099–3102. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Monfroy, E.; Palma, W.; Castro, C.; Paredes, F. Parameter tuning of a choice-function based hyperheuristic using Particle Swarm Optimization. Expert Syst. Appl. 2013, 40, 1690–1695. [Google Scholar] [CrossRef]
- Pluhacek, M.; Senkerik, R.; Viktorin, A.; Kadavy, T.; Zelinka, I. A Review of Real-World Applications of Particle Swarm Optimization Algorithm BT-AETA 2017-Recent Advances in Electrical Engineering and Related Sciences: Theory and Application; Springer International Publishing: Cham, Switzerland, 2018; pp. 115–122. [Google Scholar]
- Ozcan, E.; Mohan, C.K. Particle swarm optimization: Surfing the waves. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406), Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1939–1944. [Google Scholar] [CrossRef]
- Trelea, I.C. The particle swarm optimization algorithm: Convergence analysis and parameter selection. Inf. Process. Lett. 2003, 85, 317–325. [Google Scholar] [CrossRef]
- Liu, Q. Order-2 Stability Analysis of Particle Swarm Optimization. Evol. Comput. 2014, 23. [Google Scholar] [CrossRef] [PubMed]
- Bonyadi, M.R.; Michalewicz, Z. Stability Analysis of the Particle Swarm Optimization Without Stagnation Assumption. IEEE Trans. Evol. Comput. 2016, 20, 814–819. [Google Scholar] [CrossRef]
- Cleghorn, C.W.; Engelbrecht, A.P. Particle swarm stability: A theoretical extension using the non-stagnate distribution assumption. Swarm Intell. 2018, 12, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y.; Zheng, Z.Y. Research Advance in Swarm Robotics. Def. Technol. 2013, 9, 18–39. [Google Scholar] [CrossRef] [Green Version]
- Nedjah, N.; Junior, L.S. Review of methodologies and tasks in swarm robotics towards standardization. Swarm Evol. Comput. 2019, 50, 100565. [Google Scholar] [CrossRef]
- Senanayake, M.; Senthooran, I.; Barca, J.C.; Chung, H.; Kamruzzaman, J.; Murshed, M. Search and tracking algorithms for swarms of robots: A survey. Robot. Auton. Syst. 2016, 75, 422–434. [Google Scholar] [CrossRef]
- Couceiro, M.S.; Rocha, R.P.; Ferreira, N.M.F. A novel multi-robot exploration approach based on Particle Swarm Optimization algorithms. In Proceedings of the 2011 IEEE International Symposium on Safety, Security, and Rescue Robotics, Kyoto, Japan, 31 October–5 November 2011; pp. 327–332. [Google Scholar] [CrossRef]
- Wang, Z.; Qin, L.; Yang, W. A self–organising cooperative hunting by robotic swarm based on particle swarm optimisation localisation. Int. J. Bio-Inspired Comput. 2015, 7, 68–73. [Google Scholar] [CrossRef]
- Kumar, A.S.; Manikutty, G.; Bhavani, R.R.; Couceiro, M.S. Search and rescue operations using robotic darwinian particle swarm optimization. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1839–1843. [Google Scholar] [CrossRef]
- Hereford, J.M.; Siebold, M.; Nichols, S. Using the Particle Swarm Optimization Algorithm for Robotic Search Applications. In Proceedings of the 2007 IEEE Swarm Intelligence Symposium, Honolulu, HI, USA, 1–5 April 2007; pp. 53–59. [Google Scholar] [CrossRef]
- Clerc, M.; Kennedy, J. The particle swarm-explosion, stability, and convergence in a multidimensional complex space. IEEE Trans. Evol. Comput. 2002, 6, 58–73. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J. Particle swarm optimization. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 760–766. [Google Scholar]
- Shi, Y.; Eberhart, R.C. Parameter selection in particle swarm optimization. In Evolutionary Programming VII; Springer: Berlin/Heidelberg, Germany, 1998; pp. 591–600. [Google Scholar]
- Poli, R. Dynamics and Stability of the Sampling Distribution of Particle Swarm Optimisers via Moment Analysis. J. Artif. Evol. Appl. 2008, 2008. [Google Scholar] [CrossRef] [Green Version]
- Spears, W.M.; Spears, D.F.; Hamann, J.C.; Heil, R. Distributed, Physics-Based Control of Swarms of Vehicles. Auton. Robot. 2004, 17, 137–162. [Google Scholar] [CrossRef]
- Khaldi, B.; Cherif, F. A Virtual Viscoelastic Based Aggregation Model for Self-Organization of Swarm Robots System; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016; Volume 9716, pp. 202–213. [Google Scholar] [CrossRef]
- Garone, E.; Nicotra, M.; Ntogramatzidis, L. Explicit reference governor for linear systems. Int. J. Control 2018, 91, 1415–1430. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Garone, E. An Explicit Reference Governor for the Intersection of Concave Constraints. IEEE Trans. Autom. Control 2020, 65, 1–11. [Google Scholar] [CrossRef]
- Utkin, V. Chattering Problem. IFAC Proc. Vol. 2011, 44, 13374–13379. [Google Scholar] [CrossRef]
- Koenig, N.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar] [CrossRef] [Green Version]
- Robotnik Automation S.L.L. SUMMIT-XL STEEL MOBILE ROBOT. Available online: https://robotnik.eu/products/mobile-robots/summit-xl-steel-en (accessed on 10 January 2021).
- Benewake (Beijing) Co., Ltd. CE30 3D Obstacle-Avoidance LiDAR. Available online: http://en.benewake.com/product/detail/5c34571eadd0b639f4340ce5 (accessed on 15 February 2021).
- Taheri, H.; Qiao, B.; Ghaeminezhad, N. Kinematic model of a four mecanum wheeled mobile robot. Int. J. Comput. Appl. 2015, 113, 6–9. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Case | ||||||
|---|---|---|---|---|---|---|---|
| Adapted RPSO | DVC | 0.9 | 0.9 | 1 | 1 | - | - |
| - | 0.9 | 1 | 1 | 0.2864 | 1.1455 | ||
| 0.4296 | 0.8591 | ||||||
| 0.5728 | 0.5728 | ||||||
| Original RPSO | - | 0.9 | 1 | 1 | 0.2864 | 1.1455 | |
| 0.4296 | 0.8591 | ||||||
| 0.5728 | 0.5728 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rossides, G.; Metcalfe, B.; Hunter, A. Particle Swarm Optimization—An Adaptation for the Control of Robotic Swarms. Robotics 2021, 10, 58. https://doi.org/10.3390/robotics10020058
Rossides G, Metcalfe B, Hunter A. Particle Swarm Optimization—An Adaptation for the Control of Robotic Swarms. Robotics. 2021; 10(2):58. https://doi.org/10.3390/robotics10020058
Chicago/Turabian StyleRossides, George, Benjamin Metcalfe, and Alan Hunter. 2021. "Particle Swarm Optimization—An Adaptation for the Control of Robotic Swarms" Robotics 10, no. 2: 58. https://doi.org/10.3390/robotics10020058
APA StyleRossides, G., Metcalfe, B., & Hunter, A. (2021). Particle Swarm Optimization—An Adaptation for the Control of Robotic Swarms. Robotics, 10(2), 58. https://doi.org/10.3390/robotics10020058