1. Introduction
Autonomy is increasingly being discussed regarding cooperation. A gentler breed of robots, “cobots”, have started to appear in factories, workshops and construction sites, working together with humans. A challenge in the deployment of such robots is producing desirable trajectories for object carrying tasks. A desirable trajectory not only meets the task constraints (e.g., collision-free movement from start to goal), but also adheres to user preferences. Such preferences may vary between users, environments and tasks. It is infeasible to manually encode them without exact knowledge of how, with whom and where the robot is being deployed [
1]. Manual programming is even more detrimental in cooperative environments, where robots are required to be easily and rapidly reprogrammed. In this context, learning preferences directly from humans emerges as an attractive solution.
We address the challenge of learning personalized human preferences, starting from a robot plan that may not match the execution style or safety standards of a specific human user (e.g., robot carries the object closer to the obstacle than the user prefers).
Figure 1 illustrates how a user may demonstrate a trajectory encoding multiple implicit preferences to correct the original robot plan.
One way to adhere to human preferences is by means of variable impedance control [
2,
3]. Although such strategies can ensure safe and responsive adaptation, they suffer from being purely reactive (i.e., they do not remember the corrections). The robot should not only conform to a new trajectory, but it has to update its internal model in order to understand the improvements in the corrected trajectory [
4,
5,
6]. Thus, ideally, we should encode knowledge of humans’ desired trajectories as a set of parameters that are incrementally updated based on the corrected trajectory.
To this end, the Learning from Demonstration (LfD) approach enables robots to encode human-demonstrated trajectories. LfD frameworks have the advantage of enabling non-experts to naturally teach trajectories to robots. A widespread trajectory learning method in LfD is Dynamic Movement Primitives (DMPs) [
7]. In addition to encoding trajectories, DMPs are able to adapt the learned path by updating an interactive term in the model [
8,
9]. Additionally, they can adapt the velocity of the motion by estimating the frequency and the phase of a periodic task [
3] or learning a speed scaling factor [
10]. As a result, DMPs can capture human path and velocity preferences on a trajectory level. Losey and O’Malley [
5] demonstrated that such velocity preferences can also be learned online from interactive feedback, although with some effort. However, these methods lack any knowledge about the task context or why the trajectory was adjusted in the first place. Hence, such an approach fails to generalize user preferences to new scenarios due to the lack of a higher-level understanding of human actions.
A better approach is to pair parameters with features that capture contextual information (e.g., distance to obstacle) and utilizes this information to find an optimal solution in new scenarios. Such generalizations can be achieved by learning a model of what makes a trajectory desirable. Modeling assumptions can be made to form a conditional probability distribution over trajectories and contextual information, e.g., as demonstrated by Ewerton et al. [
11]. Although this has been proven effective in simple reaching tasks, whether such models can directly capture complex human preferences in a contextually rich environment remains an open question. However, Inverse Reinforcement Learning (IRL) approaches have already proven to be capable of this [
12].
Unlike traditional IRL methods requiring expert demonstrations [
13,
14], more recently derived algorithms allow preference learning from user comparisons of sub-optimal trajectories [
12]. Potentially, a much wider range of human behavior can be interpreted as feedback for preference learning in general [
15]. In this paper, however, we focus on reward learning for robot trajectories. A model-free approach can be used to learn complex non-linear reward functions [
16], but such an approach requires many queries to learn from, which is time-intensive. Therefore, we keep a simple linear reward structure. To shape this reward, we identified four fundamental preference features of the pick-and-place type of object transportation tasks in the literature: height from table/ground [
1,
4,
6], distance to obstacle [
1,
17], obstacle side [
18,
19] and velocity [
3,
10]. These features are relatively scenario-unspecific, and are therefore suitable for generalization in object transportation tasks of the kind we consider in this paper: pick-and-place tasks in the presence of obstacles. To the best of our knowledge, there is no method to account for all these features together in a unified framework.
Given such a set of features, coactive learning [
20] can be used to learn a reward function. In coactive learning, the learner and the teacher both play an active role in the learning process; the learner proposes one or multiple solutions and learns from the relative feedback provided by the teacher in response. Coactive learning has an upper boundary on regret, leaving room for noisy and imperfect user feedback. Furthermore, it is an online algorithm, i.e., the system can learn incrementally from sequential feedback. An adapted version of coactive learning was applied by Jain et al. [
1] to learn trajectory preferences in object carrying tasks. To this end, users iteratively ranked trajectories proposed by the system. Although selected based on the learned reward, the trajectories were generated using randomized sampling, which increases the number of feedback iterations necessary for convergence. Methods by Bajcsy et al. [
4] and Losey et al. [
6] adapt the robot trajectory to the user’s preferences based on force feedback and optimize the remaining trajectory with online correction in a specific scenario. However, these methods cannot capture velocity preferences on top of path preferences.
To address this gap in the state-of-the-art methods, we propose a novel framework for optimizing trajectories in object transportation tasks that meet the user’s path and velocity preferences, where we first optimize the path and then the velocity on the path. The objective function for the optimization comprises a human preference reward function and a robot objective function that ensures the safety and efficiency of the trajectories. This explicit separation of the agents’ objectives allows for negotiation, where the robot is recognized as an intelligent agent which may give valuable input of its own.
The approach takes a full demonstrated trajectory as the feedback for the learning model, comparing it to the robot’s previous plan at each iteration. A minimum acceleration trajectory model significantly reduces the size of the task space, hence increasing the optimization efficiency. To capture the preferences, we design a set of features that correspond to the four preferences, covering both the motion shape and timing, which we identified from the literature to be fundamental for the considered pick-and-place tasks.
Unlike Bajcsy et al. [
4] and Losey et al. [
6], we request iterative feedback and employ an optimization scheme that samples from the global trajectory space. Although this is less efficient in terms of human effort for teaching preferences in a specific scenario (i.e., the user has to provide at least one full task demonstration), it allows us to additionally capture velocity preferences on top of the path preferences. Furthermore, our method enables the separation of velocity and path preferences both during the learning and in the trajectory optimization stage. With our combination of a trajectory optimization scheme and carefully selected preference features, we can generalize to new contexts without needing (many) additional corrective demonstrations. In contrast to work by Jain et al. [
1], we learn from a few informative feedback demonstrations and give special attention to the trajectory sampling by employing model-based trajectory optimization. This facilitates fast learning and generalization of preferences to entirely new contexts.
We evaluate the proposed method in a user study on a 7-DoF Franka Emika robot arm. In the key previous user studies of learning human preferences [
4,
6,
21], the experimenter instructed the human participants what preference to demonstrate to the robot. In contrast, in our user study, we let the participants freely select their own preferences while demonstrating the task execution to the robot. Additionally, our study examines whether the users can actually distinguish the learned trajectory capturing their preference from the trajectories capturing only part of their preference. In a supplementary study, we qualitatively compare our method to two relevant methods from the literature. We discuss the structural differences between the methods and show by simulation how these differences affect the learning of preferences from human (corrective) demonstrations.
In summary, this paper’s main contribution is a methodology that is able to capture velocity preferences on top of path preferences by separating the velocity optimization from the path optimization. Learning the path and velocity separately provides users with the option to avoid the challenge of providing a temporally consistent demonstration at each iteration. This offers users the flexibility to demonstrate their path and velocity preferences either simultaneously or in separate demonstrations. Secondly, the learned preferences are transferred to new scenarios by exploiting a trajectory model. Importantly, we perform a user study to validate whether the proposed method can learn and generalize freely chosen preferences, in contrast to the many user studies in the literature which prescribe user preferences. Additionally, we perform a supplementary study to compare the pros and cons of the proposed approach with two common methods from the literature.
The rest of the paper is organized as follows: In
Section 2, we explain the algorithm and methodology in detail. The user study is described in
Section 3 and the experimental results are also shown and discussed. A supplementary study is presented and discussed in
Section 4. Finally, we present our conclusions and a view on future work in
Section 5.
2. Method
The problem is defined in the following manner: given a context describing start, goal and obstacle positions, the robot has to determine the trajectory (set of state sequences) that conforms to the human preferences and meets the task goals. The states are defined as (position and velocity), with k indicating trajectory samples.
In our setting, the true reward functions are known by the user but not directly observable by the robot. Hence, the problem can be seen as a Partially Observable Markov Decision Process (POMDP) [
4]. Our reward functions have parameters that are part of the hidden state, and the trajectories provided by the user are observations about these parameters. Solving such problems, where the control space is very complex and highly dimensional, is challenging. Therefore, we simplify the problem through approximation of the policy by separating planning and control and treating it as an optimization problem. Furthermore, we make the problem tractable by reducing our state space to one of viable smooth trajectories.
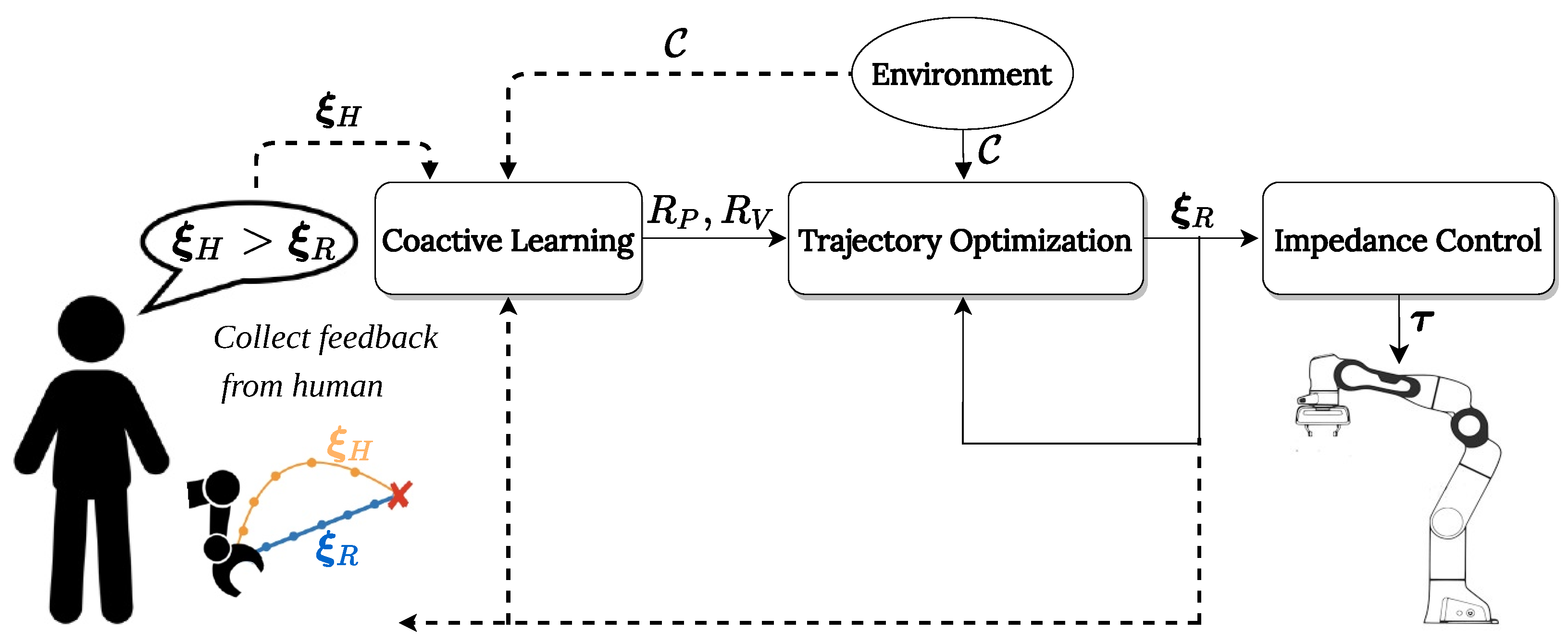
The resulting framework, depicted in
Figure 2, first learns the appropriate reward functions, then plans a trajectory maximizing the rewards via optimization. Once the trajectory is defined, we use impedance control to track it in a safe manner. Notably, we separate the problem of path and velocity planning in the learning and optimization steps. Updating the path and velocity weights separately provides users with the option to avoid the challenge of providing a temporally consistent demonstration at each iteration. As a result, users have the flexibility to demonstrate their path and velocity preferences either simultaneously or in separate demonstrations.
2.1. Learning Human Reward Functions from Demonstration
We follow previous IRL work [
1,
13] in assuming that the reward functions are a linear combination of features
with weights
. Accordingly, we define path and velocity reward functions
and
as
where
and
denote the unknown weights that, respectively, capture the human path and velocity preferences. In the case of the velocity reward, we divide the trajectory into equal segments (i.e., a range of samples) indicated by
r. Then,
and
are the average of the position vectors and the velocity norms in a segment.
and
are the total path and velocity feature counts along the trajectory:
Note that the velocity features are a function of both the segment’s velocity and position, allowing us to capture position-dependent velocity preferences.
To have comparable rewards, all trajectories are re-sampled to contain a fixed number of N states. The velocity inherently affects the number of samples within a trajectory, which is why we divide the trajectory into M segments and consider the average velocity within each segment (). Features are directly computed from the robot state and context of the task. We describe them in the next subsection.
During kinesthetic demonstration, the robot is in gravity compensation mode. That gives the human full control over the demonstrated trajectories, which we assume to correlate exponentially to the human’s internal reward:
which, for brevity, we can write as
.
Assuming that the human behavior is approximately optimal with respect to the true reward (i.e., their preferences), we use a variant of coactive learning introduced by Bajcsy et al. [
4] to learn the weights
. However, we can only compute
(
3) over full trajectories. Therefore, instead of updating the weights based on an estimate of the human’s intended trajectory from physical interaction, we use a full kinesthetic trajectory demonstration by the human after each task execution to update the sum of the features over the trajectory (
3). This results in the following incremental update rule:
at iteration
i, with learning rate
. Intuitively, the update rule is a gradient that shifts the weights in the direction of the human’s observed feature count. It should be noted that we update the path preferences only using the position part of the state, and the velocity preferences are updated depending on where in space the velocities were observed.
2.2. Features and Rewards
We define the objective function for trajectory optimization as a combination of human rewards and robot objectives. The human rewards consist of features that capture human preferences (
1)–(
2), whereas the robot objectives define a basic behavior for the robot. Moreover, the robot objectives counterbalance the effect of the human rewards in the optimization, while we learn the weights in the human rewards (
Section 2.1). The weights in the robot objectives are hand-tuned. In this section, we first describe the features associated with the human rewards, and then the robot objectives.
The human preferences are captured via the four features listed in
Section 2.2.1–
Section 2.2.4 (see
Figure 1 for an example of the listed path preferences). We chose these features as they characterize dominant behaviors in manipulation applications that depend on user preferences. Additionally, the features cover the different dimensions of the workspace (in space and time), creating a complete definition of motion behavior. The robot’s objectives are composed of the rewards listed in
Section 2.2.5–
Section 2.2.7.
2.2.1. Height from the Table
The preferred height from the table, in the range of “low” to “high” is captured by the sigmoid function , with h indicating the vertical distance from the table, p indicating the center of the function (an arbitrary “medium” height above the table) and indicating the parameter defining the shape of the function. The choice of a sigmoid function is to hinder the effect of this preference when close to upper and lower boundaries during the weight update (e.g., a demonstration at 75 cm above the table should not impact the weight update very differently from a demonstration at 70 cm). The decreasing slope at the boundaries additionally allows other objectives to have a higher impact on the trajectory in such regions during optimization.
2.2.2. Distance to the Obstacle
We encode the user’s preferred distance to the obstacle, in the range of “close” to “far”, using the exponential feature , where d is the Euclidean distance to the center of the obstacle and is the shape parameter. This exponential function gradually drops to 0 at a certain distance from the obstacle. This distance is a threshold outside which the local behavior of the optimization is no longer affected by the distance to the obstacle. Importantly, if a negative weight is learned associated with this feature, the trajectory is still attracted towards the obstacle even if the initial trajectory lies outside of this threshold. This is because our optimization strategy globally explores different regions of the workspace, and in this case it would detect that there is a reward associated with being closer to the obstacle.
2.2.3. Obstacle Side
We define this feature in the range of “close” (the side of the obstacle closer to the robot) to “far” (the side of the obstacle far from the robot) via the tangent hyperbolic function . Here, S is the lateral distance between a trajectory sample and the vertical plane at the center of the obstacle and is a shape parameter. This symmetric function is designed to have a large span in order to be active in all regions of the workspace. However, as the gradient of this function decreases at larger lateral distances, so does the influence of this function on the local trajectory optimization.
2.2.4. Velocity
To encapsulate the user’s velocity preferences, we adopt a different approach using a discretized linear combination of uniformly distributed Radial Basis Functions (RBFs) in the range
. For each segment
r, we map the average velocity norm
onto these RBFs, given by:
where the shape variable
defines the width and
defines the center of the
jth RBF, with
(we use
n = 9).
Inspired by Fahad et al. [
22], we discretize the above feature to two bins, based on the distance
of each segment center to the obstacle. Hence, we have two cumulative feature vectors:
for
and
for
. This allows us to approximate the speed of motion separately in areas considered to be “close” to or “far” from the obstacle based on the distance threshold
(obtained from demonstration data). This way, we capture velocity preferences relative to the obstacle position. Similarly, features can be defined relative to other context parameters to capture velocity preferences that depend on other parameterized positions.
However, the issue might arise that the two trajectories do not have the same number of segments in each distance bin. In such a case, we employ feature imputation using the mean of the available values.
The following subsections describe the rewards that make up the robot’s objectives.
2.2.5. Path Efficiency Reward
We calculate the total length of a trajectory, which we use as a negative reward. Penalizing the trajectory length is essential in counterbalancing the human preference features in the optimization process. Essentially, it pulls the trajectories towards the straight line path from start to goal and rewards, keeping them short.
2.2.6. Collision Avoidance Reward
We use the obstacle cost as formulated by Zucker et al. [
23], which increases exponentially once the distance to the obstacle drops below a threshold. The negative cost is our reward.
2.2.7. Robot Velocity Reward
This reward achieves a low and safe velocity in the absence of human velocity preferences and is defined based on (
6). In IRL, it is beneficial to learn how people balance other features against a default reward [
24].
2.3. Motion Planning via Trajectory Optimization
We discuss the problem of motion planning in two parts. First, we address the optimization of the path of the trajectory in the workspace. We then address the optimization of the velocity along this path, defining the timing of the motion.
Solving the path optimization problem over the Cartesian task space would be complex and inefficient. Instead, we employ a trajectory planning algorithm [
25] that interpolates between waypoints with piecewise clothoid curves. This algorithm minimizes the acceleration, which results in a smooth and realistic motion. We exploit this algorithm to significantly reduce the search space for the path optimization and sample trajectories using a vector of waypoint coordinates
and its corresponding time vector
,
.
We consider three waypoints , corresponding to the start position, an arbitrary position within the path and the goal position, respectively. We further simplify the problem by fixing the time vector to , where indicates the Euclidean distance of a waypoint to and is the time, we assume all trajectories take to finish, just for the path optimization (the shape of the paths is not affected by in the time ranges of our manipulations; therefore, we assume the path to be independent of velocity). An uneven distribution of waypoints would bias the reward value. Setting up the time vector in this manner ensures a constant velocity throughout the trajectory, which results in an even distribution of samples over the path. Trajectories can then be sampled only as a function of waypoint positions .
We then solve for the optimal waypoint vector
using the following non-linear program formulation:
Here, the objective function consists of the human path reward
and the robot’s path objective, which is a linear combination of predetermined weights
and the aforementioned path reward functions
. The equality constraint ensures the start and goal positions are met. As a result, we are effectively searching for the waypoint
that maximizes the objective function. The upper and lower boundaries
and
limit the trajectory to stay within the robot’s workspace. Once
is found, we construct the full trajectory using
.
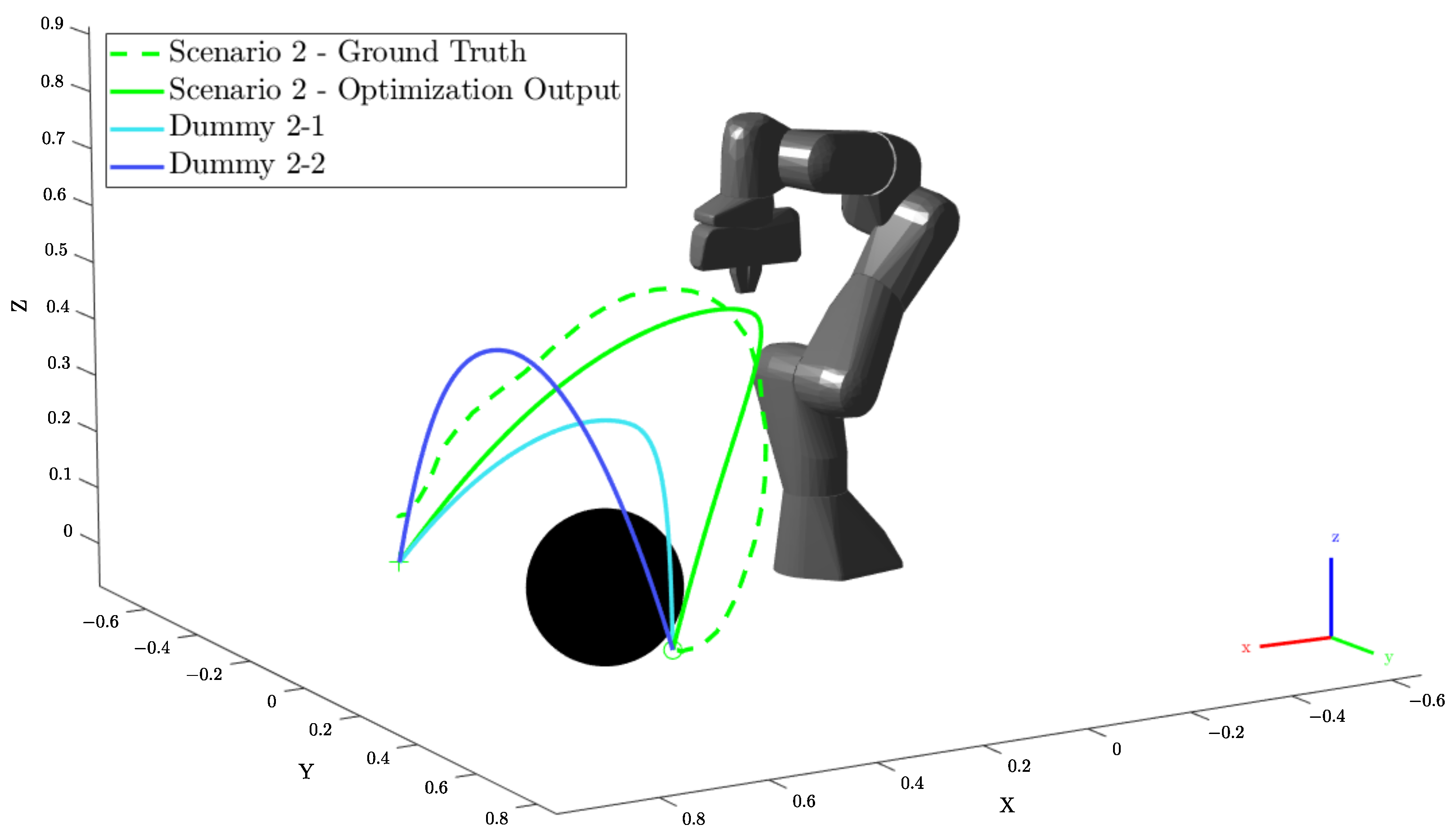
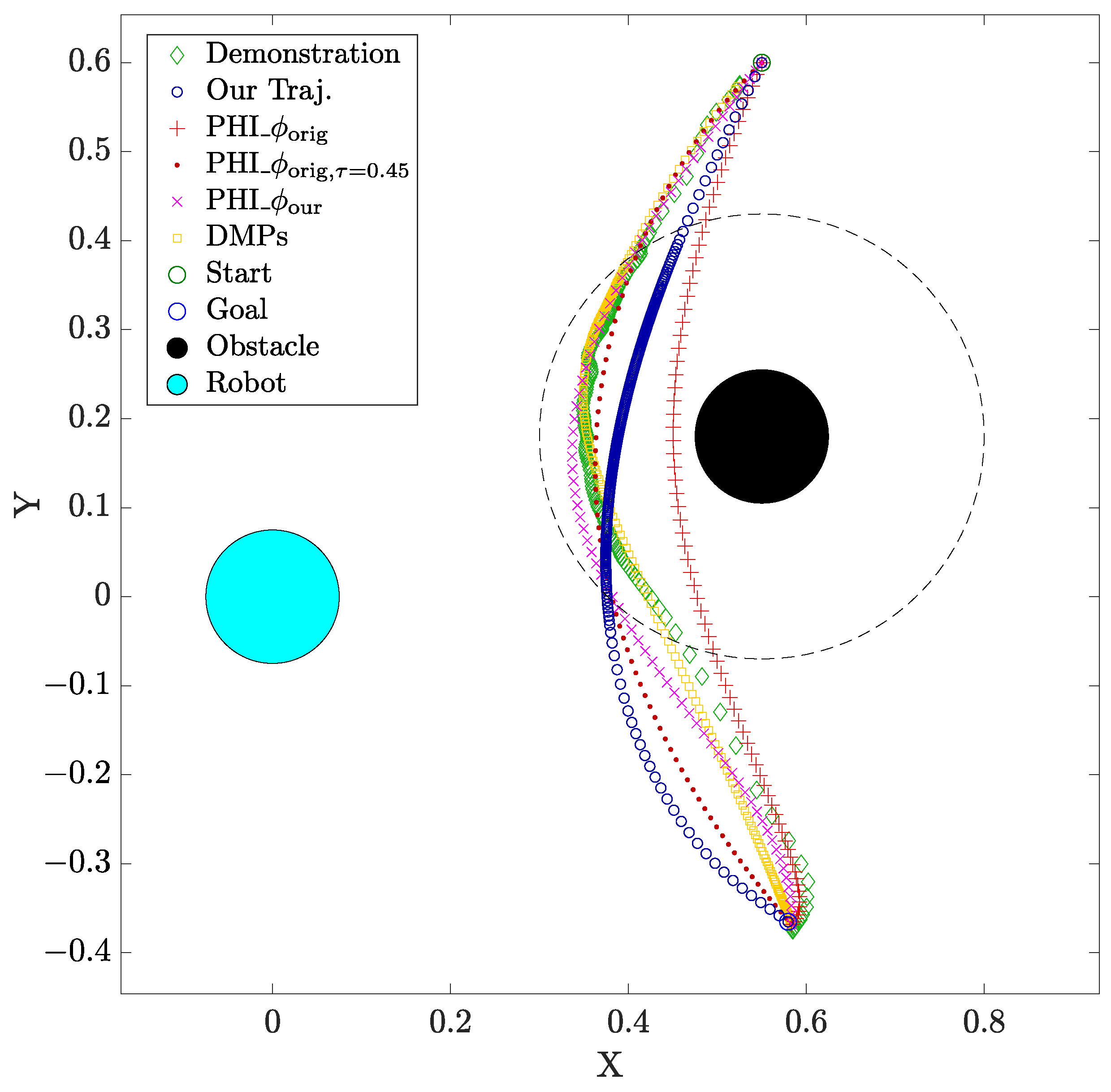
Figure 3 shows an example of the convergence of the optimizer towards a path that adheres to “low height”, “close side” and “close to obstacle” preferences.
Having the optimal path
, we divide the trajectory into
M segments (as described in
Section 2.1). Next, we store the positions of the waypoints at the end of the segments in
. This vector is fixed to maintain the shape of the trajectory. The corresponding timestamps, stored in
, are the variables we optimize. Thus, trajectories sampled by the optimizer are only a function of the time vector
. By optimizing
, we optimize the average velocity of each segment. The optimal time vector is
where the objective function is composed of
and the robot’s velocity objective
, which provides a reward for carrying objects at
with a fixed weight
. The inequality constraint
bounds the velocity over each segment to
and
, not allowing the timestamps to get too close or far from each other. The upper boundary on
acts as a limit on the total duration of motion.
Finally, the trajectory that adheres to both the path and velocity preferences is constructed using
. The full method is summarized in Algorithm 1.
| Algorithm 1: Learning human preferences from kinesthetic demonstration |
![Robotics 12 00061 i001]() |
3. Method Validation with User Study
To validate our framework, we conducted two user experiments on a Franka Emika 7-DoF robot arm. Thereby, we demonstrated a proof-of-concept of our approach in a real-world scenario with non-expert users. In both experiments, we use a set of three pick-and-place tasks in an agricultural setting, as shown in
Figure 4. The primary goal of each task was moving the tomatoes from the initial position to the goal without any collisions with the obstacle. The experiments were approved by the Human Research Ethics Committee at Delft University of Technology on 6 September 2021.
We recruited 14 participants (4 women and 10 men) between 23 and 36 years old (mean , SD ), 6 of whom had prior experience with robotic manipulators, but none of whom had any exposure to our framework.
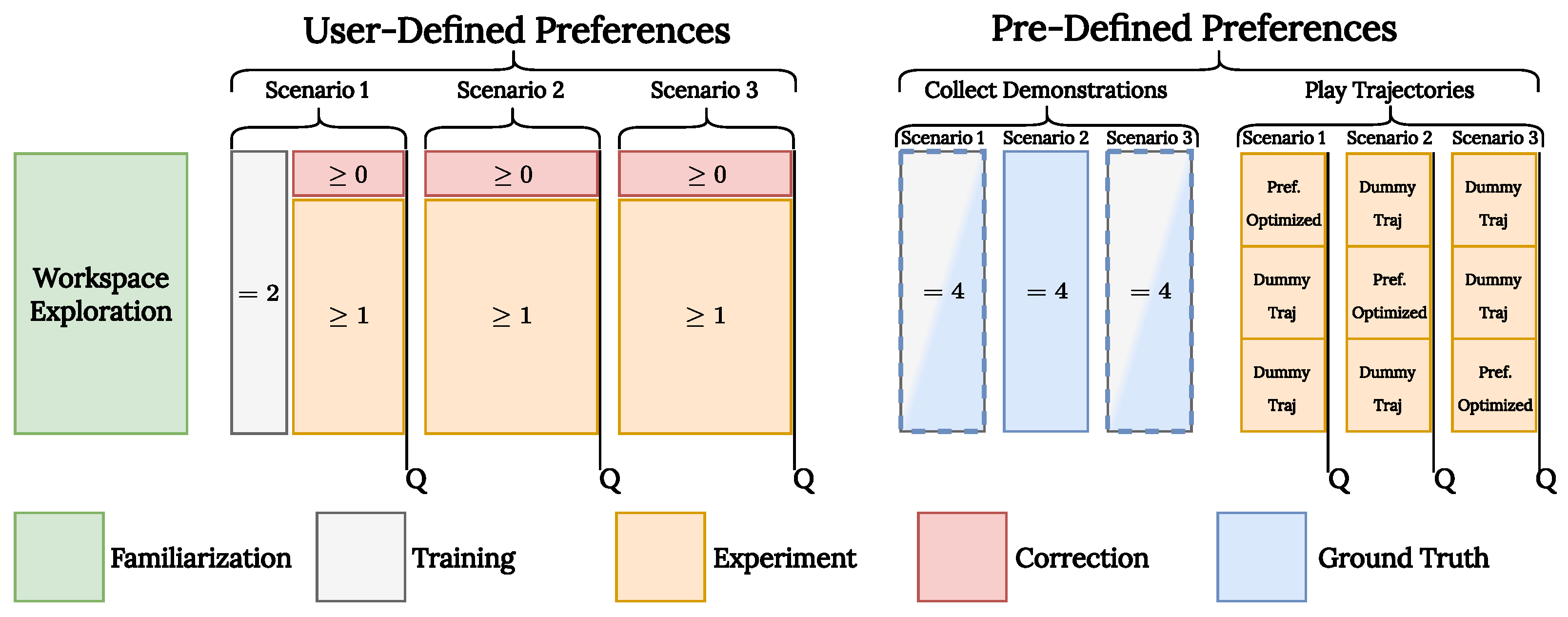
Each user first took approximately 10 min to get familiar with physically manipulating the robot in the workspace. In this period, we also instructed users about the goal of the task and the preferences the robot could capture. Users then proceeded with the two experiments. To subjectively assess whether the framework can capture a range of different behaviors, in the first experiment, we let the users freely choose their path and velocity preferences. Once users were more familiar with the framework, in the second experiment, we assessed how effectively they could teach a set of pre-defined preferences to the robot. The overview of the user study is provided in
Figure 5. We discuss each experiment in the following subsections. A video of the experiments can be found here:
https://youtu.be/hhL5-Lpzj4M, accessed on 13 April 2023.
3.1. User-Defined Preferences
In the first experiment, we investigated how our framework performs when users openly chose their set of preferences. We were specifically interested in assessing how well the robot plans motions in new task instances with a context it has not seen before (i.e., generalization of preferences to new scenarios). We also evaluated the user experience in terms of acceptability and effort required from the user’s perspective. Accordingly, we tested the following hypotheses:
Hypothsis 1 (H1). The proposed framework can capture and generalize user preferences to new task instances.
Hypothsis 2 (H2). Users feel a low level of interaction effort.
3.1.1. Procedure and Measures
Users first performed a demonstration in Scenario 1 (
Figure 4) for path preferences with the robot in gravity compensation mode. Notably, we did not limit users to a discrete set of preferences. For instance, instead of asking users to pass on either the close or far side of the obstacle, we asked them to intuitively demonstrate how far to either side of the obstacle they would prefer to pass. They could, for example, decide to pass right above the obstacle, which would correspond to a “stay to the middle of the obstacle” for the “obstacle side” path preference. We then collected a second separate demonstration for the velocity preferences. During velocity demonstrations, the robot was only compliant along a straight line path covering the full range of distances to the obstacle. This allowed the users to demonstrate their preferred speed without having to care about the path. The velocity optimization step can take up to 3 min; therefore, we simplified the method for learning and planning velocity preferences to find the velocity
with the highest feature count in this part of the study. Users were instructed to provide corrections via additional kinesthetic demonstrations (max 10 min per scenario) until they were satisfied with the resulting trajectory. However, the users were informed that the trajectory speed was only trained once and would not be updated further.
After observing each trajectory, the users filled out a subjective questionnaire for qualitative evaluation, rating the following statements on a 7-point Likert scale:
The robot accomplished the task well.
The robot understood my path preferences.
The robot understood my motion preferences.
To evaluate the effort, we counted the number of times a user provided feedback, and let the participants fill out the NASA Task Load Index (TLX) at the end of this experiment. The independent variables of this experiment are the contexts which are varied for each scenario for assessing workload. Although we do not compare results with a baseline here, NASA-TLX is still appropriate since it can capture absolute results [
26].
3.1.2. Results
Users demonstrated a multitude of path preferences, including “keep a low distance to the obstacle” and “stay at a medium height above the table”. Similarly, for velocity preferences, while the majority opted for a constant “medium” speed, both the preferences of going “slower when close to the obstacle” and “faster when close to the obstacle” were demonstrated at least once.
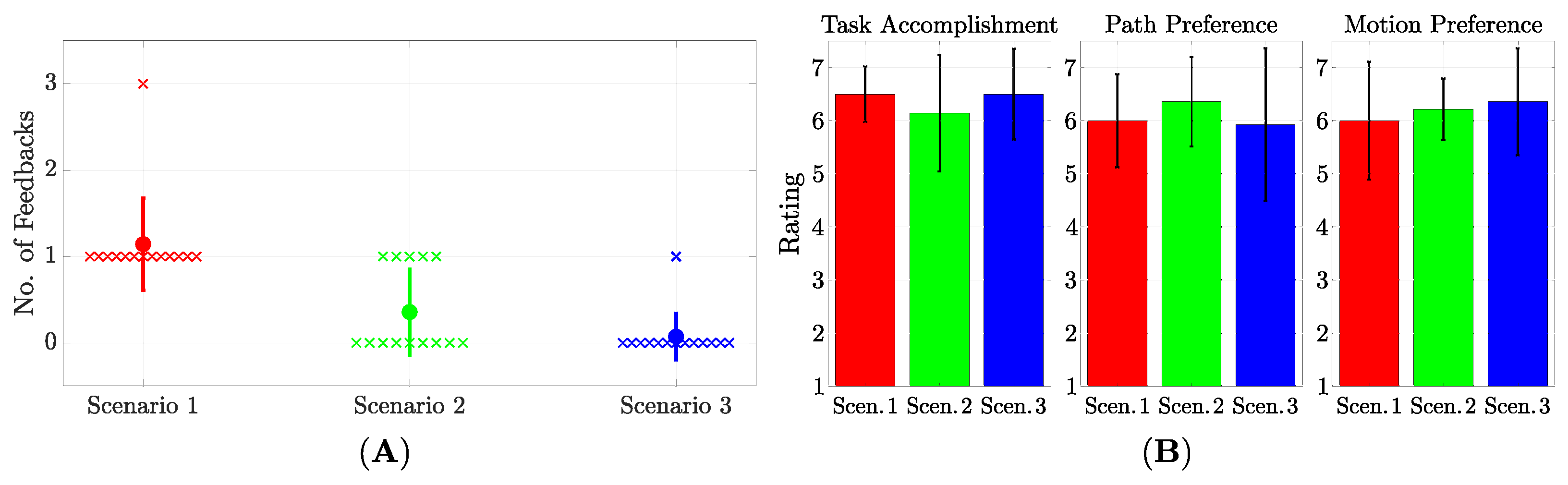
Figure 6A shows that the average amount of feedback given to the system after the first task dropped, with the majority of the users satisfied with the results of generalization after the initial demonstration (we counted the training step in Task 1 as feedback). This result is also reflected in
Figure 6B, showing that the users scored the first trajectory produced in every scenario consistently high for all three statements, supporting the claim that the framework can generalize both path and velocity preferences to new task instances. This provides strong evidence in favor of both
H1 and
H2.
The NASA-TLX results in
Figure 7 show that the users experienced low mental and physical workload. Although kinesthetic teaching is normally associated with high effort, our framework’s effort scores remain mostly on the lower side of the scale. One participant was particularly strict on a height preference the algorithm failed to capture, resulting in three iterations of feedback in Scenario 1. Overall, the results in
Figure 7 support
H2.
3.2. Pre-Defined Preferences
To objectively evaluate the accuracy and the user’s ability to discern preferences, we conducted an experiment where users are asked to adhere to the following path preferences (we did not consider velocity preferences in this experiment):
Pass on the side of the obstacle that is closer to the robot.
Stay far from the obstacle.
Keep a high elevation from the table.
Exactly how to express these preferences and how to trade off between them if necessary was left to the users. We tested the following hypotheses:
Hypothsis 3 (H3). The method remains consistently accurate in all scenarios.
Hypothsis 4 (H4). Users can clearly distinguish that the output of the framework follows the specified preferences.
3.2.1. Procedure and Measures
We collected four demonstrations per scenario. For half of the participants, we trained the model on the mean of the four demonstrations from the first scenario, and for the other half, we used the mean of data from the third scenario. This was to establish that our method can be generalized, even when changing the set used as the training data.
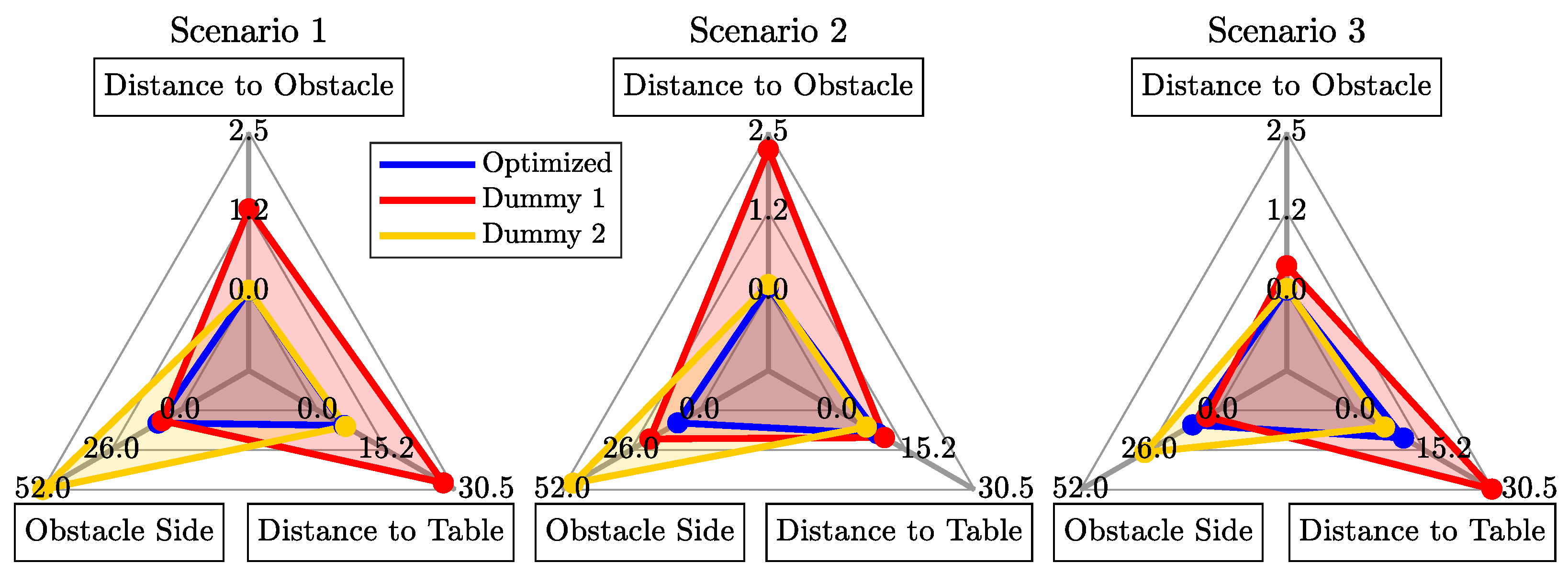
After that, the users were shown three trajectories per scenario: the output of our framework and two dummy trajectories (
Figure 8). The dummy trajectories were designed to adhere to two out of three path preferences. This allowed us to observe if users could distinguish our method’s results compared to sub-optimal trajectories.
As an objective measure of the accuracy of our method, we computed, per scenario, the total Euclidean distance of samples within each trajectory with respect to the mean of the demonstrations (using N = 80). Furthermore, we compared the total feature counts along each trajectory and measured the error with respect to the ground truth in the feature space.
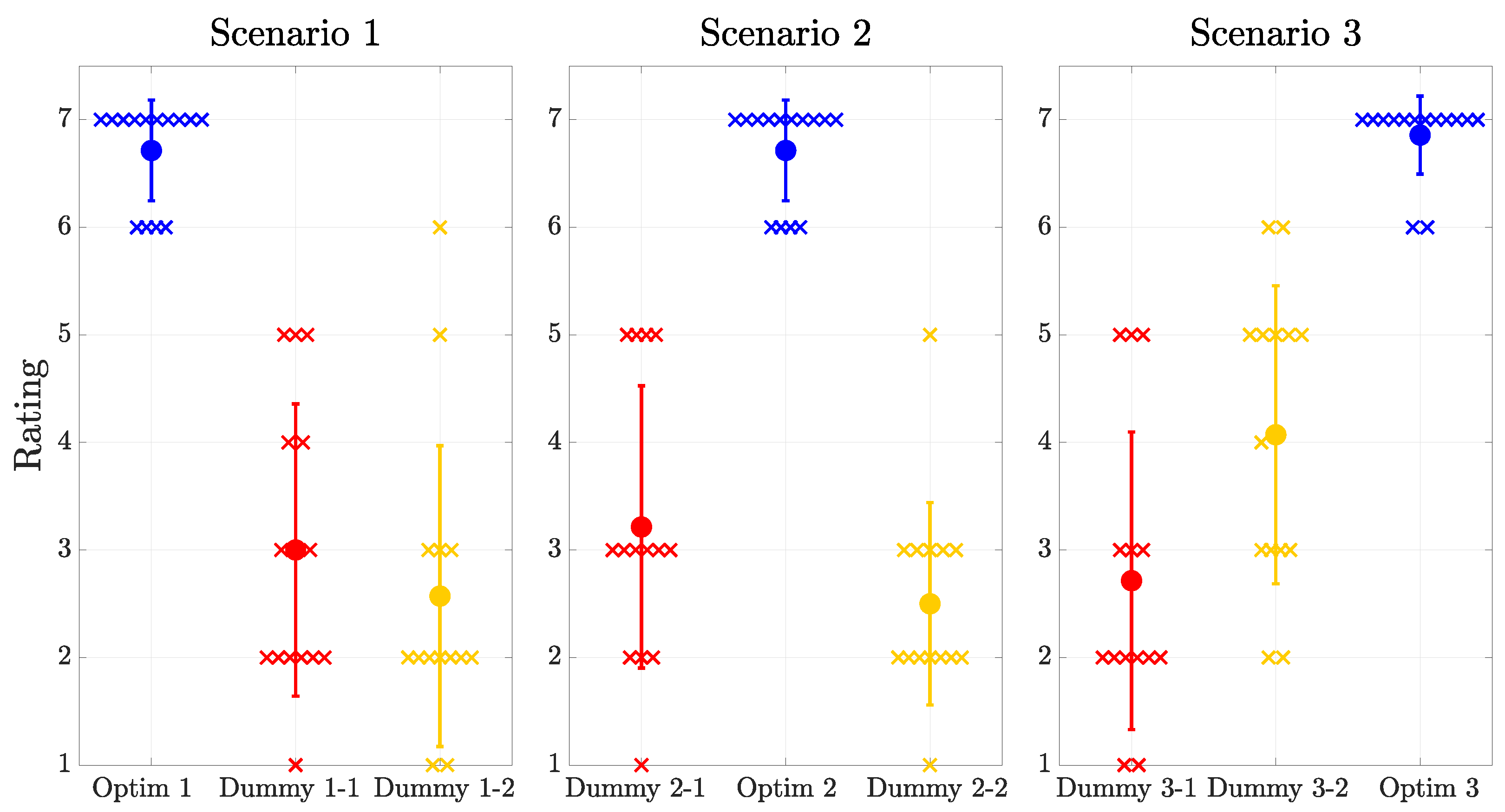
Subjectively, users rated a 7-point Likert scale per trajectory: “the robot adhered to the demonstrated preferences”.
3.2.2. Results
Figure 8 shows a generalization of the results of our method under the aforementioned path preferences. The robot attempted to capture and optimize each user’s personal interpretation of the preferences (e.g., one user’s definition of “high” is different from another). We show the combined results of all users in
Table 1, listing the trajectories’ mean, min and max Euclidean distance to the ground truth, normalized relative to the start-to-goal distance in each scenario (respectively 1.08, 0.74 and 0.88 m). The optimized trajectories have the smallest error, but the results only partially support
H3, as the errors in Scenarios 2 and 3 are slightly larger than in Scenario 1. This scenario has the longest distance from start to goal, for which the framework seems to perform better.
Figure 9 shows the errors of the trajectories in feature space. In all scenarios, our optimization result occupies the smallest area. However, in Scenarios 2 and 3, the optimized trajectories occupy a slightly larger area than in Scenario 1, showing the same trend of performance loss in scenarios with a shorter length. Furthermore, in Scenarios 2 and 3, dummy trajectories occasionally perform slightly better for one of the preferences. Nevertheless, we see in
Figure 10 that users clearly score the output of our framework higher, which strongly supports
H4. This indicates that users prefer all preferences to be satisfied simultaneously. The best performing dummy (S3-D2), with the smallest area in
Figure 9 and lowest values in
Table 1, correlates to a high rating in
Figure 10. This also supports
H4, suggesting that non-expert users intuitively recognize such preferences in trajectories.
3.3. Discussion
As the state-of-the-art methods do not have the same functionalities (e.g., path–velocity separation) as the proposed method, we conducted a user study only on the proposed method itself. To account for that, we employed absolute types of metrics (i.e., Likert and NASA-TLX), which can be interpreted independently, rather than tied to a specific external baseline. For example, the Likert scale is tied to an agreement with the given statements and the natural point on the agreement scale serves as a general baseline. The advantage of this is that the results are not tied to a specific relative baseline. If methods that enable the same functionalities are developed in the future, the same Likert scale/questionnaire can be employed to compare the subjective results independently of a specific baseline.
An advantage of the proposed method is that it learns fast. During the first part of the user study, participants spent on average 16.5 s interacting with the robot before expressing satisfaction with the results. This is partially due to having access to kinesthetic demonstrations. This method of demonstration has been criticized as challenging in applications involving high DoF manipulators [
1,
27]. However, the separation of learning and control in our framework means that users do not have to provide the correct configuration of the arm in their demonstrations. This feature made it significantly easier for the users to provide demonstrations, which is reflected in the reported low mental and physical loads (
Figure 7).
The separation of path and velocity planning has additional benefits. Formulating the optimization as a multi-objective problem with both position and velocity features results in undesirable interactions of objectives. For instance, when velocity features reward high speeds, the trajectory converges to a longer path. Conversely, path features with high rewards in specific regions of space result in slow motion in those regions to increase the density of samples and consequently the overall reward. On the other hand, the separated trajectory optimization has the limitation that it cannot account for dynamical quantities such as joint velocity and acceleration, and the efficiency of movements in the robot’s joint space cannot be considered.
A challenge with our definition of robot and user objectives is that the trajectory optimization outcome does not always align with task requirements. For instance, a strong “stay close to the object” preference can result in a minimum cost for a trajectory that is briefly in a collision. Tuning the collision weight can only partially solve this issue, as at a certain point, this cost can interfere with the path preferences.
Our user study results showed that non-expert users can intuitively use our method to quickly teach a wide range of preferences to the robot. Although the generalization results of different task instances show that we do not always reproduce trajectories with the exact desired shapes in the workspace (see
Figure 8), the subjective performance evaluation shows that users still deem these trajectories highly suitable in terms of task accomplishment and the preferences achieved. State-of-the-art LfD methods are very capable of producing accurate and complex dynamic movements [
28]. However, in tasks where there are multiple ways of achieving the same goal, we prefer to trade off motion accuracy for achieving planning propensities on a higher level.
Unfortunately, our approach inherits the limitations of IRL approaches that require specifying reward features by hand. Both features and robot rewards depend on several parameters which require tuning. The problem becomes especially difficult as our features simultaneously govern the behavior of reward learning and trajectory optimization. For instance, high gradients in the feature function lead to erratic behavior of the optimizer, leading to poor solutions and convergence to local optima. Yet, for certain features, a sufficiently high gradient is required to facilitate the learning of preference weights that are large enough to counterbalance each other. As a result, we had to resort to further tuning of parameters, such as the learning rate in (
5). An interesting direction for future work would be to test whether and how well these issues can be alleviated by feature learning from additional demonstrations, as was demonstrated by Bobu et al. [
29]. Furthermore, an approach similar to that in [
30] could be employed to learn the relative weighting among features and add additional features through nonlinear functions using neural networks.
In feature engineering or learning, the definition of the context determines how expressive the features are. We considered a limited set of vectors as the context in this work (i.e., obstacle position and start and goal positions). It is possible to include additional information, such as object properties (e.g., sharp, fragile or liquid) [
1], human position [
4,
6] and the number of objects. The more rich the context, the more preferences the model can capture in complex environments. However, training diversity can become an issue with contextually rich features, as the model would require more demonstrations to cover a wider range of situations. This will increase the training time. An evaluation of the trade-off between improved generalization and higher training time is left for future work.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}