On the Benefits of Color Information for Feature Matching in Outdoor Environments

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Feature Detection and Description
2.1. Scale-Invariant Feature Transform (SIFT)
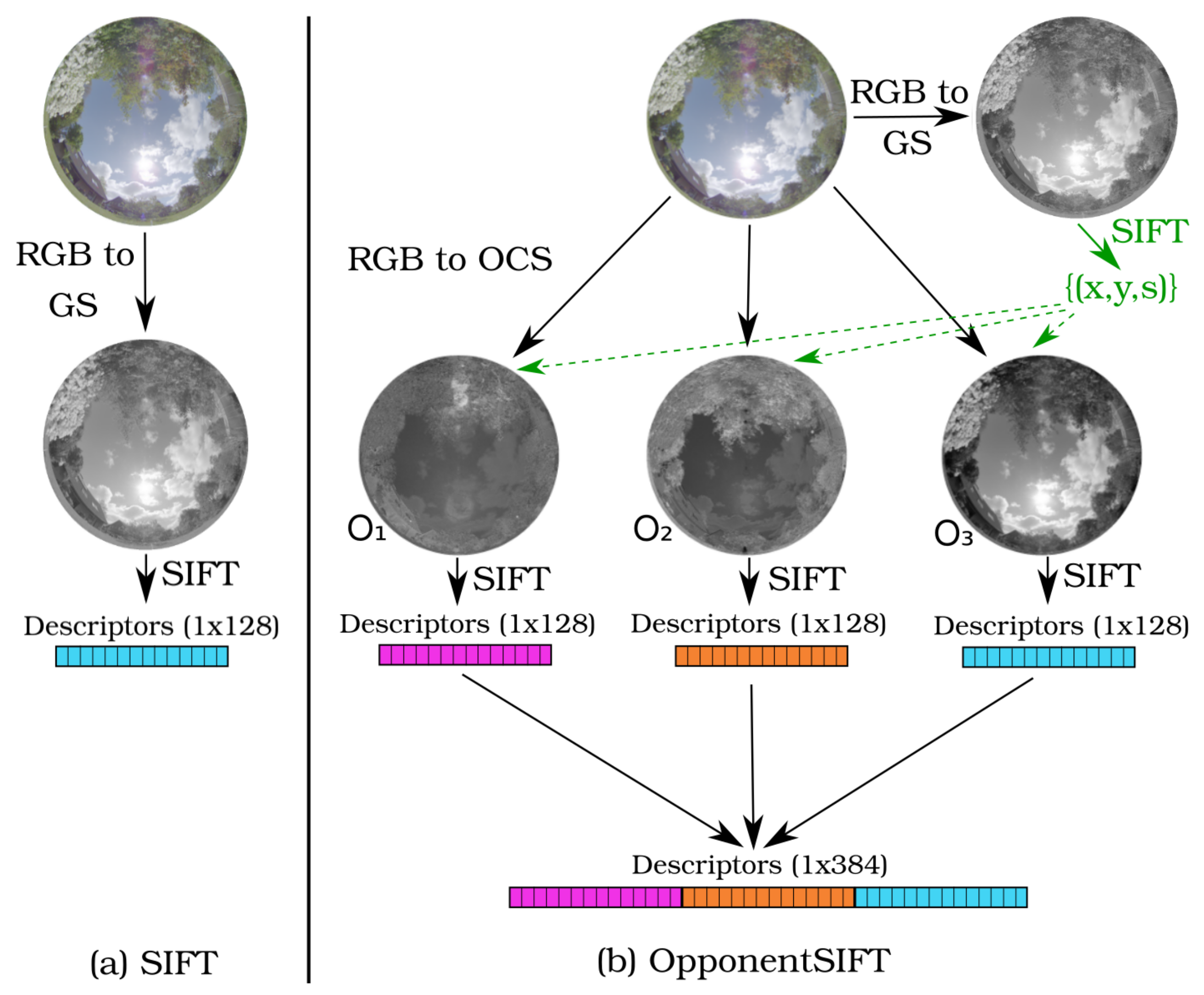
2.2. OpponentSIFT
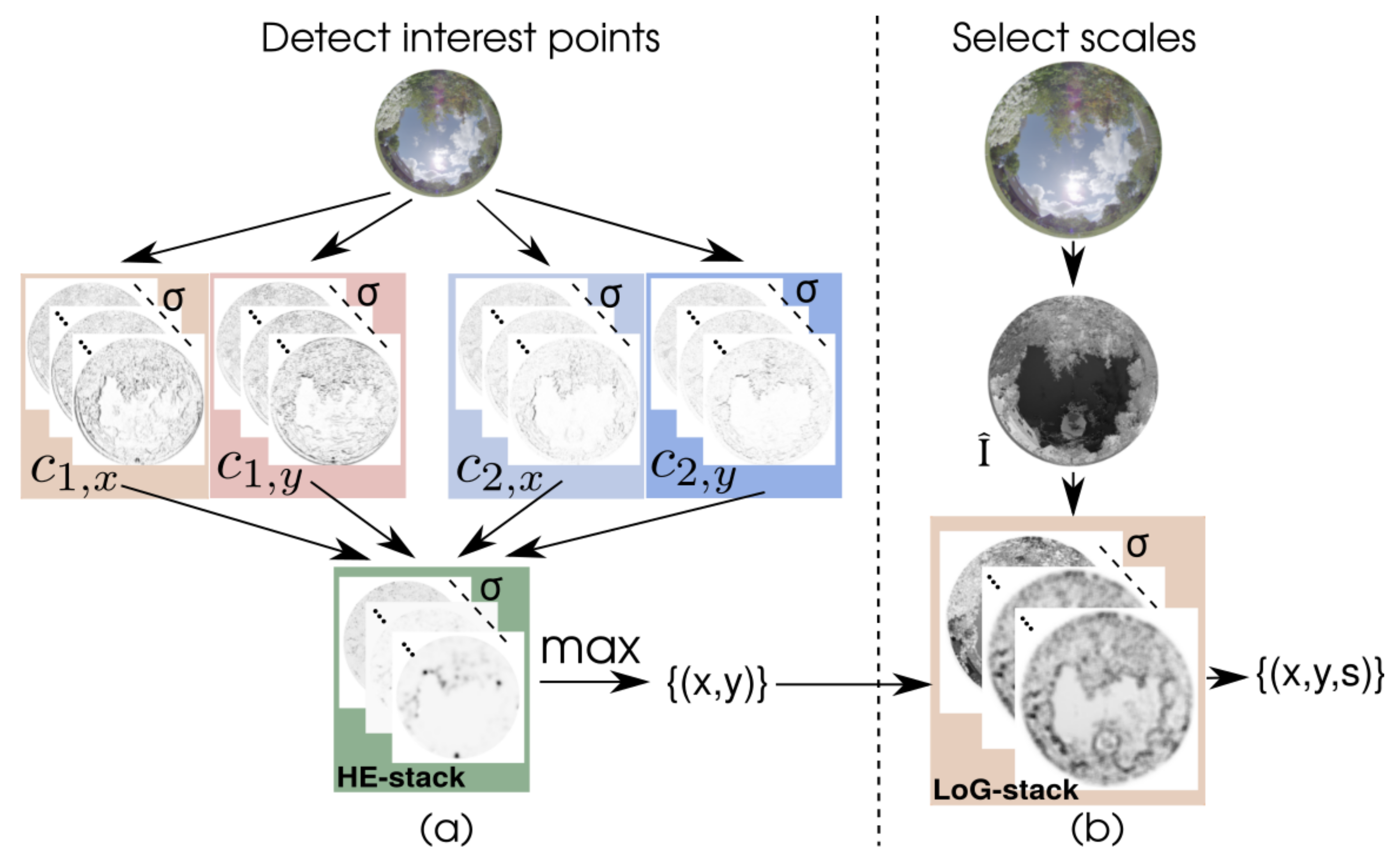
2.3. Sparse Color Interest Points (CIP)
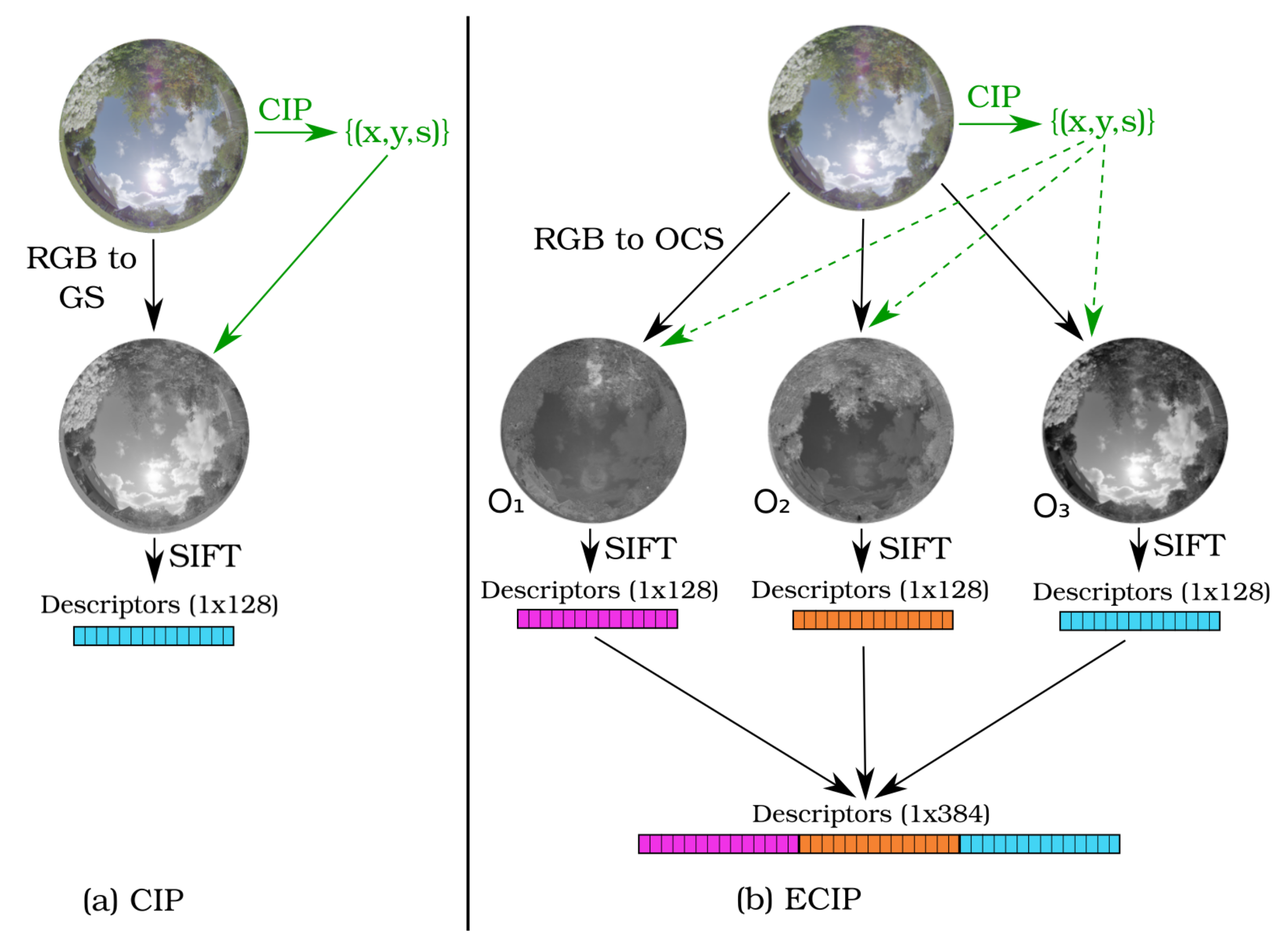
2.4. Extended Color Interest Points (ECIP)
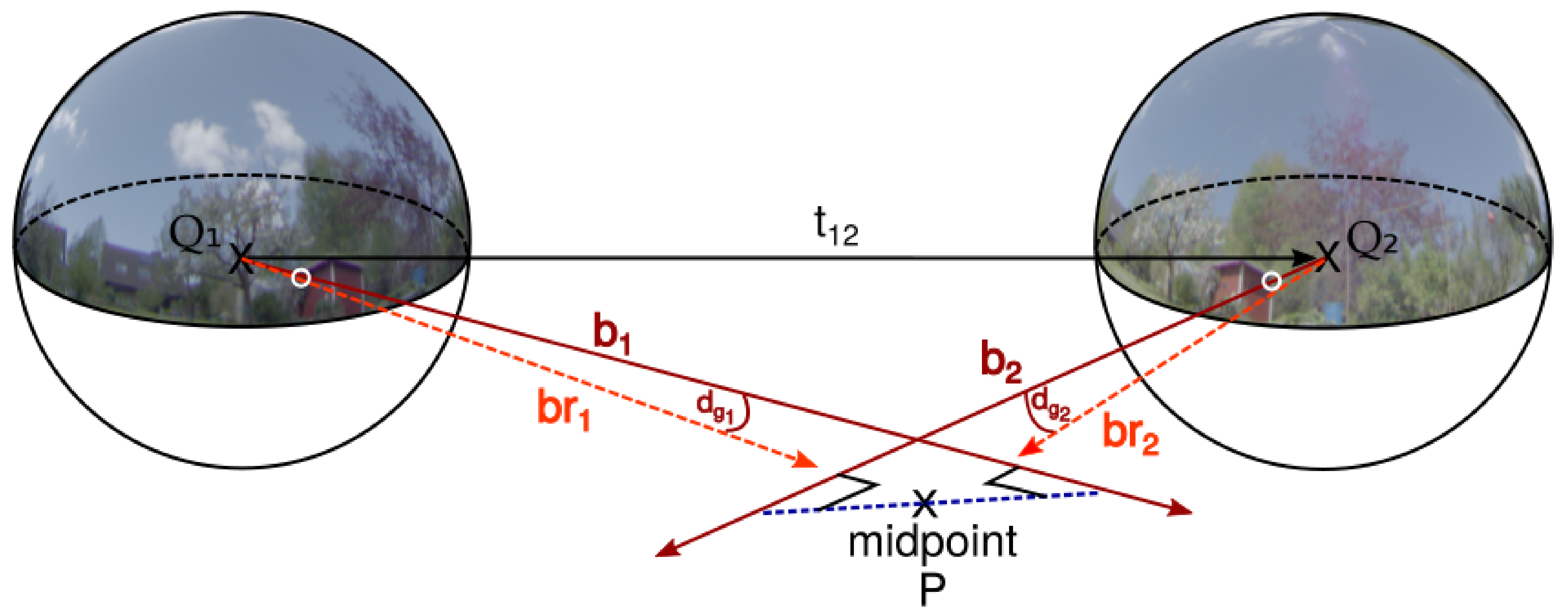
2.5. Feature Matching
3. Evaluation
3.1. Evaluation Criteria
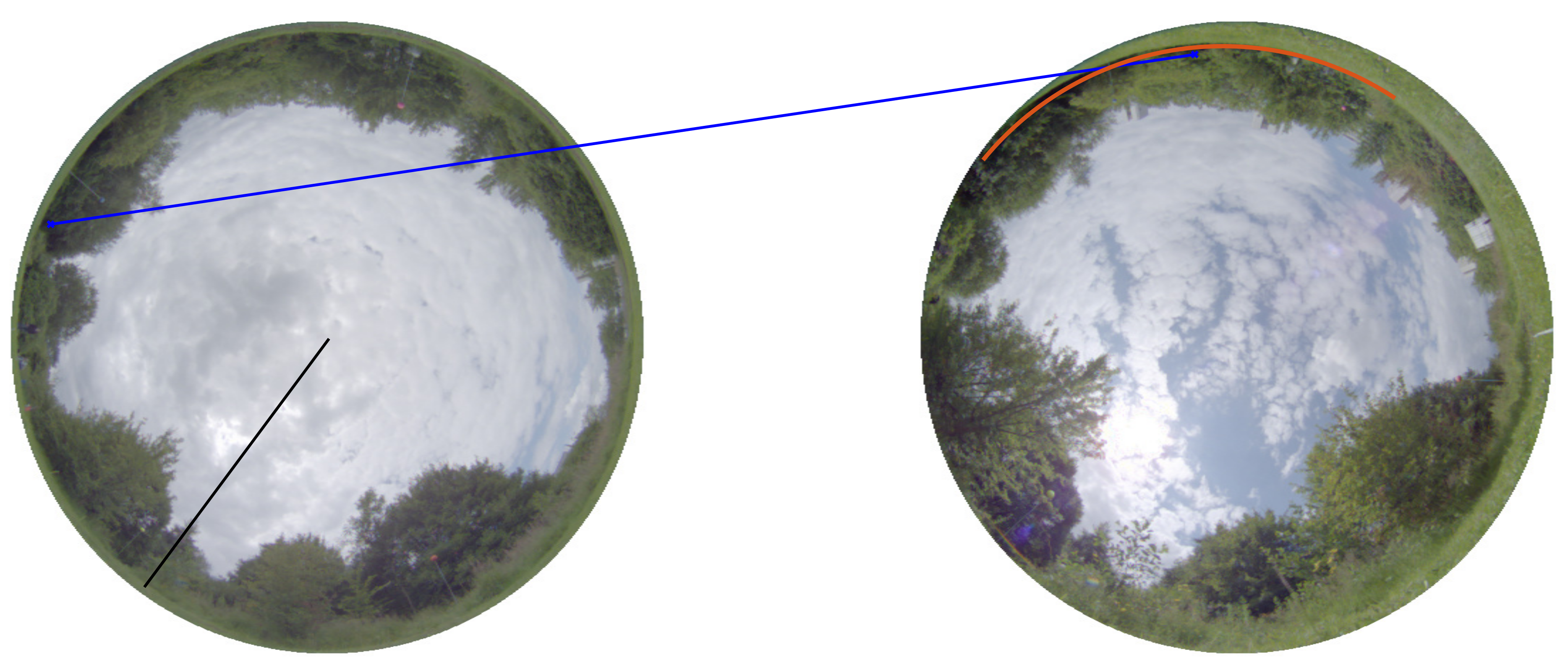
3.2. Datasets and Experimental Setup
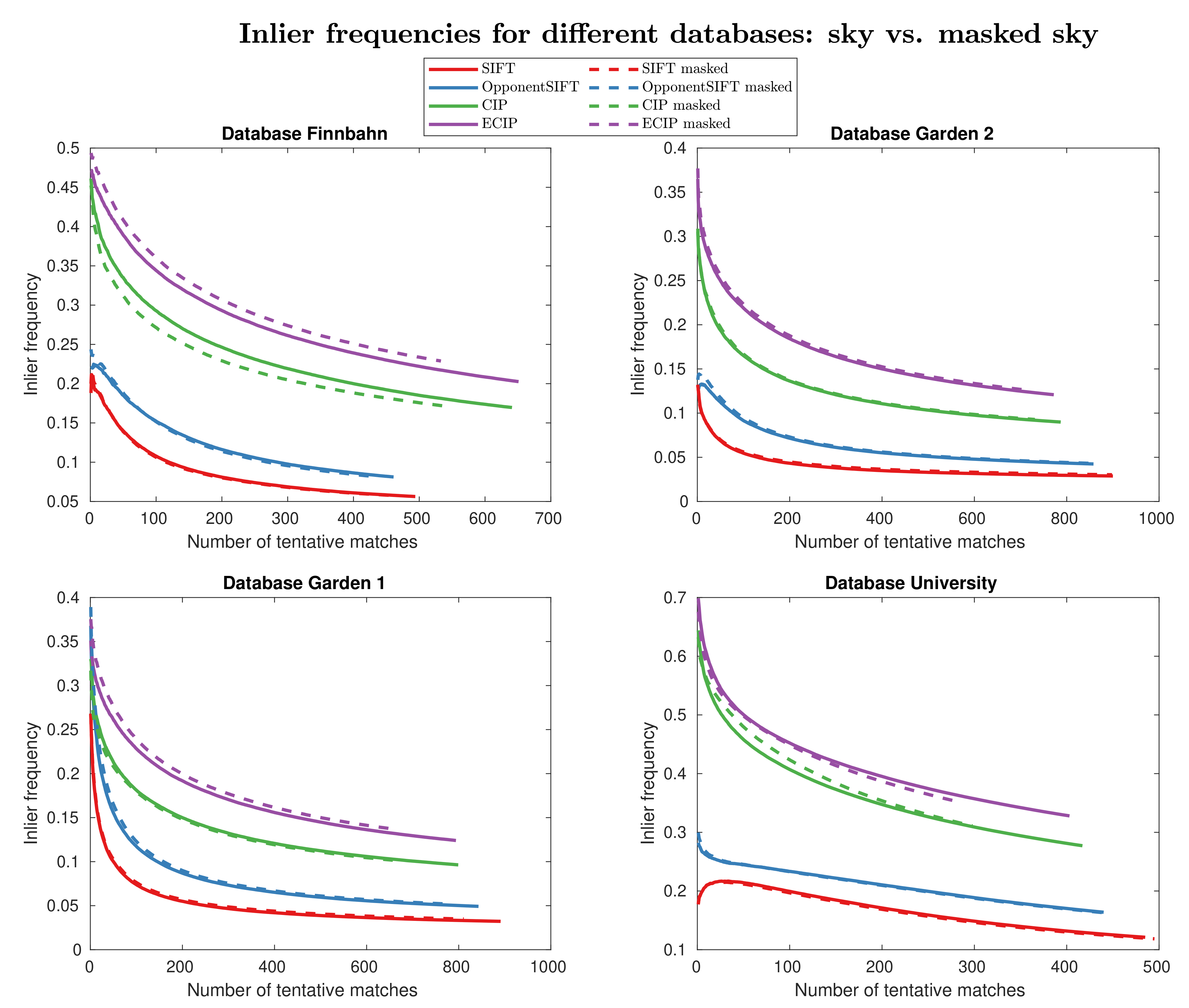
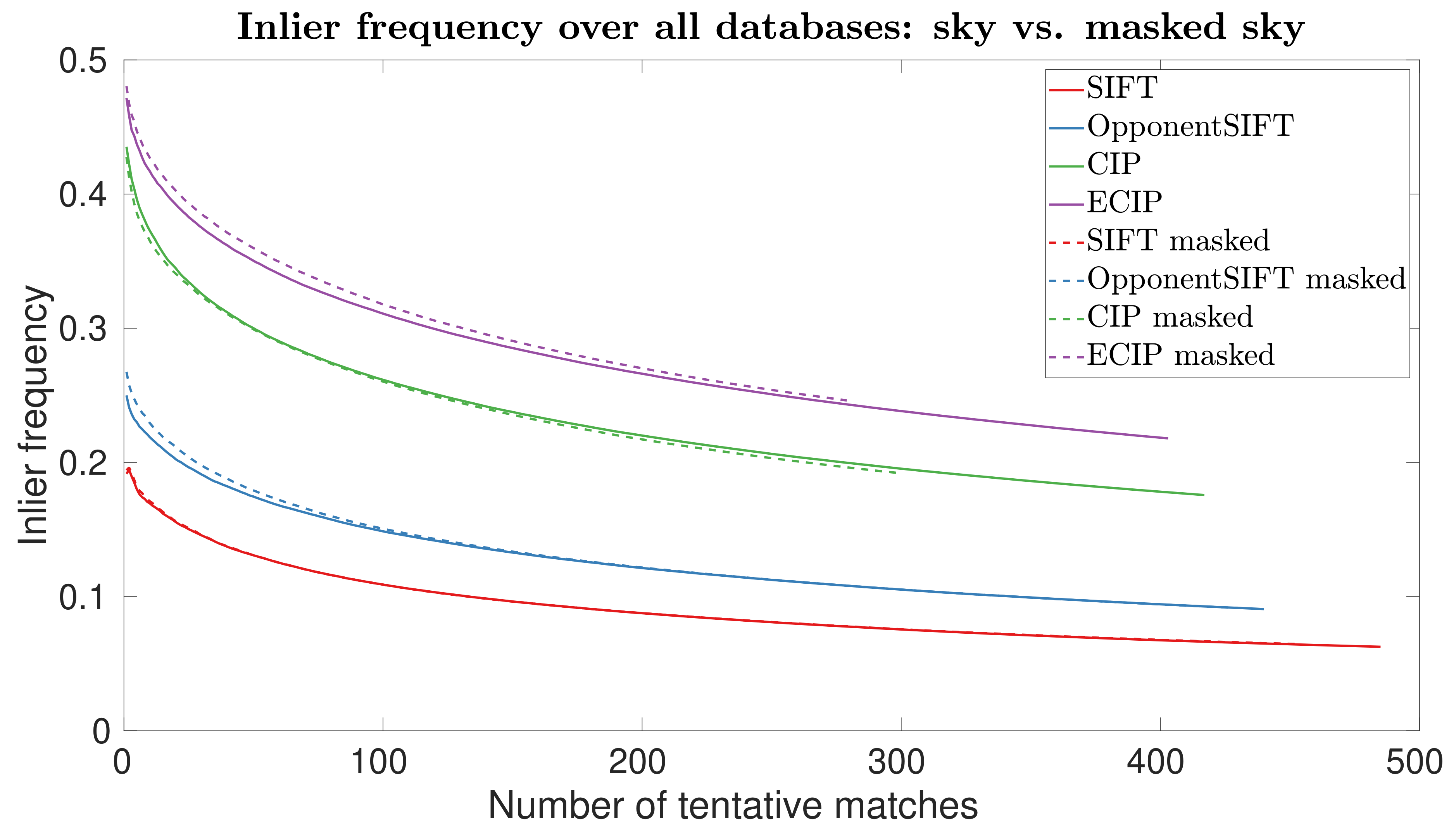
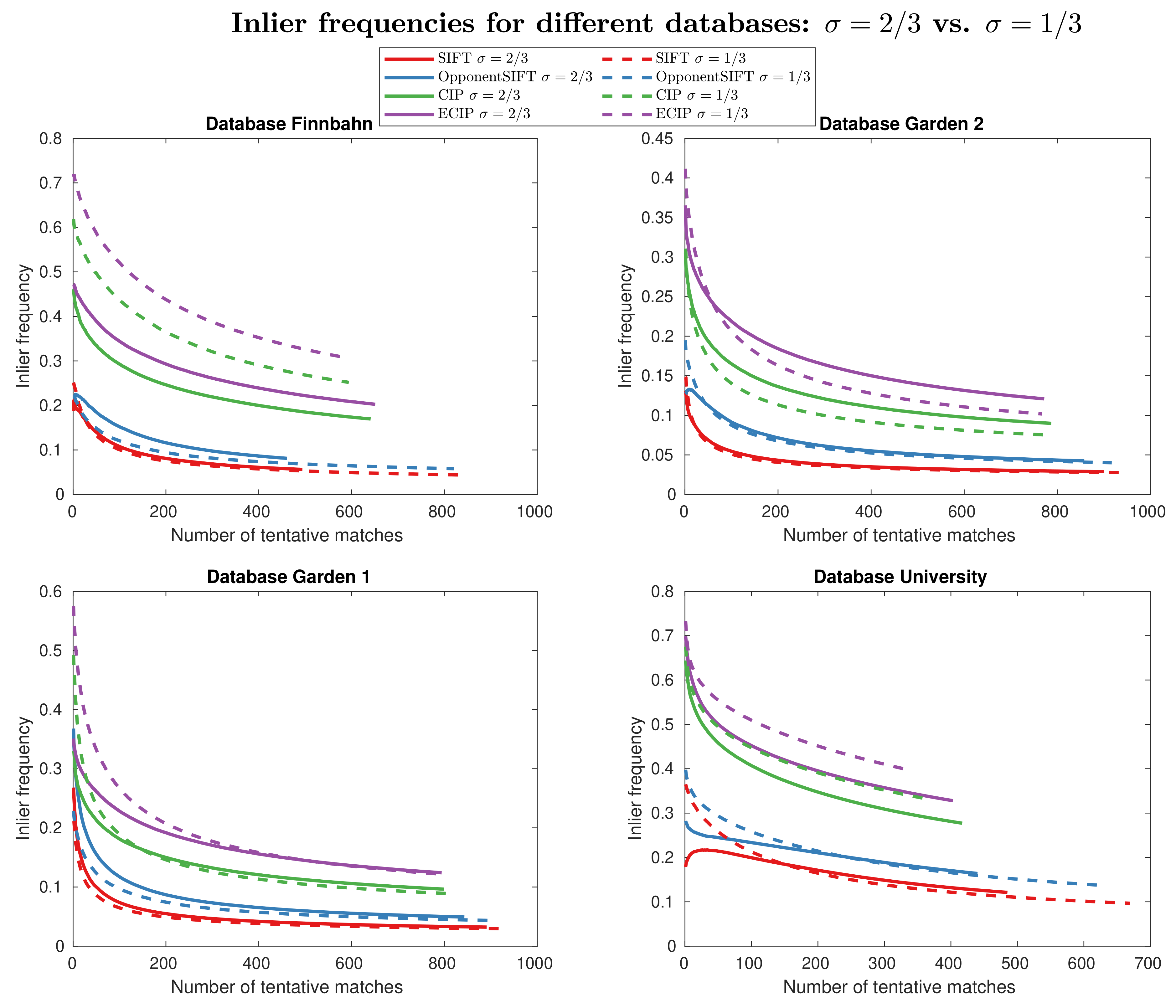
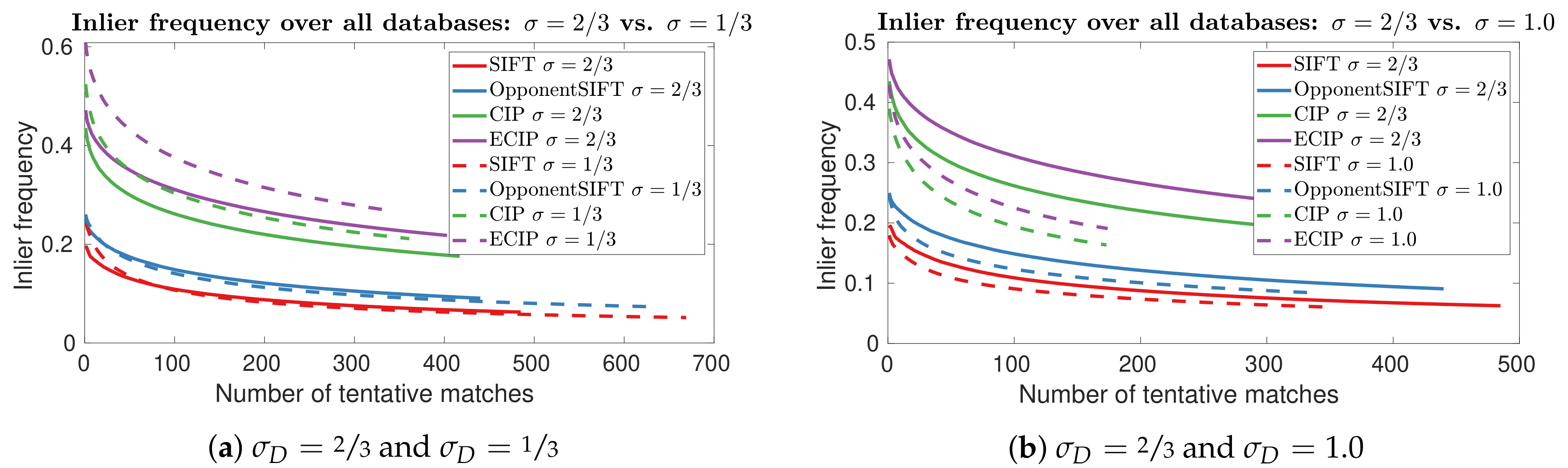
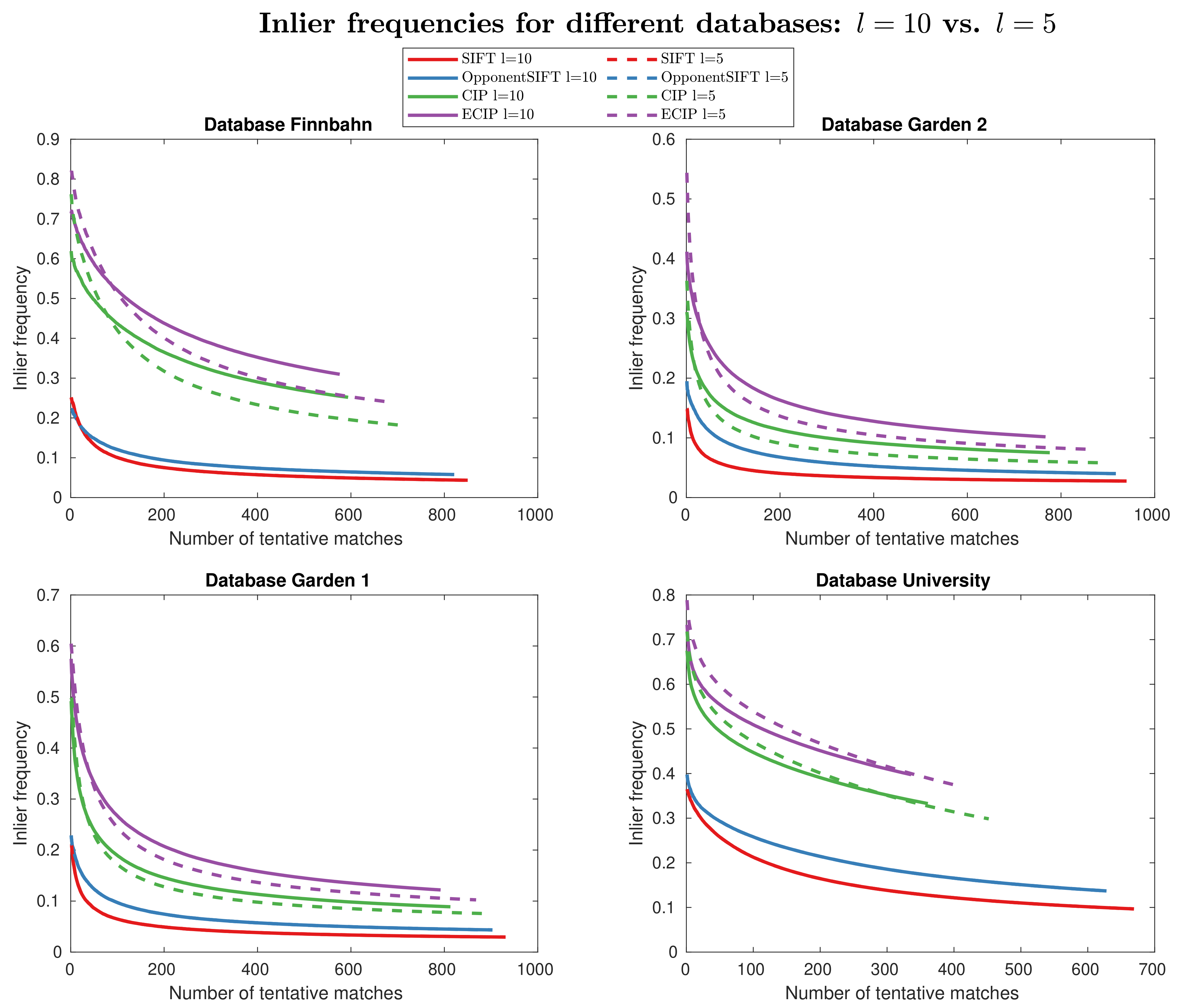
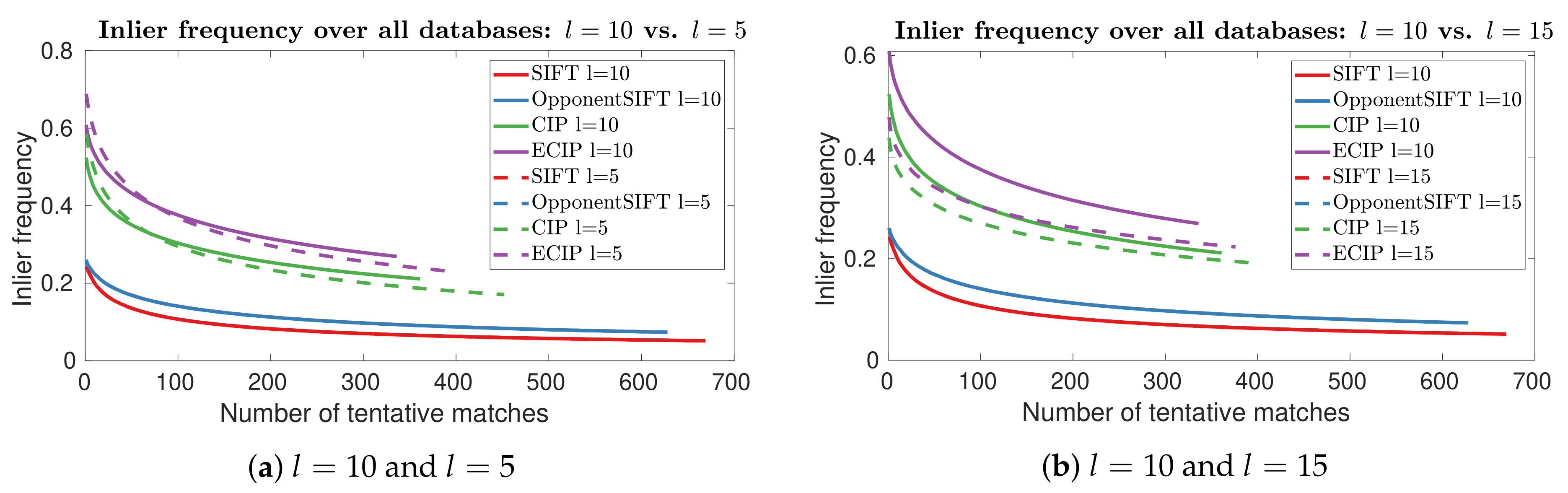
4. Results
5. Discussion
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Implementation Details of CIP
References
- Mikolajczyk, K.; Schmid, C. A performance evaluation of local descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [Green Version]
- Van de Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1582–1596. [Google Scholar] [CrossRef]
- Schmidt, A.; Kraft, M. The impact of the image feature detector and descriptor choice on visual SLAM accuracy. In Image Processing & Communications Challenges 6; Choraś, R.S., Ed.; Springer: Cham, Switzerland, 2015; pp. 203–210. [Google Scholar]
- Schmidt, A.; Kraft, M.; Kasiński, A. An evaluation of image feature detectors and descriptors for robot navigation. In International Conference on Computer Vision and Graphics; Springer: Berlin/Heidelberg, Germany, 2010; pp. 251–259. [Google Scholar]
- Gil, A.; Mozos, O.M.; Ballesta, M.; Reinoso, O. A comparative evaluation of interest point detectors and local descriptors for visual SLAM. Mach. Vis. Appl. 2010, 21, 905–920. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, A.; Kraft, M.; Fularz, M.; Domagala, Z. Comparative assessment of point feature detectors and descriptors in the context of robot navigation. J. Autom. Mob. Rob. Intell. Syst. 2013, 7, 11–20. [Google Scholar]
- Barroso, T.M.; Ghita, O.; Whelan, P.F. Evaluating the performance and correlation of colour invariant local image feature detectors. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5751–5755. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Mathibela, B.; Posner, I.; Newman, P. A roadwork scene signature based on the opponent colour model. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 4394–4400. [Google Scholar]
- Kirk, R.; Cielniak, G.; Mangan, M. L* a* b* Fruits: A Rapid and Robust Outdoor Fruit Detection System Combining Bio-Inspired Features with One-Stage Deep Learning Networks. Sensors 2020, 20, 275. [Google Scholar] [CrossRef] [Green Version]
- Dzulfahmi; Ohta, N. Performance evaluation of image feature detectors and descriptors for outdoor-scene visual navigation. In Proceedings of the 2013 2nd IAPR Asian Conference on Pattern Recognition, Naha, Japan, 5–8 November 2013; pp. 872–876. [Google Scholar]
- Krajník, T.; Cristóforis, P.; Kusumam, K.; Neubert, P.; Duckett, T. Image features for visual teach-and-repeat navigation in changing environments. Rob. Autom. Syst. 2017, 88, 127–141. [Google Scholar] [CrossRef] [Green Version]
- Valgren, C.; Lilienthal, A.J. SIFT, SURF & seasons: Appearance-based long-term localization in outdoor environments. Rob. Autom. Syst. 2010, 58, 149–156. [Google Scholar]
- Milford, M.; McKinnon, D.; Warren, M.; Wyeth, G.; Upcroft, B. Feature-based visual odometry and featureless place recognition for SLAM in 2.5 D environments. In Proceedings of the Australasian Conference on Robotics and Automation, Melbourne, Australia, 7–9 December 2011. [Google Scholar]
- Möller, R.; Krzykawski, M.; Gerstmayr-Hillen, L.; Horst, M.; Fleer, D.; de Jong, J. Cleaning robot navigation using panoramic views and particle clouds as landmarks. Rob. Autom. Syst. 2013, 61, 1415–1439. [Google Scholar] [CrossRef]
- Bai, X.; Wen, W.; Hsu, L.T. Using Sky-pointing fish-eye camera and LiDAR to aid GNSS single-point positioning in urban canyons. IET Intel. Transport Syst. 2020. [Google Scholar] [CrossRef]
- Hsu, L.T.; Tokura, H.; Kubo, N.; Gu, Y.; Kamijo, S. Multiple faulty GNSS measurement exclusion based on consistency check in urban canyons. IEEE Sens. J. 2017, 17, 1909–1917. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vision 2020, 1–57. [Google Scholar] [CrossRef]
- Maffra, F.; Teixeira, L.; Chen, Z.; Chli, M. Real-time wide-baseline place recognition using depth completion. IEEE Rob. Autom Lett. 2019, 4, 1525–1532. [Google Scholar] [CrossRef]
- Kendall, A.; Cipolla, R. Geometric loss functions for camera pose regression with deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5974–5983. [Google Scholar]
- McManus, C.; Churchill, W.; Maddern, W.; Stewart, A.D.; Newman, P. Shady dealings: Robust, long-term visual localisation using illumination invariance. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 901–906. [Google Scholar]
- Maddern, W.; Stewart, A.; McManus, C.; Upcroft, B.; Churchill, W.; Newman, P. Illumination invariant imaging: Applications in robust vision-based localisation, mapping and classification for autonomous vehicles. In Proceedings of the Visual Place Recognition in Changing Environments Workshop, IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; Volume 2, p. 3. [Google Scholar]
- Stöttinger, J.; Hanbury, A.; Sebe, N.; Gevers, T. Sparse color interest points for image retrieval and object categorization. IEEE Trans. Image Process. 2012, 21, 2681–2692. [Google Scholar] [CrossRef] [Green Version]
- Barata, C.; Marques, J.S.; Rozeira, J. Evaluation of color based keypoints and features for the classification of melanomas using the bag-of-features model. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 40–49. [Google Scholar]
- Bradski, G. The OpenCV Library. 2000. Available online: https://www.drdobbs.com/open-source/the-opencv-library/184404319 (accessed on 29 July 2020).
- Gevers, T.; van de Weijer, J.; Stokman, H. Color feature detection. In Color Image Processing: Methods and Applications; Lukac, R., Plataniotis, K.N., Eds.; CRC Press: Boca Raton, FL, USA, 2006; Volume 9, pp. 203–226. [Google Scholar]
- Vigo, D.A.R.; Khan, F.S.; van de Weijer, J.; Gevers, T. The impact of color on bag-of-words based object recognition. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1549–1553. [Google Scholar]
- Leonardis, A.; Bischof, H. Robust recognition using eigenimages. Comput. Vis. Image Underst. 2000, 78, 99–118. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [Green Version]
- Olson, C.F.; Zhang, S. Keypoint recognition with histograms of normalized colors. In Proceedings of the 2016 13th Conference on Computer and Robot Vision (CRV), Victoria, BC, Canada, 1–3 June 2016; pp. 311–318. [Google Scholar]
- Mikolajczyk, K.; Schmid, C. Scale & affine invariant interest point detectors. Int. J. Comput. Vis. 2004, 60, 63–86. [Google Scholar]
- Schmid, C.; Mohr, R.; Bauckhage, C. Evaluation of interest point detectors. Int. J. Comput. Vis. 2000, 37, 151–172. [Google Scholar] [CrossRef] [Green Version]
- Chum, O.; Matas, J. Matching with PROSAC-progressive sample consensus. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 220–226. [Google Scholar]
- Forssén, P.E.; Lowe, D.G. Shape descriptors for maximally stable extremal regions. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Pagani, A.; Stricker, D. Structure from motion using full spherical panoramic cameras. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 375–382. [Google Scholar]
- Hartley, R.I.; Sturm, P. Triangulation. Comput. Vis. Image Underst. 1997, 68, 146–157. [Google Scholar] [CrossRef]
- Churchill, D.; Vardy, A. Homing in scale space. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 1307–1312. [Google Scholar]
- Hoffmann, A.; Möller, R. Cloud-Edge Suppression for Visual Outdoor Navigation. Robotics 2017, 6, 38. [Google Scholar] [CrossRef] [Green Version]
- Stone, T.; Mangan, M.; Ardin, P.; Webb, B. Sky segmentation with ultraviolet images can be used for navigation. In Proceedings of the 2014 Robotics: Science and Systems Conference, Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Stone, T.; Differt, D.; Milford, M.; Webb, B. Skyline-based localisation for aggressively manoeuvring robots using UV sensors and spherical harmonics. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5615–5622. [Google Scholar]
- Chen, Z.; Liu, L.; Sa, I.; Ge, Z.; Chli, M. Learning context flexible attention model for long-term visual place recognition. IEEE Rob. Autom. Lett. 2018, 3, 4015–4022. [Google Scholar] [CrossRef] [Green Version]
- Lourenco, M.; Barreto, J.P.; Vasconcelos, F. sRD-SIFT: Keypoint detection and matching in images with radial distortion. IEEE Trans. Rob. 2012, 28, 752–760. [Google Scholar] [CrossRef]
- Van de Weijer, J.; Gevers, T.; Geusebroek, J.M. Color Edge Detection by Photometric Quasi-Invariants. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1520–1525. [Google Scholar]
- Lindeberg, T. Image matching using generalized scale-space interest points. J. Math. Imaging Vis. 2015, 52, 3–36. [Google Scholar] [CrossRef] [Green Version]














© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoffmann, A. On the Benefits of Color Information for Feature Matching in Outdoor Environments. Robotics 2020, 9, 85. https://doi.org/10.3390/robotics9040085
Hoffmann A. On the Benefits of Color Information for Feature Matching in Outdoor Environments. Robotics. 2020; 9(4):85. https://doi.org/10.3390/robotics9040085
Chicago/Turabian StyleHoffmann, Annika. 2020. "On the Benefits of Color Information for Feature Matching in Outdoor Environments" Robotics 9, no. 4: 85. https://doi.org/10.3390/robotics9040085
APA StyleHoffmann, A. (2020). On the Benefits of Color Information for Feature Matching in Outdoor Environments. Robotics, 9(4), 85. https://doi.org/10.3390/robotics9040085