
Machine Learning-Based Processing Proof-of-Concept Pipeline for Semi-Automatic Sentinel-2 Imagery Download, Cloudiness Filtering, Classifications, and Updates of Open Land Use/Land Cover Datasets



Abstract
:1. Introduction
- (1)
- Collects Sentinel-2 imagery.
- (2)
- Filters cloudiness through multitemporal vectors.
- (3)
- Examines the possibility of the pipeline to perform LULC classification over the imagery.
- (4)
- Semi-automatically updates OLU/OLC databases accordingly.
2. Related Research
3. Materials and Methods
3.1. Materials
3.1.1. Open Land Use and Open Land Cover
- UA is a pan-European LULC dataset developed under the initiative of European Commission as a part of the ESA (European Space Agency) Copernicus program. The data cover only functional urban areas [56] of the EU (European Union), the EFTA (European Free Trade Association) countries, West Balkans, and Turkey. The most recent Urban Atlas dataset came from 2018. It distinguishes urban areas with a minimal mapping unit (MMU) of 0.25 ha and 17 urban classes and distinguishes rural areas with an MMU of 1 ha and 10 rural classes [57].
- CLC is an EU LULC dataset provided by the European Environment Agency. It is produced from RS data: the most recent 2018 version was especially supplemented with Sentinel-2 satellite imagery. CLC 2018 covers EEA39 (European Environment Agency) countries and distinguishes 44 mixed land use and land cover classes with an MMU of 0.25 ha of polygon features and 100 m of linear features. CLC also features observing LULC changes with an MMU of 5 ha [58].
- The MMU of CLC is 0.25 ha (500 × 500m), and the MMU of UA in rural areas is 1 ha (100 ×100 m).
- The MMU of UA goes down to 0.1 ha (approximately 31 ×31 m) in urban areas, but the dataset covers only functional urban areas and is not seamless.
- The update period for both datasets is 6 years.
- Even a combination of both datasets is insufficient to cover certain areas in Europe.
3.1.2. Sentinel-2 Data
3.2. Methods
3.2.1. Development of the Processing Pipeline for the Supplementation of OLU/OLC with RS Data
3.2.2. Eo-Learn: Overview and Rationale of Choice
- Using eo-learn would comply with the open licensing requirements of OLU/OLC, because OLU/OLC have been so far developed using open-source software to be financially sustainable.
- It should be possible to manipulate and modify the code of the processing operations to integrate it into OLU/OLC. Considering the previous point, most open-source solutions, including eo-learn, support such an approach.
- eo-learn has been primarily developed for Sentinel-2 data; however, it can handle any imagery if it is adequately pre-processed.
3.2.3. Manipulating with the Area of Interest
3.2.4. Training Data Pre-Processing
3.2.5. Custom Acquisition of Sentinel-2 Imagery
3.2.6. Processing Sentinel-2 Imagery for EOPatches
3.2.7. Cloud and No-Data Masking
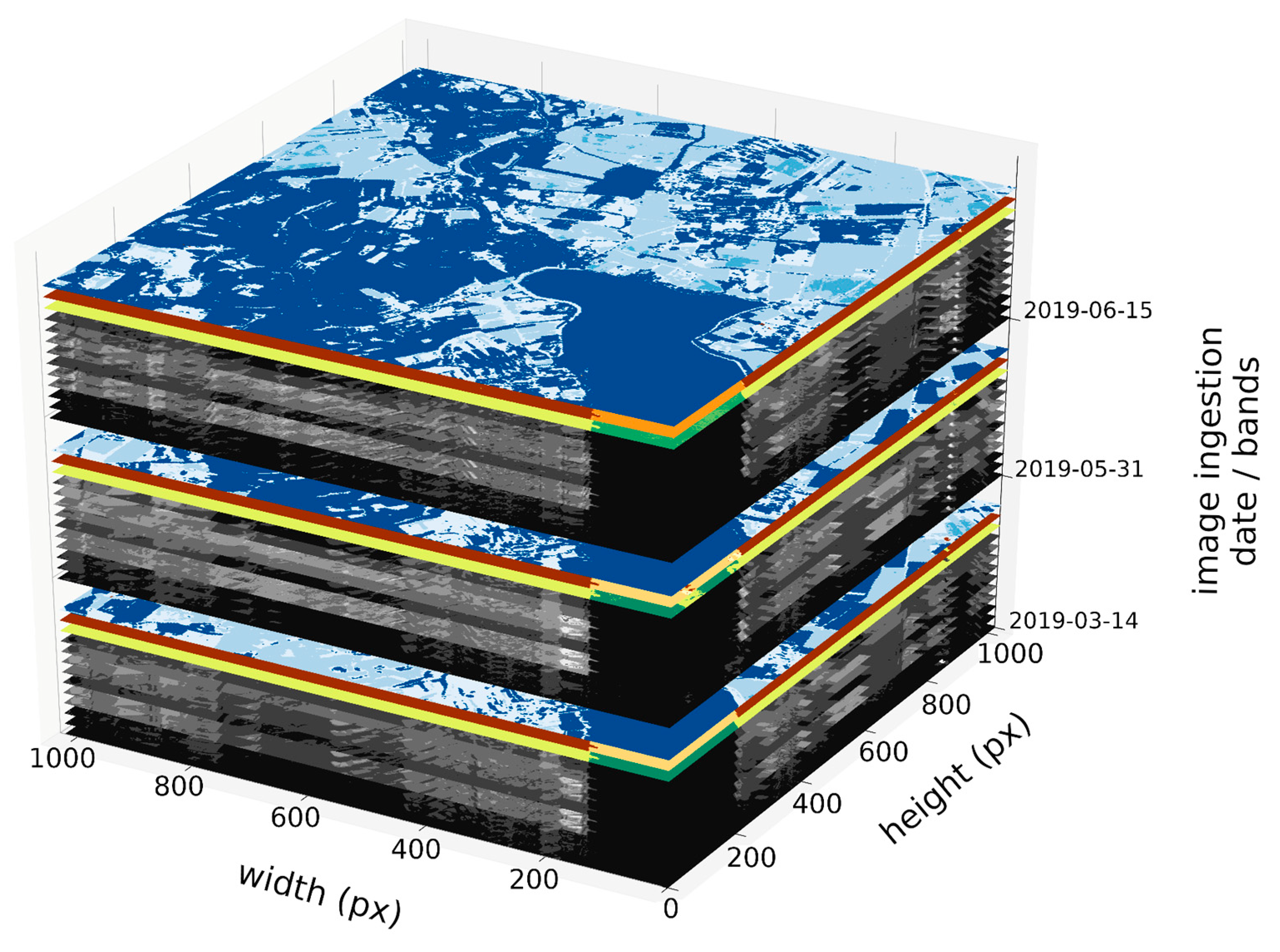
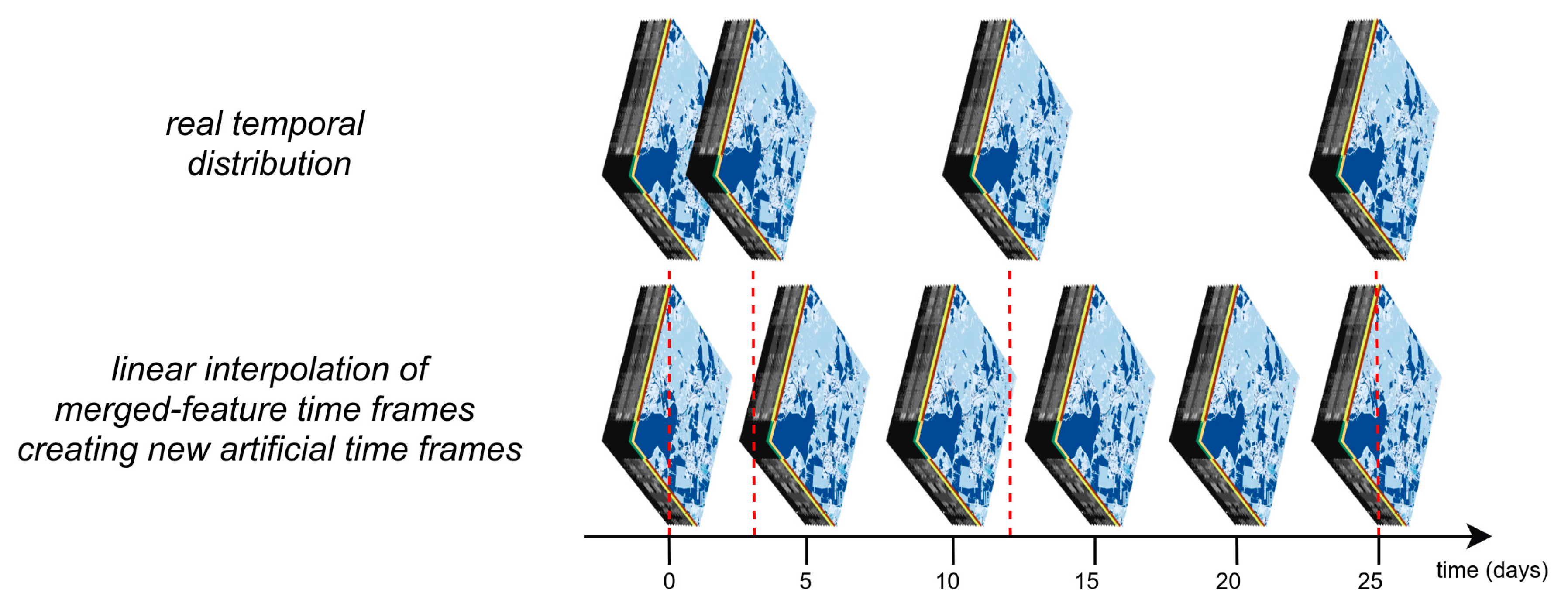
3.2.8. Sentinel-2 Multi-Image Features
3.2.9. Data Post-Processing and Sampling For The Classification Stage
3.2.10. Estimator Choice, Model Training, and Prediction
- If multi-image features are included in the classification process, depending on the formula, division by zero can occur. eo-learn handles this problem by substituting a no-data value for the erroneous result.
- If some pixels are masked throughout the whole time series by the SCL mask, they remain unknown and there is nothing to interpolate them from.
3.3. Pipeline Demonstration
4. Results
4.1. Processing Pipeline, Experimental Outputs and Integration to OLU/OLC
4.2. Experimental Outputs
4.3. Integration of Pipeline to OLU/OLC
5. Discussion
5.1. Processing Pipeline Prospects and Its Significance for OLU/OLC
5.2. Conducted Experiment Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
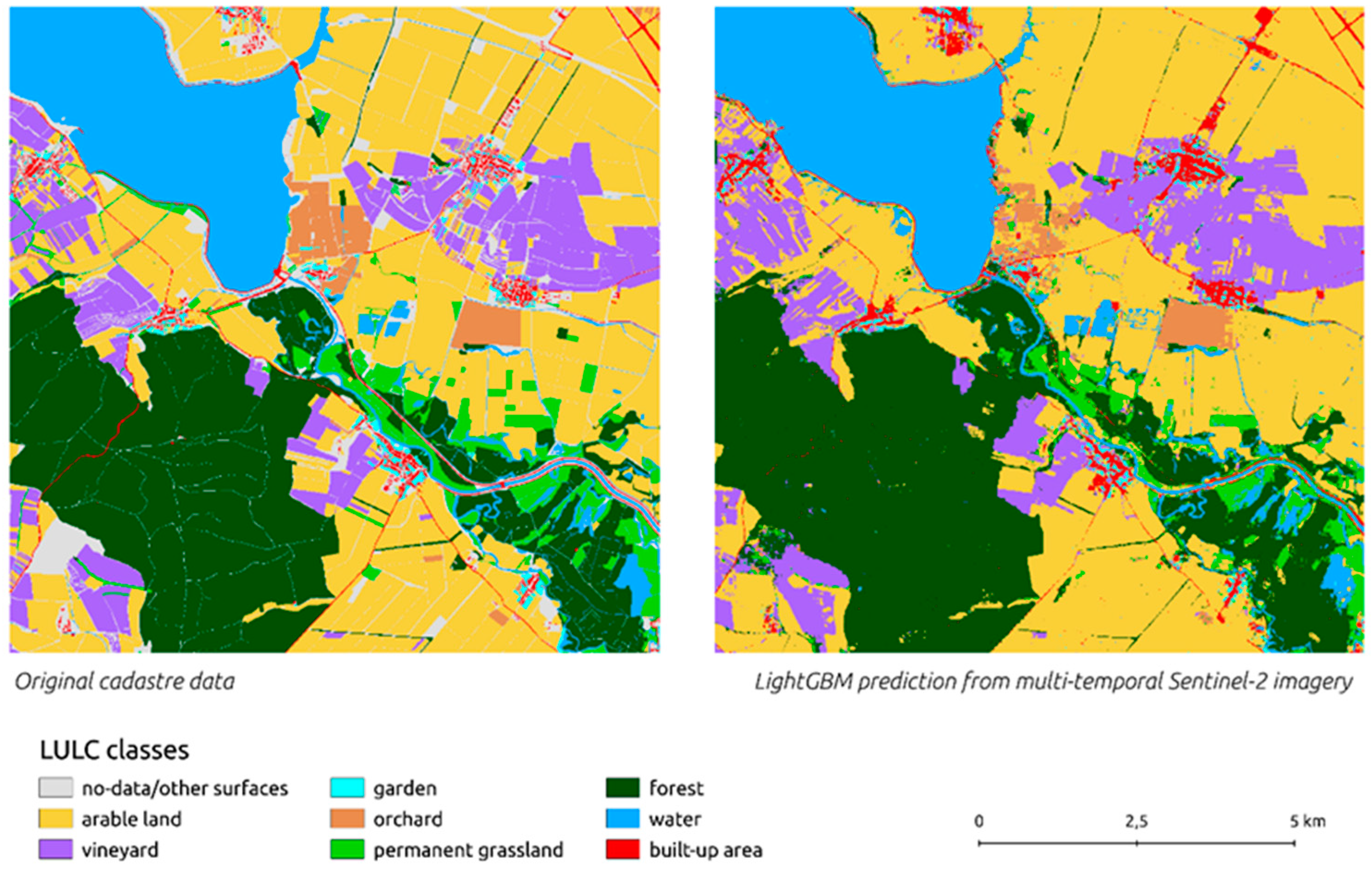
Appendix A. Prediction of Land Use and Land Cover in Southern Part of Sout Moravian Region, Czech Republic, 2019

References
- Fisher, P.F.; Comber, A.; Wadsworth, R. Land use and land cover: Contradiction or complement. In Re-presenting GIS; John Wiley: Chichester, NH, USA, 2005; pp. 85–98. [Google Scholar]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land Use Classification in Remote Sensing Images by Convolutional Neural Networks. ArXiv Comput. Sci. 2015, 1–11. Available online: https://arxiv.org/abs/1508.00092 (accessed on 2 December 2020).
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Zheng, H.; Du, P.; Chen, J.; Xia, J.; Li, E.; Xu, Z.; Li, X.; Yokoya, N. Performance Evaluation of Downscaling Sentinel-2 Imagery for Land Use and Land Cover Classification by Spectral-Spatial Features. Remote Sens. 2017, 9, 1274. [Google Scholar] [CrossRef] [Green Version]
- Rosina, K.; Batista e Silva, F.; Vizcaino, P.; Marín Herrera, M.; Freire, S.; Schiavina, M. Increasing the detail of European land use/cover data by combining heterogeneous data sets. Int. J. Digit. Earth 2020, 13, 602–626. [Google Scholar] [CrossRef]
- Čerba, O. Ontologie Jako Nástroj pro Návrhy Datových Modelů Vybraných Témat Příloh Směrnice INSPIRE. Ph.D. Thesis, Charles University, Prague, Czech Republic, 2012. Available online: http://hdl.handle.net/20.500.11956/47841 (accessed on 2 December 2020).
- Feiden, K.; Kruse, F.; Řezník, T.; Kubíček, P.; Schentz, H.; Eberhardt, E.; Baritz, R. Best Practice Network GS SOIL Promoting Access to European, Interoperable and INSPIRE Compliant Soil Information. In Environmental Software Systems. Frameworks of eEnvironment; IFIP Advances in Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2011; pp. 226–234. ISBN 978-3-642-22284-9. [Google Scholar] [CrossRef] [Green Version]
- Palma, R.; Reznik, T.; Esbrí, M.; Charvat, K.; Mazurek, C. An INSPIRE-Based Vocabulary for the Publication of Agricultural Linked Data. In Ontology Engineering; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 124–133. ISBN 978-3-319-33244-4. Available online: http://doi-org-443.webvpn.fjmu.edu.cn/10.1007/978-3-319-33245-1_13 (accessed on 2 December 2020).
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- INSPIRE Data Specification on Land Cover—Technical Guidelines. Available online: https://inspire.ec.europa.eu/id/document/tg/lc (accessed on 2 December 2020).
- European Environment Agency. CORINE Land Cover. Available online: https://land.copernicus.eu/pan-european/corine-land-cover (accessed on 2 December 2020).
- Copernicus Programme. Urban Atlas. Available online: https://land.copernicus.eu/local/urban-atlas (accessed on 2 December 2020).
- INSPIRE Land Cover and Land Use Data Specifications. Available online: https://eurogeographics.org/wp-content/uploads/2018/04/2.-INSPIRE-Specification_Lena_0.pdf (accessed on 2 December 2020).
- OSM. Landuse Landcover. Available online: https://osmlanduse.org/#12/8.7/49.4/0/ (accessed on 2 December 2020).
- USGS. Land Cover Data Overview. Available online: https://www.usgs.gov/core-science-systems/science-analytics-and-synthesis/gap/science/land-cover-data-overview?qt-science_center_objects=0#qt-science_center_objects (accessed on 2 December 2020).
- FAO. Global Land Cover SHARE (GLC-SHARE). Available online: http://www.fao.org/uploads/media/glc-share-doc.pdf (accessed on 2 December 2020).
- Lubej, M. Land Cover Classification with Eo-Learn: Part 1, Medium. Available online: https://medium.com/sentinel-hub/land-cover-classification-with-eo-learn-part-1-2471e8098195 (accessed on 2 December 2020).
- Lubej, M. Land Cover Classification with Eo-Learn: Part 2, Medium. Available online: https://medium.com/sentinel-hub/land-cover-classification-with-eo-learn-part-2-bd9aa86f8500 (accessed on 2 December 2020).
- Sibanda, M.; Mutanga, O.; Rouget, M. Examining the potential of Sentinel-2 MSI spectral resolution in quantifying above ground biomass across different fertilizer treatments. ISPRS J. Photogramm. Remote Sens. 2015, 110, 55–65. [Google Scholar] [CrossRef]
- Pesaresi, M.; Corbane, C.; Julea, A.; Florczyk, A.; Syrris, V.; Soille, P. Assessment of the Added-Value of Sentinel-2 for Detecting Built-up Areas. Remote Sens. 2016, 8, 299. [Google Scholar] [CrossRef] [Green Version]
- Korhonen, L.; Hadi; Packalen, P.; Rautiainen, M. Comparison of Sentinel-2 and Landsat 8 in the estimation of boreal forest canopy cover and leaf area index. Remote Sens. Environ. 2017, 195, 259–274. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How much does multi-temporal Sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Caballero, I.; Ruiz, J.; Navarro, G. Sentinel-2 Satellites Provide Near-Real Time Evaluation of Catastrophic Floods in the West Mediterranean. Water 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Kuc, G.; Chormański, J. Sentinel-2 Imagery for Mapping and Monitoring Imperviousness in Urban Areas. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-1/W2, 43–47. [Google Scholar] [CrossRef] [Green Version]
- Řezník, T.; Pavelka, T.; Herman, L.; Lukas, V.; Širůček, P.; Leitgeb, Š.; Leitner, F. Prediction of Yield Productivity Zones from Landsat 8 and Sentinel-2A/B and Their Evaluation Using Farm Machinery Measurements. Remote Sens. 2020, 12, 1917. [Google Scholar] [CrossRef]
- Bruzzone, L.; Bovolo, F.; Paris, C.; Solano-Correa, Y.T.; Zanetti, M.; Fernandez-Prieto, D. Analysis of multitemporal Sentinel-2 images in the framework of the ESA Scientific Exploitation of Operational Missions. In Proceedings of the 2017 9th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Brugge, Belgium, 27–29 June 2017; IEEE: New York, NY, USA, 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Phiri, D.; Simwanda, M.; Salekin, S.; Nyirenda, V.R.; Murayama, Y.; Ranagalage, M. Sentinel-2 Data for Land Cover/Use Mapping: A Review. Remote Sens. 2020, 12, 2291. [Google Scholar] [CrossRef]
- Cavur, M.; Duzgun, H.S.; Kemec, S.; Demirkan, D.C. Land use and land cover classification of sentinel 2-a: St Petersburg case study. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-1/W2, 13–16. [Google Scholar] [CrossRef] [Green Version]
- Weigand, M.; Staab, J.; Wurm, M.; Taubenböck, H. Spatial and semantic effects of LUCAS samples on fully automated land use/land cover classification in high-resolution Sentinel-2 data. Int. J. Appl. Earth Obs. Geoinf. 2020, 88. [Google Scholar] [CrossRef]
- Nguyen, H.T.T.; Doan, T.M.; Tomppo, E.; McRoberts, R.E. Land Use/Land Cover Mapping Using Multitemporal Sentinel-2 Imagery and Four Classification Methods—A Case Study from Dak Nong, Vietnam. Remote Sens. 2020, 12, 1367. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for land cover mapping via a multi-source deep learning architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Rumora, L.; Miler, M.; Medak, D. Impact of Various Atmospheric Corrections on Sentinel-2 Land Cover Classification Accuracy Using Machine Learning Classifiers. ISPRS Int. J. Geo-Inf. 2020, 9, 277. [Google Scholar] [CrossRef] [Green Version]
- Jain, M.; Dawa, D.; Mehta, R.; Dimri, A.P.; Pandit, M.K. Monitoring land use change and its drivers in Delhi, India using multi-temporal satellite data. Modeling Earth Syst. Environ. 2016, 2. [Google Scholar] [CrossRef]
- Talukdar, S.; Singha, P.; Mahato, S.; Shahfahad; Pal, S.; Liou, Y.-A.; Rahman, A. Land-Use Land-Cover Classification by Machine Learning Classifiers for Satellite Observations—A Review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.-C.; Zhang, Y.-C.; Chen, P.-Y.; Lai, C.-C.; Chen, Y.-H.; Cheng, J.-H.; Ko, M.-H. Clouds Classification from Sentinel-2 Imagery with Deep Residual Learning and Semantic Image Segmentation. Remote Sens. 2019, 11, 119. [Google Scholar] [CrossRef] [Green Version]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A Multi-Temporal and Multi-Spectral Method to Estimate Aerosol Optical Thickness over Land, for the Atmospheric Correction of FormoSat-2, LandSat, VENμS and Sentinel-2 Images. Remote Sens. 2015, 7, 2668–2691. [Google Scholar] [CrossRef] [Green Version]
- Hollstein, A.; Segl, K.; Guanter, L.; Brell, M.; Enesco, M. Ready-to-Use Methods for the Detection of Clouds, Cirrus, Snow, Shadow, Water and Clear Sky Pixels in Sentinel-2 MSI Images. Remote Sens. 2016, 8, 666. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Flood, N.; Gillingham, S. PythonFmask Documentation, Release 0.5.4. Available online: http://www.pythonfmask.org/en/latest/#python-developer-documentation (accessed on 2 December 2020).
- Main-Knorn, M.; Pflug, B.; Louis, J.; Debaecker, V.; Müller-Wilm, U.; Gascon, F.; Bruzzone, L.; Bovolo, F.; Benediktsson, J.A. Sen2Cor for Sentinel-2. In Proceedings of the Image and Signal Processing for Remote Sensing XXIII, Warsaw, Poland, 11–13 September 2017; SPIE: Washington, DC, USA, 2017; p. 3. [Google Scholar] [CrossRef] [Green Version]
- Baetens, L.; Desjardins, C.; Hagolle, O. Validation of Copernicus Sentinel-2 Cloud Masks Obtained from MAJA, Sen2Cor, and FMask Processors Using Reference Cloud Masks Generated with a Supervised Active Learning Procedure. Remote Sens. 2019, 11, 433. [Google Scholar] [CrossRef] [Green Version]
- Centre National d’Études Spatiales. MAJA. Available online: https://logiciels.cnes.fr/en/content/MAJA (accessed on 2 December 2020).
- Zhao, B.; Zhong, Y.; Zhang, L. A spectral–structural bag-of-features scene classifier for very high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2016, 116, 73–85. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GIScience Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; 2017; pp. 3146–3154. Available online: https://arxiv.org/pdf/1810.10380.pdf (accessed on 2 December 2020).
- EO-LEARN. 0.4.1 Documentation. Available online: https://eo-learn.readthedocs.io/en/latest/index.html# (accessed on 2 December 2020).
- EO-LEARN. 0.7.4 Documentation. Available online: https://eo-learn.readthedocs.io/en/latest/index.html (accessed on 2 December 2020).
- OLU. Open Land Use. Available online: https://sdi4apps.eu/open_land_use/ (accessed on 2 December 2020).
- Mildorf, T. Uptake of Open Geographic Information through Innovative Services Based on Linked Data; Final Report; University of West Bohemia: Pilsen, Czech Republic, 2017; 30p, Available online: https://sdi4apps.eu/wp-content/uploads/2017/06/final_report_07.pdf (accessed on 2 December 2020).
- Kožuch, D.; Charvát, K.; Mildorf, T. Open Land Use Map. Available online: https://eurogeographics.org/wp-content/uploads/2018/04/5.Open_Land_Use_bruxelles.pdf (accessed on 2 December 2020).
- Kožuch, D.; Čerba, O.; Charvát, K.; Bērziņš, R.; Charvát, K., Jr. Open Land-Use Map. 2015. Available online: https://sdi4apps.eu/open_land_use/ (accessed on 2 December 2020).
- OGC. OpenGIS Web Map Server Implementation Specification; Open Geospatial Consortium: Wayland, MA, USA; 85p, Available online: https://www.ogc.org/standards/wms (accessed on 2 December 2020).
- OGC. OpenGIS Web Feature Service 2.0 Interface Standard; Open Geospatial Consortium: Wayland, MA, USA; 253p, Available online: https://www.ogc.org/standards/wfs (accessed on 2 December 2020).
- Dijkstra, L.; Poelman, H.; Veneri, P. The EU-OECD definition of a functional urban area. In OECD Regional Development Working Papers 2019; OECD Publishing: Paris, French, 2019; pp. 1–19. ISSN 20737009. [Google Scholar] [CrossRef]
- European Commission. Copernicus—Europe’s Eyes on Earth; European Commission: Brussels, Belgium; Available online: https://www.copernicus.eu/en (accessed on 2 December 2020).
- Kosztra, B.; Büttner, G.; Soukup, T.; Sousa, A.; Langanke, T. CLC2018 Technical Guidelines. European Enivonment Agency 2017; Environment Agency: Wien, Austria, 2017; 61p, Available online: https://land.copernicus.eu/user-corner/technical-library/clc2018technicalguidelines_final.pdf (accessed on 2 December 2020).
- RÚIAN. Registry of Territorial Identification, Addresses and Real Estates. Available online: https://geoportal.cuzk.cz/mGeoportal/?c=dSady_RUIAN_A.EN&f=paticka.EN&lng=EN (accessed on 2 December 2020).
- European Space Agency. User Guides—Sentinel-2. Available online: https://sentinel.esa.int/web/sentinel/user-guides/sentinel-2-msi (accessed on 2 December 2020).
- European Space Agency. Sentinel-2 User Handbook; ESA: Paris, French; 64p, Available online: https://sentinels.copernicus.eu/documents/247904/685211/Sentinel-2_User_Handbook (accessed on 2 December 2020).
- U.S. Geological Survey. USGS EROS Archive—Sentinel-2—Comparison of Sentinel-2 and Landsat. Available online: https://www.usgs.gov/centers/eros/science/usgs-eros-archive-sentinel-2-comparison-sentinel2-and-landsat?qt-science_center_objects=0#qt-science_center_objects (accessed on 2 December 2020).
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Verburg, P.H.; Neumann, K.; Nol, L. Challenges in using land use and land cover data for global change studies. Glob. Chang. Biol. 2011, 17, 974–989. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2826–2830. Available online: http://jmlr.org/papers/v12/pedregosa11a.html (accessed on 2 December 2020).
- SCIKIT-LEARN DEVELOPERS. An Introduction to Machine Learning with Scikitlearn—Scikit-Learn 0.23.1 Documentation. Available online: https://scikit-learn.org/stable/tutorial/basic/tutorial.html (accessed on 2 December 2020).
- SINERGISE. Sentinel Hub 3.0.2 Documentation. Available online: https://sentinelhubpy.readthedocs.io/en/latest/areas.html (accessed on 2 December 2020).
- SINERGISE. Sentinel Hub. Available online: https://www.sentinel-hub.com/ (accessed on 2 December 2020).
- Gillies, S. Shapely 1.8dev Documentation. Available online: https://shapely.readthedocs.io/en/latest/manual.html#polygons (accessed on 2 December 2020).
- Geopandas Developers. GeoPandas 0.7.0 Documentation. Available online: https://geopandas.org/ (accessed on 2 December 2020).
- OGC Web Coverage Service (WCS) 2.1 Interface Standard; Open Geospatial Consortium: Wayland, MA, USA; 16p, Available online: https://www.ogc.org/standards/wcs (accessed on 2 December 2020).
- Wille, M.; Clauss, K. Sentinelsat 0.13 Documentation. Available online: https://sentinelsat.readthedocs.io/en/stable/api.html (accessed on 2 December 2020).
- ESA. Open Access Hub. Available online: https://scihub.copernicus.eu/ (accessed on 2 December 2020).
- Pandas Development Team. Pandas.DataFrame—Pandas 1.0.3 Documentation. Available online: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html (accessed on 2 December 2020).
- OSGEO. GDAL/OGR Python API. Available online: https://gdal.org/python/ (accessed on 2 December 2020).
- OSGEO. GDAL Virtual File Systems. Available online: https://gdal.org/user/virtual_file_systems.html (accessed on 2 December 2020).
- OSGEO. Sentinel-2 Products—GDAL Documentation. Available online: https://gdal.org/drivers/raster/sentinel2.html (accessed on 2 December 2020).
- MAPBOX. Rasterio: Access to Geospatial Raster Data—Rasterio Documentation. Available online: https://rasterio.readthedocs.io/en/latest/ (accessed on 2 December 2020).
- MAPBOX. In-Memory Files—Rasterio Documentation. Available online: https://rasterio.readthedocs.io/en/latest/topics/memory-files.html (accessed on 2 December 2020).
- European Space Agency. Sentinel-2 Imagery from 30 March 2019 to 30 November 2019. Available online: https://scihub.copernicus.eu/ (accessed on 2 December 2020).
- Index DataBase. Available online: https://www.indexdatabase.de/ (accessed on 2 December 2020).
- SCIKIT-LEARN DEVELOPER. Imputation of Missing Values—Scikit-Learn 0.23.1 Documentation. Available online: https://scikit-learn.org/stable/modules/impute.html (accessed on 2 December 2020).
- Legendre, P.; Legendre, L. Numerical Ecology; Elsevier: Amsterdam, The Netherlands, 2012; 990p, ISBN 9780444538680. [Google Scholar] [CrossRef]
- Lillesand, T.M.; Kiefer, R.W.; Chipman, J.W. Remote Sensing and Image Interpretation, 7th ed.; John Wiley: Hoboken, NJ, USA, 2015; p. 736. ISBN 978-1-118-34328-9. [Google Scholar]
- ČÚZK. Katastrální Mapa ČR ve Formátu SHP Distribuovaná po Katastrálních Územích (KM-KU-SHP). Available online: http://services.cuzk.cz/shp/ku/epsg-5514/ (accessed on 2 December 2020).
- Schultz, M.; Voss, J.; Auer, M.; Carter, S.; Zipf, A. Open land cover from OpenStreetMap and remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 63, 206–213. [Google Scholar] [CrossRef]
- Foody, G.M. Sample size determination for image classification accuracy assessment and comparison. Int. J. Remote Sens. 2009, 30, 5273–5291. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Malinowski, R.; Lewiński, S.; Rybicki, M.; Gromny, E.; Jenerowicz, M.; Krupiński, M.; Nowakowski, A.; Wojtkowski, C.; Krupiński, M.; Krätzschmar, E.; et al. Automated Production of a Land Cover/Use Map of Europe Based on Sentinel-2 Imagery. Remote Sens. 2020, 12, 3523. [Google Scholar] [CrossRef]
- SCIPY COMMUNITY. Numpy.array—NumPy v1.18 Manual. Available online: https://numpy.org/doc/1.18/reference/generated/numpy.array.html (accessed on 2 December 2020).
- Kern, R. NEP 1—A Simple File Format for NumPy Arrays, GitHub. Available online: https://github.com/numpy/numpy (accessed on 2 December 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | Band Name/Spectral Region | Central Wavelength (nm) | Geometric Resolution (m) | |
|---|---|---|---|---|
| Sentinel-2A | Sentinel-2B | |||
| 1 | Coastal aerosol (NVIS) | 443.9 | 442.3 | 60 |
| 2 | Blue (VIS) | 496.6 | 492.1 | 10 |
| 3 | Green (VIS) | 560.0 | 559.0 | 10 |
| 4 | Red (VIS) | 664.5 | 665.0 | 10 |
| 5 | Vegetation red edge (NIR) | 703.9 | 703.8 | 20 |
| 6 | Vegetation red edge (NIR) | 740.2 | 739.1 | 20 |
| 7 | Vegetation red edge (NIR) | 782.5 | 779.7 | 20 |
| 8 | NIR | 835.1 | 833.0 | 10 |
| 8a | Narrow NIR | 864.8 | 864.0 | 20 |
| 9 | Water vapor (SWIR) | 945.0 | 943.2 | 60 |
| 10 | Cirrus (SWIR) | 1373.5 | 1376.9 | 60 |
| 11 | SWIR | 1613.7 | 2185.7 | 20 |
| 12 | SWIR | 2202.4 | 2185.7 | 20 |
| EOPatch ID | H | H Rank | Selected for |
|---|---|---|---|
| 0 | 1.110 | 8 | Testing |
| 1 | 0.895 | 9 | Training |
| 2 | 1.281 | 7 | Training |
| 3 | 1.476 | 4 | Testing |
| 4 | 1.575 | 3 | Training |
| 5 | 1.424 | 5 | Training |
| 6 | 1.584 | 2 | Testing |
| 7 | 1.679 | 1 | Training |
| 8 | 1.287 | 6 | Testing |
| P | Arable Land | Vine-Yard | Garden | Orchard | Permanent Grassland | Forest | Water | Built-Up Areas | Sum of Pixels |
|---|---|---|---|---|---|---|---|---|---|
| Arable land | 312,481 | 4853 | 1522 | 725 | 1170 | 1865 | 1236 | 1705 | 325,557 |
| Vineyard | 10,235 | 15,518 | 162 | 306 | 110 | 286 | 102 | 95 | 26,814 |
| Garden | 5727 | 581 | 2387 | 328 | 217 | 298 | 22 | 1459 | 11,019 |
| Orchard | 5427 | 902 | 79 | 3485 | 500 | 268 | 27 | 48 | 10,736 |
| Permanent grassland | 7892 | 355 | 90 | 77 | 2436 | 1642 | 469 | 120 | 13,081 |
| Forest | 6824 | 409 | 206 | 66 | 671 | 60,947 | 967 | 226 | 70,316 |
| Water | 3084 | 39 | 139 | 483 | 177 | 1140 | 20,328 | 278 | 25,668 |
| Built-up areas and roads | 3644 | 319 | 562 | 40 | 111 | 189 | 165 | 11,779 | 16,809 |
| Sum of pixels | 355,314 | 22,976 | 5147 | 5510 | 5392 | 66,635 | 23,316 | 15,710 | 500,000 |
| Omission error | 12.1% | 31.1% | 42.7% | 36.8% | 54.8% | 8.5% | 12.8% | 25.0% | |
| Commission error | 4.0% | 42.1% | 78.3% | 67.5% | 81.4% | 13.3% | 20.8% | 29.9% | |
| Provider accuracy | 87.9% | 67.5% | 46.4% | 63.2% | 45.2% | 91.5% | 87.2% | 75.0% |
| Discussion Points To Defined Goals | Related Work |
|---|---|
| (1) Collects Sentinel-2 Imagery A collection of Sentinel-2 imagery is publicly available at Sentinel Hub (https://www.sentinel-hub.com/). This paper presents an open and free-of-charge solution contrasting with the paid Sentinel Hub. Moreover, the presented research is modular. The Sentinel-2 imagery collection module (see Supplementary Materials) can be deployed to any open Sentinel-2 based solution. The following features needed to be newly developed or re-created:
| The methodology of Lubej [17,18] avoided the functionality of the developed module by direct connection to the (paid) Web Coverage Service (WCS) interface of the Sentinel Hub. Similar parts (from the paid Sentinel Hub) were also used by Lubej [17,18], especially in the preparation of ground data (rasterization, sampling to patches, and selecting train/test samples), imagery interpolation, and sampling. |
| (2) Filters Cloudiness through Multitemporal Vectors In this case, too, a paid module named ‘Sen2Cloudless’ is provided as a functionality of the Sentinel Hub. The presented approach offers a newly developed open and free-of-charge alternative. | In contrast to the work of Lubej [17,18], masking was newly developed with the functionality equivalent to the subscription-based features of the Sentinel Hub platform. The used cloudiness filtering originated from the Sen2Cor product [42]. A more advanced cloudiness filtering is available under the designation ‘Fmask’ [38]. Nevertheless, this filter has not been implemented in the Python language at the time when this study was being prepared due to certain issues in ‘Fmask’ implementation. |
| (3) Examines the Possibility of the Pipeline to Perform LULC Classification over the Imagery Throughout the study, the main emphasis was to populate the data gaps within the open land use/open land cover (OLU/OLC) datasets. Such gaps appeared commonly, typically due to missing information in input data: cadastral maps, Urban Atlas (UA), and Corinne Land Cover (CLC). A feasibility study on classification performance over the imagery was conducted on an area larger than 7000 km2. The presented OA (85.9%) arose as a consequence of the high percentage (71.1%) of arable land class in the conducted experiment. It seems that the ‘learning effect’ favored the most represented class, arable land. The lowest OA values were achieved in gardens (46.4%) and permanent grasslands (45.2%). Gardens were a priori expected to become the class with the worst results due to its heterogeneity. Some pixels containing gardens were mainly misclassified as arable land (in a half of the cases) and less commonly as built-up areas, vineyards, orchards, and forests. Permanent grasslands were mainly misclassified as arable land (in about 60% of the cases). This result seemed to originate from the time span of the satellite images series. Verifications were performed on pseudo-continuous (vector) ‘ground truth’ data, represented by the cadastral maps at a scale of 1:2000, reclassified to spatial resolution equal to 10 m. Accuracy assessment followed the methodology of ‘random stratified sampling design.’ Shannon’s entropy helped to expose hidden errors that could be caused by favoring underrepresented classes. Using Shannon’s entropy was a novel approach in comparison to the state-of-the-art. In the future, the accuracy of heterogeneous classes, such as gardens and orchards, could be assessed using a cluster sampling design to mitigate outsourcing their pixels to different classes. The grey level co-occurrence matrix (GLCM) should be used to improve the classification matrix (see Section 5.1 for details). | Schultz et al. [86] populated an LULC dataset through another approach. They attempted to fill in the gaps by remote sensing (RS) of classified land cover data from OpenStreetMap tags. However, the achieved results do not seem convincing [86]. The related research takes discrete information from field measurements, which usually comprise tens or hundreds of discrete points, into account [87]. Using a large test sample could lead to an over-powered testing, as suggested by Foody [87]. The accuracy assessment methodology of ‘random stratified sampling design’ was recommended in [88,89]. Foody [87] noted that using Shannon’s entropy exposes the false negatives. |
| (4) Semi-Automatically Updates OLU/OLC Databases Accordingly The presented approach was found to be feasible. The full potential of the developed pipeline appears when combining the pipeline with the open data model of the OLU/OLC datasets (currently being prepared as a follow-up paper). The discussion regarding this point is provided in Section 5.1 due to its complexity and extent. | The need for semi-automatic updates of LULC is emphasized in similar research, as presented by Weigand et al. [27], with an OA of 80–93.1%, and Malinowski et al. [90], with an OA of 89%. Both were considerably larger studies, thus proving that such a workflow can have a large-scale LU/LC derivation potential. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Řezník, T.; Chytrý, J.; Trojanová, K. Machine Learning-Based Processing Proof-of-Concept Pipeline for Semi-Automatic Sentinel-2 Imagery Download, Cloudiness Filtering, Classifications, and Updates of Open Land Use/Land Cover Datasets. ISPRS Int. J. Geo-Inf. 2021, 10, 102. https://doi.org/10.3390/ijgi10020102
Řezník T, Chytrý J, Trojanová K. Machine Learning-Based Processing Proof-of-Concept Pipeline for Semi-Automatic Sentinel-2 Imagery Download, Cloudiness Filtering, Classifications, and Updates of Open Land Use/Land Cover Datasets. ISPRS International Journal of Geo-Information. 2021; 10(2):102. https://doi.org/10.3390/ijgi10020102
Chicago/Turabian StyleŘezník, Tomáš, Jan Chytrý, and Kateřina Trojanová. 2021. "Machine Learning-Based Processing Proof-of-Concept Pipeline for Semi-Automatic Sentinel-2 Imagery Download, Cloudiness Filtering, Classifications, and Updates of Open Land Use/Land Cover Datasets" ISPRS International Journal of Geo-Information 10, no. 2: 102. https://doi.org/10.3390/ijgi10020102
APA StyleŘezník, T., Chytrý, J., & Trojanová, K. (2021). Machine Learning-Based Processing Proof-of-Concept Pipeline for Semi-Automatic Sentinel-2 Imagery Download, Cloudiness Filtering, Classifications, and Updates of Open Land Use/Land Cover Datasets. ISPRS International Journal of Geo-Information, 10(2), 102. https://doi.org/10.3390/ijgi10020102