1. Introduction
Spatial information technology (SIT) has been extensively applied to vehicle navigation. Intelligent transport systems (ITS) have been successfully applied to transportation management, and the map matching algorithm plays an important role in such systems [
1,
2,
3,
4,
5]. The efficiency and accuracy of map matching have been discussed for many years. Large trucks (i.e., those over fifteen tons) with freight containers, and therefore, large turning circles are commonly used in fleet dispatching. Although previous studies have provided turning radius studies for general vehicles [
6,
7], the driving tracks of large trucks are different from those of ordinary vehicles. It is difficult for the map matching procedure to efficiently handle situations such as when a driver makes a U-turn on a complex and narrow road, or when dealing with large trucks using large-scale positioning data, which can reduce computing accuracy in determining their positions. In general, large fleet positioning is monitored by global positioning systems (GPS), which have rapidly gained importance in accurately locating the position of large trucks in logistics applications. Not all roads and road sections are suitable for a large truck fleet and, since actual road networks are highly complex, it is very important to be able to display real-time location information. Improvements in fleet dispatching are therefore imperative and in this paper we propose a new, more efficient system to assist vehicle navigation and to rapidly determine the positions of large truck fleets.
Map matching involves placing the positions from a GPS on a digital map. Many studies utilize computers to perform such map matching procedures, which use coordinate computations received by the GPS tracking information from the vehicles that correspond to the road on the map. Moreover, the map matching method involves using the road network information in a digital map as the classification basis for pattern recognition to correct the GPS positioning errors according to the identified results [
1,
2]. Obtaining accurate large-scale location data using currently available technology is the first step toward determining the most appropriate driving route. In the context of location-based services (LBS), this paper employed SIT in ITS to collect large-scale data from various sensors in order to handle the routing problems of large trucks.
Geographic information systems (GIS) have developed using projection technology to convert three-dimensional data into two-dimensional maps. Since map projection is conducted using three-dimensional space, the procedures for coordinate conversion used by projection technology can take considerable time. To limit this timeframe, it is necessary to complete the procedure of converting all coordinates using a map matching algorithm. GPS point data of maximum size, depending on the amount of data, are continuously received for all processing operations [
5,
8]. Logistics services are now commonly employed and smart transportation management has emerged, which uses state-of-the-art fleet management for automatic vehicle dispatching, together with GIS, which provides real-time information on the actual road network. Intelligent fleet management and dispatching involves an interconnected information system that is applied to allow for more effective completion of logistics tasks. With the rapid development of information and communication technology (ICT), the Internet of Vehicles (IoV) has become the most popular smart transportation tool for information collection from sensors and the analysis of vehicle dispatching data to provide full services for intelligent transportation. With the ongoing increase in road transport globally, effective fleet management has thus become imperative. Fleet management systems use computer-based technology to handle large-scale datasets for analysis [
2,
3,
5] and combine SIT with ICT for vehicle dispatching. This system needs to be able to continuously monitor the fleet location and frequently match the position to ensure that the vehicles operate at optimum capacity. Large fleet dispatching strives for efficiency and to offer the most appropriate fleet management services. However, complex road networks result in distance calculation errors so the calculated precise position of the fleet may not always be accurate. As a consequence, many studies have been conducted on position error correction using map matching algorithms.
Probe vehicles (or floating vehicles) are now used to collect floating data to obtain real-time road information and can also be used in a variety of effective ways with ITS data. Probe vehicles communicate at a fixed frequency with the control center and track the vehicles’ positions on the road. These large-scale data are immediately used for reception, converting different types of data structures into useful traffic information for processing the map matching algorithm [
9,
10,
11]. Data structures include vector-based and raster-based formats for the map matching algorithm. The processed spatial data can be converted into both data formats, while data from different structures can be converted into each other [
5]. Therefore, in this paper, we used the probe vehicle concept in large truck fleet management. Traffic information was collected from the current traffic situation, and the driving time was also provided for each segment of the road to facilitate urgent dispatching.
In general, many types of traffic information can be displayed in digital road networks. Map matching algorithms focus on position error correction and efficiency improvements to show the current positions of the vehicles. However, most studies on map matching algorithms discuss position accuracy. Moreover, the road network is becoming increasingly more complex. For the practical application of transportation, road network planning affects the performance of map matching which, in turn, influences the paths of large truck fleet dispatching. In this paper, we present a novel method to develop an effective map matching application. With limited resources to upgrade the hardware and software for improving the map-matching algorithm to implement map positioning, two key factors including time and money (cost) had to be considered in this study. The aim was to enhance the efficiency of large fleet dispatching, provide efficient map positioning based on large fleet data volumes, and solve the relevant big data problems to improve computational efficiency.
The rest of this paper is organized as follows.
Section 2 provides a brief review of map matching algorithms and their spatial data structure. In
Section 3, we develop the multilayer-based map matching approach.
Section 4 provides comparison results and analysis using our presented multilayer-based map matching algorithm with two different types of data structures.
Section 5 reflects on the results, on the basis of which we present the most important discussion and conclusions.
3. Research Methodology
Since the return of coordinate data from vehicles is continuous, the fleet dispatching management platform may quickly become overloaded. This paper uses a point-to-polygon method to deal with the high volumes and rates of location GPS data returned by large truck fleets. We also used the same technology to process large fleet location data and found that multiple layer grouping combinations can be used to reduce loading.
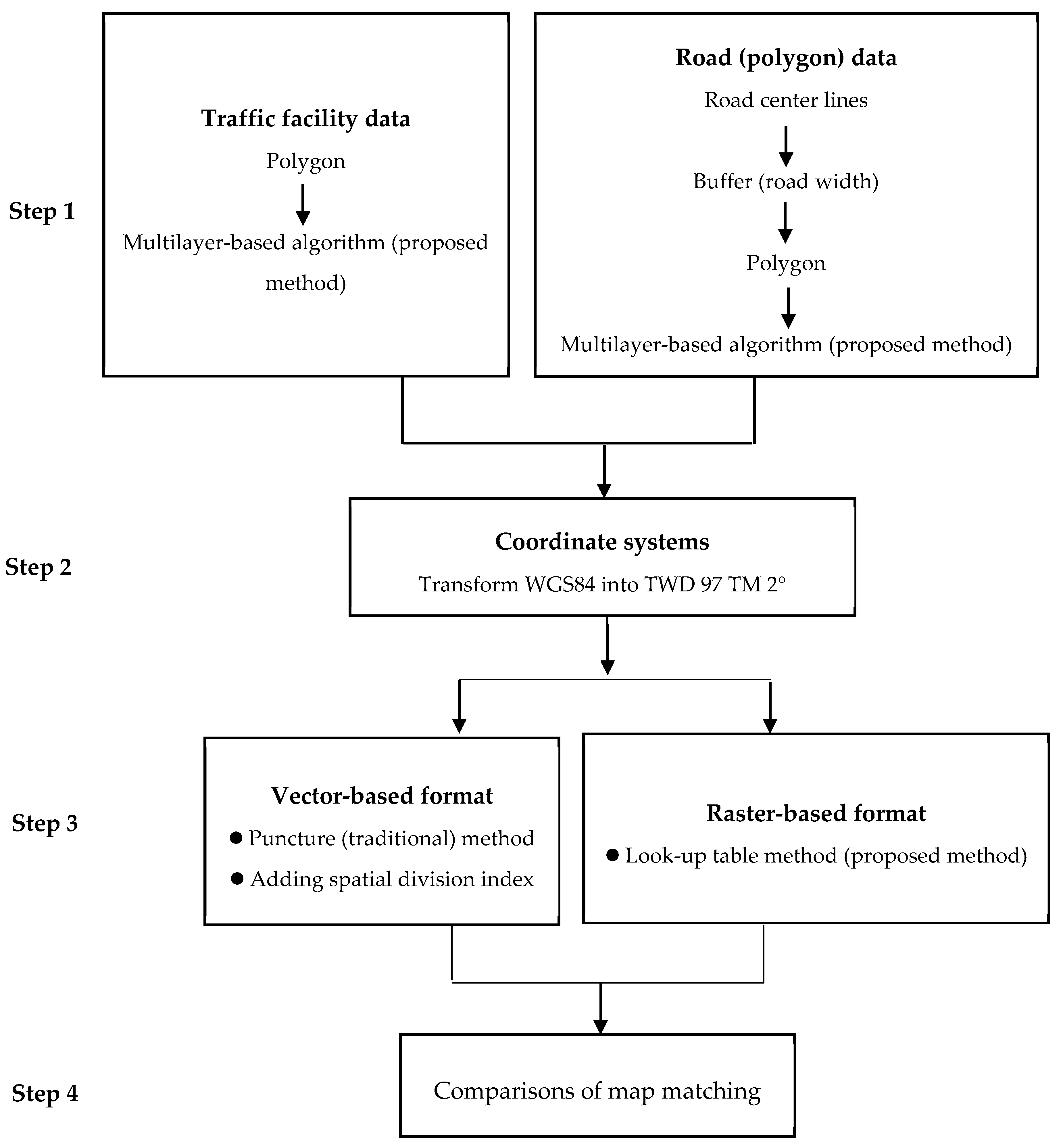
Figure 1 shows four steps of the process to achieve efficiency improvements with a new multilayer-based algorithm for map matching.
Step 1: Initially, there are two procedures for traffic facility and road data. The traffic facility can be constructed as a polygon. For road data, center lines using vector data are collected from ArcGIS [
37]. These center lines were used to produce buffers, and then the road can be constructed as a polygon. For the proceeding multilayer-based map matching, we constructed a large fleet management system based on a structured query language (SQL) database for several segments from the road network data to process map matching.
Step 2: Truck fleet data were collected from onboard GPS and plane coordinates of TWD 97 TM 2° obtained for sample testing.
Step 3: The puncture (traditional) method using vector data that has more relevant but complex structures was used to partition and compose the digital map. Thereafter, we used an improvement method, adding a spatial division index, which still requires complex mathematical procedures. Since more large-scale data are used for reception and cause a computational bottleneck, we proposed a look-up table method using raster data to improve efficiency.
Step 4: A comparison of the methods based on the two data types was made to provide guidance for large truck fleet management.
3.1. Multilayer-Based Map Matching
To construct the framework of the multi-layer structure in Step 1, we assumed that the digital map of the national road network took a single-line network in a vector-based format based on the road center lines. The road center lines were used to complete the conversion procedures of the segments. These procedures include road data stratification, defining the segments and facility ranges, and determining the surrounding point distance.
In the past, road networks were described according to each section of the road but were not considered altogether. Large truck fleets usually have common routes for dispatching. To enhance the technology of map matching efficiency in a fleet management system, we proposed a multi-layer method with road networks for large fleet dispatching. We suggest that the constraint of road networks can be divided into two categories, viz. traffic facilities and roads, and can be written as
where
GPS is the quantity (
QTY) of
GPS data.
TF denotes the quantity of
GPS data for each traffic facility and there are
i categories of
TF.
R denotes the quantity of
GPS data for each road and there are
j categories of
R. Usually, traffic facilities have smaller categories than roads. It is very important to enhance efficiency when the large truck fleet data volume increases in size. Several layers are taken from road network information. For the planning of large truck dispatching routes, multi-layer selection can be associated with the road network. This study considered the road network as the interplay between traffic facilities and roads. Different combinations can affect the performance of the map matching algorithm. The multilayer-based map matching can have an important influence on the efficiency of the map matching algorithm; therefore, we proposed this approach to enhance the overall efficiency for determining map positioning.
3.2. Coordinate Conversion
In executing map matching, this study also used coordinate conversion to improve time efficiency. In Step 2, we used linear coordinate transformation to enhance map matching performance and used the area of coordinate conversion with an interval of 2 arcminutes for the transformation procedure. Here, we adopted the formulae for linear coordinate transformation as described in [
38]; this is written as:
where
and
, respectively, denote the values of the plane coordinates;
and
are the values of the longitude and latitude;
and
are the initial values of the transformation of coordinate areas;
and
are the initial values of the longitude and latitude; and
,
,
and
are undetermined coefficients. When applying the transformation procedures, the values of
,
,
, and
may be different due to the location and size of the coordinate conversion area.
and
are the key conversion coefficients from the longitude and latitude to the
and
coordinates.
and
have a proportional relationship.
and
are auxiliary transformation coefficients, where
indicates an increase of the same latitude with longitude, and
indicates an increase of the same longitude with latitude. Moreover,
and
are the increments of longitude and latitude from the origin to the end of the coordinate conversion area. The ranges of four points, (
), (
), (
), and (
), provide an approximately trapezoidal area. Since
and
are very small, the longitude and latitude can be regarded as approximately parallel. There is a linear correspondence between the geographical coordinates of points and the increase in the longitude and latitude of points relative to (
) and the plane coordinates. Moreover, the transformation errors can be controlled within a certain range for the coordinate conversion area [
38,
39]. Using the dimension reduction technique, linear transformation can simplify complicated conversion and enhance traditional coordinate transformation.
3.3. Comparative Methods
This study evaluates our proposed multilayer-based map matching algorithm under both spatial data structures, vector and raster (Step 3), in order to compare performance (Step 4). The point-in-polygon algorithm described in [
40,
41] was applied to verify performance efficiency using the puncture (traditional) method to determine whether the point falls within the polygon. In this scenario, the puncture method can be used with vector data to process the mapping between coordinates and map features and can be applied to map matching algorithms [
39].
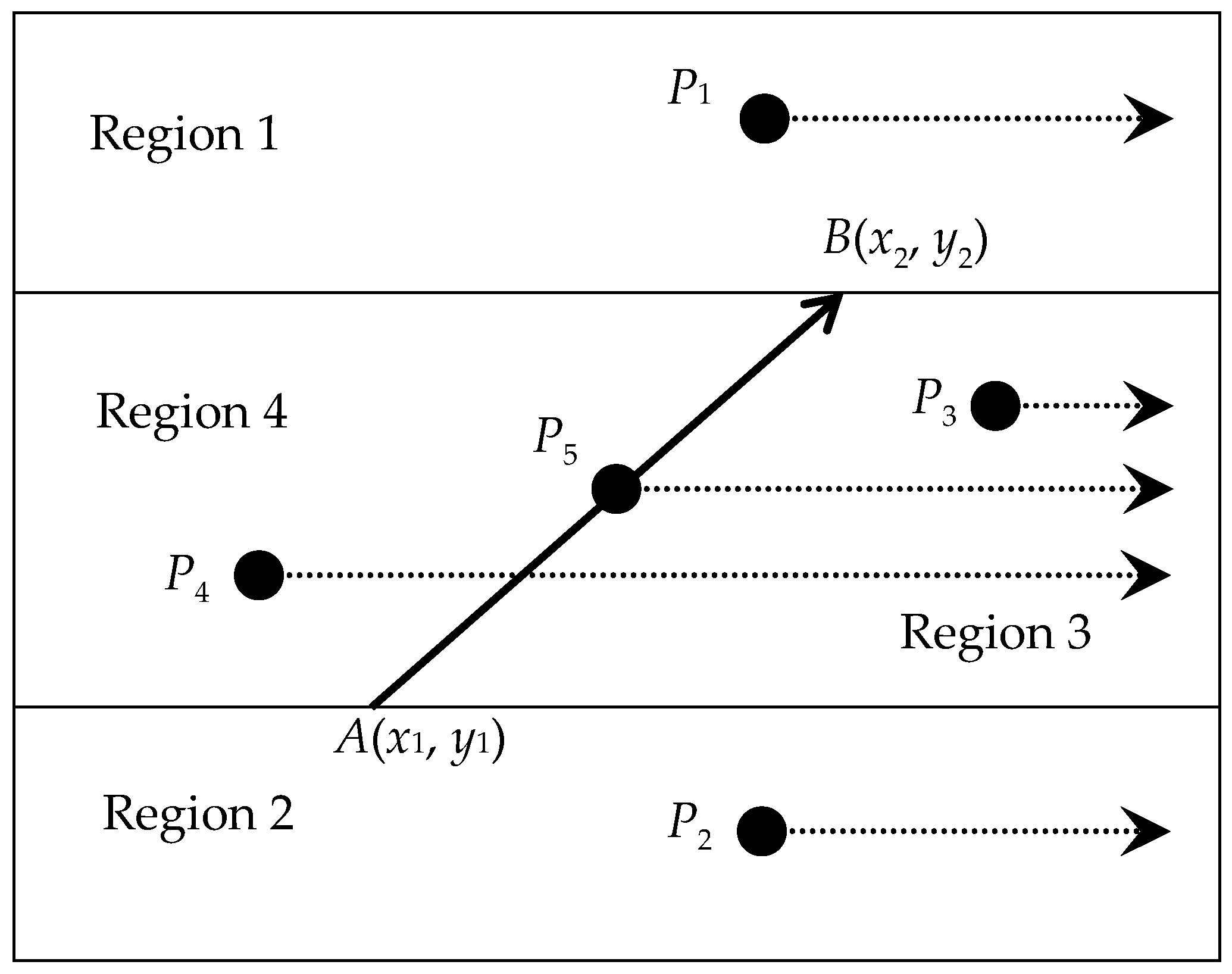
This paper extends the puncture method to multilayer complex road network design. Assume that ray
extends
to point
, and
is the initial point to make a ray from left to right. For each edge of the polygon, the puncture method is used to determine whether
P is on
or if
P and
are intersected. We then distinguish this into four regions for the puncture method, as shown in
Figure 2. The lines of
P1,
P2, and
P3 and
do not intersect, while
P4 and
are intersected.
P5 is on the ray
and
P5 is within the polygon. To provide all edges of the vertices on the polygon, the difference-product’s y-coordinate is given by
where
is for
P;
is for
A; and
is for
B. As stated above, the polygonal areas of
A,
B, and
P can be shown as
If > 0, P is on the left of ;
If < 0, P is on the right of ;
If = 0, when ≤ 0, P is on ray . Otherwise, P is on the extended line of .
A segment polygon was built in the continuous-node data table using the puncture method. A polygon is a set of node coordinates built on the feature. The proposed approach uses the polygon features as the road segments. This functions like an electronic fence, where the number corresponding to the feature is the segment code. The surrounding point coordinates are composed of the surrounding points on the perimeter line of the segments. The number of surrounding points is set according to the size of the segment region, and the density of the surrounding coordinates affects the fineness of the segments. This study used 50 m as the criterion for the collection of the surrounding points. When considering the length of a road segment, the goal is to make the large truck fleet travel at a normal speed on the road, where each return can be on a different segment. Performance bottlenecks may occur when applying the puncture method to process large amounts of data. In general, sophisticated mathematical and computational techniques are required for vector data structures and, when the data sources are themselves complex, it becomes difficult to solve the problems.
The second approach involves adding the spatial division index in the puncture method. In this way, a simple division operation can be used to quickly determine which point coordinates of the square block are located. This multilayer-based map matching algorithm uses a method with a spatial division index. However, large-scale data can seriously reduce the retrieval efficiency. If the spatial division index table is well established, it can more efficiently determine the improvements to the multilayer-based map matching.
According to the literature in [
40], the authors concluded that the polygon in raster format using the grid method was more efficient due to a few mathematical computations. Therefore, we extended the idea and proposed a third approach that involves a look-up table method using a raster-based format. The raster data structure has the same square size as the grid, and no complicated mathematics are required. For the grid procedures, the DDA is considered to take the grids of the polygon boundary. The polygon boundary grid point of the extraction operation is shared among the segments. The DDA method uses the slope of a line segment to take a grid point on a line at a unit interval (the minimum grid size) to determine the corresponding integer value on the other axis of the closest line. The polygon boundary of the grid data can be extracted without using complicated trigonometric functions. BAF is used to determine the entire grid within the polygon. The whole polygon grids are achieved using DDA and BAF. Encoding and compression are the last steps needed to complete the raster-based procedure before the grid spatial database is ready for use.
The above three spatial data structure approaches can be used for comparing performance using multilayer-based map matching. Based on Equation (3), we constructed an equation to calculate the time as below:
where
T denotes the computation time;
QTY of
GPS includes the
QTY of traffic facilities and roads of
GPS data;
Pu is the puncture method;
Ind is the puncture method with the spatial division index;
is based on Equation (7);
Lt is the look-up table method; and
n denotes the sample, which has lower bound (
) and upper bound (
) samples. In general, the sample is based on the scale of large truck fleet. This study aimed to use this multilayer-based method with different data structures to effectively achieve improvement for map matching under existing limited software and hardware resources.
4. Results and Analysis
This section illustrates the comparison results using multi-layer map matching algorithms. Based on spatial map matching of a complex road network, this study used the national electronic map road center single-line vector data produced by the GIS Research Center, Feng Chia University (GIS.FCU), and processes the segments by buffers according to the width of the road. This method then utilizes the surrounding points on the perimeter of the road segments to generate the nodes of the road segments. We adopted different categories of segments in Taiwan’s road networks for the case study. This study provides an applicable map matching algorithm and efficiently matches geographic coordinates to an actual route. The empirical data were actual GPS car driving records from Taiwan’s large truck fleet dataset, which were collected from car kits on large trucks. The coordinates were taken from large trucks ready to travel, and the proportion of GPS coordinates was chosen to match the actual road for navigation.
We considered that traffic facilities consisted of interchange and service stations. Roads included national highways, express highways, provincial highways, county highways, district roads, and normal roads. Our large fleet management system included the segment data arranged as in
Table 1. Traffic facilities and roads as eight-segment layers on Taiwan main island were collected from GPS instruments installed on large trucks.
Table 2 shows that the quantity (
QTY) of GPS data has one million empirical data points. Transmission was the fourth generation of mobile phone mobile communication technology standards (4G). The source data were collected from 35 trucks with eight working hours per day for one month, and the sampling interval was 30 s. Plane coordinates were used in the large fleet management system, thus type of orography was not considered in this study.
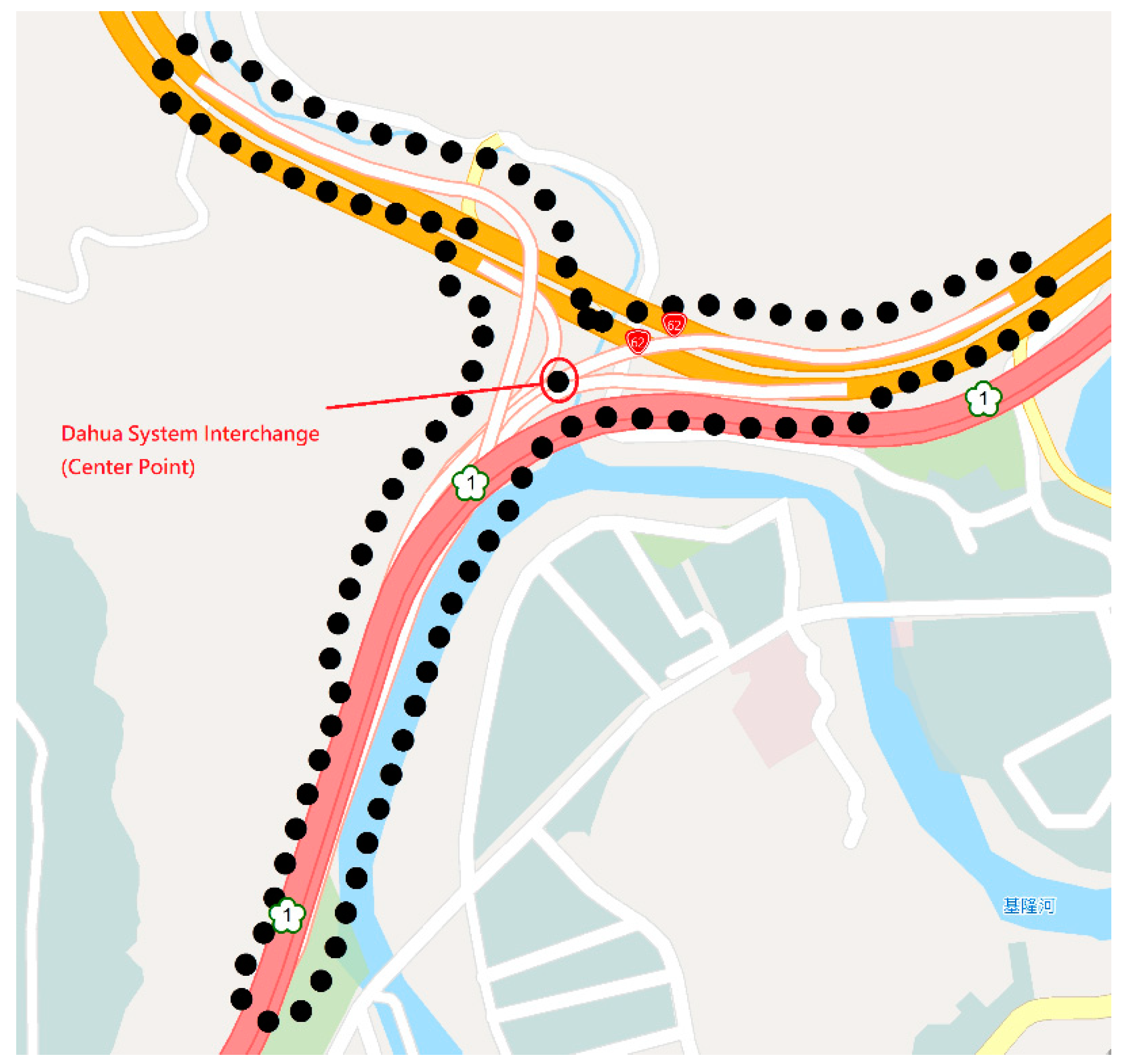
Table 3 gives an example of an interchange, which includes one center point and 99 vertices from our system. A polygon was composed of 99 vertices.
Figure 3 illustrates the example from
Table 3 on a map using ArcGIS software. When a point falls within this polygon, the point information can be displayed in the caption field.
For the map matching comparison of the two data structure types, it is necessary to convert the geodetic coordinates to plane coordinates. For all GPS coordinates, the WGS 84 longitude and latitude geodetic coordinates can be immediately used via linear transformation formulae to transform them into Taiwan TWD 97 TM 2° plane coordinates. The scope of implementation and testing was based on Taiwan’s main island. The scope ranged from 120° to 122° eastern longitude, 21°55′ to 25°31′ northern latitude, spanned south and north by 216 arcminutes, and crossed east and west by 120 arcminutes. According to 2 arcminutes sections, there were 60 × 108 coordinate conversion areas. The two orders in
Table 4 are expressed as:
where
is the longitude order, and
denotes the longitude value.
is the latitude order, and
denotes the latitude value (units: arcminutes). Here, 120° was 7200 arcminutes, 21°55′ was 1315 arcminutes, 2 denotes arcminutes sections, and square brackets denote Gauss notation.
This paper used the two arcminute interval linear coordinate transformation formulae with six parameters, as shown in
Table 4. The notations have already been described in Equations (9) and (10). There were 60 longitude serial numbers, and 108 latitude serial numbers, representing a total of 6480 points. The results showed that the conversion errors could be controlled within one meter, which represents the overall efficiency improvement of map matching.
For example, the linear transformation formulae employed in this study used two arcminute intervals to transform WGS84 coordinates into TWD 97, which is the commonly used coordinate projection system used in Taiwan. The transformation errors were within one meter, both latitudinally and longitudinally. The linear transformation computation time was about 1.737 × 10
−5 s. For the traditional coordinate transformation using the GIS software tool, the computing time was 2.784 × 10
−5 s [
39]. Therefore, linear transformation was used in this study to enhance the efficiency of our large truck fleet case study.
Moreover, the space is divided horizontally and vertically over 5000 m. Using Taiwan’s main island as the range, the origin coordinates are (135,000; 2,400,000) from the lower left corner coordinates (which are origin coordinates (135,000; 2,400,000)) to the upper right corner coordinates (355,000; 2,800,000), which can be divided into 44 × 80 square blocks. In the empirical operating procedure, the longitude and latitude coordinates are converted into TM 2° plane coordinates, and the plane coordinates are subtracted from the origin coordinates (135,000; 2,400,000). The coordinate values are divided by the division distance of 5000 m, and (
,
) are index values using Equations (11) and (12). For example, assuming that
is 230,529 and
is 2,621,656, the values of index code can be given as follows:
Furthermore, the raster-base format consists of horizontal encoding, vertical encoding, and Quadtree MD code. As most of Taiwan’s roads run in a north and south direction, vertical encoding and compression obtain the best performance. The procedure for encoding and compression may take time, but it can be replaced by subsequent efficiency improvements since digital maps are not changed frequently.
For the output of Equation (8), the computing time (
T) divided by 50 runs is the average processing time (i.e., the average case), which is calculated by the following formula:
For the outcomes, the performance of the best and worst case have been shown. The experiments included 100,000 samples with 50 runs, and the computational results are shown in
Table 5. According to the performance of the individual segment layers for the puncture method, normal roads offered the worst results. All the values were large. An individual segment layer for the puncture method with the addition of a spatial division index showed significantly improved performance. The values for computational time were between 24 and 1076 s. Adding the spatial division index was more efficient than using the puncture method, except for service stations.
According to this 50-run outcome, as
Table 5 shows, the values for the normal road case were slightly higher than those of the other seven layers. The look-up table method yielded the excellent results listed in
Table 5. The best case for the normal road using the look-up table method yielded good performance, from 11,654 down to 14 s. Since the quantity of service station had less data and the position distribution was scattered, service stations with a spatial division index may not be efficient.
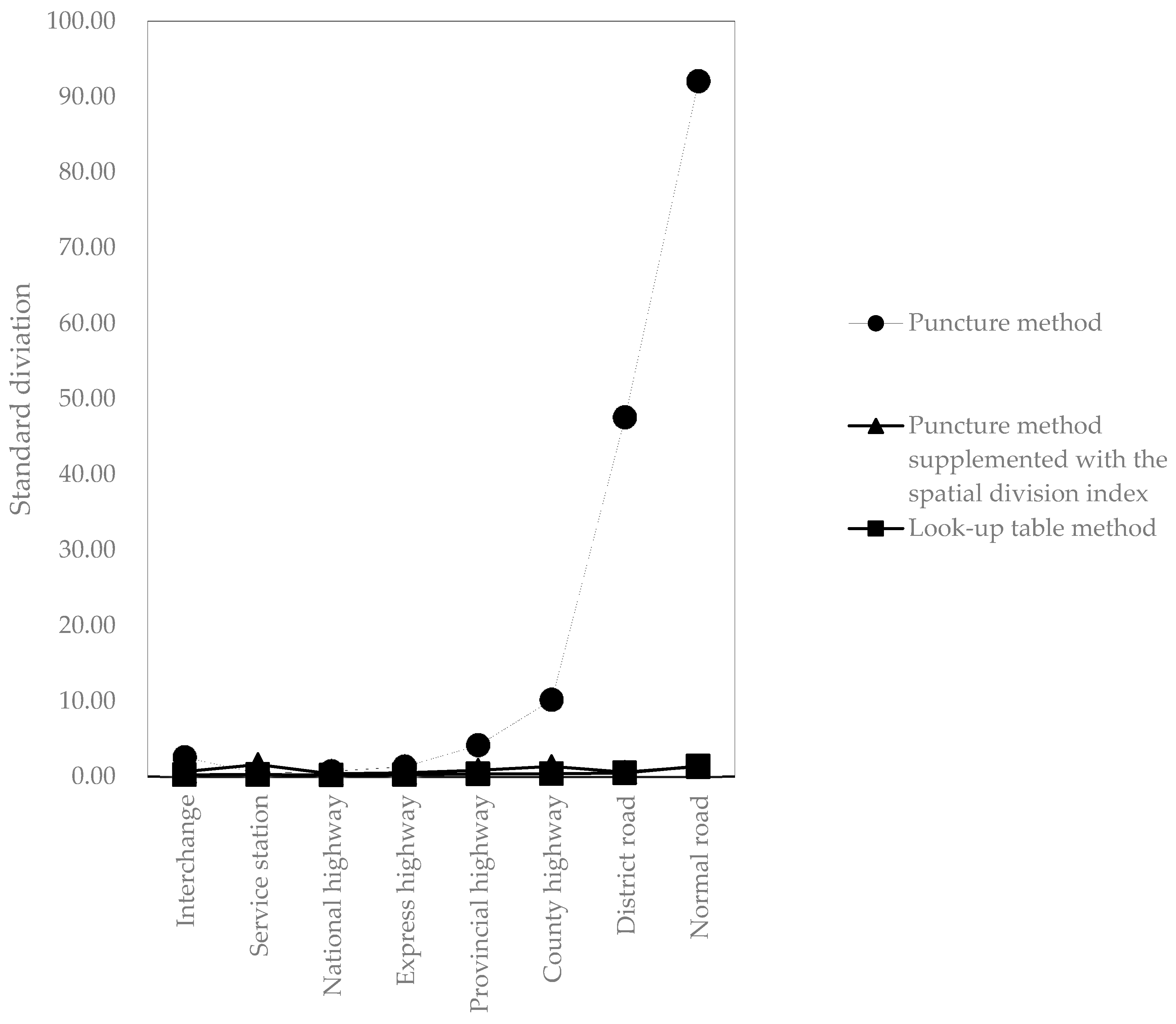
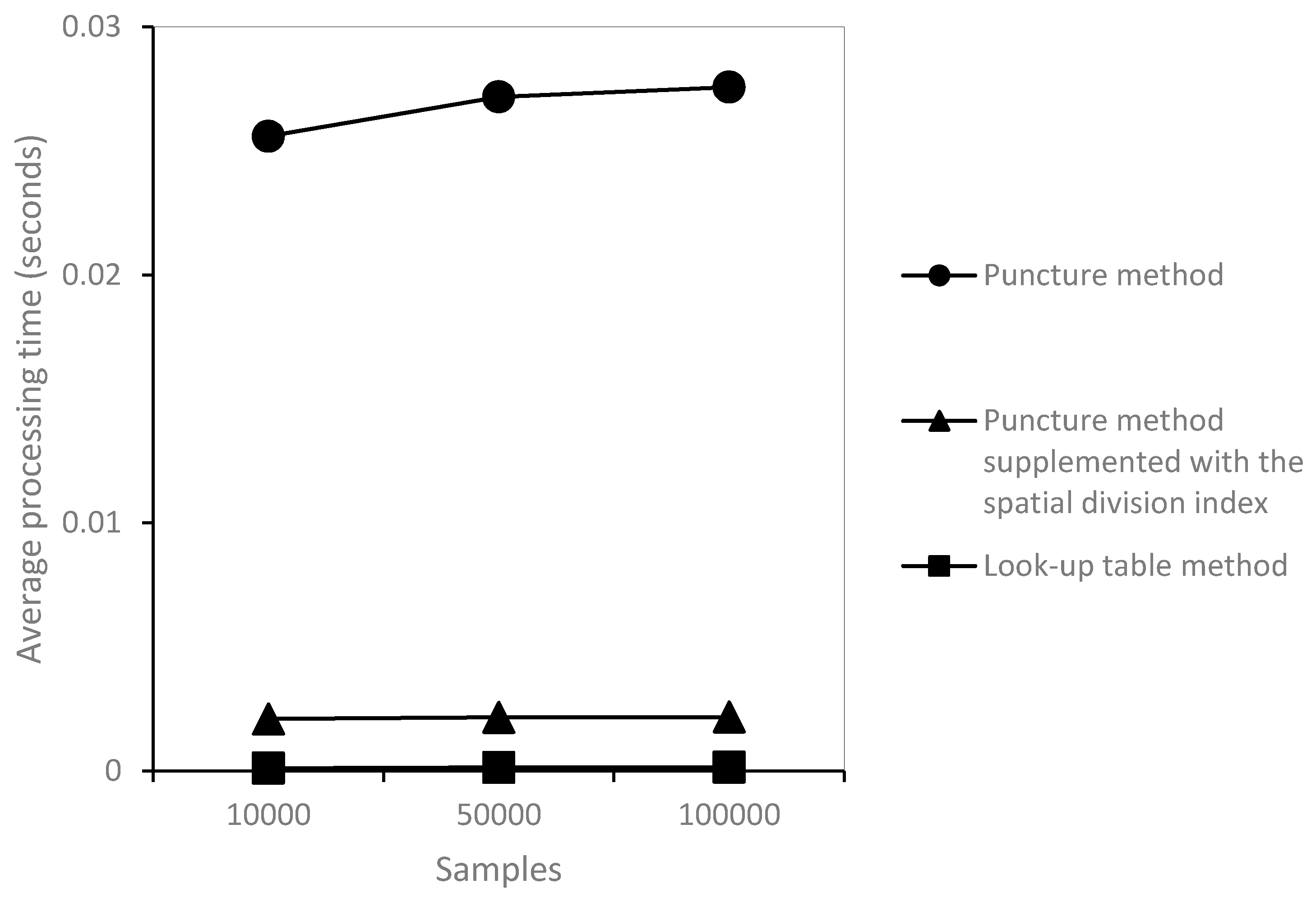
Figure 4 shows that the puncture method provided a steep increase from the county highway and included 100,000 samples with 50 runs. Overall, the look-up table method with individual segment layers could produce a more stable performance than the other two methods.
As stated above, if a normal road is chosen as the first layer, the computational process may take a great deal of time; thus, a normal road should not be chosen as the first layer. Moreover, once the individual computation of each layer is done, then the combination of all layers together may also be time-consuming. To improve efficiency, we grouped interchanges and service stations for traffic facilities and the other six layers for roads.
In
Table 6, the experiments still featured 100,000 samples with 50 runs. To compare individual calculations with the groupings,
Table 6 performed better than
Table 5. The grouping of roads took more time than the grouping of traffic facilities. In this case, the puncture method reduced the efficiency of process execution and affected the output performance. The look-up table method still required much less computation time than the other two methods. The look-up table method also produced a stable performance. The three categories of standard deviations are summarized in
Table 7. For traffic facilities and roads, the puncture method had larger standard deviations. Grouping traffic facilities and roads provided better results than using individual layer calculations. All eight-segment layers were grouped together (i.e., traffic facilities and roads). The puncture method provided a very large standard deviation value of 49.8420, whereas the other two methods had low standard deviations. Therefore, different grouping combinations can affect the efficiency of multilayer-based map matching in different ways. The category of roads is also more complicated than traffic facilities, so applying the puncture method with vector data may yield excess computing loads and delays. However, the grouping using the puncture method supplemented with the spatial division index and look-up table method can retain small standard errors of measurements.
Computation time using all eight-segment layers together and the average processing time for every point was considered. The experiments outlined in
Table 8 still featured 100,000 samples with 50 runs. As shown in
Table 8, the puncture method took 2756.76 s, and its average processing time was 0.0275676 s. The computation time for the puncture method supplemented with the spatial division index was 217.52 s, and its average processing time was 0.0021752 s. The computation time of the look-up table method was 15.12 s, and its average processing time was 0.0001512 s. The puncture method supplemented with the spatial division index improved the efficiency by 12.67 times compared to the method without a spatial division index. Using the look-up table method with raster as the data structure along with the data compression technology improved the average map matching processing time by 14.39 times compared to the puncture method supplemented with the spatial division index and by 182.33 times compared to the puncture method. The computation time of the look-up table method was the shortest. The percentage of deviation (PoD) was between the best-solution (BS) and the solution-so-far (SSF):
Based on Equation (15), comparing other puncture methods with the puncture method supplemented with the spatial division index, the improvement was 92.11%; thus, the efficiency was significantly improved. This indicates that the spatial division index can enhance the efficiency of map matching. The highest improvement was 99.45% between the puncture method and the look-up table method. In terms of average processing time, the puncture method with the spatial division index was the second-best approach. Thus, map matching based on a raster data structure using the look-up table method was more efficient than the other two methods.
Figure 5 shows three samples of 10,000, 50,000, and 100,000, and illustrates that the line of the puncture method was higher than the other two lines when the sample increased. This study employed a statistical test method using the independent samples test [
42] and arranged the values in SPSS software.
Table 9 shows that the
P-value for Levene’s test was 0.000, which is statistically significant at a
P < 0.05 level. Thus, the variances were not equal. The
P-value of the independent
T-test was 0.000, which is statistically significant at a
P < 0.05 level. Therefore, the puncture method supplemented with the spatial division index and the look-up table method offer significant improvements.
To evaluate the look-up table method’s performance, four samples of 10,000, 50,000, 100,000, and 500,000 were used.
Table 10 demonstrates that the average processing time for every point with four samples was less than 0.0002. Thus, the look-up table method is a competitive solution for using a multilayer-based map matching approach to group eight-segment layers. In the row for the average processing time of every point, the look-up table method provides stable performance using different samples. To evaluate the performance, the multilayer-based map matching algorithm using a look-up table with raster data provided the best efficiency for large truck fleet dispatching.
The computer used for the empirical tests was a desktop PC running Microsoft Windows 10, with an Intel Core i5-9400F CPU at 2.9 GHZ and 32 GB of RAM.
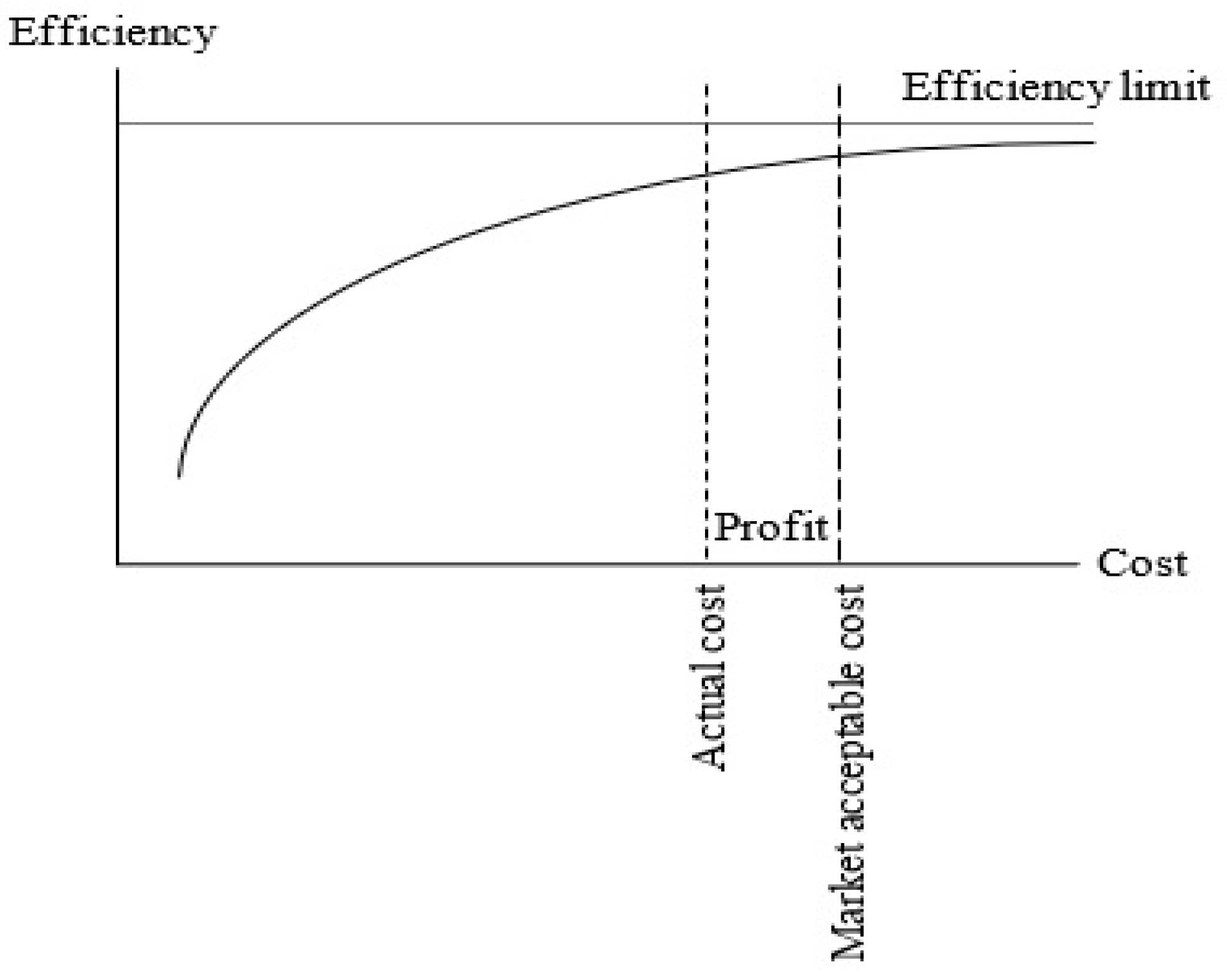
Figure 6 shows the trade-off between efficiency and cost [
39]. First, when the data structure and algorithm procedures are the same, marginal efficiency improvements can be realized by improving the hardware and software. After the hardware and software are upgraded to a certain extent, the marginal efficiency increase will gradually decrease. The efficiency limit is shown in
Figure 6. When determining the investment costs of hardware and software, the actual cost, the market acceptable cost, and the profit should be considered. The best option may not be to upgrade only the hardware and software.
Ultimately, this study used different data structures to effectively improve map matching and maximize the efficiency of map matching under existing software and hardware constraints. The number and complexity of the road sections will obviously affect the efficiency of multilayer-based map matching with the puncture method, but the number of GPS coordinate data do not greatly affect the computation time when using the look-up table method. The look-up method uses a database to sort the raster data and build an index for search and analysis. It is possible to reduce the length of the raster data and improve searching efficiency through coding and compression. The method of the spatial division index involves dividing the data into several layers and large blocks, which effectively reduces the number of data to be searched and improves the efficiency of map matching. Although multilayer-based map matching using raster data loses the partial geometry elements of the road networks, which negatively affects accuracy, the efficiency is also increased.
5. Discussion and Conclusions
The aim of this paper was to enhance the efficiency of large truck fleet dispatch to achieve timely deliveries. Our proposed multilayer-based map matching method can provide appropriate grouping combinations to handle complicated road networks for managing large truck fleet dispatch. The linear transformation process was verified for handling GPS coordinates in a short time and rapidly providing all transformation coordinates in the case study. Overall, the computation time for individual layers was higher than that for the grouping layers.
The multilayer-based map matching approach presented here provided different outcomes with the three approaches used to compare the efficiency. Employing computers to perform the puncture method is time-consuming. The puncture method with multilayer-based map matching, however, can reduce the average processing time for every point. Establishing a spatial division index for the puncture method can improve performance, since indexing is a technical approach to reduce the scope of information data. Although indices speed up queries when many of the fields are indexed, they require even more space than the original data table. By maintaining the organization of the index tables, it takes more time for the data to change. Adding a spatial division index is recommended as the second-best approach. Raster-based compression can also take a great deal of time unless the map undergoes large revisions. Thus, raster maps cannot be frequently redrawn in practice.
Previous studies have focused on improving vehicle positioning accuracy and used the map matching method for general vehicle cases. This paper focused on map positioning and efficiency performance. Vector-based and raster-based formats have been shown to have advantages depending on different scenarios and so in this study, we used the point-to-polygon approach and then integrated these technologies and methods for improving performance. Based on the conclusion for polygons in raster-based format from [
40], we extended the idea to solve large trucks with large-scale positioning data. The method contributes to large truck fleet management and shows that multilayer-based map matching with a raster-based data structure can improve fleet dispatch. Furthermore, a multilayer-based map-matching algorithm using the look-up table method does not require complicated mathematical equations or programming languages and can yield the lowest average processing time. When the sample size increased, the look-up table method offered a stable performance. With the increase in large truck fleets, our proposed approach can handle the computational bottleneck. Generally, mobile phones have limited computational ability, but installing a multilayer-based map-matching algorithm with a look-up table in the dispatching system can reduce load, and logistics technicians can operate obtain fleet coordinate information via mobile phone.
A limitation of our study is that we did not consider the overlapping of facilities. Generally, actual road networks contain various irregular intersections. Future research could address the intersections in facilities based on extending the center of the road a certain distance in the horizontal and vertical directions, rather than using a polygonal design. Internal consistency, which is a reliability topic [
43], should be achieved in preliminary evaluations to reduce sample and measurement errors. In this study, the smaller truck fleet scenario was not our objective to assess the financial viability, and economies of scale are such that it is probably more feasible economically in large truck fleets, but this was not a consideration in this paper. Therefore, this study only focused on large trucks. In the near future, a similar approach can be applied to other regions and countries, and the types of orography can be considered for further research. The multilayer-based map matching approach can also determine fleet locations for further comparisons with different logistics vehicle sizes. This multilayer-based map matching algorithm using the look-up table method can serve as a useful reference in enhancing the performance of large truck fleet dispatching. Ultimately, by improving efficiency, our proposed map matching method can help large truck fleet drivers to quickly obtain the relevant point coordinates and complete their dispatching tasks.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}