4.2. Deep Learning Evaluation
In order to evaluate the classification performance, several commonly used classification metrics were adopted: Accuracy (ACC), precision, recall (sensitivity), and F1-score.
indicates how well a classification algorithm can discriminate the classes of the trajectories in the test set. As shown in Equation (
13),
can be defined as the proportion of the predicted correct labels (
TP +
TN) to the total number of labels (
N).
is the proportion of predicted correct labels to the total number of actual labels, as shown in Equation (
14), while
is the proportion of predicted correct labels to the total number of predicted labels, as shown in Equation (
15). Recall is also known as sensitivity or the True Positive Rate (TPR).
The
F1-score consists of the harmonic mean of precision and recall, where precision is the average precision in each class and recall is the average recall in each class, as illustrated in Equation (
16).
TP, TN, FP, and FN refer to the True Positive, True Negative, False Positive, and False Negative samples for each class (anchored, moored, underway, and fishing).
The classification performance of several pre-trained CNNs, namely VGG16, InceptionV3, NASNetLarge, and DenseNet201, was evaluated on the effectiveness of vessel pattern recognition. For each CNN, we performed a five-fold cross-validation on the 800 samples (200 samples per class) for both data sets, keeping at each fold
of the data for training and
of the data for validation, and reported the macro-average results. The trajectories were segmented into equally-sized temporal-window trajectories of 8 h in length. This particular temporal-window was selected because the mobility patterns of the vessels require some time to form [
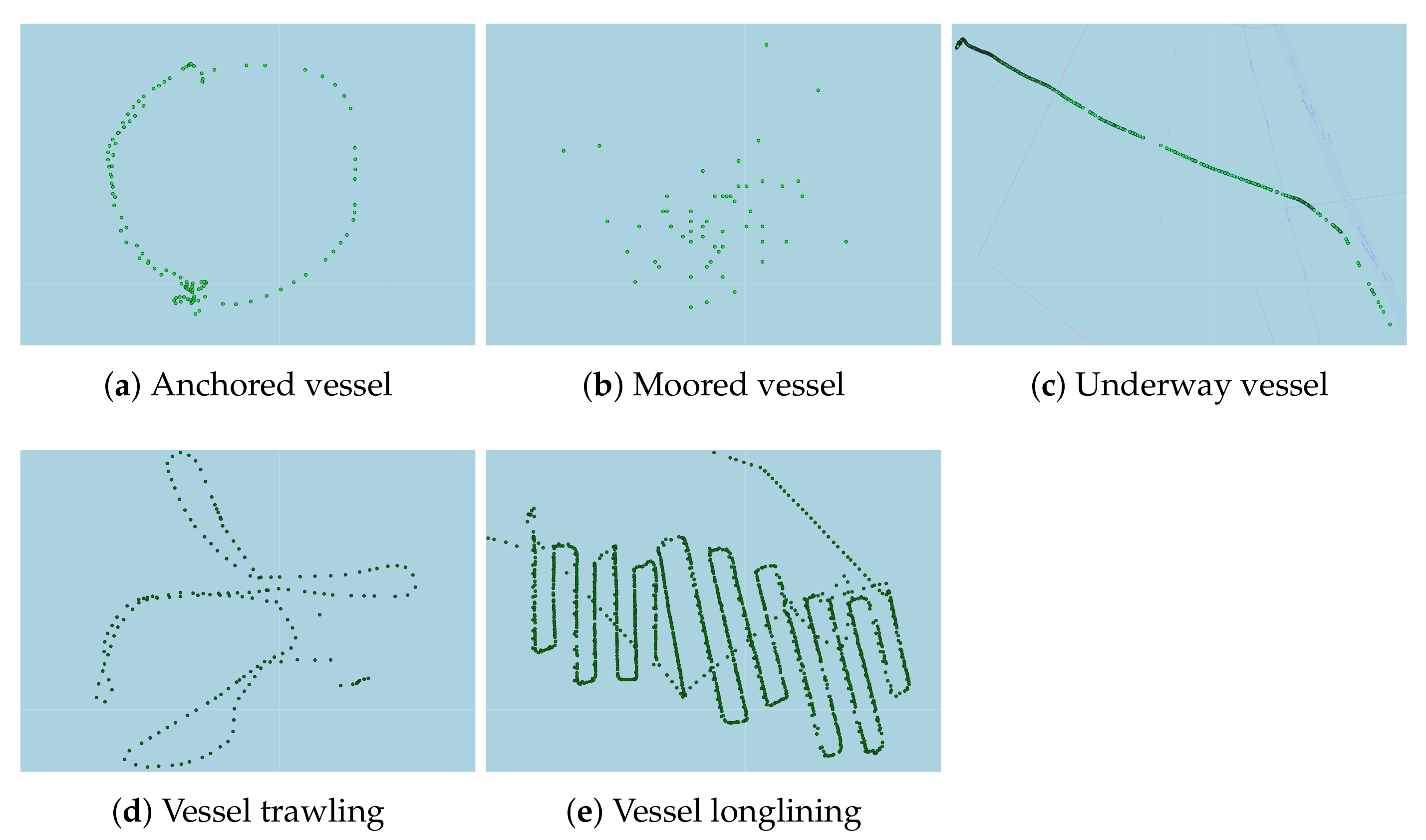
10]. During a one-hour window, for instance, the anchored pattern as described in
Section 3.1 will most probably not have fully formed.
Table 3 illustrates the classification results of each model of the first data set (Pattern A).
The Keras package and a TensorFlow backend were employed along with the Python programming language for training the deep learning models. Keras is a simple-to-use neural network library built on top of Theano or TensorFlow.
The results suggested that the VGG16 model achieved the best classification accuracy of almost 99% followed by InceptionV3 and NASNetLarge with almost the same accuracy of 92%. DenseNet201 presented the worst results with an accuracy of 88%. A sensitivity of 100% for anchored and moored and 97% for the underway class can be observed for VGG16. This practically means that confirmed anchored or moored vessel mobility patterns would be accurately identified as such 100% of the time, while confirmed underway patterns would be misclassified only 3% of cases. Furthermore, VGG16 showed high precision values for all classes, specifically 100% for moored and underway and 96% for anchored. This implies that there were no classes incorrectly classified as moored or underway from another class, while only one anchored class was incorrectly classified as underway. This can be seen in the confusion matrix of the VGG16 model with the best classification performance out of the five folds (
Figure 11a). Regarding the F1-score, the moored class achieved 100% in all performance metrics, which means that the FPs and FNs were minimized at zero.
InceptionV3 and NASNetLarge presented very similar results. A precision of 100% in the moored class was observed, which means that there were no anchored or underway classes falsely misclassified as moored. On the other hand, the precision and F1-score regarding the anchored class depicted low results. Indeed, these low values were justified by a large number of FPs.
Figure 11b,c depicts that the anchored class had seven misclassified cases as underway in both models. Furthermore, the models presented high sensitivity values for the anchored and moored class, while the underway class depicted a moderate value of 80%. Again, the moored class achieved 100% in all performance metrics.
Although DenseNet201 presented the worst results in terms of accuracy, the moored class achieved again high values for all performance metrics. As the results suggest, the precision regarding the anchored class was very low at about 68% and followed the same trend as the InceptionV3 and NASNetLarge models for the particular class. However, the model was able to correctly identify confirmed anchored and moored classes as such, 100% and 97% of the time, respectively, while only 71% of confirmed underway cases would accurately be identified correctly. The anchored class presented 11 FPs, as illustrated in
Figure 11d, which was strongly associated with a moderate value of the F1-score.
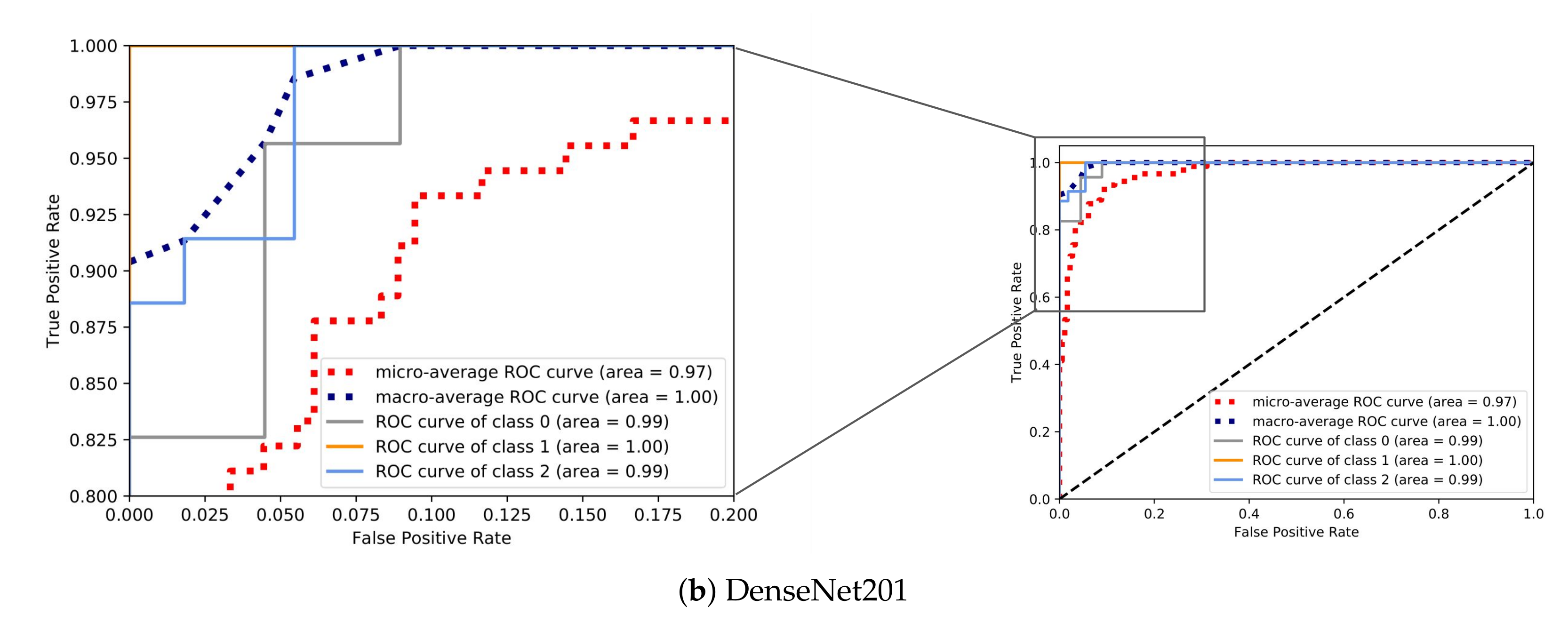
In order to visualize how well the examined models distinguished the classes in terms of the predicted probability, for each CNN, we visualize the ROC curves of the model with the best classification performance out of the five folds in
Figure 12. Specifically,
Figure 12a,b demonstrates the ROC curves for the models with the highest and lowest accuracy, VGG16 and DenseNet201, respectively. As expected, the area covered (AUC) by VGG16 was bigger as the model was able to discriminate the classes with a much higher probability in comparison with DenseNet201.
The same patterns can be observed between the different models for particular performance metrics. The precision of the anchored class followed a downward trend as the overall accuracy decreased. The same behavior was presented in the sensitivity of the underway class. On the other hand, moored class achieved high values in all performance metrics even with a moderate accuracy in the case of DenseNet201. Furthermore, all the CNN models presented quite high precision values for moored and underway classes regardless of the accuracy.
Subsequently, for each CNN, we visualize the loss and accuracy of the model with the best classification performance out of the five folds during their training in
Figure 13. VGG16 demonstrated a smooth training process, as shown in
Figure 13a, during which the loss gradually decreased and the accuracy increased. Moreover, it can be observed that the accuracy of both training and validation did not deviate much from one another, a phenomenon that can also be observed for the training and validation loss, indicating that the model did not overfit. The same behavior was presented by the NASNetLarge model, as shown in
Figure 13c. On the other hand, in the case of InceptionV3 and DenseNet201, their validation loss was either increasing or fluctuating, as shown in
Figure 13b,c, respectively, which means that the models most probably overfit. An interesting fact is that the VGG16 model, which contained the least number of layers, achieved a better classification performance. This can be explained by the fact that neural networks with more hidden layers require more training data; thus, an even larger number of mobility pattern samples was required as an input in these networks.
Additionally, we compared our results with other methodologies for trajectory classification, which were illustrated in the recent survey of Wang et al. [
5]. Well-known classifiers such as Random Forests (RFs) and Support Vector Machines (SVMs) are employed by state-of-the-art methodologies for trajectory classification, on features extracted from the AIS messages or data points of the trajectories. Thus, three features from the trajectories during each type of activity (anchored, moored, and underway) were extracted: (i) the average speed of the vessel, (ii) the standard deviation of its speed, and (iii) the haversine distance between the first and the last vessel position. These features were selected because they demonstrated distinct differences between these specific activities. A moored vessel typically has a zero speed, while an anchored vessel moves with slightly greater speeds on average due to the effects of the wind and the currents of the sea. A vessel underway presents much higher speeds, and the distance between the first and the last position is greater compared to the distance of anchored or moored vessels. Subsequently, these aforementioned features were then fed to two classifiers, random forests and support vector machines. The methodologies employed in the comparison are shown below:
M1: the proposed deep learning methodology of this paper (image classification by employing the VGG16 model, as it presented the best classification accuracy results).
M2: the random forests classifier with the features extracted from the AIS messages of the trajectories.
M3: the support vector machines classifier with the features extracted from the AIS messages of the trajectories.
Table 4 illustrates the cross-validation macro average results of the comparison between the different approaches. Results show that our proposed methodology (M1) surpassed the other methodologies (M2, M3) in terms of classification performance. M1 achieved an F1-score of
, and M2 and M3 achieved an F1-score of
and
, respectively.
To further evaluate our methodology on vessel activities of utmost importance to the maritime authorities, we performed the same deep learning classifiers employed on Pattern A on the second data set (Pattern B), which contained fishing vessels engaged in trawling, longlining, moored at the port, or traveling towards a fishing area (underway). A fishing vessel is typically moored at a port, then travels towards a fishing area and is finally engaged in the fishing activity. After the fishing ends, the vessel travels back to the port and moors.
Table 5 illustrates the classification results of each model for Pattern B.
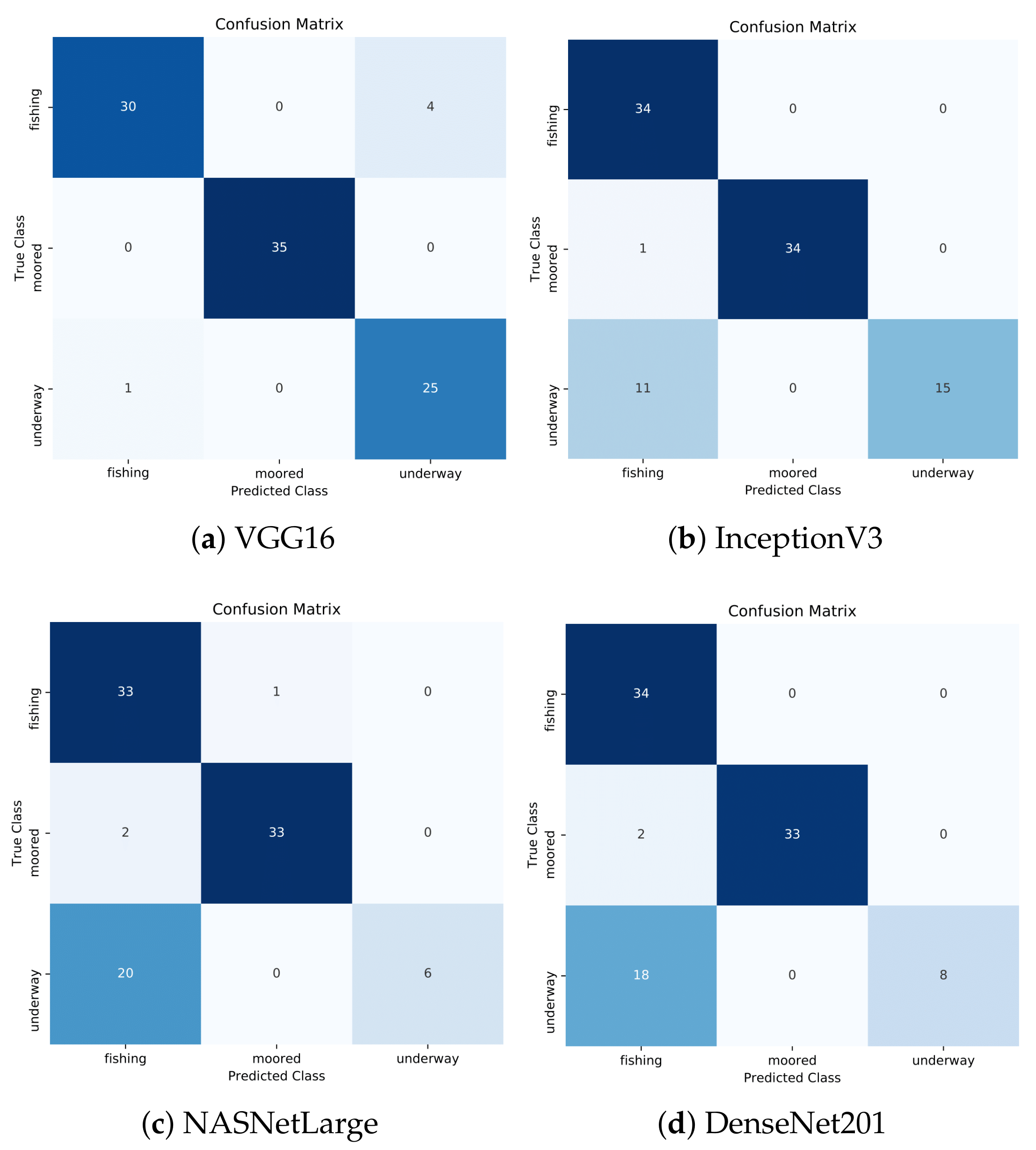
As the results suggest, VGG16 model achieved again the best classification accuracy of almost 95% followed by InceptionV3 with an accuracy of 87%. NASNetLarge exhibited the worst results with an accuracy of 76%, while DenseNet201 presented slightly better results with an overall accuracy of 79%. A recall (sensitivity) of 100% and 96% for the moored and underway class, respectively, can be observed for VGG16. This practically means that confirmed moored vessel mobility patterns would be accurately identified as such 100% of the time, while confirmed underway patterns would be misclassified for only 4% of cases. In contrast, fishing presented a moderate recall of 88%. Furthermore, VGG16 presented high precision values for fishing and moored and a moderate precision for underway. This implies that there were no classes incorrectly classified as moored from another class, while only one fishing class was incorrectly classified as underway. The moderate precision of underway was justified by a moderate number of FPs. Indeed, four underway classes were incorrectly classified as fishing, as shown in
Figure 14a, which represents the confusion matrix of the VGG16 model with the best classification performance out of the five folds. The moored class achieved an F1-score of 100%, while the remaining classes exhibited a high percentage of about 92% for fishing and 91% for underway.
In the InceptionV3 model, the moored class presented high values for all performance metrics. Furthermore, a precision of 100% in both underway and moored was observed. On the other hand, the precision of the fishing class presented a low value of 74% and justified by the large number of FPs (12 in total), as shown in
Figure 14b. Furthermore, the recall of the underway class was low, 58%, as well as the F1-score, which in turn justified the large number of FNs (11 in total). The other classes exhibited large values regarding recall, 100% for fishing and 97% for moored.
NASNetLarge and DenseNet201 presented several similarities. The fishing class had a low value of precision, almost 60% in both models.
Figure 14c,d depicts that the fishing class had 22 and 20 misclassified cases, respectively. On the other hand, high precision values were observed for the moored and underway classes in both models. The moored class presented yet again high values in all performance metrics. Furthermore, recall regarding the underway class was very low at about 23% in NASNetLarge and 31% in DenseNet201 and followed the same trend as the InceptionV3 model for the particular class. In combination with the low values of the F1-score, only a small number of confirmed underway classes were identified correctly.
Figure 15 demonstrates the ROC curves for the models with the highest and lowest accuracy for Pattern B, VGG16 in
Figure 15a and NASNetLarge in
Figure 15b, respectively. For these two CNNs, we visualized the ROC curves of the model with the best classification performance out of the five folds.
Subsequently, for each CNN, we visualized the loss and accuracy of the model with the best classification performance out of the five folds during their training for Pattern B, as shown in
Figure 16. VGG16 demonstrated a smooth training process for Pattern B, as shown in
Figure 16a, during which, the loss gradually decreased and the accuracy increased. Almost the same behavior was presented by the InceptionV3 model, as shown in
Figure 16b, except for the last epochs where the loss increased. On the other hand, in the case of NASNetLarge and DenseNet201, their validation loss was either increasing or fluctuating, as shown in
Figure 16c,d, respectively, which means that the models most probably overfit. Indeed, the growth rate of validation loss was extremely high in the case of NASNetLarge.
Finally, we compared our classification methodology results to the approach proposed in [
10] for the fishing vessels (M4). The authors in [
10] used a set of features suitable for the fishing activities, which were then used by random forests to classify the vessel activities. Moreover, we also used the methodology of the previous experiment (M2), which uses features that were suitable for Pattern A. Similar to the previous set of experiments, we employed only the VGG16 model as it presented the best overall classification accuracy. The macro average results are reported in
Table 6. The results again validate that the proposed approach (M1) was by far more accurate than the set of features selected specifically for the classification of fishing activities (M4). Furthermore, the results demonstrate that the methodology M2 did not perform well (F1-score of
). This is explained by the fact that the features used for Pattern A were not able to discriminate Pattern B. On the other hand, the proposed methodology (M1) was able to perform well on both sets of patterns due to the fact that the patterns had distinct visual differences.
4.3. Streaming Evaluation
In this section, we provide experimental results of the execution performance of the proposed streaming methodology. To this end, different sets of experiments were conducted in order to evaluate the streaming application’s:
The experimental evaluation presented below was performed on a cluster consisting of four machines with four cores (Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00 GHz) and 8 GB of RAM each, totaling 16 cores and 32 GB of RAM, running Ubuntu 18.04 LTS with Python 3.6 and Apache Kafka 2.4.0.
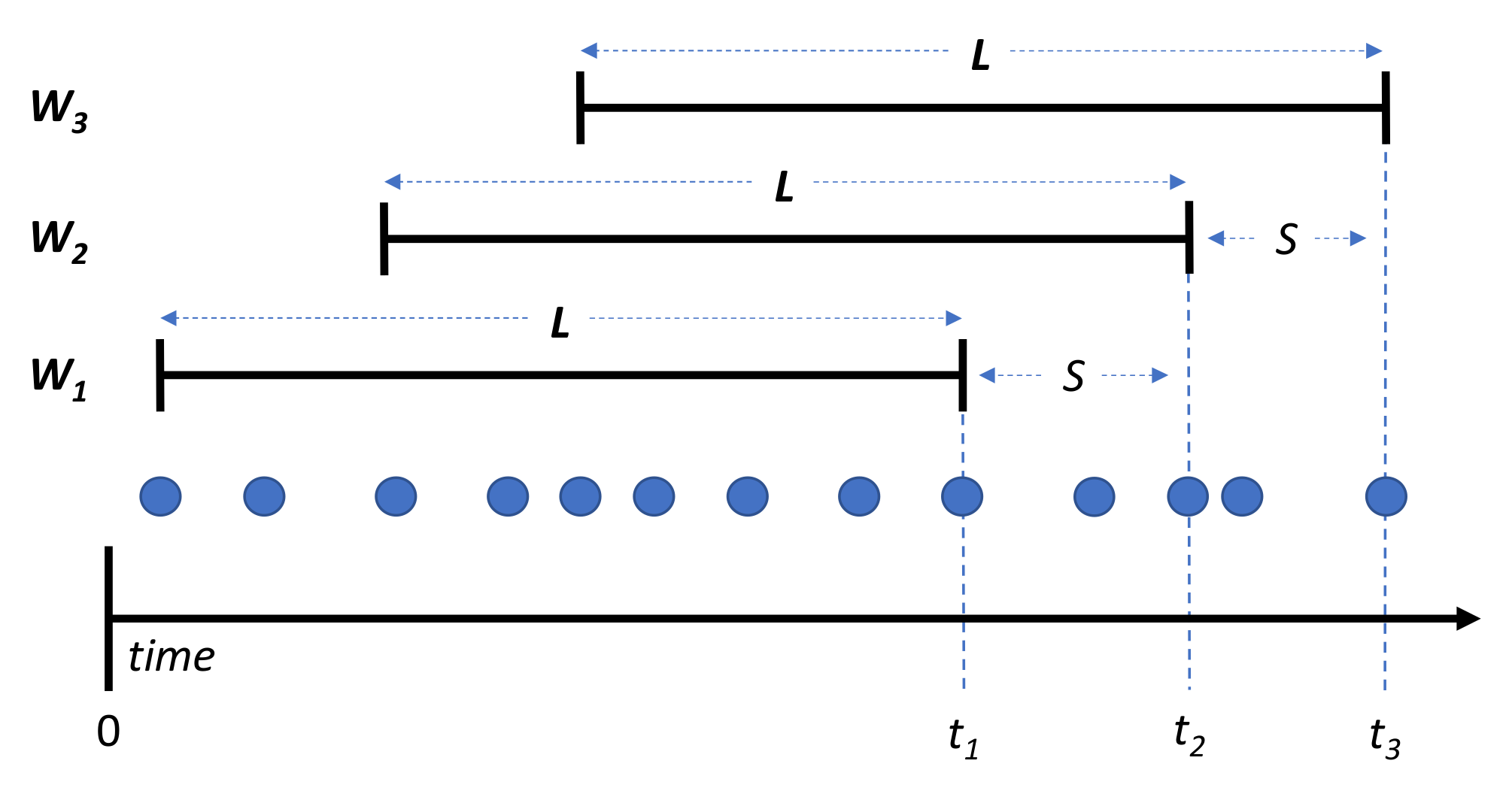
To evaluate the scalability of our approach, we ran experiments using 1, 2, 3, and 4 machines incrementally. Each machine employed a prediction module and kept the window size and window step constant equal to 4 h and 30 events, respectively. As mentioned in
Section 3.4, the streaming methodology used a sliding window over the streams of AIS messages to perform the classification. A window size of 8 h was sufficient to have a fully formed pattern per vessel [
10]. Since the highest transmission rate of the AIS protocol was one message every 2 s, a window step of 30 events or messages implies that a classification will be triggered by the prediction modules every one minute, a time period during which the pattern would not have changed significantly. Furthermore, we repeated each experiment four times to evaluate the four different CNN architectures (VGG16, InceptionV3, DenseNet, NASNet).
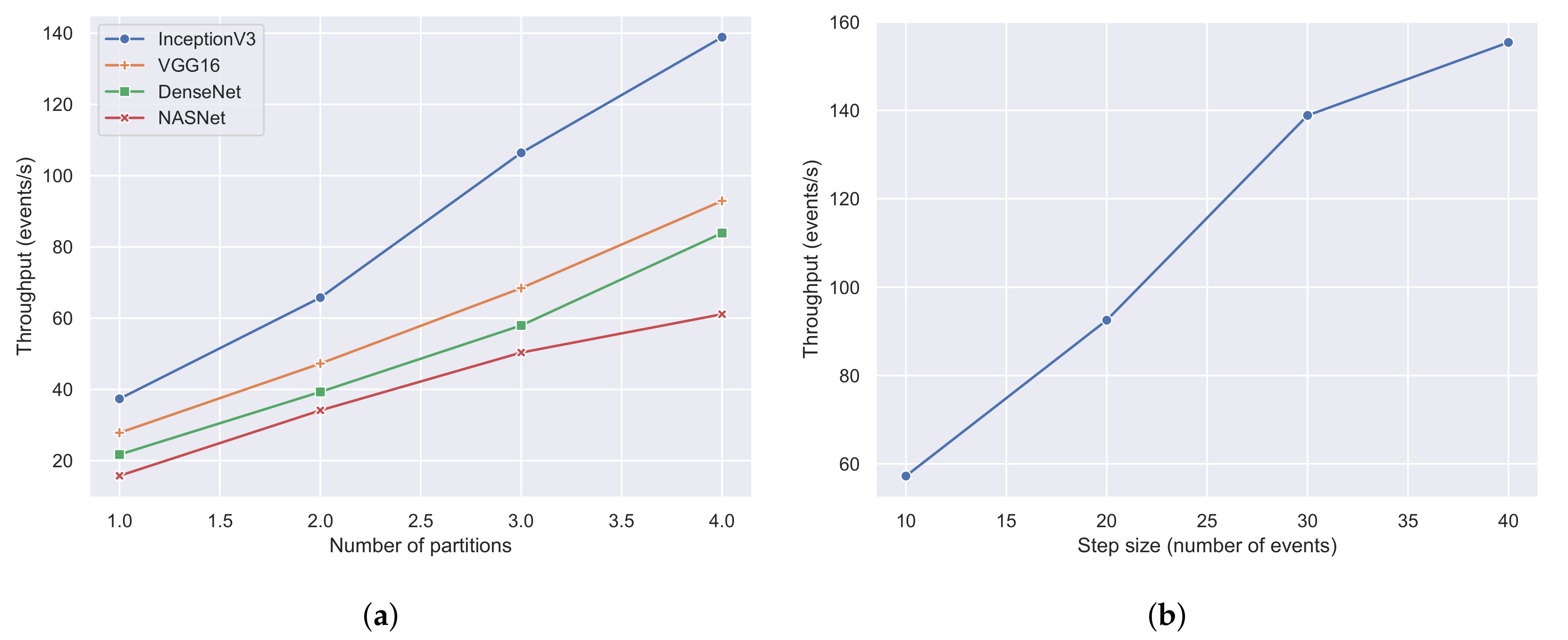
Figure 17a illustrates the throughput of each CNN architecture with a different number of machines or partitions. It can be observed that the proposed streaming methodology can benefit when more machines and prediction modules were used regardless of the employed CNN architecture. Moreover, it is apparent that InceptionV3 was the fastest CNN architecture achieving a maximum throughput of 140 events per second, outperforming all of its contestants. The next CNN architecture was VGG16 with a throughput of 90 events per second, which is similar to DenseNet’s throughput of 80 events per second. The slowest CNN architecture was NASNet, which achieved a maximum throughput of 60 events per second. The performance of the two last architectures, which presented the worst results, can be explained by the fact that these architectures are more complex than the former two, consisting of more hidden layers and pooling layers. To further evaluate the throughput of the proposed methodology, we selected InceptionV3, which was the fastest CNN architecture, and performed experiments using four machines and a varying number of window steps.
Figure 17b visualizes the results of the aforementioned experiment using window steps that range from 10 events to 40 events. The value of the window step denotes how often the classification will be triggered; thus, the smaller the number of steps is, the larger the amount of classifications that are triggered, resulting in a lower throughput. Indeed, this was confirmed by the experiments in
Figure 17b, where the throughput was 155 events per second when using a step of 40 and 57 events per second when using a step of 10.
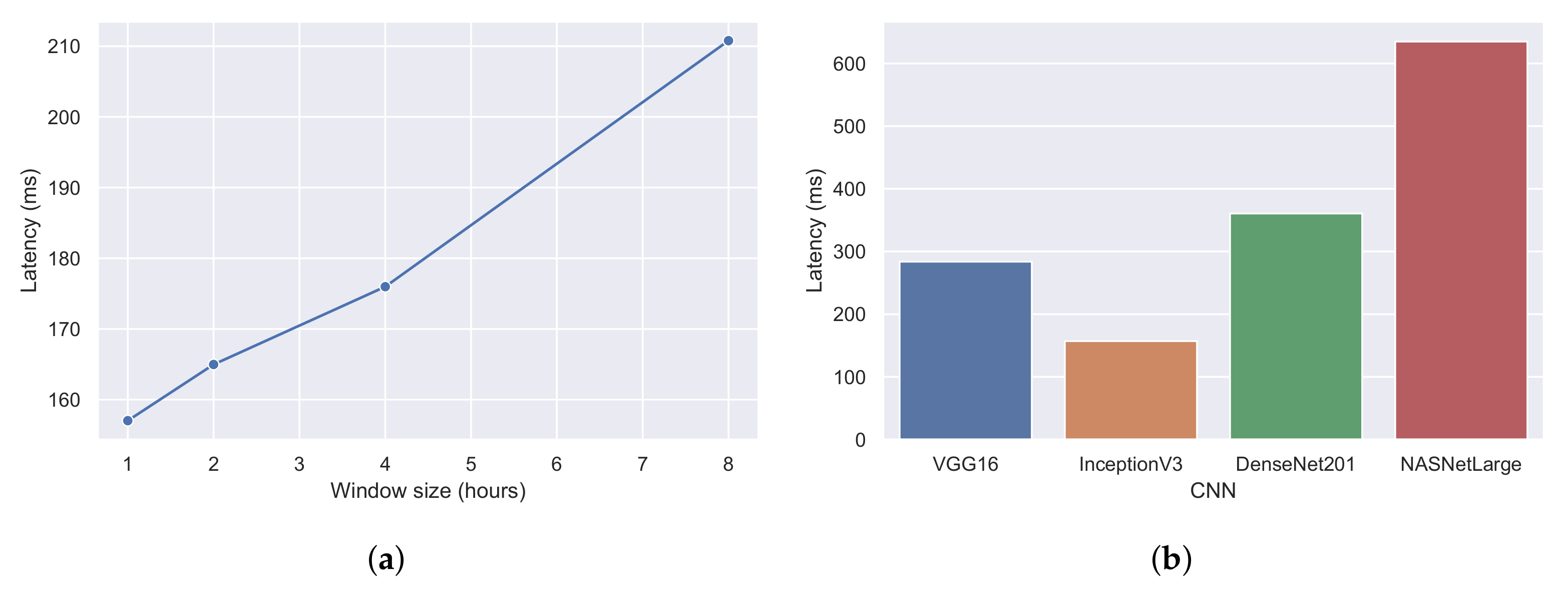
The first experiment, which yielded the results of
Figure 17a, also provided the average processing latency of each CNN architecture in
Figure 18b. Processing latency is defined as the amount of time required by a CNN to perform the image classification. Again, it can be observed that InceptionV3 was the fastest CNN architecture with a processing latency of 157 ms. Next was the VGG16 network with a latency of 283 ms, followed by DenseNet (360 ms) and NASNet (634 ms). To evaluate the image latency, which is defined as the amount of time required to create an image from the AIS messages, we kept the same configurations of the first experiment (four machines and a window step of 30 events), but changed the window size.
Figure 18a illustrates the average image latency with a window size of 1, 2, 4, and 8 h. Since a larger time window contains more AIS messages, it is expected that the creation of the image will be greater in larger window settings. As shown and confirmed in
Figure 18a, the average image latency in a one-hour window was 157 ms, and in an eight-hour window, the latency could reach up to 210 ms.
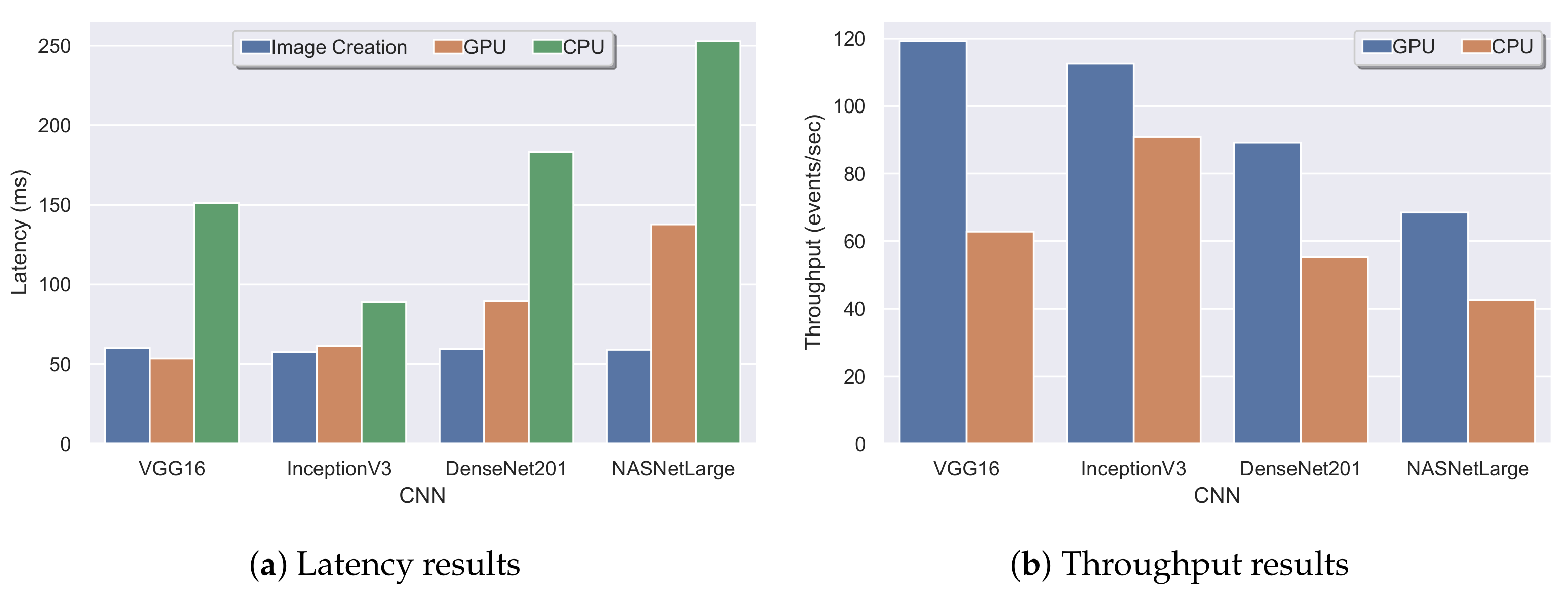
To further evaluate our approach, we demonstrate experimental results with and without the use of a GPU. The following experiments presented below were performed on a commodity machine with eight logical cores (Intel(R) Core(TM) i7-7700HQ CPU @ 2.8 GHz), 32 GB of RAM, and a GPU (NVIDIA 1050 with 4 GB of VRAM), running Windows 10. To demonstrate the performance boost by the GPU, we ran an experiment with a window size and step of 4 h and 30 events, respectively, twice for each CNN architecture, with and without the use of the GPU. The experimental results are presented in
Figure 19. Specifically,
Figure 19a illustrates the image latency and the latency of each CNN architecture. The image latency in each experiment was approximately 60 ms (at least two-times faster than the same experiment with a lower frequency CPU in
Figure 18a). On the other hand, a tremendous performance gain can be observed in the processing latency of each CNN. The processing latency of VGG16, InceptionV3, DenseNet, and NASNet was 150 ms, 80 ms, 180 ms, and 250 ms, respectively, without the use of GPU, while when a GPU was employed, the processing latency reduced to 50 ms, 60 ms, 80 ms, and 140 ms correspondingly. The same pattern can also be observed in the throughput of our approach in
Figure 19b, where the throughput of each CNN architecture increased. An indicative example is VGG16, where the throughput from 60 events per second was increased to 120 events per second.
Finally, it is worth noting that all of the experiments presented in this section achieved a throughput higher than the transmission rate of AIS messages per receiver (five to eight messages per second), as stated in
Section 3.4, making the prediction module suitable to be employed on a terrestrial receiver basis.
4.4. Compression Evaluation
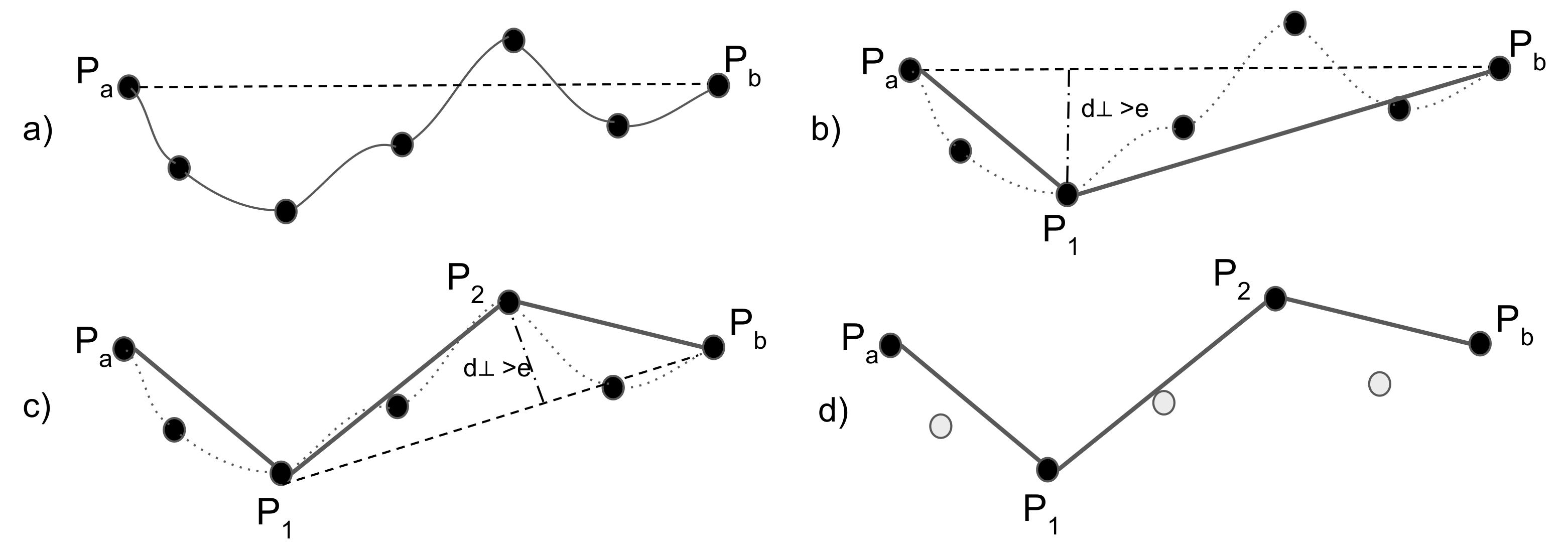
In order to evaluate the trajectory compression algorithms, some validation criteria were employed. The main validation solutions include performance and accuracy metrics. For performance, the following metrics were considered: (i) compression ratio and (ii) compression time. The compression ratio refers to the ratio of the points remaining after compression (a) compared to the original points (n), being defined as , while compression time refers to the total time required for the compression execution. On the other hand, accuracy metrics are used to measure information loss and therefore the accuracy of the compression algorithms.
At this point, it should be mentioned that in order to evaluate the compression results, we employed a subset of the first data set, which is mentioned in
Section 4.1. Specifically, this sub-data set contained information for 472 unique vessels that were monitored for a three-day period starting 1 March 2020 and ending 3 March 2020. Our goal was to perform some preliminary experiments in order to demonstrate the effect of trajectory compression over the classification accuracy of mobility patterns.
Figure 20 illustrates the compression ratio achieved by the different algorithms. The highest compression was achieved by
DP with a ratio of 94%. Compression was slightly lower in
TR, but nevertheless remained extremely high at about 92%. Algorithms that considered time information to decide whether or not to discard a point tended to preserve more points in a trajectory.
DP possessed the highest compression rates as it treated a trajectory as a line in two-dimensional space and did not consider the temporal aspect. The compression ratio was decreased in the case of
SP, but maintained at a high level of about 80%.
HB and
SP_HD held the lowest compression rates of 59% and 54%, respectively.
SP_HD incorporated two thresholds simultaneously, and it was expected to present the lowest compression ratio. Generally, the less the compression ratio is, the more points are included in the resulting set.
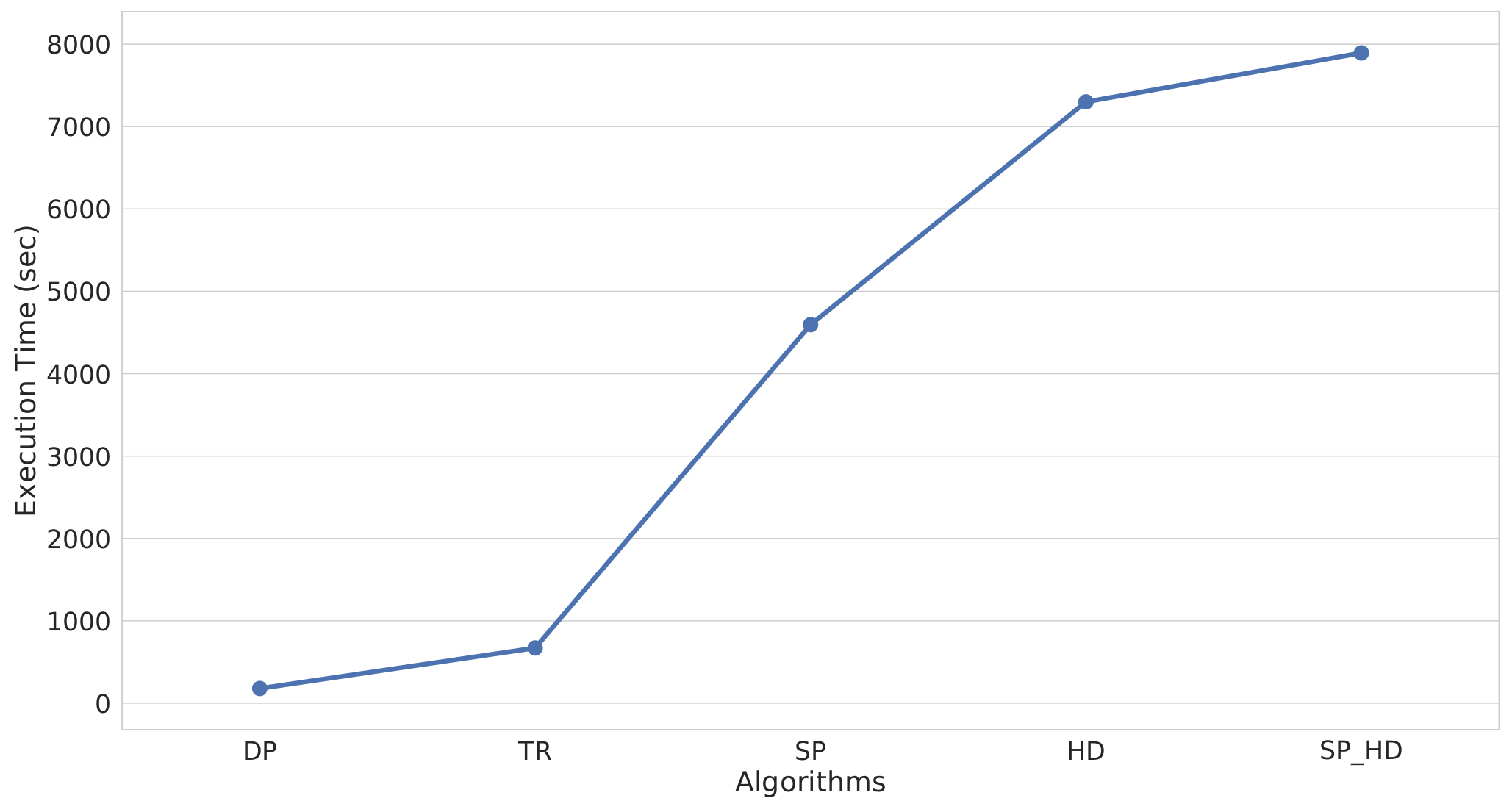
Besides the compression ratio, it is important to assess the execution time of each algorithm as it constitutes an important index to measure efficiency.
Figure 21 presents the execution times of all algorithms.
DP and
TR presented the lowest execution among all algorithms. However, the compression presented the highest rates for these algorithms. In fact,
DP was executed in only 180 s, almost four-times faster than
TR.
SP spent considerably more time than
DP and
TR. Specifically,
SP was 27- and seven-times slower than
DP and
TR, respectively. The execution time of
HD and
SP_HD was quite high, more than two hours for both algorithms. As expected,
SP_HD had the worst performance due to its exponential complexity.
As stated in
Section 3.5, the examined algorithms are lossy, which means that they present some information loss as compressed data cannot be recovered or reconstructed exactly [
83]. Thus, it is important to measure the compression performance by evaluating the quality of the compressed data. Existing techniques evaluate the trajectory compression algorithms using various error metrics such as spatial distance, synchronized Euclidean distance, time-distance ratio, speed, heading, acceleration, and enclosed area. Muckell et al. [
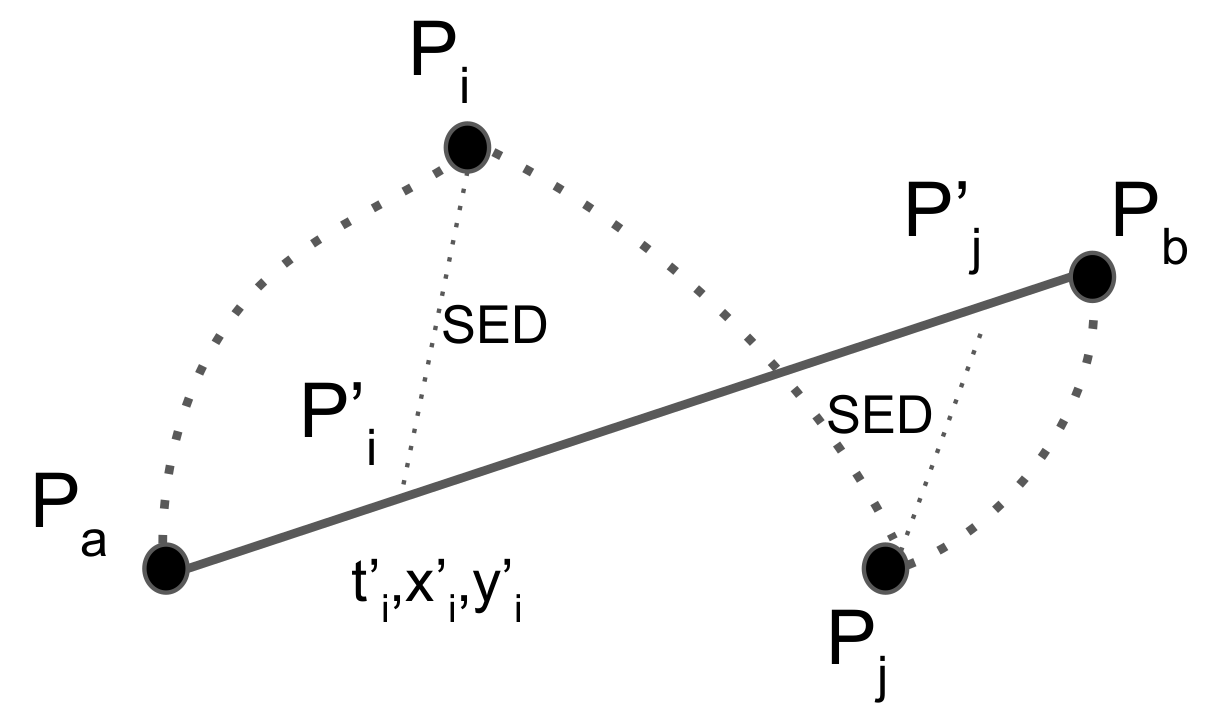
77] employed the average SED and average speed error, while in [
75], the same metrics with the addition of heading error were applied. Furthermore, three assessment criteria were used in [
84], average SED, spatial, and speed error, while Liu et al. [
85] evaluated several compression algorithms through the average PD, SED, and enclosed area. Additionally, in [
80], the error was provided by a formula that measured the mean distance error between the original and compressed trajectory.
As there is a trade-off between the achieved compression ratio and the acceptable error, the effectiveness of the trajectory compression algorithms was evaluated in terms of “information” quality obtained after compression using deep learning. Deep learning was applied over the compressed trajectory data in order to evaluate their accuracy. To the best of our knowledge, this is the first research work that has investigated and evaluated the impact of trajectory compression techniques over vessel mobility pattern classification through neural networks.
Each unique vessel inside the examined sub-data set consisted of a different number of initial points, which ranged from one to 25,000. In order to evaluate the compression results, forty-seven unique vessels (10%) were selected from the total of 472 out of a normal distribution of the points per vessel. Then, the sub-trajectories of these different vessels were extracted and visualized as trajectory images, as described in
Section 3.2, for both the original (uncompressed) and compressed data. Finally, we performed vessel pattern classification on both trajectory data (compressed and uncompressed), by employing the VGG16 model, as it achieved the highest accuracy.
Table 7 illustrates the percentage
of correctly classified mobility patterns extracted from the sub-trajectories’ images for each compression algorithm (
m) compared to the total number of examined mobility patterns (
n). In fact, the higher the percentage, the better the quality of the data obtained after compression was.
The results demonstrate that accuracy was strongly related to the compression ratio. DP presented the highest compression, but exhibited the worst accuracy, about 65%. Similarly, TR achieved extremely high compression, but the accuracy was low (69%), slightly better than DP. SP neither had the worst, nor the best results and presented a moderate accuracy of 74%. Nevertheless, the compression obtained in the case of SP was 12% lower than TR, while the accuracy between these algorithms differed only 5%. HD achieved the highest accuracy as it presented the most correctly classified vessel patterns from the sub-trajectory images with a ratio of 93%. Accuracy was slightly lower for SP_HD, but nevertheless remained high at about 86%. The compression achieved in the case of HD and SP_HD was significantly lower in comparison with the other algorithms, but it was accompanied by extremely high accuracy, especially in the case of HD.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}