
Mapping Public Urban Green Spaces Based on OpenStreetMap and Sentinel-2 Imagery Using Belief Functions

 , ,
, ,  , and
, and
Abstract
:1. Introduction
- RQ1: Can OSM data compensate for the insufficient spatial resolution of the Sentinel-2 imagery when mapping public urban green spaces?
- RQ2: Is it possible to distinguish public from private green spaces using OSM data despite its possibly inconsistent tag usage and insufficient completeness?
- RQ3: How do the uncertainties originating from the two data sources and the analysis influence the overall accuracy of the model to predict public urban green spaces?
2. Related Work
3. Theoretical Background on the Dempster–Shafer Theory
3.1. Basic Probability Assignment
3.2. Dempster’s Rule of Combination
3.3. Classification and Uncertainty Quantification
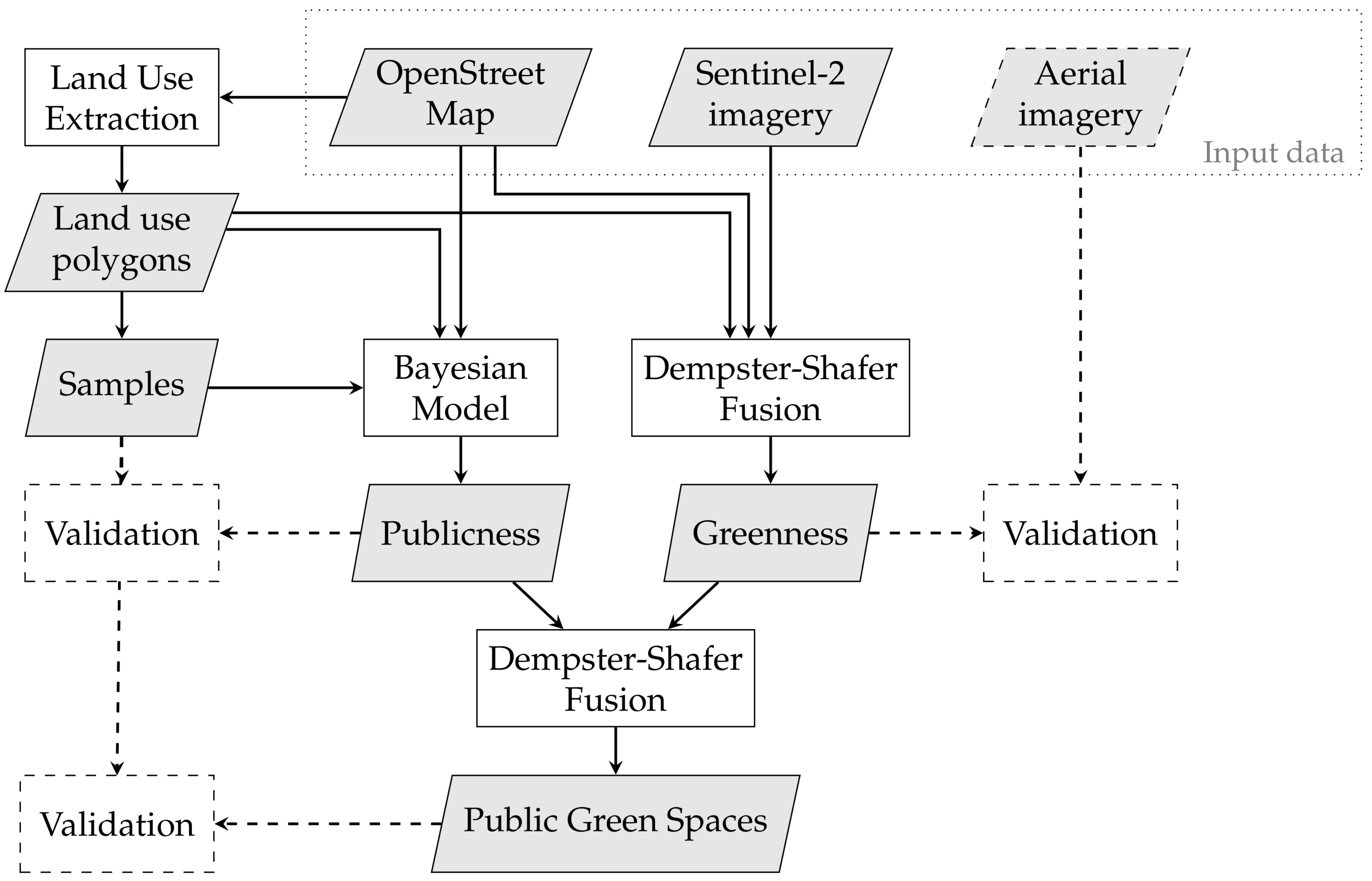
4. Materials and Method for Public Urban Green Space Mapping
4.1. Study Area
4.2. Data
4.2.1. OpenStreetMap
4.2.2. Sentinel-2 Imagery
4.2.3. Aerial Imagery
4.3. Methodology
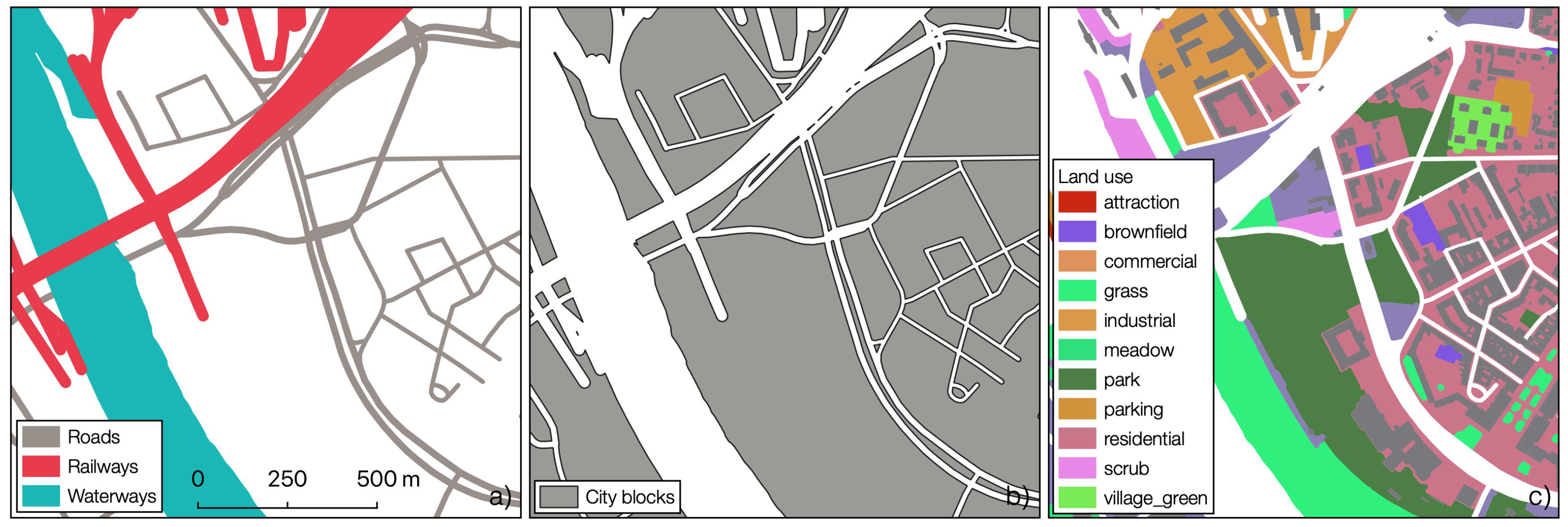
4.3.1. Land Use Polygons
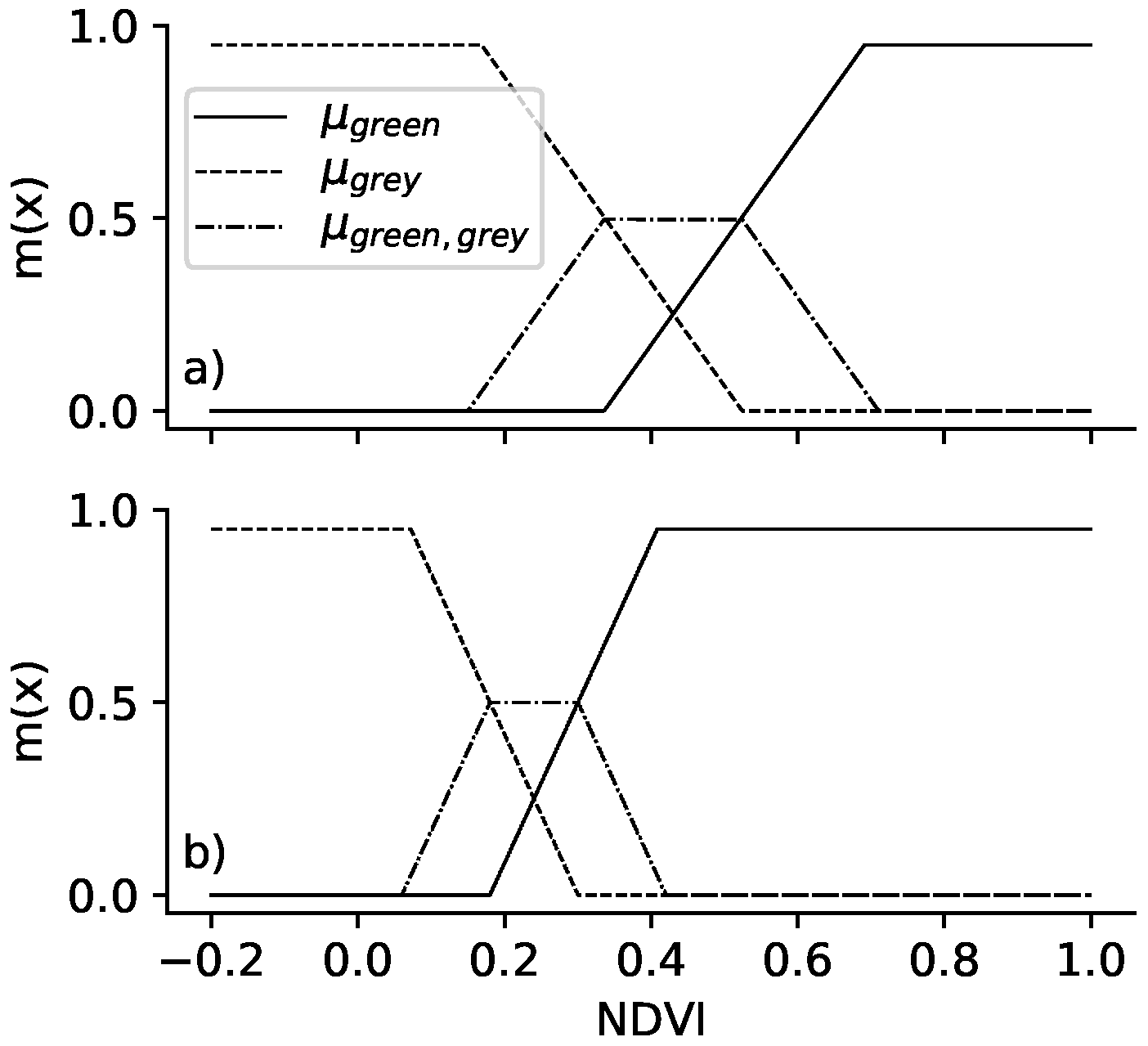
4.3.2. Greenness Model
Basic Probability Assignment Based on Sentinel-2
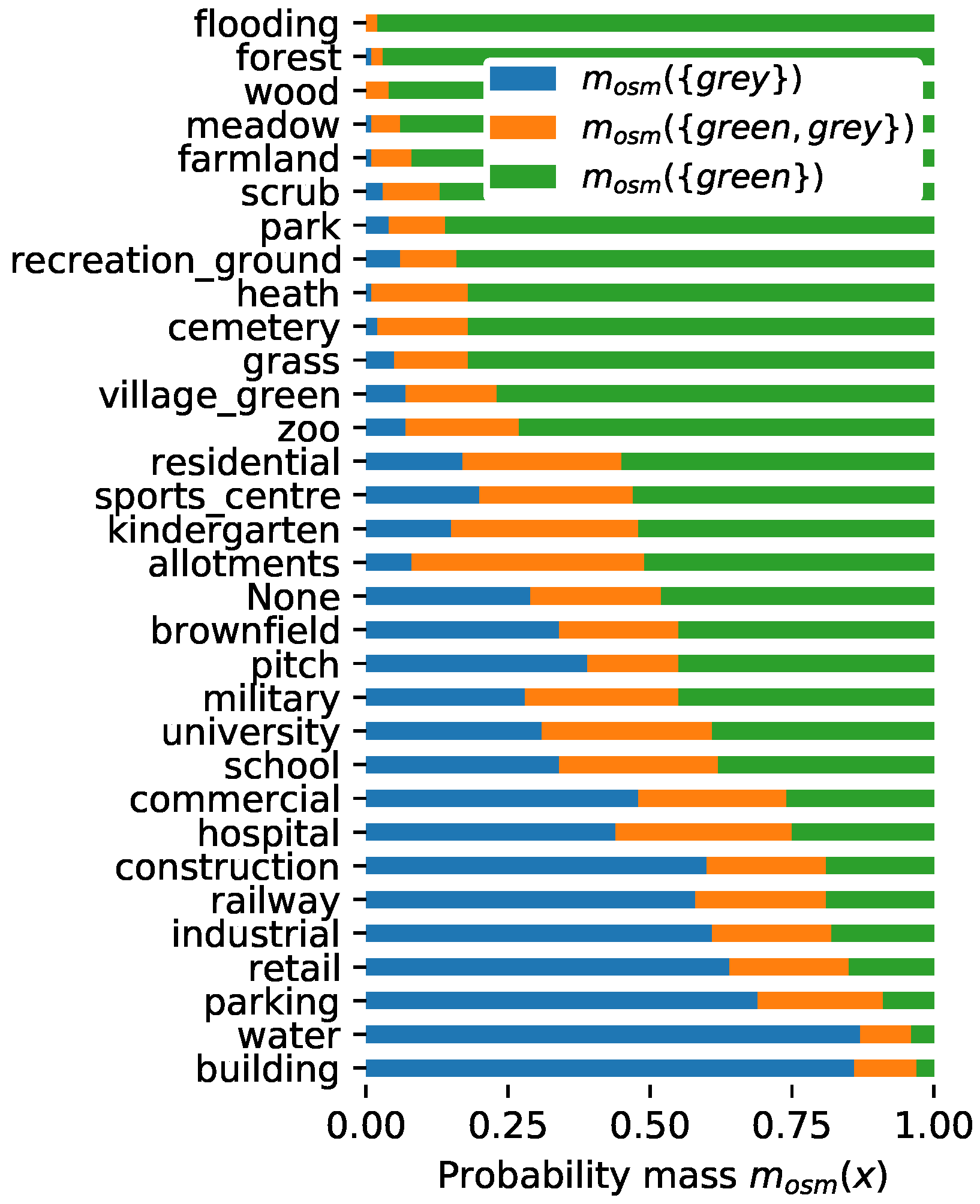
Basic Probability Assignment Based on OSM
Validation
4.3.3. Public Accessibility Model
Indicators in OSM for Predicting Public Accessibility
Model Structure
Model Training and Validation
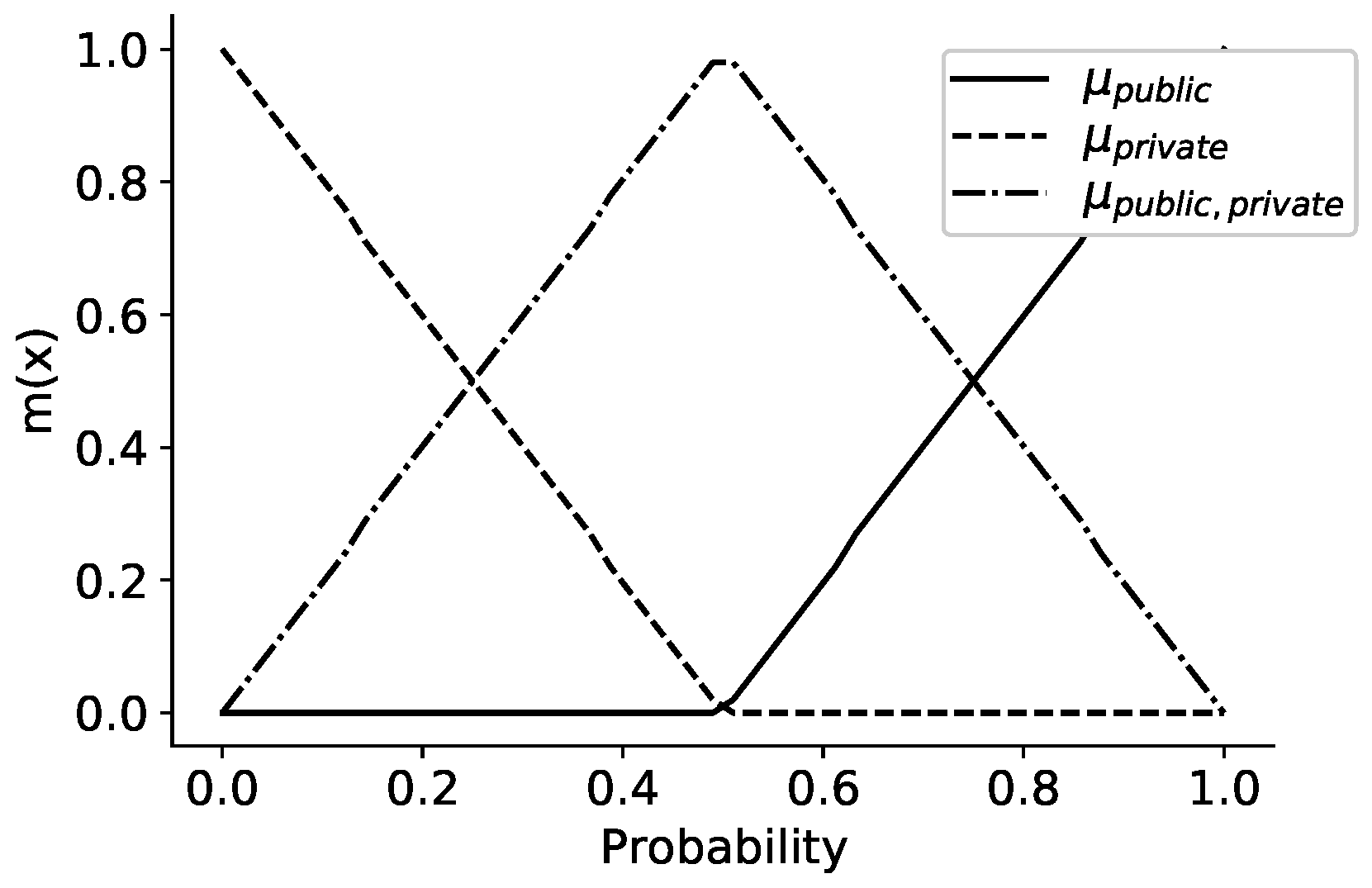
Conversion of Posterior Probabilities to Probability Masses
4.3.4. Fusion of Greenness and Public Accessibility
4.3.5. Validation
5. Results
5.1. Land Use Polygons
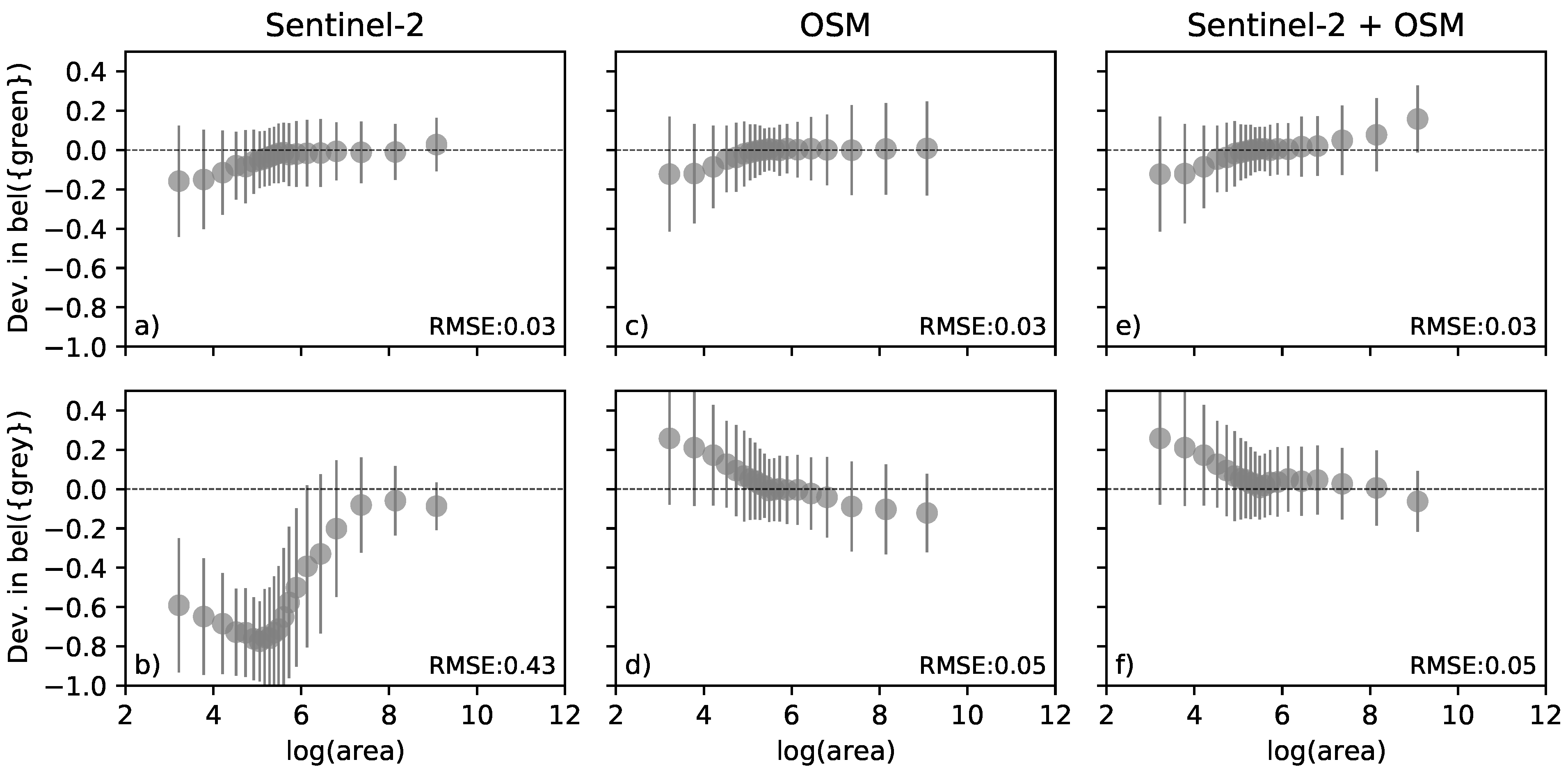
5.2. Greenness
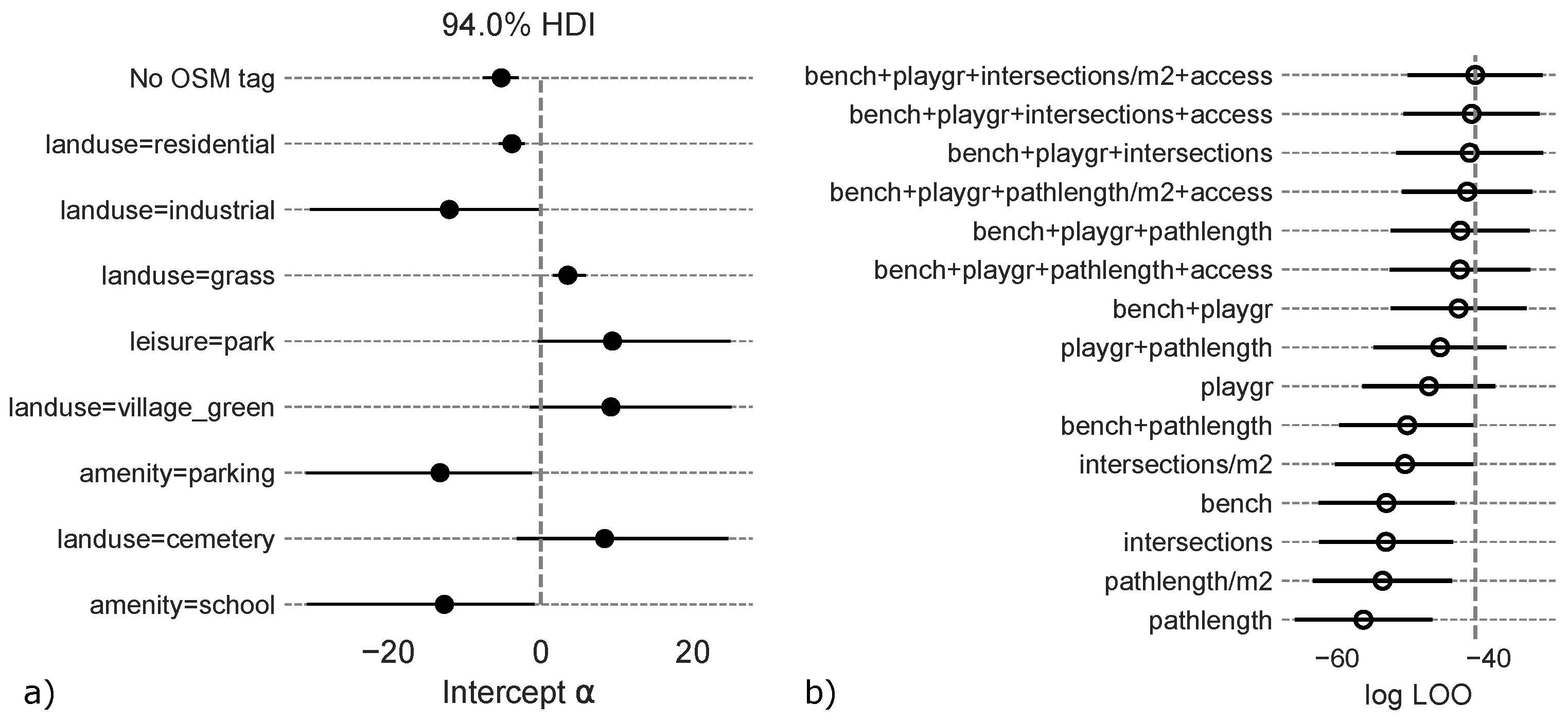
5.3. Public Accessibility
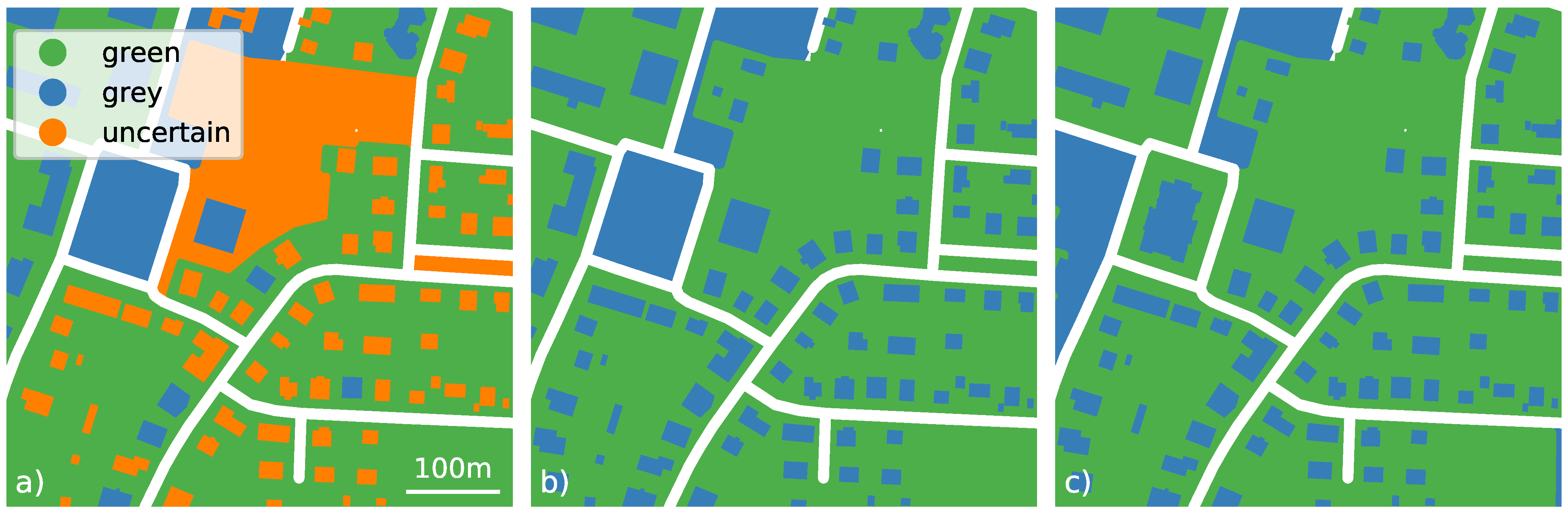
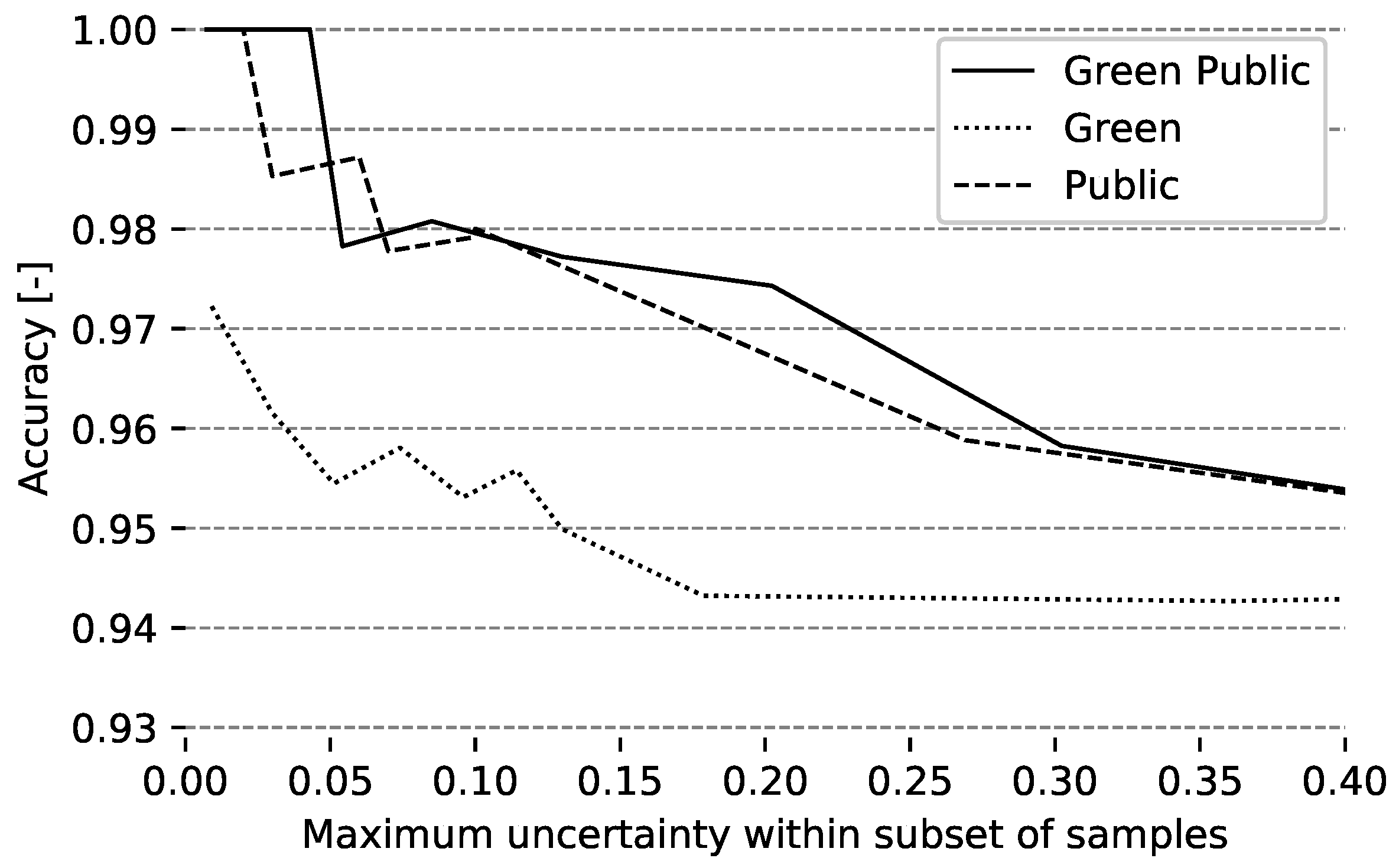
5.4. Fusion of Greenness and Public Accessibility
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LOO | Leave-one-out cross validation |
| NDVI | Normalized Difference Vegetation Index |
| OSHDB | OpenStreetMap History Database |
| OSM | OpenStreetMap |
| RSME | Root Mean Square Error |
References
- Gómez-Baggethun, E.; Gren, Å.; Barton, D.N.; Langemeyer, J.; McPhearson, T.; O’farrell, P.; Andersson, E.; Hamstead, Z.; Kremer, P. Urban ecosystem services. In Urbanization, Biodiversity and Ecosystem Services: Challenges and Opportunities; Springer: Dordrecht, The Netherlands, 2013; pp. 175–251. [Google Scholar] [CrossRef] [Green Version]
- Yu, C.; Hien, W.N. Thermal benefits of city parks. Energy Build. 2006, 38, 105–120. [Google Scholar] [CrossRef]
- Dickinson, D.C.; Hobbs, R.J. Cultural ecosystem services: Characteristics, challenges and lessons for urban green space research. Ecosyst. Serv. 2017, 25, 179–194. [Google Scholar] [CrossRef]
- Krellenberg, K.; Welz, J.; Reyes-Päcke, S. Urban green areas and their potential for social interaction–A case study of a socio-economically mixed neighbourhood in Santiago de Chile. Habitat Int. 2014, 44, 11–21. [Google Scholar] [CrossRef]
- Schetke, S.; Qureshi, S.; Lautenbach, S.; Kabisch, N. What determines the use of urban green spaces in highly urbanized areas?—Examples from two fast growing Asian cities. Urban For. Urban Green. 2016, 16, 150–159. [Google Scholar] [CrossRef]
- Tost, H.; Reichert, M.; Braun, U.; Reinhard, I.; Peters, R.; Lautenbach, S.; Hoell, A.; Schwarz, E.; Ebner-Priemer, U.; Zipf, A.; et al. Neural correlates of individual differences in affective benefit of real-life urban green space exposure. Nat. Neurosci. 2019, 22, 1389–1393. [Google Scholar] [CrossRef] [PubMed]
- Houlden, V.; Weich, S.; de Albuquerque, J.P.; Jarvis, S.; Rees, K. The relationship between greenspace and the mental wellbeing of adults: A systematic review. PLoS ONE 2018, 13, e0203000. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maas, J. Green space, urbanity, and health: How strong is the relation? J. Epidemiol. Community Health 2006, 60, 587–592. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lega, C.; Gidlow, C.; Jones, M.; Ellis, N.; Hurst, G. The relationship between surrounding greenness, stress and memory. Urban For. Urban Green. 2021, 59, 126974. [Google Scholar] [CrossRef]
- Venter, Z.; Barton, D.; Figari, H.; Nowell, M. Urban nature in a time of crisis: Recreational use of green space increases during the COVID-19 outbreak in Oslo, Norway. Environ. Res. Lett. 2020, 6, 104075. [Google Scholar] [CrossRef]
- Kabisch, N.; Strohbach, M.; Haase, D.; Kronenberg, J. Urban green space availability in European cities. Ecol. Indic. 2016, 70, 586–596. [Google Scholar] [CrossRef]
- Krellenberg, K.; Artmann, M.; Stanley, C.; Hecht, R. What to do in, and what to expect from, urban green spaces—Indicator-based approach to assess cultural ecosystem services. Urban For. Urban Green. 2021, 59, 126986. [Google Scholar] [CrossRef]
- Wüstemann, H.; Kalisch, D.; Kolbe, J. Access to urban green space and environmental inequalities in Germany. Landsc. Urban Plan. 2017, 164, 124–131. [Google Scholar] [CrossRef]
- Feltynowski, M.; Kronenberg, J.; Bergier, T.; Kabisch, N.; Łaszkiewicz, E.; Strohbach, M.W. Challenges of urban green space management in the face of using inadequate data. Urban For. Urban Green. 2018, 31, 56–66. [Google Scholar] [CrossRef]
- Le Texier, M.; Schiel, K.; Caruso, G. The provision of urban green space and its accessibility: Spatial data effects in Brussels. PLoS ONE 2018, 13, e0204684. [Google Scholar] [CrossRef]
- Bossard, M.; Feranec, J.; Otahel, J. CORINE Land Cover Technical Guide: ADDENDUM 2000; EEA: Copenhagen, Denmark, 2000. [Google Scholar]
- Seifert, F.M. Improving urban monitoring toward a European urban atlas. In Global Mapping of Human Settlement: Experiences, Datasets, and Prospects; CRC Press: Boca Raton, FL, USA, 2009; p. 231. [Google Scholar] [CrossRef]
- The Trust for Public Land: ParkServe Data Set. Available online: https://www.tpl.org/parkserve (accessed on 6 April 2021).
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- OpenStreetMap Contributors. Open Database License. Available online: https://wiki.openstreetmap.org/wiki/Open_Database_License (accessed on 6 April 2021).
- Lange, M.; Dechant, B.; Rebmann, C.; Vohland, M.; Cuntz, M.; Doktor, D. Validating MODIS and sentinel-2 NDVI products at a temperate deciduous forest site using two independent ground-based sensors. Sensors 2017, 17, 1855. [Google Scholar] [CrossRef] [Green Version]
- Kopecká, M.; Szatmári, D.; Rosina, K. Analysis of urban green spaces based on Sentinel-2A: Case studies from Slovakia. Land 2017, 6, 25. [Google Scholar] [CrossRef] [Green Version]
- Frick, A.; Tervooren, S. A framework for the long-term monitoring of urban green volume based on multi-temporal and multi-sensoral remote sensing data. J. Geovisualization Spat. Anal. 2019, 3, 6. [Google Scholar] [CrossRef]
- Stein, A.; Hamm, N.; Ye, Q. Handling uncertainties in image mining for remote sensing studies. Int. J. Remote Sens. 2009, 30, 5365–5382. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Mooney, P.; Zipf, A.; Schauss, A. Quality assessment of the contributed land use information from OpenStreetMap versus authoritative datasets. In OpenStreetMap in GIScience; Springer: Berlin/Heidelberg, Germany, 2015; pp. 37–58. [Google Scholar] [CrossRef]
- Ludwig, C.; Hecht, R.; Lautenbach, S.; Schorcht, M.; Zipf, A. Assessing the Completeness of Urban Green Spaces in OpenStreetMap. In Proceedings of the Academic Track at the State of the Map 2019, Heidelberg, Germany, 21–23 September 2019; Minghini, M., Grinberger, A.Y., Mooney, P., Juhász, L., Yeboah, G., Eds.; pp. 21–22. [Google Scholar] [CrossRef]
- Neis, P.; Zielstra, D.; Zipf, A. The street network evolution of crowdsourced maps: OpenStreetMap in Germany 2007–2011. Future Internet 2012, 4, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Hecht, R.; Kunze, C.; Hahmann, S. Measuring Completeness of Building Footprints in OpenStreetMap over Space and Time. ISPRS Int. J. Geo-Inf. 2013, 2, 1066–1091. [Google Scholar] [CrossRef]
- Der Kiureghian, A.; Ditlevsen, O. Aleatory or epistemic? Does it matter? Struct. Saf. 2009, 31, 105–112. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Schultz, M.; Voss, J.; Auer, M.; Carter, S.; Zipf, A. Open land cover from OpenStreetMap and remote sensing. Int. J. Appl. Earth Obs. Geoinf. 2017, 63, 206–213. [Google Scholar] [CrossRef]
- Luo, N.; Wan, T.; Hao, H.; Lu, Q. Fusing high-spatial-resolution remotely sensed imagery and OpenStreetMap data for land cover classification over urban areas. Remote Sens. 2019, 11, 88. [Google Scholar] [CrossRef] [Green Version]
- Wan, T.; Lu, H.; Lu, Q.; Luo, N. Classification of high-resolution remote-sensing image using openstreetmap information. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2305–2309. [Google Scholar] [CrossRef]
- Hecht, R.; Meinel, G.; Buchroithner, M.F. Estimation of urban green volume based on single-pulse LiDAR data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3832–3840. [Google Scholar] [CrossRef]
- Puissant, A.; Rougier, S.; Stumpf, A. Object-oriented mapping of urban trees using Random Forest classifiers. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 235–245. [Google Scholar] [CrossRef]
- Wegner, J.D.; Branson, S.; Hall, D.; Schindler, K.; Perona, P. Cataloging public objects using aerial and street-level images-urban trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 6014–6023. [Google Scholar] [CrossRef] [Green Version]
- Hu, T.; Yang, J.; Li, X.; Gong, P. Mapping urban land use by using landsat images and open social data. Remote Sens. 2016, 8, 151. [Google Scholar] [CrossRef]
- Chen, W.; Huang, H.; Dong, J.; Zhang, Y.; Tian, Y.; Yang, Z. Social functional mapping of urban green space using remote sensing and social sensing data. ISPRS J. Photogramm. Remote Sens. 2018, 146, 436–452. [Google Scholar] [CrossRef]
- Schöpfer, E.; Lang, S.; Blaschke, T. A green index incorporating remote sensing and citizen’s perception of green space. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2005, XXXVI, 1–6. [Google Scholar]
- Hancock, S.; Anderson, K.; Disney, M.; Gaston, K.J. Measurement of fine-spatial-resolution 3D vegetation structure with airborne waveform lidar: Calibration and validation with voxelised terrestrial lidar. Remote Sens. Environ. 2017, 188, 37–50. [Google Scholar] [CrossRef] [Green Version]
- Lahoti, S.; Lahoti, A.; Saito, O. Application of Unmanned Aerial Vehicle (UAV) for Urban Green Space Mapping in Urbanizing Indian Cities. In Unmanned Aerial Vehicle: Applications in Agriculture and Environment; Springer: Berlin, Germany, 2020; pp. 177–188. [Google Scholar] [CrossRef]
- Krüger, T.; Hecht, R.; Herbrich, J.; Behnisch, M.; Oczipka, M. Investigating the suitability of Sentinel-2 data to derive the urban vegetation structure. In Proceedings of the Remote Sensing Technologies and Applications in Urban Environments III, Berlin, Germany, 10–13 September 2018; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10793, p. 107930K. [Google Scholar] [CrossRef]
- Weigand, M.; Staab, J.; Wurm, M.; Taubenböck, H. Spatial and semantic effects of LUCAS samples on fully automated land use/land cover classification in high-resolution Sentinel-2 data. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102065. [Google Scholar] [CrossRef]
- Gašparović, M.; Dobrinić, D. Comparative assessment of machine learning methods for urban vegetation mapping using multitemporal sentinel-1 imagery. Remote Sens. 2020, 12, 1952. [Google Scholar] [CrossRef]
- Myint, S.W. Urban vegetation mapping using sub-pixel analysis and expert system rules: A critical approach. Int. J. Remote Sens. 2006, 27, 2645–2665. [Google Scholar] [CrossRef]
- Yin, W.; Yang, J. Sub-pixel vs. super-pixel-based greenspace mapping along the urban–rural gradient using high spatial resolution Gaofen-2 satellite imagery: A case study of Haidian District, Beijing, China. Int. J. Remote Sens. 2017, 38, 6386–6406. [Google Scholar] [CrossRef]
- Dennis, M.; Barlow, D.; Cavan, G.; Cook, P.A.; Gilchrist, A.; Handley, J.; James, P.; Thompson, J.; Tzoulas, K.; Wheater, C.P.; et al. Mapping urban green infrastructure: A novel landscape-based approach to incorporating land use and land cover in the mapping of human-dominated systems. Land 2018, 7, 17. [Google Scholar] [CrossRef] [Green Version]
- Baker, F.; Smith, C.L.; Cavan, G. A combined approach to classifying land surface cover of urban domestic gardens using citizen science data and high resolution image analysis. Remote Sens. 2018, 10, 537. [Google Scholar] [CrossRef] [Green Version]
- Lahoti, S.; Kefi, M.; Lahoti, A.; Saito, O. Mapping methodology of public urban green spaces using GIS: An example of Nagpur City, India. Sustainability 2019, 11, 2166. [Google Scholar] [CrossRef] [Green Version]
- Kabisch, N.; Kraemer, R. Physical activity patterns in two differently characterised urban parks under conditions of summer heat. Environ. Sci. Policy 2020, 107, 56–65. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.; Huang, H.; Wu, W.; Du, X.; Wang, H. The combined use of remote sensing and social sensing data in fine-grained urban land use mapping: A case study in Beijing, China. Remote Sens. 2017, 9, 865. [Google Scholar] [CrossRef] [Green Version]
- Arsanjani, J.J.; Zipf, A.; Mooney, P.; Helbich, M. OpenStreetMap in GIScience; Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Fonte, C.C.; Lopes, P.; See, L.; Bechtel, B. Using OpenStreetMap (OSM) to enhance the classification of local climate zones in the framework of WUDAPT. Urban Clim. 2019, 28, 100456. [Google Scholar] [CrossRef]
- Grippa, T.; Georganos, S.; Zarougui, S.; Bognounou, P.; Diboulo, E.; Forget, Y.; Lennert, M.; Vanhuysse, S.; Mboga, N.; Wolff, E. Mapping urban land use at street block level using openstreetmap, remote sensing data, and spatial metrics. ISPRS Int. J. Geo-Inf. 2018, 7, 246. [Google Scholar] [CrossRef] [Green Version]
- Ran, Y.; Li, X.; Lu, L.; Li, Z. Large-scale land cover mapping with the integration of multi-source information based on the Dempster–Shafer theory. Int. J. Geogr. Inf. Sci. 2012, 26, 169–191. [Google Scholar] [CrossRef]
- Luo, H.; Liu, C.; Wu, C.; Guo, X. Urban change detection based on Dempster–Shafer theory for multitemporal very high-resolution imagery. Remote Sens. 2018, 10, 980. [Google Scholar] [CrossRef] [Green Version]
- Comber, A.; Law, A.; Lishman, J. A comparison of Bayes’, Dempster-Shafer and Endorsement theories for managing knowledge uncertainty in the context of land cover monitoring. Comput. Environ. Urban Syst. 2004, 28, 311–327. [Google Scholar] [CrossRef]
- Liu, L.; Olteanu-Raimond, A.M.; Jolivet, L.; Bris, A.l.; See, L. A data fusion-based framework to integrate multi-source VGI in an authoritative land use database. Int. J. Digit. Earth 2020, 1–30. [Google Scholar] [CrossRef]
- Sentz, K.; Ferson, S. Combination of Evidence in Dempster-Shafer Theory; Sandia National Laboratories Albuquerque: Albuquerque, NM, USA, 2002; Volume 4015. [CrossRef] [Green Version]
- Smets, P.; Kennes, R. The transferable belief model. Artif. Intell. 1994, 66, 191–234. [Google Scholar] [CrossRef]
- Artmann, M.; Bastian, O.; Grunewald, K. Using the concepts of green infrastructure and ecosystem services to specify Leitbilder for compact and green cities—The example of the landscape plan of Dresden (Germany). Sustainability 2017, 9, 198. [Google Scholar] [CrossRef] [Green Version]
- OpenStreetMap Contributors. OSM Wiki. 2020. Available online: https://wiki.openstreetmap.org (accessed on 1 December 2020).
- German Federal Agency for Cartography and Geodesy. Digital Orthophotos and Satellite Imagery. Available online: https://gdz.bkg.bund.de/index.php/default/digitale-geodaten/digitale-orthophotos.html?___store=default (accessed on 24 February 2021).
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Salvatier, J.; Wiecki, T.V.; Fonnesbeck, C. Probabilistic programming in Python using PyMC3. PeerJ Comput. Sci. 2016, 2, e55. [Google Scholar] [CrossRef] [Green Version]
- Reineking, T. Belief Functions: Theory and Algorithms. Ph.D. Thesis, Universität Bremen, Bremen, Germany, 2014. [Google Scholar]
- Safe Software Inc. FME Software. 2020. Available online: https://www.safe.com/fme (accessed on 6 April 2021).
- Raifer, M.; Troilo, R.; Kowatsch, F.; Auer, M.; Loos, L.; Marx, S.; Przybill, K.; Fendrich, S.; Mocnik, F.B.; Zipf, A. OSHDB: A framework for spatio-temporal analysis of OpenStreetMap history data. Open Geospat. Data Softw. Stand. 2019, 4, 3. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017. [Google Scholar] [CrossRef]
- Ludwig, C.; Hecht, R.; Lautenbach, S.; Schorcht, M.; Zipf, A. Mapping of Public Urban Green Spaces Based on OpenStreetMap and Sentinel-2 Imagery Using Belief Functions: Data and Source Code; University of Heidelberg: Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Myneni, R.B.; Hall, F.G.; Sellers, P.J.; Marshak, A.L. The interpretation of spectral vegetation indexes. IEEE Trans. Geosci. Remote Sens. 1995, 33, 481–486. [Google Scholar] [CrossRef]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Ludwig, C.; Zipf, A. Exploring regional differences in the representation of urban green spaces in OpenStreetMap. In Proceedings of the “Geographical and Cultural Aspects of Geo-Information: Issues and Solutions” AGILE 2019 Workshop, Limassol, Cyprus, 17 June 2019. [Google Scholar]
- Ludwig, C.; Fendrich, S.; Zipf, A. Regional variations of context-based association rules in OpenStreetMap. Trans. GIS 2020. [Google Scholar] [CrossRef]
- Yeo, I.K.; Johnson, R.A. A new family of power transformations to improve normality or symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Lemoine, N.P. Moving beyond noninformative priors: Why and how to choose weakly informative priors in Bayesian analyses. Oikos 2019, 128, 912–928. [Google Scholar] [CrossRef] [Green Version]
- Polson, N.G.; Scott, J.G. On the half-Cauchy prior for a global scale parameter. Bayesian Anal. 2012, 7, 887–902. [Google Scholar] [CrossRef]
- Anguelov, D.; Dulong, C.; Filip, D.; Frueh, C.; Lafon, S.; Lyon, R.; Ogale, A.; Vincent, L.; Weaver, J. Google street view: Capturing the world at street level. Computer 2010, 43, 32–38. [Google Scholar] [CrossRef]
- Vehtari, A.; Gelman, A.; Gabry, J. Practical Bayesian model evaluation using leave-one-out cross-validation and WAIC. Stat. Comput. 2017, 27, 1413–1432. [Google Scholar] [CrossRef] [Green Version]
- Chinchor, N.; Sundheim, B.M. MUC-5 evaluation metrics. In Proceedings of the Fifth Message Understanding Conference (MUC-5), Baltimore, MD, USA, 25–27 August 1993. [Google Scholar] [CrossRef] [Green Version]
- Degrossi, L.C.; Porto de Albuquerque, J.; dos Santos Rocha, R.; Zipf, A. A taxonomy of quality assessment methods for volunteered and crowdsourced geographic information. Trans. GIS 2018, 22, 542–560. [Google Scholar] [CrossRef] [PubMed]
- Grunewald, K.; Richter, B.; Behnisch, M. Multi-Indicator Approach for Characterising Urban Green Space Provision at City and City-District Level in Germany. Int. J. Environ. Res. Public Health 2019, 16, 2300. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | OSM Tags | Geometry Type |
|---|---|---|
| Roads | highway=motorway, trunk, primary, secondary, tertiary, residential, unclassified, motorway_link, trunk_link, primary_link, secondary_link, tertiary_link, living_street | Polygon, Line |
| Railways | railway=* | Line |
| Waterways | waterway=* | Polygon |
| Buildings | building=* | Polygon |
| s | ||||
|---|---|---|---|---|
| Sentinel-2 | 0.71 | 0.43 | 0.15 | 0.094 |
| Aerial image | 0.42 | 0.24 | 0.06 | 0.06 |
| Feature | Unit |
|---|---|
| Land use class based on OSM | [-] |
| Presence of an access=* tag | [true/false] |
| Presence of benches | [true/false] |
| Presence of playgrounds | [true/false] |
| Total length of footpaths | [m] |
| Density of footpaths | [1/m] |
| Number of footpath intersections | [-] |
| Density of footpath intersections | [1/m] |
| Class | Precision | Recall | f1-Score | Support |
|---|---|---|---|---|
| private | 0.98 | 0.98 | 0.98 | 54 |
| public | 0.97 | 0.97 | 0.97 | 36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ludwig, C.; Hecht, R.; Lautenbach, S.; Schorcht, M.; Zipf, A. Mapping Public Urban Green Spaces Based on OpenStreetMap and Sentinel-2 Imagery Using Belief Functions. ISPRS Int. J. Geo-Inf. 2021, 10, 251. https://doi.org/10.3390/ijgi10040251
Ludwig C, Hecht R, Lautenbach S, Schorcht M, Zipf A. Mapping Public Urban Green Spaces Based on OpenStreetMap and Sentinel-2 Imagery Using Belief Functions. ISPRS International Journal of Geo-Information. 2021; 10(4):251. https://doi.org/10.3390/ijgi10040251
Chicago/Turabian StyleLudwig, Christina, Robert Hecht, Sven Lautenbach, Martin Schorcht, and Alexander Zipf. 2021. "Mapping Public Urban Green Spaces Based on OpenStreetMap and Sentinel-2 Imagery Using Belief Functions" ISPRS International Journal of Geo-Information 10, no. 4: 251. https://doi.org/10.3390/ijgi10040251
APA StyleLudwig, C., Hecht, R., Lautenbach, S., Schorcht, M., & Zipf, A. (2021). Mapping Public Urban Green Spaces Based on OpenStreetMap and Sentinel-2 Imagery Using Belief Functions. ISPRS International Journal of Geo-Information, 10(4), 251. https://doi.org/10.3390/ijgi10040251