1. Introduction
As cities develop, various types of functional regions that support residents in their daily life, and work, form gradually. The functional type of a region is determined by various factors, such as human economic activities, infrastructure, and human mobility trends [
1]. Monitoring how functional regions and land use evolve across a city is of great practical significance to urban planners, and can be achieved by efficiently and accurately extracting and identifying the functional types of regions [
2,
3]. Remote sensing images with high spatial resolution have become a widely used data source for extracting urban functional regions because they accurately reflect the physical features of the land surface, such as its shape, texture, and spectral characteristics [
4,
5,
6]. In addition to these natural attributes, however, the function of an urban region is strongly influenced by human social and economic activities, the characteristics of which cannot be adequately extracted from remote sensing images.
To overcome this limitation, urban computing studies have used various types of geospatial data with social and economic attributes, such as points of interest (POIs), social media data, smartphone signal data, and taxi trajectory data [
3,
7,
8,
9,
10,
11]. Of these geospatial data sources, the easy accessibility of POIs makes them advantageous for studying the structure and function of urban spaces [
12,
13,
14]. However, although most existing methods for extracting and identifying urban functional regions based on POIs utilize either POI statistics [
12,
14] or their relative spatial relationships [
15], these play equally important roles in defining the functional type of a given local space [
16]. For example, both the relationship between shopping malls and restaurants in local space and the co-occurrence information in global space are important when defining commercial regions.
In the process of rapid urban development, the human–land relationship (e.g., the spatial distribution of human activities, the intensity of land use) is constantly changing. In the era of big data, POIs have the beneficial characteristics of being lightweight and easy to access. Furthermore, human activities usually take place in POIs [
12]. Therefore, POIs play an important role in the effective and accurate simulation and prediction of changing trends in the human–land relationship. With the objective of extracting and identifying urban functional regions, we propose a POI information mining method that takes into account both the global co-occurrence frequency of POIs and their geographical relevance in a specific geographic window, thus integrating POI statistics with spatial semantic features to construct a Global Vectors (GloVe)-based POI type embedding model (GPTEM), in which POI type vectors can more accurately express the role of POIs in urban spaces. The main contributions of this paper are as follows:
Based on the advantages of existing topic model-based and neural network-based methods, the method outlined in this paper takes the global statistical information and the spatial context of POIs into account, and accurately captures the co-occurrence information and spatial semantic features of POI types using the POI type embedding model. The proposed method more accurately extracts large-scale and spatial feature information from POI datasets, thus improving on existing POI information mining methods.
Based on the obtained POI type embedding, this method can capture sufficient human–land interaction information for each study unit in the extraction and identification of urban functional regions. Compared with the baseline method, it therefore enables more efficient and accurate modeling of the relationship among POIs, human activities, and urban functional types. Moreover, we qualitatively and quantitatively verify the results by comparing them to manual annotations and food takeout delivery data.
With the ever-changing trends in human–land relationships, the method proposed in our study can produce rapid and effective scientific simulations and predictions of urban spatial functions by collecting related data. This presents a great opportunity for city managers to promote future urban planning and smart governance in defining future cities.
2. Related Work
In the field of urban computing, topic model-based methods can be used to mine information hidden in data with socioeconomic attributes. Conventionally, physical characteristics of land surfaces extracted from remote sensing images have been widely used to classify land use type and extract urban functional regions [
17,
18]. However, the functional types of regions in a city are strongly influenced by the interaction between humans and the surface [
19,
20]. Hence, solutions that analogize data with socioeconomic attributes, such as POIs, social media data, and taxi trajectory data, to natural language are essential for mining the latent features of urban spaces.
Yuan et al. [
14] applied the topic model and natural language processing (NLP) to analogize urban regions to documents, urban functions to topics, POI types to metadata, and human movement patterns to words; in doing so, they identified urban functional regions by combining POI and taxi trajectory data. In cities, however, highly precise dynamic mobility data are difficult to obtain. Gao et al. [
12] extracted urban functional regions by analyzing POI co-occurrence patterns after combining social media check-in data with POIs and integrating the data into the latent Dirichlet allocation (LDA) model. LDA, a topic model in the field of NLP, is typically used to distinguish words by mining the topic of the document and classifying the words into different topics [
21], and to estimate the continuous representation of words in vector space. When applied to large geospatial datasets, LDA has the disadvantages of high computational cost and low efficiency [
22]. Moreover, topic models such as LDA often ignore the linear relationship of words in vector space; that is, similar words should be closer to each other in vector space [
23]. In addition, according to Tobler’s first law of geography, closer geographical elements have stronger correlations. The contextual information of geospatial data is thus essential to a spatial semantic understanding. However, when using a topic model to extract urban functional regions, a large amount of spatial contextual information is lost [
23].
With advances in machine learning, neural network-based methods are increasingly used to explore the relationships among POIs or other data with socioeconomic attributes in geographic space. Mikolov et al. [
23,
24] proposed the word2vec algorithm composed of two architectures, namely, CBOW and Skip-gram. This algorithm considers trained model parameters as vectorized representations of the input words and embeds each word in the document as a low-dimensional dense vector. Neural network-based approaches, such as word2vec, overcome the problem of a loss of spatial contextual information, which is encountered when using topic models.
Recently, urban computing researchers have used word2vec to extract the semantic features of data with socioeconomic attributes and to examine the urban spatial distribution pattern. For example, Yan et al. [
25] proposed a method to capture the semantic information of place types by measuring similarities and relations between them. They achieved this by enhancing the spatial context to learn the word embedding of the place types. Using a word embedding model, Liu et al. [
26] used POI data to examine the niche pattern of locations in a city, with the set of locations co-occurring with a central location defined as the niche of the central location, and quantitatively analyzed regional variability. Trajectory data [
27], Twitter data [
28] and user review data on travel websites [
29] have also been combined with word embedding models to extract urban spatial features.
The aforementioned works have focused on examining the spatial features of cities at a micro level. However, as urban functional regions are the result of the interaction between humans and the land surface and the spatial accumulation of social and economic features in cities [
3,
30], the features of a single place type cannot completely describe the functional types of an urban region. Yao et al. [
15] modeled the relationship between spatial distributions of POIs and land use types based on word2vec. Following the work of Yan et al. [
25], Zhai et al. [
31] identified functional types in various regions of a city by combining place2vec with POI data and clustering the POI feature vectors at the neighborhood area (NA) scale. Aside from neighborhood area, traffic analysis zones (TAZs) generated from OpenStreetMap road network data provide an alternative scale for applying POIs to the field of urban studies [
32,
33]. TAZs are also used to divide the urban space in this study. Different from the work of Wang et al. [
33], which regard POIs as the basis for analyzing land use intensity, we extract and identify urban functional regions based on the information mined from POI. In addition, place2vec, proposed by Yan et al. [
25], as an improvement on word2vec, performs well in word analogy tasks and better retains the contextual information of geospatial data. However, word2vec and its improved methods (e.g., place2vec) ignore the statistical information, such as global co-occurrence frequency, in geospatial data, which is not ideal for urban computing applications [
16]. Co-occurrence patterns are crucial pieces of spatial feature information in urban regions. For example, if shopping malls and restaurants appear more frequently in a region, then it is likely to be annotated as a commercial region.
To solve the this drawback of word2vec, Pennington et al. [
16] proposed a word embedding model named Global Vectors (GloVe) that integrates the global statistical information on the basis of the local context window-based method, thus combining the advantages of both topic models and neural network-based models. Jeawak et al. [
34] combined Flickr (a photo sharing website) tag data and traditional structured data (e.g., temperature, land use) to embed geographical locations into vectors, verifying that GloVe is more effective than are traditional bag-of-words models in ecology-related tasks (e.g., predicting species distribution, soil types, and land cover). To the best of our knowledge, the feasibility of applying the GloVe model to urban computing remains to be proven. In this work, we use the architecture of the GloVe model to train POI type vectors.
3. Methodology
The method proposed in this study consists of the following sections: Construction of the urban functional corpus, Embedding the POI type in vector space, Identifying the urban functional type, and Evaluating the accuracy of the urban functional label.
3.1. Construction of the Urban Functional Corpus
In NLP, a corpus is a large number of processed text collections in a predetermined format [
35], typically containing documents that can be used to simulate natural language on a large scale. Specifically, the contextual relationship between words in each document can be used to simulate the contextual relationship of words in real-world human languages. The distribution of POIs in cities is similar to the distribution of word frequencies in natural language corpora, both of which follow the power law distribution [
25]. Therefore, the semantic relationship of POIs in urban space can be obtained using a word embedding model. Inspired by this concept, in this work, we analogize the study area to a corpus in natural language and call it the urban functional corpus. We then analogize the collection of POIs in the buffers centered on each POI to documents in natural language.
First, we allow the word embedding model to learn the contextual relationship between adjacent POI types within a certain range. In addition, we make the POI types that are closer to each other co-occur more frequently; this allows us to account for the proximity of geographic space in the model, enabling it to distinguish the relationships between POI types with different spatial distance. Each document contains an indefinite number of POIs to be analogized to words in natural language. We use the POI dataset on Gaode Map as the research object. To capture semantic information in richer detail when training POI type vectors, we include third-level POI types in the dataset in addition to both first- and second-level POI types.
Table 1 shows examples of urban functional corpus. We can find that the POI types in the collection have similar effects on shaping the urban function types, and POIs of similar types (e.g.,
government agencies and
township-level governments and institutions) co-occur frequently.
To reflect the distribution features of POIs in geographic space and preserve the positional relationship between adjacent POIs, we need to make the geographically adjacent POIs relatively close to each other when constructing the documents. However, POIs are distributed nonuniformly in urban space. In other words, the number of words in each document is uncertain, and the distribution of POIs is relatively dense in some regions. If documents are constructed based on the principle of global optimization, the time cost is extremely high, rendering the method unfeasible. Therefore, we refer to the shortest-path method proposed by Yao et al. [
15] when constructing documents. We build buffer-based documents based on the greedy algorithm, which integrates a series of POIs in the buffer into documents that have actual geographic spatial meanings and can reflect the positional relationships between POIs to some extent. The algorithm flow is as follows:
- (1)
We assume that the set of
n POIs in a buffer is
. First, we calculate the distance between all POI pairs in the buffer. We then take the farthest POI pair as the end points of the path, namely
and
(e.g.,
frontage courtyard and
township-level governments and institutions in the first item of
Table 1). We record the path length as
(e.g., in the first item of
Table 1,
is the spatial distance between
frontage courtyard and
township-level governments and institutions in the current step). The remaining POIs in the buffer are included in the set of wait-to-insert. At this time, the set composed of the starting and ending points of the current path is
and the wait-to-insert set is
.
- (2)
In this step, all POIs to be inserted are traversed. For each POI
in
, we calculate the distance
of the path after
is inserted into any segment in
(e.g., in the first item of
Table 1, in the first traversal, there is only one segment between
frontage courtyard and
township-level governments and institutions; in the next traversal, when
government agencies is inserted into
, there are two segments between
frontage courtyard and
government agencies,
government agencies and
township-level governments and institutions). This traversal is to ensure that POI
(where
can be any POI in wait-to-insert set
) is inserted into the proper position. Here, the “proper position” means that if
is inserted into the position between
and
in the path, the total length
(i.e., the sum of spatial distances between the POI pairs calculated in the order in
: in the first item of
Table 1, in the first traversal, the total length
is the sum of spatial distances between
frontage courtyard and
, and between
and
township-level governments and institutions) of the set
after insertion is the shortest among all possible options.
- (3)
The previous step is repeated until the wait-to-insert set is empty. The resulting shortest-path sequence is the buffer-based document.
3.2. Embedding the POI Type in Vector Space
In NLP, word embedding—first proposed by Bengio et al. [
36]—is a language feature extraction technology that transforms words into numerical representations in a high-dimensional vector space [
37]. The biggest advantage of word embedding models is that they do not require manually labelled data; instead, these models can quickly train unlabeled data using unsupervised methods at a low computing cost [
23,
24,
38]. In contrast to word2vec and other word embedding models trained on local context windows, GloVe trains word embedding on the basis of the number of global word co-occurrences, making it possible to directly capture global statistical information in the corpus and to represent the semantics of words as vectors [
16]. In addition, GloVe optimally uses the available computing resources, making it easy to train large datasets quickly to efficiently obtain the semantic features of urban spaces. As described earlier, we analogize the urban space in our study area to a corpus in natural language, called an urban functional corpus, which contains a large number of POIs. The co-occurrence pattern of various types of POIs is of great significance to understanding the semantics in urban spaces. For example,
Table 2 shows some statistical indexes of POI collections in the urban functional corpus. It is noted that the length of “sentences” (i.e., POI collections) in urban functional corpus differs greatly. For the long sentence (e.g., the POI collection with maximum length), GloVe can capture the global co-occurrence information for the whole sentence. Inspired by GloVe, this paper presents a GloVe-based POI type embedding model (GPTEM).
Assuming that the co-occurrence matrix of POIs is and that the element in represents the number of occurrences of POI type in the context of POI type , represents the number of occurrences of any POI type in the context of POI type , and represents the probability that POI type appears in the context of POI type . When training POI type vectors based on urban functional corpora, the ratio of the co-occurrence probabilities of the POI types is more useful for identifying highly spatially related POI types than the co-occurrence probability itself. As examples, we take the following third-level POI types on Gaode Map: College and University, Research Institution, Government and Institution below the Township Level, Other Agriculture, Forestry, Animal Husbandry and Fishing Base, Logistics Express, and Securities Company. We assume that College and University, Government and Institution below the Township Level, and is the other types of POI to be compared. In cities, Research Institution is usually spatially related to College and University, whereas its correlation with Government and Institution below the Township Level in urban space is relatively weak. In other words, when Research Institution, we expect to be much larger than and therefore to be very large; conversely, when Other Agriculture, Forestry, Animal Husbandry and Fishing Base, we expect this ratio is very small. In addition, for Logistics Express types that are spatially related or for the Securities Company unrelated to College and University and Government and Institution below the Township Level, for which the values of and are very close, the co-occurrence probability ratios are close to 1. Therefore, compared with the co-occurrence probability itself, the ratio of the co-occurrence probabilities is more helpful in distinguishing different types of POIs, and thus in more accurately obtaining the spatial semantic features of POIs in cities.
Moreover, the co-occurrence pattern of POIs in our study is symmetrical—that is, the roles of the POI type
and its contextual POI type
in the training process are interchangeable. In addition, considering that the vector space is linear and the final loss function should be as simple as possible, the generalized form of the model is as follows:
In Equation (1),
and
refer to the vectors of POI type
and
, respectively,
represents the vector of POI type
in the context; and
represents a function of
,
, and
. Setting
, to keep our model symmetrical, we introduce a deviation term
and obtain the following formula:
Clearly, the co-occurrence matrix we obtain is sparse. To limit the value of our loss function when
and to ensure that POI types overly small or large co-occurrence frequencies are not overrepresented [
16], we define the loss function of the model as follows:
In Equation (3),
refers to the total number of POI types in the urban functional corpus, and the weight function
is defined as follows [
16]:
The number of dimensions of the embedding vectors is an important parameter of the GPTEM. Considering that the total number of POIs in the dataset is not as rich as natural language vocabulary, we set the dimensions of the POI type vectors to 70, which has been proven to be effective in related studies [
25,
31].
To visually analyze the spatial distribution features of the 70-dimensional POI type vectors, we apply the data dimensionality reduction technique for mining information from high-dimensional data [
39,
40]. The dimensionality reduction method used in this study is t-distributed stochastic neighbor embedding (t-SNE), which is a widely used unsupervised machine learning algorithm for dimensionality reduction [
41]. Compared with other dimensionality reduction methods (e.g., principal component analysis), t-SNE better maintains the local structure, meaning that it can better map POI type vectors that are closer in high-dimensional vector space into the adjacent low-dimensional vector space [
42].
3.3. Identifying the Urban Functional Type
We obtain all POI type vectors using the GloVe-based POI type embedding model. In related studies, the features of documents have usually been described by calculating the weighted average of words in the documents. In this study, the urban space study area is divided into a series of TAZs based on its administrative area boundaries and the first three levels of the road network. The functional features of a TAZ are then represented by the weighted average of all POI type vectors it contains, as follows:
where
represents the feature vector of the
i-th TAZ,
refers to the vector of POI type
in the
i-th TAZ, and
represents the total number of POIs in the
i-th TAZ.
The TAZ feature vectors calculated using the above formula are very high-dimensional. K-means is an algorithm widely used in high-dimensional data clustering and has the advantages of fast convergence and strong interpretability. However, in the original K-means algorithm, the initial clustering center needs to be determined manually, and different clustering centers may yield completely different clustering results. To solve this problem, this paper selects K-means++, an improved clustering algorithm, to extract the urban functional clusters based on TAZs. The basic principle of the K-means++ algorithm is to select the initial clustering center such that the distance between clusters is as far as possible and the final clustering result is as close as possible to the global optimal solution [
43].
In the K-means++ algorithm, the choice of the number of clusters (K) strongly affects the quality of the clustering. Recent studies have used the silhouette coefficient to evaluate the clustering results [
12,
15]. This coefficient evaluates whether a data point is accurately classified by measuring its similarity to the category to which it belongs. To make the clustering results more objective and accurate than the methods of selecting the number of clusters based on experience or expertise, we evaluate the accuracy of the clustering by calculating the average silhouette coefficient for all data samples.
After obtaining the clustering results, actual spatial meanings must be assigned to each cluster to identify the urban functional regions; that is, the clusters must be annotated with urban function labels. Previous studies have typically annotated urban functions based on indicators related to the occurrence frequency (or density) of POI types (e.g., composition ratio, density) [
15]. However, in urban spaces, some types of POIs may appear frequently, meaning that this frequency- or density-based approach may produce large errors. To avoid this problem, we evaluate the urban functions of the clustering regions by calculating the enrichment factors (EF) of the POI types in each clustering region, as follows:
where
refers to the EF of POI type
in the
i-th cluster region,
represents the number of POI type
in the
i-th cluster region,
represents the total number of POIs in the
i-th cluster region,
represents the total number of POI type
in the city, and
represents the total number of POIs in the city.
3.4. Evaluating the Accuracy of the Urban Functional Label
To quantitatively verify the accuracy of our identification of urban functional regions, we need data with urban functional labels for each TAZ; that is, the accuracy of unsupervised clustering needs to be evaluated through a supervised task. Accordingly, to label the data as accurately as possible, with the urban land use plan issued by the government, 10 volunteers graduate students and experts with background knowledge of urban planning were invited to annotate the urban functional types in each TAZ according to the list of urban functional types identified by the proposed method.
Assigning some TAZs to a single urban functional type may be difficult, as different volunteers could judge the urban functional type of the same TAZ differently. Therefore, the volunteers were asked to annotate the urban functional types in each TAZ as two different urban functions, thus eliminating subjective interpretations as much as possible. Assuming that the first and second annotation by the
i-th volunteer for the
j-th TAZ are
and
, respectively, we calculate the manual labeling output of the urban functional type in the
j-th TAZ as follows:
In Equation (7),
represents the final result of the manually annotated urban functional type,
represents the weighted mode of the urban functional type, and
. Considering that Zhai et al. [
31] demonstrated that the first manual annotation of an urban functional type is much more important than the second, we set
and
.
To qualitatively evaluate our identification of urban functional regions, we use food takeout origin–destination (OD) data for the main urban area of our study area. Here, “takeout” refers to services that deliver food from restaurants to areas such as residential buildings, schools, and workplaces. The reason why we use food takeout OD data is that food takeout OD data can be a kind of supplementary data to verify the identification results from the side. Specifically, because takeout OD data show the start (origin) and end (destination) points of takeout deliveries ordered by residents, they can reflect the distribution of different urban functional types of regions in a city to some extent. These data can then be used to evaluate the accuracy of identification of residential regions, public service regions, daily life service regions, and other similar urban functional region types. In this study, the spatial distribution of the origins and destinations of takeout food are expressed through kernel density estimation, a nonparametric method used to estimate the probability density function. This is an effective means to estimate the density distribution of any discrete points and does not depend on the scale of the space division [
44]. Thus, the kernel density estimation of takeout OD data can reveal the regions where takeout orders are concentrated to a certain extent, which is helpful when evaluating the results of identification of urban functional regions.
3.5. Overall Architecture
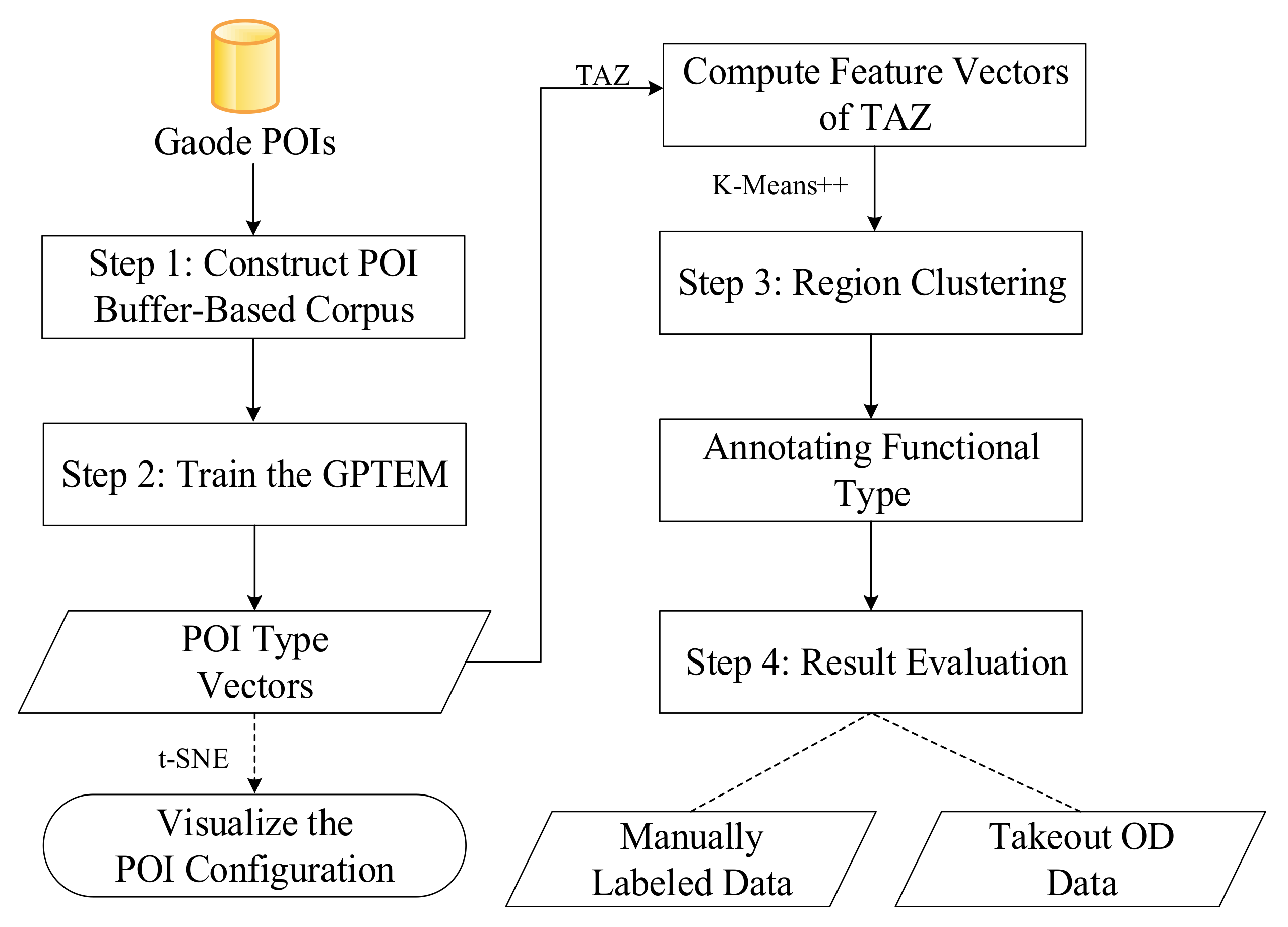
Figure 1 depicts the overall flowchart of the proposed method in the study, in which we perform the following four-stage extraction and identification method:
- (1)
We construct an urban functional corpus based on the greedy algorithm using POI data and the buffer centered on each POI.
- (2)
Based on the urban functional corpus, we obtain POI type vectors using the GPTEM and visualize the configuration pattern of the POI type vectors.
- (3)
We cluster the TAZ feature vectors calculated using the POI type vectors and calculate the enrichment factor of each POI type in the clustered regions to extract the urban functional type of each region in the study area.
- (4)
Finally, we quantitatively and qualitatively evaluate the identification results by comparing them to the urban functional labels of each TAZ annotated by volunteers and the takeout OD data.
4. Study Area and Dataset
The study area is the main urban area of Hangzhou in Zhejiang province, southeastern China. Hangzhou is the political, economic, and cultural center of Zhejiang, and the central city in the southern part of the Yangtze River Delta. With the rapid development of the city over recent years, the urban functions of the main urban area have become highly heterogeneous and mixed. Considering the distribution of public activities, we take the eight major districts of Hangzhou, namely West Lake, Gongshu, Jianggan, Xiacheng, Shangcheng, Binjiang, Xiaoshan, and Yuhang, as our study area.
In this study, the POI dataset is obtained through the API (
https://restapi.amap.com/ (accessed on 1 June 2020)) of the Gaode Map Service in 1 June 2020, one of the most widely used map service providers in China. An example request example submitted to this service is
https://restapi.amap.com/v3/place/text?key=myKey&extensions=all&keywords=&types=010100&city=myCity&citylimit=true&offset=25&page=1&output=json (accessed on 1 June 2020) (where “myKey” and “myCity” are replaced according to actual needs. We accessed the service in 1 June 2020). This dataset contains more than 300,000 POI records with multiple category levels.
Figure 2 shows a data sample of Gaode POIs. From the first-level POI types, we remove
Address Information (which has negligible influence on urban function) and
Vehicle (there are few POIs under
Vehicle, and this does not affect evaluation of the accuracy of identification of urban functional regions). We include third-level POI types in the dataset because they reflect the nuances of urban functions more than the first and second-level POI types. For example,
Internet Technology and
Metallurgy & Chemical Industry are third-level POI types under the second-level POI type
Company, which in turn is under the first-level POI type
Company & Enterprise. The constructed POI dataset has 17 first-level POI types—
Catering Service,
Road Ancillary Facilities,
Famous Tourist Sites,
Public Utilities,
Company & Enterprise,
Shopping Service,
Transportation Facilities Service,
Financial Insurance Service,
Science Education and Cultural Services,
Business Residence,
Life Service,
Event & Activity,
Sports and Leisure Service,
Access Facilities,
Healthcare Service,
Government Agency & Social Group, and
Accommodation Service—115 second-level POI types, and more than 400 third-level POI types.
Furthermore, by merging the administrative area boundary data with data on the first three levels of the road network, the study area is divided into 997 TAZs. To improve the validity and reliability of the results, small patches of area less than 500,000 square meters and TAZs without any POIs are merged into their neighboring TAZs.
5. Experiments and Results
5.1. Training and Visualizing POI Type Vectors
In our study area, 357,990 POIs are distributed across 997 TAZs. To avoid confusion between the POI types, we establish an index table giving each POI type a corresponding unique index value to replace the role of the POI type in the remainder of the analysis.
Table 3 presents examples of this index table.
To construct the urban functional corpus, the buffer zone radius is set to 50 m. Before training the POI type vectors using the proposed model, we set the number of POI type vector dimensions to 70, window size to 10, and epoch to 10. Thus, 476 third-level POI types are converted into POI type vectors that indicate the spatial context relationship.
Table 4 presents examples of POI type vectors.
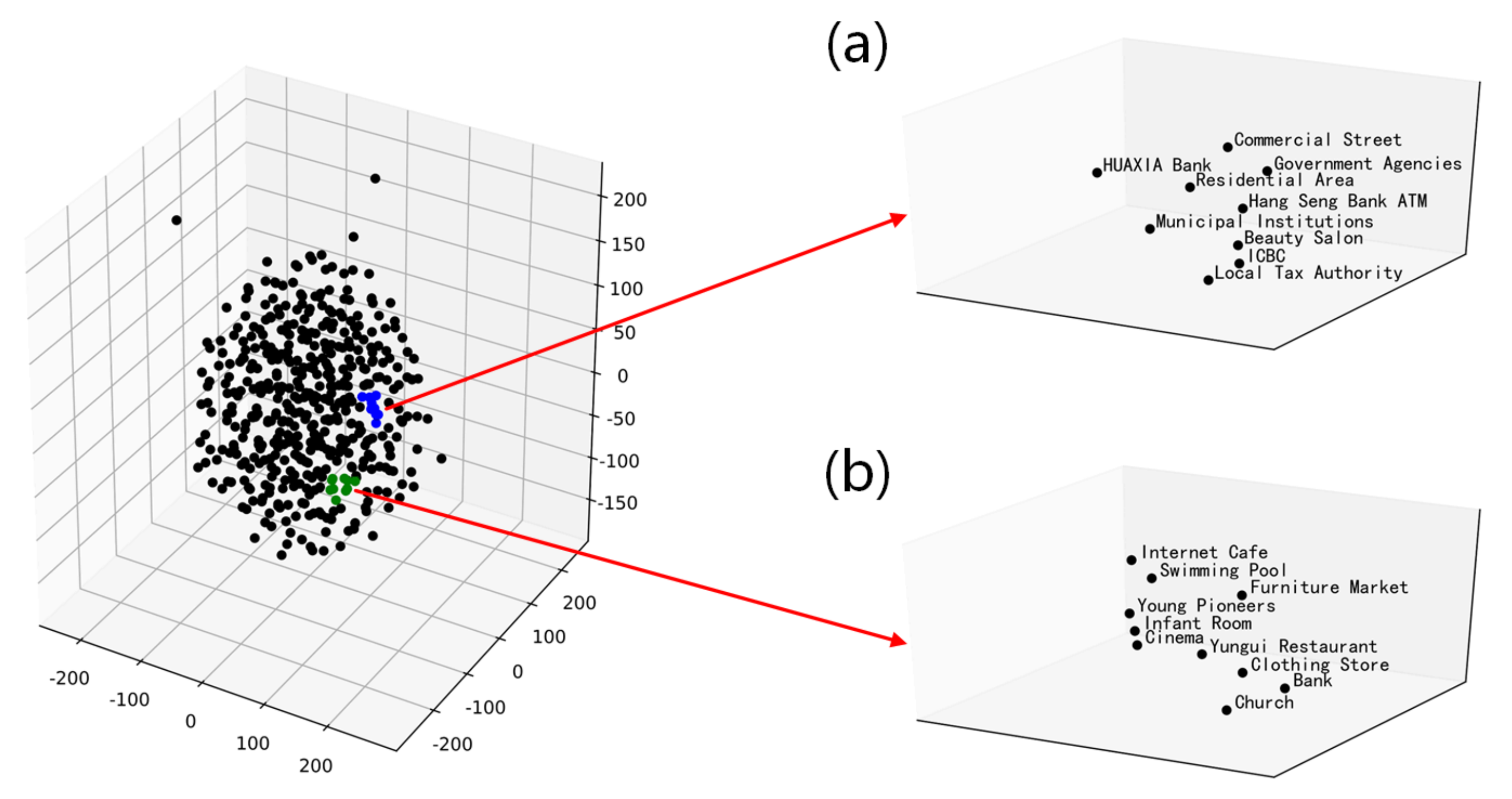
Through the dimensionality reduction method of t-SNE, all POI type vectors are mapped into three-dimensional semantic space, as shown in
Figure 3. In the semantic space after dimensionality reduction, POI types with similar or related spatial semantics tend to be close to each other. For example, the subplot (a) of
Figure 3 includes several types of financial POIs (e.g., HUAXIA Bank, ICBC, and Hang Seng Bank ATM), all of which play a similar role in urban space; hence, these POIs are relatively close to each other in the semantic space. Of note is that some of the closer POIs in the subplot (b) of
Figure 3 belong to different first-level POI types. For example, Cinema belongs to Sports and Leisure Service, Infant Room belongs to Public Utilities, and Yungui Restaurant belongs to Catering Service. However, they usually appear together as they all meet people’s daily leisure and entertainment needs. These accurate and nuanced results demonstrate the rationality of choosing third-level POI types in addition to first- and second-level types to construct the urban functional corpus.
5.2. Clustering the Urban Regions
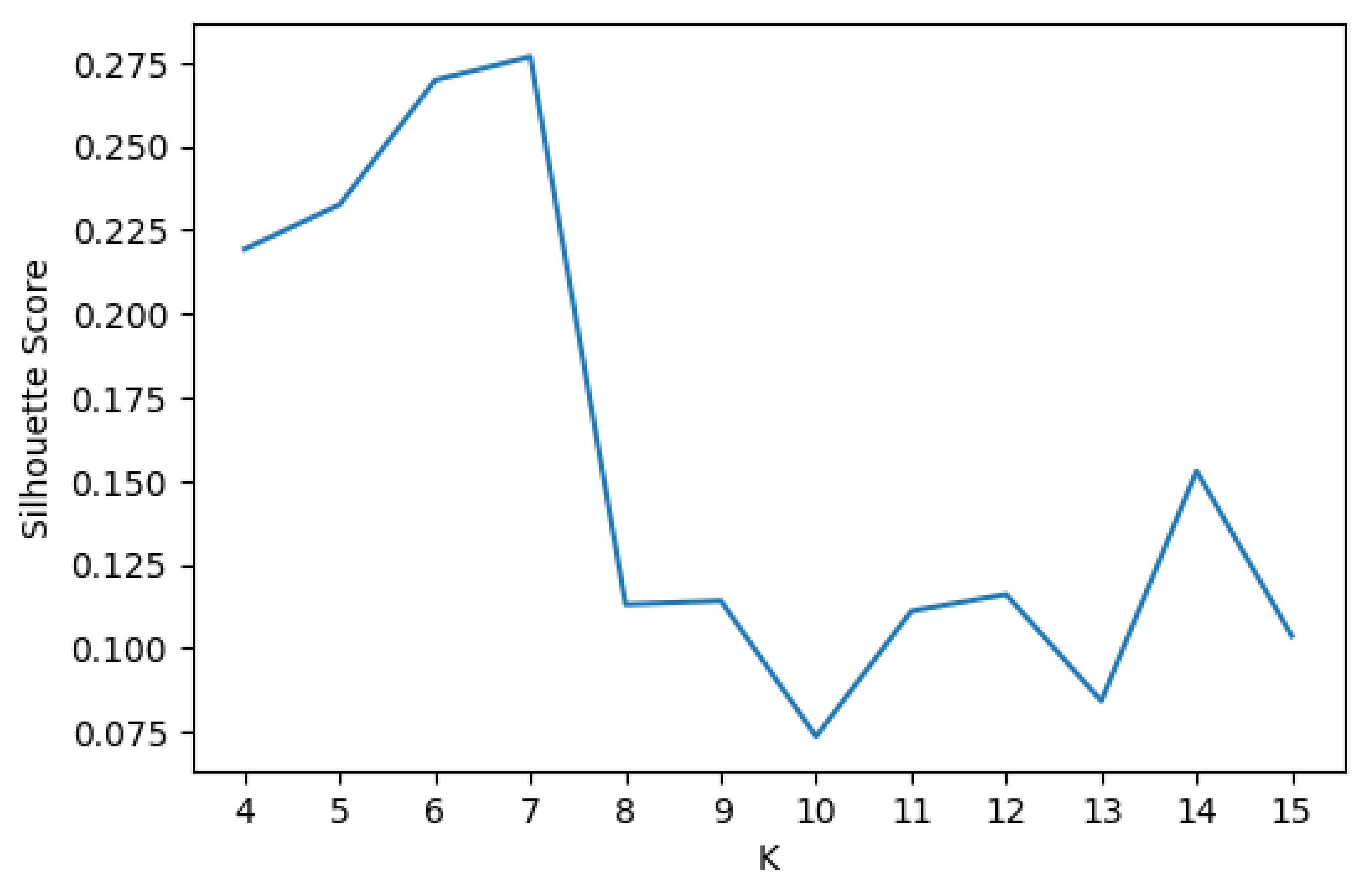
The feature vectors of TAZs are obtained by calculating the weighted average of the POI type vectors in any given TAZ. While clustering TAZ feature vectors using K-Means++, we experimentally determine the optimal K value (i.e., the number of clusters, which is the most influential parameter) by varying K from 4 to 15; the resulting TAZ feature vectors are clustered using K-Means++ and the corresponding silhouette coefficients calculated.
Figure 4 shows that the silhouette score is highest when K = 7. Therefore, we set K = 7, with the resulting clustering shown in
Figure 5.
5.3. Annotating the Urban Functional Type
To identify the urban functions of each cluster, from among the 476 three-level POI types, we list the top 20 POI types by EF in each cluster in
Table 5:
Cluster 1: Agriculture, Forestry, Animal Husbandry, Fishing, and Industrial Regions. The EFs of the POI types of agriculture, forestry, animal husbandry, and fishery (e.g., Pasture = 188.27, Farm = 51.35, Fishing Park = 15.37) and industry (e.g., Factory = 14.01, Industrial Park = 10.62) are relatively high (see
Table 5). In addition, the TAZs covered in this cluster area are mainly distributed away from downtown, indicating that the urban functions of this clustering area are mainly agriculture, forestry, animal husbandry, fishing, and industry.
Cluster 2: Commercial Regions. We define this cluster as commercial because it is concentrated in the most central and prosperous areas of the city. More importantly, POIs with high EFs in this clustering area are mainly commercial banks (e.g., Citibank = 4.18) and insurance firms (e.g., Xinhua Life Insurance Company = 4.18).
Cluster 3: Scenic, Daily Life Service, and Residential Regions. The TAZs of this cluster area are mainly distributed in the scenic areas of the West Lake (the most famous tourist attraction in the study area) and its surroundings. This cluster is annotated as a mixed urban functional area with scenic, daily life service, and residential features because the area shows a mixed POI distribution pattern, covering scenic spots (e.g., National Attraction) and POIs closely related to people’s everyday lives (e.g., Tea House, or Service Center).
Cluster 4: Public Service, Agriculture, Forestry, Animal Husbandry, and Fishing Regions. Similar to Cluster 1, most of the TAZs in this cluster area are located on the outskirts of the city. Unlike Cluster 1, however, this cluster area covers one of the most important transportation hubs in the study area—the Hangzhou Xiaoshan International Airport—and related infrastructure providing public services. Some of the POI types with high EF rankings are similar to those in Cluster 1 (e.g., Fruit Base). However, several types of infrastructural POIs related to airports, transportation, and other public services (e.g., Waiting Room) are evident in the EF ranking table (see
Table 5).
Cluster 5: Daily Life Service and Public Service Regions. The TAZs in this clustering area are mainly distributed in the areas surrounding the city center and contain colleges (e.g., Yuquan Campus, Zhejiang University, Zhejiang Provincial Institute of Socialism), railway stations (e.g., Hangzhou North Railway Station), and places of daily life and leisure (e.g., Qingzhiwu). In this clustering area, the EFs for POIs of daily life service (e.g., Walmart) and public service (e.g., Vehicle Pass Office = 3.27) are relatively high.
Cluster 6: Commercial and Daily Life Service Regions. Similar to Cluster 2, most of the TAZs in this cluster area are located in the city center. However, in addition to covering business and office premises (e.g., law firms, and banks), this cluster also contains facilities for dining, leisure, and other life services (e.g., Hangzhou World Trade Plaza), as reflected in
Table 5. Specifically, the EFs of commercial categories (e.g., Audit Firm, and NCB) and POIs related to people’s daily life (e.g., Carrefour, Fujian Restaurant, and Watsons) are relatively high.
Cluster 7: Residential and Daily Life Service Regions. This cluster area contains only two TAZs, mainly covering residential regions and daily life service facilities (e.g., Zijingang Community).
Table 5 verifies the presence of such urban functional types in this area, as residential POIs and those related to people’s daily lives, such as Furniture Mall, Flower Market, GOME, and Korean Restaurant, have relatively high EFs.
5.4. Evaluating Identification Accuracy
To verify the reliability of the results, we invited volunteers with background knowledge of urban planning to manually annotate each TAZ with its urban functional types on the basis of urban land use planning data (see
Figure 6c). As described in
Section 3.5, we take the mode of their labels as the final urban functional labels.
For this evaluation, word2vec is used as the baseline method. To eliminate the interference of other factors (e.g., the effects of different POI type vector dimensions on training speed) in the result to the greatest extent possible, when training POI type vectors using word2vec, the hyperparameter values are kept consistent with those set in
Section 5.1.
Figure 6a,b present the extraction and identification results obtained using GPTEM and word2vec, respectively. According to the calculation results of the enrichment factor in
Table 5, each cluster area may contain more than one urban functional type, consistent with a real-world city containing highly heterogeneous and mixed function types. However, as described in
Section 3.4, the volunteers manually labelled each TAZ with a single urban functional type, leading to inconsistent legends in
Figure 6a–c. For a cluster region that contains more than one urban functional type, we assume that the composition ratio of each urban functional type is the same when calculating the confusion matrix.
Table 6 and
Table 7 illustrates the confusion matrixes of the identification results based on word2vec and GPTEM. To demonstrate the advantages of our GloVe-based method over word2vec, we compare the two models in terms of model training time and overall accuracy (
Table 8). The training time with GPTEM is more than seven times shorter than with word2vec. In terms of overall accuracy, GloVe accounts for the relative co-occurrence patterns between POIs in the urban space, and its trained POI type vectors capture urban spatial semantic information more accurately, resulting in the higher overall accuracy of GPTEM. Clearly, the GloVe-based method outperforms the word2vec-based method.
Furthermore, using more than 3,400,000 takeout OD data points provided by Dianwoda Company and covering a one-month period (August 2017), we qualitatively evaluate the extraction and identification results.
Figure 7 presents the results of kernel density estimation on the origin and destination of the takeout deliveries.
Comparing the results of the kernel density estimation in
Figure 7b,c with the results of urban functional region identification in
Figure 7a, the start points of takeouts (
Figure 7b) are mainly concentrated in the commercial regions (e.g., area a. in
Figure 7b) and daily life service regions (e.g., area b, c, and d in the subplot (b) of
Figure 7). These two region types include most of the restaurants that provide takeout service. The end points of takeout deliveries are mainly concentrated in residential regions (e.g., area a. in the subplot (c) of
Figure 7), commercial regions (e.g., area b in the subplot (c) of
Figure 7), and public service regions (e.g., area c in the subplot (c) of
Figure 7). Because the takeout data used in this study cover a long period of time (i.e., one month), places in commercial regions (e.g., companies, and banks) and public service regions (e.g., government organizations, hospitals, and schools) may be common destinations for takeout deliveries during working hours, whereas apartments in residential regions would be more common destinations at other times. Thus, the kernel density estimation in
Figure 7 demonstrates the soundness of our identified urban functional regions.
5.5. Discussion
In this section, we first discuss the construction of the urban functional corpus. Unlike the construction of the corpus based on the TAZ in the research of Yao et al. [
15] and the construction based on tuples consisting of the central POIs and its K-nearest POIs in the research of Zhai et al. [
31], we aim to make the urban functional corpus more continuous and closer in structure to the corpus composed of natural language while taking into account geographical proximity. Therefore, we construct the urban functional corpus in units of buffers centered on each POI. As mentioned in
Section 3.2, the buffer-based method enhances the spatial context relationship. Furthermore, as the Gaode POIs dataset contains relatively complete POI types, it has practical significance to the extraction and identification of urban functional regions.
In addition, according to the confusion matrix displayed in
Table 7, we note that the proposed method is extremely accurate for the extraction of public service regions and agriculture, forestry, animal husbandry, and fishing (AFAHF) regions. The results based on the proposed method and manual annotations exhibit spatial homogeneity in these two regions, mainly because they are mostly located in the suburbs of the study area where the POIs are relatively homogeneous and sparse and the spatial features are relatively easy to capture. Meanwhile, there is obvious spatial heterogeneity in residential areas, mainly due to the fact that there are fewer POIs in residential categories. More importantly, in most cases, residential regions are mixed with other types of urban functional regions such as public service regions and daily life service regions, which makes it difficult to extract their spatial features and results in large classification errors.
6. Conclusions and Future Work
We proposed a GloVe-based POI type embedding model that accounts for the co-occurrence statistics of POIs and spatial context while training POI type vectors. Using the proposed model, we extract and identifyurban functional regions using POIs at the scale of traffic analysis zones. Through comparison against a baseline method based on word2vec, we proved that our method outperforms the word2vec-based method in terms of training speed and overall accuracy.
To extract and identify urban functional regions with very high accuracy, conventional data (e.g., geodemographic data, questionnaire data) may be more reliable. The goal of our study is to help city planners monitor regional development after initial urban planning, and we have achieved this by providing a new method to mine information hidden in POIs. Given their easy accessibility, POIs are a low cost and effective data source for quickly evaluating the development and changes in the functions of various regions in a city.
This study has some limitations. First, because each POI can only represent one point in an urban space, we could not account for its influence on nearby areas. In the future, other types of data could be merged into the methodology presented in this study to make the urban functional corpus more practical by assigning weights to POIs. Second, this study introduces TAZ as the basic unit of analysis and thus is inevitably prone to the modifiable areal unit problem due to the zoning effect. In the future, the impact of different urban space division schemes on the results could be considered. Finally, our accuracy evaluation process is based on the judgment of volunteers and is hence subjective, the multiple annotations for each region notwithstanding. In the future, more labelled data can be introduced to make the accuracy evaluation more rigorous and reliable, and the proposed method can be refined accordingly to make it even more effective in meeting the needs of urban planners and managers.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}