1. Introduction
Population distribution prediction refers to estimating the population of a specific geographic unit, taking into account the impact of natural geography and the socioeconomic environment and applying scientific methods (predictive models) to estimate population development in another temporal period [
1]. However, traditional population prediction generally has extremely coarse spatiotemporal granularity. With the advent of information handling techniques, new data collection methods, data processing algorithms, and improvements in computing power have made population prediction with micro-spatiotemporal granularity possible. Since ancient times, population estimation and prediction have been essential in human society for policymaking and socioeconomic planning, such as urban and health care planning at different administration levels. Studies on population prediction can be traced back to the United Kingdom in 1695 [
2]. After years of exploration and efforts by mathematicians, statisticians, demographers, geographers, and other scholars, a series of models for population prediction is proposed.
In general, population prediction models can be grouped into four categories, given the approaches they adopt: (1) mathematical models, (2) statistical models, (3) demographic models, and (4) machine learning models. In the past, many mathematical models were proposed [
3,
4]. Due to insufficient assumptions, however, data utilization is limited in these mathematical models, and it is difficult to determine parameters in an objective manner. The above constraints led to the development and application of statistical models in population prediction. Statistical models in population prediction mainly include regression, such as linear regression and non-linear regression models (e.g., Gompertz models), and time series models such as the autoregressive integrated moving average model (ARIMA) that combines differential, moving average, and autoregressive analysis. For example, Zakria and Muhammad [
5] applied this model to simulate the population dynamics in Pakistan from 1951 to 2007, and they predicted that the country’s population would reach 229 million by 2025. Despite more data and parameters that ultimately improve the prediction results, statistical models often fail to consider other factors that play significant roles in population growth, such as factors regarding societal settings and economic influences. In comparison, demographic models such as the cohort-component models consider not only the information of birth-rate, mortality-rate, and migration-rate but also age-specific information, providing detailed descriptions on the population spectrum, thus rendering more accurate results compared to pure statistical methods [
6]. A study by Stoto found that the distribution of error statistics in the US Census Bureau and the UN’s forecast samples was relatively stable, and such information could be utilized to predict the total population of the United States in 2000 [
7]. Lee and Carter [
8] used the time series method to predict age-specific mortality in the United States between 1990 and 2065. In 1996, based on an expert’s judgment on the trends and uncertainties of future birth rate, mortality, and migration rates in global regions, Lutz et al. [
9] predicted the demographics at global and selected regions by 2100.
Based on this study’s perspectives, all methods mentioned above can be classified as the traditional methods because they largely rely on structured census and statistical data from yearbooks. Moreover, their predictions tend to have coarse spatiotemporal granularity, with yearly temporal units and coarse spatial scales (e.g., national or global). Recently, the improvement of data collecting methods and the arrival of the Big Data era, the development of Big Data analytics, and the increasing maturity of machine learning have fostered new ideas in population prediction studies. For example, Reichstein et al. [
10] argued that the next-generation researches in geographic sciences should involve hybrid models that integrate physical and machine learning models. Robinson et al. [
11] trained a Convolutional Neural Network (CNN) [
12] with one-year synthetic remote sensing images of Landsat with a grid resolution of 0.01 × 0.01 (unit: degree) to predict the US population. Griffith et al. [
13] observed the increasing popularity of fine-scale population studies and indicated that the future prediction methods could start at the family or even the individual level, thanks to the development of new modeling algorithms, such as agent models and artificial neural networks (ANN).
LSTM is a variation of recurrent neural networks (RNN) first proposed by Hochreiter and Schmidhuber in 1997 [
14]. Since RNNs often experience problems of gradient vanishing during training, such networks can only retain short-term memory. LSTM relies on a unique set of internal mechanisms (e.g., gates and memory cells) to grant the networks the capability of long-term memory. It has been widely adopted in handwriting [
15] and speech recognition [
16]. However, we have found that this feature is particularly suitable for expressing the irregularities within the population change. The cellular automata (CA) with discrete states and local spatiotemporal interactions were proposed by American mathematician Stanisław Marcin Ulam in the 1940s and were used by Von Neumann to study the logical nature of self-replicating systems (White and Engelen, 1993) [
17]. At present, CA models are mainly used for modeling complex systems. Compared with mathematical models, CA can simulate the evolution of natural phenomena in a more accurate manner [
18], and therefore it has been adopted in simulation studies such as human migration, urban development, and land-use dynamics [
19,
20].
This study uses mobile phone signaling data, an emerging type of population data different from population data collected by traditional methods. Mobile phone data enables population prediction with micro-spatiotemporal granularity, characterized by fine-grained spatiotemporal granularity compared with traditional methods. The temporal resolution can be as fine as hours or even minutes, and the spatial resolution can be at a sub−1 km scale. Mobile phone signaling data have extensive spatial coverages, high data collection frequencies, long temporal spans, and spatial grid as a regular statistical unit. Based on the literature, extremely few methods can handle population datasets with such spatiotemporal granularity. LSTM has the ability to solve long-term dependency problems, given its unique design structure. Its design makes it suitable for processing and predicting important events with long intervals and delays in time series, ideal for investigating population dynamics. CA is a dynamic grid model with discrete time, space, and state. Since its spatial interactions and time causality are local-focused, CA is often adopted to simulate the process of the spatiotemporal evolution of complex systems (e.g., geographical environment). In addition, the concept of cells in CA is suitable to express the spatial distribution of the population.
Although there exist some efforts that integrate LSTM and CA models [
21,
22], their models lack the ability to integrate multi-source geographic information and, to our best knowledge, no effort has been made to investigate such integration in predicting the spatial distribution of population. In light of the background of population prediction with micro-spatiotemporal granularity and the unique characteristics of such data, we attempt to build a data-driven population prediction framework by integrating two basic models: LSTM and CA.
3. Method of Model Integration
3.1. Overview of the LSTM and CA Models
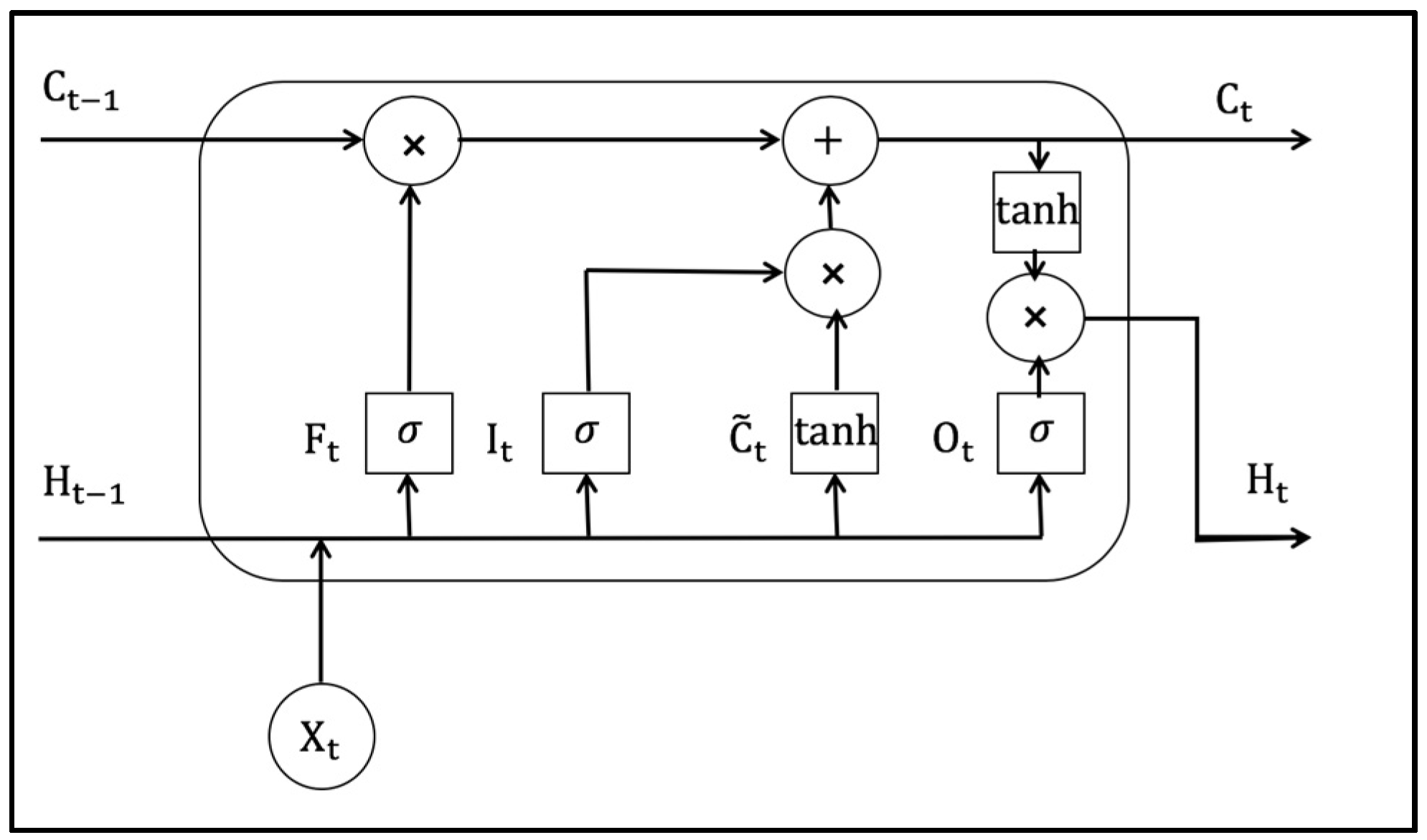
In this study, the temporal period for data collection is considerably long. Compared with classic time series models, LSTM can benefit the extraction of long-term features in the temporal dimension and the extraction of those features in an unsupervised manner, largely increasing its utility and generalizability. The internal structure of the neural networks is presented in
Figure 4.
denotes the original input in the current time step.
and
represent the memory units of the previous time step and the current time step, respectively.
and
represent the hidden state of the previous time step and the current time step, respectively.
As mentioned above, to mitigate the problem of short-term memory, LSTM constructs a special structure inside the networks with memory cells, which can pass the information along the sequence, and the structure can be understood as the “memory” of the networks. It includes three gates: forget gate, input gate, and output gate.
Given time step
, the calculating process of the forget gate, input gate, and output gate can be presented as follows:
where
(
n is the number of samples and
h is the number of hidden units) are forget gate, input gate, and output gate, respectively. The current time step
(
d is the number of features) is the input, and the hidden state of the previous time step is
.
and
are the weights.
denote the bias parameters.
At time step
, the candidate memory cell
is calculated as:
where
and
are the weights of the parameters, and
is the bias parameter. The update of the memory cells is based on the memory cells passed in the previous time step. The combination of the forget gate, and the input gate is able to control the flow of internal information:
where the forget gate
determines how much information is retained in the memory cell
, and the input gate
determines how much information is added in the candidate memory cell
.
The hidden state is realized by controlling the flow of internal information of the memory cell through the output gate. The calculating process of the hidden state is as follows:
With the gates mentioned above, LSTM can effectively extract long-term temporal patterns in mobile phone signaling data.
A CA system contains four basic elements: cells, states, neighborhoods, and conversion rules. Cells are the basic objects (or units) of a CA system. Space formed by all cells is called cell space. States of cells (generally discrete) have different choices based on different scenarios. However, the population data in this study are continuous. Conversion rules act on local scopes, and neighboring cells need to be defined to form neighborhoods. The conversion rule is a function that determines the state of the next moment according to the current state of the cell and the states of the neighboring cells. Therefore, this study aims to determine the neighborhood and extract the conversion rules effectively.
3.2. Model Integration
The integrated model we proposed is a data-driven model that can adapt to the spatiotemporal characteristics of mobile phone signaling data. Due to the high frequency and long acquisition period, classic time series methods such as ARIMA may not be feasible, as they cannot analyze multi-dimensional data and require stationary data or stationary after differentiating. LSTM benefits the extraction of both short-term and long-term temporal features. In addition, the population data is collected at the grid level, similar to the concept of cells in CA. Moreover, the neighborhood and extraction algorithms of conversion rules in CA have good scalability. Therefore, we integrate these two models to build a population prediction model with a micro-spatiotemporal granularity that can fully adapt to the characteristics of mobile phone signaling data. In the process of integrating LSTM and CA models, we consider two main aspects. First, we need to take advantage of the respective advantages of LSTM in sequence data and CA in spatial simulation. Second, we need to ensure the generalizability of the model.
From a macro perspective, a CA model is the upper-level framework of the integrated model, which defines the interaction between the cells in the simulation space through varying definitions of neighborhoods. The LSTM can be seen as an underlying algorithm for automatically extracting conversion rules in CA. In this study, LSTM is able to handle sequential data with the input of a three-dimensional tensor that includes samples (corresponding to the grids), timesteps, and features. Relying on the upper-level CA model, features can incorporate geographical information from various neighboring scenarios. The output of the CA-LSTM-integrated model is a two-dimensional tensor that includes samples (grids) and the corresponding population counts (in this study, mobile user counts). In this integration framework, CA and LSTM, respectively, handle information from spatial and temporal perspectives. Their integration benefits efficient spatiotemporal data fusion that leads to accurate population prediction. Specifically, there are two considerations: one is to use the cells in the CA to represent the grid. Different definitions of the neighborhood can incorporate more spatial information into the model. The second is to take advantage of the unique mechanism of LSTM for extracting complex time series features in population data.
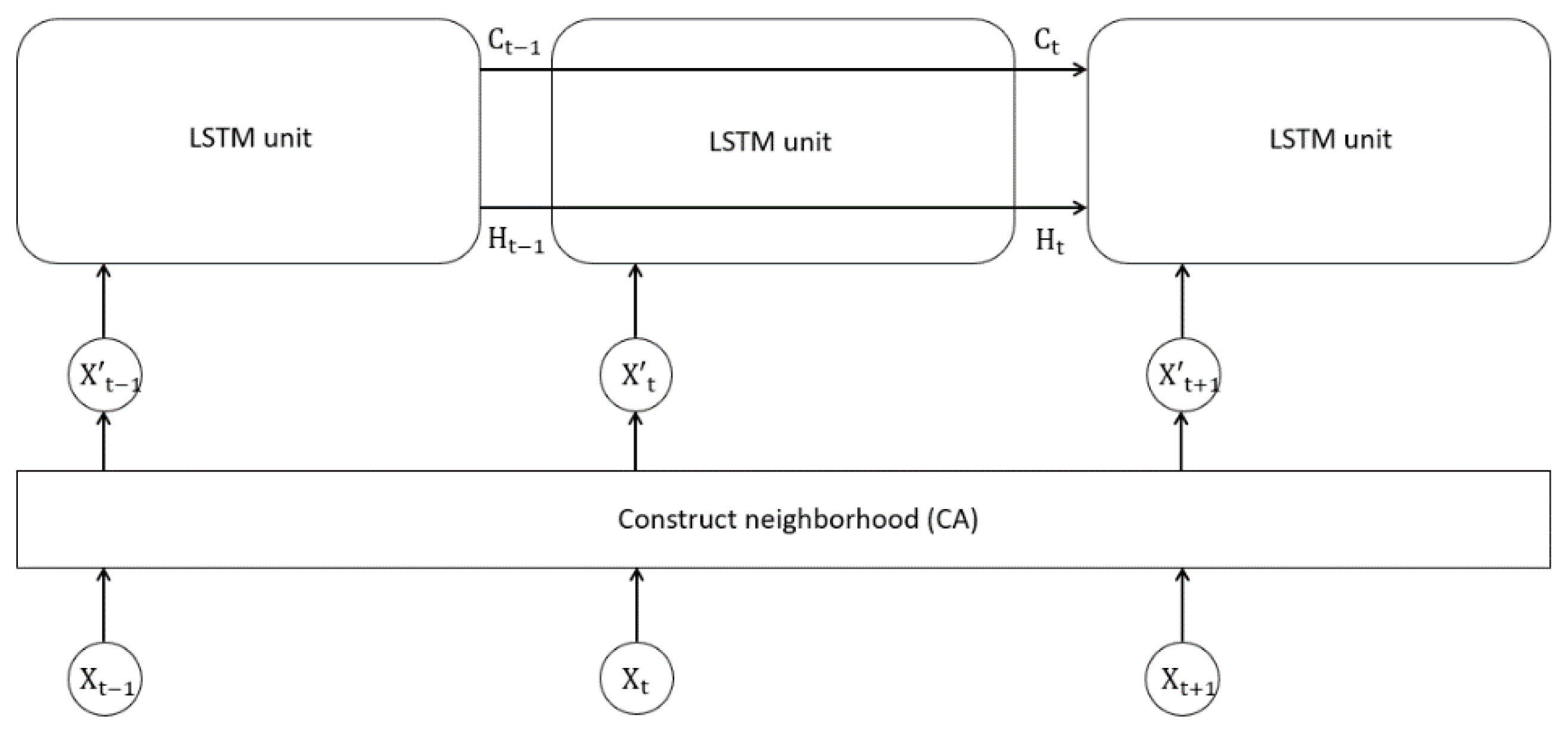
Figure 5 presents the schematic diagram of the integration between LSTM and CA.
In
Figure 5,
denotes the original input while
denotes the model input after temporal selection and neighborhood construction. Different uses of
represent different timestamps.
,
,
, and
are the intermediate input and output of the LSTM unit during the training process, and
represents the model output.
In general, the integrated model first selects the time series of the original data, then builds features in the attribute dimension according to the definition of the neighborhood in CA. Further, structurally transformed data are fed into the LSTM for training. The calculation at each time step generates new memory cells and hidden states. At the end of the entire training process, LSTM learns a set of parameters inside the model that can be used for later predictions.
Another consideration of this model integration is whether the model itself is with sufficient scalability and universality. The structural requirements of the integrated model for the input data are three-dimensional tensors with the form of sample, timestep, and feature, where the timestep corresponds to the information on the time series, and the feature corresponds to the definition of the neighborhood in the CA. The training of the integrated model is data-driven, and the information in the temporal and spatial dimensions is implicit in the input data. As no additional controls are required besides the adjustment of input data, the integrated model is with strong scalability and generalizability. In addition, given that internal parameters are with acceptable initialization settings, manual adjustments are not required, which demonstrates the robustness and automaticity of the proposed model.
3.3. Spatial Extension
The spatial extension of the model in this paper is achieved via the perspective of neighborhood construction. In the experiment, we select three different neighborhoods: the special neighborhood of the central cell, the Moore neighborhood (R = 1), and the extended Moore neighborhood (R = 1) by extracting cell weights based on road networks.
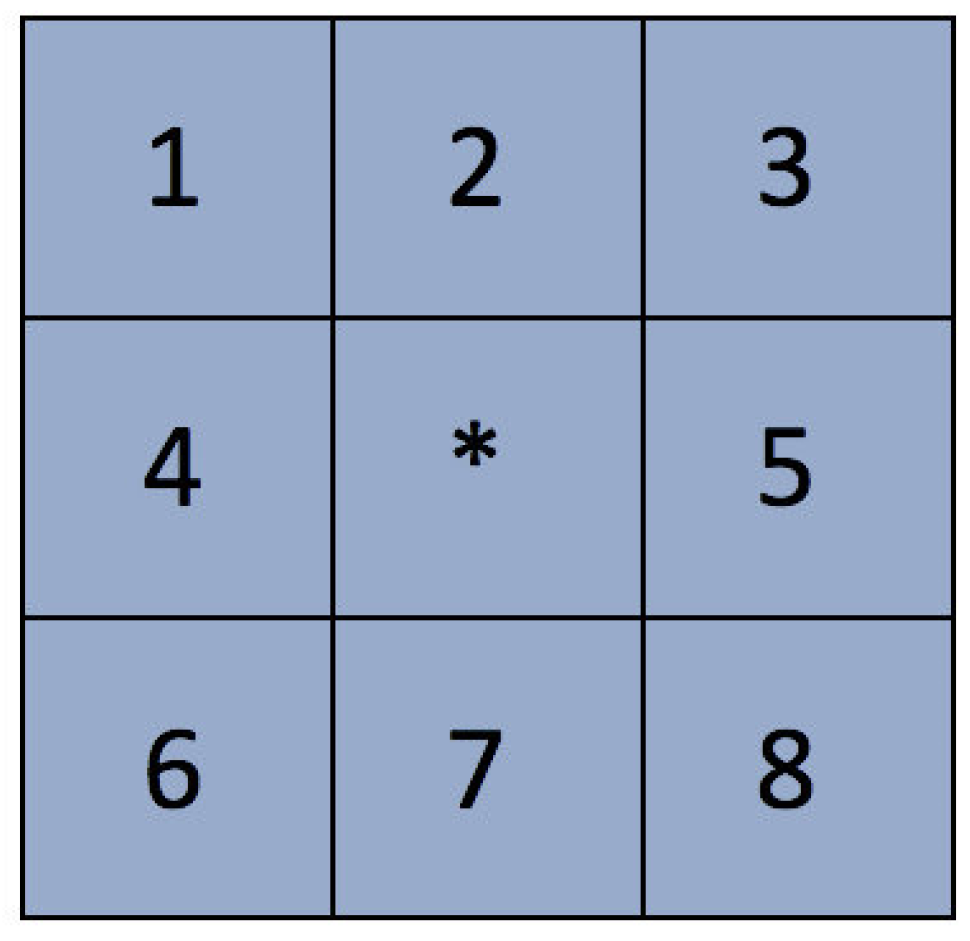
The first neighborhood construction is relatively simple, that is, the choice of the central cell while ignoring its neighborhoods. The Moore neighborhood (R = 1) is a classic method of defining neighborhood, as shown in
Figure 6.
The combination of the Moore neighborhood (R = 1) and algorithm for extracting cell weights based on road networks is another way to build neighborhoods. This paper draws on the idea of “decay neighborhood with distance” [
24,
25,
26] from the previous studies and uses data of road networks to ensure that proper spatial information is considered.
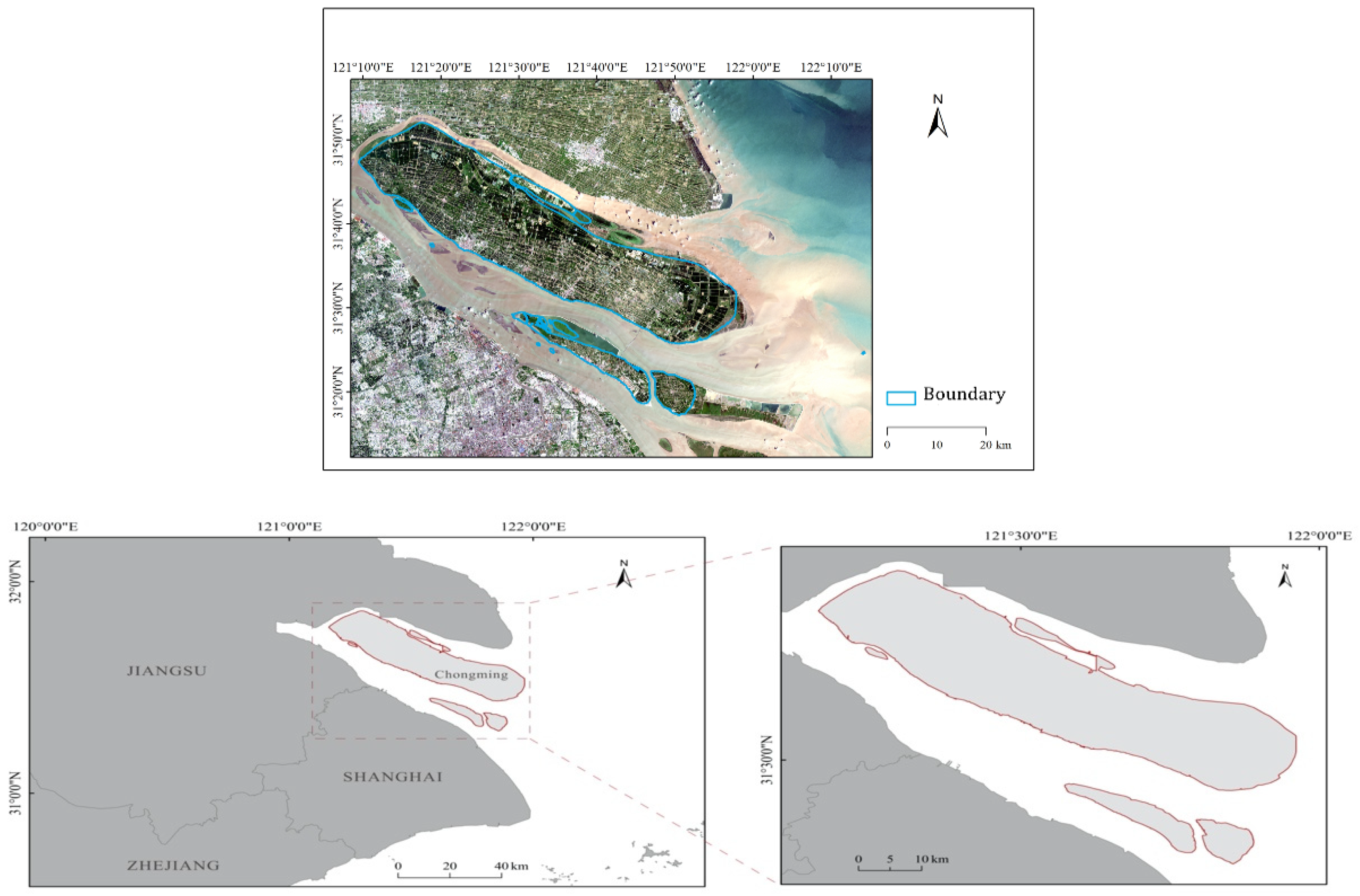
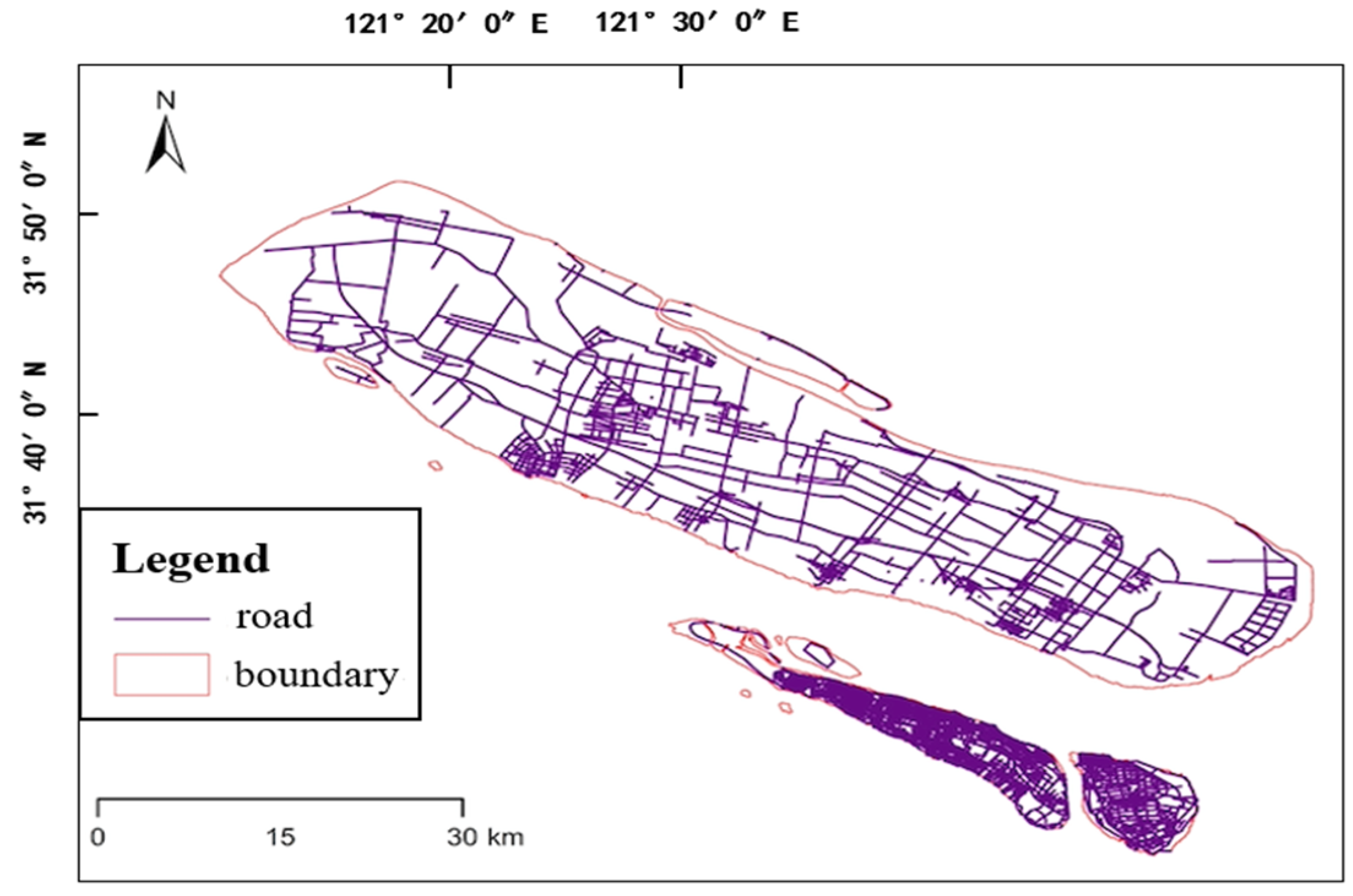
Figure 7 presents the road networks in Chongming District.
The method of constructing neighborhoods from road networks is based on the assumption that population movements are affected by surrounding areas of interest (such as roads, tourist areas, etc.). With the consideration of road elements, people are with a tendency to move towards the road in a random state, as the cells closer to the road have a greater impact on the central cell. To ensure that the total impact weight of all cells is 1, the weights are normalized via the following formula:
where
represents the weight of the i-th cell, and
represents the distance of the i-th cell from the nearest road. Given the distance to the nearest road, the weights are first calculated considering an exponential decaying effect, then normalized after the summation.
With the use of the Moore neighborhood (R = 1), road data are integrated into the model, as cell weights of the neighborhood are calculated based on the road network. Such information affects the extraction of spatial features during model training.
4. Experiments and Results
In the first experiment, we selected the central cell without considering its neighborhood. Since the period of the data covers the Chinese National Day (1 October) and ordinary dates, the training was conducted separately to investigate the heterogeneity in the temporal pattern of population changes. In addition, the minimum time granularity of the data (10 min) and different time granularities (i.e., 1 h) were used to show the impact on the generalization effect of the different models. We also considered combining data from multiple days to reveal the longer-term characteristics in the time series. An additional experiment was conducted by applying extended neighborhoods that aim to include spatial information in the model.
Figure 8 presents the specific training method.
In total, we trained six models, in which the first four models were constructed based on a single temporal dimension, and the other two were composite models that integrated spatiotemporal perspectives. For purposes of evaluating the generalization effect of the model, we used two evaluation methods: an absolute evaluation and a relative evaluation. The absolute evaluation applies the mean absolute error (MAE) as the evaluation metric:
where
is the true value,
is the training weights, and
is the model output.
Relative evaluation is a baseline assessment. Before training the model, an ideal model based on common sense as a reasonable reference point was established. After comparing the trained model with the baseline model, the relative quality of the model can be judged. Since our research problem targets time series population prediction, the simplest model assumption is that the predicted results at the current time step in the test set are the same as the value at the same time in the training set. In this study, the division of training set and testing set is unique, given the fact that our model has spatial and temporal dependencies. Therefore, unlike the traditional method of splitting the dataset in a fixed ratio, we train with data for a period of time and predict with data for another period of time. All implementations in this study are completed via Python programming language, specifically using TensorFlow and Keras libraries. In this study, the hyperparameters for all models are the same. We use RELU as the activation function with the Adam algorithm as the optimizer (default setting).
4.1. Time Dimension
Neural network training requires a balance between optimization and generalization. One of the focuses of this study is to improve the generalizability of the model, as the application of population prediction models requires a certain degree of robustness. Since neural networks have a strong ability in data fitting, the problem of overfitting often occurs during training. We added an L2 regular term to the loss function when designing the model to solve this problem. Another possible solution is to perform manual adjustment by regulating the number of learning parameters. The number of learning parameters determines the number of features that a model can learn, and the larger the number, the more complex the model. A small number of parameters can lead to underfitting, while a high number can lead to overfitting, which greatly affects the model’s generalization ability. Therefore, the adjustment of hyperparameters in studies should primarily target this parameter. Despite that, there are many hyperparameters in the deep learning framework (e.g., batch size and epoch); only the number of learning parameters remained adjustable in this experiment with other hyperparameters fixed to ensure comparability in this study.
Four models were trained, respectively, using 1 h granularity data on 27 September 2018 (Model 1), 1 h granularity data on 1 October 2018 (Model 2), 10 min granularity data on 27 September 2018 (Model 3), and 1 h granularity data on 27–29 September 2018 (Model 4). The numbers of best learning parameters are, respectively, set as 10, 10, 18, and 22. The baseline errors are 1.245, 1.636, 1.245, and 1.871, respectively. The generalization performance on the test set is shown in
Table 2,
Table 3,
Table 4 and
Table 5.
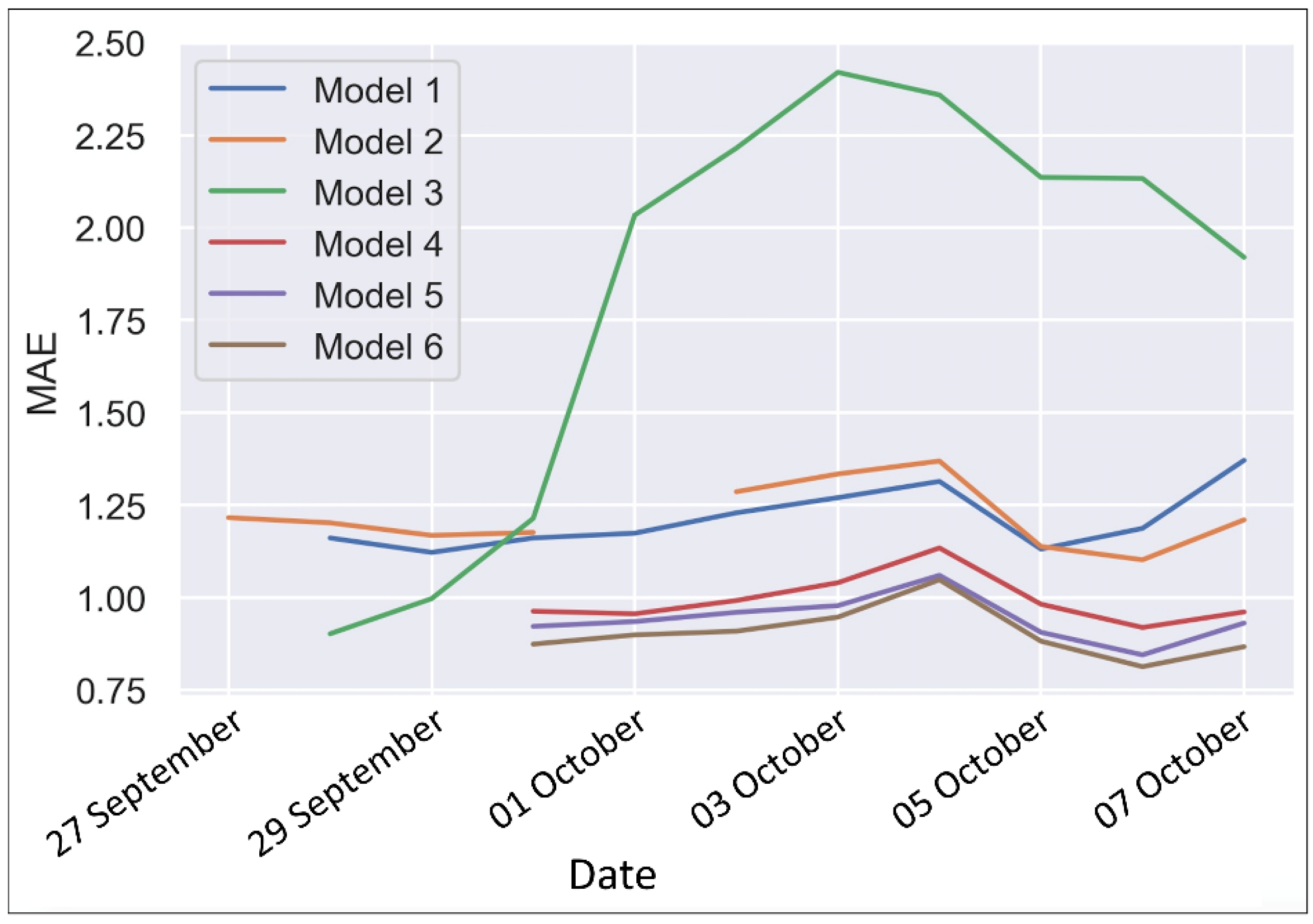
Figure 9 presents the generalization error plot of the four models on the test set. Baseline error is calculated from baseline assessment, and the test error is derived from the prediction of the trained model.
According to
Figure 9, it is observed that with an increase in the amount of data and the decrease in time granularity, the number of optimal learning parameters of the model increases, suggesting that the model needs more parameters to express such characteristics in the time dimension. When comparing Model 1 and Model 2, we found that there exists a certain periodic feature in the single-day population data, and the expression of this feature on the normal date and the National Day is different. Despite such discrepancies, the similarity of changes in population dynamics during one day is notable. We also observed that this rule performs better on data of ordinary dates. When comparing Model 1 and Model 3, we found that a small time granularity does not necessarily perform better. The generalization error of the data at 1 h granularity is lower than that of the data at 10 min. As in certain occasions, specific characteristics exist under a specific granularity. Sometimes, data with a fine time granularity may lose key features. In addition, even random data can express certain correlations, as some scholars have found that some correlations can be found even for data with complete noises [
21]. When comparing Model 1 and Model 4, we found that the multi-day data generally contain richer information and have hidden features on the long-term sequence. Given its great performance, the subsequent model training is based on Model 4.
4.2. Spatiotemporal Dimension
The above four models only consider a single time dimension and do not adopt the concept of neighborhood. In this experiment, we incorporate spatial attribute information into the model from two perspectives: (1) the classic Moore neighborhood (R = 1) (Model 5), and (2) the extended Moore neighborhood (R = 1) combined with extracting cell weights based on road networks (Model 6). The best learning parameters are set as 30 and 35, respectively, and the baseline errors are both 1.871. The generalization errors on the test set are shown in
Table 6 and
Table 7.
Figure 10 presents the errors for all six models.
We observed that the quality of the models is further improved with the consideration of spatial information. The spatial assumption of the Moore neighborhood is spatially contiguous, which limits model performance to a certain degree. In comparison, Model 6 fuses road network information, allowing more detailed spatial information to be introduced into the model, thereby further improving the quality of the model. However, the introduction of road network information leads to increased model complexity.
5. Discussion
Population distribution prediction has always been a hot research topic in geography and other spatial science-related fields. Better population distribution knowledge is expected to benefit a wide range of domains that include smart cities [
27], regional planning [
28,
29], transportation management [
29], and disaster mitigation [
30], to list a few. After reviewing traditional population distribution prediction models, we notice that traditional methods, largely relying on the structured census, tend to have coarse spatiotemporal granularity. In recent years, the advances in information handing techniques, the introduction of data processing approaches, and improved computational power led to the popularity of population distribution prediction with fine spatiotemporal granularity. Entering the Big Data era, scholars start to resort to machine learning and automated algorithms, aiming to address the challenges in fine-scale population modeling studies.
LSTM and CA are popular approaches that, respectively, address temporal and spatial problems. Given its design, LSTM is featured by its capability in predicting events with long intervals and delays in time series, making it an ideal algorithm for population distribution prediction. On the other hand, CA has the capability of simulating spatiotemporal evolutions. The unique features from LSTM and CA motivate us to think about their potential integration, with CA as the upper-level framework and LSTM as the underlying algorithm to derive the conversion rules. Taking advantage of the mobile phone signaling data collected by China Unicom, we test the proposed CA-LSTM-integrated model in predicting the population distribution in Chongming District, Shanghai by setting different time granularity, timesteps, and neighboring scenarios. The results suggested that models with finer time granularity do not guarantee better performance, as data separated by finer granularity may lose key features, posing challenges for the models when they are making the prediction. We also notice that an increase in data put benefits the accuracy of the prediction, which is expected because deep learning models rely on data to establish a robust mapping between the input and the output. As for neighboring scenarios, we notice that models that consider spatial information outperform models that do not, which proves the important role of spatial dependency in population distribution prediction. In addition, we observe that models that consider spatial information characterized by road networks outperform models that consider spatial information characterized by the Moore neighborhood (spatially contiguous). This result points to the fact that population dynamics are more intertwined with road network settings than spatial closeness. Further efforts can be made to involve other spatial scenarios in population distribution prediction, aiming to better capture the factors that drive population movement.
Unfortunately, the mobile phone signaling data we have only lasted 14 days, which, to some degree, limits our investigation. In addition, cellphone counts only capture a certain spectrum of the population, while people who do not have access to mobile devices or who do not carry devices outside are underrepresented. In our future work, we plan to explore the capability of the proposed model in handling a longer time period and include different time granularities. In addition, the performance of different granularities needs to be tested with more case studies. We also intend to integrate more geographic information to investigate the potential improvement of the model’s performance.
6. Conclusions
Although there exist some efforts that integrate LSTM and CA models, their models lack the ability to integrate multi-source geographic information and, to our best knowledge, no effort has been made to investigate such integration in predicting the spatial distribution of population. Taking mobile phone signaling data as input and Chongming District of China as the study case, we proposed a model that integrates LSTM and CA to extract population dynamics from spatiotemporal dimensions. The integrated model is constructed in an unsupervised manner with great scalability and the capability of fusing multi-source geographic data. We also applied different time granularities and varying methods of spatial neighborhoods.
Despite the great performance of the proposed model, challenges still remain. In this case study, we observed that the generalization abilities of trained models differ greatly, indicating that the training methods should be dependent on different research data types and scenarios. That is to say, different training data can lead to different best parameter settings. The internal parameters of the model should be adjusted appropriately in order to achieve optimal performance. The best model obtained in this paper is based on the training data of the extended Moore neighborhood (R = 1), combined with three-day ordinary dates, one-hour granularity, and extracting cell weights from road networks. The calculated testing error (MAE) for all cells is 0.905. The generality and robustness of the integrated model can be further improved by including more data sources. Benefiting from the proposed method of neighborhood construction, other data sources can be easily incorporated into our proposed model.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}