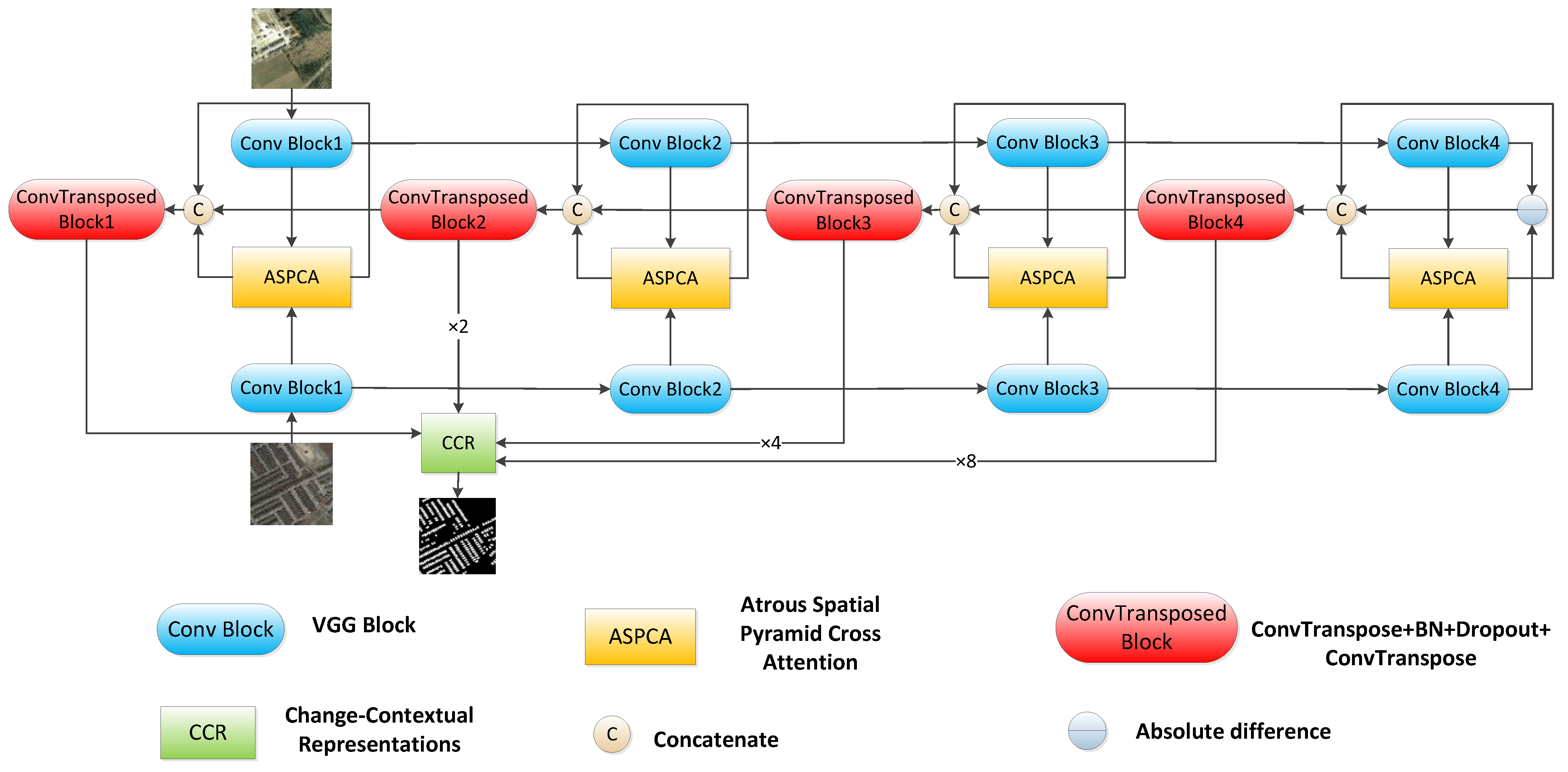
In this subsection, the multi-level change contextual refinement net (MCCRNet) pipeline is presented, then the designed atrous spatial pyramid cross attention and change contextual representation (CCR) modules are described in detail.
2.1.3. Decoder
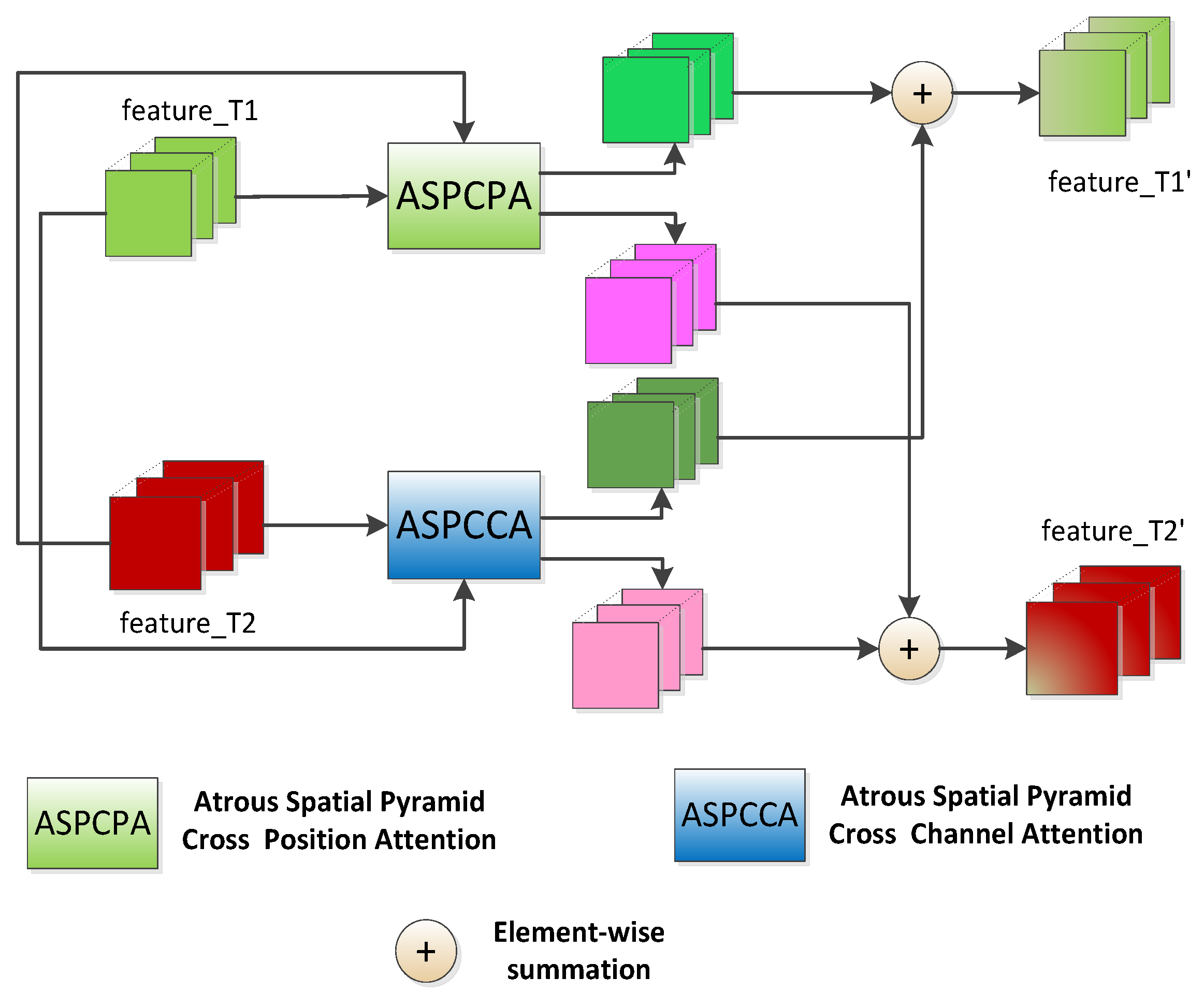
After obtaining the feature sets of the bi-temporal images, they were not fused directly like the current methods but were forwarded into an atrous spatial pyramid cross-attention (ASPCA) module to strengthen the representation ability between feature pairs at the same level. As mentioned above, the ASPCA module was also realized based on self-attention theory shown in
Figure 3. The subgraphs in the third column represent the dual spatial features and dual channel features refined by ASPCPA and ASPCCA, respectively. Unlike most attention-based works that forward a concatenated single feature into the attention module and output a single weighted feature, our module utilized dual features without fusing or adding operations.
The ASPCA module comprises an atrous spatial pyramid cross-position attention (ASPCPA) module and an atrous spatial pyramid cross-channel attention (ASPCPA) module, both of which accept dual features of the same size from the same level of feature extraction layers. The former captured the long-range spatial–temporal interdependencies, while the latter captured the long-range channel–temporal interdependencies. Although there are many operations to fuse spatial attention features and channel attention features such as concatenating or cascading in parallel, the experiments indicated that they were not suitable for this task, so a summing operation was employed. It is worth noting that the updated image feature of the previous time (expressed as
) and that the updated image feature of the latter time (expressed as
) equaled the element-wise summation of the spatial attention feature and channel attention feature in the form of crossover. The mathematical expression is as follows:
where
denote the feature pairs updated by the ASPCA module for a certain layer;
denote the output bi-temporal features from the ASPCPA module, and
denote the output bi-temporal features from the ASPCCA module.
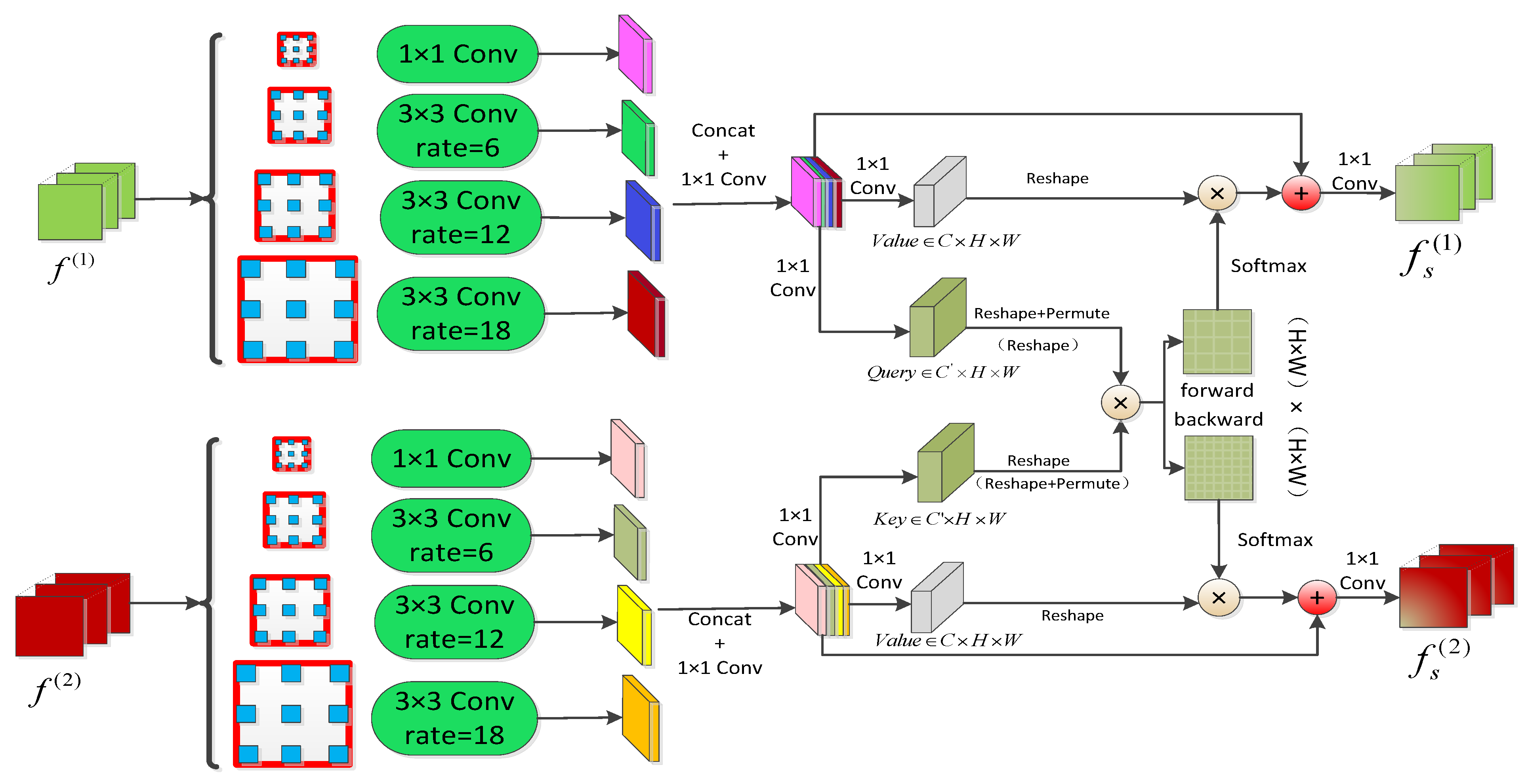
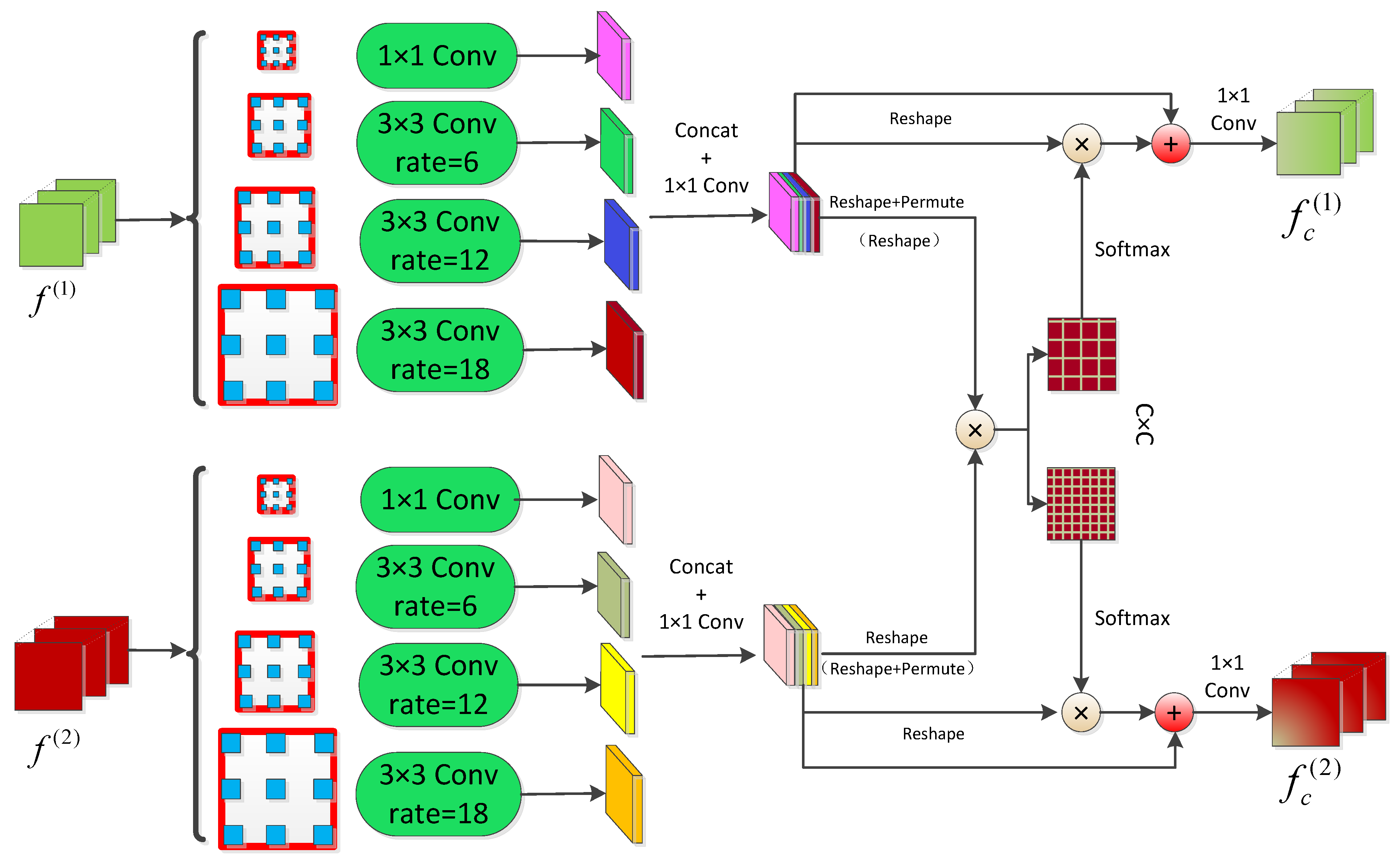
The structure of the ASPCPA module is shown in
Figure 4. The green boxes represent the atrous convolution with rates of 1, 6, 12, and 18, respectively and 1 × 1 Conv represents the convolution of kernel size 1 × 1, BatchNorm, and ReLU. We referred to the idea of atrous spatial pyramid pooling (ASPP) in [
49]; the dual features were forwarded into an atrous spatial pyramid module containing four atrous convolution operations with ratios of 1, 6, 12, and 18, respectively, and then these output features were concatenated in channel dimension. To increase the nonlinear capability of the model, a convolution with kernel size 1 × 1 operation was performed; we kept the number of channels the same in our work. Given the dual features fused by the atrous spatial pyramid block (denoted as
and
, respectively), where
and
(
C denotes the channel number, and
indicates the spatial size), two parallel
convolutions were applied to
and
, respectively, which produced
(expressed as
) and
(expressed as
), where
is the channel number. Generally,
is reduced to 1/4 or 1/8 of
for saving memory, but here we kept them the same. Meanwhile, we forwarded
into another two convolution layers to generate corresponding value features
(expressed as
and
, respectively), which were reshaped into
, where
. Simultaneously, we also reshaped
and
into
. To capture the spatial contextual relationships of feature pairs, we calculated an attention map with forward and backward directions. For the forwarded = direction (“T1 to T2”),
is permuted to
, while
kept the original size; thus, we constructed the forward energy matrix
, formulated as
, where the element at
of
is the sum product of the
row elements of
and the
column elements of
and measures the similarity between
position in
and
position in
.
then performed the normalization by Softmax operation and matrix multiplication with
, as mentioned above, where the former is calculated as follows:
where
indicates the element at position
, and
indicates columns of
. Similar to this, another energy matrix of the backward direction (“T2 to T1”) is formulated as
, which means the matrix multiplication of
after transposed and
. We also applied Softmax to
as follows:
Slightly different from the above, a backward direction attention map was used to measure the similarity between the
position in
and the
position in
.
is the rows of the
matrix. The bidirectional similarity measurements contributed more comprehensive spatial change context between dual features. Finally, we obtained the updated spatial attention map of
named
by adding
to the weighted
:
where
and
is a model parameter with an initial value of 1, leveraging the dissimilarity importance of
compared to
. Conversely, an argument spatial attention map of
named
was generated by adding
to the weighted
:
and
The model parameter was also initialized to 1, which leverages the dissimilarity importance of compared to .
In a word, long-range spatial independencies form two directions, both with a strengthened change representation ability for bi-temporal features.
The ASPCCA module was designed to capture long-range channel independencies between
and
. As shown in
Figure 5, the atrous spatial pyramid and bidirectional structures are identical to ASPCPA except that the latter has to produce
,
,
and
by four 1 × 1 convolution layers before calculating attention maps. Here, we performed matrix multiplication of the original concatenated features directly. Given dual multi-scale features
and
mapped by four atrous convolutions at rates of 1, 6, 12, and 18, respectively, we reshaped both of them into
, where
. For the forward direction (T1 to T2), the transposed
performed matrix multiplication with
formulated as
to generate forward energy map
.
was also normalized by a Softmax operation to get an attention map:
Finally, the augmented channel attention map of
could be calculated as follows:
where
and
is a model parameter like
; here,
models the channel context from
to
.
In the same way, a backward energy map
was calculated by
and normalized as follows:
Thereby, the augmented channel attention map of
was obtained:
where
and
is a model parameter with an identical initial value like
;
models the channel context from
to
.
Whether in the ASPCPA module or the ASPCCA module, a norm layer comprising 1 × 1 convolution, BatchNorm, and a ReLU activation function was separately applied to
,
,
, and
, which ensured that the channel number of the input remains unchanged after being updated by ASPCA. As shown in
Figure 2, the decoder gradually restored the change feature map resolution by forwarding concatenated
,
and
(where abs denotes absolute operation) into the upsampling block
from high layers to bottom layers. For each
block, the first two
layers are used for dimension reduction, while the other one aims to upsample the doubled spatial size. The specific parameters and feature sizes are shown in
Table 1.
The multi-scale features up-sampled by the four ConvTransposed blocks contain abundant change discriminatory information with different levels, which means that high layers contain rich abstract semantic information, while low levels represent detailed texture information.
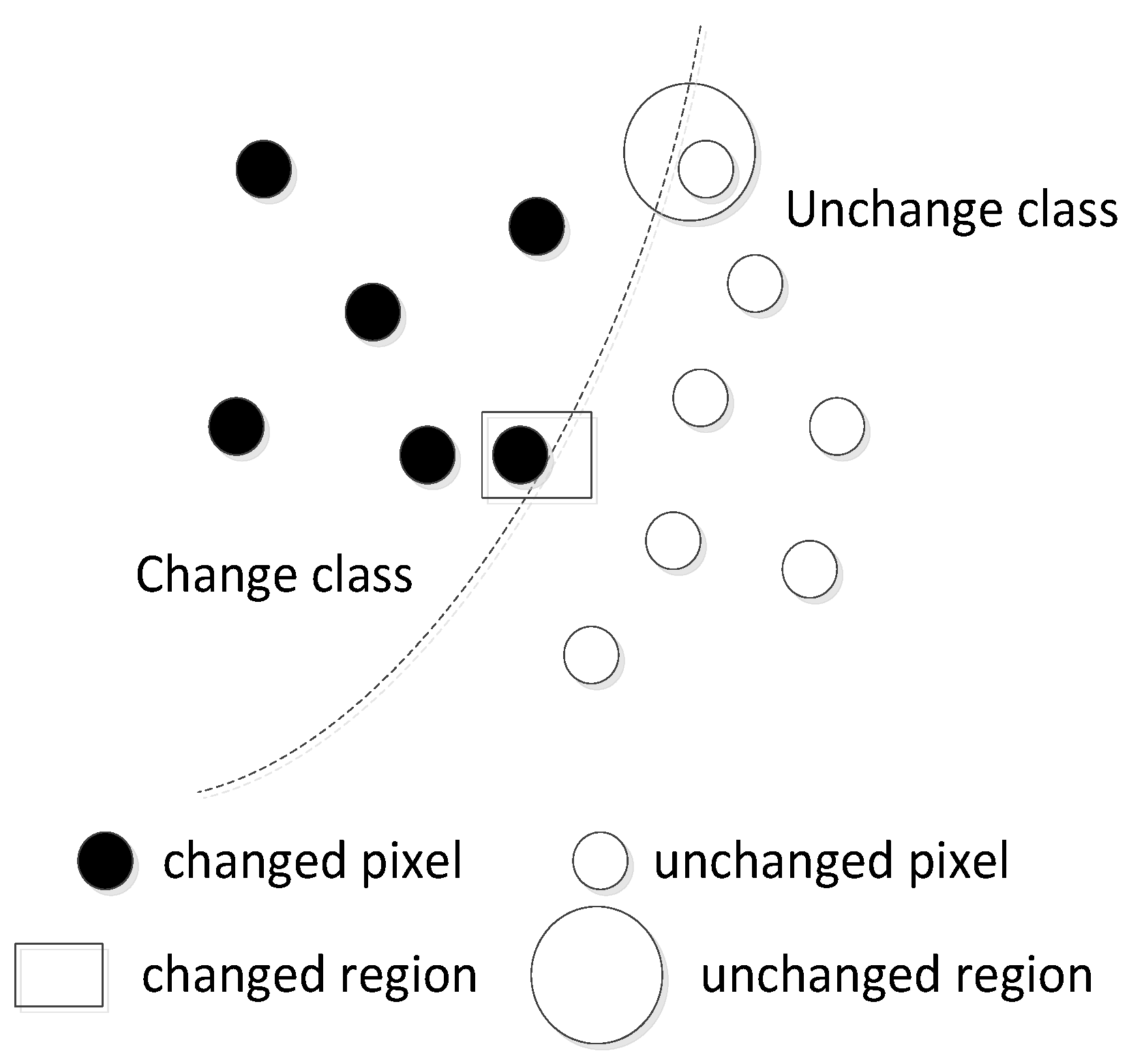
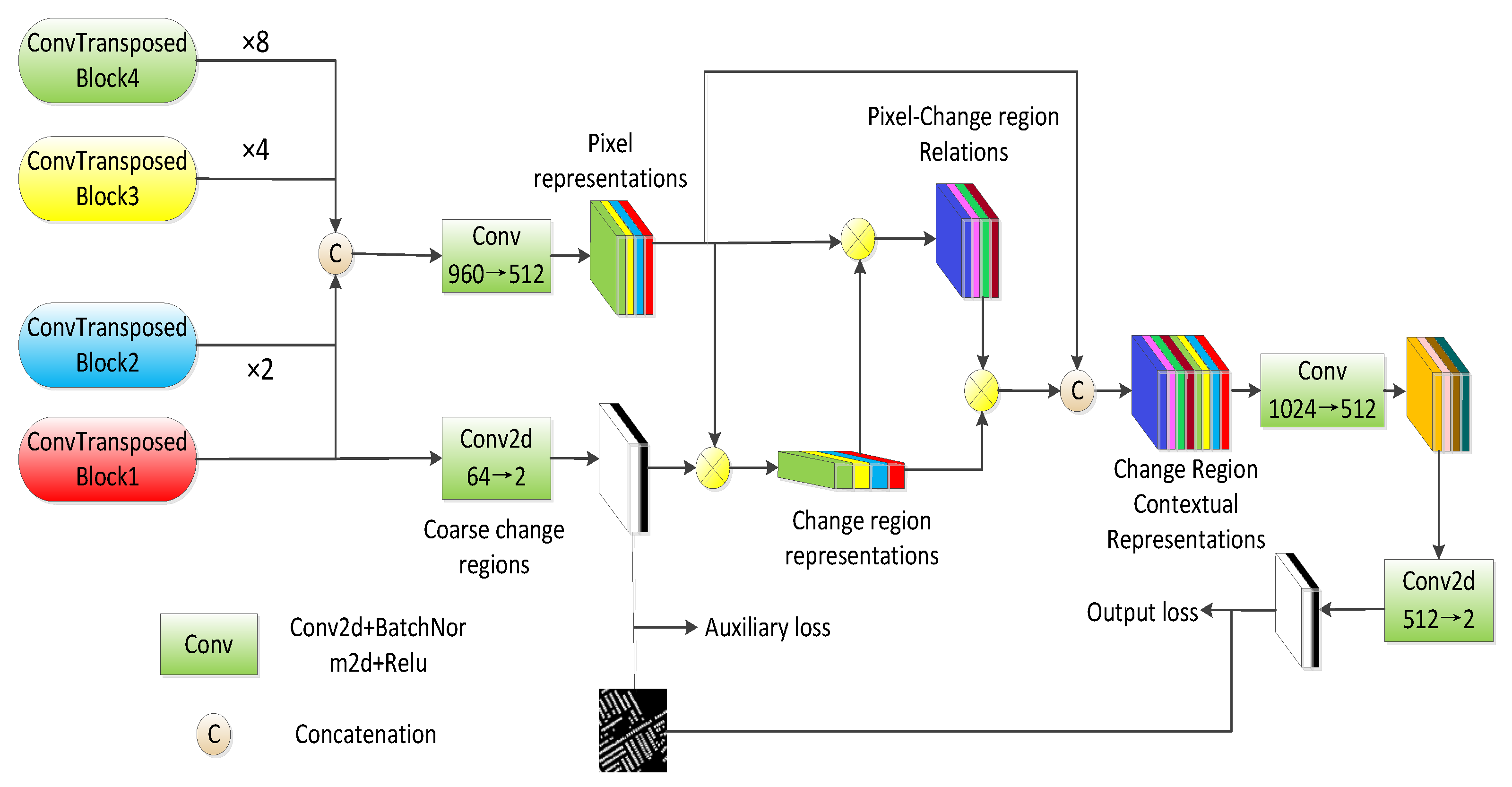
2.1.4. Change Contextual Representational Module
The multi-level features updated by the ASPCA module in
Section 2.1.3 only capture the long-range interdependencies between pixels of feature pairs. This subsection proposes a change contextual representational (CCR) module, which captures pixel-change region relation and change region contextual representations by exploiting representations of change regions that the pixels belong to. In
Figure 6, ×8, ×4, and ×2 represent bilinear interpolation to 8, 4, and 2 times the original size, respectively, and Conv2d, in the green box, represents a general 1 × 1 convolution while Conv in the green box represents
. The features outputted from the four ConvTransposed blocks were resized to be the same as the output from ConvTransposed Block 1, then the fused feature was forwarded into a linear activation layer called Conv to get the pixel representations. Meanwhile, an auxiliary output from a fully convolution layer contributed to the coarse change detection result, which was supervised by an auxiliary loss. Given pixel representations
and coarse change regions
, where 2 indicates the change class and unchanged class, both
and
were separately reshaped to
(to reduce calculation complexity,
means 512 in this work) and
. Then the change region representations
could be obtained by a matrix multiplication between regularized
and
formulated as follows:
Similar to the attention map in ASPCA, the pixel-change region relation
was calculated by:
where
and
were both implemented as
and
. Then the matrix multiplication of change region representations
and attention map
. were calculated as follows:
where
and
are also transform functions like
and
, but it is worth noting that
,
, and
are all dimension reduction transformation (512 to 256 in this work), while
denotes
from 256 channel to 512. For reusing the pixel representations,
was first reshaped to
and then concatenated with
to generate change region contextual representations, updated by a Conv layer to restore the original channel dimensions. Finally, a pixel-level convolution predicted the change intensity map.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}