



Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection


Abstract
:1. Introduction
- (1)
- Clouds and their shadows have complex and diverse boundaries, uneven distribution, and large-scale changes. As is mentioned above, although the general semantic segmentation models can extract rich semantic information, it is easy to overlook details and they are not friendly to the boundary and small-scale segmentation. Multi-level fusion mechanisms were used to overcome this shortcoming [44,45,46]. This enhances the performance of the model by fusing shallow feature maps with rich location information and deep feature maps with abundant semantic information.
- (2)
- Cloud and cloud shadow images have complex and diverse backgrounds since they carry massive amounts of information about ground objects. The high-intraclass and low-interclass variance make semantic segmentation more difficult. The problem of how to segment small-scale targets from interference deserves to be studied.
- (3)
- Clouds have a unique visual appearance in imagery but can still be mistaken for other objects under some backgrounds. Cloud shadows are also difficult to identify under certain circumstances.
- (1)
- This paper designs a multi-scale feature fusion block. Unlike existing multi-scale feature fusion networks [23,47], which fuse features in a simple linear fashion, the block we built allows the network to automatically learn the parameters that aid in selecting appropriate feature representations from deep and shallow feature maps.
- (2)
- This work develops a multi-scale channel attention mechanism to focus on local as well as global information, hence improving the expression of local features. It can assist us in more precisely identifying cloud shadow boundaries and detailed information. The background of remote sensing images is complex and diverse, and paying too much attention to local details may introduce interference. As a result, we also added a spatial attention mechanism to focus on task-related areas while limiting background interference.
- (3)
- Some clouds and shadows are inconspicuous. Since they have unique properties, we provided a class feature attention mechanism to learn class features. It helps balance background interference and local representations.
2. Proposed Network
2.1. Network Architecture
2.2. Feature Fusion Block (FFB)
2.2.1. Fusion Convolution Block (FCB)
2.2.2. Channel Attention Block (CAB)
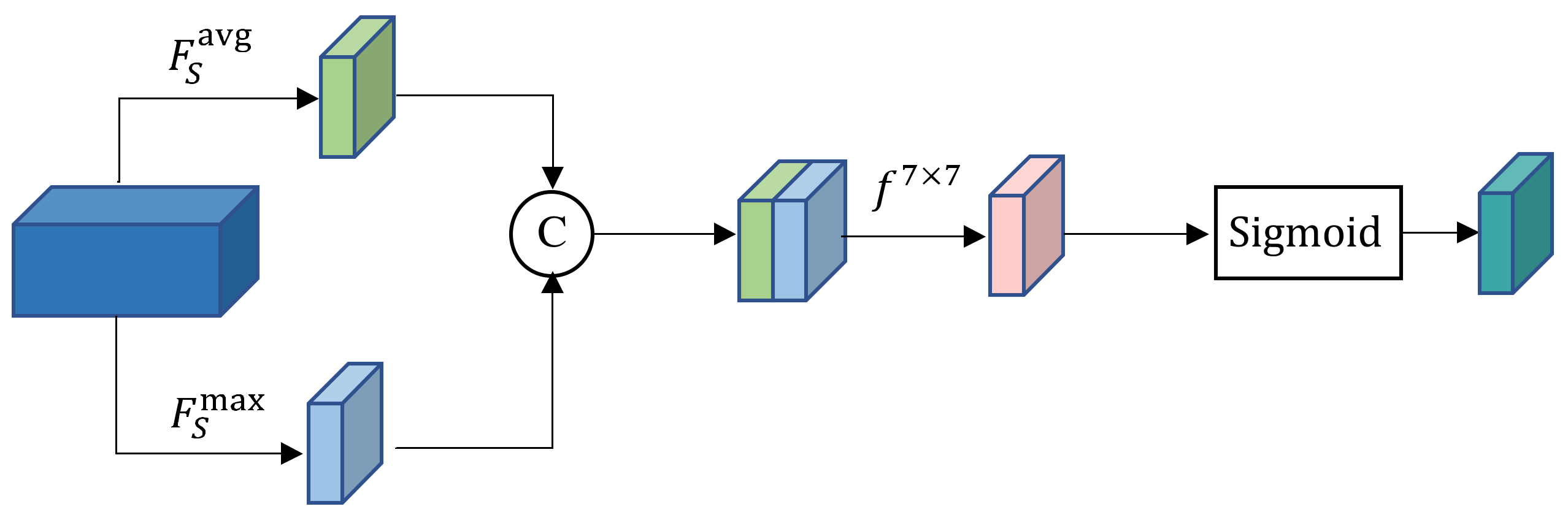
2.2.3. Spatial Attention Block (SPA)
2.3. Category Feature Attention Block (CFAB)
3. Experiments and Result Analysis
3.1. Experimental Datasets
3.2. Execution Details
3.2.1. Super Parameter Setting
3.2.2. Loss Function
3.2.3. Evaluation Indicators
3.3. Ablation Study on Cloud and Cloud Shadow Dataset
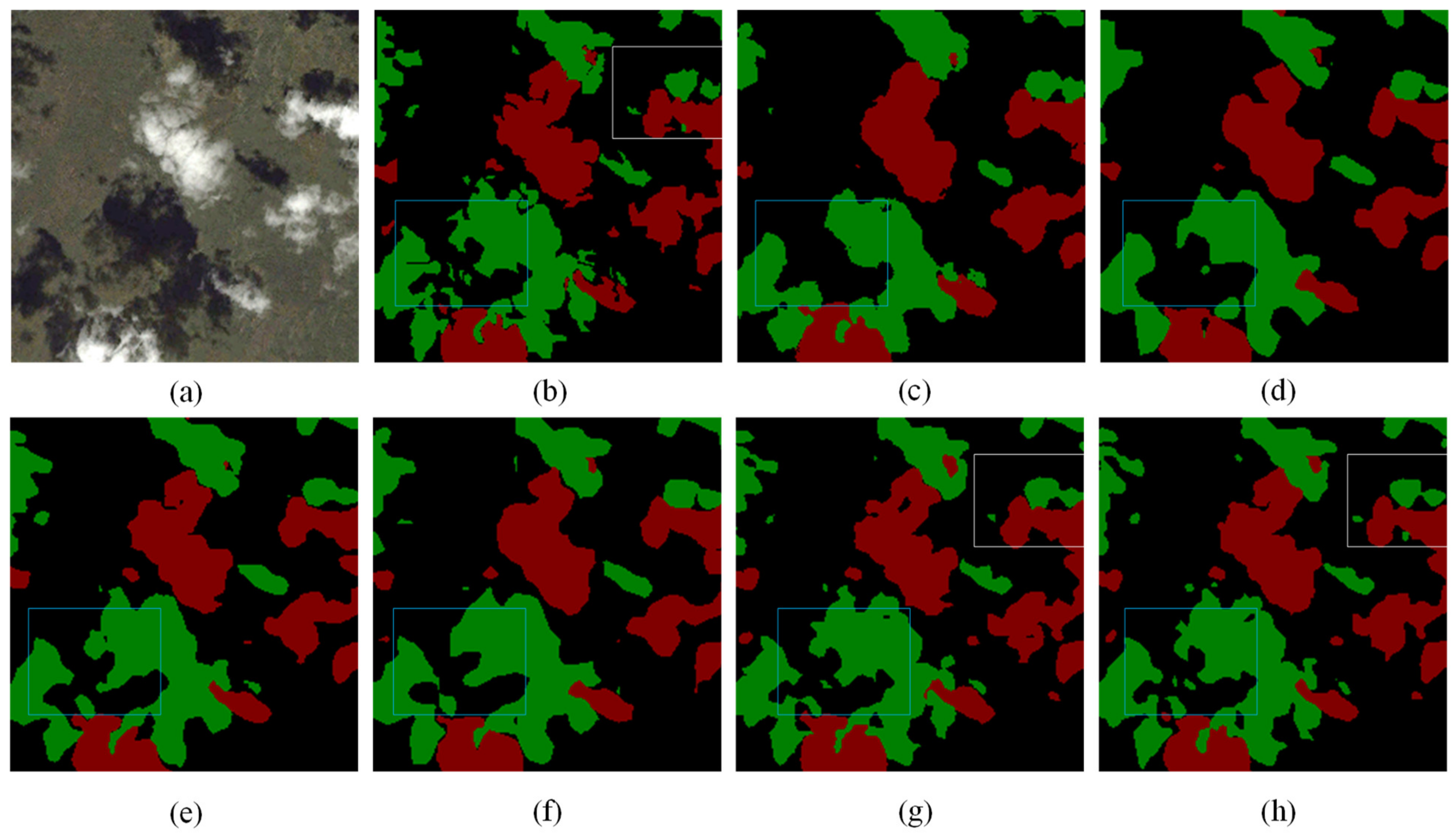
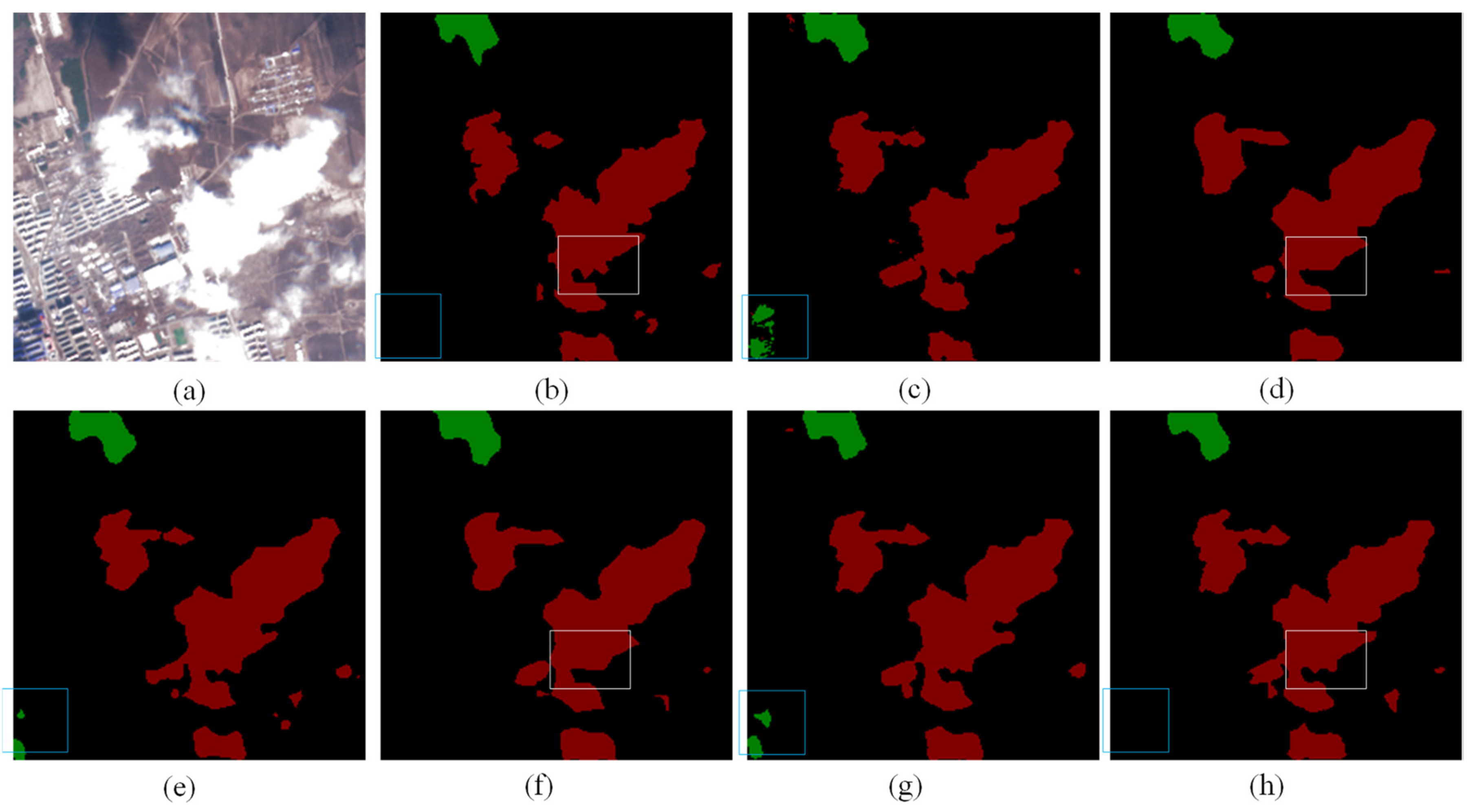
3.4. Analysis of Comparative Experiments
3.5. Generalization Performance Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhu, Z.; Woodcock, C.E. Automated cloud, cloud shadow, and snow detection in multitemporal Landsat data: An algorithm designed specifically for monitoring land cover change. Remote Sens. Environ. 2014, 152, 217–234. [Google Scholar] [CrossRef]
- Li, S.; Sun, D.; Yu, Y. Automatic cloud-shadow removal from flood/standing water maps using MSG/SEVIRI imagery. Int. J. Remote Sens. 2013, 34, 5487–5502. [Google Scholar] [CrossRef]
- Huang, C.; Thomas, N.; Goward, S.N.; Masek, J.G.; Zhu, Z.; Townshend, J.R.G.; Vogelmann, J.E. Automated masking of cloud and cloud shadow for forest change analysis using Landsat images. Int. J. Remote Sens. 2010, 31, 5449–5464. [Google Scholar] [CrossRef]
- Oishi, Y.; Ishida, H.; Nakamura, R. A new Landsat 8 cloud discrimination algorithm using thresholding tests. Int. J. Remote Sens. 2018, 39, 9113–9133. [Google Scholar] [CrossRef]
- Irish, R.R.; Barker, J.L.; Goward, S.N.; Arvidson, T. Characterization of the Landsat-7 ETM+ automated cloud-cover assessment (ACCA) algorithm. Photogramm. Eng. Remote Sens. 2006, 72, 1179–1188. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4–7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Qiu, S.; He, B.; Zhu, Z.; Liao, Z.; Quan, X. Improving Fmask cloud and cloud shadow detection in mountainous area for Landsats 4–8 images. Remote Sens. Environ. 2017, 199, 107–119. [Google Scholar] [CrossRef]
- Frantz, D.; Haß, E.; Uhl, A.; Stoffels, J.; Hill, J. Improvement of the Fmask algorithm for Sentinel-2 images: Separating clouds from bright surfaces based on parallax effects. Remote Sens. Environ. 2018, 215, 471–481. [Google Scholar] [CrossRef]
- Qiu, S.; Zhu, Z.; He, B. Fmask 4.0: Improved cloud and cloud shadow detection in Landsats 4–8 and Sentinel-2 imagery. Remote Sens. Environ. 2019, 231, 111205. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Helmer, E.H. An automatic method for screening clouds and cloud shadows in optical satellite image time series in cloudy regions. Remote Sens. Environ. 2018, 214, 135–153. [Google Scholar] [CrossRef]
- Candra, D.S.; Phinn, S.; Scarth, P. Cloud and cloud shadow removal of landsat 8 images using Multitemporal Cloud Removal method. In Proceedings of the 2017 6th International Conference on Agro-Geoinformatics, Fairfax, VA, USA, 7–10 August 2017; pp. 1–5. [Google Scholar]
- Lin, J.; Huang, T.Z.; Zhao, X.L.; Ding, M.; Chen, Y.; Jiang, T.X. A Blind Cloud/Shadow Removal Strategy for Multi-Temporal Remote Sensing Images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4656–4659. [Google Scholar]
- Racoviteanu, A.; Williams, M.W. Decision tree and texture analysis for mapping debris-covered glaciers in the Kangchenjunga area, Eastern Himalaya. Remote Sens. 2012, 4, 3078–3109. [Google Scholar] [CrossRef] [Green Version]
- Hollstein, A.; Segl, K.; Guanter, L.; Brell, M.; Enesco, M. Ready-to-use methods for the detection of clouds, cirrus, snow, shadow, water and clear sky pixels in Sentinel-2 MSI images. Remote Sens. 2016, 8, 666. [Google Scholar] [CrossRef] [Green Version]
- Lu, F.; Gong, Z. Construction of cloud-shadow-water mask based on Random Forests algorithm. Remote Sens. Land Resour. 2016, 28, 73–79. [Google Scholar]
- Ghasemian, N.; Akhoondzadeh, M. Introducing two Random Forest based methods for cloud detection in remote sensing images. Adv. Space Res. 2018, 62, 288–303. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Sun, L.; Zhu, X.; Yuan, Q.; Liu, L.; Cribb, M. Cloud detection for Landsat imagery by combining the random forest and superpixels extracted via energy-driven sampling segmentation approaches. Remote Sens. Environ. 2020, 248, 112005. [Google Scholar] [CrossRef]
- Dai, X.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Qian, M. Multiscale Location Attention Network for Building and Water Segmentation of Remote Sensing Image. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5609519. [Google Scholar] [CrossRef]
- Hughes, M.J.; Hayes, D.J. Automated detection of cloud and cloud shadow in single-date Landsat imagery using neural networks and spatial post-processing. Remote Sens. 2014, 6, 4907–4926. [Google Scholar] [CrossRef] [Green Version]
- Chai, D.; Newsam, S.; Zhang, H.K.; Qiu, Y.; Huang, J. Cloud and cloud shadow detection in Landsat imagery based on deep convolutional neural networks. Remote Sens. Environ. 2019, 225, 307–316. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1029–1032. [Google Scholar]
- Segal-Rozenhaimer, M.; Li, A.; Das, K.; Chirayath, V. Cloud detection algorithm for multi-modal satellite imagery using convolutional neural-networks (CNN). Remote Sens. Environ. 2020, 237, 111446. [Google Scholar] [CrossRef]
- Wieland, M.; Li, Y.; Martinis, S. Multi-sensor cloud and cloud shadow segmentation with a convolutional neural network. Remote Sens. Environ. 2019, 230, 111203. [Google Scholar] [CrossRef]
- Shendryk, Y.; Rist, Y.; Ticehurst, C.; Thorburn, P. Deep learning for multi-modal classification of cloud, shadow and land cover scenes in PlanetScope and Sentinel-2 imagery. ISPRS J. Photogramm. Remote Sens. 2019, 157, 124–136. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, D.; Weng, L.; Xia, M.; Lin, H. MBCNet: Multi-Branch Collaborative Change-Detection Network Based on Siamese Structure. Remote Sens. 2023, 15, 2237. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bibranch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 32–43. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. FENet: Feature enhancement network for land cover classification. Int. J. Remote Sens. 2023, 44, 1702–1725. [Google Scholar] [CrossRef]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel feature fusion lozenge network for land segmentation. J. Appl. Remote Sens. 2022, 16, 016513. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Weng, L.; Lin, H. Local Feature Search Network for Building and Water Segmentation of Remote Sensing Image. Sustainability 2023, 15, 3034. [Google Scholar] [CrossRef]
- Hu, K.; Li, M.; Xia, M.; Lin, H. Multi-scale feature aggregation network for water area segmentation. Remote Sens. 2022, 14, 206. [Google Scholar] [CrossRef]
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double Branch Parallel Network for Segmentation of Buildings and Waters in Remote Sensing Images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. Mcanet: A multi-branch network for cloud/snow segmentation in high-resolution remote sensing images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-branch network for cloud and cloud shadow segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/shadow segmentation based on multi-level feature enhanced network for remote sensing imagery. Int. J. Remote Sens. 2022, 43, 5940–5960. [Google Scholar] [CrossRef]
- Chen, Y.; Weng, Q.; Tang, L.; Wang, L.; Xing, H.; Liu, Q. Developing an intelligent cloud attention network to support global urban green spaces mapping. ISPRS J. Photogramm. Remote Sens. 2023, 198, 197–209. [Google Scholar] [CrossRef]
- Chen, Y.; Tang, L.; Huang, W.; Guo, J.; Yang, G. A Novel Spectral Indices-Driven Spectral-Spatial-Context Attention Network for Automatic Cloud Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3092–3103. [Google Scholar] [CrossRef]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and Cloud Shadow Refinement Segmentation Networks for Remote Sensing Imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Hu, K.; Zhang, D.; Xia, M. Cdunet: Cloud detection unet for remote sensing imagery. Remote Sens. 2021, 13, 4533. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Xia, M.; Wang, T.; Zhang, Y.; Liu, J.; Xu, Y. Cloud/shadow segmentation based on global attention feature fusion residual network for remote sensing imagery. Int. J. Remote Sens. 2021, 42, 2022–2045. [Google Scholar] [CrossRef]
- Yan, Z.; Yan, M.; Sun, H.; Fu, K.; Hong, J.; Sun, J.; Zhang, Y.; Sun, X. Cloud and cloud shadow detection using multilevel feature fused segmentation network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1600–1604. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2022, 37, 3155–3163. [Google Scholar] [CrossRef]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2736–2746. [Google Scholar]
- Zhang, S.; Weng, L. STPGTN–A Multi-Branch Parameters Identification Method Considering Spatial Constraints and Transient Measurement Data. Comput. Model. Eng. Sci. 2023, 136, 2635–2654. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yuan, Y.; Chen, X.; Chen, X.; Wang, J. Segmentation transformer: Object-contextual representations for semantic segmentation. arXiv 2019, arXiv:1909.11065. [Google Scholar]
- Li, Z.; Shen, H.; Liu, Y. HRC_WHU: High-Resolution Cloud Cover Validation Data; Wuhan University: Wuhan, China, 2019. [Google Scholar]
- Hughes, M.J.; Kennedy, R. High-Quality Cloud Masking of Landsat 8 Imagery Using Convolutional Neural Networks. Remote Sens. 2019, 11, 2591. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Parameters (M) | Flops (G) | PA (%) | MIoU (%) |
|---|---|---|---|---|
| ResNet50 | 27.00 | 4.95 | 96.58 | 92.18 |
| ResNet50 + CAB | 27.53 | 5.17 | 96.93 | 92.79 |
| ResNet50 + FCB + CAB | 43.53 | 7.94 | 97.25 | 93.60 |
| ResNet50 + FCB + CAB + SPA | 43.53 | 7.95 | 97.36 | 93.82 |
| ResNet50 + FCB + CAB + SPA + CFAB | 44.06 | 8.52 | 97.39 | 93.99 |
| Methods | Backbone | PA (%) | mP (%) | mR (%) | F1 (%) | MIoU (%) | FwioU (%) |
|---|---|---|---|---|---|---|---|
| SegNet [57] | VGG16 | 95.58 | 94.32 | 94.79 | 94.55 | 89.74 | 91.60 |
| U-Net [58] | VGG16 | 96.46 | 95.51 | 95.84 | 95.67 | 91.74 | 93.20 |
| FCN8s [59] | Resnet50 | 96.55 | 95.76 | 95.74 | 95.75 | 91.89 | 93.36 |
| DeepLabv3+ [60] | Resnet50 | 96.85 | 96.09 | 96.18 | 96.14 | 92.59 | 93.91 |
| PSPNet [61] | Resnet50 | 96.96 | 96.25 | 96.30 | 96.28 | 92.85 | 94.12 |
| HRNet [62] | HRNet-W48 | 97.09 | 96.16 | 96.74 | 96.45 | 93.17 | 94.38 |
| OCRNet [54] | HRNet-W48 | 97.30 | 96.63 | 96.80 | 96.71 | 93.66 | 94.76 |
| Ours | Resnet50 | 97.44 | 96.95 | 96.84 | 96.89 | 93.99 | 95.02 |
| Ours | Res2net50 | 97.48 | 97.03 | 96.88 | 96.95 | 94.10 | 95.10 |
| Methods | Urban (%) | Farmland (%) | Plant (%) | Water (%) | Wasteland (%) |
|---|---|---|---|---|---|
| SegNet | 85.12 | 81.76 | 83.96 | 84.50 | 87.60 |
| U-Net | 85.84 | 82.66 | 84.75 | 85.21 | 88.73 |
| FCN8s | 87.07 | 83.92 | 87.40 | 86.53 | 90.56 |
| DeepLabv3+ | 88.01 | 85.27 | 87.88 | 87.21 | 91.07 |
| PSPNet | 87.60 | 85.28 | 88.13 | 87.29 | 91.30 |
| HRNet | 88.61 | 85.11 | 89.64 | 88.12 | 92.25 |
| OCRNet | 89.22 | 85.40 | 90.05 | 88.30 | 93.77 |
| Ours | 90.38 | 85.98 | 90.74 | 88.94 | 93.90 |
| Methods | PA (%) | mP (%) | mR (%) | F1 (%) | MIoU (%) | FwioU (%) |
|---|---|---|---|---|---|---|
| SegNet | 94.73 | 94.63 | 94.54 | 94.58 | 89.74 | 89.99 |
| UNet | 95.94 | 95.86 | 95.81 | 95.84 | 92.01 | 92.20 |
| HRNet | 95.97 | 95.87 | 95.86 | 95.87 | 92.07 | 92.27 |
| FCN8s | 96.87 | 96.75 | 96.84 | 96.80 | 93.80 | 93.94 |
| DeepLabv3+ | 97.04 | 96.91 | 97.02 | 96.97 | 94.11 | 94.26 |
| OCRNet | 97.24 | 97.14 | 97.19 | 97.16 | 94.49 | 94.63 |
| PSPNet | 97.25 | 97.16 | 97.21 | 97.18 | 94.53 | 94.65 |
| Ours | 97.63 | 97.55 | 97.59 | 97.57 | 95.26 | 95.37 |
| Methods | PA (%) | mP (%) | mR (%) | F1 (%) | MIoU (%) | FwioU (%) |
|---|---|---|---|---|---|---|
| SegNet | 92.19 | 89.46 | 87.64 | 88.48 | 80.07 | 85.80 |
| PSPNet | 95.56 | 94.02 | 92.81 | 93.39 | 87.84 | 91.61 |
| UNet | 95.48 | 93.92 | 92.92 | 93.40 | 87.91 | 91.47 |
| FCN8s | 95.60 | 94.27 | 92.68 | 93.44 | 87.94 | 91.69 |
| DeepLabv3+ | 96.43 | 95.21 | 94.16 | 94.67 | 90.05 | 93.18 |
| HRNet | 96.60 | 95.15 | 94.90 | 95.03 | 90.67 | 93.51 |
| OCRNet | 96.79 | 95.66 | 94.76 | 95.20 | 90.97 | 93.85 |
| Ours | 96.90 | 95.76 | 95.03 | 95.39 | 91.31 | 94.05 |
| Methods | Clouds (%) | Cloud Shadows (%) | Snow (%) | Water (%) | Backgrounds (%) | Average (%) |
|---|---|---|---|---|---|---|
| SegNet | 81.71 | 59.67 | 89.28 | 78.92 | 90.75 | 80.07 |
| PSPNet | 89.42 | 75.77 | 93.33 | 85.98 | 94.72 | 87.84 |
| UNet | 88.57 | 74.22 | 93.48 | 88.61 | 94.68 | 87.91 |
| FCN8s | 89.59 | 75.97 | 93.41 | 85.95 | 94.75 | 87.94 |
| DeepLabv3+ | 91.45 | 80.31 | 94.50 | 88.27 | 95.72 | 90.05 |
| HRNet | 91.57 | 81.24 | 94.87 | 89.73 | 95.93 | 90.67 |
| OCRNet | 92.39 | 82.46 | 95.05 | 88.78 | 96.15 | 90.97 |
| Ours | 92.41 | 82.63 | 95.26 | 89.90 | 96.32 | 91.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, H.; Xia, M.; Zhang, D.; Lin, H. Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection. ISPRS Int. J. Geo-Inf. 2023, 12, 247. https://doi.org/10.3390/ijgi12060247
Ji H, Xia M, Zhang D, Lin H. Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection. ISPRS International Journal of Geo-Information. 2023; 12(6):247. https://doi.org/10.3390/ijgi12060247
Chicago/Turabian StyleJi, Huiwen, Min Xia, Dongsheng Zhang, and Haifeng Lin. 2023. "Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection" ISPRS International Journal of Geo-Information 12, no. 6: 247. https://doi.org/10.3390/ijgi12060247
APA StyleJi, H., Xia, M., Zhang, D., & Lin, H. (2023). Multi-Supervised Feature Fusion Attention Network for Clouds and Shadows Detection. ISPRS International Journal of Geo-Information, 12(6), 247. https://doi.org/10.3390/ijgi12060247