
Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data



Abstract
:1. Introduction
2. Related Work
2.1. Hadoop for Geospatial Data Processing
2.2. Auto-Sscaling Hadoop in the Cloud
3. Methods
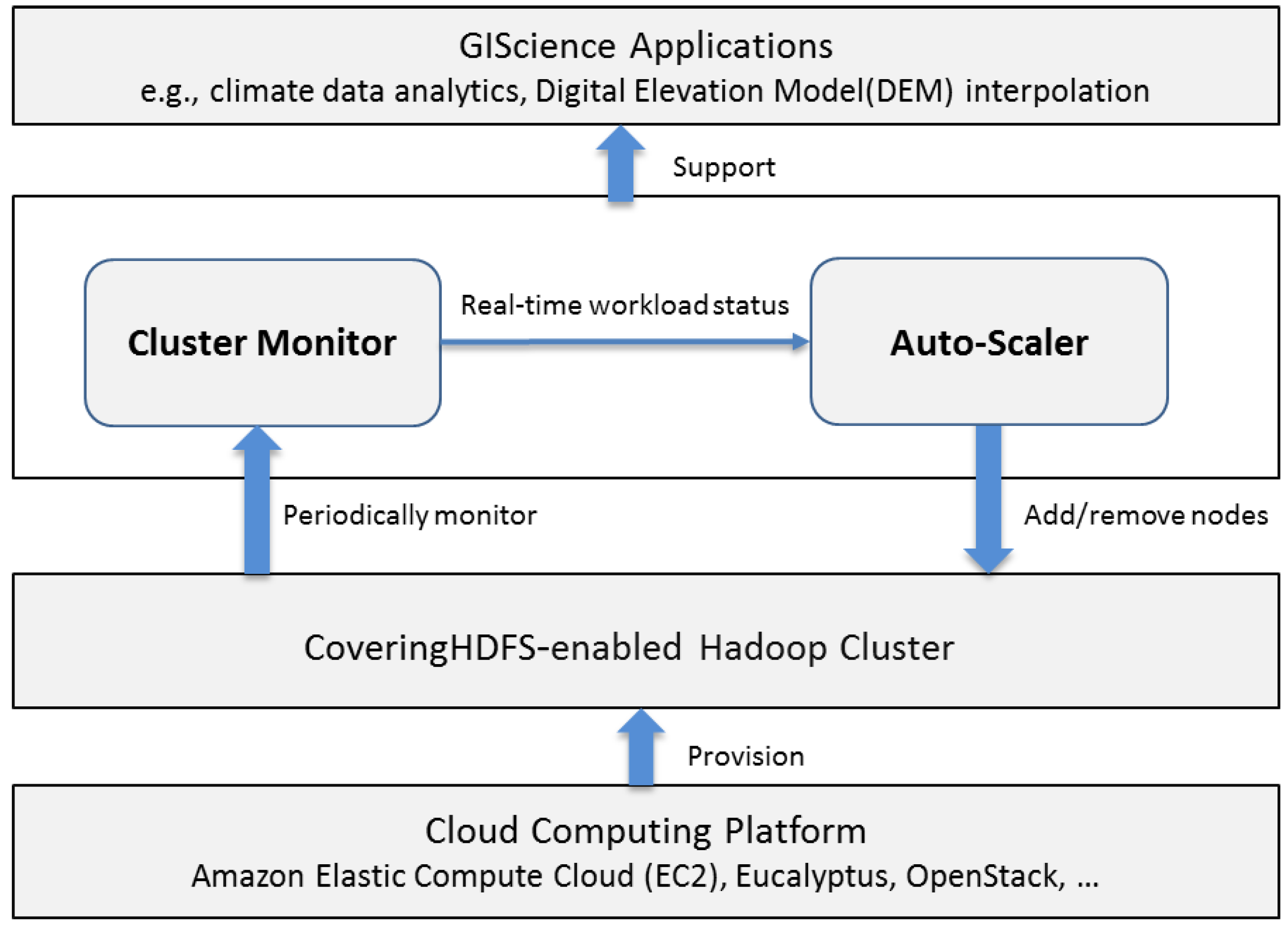
3.1. Auto-Scaling Framework
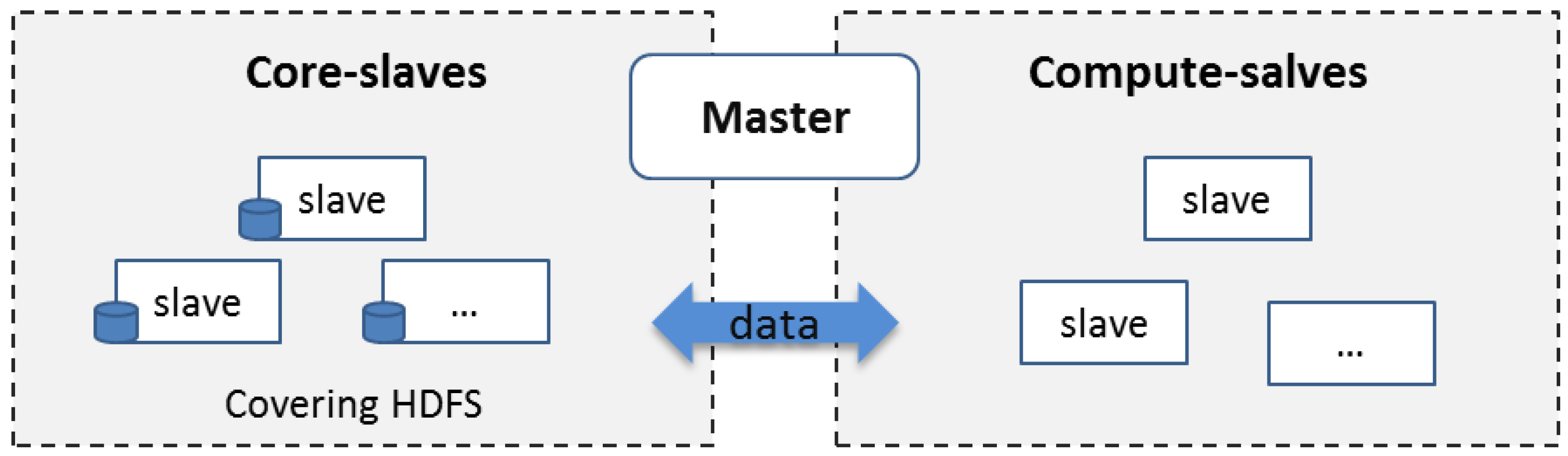
3.2. CoveringHDFS
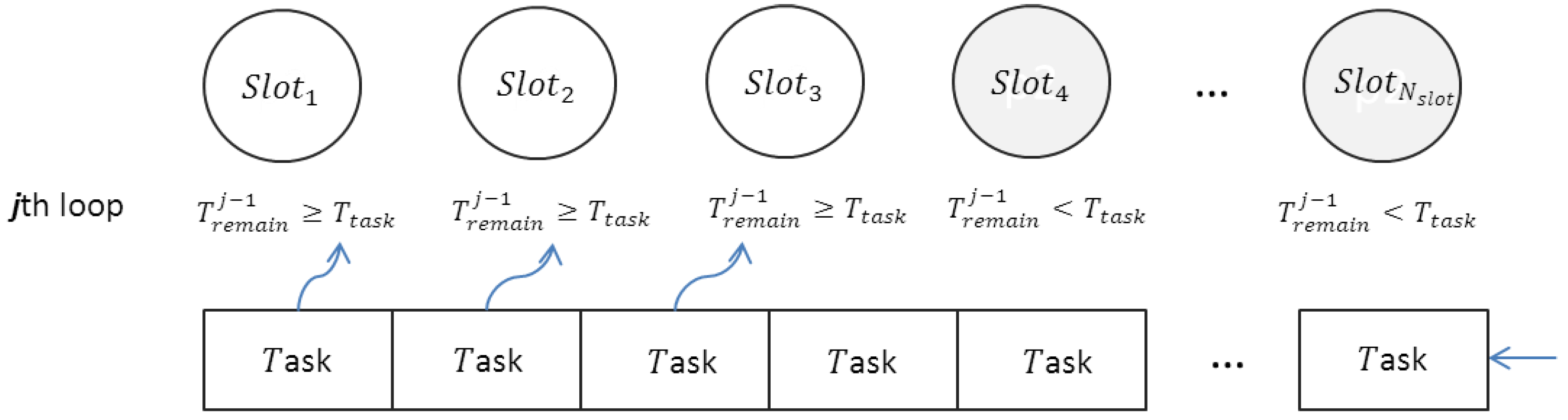
3.3. Auto-Scaling Algorithm
3.3.1. Scaling up
3.3.2. Scaling down
4. Auto-Scaling Prototype and Experimental Result
4.1. Prototype Implementation
4.2. Experimental Design
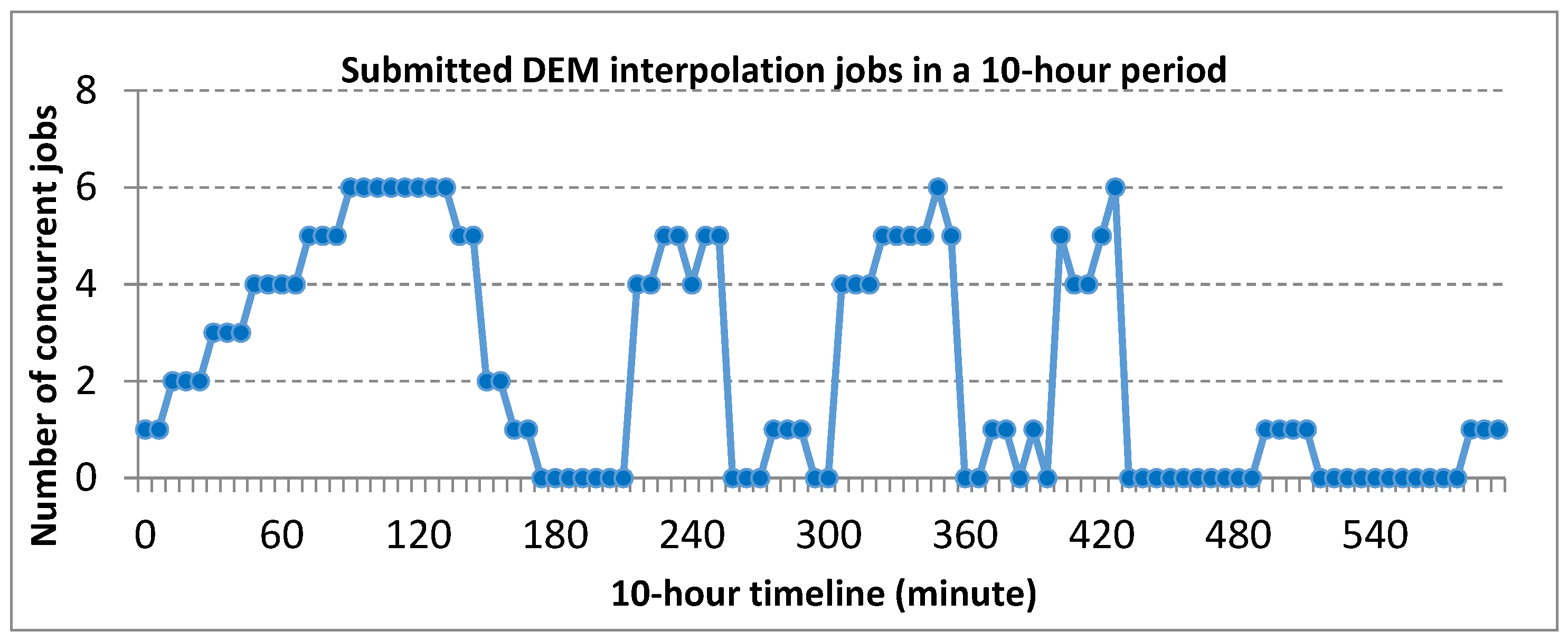
4.2.1. DEM Interpolation and Dynamic Workload Simulation
4.2.2. Hadoop Cluster Setup
4.3. Result and Discussion
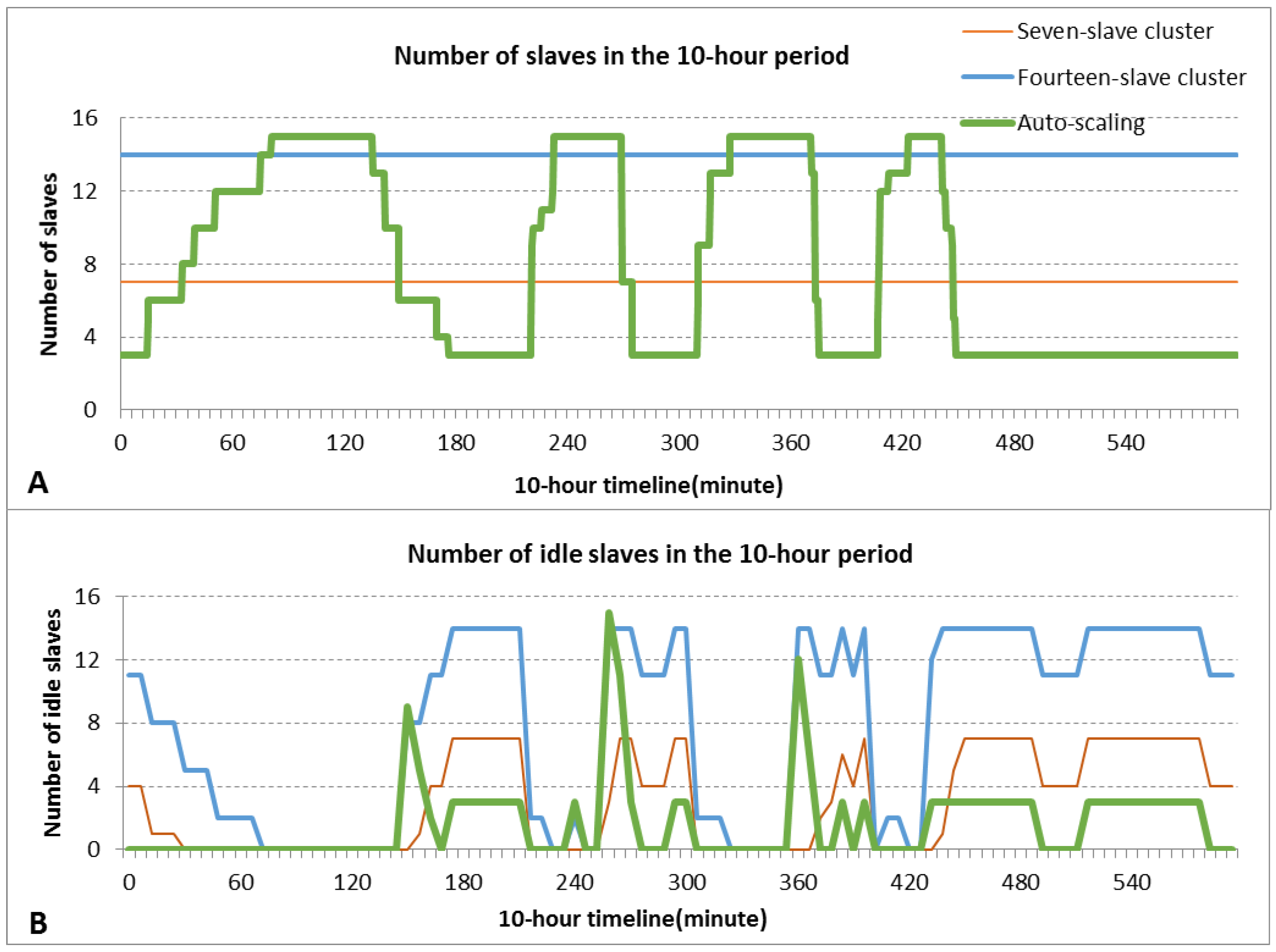
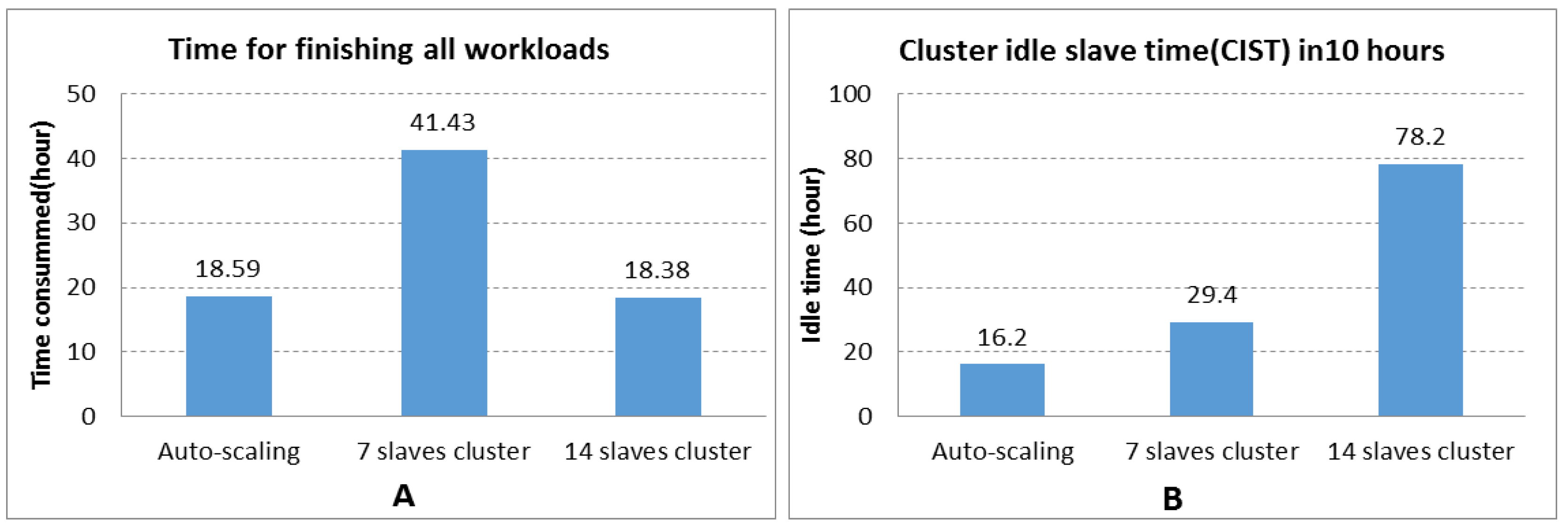
4.3.1. Performance
4.3.2. Resource Consumption
4.3.3. Data Locality
5. Conclusions
- The auto-scaling cluster was only allowed to scale up 12 slaves in our experiment. The auto-scaling capability could be better evaluated if we can scale up further with a larger cloud. In addition, we plan to further test the framework on different public cloud platforms, such as Amazon EC2.
- When implementing the framework in a public cloud, it is desirable to investigate how to integrate the cloud service cost model into the auto-scaling algorithm to further enhance the resource utilization. For example, the minimum billing cycle of Amazon EC2 is one hour; there is no need to terminate an idle slave if it is not at the end of a billing cycle.
- The Hadoop-related big data processing platforms such as Spark [39] are gaining increasing popularity. While the CoveringHDFS mechanism is able to work with those platforms as long as they use HDFS for data storage, the manner in which to adjust the MapReduce-based scaling algorithm for programming models warrants further investigation.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lee, J.G.; Kang, M. Geospatial big data: Challenges and opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Yang, C.; Wu, H.; Huang, Q.; Li, Z.; Li, J. Using spatial principles to optimize distributed computing for enabling the physical science discoveries. Proc. Natl. Acad. Sci. 2011, 108, 5498–5503. [Google Scholar] [CrossRef] [PubMed]
- Wang, S. A cyberGIS framework for the synthesis of cyberinfrastructure, GIS, and spatial analysis. Ann. Assoc. Am. Geogr. 2010, 100, 535–557. [Google Scholar] [CrossRef]
- Asimakopoulou, E. Advanced ICTs for Disaster Management and Threat Detection: Collaborative and Distributed Frameworks: Collaborative and Distributed Frameworks; IGI Global: Hershey, PA, USA, 2010. [Google Scholar]
- Yang, C.; Goodchild, M.; Huang, Q.; Nebert, D.; Raskin, R.; Xu, Y.; Fay, D. Spatial cloud computing: How can the geospatial sciences use and help shape cloud computing? Int. J. Digit. Earth 2011, 4, 305–329. [Google Scholar] [CrossRef]
- Karimi, H.A. Big Data: Techniques and Technologies in Geoinformatics; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Schnase, J.L.; Duffy, D.Q.; Tamkin, G.S.; Nadeau, D.; Thompson, J.H.; Grieg, C.M.; Webster, W.P. MERRA analytic services: Meeting the big data challenges of climate science through cloud-enabled climate analytics-as-a-service. Comput. Environ. Urban Syst. 2014. [Google Scholar] [CrossRef]
- Huang, Q.; Yang, C. Optimizing grid computing configuration and scheduling for geospatial analysis: An example with interpolating DEM. Comput. Geosci. 2011, 37, 165–176. [Google Scholar] [CrossRef]
- Buck, J.B.; Watkins, N.; LeFevre, J.; Ioannidou, K.; Maltzahn, C.; Polyzotis, N.; Brandt, S. SciHadoop: Array-based query processing in Hadoop. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, Seattle, DC, USA, 12–18 November 2011.
- Eldawy, A.; Mokbel, M.F. A demonstration of spatial Hadoop: An efficient MapReduce framework for spatial data. Proc. VLDB Endow. 2013, 6, 1230–1233. [Google Scholar] [CrossRef]
- Li, Z.; Hu, F.; Schnase, J.L.; Duffy, D.Q.; Lee, T.; Bowen, M.K.; Yang, C. A spatiotemporal indexing approach for efficient processing of big array-based climate data with MapReduce. Int. J. Geogr. Inf. Sci. 2016, 1–19. [Google Scholar] [CrossRef]
- Gao, S.; Li, L.; Li, W.; Janowicz, K.; Zhang, Y. Constructing gazetteers from volunteered big geo-data based on Hadoop. Comput. Environ. Urban Syst. 2014. [Google Scholar] [CrossRef]
- Li, Z.; Yang, C.; Jin, B.; Yu, M.; Liu, K.; Sun, M.; Zhan, M. Enabling big geoscience data analytics with a cloud-based, MapReduce-enabled and service-oriented workflow framework. PLoS ONE 2015. [Google Scholar] [CrossRef] [PubMed]
- Pierce, M.E.; Fox, G.C.; Ma, Y.; Wang, J. Cloud computing and spatial cyberinfrastructure. J. Comput. Sci. Indiana Univ. 2009. [Google Scholar] [CrossRef]
- Yang, C.; Raskin, R. Introduction to distributed geographic information processing research. Int. J. Geogr. Inf. Sci. 2009, 23, 553–560. [Google Scholar] [CrossRef]
- Xia, J.; Yang, C.; Liu, K.; Gui, Z.; Li, Z.; Huang, Q.; Li, R. Adopting cloud computing to optimize spatial web portals for better performance to support Digital Earth and other global geospatial initiatives. Int. J. Digit. Earth 2015, 8, 451–475. [Google Scholar] [CrossRef]
- Tu, S.; Flanagin, M.; Wu, Y.; Abdelguerfi, M.; Normand, E.; Mahadevan, V.; Shaw, K. Design strategies to improve performance of GIS web services. In Proceedings of the International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 5–7 April 2004.
- Schadt, E.E.; Linderman, M.D.; Sorenson, J.; Lee, L.; Nolan, G.P. Computational solutions to large-scale data management and analysis. Nat. Rev. Genet. 2010, 11, 647–657. [Google Scholar] [CrossRef] [PubMed]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Lin, F.C.; Chung, L.K.; Wang, C.J.; Ku, W.Y.; Chou, T.Y. Storage and processing of massive remote sensing images using a novel cloud computing platform. GISci. Remote Sens. 2013, 50, 322–336. [Google Scholar]
- Krishnan, S.; Baru, C.; Crosby, C. Evaluation of MapReduce for gridding LIDAR data. Cloud Comput. Technol. Sci. 2010. [Google Scholar] [CrossRef]
- Aji, A.; Wang, F.; Vo, H.; Lee, R.; Liu, Q.; Zhang, X.; Saltz, J. Hadoop GIS: A high performance spatial data warehousing system over MapReduce. Proc. VLDB Endow. 2013, 6, 1009–1020. [Google Scholar] [CrossRef]
- Leverich, J.; Kozyrakis, C. On the energy (in) efficiency of Hadoop clusters. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 61–65. [Google Scholar] [CrossRef]
- Kaushik, R.T.; Bhandarkar, M. GreenHDFS: Towards an energy-conserving storage-efficient, hybrid Hadoop compute cluster. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 23–25 June 2010.
- Maheshwari, N.; Nanduri, R.; Varma, V. Dynamic energy efficient data placement and cluster reconfiguration algorithm for MapReduce framework. Futur. Gener. Comput. Syst. 2012, 28, 119–127. [Google Scholar] [CrossRef]
- Mell, P.; Grance, T. The NIST definition of cloud computing. Natl. Ins. Stand. Technol. 2009, 53, 1–7. [Google Scholar]
- Getting Started with Hadoop with Amazon’s Elastic MapReduce. Available online: http://www.slideshare.net/DrSkippy27/amazon-elastic-map-reduce-getting-started-with-hadoop (accessed on 20 September 2016).
- Baheti, V.K. Windows azure HDInsight: Where big data meets the cloud. IT Bus. Ind. Gov. 2014. [Google Scholar] [CrossRef]
- Herodotou, H.; Dong, F.; Babu, S. No one (cluster) size fits all: automatic cluster sizing for data-intensive analytics. In Proceedings of the 2nd ACM Symposium on Cloud Computing, Cascais, Portugal, 26–28 October 2011.
- Agrawal, D.; Das, S.; Abbadi, A. Big data and cloud computing: Current state and future opportunities. In Proceedings of the 14th International Conference on Extending Database Technology, Uppsala, Sweden, 21–25 March 2011.
- Wang, Y.; Wang, S.; Zhou, D. Retrieving and Indexing Spatial Data in the Cloud Computing Environment; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Huang, Q.; Li, Z.; Liu, K.; Xia, J.; Jiang, Y.; Xu, C.; Yang, C. Handling intensities of data, computation, concurrent access, and spatiotemporal patterns. In Spatial Cloud Computing: A Practical Approach; Yang, C., Huang, Q., Li, Z., Xu, C., Liu, K., Eds.; CRC Press: Boca Raton, FL, USA, 2015; Volume 16, pp. 275–293. [Google Scholar]
- Li, Z.; Yang, C.; Huang, Q.; Liu, K.; Sun, M.; Xia, J. Building model as a service for supporting geosciences. Comput. Environ. Urban Syst. 2014. [Google Scholar] [CrossRef]
- Röme, T. Autoscaling Hadoop Clusters. Master’s Thesis, University of Tartu, Tartu, Estonia, 2010. [Google Scholar]
- Gandhi, A.; Thota, S.; Dube, P.; Kochut, A.; Zhang, L. Autoscaling for Hadoop clusters. In Proceedings of the NSDI 2016, Santa Clara, CA, USA, 16–18 March 2016.
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop distributed file system. IEEE Comput. Soc. 2010. [Google Scholar] [CrossRef]
- Amazon EC2 Pricing. Available online: https://aws.amazon.com/ec2/pricing/ (accessed on 22 September 2016).
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 10. [Google Scholar]
- Yang, C.; Raskin, R.; Goodchild, M.; Gahegan, M. Geospatial cyberinfrastructure: Past, present and future. Comput. Environ. Urban Syst. 2010, 34, 264–277. [Google Scholar] [CrossRef]
- Wang, S.; Armstrong, M.P. A theoretical approach to the use of cyberinfrastructure in geographical analysis. Int. J. Geogr. Inf. Sci. 2009, 23, 169–193. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster Type | Master | Slaves | HDFS |
|---|---|---|---|
| Auto-scaling cluster | One medium instance | Dynamic, start with three core-slaves with medium instances, can scale up 12 compute-slaves with small instances | CoveringHDFS, starting with 3 core-slaves |
| Seven-slave cluster | One medium instance | Static, 7 slaves with three medium instances and four small instances | Traditional HDFS with 7 slaves |
| Fourteen-slave cluster | One medium instance | Static, 14 slaves with three medium instances and 11 small instances | Traditional HDFS with 14 slaves |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Yang, C.; Liu, K.; Hu, F.; Jin, B. Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data. ISPRS Int. J. Geo-Inf. 2016, 5, 173. https://doi.org/10.3390/ijgi5100173
Li Z, Yang C, Liu K, Hu F, Jin B. Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data. ISPRS International Journal of Geo-Information. 2016; 5(10):173. https://doi.org/10.3390/ijgi5100173
Chicago/Turabian StyleLi, Zhenlong, Chaowei Yang, Kai Liu, Fei Hu, and Baoxuan Jin. 2016. "Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data" ISPRS International Journal of Geo-Information 5, no. 10: 173. https://doi.org/10.3390/ijgi5100173
APA StyleLi, Z., Yang, C., Liu, K., Hu, F., & Jin, B. (2016). Automatic Scaling Hadoop in the Cloud for Efficient Process of Big Geospatial Data. ISPRS International Journal of Geo-Information, 5(10), 173. https://doi.org/10.3390/ijgi5100173