3.1. The Study Area and Datasets
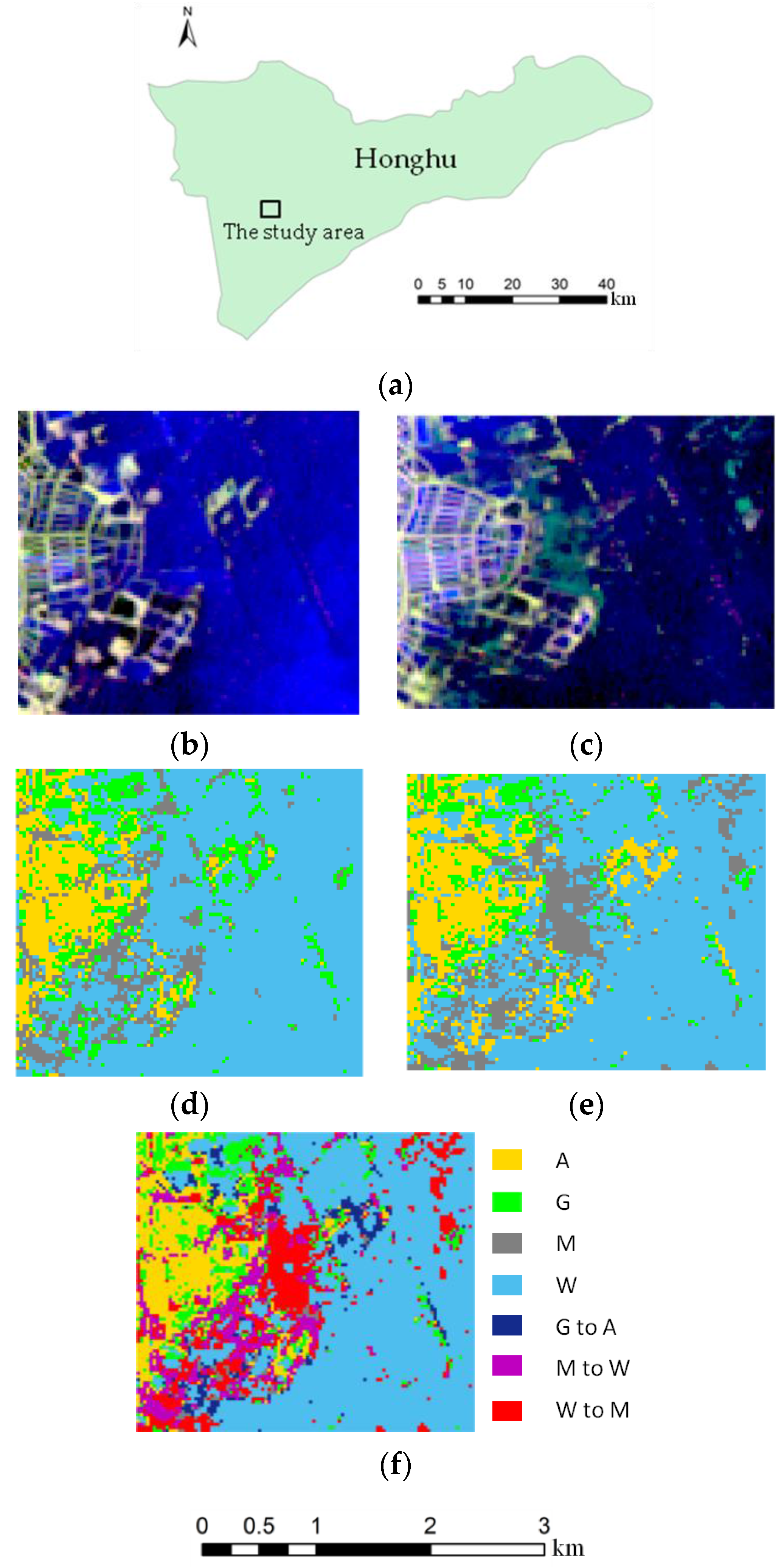
Honghu municipality, Hubei Province, China, which is shown in
Figure 1a, is situated in the north of the middle reaches of the Yangtze River and the southeast of the Jianghan Plain. It spans N Latitude
and E Longitude
, enjoys a subtropical humid monsoon climate and features lowlands with elevations mostly in the range of 23 m to 28 m above mean sea level. About 30% of its total areas are water bodies comprising a dense network of rivers, streams, lakes and aqueducts (interestingly, both “hu” in “Honghu” and “Hu” in “Hubei” mean lakes in Chinese). Precipitation occurs mostly in the spring and summer, resulting in frequent floods.
Historically, arable land and water bodies are Honghu’s major land resources. From 2011, there was about 40% to 60% less rainfall in the middle and lower reaches of the Yangtze River. Honghu faced the danger of lakes drying up. There were significant changes in land cover types there due to excessive reclamation and cultivation and the situation of more people and less land, such as the transitions from water bodies to mixed land and from natural vegetation (e.g., grasslands) to arable land, suggesting ecological and environmental degradation. With the implementation of lake protection measures by encouraging land reclamation, improving land resources utilization and developing water resources from 2012 through 2015, mixed land cover, which was previously un-used, was gradually restored to water bodies and wetlands. This helped to meet local demands for water resources and restore local ecological environment.
Two sub-scene Landsat ETM+ images of Honghu municipality, flown on 17 May 2012 (Time 1) and 8 August 2013 (Time 2) with Bands 1 to 5 and 7 at 30-m resolution, respectively, were used to derive land cover change information. Composite images for the 2012 and 2013 sub-scene Landsat ETM+ images using Bands 5, 4 and 3 are shown in
Figure 1b,c, respectively. The rectangular study area, which is marked in
Figure 1a, covers 9964 pixels (94 rows by 106 columns), each of a size of 30 m by 30 m.
Given the aforementioned characteristics of the study area (and land use therein) and the limited spatial resolution of the satellite images employed, for studies of local land cover and its dynamics, we adopted a four-class classification scheme: arable land, grass land, mixed land and water bodies. The mixed land cover type includes abandoned lands and may represent a mixture of all candidate land cover types, which are not easy to discern from satellite image data alone. The type of water bodies includes wetlands and is thus likely a mixture of wetlands with growing habitats and water bodies, per se.
In change detection based on post-classification comparison, images of Times 1 and 2 were classified separately, generating classification maps for Times 1 and 2, as shown in
Figure 1d,e, respectively. The classification maps were then compared to create a change map with specific “from-to” change information. A land cover change map with 16 possible combinations of “from-to” change information could be derived for a single-date four-class classification scheme: arable, grass, mixed and water. As there are some non-existing and unlikely change categories, we only kept 7 categories in the final land cover change map, including 4 unchanged or persistent classes and 3 change classes, as shown in
Figure 1f.
The 3 change classes shown in
Figure 1f are grass land to arable land, mixed land cover to water bodies and water bodies to mixed land cover. Explanations for these changes are: (1) some grasslands changed to arable land because of the increasing demand for agriculture (due to pressure to feed people on limited agricultural land); (2) due to decreased rainfalls during the period, parts of the lakes started to dry out, leading to increased mixed land cover; and (3) ecological restoration led to some restored water bodies from previously-abandoned mixed land.
Reference data corresponding to the image data were collected from a combination of field visits and photo-interpretation based on high (spatial) resolution images. Reference cover types for sampled sites in 2013 were ground checked on several dates in October, 2013, while those for 2012 were confirmed using photo-interpretation based on the high-resolution images considered to be in the temporal proximity of the 2012 ETM+ image subset. Photo interpretation was assisted by field surveys and local knowledge to ensure reasonable accuracy in the acquired reference data. The class labeling of all sample locations, whether single-date cover types or bi-temporal change types, were double-checked, with those deleted if the labeling was questionable. Reference data collected were used to determine whether the corresponding pixels on the land cover change map were correctly classified or not.
We should follow statistical principles regarding spatial sampling [
28] for collecting references samples, which were used for building models and validating the built models (for local accuracy prediction), respectively. The former set of samples were called training samples, the latter testing samples (which were for the comparison of alternative methods and will be addressed in
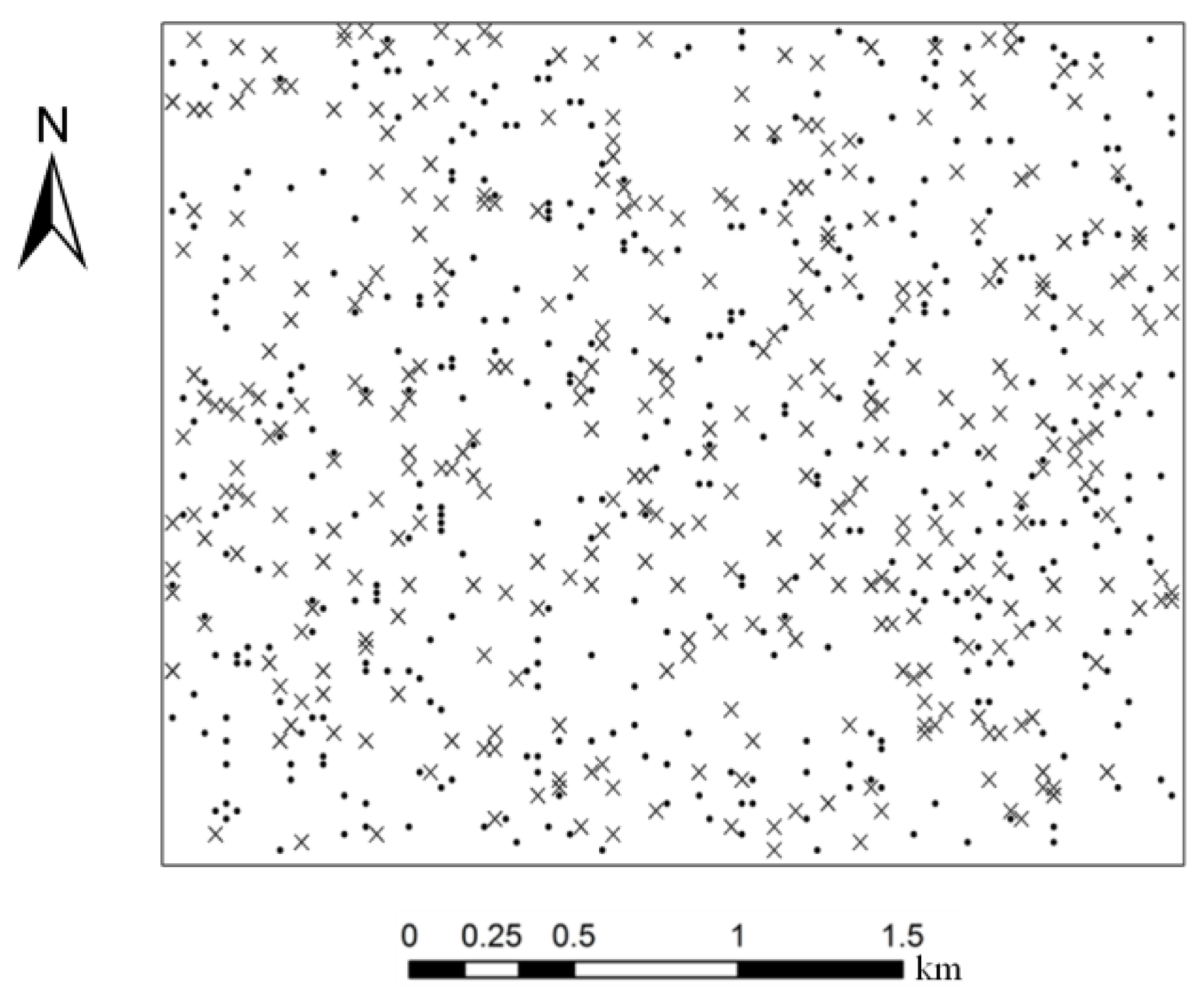
Section 3.3), in line with the tradition in remote sensing image classification. For collecting both training and testing samples, sampling was carried out using class stratification, with each map class sampled at a fixed proportion or in minimum numbers in the case of minority classes. We set 25 as the minimum number of sample points for minority classes (e.g., the mixed cover type), resulting in 400 and 350 samples for training and testing, respectively. Numbers of samples for individual classes are shown in
Table 1, while their distributions are shown in
Figure 2.
Testing of the randomness of sample locations was performed based on the “spatial statistic tool” in ArcGIS software system. Using the module of “analyzing patterns”, the Z-test was applied to determine whether the average distance to the nearest neighbors was significantly different from the mean random distance. Z-scores of 0.72 and 0.85 were obtained for the training and testing samples, respectively, which correspond to p-values of 0.46 and 0.39, respectively. Thus, the null hypothesis is accepted that the pattern of the two sets of samples is random at a significance level α = 0.05.
There were a set of 215 extra samples that were used for testing the effectiveness of adaptive sampling by locating a number of further training samples (say 30) according to SEs evaluated at candidate sample locations. This set of 215 samples was set aside, because the so-called adaptive sampling was compared to a random sampling alternative, which requires a larger pool for randomness in sample locations. We will describe this in
Section 3.2.
3.2. Results
Based on the training samples, we constructed an error matrix. It was summarized to derive PCC and users’ accuracies for individual classes, as shown in
Table 2.
Simple kriging was used to predict the probabilities of correct classification at unsampled locations from training samples. The global mean of RF
I indicating classification correctness was assumed to be the PCC measure estimated from training samples, as shown in
Table 2. The variogram model for RF
I was fitted with indicator data, which coded the (in)correctness in change detection as 1/0. The surface of the probabilities of correct classification at individual pixels is shown in
Figure 3a, where it is apparent that predicted probabilities are more similar to sampled values in closer proximity to sampled locations while they appear uniform elsewhere due to the relatively short influence range indicated by the variogram model (fitted with indicator training data) and the nature of simple kriging. As understood, simple kriging predictions will be the known mean value at locations where no sample data are within the specified search radius or where sample data are beyond the influence range. The variogram range was 2 pixels for the datasets here, with the search radius set to equal the range parameter. There were 6967 unsampled locations (i.e., pixels to be predicted), which were beyond the influence range of sample data and, hence, assigned the mean value, which is 73.25%, as shown in
Table 1. Consequently, there was a uniform appearance of predicted probabilities at the majority of unsampled locations, as shown in
Figure 3a, although local variability in predicted values can be seen clearly by a properly-enlarged version of
Figure 3a (or zooming in its softcopy). Kriging variance was also computed, generating a surface showing SEs (the squared root of kriging variance) at individual locations, as shown in
Figure 4a, which depicts the typical appearance of kriging variance: SEs increase with greater distance from sampled locations.
For logistic regression, land cover change class (
Class), block contiguity size (
L10
B), heterogeneity (
HET), dominance (
DMG) and probability vector of class occurrences in the focal neighborhood (
PROB = (
p1(
x),
p2(
x),…,
p6(
x))
T) were used as covariates in different combinations (as shown in
Table 3) to predict per-pixel probabilities of correct change categorization.
Class was coded by 6 binary variables to indicate the presence of one of the 7 classes (as there is one redundancy in the coding of classes).
PROB represents the probabilities of individual classes in the focal neighborhood of each pixel (note there is also one redundancy in the probabilities of 7 possible classes as their sum equals 1.0). The models tested are shown in
Table 3. Model numbers indicate how many sets of covariates (in addition to the intercept
) are employed for logistic regression: Models 1a to 1e account for the effects of
Class,
L10
B,
HET,
DMG and
PROB on the accuracy of change categorization, respectively; Models 2a to 2d accommodate the effects of
L10
B,
HET,
DMG and
PROB, respectively
, when
Class is already taken into account; Models 3a to 3c account for the effects of
L10
B,
HET and
PROB, respectively, when
Class and
DMG are already incorporated; Models 4a and 4b seek to quantify the effects of all
L10
B and
HET, respectively, when
Class,
DMG and
PROB are already included. In other words, the addition of
L10
B or
HET to Model 3c creates Model 4a or 4b, as shown in
Table 3.
An exhaustive model selection procedure was applied for finding the model containing the highest number of significant (at α = 0.01) explanatory variables. At each step in the procedure, the significance of the addition of a covariate to a model was tested. The difference between the deviances of two models follows a distribution, where df is the number of covariates additional to those shared by the two models. A -test can thus be used to test if adding these df variables to the model significantly improves the fit of the model.
Table 4 shows the significance testing regarding the improvement of the fit of the models by adding an additional covariate (or set of covariates, as for
Class and
PROB)
F+1. As shown by
Table 4, all of the sets of covariates were significant at
= 0.01. The impact of local pattern indices (
L10
B,
HET,
DMG and
PROB) was relatively small, but significant (at
= 0.01) if the model contained
Class, which indicates that part of the impact of these variables was already accounted for by
Class.
DMG was the most significant at
= 0.01 if
Class were already in the model. Therefore, the analysis was continued with
Class and
DMG. Adding
L10
B or
HET to a model containing
Class and
DMG was not significant at α = 0.01. Adding
PROB to a model with
Class and
DMG (Model 3c) was significant at
= 0.1. Finally, it was tested that adding to Model 3c covariate
L10
B or
HET would not significantly (at α = 0.1 or 0.01) improve the fit. Thus, Model 3c (1&
Class&
DMG&
PROB) was the model containing the highest number of significant covariates.
With Model 3c (1&
Class&
DMG&
PROB) selected using significance testing as above, logistic regression was performed using this model for the pixel-level prediction of classification accuracy. A probability surface was generated assuming spatial independence in binary samples of (in)correct classification, as shown in
Figure 3b. Furthermore, SEs in logistic predictions were computed using Equation (15), with the resulting map of SEs shown in
Figure 4b.
As described in
Section 2.3, binary data indicating the (in)correctness in change categorization are often spatially correlated. A challenge in logistic regression involving spatially-correlated binary data is to model spatial dependence in binary response data while estimating regression coefficients β′s. For this, an iterative procedure was undertaken to estimate both logistic model coefficients and variogram parameters via standardized residuals. Upon convergence of the estimates of variogram model parameters and logistic model coefficients, we obtained variogram model parameter values (as shown in
Table 5, the final set of parameters values) and logistic model coefficients β′s. β′s were used to predict pixel-level accuracies of change categorization with spatial dependence accommodated. Furthermore, standard errors can be estimated using Equation (15). The predicted accuracies and associated SEs are shown in
Figure 3c and
Figure 4c, respectively. The differences between the results obtained by logistic regression with spatial correlation accommodated and those without in terms of predicted probabilities and prediction errors are hardly appreciable. The reason is that the range of spatial correlation is just at the scale of about 3 pixels, far less than the average spacings between sampled locations.
After logistic regression, the residuals of logistic regression at sample pixels were used for estimating corrections to regression predictions through simple kriging and then added to the regression predictions (i.e., local means,
) to obtain the corrected probabilistic measures of classification accuracies for individual pixels. Equations (21) and (22) were the formulas applied for computing the corrected probabilities of correct classification and the corresponding standard errors, respectively. For kriging of regression residuals, two approaches were implemented: one without consideration for spatial correlation in logistic regression (
Table 5, the initial set of variogram parameter values) and the other with consideration for spatial correlation therein, as shown in
Section 2.3 (see
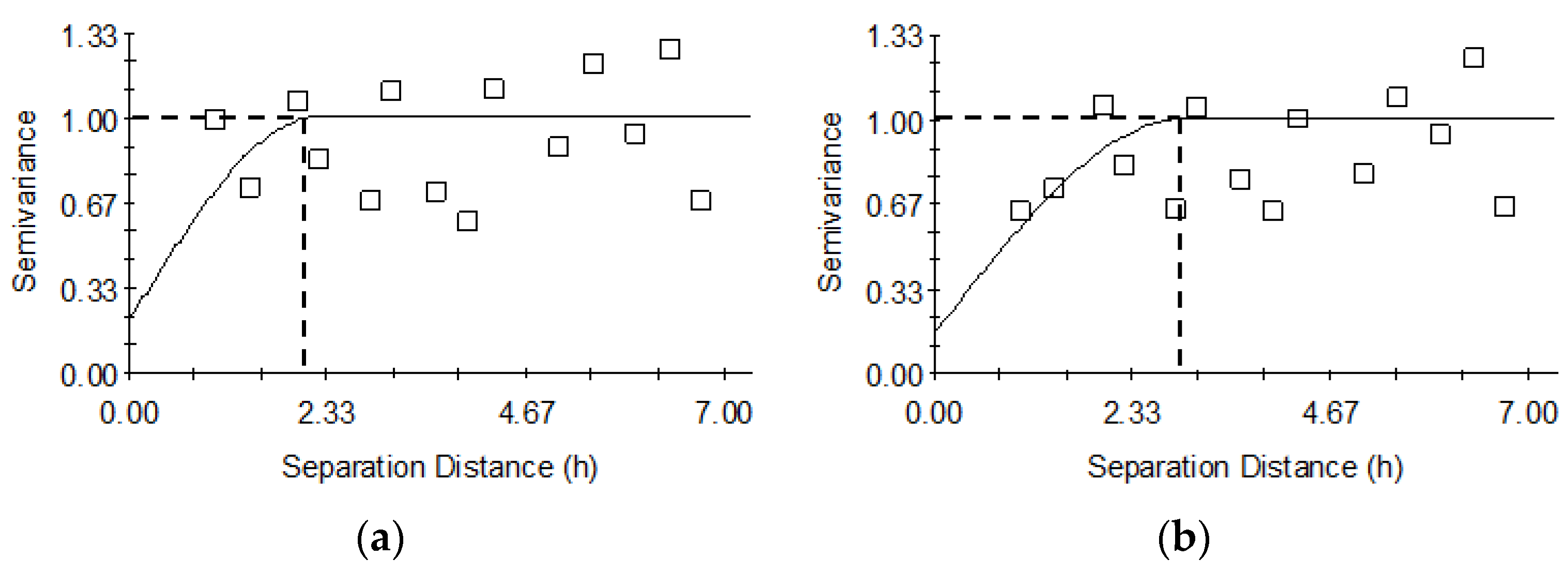
Table 5, the final set of variogram parameter values as mentioned previously). To aid the interpretation of the results,
Figure 5a shows variogram model parameters with no spatial correlation incorporated in logistic regression (corresponding to the initial set of parameters in
Table 5), while
Figure 5b shows variogram model parameters fitted iteratively with those of logistic regression where spatial correlation was considered (pertaining to the final set of parameters in
Table 5). The sills shown in
Figure 5a,b, which are the sum of nugget and structural variances, were set to 1.0 because standardized residuals were used to compute experimental variograms. Results with the former were meant to provide a baseline for the latter, which is computationally more expensive due to the iteration involved in parameter estimation and variogram modeling.
For the former, the map depicting corrected probabilities of correct change categorization and the SEs in the corrected probabilistic measures are shown in
Figure 3d and
Figure 4d, respectively. For the latter, the maps depicting corrected probabilities and their SEs are shown in
Figure 3e and
Figure 4e, respectively. Unsurprisingly, the results shown in pairs (i.e.,
Figure 3b,c and
Figure 3d,e) indicate no apparent differences. This visual interpretation will be supported with testing results in the next subsection.
Having undertaken experiments about significant covariates for logistic regression and the advantages of logistic-regression-kriging (with or without full treatment of spatial correlation in the estimation of variogram model parameters and regression coefficients) against regression or kriging alone, we turn to the effects of adaptive sampling guided by uncertainty measures (i.e., SEs) in current local accuracy predictions (based on existing training sample data). To test the effectiveness of adaptive sampling (it is labeled so because further samples are selected according to SEs in existing accuracy predictions), we used the pool of the extra 215 samples as the population to get some further training samples. Adaptive sampling was actually undertaken based on the results obtained by logistic-regression-kriging with or without fuller treatment of spatial correlation. We selected 30 further training samples, whose SEs were significantly larger than the rest in the set of 215 samples. For comparison with adaptive sampling pursued here, we also applied stratified random sampling (regardless of SEs) based on the same pool of extra 215 samples to get 30 random training samples. Two sampling approaches and two sets of prior logistic-regression-kriging results gave rises to four more sets of results. These four prediction results are shown in
Figure 3f to
Figure 3i, while their corresponding maps of SEs are shown in
Figure 4f to
Figure 4i. Clearly, SEs shown in
Figure 4f,g and
Figure 4h,i indicate a slight decrease as compared to those shown in
Figure 4d,e, respectively.
3.3. Testing
The performance of the nine different methods described previously for accuracy prediction can be evaluated by comparing predicted values
with actual observations
at 350 testing sample locations using the following four measure: mean error (
ME), mean absolute error (
MAE), root mean square error (
RMSE) and sums-of-squares (
). They are computed as follows:
where
nt is the number of testing samples and
is the mean of observed values. As recommended in the literature,
measures the proportion of explained variation by logistic regression [
29]. As the predictions of probabilities of (in)correct classification can be transformed to indicator data at the threshold of 0.5, we can also compute measures of PCCs to assess the accuracy of predictions. These measures were computed for the nine prediction methods, as presented in
Table 6. The results for the null model, which assigns 73.25% (the PCC estimate from
Table 2) as the prediction of accuracy for all pixels, are used as the baseline for the methods shown in
Table 6.
As seen from
Table 6, all methods register negative
ME values (i.e.,
ME < 0). This suggested that all of the methods of prediction used here over-estimated accuracy in change categorization (as observed values < predicted values). Because of unbiasedness in kriging, the
ME value of predictions by indicator kriging is the closest to 0.
As indicated by
Table 6, there is a tendency of better performances, as demonstrated by decreasing
MAEs and
RMSEs, but increasing PCCs and
for methods shown top down in the rows in
Table 6. In particular, as shown in
Table 6, indicator kriging is the worst at predicting local accuracies, while logistic-regression-kriging accommodating spatial correlation was the best. Note that the null model, which sets a baseline for all other methods tested, was worse than any of the other methods tested, as shown in
Table 6.
However, there are only modest gains in accuracy achieved by logistic-regression-kriging accommodating spatial correlation as opposed to the alternative implementation without considering spatial correlation. This is also true of logistic regression with spatial correlation considered as opposed to that without. The trade-off between computation cost and accuracy gain in prediction accuracy is thus important. Map users must decide whether the extra cost involved in regression-kriging is justifiable with the modest gains in prediction accuracy.
It should be noted that adequate reference samples are always important for ensuring reasonable accuracy in predictions (about local classification accuracies) by the methods tested here regardless of their sophistication. Given a specific sample size, the sample design will be important for optimum predictions. As mentioned previously, SEs maps shown in
Figure 4 could be used to locate densification training samples to facilitate the developments of sampling strategies for accurate yet efficient characterization of classification accuracy, as ground sampling is often expensive. We tested the results (shown in subfigures (f) to (i)) obtained by adding extra training samples (adaptive and random modes), using the same testing samples. The testing statistics are listed in
Table 6’s lower block of rows regarding the effects of extra training samples. They indicate that adaptive sampling for extra training samples is more cost-effective than random sampling. For instance, for the case of combined logistic-regression-kriging with the treatment of spatial correlation in regression, 7.5% more training samples led to about 8.8% and 57.3% increases in prediction accuracy, as measured by PCCs and
, respectively. In comparison, for random sampling, the same increase in training sample size led to only about 2.0% and 27.5% increases in prediction accuracy, as measured by PCCs and
, respectively The relationships between uncertainty-informed adaptive sampling and prediction performances should be studied further, although this is beyond the scope of this paper.
3.4. Discussion
The proposed methods for mapping local accuracies in land cover change maps can be usefully explored in combination with work on landscape dynamics monitoring and modelling, such as that described by Millington et al. [
1] and Rutherford et al. [
2], and related research efforts [
28,
30,
31,
32]. Firstly, results from maps of predicted changes using methods developed in [
1,
2] may well be evaluated with respect to their local accuracies by using the methods proposed in this paper. This would provide useful information about local variations of accuracies in predicted changes, which would in turn be valuable for improving model performances. Secondly, the accuracies of the predicted change maps using models developed in [
1,
2] are subject not only to model performances, but also accuracies of the input datasets that are used as covariates in modeling. If other categorical maps are included as covariate map layers, it is possible to apply the methods proposed in this paper to quantify their local accuracies, which can be used along with information about accuracies in other types of input maps to analyze inaccuracies from the input, through the modeling process, to the output. Thirdly, inaccuracies in reference data are yet another dimension of the accuracy issues raised here in this paper and in related literature, such as Wickham et al. [
30]. Reference data imperfection should be examined so that we have a clearer picture of inaccuracies in the gathering and processing of land cover information and in the broader context of landscape dynamics modeling. Fourthly, the issue of scale raised in the literature, such as Millington et al. [
1], Zhang et al. [
15] and Pontius et al. [
31], should be considered for further developments of the methods proposed here in this paper, given that the proposed methods are designed to work on the local scale (focal to be exact) and may not be linearly translatable to coarser scales, as discussed previously in
Section 2.2. Fifthly, we should be aware of the limitations of single-date map comparisons between years, as pointed by Bontemps et al. [
32], and promote time series analysis in landscape change monitoring and dynamics modelling, seeking to account for temporal dependence and
phenology in data analysis and modeling. Lastly, sampling design [
28] remains essential for accuracy characterization, especially for change analysis and dynamics modeling, no matter how sophisticated the methods for regression, kriging and others become. The adaptive sampling strategy preliminarily developed and tested in this paper should be explored further for large-scale problem-solving and in operational settings.
The methods tested in this paper are suitable for predicting local classification accuracies, which, however, cannot be directly used for computing accuracies in derivative products or analyses, such as those for landscape ecology, unless we are willing to assume independence among RVs representing classification (in)correctness at individual locations. To accommodate the spatial dependence existing among these RVs, geostatistical simulation should be applied [
33]. For instance, simulation approaches are needed for: (1) the determination of local accuracies in coarsened and object-based [
34] land cover change maps based on maps of finer resolution, as neighboring pixels in fine-resolution maps are likely spatially correlated in terms of misclassification; (2) the rigorous quantification of SEs in predicted local accuracies, especially when normality cannot be assumed for the small samples of binary data; (3) the error propagation in area estimates that are likely to involve counting numbers of pixels belonging to certain classes, where pixels close by cannot be assumed independent; and (4) the other ecological modeling and application scenarios where land cover change maps are part of the input data. These will form topics for further research.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}