
A New Look at Public Services Inequality: The Consistency of Neighborhood Context and Citizens’ Perception across Multiple Scales



Abstract
:1. Introduction
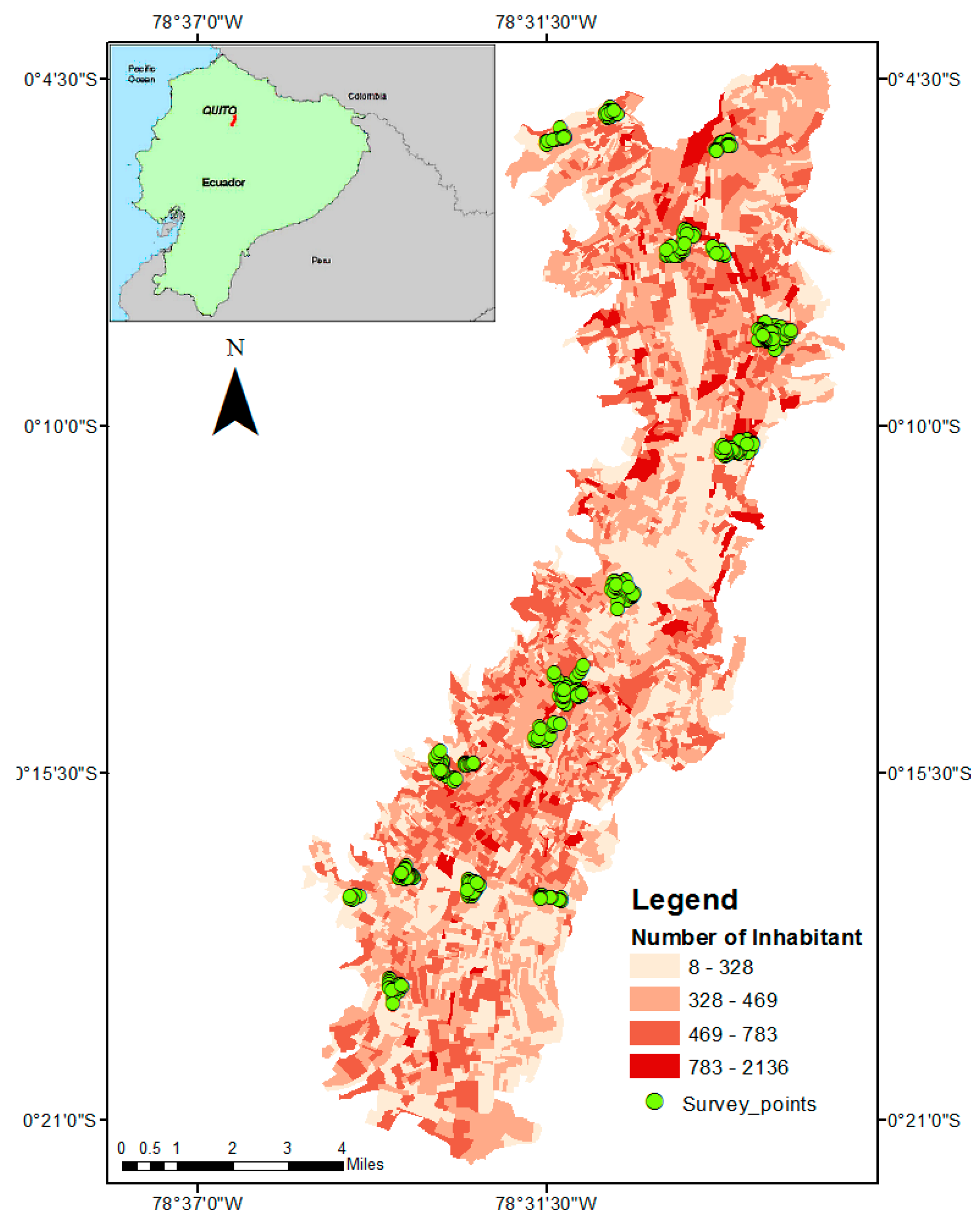
2. Study Area
3. Data Collection and Methodology
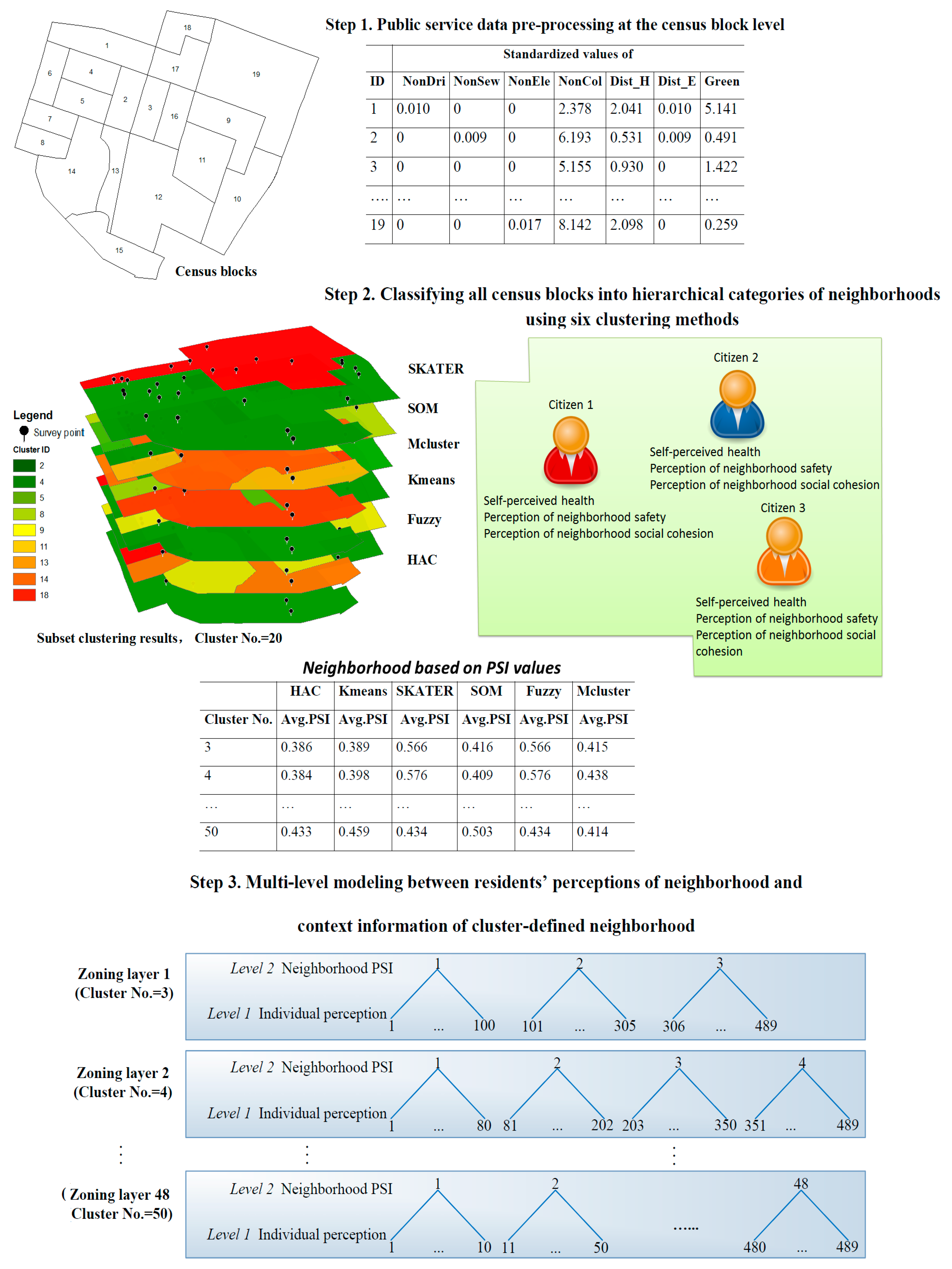
3.1. Step 1: Measuring PSI Indicators at the Census Block Level
3.2. Step 2: Classifying Census Blocks Into Hierarchical Categories of Neighborhoods Using Six Clustering Methods
- (1)
- K-means clustering (Kmeans) is a simple algorithm that uses the unsupervised learning method. We used the K-means algorithm to minimize the average squared distance (absolute distance in K-means) from each data point to the cluster center [65]. The K-means is well explained by Hartigan and Wong [65].
- (2)
- Hierarchical clustering (HAC) builds a hierarchy from the bottom-up until all the data points are in a single cluster, whereby the number of clusters does not have to be defined beforehand. We thus chose the “average linkage clustering” method to find the maximum possible distance between points belonging to different clusters. This methodology has been well explained by Murtagh and Legendre [66].
- (3)
- The self-organization maps (SOM) method, which is one of the most popular neural network models, can provide a topology preserving mapping from the high dimensional space to map units [67]. We thus used the SOM to convert complex, nonlinear statistical relationships between high-dimensional original objects into simple geometric relationships on a two-dimensional display medium. This method has been fully described by Kohonen [67].
- (4)
- Spatial “K”luster Analysis by Tree Edge Removal (SKATER) is an efficient regionalization technique that uses minimum spanning trees (MST) [68]. It transforms the regionalization problem into an optimal graph partitioning problem [35]. In this research, the seven PSI indicators represent unequal attributes to measure the dissimilarity between data points. This procedure has been fully described by Assunção et al. [35].
- (5)
- Fuzzy clustering (Fuzzy) has the advantage over other methods that the data points possess a membership function, which ranges from 0 to 1, to indicate the strength of membership of all the clusters. We thus used the probabilistic membership to configuration the original census blocks into a multilevel zoning group. Fuzzy clustering is well explained by Rousseeuw et al. [69].
- (6)
- Gaussian Mixture Modelling for Model-Based Clustering (Mcluster) is useful to establish a statistical model consisting of a finite mixture of Gaussian distributions to fit the data. This algorithm offers a flexible way of inferentially learning the patterns/rules of reality from the original data points, and clusters maximize the similarity between the points. This procedure has been fully described by Fraley et al. [70].
3.3. Step 3: Multilevel Modeling Between Residents’ Perceptions of Neighborhood and Context Information of Cluster-Defined Neighborhood
3.3.1. Collection the Citizens’ Perceptions
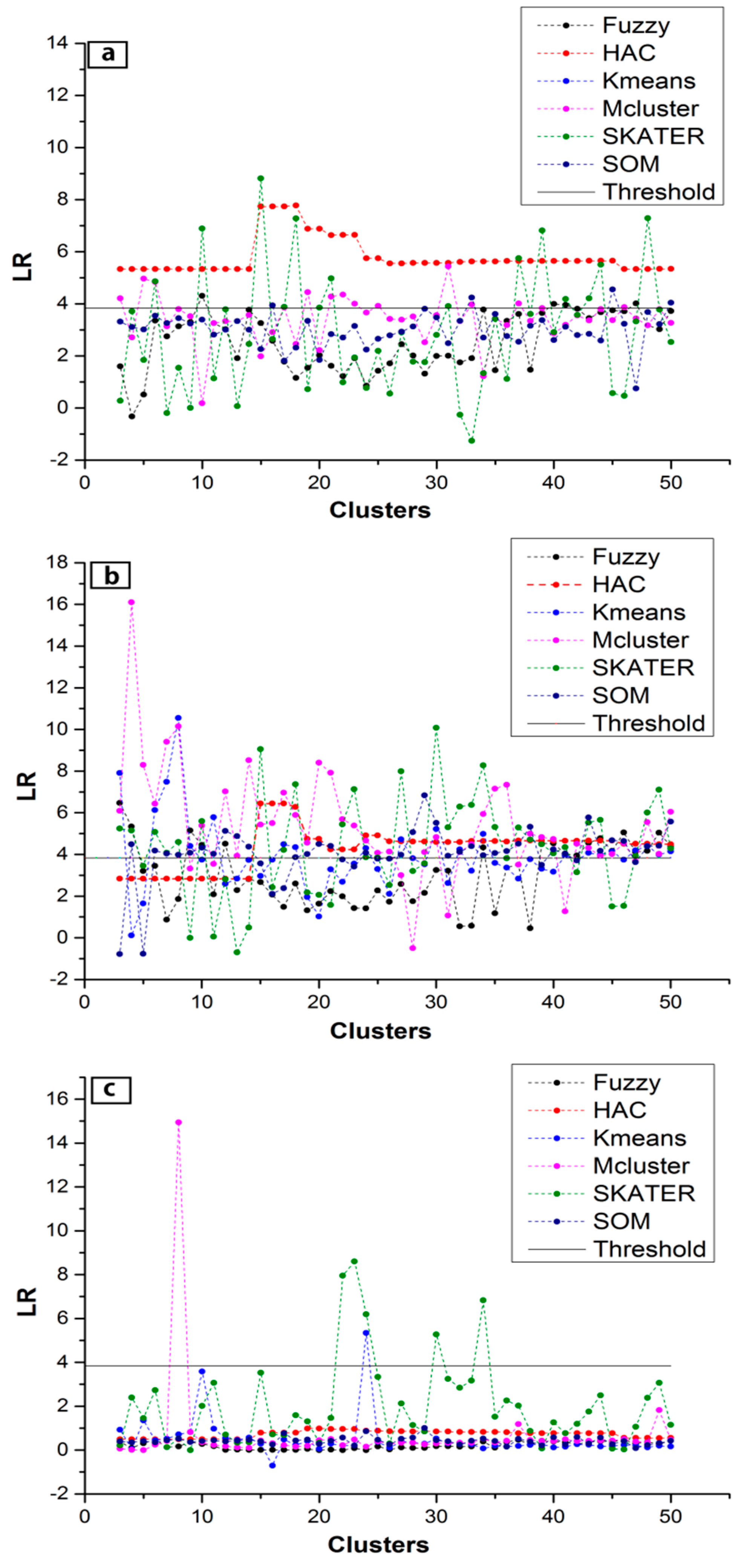
3.3.2. Multilevel Modeling
4. Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Funding
References
- Huie, S.A.B. The Concept of Neighborhood in Health and Mortality Research. Soc. Spectr. 2001, 21, 341–358. [Google Scholar] [CrossRef]
- Haynes, R.; Daras, K.; Reading, R.; Jones, A. Modifiable neighbourhood units, zone design and residents’ perceptions. Health Place 2007, 13, 812–825. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, S.V.; Lochner, K.A.; Kawachi, I. Neighborhood differences in social capital: A compositional artifact or a contextual construct? Health Place 2003, 9, 33–44. [Google Scholar] [CrossRef]
- Dunford, M. Capital accumulation and regional development in France. Geoforum 1979, 10, 81–108. [Google Scholar] [CrossRef]
- Bógus, L.M.M. Urban segregation: A theoretical approach. In Proceedings of the 13th Biennial Conference of International Planning History Society, IPHS, Chicago, IL, USA, 10–13 July 2008. [Google Scholar]
- Weeks, J.R. Population, An Introduction to Concepts and Issues; Cram101 Textbook Reviews; Wadsworth Publishing Company: Belmont, CA, USA, 2016; ISBN 978-1-4970-5055-6. [Google Scholar]
- Kawachi, I.; Berkman, L.F. Neighborhoods and Health; Oxford University Press: Oxford, UK, 2003; ISBN 978-0-19-974792-4. [Google Scholar]
- Guo, J.Y.; Bhat, C.R. Operationalizing the concept of neighborhood: Application to residential location choice analysis. J. Transp. Geogr. 2007, 15, 31–45. [Google Scholar] [CrossRef]
- Schuurman, N.; Bell, N.; Dunn, J.R.; Oliver, L. Deprivation indices, population health and geography: An evaluation of the spatial effectiveness of indices at multiple scales. J. Urban Health 2007, 84, 591–603. [Google Scholar] [CrossRef] [PubMed]
- LeClere, F.B.; Rogers, R.G.; Peters, K.D. Ethnicity and Mortality in the United States: Individual and Community Correlates. Soc. Forces 1997, 76, 169–198. [Google Scholar] [CrossRef]
- Diez-Roux, A.V.; Nieto, F.J.; Muntaner, C.; Tyroler, H.A.; Comstock, G.W.; Shahar, E.; Cooper, L.S.; Watson, R.L.; Szklo, M. Neighborhood Environments and Coronary Heart Disease: A Multilevel Analysis. Am. J. Epidemiol. 1997, 146, 48–63. [Google Scholar] [CrossRef] [PubMed]
- Stafford, M.; Duke-Williams, O.; Shelton, N. Small area inequalities in health: Are we underestimating them? Soc. Sci. Med. 2008, 67, 891–899. [Google Scholar] [CrossRef] [PubMed]
- Lin, N. Inequality in Social Capital. Contemp. Soc. 2000, 29, 785–795. [Google Scholar] [CrossRef]
- World Health Organization (WHO). Environment and Health Risks: A Review of the Influence and Effects of Social Inequalities; WHO: Geneva, Switzerland, 2010. [Google Scholar]
- Pearl, M.; Braveman, P.; Abrams, B. The relationship of neighborhood socioeconomic characteristics to birthweight among 5 ethnic groups in California. Am. J. Public Health 2001, 91, 1808–1814. [Google Scholar] [CrossRef] [PubMed]
- Macintyre, S.; Ellaway, A.; Cummins, S. Place effects on health: How can we conceptualise, operationalise and measure them? Soc. Sci. Med. 2002, 55, 125–139. [Google Scholar] [CrossRef]
- Lotfi, S.; Koohsari, M.J. Measuring objective accessibility to neighborhood facilities in the city (A case study: Zone 6 in Tehran, Iran). Cities 2009, 26, 133–140. [Google Scholar] [CrossRef]
- Apparicio, P.; Abdelmajid, M.; Riva, M.; Shearmur, R. Comparing alternative approaches to measuring the geographical accessibility of urban health services: Distance types and aggregation-error issues. Int. J. Health Geogr. 2008, 7, 7. [Google Scholar] [CrossRef] [PubMed]
- De la Fuente, H.; Rojas, C.; Salado, M.J.; Carrasco, J.A.; Neutens, T. Socio-Spatial Inequality in Education Facilities in the Concepción Metropolitan Area (Chile). Curr. Urban Stud. 2013, 1, 117–129. [Google Scholar] [CrossRef]
- Wei, C.; Cabrera-Barona, P.; Blaschke, T. Local Geographic Variation of Public Services Inequality: Does the Neighborhood Scale Matter? Int. J. Environ. Res. Public. Health 2016, 13. [Google Scholar] [CrossRef] [PubMed]
- Lopez, R.P.; Hynes, H.P. Obesity, physical activity, and the urban environment: Public health research needs. Environ. Health 2006, 5, 25. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention (CDC). Neighborhood safety and the prevalence of physical inactivity—Selected states, 1996. MMWR Morb. Mortal. Wkly. Rep. 1999, 48, 143–146. [Google Scholar]
- Zenk, S.N.; Schulz, A.J.; Israel, B.A.; James, S.A.; Bao, S.; Wilson, M.L. Neighborhood Racial Composition, Neighborhood Poverty, and the Spatial Accessibility of Supermarkets in Metropolitan Detroit. Am. J. Public Health 2005, 95, 660–667. [Google Scholar] [CrossRef] [PubMed]
- Dietz, R.D. The estimation of neighborhood effects in the social sciences: An interdisciplinary approach. Soc. Sci. Res. 2002, 31, 539–575. [Google Scholar] [CrossRef]
- White, A.N. Accessibility and Public Facility Location. Econ. Geogr. 1979, 55, 18–35. [Google Scholar] [CrossRef]
- Gao, Y.; Gao, J.; Chen, J.; Xu, Y.; Zhao, J. Regionalizing aquatic ecosystems based on the river subbasin taxonomy concept and spatial clustering techniques. Int. J. Environ. Res. Public Health 2011, 8, 4367–4385. [Google Scholar] [CrossRef] [PubMed]
- Hosking, J.R.M.; Wallis, J.R. Some statistics useful in regional frequency analysis. Water Resour. Res. 1993, 29, 271–281. [Google Scholar] [CrossRef]
- Breiger, R.L.; Boorman, S.A.; Arabie, P. An algorithm for clustering relational data with applications to social network analysis and comparison with multidimensional scaling. J. Math. Psychol. 1975, 12, 328–383. [Google Scholar] [CrossRef]
- Caspi, A.; Taylor, A.; Moffitt, T.E.; Plomin, R. Neighborhood Deprivation Affects Children’s Mental Health: Environmental Risks Identified in a Genetic Design. Psychol. Sci. 2000, 11, 338–342. [Google Scholar] [CrossRef] [PubMed]
- Lalloué, B.; Monnez, J.M.; Padilla, C.; Kihal, W.; Meur, N.; Zmirou-Navier, D. A statistical procedure to create a neighborhood socioeconomic index for health inequalities analysis. Int. J. Equity Health 2013, 12. [Google Scholar] [CrossRef] [PubMed]
- Andrews, F.M.; Withey, S.B. Social Indicators of Well-Being: Americans’ Perceptions of Life Quality; Springer: New York, NY, USA, 2012; ISBN 978-1-4684-2253-5. [Google Scholar]
- Marques, E.C.L. Opportunities and Deprivation in the Urban South: Poverty, Segregation and Social Networks in São Paulo; Routledge: London, UK, 2016; ISBN 978-1-317-08533-1. [Google Scholar]
- Openshaw, S.; Rao, L. Algorithms for Reengineering 1991 Census Geography. Environ. Plan. A 1995, 27, 425–446. [Google Scholar] [CrossRef] [PubMed]
- Cockings, S.; Martin, D. Zone design for environment and health studies using pre-aggregated data. Soc. Sci. Med. 2005, 60, 2729–2742. [Google Scholar] [CrossRef] [PubMed]
- AssunÇão, R.M.; Neves, M.C.; Câmara, G.; Freitas, C.D.C. Efficient regionalization techniques for socio-economic geographical units using minimum spanning trees. Int. J. Geogr. Inf. Sci. 2006, 20, 797–811. [Google Scholar] [CrossRef]
- Menezes, V.S.A.; da Silva, R.T.; de Souza, M.F.; Oliveira, J.; de Mello, C.E.R.; de Souza, J.M.; Zimbrão, G. Mining and Analyzing Organizational Social Networks Using Minimum Spanning Tree. In On the Move to Meaningful Internet Systems: OTM 2008 Workshops; Meersman, R., Tari, Z., Herrero, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 18–19. ISBN 978-3-540-88874-1. [Google Scholar]
- Banerjee, S.; Badr, Y.; Al-Shammari, E.T. Analyzing Tweet Cluster Using Standard Fuzzy C Means Clustering. In Social Networks: A Framework of Computational Intelligence; Pedrycz, W., Chen, S.-M., Eds.; Springer: Cham, Switzerland, 2014; ISBN 978-3-319-02992-4. [Google Scholar]
- Parenteau, M.-P.; Sawada, M.C. The modifiable areal unit problem (MAUP) in the relationship between exposure to NO2 and respiratory health. Int. J. Health Geogr. 2011, 10, 58. [Google Scholar] [CrossRef] [PubMed]
- Kronthaler, F. Economic capability of East German regions: Results of a cluster analysis. Reg. Stud. 2005, 39, 739–750. [Google Scholar] [CrossRef]
- Openshaw, S. A Geographical Solution to Scale and Aggregation Problems in Region-Building, Partitioning and Spatial Modelling. Trans. Inst. Br. Geogr. 1977, 2, 459–472. [Google Scholar] [CrossRef]
- Alvanides, S.; Openshaw, S. Zone Design for Planning and Policy Analysis. In Geographical Information and Planning; Stillwell, D.J., Geertman, P.S., Openshaw, D.S., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 299–315. ISBN 978-3-642-08517-8. [Google Scholar]
- Wooldredge, J. Examining the (ir)relevance of Aggregation Bias for Multilevel Studies of Neighborhoods and Crime with an Example Comparing Census Tracts to Official Neighborhoods in Cincinnati. Criminology 2002, 40, 681–710. [Google Scholar] [CrossRef]
- Stylidis, D. Place Attachment, Perception of Place and Residents’ Support for Tourism Development. Tour. Plan. Dev. 2017. [Google Scholar] [CrossRef]
- Basso, K.H. Wisdom Sits in Places: Landscape and Language among the Western Apache; UNM Press: Albuquerque, NM, USA, 1996; ISBN 978-0-8263-2705-5. [Google Scholar]
- Kudryavtsev, A.; Stedman, R.C.; Krasny, M.E. Sense of place in environmental education. Environ. Educ. Res. 2012, 18, 229–250. [Google Scholar] [CrossRef]
- Adams, P.C.; Gynnild, A. Environmental Messages in Online Media: The Role of Place. Environ. Commun. 2013, 7, 113–130. [Google Scholar] [CrossRef]
- Madanipour, A. Why are the Design and Development of Public Spaces Significant for Cities? Environ. Plan. B Plan. Urban Anal. City Sci. 1999, 26, 879–891. [Google Scholar] [CrossRef]
- Melvin, P.M. Changing Contexts: Neighborhood Definition and Urban Organization. Am. Q. 1985, 37, 357–367. [Google Scholar] [CrossRef]
- Ruddick, S. Constructing difference in public spaces: Race, class, and gender as interlocking systems. Urban Geogr. 1996, 17, 132–151. [Google Scholar] [CrossRef]
- Cook, T.; Irwin, M. Aggregation Issues in Neighborhood Research: A Comparison of Several Levels of Census Geography and Resident Defined Neighborhoods; Association for Public Policy and Management: Atlanta, GA, USA, 2004. [Google Scholar]
- Hewko, J.; Smoyer-Tomic, K.E.; Hodgson, M.J. Measuring Neighbourhood Spatial Accessibility to Urban Amenities: Does Aggregation Error Matter? Environ. Plan. A 2002, 34, 1185–1206. [Google Scholar] [CrossRef]
- Wandersman, A.; Florin, P. Citizen Participation and Community Organizations. In Handbook of Community Psychology; Rappaport, J., Seidman, E., Eds.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000; pp. 247–272. ISBN 978-1-4613-6881-6. [Google Scholar]
- Marschall, M.J. Citizen Participation and the Neighborhood Context: A New Look at the Coproduction of Local Public Goods. Polit. Res. Q. 2004, 57, 231–244. [Google Scholar] [CrossRef]
- Rende, S.; Donduran, M. Neighborhoods in Development: Human Development Index and Self-organizing Maps. Soc. Indic. Res. 2011, 110, 721–734. [Google Scholar] [CrossRef]
- Sun, I.Y.; Payne, B.K.; Wu, Y. The impact of situational factors, officer characteristics, and neighborhood context on police behavior: A multilevel analysis. J. Crim. Justice 2008, 36, 22–32. [Google Scholar] [CrossRef]
- Duncan, C.; Jones, K.; Moon, G. Context, composition and heterogeneity: Using multilevel models in health research. Soc. Sci. Med. 1998, 46, 97–117. [Google Scholar] [CrossRef]
- Scarbrough, E.; Tanenbaum, E. Research Strategies in the Social Sciences: A Guide to New Approaches; OUP Oxford: Oxford, UK, 1998; ISBN 978-0-19-829238-8. [Google Scholar]
- Hoffman, K.; Centeno, M.A. The Lopsided Continent: Inequality in Latin America. Annu. Rev. Soc. 2003, 29, 363–390. [Google Scholar] [CrossRef]
- Mideros, A. Ecuador: Defining and measuring multidimensional poverty, 2006–2010. Cepal Rev. 2012, 108, 50–67. [Google Scholar]
- Cabrera-Barona, P.; Wei, C.; Hagenlocher, M. Multiscale evaluation of an urban deprivation index: Implications for quality of life and healthcare accessibility planning. Appl. Geogr. 2016, 70, 1–10. [Google Scholar] [CrossRef]
- Schkolnik, S.; Chackiel, J. América Latina: Aspectos Conceptuales de Los Censos del 2000; Serie Manuales; Naciones Unidas: Santiago, Chile, 1999. [Google Scholar]
- Flacke, J.; Schüle, S.A.; Köckler, H.; Bolte, G. Mapping Environmental Inequalities Relevant for Health for Informing Urban Planning Interventions—A Case Study in the City of Dortmund, Germany. Int. J. Environ. Res. Public Health 2016, 13, 711. [Google Scholar] [CrossRef] [PubMed]
- Cabrera-Barona, P.; Blaschke, T.; Kienberger, S. Explaining Accessibility and Satisfaction Related to Healthcare: A Mixed-Methods Approach. Soc. Indic. Res. 2016. [Google Scholar] [CrossRef]
- OECD; European Commission. Handbook on Constructing Composite Indicators: Methodology and User Guide; OECD: Paris, France, 2008; ISBN 978-92-64-04346-6. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Murtagh, F.; Legendre, P. Ward’s Hierarchical Agglomerative Clustering Method: Which Algorithms Implement Ward’s Criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Aho, A.V.; Hopcroft, J.E.; Ullman, J. Data Structures and Algorithms, 1st ed.; Addison-Wesley Longman Publishing Co. Inc.: Boston, MA, USA, 1983; ISBN 978-0-201-00023-8. [Google Scholar]
- Rousseeuw, P.J.; Kaufman, L.; Trauwaert, E. Fuzzy clustering using scatter matrices. Comput. Stat. Data Anal. 1996, 23, 135–151. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, A.E. How Many Clusters? Which Clustering Method? Answers via Model-Based Cluster Analysis. Comput. J. 1998, 41, 578–588. [Google Scholar] [CrossRef]
- Poortinga, W. Social capital: An individual or collective resource for health? Soc. Sci. Med. 2006, 62, 292–302. [Google Scholar] [CrossRef] [PubMed]
- Diez Roux, A.V. The study of group-level factors in epidemiology: Rethinking variables, study designs, and analytical approaches. Epidemiol. Rev. 2004, 26, 104–111. [Google Scholar] [CrossRef] [PubMed]
- O’Campo, P. Invited commentary: Advancing theory and methods for multilevel models of residential neighborhoods and health. Am. J. Epidemiol. 2003, 157, 9–13. [Google Scholar] [CrossRef] [PubMed]
- Miilunpalo, S.; Vuori, I.; Oja, P.; Pasanen, M.; Urponen, H. Self-rated health status as a health measure: The predictive value of self-reported health status on the use of physician services and on mortality in the working-age population. J. Clin. Epidemiol. 1997, 50, 517–528. [Google Scholar] [CrossRef]
- Baum, F. The New Public Health; Oxford University Press: Oxford, UK, 2003; pp. 1–607. [Google Scholar]
- Gebel, K.; Bauman, A.E.; Petticrew, M. The physical environment and physical activity: A critical appraisal of review articles. Am. J. Prev. Med. 2007, 32, 361–369. [Google Scholar] [CrossRef] [PubMed]
- McCracken, M. Social cohesion and macroeconomic performance. In Proceedings of the CSLS Conference on the State of Living Standards and the Quality of Life in Canada, Ottawa, ON, Canada, 30–31 October 1998. [Google Scholar]
- Bennett, G.G.; McNeill, L.H.; Wolin, K.Y.; Duncan, D.T.; Puleo, E.; Emmons, K.M. Safe To Walk? Neighborhood Safety and Physical Activity among Public Housing Residents. PLoS Med. 2007, 4, e306. [Google Scholar] [CrossRef] [PubMed]
- Humpel, N.; Owen, N.; Leslie, E. Environmental factors associated with adults’ participation in physical activity: A review. Am. J. Prev. Med. 2002, 22, 188–199. [Google Scholar] [CrossRef]
- Sun, V.K.; Stijacic Cenzer, I.; Kao, H.; Ahalt, C.; Williams, B.A. How Safe is Your Neighborhood? Perceived Neighborhood Safety and Functional Decline in Older Adults. J. Gen. Intern. Med. 2012, 27, 541–547. [Google Scholar] [CrossRef] [PubMed]
- Lewis, D.A.; Maxfield, M.G. Fear in the Neighborhoods: An Investigation of the Impact of Crime. J. Res. Crime Delinquency 1980, 17, 160–189. [Google Scholar] [CrossRef]
- Kreft, I.G.; Kreft, I.; de Leeuw, J. Introducing Multilevel Modeling; Sage: London, UK, 1998; ISBN 0-7619-5141-5. [Google Scholar]
- Handl, J.; Knowles, J.; Kell, D.B. Computational cluster validation in post-genomic data analysis. Bioinformatics 2005, 21, 3201–3212. [Google Scholar] [CrossRef] [PubMed]
- Cormode, G.; McGregor, A. Approximation Algorithms for Clustering Uncertain Data. In Proceedings of the Twenty-Seventh ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems PODS ’08; ACM: New York, NY, USA, 2008; pp. 191–200. [Google Scholar]
- Cabrera-Barona, P.; Blaschke, T.; Gaona, G. Deprivation, Healthcare Accessibility and Satisfaction: Geographical Context and Scale Implications. Appl. Spat. Anal. Policy 2017. [Google Scholar] [CrossRef]
- Ngom, R.; Gosselin, P.; Blais, C. Reduction of disparities in access to green spaces: Their geographic insertion and recreational functions matter. Appl. Geogr. 2016, 66, 35–51. [Google Scholar] [CrossRef]
- Adlakha, D.; Hipp, J.A.; Brownson, R.C. Adaptation and Evaluation of the Neighborhood Environment Walkability Scale in India (NEWS-India). Int. J. Environ. Res. Public Health 2016, 13, 401. [Google Scholar] [CrossRef] [PubMed]
- Bauman, A.; Smith, B.; Stoker, L.; Bellew, B.; Booth, M. Geographical influences upon physical activity participation: Evidence of a “coastal effect”. Aust. N. Z. J. Public Health 1999, 23, 322–324. [Google Scholar] [CrossRef] [PubMed]
- Baum, F.E.; Ziersch, A.M.; Zhang, G.; Osborne, K. Do perceived neighbourhood cohesion and safety contribute to neighbourhood differences in health? Health Place 2009, 15, 925–934. [Google Scholar] [CrossRef] [PubMed]
- Craddock, R.C.; James, G.A.; Holtzheimer, P.E.; Hu, X.P.; Mayberg, H.S. A whole brain fMRI atlas generated via spatially constrained spectral clustering. Hum. Brain Mapp. 2012, 33, 1914–1928. [Google Scholar] [CrossRef] [PubMed]
- Gaetan, C.; Guyon, X. Statistics for spatial models. In Spatial Statistics and Modeling; Springer: New York, NY, USA, 2010; pp. 149–248. ISBN 978-0-387-92256-0. [Google Scholar]
- Anselin, L. Spatial Econometrics: Methods and Models; Springer: Amsterdam, The Netherlands, 2013; ISBN 978-94-015-7799-1. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Fuzzy | HAC | Kmeans | Mcluster | SKATER | SOM | ||
|---|---|---|---|---|---|---|---|
| Neighborhood safety | Avg VPCs (LR > 3.84) | 0.815 | 1 | 0.773 | 0.572 | 0.530 | 0.732 |
| Variance (LR > 3.84) | 0.340 | 0.446 | 0.366 | 0.270 | 0.322 | 0.260 | |
| Neighborhood social cohesion | Avg VPCs (LR > 3.84) | 0 | 0 | 0.078 | 0.060 | 0.65 | 0 |
| Variance (LR > 3.84) | 0 | 0 | 0 | 0 | 0.303 | 0 | |
| Health status | Avg VPCs (LR > 3.84) | 0.948 | 1 | 0.985 | 0.985 | 0.916 | 0.991 |
| Variance (LR > 3.84) | 0.249 | 0.143 | 0.433 | 0.433 | 0.398 | 0.272 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Cabrera Barona, P.; Blaschke, T. A New Look at Public Services Inequality: The Consistency of Neighborhood Context and Citizens’ Perception across Multiple Scales. ISPRS Int. J. Geo-Inf. 2017, 6, 200. https://doi.org/10.3390/ijgi6070200
Wei C, Cabrera Barona P, Blaschke T. A New Look at Public Services Inequality: The Consistency of Neighborhood Context and Citizens’ Perception across Multiple Scales. ISPRS International Journal of Geo-Information. 2017; 6(7):200. https://doi.org/10.3390/ijgi6070200
Chicago/Turabian StyleWei, Chunzhu, Pablo Cabrera Barona, and Thomas Blaschke. 2017. "A New Look at Public Services Inequality: The Consistency of Neighborhood Context and Citizens’ Perception across Multiple Scales" ISPRS International Journal of Geo-Information 6, no. 7: 200. https://doi.org/10.3390/ijgi6070200
APA StyleWei, C., Cabrera Barona, P., & Blaschke, T. (2017). A New Look at Public Services Inequality: The Consistency of Neighborhood Context and Citizens’ Perception across Multiple Scales. ISPRS International Journal of Geo-Information, 6(7), 200. https://doi.org/10.3390/ijgi6070200