Procedural Generation of Large-Scale Forests Using a Graph-Based Neutral Landscape Model



Abstract
:1. Introduction
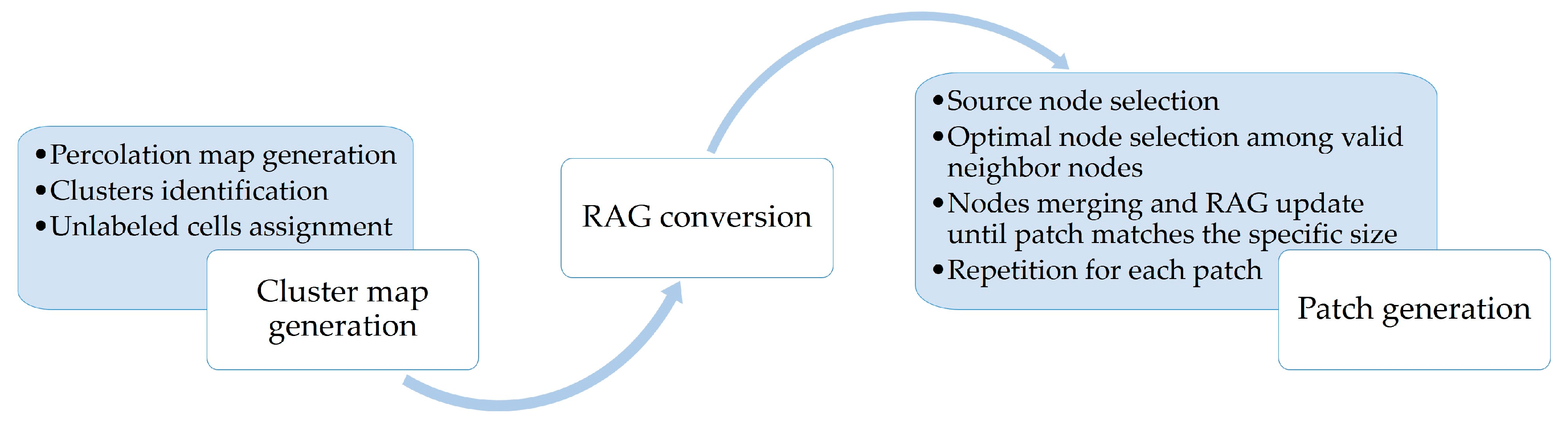
2. Methods
2.1. Model Parameters
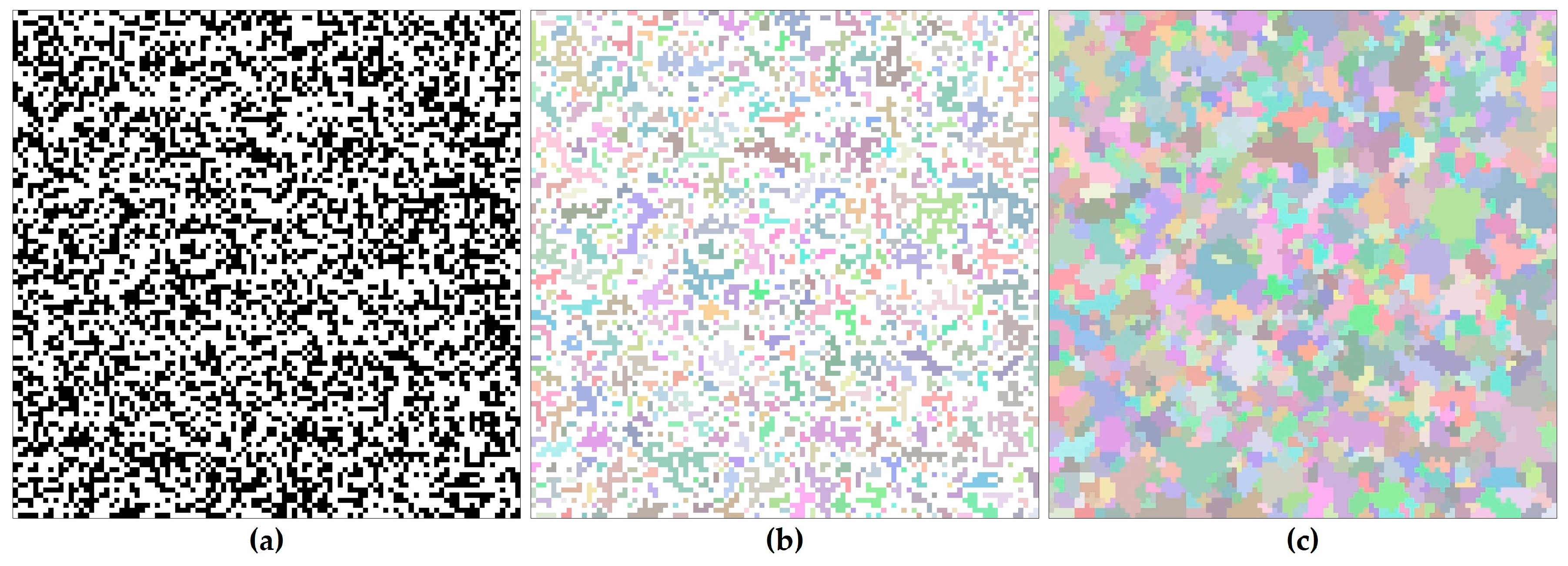
2.2. Cluster Map Generation
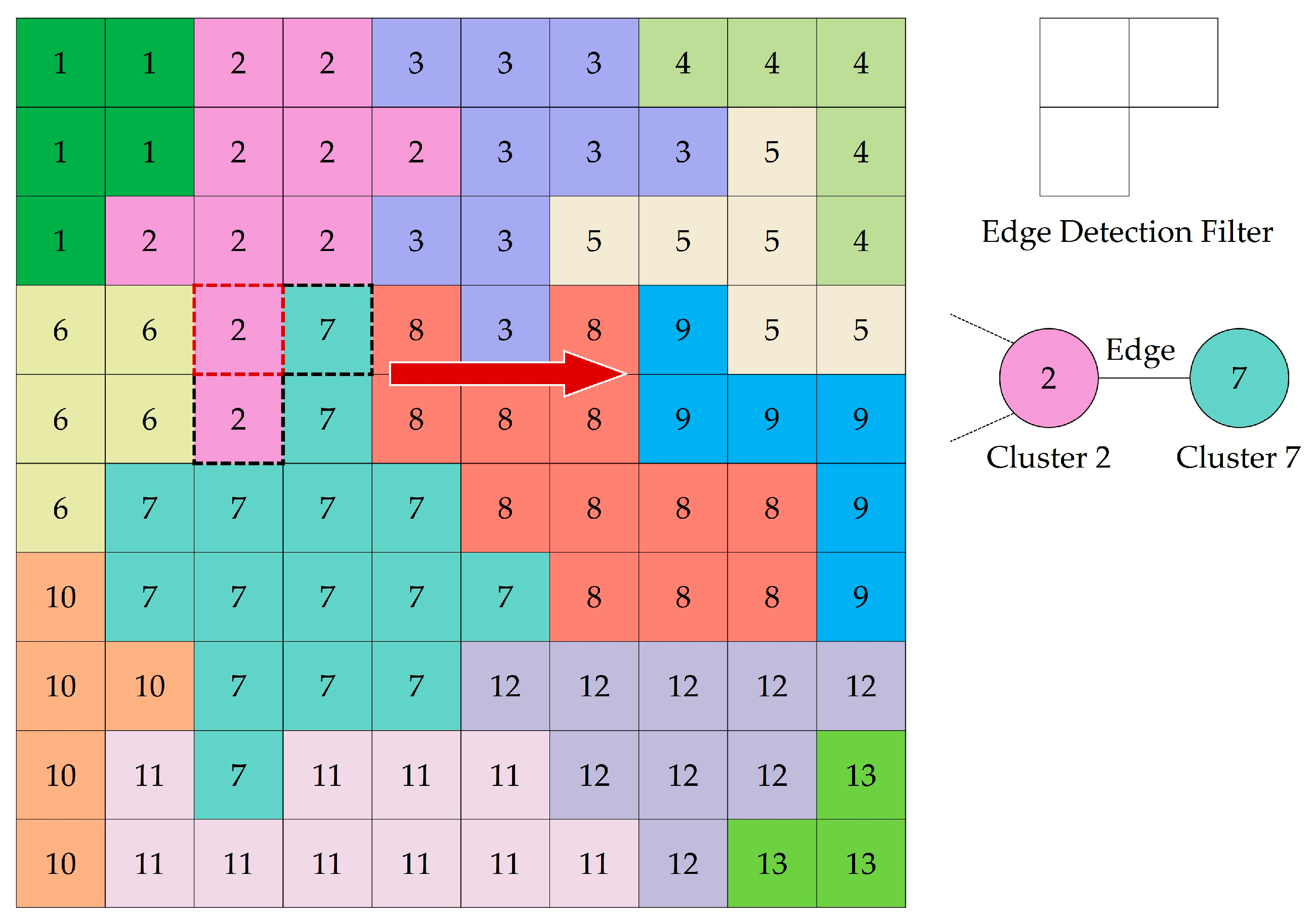
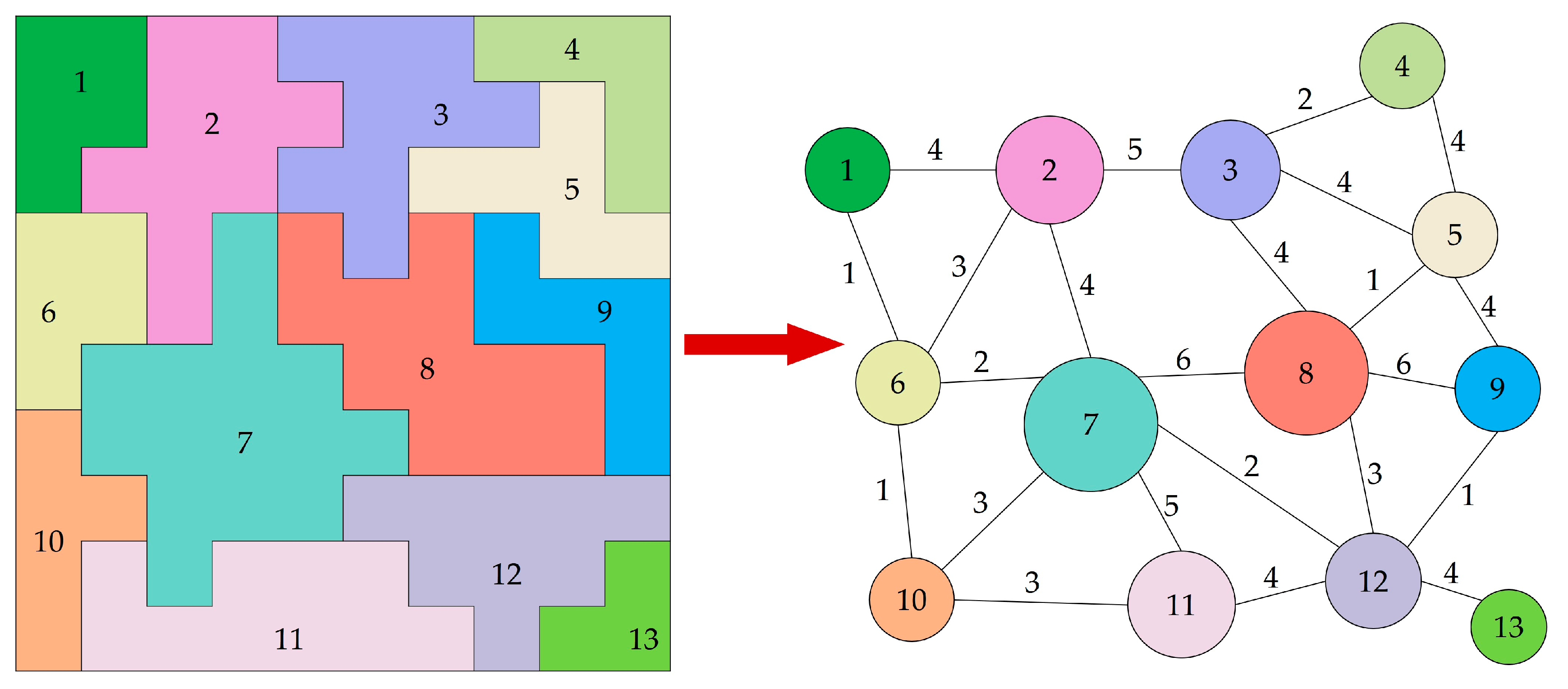
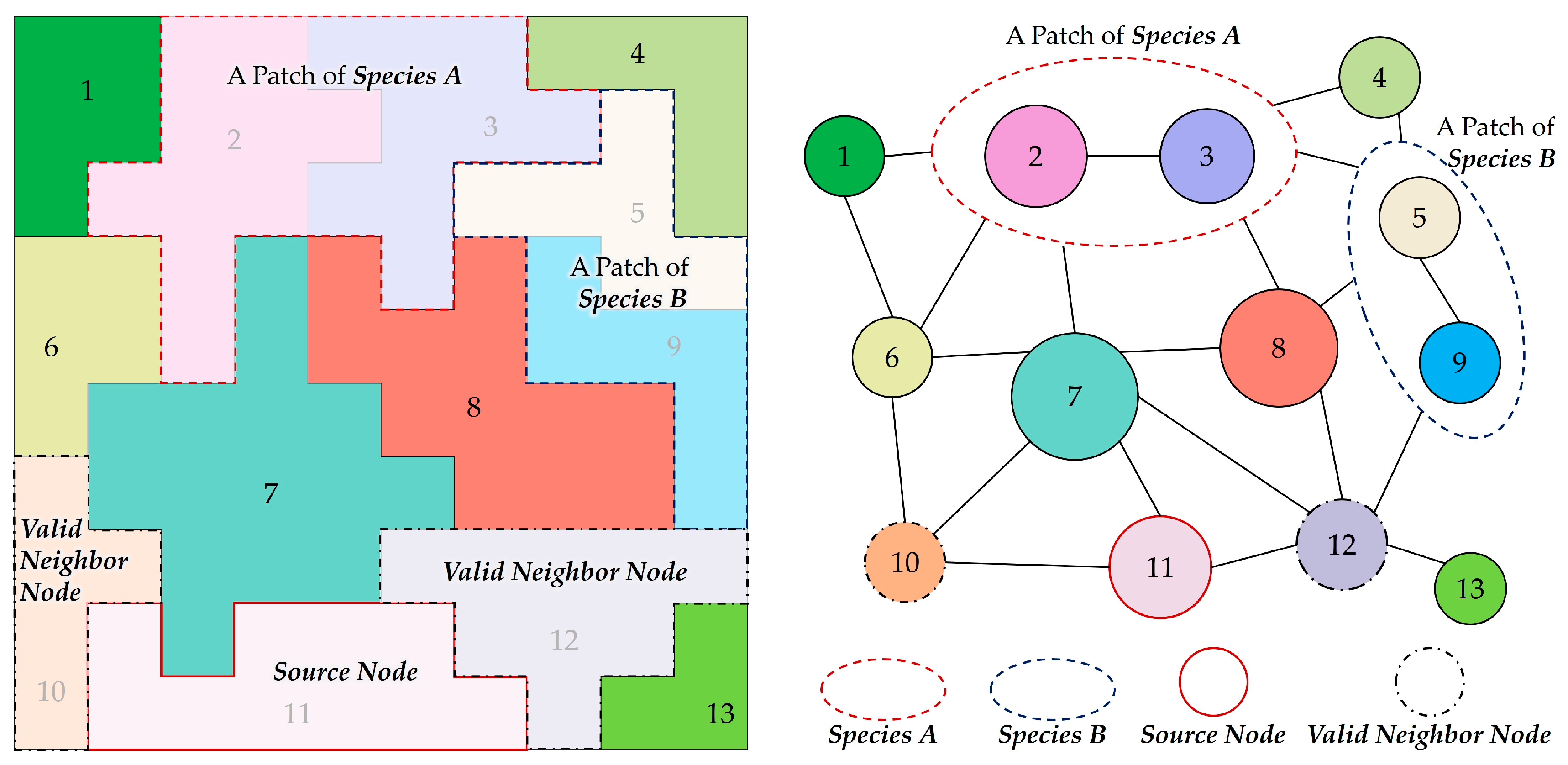
2.3. Conversion of the Cluster Map to an RAG
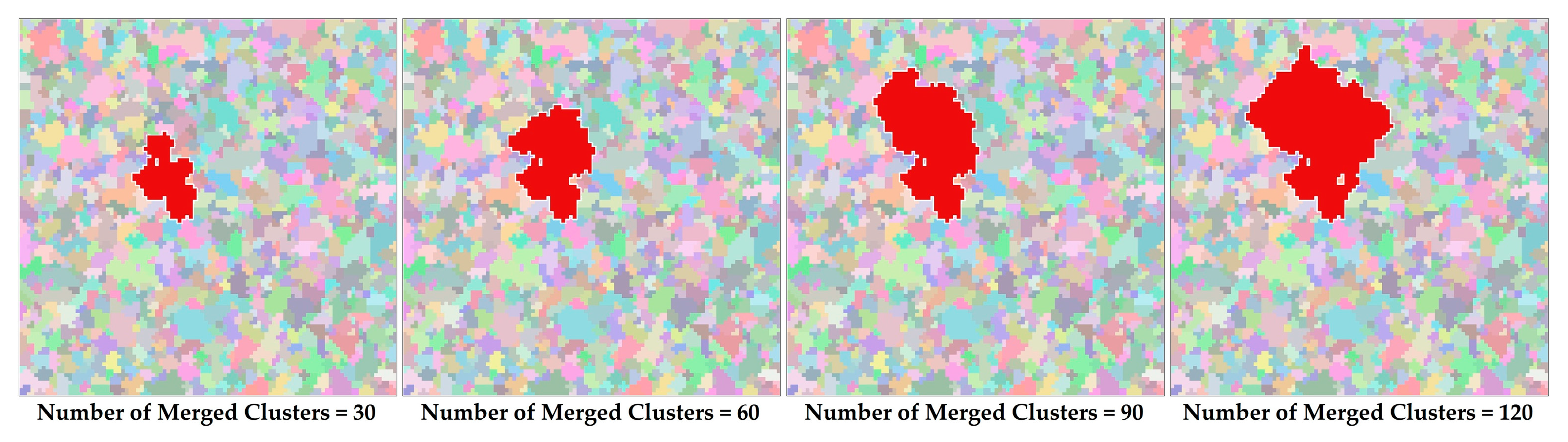
2.4. Patch Generation by Merging Clusters
- source node: a node with a species property of 0 that is not adjacent to nodes of the same species with the currently growing patch.
- valid neighbor nodes: nodes with a species property of 0 adjacent to the source node, the neighboring nodes of which are not connected to nodes of the same species with the currently growing patch.
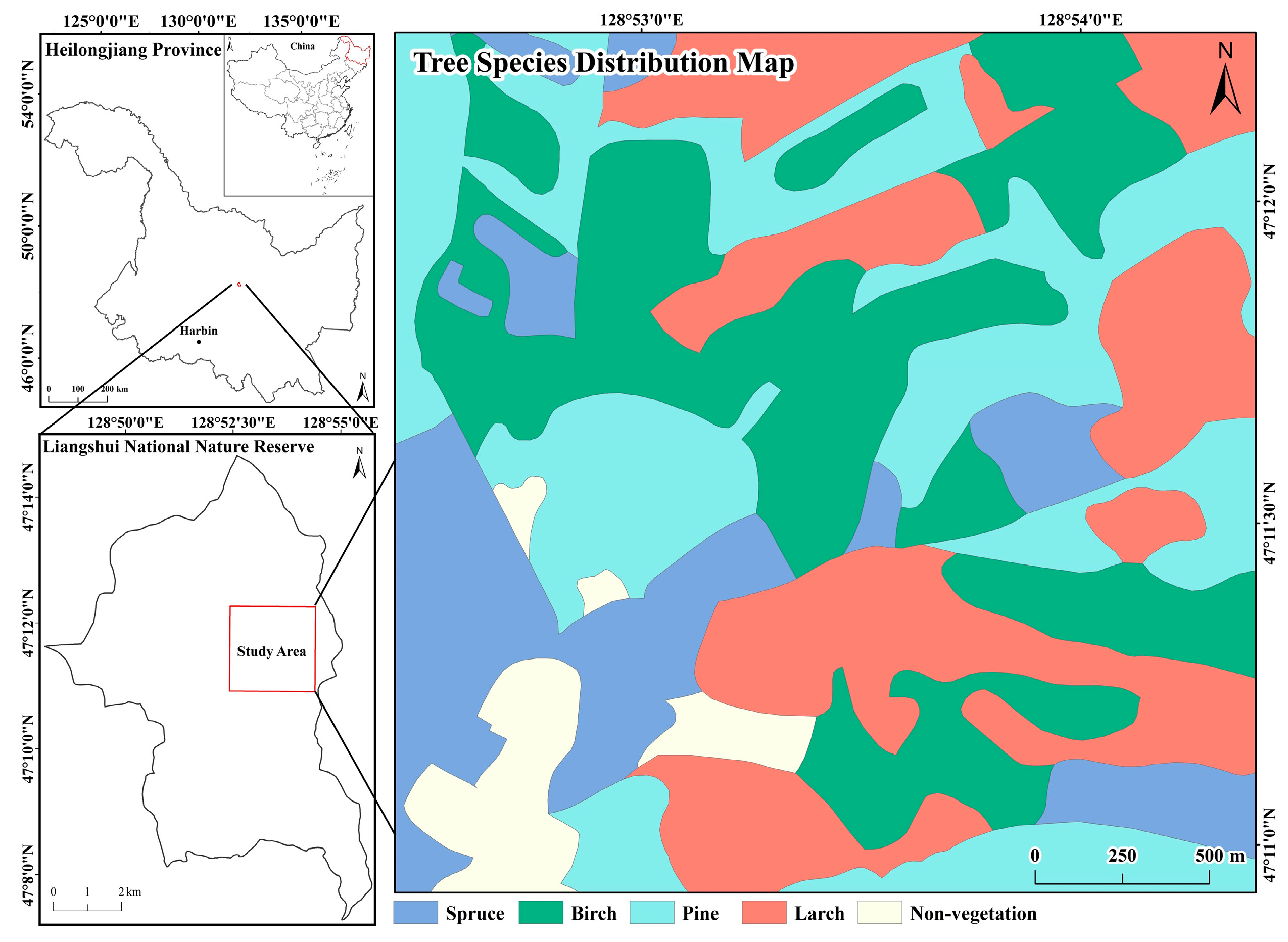
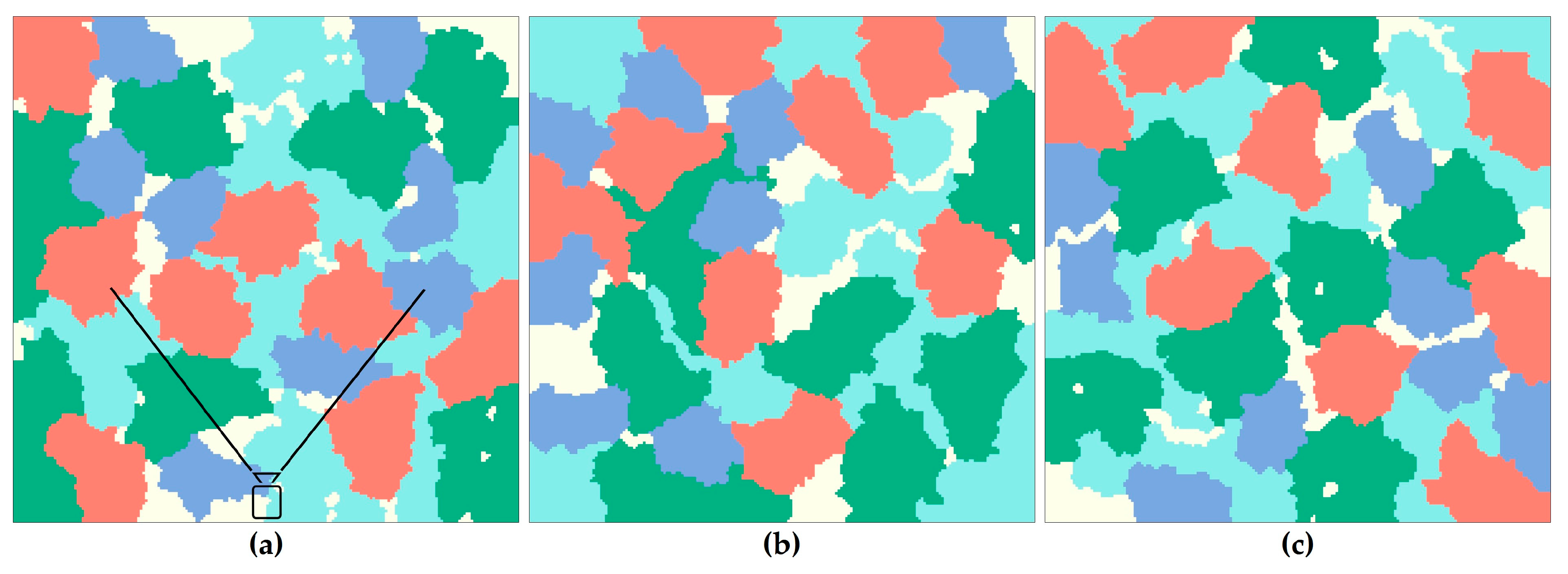
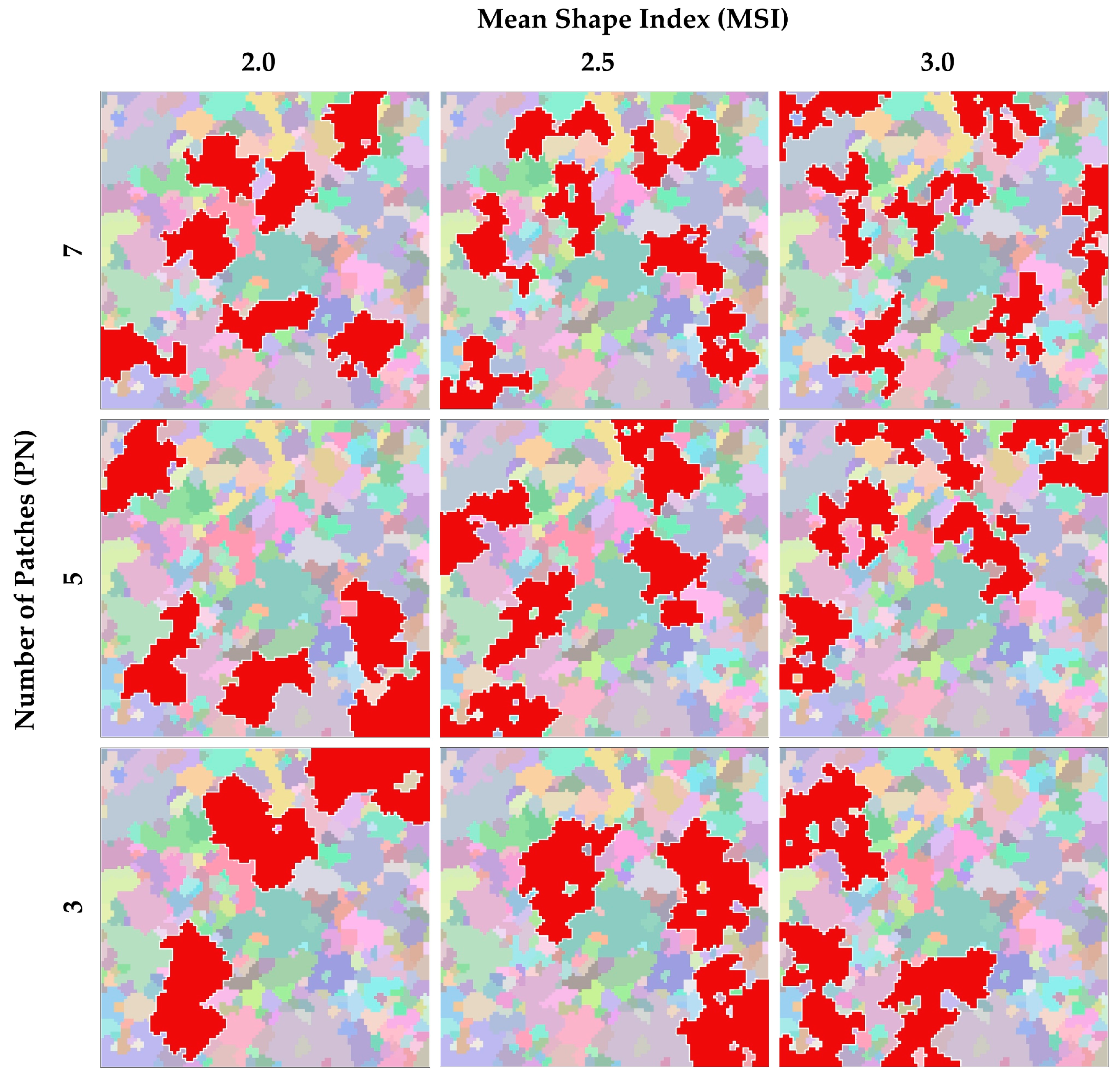
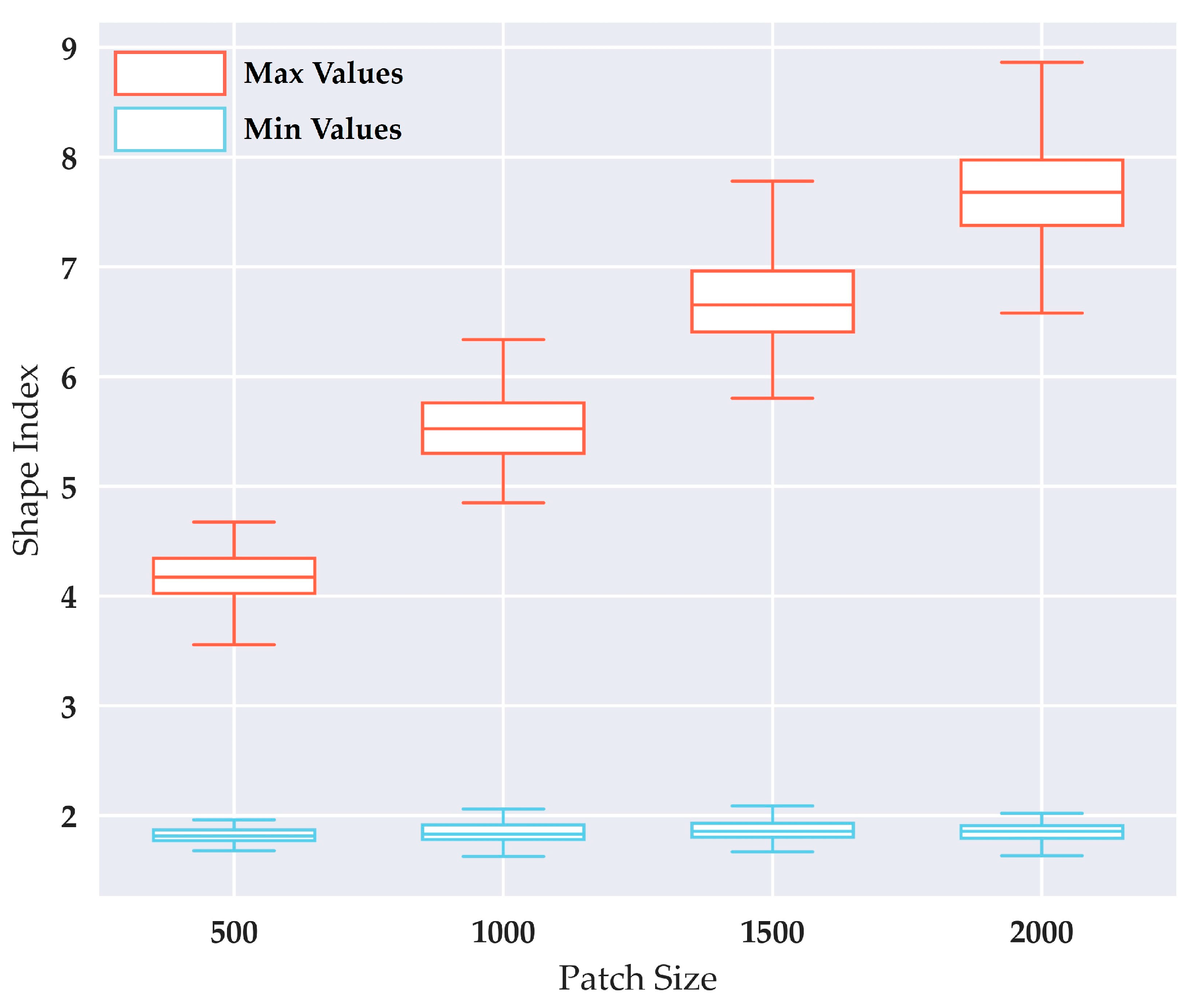
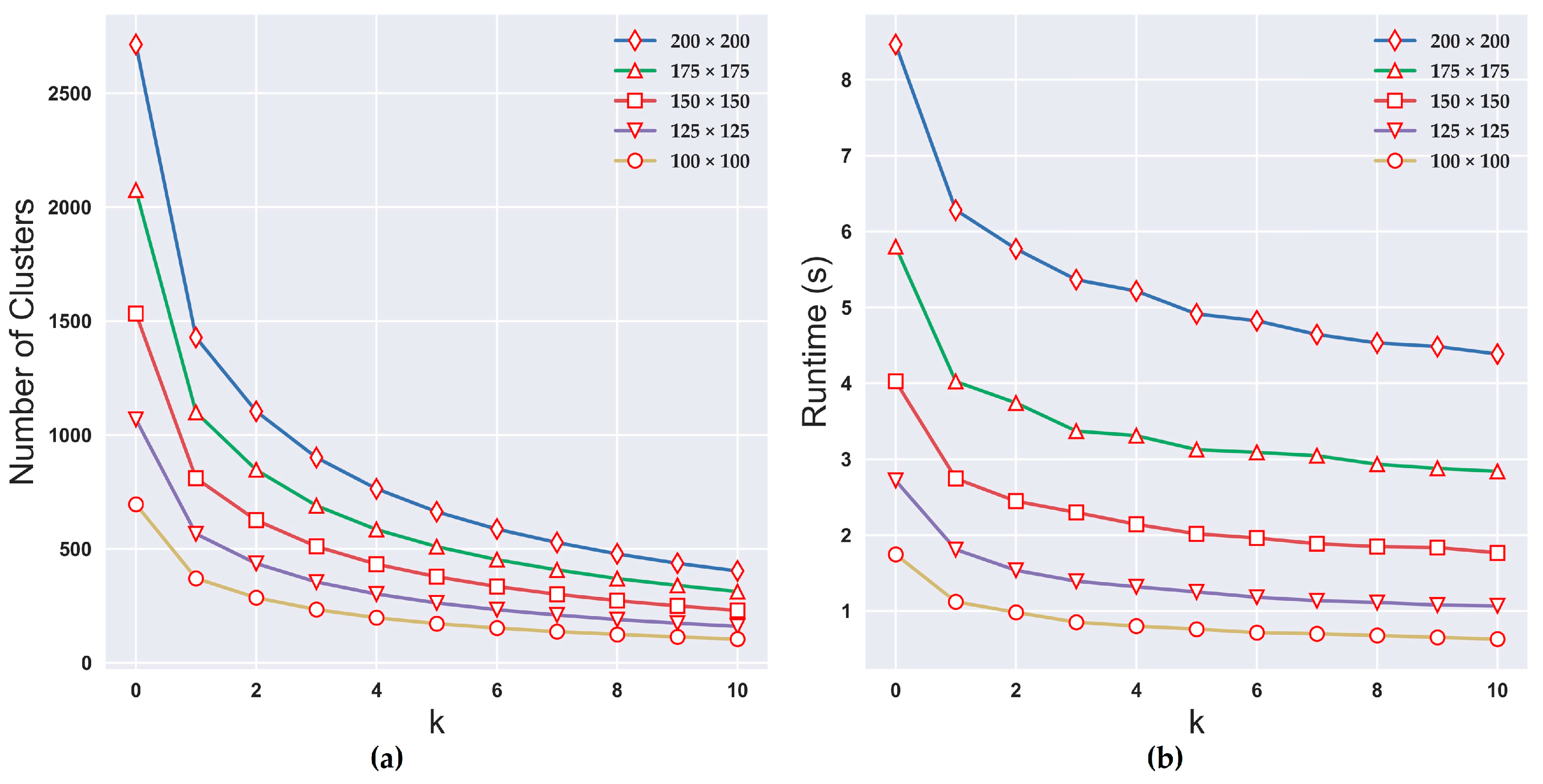
3. Results
4. Discussion
4.1. Error Analysis
4.2. Controllability of the PN and MSI Parameters
4.3. Time Efficiency Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Deussen, O.; Hanrahan, P.; Lintermann, B.; Měch, R.; Pharr, M.; Prusinkiewicz, P. Realistic Modeling and Rendering of Plant Ecosystems. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Orlando, FL, USA, 19–24 July 1998; Association for Computing Machinery (ACM): New York, NY, USA; pp. 275–286. [Google Scholar]
- Takenaka, T.; Okabe, A. Development of the seed scattering system for computational landscape design. Int. J. Archit. Comput. 2011, 9, 421–436. [Google Scholar] [CrossRef]
- Chou, C.-Y.; Song, B.; Hedden, R.L.; Williams, T.M.; Culin, J.D.; Post, C.J. Three-dimensional landscape visualizations: New technique towards wildfire and forest bark beetle management. Forests 2010, 1, 82–98. [Google Scholar] [CrossRef]
- Pradal, C.; Boudon, F.; Nouguier, C.; Chopard, J.; Godin, C. Plantgl: A python-based geometric library for 3d plant modelling at different scales. Graph. Model. 2009, 71, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Bruneton, E.; Neyret, F. Real-Time Realistic Rendering and Lighting of Forests. Comput. Graph. Forum 2012, 31, 373–382. [Google Scholar] [CrossRef]
- Santoro, F.; Tarantino, E.; Figorito, B.; Gualano, S.; D’Onghia, A.M. A tree counting algorithm for precision agriculture tasks. Int. J. Digit. Earth 2013, 6, 94–102. [Google Scholar] [CrossRef]
- Andújar, C.; Chica, A.; Vico, M.A.; Moya, S.; Brunet, P. Inexpensive reconstruction and rendering of realistic roadside landscapes. Comput. Graph. Forum 2014, 33, 101–117. [Google Scholar] [CrossRef] [Green Version]
- Dutta, D.; Wang, K.; Lee, E.; Goodwell, A.; Woo, D.K.; Wagner, D.; Kumar, P. Characterizing vegetation canopy structure using airborne remote sensing data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1160–1178. [Google Scholar] [CrossRef]
- Silva, C.A.; Hudak, A.T.; Vierling, L.A.; Loudermilk, E.L.; O’Brien, J.J.; Hiers, J.K.; Jack, S.B.; Gonzalez-Benecke, C.; Lee, H.; Falkowski, M.J.; et al. Imputation of individual longleaf pine (pinus palustris mill.) tree attributes from field and lidar data. Can. J. Remote Sens. 2016, 42, 554–573. [Google Scholar] [CrossRef]
- Trochta, J.; Krucek, M.; Vrska, T.; Kral, K. 3d forest: An application for descriptions of three-dimensional forest structures using terrestrial lidar. PLoS ONE 2017, 12, e0176871. [Google Scholar] [CrossRef] [PubMed]
- Abegg, M.; Kükenbrink, D.; Zell, J.; Schaepman, M.E.; Morsdorf, F. Terrestrial laser scanning for forest inventories—Tree diameter distribution and scanner location impact on occlusion. Forests 2017, 8, 184. [Google Scholar] [CrossRef]
- Samavati, F.; Runions, A. Interactive 3d content modeling for digital earth. Vis. Comput. 2016, 32, 1293–1309. [Google Scholar] [CrossRef]
- Berger, U.; Hildenbrandt, H. A new approach to spatially explicit modelling of forest dynamics: Spacing, ageing and neighbourhood competition of mangrove trees. Ecol. Model. 2000, 132, 287–302. [Google Scholar] [CrossRef]
- Ch’Ng, E. Model resolution in complex systems simulation: Agent preferences, behavior, dynamics and n-tiered networks. Simulation 2013, 89, 635–659. [Google Scholar] [CrossRef]
- Lane, B.; Prusinkiewicz, P. Generating spatial distributions for multilevel models of plant communities. In Proceedings of the Graphics Interface, Calgary, AB, Canada, 27–29 May 2002; Canadian Human-Computer Communications Society (CHCCS): Mississauga, ON, Canada, 2002; pp. 69–87. [Google Scholar]
- Zamuda, A.; Brest, J. Environmental framework to visualize emergent artificial forest ecosystems. Inf. Sci. 2013, 220, 522–540. [Google Scholar] [CrossRef]
- Bradbury, G.A.; Subr, K.; Koniaris, C.; Mitchell, K.; Weyrich, T. Guided ecological simulation for artistic editing of plant distributions in natural scenes. J. Comput. Graph. Tech. 2015, 4, 28–53. [Google Scholar]
- Gain, J.; Long, H.; Cordonnier, G.; Cani, M.P. Ecobrush: Interactive control of visually consistent large-scale ecosystems. Comput. Graph. Forum 2017, 36, 63–73. [Google Scholar] [CrossRef]
- Soares-Filho, B.S.; Cerqueira, G.C.; Pennachin, C.L. Dinamica—A stochastic cellular automata model designed to simulate the landscape dynamics in an amazonian colonization frontier. Ecol. Model. 2002, 154, 217–235. [Google Scholar] [CrossRef]
- Scheller, R.M.; Domingo, J.B.; Sturtevant, B.R.; Williams, J.S.; Rudy, A.; Gustafson, E.J.; Mladenoff, D.J. Design, development, and application of landis-ii, a spatial landscape simulation model with flexible temporal and spatial resolution. Ecol. Model. 2007, 201, 409–419. [Google Scholar] [CrossRef]
- Alsweis, M.; Deussen, O. Wang-tiles for the simulation and visualization of plant competition. In Advances in Computer Graphics; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–11. [Google Scholar]
- Weier, M.; Hinkenjann, A.; Demme, G.; Slusallek, P. Generating and rendering large scale tiled plant populations. J. Virtual Real. Broadcast. 2013, 10. [Google Scholar] [CrossRef]
- Öztireli, A.C.; Gross, M. Analysis and synthesis of point distributions based on pair correlation. ACM Trans. Graph. 2012, 31, 170. [Google Scholar] [CrossRef]
- Emilien, A.; Vimont, U.; Cani, M.-P.; Poulin, P.; Benes, B. Worldbrush: Interactive example-based synthesis of procedural virtual worlds. ACM Trans. Graph. 2015, 34, 106. [Google Scholar] [CrossRef] [Green Version]
- Turner, M.G.; Gardner, R.H.; O’neill, R.V. Landscape Ecology in Theory and Practice; Springer: Berlin/Heidelberg, Germany, 2001; Volume 401. [Google Scholar]
- Houet, T.; Schaller, N.; Castets, M.; Gaucherel, C. Improving the simulation of fine-resolution landscape changes by coupling top-down and bottom-up land use and cover changes rules. Int. J. Geogr. Inf. Sci. 2014, 28, 1848–1876. [Google Scholar] [CrossRef]
- Lustig, A.; Stouffer, D.B.; Roigé, M.; Worner, S.P. Towards more predictable and consistent landscape metrics across spatial scales. Ecol. Indic. 2015, 57, 11–21. [Google Scholar] [CrossRef]
- Gardner, R.H.; Milne, B.T.; Turnei, M.G.; O’Neill, R.V. Neutral models for the analysis of broad-scale landscape pattern. Landsc. Ecol. 1987, 1, 19–28. [Google Scholar] [CrossRef]
- O’neill, R.; Gardner, R.; Turner, M. A hierarchical neutral model for landscape analysis. Landsc. Ecol. 1992, 7, 55–61. [Google Scholar] [CrossRef]
- Gardner, R.H. Rule: Map generation and a spatial analysis program. In Landscape Ecological Analysis: Issues and Applications; Springer: Berlin/Heidelberg, Germany, 1999; pp. 280–303. [Google Scholar]
- Saura, S.; Martínez-Millán, J. Landscape patterns simulation with a modified random clusters method. Landsc. Ecol. 2000, 15, 661–678. [Google Scholar] [CrossRef]
- Gaucherel, C. Neutral models for polygonal landscapes with linear networks. Ecol. Model. 2008, 219, 39–48. [Google Scholar] [CrossRef]
- Li, X.; He, H.S.; Wang, X.; Bu, R.; Hu, Y.; Chang, Y. Evaluating the effectiveness of neutral landscape models to represent a real landscape. Landsc. Urban Plan. 2004, 69, 137–148. [Google Scholar] [CrossRef]
- Slager, C.T.J.; de Vries, B. Landscape generator: Method to generate landscape configurations for spatial plan-making. Comput. Environ. Urban Syst. 2013, 39, 1–11. [Google Scholar] [CrossRef]
- Van Strien, M.J.; Slager, C.T.; Vries, B.; Grêt-Regamey, A. An improved neutral landscape model for recreating real landscapes and generating landscape series for spatial ecological simulations. Ecol. Evol. 2016, 6, 3808–3821. [Google Scholar] [CrossRef] [PubMed]
- Danz, N.P.; Frelich, L.E.; Reich, P.B.; Niemi, G.J. Do vegetation boundaries display smooth or abrupt spatial transitions along environmental gradients? Evidence from the prairie-forest biome boundary of historic minnesota, USA. J. Veg. Sci. 2013, 24, 1129–1140. [Google Scholar] [CrossRef]
- Oliphant, T.E. Python for scientific computing. Comput. Sci. Eng. 2007, 9. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landscape Metric | Variable Name | Formula | Value Range |
|---|---|---|---|
| Landscape proportion | 0.0~1.0 | ||
| Number of patches | Integers (≥1) | ||
| Mean shape index | ≥1.0 |
| Tree Species | Landscape Metric | Target Value | Figure 8a | Figure 8b | Figure 8c |
|---|---|---|---|---|---|
| Spruce | P | 15.8% | 15.9% | 15.9% | 15.9% |
| PN | 8 | 8 | 8 | 8 | |
| MSI | 1.51 | 1.60 | 1.54 | 1.57 | |
| Birch | P | 27.6% | 27.9% | 27.9% | 27.9% |
| PN | 7 | 7 | 7 | 7 | |
| MSI | 1.74 | 1.79 | 1.83 | 1.75 | |
| Pine | P | 26.7% | 24.3% | 23.6% | 23.8% |
| PN | 7 | 7 | 7 | 7 | |
| MSI | 2.20 | 2.35 | 2.29 | 2.43 | |
| Larch | P | 24.4% | 24.0% | 23.9% | 24.0% |
| PN | 8 | 8 | 8 | 8 | |
| MSI | 1.56 | 1.62 | 1.65 | 1.56 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Gu, X.; Li, X.; Tan, J.; She, J. Procedural Generation of Large-Scale Forests Using a Graph-Based Neutral Landscape Model. ISPRS Int. J. Geo-Inf. 2018, 7, 127. https://doi.org/10.3390/ijgi7030127
Li J, Gu X, Li X, Tan J, She J. Procedural Generation of Large-Scale Forests Using a Graph-Based Neutral Landscape Model. ISPRS International Journal of Geo-Information. 2018; 7(3):127. https://doi.org/10.3390/ijgi7030127
Chicago/Turabian StyleLi, Jiaqi, Xiaoyan Gu, Xinchi Li, Junzhong Tan, and Jiangfeng She. 2018. "Procedural Generation of Large-Scale Forests Using a Graph-Based Neutral Landscape Model" ISPRS International Journal of Geo-Information 7, no. 3: 127. https://doi.org/10.3390/ijgi7030127
APA StyleLi, J., Gu, X., Li, X., Tan, J., & She, J. (2018). Procedural Generation of Large-Scale Forests Using a Graph-Based Neutral Landscape Model. ISPRS International Journal of Geo-Information, 7(3), 127. https://doi.org/10.3390/ijgi7030127