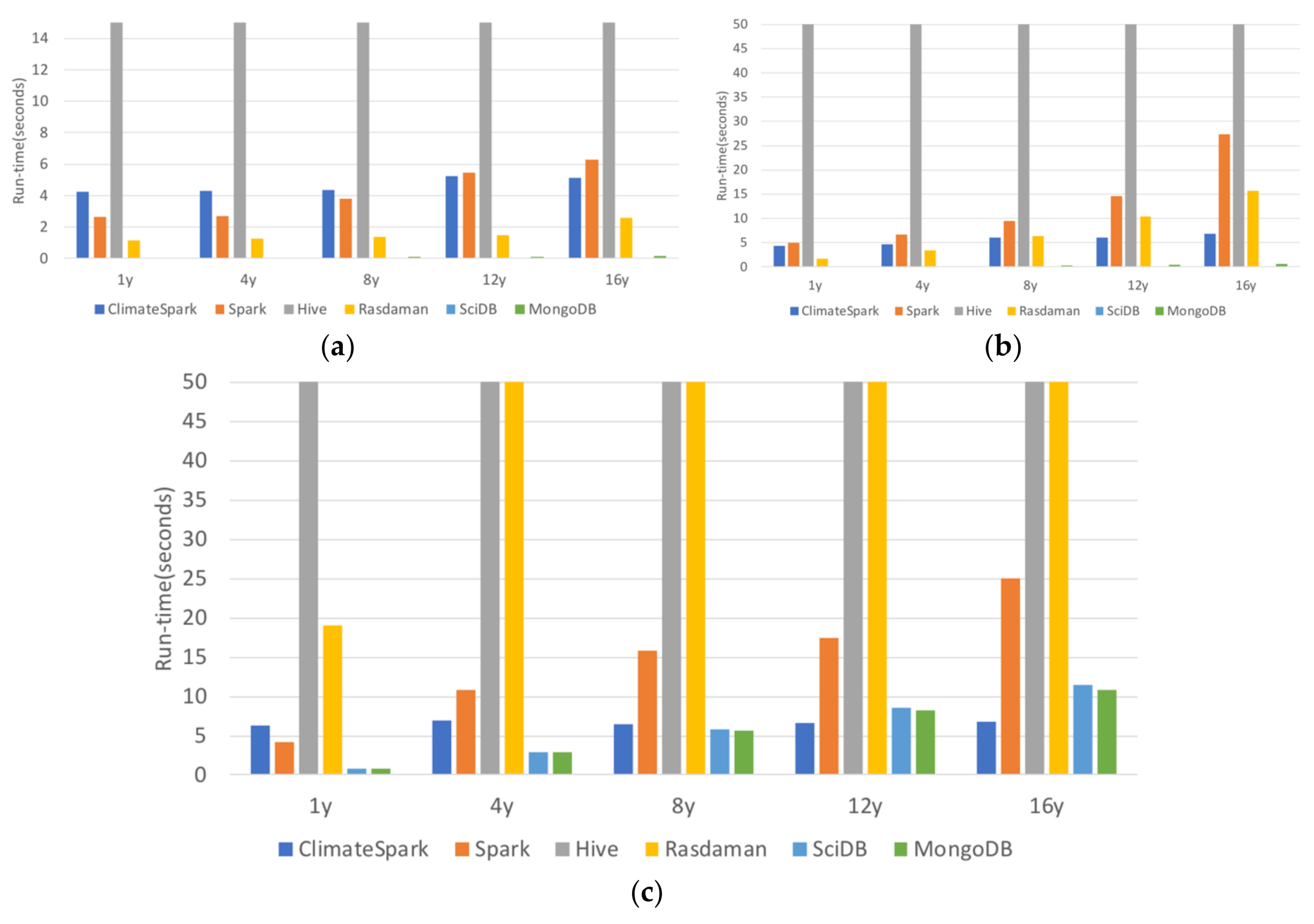
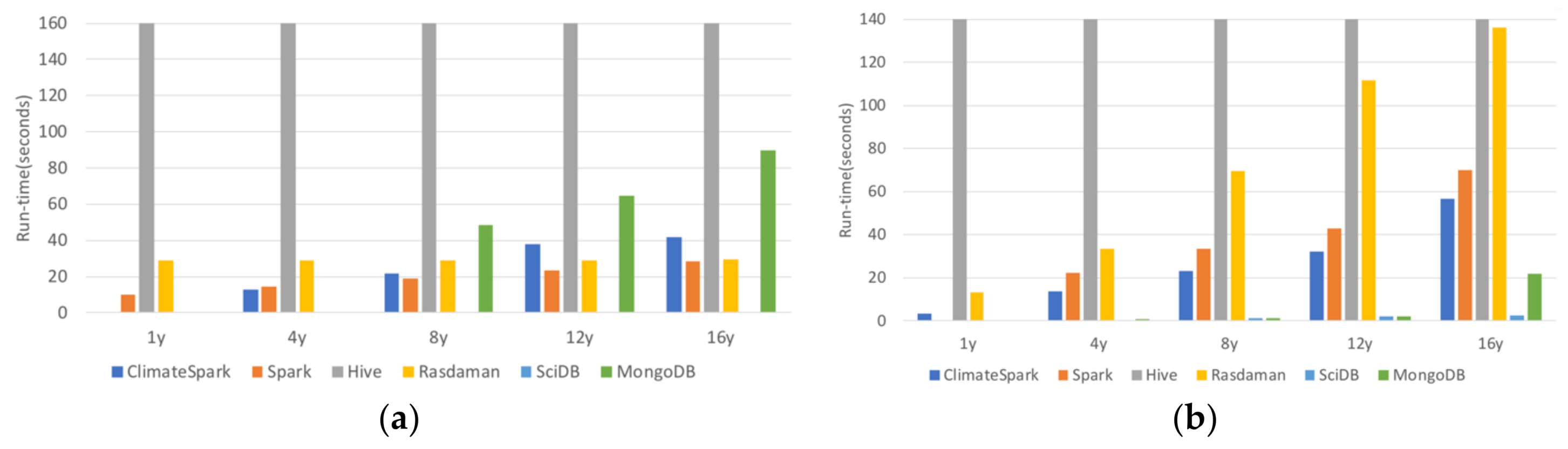
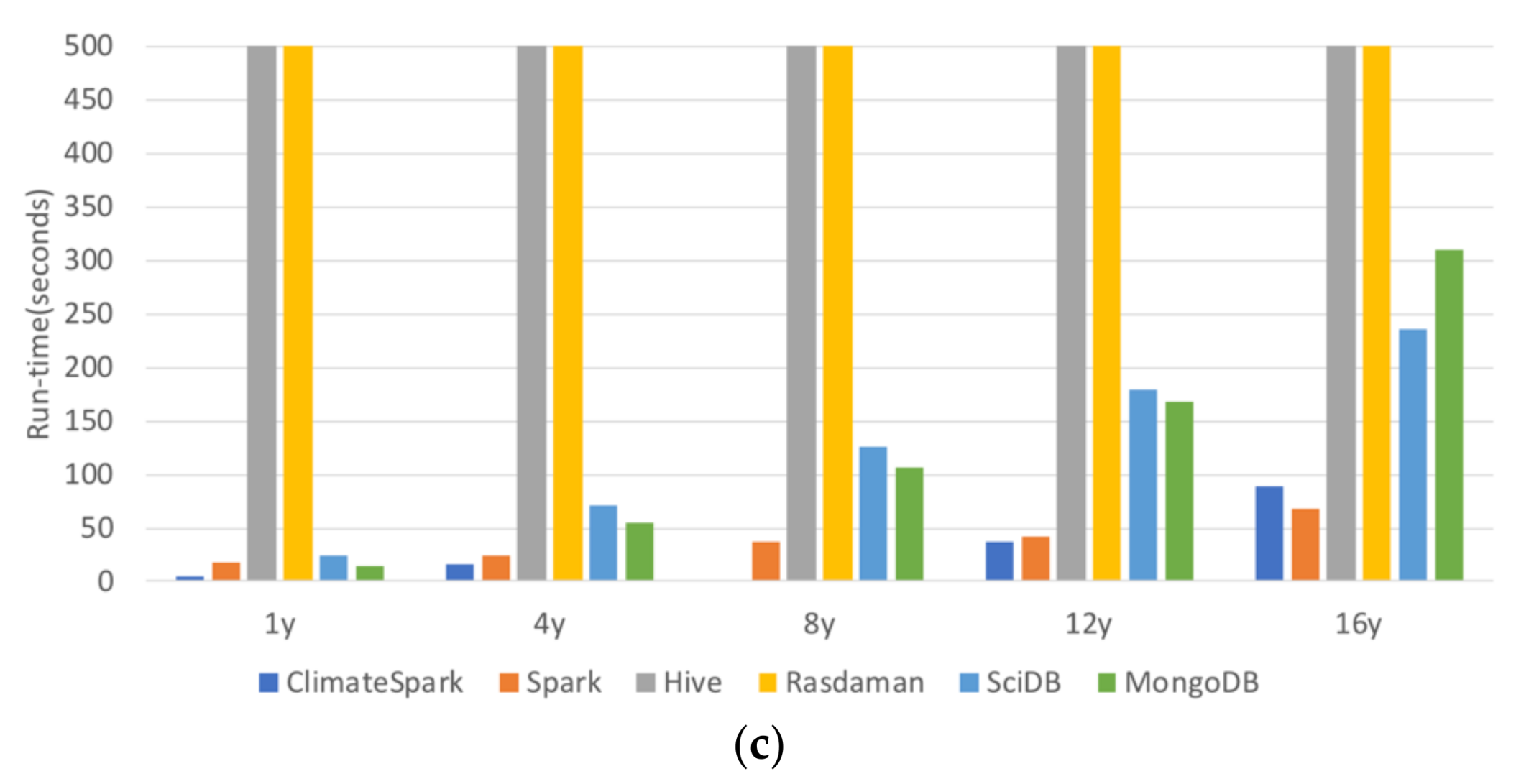
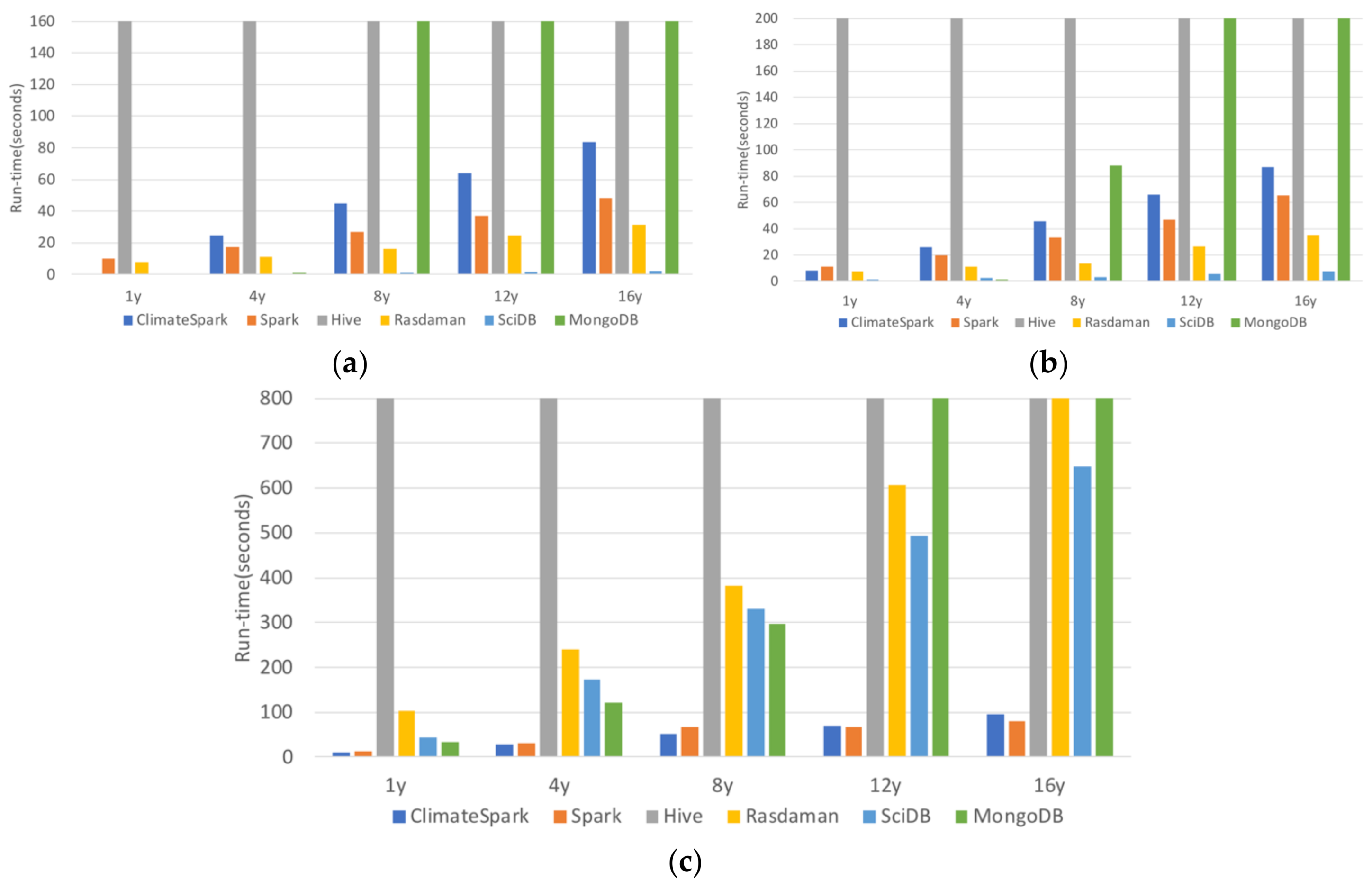
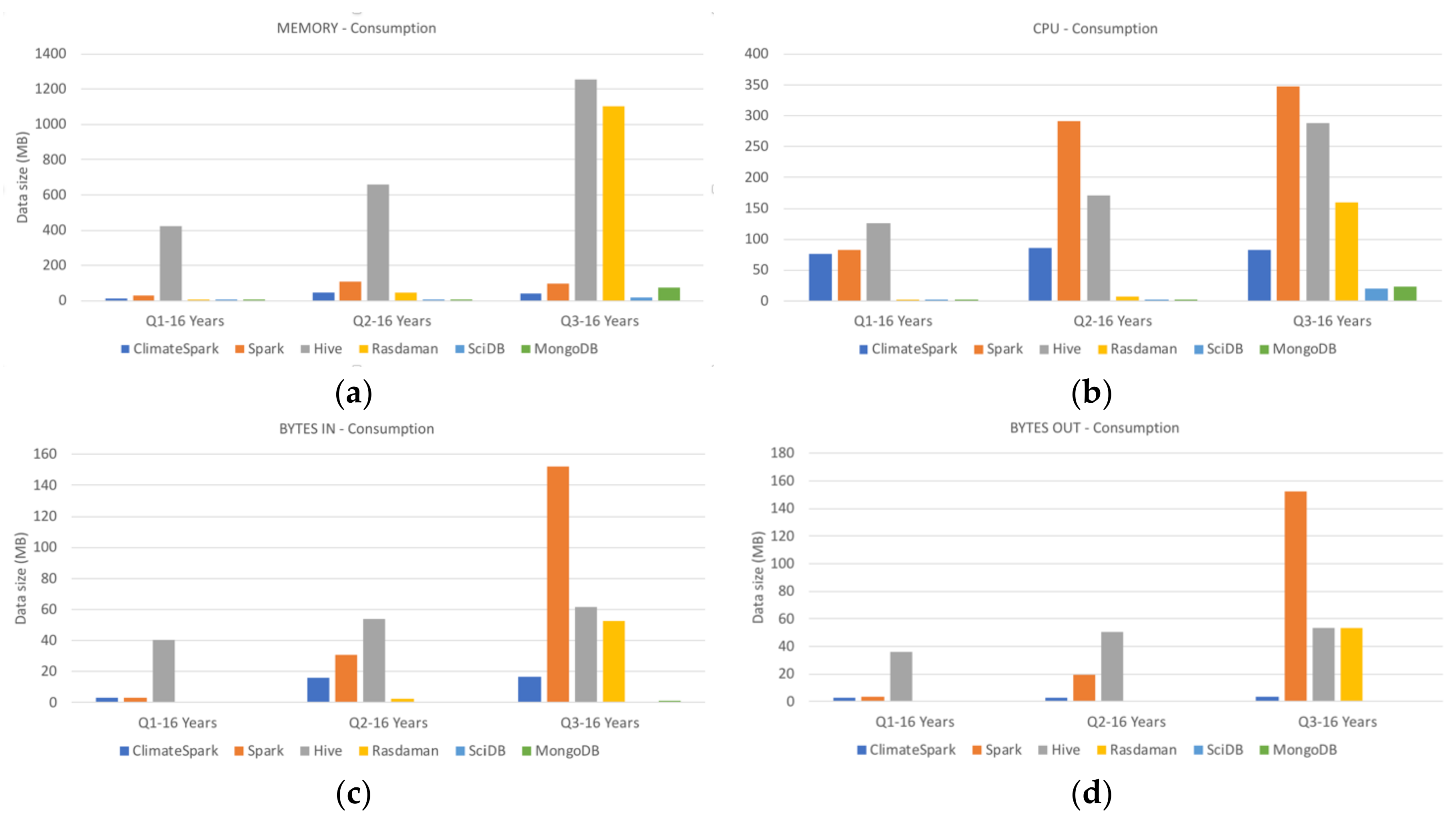
The six containers (Spark, ClimateSpark, Hive, Rasdaman, SciDB, and MongoDB) are compared for their handling of geospatial data from the perspective of architecture, logical data model, physical data model, and data operations. Among the six compared, Rasdaman was developed by the geoscience community and ClimateSpark is enhanced from Spark for geoscience community.
3.3. Physical Data Model
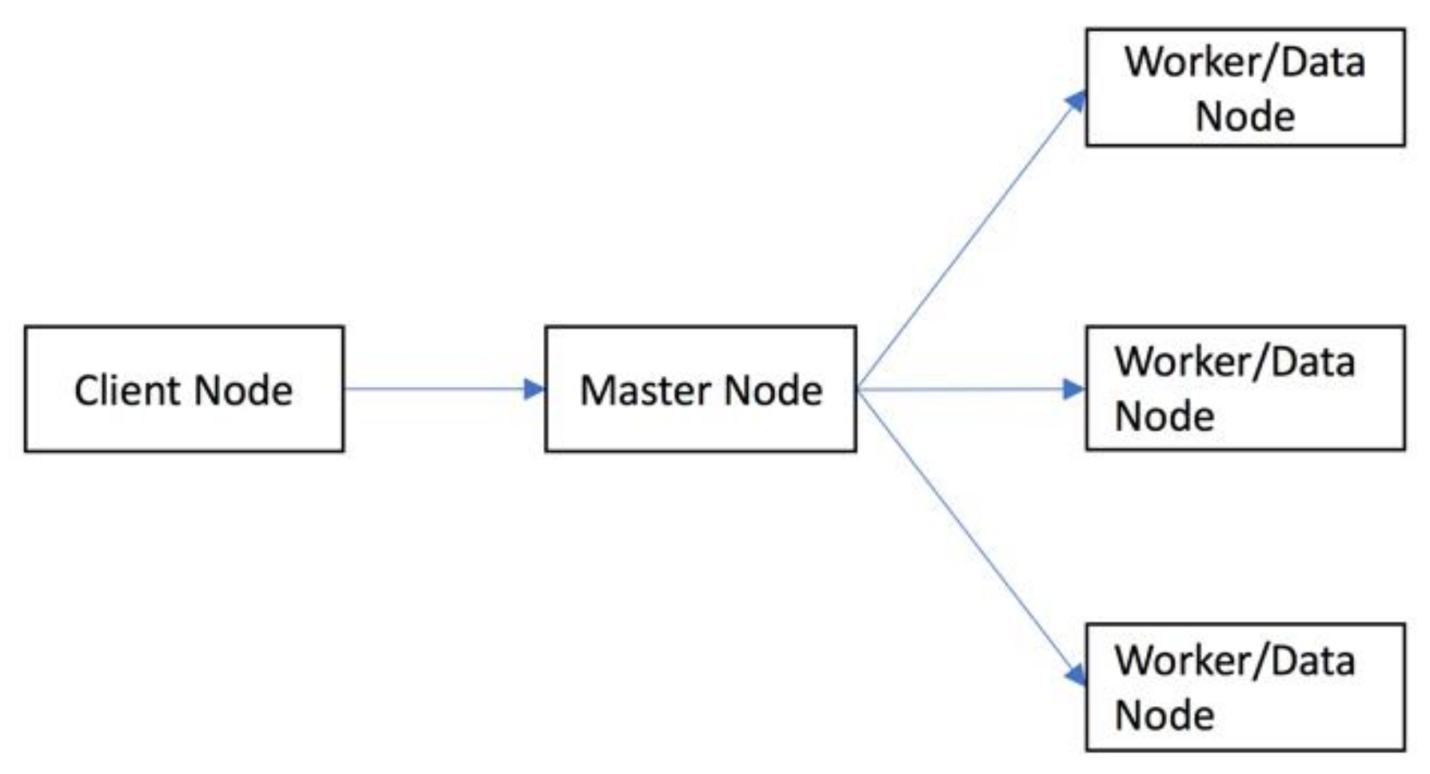
The data containers partition the datasets into small pieces and store them in their own specially designed physical data models to obtain the high query performance and scalability.
Table 4 summarize the features of the physical data models of Spark, ClimateSpark, Hive, Rasdaman, SciDB, and MongoDB.
3.3.1. Rasdaman, SciDB, and ClimateSpark
Rasdaman, SciDB, and ClimateSpark use arrays to represent data, but the default array size is usually too large to fit entirely in memory, and the entire array is required to be read whenever an element is queried. Thus, the array is often partitioned into smaller chunks as a basic I/O unit organized on disk, like the page for file systems and the block for relational databases [
13], and the chunking structure is invisible to the query client. With the chunking strategy the query process is more efficient since only the involved chunks need to be read instead of the entire array.
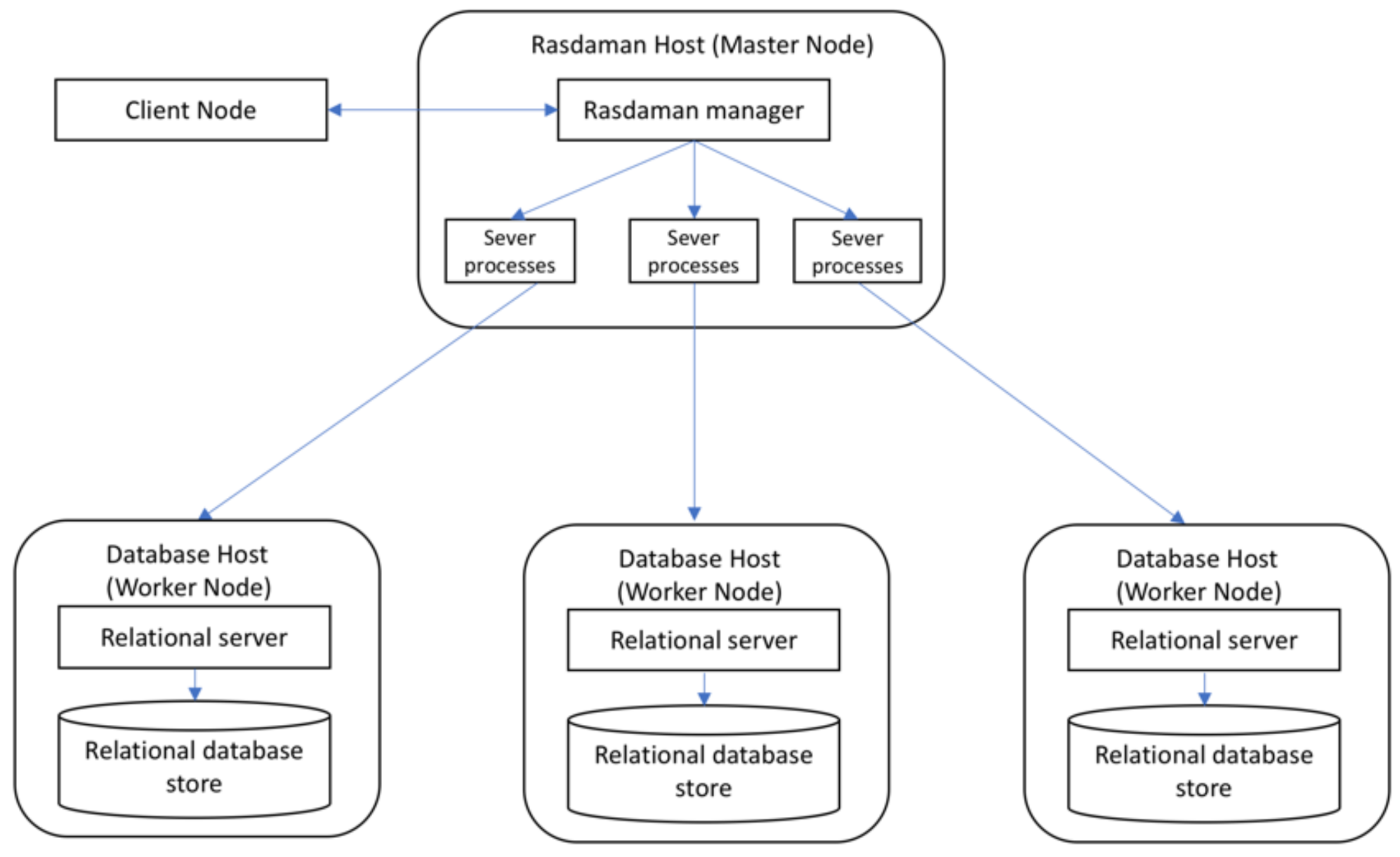
Although Rasdaman, SciDB, and ClimateSpark support chunking storage, there are differences when storing data. Rasdaman offers an array storage layout language in its query language to enable users to control the important physical tuning parameter (e.g., chunk size and chunk scheme). The chunk schemes include regular, aligned, directional, and area of interest chunking. The regular chunking method is to equally split array-based datasets into multiple chunks with same dimension size and no overlapping. After users set the chunking parameters, Rasdaman automatically partitions the input data to chunks in the data loading process and stores them with the metadata in local database. Rasdaman also supports different indices for different chunking schemes. Both R+ tree and directory index work with all chunking schemes, whereas the regular computed index only works with regular tiling but is faster than the other indexes.
Data stored in SciDB uses a SciDB-specific binary format. The SciDB version (15.12) adopted in this paper utilizes PostgreSQL to store system catalogued data and the metadata of arrays (e.g., names, dimensions, attributes, residency). Chunk size is optional, and using chunks may enlarge the storage size for an array while enhancing the query speed. To ensure a balance between storage size and query speed, the amount of data in each chunk is recommended to be between 10 and 20 MB. Multidimensional Array Clustering (MAC), the mechanism for organizing data loaded into SciDB, keeps data close to each other in the user defined system stored in the same chunk in the storage media. Data with MAC are split into rectilinear chunks. Within the simple hash function, chunks are stored into different SciDB instances, and the hash function allows SciDB to quickly find the right chunk for any piece of data based on a coordinate. After the chunk size is defined, data are split into chunks continuously. When executing a range search, this minimizes the reads across chunks. Run-length encoding is applied when storing data into SciDB, reducing the array size and producing better performance. Different attributes in one array are stored separately, so a query looking for an attribute does not need to scan for another attribute, saving time for data reading and movement.
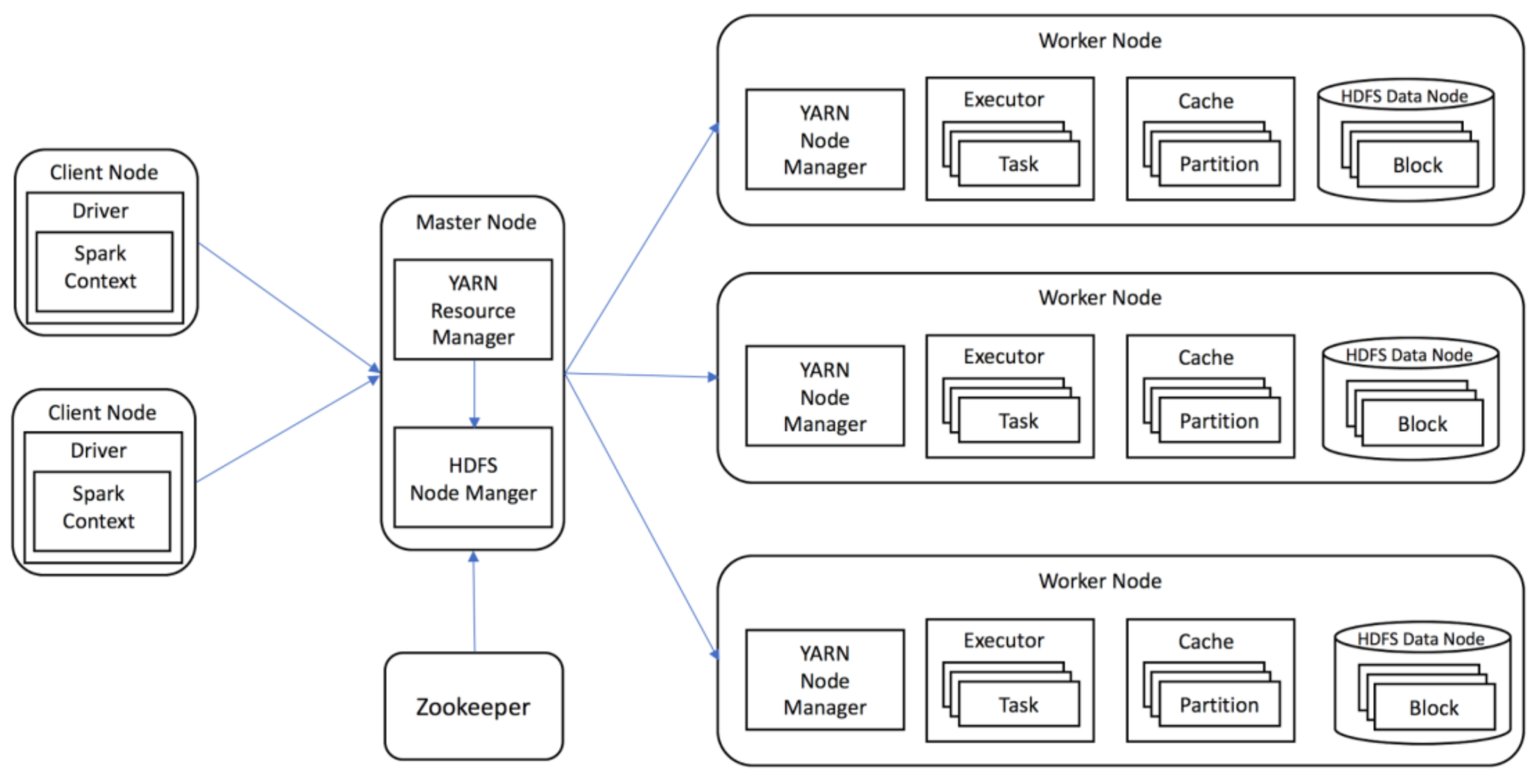
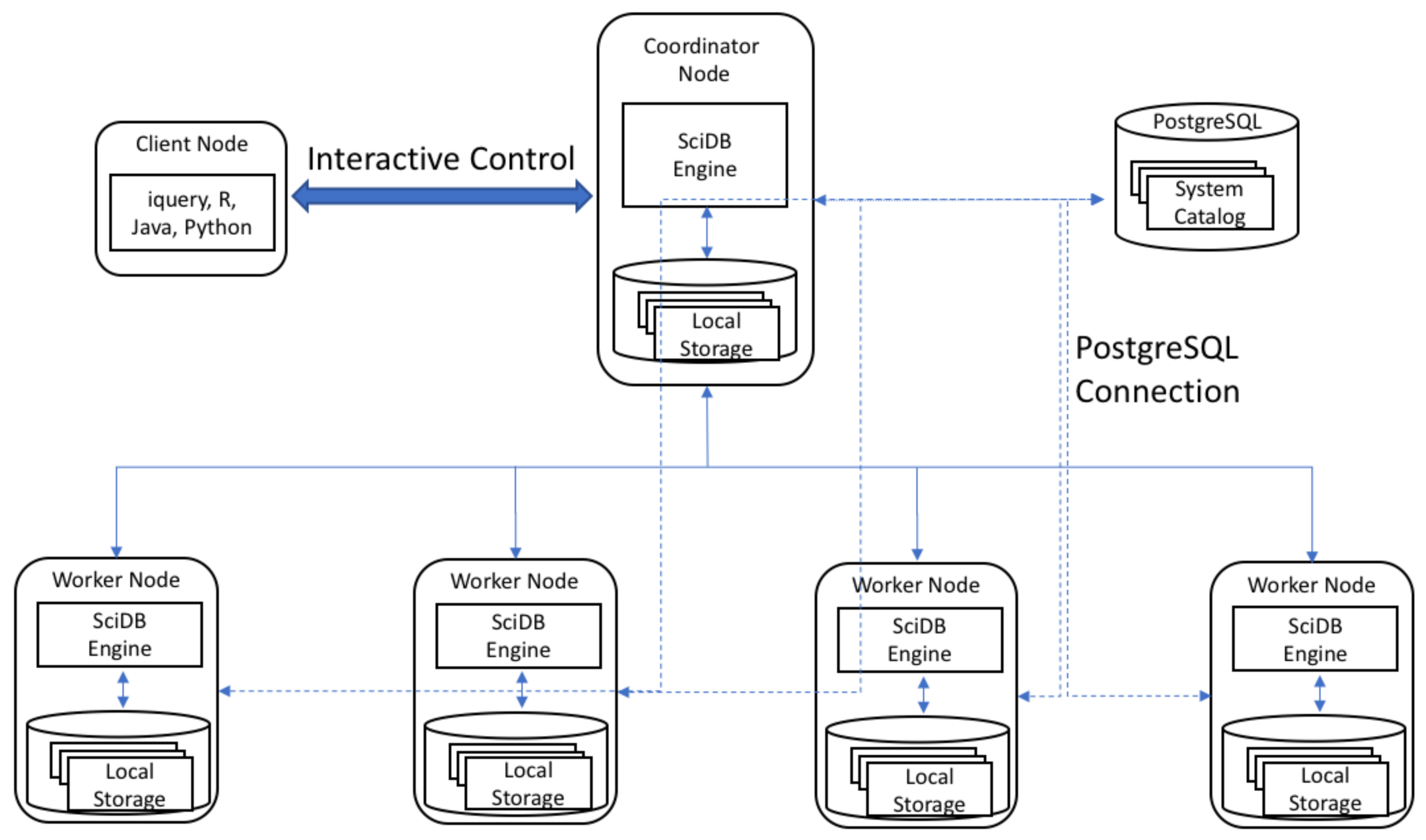
ClimateSpark stores the collection of arrays in HDF/NetCDF file, taking advantages of HDF/NetCDF (e.g., chunking, indexing, and hierarchical structure). ClimateSpark supports the regular chunking, and the chunks are stored in any order and any position within the file, enabling chunks to be read individually, while the cells in a chunk are stored in “row-major” order. ClimateSpark utilizes HDFS to get the scalable storage capability for fast increasing data volume. The HDF/NetCDF files are uploaded into HDFS without preprocessing. However, HDFS automatically splits a file into several blocks, usually 64 MB or 128 MB, and distributes them across the cluster. To better manage these chunks and improve data locality, ClimateSpark builds a spatiotemporal index to efficiently organize distributed chunks, and the index exactly identifies the chunk location information at the node, file, and byte. level. These characteristics greatly improves the partial I/O efficiency with high data locality and avoids unnecessary data reading.
3.3.2. MongoDB
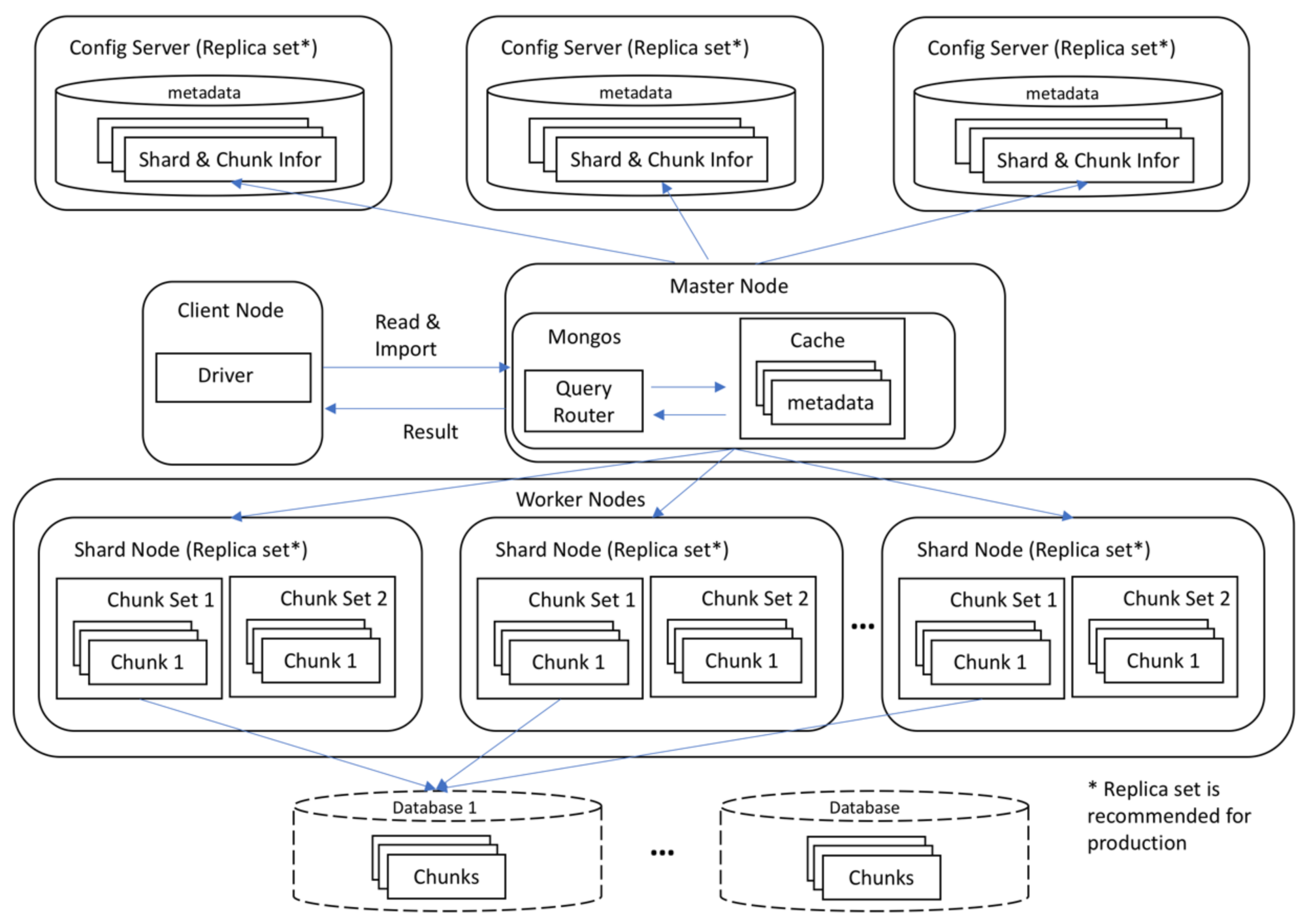
MongoDB does not support multidimensional data natively, and the array data need to be projected into key-value pairs and stored in a binary-encoded format called BSON behind the scenes. Chunking is achieved by splitting data into smaller pieces and spreading them equally among shard nodes in collection level. MongoDB supports chunking natively in sharding with a default size of 64 megabytes. However, smaller chunk sizes (e.g., 32 MB, 16 MB) is recommended for spreading the data more evenly across the shards. MongoDB defines indices at the collection level and supports indices on any field or sub-field of the documents [
36]. It provides six types of indices: single field, compound, multi-key, geospatial, test and hashed index. The index is created automatically for the target field, irrespective of the kind of index performed. The purpose is to allow MongoDB to process and fulfill queries quickly by creating small and efficient representations of the documents in a collection [
36]. Loading balance is conducted at chunk level to keep chunks equally distributed across the shard nodes.
3.3.3. Spark and Hive
Spark and Hive leverage Parquet, a columnar storage format, to store the data in a relation table. Compared with the traditional row-oriented table (e.g., csv text files), Parquet is more disk saving and efficient in queries. In a Parquet table each column is stored and loaded separately, and this has two advantages: (1) the columns are efficiently compressed using the most suitable encoding schemes to save storage space; and (2) queries only need to read the specific columns rather than the entire rows. Meanwhile, each column is split into several column chunks with a column chunk containing one or more pages. The page is an indivisible unit in terms of compression and encoding and is composed of the header information and encoded values. Spark SQL and Hive SQL natively support Parquet files in HDFS and reads them with high data locality, an efficient and convenient way to query Parquet files in HDFS using Spark/Hive SQL.
3.4. Data Operations
Aiming to improve the usability and ease data operations, all containers develop their strategies for the users at different levels. However, these strategies (e.g., query language, API, extensibility, and support data format) are dissimilar (
Table 5) due to their different design purpose and targeted user groups.
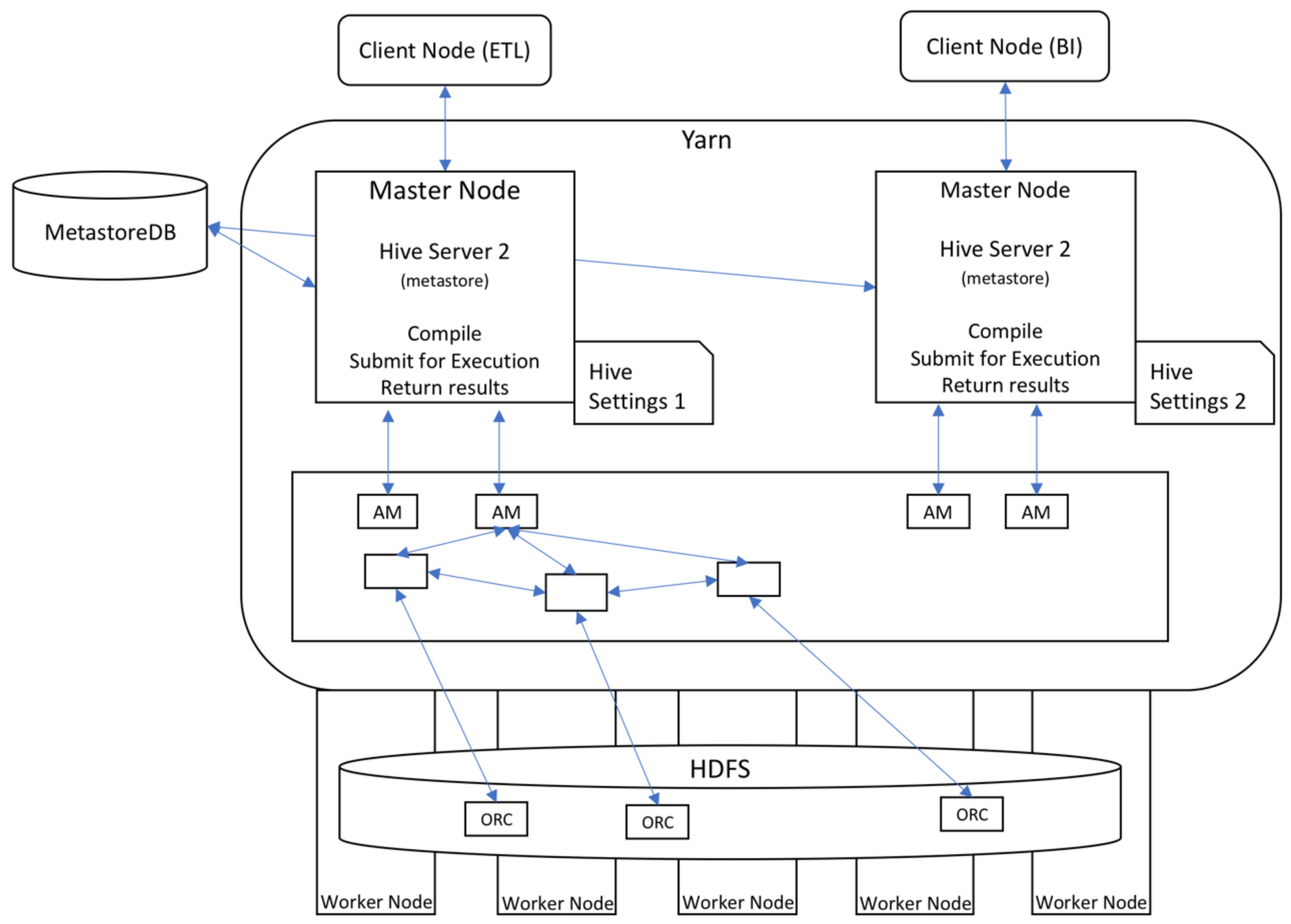
Spark and Hive need to convert the input array datasets into the support data formats (e.g., CSV and Parquet), but the projection coordination is kept in the relation table for geospatial queries. They also support the standard SQL and enable users to extend SQL functions by using user-defined-function APIs.
The ClimateSpark develops a HDFS-based middleware for HDF/NetCDF to natively support HDF and NetCDF datasets and keeps the projection information to support geospatial query. It provides the basic array operations (e.g., concatenation, average, max, conditional query) available at Spark-shell terminal in Scala API. The array can be visualized as PNG or GIF file. Users develop their own algorithms based on Scala and Java API. The Spark SQL is extended by using user-defined functions to support SQL operation on the geospatial data, but its operation is designed for the points rather than the array because Spark SQL does not support array data structure yet.
The Rasdaman provides the query language, rasql, to support retrieval, manipulation, and data definition (e.g., geometric operations, scaling, concatenation). It implements various data loading functions based on GDAL to natively support different raster data formats, including GeoTiff, NetCDF, and HDF. Users do not need to preprocess their original datasets, which are automatically loaded as multi-dimensional arrays. It also enables users to customize their functions via C++, Java, and Python API. However, it cannot automatically distribute the input data across the cluster, and users need to specify which data are loaded into which node. The project coordination information is lost after the data are imported.
The SciDB provides two query language interfaces, Array Functional Language (AFL) and prototype Array Query Language (AQL). Both work on the iquery client, a basic command line for connecting SciDB. Scripts for running AQL are similar to SQL for relational databases, while AFL is a functional language using operators to compose queries or statements. In AFL, operators are embedded according to user requirements, meaning each operator takes the output array of another operator as its input. The SciDB not only provides resourceful operators for satisfying users’ expectations, but it is also programmable from R and Python and support plugins as extension to better serve the needs (e.g., dev tools support installations of SciDB plugins from GitHub repositories). The CSV files, SciDB-formatted text, TSV files, and binary files are date formats currently supported by SciDB.
The query language in MongoDB is an object-oriented language, and similar to other NoSQL databases, it does not support join operation. Conversely, it supports dynamic queries on documents and is nearly as powerful as SQL. Since it is a schema-free database, the query language allows users to query data in a different manner which would have higher performance in some special cases. “Find” method in MongoDB, which is similar to “select” in SQL but limited to one table, is used to retrieve data from a collection. Different from traditional SQL, the query system in MongoDB is from top to bottom, operations take place inside a collection, and one collection contains millions of records. The MongoDB also supports aggregation operations, which groups values from multiple documents and performs as many operations as needed to return results. The aggregation framework is modeled on the concept of data processing pipelines [
40]. Finally, map-reduce operation is supported, using custom JavaScript functions to perform map and reduce operations.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


