1. Introduction
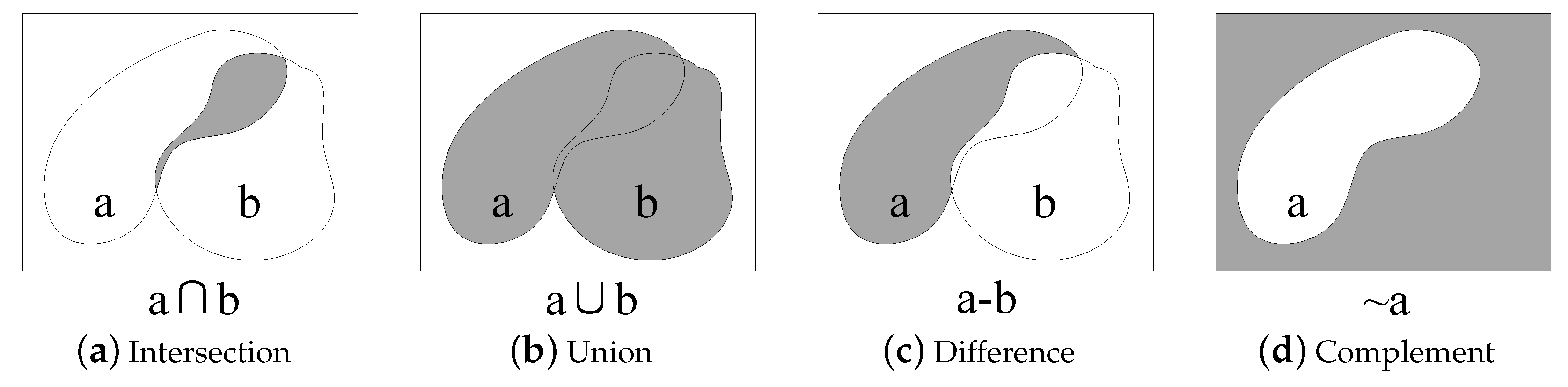
A buffer is defined as the zone with a certain width around a geometric geographic feature, according to a specified buffer distance, and an overlay creates a composite map by combining the geometry and attributes of multiple data layers [
1]. Buffer and overlay analysis are two basic Geographic Information System (GIS) spatial operations for resource allocation, land planning, and many other relevant fields [
2,
3]. In practical applications, the two operations are usually combined to solve spatial decision problems; typically, the site selection problem [
4]. In this paper, we use buffer-overlay analysis to represent the combined operation.
Buffer-overlay analysis is computationally intensive and time-consuming. Moreover, with the rapid development of surveying and mapping technology, the computational limitation becomes more prominent as greater volumes of large-scale spatial data is produced.
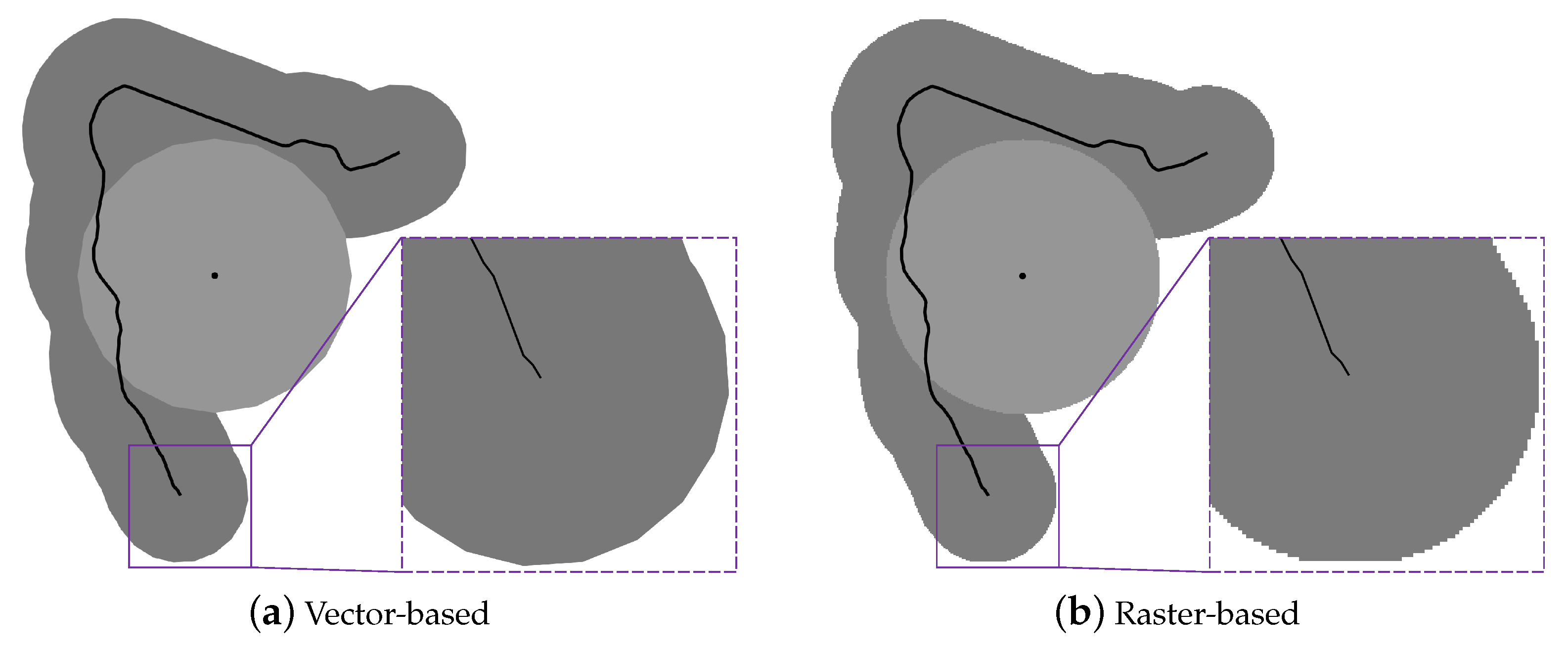
Buffer and overlay generation are the keys to buffer-overlay analysis. Several methods for solving generation problems have been proposed. These methods can be summarized into two categories, by the types of results they produce: Vector-based methods and raster-based methods. Vector-based methods use vector polygons to represent results, while raster-based methods use values of pixels in raster images to indicate result zones.
Table 1 lists the advantages and disadvantages of the two types of methods. Due to their large storage space occupancy, raster-based methods are generally not applied to large-scale spatial data, and the related research mainly focuses on the calculation of raster buffers using a serial computing model [
5,
6]. For vector-based methods, the edge constraint triangulation method [
7] and the buffer equation approximation strategy are widely used [
8] in buffer generation; in addition, in order to deal with large-scale data, several parallel strategies have been proposed to solve the vector-based buffer and overlay generation problems [
9,
10,
11,
12,
13,
14,
15,
16,
17]. However, the performance is still far from satisfactory as it is impossible to support real-time buffer-overlay analysis using the traditional methods, even when high-performance computing technologies are applied. For example, Shen [
10] proposed a parallel vector buffer generation method, HPBM, based on Spark [
18], and conducted an experiment on a high-performance cluster which compared HBPM to three optimized parallel methods and the popular GIS software programs (
Table 2); as shown in the table, HBPM outperformed the other traditional data-oriented methods and is able to generate buffers for 597k linestring objects in around 3 min. As another example, Puri [
16] presented a parallel GIS system, MPI-GIS, for polygon overlay processing of two GIS layers which employs R-tree for efficient indexing and identification of potentially intersecting sets of polygon objects; using MPI-GIS, the processing time of hundred-thousand-scale datasets is in the ten-second-level.
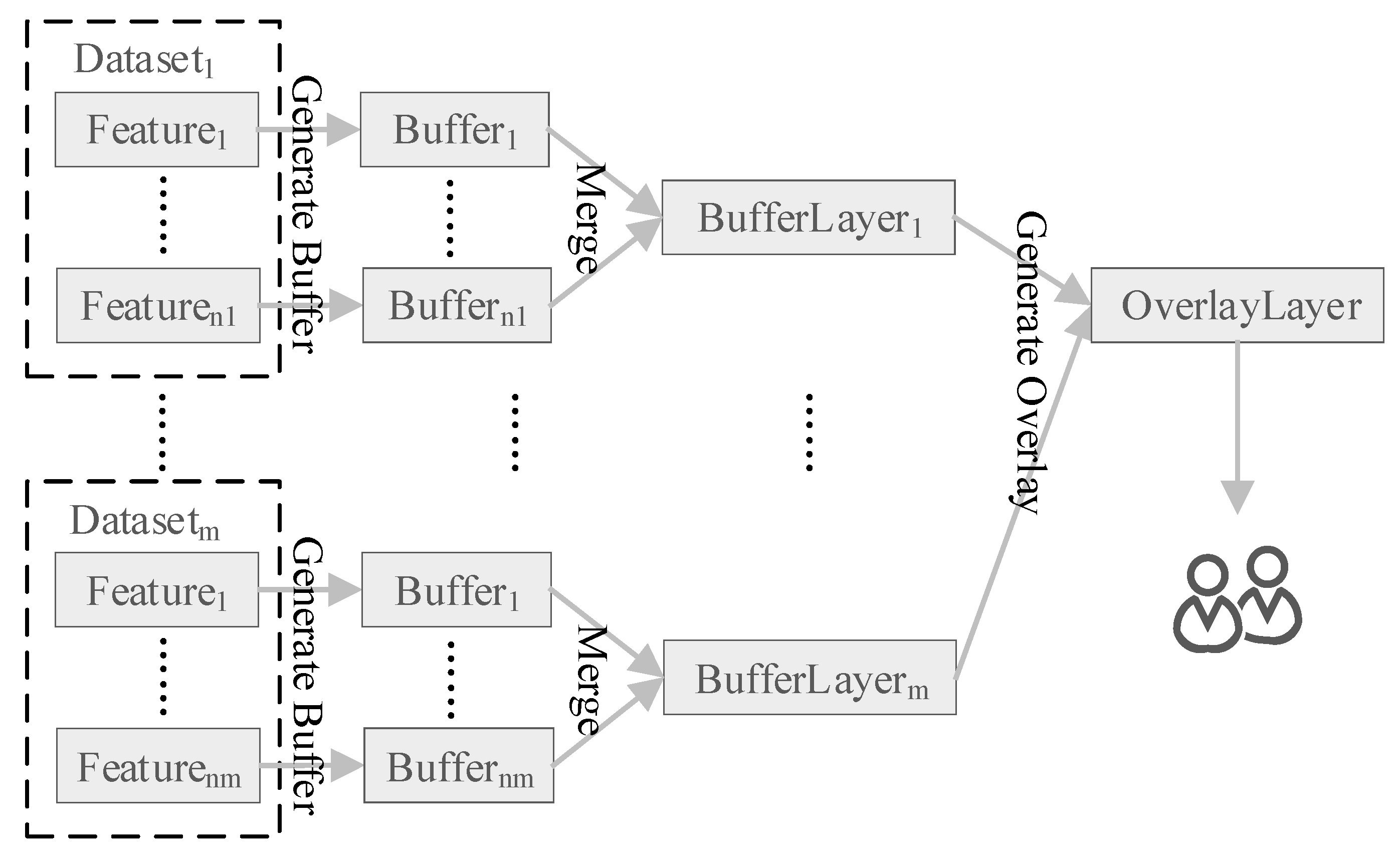
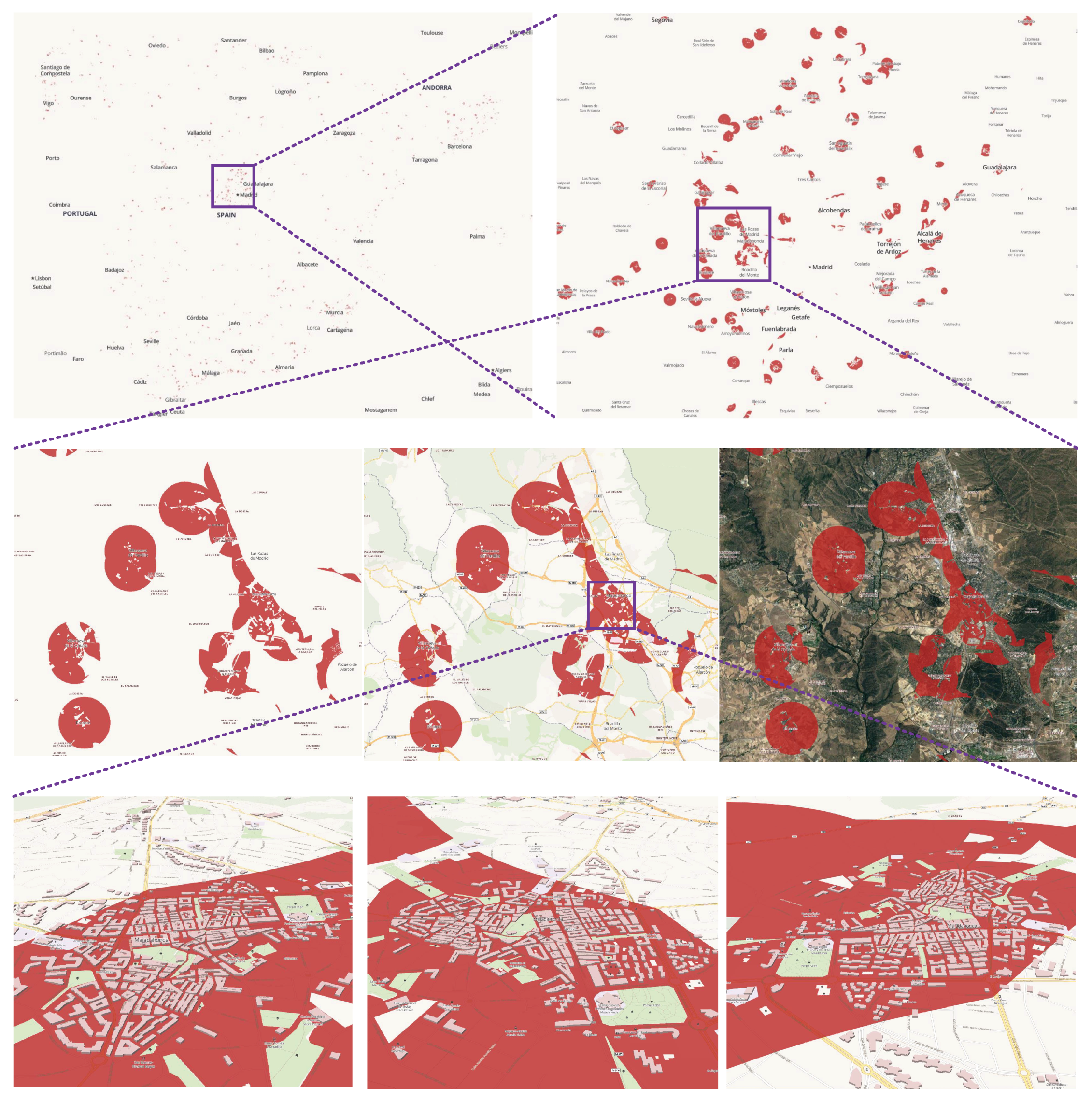
Figure 2 presents the general buffer-overlay analysis flow using existing generation methods. In the flow, buffers of spatial objects are generated separately and merged to create buffer layers of datasets, then the buffer layers are combined to get the final overlay layer. It is data-oriented and straightforward, with computational scales expanding rapidly with the volume of spatial objects. The final overlay layer is provided to users on screens, though it can be extremely large and complex.
Based on this, we present a visualization-oriented parallel buffer-overlay analysis model, HiBO, to provide interactive and online buffer-overlay analysis of large-scale spatial data. In our previous work, we presented a visualization-oriented buffer analysis method named HiBuffer, which is capable of handling large-scale spatial point and linestring data in real time [
21]. Our previous experiments showed that HiBuffer has the striking performance of generating buffers for all of the datasets shown in
Table 2 in less than 1 s. In addition, HiBuffer is able to provide interactive buffer analysis for much larger datasets. In this paper, we extend HiBuffer to support buffer analysis of polygon objects and overlay analysis as well, which also achieves remarkable effects. The buffer-overlay analysis flow in HiBO is shown in
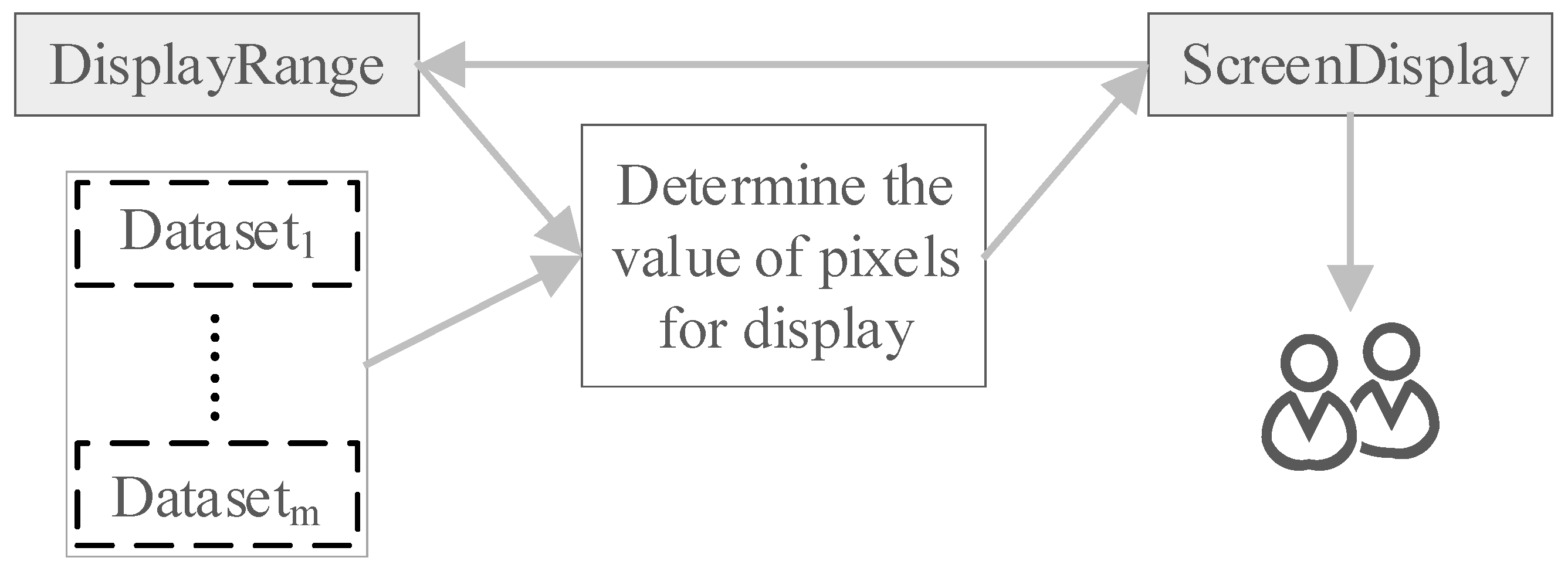
Figure 3, its core task is to determine the value of pixels for display. To the best of our knowledge, the approach is a brand new idea for buffer and overlay analysis, with the advantage of being insensitive to data volumes. Experimental results verify that HiBO is capable of handling ten-million-scale data in real time.
The remainder of this paper proceeds as follows:
Section 2 introduces the core ideas of the buffer and overlay generation methods in HiBO. In
Section 3, the architecture of HiBO is described in detail.
Section 4 provides an online demonstration, as well as an experiment to validate the performance of HiBO. The conclusions are drawn in
Section 5.
3. Architecture
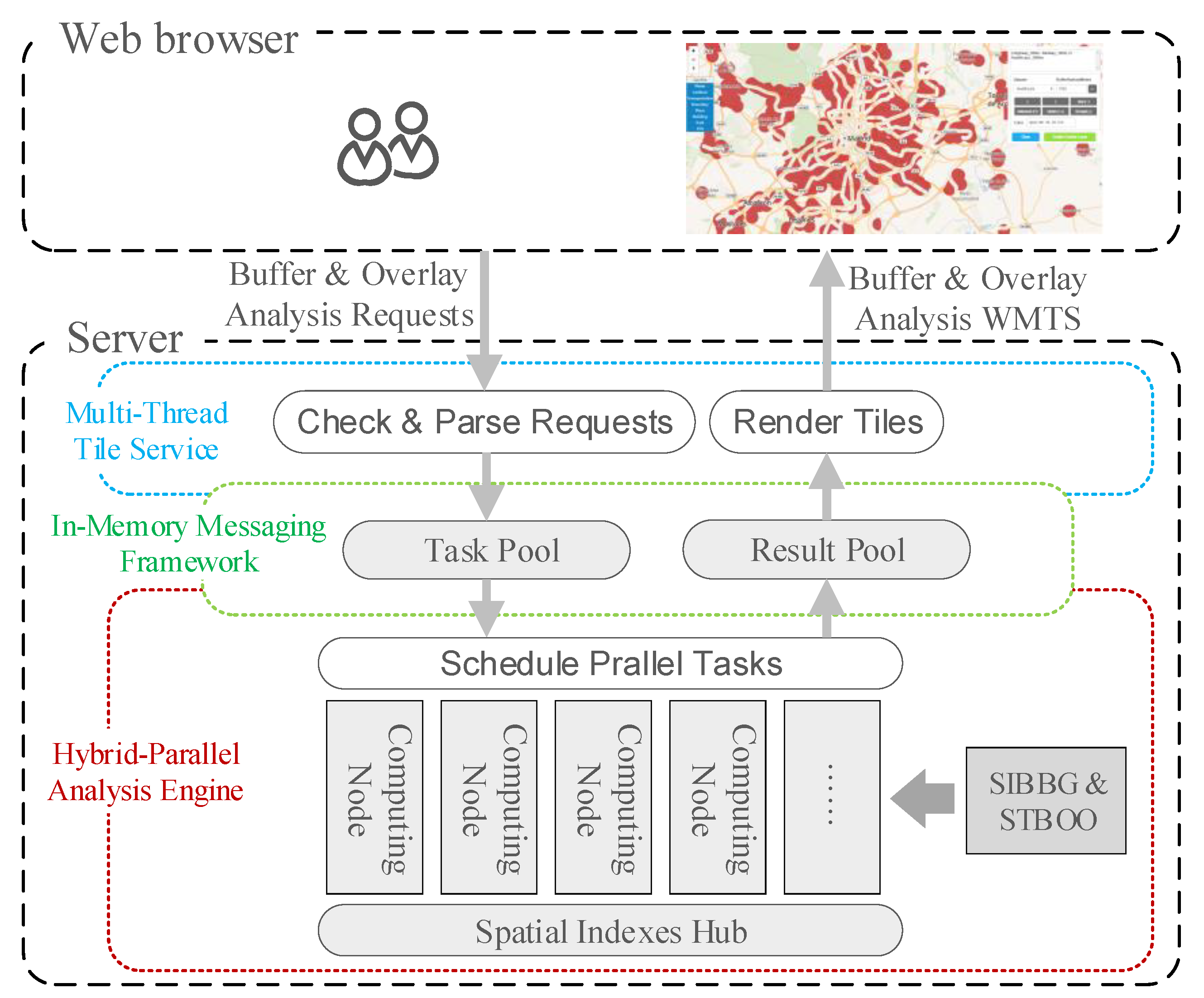
The architecture of HiBO is illustrated in
Figure 6. It adopts the browser-server model. Specially, analysis results are organized into a tile-pyramid structure, provided as a Web Map Tile Service (WMTS). Tiles of different levels are selected for the screen display, according to zoom levels. When a user browses the analysis results, only tiles in the screen range need to be generated. Zooming in the results, tiles with higher levels and higher resolution will be used, and there is no sawtooth distortion. The server side of HiBO comprises three parts: Multi-Thread Tile Service (MTTS), In-Memory Messaging Framework (IMMF), and Hybrid-Parallel Analysis Engine (HPAE).
3.1. Multi-Thread Tile Service
MTTS encapsulates the buffer-overlay analysis service as a WMTS. We treat the analysis task in one tile range as an independent task. In the Check&Parse Requests process, MTTS analyzes the tile requests and filters out improper tasks, including (1) tasks with wrong operation expressions in the requests; and (2) tasks once processed with analysis results are still in the Result Pool. In the Render Tiles process, MTTS gets analysis results from the Result Pool and renders tiles according to the styles in the requests. To be more specific, the analysis results in the Result Pool are stored in the form of two-dimensional boolean arrays (true indicates zones in analysis results). In order to improve concurrency, multi-thread technology is adopted in the tile server.
3.2. In-Memory Messaging Framework
IMMF is a messaging framework based on Redis, which is an In-Memory Key-Value database. In this messaging framework, tasks and results are transferred rapidly in memory without disk I/O. The tasks are stored in a first-in-first-out (FIFO) queue in Redis. Tasks are pushed to the queue and popped to suspended MPI processes. To avoid errors in parallel processing, the push and pop operations are performed in blocking mode. After a task is finished, the analysis result will be written to Redis, and a task completion message will be sent to MTTS using the subscribe/publish functions in Redis. To avoid taking up too much memory, analysis results are set with expiry time, and expired data will be cleaned up once the max memory limit is exceeded.
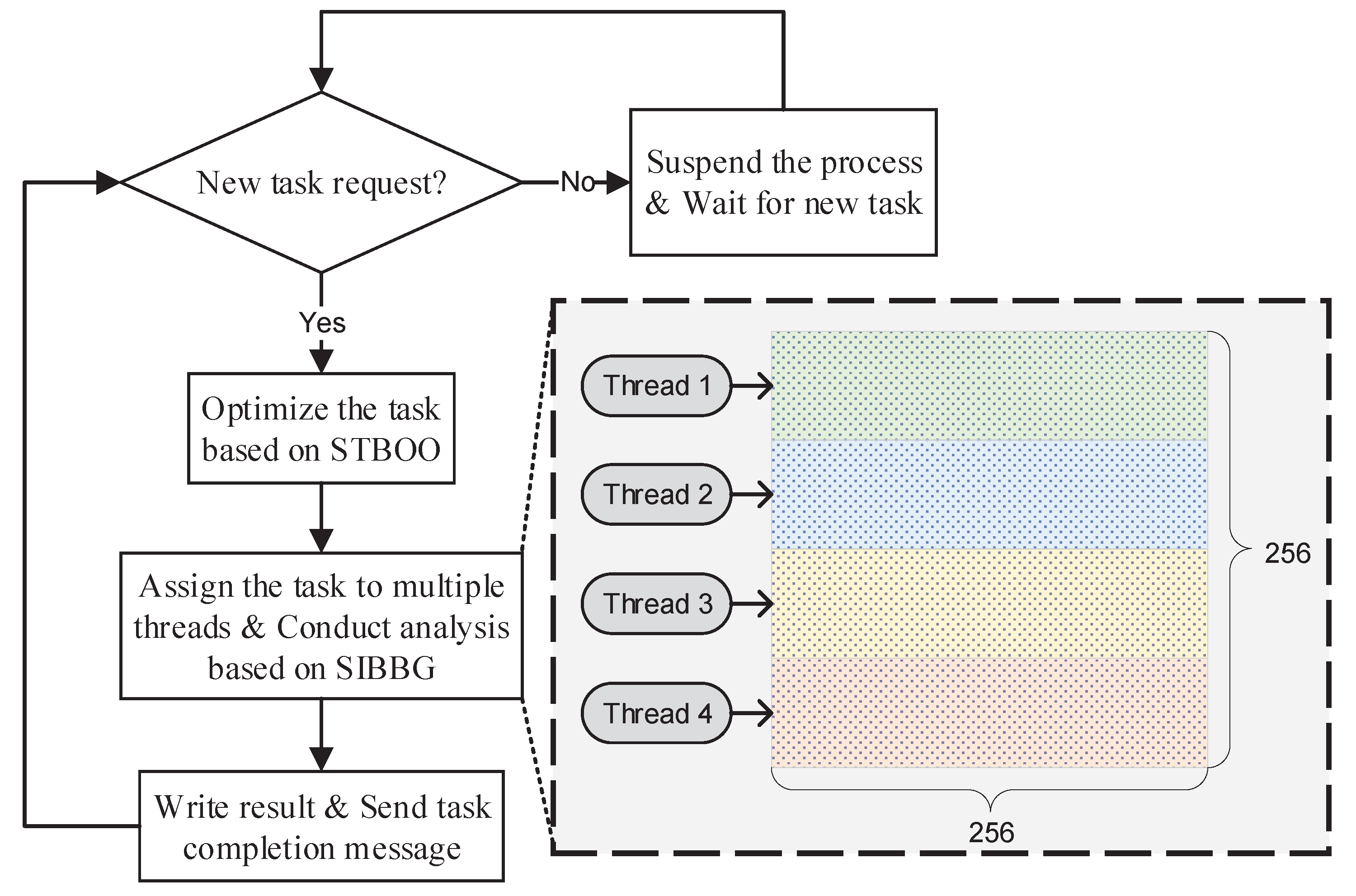
3.3. Hybrid-Parallel Analysis Engine
HPAE adopts the hybrid MPI-OpenMP parallel processing model to achieve real-time buffer-overlay analysis. In HiBO, each task is processed with multiple OpenMP threads in one MPI process. As the task requests are generated by way of streaming, the tasks are dynamically allocated to the MPI processes. An MPI process will be suspended after the assigned task is accomplished, and new tasks will be handled on a first in, first served basis. The parallel strategy has the property of good load balancing. An example of the task process is shown in
Figure 7.
5. Conclusions and Future Work
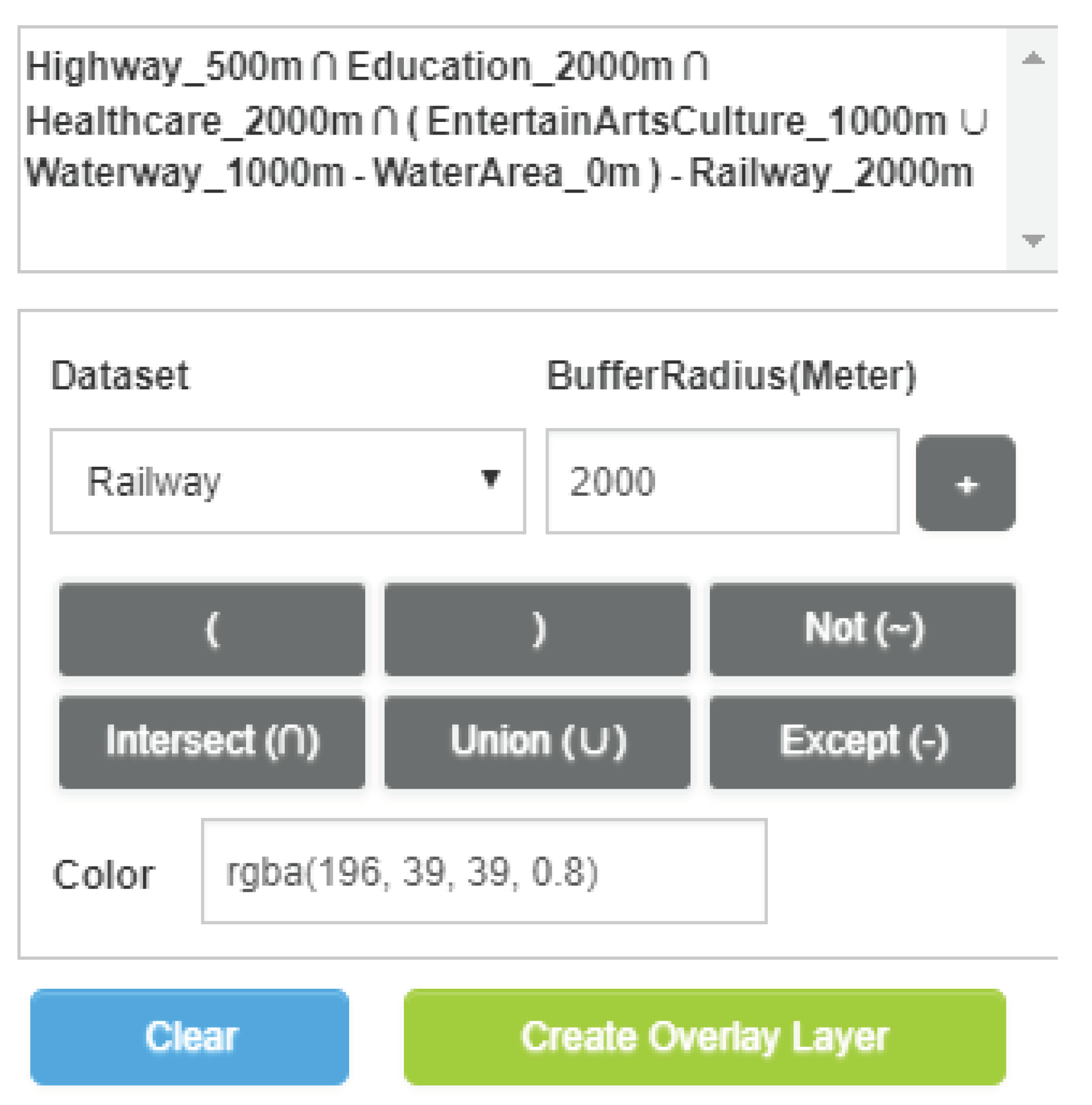
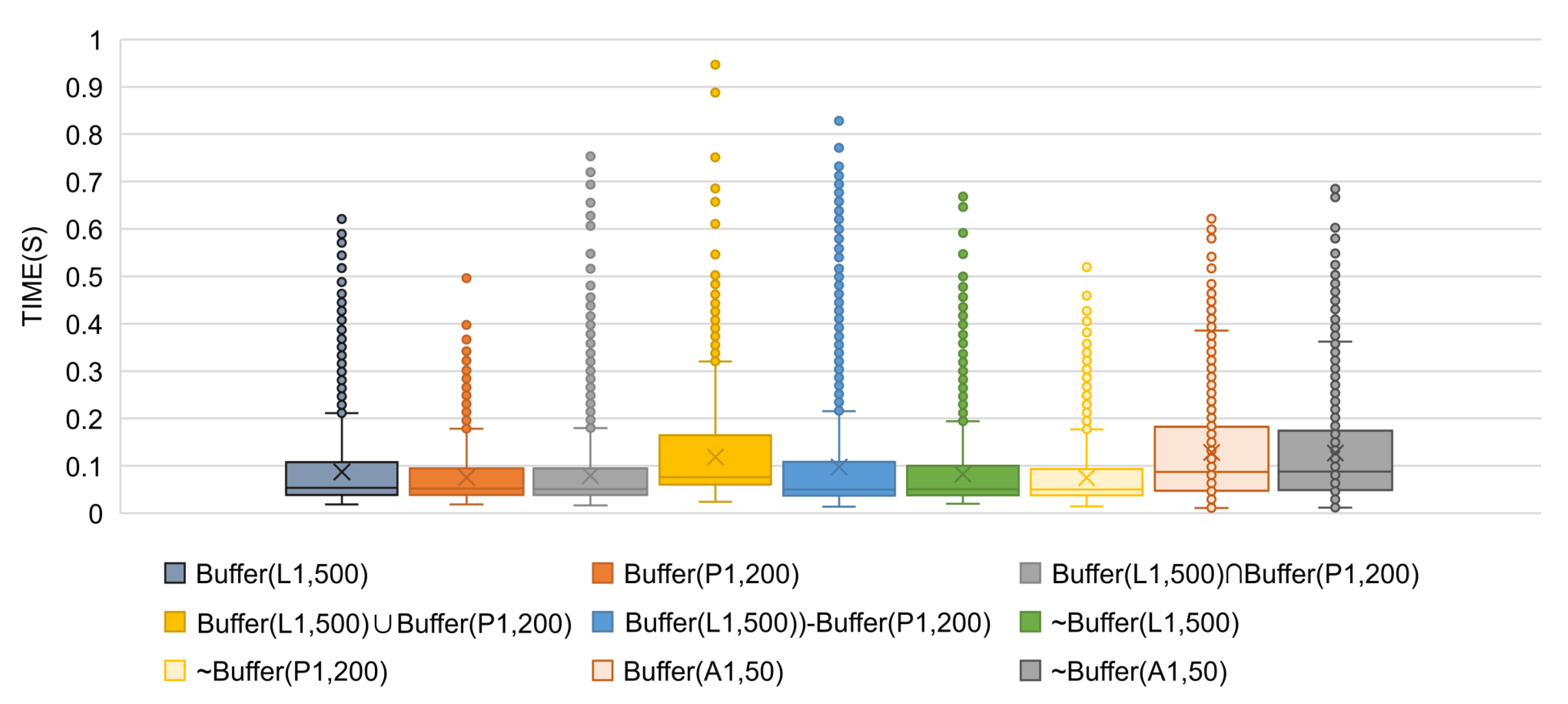
This paper presents a parallel processing model, HiBO, for real-time buffer-overlay analysis when the data scale becomes extremely large. Differing from the traditional data-oriented methods, HiBO is visualization-oriented, with the core task transformed into determining the value of pixels for screen display. In HiBO, we employ R-tree to determine whether a pixel is in the buffers of spatial objects, and propose an efficient buffer generation method named SIBBG. HiBO supports complex mixed set operations of multiple buffer analysis results, and we present an effective overlay optimizaation method named STBOO. Parallel computing technologies are used to accelerate analysis in HiBO, and we propose a fully optimized hybrid-parallel processing architecture with good load balancing. Experiments on real-world datasets show that our approach is capable of handling ten-million-scale spatial data. In the future, we will apply our approach to solve the problem of rapid visualization for large-scale vector data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}