Dynamic Recommendation of POI Sequence Responding to Historical Trajectory



Abstract
:
1. Introduction
- this paper proposes a novel POI sequence recommendation framework named DRPS, which can make dynamic POI sequence recommendation according to the historical trajectory;
- in order to make full use of various information about POIs, the POI embedding feature, the geographical and categorical influences of historical trajectory and the positional encoding are jointly taken into account in DRPS;
- this paper also proposes two new metrics, i.e., the Aligned Precision (AP) and the Order-aware Sequence Precision (OSP), which consider both the POI identity and visiting order, in order to evaluate the recommendation accuracy of the POI sequence;
- detailed experiments are conducted to evaluate the proposed method, and the experimental results demonstrate the effectiveness of DRPS in a POI sequence recommendation task.
2. Related Work
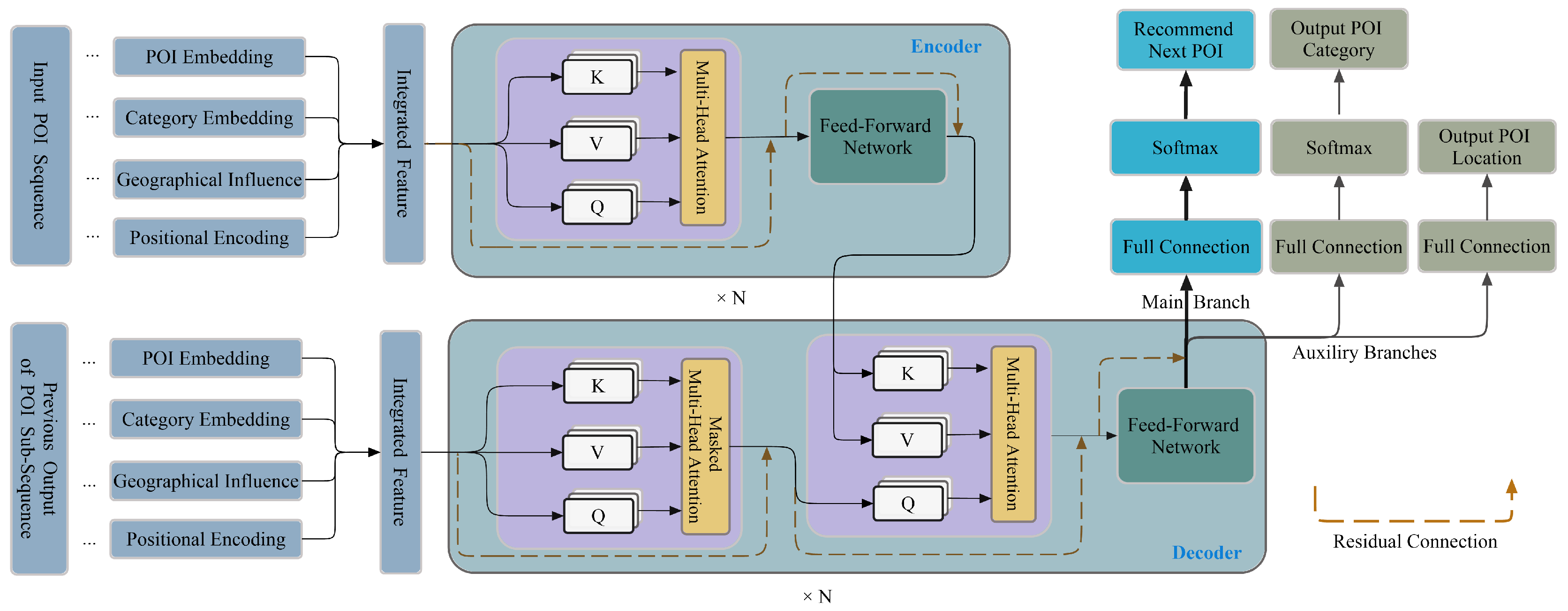
3. Methodology
3.1. Problem Statement
3.2. Overview of the Proposed Framework
3.3. Details of Module Design
3.3.1. Input Module
3.3.2. Encoder–Decoder Module
3.3.3. Output Module
3.4. Dynamic Recommendation
4. Experiments
4.1. Experimental Settings
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Baseline Methods
4.1.4. Parameter Setting
4.2. Experimental Results
4.3. Effect of Components
4.4. Cold-Start Scenario
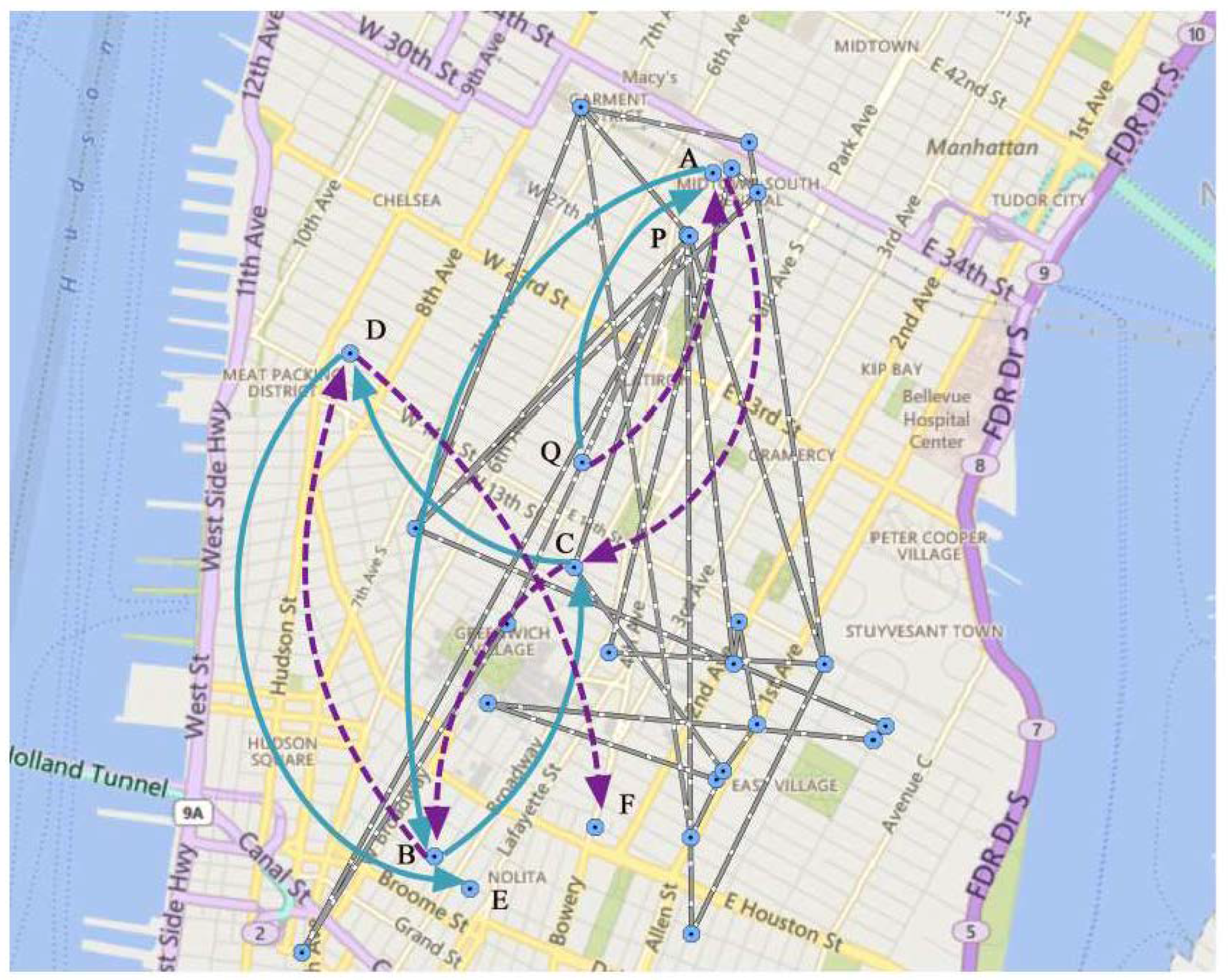
4.5. An Illustrative Example
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Funder, D.C.; Colvin, C.R. Explorations in behavioral consistency: Properties of persons, situations, and behaviors. J. Personal. Soc. Psychol. 1991, 60, 773–794. [Google Scholar] [CrossRef]
- Khan, S.A.; Arif, S.; Bölöni, L. Emulating the Consistency of Human Behavior with an Autonomous Robot in a Market Scenario. In Proceedings of the 13th AAAI Conference on Plan, Activity, and Intent Recognition, Bellevue, WA, USA, 14–15 June 2013; pp. 17–23. [Google Scholar]
- Zheng, Y.; Zhou, X. Computing with Spatial Trajectories, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Mei, T.; Hsu, W.H.; Luo, J. Knowledge Discovery from Community-Contributed Multimedia. IEEE Multimed. 2010, 17, 16–17. [Google Scholar] [CrossRef]
- Cheng, C.; Yang, H.; Lyu, M.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2605–2611. [Google Scholar]
- Zhao, P.; Zhu, H.; Liu, Y.; Li, Z.; Xu, J.; Sheng, V.S. Where to Go Next: A Spatio-temporal LSTM model for Next POI Recommendation. arXiv 2018, arXiv:1806.06671. [Google Scholar]
- Ding, R.; Chen, Z. RecNet: A deep neural network for personalized POI recommendation in location-based social networks. Int. J. Geogr. Inf. Sci. 2018, 32, 1631–1648. [Google Scholar] [CrossRef]
- Liu, Q.; Wu, S.; Wang, L.; Tan, T. Predicting the Next Location: A Recurrent Model with Spatial and Temporal Contexts. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 194–200. [Google Scholar]
- Baral, R.; Li, T. Exploiting the roles of aspects in personalized POI recommender systems. Data Min. Knowl. Discov. 2017, 32, 320–343. [Google Scholar] [CrossRef]
- De Choudhury, M.; Feldman, M.; Amer-Yahia, S.; Golbandi, N.; Lempel, R.; Yu, C. Automatic Construction of Travel Itineraries Using Social Breadcrumbs. In Proceedings of the 21st ACM Conference on Hypertext and Hypermedia, Toronto, ON, Canada, 13–16 June 2010; ACM: New York, NY, USA, 2010; pp. 35–44. [Google Scholar]
- Bolzoni, P.; Helmer, S.; Wellenzohn, K.; Gamper, J.; Andritsos, P. Efficient Itinerary Planning with Category Constraints. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; ACM: New York, NY, USA, 2014; pp. 203–212. [Google Scholar]
- Bin, C.; Gu, T.; Sun, Y.; Chang, L.; Sun, W.; Sun, L. Personalized POIs Travel Route Recommendation System Based on Tourism Big Data. In Proceedings of the 15th Pacific Rim International Conference on Artificial Intelligence, Nanjing, China, 28–31 August 2018; pp. 290–299. [Google Scholar]
- Zhao, S.; Chen, X.; King, I.; Lyu, M.R. Personalized Sequential Check-in Prediction: Beyond Geographical and Temporal Contexts. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- Lim, K.H.; Chan, J.; Leckie, C.; Karunasekera, S. Personalized trip recommendation for tourists based on user interests, points of interest visit durations and visit recency. Knowl. Inf. Syst. 2017, 54, 375–406. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1724–1734. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3104–3112. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Shen, H.; Ouyang, W.; Cheng, X. Exploiting POI-Specific Geographical Influence for Point-of-Interest Recommendation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3877–3883. [Google Scholar]
- Hosseini, S.; Yin, H.; Zhou, X.; Sadiq, S.; Kangavari, M.R.; Cheung, N.M. Leveraging multi-aspect time-related influence in location recommendation. World Wide Web 2019, 22, 1001–1028. [Google Scholar] [CrossRef]
- Griesner, J.B.; Abdessalem, T.; Naacke, H. POI Recommendation: Towards Fused Matrix Factorization with Geographical and Temporal Influences. In Proceedings of the 9th ACM Conference on Recommender Systems, RecSys, Vienna, Austria, 16–20 September 2015; ACM: Vienne, Austria, 2015; pp. 301–304. [Google Scholar]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware Point-of-interest Recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; ACM: New York, NY, USA, 2013; pp. 363–372. [Google Scholar]
- Zhang, J.D.; Chow, C.Y. GeoSoCa: Exploiting Geographical, Social and Categorical Correlations for Point-of-Interest Recommendations. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; ACM: New York, NY, USA, 2015; pp. 443–452. [Google Scholar]
- Ye, M.; Yin, P.; Lee, W.C.; Lee, D.L. Exploiting Geographical Influence for Collaborative Point-of-interest Recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; ACM: New York, NY, USA, 2011; pp. 325–334. [Google Scholar]
- Aliannejadi, M.; Crestani, F. Personalized Context-Aware Point of Interest Recommendation. ACM Trans. Inf. Syst. 2018, 36, 45. [Google Scholar] [CrossRef]
- Feng, S.; Li, X.; Zeng, Y.; Cong, G.; Chee, Y.M.; Yuan, Q. Personalized Ranking Metric Embedding for Next New POI Recommendation. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2069–2075. [Google Scholar]
- Alvarado-Uribe, J.; Gómez-Oliva, A.; Barrera-Animas, A.Y.; Molina, G.; Gonzalez-Mendoza, M.; Parra-Meroño, M.C.; Jara, A.J. HyRA: A Hybrid Recommendation Algorithm Focused on Smart POI. Ceutí as a Study Scenario. Sensors 2018, 18, 890. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Bai, L.; Zhang, C.; Yuan, Q.; Han, J. Bridging Collaborative Filtering and Semi-Supervised Learning: A Neural Approach for POI Recommendation. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 1245–1254. [Google Scholar]
- Chang, B.; Park, Y.; Park, D.; Kim, S.; Kang, J. Content-aware Hierarchical Point-of-interest Embedding Model for Successive POI Recommendation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3301–3307. [Google Scholar]
- Gionis, A.; Lappas, T.; Pelechrinis, K.; Terzi, E. Customized Tour Recommendations in Urban Areas. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; ACM: New York, NY, USA, 2014; pp. 313–322. [Google Scholar]
- Baral, R.; Iyengar, S.S.; Li, T.; Zhu, X. HiCaPS: Hierarchical Contextual POI Sequence Recommender. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; ACM: New York, NY, USA, 2018; pp. 436–439. [Google Scholar]
- Debnath, M.; Tripathi, P.K.; Biswas, A.K.; Elmasri, R. Preference Aware Travel Route Recommendation with Temporal Influence. In Proceedings of the 2nd ACM SIGSPATIAL Workshop on Recommendations for Location-based Services and Social Networks, Seattle, WA, USA, 6 November 2018; ACM: New York, NY, USA, 2018. [Google Scholar]
- Cui, Q.; Wu, S.; Liu, Q.; Zhong, W.; Wang, L. MV-RNN: A Multi-View Recurrent Neural Network for Sequential Recommendation. IEEE Trans. Knowl. Data Eng. 2018. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5998–6008. [Google Scholar]
- Covington, P.; Adams, J.; Sargin, E. Deep Neural Networks for YouTube Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; ACM: New York, NY, USA, 2016; pp. 191–198. [Google Scholar] [Green Version]
- Lin, I.C.; Lu, Y.S.; Shih, W.Y.; Huang, J.L. Successive POI Recommendation with Category Transition and Temporal Influence. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018. [Google Scholar]
- Hornik, K. Approximation Capabilities of Multilayer Feedforward Networks. Neural Netw. 1991, 4, 251–257. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Gordon, G., Dunson, D., Dudík, M., Eds.; PMLR: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured Attention Networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Liu, X.; Liu, Y.; Aberer, K.; Miao, C. Personalized Point-of-interest Recommendation by Mining Users’ Preference Transition. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; ACM: New York, NY, USA, 2013; pp. 733–738. [Google Scholar]
- Zhang, J.D.; Chow, C.Y.; Li, Y. LORE: Exploiting Sequential Influence for Location Recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; ACM: New York, NY, USA, 2014; pp. 103–112. [Google Scholar]
- Usatenko, O. Random Finite-Valued Dynamical Systems: Additive Markov Chain Approach; Kharkov Series in Physics and Mathematics; Cambridge Scientific Publishers: Cambridge, UK, 2009. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; USENIX Association: Savannah, GA, USA, 2016; pp. 265–283. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| City | #Check-In | #User | #POI |
|---|---|---|---|
| New York | 720,350 | 4811 | 28,333 |
| San Francisco | 330,975 | 3220 | 13,366 |
| Brooklyn | 159,946 | 2724 | 7334 |
| London | 147,610 | 1935 | 10,405 |
| % | New York | San Francisco | Brooklyn | London | ||||
|---|---|---|---|---|---|---|---|---|
| AP | OSP | AP | OSP | AP | OSP | AP | OSP | |
| RAND | ||||||||
| AMC | ||||||||
| LORE | ||||||||
| LSTM-Seq2Seq | ||||||||
| DRPS | ||||||||
| % | New York | San Francisco | Brooklyn | London | ||||
|---|---|---|---|---|---|---|---|---|
| AP | OSP | AP | OSP | AP | OSP | AP | OSP | |
| RAND | ||||||||
| AMC | ||||||||
| LORE | ||||||||
| LSTM-Seq2Seq | ||||||||
| DRPS | ||||||||
| % | New York | San Francisco | Brooklyn | London | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| RAND | ||||||||
| AMC | ||||||||
| LORE | ||||||||
| LSTM-Seq2Seq | ||||||||
| DRPS | ||||||||
| % | New York | San Francisco | Brooklyn | London | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| RAND | ||||||||
| AMC | ||||||||
| LORE | ||||||||
| LSTM-Seq2Seq | ||||||||
| DRPS | ||||||||
| % | New York | San Francisco | Brooklyn | London | ||||
|---|---|---|---|---|---|---|---|---|
| AP | OSP | AP | OSP | AP | OSP | AP | OSP | |
| DRPS | ||||||||
| Without PE | ||||||||
| Without CE | ||||||||
| Without GI | ||||||||
| Without Pos | ||||||||
| % | New York | San Francisco | Brooklyn | London | ||||
|---|---|---|---|---|---|---|---|---|
| AP | OSP | AP | OSP | AP | OSP | AP | OSP | |
| RAND | ||||||||
| AMC | ||||||||
| LORE | ||||||||
| LSTM-Seq2Seq | ||||||||
| DRPS | ||||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, J.; Liu, Y.; Chen, Y.; Jia, C. Dynamic Recommendation of POI Sequence Responding to Historical Trajectory. ISPRS Int. J. Geo-Inf. 2019, 8, 433. https://doi.org/10.3390/ijgi8100433
Huang J, Liu Y, Chen Y, Jia C. Dynamic Recommendation of POI Sequence Responding to Historical Trajectory. ISPRS International Journal of Geo-Information. 2019; 8(10):433. https://doi.org/10.3390/ijgi8100433
Chicago/Turabian StyleHuang, Jianfeng, Yuefeng Liu, Yue Chen, and Chen Jia. 2019. "Dynamic Recommendation of POI Sequence Responding to Historical Trajectory" ISPRS International Journal of Geo-Information 8, no. 10: 433. https://doi.org/10.3390/ijgi8100433
APA StyleHuang, J., Liu, Y., Chen, Y., & Jia, C. (2019). Dynamic Recommendation of POI Sequence Responding to Historical Trajectory. ISPRS International Journal of Geo-Information, 8(10), 433. https://doi.org/10.3390/ijgi8100433