Point of Interest Matching between Different Geospatial Datasets


Abstract
:1. Introduction
2. Related Work
3. The Improved D–S Evidence Theory Approach for Finding Matched POIs
3.1. The Definition of POI Similarity and Matching Restrictions
3.2. The Attribute Selection Strategy
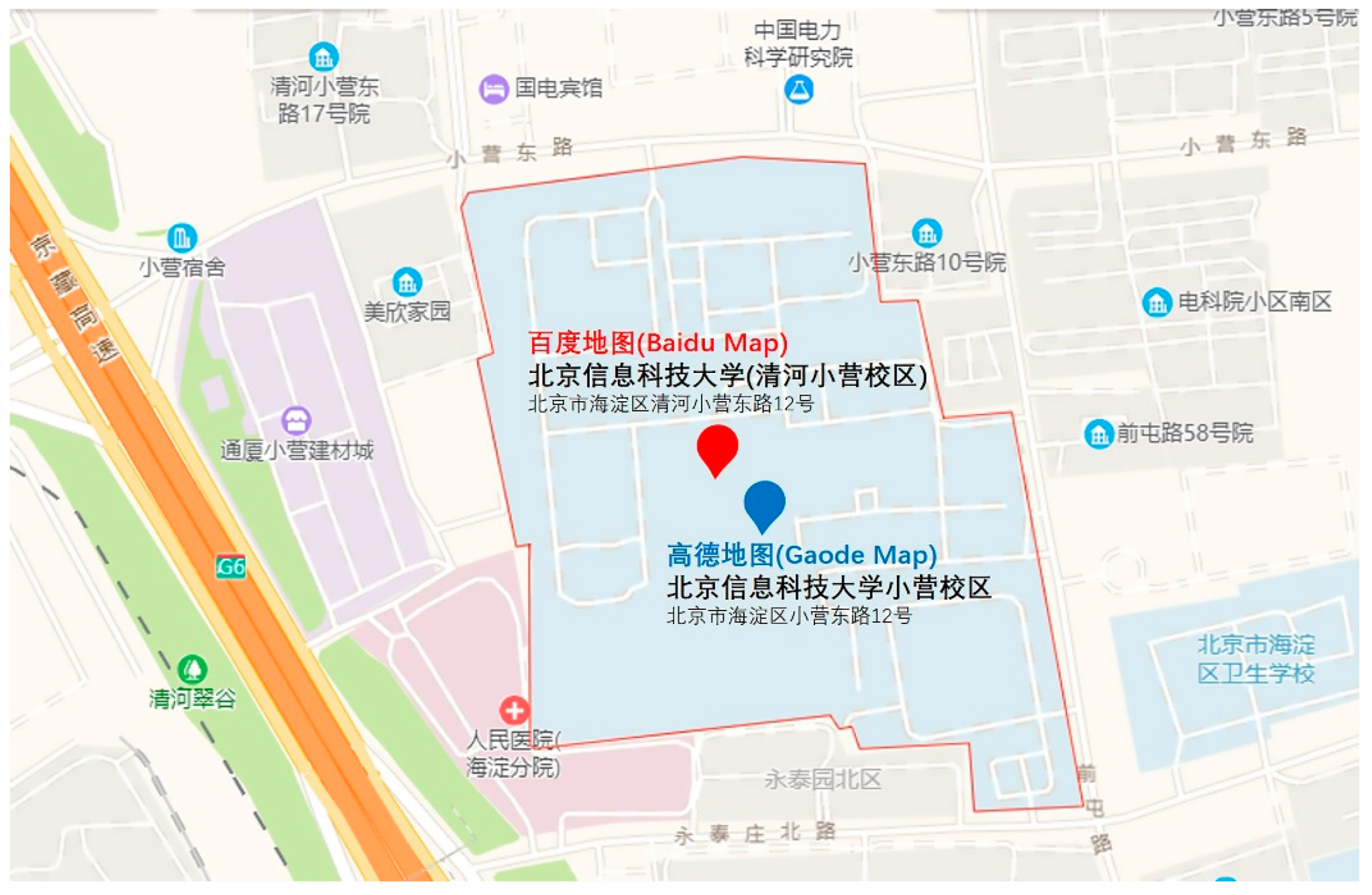
3.3. Spatial Similarity
3.4. Name Similarity
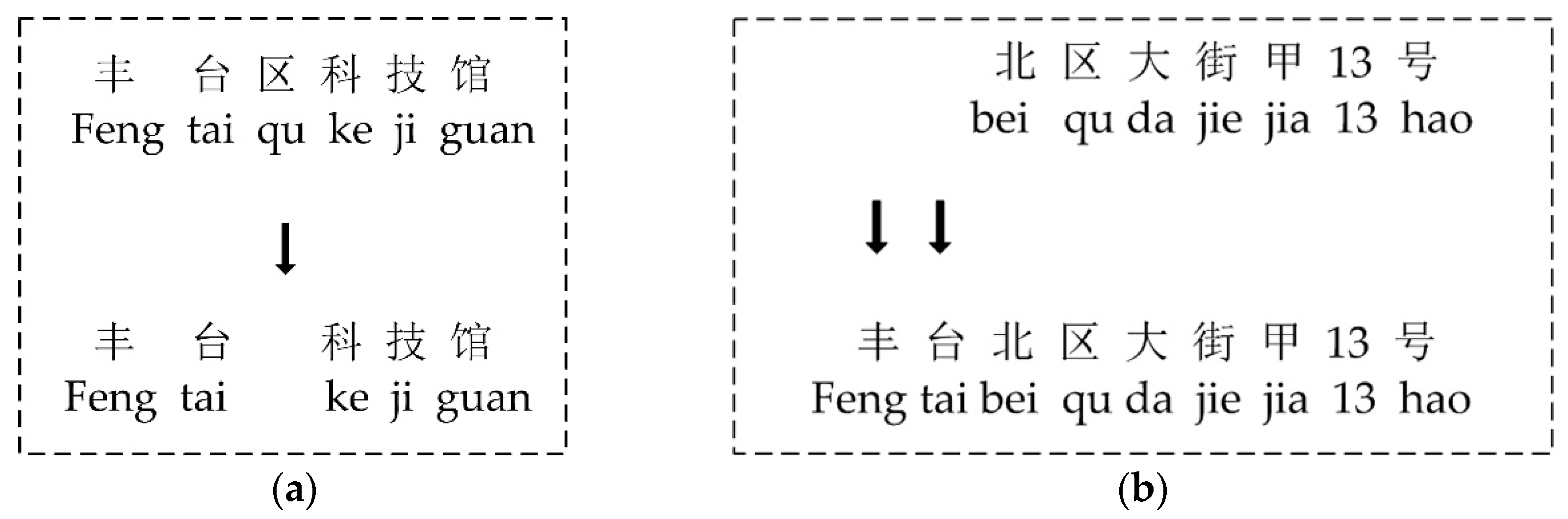
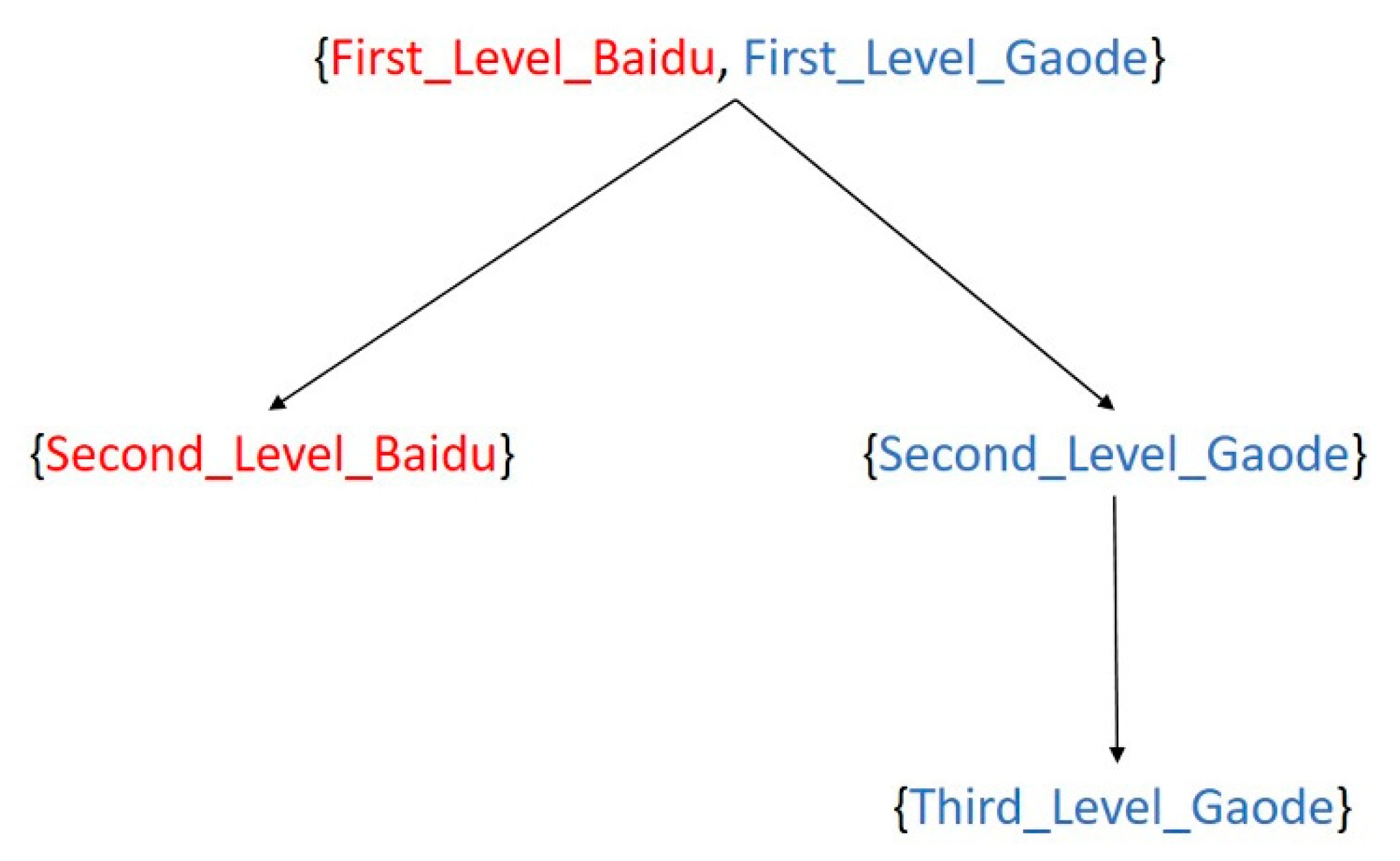
3.5. Address Similarity
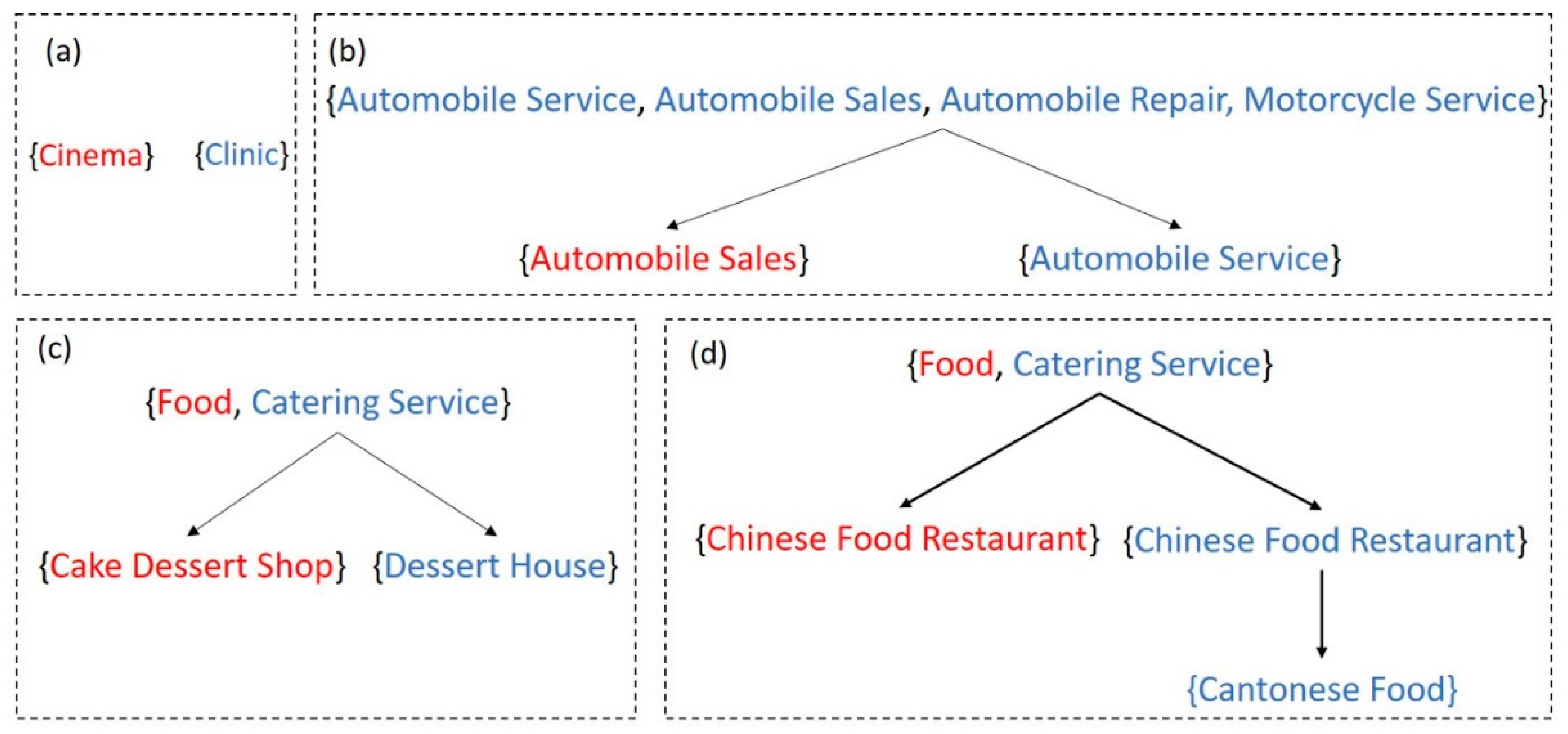
3.6. Category Similarity
3.7. The Improved D–S Evidence Theory Method
4. Case Study
4.1. Experimental Dataset
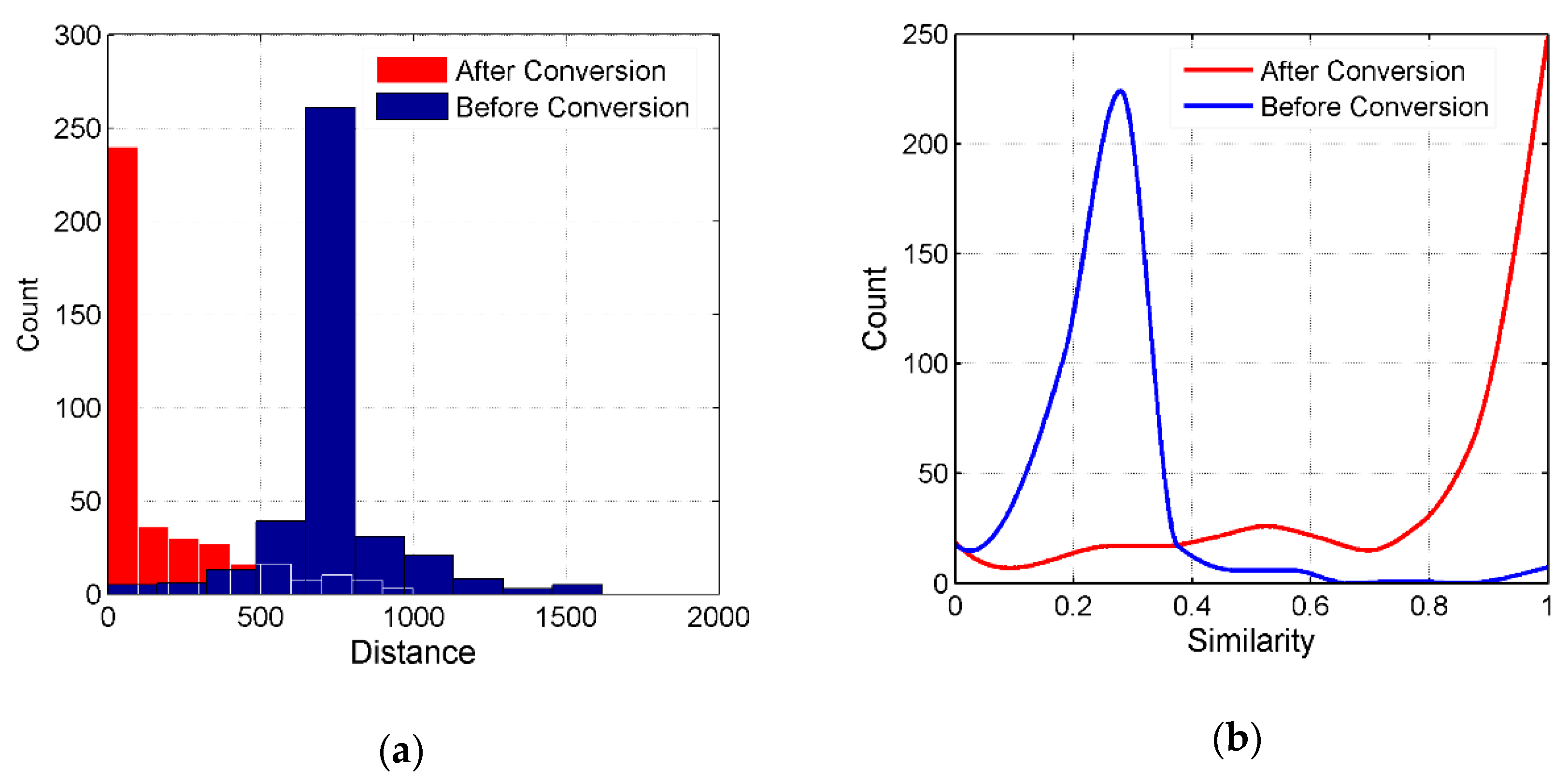
4.2. Spatial Similarity
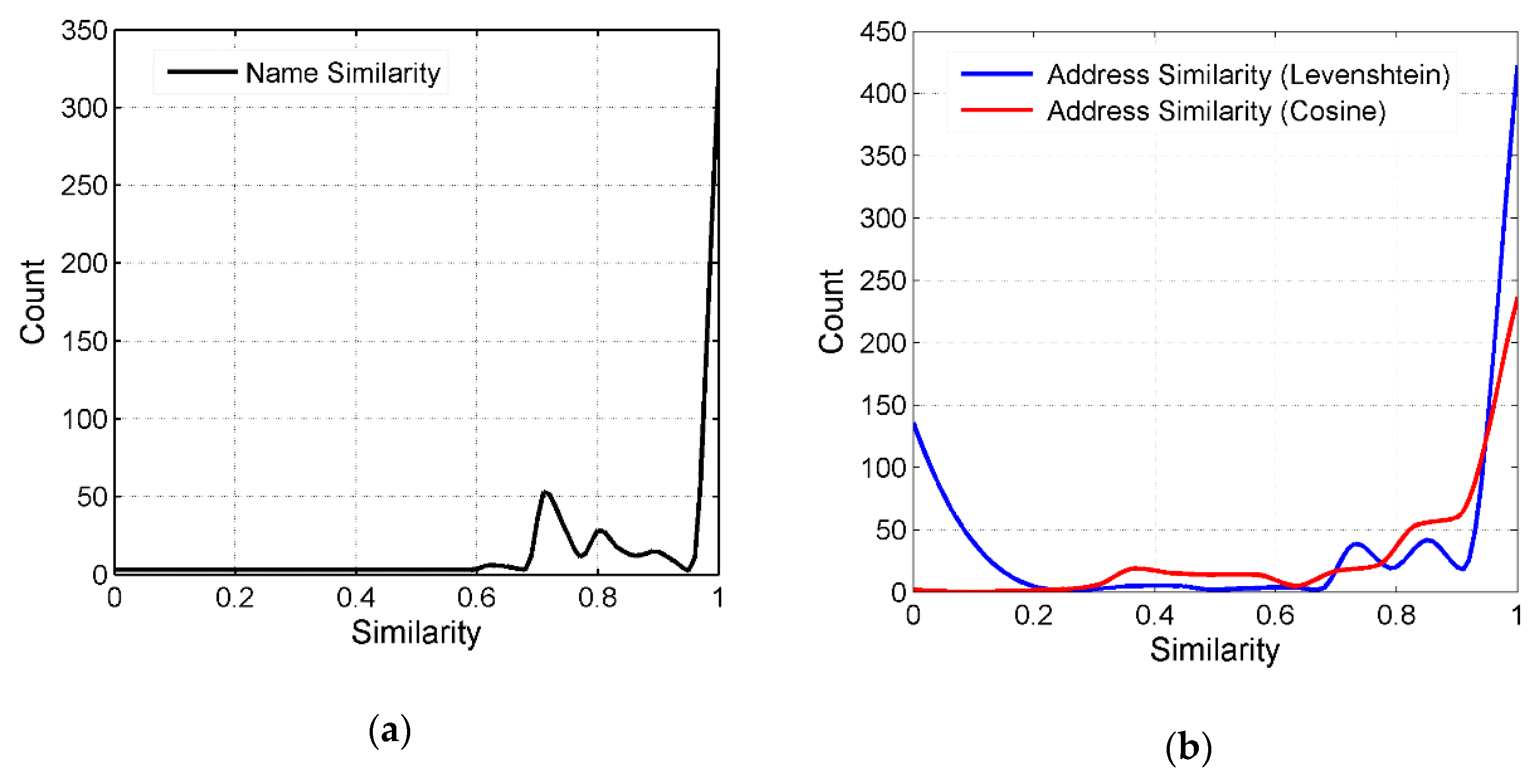
4.3. Name Similarity and Address Similarity
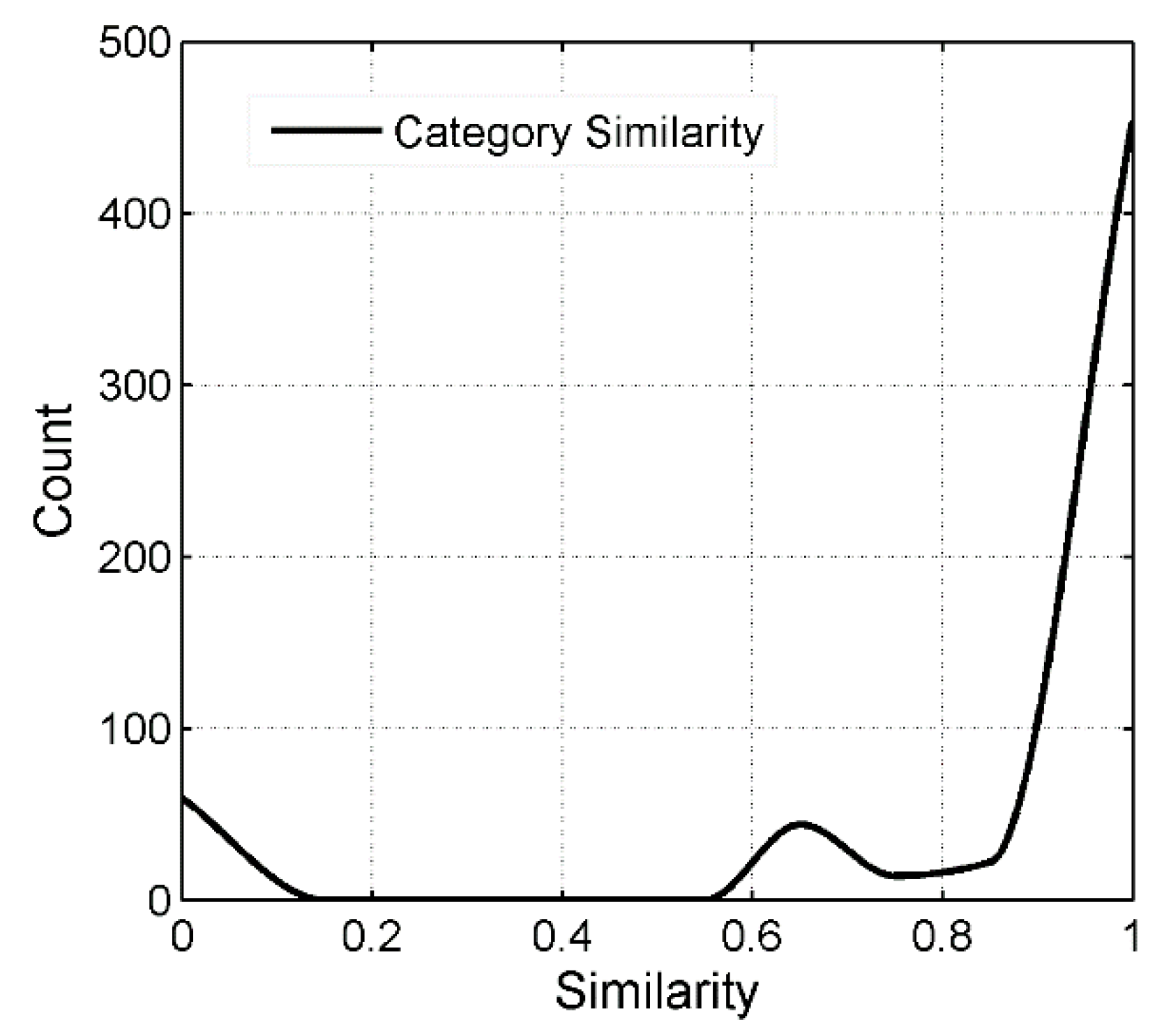
4.4. Category Similarity
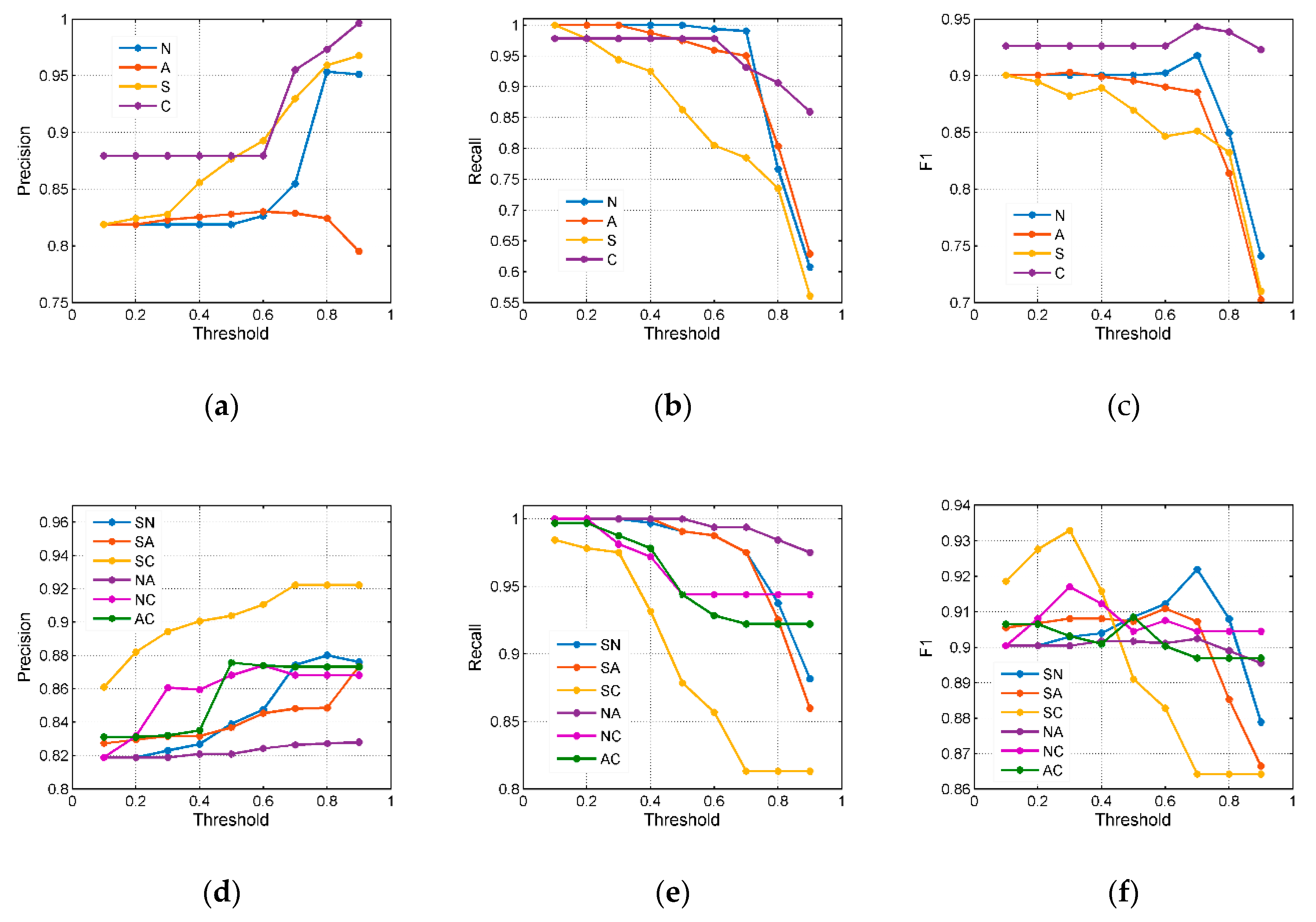
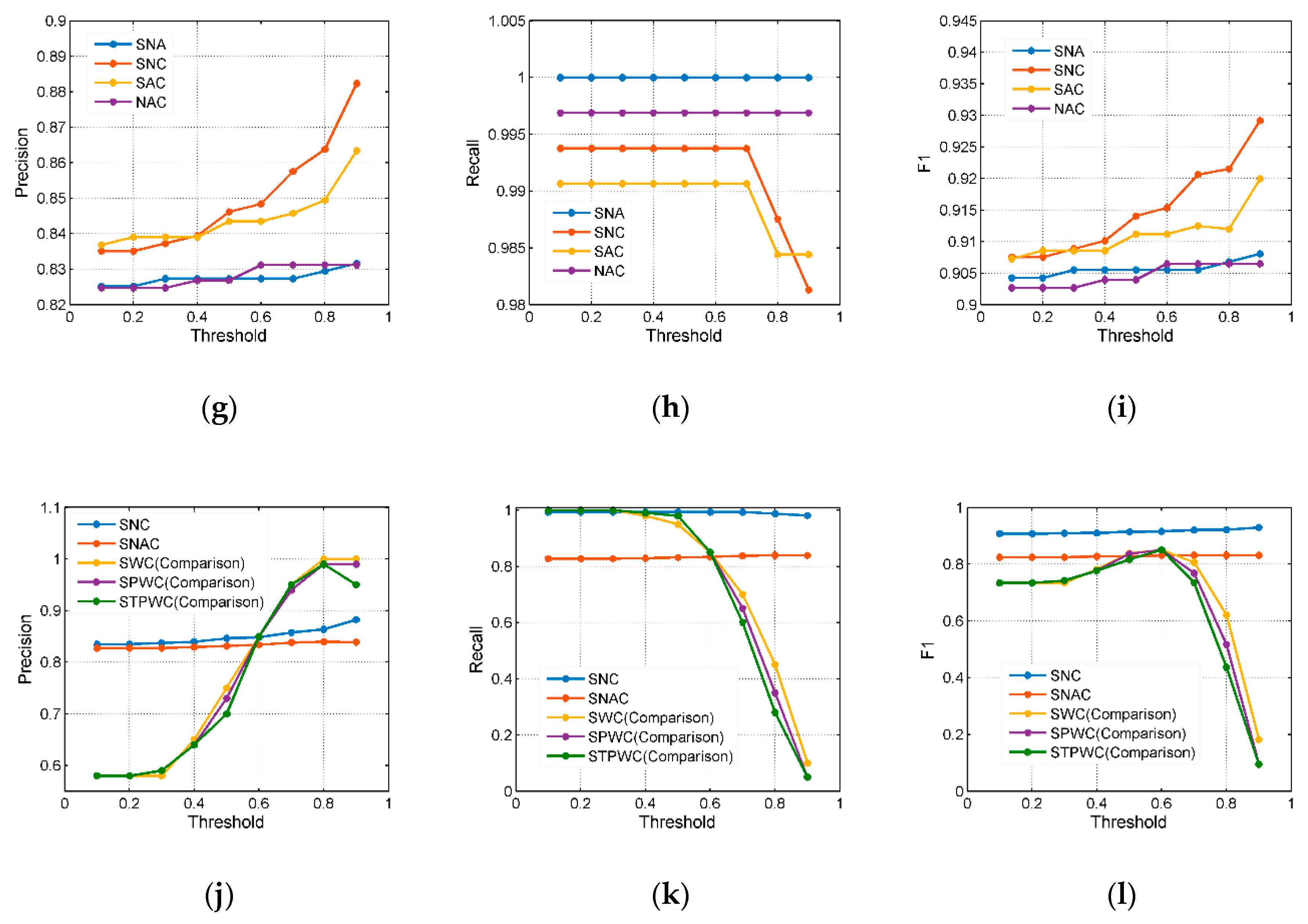
4.5. The Improved D–S Evidence Theory Model Analysis
4.5.1. Simulation Calculation
4.5.2. Multiattribute Model Entity Analysis
5. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. Geojournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Yuan, Q.; Cong, G.; Ma, Z.; Sun, A.; Thalmann, N.M. Time-aware point-of-interest recommendation. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2003; pp. 363–372. [Google Scholar]
- Li, S.; Dragicevic, S.; Castro, F.A.; Sester, M.; Winter, S.; Coltekin, A.; Pettit, C.; Jiang, B.; Haworth, J.; Stein, A. Geospatial big data handling theory and methods: A review and research challenges. ISPRS J. Photogramm. Remote Sens. 2016, 115, 119–133. [Google Scholar] [CrossRef]
- Wiemann, S.; Bernard, L. Spatial data fusion in Spatial Data Infrastructures using Linked Data. Int. J. Geogr. Inf. Sci. 2016, 30, 613–636. [Google Scholar] [CrossRef]
- Cueto, K. A feature–based approach to conflation of geospatial sources. Int. J. Geogr. Inf. Sci. 2004, 18, 459–489. [Google Scholar]
- Wang, S.S.; Stefanone, M.A. Showing Off? Human Mobility and the Interplay of Traits, Self-Disclosure, and Facebook Check–Ins. Soc. Sci. Comput. Rev. 2013, 31, 437–457. [Google Scholar] [CrossRef]
- Chen, L.; Roy, A. Event detection from flickr data through wavelet–based spatial analysis. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 523–532. [Google Scholar]
- Antoniou, V.; Skopeliti, A. Measures and Indicators of Vgi Quality: An Overview. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, II–3/W5. [Google Scholar] [CrossRef]
- Scheffler, T.; Schirru, R.; Lehmann, P. Matching Points of Interest from Different Social Networking Sites; Springer: Berlin, Germany, 2012; pp. 245–248. [Google Scholar]
- Stankutė, S.; Asche, H. An Integrative Approach to Geospatial Data Fusion; Springer: Berlin, Germany, 2009; pp. 490–504. [Google Scholar]
- Hastings, J.T. Automated conflation of digital gazetteer data. Int. J. Geogr. Inf. Sci. 2008, 22, 1109–1127. [Google Scholar] [CrossRef]
- Beeri, C.; Doytsher, Y.; Kanza, Y.; Safra, E.; Sagiv, Y. Finding corresponding objects when integrating several geo–spatial datasets. In Proceedings of the 13th Annual ACM International Workshop on Geographic Information Systems, Bremen, Germany, 4–5 November 2005; pp. 87–96. [Google Scholar]
- Christen, P. Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection; Springer Publishing Company, Incorporated: Berlin, Germany, 2012; p. 289. [Google Scholar]
- Wong, E.; Law, R.; Li, G. Reviewing Geotagging Research in Tourism; Springer: Cham, Germany, 2017; pp. 43–58. [Google Scholar]
- Lenzerini, M. Data integration: A theoretical perspective. In Proceedings of the Twenty-First ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 233–246. [Google Scholar]
- Wang, J.; Li, G.; Yu, J.X.; Feng, J. Entity Matching: How Similar Is Similar. Proc. VLDB Endow. 2011, 4, 622–633. [Google Scholar] [CrossRef]
- Novack, T.; Peters, R.; Zipf, A. Graph–based matching of points–of–interest from collaborative geo–datasets. ISPRS Int. J. Geo–Inf. 2018, 7, 117. [Google Scholar] [CrossRef]
- Kitchin, R.M. Increasing the integrity of cognitive mapping research: Appraising conceptual schemata of environment behaviour interaction. Prog. Hum. Geogr. 1996, 20, 56–84. [Google Scholar] [CrossRef]
- Safra, E.; Kanza, Y.; Sagiv, Y.; Beeri, C.; Doytsher, Y. Location-based algorithms for finding sets of corresponding objects over several geo-spatial data sets. Int. J. Geogr. Inf. Sci. 2010, 24, 69–106. [Google Scholar] [CrossRef]
- Devogele, T.; Parent, C.; Spaccapietra, S. On spatial database integration. Int. J. Geogr. Inf. Syst. 1998, 12, 335–352. [Google Scholar] [CrossRef]
- Fonseca, F.T.; Egenhofer, M.J.; Agouris, P.; Câmara, G. Using Ontologies for Integrated Geographic Information Systems. Trans. GIS 2010, 6, 231–257. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, J.; Li, B. A formal method for integrating distributed ontologies and reducing the redundant relations. Kybernetes 2009, 38, 1870–1879. [Google Scholar] [CrossRef]
- Li, J.; He, Z.; Zhu, Q. An Entropy–Based Weighted Concept Lattice for Merging Multi–Source Geo–Ontologies. Entropy 2013, 15, 2303–2318. [Google Scholar] [CrossRef]
- Li, X.; Morie, P.; Dan, R. Semantic Integration in Text: From Ambiguous Names to Identifiable Entities. AI Mag. 2005, 26, 45–58. [Google Scholar]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Syst. 2016, 31, 56–80. [Google Scholar] [CrossRef]
- Liu, S.; Chu, Y.; Hu, H.; Feng, J.; Zhu, X. Top-k Spatio-textual Similarity Search. In Proceedings of the Web-Age Information Management (WAIM 2014), Macau, China, 16–18 June 2014; Li, F., Li, G., Hwang, S., Yao, B., Zhang, Z., Eds.; Springer: Cham, Switzerland, 2014; Volume 8485. [Google Scholar] [CrossRef]
- Safra, E.; Kanza, Y.; Sagiv, Y.; Doytsher, Y. Integrating Data from Maps on the World-Wide Web; Springer: Berlin, Germany, 2006; pp. 180–191. [Google Scholar]
- Mckenzie, G.; Janowicz, K.; Adams, B. A weighted multi–attribute method for matching user–generated Points of Interest. Cartogr. Geogr. Inf. Sci. 2014, 41, 125–137. [Google Scholar] [CrossRef]
- Lin, L.; Xing, X.; Hui, X.; Huang, X. Entropy–Weighted Instance Matching Between Different Sourcing Points of Interest. Entropy 2016, 18, 45. [Google Scholar]
- Vincent, A.; Pierre, F.; Xavier, P.; Nicholas, A. Log–Euclidean metrics for fast and simple calculus on diffusion tensors. Magn. Reson. Med. 2010, 56, 411–421. [Google Scholar]
- Levenshtein, V.I. Binary Codes Capable of Correcting Deletions. Sov. Phys. Dokl. 1966, 6, 707–710. [Google Scholar]
- Zhang, J.; Ouyang, Y.; Li, W.; Hou, Y. A Novel Composite Kernel Approach to Chinese Entity Relation Extraction. In Proceedings of the 22nd International Conference on Computer Processing of Oriental Languages. Language Technology for the Knowledge-based Economy (ICCPOL ’09), Hong Kong, China, 26–27 March 2009; Li, W., Mollá-Aliod, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 236–247. [Google Scholar] [CrossRef]
- Nie, X.; Feng, W.; Wan, L.; Xie, L. Measuring semantic similarity by contextualword connections in Chinese news story segmentation. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8312–8316. [Google Scholar]
- Sehgal, V.; Getoor, L.; Viechnicki, P.D. Entity resolution in geospatial data integration. In Proceedings of the 14th Annual ACM International Symposium on Advances in Geographic Information Systems (GIS ’06), Arlington, VA, USA, 10–11 November 2006; ACM: New York, NY, USA, 2006; pp. 83–90. [Google Scholar] [CrossRef]
- Zhang, W.; Ji, X.; Yang, Y.; Chen, J.; Gao, Z.; Qiu, X. Data Fusion Method Based on Improved D–S Evidence Theory. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing (BigComp), Shanghai, China, 15–17 Januray 2018; pp. 760–766. [Google Scholar]
- Silva, L.; De Almeida–Filho, A. A multicriteria approach for analysis of conflicts in evidence theory. Inf. Sci. 2016, 346. [Google Scholar] [CrossRef]
- Jiang, W.; Zhuang, M.; Qin, X.; Tang, Y. Conflicting evidence combination based on uncertainty measure and distance of evidence. Springerplus 2016, 5, 1217. [Google Scholar] [CrossRef] [PubMed]
- Zadeh, L.A. Review of A Mathematical Theory of Evidence. AI Mag. 1984, 5, 235–247. [Google Scholar]
- Ye, F.; Chen, J.; Li, Y. Improvement of DS Evidence Theory for Multi–Sensor Conflicting Information. Symmetry 2017, 9, 69. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Similarity | Dissimilarity |
|---|---|---|
| Name | 1 | 0 |
| Address | 0 | 1 1 |
| D–S Evidence Theory | Invalid | Invalid |
| Improved D–S Evidence Theory | 0.5 | 0.5 |
| Attributes | Similarity | Dissimilarity |
|---|---|---|
| Name | 0.9 | 0.1 |
| Address | 0.8 | 0.2 1 |
| Spatial | 0 | 1 |
| D–S Evidence Theory | 0 | 1 |
| Improved D–S Evidence Theory | 0.962 | 0.038 |
| Attributes | Similarity | Dissimilarity |
|---|---|---|
| Name | 0.85 | 0.15 |
| Address | 0.2 | 0.8 1 |
| Spatial | 0.1 | 0.9 |
| Category | 1 | 0 |
| D-S Evidence Theory | 1 | 0 |
| Improved D-S Evidence Theory | 0.67 | 0.33 |
| Models | ||||||
|---|---|---|---|---|---|---|
| Two-Attribute Models | SN | SA | SC | NA | NC | AC |
| Three-Attribute Models | SNA | SNC | SAC | NAC | ||
| Four-Attribute Models | SNAC 1 | |||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Luo, A.; Liu, J.; Wang, Y. Point of Interest Matching between Different Geospatial Datasets. ISPRS Int. J. Geo-Inf. 2019, 8, 435. https://doi.org/10.3390/ijgi8100435
Deng Y, Luo A, Liu J, Wang Y. Point of Interest Matching between Different Geospatial Datasets. ISPRS International Journal of Geo-Information. 2019; 8(10):435. https://doi.org/10.3390/ijgi8100435
Chicago/Turabian StyleDeng, Yue, An Luo, Jiping Liu, and Yong Wang. 2019. "Point of Interest Matching between Different Geospatial Datasets" ISPRS International Journal of Geo-Information 8, no. 10: 435. https://doi.org/10.3390/ijgi8100435
APA StyleDeng, Y., Luo, A., Liu, J., & Wang, Y. (2019). Point of Interest Matching between Different Geospatial Datasets. ISPRS International Journal of Geo-Information, 8(10), 435. https://doi.org/10.3390/ijgi8100435