Accumulative Errors Optimization for Visual Odometry of ORB-SLAM2 Based on RGB-D Cameras



Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Visual Odometry Algorithm in ORB-SLAM2
3.1.1. Feature Extraction and Description
3.1.2. Image Matching and Error Elimination
3.1.3. Pose Estimation
3.2. Improved Visual Odometry Algorithm for ORB-SLAM2
3.2.1. Adaptive Threshold oFAST Algorithm for Feature Extraction Algorithm
3.2.2. New Image Matching Algorithm
| Algorithm 1. Progressive sample consensus (PROSAC) algorithm steps |
| Input: Maximum number of iterations , interior point error threshold and interior point number threshold Output: Homography matrix |
|
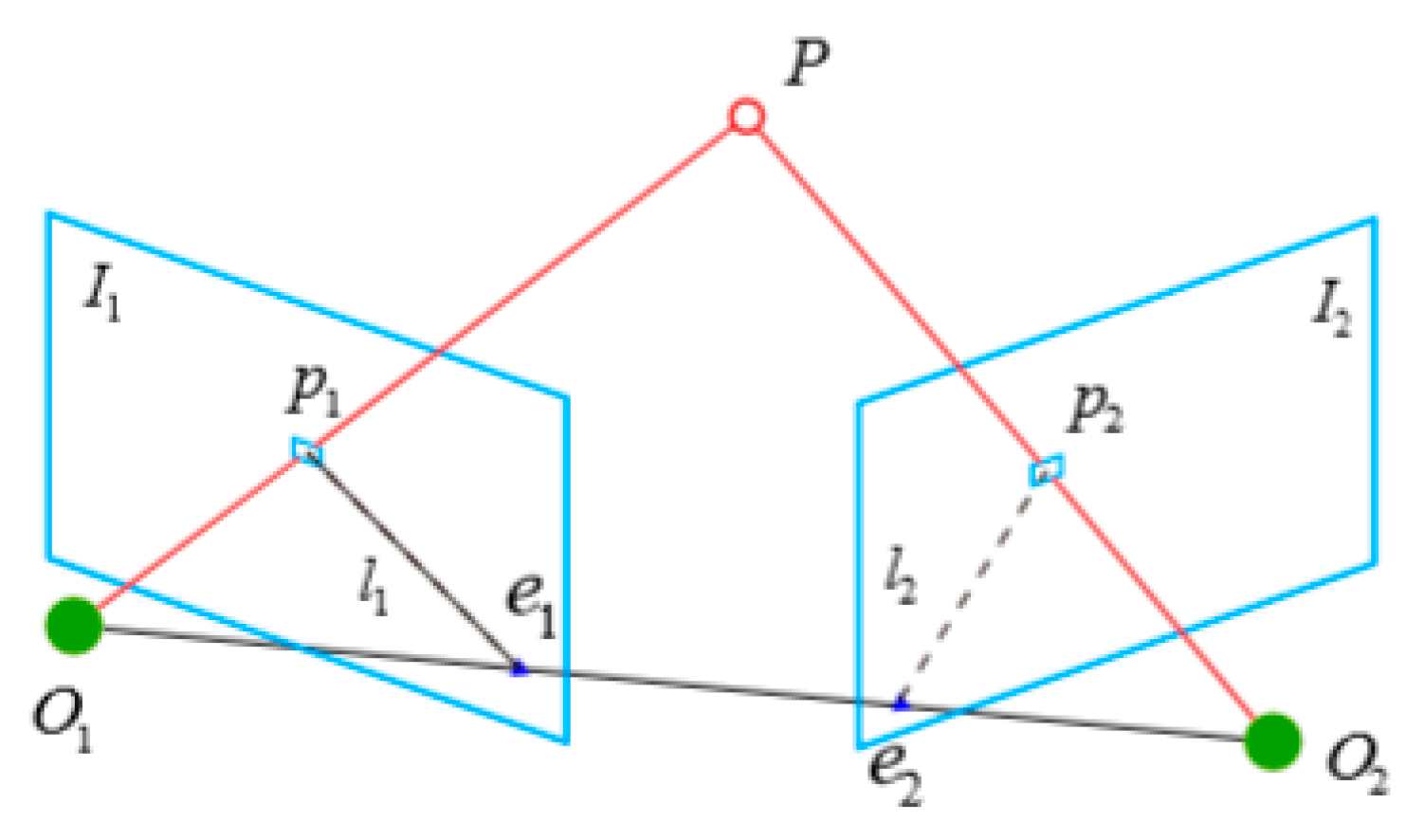
3.2.3. Pose Estimation Algorithm
4. Experiments and Analysis
4.1. Experimental Data and Computing Environment
4.2. Experimental Analysis
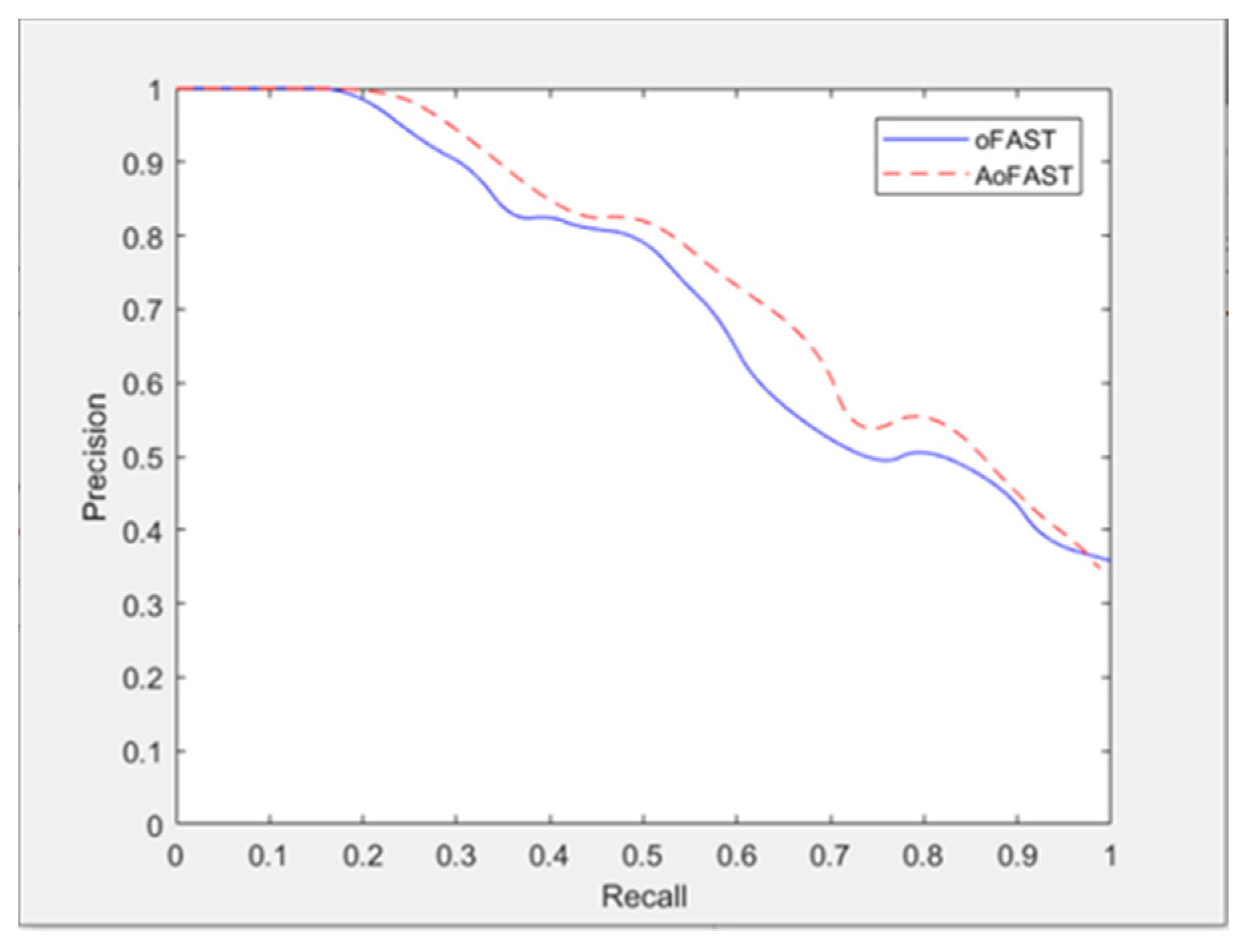
4.2.1. Experimental Results and Analysis of Image Feature Extraction Algorithm
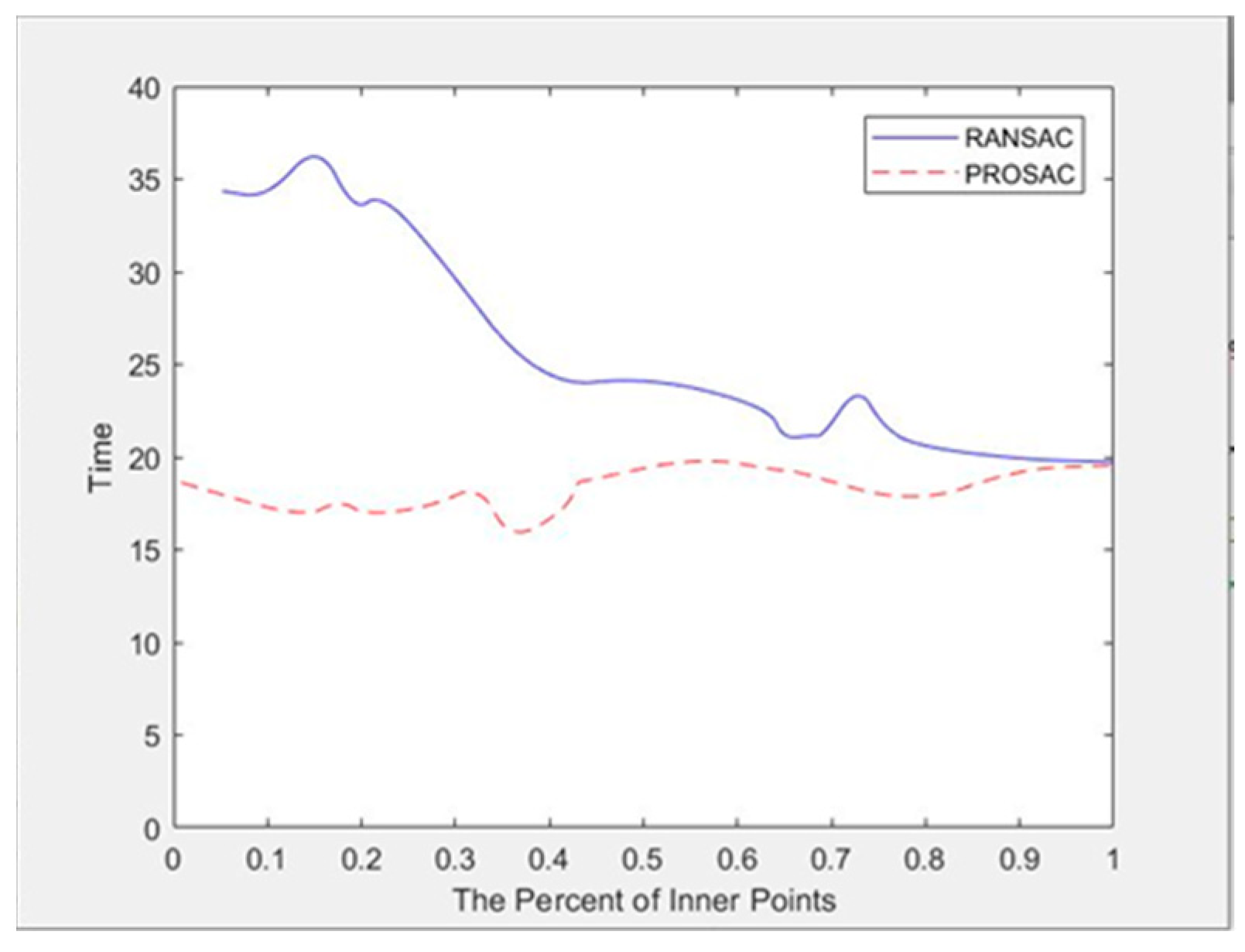
4.2.2. Experimental Results and Analysis of Image Feature Matching Algorithm
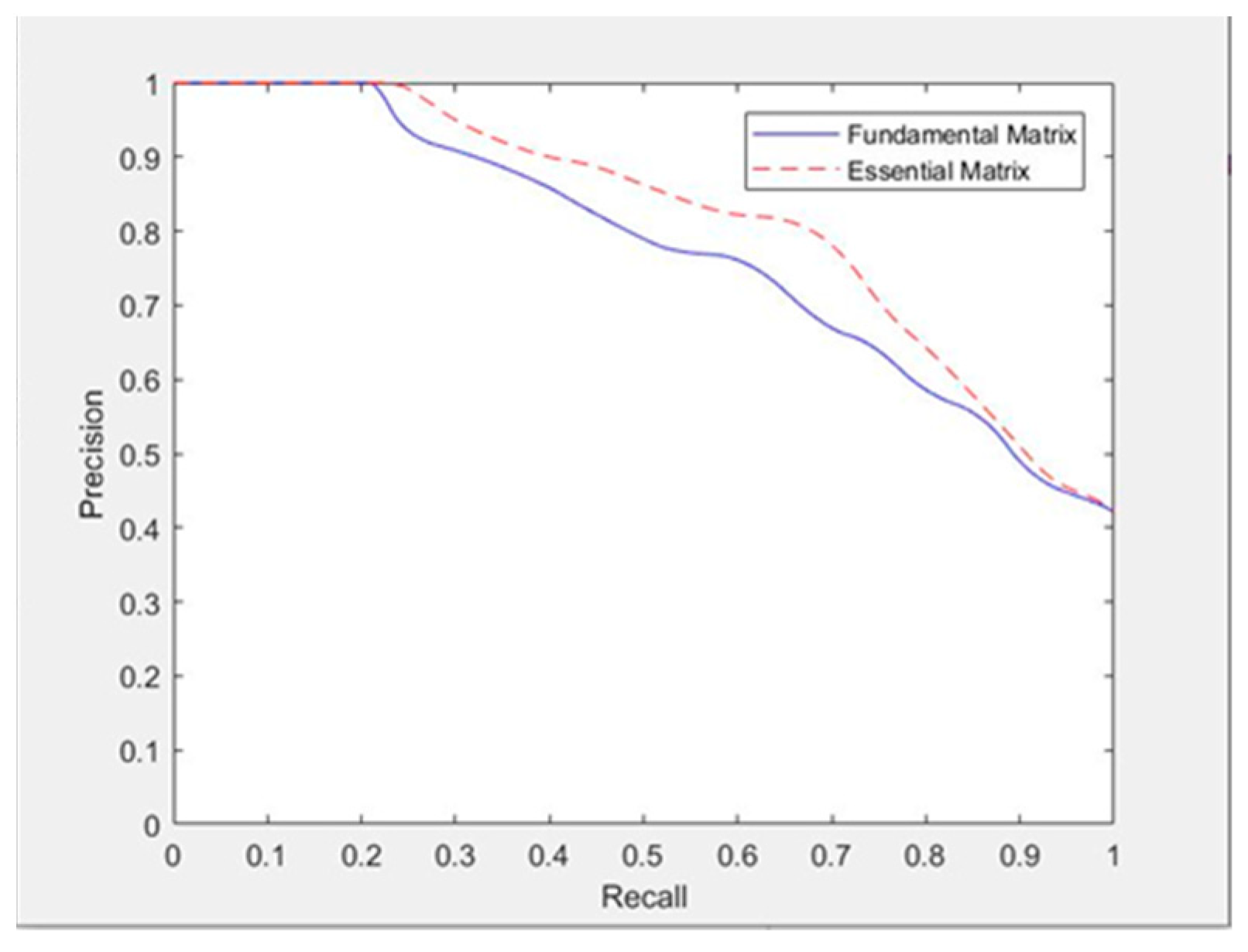
4.2.3. Experimental Results and Analysis of Different Epipolar Line Constraints
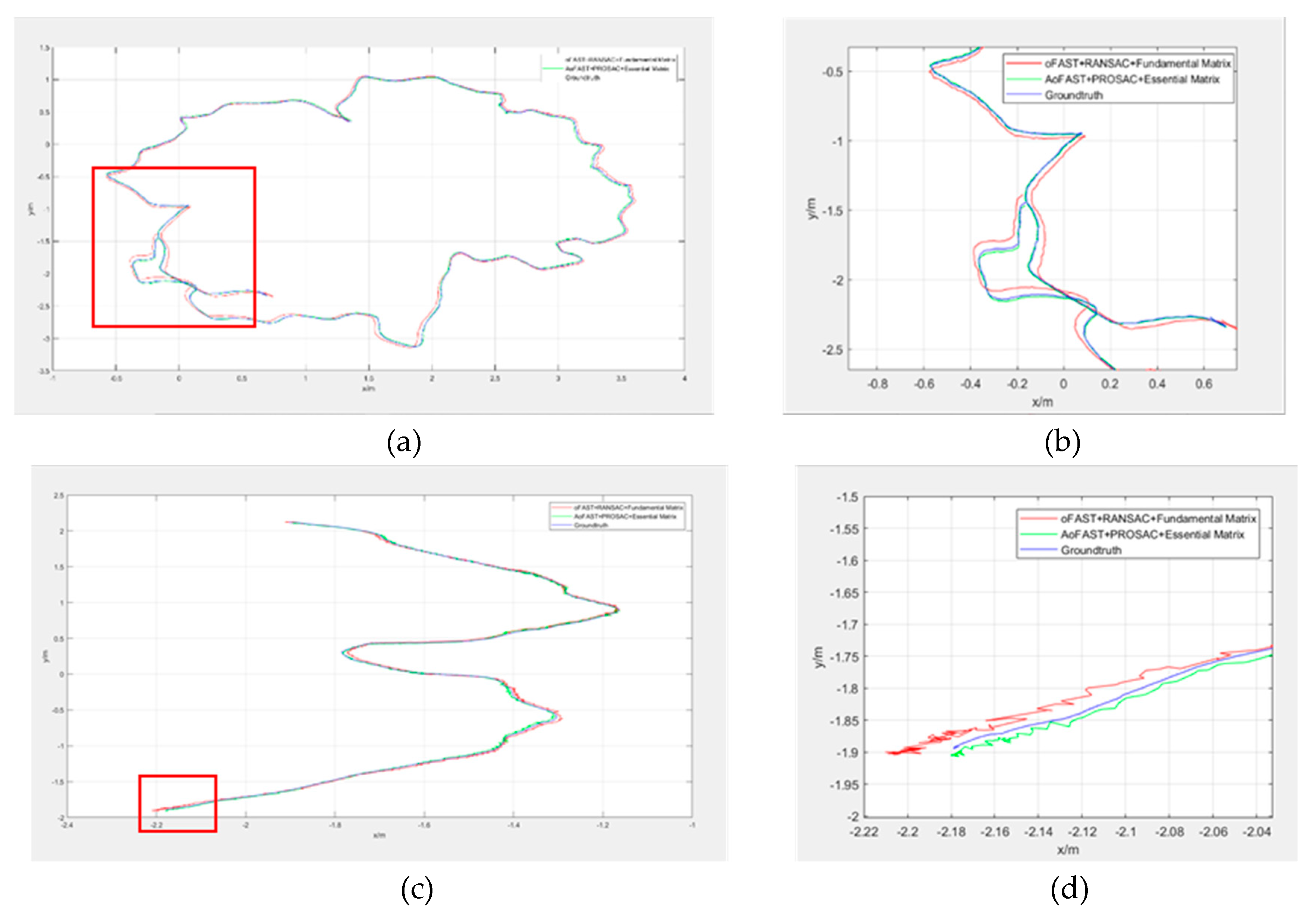
4.2.4. Experimental Results and Analysis of Two Visual Odometry Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2017, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Chen, Z.; Li, Y.; Su, Z. Rapid relocation method for mobile robot based on improved ORB-SLAM2 algorithm. Remote Sens. 2019, 11, 149. [Google Scholar] [CrossRef] [Green Version]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning Rich Features from RGB-D Images for Object Detection and Segmentation. In Proceedings of the 13th European Conference on Computer Vision (ECCV 2014), Zurich, Switzerland, 6–12 September 2014; pp. 345–360. [Google Scholar]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual Odometry and Mapping for Autonomous Flight Using an RGB-D Camera. In Proceedings of the 2017 15th International Symposium of Robotics Reasearch, Flagstaff, AZ, USA, 9–12 December 2011; pp. 235–252. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar]
- Lee, Y.J.; Song, J.B. Visual SLAM in Indoor Environments Using Autonomous Detection and Registration of Objects. In Proceedings of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, Seoul, Korea, 20–22 August 2008; pp. 671–676. [Google Scholar]
- Wang, Y. Research on Binocular Visual Inertial Odometry with Multi-Position Information Fusion. Ph.D.’s Thesis, University of Chinese Academy of Sciences (Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences), Beijing, China, 2019. [Google Scholar]
- Muja, M.; Lowe, D.G. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. In Proceedings of the Fourth International Conference on Computer Vision Theory and Application, Lisboa, Portugal, 5–8 February 2009; pp. 331–340. [Google Scholar]
- Chum, O.; Matas, J. Matching with PROSAC-Progressive Sample Consensus. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 20–26 June 2005; pp. 220–226. [Google Scholar]
- Brand, C.; Schuster, M.J.; Hirschmuller, H.; Suppa, M. Stereo-Vision Based Obstacle Mapping for Indoor/Outdoor SLAM. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 1846–1853. [Google Scholar]
- Yan, K.; Sukthankar, R. PCA-SIFT: A More Distinctive Representation for Local Image Descriptors. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; pp. 506–513. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. SURF: Speeded Up Robust Features. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Hu, M.; Ren, M.; Yang, J. A fast and practical feature point matching algorithm. Comput. Eng. 2004, 30, 31–33. [Google Scholar]
- Mount, D.M.; Netanyahu, N.S.; Moigne, J.L. Efficient algorithms for robust feature matching. Pattern Recognit. 1997, 32, 17–38. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.; Bolles, R. Random sample consensus: A para-digm for model fitting with applications to image analysis and automated cartography. Commun. ACM. 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Choi, S.; Kim, T.; Yu, W. Performance evaluation of RANSAC family. J. Comput. Vision 1997, 24, 271–300. [Google Scholar]
- Derpanis, K.G. Overview of the RANSAC Algorithm; Technical report for Computer Science; York University: North York, ON, Canada, May 2010. [Google Scholar]
- Schnabel, R.; Wahl, R.; Klein, R. Efficient RANSAC for Point-Cloud Shape Detection. Comp. Graph. Forum 2010, 26, 214–226. [Google Scholar] [CrossRef]
- Kitt, B.; Geiger, A.; Lategahn, H. Visual Odometry Based on Stereo Image Sequences with RANSAC-Based Outlier Rejection Scheme. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, San Diego, CA, USA, 21–24 June 2010; pp. 486–492. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient Variants of the ICP Algorithm. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Gao, X.-S.; Hou, X.-R.; Tang, J.; Cheng, H.-F. Complete solution classification for the perspective-three-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 930–943. [Google Scholar]
- Zhu, Z.; Oskiper, T.; Samarasekera, S.; Kumar, R.; Sawhney, H.S. Ten-Fold Improvement in Visual Odometry Using Landmark Matching. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Ramezani, M.; Acharya, D.; Gu, F.; Khoshelham, K. Indoor Positioning by Visual-Inertial Odometry. In Proceedings of the ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, Wuhan, China, 18–22 September 2017; Volume 4, pp. 371–376. [Google Scholar]
- Acharya, D.; Ramezani, M.; Khoshelham KWinter, S. BIM-Tracker: A model-based visual tracking approach for indoor localisation using a 3D building model. ISPRS J. Photogramm. Remote Sens. 2019, 150, 157–171. [Google Scholar] [CrossRef]
- Gu, F.; Hu, X.; Ramezani, M.; Acharya, D.; Khoshelham, K.; Valaee, S.; Shang, J. Indoor localization improved by spatial context—A survey. ACM Comput. Surv. 2018, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Piasco, N.; Sidib, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on visualbased localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109. [Google Scholar] [CrossRef] [Green Version]
- Venkatachalapathy, V. Visual Odometry Estimation Using Selective Features. Master’s Thesis, Rochester Institute of Technology, Rochester, NY, USA, July 2016; pp. 19–24. [Google Scholar]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox DRoy, N. Visual odometry and mapping for autonomous flight using an RGB-D camera. In Robotics Research; Springer: Cham, Southeast Asia, 2017; pp. 235–252. [Google Scholar]
- Xin, G.X.; Zhang, X.T.; Xi, W. A RGBD SLAM Algorithm Combining ORB with PROSAC for Indoor Mobile Robot. In Proceedings of the 2015 4th International Conference on Computer Science and Network Technology, Harbin, China, 19–20 December 2015; pp. 71–74. [Google Scholar]
- Chum, O.; Matas, J.; Kittler, J. Locally optimized RANSAC. Lecture Notes Comput. Sci. 2003, 2781, 236–243. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chum, O.; Werner, T.; Matas, J. Epipolar Geometry Estimation via RANSAC Benefits from the Oriented Epipolar Constraint. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 26 August 2004; pp. 112–115. [Google Scholar]
- Kapur, J.N.; Sahoo, P.K.; Wong, A.K.C. A new method for gray-level picture thresholding using the entropy of the histogram. Comp. Vision Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Dubrofsky, E. Homography Estimation; Diplomová práce, Univerzita Britské Kolumbie: Vancouver, BC, Canada, 2009. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate o(n) solution to the pnp problem. Int. J. Comput. Vision 2008, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Penate-Sanchez, A.; Andrade-Cetto, J.; Moreno-Noguer, F. Exhaustive linearization for robust camera pose and focal length estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2387–2400. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hesch, J.A.; Roumeliotis, S.I. A Direct Least-Squares (DLS) method for PnP. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2011), Barcelona, Spain, 6–13 November 2011; pp. 383–390. [Google Scholar]
- Li, L. Research on indoor positioning algorithm based on PROSAC algorithm. Ph.D.’s Thesis, Harbin Institute of technology, Harbin, China, 2018. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Error (mm) | Time (ms) |
|---|---|---|
| PnP | 4.277 | 5.531 |
| EPnP | 1.311 | 5.111 |
| UPnP | 2.796 | 5.309 |
| DLS | 2.684 | 5.479 |
| Image | oFAST (ms) | AoFAST (ms) |
|---|---|---|
| Figure 4a | 0.200 | 0.215 |
| Figure 4b | 0.401 | 0.447 |
| Figure 4c | 0.443 | 0.451 |
| Figure 4d | 0.429 | 0.444 |
| Data | Fundamental Matrix (ms) | Essential Matrix (ms) |
|---|---|---|
| Figure 4a | 4.710 | 4.598 |
| Figure 4b | 5.351 | 5.346 |
| Figure 4c | 5.095 | 4.961 |
| Figure 4d | 5.826 | 5.809 |
| Direction | Ground Truth (M) | ORB-SLAM2 (m) | Our Method (m) |
|---|---|---|---|
| X | 0.905 | 0.909 | 0.904 |
| Y | –0.046 | –0.042 | –0.047 |
| Z | 0.421 | 0.414 | 0.424 |
| RMS | 0.009 | 0.003 |
| Data/Direction | ORB-SLAM2 (cm) | Our Method (cm) |
|---|---|---|
| Video1 | ||
| X | 2.626 | 2.352 |
| Y | 4.868 | 2.410 |
| Video2 | ||
| X | –1.147 | 0.721 |
| Y | 1.365 | 0.793 |
| ORB-SLAM2 (m) | Our Method (m) | |
|---|---|---|
| Video1 | ||
| translational_error.rmse | 0.075 | 0.047 |
| translational_error.mean | 0.058 | 0.040 |
| rotational_error.rmse | 2.407 | 1.544 |
| rotational_error.mean | 1.969 | 1.382 |
| Video2 | ||
| translational_error.rmse | 0.047 | 0.027 |
| translational_error.mean | 0.034 | 0.023 |
| rotational_error.rmse | 1.002 | 0.964 |
| rotational_error.mean | 0.848 | 0.816 |
| Data | ORB-SLAM2 (ms) | Our Method (ms) |
|---|---|---|
| Video1 | 28.613 | 26.373 |
| Video2 | 26.066 | 23.726 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, J.; Li, M.; Liao, X.; Zhong, J. Accumulative Errors Optimization for Visual Odometry of ORB-SLAM2 Based on RGB-D Cameras. ISPRS Int. J. Geo-Inf. 2019, 8, 581. https://doi.org/10.3390/ijgi8120581
Qin J, Li M, Liao X, Zhong J. Accumulative Errors Optimization for Visual Odometry of ORB-SLAM2 Based on RGB-D Cameras. ISPRS International Journal of Geo-Information. 2019; 8(12):581. https://doi.org/10.3390/ijgi8120581
Chicago/Turabian StyleQin, Jiangying, Ming Li, Xuan Liao, and Jiageng Zhong. 2019. "Accumulative Errors Optimization for Visual Odometry of ORB-SLAM2 Based on RGB-D Cameras" ISPRS International Journal of Geo-Information 8, no. 12: 581. https://doi.org/10.3390/ijgi8120581
APA StyleQin, J., Li, M., Liao, X., & Zhong, J. (2019). Accumulative Errors Optimization for Visual Odometry of ORB-SLAM2 Based on RGB-D Cameras. ISPRS International Journal of Geo-Information, 8(12), 581. https://doi.org/10.3390/ijgi8120581