Spatiotemporal Data Clustering: A Survey of Methods

Abstract
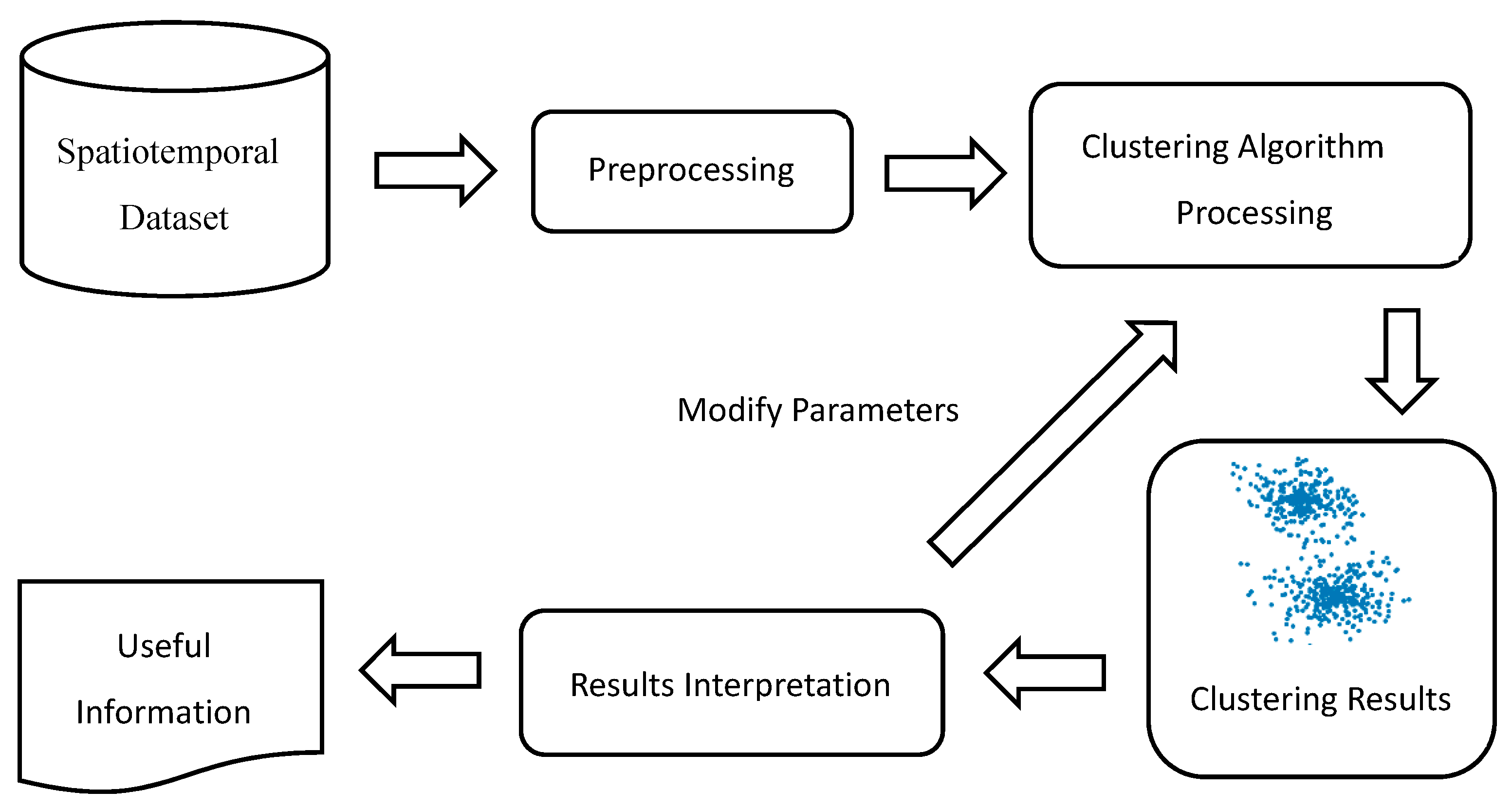
:1. Introduction
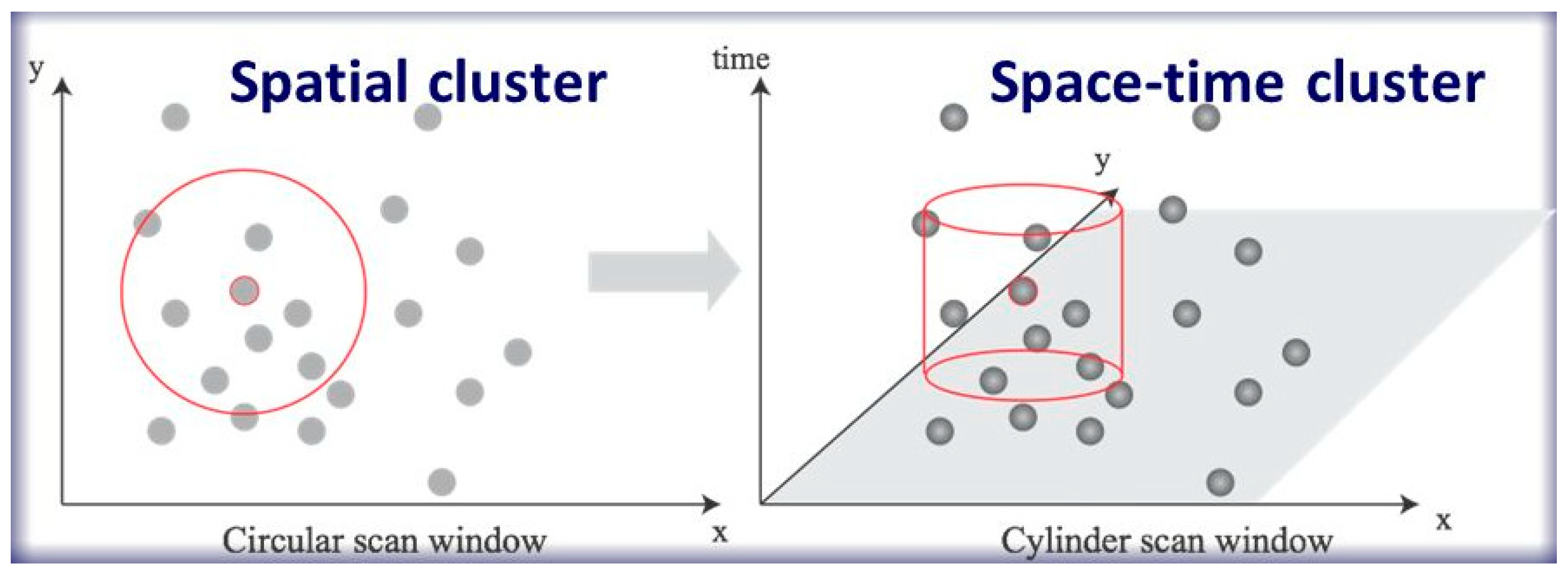
2. From Spatial to ST Clustering
3. Hypothesis testing-based methods
3.1. Space–time interaction methods
3.2. Spatiotemporal k Nearest Neighbors Test
- N: Number of cases.
- dij: Spatial measure, when case is a nearest neighbor of case in space, otherwise equal to 0.
- tij: Spatial measure, when case is a nearest neighbor of case in time, otherwise equal to 0.
- : Is a cumulative test statistic, where .
- : Is specific test statistic, where .
3.3. Scan Statistics
4. Partitional Clustering Methods
4.1. DBSCAN
4.2. Kernel Density Estimation
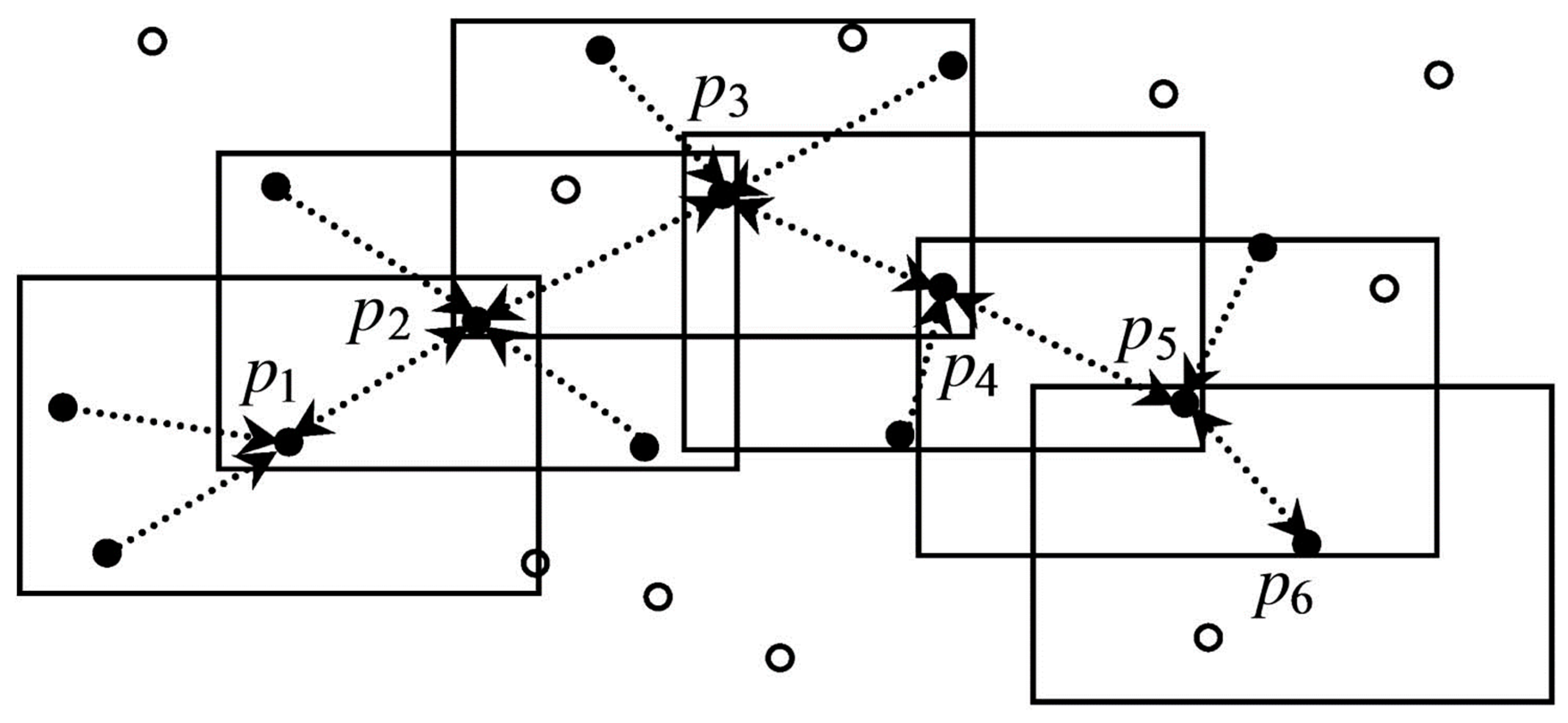
4.3. Windowed Nearest Neighbor Method
5. Applications
6. Conclusion and Future Works
- Multiple scales clustering of ST data is an important research topic. Clustering results could be different with both changing map scales and data scale of nominal, ordinal, interval, or ratio value (i.e., with increasing attribute information). The problem of multiple scales is related to different shapes, sizes, and densities of event distribution. A changing clustering algorithm with changing scales for different applications is worth investigating in the future.
- Modifiable areal unit problem is still a problem in clustering. It has a strong relationship with scale selection. With different units of spatial and temporal data, clustering results could be variable with the choices of appropriate spatial and temporal units. Especially for temporal information, diverse time periods could indicate different cluster patterns. The identification of optimal spatial and temporal units should be considered.
- Different types of ST data analysis should be considered to develop diverse clustering methods. In many existing studies, most algorithms are focused on point features or events. However, trajectory data from GPS and other positioning equipment can record locational information in a linear dimension, thus demanding new methods for line clustering. The same applies for outliers’ detection [74,75] and classification algorithms that have not been investigated thoroughly yet.
- Different patterns could result from using different methods or time periods. It is difficult to detect the best pattern based on one algorithm. Generally speaking, raw data could contain many different kinds of pattern. For efficient mining of potential patterns, new algorithms for evaluating the accuracy or reliability of various patterns should be investigated in the future.
- Clustering methods for multiple dimensional data beyond the third dimension need to be developed for analysis and visualization.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. 2015, 6, 29. [Google Scholar] [CrossRef]
- Tang, J.; Chang, Y.; Liu, H. Mining social media with social theories: A survey. ACM SIGKDD Explor. Newsl. 2014, 15, 20–29. [Google Scholar] [CrossRef]
- Kisilevich, S.; Mansmann, F.; Nanni, M.; Rinzivillo, S. Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Shekhar, S.; Evans, M.R.; Kang, J.M.; Mohan, P. Identifying patterns in spatial information: A survey of methods. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 193–214. [Google Scholar] [CrossRef]
- Miller, H.J.; Han, J. Geographic Data Mining and Knowledge Discovery; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Atluri, G.; Karpatne, A.; Kumar, V. Spatio-Temporal Data Mining: A Survey of Problems and Methods. ACM Comput. Surv. 2017, 1. [Google Scholar] [CrossRef]
- Cheng, T.; Haworth, J.; Anbaroglu, B.; Tanaksaranond, G.; Wang, J. Spatiotemporal data mining. In Handbook of Regional Science; Springer: Berlin/Heidelberg, Germany, 2014; pp. 1173–1193. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.-P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. In Proceedings of the ACM SIGMOD Record, Philadelphia, PA, USA, 31 May–3 June 1999; pp. 49–60. [Google Scholar]
- Pei, T.; Jasra, A.; Hand, D.J.; Zhu, A.-X.; Zhou, C. DECODE: A new method for discovering clusters of different densities in spatial data. Data Min. Knowl. Discov. 2009, 18, 337–369. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Montreal, QC, Canada, 4–6 June 1996; pp. 103–114. [Google Scholar]
- Rokach, L.; Maimon, O. Clustering methods. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005; pp. 321–352. [Google Scholar]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.-T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Ng, R.T.; Han, J. CLARANS: A method for clustering objects for spatial data mining. IEEE Trans. Knowl. Data Eng. 2002, 14, 1003–1016. [Google Scholar] [CrossRef]
- Karypis, G.; Han, E.-H.; Kumar, V. Chameleon: Hierarchical clustering using dynamic modeling. Computer 1999, 32, 68–75. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. CURE: An efficient clustering algorithm for large databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Seattle, WA, USA, 1–4 June 1998; pp. 73–84. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Proceedings of the 2nd International Conference on Knowledge and Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231.
- Gaonkar, M.N.; Sawant, K. AutoEpsDBSCAN: DBSCAN with Eps automatic for large dataset. Int. J. Adv. Comput. Theory Eng. 2013, 2, 11–16. [Google Scholar]
- Ghanbarpour, A.; Minaei, B. EXDBSCAN: An extension of DBSCAN to detect clusters in multi-density datasets. In Proceedings of the 2014 Iranian Conference on Intelligent Systems (ICIS), Bam, Iran, 4–6 February 2014; pp. 1–5. [Google Scholar]
- Liu, P.; Zhou, D.; Wu, N. VDBSCAN: Varied density based spatial clustering of applications with noise. In Proceedings of the International Conference on Service Systems and Service Management, Chengdu, China, 9–11 June 2007; pp. 1–4. [Google Scholar]
- Ruiz, C.; Spiliopoulou, M.; Menasalvas, E. C-dbscan: Density-based clustering with constraints. In Proceedings of the International Workshop on Rough Sets, Fuzzy Sets, Data Mining, and Granular-Soft Computing, Toronto, ON, Canada, 14–16 May 2007; pp. 216–223. [Google Scholar]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. Wavecluster: A multi-resolution clustering approach for very large spatial databases. In Proceedings of the VLDB, New York, NY, USA, 24–27 August 1998; pp. 428–439. [Google Scholar]
- Wang, W.; Yang, J.; Muntz, R. STING: A statistical information grid approach to spatial data mining. In Proceedings of the International Conference on Very Large Data Bases (VLDB), New York, NY, USA, 24–27 August 1998; pp. 186–195. [Google Scholar]
- Fisher, D.H. Knowledge acquisition via incremental conceptual clustering. Mach. Learn. 1987, 2, 139–172. [Google Scholar] [CrossRef] [Green Version]
- Vesanto, J.; Alhoniemi, E. Clustering of the self-organizing map. IEEE Trans. Neural Netw. 2000, 11, 586–600. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Hu, Y.; Wang, F.; Guin, C.; Zhu, H. A spatio-temporal kernel density estimation framework for predictive crime hotspot mapping and evaluation. Appl. Geogr. 2018, 99, 89–97. [Google Scholar] [CrossRef]
- Lee, J.; Gong, J.; Li, S. Exploring spatiotemporal clusters based on extended kernel estimation methods. Int. J. Geogr. Inf. Sci. 2017, 31, 1154–1177. [Google Scholar]
- Tango, T.; Takahashi, K.; Kohriyama, K. A space–time scan statistic for detecting emerging outbreaks. Biometrics 2011, 67, 106–115. [Google Scholar] [CrossRef] [PubMed]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Diggle, P.J. Statistical Analysis of Spatial and Spatio-Temporal Point Patterns; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Diggle, P.J. A point process modelling approach to raised incidence of a rare phenomenon in the vicinity of a prespecified point. J. R. Stat. Soc. Ser. A (Stat. Soc.) 1990, 153, 349–362. [Google Scholar] [CrossRef]
- Di Martino, F.; Sessa, S. The extended fuzzy C-means algorithm for hotspots in spatio-temporal GIS. Expert Syst. Appl. 2011, 38, 11829–11836. [Google Scholar] [CrossRef]
- Knox, E.; Bartlett, M. The detection of space-time interactions. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1964, 13, 25–30. [Google Scholar] [CrossRef]
- Knox, G. Detection of low intensity epidemicity: Application to cleft lip and palate. Br. J. Prev. Soc. Med. 1963, 17, 121–127. [Google Scholar] [CrossRef] [PubMed]
- Kulldorff, M.; Hjalmars, U. The Knox method and other tests for space-time interaction. Biometrics 1999, 55, 544–552. [Google Scholar] [CrossRef] [PubMed]
- Mantel, N. The detection of disease clustering and a generalized regression approach. Cancer Res. 1967, 27, 209–220. [Google Scholar] [PubMed]
- Jacquez, G.M. A k nearest neighbour test for space–time interaction. Stat. Med. 1996, 15, 1935–1949. [Google Scholar] [CrossRef]
- Kulldorff, M. SaTScan v9.6: Software for the Spatial, Temporal, and Space-Time Scan Statistics; Information Management Services Inc.: Calverton, MD, USA, 2018. [Google Scholar]
- Glaz, J.; Naus, J.I.; Wallenstein, S.; Wallenstein, S.; Naus, J.I. Scan Statistics; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Kulldorff, M. A spatial scan statistic. Commun. Stat.-Theory Methods 1997, 26, 1481–1496. [Google Scholar] [CrossRef]
- Kulldorff, M. Prospective time periodic geographical disease surveillance using a scan statistic. J. R. Stat. Soc. Ser. A (Stat. Soc.) 2001, 164, 61–72. [Google Scholar] [CrossRef]
- Kulldorff, M.; Heffernan, R.; Hartman, J.; Assunçao, R.; Mostashari, F. A space–time permutation scan statistic for disease outbreak detection. PLoS Med. 2005, 2, e59. [Google Scholar] [CrossRef] [PubMed]
- Tango, T.; Takahashi, K. A flexibly shaped spatial scan statistic for detecting clusters. Int. J. Health Geogr. 2005, 4, 11. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, K.; Kulldorff, M.; Tango, T.; Yih, K. A flexibly shaped space-time scan statistic for disease outbreak detection and monitoring. Int. J. Health Geogr. 2008, 7, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Takahashi, K.; Yokoyama, T.; Tango, T. FleXScan v3. 1. 2: Software for the Flexible Scan Statistic; National Institute of Public Health: Wako, Japan, 2013. [Google Scholar]
- Neill, D.B. Detection of Spatial and Spatio-Temporal Clusters. Tech. Rep. CMU-CS-06-142. Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, 2006. [Google Scholar]
- Wang, M.; Wang, A.; Li, A. Mining spatial-temporal clusters from geo-databases. In Proceedings of the International Conference on Advanced Data Mining and Applications, Xi’an, China, 14–16 August 2006; pp. 263–270. [Google Scholar]
- Birant, D.; Kut, A. An algorithm to discover spatial–temporal distributions of physical seawater characteristics and a case study in Turkish seas. J. Mar. Sci. Technol. 2006, 11, 183–192. [Google Scholar] [CrossRef]
- Scott, D.W. Multivariate Density Estimation: Theory, Practice, and Visualization; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986; Volume 26. [Google Scholar]
- Brunsdon, C.; Corcoran, J.; Higgs, G. Visualising space and time in crime patterns: A comparison of methods. Comput. Environ. Urban Syst. 2007, 31, 52–75. [Google Scholar] [CrossRef] [Green Version]
- Nakaya, T.; Yano, K. Visualising Crime Clusters in a Space-time Cube: An Exploratory Data-analysis Approach Using Space-time Kernel Density Estimation and Scan Statistics. Trans. GIS 2010, 14, 223–239. [Google Scholar] [CrossRef]
- Wei, Q.; She, J.; Zhang, S.; Ma, J. Using individual GPS trajectories to explore foodscape exposure: A case study in Beijing metropolitan area. Int. J. Environ. Res. Public Health 2018, 15, 405. [Google Scholar]
- Pei, T.; Zhou, C.; Zhu, A.-X.; Li, B.; Qin, C. Windowed nearest neighbour method for mining spatio-temporal clusters in the presence of noise. Int. J. Geogr. Inf. Sci. 2010, 24, 925–948. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Byers, S.; Raftery, A.E. Nearest-neighbor clutter removal for estimating features in spatial point processes. J. Am. Stat. Assoc. 1998, 93, 577–584. [Google Scholar] [CrossRef]
- Cheng, T.; Wicks, T. Event detection using Twitter: A spatio-temporal approach. PLoS ONE 2014, 9, e97807. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Liu, J.; Ge, H. Pattern characteristics of foreshock sequences. In Seismicity Patterns, their Statistical Significance and Physical Meaning; Springer: Berlin/Heidelberg, Germany, 1999; pp. 395–408. [Google Scholar]
- Ripepe, M.; Piccinini, D.; Chiaraluce, L. Foreshock sequence of September 26th, 1997 Umbria-Marche earthquakes. J. Seismol. 2000, 4, 387–399. [Google Scholar] [CrossRef]
- Zhou, Z.; Matteson, D.S. Predicting ambulance demand: A spatio-temporal kernel approach. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 2297–2303. [Google Scholar]
- Anderson, T.K. Kernel density estimation and K-means clustering to profile road accident hotspots. Accid. Anal. Prev. 2009, 41, 359–364. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Ferreira, J., Jr.; Gonzalez, M.C. Discovering urban spatial-temporal structure from human activity patterns. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12 August 2012; pp. 95–102. [Google Scholar]
- Krisp, J.M.; Peters, S.; Burkert, F. Visualizing crowd movement patterns using a directed kernel density estimation. In Earth Observation of Global Changes (EOGC); Springer: Berlin/Heidelberg, Germany, 2013; pp. 255–268. [Google Scholar]
- Delmelle, E.; Casas, I.; Rojas, J.H.; Varela, A. Spatio-temporal patterns of dengue fever in Cali, Colombia. Int. J. Appl. Geospat. Res. 2013, 4, 58–75. [Google Scholar] [CrossRef]
- Delmelle, E.; Dony, C.; Casas, I.; Jia, M.; Tang, W. Visualizing the impact of space-time uncertainties on dengue fever patterns. Int. J. Geogr. Inf. Sci. 2014, 28, 1107–1127. [Google Scholar] [CrossRef]
- Gomide, J.; Veloso, A.; Meira Jr, W.; Almeida, V.; Benevenuto, F.; Ferraz, F.; Teixeira, M. Dengue surveillance based on a computational model of spatio-temporal locality of Twitter. In Proceedings of the 3rd International Web Science Conference, Koblenz, Germany, 15–17 June 2011; p. 3. [Google Scholar]
- Napier, G.; Lee, D.; Robertson, C.; Lawson, A. A Bayesian space–time model for clustering areal units based on their disease trends. Biostatistics 2018. [Google Scholar] [CrossRef] [PubMed]
- Adin, A.; Lee, D.; Goicoa, T.; Ugarte, M.D. A two-stage approach to estimate spatial and spatio-temporal disease risks in the presence of local discontinuities and clusters. Stat. Methods Med. Res. 2018. [Google Scholar] [CrossRef] [PubMed]
- Shekhar, S.; Jiang, Z.; Ali, R.Y.; Eftelioglu, E.; Tang, X.; Gunturi, V.; Zhou, X. Spatiotemporal data mining: a computational perspective. ISPRS Int. J. Geo-Inf. 2015, 4, 2306–2338. [Google Scholar] [CrossRef]
- Vatsavai, R.R.; Ganguly, A.; Chandola, V.; Stefanidis, A.; Klasky, S.; Shekhar, S. Spatiotemporal data mining in the era of big spatial data: Algorithms and applications. In Proceedings of the 1st ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data, Redondo Beach, CA, USA, 6 November 2012; pp. 1–10. [Google Scholar]
- Shekhar, S.; Vatsavai, R.R.; Celik, M. Spatial and spatiotemporal data mining: Recent advances. In Data Mining: Next Generation Challenges and Future Directions; Chapman and Hall/CRC: Boca Raton, FL, USA, 2008; pp. 1–34. [Google Scholar]
- Cheng, T.; Li, Z. A hybrid approach to detect spatial-temporal outliers. In Proceedings of the 12th International Conference on Geoinformatics Geospatial Information Research, Gävle, Sweden, 7–9 June 2004; pp. 173–178. [Google Scholar]
- Cheng, T.; Li, Z. A multiscale approach for spatio-temporal outlier detection. Trans. GIS 2006, 10, 253–263. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Methods |
|---|---|
| Brunsdon, et al. [53] Nakaya and Yano [54] Wei, et al. [55] | Temporal attribute is regarded as another dimension, calculate space and time kernel density estimations separately. |
| Lee, et al. [29] | 1. Setting a threshold to filter inappropriate space and time distances. 2. Standardization of space and time data for integrating them with same kernel function. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, Z.; Pun-Cheng, L.S.C. Spatiotemporal Data Clustering: A Survey of Methods. ISPRS Int. J. Geo-Inf. 2019, 8, 112. https://doi.org/10.3390/ijgi8030112
Shi Z, Pun-Cheng LSC. Spatiotemporal Data Clustering: A Survey of Methods. ISPRS International Journal of Geo-Information. 2019; 8(3):112. https://doi.org/10.3390/ijgi8030112
Chicago/Turabian StyleShi, Zhicheng, and Lilian S.C. Pun-Cheng. 2019. "Spatiotemporal Data Clustering: A Survey of Methods" ISPRS International Journal of Geo-Information 8, no. 3: 112. https://doi.org/10.3390/ijgi8030112
APA StyleShi, Z., & Pun-Cheng, L. S. C. (2019). Spatiotemporal Data Clustering: A Survey of Methods. ISPRS International Journal of Geo-Information, 8(3), 112. https://doi.org/10.3390/ijgi8030112