GeoAnnotator: A Collaborative Semi-Automatic Platform for Constructing Geo-Annotated Text Corpora


Abstract
:1. Introduction
2. Background and Related Work
2.1. Review of Annotation Tools in Other Domains
2.2. Geo-Annotation Tools
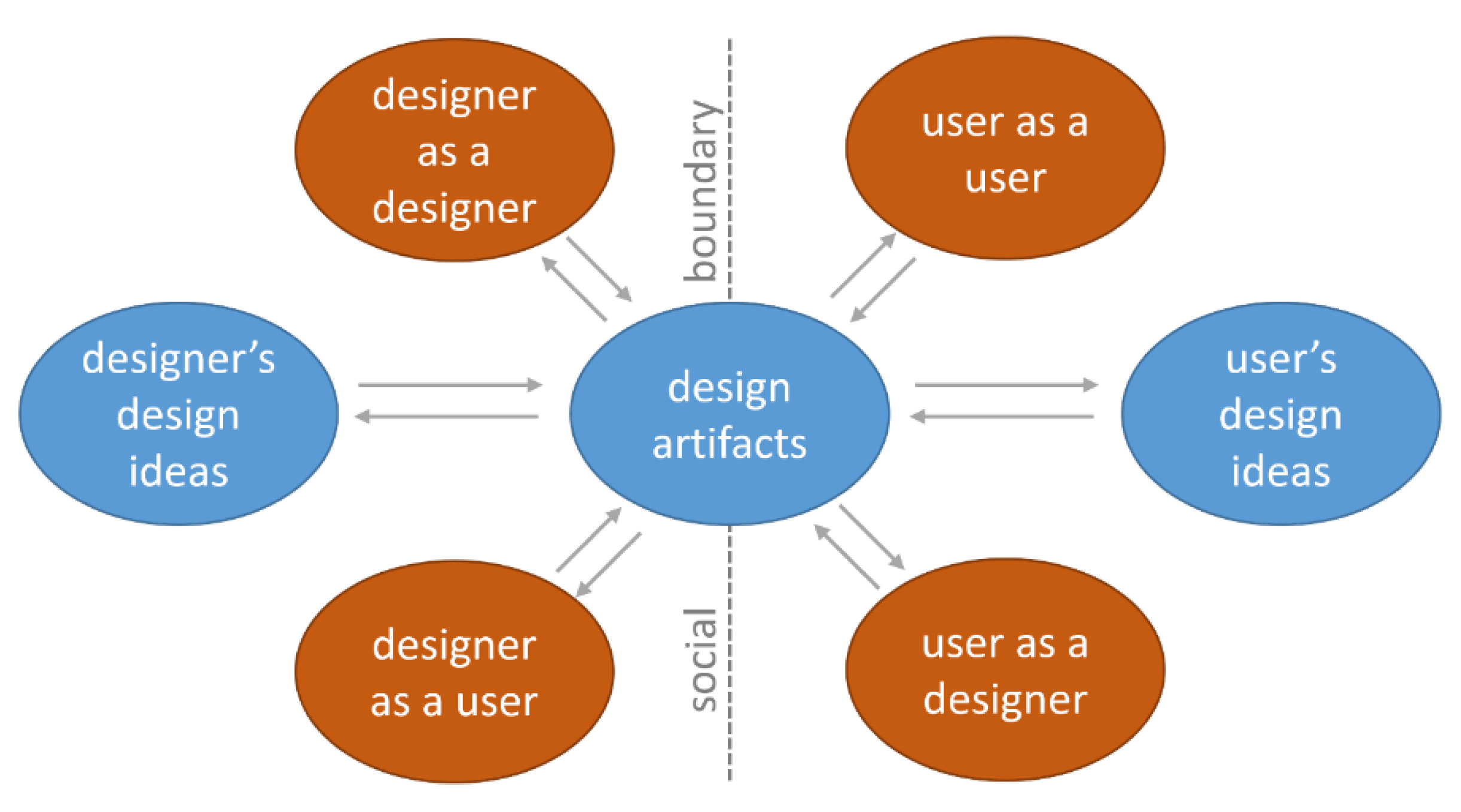
2.3. Iterative Design with the Designer as a User
3. Methods: Iterative Design
3.1. Iterative Design Pattern
3.2. Feature Modification and Tool Expansion
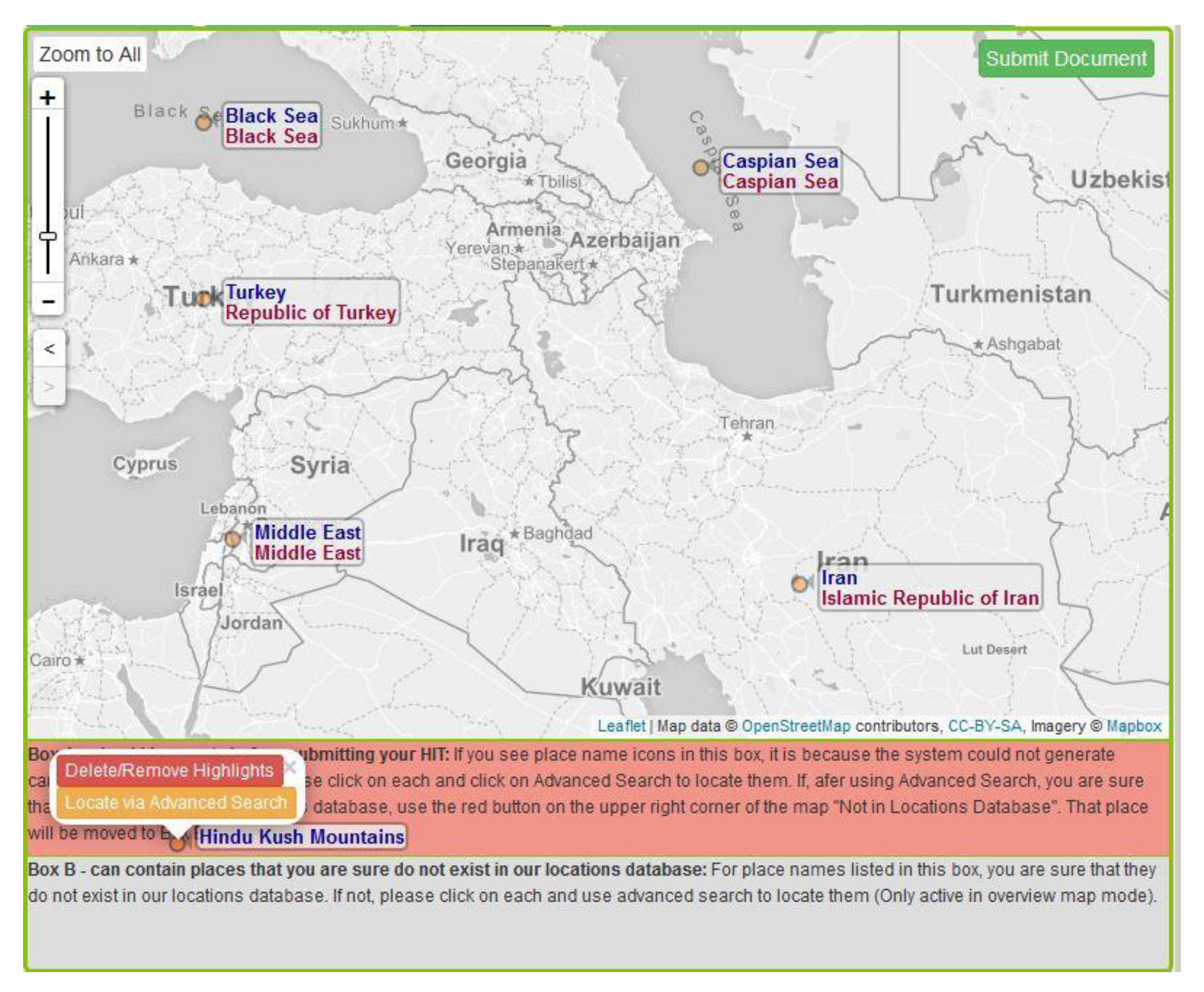
3.2.1. Global and Cross-Document Part Geo-Annotation
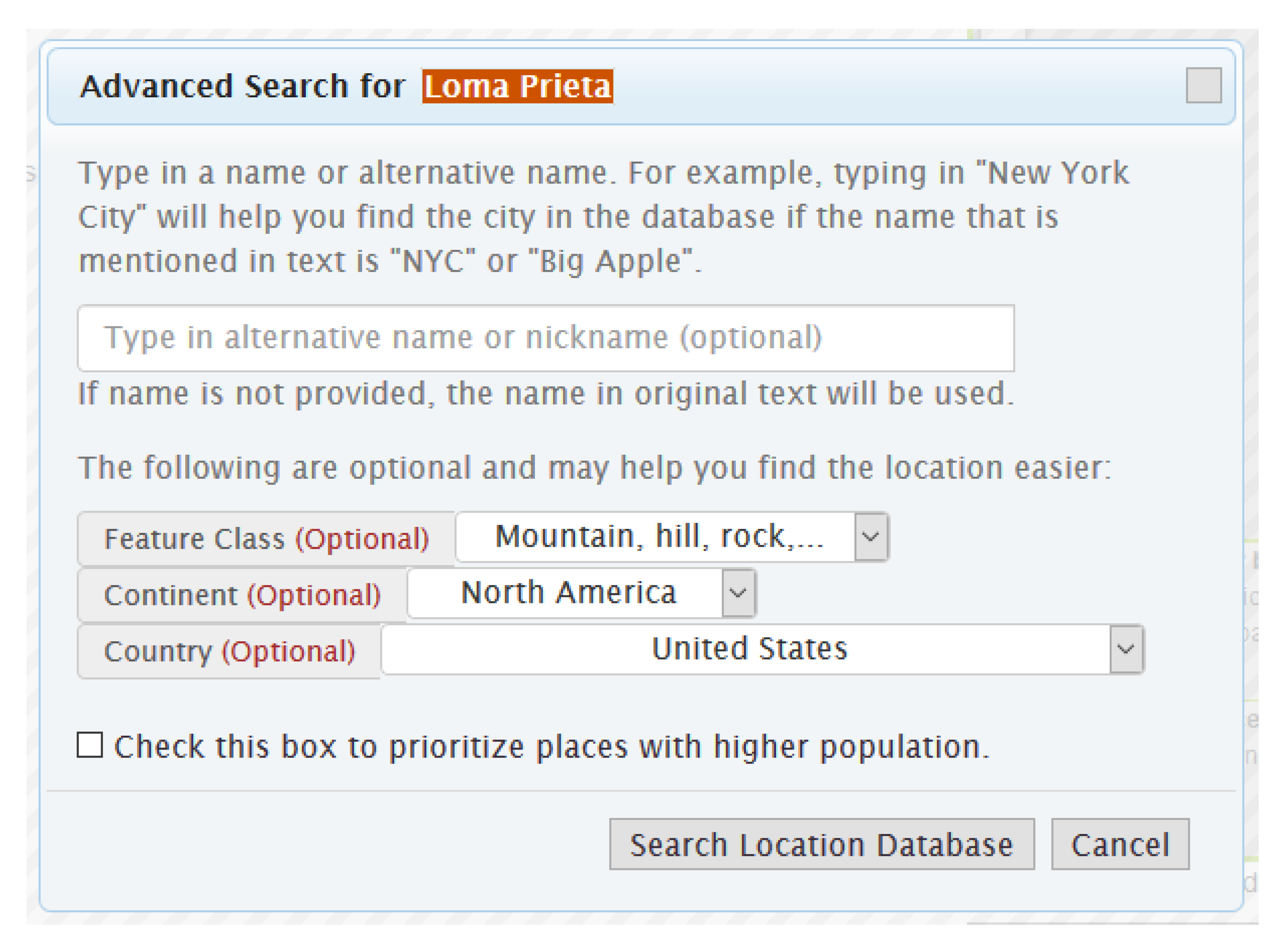
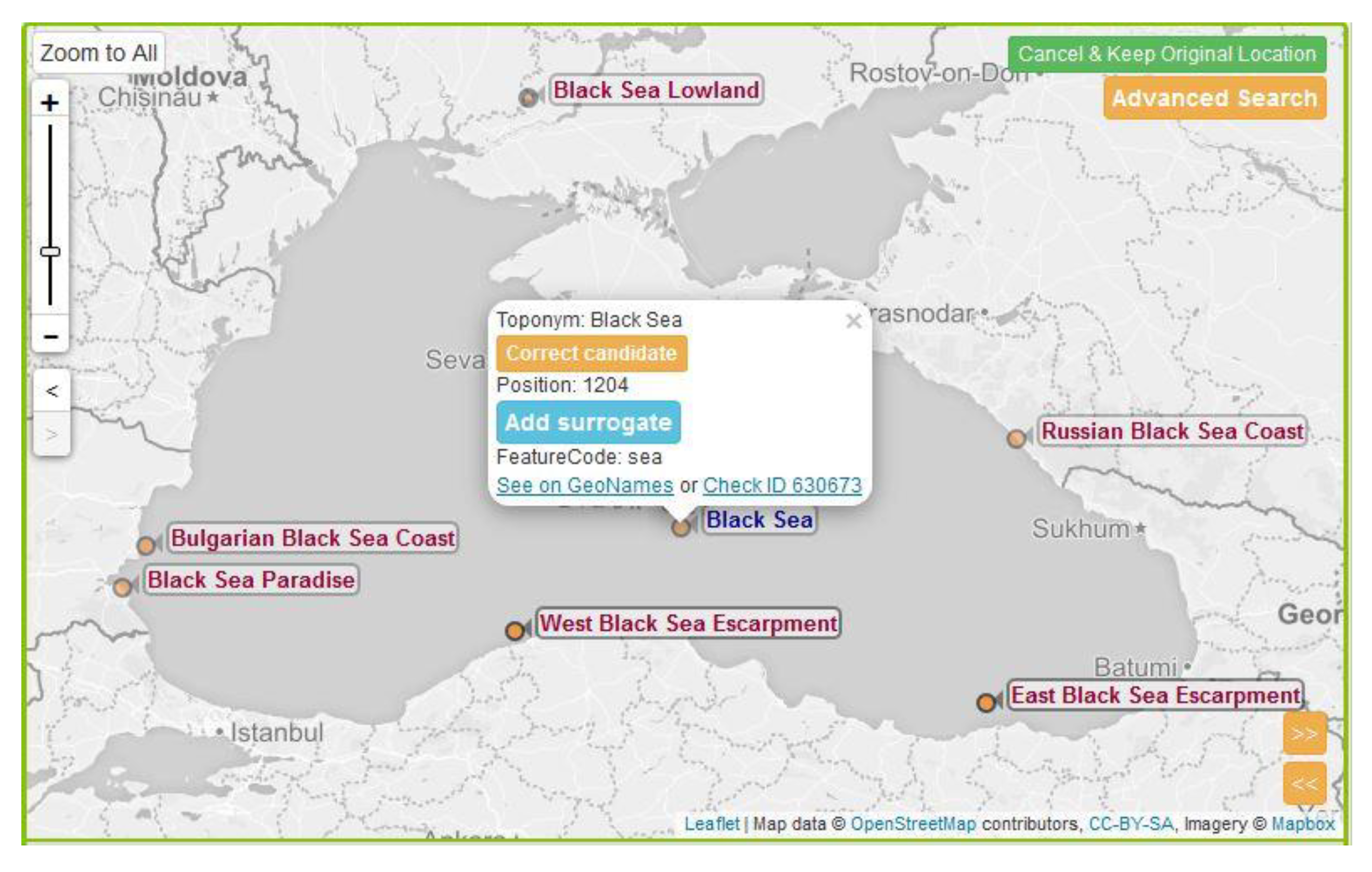
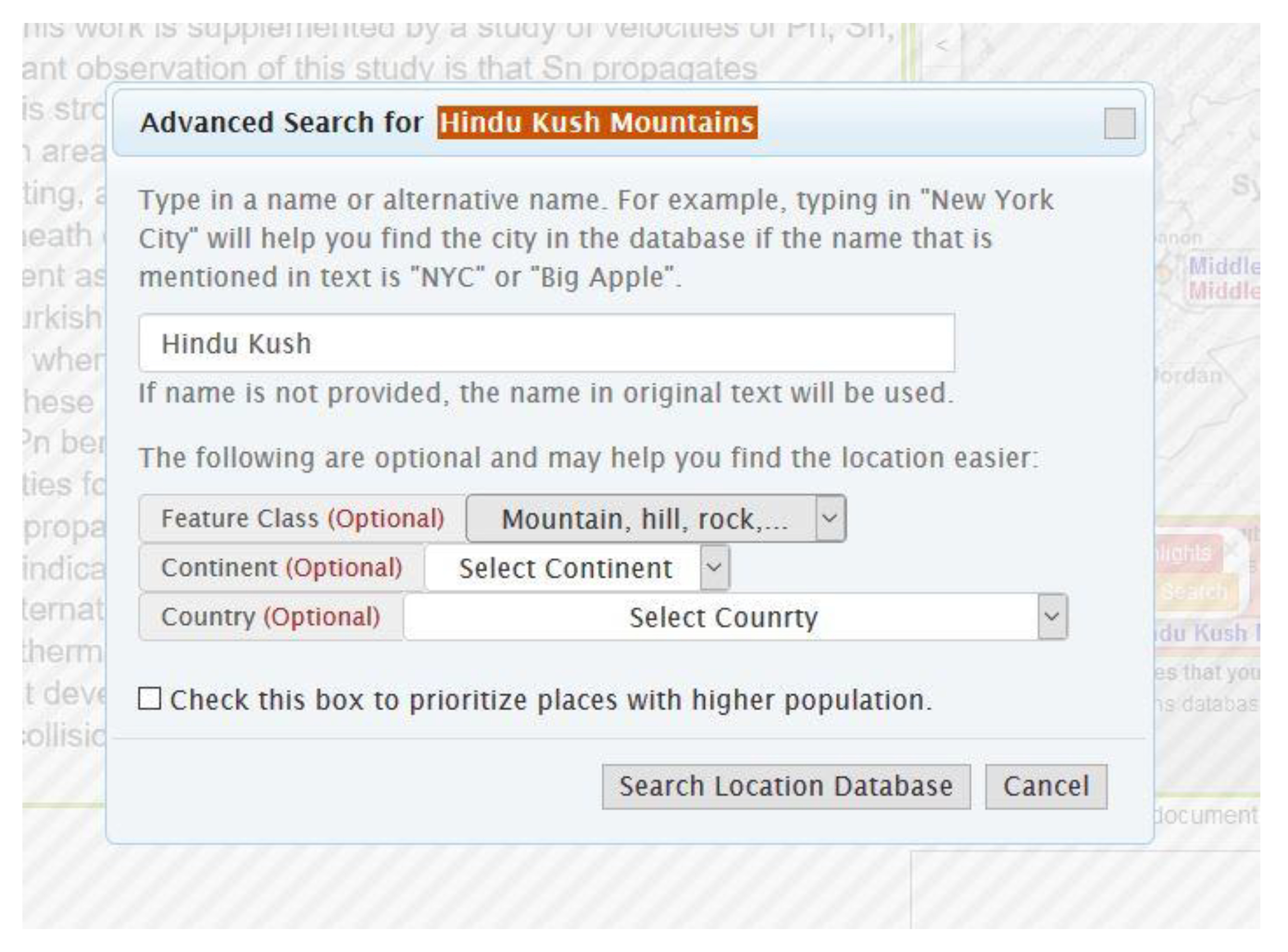
3.2.2. Advanced Toponym Search
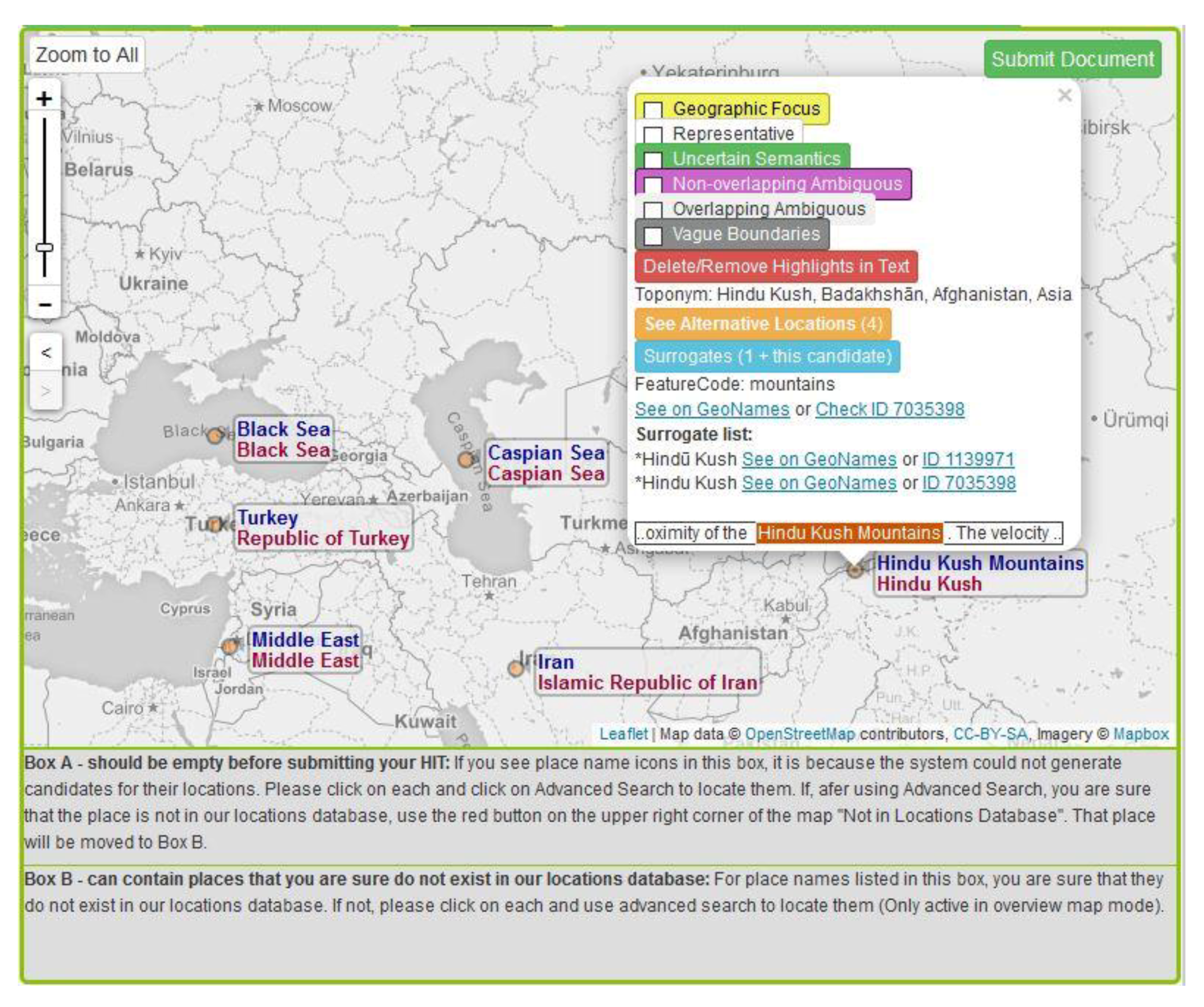
3.2.3. Special Tags
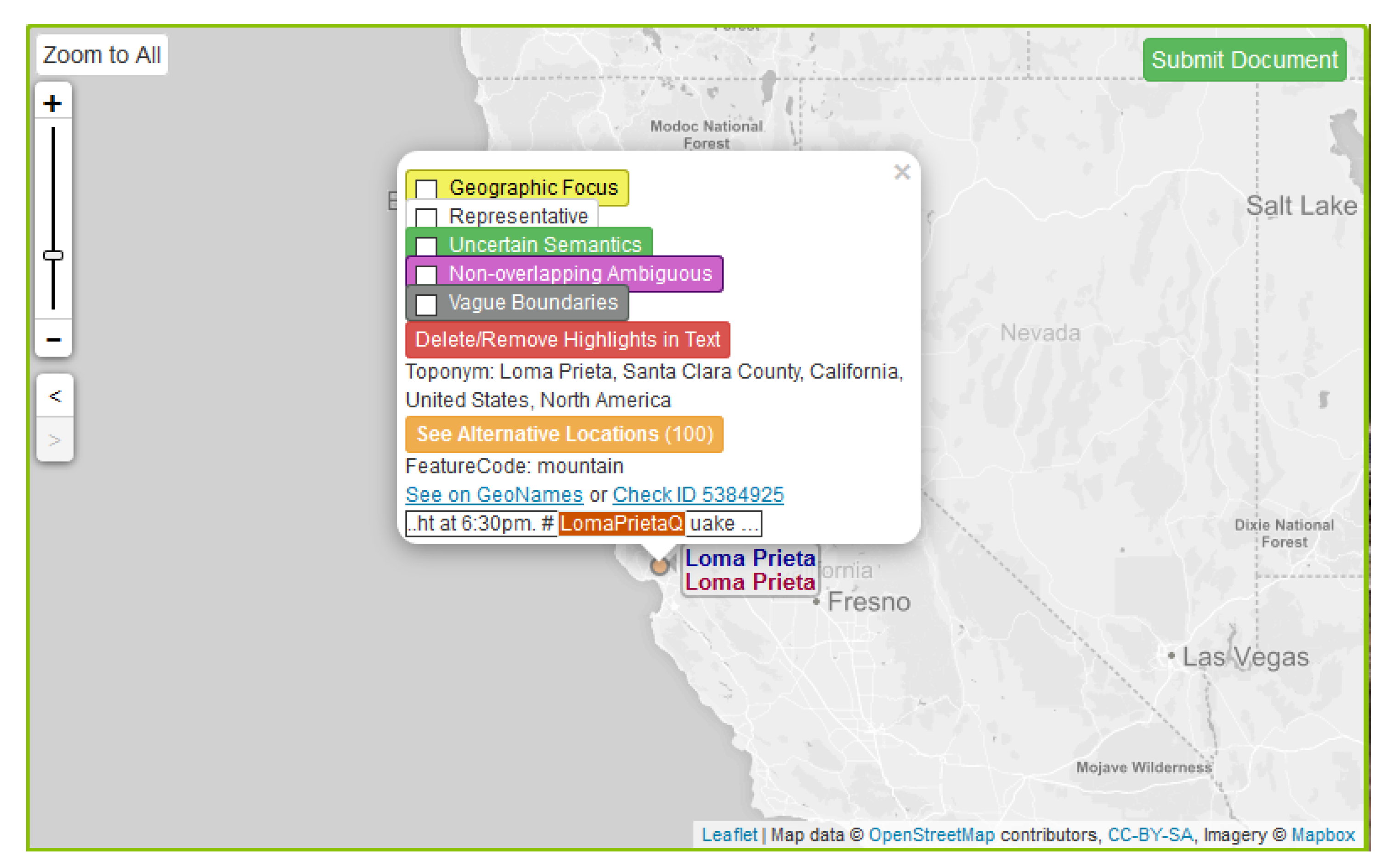
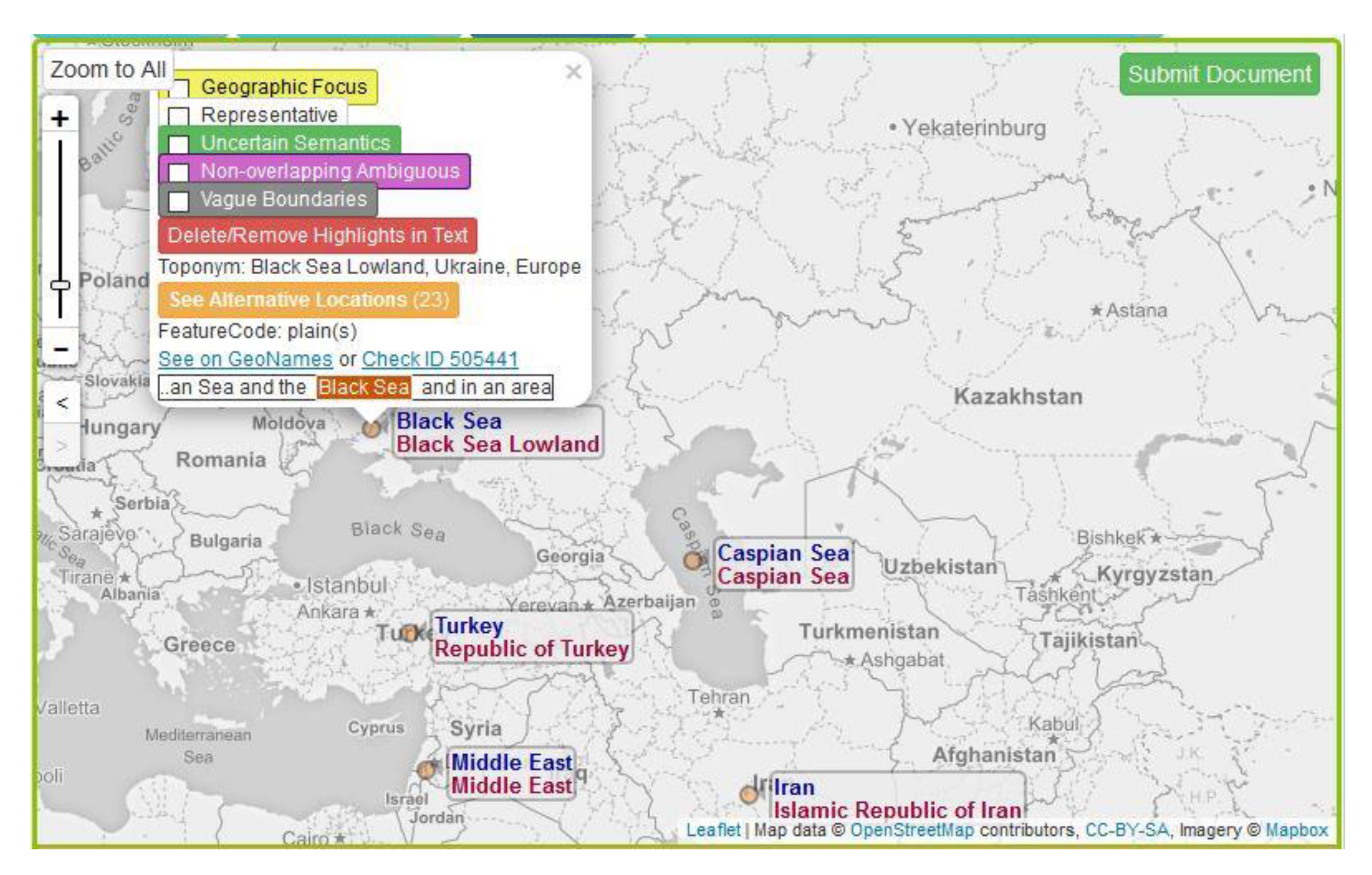
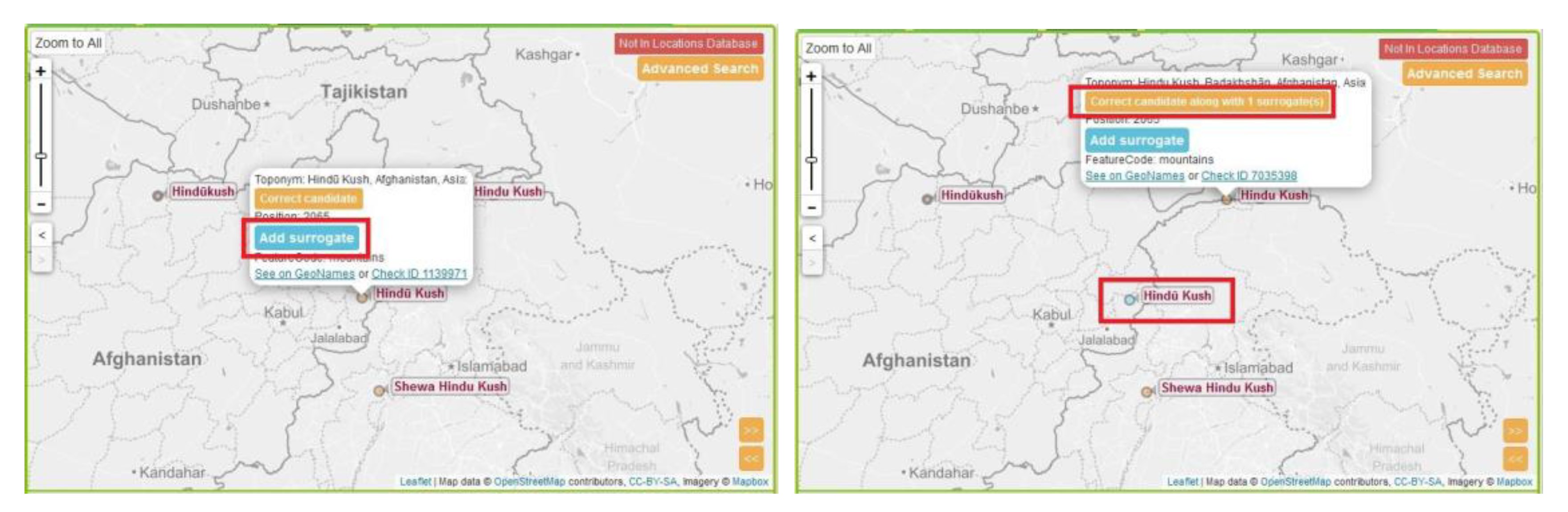
3.2.4. Toponym Differentiation on the Map
3.2.5. Toponym Map Symbolization
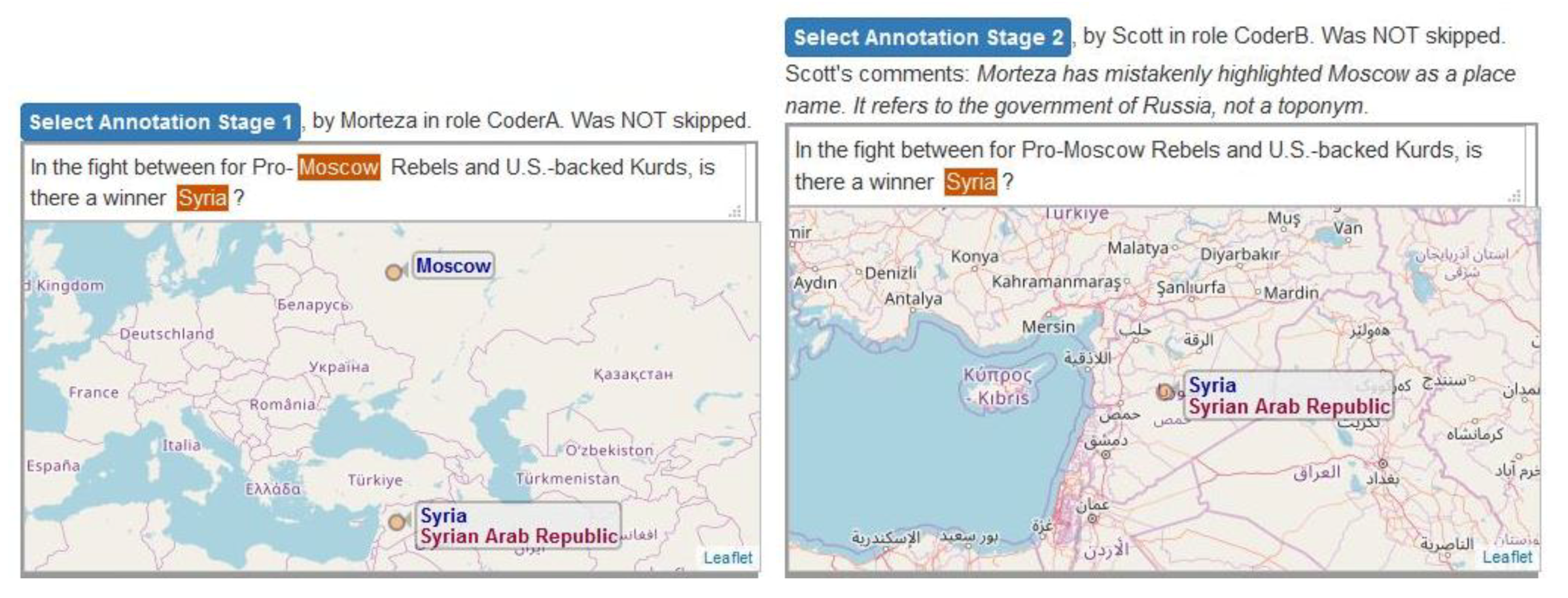
3.2.6. Conversational Mechanism and Annotation Agreement Criteria
3.3. Case Study and Generated Corpus
4. Results
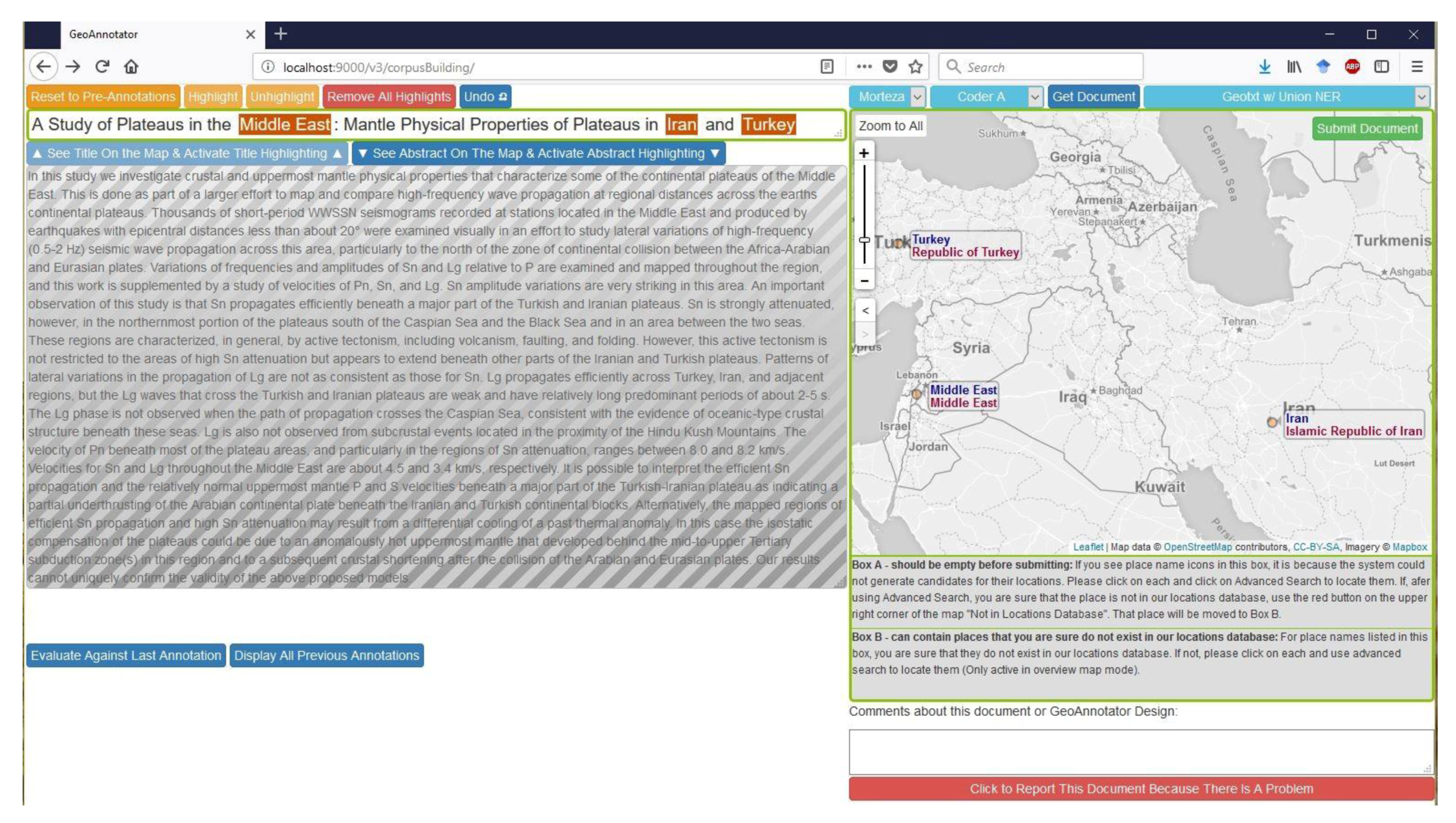
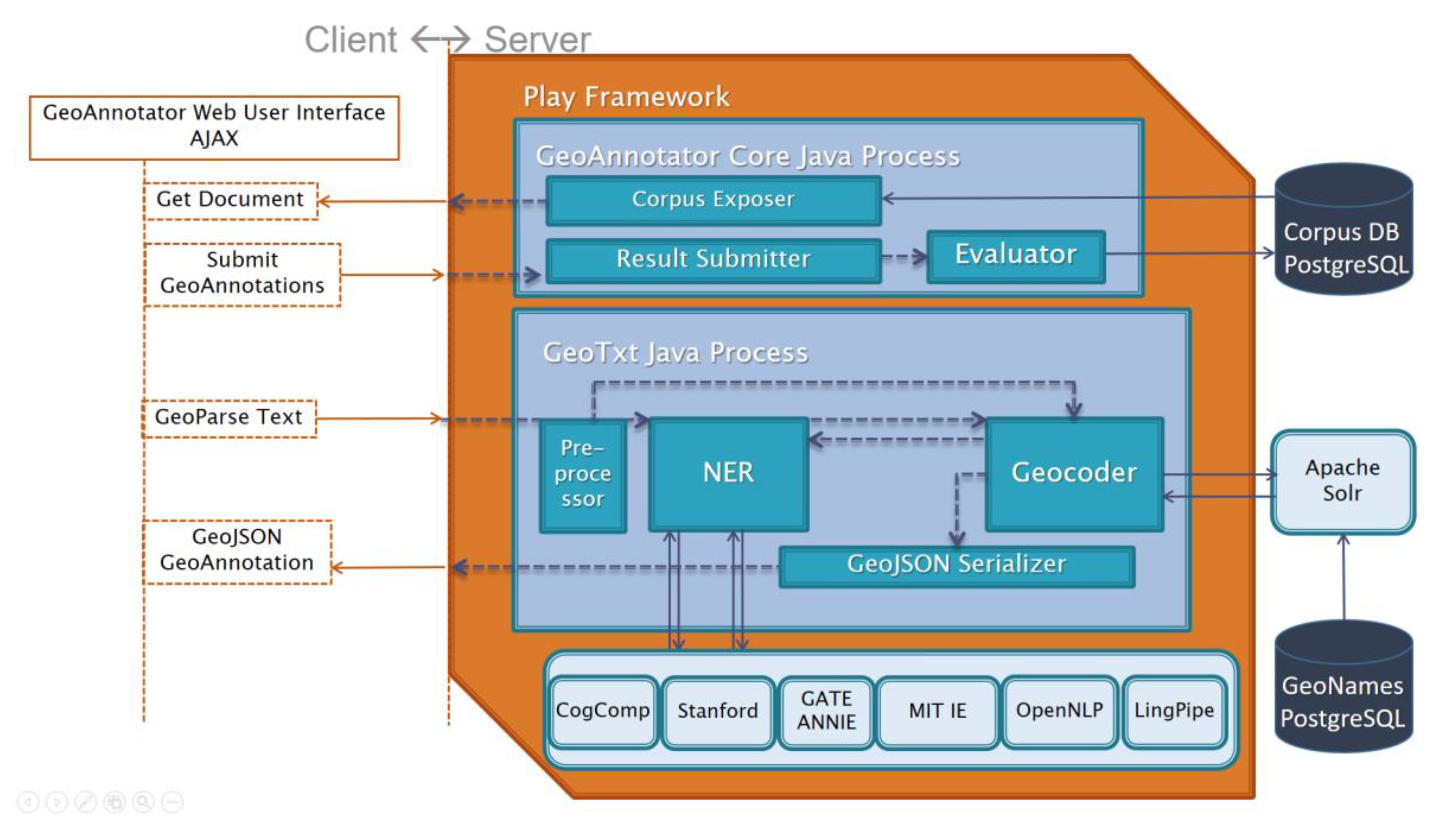
4.1. System Overview
4.2. Architecture
5. Concluding Discussions: Insights from the Iterative Development Process
6. Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Finlayson, M.A. Report on the 2015 NSF Workshop on Unified Annotation Tooling. 2016. Available online: https://dspace.mit.edu/handle/1721.1/105270 (accessed on 17 March 2019).
- Lieberman, M.D.; Samet, H.; Sankaranarayanan, J. Geotagging with local Lexicons to build indexes for textually-specified spatial data. In Proceedings of the 26th International Conference on Data Engineering (ICDE 2010), Long Beach, CA, USA, 1–6 March 2010; pp. 201–212. [Google Scholar]
- Wallgrün, J.O.; Karimzadeh, M.; MacEachren, A.M.; Pezanowski, S. GeoCorpora: Building a corpus to test and train microblog geoparsers. Int. J. Geogr. Inf. Sci. 2018, 32, 1–29. [Google Scholar] [CrossRef]
- Gritta, M.; Pilehvar, M.T.; Limsopatham, N.; Collier, N. What’s missing in geographical parsing? Lang. Resour. Eval. 2018, 52, 603–623. [Google Scholar] [CrossRef]
- Leidner, J.L. Toponym Resolution in Text; University of Edinburgh: Edinburgh, UK, 2007. [Google Scholar]
- DeLozier, G.; Wing, B.; Baldridge, J.; Nesbit, S. Creating a novel geolocation corpus from historical texts. In Proceedings of the 10th Linguistic Annotation Workshop Held in Conjunction with ACL 2016 (LAW-X 2016), Berlin, Germany, 11 August 2016. [Google Scholar]
- Acheson, E.; De Sabbata, S.; Purves, R.S. A quantitative analysis of global gazetteers: Patterns of coverage for common feature types. Comput. Environ. Urban Syst. 2017, 64, 309–320. [Google Scholar] [CrossRef] [Green Version]
- Bontcheva, K.; Cunningham, H.; Roberts, I.; Roberts, A.; Tablan, V.; Aswani, N.; Gorrell, G. GATE Teamware: A web-based, collaborative text annotation framework. Lang. Resour. Eval. 2013, 47, 1007–1029. [Google Scholar] [CrossRef]
- Hovy, E.; Marcus, M.; Palmer, M.; Ramshaw, L.; Weischedel, R. OntoNotes: The 90% solution. In Proceedings of the Human Language Technology Conference of the NAACL, Companion, New York, NY, USA, 4–9 June 2006; pp. 57–60. [Google Scholar]
- Kim, J.D.; Ohta, T.; Tateisi, Y.; Tsujii, J. GENIA corpus—A semantically annotated corpus for bio-textmining. Bioinformatics 2003, 19, i180–i182. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.-D.; Ohta, T.; Tsujii, J. Corpus annotation for mining biomedical events from literature. BMC Bioinform. 2008, 9, 10. [Google Scholar] [CrossRef]
- Sabou, M.; Bontcheva, K.; Derczynski, L.; Scharl, A. Corpus Annotation through Crowdsourcing: Towards Best Practice Guidelines. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 859–866. [Google Scholar]
- Cano, C.; Monaghan, T.; Blanco, A.; Wall, D.P.; Peshkin, L. Collaborative text-annotation resource for disease-centered relation extraction from biomedical text. J. Biomed. Inf. 2009, 42, 967–977. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dumitrache, A.; Aroyo, L.; Welty, C.; Sips, R.J.; Levas, A. “Dr. Detective”: Combining gamification techniques and crowdsourcing to create a gold standard in medical text. CEUR Workshop Proc. 2013, 1030, 16–31. [Google Scholar]
- Apostolova, E.; Neilan, S.; An, G.; Tomuro, N.; Lytinen, S. Djangology: A Light-weight Web-based Tool for Distributed Collaborative Text Annotation. In Proceedings of the Seventh conference on International Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010; pp. 3499–3505. [Google Scholar]
- Papazian, F.; Bossy, R.; Nédellec, C. AlvisAE: A collaborative Web text annotation editor for knowledge acquisition. In Proceedings of the Sixth Linguistic Annotation Workshop, Jeju, Korea, 12–13 July 2012; pp. 149–152. [Google Scholar]
- Stenetorp, P.; Pyysalo, S.; Topić, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. BRAT: A Web-based Tool for NLP-assisted Text Annotation. In Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics EACL ’12, Avignon, France, 23–27 April 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 102–107. [Google Scholar]
- Meurs, M.J.; Murphy, C.; Naderi, N.; Morgenstern, I.; Cantu, C.; Semarjit, S.; Butler, G.; Powlowski, J.; Tsang, A.; Witte, R. Towards evaluating the impact of semantic support for curating the fungus scientific literature. CEUR Workshop Proc. 2011, 774, 34–39. [Google Scholar]
- Bontcheva, K.; Derczynski, L.; Roberts, I. Crowdsourcing named entity recognition and entity linking corpora. In Handbook of Linguistic Annotation; Springer: Berlin, Germany, 2014; pp. 1–18. [Google Scholar]
- Chinchor, N.; Sundheim, B. MUC-5 evaluation metrics. In Proceedings of the the 5th Conference on Message Understanding, Baltimore, Maryland, 25–27 August 1993; pp. 69–78. [Google Scholar]
- Tjong Kim Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-independent Named Entity Recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003—Volume 4 CONLL ’03, Edmonton, AB, Canada, 27 May 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; pp. 142–147. [Google Scholar]
- Ritter, A.; Clark, S.; Mausam; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1524–1534. [Google Scholar]
- Mani, I.; Hitzeman, J.; Richer, J.; Harris, D.; Quimby, R.; Wellner, B. SpatialML: Annotation Scheme, Corpora, and Tools. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2008, Marrakech, Morocco, 26 May—1 June 2008. [Google Scholar]
- Ju, Y.; Adams, B.; Janowicz, K.; Hu, Y.; Yan, B.; McKenzie, G. Things and strings: Improving place name disambiguation from short texts by combining entity Co-occurrence with topic modeling. Lecture Notes Comput. Sci. 2016, 10024 LNAI, 353–367. [Google Scholar]
- Leetaru, K.H. Fulltext Geocoding Versus Spatial Metadata for Large Text Archives: Towards a Geographically Enriched Wikipedia. D-Lib Mag. 2012, 18, 5. [Google Scholar] [CrossRef]
- Alex, B.; Byrne, K.; Grover, C.; Tobin, R. A Web-based Geo-resolution Annotation and Evaluation Tool. In Proceedings of the LAW VIII—The 8th Linguistic Annotation Workshop, Dublin, Ireland, 23–24 August 2014; pp. 59–63. [Google Scholar]
- The War of the Rebellion: Original Records of the Civil War. Available online: http://ehistory.osu.edu/books/official-records (accessed on 1 January 2018).
- Karimzadeh, M. Performance Evaluation Measures for Toponym Resolution. In Proceedings of the 10th Workshop on Geographic Information Retrieval, GIR ’16, Burlingame, CA, USA, 31 October 2016; ACM: New York, NY, USA, 2016; pp. 8:1–8:2. [Google Scholar]
- Gritta, M.; Pilehvar, M.T.; Limsopatham, N.; Collier, N. Vancouver Welcomes You! Minimalist Location Metonymy Resolution. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July 2017; pp. 1248–1259. [Google Scholar]
- Speck, R.; Ngonga Ngomo, A.-C. Ensemble Learning for Named Entity Recognition. In Proceedings of the International Semantic Web Conference, Riva del Garda, Italy, 19–23 October 2014; Mika, P., Tudorache, T., Bernstein, A., Welty, C., Knoblock, C., Vrandečić, D., Groth, P., Noy, N., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 519–534. [Google Scholar]
- Mackay, H.; Carne, C.; Beynon-Davies, P.; Tudhope, D. Reconfiguring the User: Using Rapid Application Development. Soc. Stud. Sci. 2000, 30, 737–757. [Google Scholar] [CrossRef]
- Lindsay, C. From the shadows: Users as designers, producers, marketers, distributors, and technical support. In How Users Matter: The Co-construction of Users and Technologies; MIT Press: Cambridge, MA, USA, 2003; pp. 29–50. [Google Scholar]
- Fleischmann, K.R. Do-it-yourself information technology: Role hybridization and the design-use interface. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 87–95. [Google Scholar] [CrossRef]
- Park, J.; Boland, R. Identifying a Dynamic Interaction Model: A View from the Designer-User Interactions. In Proceedings of the 18th International Conference on Engineering Design (ICED 11), Copenhagen, Denmark, 15–18 August 2011; pp. 426–432. [Google Scholar]
- Karimzadeh, M.; Pezanowski, S.; Wallgrün, J.O.; MacEachren, A.M.; Wallgrün, J.O. GeoTxt: A scalable geoparsing system for unstructured text geolocation. TransGis 2019, 23, 118–136. [Google Scholar] [CrossRef]
- Ritter, F.E.; Baxter, G.D.; Churchill, E.F. User-Centered Systems Design: A Brief History. In Foundations for Designing User-Centered Systems: What System Designers Need to Know about People; Springer: London, UK, 2014; pp. 33–54. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating non-local information into information extraction systems by Gibbs sampling. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, Michigan, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Cunningham, H. GATE, a general architecture for text engineering. Comput. Hum. 2002, 36, 223–254. [Google Scholar] [CrossRef]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning, Boulder, Colorado, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Williamson, J. What Washington Means by Policy Reform. In Latin American Adjustment: How Much Has Happened? Institute for International Economics: Washington, DC, USA, 1990; pp. 1–10. [Google Scholar]
- Buja, A.; Cook, D.; Scientist, D.F.S.R. Interactive High-Dimensional Data Visualization. J. Comput. Graph. Stat. 1996, 5, 78–99. [Google Scholar] [CrossRef] [Green Version]
- GeoJSON FeatureCollection. Available online: https://tools.ietf.org/html/rfc7946#page-12 (accessed on 1 January 2018).
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Melo, F.; Martins, B. Automated Geocoding of Textual Documents: A Survey of Current Approaches. TransGis 2017, 21, 3–38. [Google Scholar] [CrossRef]
- Kordjamshidi, P.; Van Otterlo, M.; Moens, M.-F. Spatial Role Labeling Annotation Scheme. In Proceedings of the Seventh Conference on International Language Resources and Evaluation (LREC’10), Valletta, Malta, 19–21 May 2010; pp. 413–420. [Google Scholar]
- Wallgrün, J.O.; Klippel, A.; Karimzadeh, M. Towards Contextualized Models of Spatial Relations. In Proceedings of the 9th Workshop on Geographic Information Retrieval GIR ’15, Paris, France, 26–27 November 2015; ACM: New York, NY, USA, 2015; pp. 14:1–14:2. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tag Name | Application | Example | Notes |
|---|---|---|---|
| Uncertain semantics | When it is unclear if a name is in fact a place name, attribute, reference to an organization, or a boundary case with mixed word sense. The uncertain semantics tag enables corpus end users to include, exclude or isolate such cases for different research studies. | The rising violence by Rikers Island correction officers… | Rikers Island can be interpreted to refer to the island or the Rikers Island Correctional Center Facility (both of which are “places”) or to the prison as an organization, as well as a noun adjunct modifying “correction officers”. |
| Vague boundaries | When the place name refers to an area or region whose boundaries are not clearly agreed upon. | Temperatures in Hudson Valley… | Sources indicate that there are differences in opinion on the exact bounds of Hudson Valley. |
| Not in gazetteer | When the place name in text does not exist in the gazetteer yet, or is so vaguely defined that addition to gazetteer is not justified. | Headed to the West Coast. | Explained in more detail in the following paragraph. |
| Overlapping ambiguous (always including human annotator assigned surrogates list, enforced by the system) | When human annotators cannot confidently determine which one of multiple candidate toponyms that overlap in space is being referred to. GeoAnnotator allows users to assign multiple toponyms (i.e., surrogate toponyms) to the place name, and apply the “overlapping ambiguous” tag to indicate that these toponyms can interchangeably be used as the resolved toponym for that mention of Lagos (or any other similar situation). | A man just died of Ebola in Lagos. | GeoNames lists three toponyms for “Lagos” in Nigeria: Lagos State (administrative region), Lagos (section of populated place—the city that is within Lagos State) and Lagos Island (within Lagos City, which is within Lagos State). These entities have overlapping geospatial positions and all can be correct assignments. |
| Non-overlapping ambiguous (with surrogates list) | When human annotators cannot determine which one of multiple candidate toponyms that do not overlap in space is being referred to. Users can assign a surrogate list of potential candidate toponyms to a place name and apply the “non-overlapping ambiguous” tag to indicate that these toponyms can interchangeably be used. | Washington’s changing demographics. | Washington may refer to “Washington D.C.” or “Washington State”, for example. These toponyms do not overlap and it is unclear which one the text author originally meant to refer to. |
| Non-overlapping ambiguous (without surrogates list) | When human annotators cannot determine which one of numerous candidate toponyms (that do not overlap in space) is being referred to, and there are too many potential candidates to assign as surrogates. Users can select a potential toponym and apply the “non-overlapping ambiguous” tag without providing a surrogates list (making such cases distinguishable to corpus users, who may exclude or use the cases for special studies). | Springfield feels like spring! | Without additional context, Springfield may be referring to numerous toponyms in different geographic regions. |
| Annotator | Number of Submissions | Including Comments |
|---|---|---|
| Faculty member | 2515 | 1442 |
| Graduate student | 1698 | 830 |
| Faculty member | 883 | 442 |
| Undergraduate student | 156 | 72 |
| Undergraduate student | 303 | 179 |
| X | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|
| Count | 1335 | 576 | 219 | 48 | 7 |
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | Mean | Median | Mode |
|---|---|---|---|---|---|---|---|---|---|---|
| Profile location | 676 | 573 | 66 | 11 | 1 | 0 | 0 | 1.56 | 1 | 1 |
| Tweet text | 1491 | 472 | 119 | 29 | 9 | 1 | 1 | 1.40 | 1 | 1 |
| Place/Toponym Type | Tweet Profile Location | Tweet Text |
|---|---|---|
| Total place count | 2069 | 2966 |
| Uncertain semantics | 9 | 178 |
| Non-overlapping ambiguous | 34 | 20 |
| Overlapping ambiguous | 60 | 91 |
| Vague (excluding representative) | 14 | 52 |
| Representative-non-vague | 28 | 150 |
| Representative-vague | 38 | 75 |
| GeoAnnotator | TAME | WOTR GeoAnnotate | Edinburgh Geo-annotator | |
|---|---|---|---|---|
| Gazetteer | GeoNames | GNS/GNIS | N/A | GeoNames |
| Output | GeoJSON | Toponym Resolution Markup Language | JavaScript Object Notation (JSON) | Not reported |
| Map view | ✓ | ✕ | ✓ | ✓ |
| Drawing custom geometries | ✕ | ✕ | ✓ | ✕ |
| Assigning toponyms to place names | ✓ | ✓ | ✕ | ✓ |
| Cross-document (pre)annotation | ✓ | ✕ | ✕ | ✕ |
| Simultaneous named entity and toponym manipulation | ✓ | ✕ | ✕ | ✕ |
| Special tags | ✓ | ✕ | ✕ | ✕ |
| Non-place name entities support | ✕ | ✕ | ✓ | ✕ |
| Multi-annotator Support | ✓ | ✕ | ✕ | ✕ |
| Multi-toponym assignment to a single name | ✓ | ✕ | ✕ | ✕ |
| Integrated NER for pre-annotation | ✓ | ✕ | ✕ | ✕ |
| Advanced toponym search | ✓ | ✕ | ✕ | ✕ |
| Named entity annotation manipulation | ✓ | ✕ | ✓ | ✕ |
| Document level (geographic focus) annotation | ✓ | ✕ | ✕ | ✕ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karimzadeh, M.; MacEachren, A.M. GeoAnnotator: A Collaborative Semi-Automatic Platform for Constructing Geo-Annotated Text Corpora. ISPRS Int. J. Geo-Inf. 2019, 8, 161. https://doi.org/10.3390/ijgi8040161
Karimzadeh M, MacEachren AM. GeoAnnotator: A Collaborative Semi-Automatic Platform for Constructing Geo-Annotated Text Corpora. ISPRS International Journal of Geo-Information. 2019; 8(4):161. https://doi.org/10.3390/ijgi8040161
Chicago/Turabian StyleKarimzadeh, Morteza, and Alan M. MacEachren. 2019. "GeoAnnotator: A Collaborative Semi-Automatic Platform for Constructing Geo-Annotated Text Corpora" ISPRS International Journal of Geo-Information 8, no. 4: 161. https://doi.org/10.3390/ijgi8040161
APA StyleKarimzadeh, M., & MacEachren, A. M. (2019). GeoAnnotator: A Collaborative Semi-Automatic Platform for Constructing Geo-Annotated Text Corpora. ISPRS International Journal of Geo-Information, 8(4), 161. https://doi.org/10.3390/ijgi8040161