Oil Film Classification Using Deep Learning-Based Hyperspectral Remote Sensing Technology


Abstract
:1. Introduction
2. Methods
2.1. SVM
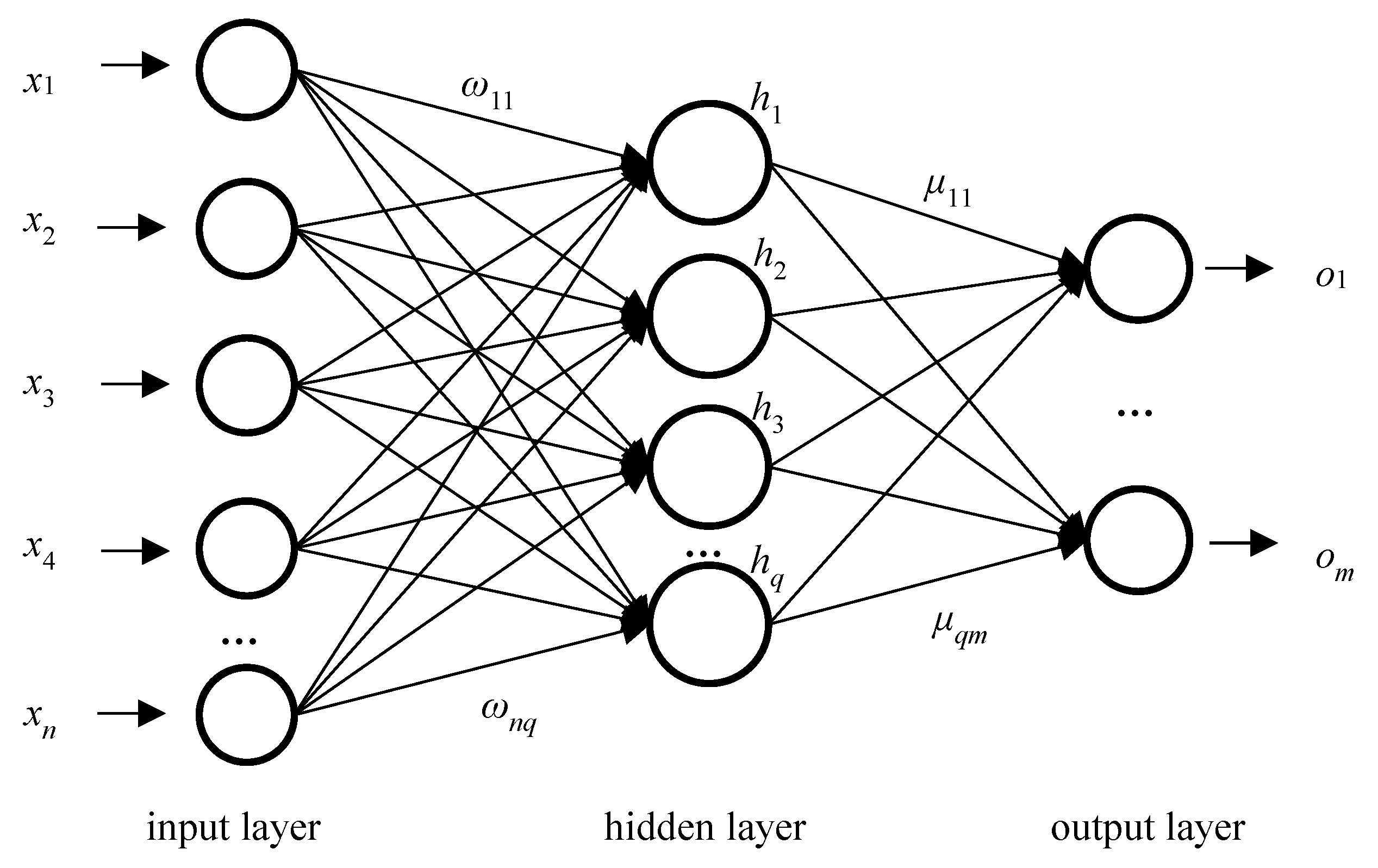
2.2. BP Neural Network
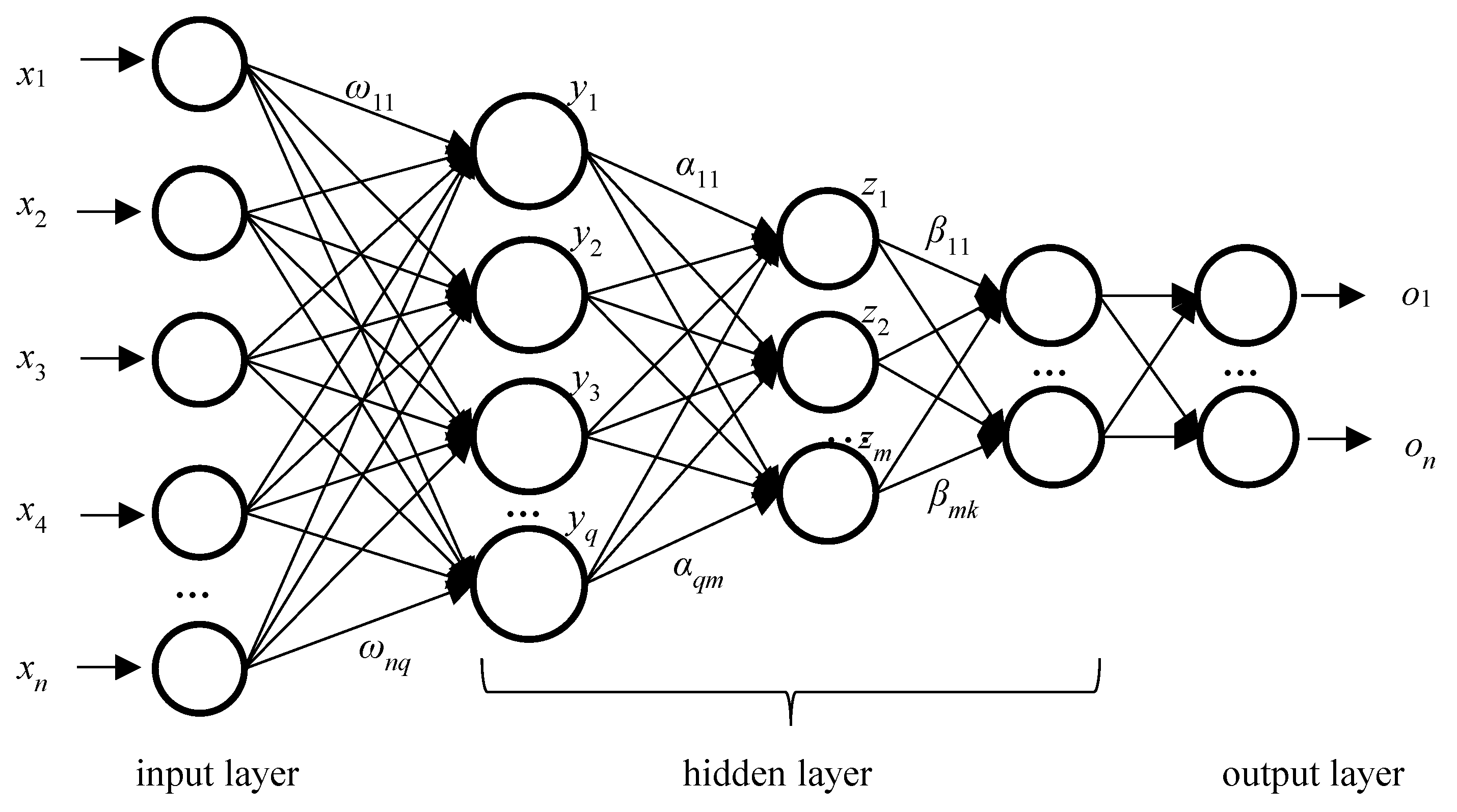
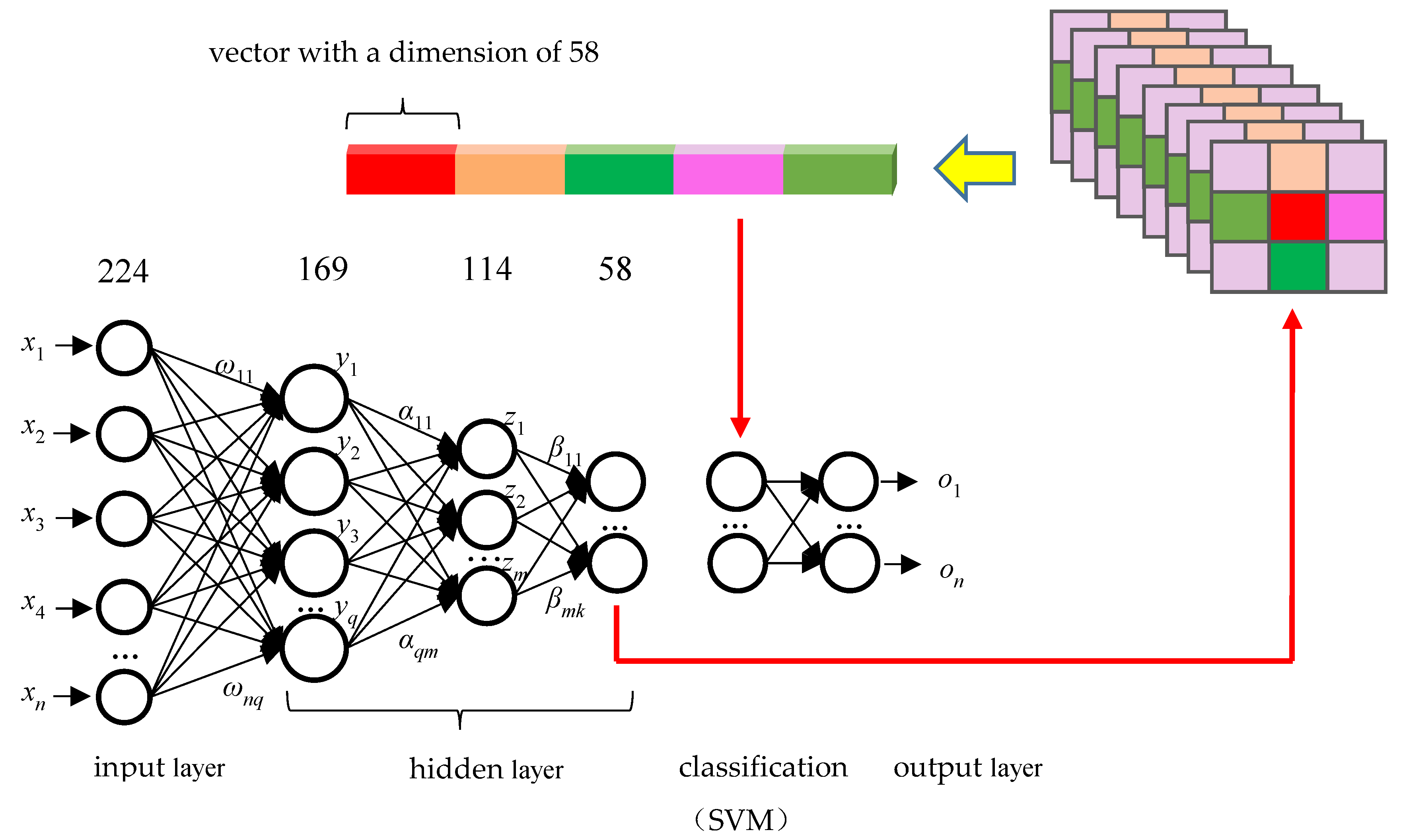
2.3. Neural Network based on Stacked Autoencoders (SAEs)
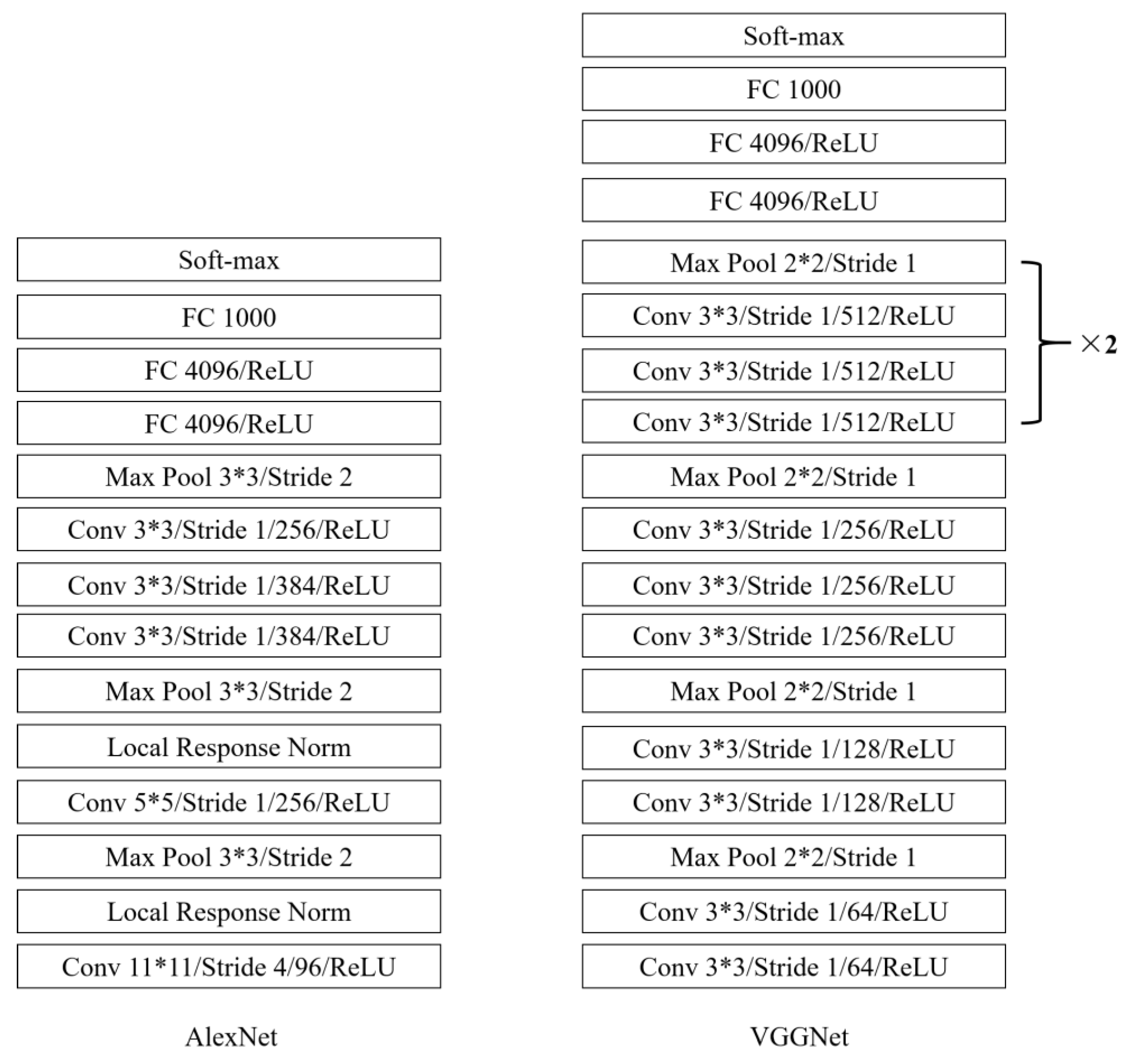
2.4. CNN
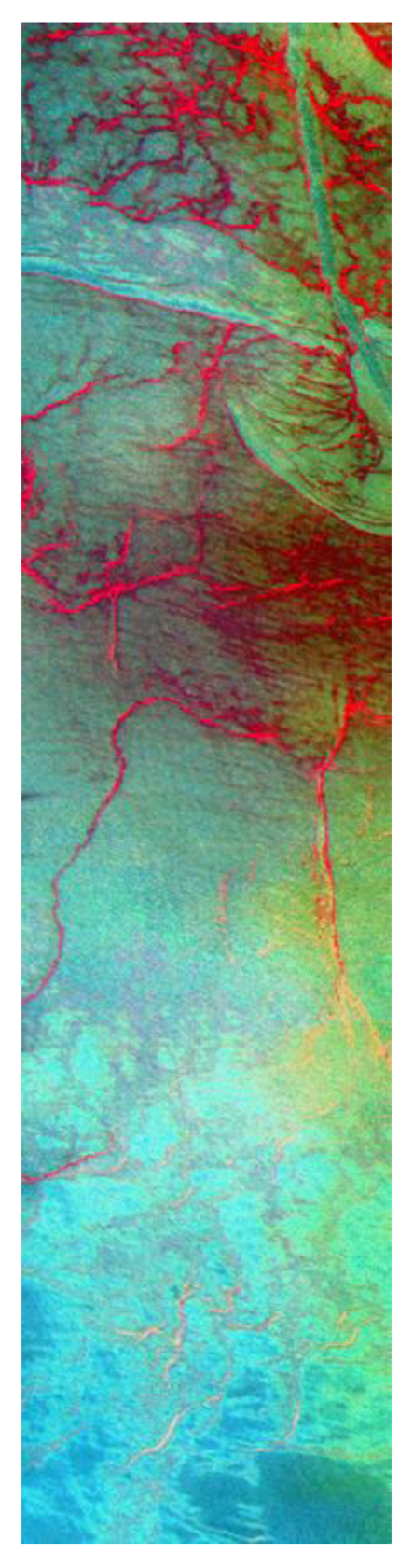
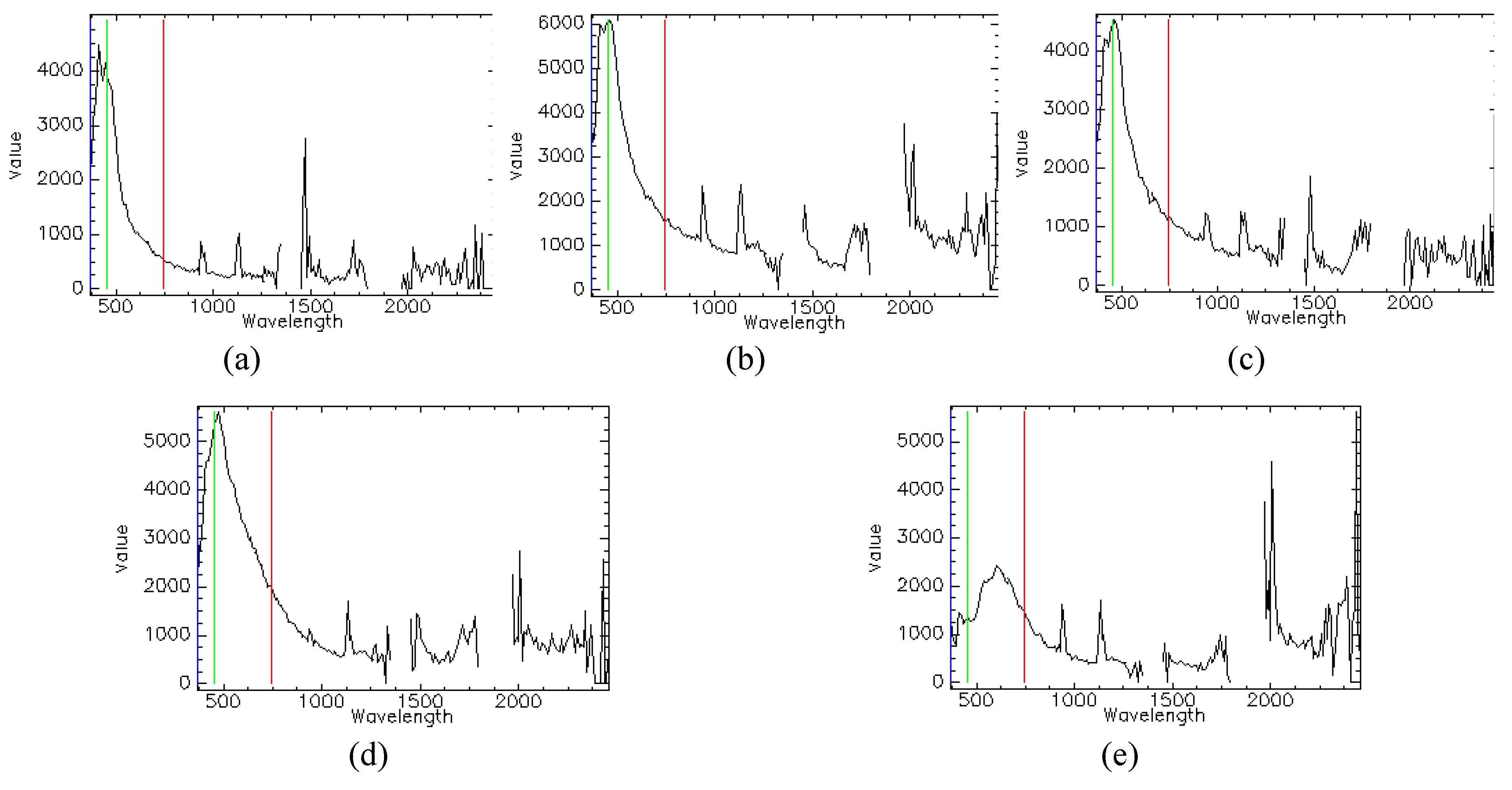
3. Experimental Data Description
4. Oil Film Recognition Model
4.1. Oil Film Recognition Model Based on SVMs
4.2. Oil Film Recognition Model Based on the BP Neural Network
4.3. Improved Oil Film Recognition Model Based on the SAE Network
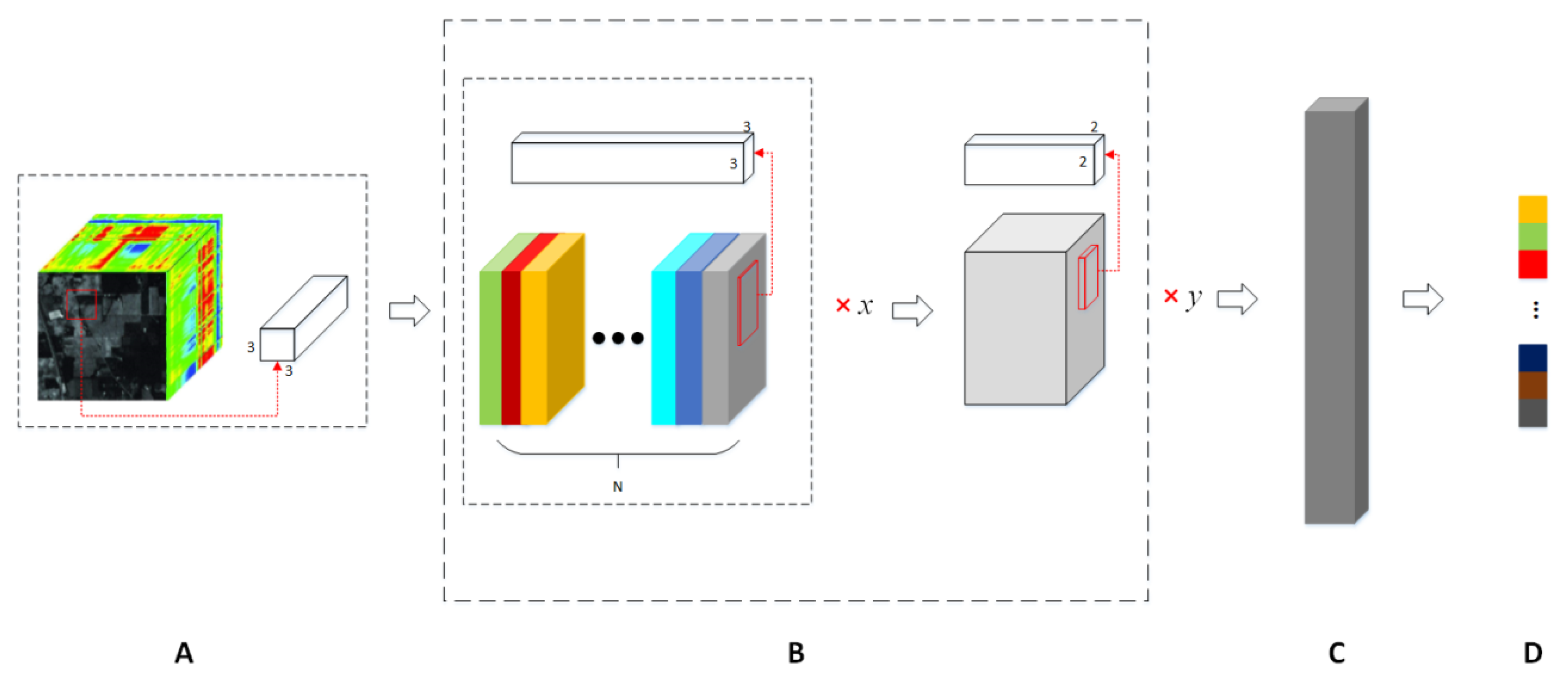
4.4. Oil Film Recognition Model Based on the CNN Model
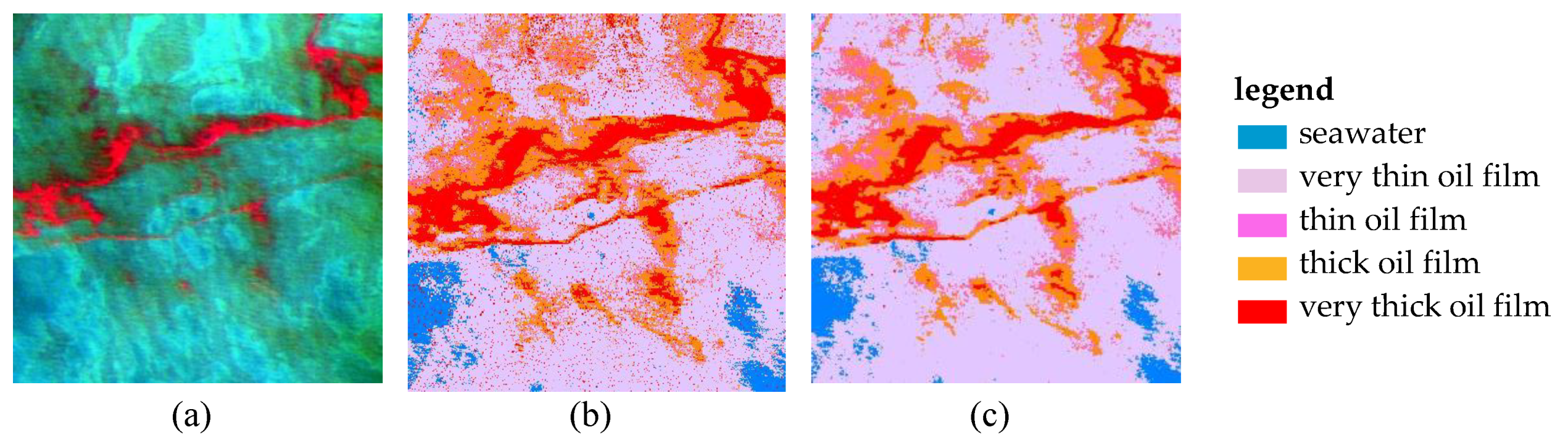
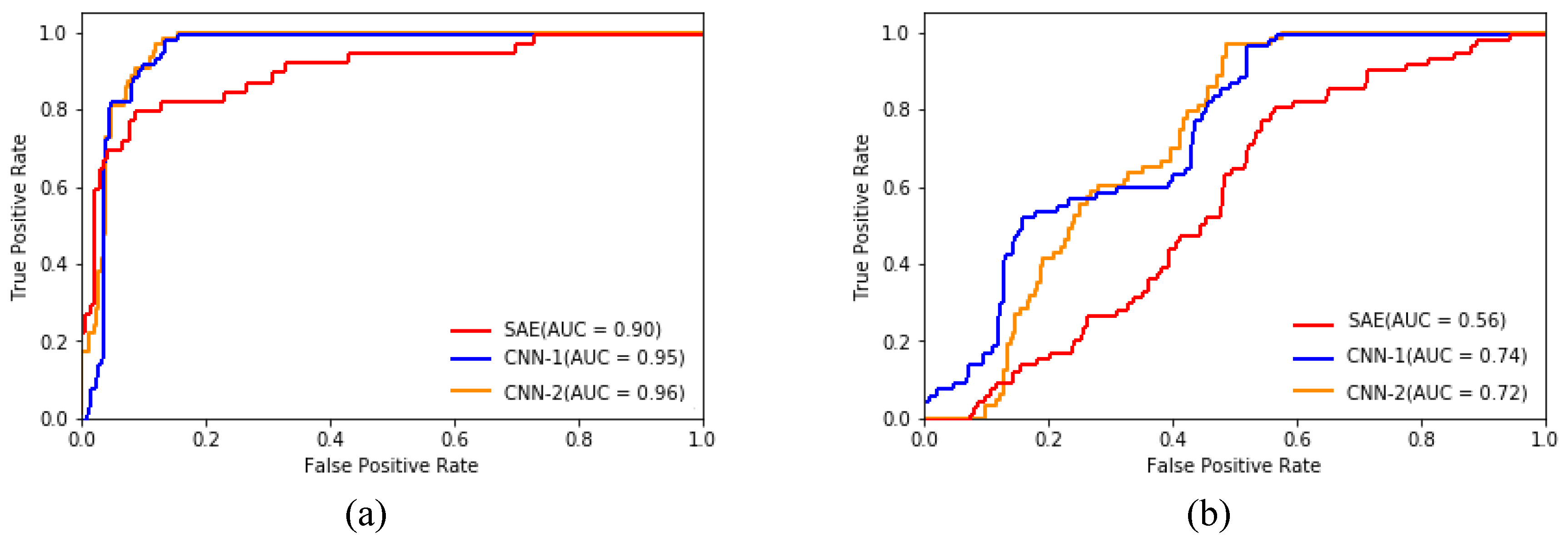
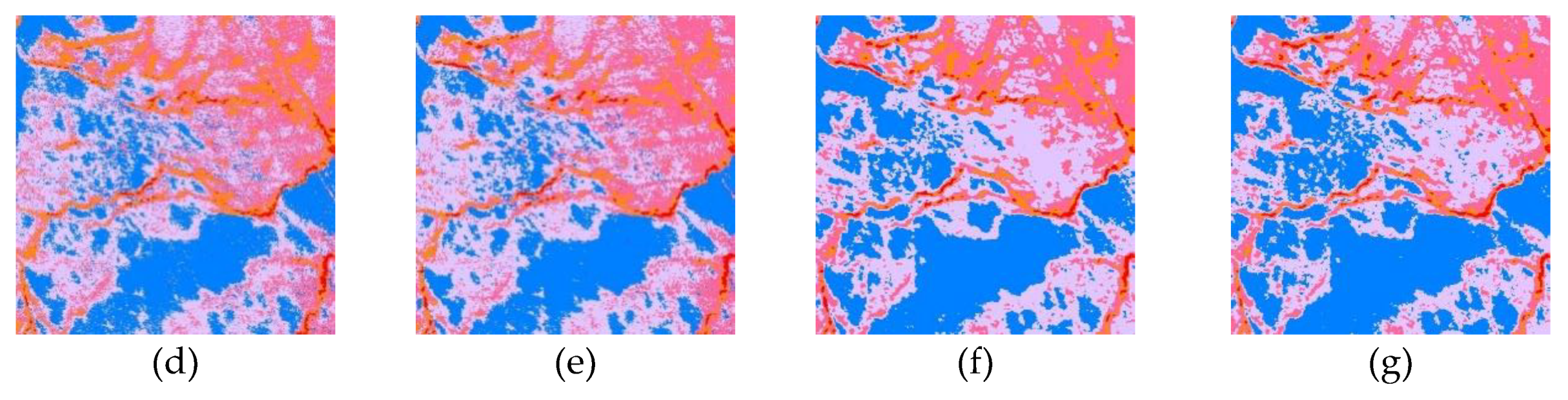
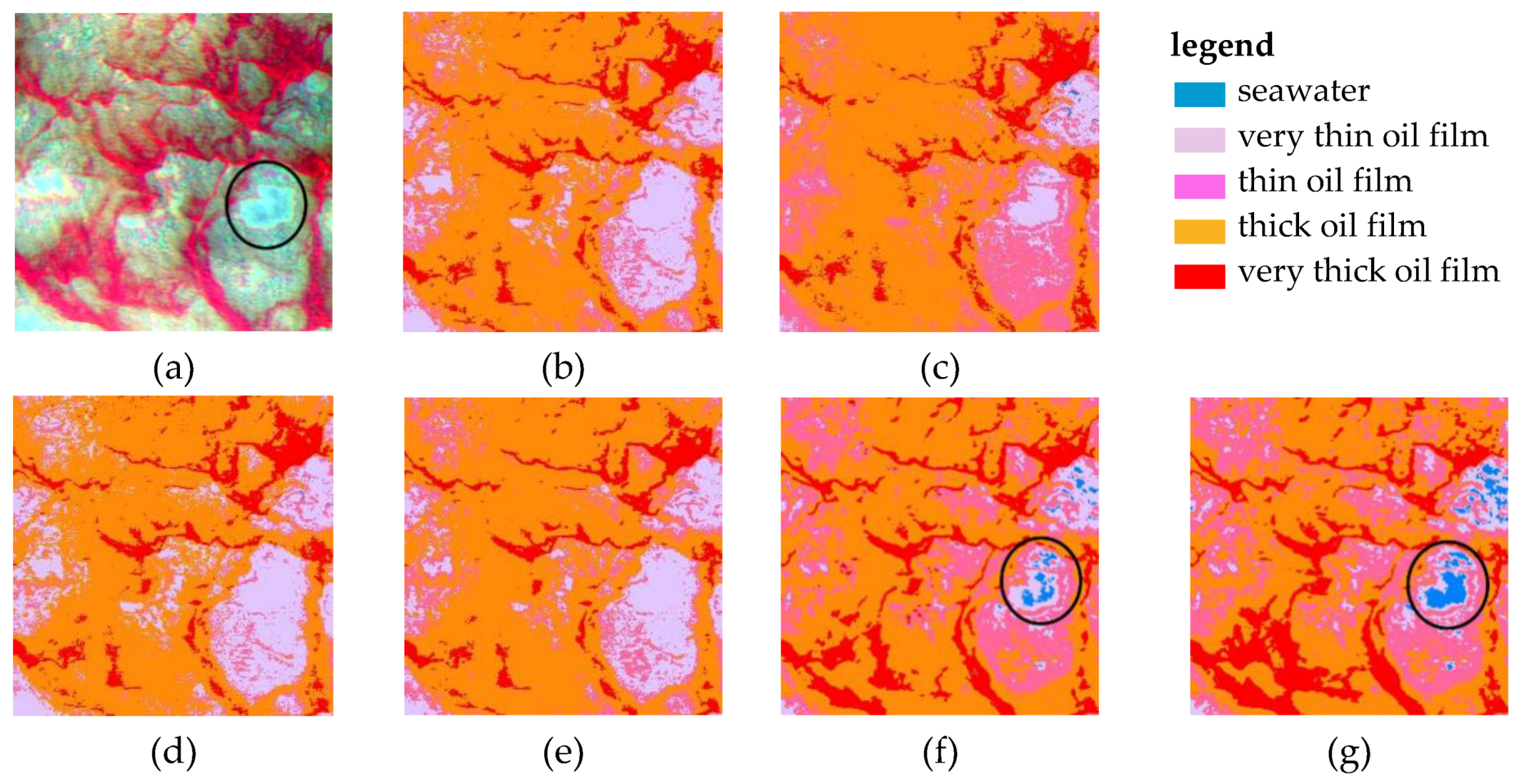
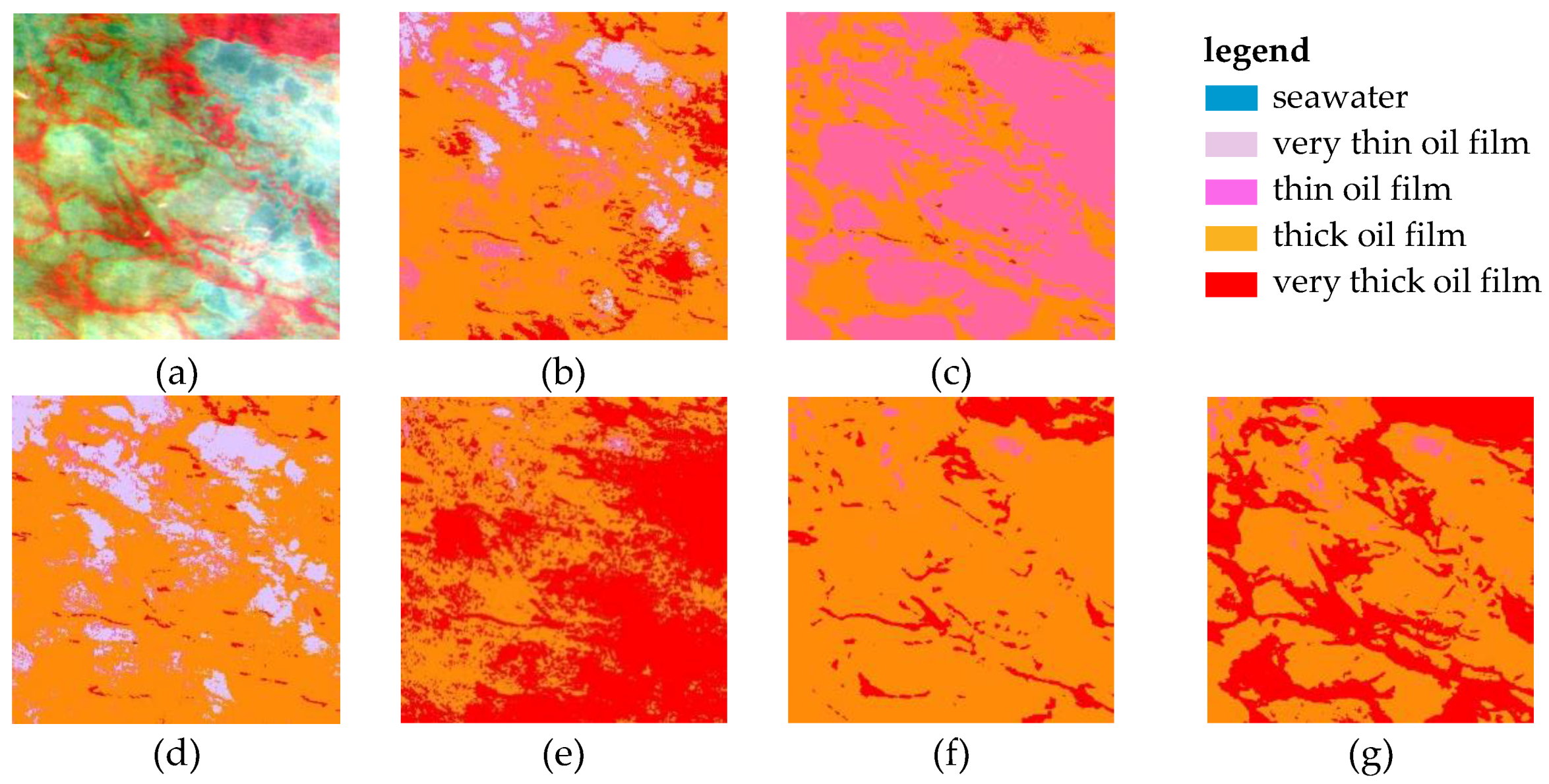
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Du, P.; Xia, J.; Xue, Z.; Tan, K.; Su, H.; Bao, R. Review of hyperspectral remote sensing image classification. J. Remote Sens. 2016, 20, 236–256. [Google Scholar]
- Sun, Q.; Liu, X.; Fu, M. Classification of hyperspectral image based on principal component analysis and deep learning. In Proceedings of the 7th IEEE International Conference on Electronics Information and Emergency Communication (ICEIEC), Macau, China, 21–23 July 2017. [Google Scholar]
- Zhang, B. Advancement of hyperspectral image processing and information extraction. J. Remote Sens. 2016, 20, 1062–1090. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Going Deeper with Contextual CNN for Hyperspectral Image Classification. Ieee Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [PubMed]
- Shi, C.; Pun, C.M. 3D multi-resolution wavelet convolutional neural networks for hyperspectral image classification. Inf. Sci. 2017, 420, 49–65. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Bruzzone, L. Kernel-based methods for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1351–1362. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Gamba, P.; Bioucas-Dias, M.J.; Zhang, L.; Benediktsson, A.J.; Plaza, A. Multiple feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1592–1606. [Google Scholar] [CrossRef]
- Minaee, S.; Wang, Y. Palmprint recognition using deep scattering convolutional network. arXiv, 2016; arXiv:1603.09027. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Salakhutdinov, R.; Hinton, G. An Efficient Learning Procedure for Deep Boltzmann Machines. Neural Comput. 2012, 24, 1967–2006. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H.; Montreal, U. Greedy layer-wise training of deep networks. Adv. Neural Inf. Process. Syst. 2007, 19, 153–160. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. Momentum 2010, 9, 926–947. [Google Scholar]
- Lecun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W. Deep Auto-Encoder Network for Hyperspectral Image Unmixing. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGASS), Valencia, Spain, 22–27 July 2018. [Google Scholar]
- Minaee, S.; Wang, Y.; Aygar, A.; Chung, S.; Wang, X.; Lui, Y.W.; Fieremans, E.; Flanagan, S.; Rath, J. Mtbi identification from diffusion mr images using bag of adversarial visual features. MTBI Identification from Diffusion MR Images Using Bag of Adversarial Visual Features. arXiv, 2018; arXiv:1806.10419. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv, 2015; arXiv:1511.05644. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 6. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2175–2184. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar]
- Liu, B. Extraction and Analysis of Oil Film on Water Using Hyperspectral Characteristics. Ph.D. Dissertation, Dalian Maritime University, Dalian, China, 2013. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Number of Hidden Layers and Nodes of Different Layers | OA (Training Sets) | OA (Validation Sets) | Kappa (Validation Sets) |
|---|---|---|---|---|
| Support vector machine (SVM) (equal-ratio SAE network) | 1(224-112) | 83% | 68% | 0.599 |
| 2(224-112-56) | 81% | 68% | 0.595 | |
| 3(224-112-56-28) | 74% | 67% | 0.583 | |
| Logistic (equal-ratio SAE network) | 1(224-112) | 79% | 64% | 0.548 |
| 2(224-112-56) | 80% | 60% | 0.503 | |
| 3(224-112-56-28) | 78% | 64% | 0.551 | |
| SVM (equal-difference SAE network) | 1(224-169) | 84% | 71% | 0.635 |
| 2(224-169-114) | 81% | 70% | 0.631 | |
| 3(224-169-114-58) | 78% | 68% | 0.603 | |
| Logistic (equal-difference SAE network) | 1(224-169) | 79% | 57% | 0.460 |
| 2(224-169-114) | 78% | 58% | 0.476 | |
| 3(224-169-114-58) | 78% | 63% | 0.540 |
| Number of Hidden Layers and Nodes at Each Layer | Predicted Number of Samples | Number of Correctly Predicted Samples | Actual Number of Thick Oil Film Samples | Precision Ratio | Recall Ratio |
|---|---|---|---|---|---|
| 1(244–169) | 45 | 45 | 63 | 100% | 71.4% |
| 3(224–169–114–58) | 71 | 54 | 63 | 76.1% | 85.7% |
| Input | Conv1–1 | Conv1–2 | Pool1 | Conv2–1 | Conv2–2 | Pool2 | FC | ||
|---|---|---|---|---|---|---|---|---|---|
| CNN-1 | 224 | 224–256 | NA | 256–256 | 256–512 | NA | 512 | 512–1024 | |
| CNN-2 | 224 | 224–256 | 224–256 | 256–256 | 256–512 | 512–512 | 512 | 512–1024 | |
| Model | OA | Kappa |
|---|---|---|
| CNN-1 | 78% | 0.729 |
| CNN-2 | 77% | 0.709 |
| the SAE model combining spectral and spatial information | 73% | 0.671 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Li, Y.; Zhang, Q.; Liu, B. Oil Film Classification Using Deep Learning-Based Hyperspectral Remote Sensing Technology. ISPRS Int. J. Geo-Inf. 2019, 8, 181. https://doi.org/10.3390/ijgi8040181
Zhu X, Li Y, Zhang Q, Liu B. Oil Film Classification Using Deep Learning-Based Hyperspectral Remote Sensing Technology. ISPRS International Journal of Geo-Information. 2019; 8(4):181. https://doi.org/10.3390/ijgi8040181
Chicago/Turabian StyleZhu, Xueyuan, Ying Li, Qiang Zhang, and Bingxin Liu. 2019. "Oil Film Classification Using Deep Learning-Based Hyperspectral Remote Sensing Technology" ISPRS International Journal of Geo-Information 8, no. 4: 181. https://doi.org/10.3390/ijgi8040181
APA StyleZhu, X., Li, Y., Zhang, Q., & Liu, B. (2019). Oil Film Classification Using Deep Learning-Based Hyperspectral Remote Sensing Technology. ISPRS International Journal of Geo-Information, 8(4), 181. https://doi.org/10.3390/ijgi8040181