Anisotropic Diffusion for Improved Crime Prediction in Urban China

Abstract
:1. Introduction
2. Related Work
2.1. Near-Repeat Theory
2.2. Environmental Criminology
2.3. Crime Prediction
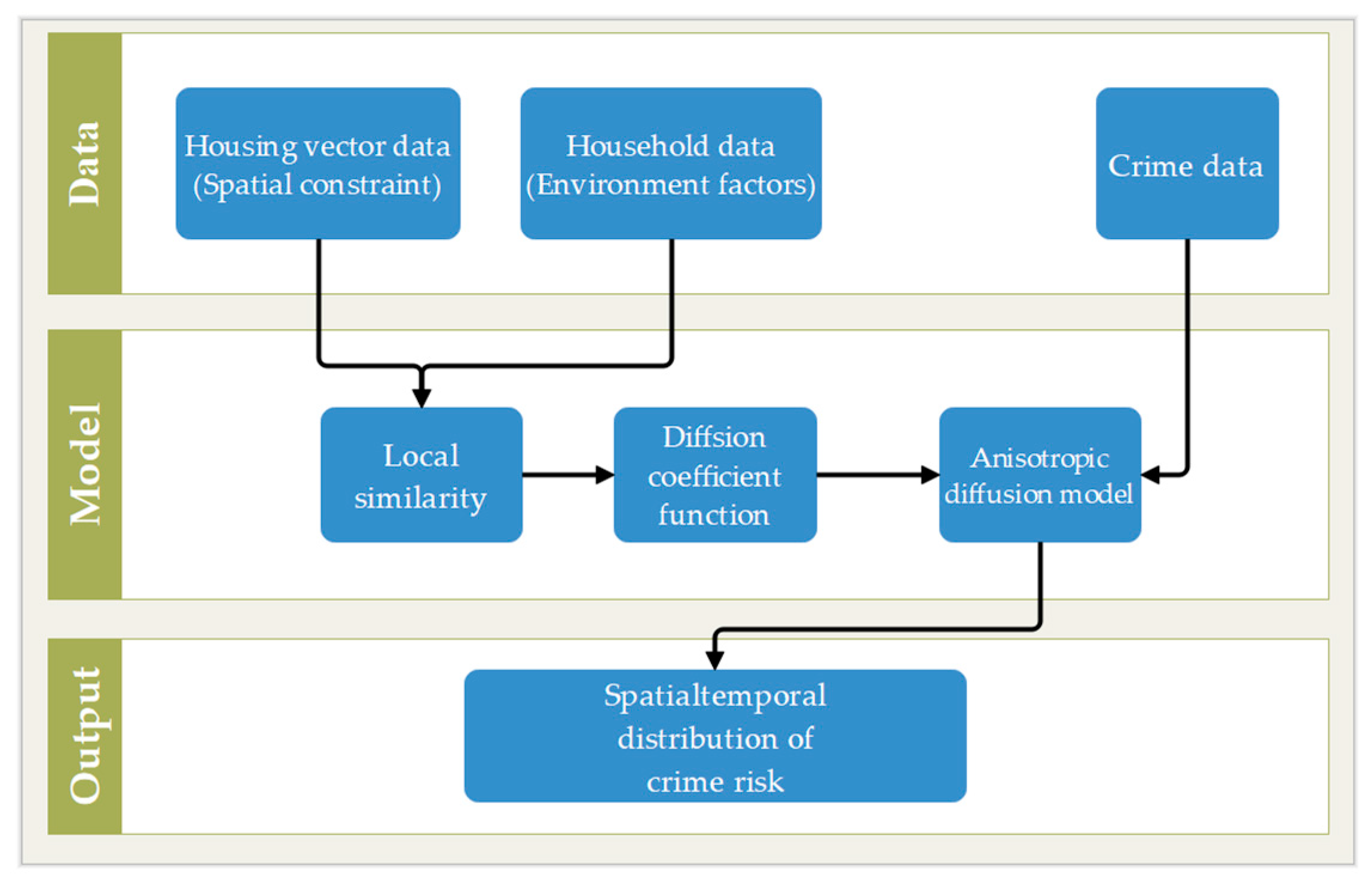
3. Data and Methods
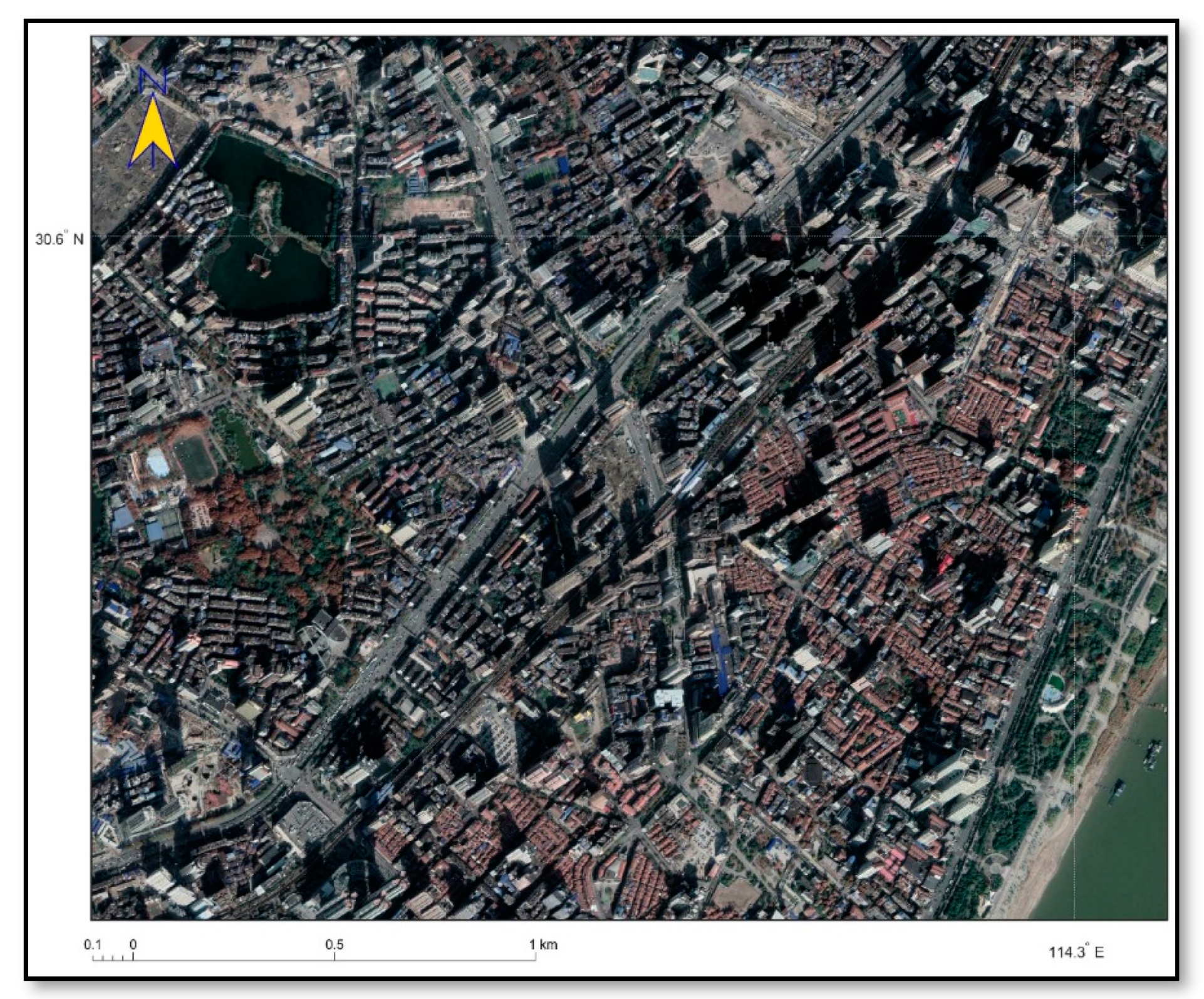
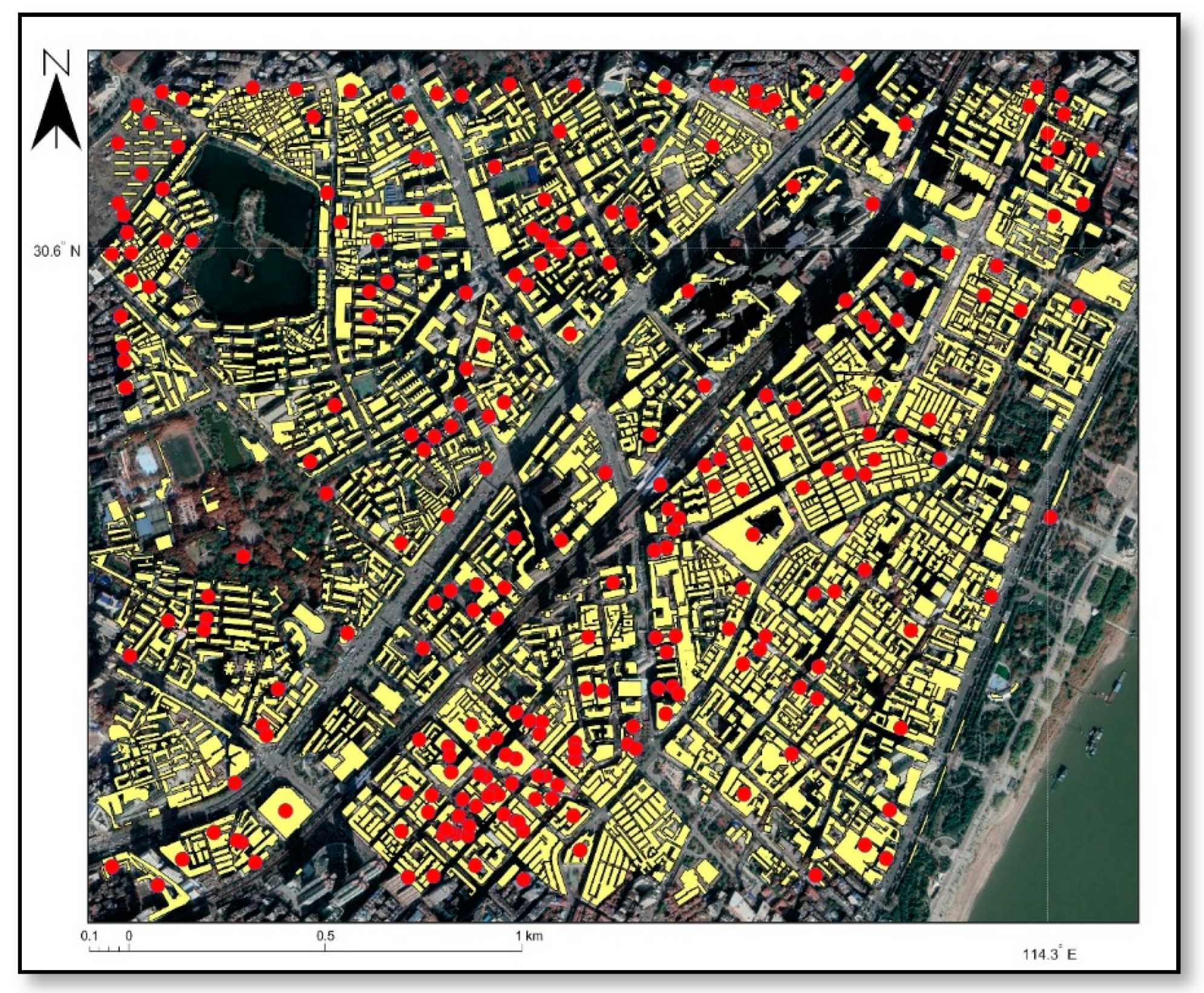
3.1. Study Area and Data
3.2. Similarity Measurement of Environmental Factors
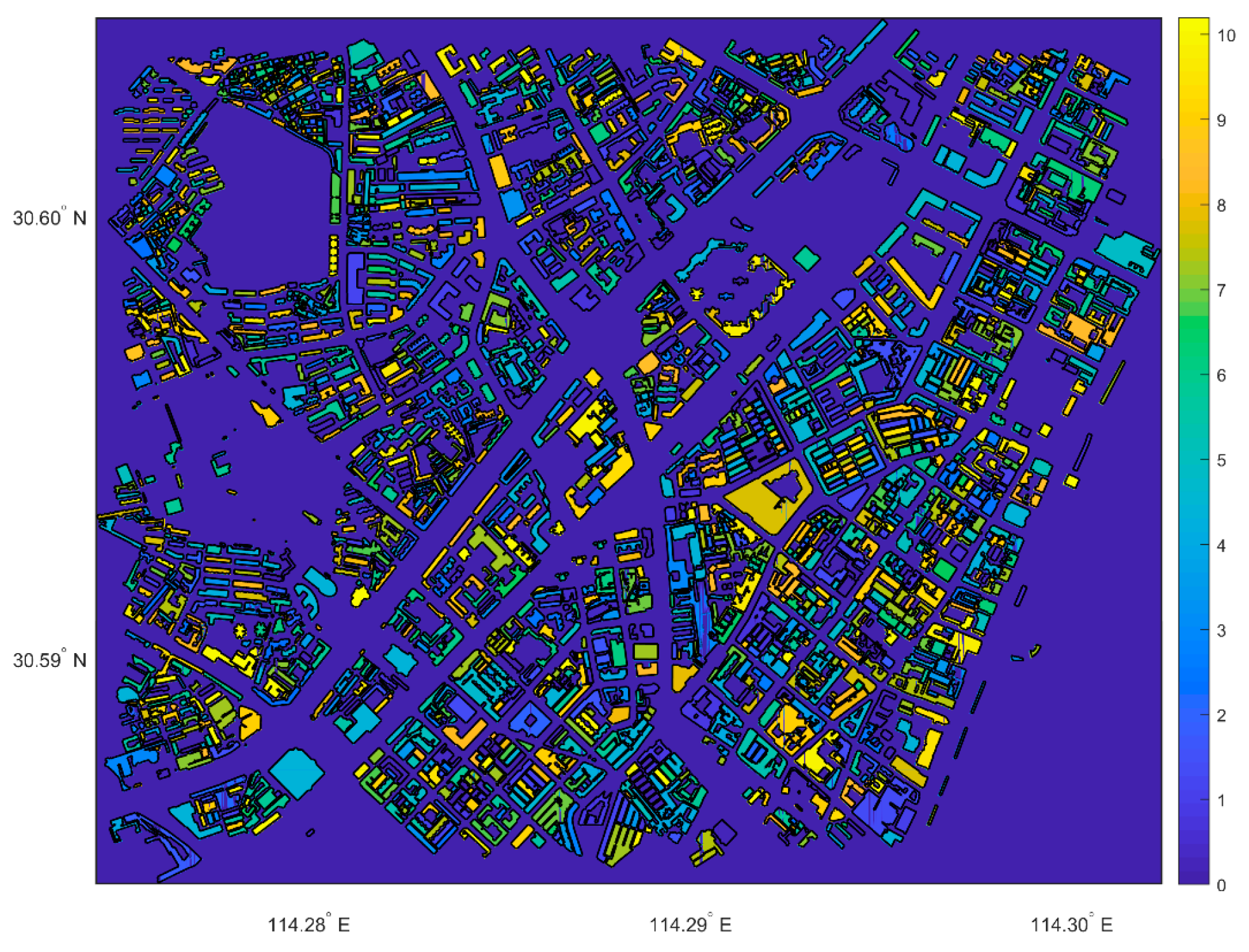
3.2.1. Spatial Distribution of Environmental Factors
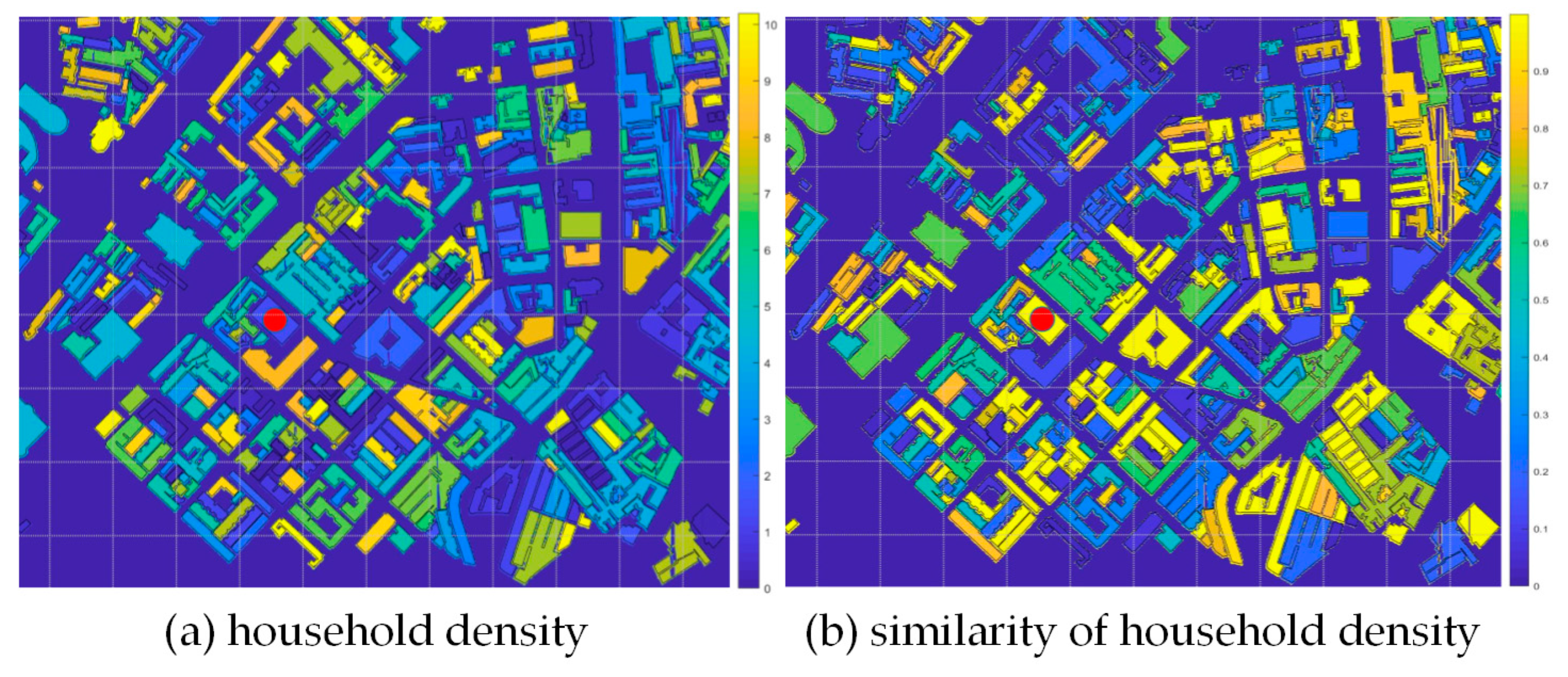
3.2.2. Similarity Measure
3.3. Diffusion Model
3.3.1. Diffusion Coefficient Function
3.3.2. Proposed AnisDM
4. Experiment, Results and Discussion
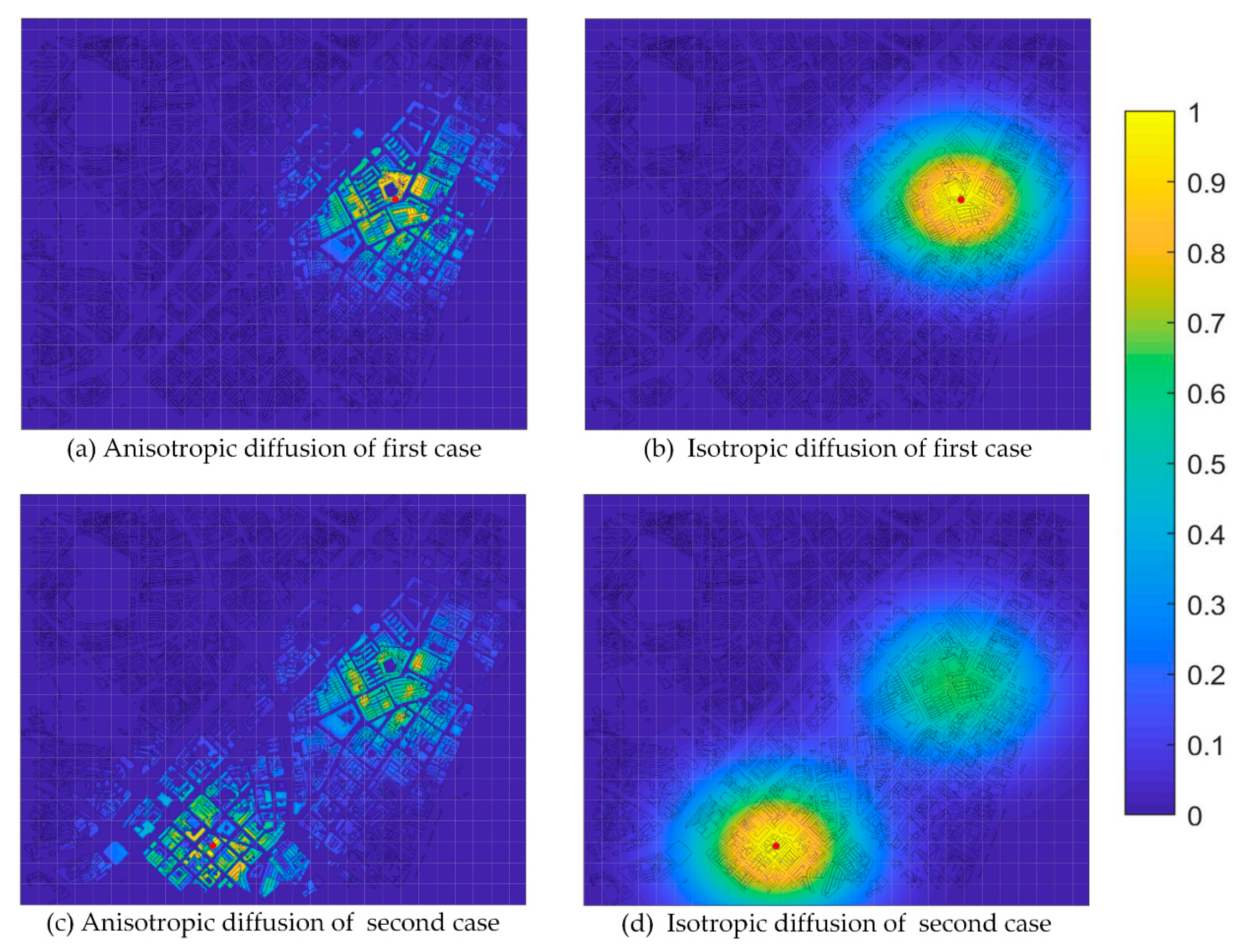
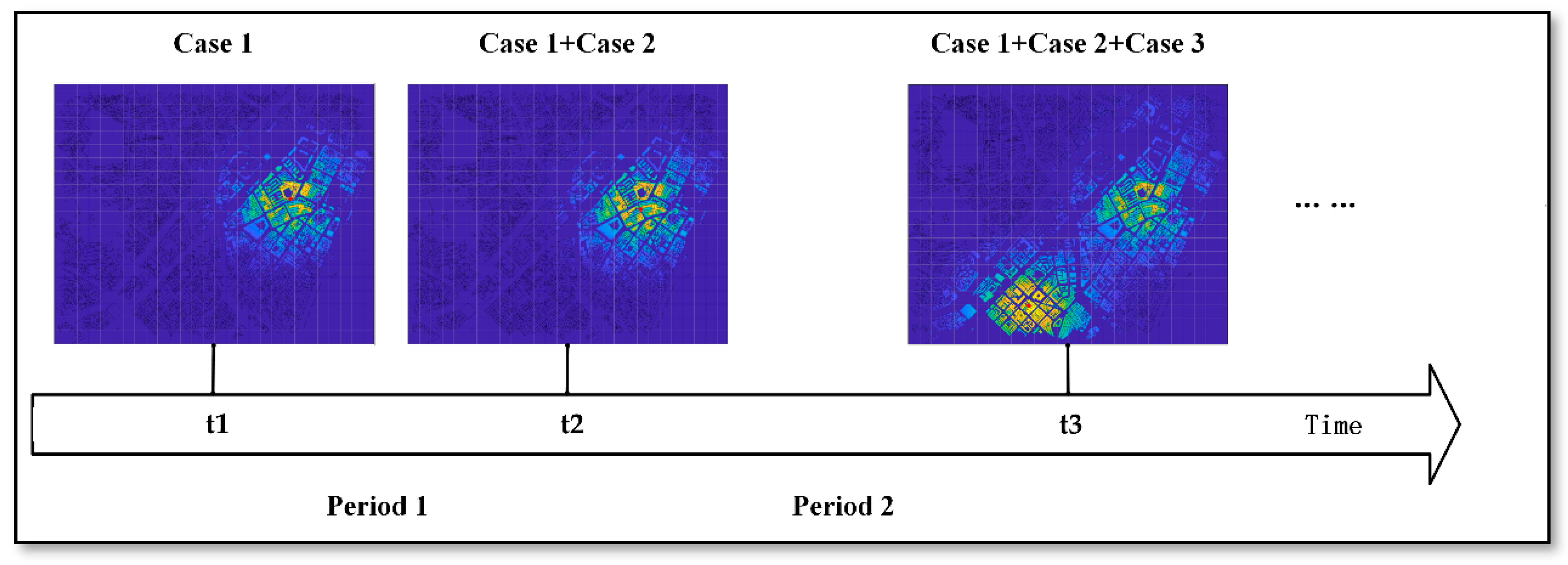
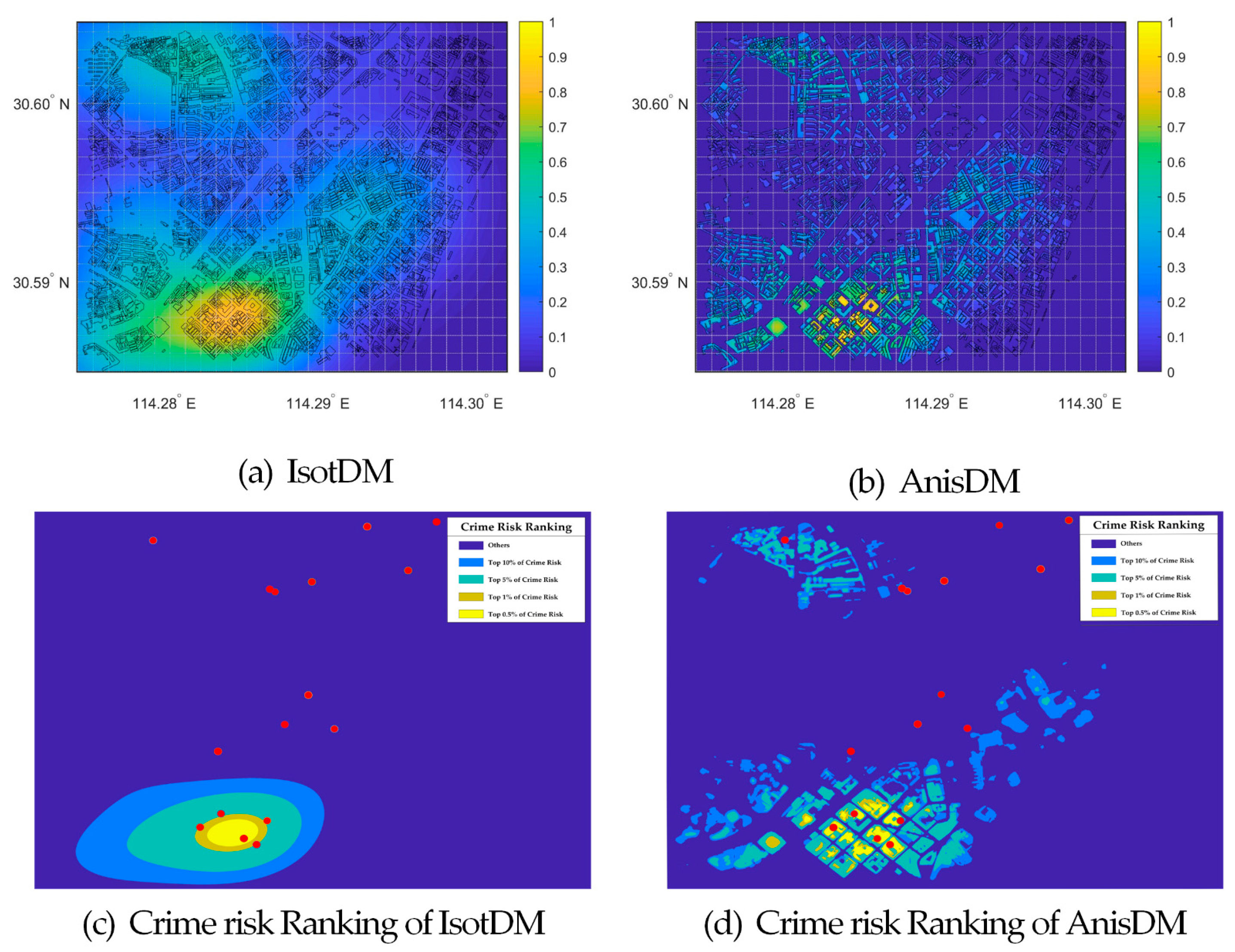
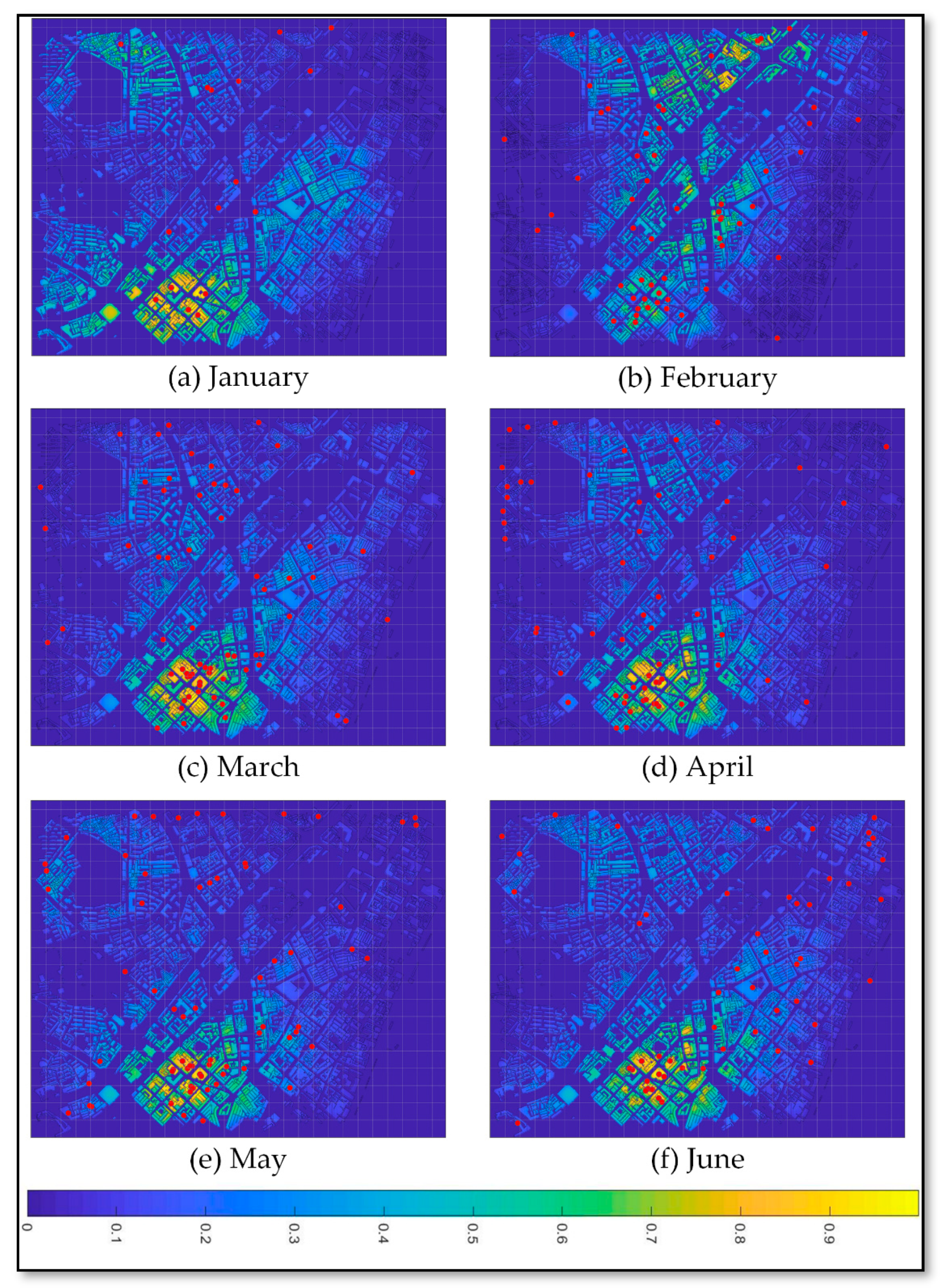
4.1. Crime Prediction Results
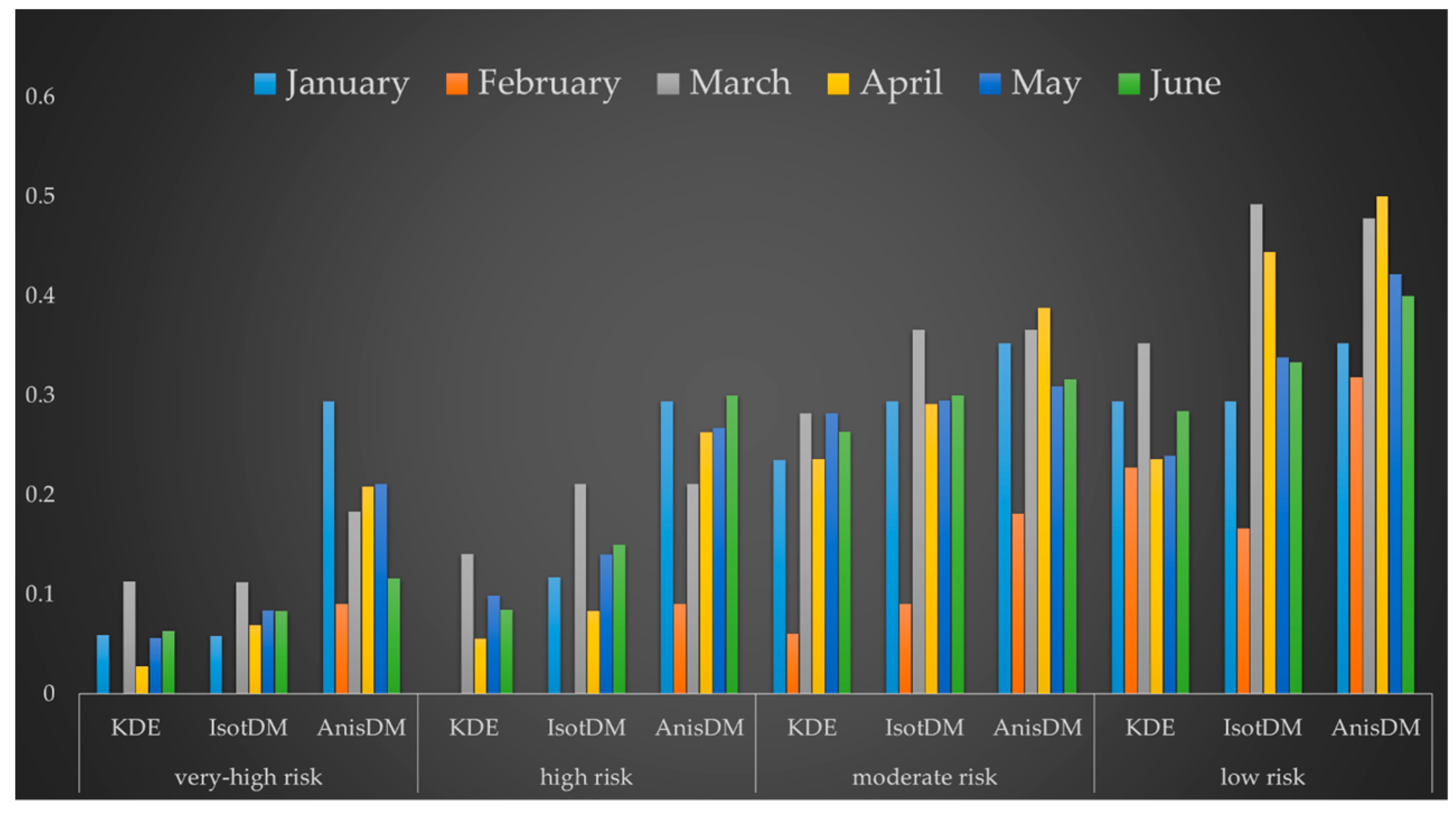
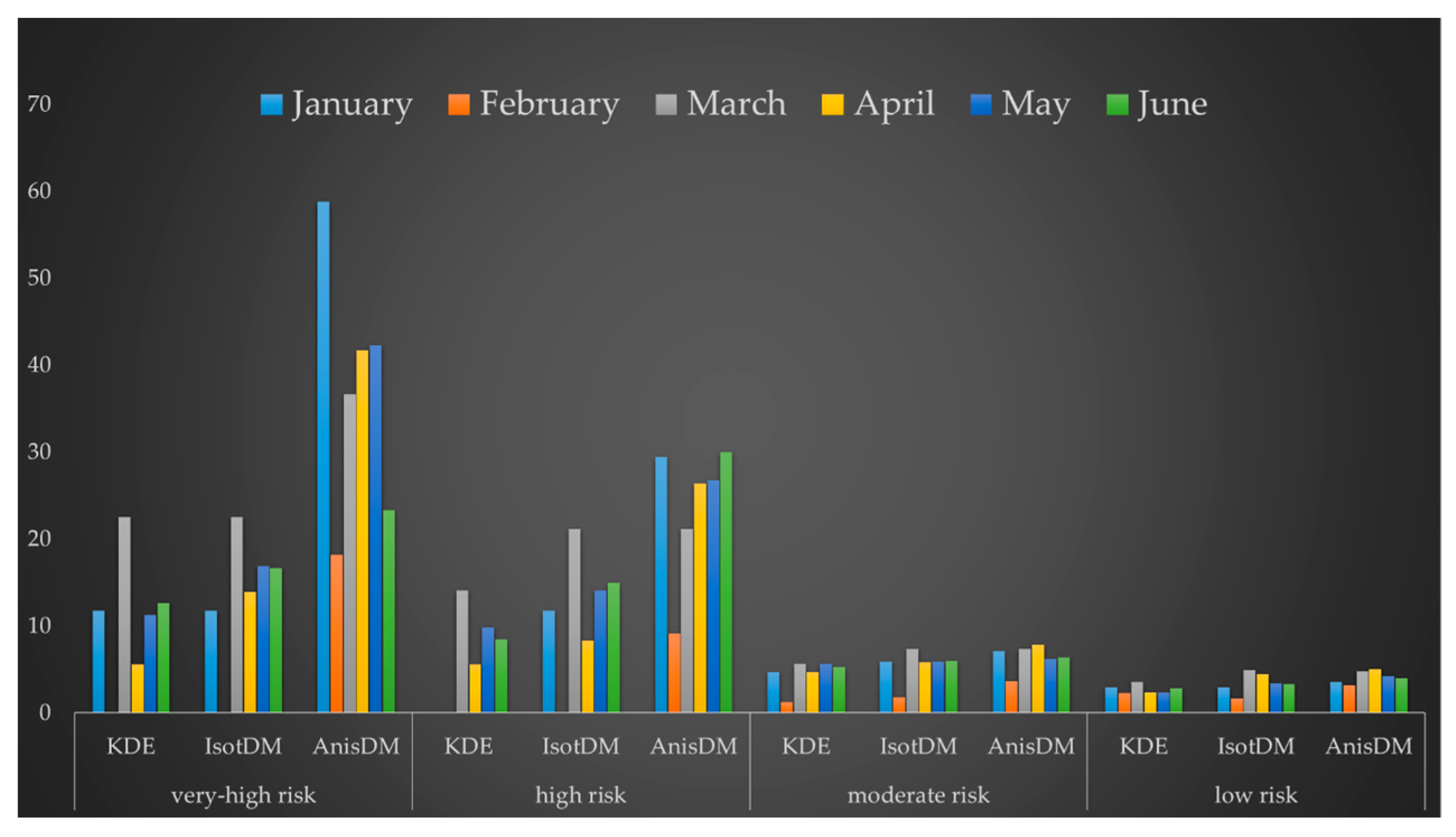
4.2. Crime Prediction Accuracy
4.3. Crime Prediction Comparison and Analysis
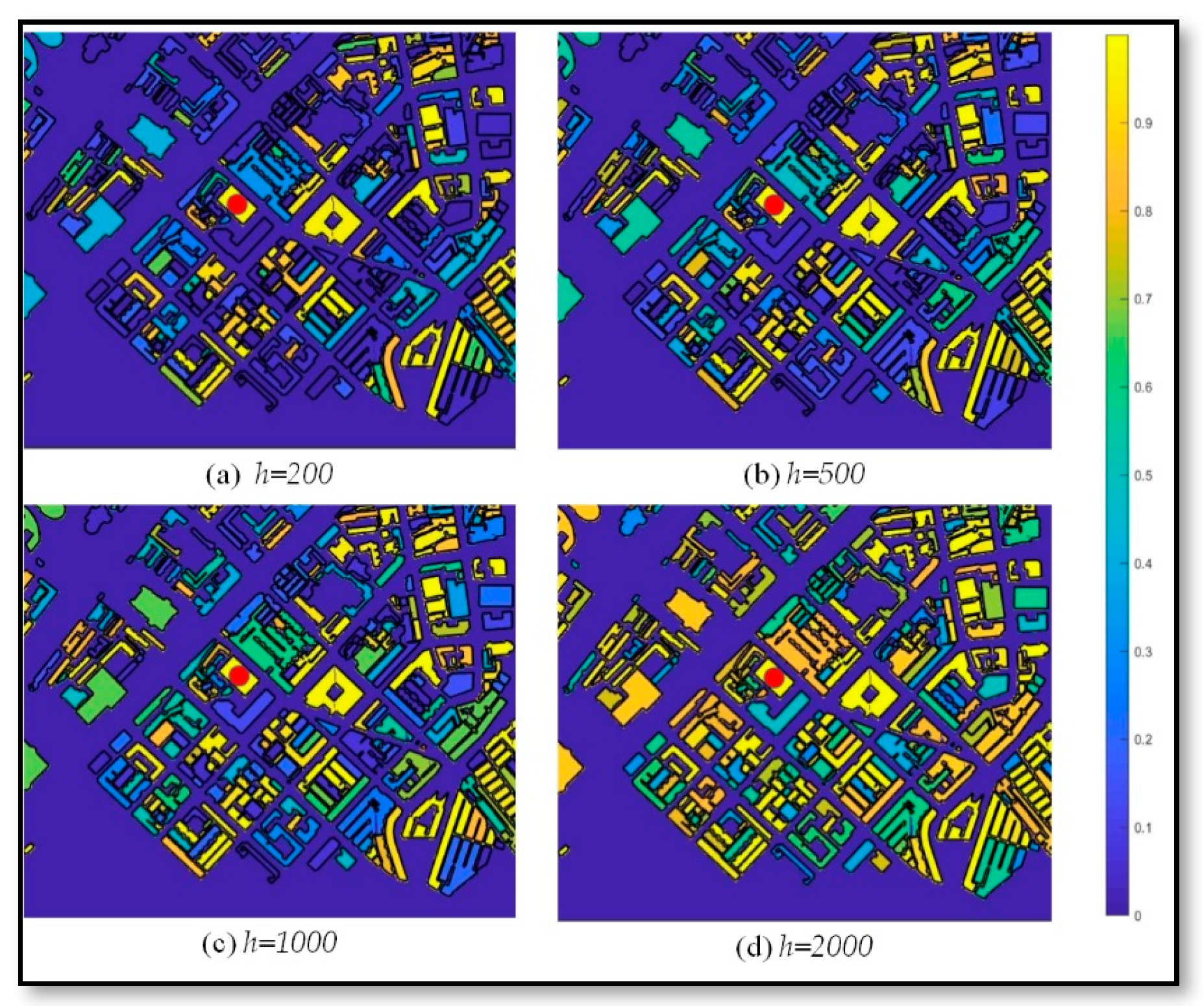
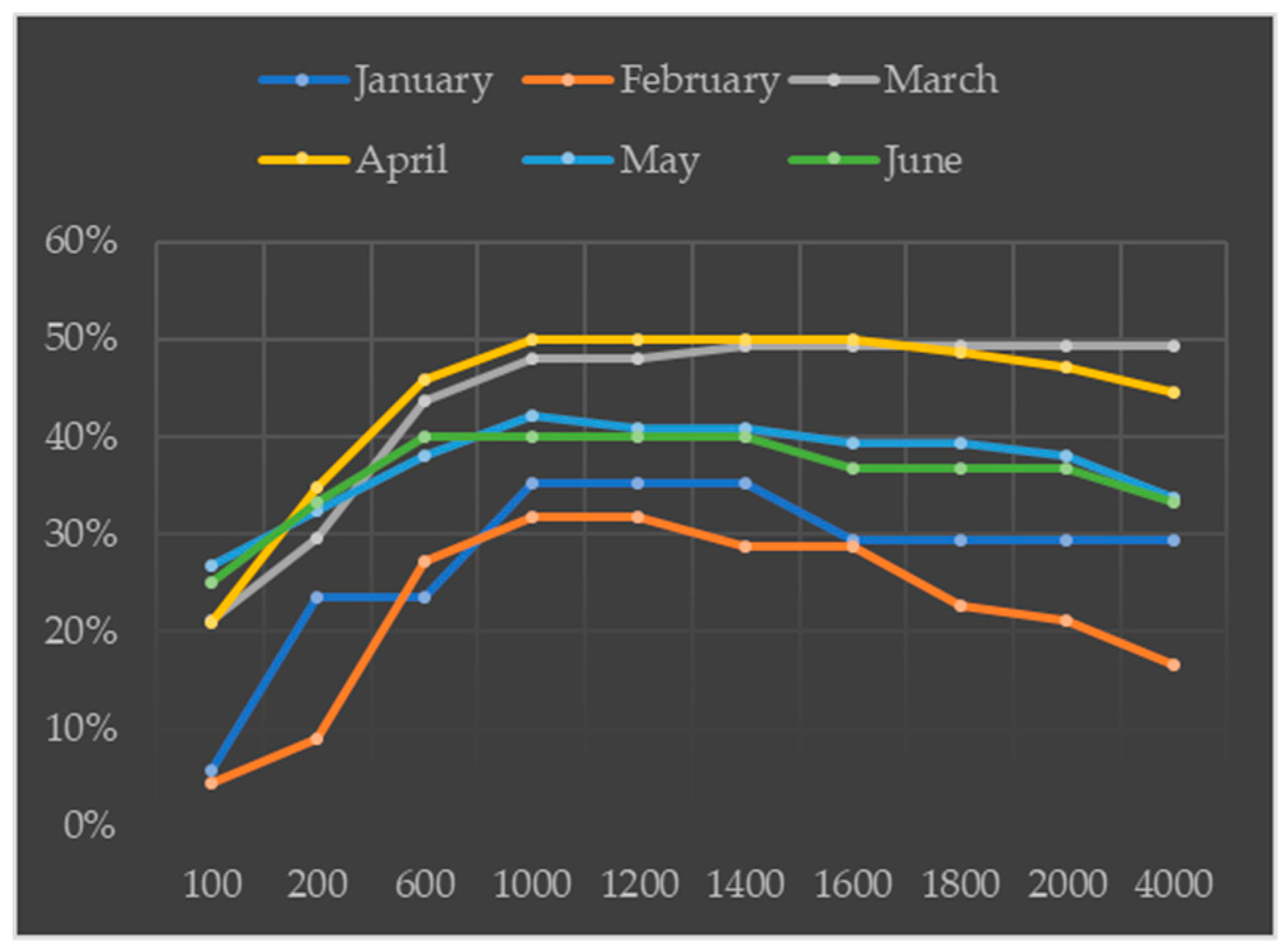
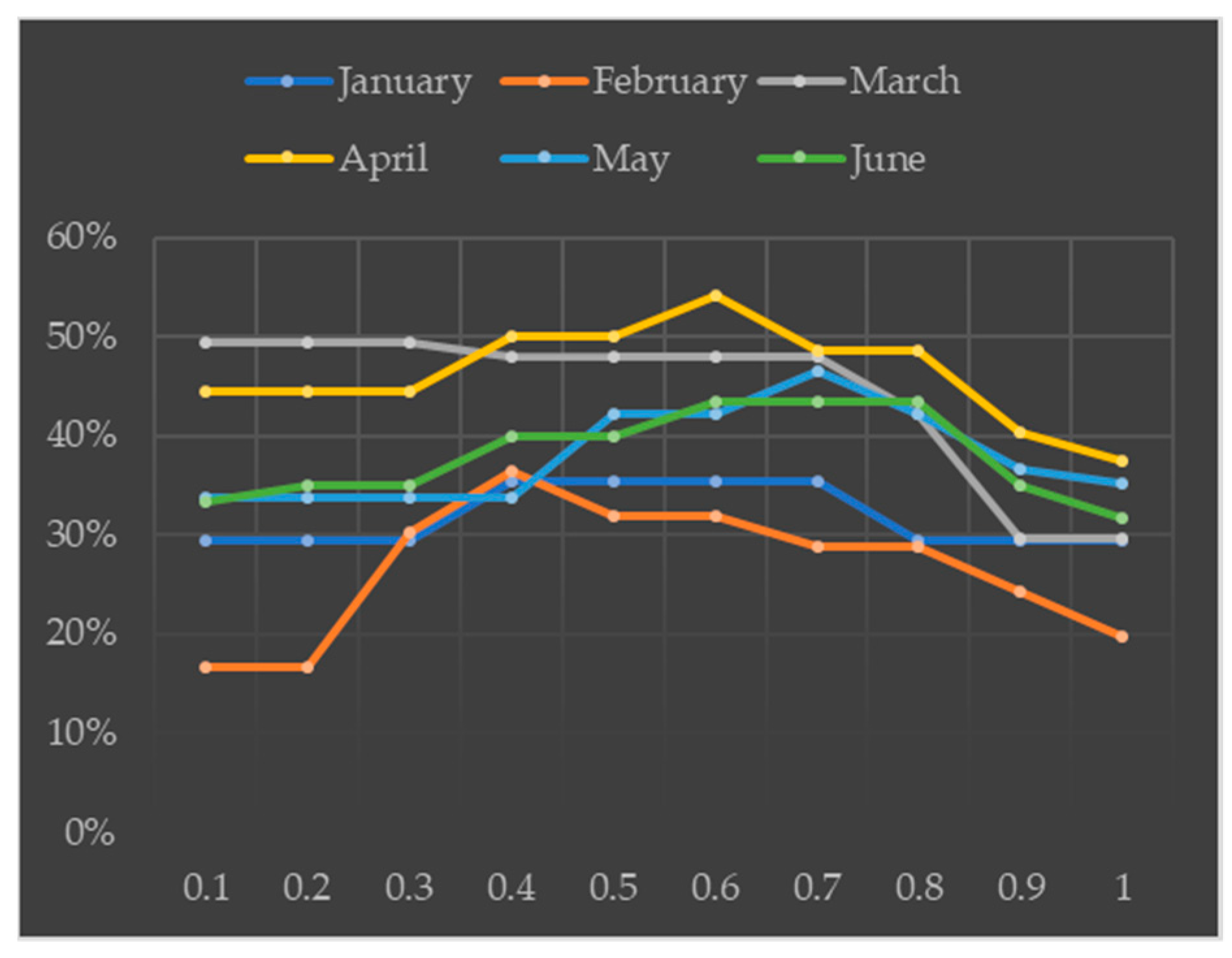
4.4. Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ye, X.; Wu, L. Analyzing the dynamics of homicide patterns in Chicago: ESDA and spatial panel approaches. Appl. Geogr. 2011, 31, 800–807. [Google Scholar] [CrossRef]
- Sherman, L.W.; Gartin, P.R.; Buerger, M.E. Hot Spots of Predatory Crime: Routine Activities and the Criminology of Place. Criminology 2010, 27, 27–56. [Google Scholar] [CrossRef]
- Farrell, G.; Pease, K. Once Bitten, Twice Bitten: Repeat Victimisation and Its Implications for Crime Prevention; Police Research Group Crime Prevention Unit Paper; Paper No. 46; Home Office Police Department: London, UK, 1993. [Google Scholar]
- Boni, M.A.; Gerber, M.S. Automatic Optimization of Localized Kernel Density Estimation for Hotspot Policing. In Proceedings of the IEEE International Conference on Machine Learning and Applications, Cancun, Mexico, 18 December 2017; pp. 32–38. [Google Scholar]
- Chiu, S.T. A comparative review of bandwidth selection for kernel density estimation. Stat. Sinica 1996, 6, 126–145. [Google Scholar]
- Turlach, B.A. Bandwidth Selection in Kernel Density Estimation: A Review. CORE Inst. Statist. 1993, 23–493. [Google Scholar]
- Kennedy, L.W.; Caplan, J.M.; Piza, E. Risk Clusters, Hotspots, and Spatial Intelligence: Risk Terrain Modeling as an Algorithm for Police Resource Allocation Strategies. J. Quant. Criminol. 2011, 27, 339–362. [Google Scholar] [CrossRef]
- Gorr, W.; Olligschlaeger, A.; Thompson, Y. Short-term forecasting of crime. Int. J. Forecast. 2003, 19, 579–594. [Google Scholar] [CrossRef]
- Gerber, M.S. Predicting crime using Twitter and kernel density estimation. Decis. Supp. Syst. 2014, 61, 115–125. [Google Scholar] [CrossRef]
- Chainey, S.; Tompson, L.; Uhlig, S. The Utility of Hotspot Mapping for Predicting Spatial Patterns of Crime. Secur. J. 2008, 21, 4–28. [Google Scholar] [CrossRef] [Green Version]
- Mohler, G. Marked point process hotspot maps for homicide and gun crime prediction in Chicago. Int. J. Forecast. 2014, 30, 491–497. [Google Scholar] [CrossRef]
- Johnson, S.D. Repeat burglary victimisation: A tale of two theories. J. Exp. Criminol. 2008, 4, 215–240. [Google Scholar] [CrossRef]
- Short, M.B.; D’Orsogna, M.R.; Brantingham, P.J.; Tita, G.E. Measuring and Modeling Repeat and Near-Repeat Burglary Effects. J. Quant. Criminol. 2009, 25, 325–339. [Google Scholar] [CrossRef] [Green Version]
- Mohler, G.O.; Short, M.B. Geographic Profiling from Kinetic Models of Criminal Behavior. Siam J. Appl. Math. 2012, 72, 163–180. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Zhu, X.; Guo, W.; Ye, X.; Hu, T.; Fan, Y.; Zhang, F. Non-Homogeneous Diffusion of Residential Crime in Urban China. Sustainability 2017, 9, 934. [Google Scholar] [CrossRef]
- Law, J.; Quick, M. Exploring links between juvenile offenders and social disorganization at a large map scale: A Bayesian spatial modeling approach. J. Geogr. Syst. 2013, 15, 89–113. [Google Scholar] [CrossRef]
- Lee, J.S.; Park, S.; Jung, S. Effect of Crime Prevention through Environmental Design (CPTED) Measures on Active Living and Fear of Crime. Sustainability 2016, 8, 872. [Google Scholar] [CrossRef]
- Law, J.; Quick, M.; Chan, P. Bayesian Spatio-Temporal Modeling for Analysing Local Patterns of Crime Over Time at the Small-Area Level. J. Quant. Criminol. 2014, 30, 57–78. [Google Scholar] [CrossRef]
- Johnson, S.D.; Bowers, K.J. The Burglary as Clue to the Future: The Beginnings of Prospective Hot-Spotting. Eur. J. Criminol. 2004, 1, 237–255. [Google Scholar] [CrossRef]
- Ye, X.; Xu, X.; Lee, J.; Zhu, X.; Wu, L. Space-time interaction of residential burglaries in Wuhan, China. Appl. Geogr. 2015, 60, 210–216. [Google Scholar] [CrossRef]
- Hoppe, L.; Gerell, M. Near-repeat burglary patterns in Malmö: Stability and change over time. Eur. J. Criminol. 2018, 1203272670. [Google Scholar] [CrossRef]
- Bediroglu, G.; Bediroglu, S.; Colak, H.E.; Yomralioglu, T. A Crime Prevention System in Spatiotemporal Principles with Repeat, Near-Repeat Analysis and Crime Density Mapping: Case Study Turkey, Trabzon. Crime Delinq. 2018, 475245375. [Google Scholar] [CrossRef]
- Sturup, J.; Rostami, A.; Gerell, M.; Sandholm, A. Near-repeat shootings in contemporary Sweden 2011 to 2015. Secur. J. 2017, 31, 73–92. [Google Scholar] [CrossRef]
- Melo, S.N.D.; Andresen, M.A.; Matias, L.F. Repeat and near-repeat victimization in Campinas, Brazil: New explanations from the Global South. Secur. J. 2017. [Google Scholar] [CrossRef]
- Chen, P.; Yuan, H.; Li, D. Space-time analysis of burglary in Beijing. Secur. J. 2013, 26, 1–15. [Google Scholar] [CrossRef]
- Wells, W.; Wu, L. Proactive Policing Effects on Repeat and Near-Repeat Shootings in Houston. Police Q. 2011, 14, 298–319. [Google Scholar] [CrossRef]
- Rosenfeld, R.; Levin, A. Acquisitive Crime and Inflation in the United States: 1960–2012. J. Quant. Criminol. 2016, 32, 427–447. [Google Scholar] [CrossRef]
- Marie, O.; Machin, S.; Vujić, S. The Crime Reducing Effect of Education. Econ. J. 2011, 121, 463–484. [Google Scholar] [Green Version]
- Zhang, L.; Messner, S.F.; Liu, J. A multilevel analysis of the risk of household burglary in the city of Tianjin, China. Brit. J. Criminol. 2007, 47, 918–937. [Google Scholar] [CrossRef]
- Harrison, R.A.; Gemmell, I.; Heller, R.F. The population effect of crime and neighbourhood on physical activity: An analysis of 15,461 adults. J. Epidemiol. Community Health 2007, 61, 34–39. [Google Scholar] [CrossRef]
- Fazel, S.; Grann, M. The population impact of severe mental illness on violent crime. Am. J. Psychiat. 2006, 163, 1397–1403. [Google Scholar] [CrossRef]
- McCann, B.J. Contesting the Mark of Criminality: Race, Place, and the Prerogative of Violence in NWA’s Straight Outta Compton. Crit. Stud. Media Commun. 2012, 29, 367–386. [Google Scholar] [CrossRef]
- Malleson, N.; Andresen, M.A. The impact of using social media data in crime rate calculations: Shifting hot spots and changing spatial patterns. Cartogr. Geogr. Inf. Sci. 2015, 42, 112–121. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, X. Joint Modeling of Multiple Crimes: A Bayesian Spatial Approach. ISPRS Int. J. Geo. Inf. 2017, 6, 16. [Google Scholar] [CrossRef]
- Liu, H.; Zhu, X. Exploring the Influence of Neighborhood Characteristics on Burglary Risks: A Bayesian Random Effects Modeling Approach. ISPRS Int. J. Geo. Inf. 2016, 5, 102. [Google Scholar] [CrossRef]
- Guerette, R.T. Analyzing Crime Displacement and Diffusion; Justice, U.D.O., Ed.; Center for Problem-Oriented Policing, 2009; Volume 10. Available online: http://www.popcenter.org/tools/displacement/print/ (accessed on 20 May 2019).
- Townsley, M.; Homel, R.; Chaseling, J. Infectious burglaries—A test of the near repeat hypothesis. Brit. J. Criminol. 2003, 43, 615–633. [Google Scholar] [CrossRef]
- Wells, W.; Wu, L.; Ye, X. Patterns of Near-Repeat Gun Assaults in Houston. J. Res. Crime Delinq. 2012, 49, 186–212. [Google Scholar] [CrossRef]
- Grubesic, T.H.; Mack, E.A. Spatio-temporal interaction of urban crime. J. Quant. Criminol. 2008, 24, 285–306. [Google Scholar] [CrossRef]
- Braga, A.A. The Effects of Hot Spots Policing on Crime. Ann. Am. Acad. Polit. Soc. Sci. 2001, 578, 104–125. [Google Scholar] [CrossRef]
- Townsley, M.; Homel, R.; Chaseling, J. Repeat Burglary Victimisation: Spatial and Temporal Patterns. Aust. N. Z. J. Criminol. 2000, 33, 37–63. [Google Scholar] [CrossRef] [Green Version]
- Mohler, G.O.; Short, M.B.; Brantingham, P.J.; Schoenberg, F.P.; Tita, G.E. Self-Exciting Point Process Modeling of Crime. Publ. Am. Stat. Assoc. 2011, 106, 100–108. [Google Scholar] [CrossRef] [Green Version]
- Short, M.B.; D’Orsogna, M.R.; Pasour, V.B.; Tita, G.E.; Brantingham, P.J.; Bertozzi, A.L.; Chayes, L.B. A statistical model of criminal behavior. Math. Mod. Meth. Appl. S 2008, 18, 1249–1267. [Google Scholar] [CrossRef]
- Zipkin, J.R.; Short, M.B.; Bertozzi, A.L. Cops on the Dots in a Mathematical Model of Urban Crime and Police Response. Discr. Cont. Dyn. B 2014, 19, 1479–1506. [Google Scholar] [CrossRef]
- Short, M.B.; Brantingham, P.J.; Bertozzi, A.L.; Tita, G.E. Dissipation and displacement of hotspots in reaction-diffusion models of crime. Proc. Natl. Acad. Sci. USA 2010, 107, 3961–3965. [Google Scholar] [CrossRef] [Green Version]
- Jones, P.A.; Brantingham, P.J.; Chayes, L.R. Statistical Models of Criminal Behavior: The Effects of Law Enforcement Actions. Math. Mod. Meth. Appl. S 2010, 201, 1397–1423. [Google Scholar] [CrossRef]
- Berestycki, H.; Nadal, J. Self-organised critical hot spots of criminal activity. Eur. J. Appl. Math. 2010, 21, 371–399. [Google Scholar] [CrossRef]
- Kolokolnikov, T.; Ward, M.J.; Wei, J. The Stability of Steady-State Hot-Spot Patterns for a Reaction-Diffusion Model of Urban Crime. Discr. Cont. Dyn. B 2014, 19, 1373–1410. [Google Scholar]
- Davies, T.P.; Bishop, S.R. Modelling patterns of burglary on street networks. Crime Sci. 2013, 2, 10. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Wang, Q.; Yi, G. Stationary patterns and their selection mechanism of urban crime models with heterogeneous near-repeat victimization effect. Eur. J. Appl. Math. 2017, 28, 141–178. [Google Scholar] [CrossRef]
- D’Orsogna, M.R.; Perc, M. Statistical physics of crime: A review. Phys. Life Rev. 2015, 12, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Pitcher, A.B. Adding police to a mathematical model of burglary. Eur. J. Appl. Math. 2010, 21, 401–419. [Google Scholar] [CrossRef]
- Nelson, J.F. Multiple Victimization in American Cities: A Statistical Analysis of Rare Events. Am. J. Sociol. 1980, 85, 870–891. [Google Scholar] [CrossRef]
- Caplan, J.M.; Kennedy, L.W.; Miller, J. Risk Terrain Modeling: Brokering Criminological Theory and GIS Methods for Crime Forecasting. Justice Q. 2011, 28, 360–381. [Google Scholar] [CrossRef]
- Barnum, J.D.; Campbell, W.L.; Trocchio, S.; Caplan, J.M.; Kennedy, L.W. Examining the Environmental Characteristics of Drug Dealing Locations. Crime Delinq. 2016, 63, 456385799. [Google Scholar] [CrossRef]
- Strobl, C. Dimensionally Extended Nine-Intersection Model (DE-9IM). Encycl. GIS 2008, 240–245. [Google Scholar]
- Tebini, S.; Mbarki, Z.; Seddik, H.; Ben Braiek, E. Rapid and efficient image restoration technique based on new adaptive anisotropic diffusion function. Digit. Signal Proces 2016, 48, 201–215. [Google Scholar] [CrossRef]
- Perona, P.; Malik, J. Scale-Space and Edge-Detection Using Anisotropic Diffusion. IEEE T Patt. Anal. 1990, 12, 629–639. [Google Scholar] [CrossRef]
- Tu, J.; Yang, B. A Sobel-TV Based Hybrid Model for Robust Image Denoising. Appl. Math. 2014, 5, 1310–1316. [Google Scholar] [CrossRef]
- Adepeju, M.; Rosser, G.; Cheng, T. Novel Evaluation Metrics for Sparse Spatio-Temporal Point Process Hotspot Predictions—A Crime Case Study. Int. J. Geogr. Inf. Sci. 2016, 30, 2133–2154. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Kubrin, C.E.; Stewart, E.A. Predicting who reoffends: The neglected role of neighborhood context in recidivism studies. Criminology 2006, 44, 165–197. [Google Scholar] [CrossRef]
- Cahill, M.; Mulligan, G. Using geographically weighted regression to explore local crime patterns. Soc. Sci. Comput. Rev. 2007, 25, 174–193. [Google Scholar] [CrossRef]
- Rosser, G.; Davies, T.; Bowers, K.J.; Johnson, S.D.; Cheng, T. Predictive Crime Mapping: Arbitrary Grids or Street Networks? J. Quant. Criminol. 2017, 33, 569–594. [Google Scholar] [CrossRef]
- Wan, N.; Zhan, F.B.; Cai, Z. A spatially weighted degree model for network vulnerability analysis. Geo-Spat. Inf. Sci. 2011, 14, 274–281. [Google Scholar] [CrossRef]
- Domingo, M.; Thibaud, R.; Claramunt, C. A graph-based approach for the structural analysis of road and building layouts. Geo-Spat. Inf. Sci. 2019, 22, 59–72. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Format | Year | Major Attributes | Datapoints |
|---|---|---|---|---|
| Crime case | Vector point data | 2013 | Type, time, location, and description | 392 |
| Building boundary | Vector plane data | 2013 | Vector data of buildings | 2428 |
| Household registry | Vector point data | 2013 | ID and address | 222,413 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Zhu, X.; Guo, W.; Wu, L.; Fan, Y. Anisotropic Diffusion for Improved Crime Prediction in Urban China. ISPRS Int. J. Geo-Inf. 2019, 8, 234. https://doi.org/10.3390/ijgi8050234
Tang Y, Zhu X, Guo W, Wu L, Fan Y. Anisotropic Diffusion for Improved Crime Prediction in Urban China. ISPRS International Journal of Geo-Information. 2019; 8(5):234. https://doi.org/10.3390/ijgi8050234
Chicago/Turabian StyleTang, Yicheng, Xinyan Zhu, Wei Guo, Ling Wu, and Yaxin Fan. 2019. "Anisotropic Diffusion for Improved Crime Prediction in Urban China" ISPRS International Journal of Geo-Information 8, no. 5: 234. https://doi.org/10.3390/ijgi8050234
APA StyleTang, Y., Zhu, X., Guo, W., Wu, L., & Fan, Y. (2019). Anisotropic Diffusion for Improved Crime Prediction in Urban China. ISPRS International Journal of Geo-Information, 8(5), 234. https://doi.org/10.3390/ijgi8050234