4.4.1. Experimental Results and Analysis
To examine the feasibility of the hybrid optimized LSTM model for short-term passenger flow prediction, the hybrid optimized LSTM model is compared with five baselines. To make a fair comparison, Naïve [
36,
37,
38], autoregressive integrated moving average model (ARIMA) [
39], support vector regression (SVR) and five LSTM models with a non-hybrid optimization algorithm (LSTM with SGD algorithm, LSTM with Adagrad algorithm, LSTM with RMSProp algorithm, LSTM with the Adam algorithm and LSTM with Nadam algorithm) are selected as benchmarks. Taking Licun Park as an example, experimental results are shown in
Table 4.
As shown in
Table 4, the proposed LSTM
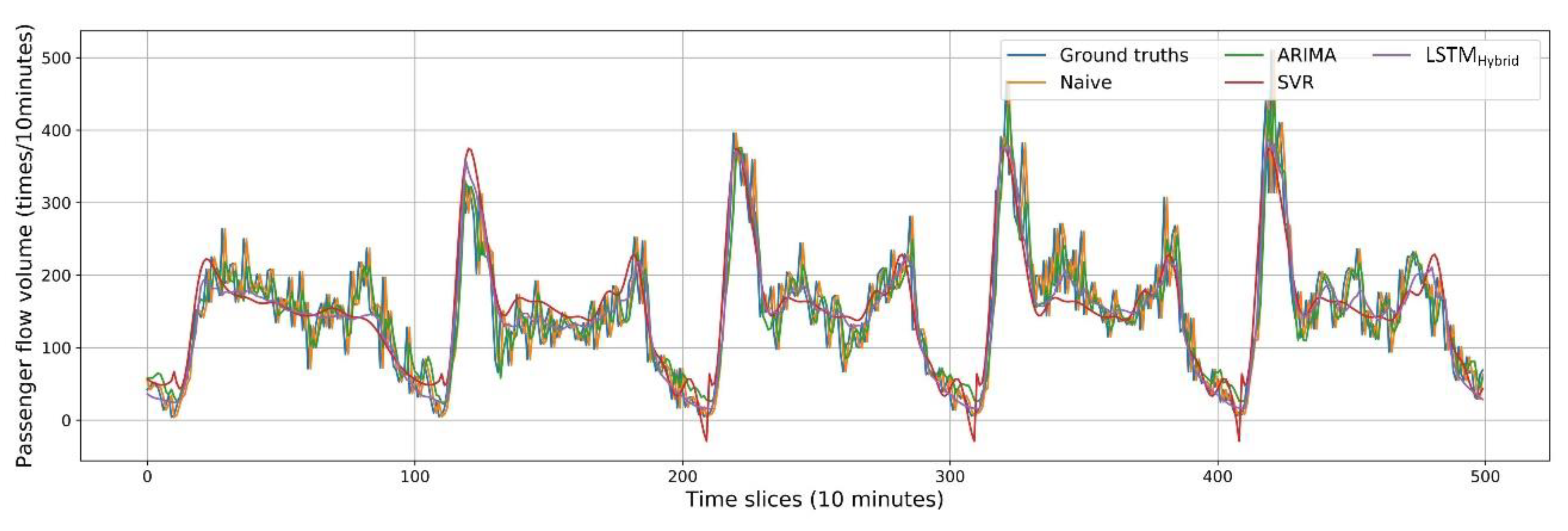
Hybrid model outperforms the other eight benchmarks in MAE, MAPE, and RMSE, which means its prediction accuracy was best. To further examine the prediction performance in a more intuitive way, we first draw the predicted passenger flow of Naïve, ARIMA, SVR and the proposed LSTM
Hybrid model from 27 to 31 March 2016 in
Figure 9.
The Naïve model assumes that the passenger flow does not change with systematic trends within the observed time interval and uses the previous observation as the prediction in the next time step. As one may expect, Naïve is the worst performing model. It can be seen from
Figure 9 that compared with the ground truths, the predicted results of the Naïve model are always at a delay, which makes it worse than other models.
Compared with ARIMA, the LSTM
Hybrid model has a 19.66% relative reduction in MAE, a 44.23% relative reduction in MAPE and a 16.56% relative reduction in RMSE. This is mainly because ARIMA can only capture linear relationship in the time series, but not nonlinear relationship. As shown in
Figure 9, ARIMA captures the general trend of passenger flow, but the fitting degree is not accurate. Mismatches are common in many time slices.
Compared with SVR, the LSTM
Hybrid model has a 14.58% relative reduction in MAE, a 46.59% relative reduction in MAPE and a 16.56% relative reduction in RMSE. The performance of SVR can also be seen in
Figure 9.
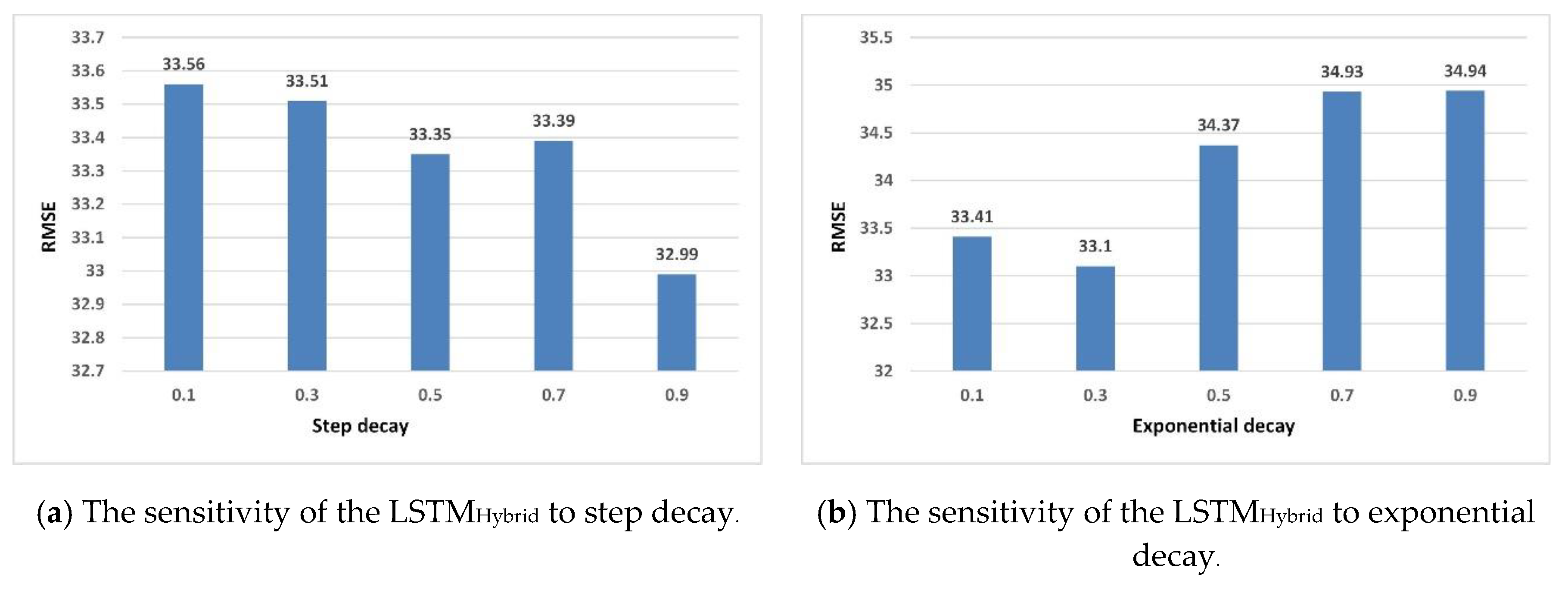
Next, we compare the LSTM
Hybrid model with the other five LSTM models. The learning rate is chosen from the discrete range between [0.5, 0.2, 0.05, 0.01] for SGD and [0.002, 0.001, 0.0005, 0.0001] for adaptive learning methods and then exponentially decayed or step decayed every 10 steps with a base ranging between [0.1, 0.3, 0.5, 0.7, 0.9]. To determine the optimal configuration, the grid search method is used to find the best parameter settings by changing one of the parameters while keeping the others unchanged for each algorithm. Finally, the best results of each algorithm are exhibited in
Table 4.
Compared with the LSTM
SGD model, the LSTM
Hybrid model has an 8.14% relative reduction in MAE, a 15.82% relative reduction in MAPE, and a 6.50% relative reduction in RMSE. As shown in
Figure 10, for the LSTM
SGD model, the loss of the model decreases very slowly in the early stage, which makes the model have a poor convergence level within the same iteration number, so it takes more time to reach a better level.
Through parameters tuning, the errors of LSTMAdagrad, LSTMRMSProp, LSTMAdam and LSTMNadam are very close, but they are still much higher than that of LSTMHybrid. This is mainly due to the inability of a single optimizer to combine the advantages of multiple optimizers. It is worth noting that LSTMNadam performs a bit better than the other three models. This maybe because it contains Nesterov’s accelerated gradient, which is general superior to classical momentum.
Taking Nadam as a representative of the adaptive algorithms, we find that compared with the LSTM
Nadam model, the LSTM
Hybrid model has a 5.94% relative reduction in MAE, a 4.23% relative reduction in MAPE, and a 7.69% relative reduction in RMSE.
Figure 10 exhibits that the convergence speed of LSTM
Nadam model is obviously better than LSTM
SGD, but it oscillates violently even though we reduce its learning rate every 10 epochs, which makes it difficult to find the optimal solution of the algorithm. In addition, the generalization and out-of-sample behavior of the LSTM
Nadam model remain poorly understood.
The MAE, MAPE and RMSE of the LSTM
Hybrid model are 24.320, 24.002%, and 32.994, respectively, which are the lowest among all models. As shown in
Figure 10, by switching Nadam to SGD when the former is oscillating, the LSTM
Hybrid model keeps the error at a low level and continues training, achieving better prediction accuracy.
To sum up, the LSTM
Hybrid model proposed in this paper combines the advantages of Nadam and SGD. At the early stage, it utilizes Nadam to make the error decrease rapidly. When Nadam shows weakness, the LSTM
Hybrid model automatically switches to SGD to continue training. The LSTM
Hybrid model enables the model to have a faster convergence rate and smaller final training error, which makes the training of short-term prediction of bus passenger flow based on LSTM efficient and accurate. The training process of the LSTM
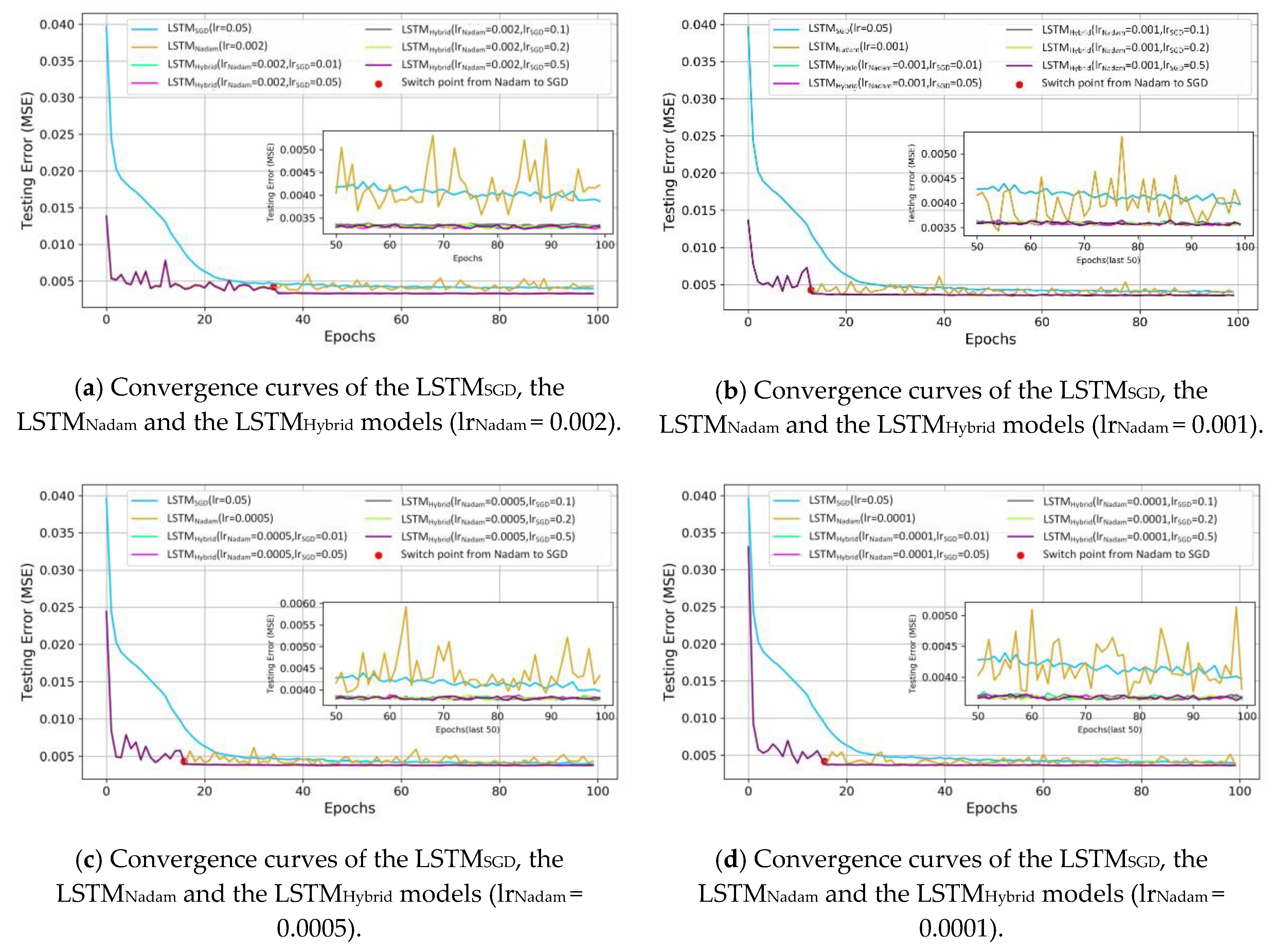
SGD, the LSTM
Nadam, and the LSTM
Hybrid models with different learning rates is shown in
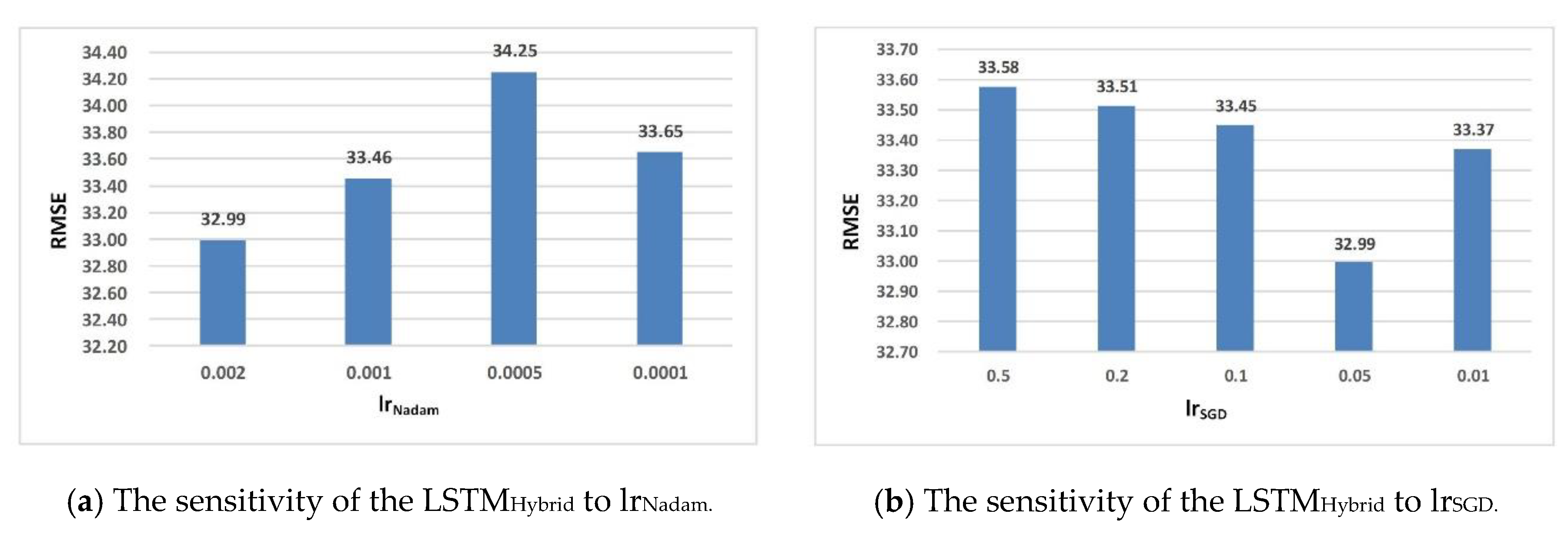
Figure 10. The lr
Nadam and lr
SGD are used to represent the value of learning rate in Nadam and SGD, respectively. The changes of different learning rates of SGD (from 0.01 to 0.5) are too small, so it is difficult to distinguish their error lines. The error lines of different learning rates of Nadam (0.002, 0.001, 0.0005 and 0.0001) show similar convergent tendencies. When lr
Nadam is 0.002 and lr
SGD is 0.05, the model obtains the best prediction accuracy (RMSE is 32.99). Thus, the better performance of the proposed model is due to the hybrid strategy, not the various learning rates.
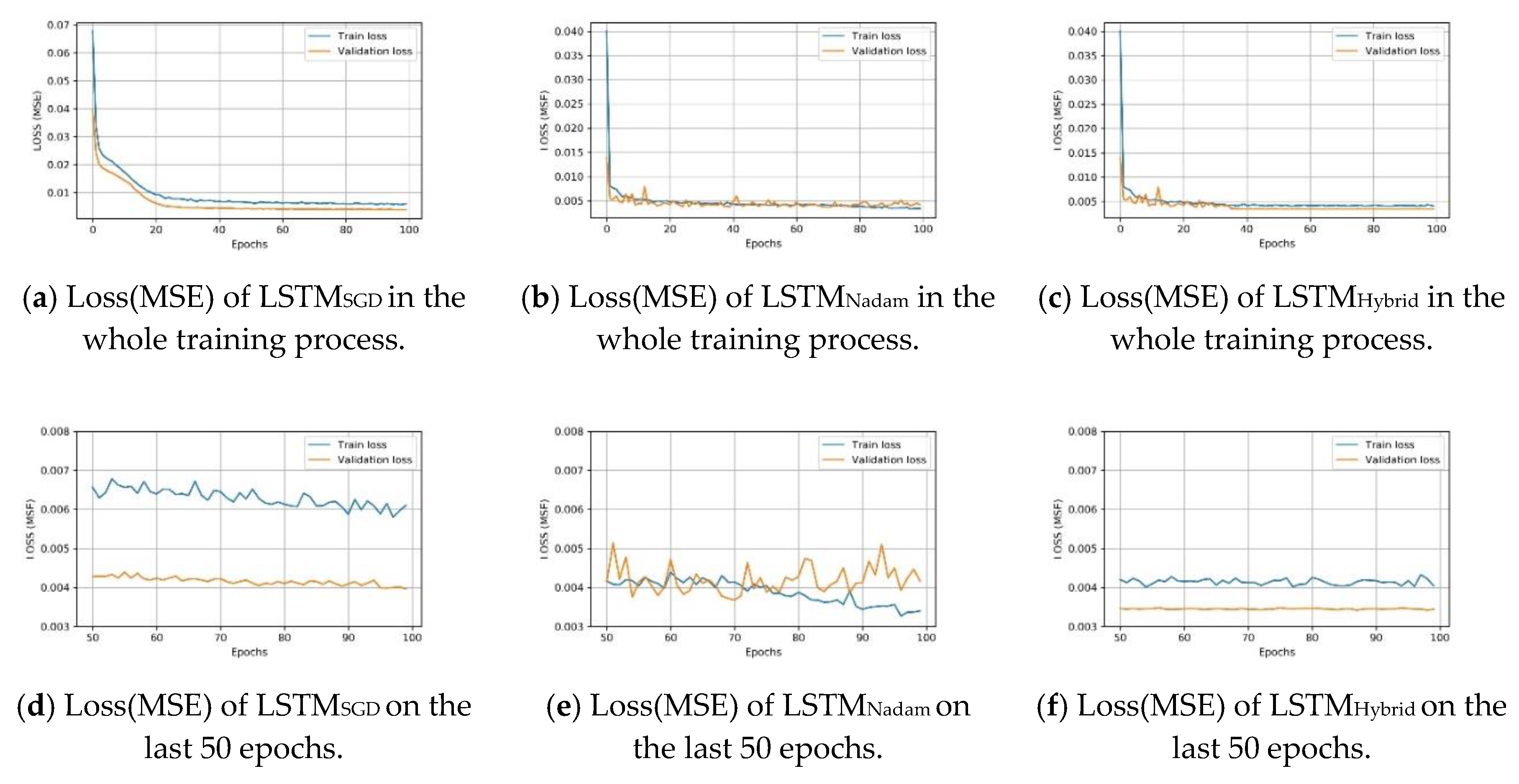
Moreover, when drawing the training loss and validation loss of the LSTM
SGD, the LSTM
Nadam and the LSTM
Hybrid models with the best parameters (lr
Nadam = 0.002, lr
SGD = 0.05) (
Figure 11), it can be seen that during the same iterations, the LSTM
Nadam model appears to be overfitting in the later stage. The LSTM
Hybid model avoids overfitting very well.
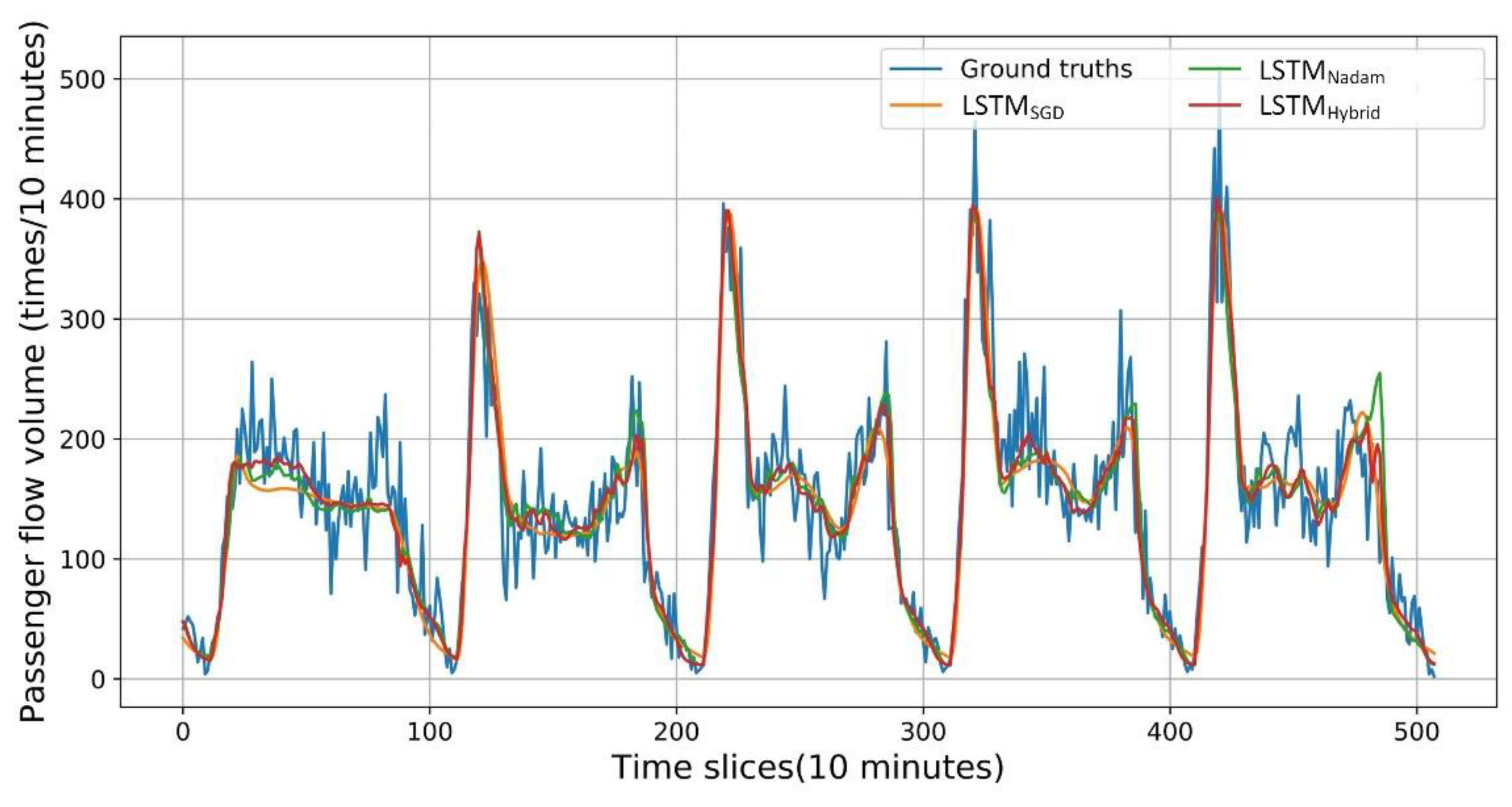
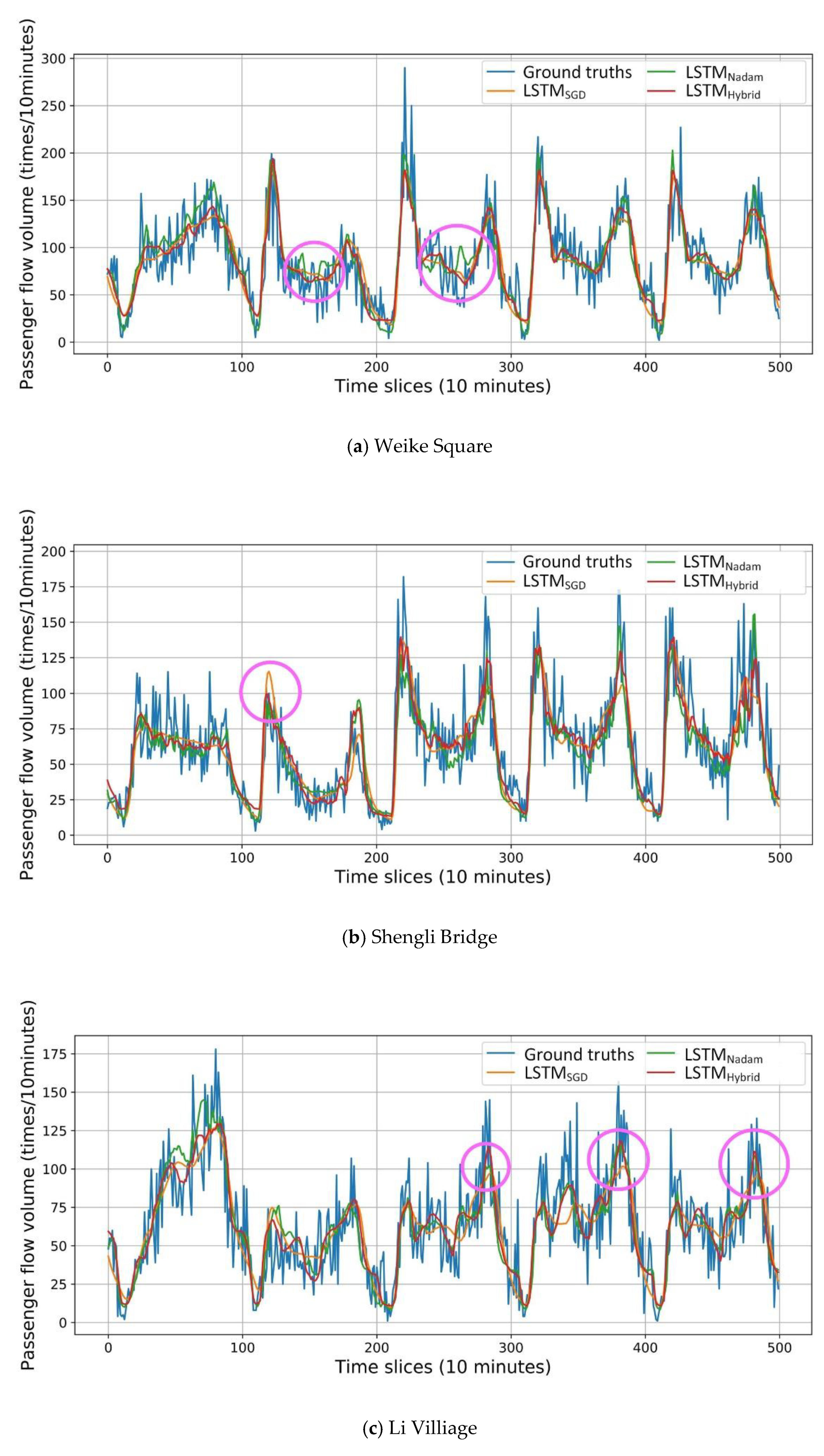
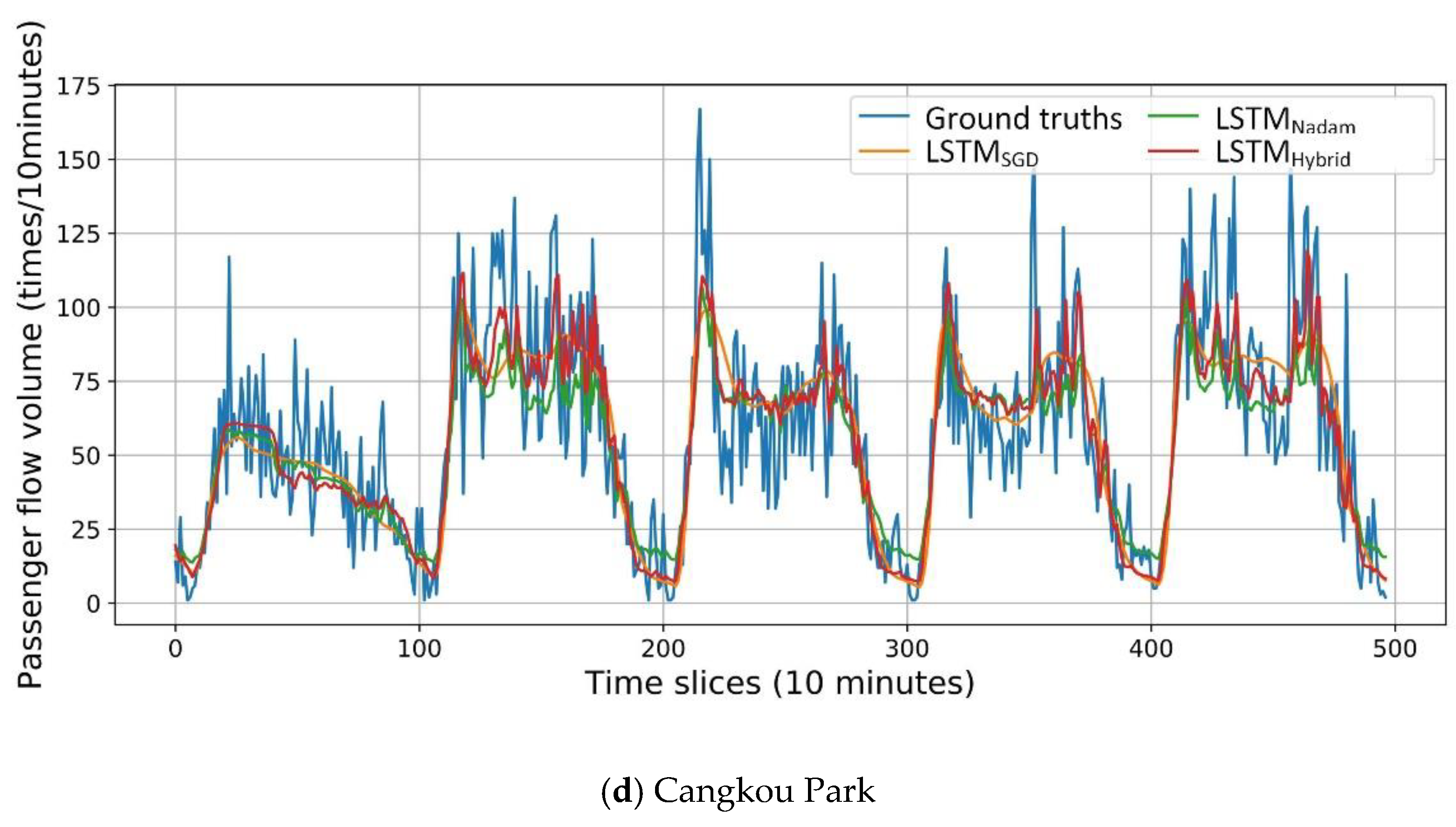
To further examine the prediction performance in a more intuitive way, the predicted passenger flow of LSTM models is drawn in
Figure 12. LSTM models with two traditional optimized algorithms (SGD and Nadam) are selected to compare with the LSTM
Hybrid model and ground truths. Through the figure, the detailed prediction results can be visualized: the LSTM
Hybrid model fits the ground truths better, while the LSTM
SGD model over smooths the curve, making the results worse. The LSTM
Nadam model fits the curve well, but still fails to fit the peak.
Several useful findings can be summarized based on the above algorithm result analysis:
Non-adaptive methods over smooth the curve, which results from their slow descent and falling into a local optimal.
Adaptive methods fit the curve, but they do not fit the peak well. These phenomena result from violent oscillation.
The hybrid method combines the advantages of those two methods, taking advantages of adaptive methods to fit the curve and utilizing non-adaptive methods to train in detail, and thus achieving satisfying results.
4.4.2. Switching Other Adaptive Methods to SGD
In
Section 4.4.1, we compared the performance of the LSTM
Hybrid model with five other traditional LSTM models, finding that the model accuracy has been greatly improved by switching Nadam to SGD. In this section, we try to switch other adaptive algorithms (Adagrad, RMSProp, Adam) to SGD to explore whether we should use Nadam in the first stage. The experimental results are shown in
Table 5.
Comparing
Table 5 with
Table 4, we find that the hybrid algorithms are better than the single algorithms in RMSE and MAE, and slightly improves in MAPE. For example, compared with the LSTM
Adagrad model, the LSTM
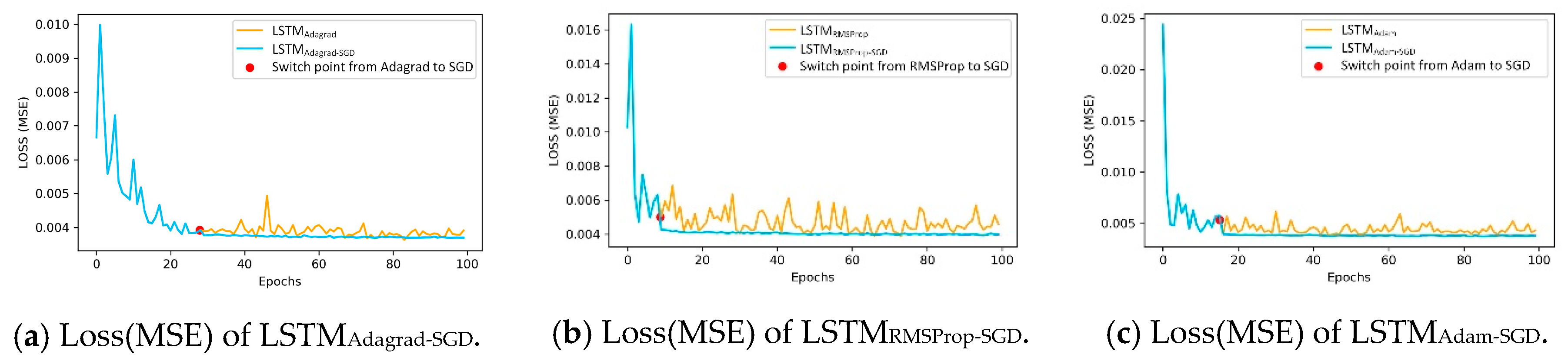
Adagrad-SGD model has a 4.63% relative reduction in MAE and an 8.61% relative reduction in RMSE, but a 5.55% relative increase in MAPE. From these results we find that compared with single algorithms, the hybrid algorithms are effective at passenger flow prediction. When drawing the training process of the LSTM
Adagrad-SGD, the LSTM
RMSProp-SGD and the LSTM
Adam-SGD models compared with the LSTM model with a single optimization algorithm (
Figure 13), we see that similar to the LSTM
Hybrid model, the losses of those three models all decline rapidly in the first stage and then decline steadily in the second stage.
When comparing the LSTMAdagrad-SGD, the LSTMRMSProp-SGD and the LSTMAdam-SGD models with the LSTMHybrid model, it is easily seen that the LSTMHybrid model outperforms the other three models in either RMSE, MAPE or MAE. This is mainly because Nesterov’s accelerated gradient in Nadam makes the loss of LSTMHybrid decrease at a better level in the first stage and promotes the fine-tuning of SGD in the second stage.
4.4.3. Application of the Hybrid Algorithm on Different Models
In this section, we apply the hybrid algorithm to the SimpleRNN and GRU models. To make a fair comparison, five SimpleRNN/GRU models with non-hybrid optimization algorithm (SGD, Adagrad, RMSProp, Adam and Nadam) are selected as benchmarks. The model results are shown in
Table 6.
In terms of prediction accuracy, SimpleRNNHybrid outperforms SimpleRNNSGD, SimpleRNNAdagrad, SimpleRNNRMSProp, SimpleRNNAdam and SimpleRNNNadam for short-term traffic flow prediction, GRUHybrid outperforms GRUSGD, GRUAdagrad, GRURMSProp, GRUAdam and GRUNadam. This validates the general strategy of switching Nadam to SGD. In addition, compared to the optimal baselines in SimpleRNN (SimpleRNNHybrid), the LSTMHybrid model has a 10.71% relative reduction in MAE, a 14.37% relative reduction in MAPE, and an 8.18% relative reduction in RMSE. This is mainly because the input gate, forget gate and output gate can effectively retain important features to ensure that they will not be lost during long-term propagation, so as to capture long-term dependencies in data. The error of GRUHybrid is close to that of LSTMHybrid. However, LSTMHybrid is better in terms of those three indicators, which proves that LSTMHybrid is more suitable for this case.
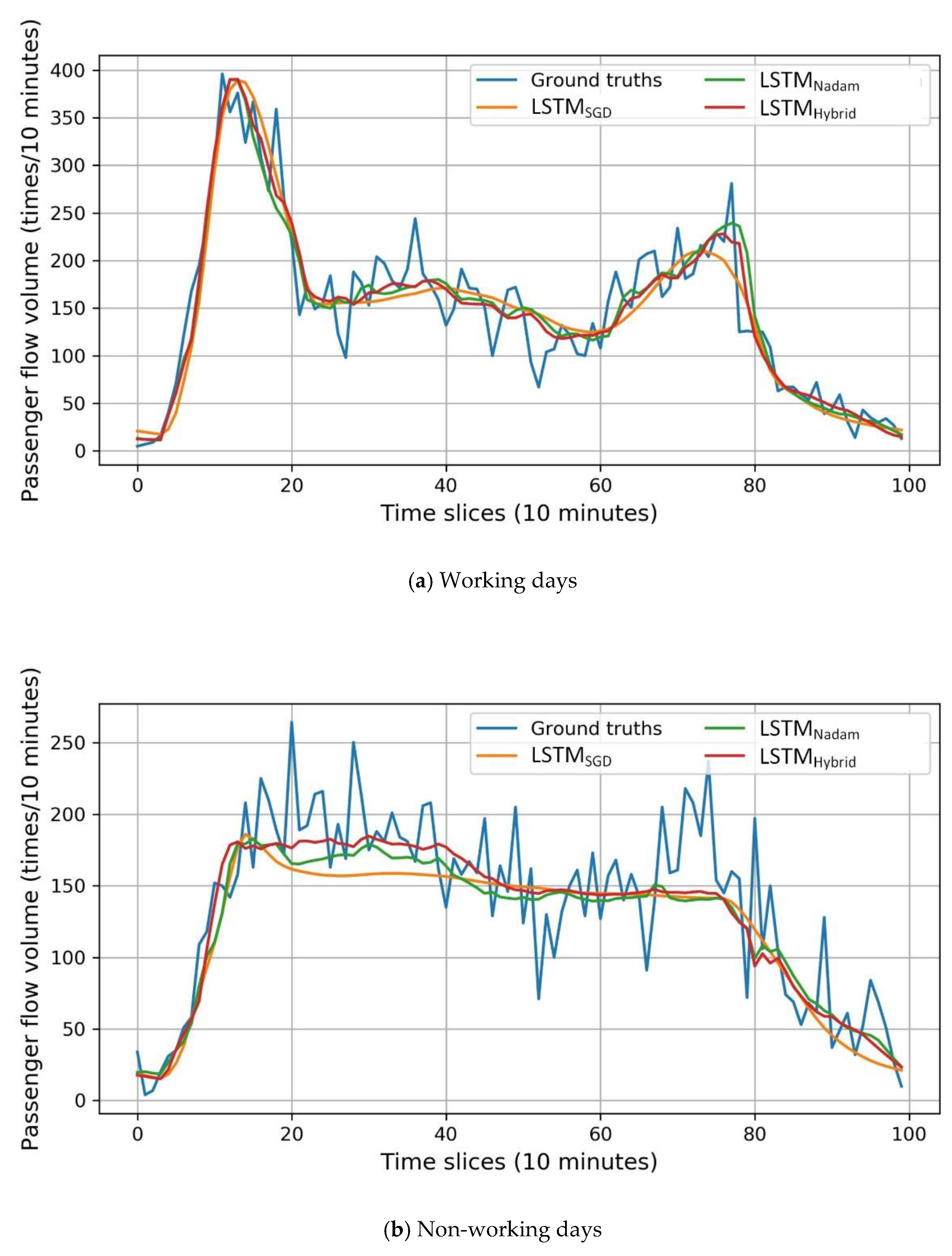
4.4.4. Temporal Analysis
In the previous section, we compared the performance of the LSTMHybrid model with LSTMSGD and LSTMNadam as a whole. In this section, we extend the analysis to different kinds of temporal scales.
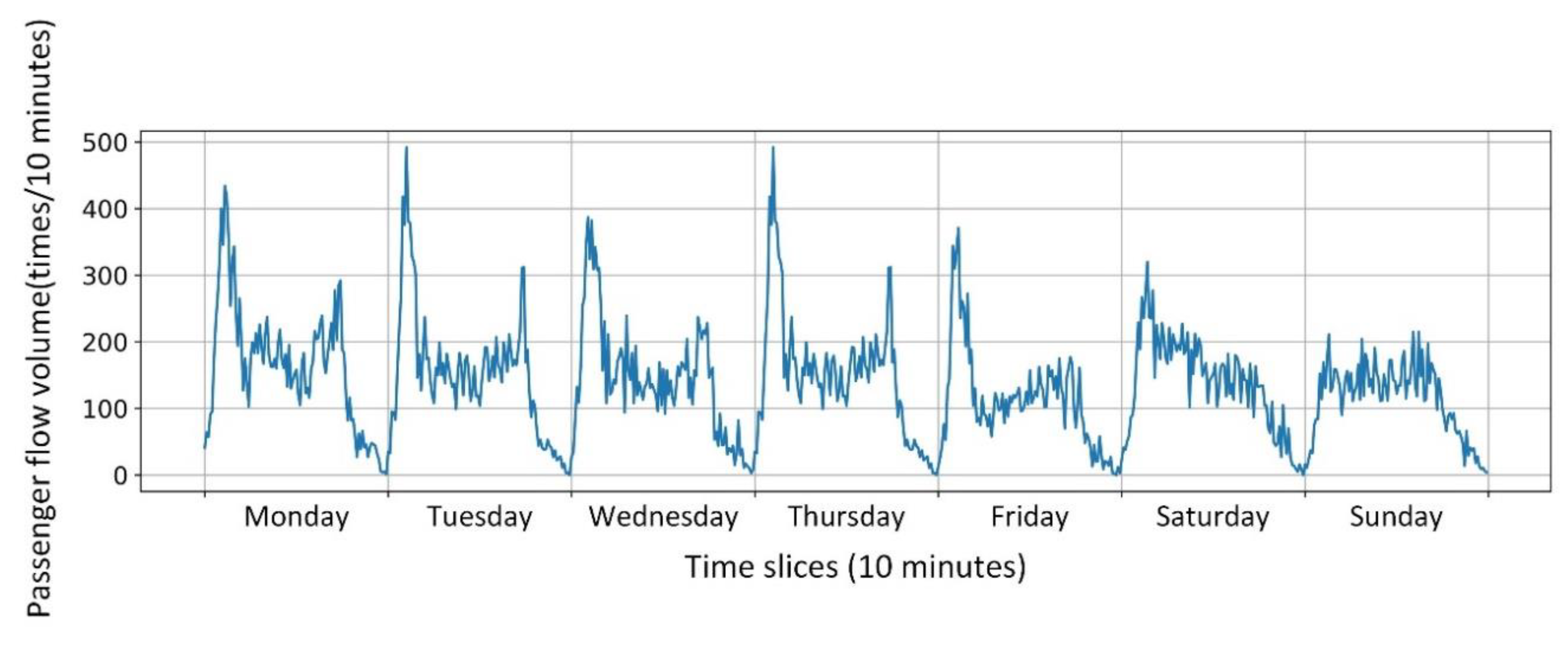
As shown in
Figure 8, the passenger flow on working days and non-working days has different variations.
Table 7 shows the performance of each model on working days and non-working days, through which we find that the LSTM
Hybrid model outperforms the other two LSTM models with traditional algorithms on both working days and non-working days.
On working days, the LSTM
Hybrid model has an 8.48% relative reduction in MAE, a 17.93% relative reduction in MAPE and a 6.07% relative reduction in RMSE compared with the LSTM
SGD model. For the LSTM
Nadam model, the LSTM
Hybrid model has a 2.93% relative reduction in MAE, a 1.19% relative reduction in MAPE, and a 5.94% relative reduction in RMSE. The predicted passenger flow on a working day (27 March 2016) is drawn in
Figure 14a, through which we can see that the LSTM
Hybrid model fits each peak of the curve, showing good robustness.
On non-working days, the errors of all three models have increased, which is mainly caused by the small number of training samples. However, the LSTM
Hybrid model still outperforms the other two models. Compared with the LSTM
SGD model, the LSTM
Hybrid model has a 13.92% relative reduction in MAE, a 9.65% relative reduction in MAPE, and a 9.54% relative reduction in RMSE. For the LSTM
Nadam model, the LSTM
Hybrid model has a 6.39% relative reduction in MAE, a 7.09% relative reduction in MAPE, and a 4.15% relative reduction in RMSE. The predicted passenger flow on a non-working day (29 March 2016) is drawn in
Figure 14b.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}