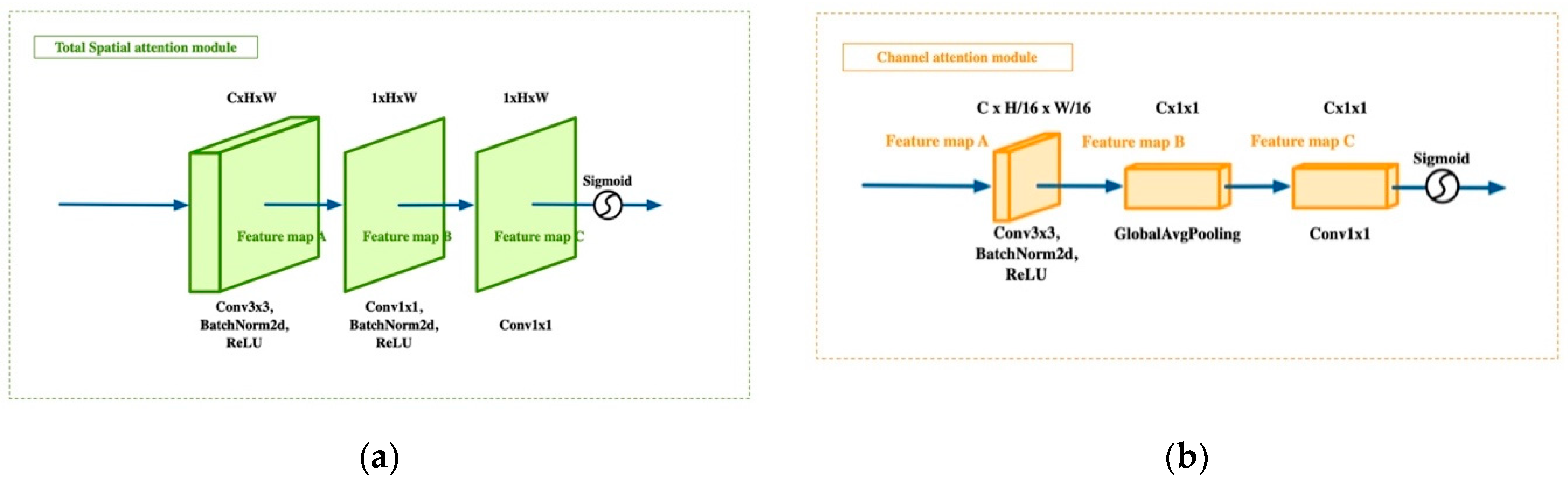
4.3.1. Ablation Study of Total Spatial Attention Module-Related Improvements
Numerous approaches have used channel and spatial attention modules in recent years [
20,
22,
26]. Most use the feature map, F
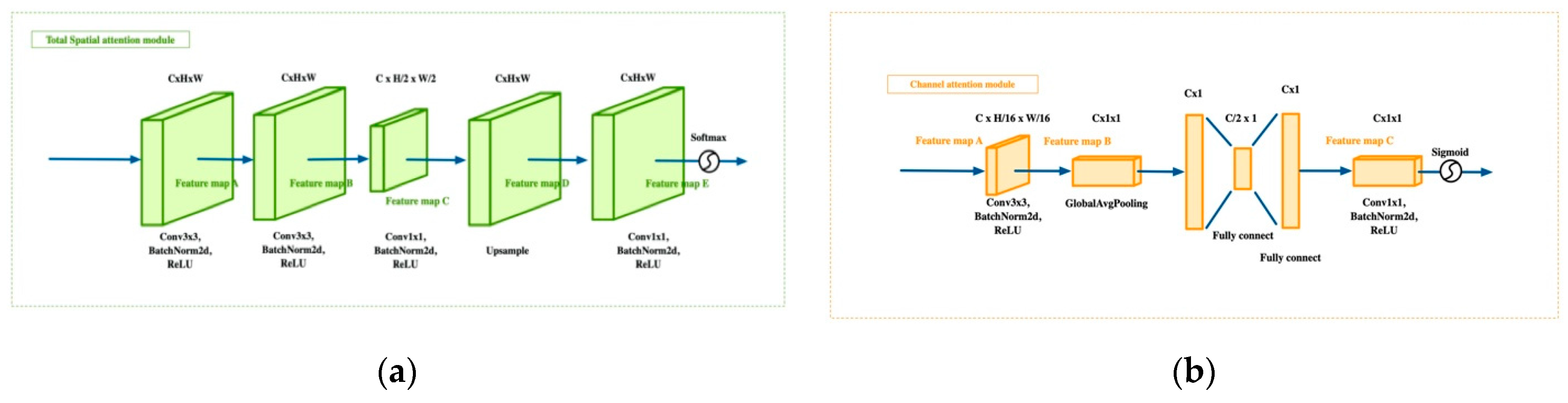
1, as input (see
Figure 2). In our total spatial attention module (TSAM), the basic idea of a spatial attention module is modified by moving its location and simplifying the structure to ensure the method’s overall simplicity. The part to be played by a CAM is well-established, so there is no need to repeat studies of the CAM here. Therefore, our experiments primarily focused on the potential improvements arising from using a TSAM.
As the TSAM extracts features from the original image, it is possible that a lack of advanced semantic information might affect its effectiveness. To assess this possibility, we extracted a spatial weighting factor matrix from the backbone and fused it with the TSAM’s output to increase the high-level semantic information. Then, a method without any high-level spatial attention (HLSA) was compared with methods that use high-level spatial attention in various ways. We used PSP-Net for the experiment (DPA-PSP-Net) because DPA-Net can be appended to any network. The experiment showed that using the TSAM without HLSA for the original image was sufficiently effective. It delivered results of 82.75% for Acc and 67.92% for the mean IoU. HLSA did not improve the network performance, so we did not employ it. The experimental results are shown in
Table 1.
As a network deepens, the feature map becomes smaller, and the spatial information decreases. This was the basis of our reasoning that it would be more effective to capture the spatial information from the original image. To verify this assumption, we calculated the TSAM for three different locations in the model: at the beginning, in the middle, and at the end of the backbone. ResNet consists of five blocks in series. We chose the original image, the 3rd block’s ResNet output and the 5th block’s ResNet output as the TSAM input. The feature maps corresponding to the blocks in ResNet were 1, 1/4, and 1/8 times the size of the original image. As shown in
Table 2, the performance of the TSAM improved in line with an increase in the input size, confirming that our initial conjecture was correct.
To assess the effect of the depth of the TSAM, we tested different numbers of parameters to find the most efficient structure. We only changed the number of layers before the layer that makes up the feature map’s channel 1. In other words, we kept the last two 1 × 1 convolutions and increased or decreased the number of 3 × 3 convolutions. The experimental results show that the performance was most effective when there were three layers in the TSAM.
Table 3 shows the results for models using different numbers of layers.
4.3.2. Ablation Study for Both Attention Modules
In order to assess any potential differences between the effect of the two modules on improving the remote sensing semantic segmentation performance, we conducted experiments with different combinations. The results are shown in
Table 4.
Table 4 makes evident the performance improvements brought about by using both the CAM and the TSAM. Compared with a baseline PSP-Net, applying a CAM delivered a mean IoU result of 66.90% and an F1-score of 71.45%, which amounts to a 1.52% and 7.48% improvement, respectively. Employing just a TSAM increased the mean IoU to 67.37% and F1-score to 6.07%. However, the biggest performance improvement came from using both modules together. When we integrated the CAM and TSAM, the mean IoU result was 67.92%, which was 2.54% higher than the baseline. The F1-score result was 72.56%, which was 8.59% higher than the baseline. These experimental results confirm that the dual path attention approach with two modules is a more effective strategy for improving the performance of semantic segmentation models on remote sensing images.
We also considered the feasibility of a Squeeze-and-Excitation(SE) operation, so we added SE operations to CAM and TSAM for comparative experiments. The structure is illustrated in
Figure 8. For TSAM, we add a convolutional layer to reduce its size to H/2 × W/2. Then, we used an upsampling operation to restore it to its original size. For CAM, we used a fully connected layer to reshape its size to C/2 × 1 and restore it. The output of TSAM was also changed to 16 channels, i.e., the number of channels and the number of land cover types were the same. The experimental results are shown in
Table 5.
We noticed that the performance of TSAM using Squeeze-and-Excitation operations was not always as good as expected. The structure of the attention module also became more complex, although its performance was not better. The mean IoU results for the SE operations were also lower than the results using our method by 0.59%, 1.21%, and 0.44% for U-Net, PSP-Net, and Deeplab V3+, respectively. The F1-score results for the SE operations were lower than those produced by our proposed method by 1.30%, 6.81%, and 0.21%, respectively. This may be because the function of the Squeeze-and-Excitation operation is to remove redundant information. However, our CAM focuses on the features of categories and is no longer able to remove redundancy. The purpose of setting the TSAM input as the original image is to have better resolution, retain better state features, and provide a better positioning function. Therefore, the Squeeze-and-Excitation operation may not be best applied to a TSAM.
4.3.3. Comparison with Different Models
In view of the small amount of GID data, we used augmentation to offset the potential problem of network overfitting. To verify the validity of our chosen augmentation method, we conducted experiments where we trained DPA-Net on the U-Net, PSP-Net, and DeepLab V3+ semantic segmentation models, using the original dataset and the augmented dataset. The results are shown in
Table 6.
The results indicate that the augmentation strategy we employed was effective. The semantic segmentation mean IoU increased to 67.07%, 67.92%, and 67.37% for U-Net, PSP-Net, and DeepLab V3+, respectively. The F1-score increased to 65.75%, 72.56%, and 67.31% for the above techniques, respectively. This suggests that augmentation strategies can enhance the scope for network generalization by enriching the data.
To verify the effectiveness of our method in relation to actual remote sensing image segmentation tasks, we compared it against more mainstream methods based on self-attention mechanisms. These methods were Non-Local NN, SE-Net, CBAM, and DA-Net. The results of the experiment are shown in
Table 7 and
Table 8.
The experimental results show that DPA-PSP-Net provided the most effective semantic segmentation. SE-Net was the next most effective. The mean IoUs for the supposedly stronger CBAM and DA-Net were only 65.45% and 64.67%, respectively. Non-local NN and SE-Net had better F1-scores. However, they were still lower than that of DPA-PSP-Net. This confirms that the segmentation of remote sensing images is different from normal scene segmentation, so, DPA-PSP-Net may have an advantage over existing methods.
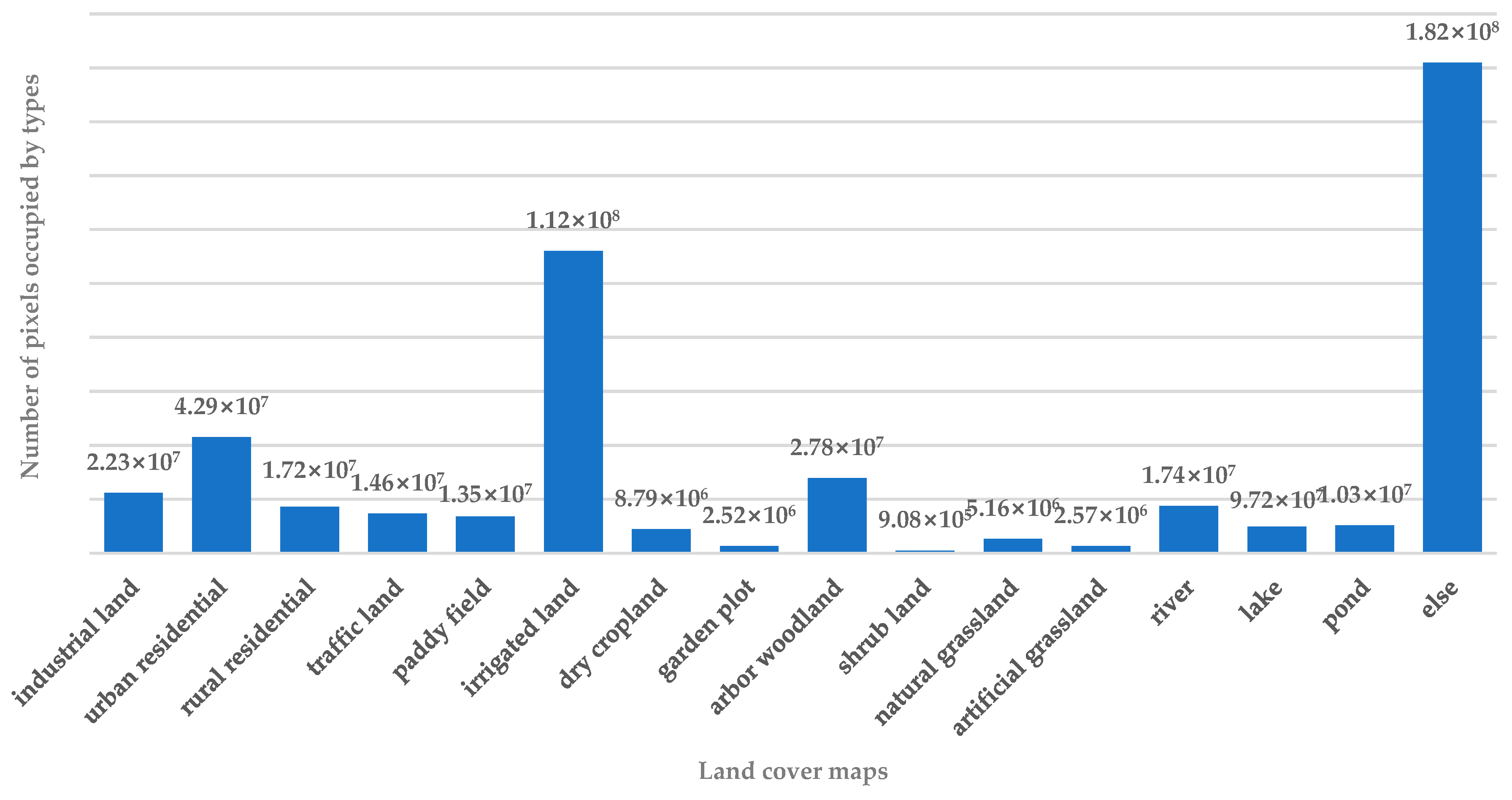
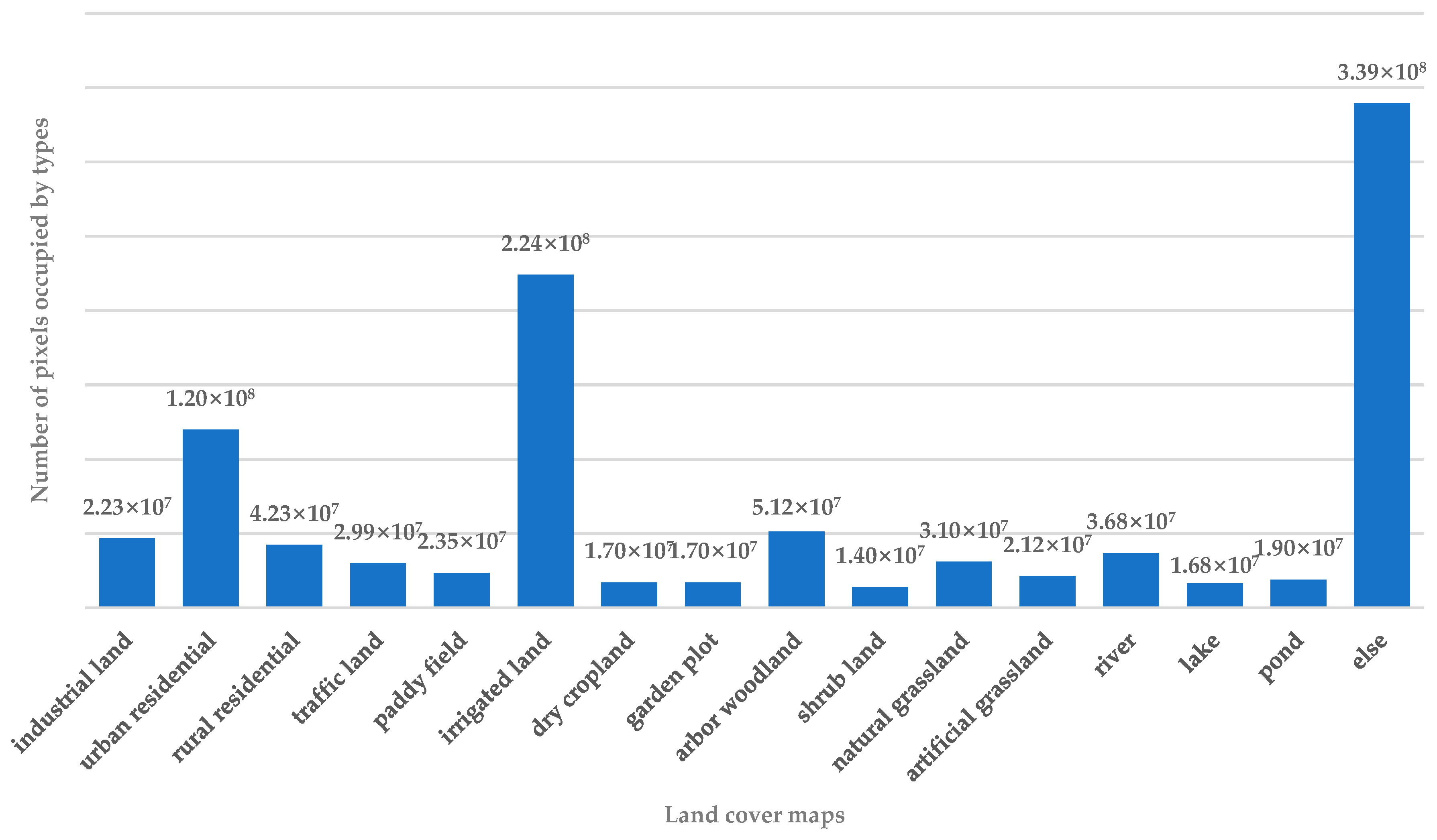
To further assess the effectiveness of the proposed method, we compared the mean IoU and F1-score for each type of land cover when using the three different models, U-Net, PSP-Net, and DeepLab V3+, with or without DPA-Net.
As shown in
Table 9 and
Table 10, every model performed better with DPA-Net than it did on its own. Note in particular that although PSP-Net had lower mean IoU results than U-Net and DeepLab V3+ on its own, DPA-PSP-Net outperformed any other approach. The same is true for the F1-scores. Another point to note is that because the distribution of shrubbery woodland was so small, no network had a good way of capturing its key features, so every approach had poor results. However, this did not change the fact that DPA-Net still improved the segmentation model. Several visual comparisons using PSP-Net as an example are shown in
Figure 9.
The output of TSAM is shown in the rightmost column in
Figure 9. Although the input of TSAM is the original image, the output does not seem to include a lot of noise. For some position attention modules, such as “lake” in the second row and “dry cropland” in the last row, the details and boundaries are even more clear. These results reveal the effectiveness of the visualized weighting factors of TSAM.
To further assess the contribution made by TSAM to DPA-Net, we visualized the differences in the output of DPA-Net with different forms of attention. We randomly selected a test image as shown in
Figure 10. We first compared the output of DPA-Net with just CAM, then with both TSAM and CAM, while saving the output feature maps that passed the softmax function. The size of these two feature maps was (C, H, W). Then, we performed an L1 Norm operation on these two feature maps for the C dimension, yielding a heat map with a size of (1000, 1000). This is shown in the right-hand column of
Figure 10.
This heat map shows the difference in output between DPA-Net with TSAM and without TSAM. The brighter the highlight, the greater the contribution of TSAM. In the images, we can see that the river and the lake areas are relatively pronounced. This means that the contribution of TSAM was especially significant in these regions. This heat map makes the contribution of TSAM to the overall prediction evident.
We also counted the Multiplication and Accumulation (MAC) results for DPA-Net and the number of parameters required, and then, we compared them with the original U-Net, PSP-Net, and DeepLab V3+ models. As can be seen in
Table 11, the MAC results only increased by 0.07G, 0.223G, and 0.069G, respectively, across the three models, and the number of parameters only increased by 0.075M, 0.077M, and 0.075M, respectively. This shows that compared with the original method, DPA-Net only increases the memory footprint by a small amount.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}