Concept Lattice Method for Spatial Association Discovery in the Urban Service Industry



Abstract
:1. Introduction
2. Prerequisite Knowledge
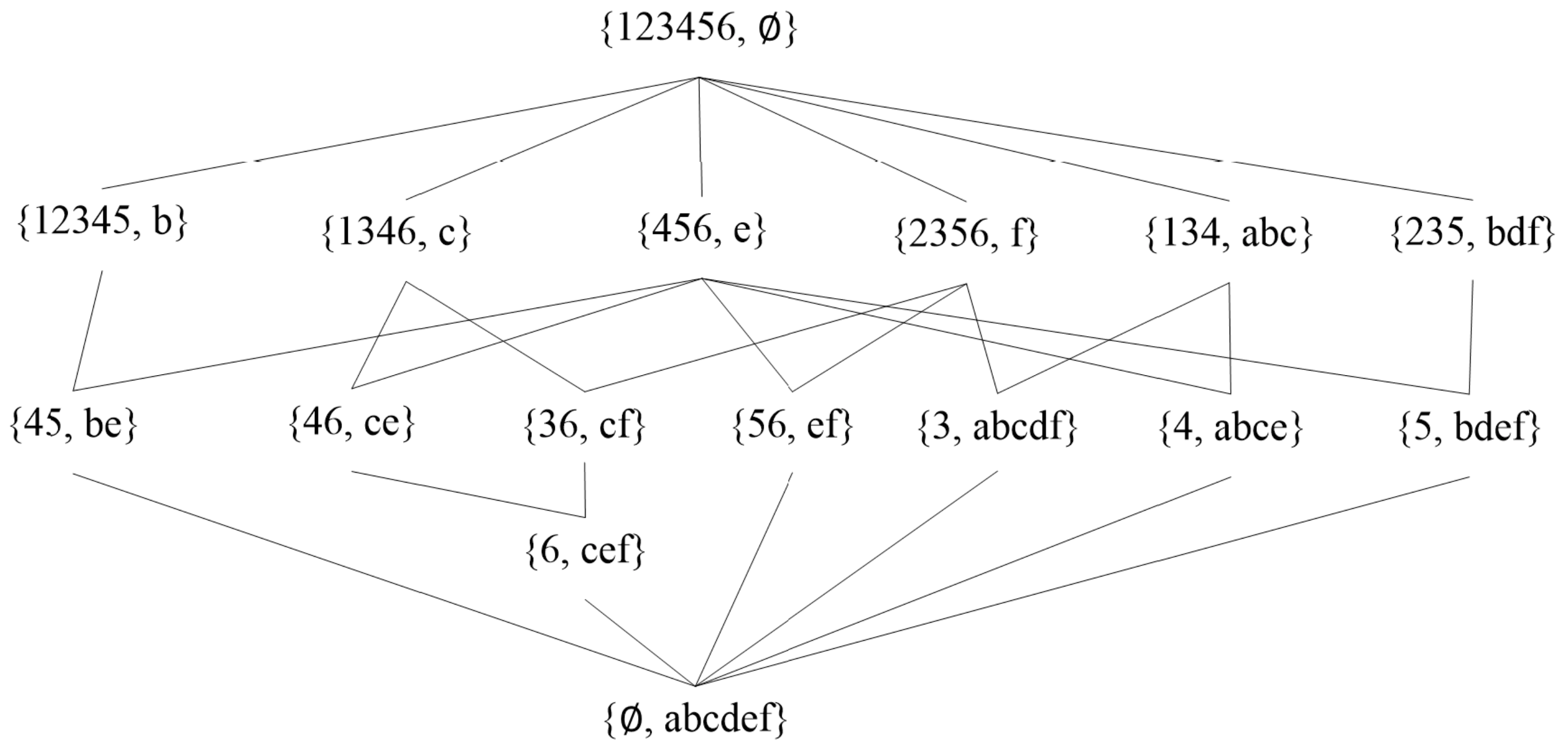
2.1. Concept Lattices
2.2. Frequent Closed Itemset
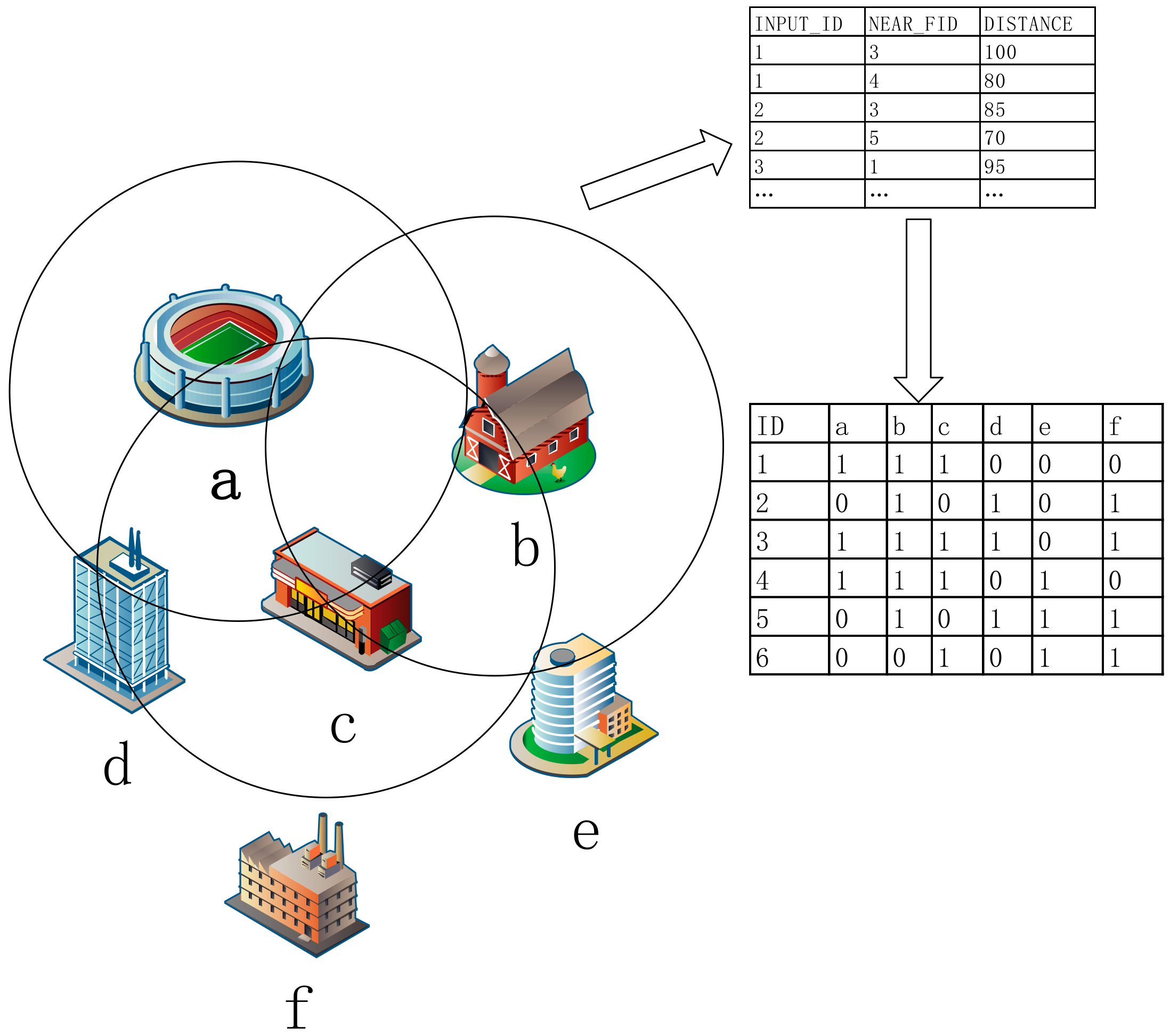
2.3. Spatial Association Rule
3. Spatial Association Discovery
3.1. Frequent Closed Itemset Discovery
- (1)
- Each node of the concept lattice is a closed itemset, but it is not necessarily a frequent closed itemset.
- (2)
- All intent sets of the concept lattice are equal to a collection of closed itemsets that can be derived from a spatial transaction database.
- (3)
- Frequent closed itemsets can filter out redundant information in frequent itemsets. This not only can determine the frequency information of all frequent itemsets, but is also several orders of magnitude smaller than frequent itemsets.
| Algorithm 1. | Frequent Closed Itemsets Lattice Discovery. |
| Input: | Formal context , frequent threshold ; |
| Output: | Frequent closed itemsets lattice ; |
| 1. | Let ; |
| 2. | FOR (each and ) DO |
| 3. | FOR (each concept ) DO |
| 4. | Let s.t. ; |
| 5. | Let when ; |
| 6. | IF(there is no s.t. ) THEN |
| 7. | IF(there is no s.t. ) THEN |
| 8. | Generate concept ; |
| 9. | Let ; |
| 10. | Update-; //Update the relationship. |
| 11. | ENDIF |
| 12. | ENDIF |
| 13. | ENDFOR |
| 14. | ENDFOR |
| Algorithm 2. | Update the Relationship of a New Concept. |
| Input: | New concept ; |
| Output: | New FL; |
| Method: | Update-; |
| 1. | // Step 1. Add all candidate parents and children relationships. |
| 2. | FOR (each concept ) DO |
| 3. | IF() THEN |
| 4. | .children =.children and .parent =.parent ; |
| 5. | ELSE IF() |
| 6. | .parent =.parent and .children =.children ; |
| 7. | ENDIF |
| 8. | ENDFOR |
| 9. | // Step 2. Remove redundant parents and children relationships. |
| 10. | FOR(each concept .parent and .parent) DO |
| 11. | Remove the edge/relationship between and if ; |
| 12. | ENDFOR |
| 13. | FOR(each concept .children and .children) DO |
| 14. | Remove the edge/relationship between and if ; |
| 15. | ENDFOR |
| 16. | // Step 3. Remove redundant grandpas and grandchildren relationships. |
| 17. | FOR(each concept .parent and .children) DO |
| 18. | Remove the edge/relationship between and if .children or .parent; |
| 19. | ENDFOR |
3.2. Spatial Association Rule Discovery
- For each frequent closed itemset, all of the non-empty subsets are generated;
- For each non-empty subset of , if , then is exported.
| Algorithm 3. | Generate Association Rules. |
| Input: | , confidence threshold ; |
| Output: | The set of association rules ; |
| Method: | GAR; |
| 1. | Initialize ; // The set of association rules. |
| 2. | FOR (each concept and ) DO |
| 3. | |
| 4. | FOR (each ) DO |
| 5. | = ; |
| 6. | IF () THEN |
| 7. | ; |
| 8. | ELSE |
| 9. | ; |
| 10. | ENDIF |
| 11. | ENDFOR |
| 12. | Longer-Rules(); |
| 13. | ENDFOR |
| Algorithm 4. | Generate Association Rules with Longer Result. |
| Input: | Concept the set of subset with length ; |
| Method: | Longer-Rules; |
| 1. | IF() THEN |
| 2. | Growth(); |
| 3. | FOR (each ) DO |
| 4. | = |
| 5. | IF () THEN |
| 6. | ; |
| 7. | ELSE |
| 8. | ; |
| 9. | ENDIF |
| 10. | Call Generate-Rules(); |
| 11. | ENDFOR |
| 12. | ENDIF |
4. Case Study
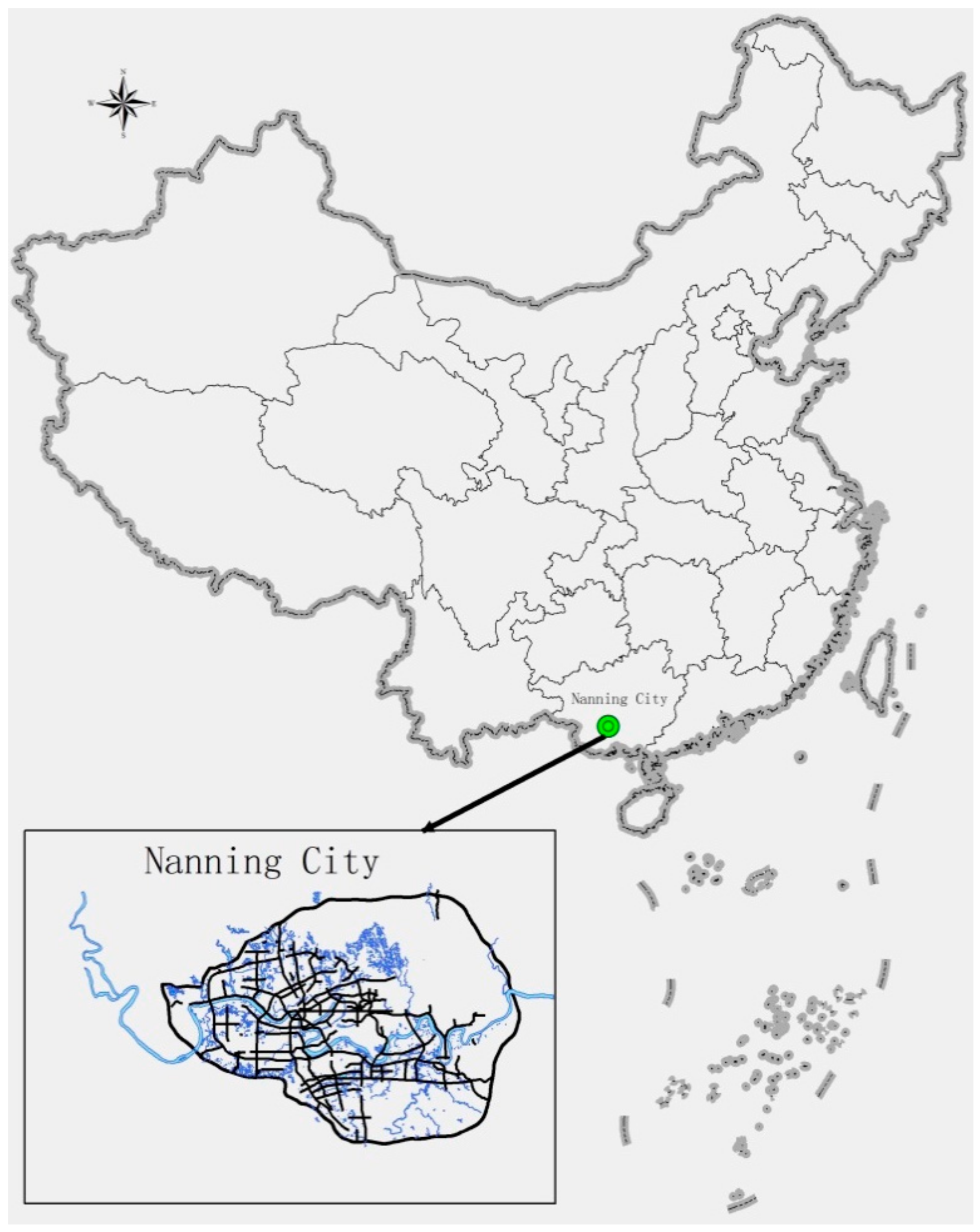
4.1. Research Area and Data Sources
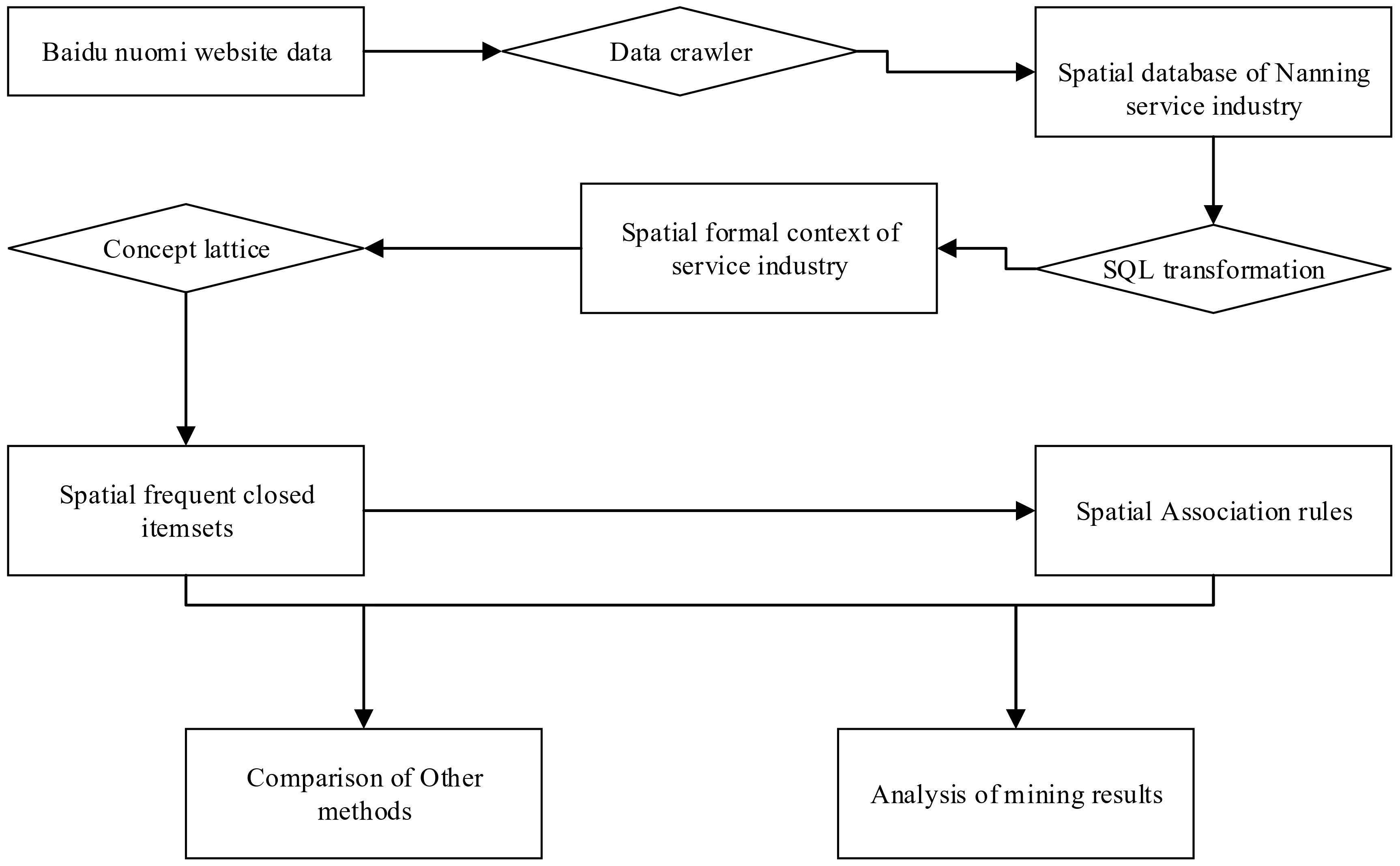
4.2. Computing Framework
4.3. Results Analysis
5. Discussions
5.1. Methods of Evaluation
5.2. Spatial Association Discovery
5.3. Limitations and Recommendations for Future Research
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Akın, D.; Dökmeci, V. Cluster analysis of interregional migration in Turkey. J. Urban Plan. Dev. 2014, 141, 05014016. [Google Scholar] [CrossRef]
- Croitoru, A.; Wayant, N.; Crooks, A.; Radzikowski, J.; Stefanidis, A. Linking cyber and physical spaces through community detection and clustering in social media feeds. Comput. Environ. Urban Syst. 2015, 53, 47–64. [Google Scholar] [CrossRef]
- Lin, J.; Cromley, R.G. Evaluating geo-located Twitter data as a control layer for areal interpolation of population. Appl. Geogr. 2015, 58, 41–47. [Google Scholar] [CrossRef]
- Shelton, T.; Poorthuis, A.; Graham, M.; Zook, M. Mapping the data shadows of Hurricane Sandy: Uncovering the sociospatial dimensions of ‘big data’. Geoforum 2014, 52, 167–179. [Google Scholar] [CrossRef]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban computing: Concepts, methodologies, and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2014, 5, 38–55. [Google Scholar] [CrossRef]
- Zheng, Y. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Trans. Big Data 2015, 1, 16–34. [Google Scholar] [CrossRef]
- Athey, S. Beyond prediction: Using big data for policy problems. Science 2017, 355, 483–485. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. Proc. SIGMOD 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Yu, W. Identifying and Analyzing the Prevalent Regions of a Co-Location Pattern Using Polygons Clustering Approach. ISPRS Int. J. Geo-Inf. 2017, 6, 259. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Lin, J.C.-W.; Shao, Y.; Fournier-Viger, P.; Djenouri, Y. Maintenance of Discovered High Average-Utility Itemsets in Dynamic Databases. Appl. Sci. 2018, 8, 769. [Google Scholar] [CrossRef] [Green Version]
- Wille, R. Restructuring lattice theory: An approach based on hierarchies of concepts. In Ordered Sets; Springer: Dordrecht, The Netherlands, 1982; pp. 445–470. [Google Scholar]
- Yen, S.J.; Lee, Y.S.; Wang, C.K. An efficient algorithm for incrementally mining frequent closed itemsets. Appl. Intell. 2014, 40, 649–668. [Google Scholar] [CrossRef]
- Kao, L.J.; Huang, Y.P.; Sandnes, F.E. Associating absent frequent itemsets with infrequent items to identify abnormal transactions. Appl. Intell. 2015, 42, 694–706. [Google Scholar] [CrossRef]
- Hamrouni, T.; Yahia, S.B.; Nguifo, E.M. Looking for a structural characterization of the sparseness measure of (frequent closed) itemset contexts. Inf. Sci. 2013, 222, 343–361. [Google Scholar] [CrossRef]
- Wang, J.; Han, J.; Pei, J. Closet+: Searching for the best strategies for mining frequent closed itemsets. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 2003; pp. 236–245. [Google Scholar]
- Grahne, G.; Zhu, J. Fast algorithms for frequent itemset mining using fp-trees. IEEE Trans. Knowl. Data Eng. 2005, 17, 1347–1362. [Google Scholar] [CrossRef]
- Zou, C.; Zhang, D.; Wan, J.; Hassan, M.M.; Lloret, J. Using concept lattice for personalized recommendation system design. IEEE Syst. J. 2017, 11, 305–314. [Google Scholar] [CrossRef]
- Kuo, R.; Hsu, C.K.; Chang, M.; Heh, J.S. A personalized webpage reconstructor based on concept lattice and association rules. J. Internet Technol. 2011, 12, 1015–1024. [Google Scholar]
- Kim, J.; Chung, H.J.; Jung, Y.; Kim, K.K.; Kim, J.H. BioLattice: A framework for the biological interpretation of microarray gene expression data using concept lattice analysis. J. Biomed. Inform. 2008, 41, 232–241. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; He, Z.; Zhu, Q. An entropy-based weighted concept lattice for merging multi-source geo-ontologies. Entropy 2013, 15, 2303–2318. [Google Scholar] [CrossRef]
- Xie, J.; Yang, M.; Li, J.; Zheng, Z. Rule acquisition and optimal scale selection in multi-scale formal decision contexts and their applications to smart city. Future Gener. Comput. Syst. 2018, 83, 564–581. [Google Scholar] [CrossRef]
- Liao, W.; Hou, D.; Jiang, W. An Approach for a Spatial Data Attribute Similarity Measure Based on Granular Computing Closeness. Appl. Sci. 2019, 9, 2628. [Google Scholar] [CrossRef] [Green Version]
- Sikder, I. A variable precision rough set approach to knowledge discovery in land cover classification. Int. J. Digit. Earth 2016, 9, 1206–1223. [Google Scholar] [CrossRef]
- Zheng, D.; Li, C. Research on Spatial Pattern and Its Industrial Distribution of Commercial Space in Mianyang Based on POI Data. J. Data Anal. Inf. Process. 2020, 8, 20–40. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.; Wang, Z.; Mu, H.; Sun, L.; Hu, F. Identification of Urban Functional Regions Based on Floating Car Track Data and POI Data. Sustainability 2019, 11, 6541. [Google Scholar] [CrossRef] [Green Version]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Tate, J. Relations between K 2 and Galois cohomology. Invent. Math. 1976, 36, 257–274. [Google Scholar] [CrossRef]
- Min, F.; Wu, Y.; Wu, X. The Apriori property of sequence pattern mining with wildcard gaps. In Proceedings of the 2010 IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW), Hong Kong, China, 18 December 2010; pp. 138–143. [Google Scholar]
- Li, J.; Mei, C.; Wang, J.; Zhang, X. Rule-preserved object compression in formal decision contexts using concept lattices. Knowl. Based Syst. 2014, 71, 435–445. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequent Itemsets | Frequent Closed Itemsets | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Itemsets | Support | Itemsets | Support | Itemsets | Support | Closed Itemsets | Support | Closed Itemsets | Support |
| 83 | 50 | 50 | 83 | 33 | |||||
| 67 | 50 | 33 | 67 | 33 | |||||
| 67 | 50 | 50 | 50 | 33 | |||||
| 50 | 33 | 67 | 33 | ||||||
| 50 | 33 | 50 | 50 | - | - | ||||
| 50 | 33 | 50 | 83 | - | - | ||||
| Rules | Support | Confidence | Rules | Support | Confidence |
|---|---|---|---|---|---|
| 50% | 100% | 50% | 100% | ||
| 50% | 100% | 33.3% | 100% | ||
| 50% | 100% | 50% | 75% | ||
| 50% | 75% | 50% | 75% | ||
| 50% | 75% | 50% | 75% | ||
| 50% | 75% | 50% | 100% | ||
| 50% | 100% | 50% | 100% | ||
| 50% | 100% | 50% | 100% |
| 2-itemsets | Support |
|---|---|
| {Sweet Drinks, Snack Food} | 0.47 |
| {Beauty, Snack Food} | 0.445 |
| {Cake, Snack Food} | 0.409 |
| {Other Food, Snack Food} | 0.401 |
| {Sweet Drinks, Beauty} | 0.359 |
| {Sweet Drinks, Cake} | 0.35 |
| {All Chinese Food, Snack Food} | 0.342 |
| {Cake, Beauty} | 0.339 |
| {Sweet Drinks, Other Food} | 0.327 |
| {General Hotel, Budget Hotel} | 0.306 |
| {Other Food, Beauty} | 0.303 |
| {Hot Pot, Snack Food} | 0.296 |
| {General Hotel, Snack Food} | 0.295 |
| {Cake, Other Food} | 0.28 |
| {Sweet Drinks, All Chinese Food} | 0.276 |
| {Barbecue, Snack Food} | 0.273 |
| {All Chinese Food, Beauty} | 0.268 |
| {All Chinese Food, Other Food} | 0.255 |
| {Japanese Cuisine, Snack Food} | 0.254 |
| {All Chinese Food, Cake} | 0.25 |
| 3-itemsets | Support |
|---|---|
| {Sweet Drinks, Beauty, Snack Food} | 0.336 |
| {Sweet Drinks, Cake, Snack Food} | 0.325 |
| {Sweet Drinks, Other Food, Snack Food} | 0.314 |
| {Cake, Beauty, Snack Food} | 0.311 |
| {Other Food, Beauty, Snack Food} | 0.283 |
| {Sweet Drinks, Cake, Beauty} | 0.27 |
| {Cake, Other Food, Snack Food} | 0.269 |
| {Sweet Drinks, All Chinese Food, Snack Food} | 0.268 |
| {All Chinese Food, Beauty, Snack Food} | 0.248 |
| {Sweet Drinks, Other Food, Beauty} | 0.244 |
| {All Chinese Food, Other Food, Snack Food} | 0.243 |
| {All Chinese Food, Cake, Snack Food} | 0.239 |
| {Sweet Drinks, Cake, Other Food} | 0.233 |
| {Cake, Other Food, Beauty} | 0.23 |
| {General Hotel, Budget Hotel, Snack Food} | 0.228 |
| {Hot Pot, Sweet Drinks, Snack Food} | 0.228 |
| {Sweet Drinks, Cafe/Bar/Teahouse, Snack Food} | 0.227 |
| {Sweet Drinks, Other Food, Beauty} | 0.215 |
| {Sweet Drinks, All Chinese Food, Beauty} | 0.214 |
| {Sweet Drinks, All Chinese Food, Other Food} | 0.211 |
| Rules | Support | Confidence Degree |
|---|---|---|
| {Sweet Drinks}{Snack Food} | 0.470 | 0.901 |
| {Snack Food}{Sweet Drinks} | 0.470 | 0.647 |
| {Beauty}{Snack Food} | 0.445 | 0.828 |
| {Snack Food}{Beauty} | 0.445 | 0.613 |
| {Cake}{Snack Food} | 0.409 | 0.863 |
| {Other Foods}{Snack Food} | 0.401 | 0.900 |
| {Sweet Drinks}{Beauty} | 0.359 | 0.688 |
| {Beauty}{Sweet Drinks} | 0.359 | 0.668 |
| {Cake}{Sweet Drinks} | 0.350 | 0.739 |
| {Sweet Drinks}{Cake} | 0.350 | 0.672 |
| {All Chinese Food}{Snack Food} | 0.342 | 0.886 |
| {Cake}{Beauty} | 0.339 | 0.716 |
| {Beauty}{Cake} | 0.339 | 0.631 |
| {Beauty, Sweet Drinks}{Snack Food} | 0.336 | 0.937 |
| {Sweet Drinks, Snack Food}{Beauty} | 0.336 | 0.716 |
| {Beauty, Snack Food}{Sweet Drinks} | 0.336 | 0.756 |
| {Other Foods}{Sweet Drinks} | 0.327 | 0.733 |
| {Sweet Drinks}{Other Foods} | 0.327 | 0.627 |
| {Cake, Sweet Drinks}{Snack Food} | 0.325 | 0.929 |
| {Cake, Snack Food}{Sweet Drinks} | 0.325 | 0.796 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, W.; Zhang, Z.; Jiang, W. Concept Lattice Method for Spatial Association Discovery in the Urban Service Industry. ISPRS Int. J. Geo-Inf. 2020, 9, 155. https://doi.org/10.3390/ijgi9030155
Liao W, Zhang Z, Jiang W. Concept Lattice Method for Spatial Association Discovery in the Urban Service Industry. ISPRS International Journal of Geo-Information. 2020; 9(3):155. https://doi.org/10.3390/ijgi9030155
Chicago/Turabian StyleLiao, Weihua, Zhiheng Zhang, and Weiguo Jiang. 2020. "Concept Lattice Method for Spatial Association Discovery in the Urban Service Industry" ISPRS International Journal of Geo-Information 9, no. 3: 155. https://doi.org/10.3390/ijgi9030155
APA StyleLiao, W., Zhang, Z., & Jiang, W. (2020). Concept Lattice Method for Spatial Association Discovery in the Urban Service Industry. ISPRS International Journal of Geo-Information, 9(3), 155. https://doi.org/10.3390/ijgi9030155