Towards Automatic Points of Interest Matching



Abstract
:1. Introduction
- The manner in which numbers are presented, e.g., Restaurant Paracas II in OpenStreetMap versus Paracas 2 in Yelp;
- Attribute value incompleteness, e.g., Daddy’s in Foursquare versus Daddy’s Pizza& Billiard in Yelp;
- Language differences, e.g., Doutor Coffee Shop in Foursquare versus ドトールコーヒーショップ in Yelp;
- Text formatting differences (blank spaces, word order, etc.), e.g., Caleta Rosa in Foursquare versus RosaCaleta in Yelp;
- Phone number formatting differences, e.g., 2129976801 in Foursquare versus +12129976801 in OpenStreetMap;
- URL format differences, e.g., http://www.juicepress.com in Foursquare versus https://juicepress.com in OpenStreetMap;
- Category distinctions: for instance, in OpenStreetMap an in-depth analysis of the object’s attributes is required to find and anticipate which attributes might point to the category (e.g., amenity, tourism, keys with a value of “yes” etc.);
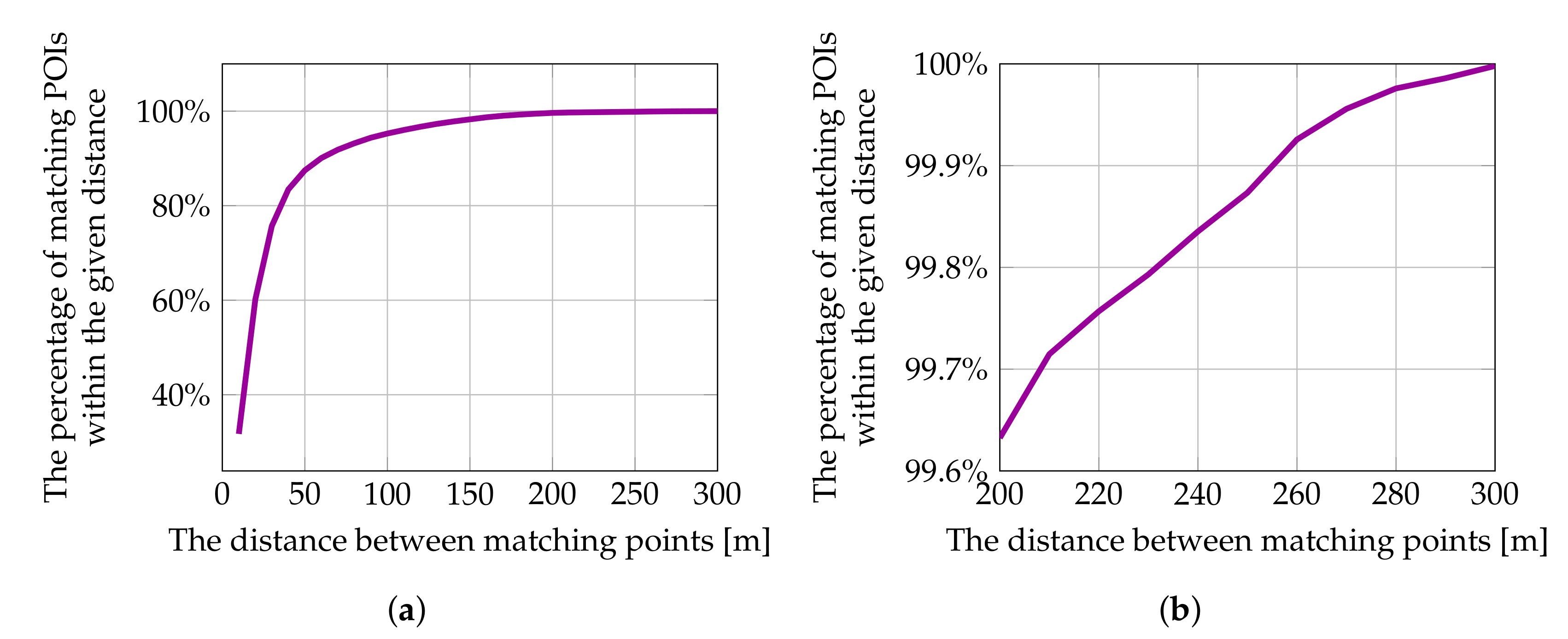
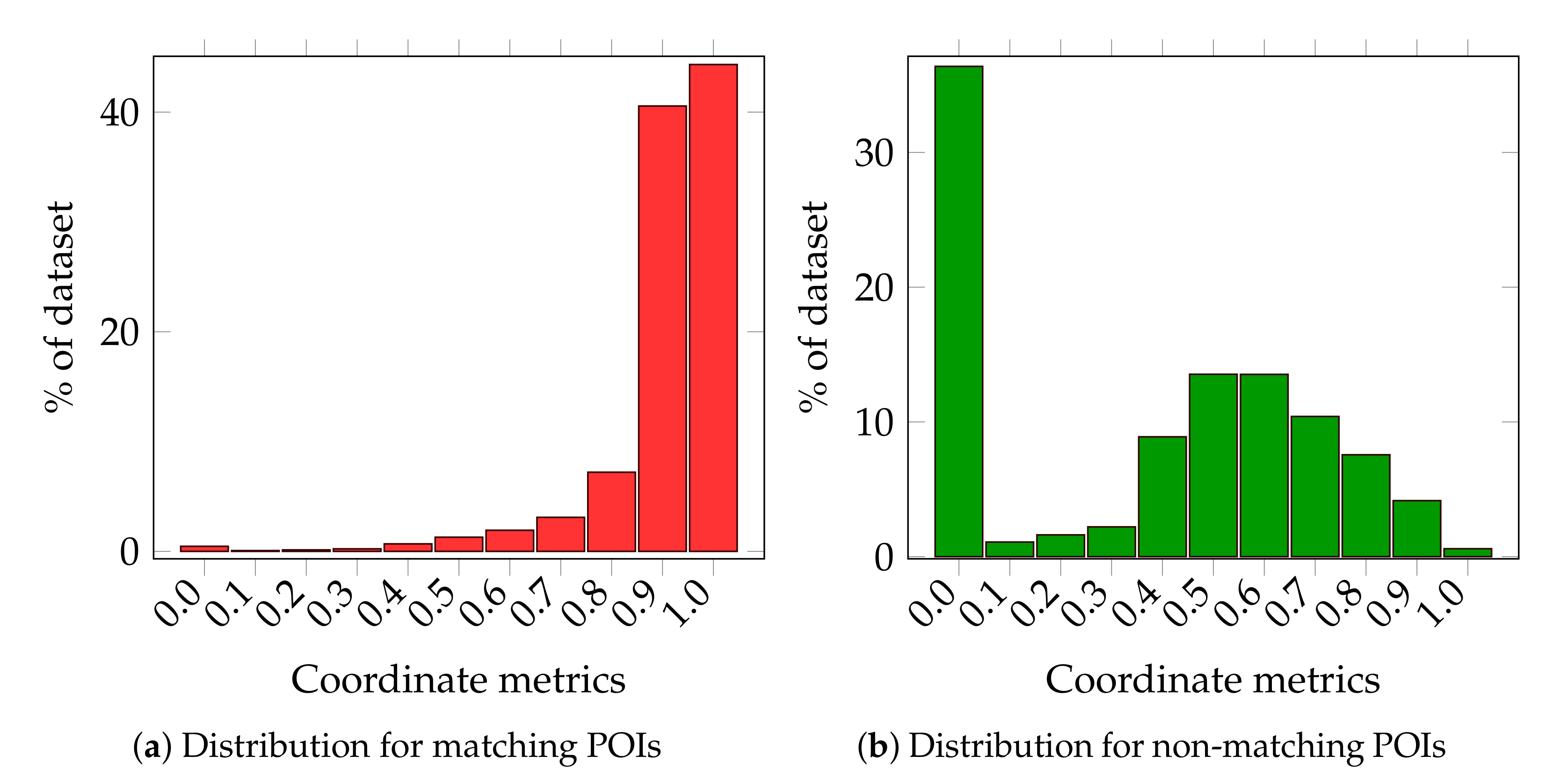
- Differences in geographical coordinates (as outlined in Section 4.1.1), which are so significant that the search radius, within which matching points in other data sources might be obtained, should be as long as 300 m to have sufficient confidence of finding a matching POI, if there is one;
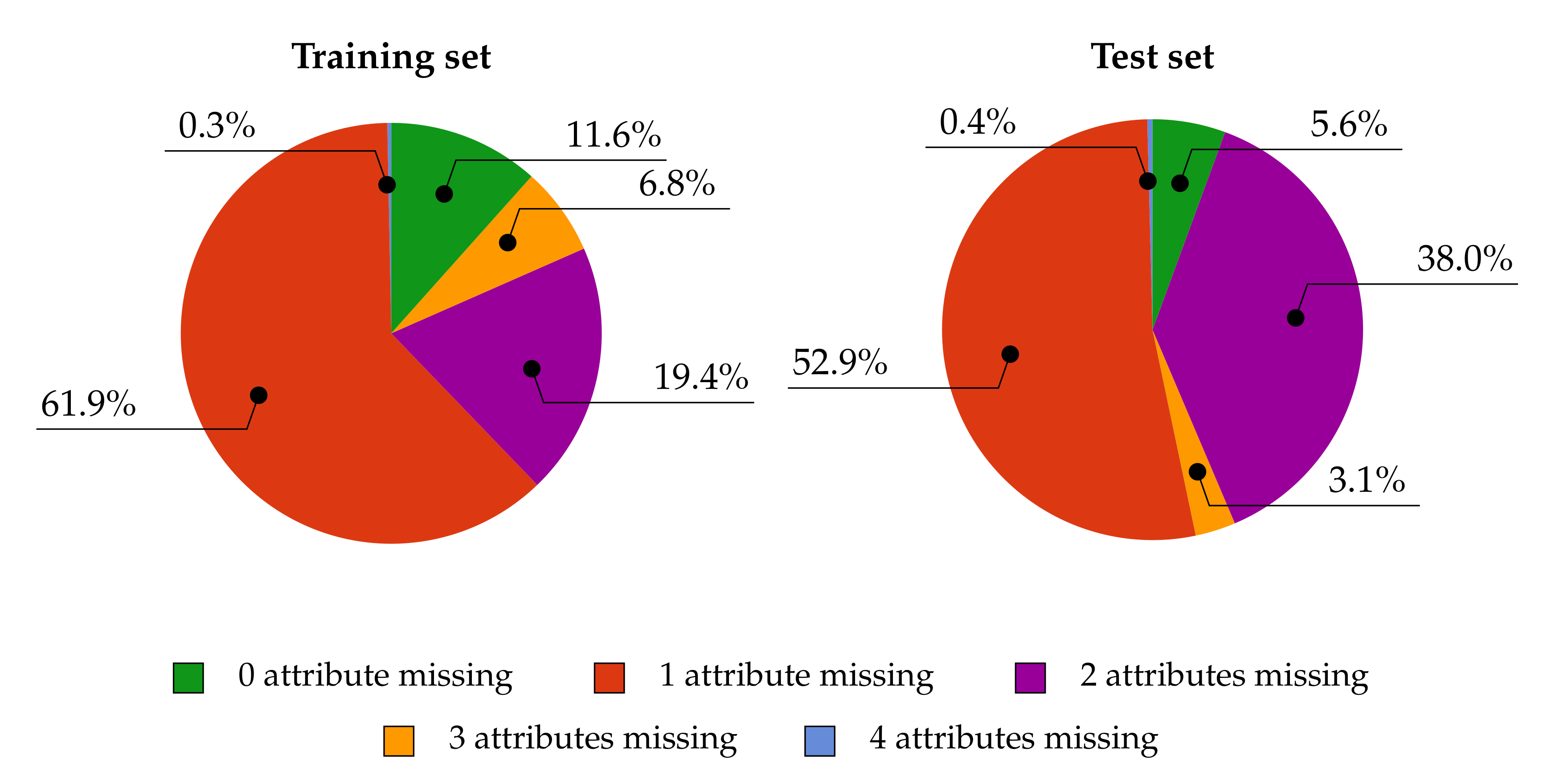
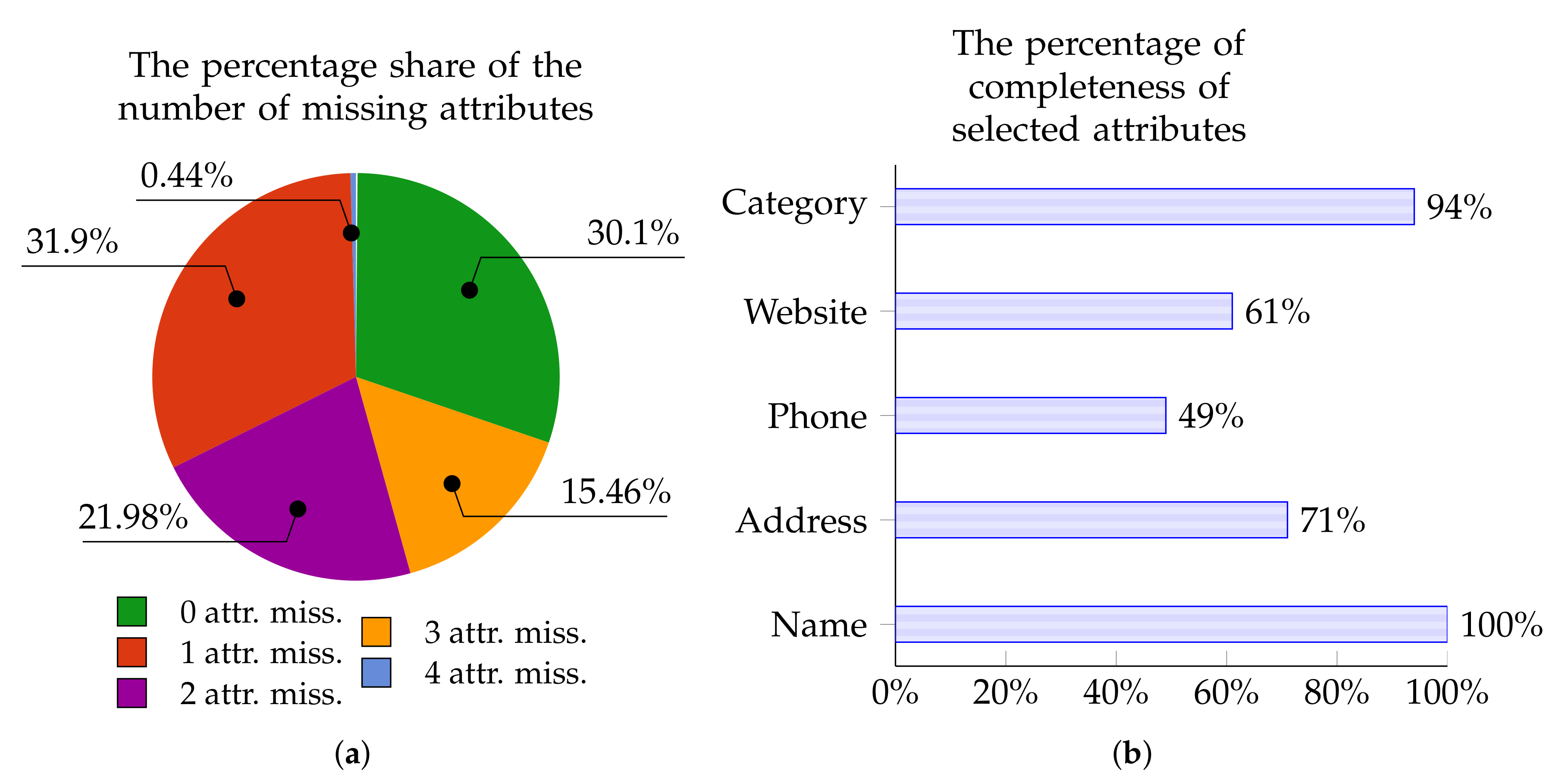
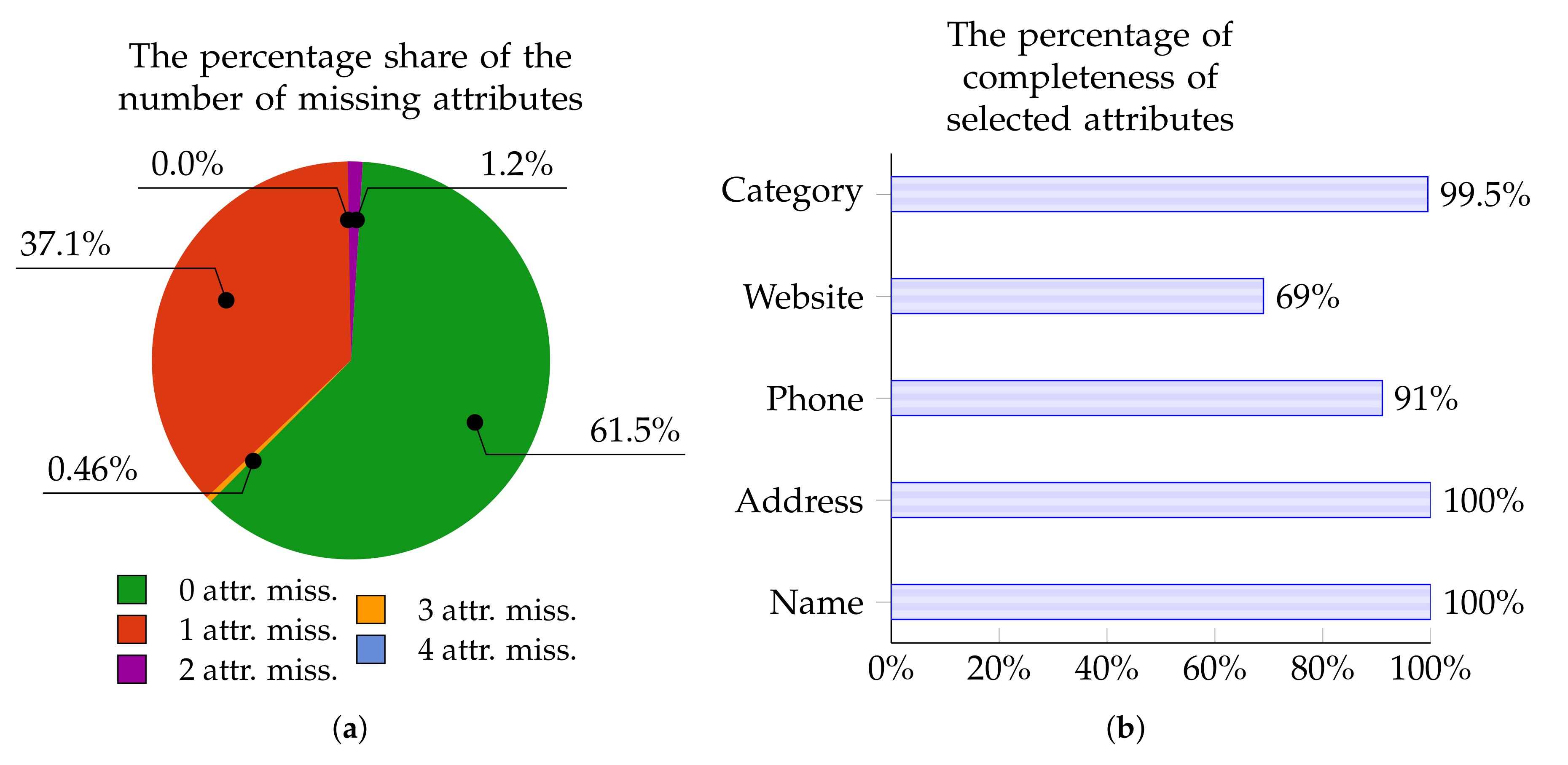
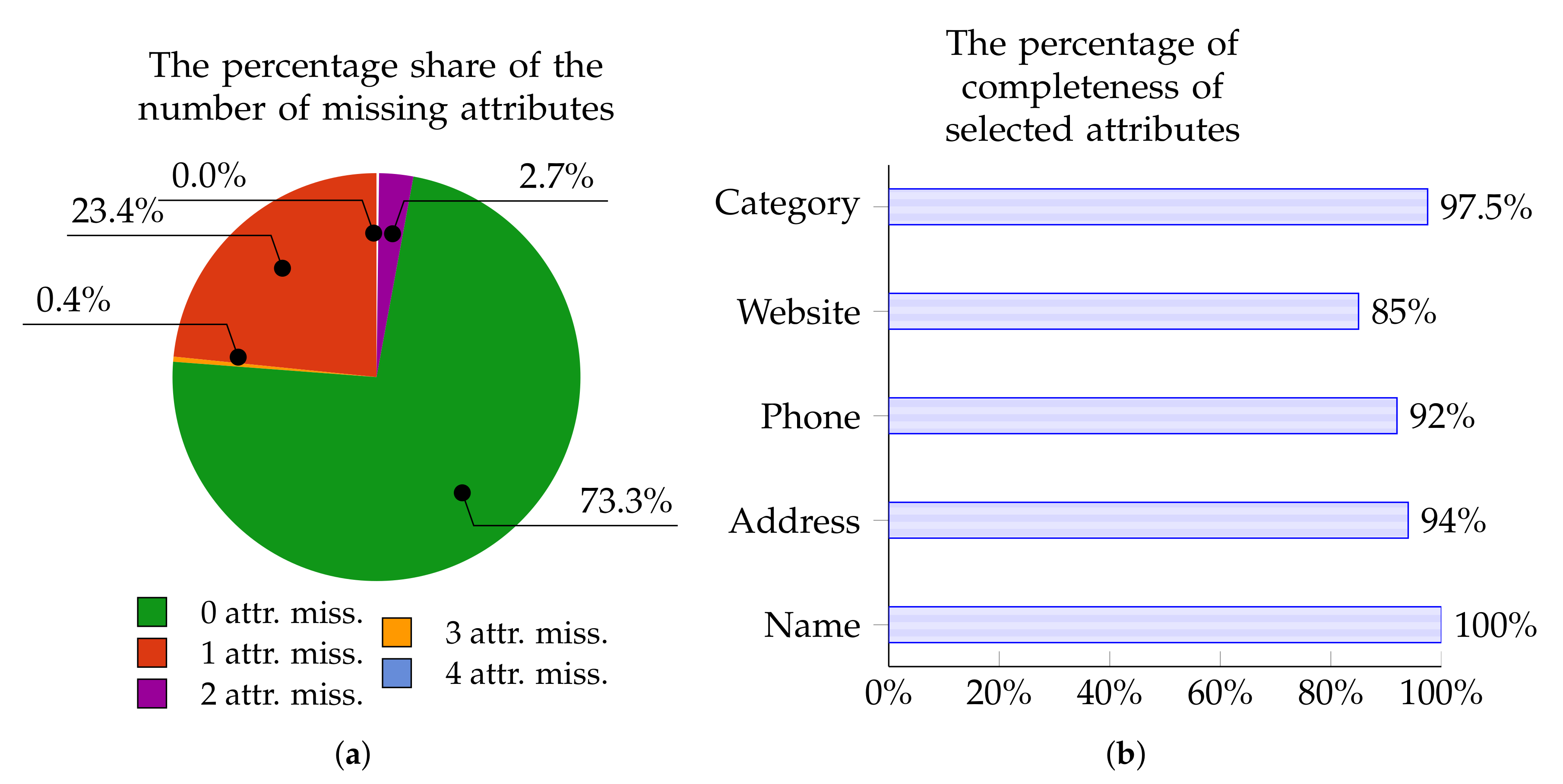
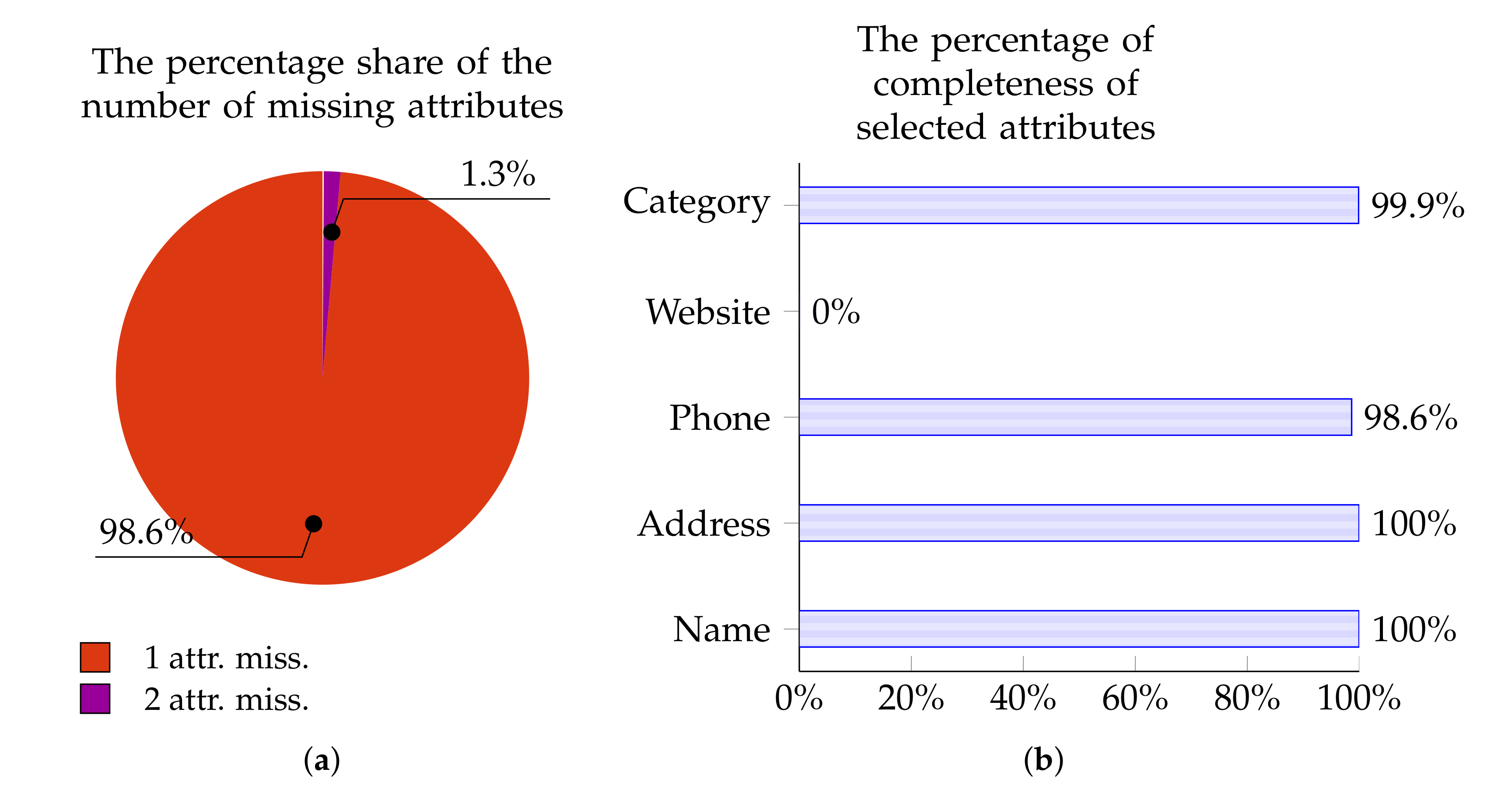
- Data incompleteness, i.e., a significant proportion of attributes for a given Point of Interest have empty values. Moreover, one part of data may be completed for a given point in one source and another part in another source. Naturally, it would be advantageous to simply assemble data which are “scattered” across various sources in the hope that we acquire a range of diverse (complementary) data points. Given this aim, in a certain sense, it is extremely helpful that there are different pieces of data arising from these various sources. However, when we wish to determine whether the analyzed POI refers to the same real place, then suddenly the task becomes rather problematic. The reason for this is that there is a scarcity of “common data” on the basis of which the POIs can be identified and classified as matching. For instance, one very distinctive attribute, namely the www address, cannot be used as a basis for identifying matching points since in Yelp the value for this attribute has been provided for 0% of Points of Interest. A broader and more detailed analysis of this problem for our 100,000-point training set, broken down into individual data sources and attributes, is given in Section 3.2.
- the size and diversity of the datasets and the data sources;
- the metrics used to assess the similarity of the Points of Interest;
- the missing values of attributes employed by the matching algorithms; and
- the classification algorithms used to match the objects.
- In Section 2, the work related to POIs matching done thus far is briefly reviewed.
- In Section 3, the data sources, the unification of Points of Interest models and the preparation of experimental datasets are discussed.
- In Section 4, three crucial elements of Points of Interest matching classifiers, namely similarity metrics (see Section 4.1), strategies for dealing with missing data (see Section 4.2), and classification algorithms (see Section 4.3), are discussed.
- In Section 5, the results of experiments are provided, which compare the efficiency of various POI-matching approaches in terms of their similarity metrics (see Section 5.1) and the classification algorithms used (see Section 5.2) while also addressing the missing-data handling strategies, and the sensitivity of classifiers to the geographical, cultural or language zones from which the data come.
- In Section 6, the algorithm for automatic Points of Interest matching along with its quality, accuracy and complexity is presented and analyzed.
- In Section 7, we draw conclusions and outline future work.
2. Related Work
3. Data Sources, Unified Data Model and Experimental Datasets
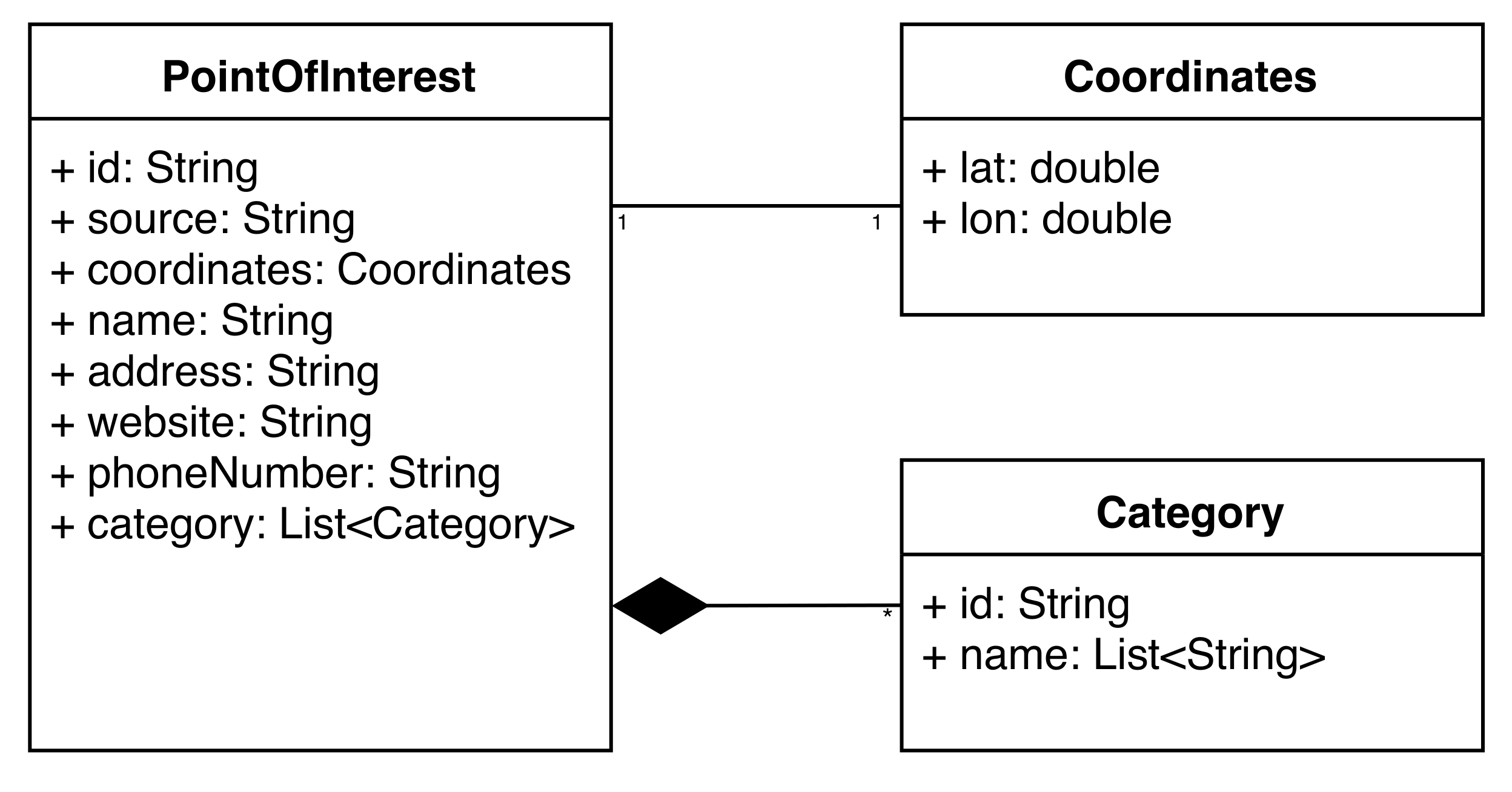
3.1. Unified Data Model
- each Point of Interest stored in OpenStreetMap has information about its geographic coordinates, which is referred to using the same pair of keys;
- most Points of Interest stored in OpenStreetMap have a tag with a name key containing the POI name;
- the address can be extracted by analyzing a key that starts with addr (https://wiki.openstreetmap.org/wiki/Key:addr); and
- contact information is usually stored in the phone and website keys.
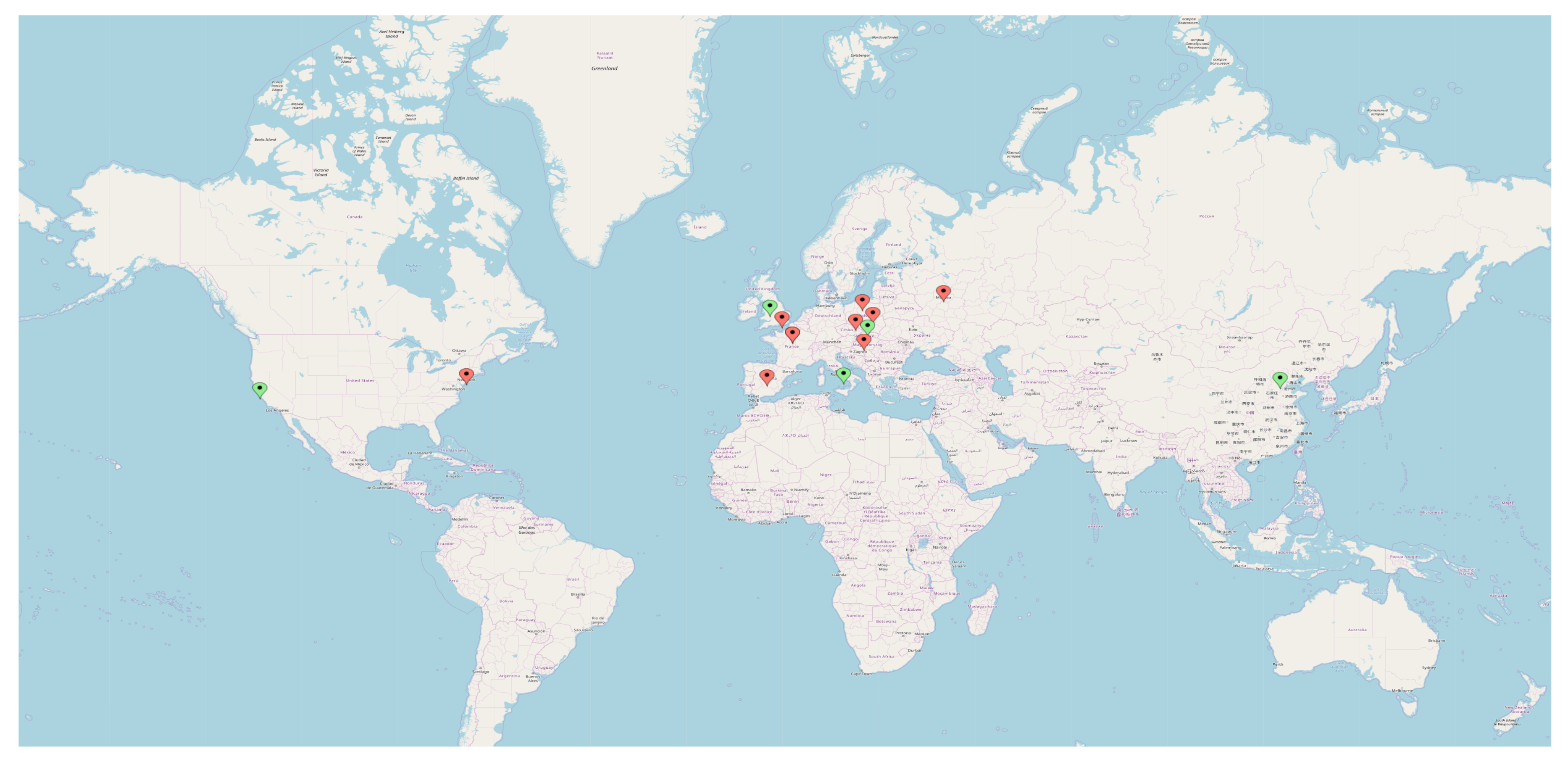
3.2. Experimental Dataset
- Krakow, 1000 pairs of objects;
- San Francisco, 500 pairs of objects;
- Naples, 500 pairs of objects;
- Liverpool, 1000 pairs of objects; and
- Beijing, 1000 pairs of objects.
4. Crucial Elements of Points of Interest Matching Classifiers: Similarity Metrics, Handling Strategies for Missing Data and Classification Algorithms
- the metrics for measuring the similarity of POIs;
- handling strategies for missing data; and
- algorithms for classifying Points of Interest as either matching or non-matching.
4.1. Similarity Metrics
4.1.1. Distance Metrics
4.1.2. String Distance Metrics
- inserting a new character into the string;
- removing a character from the string; and
- replacing a character inside the string with another character.
- the number of matching characters in both strings in relation to the length of the first string;
- the number of matching characters in both strings in relation to the length of the second string; and
- the number of matching characters that do not require transposition.
- The Ratio () is a normalized similarity between the strings calculated as the Levenshtein distance divided by the length of the longer string.
- The Partial Ratio () is an improved version of the previous one. It is the ratio of the shorter string and the most similar substring (in terms of the Levenshtein distance) of the longer string.
- The Token Sort Partial Ratio () sorts the tokens in the string and then measures the Partial Ratio on the string with the sorted tokens.
- The Token Set Partial Ratio () creates three sets of tokens:
- -
- , the common, sorted tokens from two strings;
- -
- , the common, sorted tokens from two strings along with sorted remaining tokens from the first string; and
- -
- , the common, sorted tokens from two inscriptions along with sorted remaining tokens from the second string.
Then, strings as a combination of tokens in the set are created and the maximum Partial Ratio is computed according to the equation: - The Average Ratio () is the metric we proposed, calculated as the average value of the Partial Ratio (PR) and the Token Set Ratio (TSeR):
- is the Levenshtein measure.
- is the Jaro–Winkler measure.
- is the Ratio measure.
- is the Partial-Ratio measure.
- is the Partial Token Sort Ratio measure.
- is the Partial Token Set Ratio measure.
- is the Average Ratio measure.
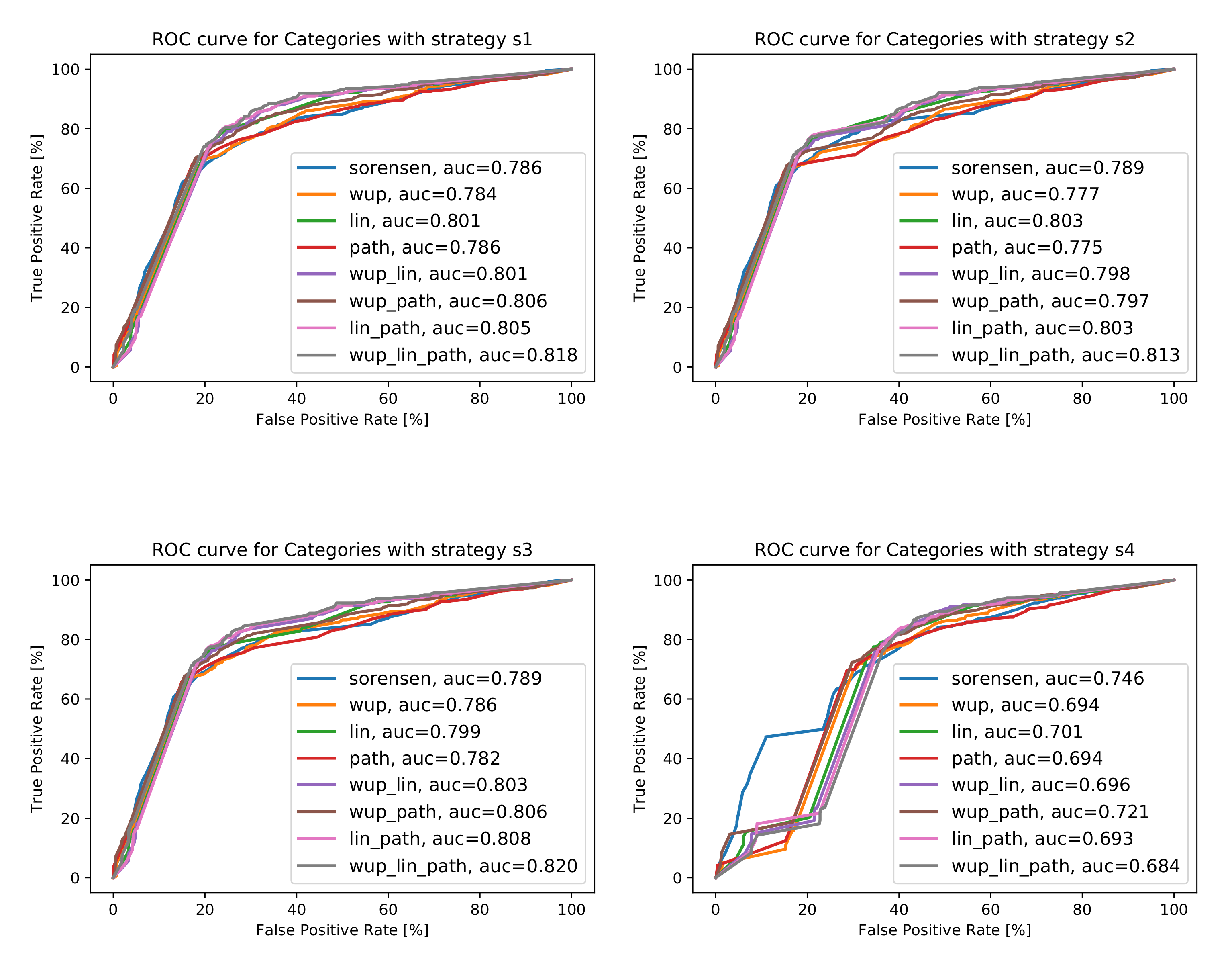
4.1.3. Category Distance Metrics
4.2. Strategies for Dealing with Missing Data
- is a strategy in which only objects with all attributes are taken for testing and analysis. This is not an approach that can be used in practice, but it was carried out merely to obtain a reference result.
- is a strategy where, in the training set, we only include objects that have all the attributes, and, in the test set, we fill in the missing values with a marker value: −1.
- is a strategy where, in both sets, we fill in the missing values with the marker value: −1.
- is a strategy in which missing values are supplemented with the median value of the attributes in the given set.
4.3. The Classifiers for Points of Interest Matching
- The k-Nearest Neighbor algorithm [20] is one of the most popular algorithms for pattern determination and classification. The classifier based on this algorithm allows one to assign an object to a given class using a similarity measure. In the case of the Points of Interest matching problem, based on the given values of the metrics, the algorithm looks for similar examples encountered during the learning process. After that, it endeavors to qualify them into one of two groups—matching or mismatching objects. In our analysis, we used the implementation provided by the Scikit Learn Framework [21]. We used the default parameters configuration (https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html), changing only the parameter value, which indicates the number of neighbors sought; we changed it from 5 to 100, due to the large dataset.
- The Decision Tree classification method [22] is a supervised method, and, on the basis of the datasets provided, it separates objects into two groups. The separation process is based on a chain of conditionals, which form a graphical tree. One of the disadvantages of this algorithm is that the decision tree is very susceptible to the prepared learning model. This is due to overfitting, and the lack of a mechanism to prevent the dominance of one resultant class. Therefore, we had to ensure that the training set was well balanced. In our analysis, we again used the implementation provided by the Scikit Learn Framework [21]. We used the default parameters configuration ( https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html). In our model, we had six input features (metrics values for two Points of Interest being compared), and two output classes (objects matched or not).
- The Random Forest classifier [23] is based on the same assumptions as those of the decision trees. However, unlike a single decision tree, it does not follow the greedy strategy when creating the conditionals. In addition, the sets provided for training individual trees are different. As a consequence, the algorithm is more resistant to overfitting phenomena and is well-suited to missing data. In our analysis, we once again used the implementation provided by the Scikit Learn Framework [21]. We used the default parameters configuration ( https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html), changing only the number of trees in the forest ( parameter) to 100.
- Isolation Forest is the method of matching objects studied in [5,6]. It is based on the outlier detection approach. This classifier, unlike those previously presented, is a weakly supervised machine learning method where, in the training process, only the positive examples are required. Next, during the classification process, the classifier decides whether the given set of attributes is similar to those that it has learned in the learning process or not. The algorithm is very sensitive to the data used and requires appropriate techniques in the case of missing attributes. In our analysis, we again used the implementation supplied by the Scikit Learn Framework [21]. We used the default parameters configuration (https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.IsolationForest.html), setting the number of samples used for training (i.e., the parameter) to 1000.
- Neural Network: We prepared two classifiers based on a Neural Networks [24]. The simpler one, termed a Perceptron, directly receives the values of the metrics, and the two output neurons are the resultant classes—the decision about any similarity or lack thereof. A more complicated one, based on deep networks, is the Feed Forward model, which in addition to the input and output layers, has six additional, arbitrarily set layers, with 128, 64, 32, 16, 16, and 16 neurons, respectively. In our analysis, we used the implementation provided by the Tensorflow [25] and Keras [26] frameworks. We trained each of the networks for 50 eras, with the batch size set to 5.
5. Experiments
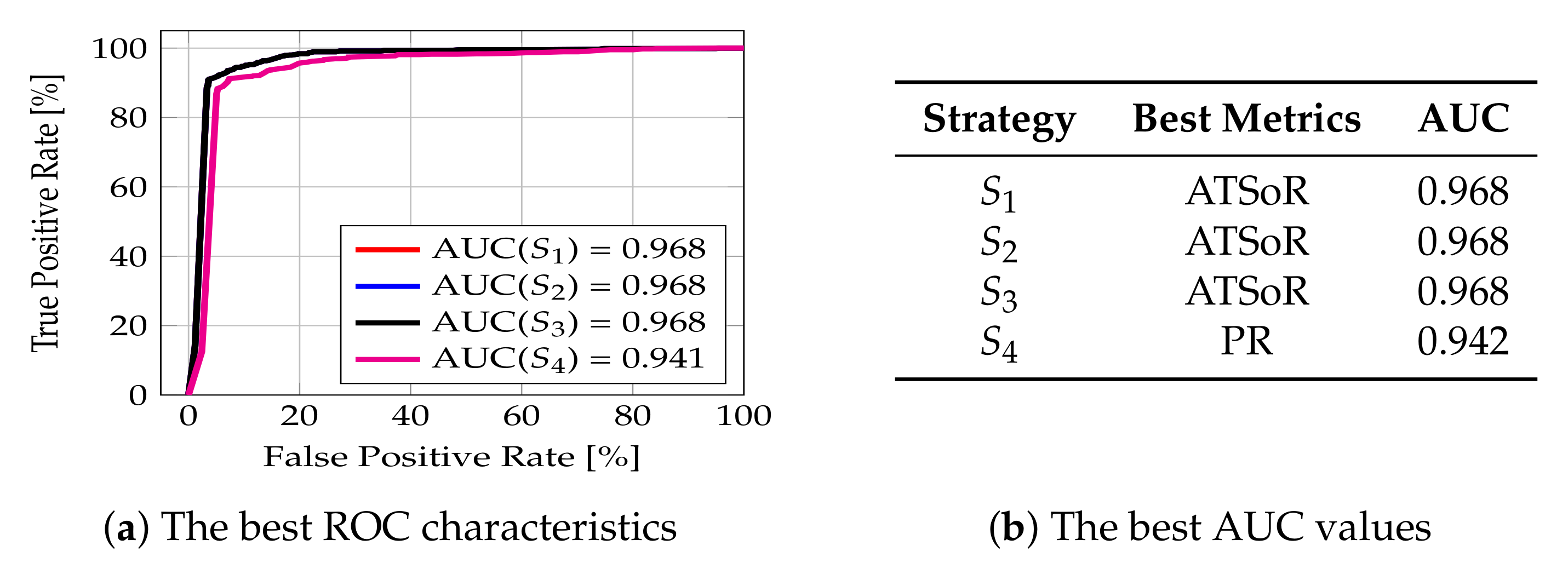
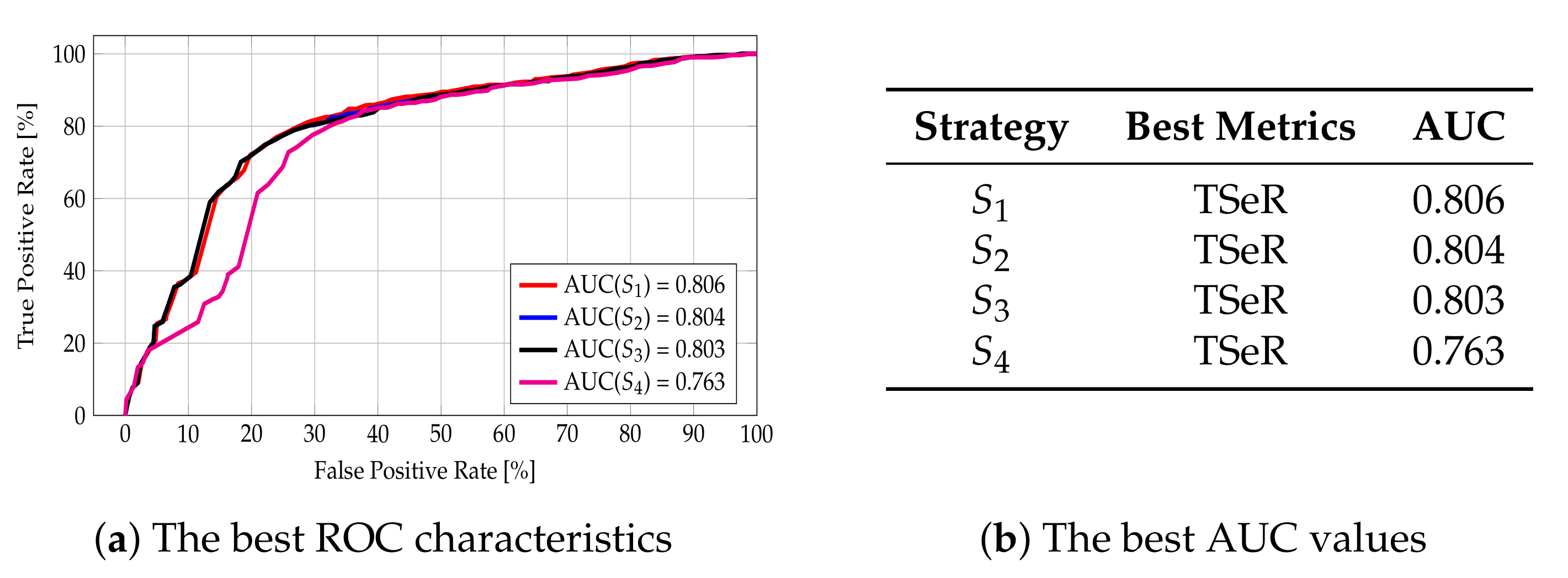
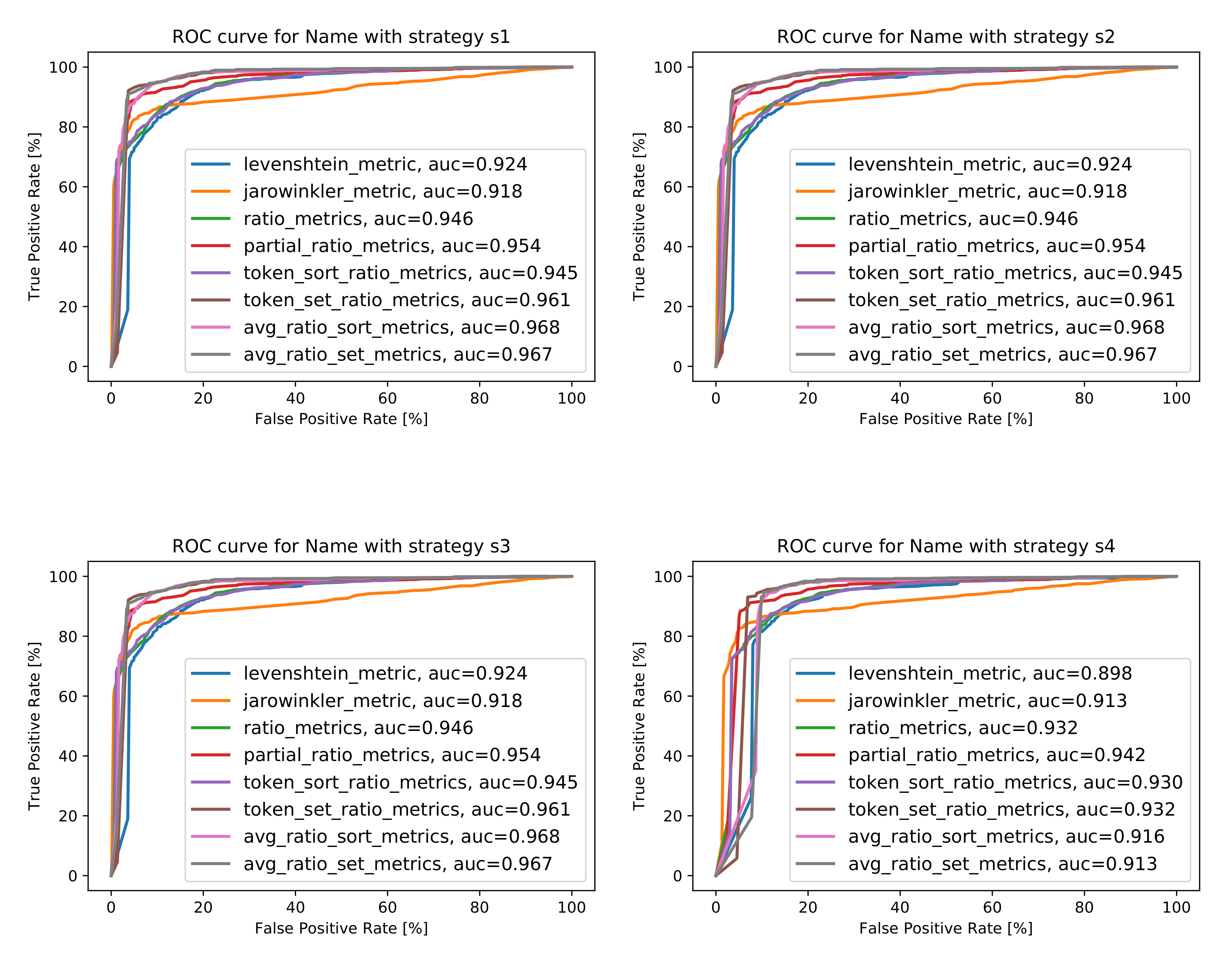
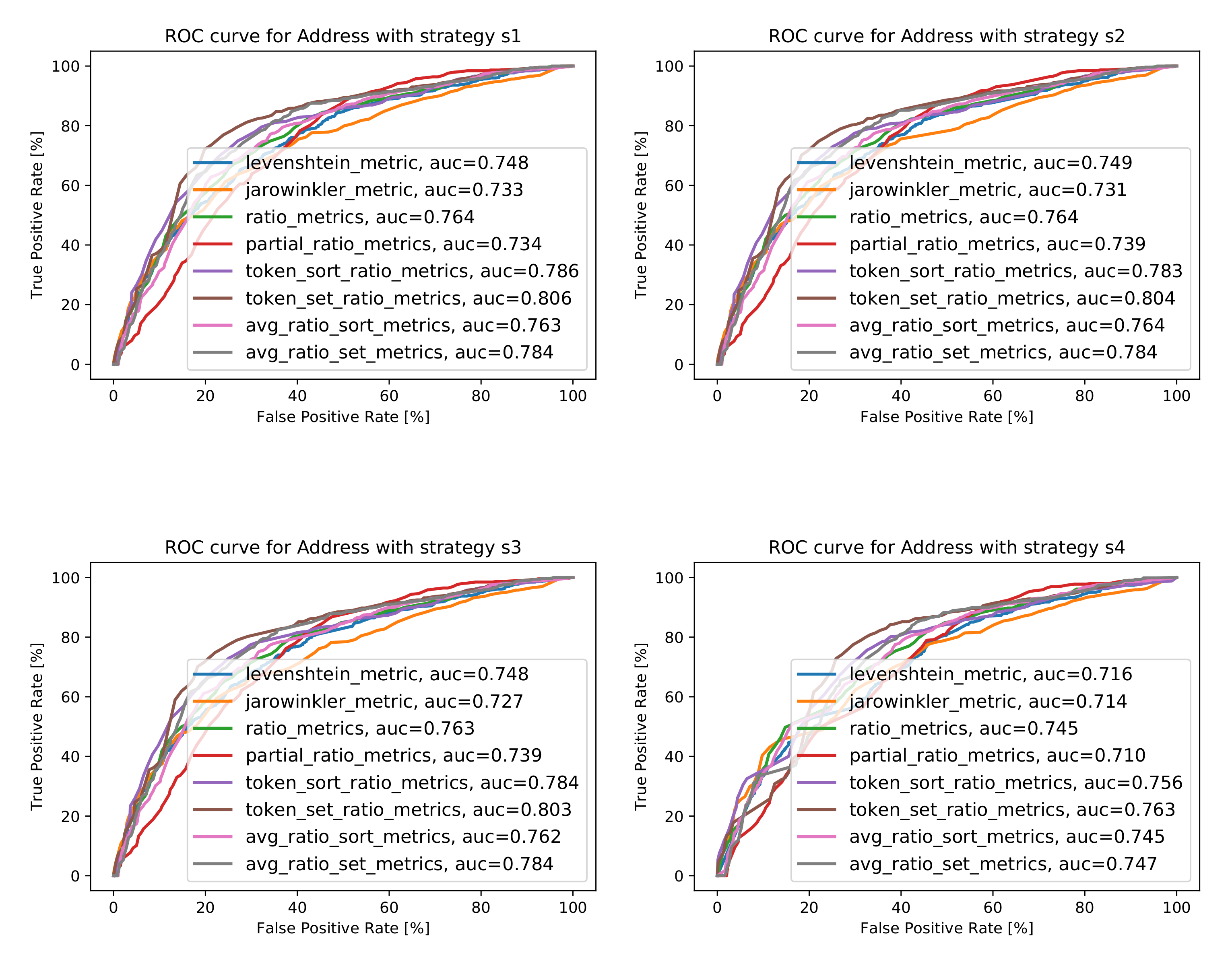
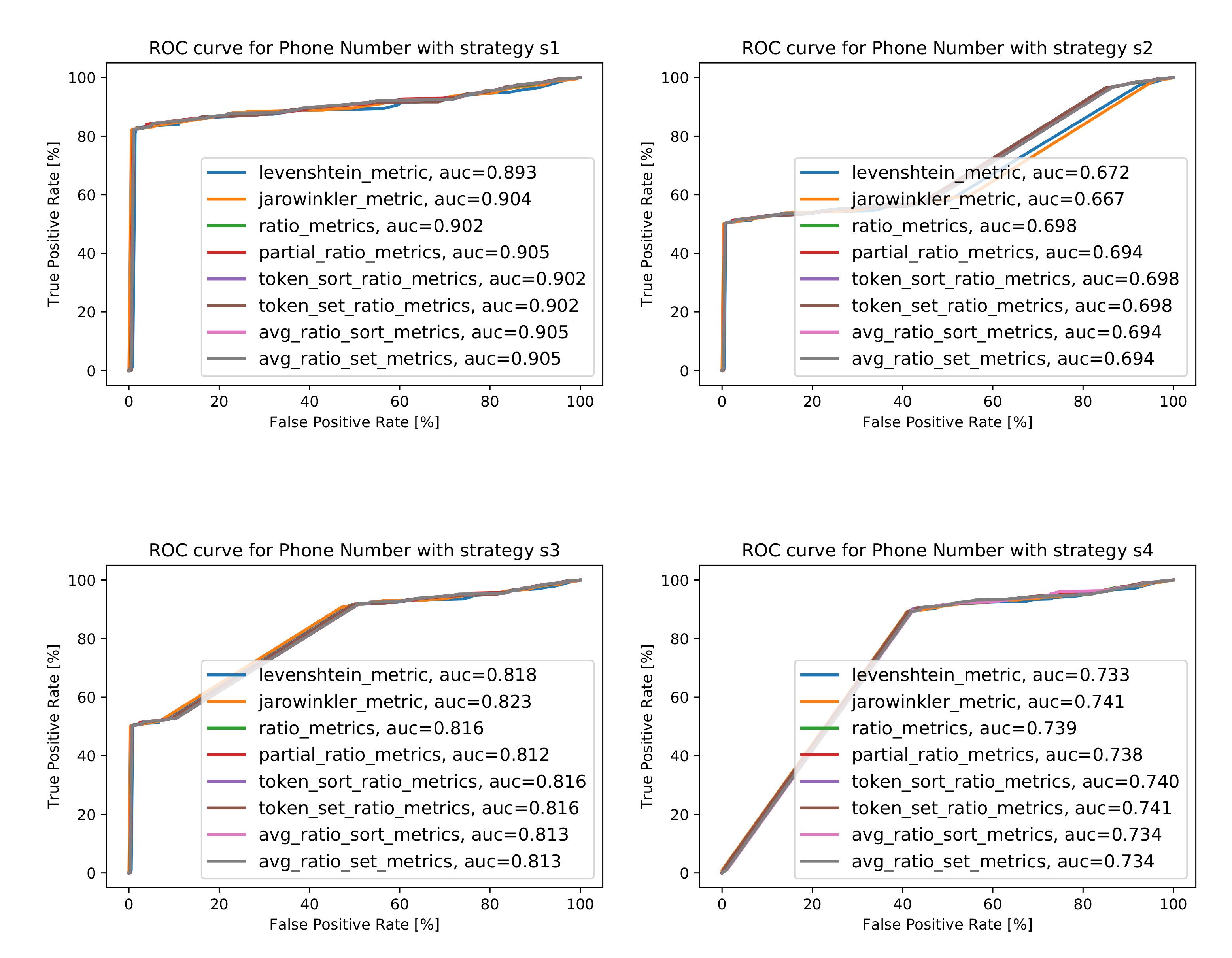
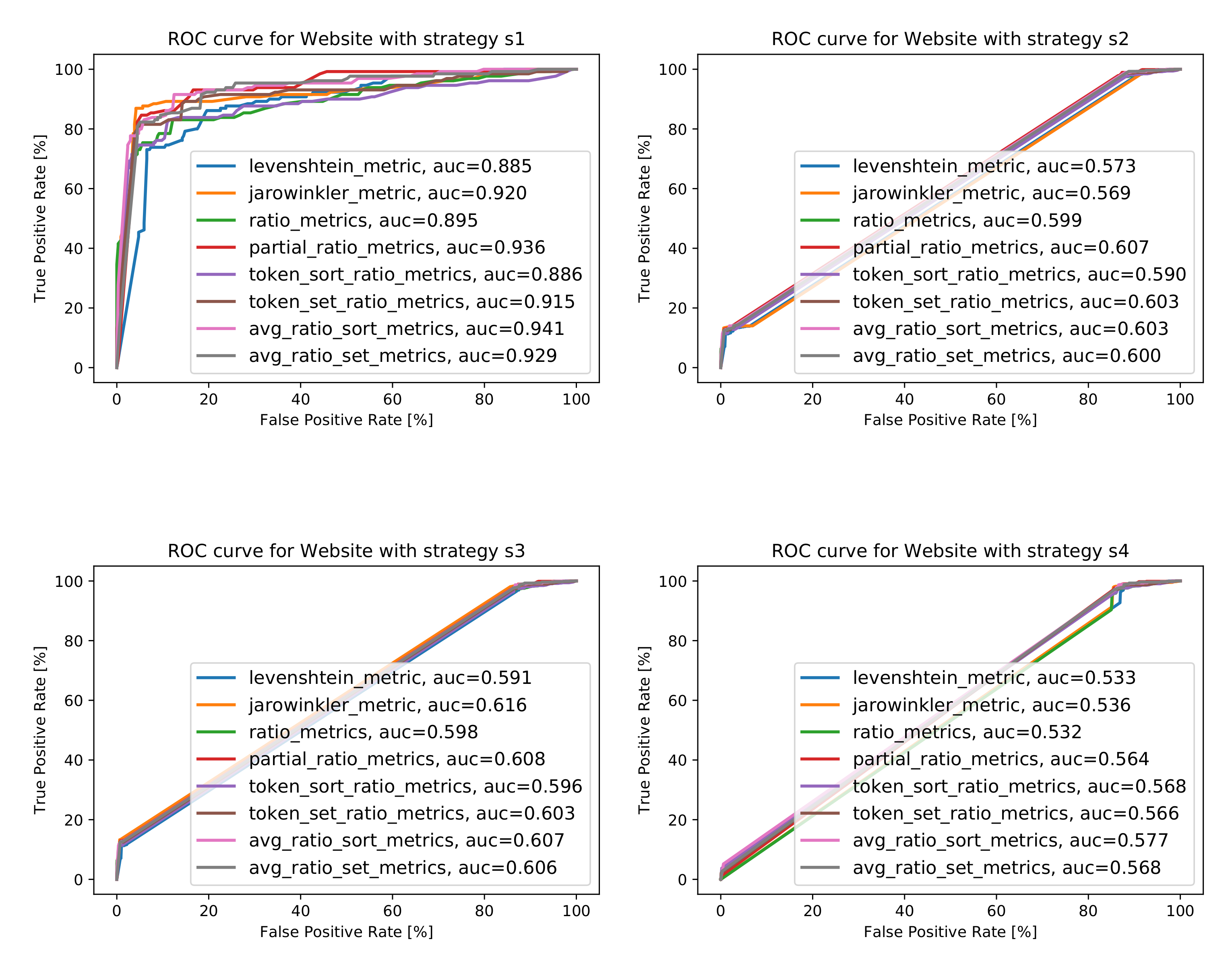
5.1. The Analysis of Different Similarity Metrics
5.1.1. The Analysis of String Similarity Metrics
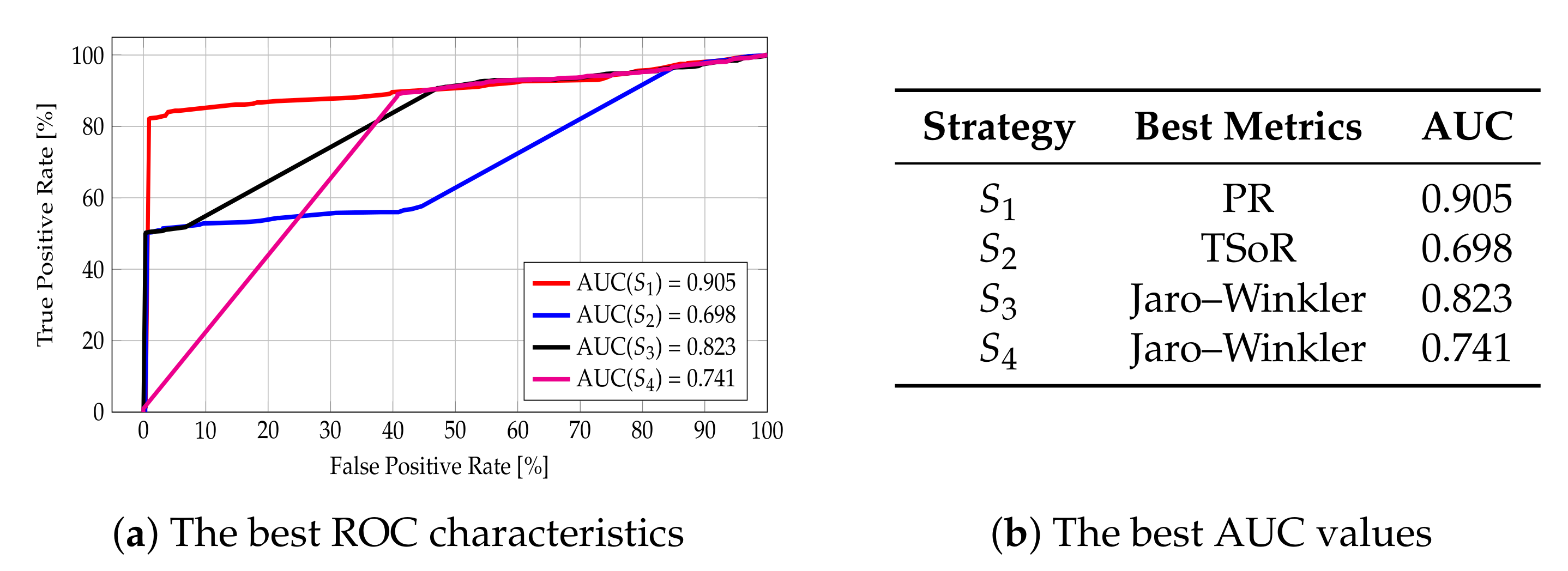
The Analysis for the Attribute Name
The Analysis for the Attribute Address
The Analysis for the Attribute Phone Number
The Analysis for the Attribute WWW
The Analysis for the Combination of Attributes
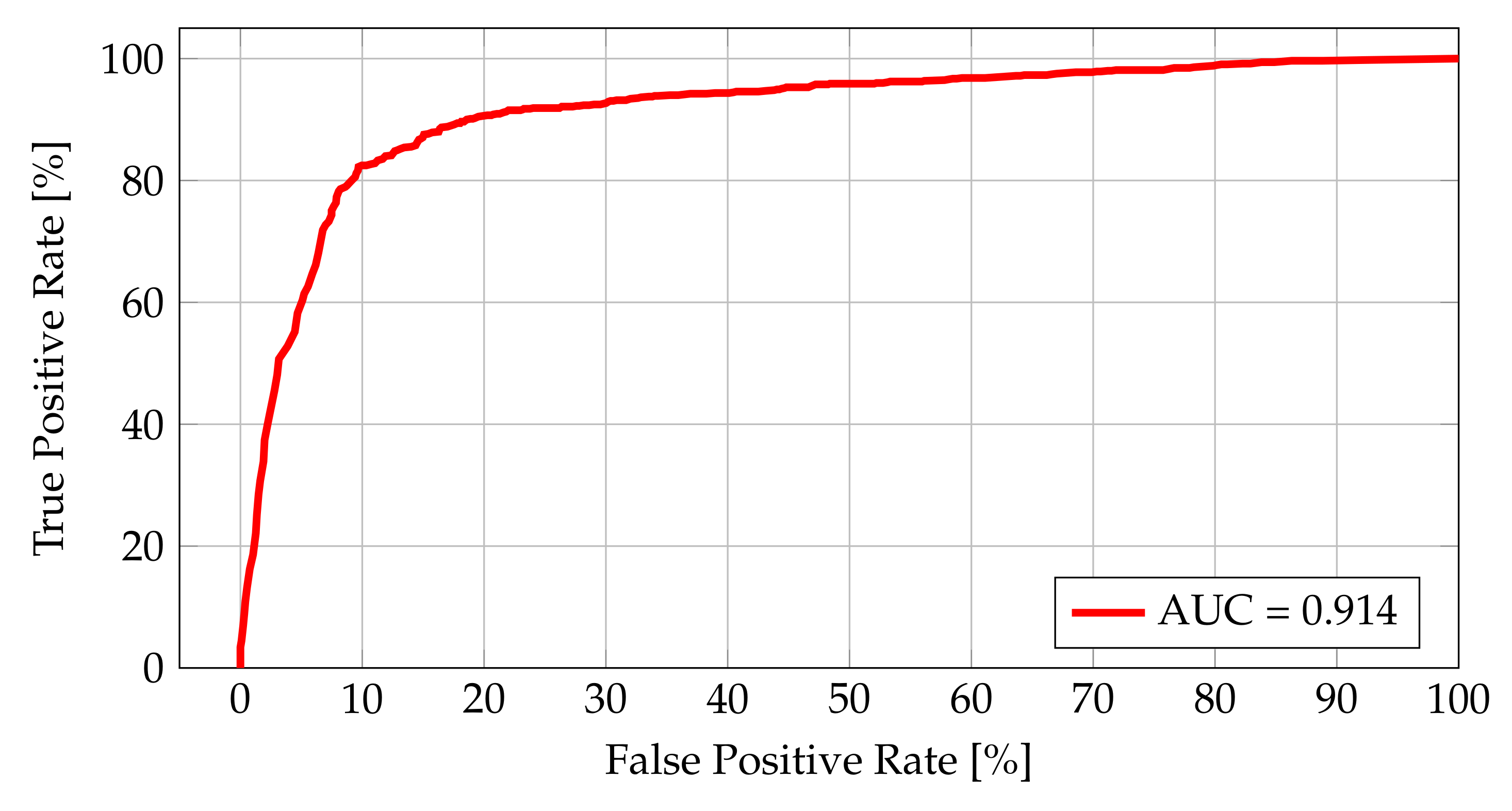
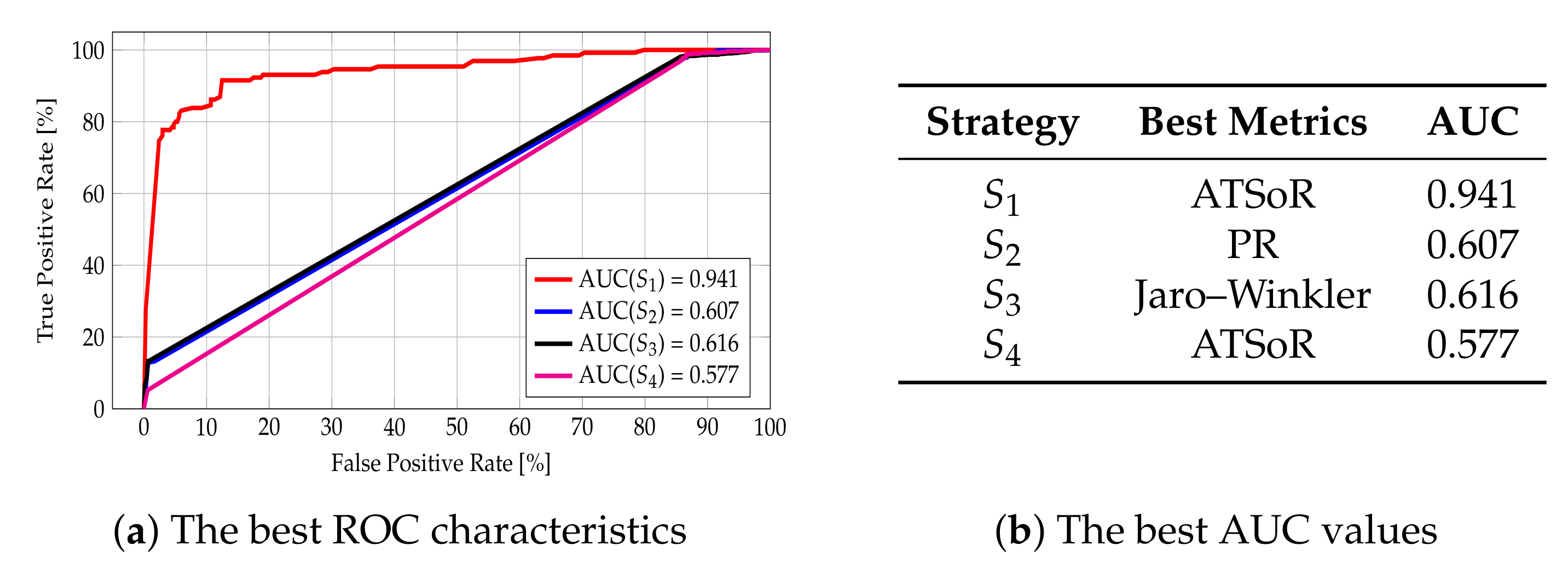
5.1.2. The Analysis for Category Distance Metrics
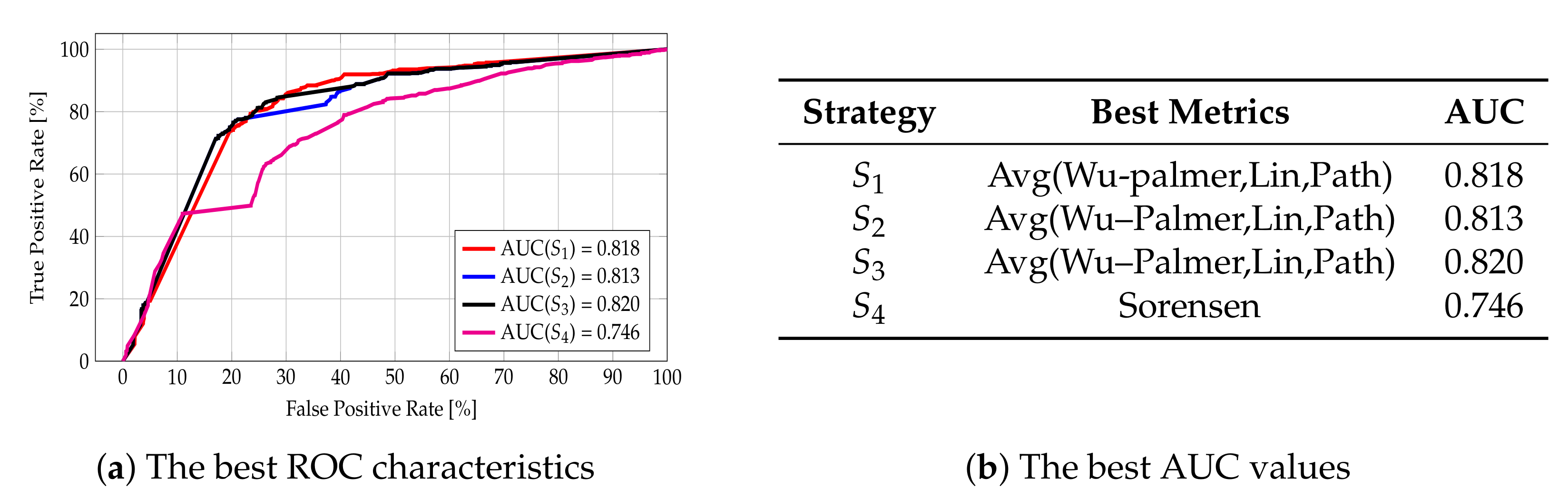
5.1.3. The Analysis for Combined Metrics
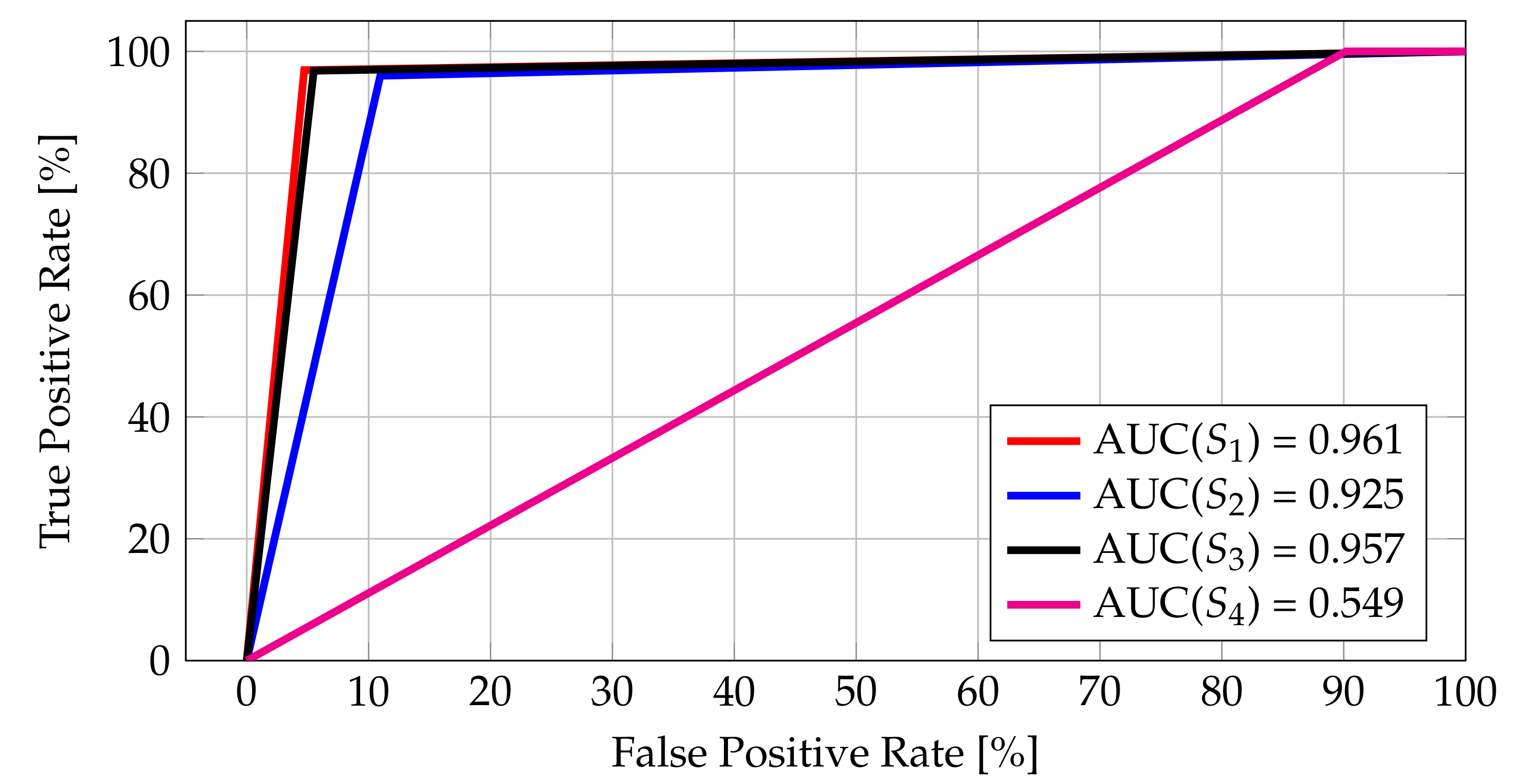
5.2. Comparison of Different Points of Interest Matching Classifiers
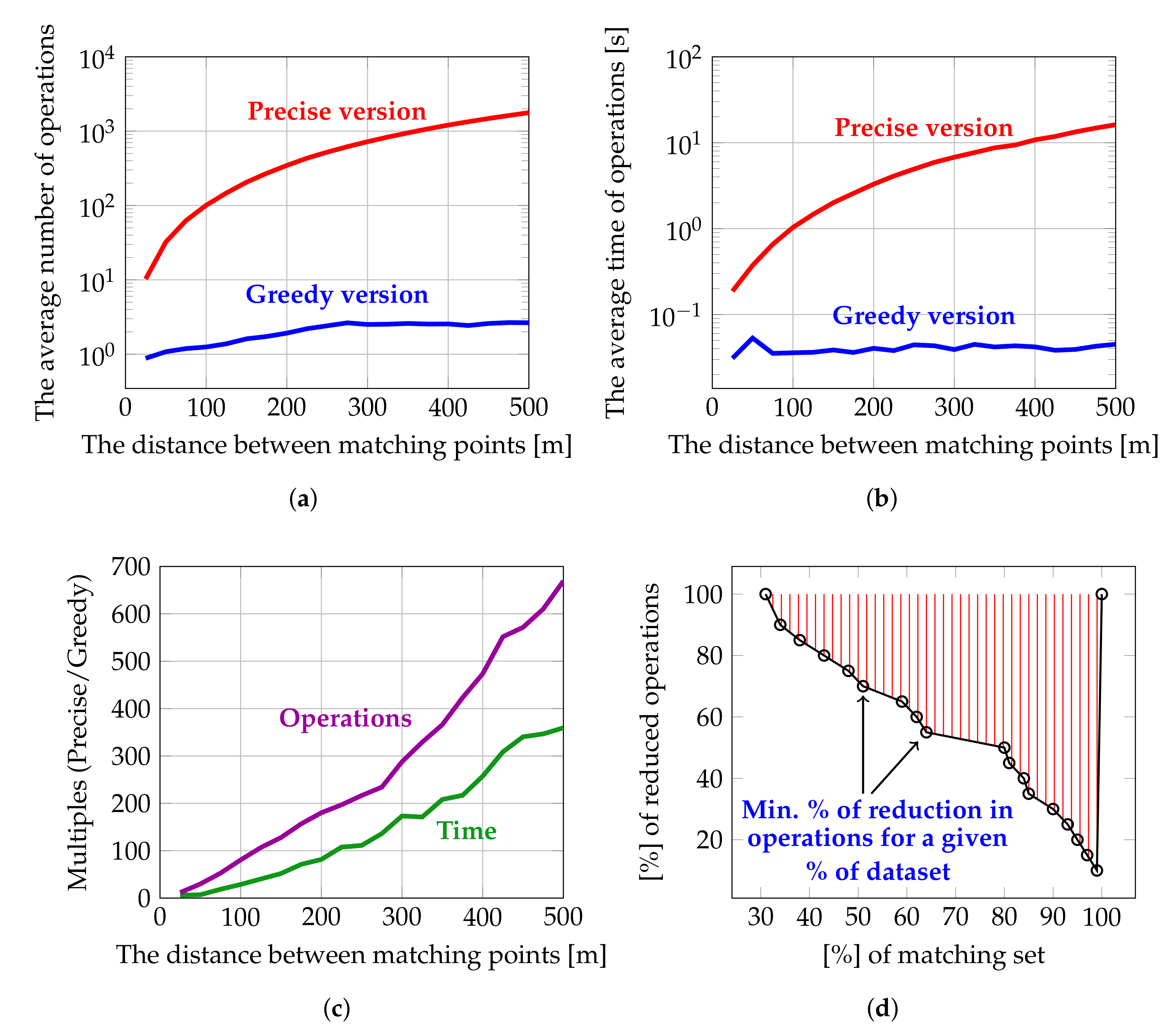
6. The Algorithm for Automatic Points of Interest Matching
- If the attribute exists in , we use it as the value for merged POI.
- If the attribute is missing in and exists in , we use the value from for merged POI.
- The value for category attribute for merged POI is the sum of and categories.
| Algorithm 1: Automatic Points of Interest matching—precise version. |
 |
| Algorithm 2: Automatic Points of Interest matching—greedy version. |
 |
7. Conclusions and Future Work
- We analyzed a selection of the most popular data sources—their structures, models, attributes, number of objects, the quality of data (number of missing attributes), etc. (see Section 3 for details).
- We defined the unified Point of Interest model and then implemented mappers for downloading data from different services and storing them in one, single, common model (see the first part of Section 3).
- We prepared a fairly large experimental dataset consisting of 50,000 matching and 50,000 non-matching points, taken from such diverse geographical, cultural and language areas as Liverpool, Beijing, and Ankara (see Section 3.2).
- We reviewed metrics that can be used for calculating the similarity between Points of Interest. For this, we analyzed three groups i.e., geographical distance, string similarity distance and semantic distance metrics (see Section 4.1).
- We verified four different strategies for dealing with missing attributes (see Section 4.2 for details).
- We reviewed and analyzed six different machine learning classifiers (k-Nearest neighbor, decision tree, random forest, isolation forest, and two neural net classifiers) for Points of Interest matching.
- We performed experiments and made comparisons taking into account different similarity metrics and different strategies for dealing with missing data (see Section 5.1 and Section 5.2 and Appendix A).
Author Contributions
Funding
Conflicts of Interest
Appendix A





References
- Scheffler, T.; Schirru, R.; Lehmann, P. Matching Points of Interest from Different Social Networking Sites. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 245–248. [Google Scholar] [CrossRef]
- Yujian, L.; Bo, L. A Normalized Levenshtein Distance Metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef] [PubMed]
- McKenzie, G.; Janowicz, K.; Adams, B. A weighted multi-attribute method for matching user-generated Points of Interest. Cartogr. Geogr. Inf. Sci. 2014, 41, 125–137. [Google Scholar] [CrossRef]
- Novack, T.; Peters, R.; Zipf, A. Graph-Based Matching of Points-of-Interest from Collaborative Geo-Datasets. ISPRS Int. J. -Geo-Inf. 2018, 7, 117. [Google Scholar] [CrossRef] [Green Version]
- Almeida, A.; Alves, A.; Gomes, R. Automatic POI Matching Using an Outlier Detection Based Approach. In Advances in Intelligent Data Analysis XVII; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 40–51. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar] [CrossRef]
- Factual Crosswalk API. Available online: https://www.factual.com/blog/crosswalk-api/ (accessed on 1 September 2019).
- Herzog, T.H.; Scheuren, F.; Winkler, W.E. Record linkage. WIREs Comput. Stat. 2010, 2, 535–543. [Google Scholar] [CrossRef]
- Li, L.; Xing, X.; Xia, H.; Huang, X. Entropy-weighted instance matching between different sourcing points of interest. Entropy 2016, 18, 45. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Vasardani, M.; Winter, S. Similarity matching for integrating spatial information extracted from place descriptions. Int. J. Geogr. Inf. Sci. 2017, 31, 56–80. [Google Scholar] [CrossRef]
- Deng, Y.; Luo, A.; Liu, J.; Wang, Y. Point of Interest Matching between Different Geospatial Datasets. ISPRS Int. J. Geo-Inf. 2019, 8, 435. [Google Scholar] [CrossRef] [Green Version]
- Haklay, M. How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance Survey datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef] [Green Version]
- Hochmair, H.H.; Juhász, L.; Cvetojevic, S. Data quality of points of interest in selected mapping and social media platforms. In Proceedings of the LBS 2018: 14th International Conference on Location Based Services, Zurich, Switzerland, 15–17 January 2018; pp. 293–313. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- OpenStreetMap TagInfo. Available online: https://taginfo.openstreetmap.org/ (accessed on 1 September 2019).
- OpenStreetMap Wiki. Available online: https://wiki.openstreetmap.org/ (accessed on 1 September 2019).
- Cohen, W.W.; Ravikumar, P.; Fienberg, S.E. A Comparison of String Metrics for Matching Names and Records. In Proceedings of the KDD Workshop On Data Cleaning and Object Consolidation, Washington, DC, USA, 24–27 August 2003. [Google Scholar]
- FuzzyWuzzy: Fuzzy String Matching in Python. Available online: https://chairnerd.seatgeek.com/fuzzywuzzy-fuzzy-string-matching-in-python/ (accessed on 1 September 2019).
- Blanchard, E.; Harzallah, M.; Briand, H.; Kuntz, P. A Typology of Ontology-Based Semantic Measures. In Proceedings of the EMOI-INTEROP 2005, Porto, Portugal, 13–14 June 2005; Volume 160. [Google Scholar]
- Fix, E.; Hodges, J.L., Jr. Discriminatory Analysis-Nonparametric Discrimination: Consistency Properties; Technical Report; University of California: Berkeley, CA, USA, 1951. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.P. Neural networks for classification: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2000, 30, 451–462. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Keras: The Python Deep Learning library. Available online: https://keras.io/ (accessed on 1 September 2019).
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- August, P.; Michaud, J.; Labash, C.; Smith, C. GPS for environmental applications: Accuracy and precision of locational data. Photogramm. Eng. Remote Sens. 1994, 60, 41–45. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Henryka Kamienskiego 11 Krakow Polska | Generala Henryka Kamienskiego 30-644 Krakow | 0.49 | 0.70 | 0.70 | 0.79 | 0.83 | 1.0 | 0.81 |
| Pokoju 44, 31-564 Krakow | Zakopianska 62 Krakow Polska | 0.25 | 0.51 | 0.42 | 0.46 | 0.55 | 1.0 | 0.51 |
| Cinema City Poland | Cinema City | 0.61 | 0.92 | 0.76 | 1.0 | 1.0 | 1.0 | 1.0 |
| 786934146 | 48786934146 | 0.75 | 0.81 | 0.86 | 1.0 | 1.0 | 1.0 | 1.0 |
| http://bestwestern\krakow.pl/en/ | http://bestwestern\krakow.pl/ | 0.88 | 0.98 | 0.93 | 1.0 | 0.90 | 1.0 | 0.95 |
| Strategy | K-Neigh | Dec Tree | Rnd Forest | Isol Forest | Perceptron | FF Net |
|---|---|---|---|---|---|---|
| 97.6% | 95.9% | 97.6% | 95.3% | 93.2% | 98.2% | |
| 92.8% | 91.7% | 95.1% | 74.5% | 76.5% | 87.4% | |
| 92.0% | 95.1% | 95.2% | 91.6% | 89.7% | 91.2% | |
| 54.1% | 35.8% | 33.2% | 93.4% | 56.7% | 60.0% |
| City | AUC | Score |
|---|---|---|
| Krakow | 99.5% | 99.4% |
| San Francisco | 92.4% | 92.2% |
| Naples | 93.8% | 92.8% |
| Liverpool | 84.0% | 83.5% |
| Beijing | 98.1% | 91.3% |
| Precise Algorithm | Greedy Algorithm | |
|---|---|---|
| Accuracy | 84.73% | 81.23% |
| Matches not found | 0% | 11.52% |
| Invalid matches | 15.27% | 7.25% |
| Precise Algorithm | Greedy Algorithm | % of Reduced Classifications | |
|---|---|---|---|
| Number of classifications required for 20,000 matching and non-matching cases | 69,783 | 29,979 | 57% |
| Number of classifications required for 7000 matching cases | 63,928 | 24,124 | 62% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piech, M.; Smywinski-Pohl, A.; Marcjan, R.; Siwik, L. Towards Automatic Points of Interest Matching. ISPRS Int. J. Geo-Inf. 2020, 9, 291. https://doi.org/10.3390/ijgi9050291
Piech M, Smywinski-Pohl A, Marcjan R, Siwik L. Towards Automatic Points of Interest Matching. ISPRS International Journal of Geo-Information. 2020; 9(5):291. https://doi.org/10.3390/ijgi9050291
Chicago/Turabian StylePiech, Mateusz, Aleksander Smywinski-Pohl, Robert Marcjan, and Leszek Siwik. 2020. "Towards Automatic Points of Interest Matching" ISPRS International Journal of Geo-Information 9, no. 5: 291. https://doi.org/10.3390/ijgi9050291
APA StylePiech, M., Smywinski-Pohl, A., Marcjan, R., & Siwik, L. (2020). Towards Automatic Points of Interest Matching. ISPRS International Journal of Geo-Information, 9(5), 291. https://doi.org/10.3390/ijgi9050291