Combining Deep Learning and Location-Based Ranking for Large-Scale Archaeological Prospection of LiDAR Data from The Netherlands

 , , and
, , and
Abstract
:1. Introduction
1.1. WODAN
1.2. Outline of this Paper
2. Research Area and Datasets
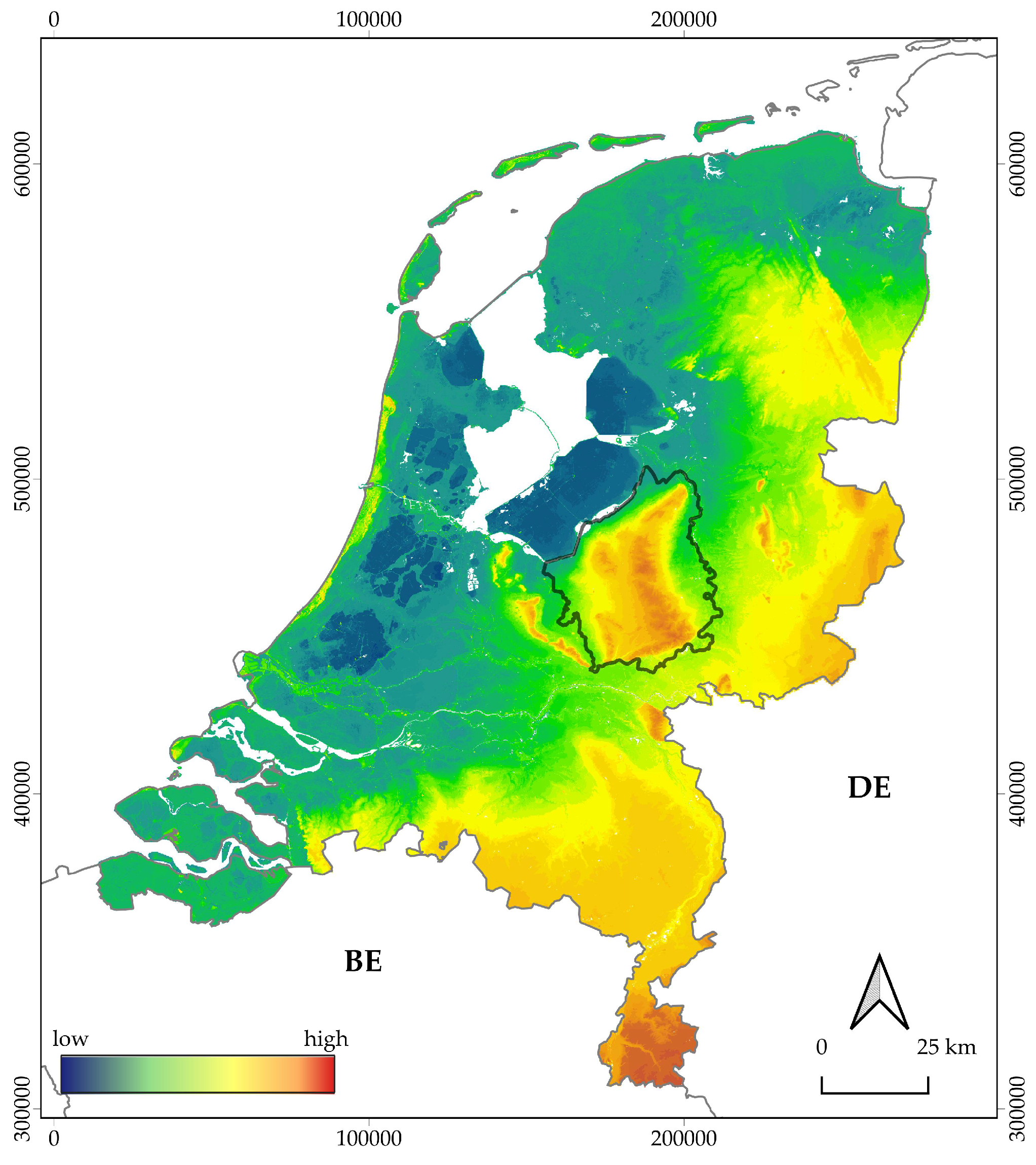
2.1. Research Area


2.2. Datasets
2.3. Test Datasets
2.4. Heritage Quest Dataset
3. Methodology
3.1. Anchor Box Sizes
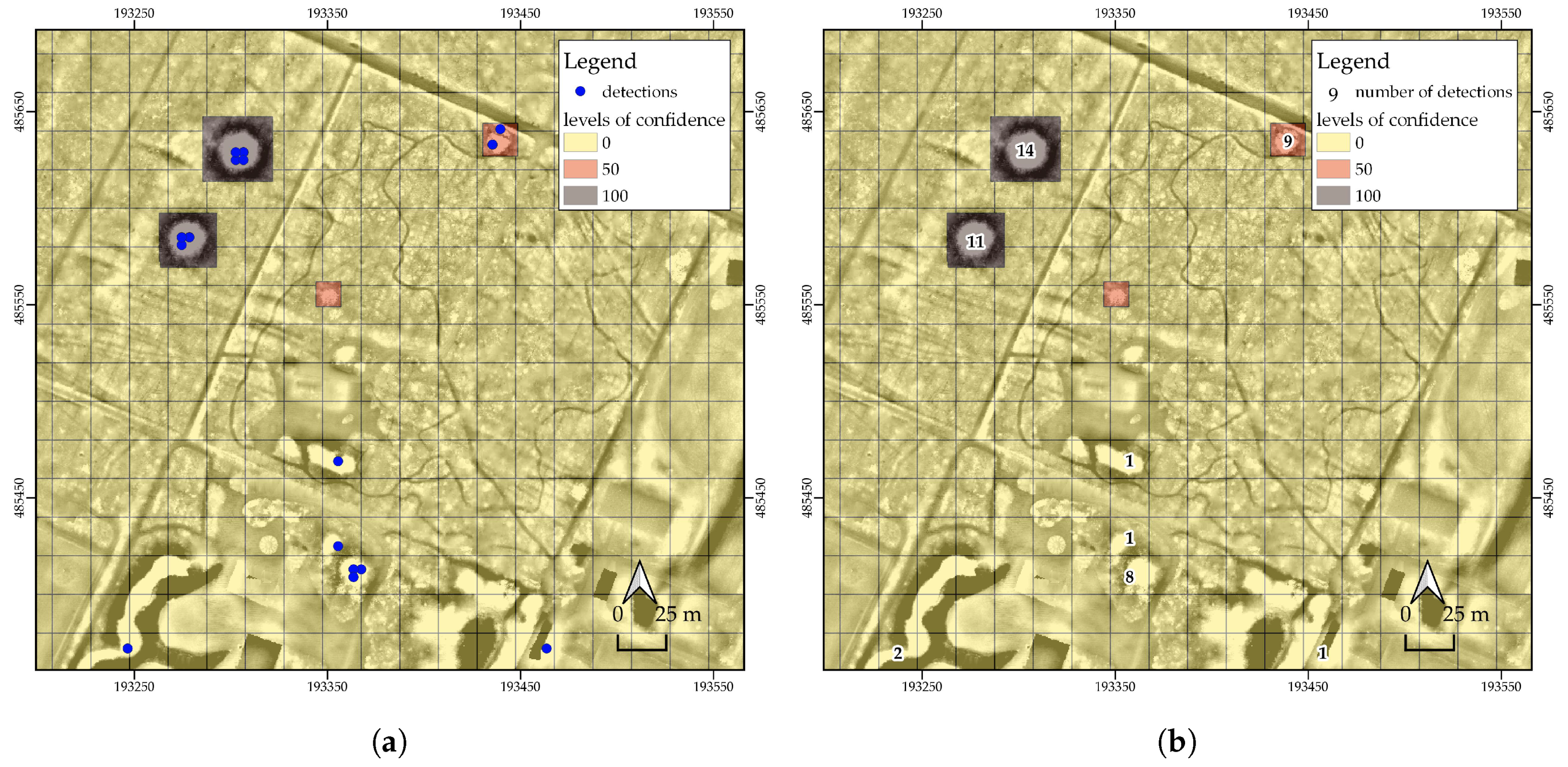
3.2. Bootstrap Aggregating
3.3. Negative Examples
4. Introducing Domain Knowledge: Location-Based Ranking
4.1. Location-Based Ranking in Practice: The Veluwe
- The lowest rank (3) is given to barrow and Celtic field detections in drift-sand areas. Charcoal kiln detections in drift-sand areas are given the highest rank (1). Any detections, regardless of class, in (post)medieval agricultural areas (plaggen soils) or in ‘badlands’ (e.g., dikes, quarries, etc.) are also given this lowest rank.
- The middle rank (2) is given to detections located in urbanized or built-up areas and in the direct vicinity of roads. While many Celtic fields are intersected by roads, this has had a limited negative impact on the preservation of the overall objects. Therefore, roads are considered Rank 1 in the case of Celtic fields.
- Any detections not located in one of the aforementioned zones are given the highest rank (1). These are generally located in heathland or forested areas, and in the case of charcoal kilns also in drift-sand areas.
4.2. Validity Test
5. Experimental Evaluation
5.1. Implementation Details
5.2. Results
6. Discussion
6.1. Non-Random versus Random Test Dataset
6.2. Computer and Human Performance
6.3. Object Detection Models Users
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cowley, D.C. In with the new, out with the old? Auto-extraction for remote sensing archaeology. Proc. SPIE 2012, 8532, 853206. [Google Scholar] [CrossRef]
- Bennett, R.; Cowley, D.; De Laet, V. The data explosion: Tackling the taboo of automatic feature recognition in airborne survey data. Antiquity 2014, 88, 896–905. [Google Scholar] [CrossRef]
- Bevan, A. The data deluge. Antiquity 2015, 89, 1473–1484. [Google Scholar] [CrossRef] [Green Version]
- Devereux, B.J.; Amable, G.S.; Crow, P.; Cliff, A.D. The potential of airborne lidar for detection of archaeological features under woodland canopies. Antiquity 2005, 79, 648–660. [Google Scholar] [CrossRef]
- Crutchley, S.; Crow, P. Using Airborne Lidar in Archaeological Survey: The Light Fantastic, 2nd ed.; Historic England: Swindon, England, 2018. [Google Scholar]
- Opitz, R.S. An overview of airborne and terrestial laser scanning in archaeology. In Interpreting Archaeological Topography: Airborne Laser Scanning, 3D Data and Ground Observation; Opitz, R.S., Cowley, D.C., Eds.; Oxbow Books: Oxford, UK; Oakville, ON, Canada, 2013; Chapter 2; pp. 13–31. [Google Scholar]
- Opitz, R.; Herrmann, J. Recent trends and long-standing problems in archaeological remote sensing. J. Comput. Appl. Archaeol. 2018, 1, 19–41. [Google Scholar] [CrossRef] [Green Version]
- Hay, G.J.; Castilla, G. Geographic object based image analysis (GEOBIA): A new name for a new discipline. In Object Based Image Analysis; Blaschke, T., Lang, S., Hay, G., Eds.; Springer: Heidelberg, Germany, 2008; pp. 93–112. [Google Scholar]
- Lambers, K.; Verschoof-van der Vaart, W.B.; Bourgeois, Q.P. Integrating remote sensing, machine learning, and citizen science in Dutch archaeological prospection. Remote. Sens. 2019, 11, 794. [Google Scholar] [CrossRef] [Green Version]
- Soroush, M.; Mehrtash, A.; Khazraee, E.; Ur, J.A. Deep Learning in Archaeological Remote Sensing: Automated Qanat Detection in the Kurdistan Region of Iraq. Remote Sens. 2020, 12, 500. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Fiorucci, M.; Khoroshiltseva, M.; Pontil, M.; Traviglia, A.; Del Bue, A.; James, S. Machine Learning for Cultural Heritage: A Survey. Pattern Recognit. Lett. 2020, 133, 102–108. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote. Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshop, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar] [CrossRef] [Green Version]
- Zingman, I. Semi-Automated Detection of Fragmented Rectangular Structures in High Resolution Remote Sensing Images with Application in Archaeology. Ph.D. Thesis, University of Konstanz, Konstanz, Germany, 2016. [Google Scholar]
- Zingman, I.; Saupe, D.; Penatti, O.A.B.; Lambers, K. Detection of fragmented rectangular enclosures in very-high-resolution remote sensing images. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 4580–4593. [Google Scholar] [CrossRef]
- Gallwey, J.; Eyre, M.; Tonkins, M.; Coggan, J. Bringing Lunar LiDAR Back Down to Earth: Mapping Our Industrial Heritage through Deep Transfer Learning. Remote. Sens. 2019, 11, 1994. [Google Scholar] [CrossRef] [Green Version]
- Trier, Ø.D.; Salberg, A.B.; Pilø, L.H. Semi automatic mapping of charcoal kilns from airborne laser scanning data using deep learning. In CAA 2016: Oceans of Data, Proceedings of the 44th Conference on Computer Applications and Quantitative Methods in Archaeology; Matsumoto, M., Uleberg, E., Eds.; Archaeopress: Oxford, UK, 2018; pp. 219–231. [Google Scholar]
- Trier, Ø.D.; Cowley, D.C.; Waldeland, A.U. Using deep neural networks on airborne laser scanning data: Results from a case study of semi-automatic mapping of archaeological topography on Arran, Scotland. Archaeol. Prospect. 2019, 26, 165–175. [Google Scholar] [CrossRef]
- Verschoof-van der Vaart, W.B.; Lambers, K. Learning to look at LiDAR: The use of R-CNN in the automated detection of archaeological objects in LiDAR data from the Netherlands. J. Comput. Appl. Archaeol. 2019, 2, 31–40. [Google Scholar] [CrossRef] [Green Version]
- David, A. The Role and Practice of Archaeological Prospection. In Handbook of Archaeological Sciences; Brothwell, D., Pollard, A., Eds.; John Wiley & Sons, LTD: Chichester, UK, 2005; pp. 521–527. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE CVPR, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Bourgeois, Q.P.J. Monuments on the Horizon. The Formation of the Barrow Landscape throughout the 3rd and 2nd Millennium BC; Sidestone Press: Leiden, The Netherlands, 2013. [Google Scholar]
- Arnoldussen, S. The fields that outlived the Celts: The use-histories of later prehistoric field systems (Celtic Fields or Raatakkers) in The Netherlands. Proc. Prehist. Soc. 2018, 84, 303–327. [Google Scholar] [CrossRef] [Green Version]
- Groenewoudt, B. Charcoal Burning and Landscape Dynamics in the Early Medieval Netherlands. Ruralia 2007, 6, 327–337. [Google Scholar]
- Van Lanen, R.J.; Groenewoudt, B.J.; Spek, M.; Jansma, E. Route persistence. Modelling and quantifying historical route-network stability from the Roman period to early-modern times (AD 100–1600): A case study from the Netherlands. Archaeol. Anthropol. Sci. 2018, 10, 1037–1052. [Google Scholar] [CrossRef] [Green Version]
- Vletter, W.F.; Van Lanen, R.J. Finding vanished routes: Applying a multi-modelling approach on lost route and path networks in the Veluwe Region, The Netherlands. Rural. Landscapes Soc. Environ. Hist. 2018, 5, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Van der Schriek, M.; Beex, W. The application of LiDAR-based DEMs on WWII conflict sites in the Netherlands. J. Confl. Archaeol. 2017, 12, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Lohof, E. Tradition and change: Burial practices in the Late Neolithic and Bronze Age in the north-eastern Netherlands. Archaeol. Dialogues 1994, 1, 98–118. [Google Scholar] [CrossRef]
- Louwen, A.; Fontijn, D.R. Death Revisited. The Excavation of Three Bronze Age Barrows and Surrounding Landscape at Apeldoorn-Wieselseweg; Sidestone Press: Leiden, The Netherlands, 2019. [Google Scholar]
- Bourgeois, Q.P.J.; Fontijn, D.R. The Tempo of Bronze Age Barrow Use: Modeling the Ebb and Flow in Monumental Funerary Landscapes. Radiocarbon 2015, 57, 47–64. [Google Scholar] [CrossRef] [Green Version]
- Kooistra, M.; Maas, G. The widespread occurrence of Celtic field systems in the central part of the Netherlands. J. Archaeol. Sci. 2008, 35, 2318–2328. [Google Scholar] [CrossRef]
- Raab, A.; Takla, M.; Raab, T.; Nicolay, A.; Schneider, A.; Rösler, H.; Heußner, K.U.; Bönisch, E. Pre-industrial charcoal production in Lower Lusatia (Brandenburg, Germany): Detection and evaluation of a large charcoal-burning field by combining archaeological studies, GIS-based analyses of shaded-relief maps and dendrochronological age determination. Quat. Int. 2015, 367, 111–122. [Google Scholar] [CrossRef]
- Deforce, K.; Boeren, I.; Adriaenssens, S.; Bastiaens, J.; De Keersmaeker, L.; Haneca, K.; Tys, D.; Vandekerkhove, K. Selective woodland exploitation for charcoal production. A detailed analysis of charcoal kiln remains (ca. 1300–1900 AD) from Zoersel (northern Belgium). J. Archaeol. Sci. 2013, 40, 681–689. [Google Scholar] [CrossRef]
- Kenzler, H.; Lambers, K. Challenges and perspectives of woodland archaeology across Europe. In Concepts, Methods and Tools. Proceedings of the 42nd Annual Conference on Computer Applications and Quantitative Methods in Archaeology; Giligny, F., Djindjian, F., Costa, L., Moscati, P., Robert, S., Eds.; Archaeopress: Oxford, UK, 2015; pp. 73–80. [Google Scholar]
- Publieke Dienstverlening Op de Kaart (PDOK). Available online: https://www.pdok.nl/ (accessed on 18 March 2020).
- Hesse, R. LiDAR-derived Local Relief Models—A new tool for archaeological prospection. Archaeol. Prospect. 2010, 17, 67–72. [Google Scholar] [CrossRef]
- Actueel Hoogtebestand Nederland (AHN). Available online: https://ahn.arcgisonline.nl/ahnviewer/ (accessed on 18 March 2020).
- Van Der Zon, N. Kwaliteitsdocument AHN2; Technical Report; Rijkswaterstaat: Amersfoort, The Netherlands, 2013. [Google Scholar]
- QGIS Development Team. QGIS Geographic Information System. Available online: https://www.qgis.org/ (accessed on 27 April 2020).
- Kokalj, Ž.; Hesse, R. Airborne Laser Scanning Raster Data Visualisation: A Guide to Good Practice; Založba ZRC: Ljubljana, Slovenian, 2017. [Google Scholar]
- Nyffeler, J. Kulturlandschaft in neuem Licht: Eine Einführung zu LiDAR in der Archäologie; University of Bamberg Press: Bamberg, Germany, 2018. [Google Scholar]
- LabelImg. Available online: https://github.com/tzutalin/labelImg/ (accessed on 8 April 2020).
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Sadr, K. The impact of coder reliability on reconstructing archaeological settlement patterns from satellite imagery: A case study from South Africa. Archaeol. Prospect. 2016, 23, 45–54. [Google Scholar] [CrossRef]
- Heritage Quest. Available online: https://www.zooniverse.org/projects/evakap/heritage-quest (accessed on 18 March 2020).
- Eitzel, M.V.; Cappadonna, J.L.; Santos-Lang, C.; Duerr, R.E.; Virapongse, A.; West, S.E.; Kyba, C.C.M.; Bowser, A.; Cooper, C.B.; Sforzi, A.; et al. Citizen science terminology matters: Exploring key terms. Citiz. Sci. Theory Pract. 2017, 2, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Van den Dries, M.H. Community Archaeology in the Netherlands. J. Community Archaeol. Heritage 2014, 1, 68–88. [Google Scholar] [CrossRef]
- The Zooniverse. Available online: https://www.zooniverse.org (accessed on 25 March 2020).
- Lyman, R.L.; VanPool, T.L. Metric data in archaeology: A study of intra-analyst and inter-analyst variation. Am. Antiq. 2009, 74, 485–504. [Google Scholar] [CrossRef]
- Kosmala, M.; Wiggins, A.; Swanson, A.; Simmons, B. Assessing data quality in citizen science. Front. Ecol. Environ. 2016, 14, 551–560. [Google Scholar] [CrossRef] [Green Version]
- Swanson, A.; Kosmala, M.; Lintott, C.; Packer, C. A generalized approach for producing, quantifying, and validating citizen science data from wildlife images. Conserv. Biol. 2016, 30, 520–531. [Google Scholar] [CrossRef] [PubMed]
- Casana, J. Global-Scale Archaeological Prospection using CORONA Satellite Imagery: Automated, Crowd-Sourced, and Expert-led Approaches. J. Field Archaeol. 2020, 45, S89–S100. [Google Scholar] [CrossRef] [Green Version]
- Freitag, A.; Meyer, R.; Whiteman, L. Strategies Employed by Citizen Science Programs to Increase the Credibility of Their Data. Citiz. Sci. Theory Practice. 2016, 1, 2. [Google Scholar] [CrossRef]
- Herfort, B.; Höfle, B.; Klonner, C. 3D micro-mapping: Towards assessing the quality of crowdsourcing to support 3D point cloud analysis. ISPRS J. Photogramm. Remote. Sens. 2018, 137, 73–83. [Google Scholar] [CrossRef]
- Salk, C.; Sturn, T.; See, L.; Fritz, S. Local knowledge and professional background have a minimal impact on volunteer citizen science performance in a land-cover classification task. Remote. Sens. 2016, 8, 774. [Google Scholar] [CrossRef] [Green Version]
- Python 3.6. Available online: https://www.python.org/ (accessed on 8 April 2020).
- Keras. Available online: https://keras.io/ (accessed on 8 April 2020).
- Keras Implementation of Faster R-CNN. Available online: https://github.com/moyiliyi/keras-faster-rcnn (accessed on 8 April 2020).
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE ICCV, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [Green Version]
- Mohamed, E.; Sirlantzis, K.; Howells, G. Application of transfer learning for object detection on manually collected data. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1037, pp. 919–931. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Ding, P.; Zhang, Y.; Deng, W.J.; Jia, P.; Kuijper, A. A light and faster regional convolutional neural network for object detection in optical remote sensing images. ISPRS J. Photogramm. Remote. Sens. 2018, 141, 208–218. [Google Scholar] [CrossRef]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Computer Vision—ACCV 2016. Lecture Notes in Computer Science, vol 10115; Lai, S., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 214–230. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small object detection in optical remote sensing images via modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap; Chapman & Hall/CRC: New York, NY, USA, 1993. [Google Scholar]
- Gupta, N.; Devillers, R. Geographic Visualization in Archaeology. J. Archaeol. Method Theory 2017, 24, 852–885. [Google Scholar] [CrossRef] [Green Version]
- Esri. ArcMap. Available online: https://desktop.arcgis.com/en/arcmap/ (accessed on 27 April 2020).
- Gao, L.; He, Y.; Sun, X.; Jia, X.; Zhang, B. Incorporating negative sample training for ship detection based on deep learning. Sensors 2019, 19, 684. [Google Scholar] [CrossRef] [Green Version]
- Verhagen, P.; Whitley, T.G. Integrating Archaeological Theory and Predictive Modeling: A Live Report from the Scene. J. Archaeol. Method Theory 2012, 19, 49–100. [Google Scholar] [CrossRef] [Green Version]
- Verhagen, P.; Whitley, T.G. Predictive spatial modelling. In Archaeological Spatial Analysis: A Methodological Guide; Gillings, M., Hacigüzeller, P., Lock, G., Eds.; Routledge: Oxon, UK; New York, NY, USA, 2020; Chapter 13; pp. 231–246. [Google Scholar]
- Casarotto, A.; Stek, T.D.; Pelgrom, J.; Otterloo, R.H.v.; Sevink, J. Assessing visibility and geomorphological biases in regional field surveys: The case of Roman Aesernia. Geoarchaeology 2018, 33, 177–192. [Google Scholar] [CrossRef] [Green Version]
- Gerritsen, F. Local Identities: Landscape and Community in the Late Prehistoric Meuse-Demer-Scheldt Region; Amsterdam University Press: Amsterdam, The Netherlands, 2003. [Google Scholar] [CrossRef] [Green Version]
- Cowley, D. Remote sensing for archaeology and heritage management-site discovery, interpretation and registration. In Remote Sensing for Archaeological Heritage Management, Proceedings of the 11th EAC Heritage Management Symposium, Reykjavîk, Iceland, 25–27 March 2010; Cowley, D.C., Ed.; Europae Archaeologia Consilium: Brussel, Belgium, 2011; Chapter 4; pp. 43–55. [Google Scholar]
- Koster, E.A. The “European Aeolian Sand Belt”: Geoconservation of Drift Sand Landscapes. Geoheritage 2009, 1, 93–110. [Google Scholar] [CrossRef] [Green Version]
- Blume, H.P.; Leinweber, P. Plaggen soils: Landscape history, properties, and classification. J. Plant Nutr. Soil Sci. 2004, 167, 319–327. [Google Scholar] [CrossRef]
- Spek, T. Het Drentse Esdorpenlandschap. Een Historisch-Geografische Studie; Matrijs: Utrecht, The Netherlands, 2004. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Sammut, C.; Webb, G.I. Encyclopaedia of Machine Learning; Springer: Boston, MA, USA, 2010. [Google Scholar] [CrossRef]
- Zou, Q.; Xie, S.; Lin, Z.; Wu, M.; Ju, Y. Finding the Best Classification Threshold in Imbalanced Classification. Big Data Res. 2016, 5, 2–8. [Google Scholar] [CrossRef]
- Risbøl, O.; Bollandsås, O.M.; Nesbakken, A.; Ørka, H.O.; Naesset, E.; Gobakken, T. Interpreting cultural remains in airborne laser scanning generated digital terrain models: Effects of size and shape on detection success rates. J. Archaeol. Sci. 2013, 40, 4688–4700. [Google Scholar] [CrossRef]
- Sumbul, G.; Kang, J.; Kreuziger, T.; Marcelino, F.; Costa, H.; Benevides, P.; Caetano, M.; Demir, B. BigEarthNet Deep Learning Models with A New Class-Nomenclature for Remote Sensing Image Understanding; Technical Report; Technische Universitat Berlin: Berlin, Germany, 2020. [Google Scholar]
- Torney, C.J.; Lloyd-Jones, D.J.; Chevallier, M.; Moyer, D.C.; Maliti, H.T.; Mwita, M.; Kohi, E.M.; Hopcraft, G.C. A comparison of deep learning and citizen science techniques for counting wildlife in aerial survey images. Methods Ecol. Evol. 2019, 10, 779–787. [Google Scholar] [CrossRef] [Green Version]
- Herfort, B.; Li, H.; Fendrich, S.; Lautenbach, S.; Zipf, A. Mapping Human Settlements with Higher Accuracy and Less Volunteer Efforts by Combining Crowdsourcing and Deep Learning. Remote. Sens. 2019, 11, 1799. [Google Scholar] [CrossRef] [Green Version]
- Traviglia, A.; Cowley, D.; Lambers, K. Finding Common Ground: Human and Computer Vision in Archaeological Prospection. AARGnews—Newsl. Aerial Archaeol. Res. Group 2016, 53, 11–24. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Subtiles | Barrows | Celtic Fields | Charcoal Kilns | Objects |
|---|---|---|---|---|---|
| training | 1024 (380) | 1261 (805) | 1504 (667) | 575 (177) | 3340 (1649) |
| validation | 88 (39) | 127 (49) | 64 (199) | 22 (24) | 213 (272) |
| non-random test | 73 | 78 | 235 | 23 | 336 |
| random test | 828 | 137 | 65/2.56 km2 | 26 | 363 |
| low confidence | 65 | 1.48 km2 | 14 | ||
| high confidence | 72 | 1.08 km2 | 12 |
| Dataset | Positive Subtiles | Negative Subtiles | Proportion |
|---|---|---|---|
| training | 1024 | 1634 | 1:1.6 |
| validation | 88 | 259 | 1:3 |
| non-random test | 63 | 10 | 6.7:1 |
| random test | 164 | 664 | 1:4 |
| Landscape Features | Rank | |||||
|---|---|---|---|---|---|---|
| Type | Area (km2) | Ratio of Research Area (%) | Barrow | Celtic Fields | Charcoal Kilns | |
| drift-sand | 338.4 | 15.2% | 3 | 3 | 1 | |
| plaggen soils | 460.8 | 20.7% | 3 | 3 | 3 | |
| badlands | 73.4 | 3.3% | 3 | 3 | 3 | |
| build-up | 218.3 | 9.8% | 2 | 2 | 2 | |
| roads | 42.2 | 1.9% | 2 | 1 | 2 | |
| other | 1090.6 | 49.1% | 1 | 1 | 1 | |
| total | 2223.7 | 100% | ||||
| Rank | Archaeological Objects | |||||||
|---|---|---|---|---|---|---|---|---|
| Barrows | Celtic Fields | Charcoal Kilns | ||||||
| Number | Ratio | m2 | Ratio | Number | Ratio | |||
| 1 | 341 | 93.4% | 414.7 | 100% | 174 | 99.4% | ||
| 2 | 17 | 4.7% | 0 | 0% | 0 | 0% | ||
| 3 | 7 | 1.9% | 0 | 0% | 1 | 0.6% | ||
| total | 365 | 100% | 414.7 | 100% | 175 | 100% | ||
| Method | Barrows | Celtic fields | Charcoal kilns | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Recall | Precision | F1 | Recall | Precision | F1 | Recall | Precision | F1 | |||
| WODAN1.0 (NR) | 62.3 | 55.2 | 58.5 | 82.3 | 57.6 | 67.8 | – | – | – | ||
| WODAN1.0 (R) | 53.3 | 9.0 | 15.3 | 43.0 | 20.5 | 27.7 | – | – | – | ||
| WODAN2.0 (NR) | 67.1 | 73.3 | 70.1 | 74.6 | 66.0 | 70.0 | – | – | – | ||
| WODAN2.0 (R) | 44.5 | 56.5 | 49.8 | 40.4 | 52.1 | 45.5 | 34.6 | 12.2 | 18.0 | ||
| WODAN2.0+NEG (R) | 47.4 | 46.4 | 46.9 | 38.5 | 45.4 | 41.7 | 19.2 | 10.2 | 13.3 | ||
| Heritage Quest (R) | 45.3 | 80.5 | 57.9 | 75.7 | 85.0 | 80.1 | 38.5 | 55.6 | 45.5 | ||
 |
| Method | Metric | Barrows | Celtic Fields | Charcoal Kilns |
|---|---|---|---|---|
| WODAN2.0 (NR) | recall | 80.5 | 92.8 | – |
| precision | 23.3 | 40.8 | – | |
| F1-score | 36.2 | 56.7 | – | |
| WODAN2.0 (R) | recall | 79.6 | 82.9 | 38.5 |
| precision | 14.1 | 13.3 | 5.1 | |
| F1-score | 24.0 | 22.9 | 8.9 | |
| Heritage Quest (R) | recall | 82.5 | 89.6 | 76.9 |
| precision | 8.1 | 43.4 | 2.6 | |
| F1-Score | 14.8 | 58.8 | 5.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Verschoof-van der Vaart, W.B.; Lambers, K.; Kowalczyk, W.; Bourgeois, Q.P.J. Combining Deep Learning and Location-Based Ranking for Large-Scale Archaeological Prospection of LiDAR Data from The Netherlands. ISPRS Int. J. Geo-Inf. 2020, 9, 293. https://doi.org/10.3390/ijgi9050293
Verschoof-van der Vaart WB, Lambers K, Kowalczyk W, Bourgeois QPJ. Combining Deep Learning and Location-Based Ranking for Large-Scale Archaeological Prospection of LiDAR Data from The Netherlands. ISPRS International Journal of Geo-Information. 2020; 9(5):293. https://doi.org/10.3390/ijgi9050293
Chicago/Turabian StyleVerschoof-van der Vaart, Wouter B., Karsten Lambers, Wojtek Kowalczyk, and Quentin P.J. Bourgeois. 2020. "Combining Deep Learning and Location-Based Ranking for Large-Scale Archaeological Prospection of LiDAR Data from The Netherlands" ISPRS International Journal of Geo-Information 9, no. 5: 293. https://doi.org/10.3390/ijgi9050293
APA StyleVerschoof-van der Vaart, W. B., Lambers, K., Kowalczyk, W., & Bourgeois, Q. P. J. (2020). Combining Deep Learning and Location-Based Ranking for Large-Scale Archaeological Prospection of LiDAR Data from The Netherlands. ISPRS International Journal of Geo-Information, 9(5), 293. https://doi.org/10.3390/ijgi9050293