A Deep Learning Approach to Urban Street Functionality Prediction Based on Centrality Measures and Stacked Denoising Autoencoder


 , , and
, , and
Abstract
:1. Introduction
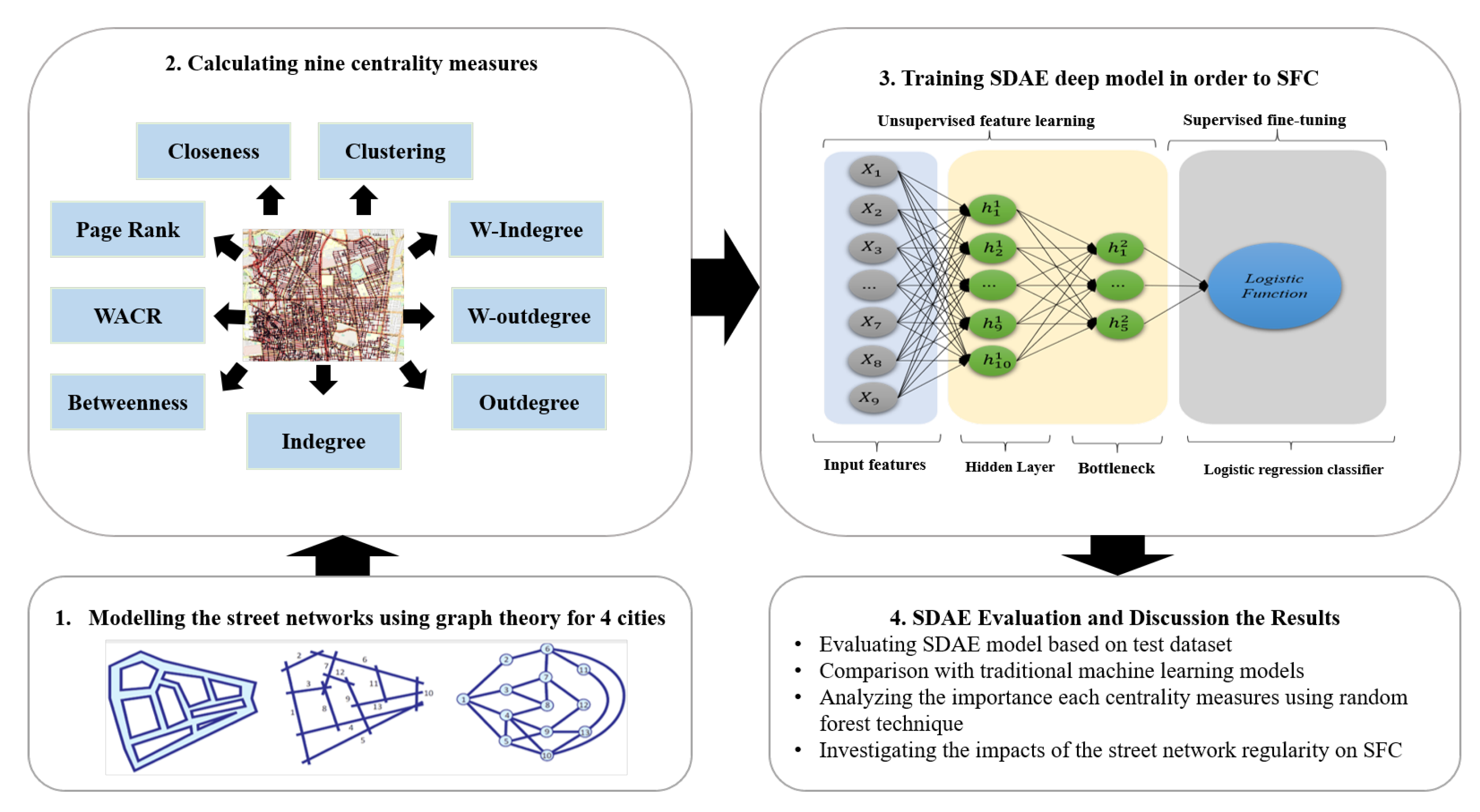
- Considering the challenge of street functional classification based on the spatial structure of streets, mainly centrality measures.
- Developing an unsupervised deep learning model to improve the accuracy of the street functional classification compared to traditional techniques.
- Analyzing the importance of each centrality measure into street functional classification by using random forest technique.
- Investigating the impacts of the street network regularity on street functional classification.
2. Materials and Methods
2.1. USN Modeling Using Graph Theory
2.2. Centrality Measures
2.2.1. Betweenness Centrality
2.2.2. In/Out-Degree and Weighted In/Out-Degree
2.2.3. Clustering Coefficient
2.2.4. Weighted Average Centrality Rank (WACR)
2.2.5. Page-Rank Centrality
2.2.6. Closeness Centrality
2.3. Regularity Measurement: Spatial Configuration of an Urban Street Network
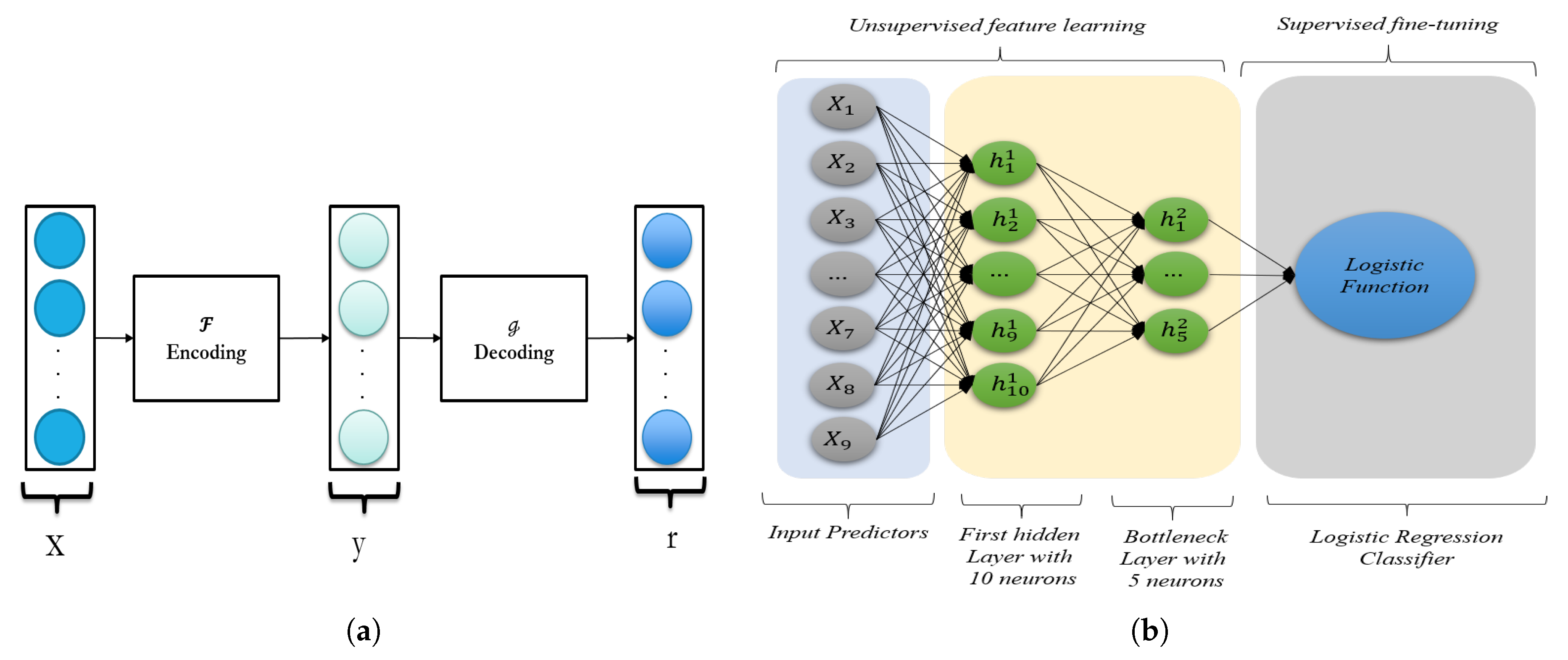
2.4. Stacked Denoising Autoencoder
3. Results
3.1. Data Description
3.2. Algorithm Set-Up
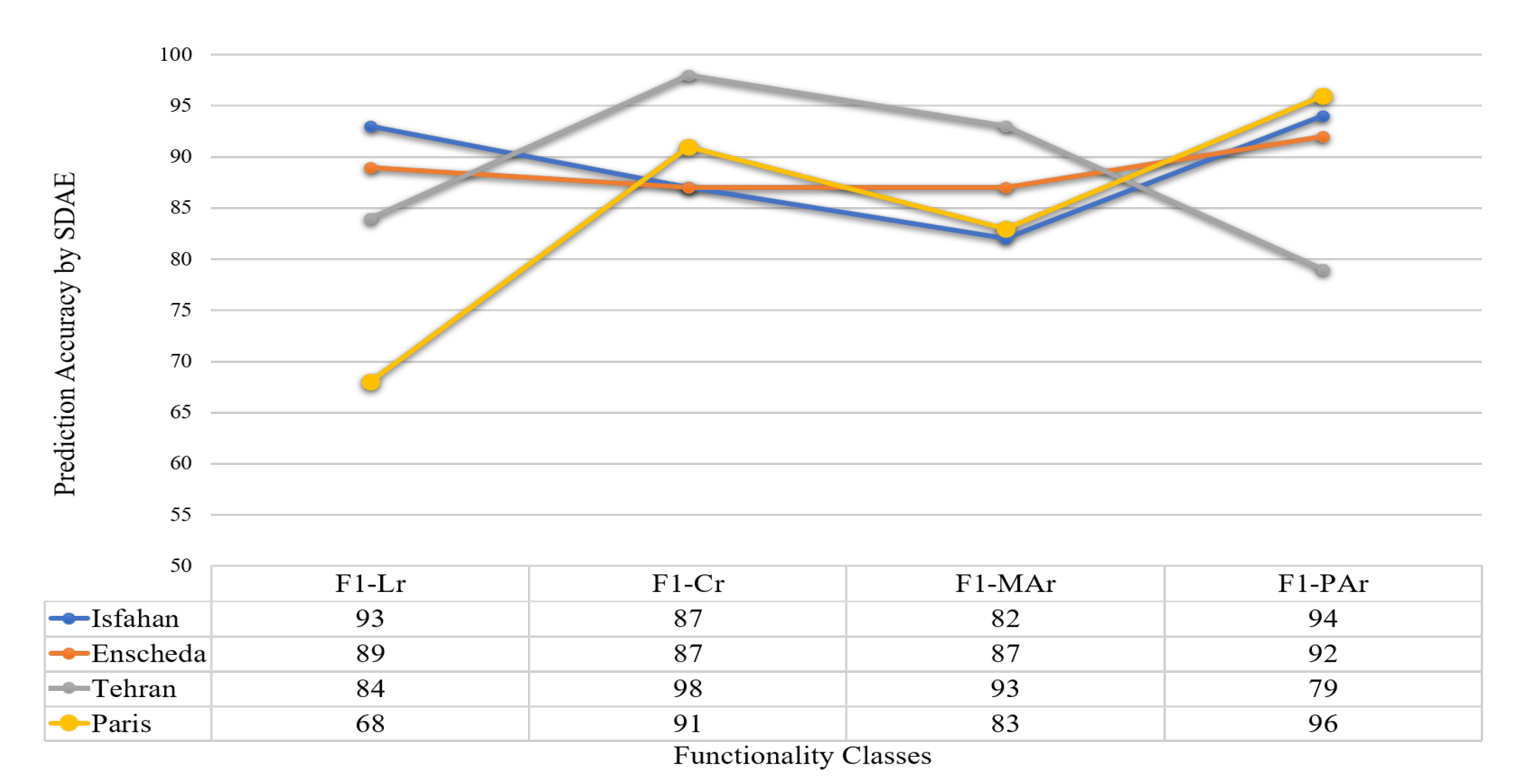
3.3. Experimental Results
4. Discussion
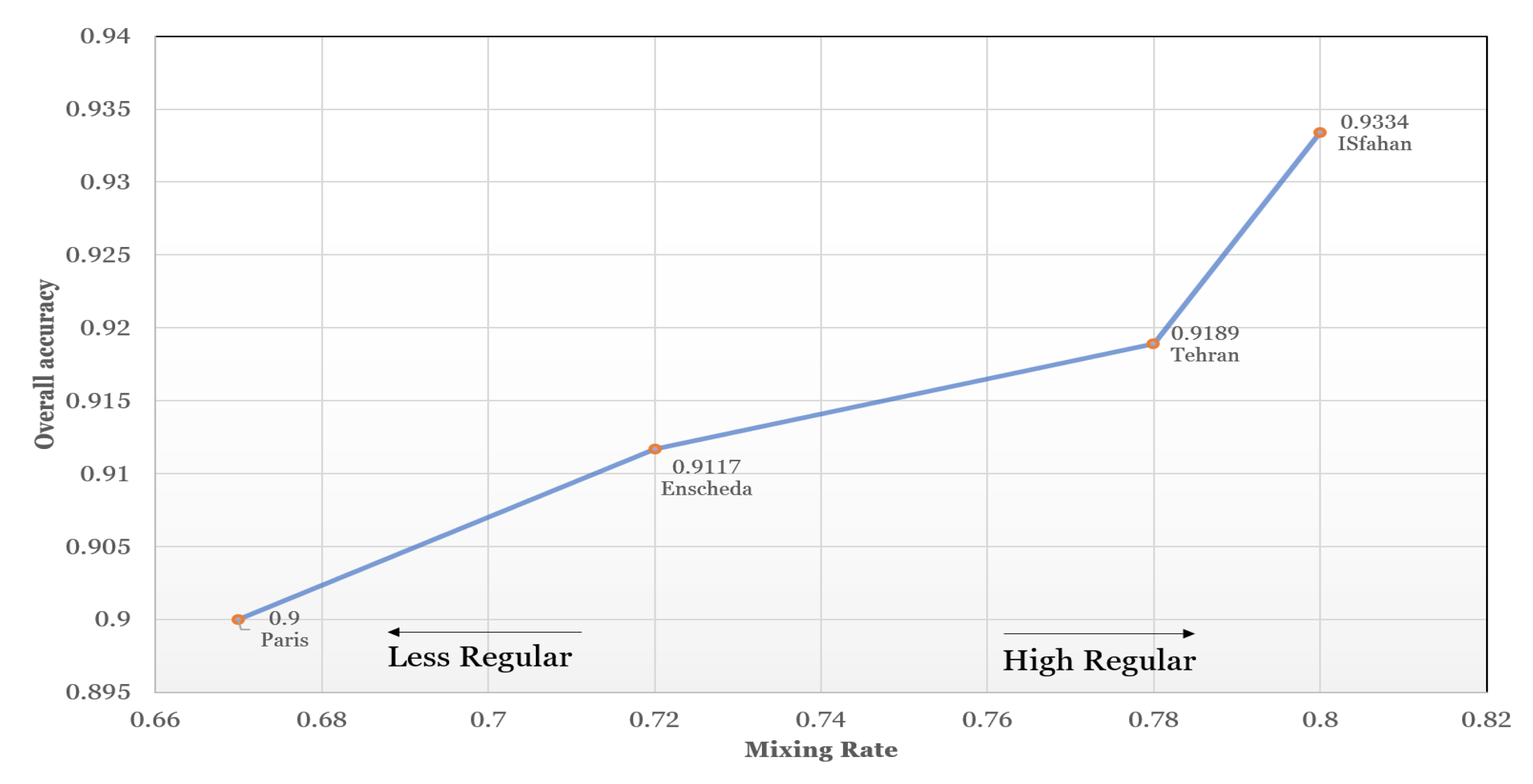
4.1. Regularity of Cities and Its Influence on Classification Results
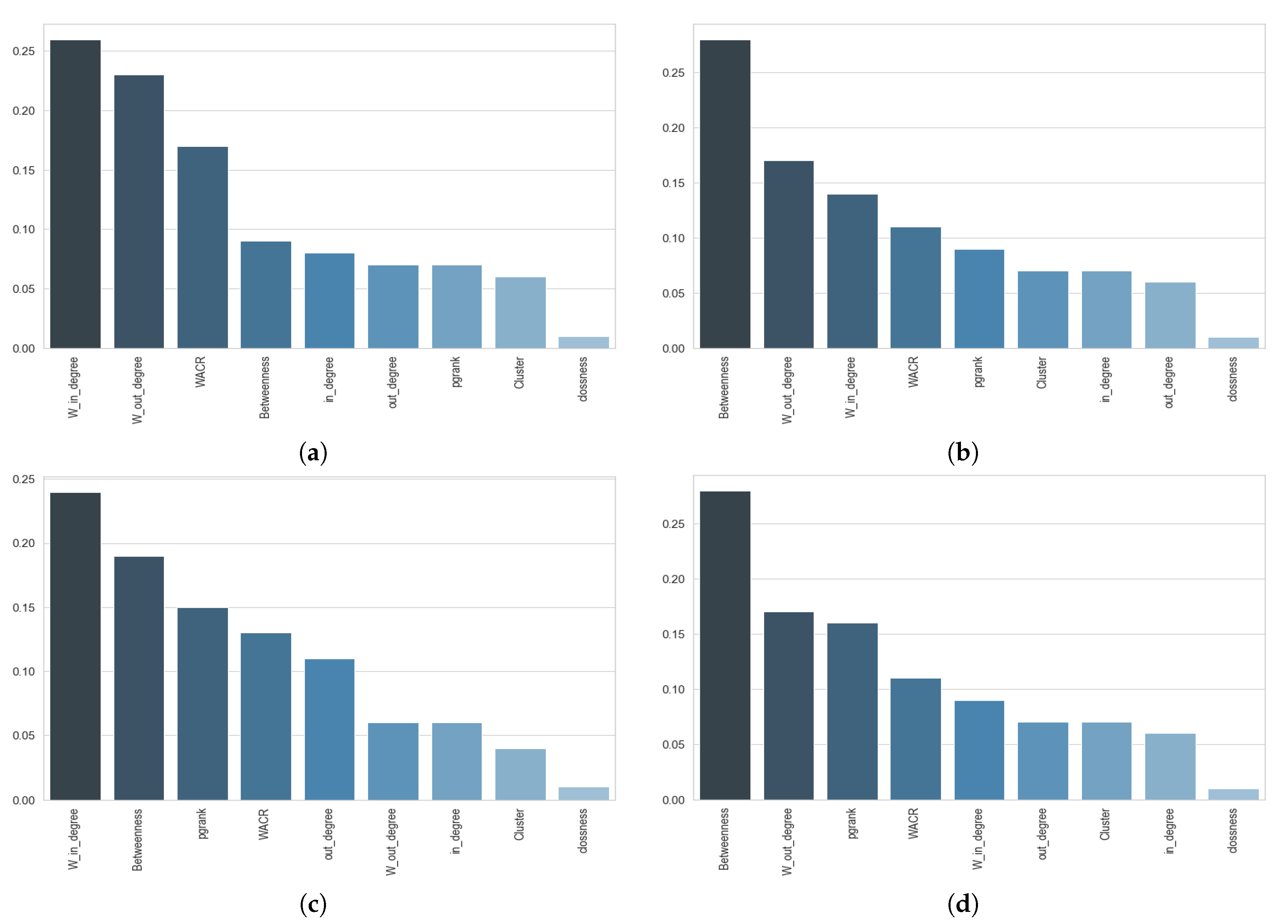
4.2. The Importance of Each Centrality Features
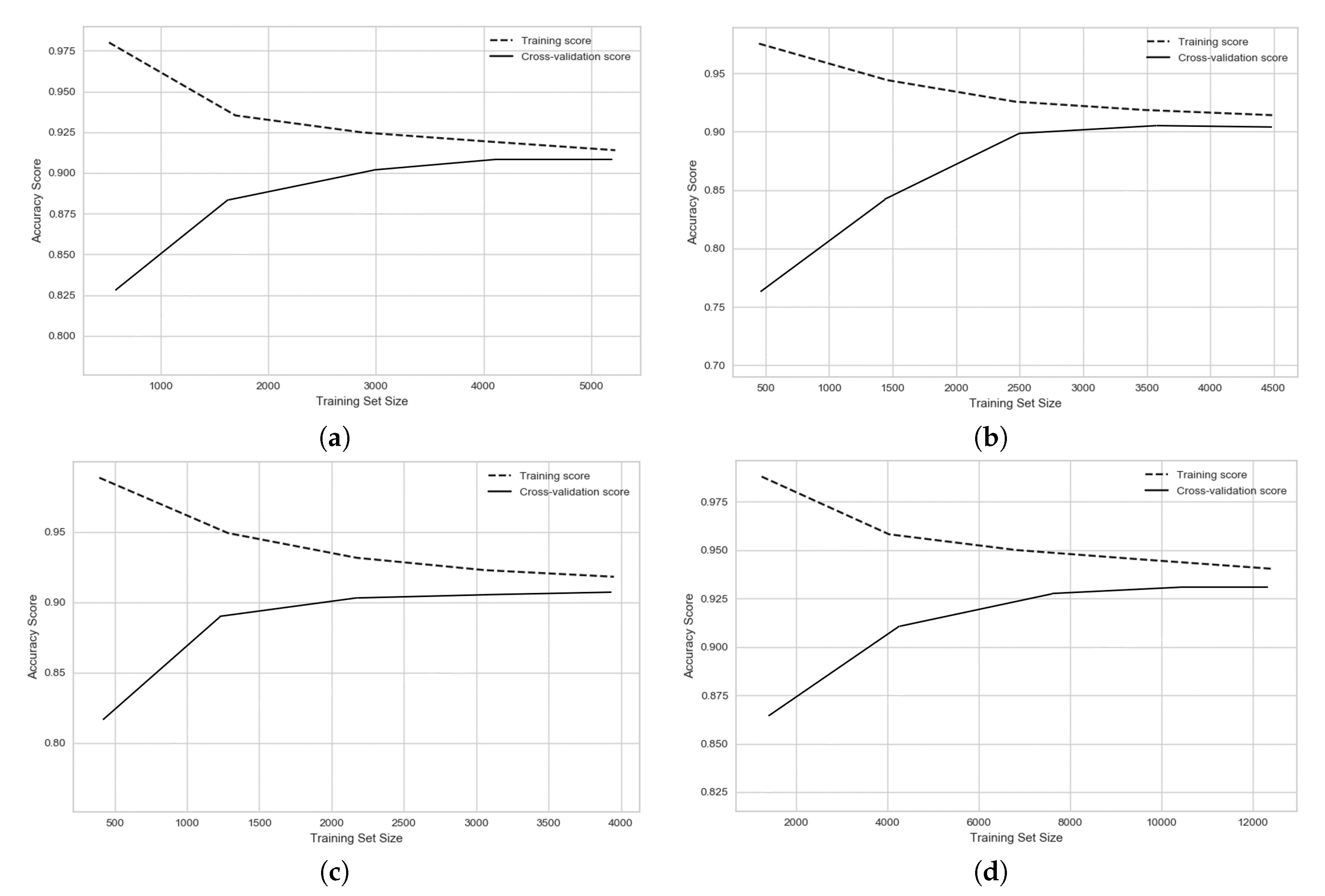
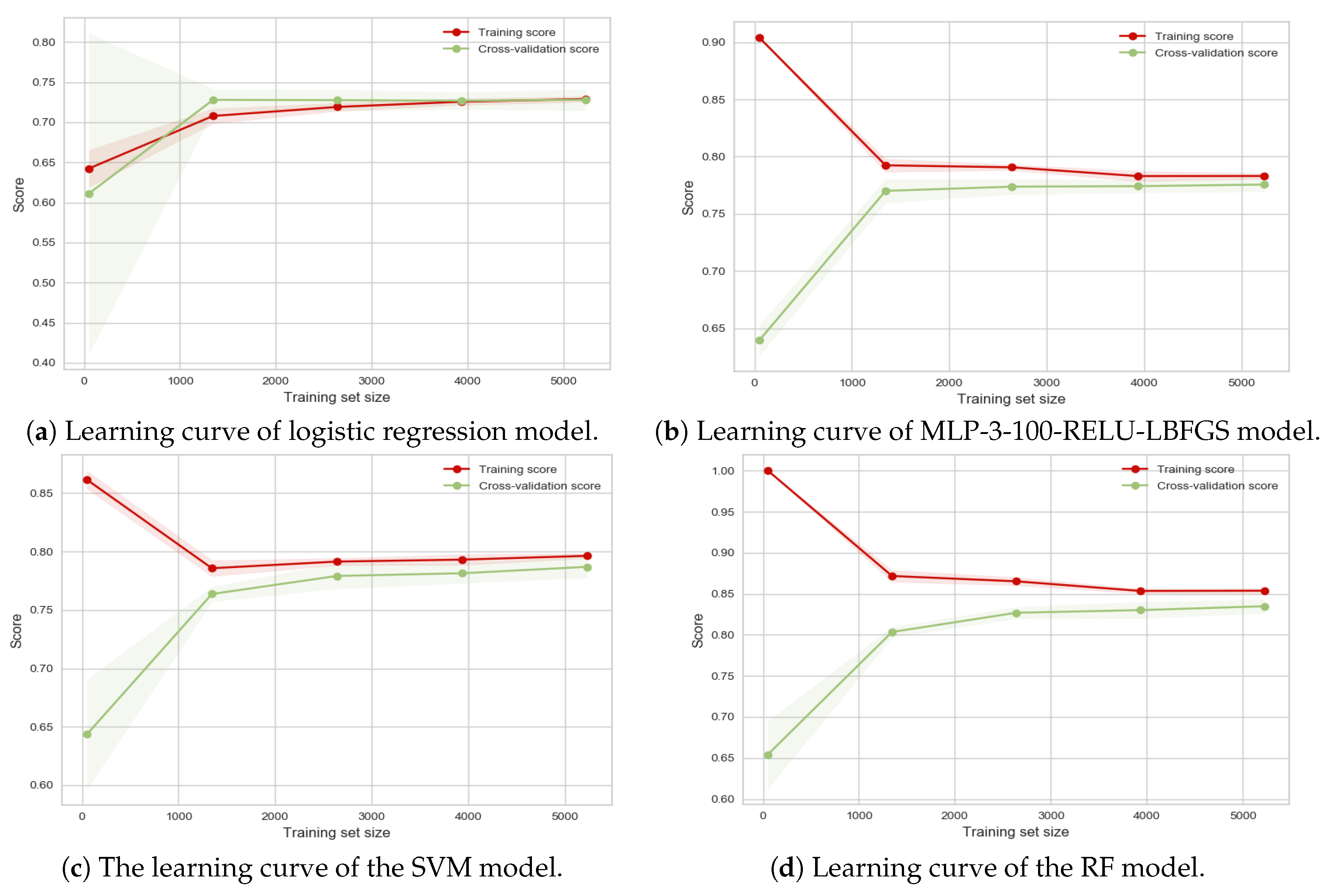
4.3. Deep Learning for Big Data Processing
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jiang, B.; Harrie, L. Selection of streets from a network using self-organizing maps. Trans. GIS 2004, 8, 335–350. [Google Scholar] [CrossRef]
- Borgatti, S.P. Centrality and network flow. Soc. Netw. 2005, 27, 55–71. [Google Scholar] [CrossRef]
- Porta, S.; Crucitti, P.; Latora, V. The network analysis of urban streets: A dual approach. Phys. A Stat. Mech. Its Appl. 2006, 369, 853–866. [Google Scholar] [CrossRef] [Green Version]
- Blanchard, P.; Volchenkov, D. Mathematical Analysis of Urban Spatial Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Kazerani, A.; Winter, S. Can betweenness centrality explain traffic flow. In Proceedings of the 12th AGILE International Conference on Geographic Information Science, Hannover, Germay, 2–5 June 2009; pp. 1–9. [Google Scholar]
- Jiang, B.; Liu, C. Street-based topological representations and analyses for predicting traffic flow in GIS. Int. J. Geogr. Inf. Sci. 2009, 23, 1119–1137. [Google Scholar] [CrossRef] [Green Version]
- Gao, S.; Wang, Y.; Gao, Y.; Liu, Y. Understanding urban traffic-flow characteristics: A rethinking of betweenness centrality. Environ. Plan. B Plan. Des. 2013, 40, 135–153. [Google Scholar] [CrossRef] [Green Version]
- U.S. Department of Transportation. Highway Functional Classification: Concepts, Criteria and Procedures; USDoT: Washington, DC, USA, 2013.
- Penn, A.; Hillier, B.; Banister, D.; Xu, J. Configurational modelling of urban movement networks. Environ. Plan. B Plan. Des. 1998, 25, 59–84. [Google Scholar] [CrossRef] [Green Version]
- Turner, F.C. The Federal-Aid Highway of 1970 and Other Related Bills Prepared for Delivery before the Subcommittee on Roads of the Senate Committee on Public Works. Available online: https://rosap.ntl.bts.gov/view/dot/43207 (accessed on 2 June 2020).
- Stamatiadis, N.; Kirk, A.; King, M.; Chellman, R. Development of a context sensitive multimodal functional classification system. Adv. Transp. Stud. 2019, 47, 5–20. [Google Scholar]
- Hasan, U.; Whyte, A.; Al Jassmi, H. A Review of the Transformation of Road Transport Systems: Are We Ready for the Next Step in Artificially Intelligent Sustainable Transport? Appl. Syst. Innov. 2020, 3, 1. [Google Scholar] [CrossRef] [Green Version]
- Han, B.; Sun, D.; Yu, X.; Song, W.; Ding, L. Classification of Urban Street Networks Based on Tree-Like Network Features. Sustainability 2020, 12, 628. [Google Scholar] [CrossRef] [Green Version]
- Xing, H.; Meng, Y. Measuring urban landscapes for urban function classification using spatial metrics. Ecol. Indic. 2020, 108, 105722. [Google Scholar] [CrossRef]
- Castro, J.T.; Vistan, E.F.L. A Geographic Information System for Rural Accessibility: Database Development and the Application of Multi-criteria Evaluation for Road Network Planning in Rural Areas. In Urban and Transit Planning; Springer: Berlin, Germany, 2020; pp. 277–288. [Google Scholar]
- Sumit, S.H.; Akhter, S. C-means clustering and deep-neuro-fuzzy classification for road weight measurement in traffic management system. Soft Comput. 2019, 23, 4329–4340. [Google Scholar] [CrossRef]
- Maeda, K.; Takahashi, S.; Ogawa, T.; Haseyama, M. Convolutional sparse coding-based deep random vector functional link network for distress classification of road structures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 654–676. [Google Scholar] [CrossRef]
- Ahmadzai, F.; Rao, K.L.; Ulfat, S. Assessment and modelling of urban road networks using Integrated Graph of Natural Road Network (a GIS-based approach). J. Urban Manag. 2019, 8, 109–125. [Google Scholar] [CrossRef]
- Van HIEP, D.; SODIKOV, J. The Role of Highway Functional Classification in Road Asset Management. J. East. Asia Soc. Transp. Stud. 2017, 12, 1477–1488. [Google Scholar]
- Zhang, H.; Li, Z. Weighted ego network for forming hierarchical structure of road networks. Int. J. Geogr. Inf. Sci. 2011, 25, 255–272. [Google Scholar] [CrossRef]
- Crucitti, P.; Latora, V.; Porta, S. Centrality in networks of urban streets. Chaos Interdiscip. J. Nonlinear Sci. 2006, 16, 015113. [Google Scholar] [CrossRef] [PubMed]
- Justen, A.; Martínez, F.J.; Cortés, C.E. The use of space–time constraints for the selection of discretionary activity locations. J. Transp. Geogr. 2013, 33, 146–152. [Google Scholar] [CrossRef]
- Zhong, C.; Arisona, S.M.; Huang, X.; Batty, M.; Schmitt, G. Detecting the dynamics of urban structure through spatial network analysis. Int. J. Geogr. Inf. Sci. 2014, 28, 2178–2199. [Google Scholar] [CrossRef]
- Berli, J.; Ducruet, C.; Martin, R.; Seten, S. The Changing Interplay Between European Cities and Intermodal Transport Networks (1970s–2010s). In European Port Cities in Transition; Springer: Berlin, Germany, 2020; pp. 241–263. [Google Scholar]
- He, S.; Yu, S.; Wei, P.; Fang, C. A spatial design network analysis of street networks and the locations of leisure entertainment activities: A case study of Wuhan, China. Sustain. Cities Soc. 2019, 44, 880–887. [Google Scholar] [CrossRef]
- Ližbetin, J. Methodology for determining the location of intermodal transport terminals for the development of sustainable transport systems: A case study from Slovakia. Sustainability 2019, 11, 1230. [Google Scholar] [CrossRef] [Green Version]
- Hillier, B.; Penn, A.; Hanson, J.; Grajewski, T.; Xu, J. Natural movement: Or, configuration and attraction in urban pedestrian movement. Environ. Plan. B Plan. Des. 1993, 20, 29–66. [Google Scholar] [CrossRef] [Green Version]
- Hillier, B.; Iida, S. Network and psychological effects in urban movement. In Proceedings of the International Conference on Spatial Information Theory, Ellicottville, NY, USA, 14–18 September 2005; Springer: Berlin, Heidelberg, 2005; pp. 475–490. [Google Scholar]
- Tsiotas, D.; Polyzos, S. Introducing a new centrality measure from the transportation network analysis in Greece. Ann. Oper. Res. 2015, 227, 93–117. [Google Scholar] [CrossRef]
- Ratti, C.; Frenchman, D.; Pulselli, R.M.; Williams, S. Mobile landscapes: Using location data from cell phones for urban analysis. Environ. Plan. B Plan. Des. 2006, 33, 727–748. [Google Scholar] [CrossRef]
- Chen, C.; Chen, J.; Barry, J. Diurnal pattern of transit ridership: A case study of the New York City subway system. J. Transp. Geogr. 2009, 17, 176–186. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer Series in Information Sciences; Springer: Berlin, Germany, 2001; Volume 30. [Google Scholar]
- Zhou, Q. Selective Omission of Road Networks in Multi-Scale Representation. Ph.D. Thesis, The Hong Kong Polytechnic University, Hong Kong, China, 2012. [Google Scholar]
- Wang, P.; Xu, W.; Jin, Y.; Wang, J.; Li, L.; Lu, Q.; Wang, G. Forecasting traffic volume at a designated cross-section location on a freeway from large-regional toll collection data. IEEE Access 2019, 7, 9057–9070. [Google Scholar] [CrossRef]
- Lenjani, A.; Dyke, S.J.; Bilionis, I.; Yeum, C.M.; Kamiya, K.; Choi, J.; Liu, X.; Chowdhury, A.G. Towards fully automated post-event data collection and analysis: Pre-event and post-event information fusion. Eng. Struct. 2020, 208, 109884. [Google Scholar] [CrossRef] [Green Version]
- Kamangir, H.; Rahnemoonfar, M.; Dobbs, D.; Paden, J.; Fox, G. Deep hybrid wavelet network for ice boundary detection in radra imagery. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain; 2018; pp. 3449–3452. [Google Scholar]
- Pashaei, M.; Kamangir, H.; Starek, M.J.; Tissot, P. Review and Evaluation of Deep Learning Architectures for Efficient Land Cover Mapping with UAS Hyper-Spatial Imagery: A Case Study Over a Wetland. Remote Sens. 2020, 12, 959. [Google Scholar] [CrossRef] [Green Version]
- Pashaei, M.; Starek, M.J.; Kamangir, H.; Berryhill, J. Deep Learning-Based Single Image Super-Resolution: An Investigation for Dense Scene Reconstruction with UAS Photogrammetry. Remote Sens. 2020, 12, 1757. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; Volume 15 of JMLR. pp. 315–323. [Google Scholar]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Koesdwiady, A.; Soua, R.; Karray, F. Improving traffic flow prediction with weather information in connected cars: A deep learning approach. IEEE Trans. Veh. Technol. 2016, 65, 9508–9517. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Siavoshani, M.J.; Zade, R.S.H.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2017, 24, 1999–2012. [Google Scholar] [CrossRef] [Green Version]
- Lenjani, A.; Dyke, S.; Bilionis, I.; Yeum, C.M.; Choi, J.; Lund, A.; Maghareh, A. Hierarchical Convolutional Neural Networks Information Fusion for Activity Source Detection in Smart Buildings. Struct. Health Monit. 2019. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1994; ISBN 978-0-13-147139-9. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2007; pp. 153–160. [Google Scholar]
- Hillier, B.; Hanson, J. The Social Logic of Space; Cambridge University Press: Cambridge, UK, 1989. [Google Scholar]
- Thomson, R.C.; Richardson, D.E. A graph theory approach to road network generalisation. In Proceedings of the 17th International Cartographic Conference-10th General Assembly of ICA, Barcelona, ES, Spain, 3–9 September 1995; pp. 1871–1880. [Google Scholar]
- Chaudhry, O.; Mackaness, W. Rural and Urban Road Network Generalisation: Deriving 1: 250,000 from OS MasterMap; Institute of Geography, The School of Geosciences, The University of Edinburgh: Edinburgh, UK, 2006. [Google Scholar]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Opsahl, T.; Panzarasa, P. Clustering in weighted networks Soc. Networks 2009, 31, 155–163. [Google Scholar] [CrossRef]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Lovász, L. Random walks on graphs: A survey. Comb. Paul Erdos Is Eighty 1993, 2, 1–46. [Google Scholar]
- Lovász, L.; Winkler, P. Mixing of Random Walks and Other Diffusions on a Graph; London Mathematical Society Lecture Note Series; Cambridge University Press: Cambridge, UK, 1995; pp. 119–154. [Google Scholar]
- Charte, D.; Charte, F.; García, S.; del Jesus, M.J.; Herrera, F. A practical tutorial on autoencoders for nonlinear feature fusion: Taxonomy, models, software and guidelines. Inf. Fusion 2018, 44, 78–96. [Google Scholar] [CrossRef]
- Li, W.; Fu, H.; Yu, L.; Gong, P.; Feng, D.; Li, C.; Clinton, N. Stacked autoencoder-based deep learning for remote-sensing image classification: A case study of African land-cover mapping. Int. J. Remote Sens. 2016, 37, 5632–5646. [Google Scholar] [CrossRef]
- Kamangir, H.; Collins, W.; Tissot, P.; King, S.A. Deep-learning model used to predict thunderstorms within 400 km2 of south Texas domains. Meteorol. Appl. 2020, 27, e1905. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. (TOMS) 1997, 23, 550–560. [Google Scholar] [CrossRef]
- Story, M. and Congalton, R.G. Accuracy assessment: A user’s perspective. Photogramm. Eng. Remote. Sens. 1986, 52, 397–399. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Cameron, A.C.; Windmeijer, F.A. An R-squared measure of goodness of fit for some common nonlinear regression models. J. Econom. 1997, 77, 329–342. [Google Scholar] [CrossRef]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Advances in Neural Information Processing Systems 26, Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, Nevada, 5–8 December 2013; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA; pp. 431–439.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Betweenness | InDegree | WeightInDegree | OutDegree | WeightOutDegree | Clustering | WACR | Page Rank | Closeness | |
|---|---|---|---|---|---|---|---|---|---|
| Count | |||||||||
| Isfahan | 8711 | 8711 | 8711 | 8711 | 8711 | 8711 | 8711 | 8711 | 8711 |
| Tehran | 6588 | 6588 | 6588 | 6588 | 6588 | 6588 | 6588 | 6588 | 6588 |
| Enschede | 7483 | 7483 | 7483 | 7483 | 7483 | 7483 | 7483 | 7483 | 7483 |
| Paris | 20,697 | 20,697 | 20,697 | 20,697 | 20,697 | 20,697 | 20,697 | 20,697 | 20,697 |
| Mean | |||||||||
| Isfahan | 89,300 | 9.37 | 3363.28 | 9.37 | 14040.49 | 0.05 | 75.30 | 2.92 | 3.22 × 10 |
| Tehran | 80,876.88 | 12.64 | 7088.23 | 12.63 | 22,891.34 | 0.05 | 129.11 | 3.19 | 1.66 × 10 |
| Enschede | 53,698.25 | 5.99 | 2662.78 | 6.03 | 6075.36 | 0.13 | 38.91 | 1.70 | 1.51 × 10 |
| Paris | 246,000 | 9.16 | 5418.65 | 9.39 | 2.21 × 10 | 0.18 | 104.12 | 2.54 | 1.19 × 10 |
| STD | |||||||||
| Isfahan | 192,000 | 12.18 | 5136.07 | 12.18 | 51,482.61 | 0.17 | 211.42 | 3.48 | 1.91 × 10 |
| Tehran | 131,445.50 | 16.70 | 9977.25 | 16.62 | 46,264.95 | 0.15 | 279.18 | 3.85 | 7.90 × 10 |
| Enschede | 112,209.45 | 5.85 | 2898.23 | 5.98 | 15,345.66 | 0.21 | 95.02 | 1.46 | 1.35 × 10 |
| Paris | 419,000 | 12.30 | 6694.80 | 13.16 | 1.00 × 10 | 0.23 | 525.52 | 3.25 | 5.34 × 10 |
| Min | |||||||||
| Isfahan | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 2.20 × 10 |
| Tehran | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 1.90 × 10 |
| Enschede | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.32 | 4.00 × 10 |
| Paris | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 7.70 × 10 |
| Max | |||||||||
| Isfahan | 1,670,000 | 69.00 | 36,490.86 | 69.00 | 423,000.00 | 1.00 | 1756.75 | 12.00 | 3.61 × 10 |
| Tehran | 662,113.00 | 72.00 | 49,335.87 | 70.00 | 176,792.70 | 1.00 | 1361.22 | 16.00 | 2.44 × 10 |
| Enschede | 783,939.00 | 38.00 | 13,336.21 | 39.00 | 111,360.20 | 1.00 | 746.41 | 10.22 | 2.57 × 10 |
| Paris | 5,580,000 | 105.00 | 38,784.84 | 115.00 | 1.24 × 10 | 1.00 | 6622.52 | 29.51 | 7.71 × 10 |
| Algorithm | Hyperparameter | Value |
|---|---|---|
| LR | Regularization, C | , , 10 |
| Optimization function | LBFGS | |
| Iteration Number | 1000 | |
| MLP | Hidden Layer size | 2–3 |
| Hidden Layer neurons | 20–100 | |
| Activation Function | Relu, Logistic | |
| Optimization function | LBFGS, SGD | |
| Momentum | ||
| Learning Rate | ||
| Alpha | ||
| Beta | ||
| Iteration Number | 1000 | |
| SVM | Regularization, C | , , 10 |
| Kernel | RBF | |
| Gamma | 10 | |
| Iteration Number | 1000 | |
| RF | Number of estimators | 1000 |
| Max-Depth | 5–10 | |
| Min leaf per node | 2–8 | |
| SDAE | Number of Hidden Layer | 2–3 |
| Number of neurons | 2–15 | |
| Regularization | , , | |
| Noise Mask | 0–30% |
| Algorithm | R2 | RMSE | OA-Tr | OA-Te | F1-Lr | F1-Cr | F1-MAr | F1-PAr |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | ||||||||
| MLP-3-100-ReLU-LBFGS | ||||||||
| SVM | ||||||||
| Random Forest | ||||||||
| SDAE |
| Algorithm | R2 | RMSE | OA-Tr | OA-Te | F1-Lr | F1-Cr | F1-MAr | F1-PAr |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | ||||||||
| MLP-3-100-ReLU-LBFGS | ||||||||
| SVM | ||||||||
| Random Forest | ||||||||
| SDAE |
| Algorithm | R2 | RMSE | OA-Tr | OA-Te | F1-Lr | F1-Cr | F1-MAr | F1-PAr |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | ||||||||
| MLP-3-100-ReLU-LBFGS | ||||||||
| SVM | ||||||||
| Random Forest | ||||||||
| SDAE |
| Algorithm | R2 | RMSE | OA-Tr | OA-Te | F1-Lr | F1-Cr | F1-MAr | F1-PAr |
|---|---|---|---|---|---|---|---|---|
| Logistic Regression | ||||||||
| MLP-3-100-ReLU-LBFGS | ||||||||
| SVM | ||||||||
| Random Forest | ||||||||
| SDAE |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noori, F.; Kamangir, H.; A. King, S.; Sheta, A.; Pashaei, M.; SheikhMohammadZadeh, A. A Deep Learning Approach to Urban Street Functionality Prediction Based on Centrality Measures and Stacked Denoising Autoencoder. ISPRS Int. J. Geo-Inf. 2020, 9, 456. https://doi.org/10.3390/ijgi9070456
Noori F, Kamangir H, A. King S, Sheta A, Pashaei M, SheikhMohammadZadeh A. A Deep Learning Approach to Urban Street Functionality Prediction Based on Centrality Measures and Stacked Denoising Autoencoder. ISPRS International Journal of Geo-Information. 2020; 9(7):456. https://doi.org/10.3390/ijgi9070456
Chicago/Turabian StyleNoori, Fatemeh, Hamid Kamangir, Scott A. King, Alaa Sheta, Mohammad Pashaei, and Abbas SheikhMohammadZadeh. 2020. "A Deep Learning Approach to Urban Street Functionality Prediction Based on Centrality Measures and Stacked Denoising Autoencoder" ISPRS International Journal of Geo-Information 9, no. 7: 456. https://doi.org/10.3390/ijgi9070456
APA StyleNoori, F., Kamangir, H., A. King, S., Sheta, A., Pashaei, M., & SheikhMohammadZadeh, A. (2020). A Deep Learning Approach to Urban Street Functionality Prediction Based on Centrality Measures and Stacked Denoising Autoencoder. ISPRS International Journal of Geo-Information, 9(7), 456. https://doi.org/10.3390/ijgi9070456