
Tomato Fruit Detection Using Modified Yolov5m Model with Convolutional Neural Networks


Abstract
:1. Introduction
2. Results and Discussion
3. Materials and Methods
3.1. Dataset for Training
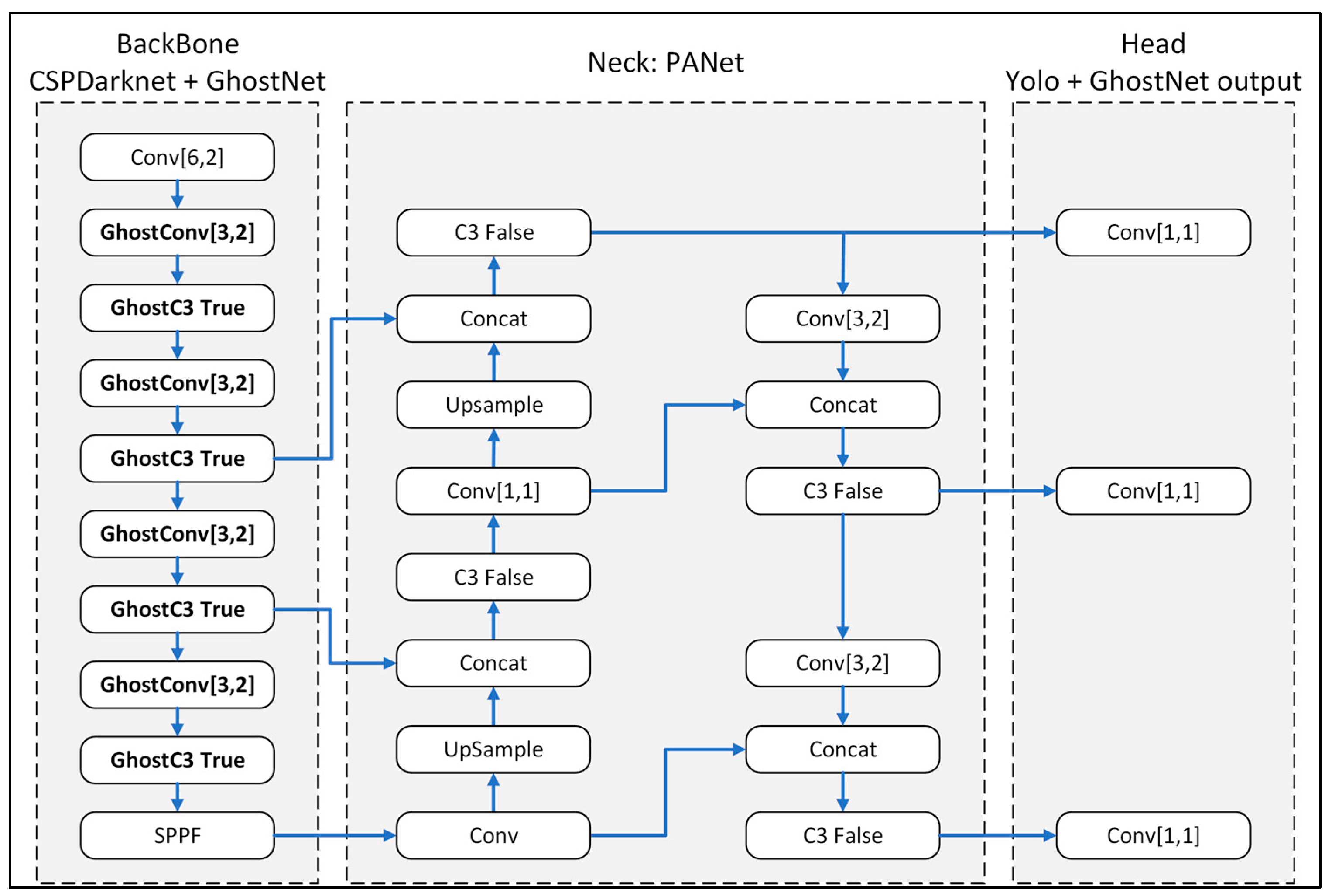
3.2. Yolov5 Model
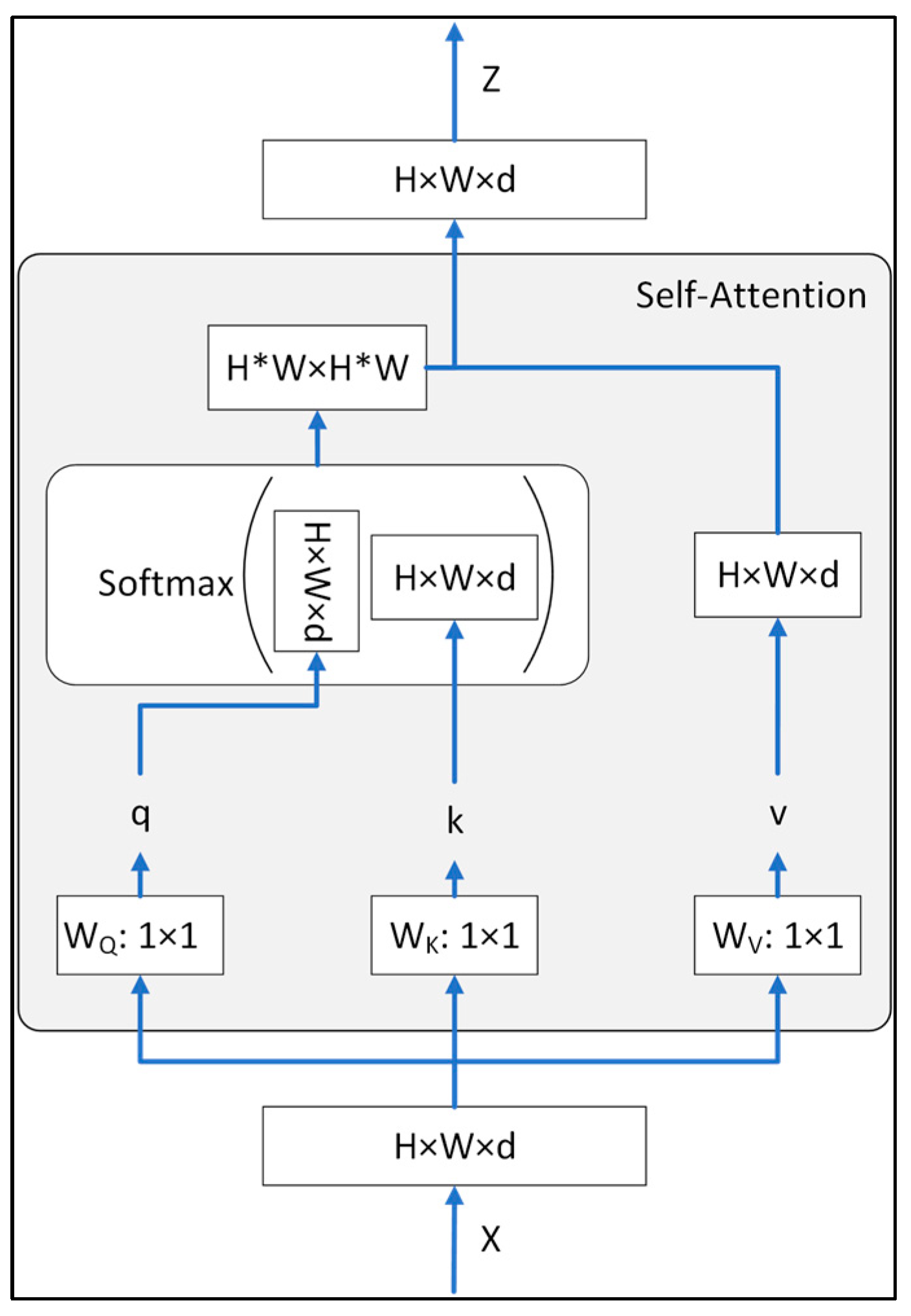
3.3. BoTNet Transform Model
3.4. ShuffleNet Model
3.5. GhostNet Model
3.6. Evaluation Metrics
3.7. Training Data
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pattnaik, G.; Shrivastava, V.K.; Parvathi, K. Transfer Learning-Based Framework for Classification of Pest in Tomato Plants. Appl. Artif. Intell. 2020, 34, 981–993. [Google Scholar] [CrossRef]
- Lin, H.T. Cherry Tomato ‘TSS ASVEG No.22’. Taiwan Seed Improvement and Propagation Station; COA: Taichung, Taiwan, 2017. [Google Scholar]
- Elbadrawy, E.; Sello, A. Evaluation of Nutritional Value and Antioxidant Activity of Tomato Peel Extracts. Arab. J. Chem. 2016, 9, S1010–S1018. [Google Scholar] [CrossRef]
- Gongal, A.; Amatya, S.; Karkee, M.; Zhang, Q.; Lewis, K. Sensors and Systems for Fruit Detection and Localization: A Review. Comput. Electron. Agric. 2015, 116, 8–19. [Google Scholar] [CrossRef]
- Kuznetsova, A.V.; Maleva, T.; Soloviev, V.N. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Bulanon, D.M.; Burr, C.; DeVlieg, M.; Braddock, T.; Allen, B. Development of a Visual Servo System for Robotic Fruit Harvesting. AgriEngineering 2021, 3, 840–852. [Google Scholar] [CrossRef]
- Mangaonkar, S.R.; Khandelwal, R.S.; Shaikh, S.A.; Chandaliya, S.; Ganguli, S. Fruit Harvesting Robot Using Computer Vision. In Proceedings of the International Conference for Advancement in Technology (2022 ICONAT), Goa, India, 21–23 January 2022; pp. 1–6. [Google Scholar]
- Zhang, L.; Jia, J.; Gui, G.; Hao, X.; Gao, W.; Wang, M. Deep Learning Based Improved Classification System for Designing Tomato Harvesting Robot. IEEE Access 2018, 6, 67940–67950. [Google Scholar] [CrossRef]
- Taqi, F.; Al-Langawi, F.; Abdulraheem, H.K.; El-Abd, M. A cherry-tomato harvesting robot. In Proceedings of the 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 463–468. [Google Scholar]
- Zu, L.; Zhao, Y.; Jiuqin, L.; Su, F.; Zhang, Y.; Liu, P. Detection and Segmentation of Mature Green Tomatoes Based on Mask R-CNN with Automatic Image Acquisition Approach. Sensors 2021, 21, 7842. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Balwinder-Singh; Shirsath, P.B.; Jat, M.L.; McDonald, A.; Srivastava, A.K.; Craufurd, P.; Rana, D.S.; Singh, A.K.; Chaudhari, S.K.; Sharma, P.; et al. Agricultural Labor, COVID-19, and Potential Implications for Food Security and Air Quality in the Breadbasket of India. Agric. Syst. 2020, 185, 102954. [Google Scholar] [CrossRef]
- Rahimi, P.; Islam, S.; Duarte, P.M.; Tazerji, S.S.; Sobur, M.A.; Zowalaty, M.E.E.; Ashour, H.M.; Rahman, M.T. Impact of the COVID-19 Pandemic on Food Production and Animal Health. Trends Food Sci. Technol. 2022, 121, 105–113. [Google Scholar] [CrossRef]
- Ramesh, K.; Desai, S.; Jariwala, D.; Shukla, V. AI Modelled Clutch Operation for Automobiles. In Proceedings of the IEEE World Conference on Applied Intelligence and Computing (AIC), Sonbhadra, India, 17–19 June 2022; pp. 487–491. [Google Scholar]
- Kumar, A.; Finley, B.; Braud, T.; Tarkoma, S.; Hui, P. Sketching an AI Marketplace: Tech, Economic, and Regulatory Aspects. IEEE Access 2021, 9, 13761–13774. [Google Scholar] [CrossRef]
- Qazi, S.; Khawaja, B.A.; Farooq, Q.U. IoT-Equipped and AI-Enabled Next Generation Smart Agriculture: A Critical Review, Current Challenges and Future Trends. IEEE Access 2022, 10, 21219–21235. [Google Scholar] [CrossRef]
- Bhat, S.A.; Huang, N.-F. Big Data and AI Revolution in Precision Agriculture: Survey and Challenges. IEEE Access 2021, 9, 110209–110222. [Google Scholar] [CrossRef]
- Furman, J.; Seamans, R. AI and the Economy. Innov. Policy Econ. 2019, 19, 161–191. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29, pp. 379–387. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.M.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer: Berlin, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Mirhaji, H.R.; Soleymani, M.; Asakereh, A.; Mehdizadeh, S.A. Fruit Detection and Load Estimation of an Orange Orchard Using the YOLO Models through Simple Approaches in Different Imaging and Illumination Conditions. Comput. Electron. Agric. 2021, 191, 106533. [Google Scholar] [CrossRef]
- Padilha, T.C.; Moreira, G.É.G.; Magalhães, S.A.; Santos, F.N.D.; Cunha, M.; Oliveira, M. Tomato Detection Using Deep Learning for Robotics Application. In Lecture Notes in Computer Science; Springer Science+Business Media: Berlin, Germany, 2021; pp. 27–38. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2016, arXiv:1612.08242v1. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Christopher, S.T.; Laughing, L.C. Ultralytics/yolov5: V4.0-nn.SILU Activations, Weights & Biases Logging, Pytorch Hub Integration. 2021. Available online: https://zenodo.org/record/4418161 (accessed on 26 June 2023).
- Junos, M.H.; Khairuddin, A.S.M.; Thannirmalai, S.; Dahari, M. Automatic Detection of Oil Palm Fruits from UAV Images Using an Improved YOLO Model. Vis. Comput. 2021, 38, 2341–2355. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An Attribution-Based Pruning Method for Real-Time Mango Detection with YOLO Network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.N. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOV3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed]
- Zhaoxin, G.; Han, L.; Zhijiang, Z.; Libo, P. Design a Robot System for Tomato Picking Based on YOLO V5. IFAC-Pap. 2022, 55, 166–171. [Google Scholar] [CrossRef]
- Egi, Y.; Hajyzadeh, M.; Eyceyurt, E. Drone-Computer Communication Based Tomato Generative Organ Counting Model Using YOLO V5 and Deep-Sort. Agriculture 2022, 12, 1290. [Google Scholar] [CrossRef]
- Srinivas, A.; Lin, T.-Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16519–16529. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Bello, I.; Zoph, B.; Le, Q.V.; Vaswani, A.; Shlens, J. Attention Augmented Convolutional Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3286–3295. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Standalone self-attention in vision models. arXiv 2019, arXiv:1906.05909, 2019. [Google Scholar]
- Petit, O.; Thome, N.; Rambour, C.; Themyr, L.; Collins, T.; Soler, L. U-Net Transformer: Self and Cross Attention for Medical Image Segmentation. In Springer eBooks; Springer: Berlin, Germany, 2021; pp. 267–276. [Google Scholar]
- Howar, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zoph, B.; Vasudevan, V.K.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Condition | |||
|---|---|---|---|
| True Condition | P + N | PP | PN |
| (Total Population) | (Predict Positive) | (Predict Negative) | |
| P | TP | FN | |
| (Positive) | (True Positive) | (False Negative) | |
| N | FP | TN | |
| (Negative) | (False Positive) | (True Negative) | |
| Parameter | Value |
|---|---|
| Optimization | Adam |
| Batch size | 32 |
| Learning rate | 0.0001 |
| Decay | 5 × 10−5 |
| Drop out | 0.1 |
| Epochs | 200 |
| Image size | 640 × 640 pixel |
| Augmentation hyperparameters | hyp.scratch-high.yaml |
| CPU | GPU | Ram | Disk |
|---|---|---|---|
| 2 × Xeon Processors @2.3 Ghz, 46 MB Cache | 2 × Tesla T4 16 GB | 16 GB | 80 GB |
| Model | Layer | Parameter | GFLOPS | mAP | F1 Score | Time (h) |
|---|---|---|---|---|---|---|
| Yolov5m | 212 | 21.0 M | 47.9 | 0.92 | 0.86 | 2.32 |
| Modified-Yolov5m-BoTNet | 162 | 6.7 M | 15.5 | 0.94 | 0.87 | 1.98 |
| Modified-Yolov5m-ShuffleNet v2 | 221 | 2.2 M | 4.8 | 0.92 | 0.84 | 1.97 |
| Modified-Yolov5m-GhostNet | 378 | 14.2 M | 29.3 | 0.93 | 0.87 | 2.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, F.-T.; Nguyen, V.-T.; Duong, T.-P.; Phan, Q.-H.; Lien, C.-H. Tomato Fruit Detection Using Modified Yolov5m Model with Convolutional Neural Networks. Plants 2023, 12, 3067. https://doi.org/10.3390/plants12173067
Tsai F-T, Nguyen V-T, Duong T-P, Phan Q-H, Lien C-H. Tomato Fruit Detection Using Modified Yolov5m Model with Convolutional Neural Networks. Plants. 2023; 12(17):3067. https://doi.org/10.3390/plants12173067
Chicago/Turabian StyleTsai, Fa-Ta, Van-Tung Nguyen, The-Phong Duong, Quoc-Hung Phan, and Chi-Hsiang Lien. 2023. "Tomato Fruit Detection Using Modified Yolov5m Model with Convolutional Neural Networks" Plants 12, no. 17: 3067. https://doi.org/10.3390/plants12173067
APA StyleTsai, F. -T., Nguyen, V. -T., Duong, T. -P., Phan, Q. -H., & Lien, C. -H. (2023). Tomato Fruit Detection Using Modified Yolov5m Model with Convolutional Neural Networks. Plants, 12(17), 3067. https://doi.org/10.3390/plants12173067