1. Introduction
Improving living conditions and a global trend in migration of population from rural to urban centers result in increasing demand for civil infrastructure [
1]. However, most present-day infrastructure has been built in the second half of the twentieth century and is close to the end of its designed service life. The deficit between demand and supply has been estimated to be USD 1 trillion in 2014 [
2] and is increasing. Replacement of all aging infrastructure is unsustainable. However, civil infrastructure are generally designed using conservative models and, thus, they may possess reserve capacity beyond code requirements [
3,
4]. For quantification of such reserve capacity, better understanding of structural behavior is needed. Thus, decision making regarding asset-management actions such as repair, retrofit and replacement, is enhanced [
5].
Measurements of structural response can be interpreted using physics-based models in order to enhance understanding of structural behavior. Increased availability and reduced cost of sensing techniques [
6,
7] and computational tools [
8] have made model-based data interpretation feasible. However, all models are idealizations of reality [
9]. Conservative modeling assumptions lead to large uncertainty, with systematic and correlated errors at measurement locations [
10]. Many researchers have studied uncertainties that affect interpretation of civil-infrastructure response [
11,
12,
13]. Improvement in quantification of uncertainties can help improve accuracy of data interpretation.
Interpretation of measurements using a physics-based model is referred to as structural identification. Due to the presence of uncertainties, structural identification, which is an abductive task, is an ill-posed problem. Methodologies for solving such inverse problems have been studied by many researchers [
14,
15,
16,
17]. In practical applications, residual minimization (also called model calibration) is the most commonly used model-based measurement-interpretation method. For residual minimization, optimal values of parameters governing model behavior are estimated by minimizing the residual between model predictions and measurements [
18]. Although popular among practicing engineers due to its simplicity, residual minimization may provide inaccurate results [
19]. An assumption made by residual-minimization methods is that the difference between model predictions and measurements is governed only by the choice of parameters [
20]. This implies that systematic bias between the approximate model and measurements is not taken into account during parameter estimation. In other words, the difference between model predictions and measurements is assumed to be distributed as zero-mean uncertainty forms [
10,
21,
22,
23].
Another methodology that has gathered much interest from the data-interpretation community is Bayesian model updating (BMU). Traditionally, BMU employs an independent zero-mean Gaussian likelihood function [
24]. Model parameters, considered as probabilistic distributions are updated using this likelihood function. Model-parameter combinations that provide predictions whose error with measurements are low are attributed higher likelihood. Many developments over the traditional implementation of BMU have been made to account for the presence of model bias [
25,
26,
27]. However, mis-evaluation of systematic bias and correlations leads to inaccurate estimation of model parameters [
28,
29,
30,
31,
32].
Goulet and Smith [
29] presented a multi-model data-interpretation methodology called error-domain model falsification (EDMF). In EDMF, model-parameter instances are falsified when their predictions are not compatible with measurements. Compatibility is determined based on falsification thresholds that are computed based on the uncertainties affecting identification of parameter values. Estimation of uncertainties involves information available from tests, guidelines and engineering heuristics. EDMF has been shown to provide more accurate identification and predictions compared with traditional BMU and residual minimization [
29,
30,
31,
32].
Data interpretation for asset management is an iterative task, with re-evaluations required as new information becomes available. New information can be: new measurements; change in uncertainty conditions; and new diagnostic information. Pasquier and Smith [
33] presented an iterative sequence-free data-interpretation framework using EDMF and highlighted the iterative nature of data interpretation. A similar framework for post-earthquake assessment using EDMF was presented by Reuland et al. [
34]. Zhang et al. [
35] developed a data-interpretation tool that employs BMU with the goal of assisting asset managers. Except from these studies, most present day research in structural identification has focused on damage detection within a sequential framework [
36]. In addition, no research is available that evaluates the usefulness of data-interpretation methodologies such as BMU and residual minimization within iterative frameworks to assist asset managers faced with real-world challenges. Model-based data-interpretation has the potential to enhance asset management strategies. These strategies have been developed by many researchers using, for example, multi-criteria decision making [
37,
38] and asset-performance metrics [
39,
40].
Application of model-based data-interpretation methodologies for full-scale structures presents challenges such as unidentifiability [
41] and, above all, constraints on computational cost [
42]. Structural identification of full-scale structures, unlike laboratory experiments, are affected by environmental conditions such as wind [
43] and temperature [
44]. Moreover, numerical models of full-scale structures are computationally expensive. Many researchers have suggested using efficient sampling methods to alleviate constraints on computational cost. Residual minimization has been implemented with optimization algorithms such as genetic algorithms [
45], artificial bee colony optimization [
46,
47], particle swarm optimization [
48] and ant colony optimization [
49] to reduce computational cost. BMU has been implemented using Markov-Chain Monte Carlo (MCMC) sampling [
50], transitional MCMC sampling [
51], and evolutionary MCMC sampling [
52]. EDMF has traditionally been implemented using grid sampling, which is computationally expensive [
53]. Adaptive-sampling strategies such as radial-basis functions [
54] and probabilistic global search optimization [
55] have been implemented to improve sampling efficiency for EDMF. While use of these search methods decreases computational cost, their efficiency for use in an iterative framework for data-interpretation has not been studied.
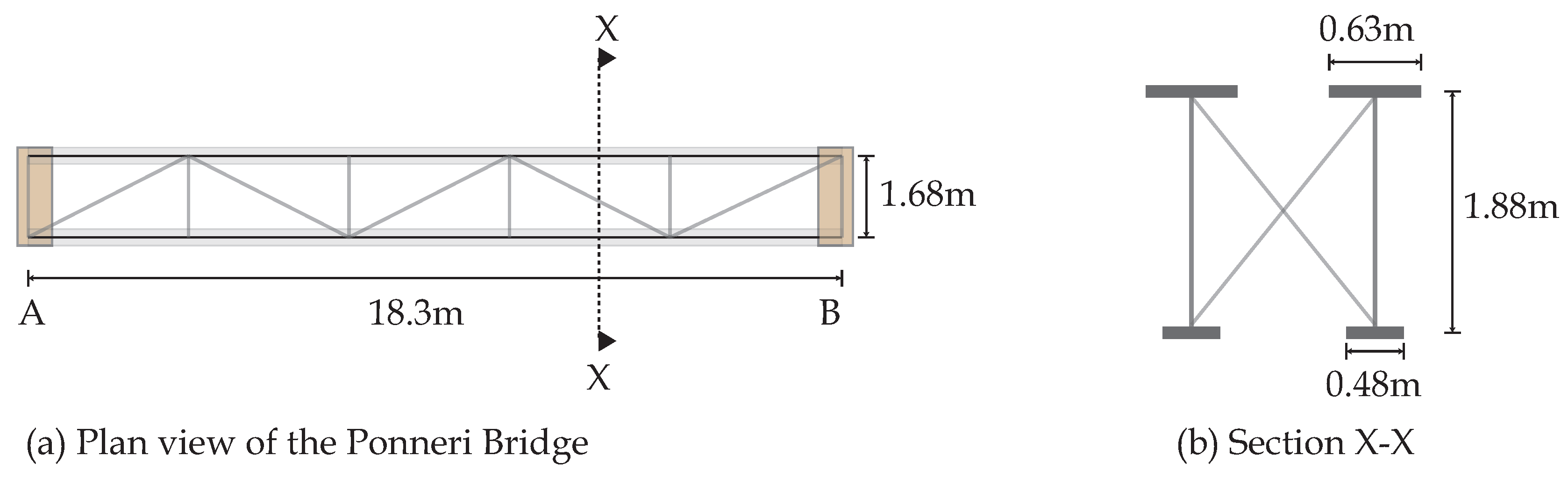
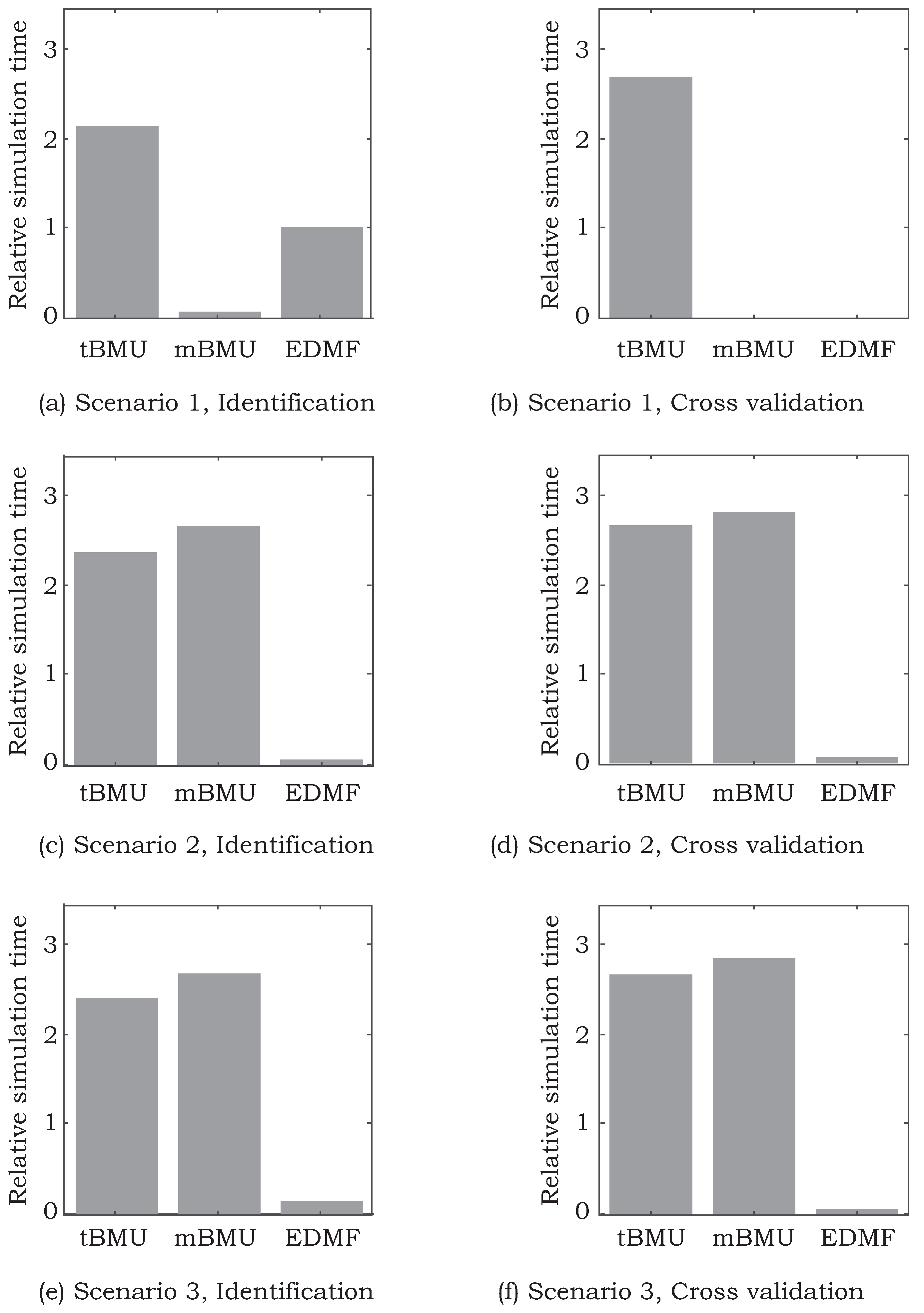
In this paper, several methodologies are compared based on their ability to efficiently incorporate new information and changing uncertainty definitions to provide accurate structural identification. Comparisons have been made using two full-scale bridge case studies to evaluate applicability of these data-interpretation methodologies outside of well-controlled laboratory environments.
2. Model-Based Data-Interpretation for Asset Management
Model-based data interpretation of civil infrastructure is difficult due to many scientific and practical challenges. To allow asset managers to exploit potential reserve capacity safely, accurate interpretation of measurement data is necessary. In addition, civil infrastructure (such as bridges and tunnels) form critical components in transportation networks. Their failure can cause loss of life and cascading disruptions to economies due to loss of connectivity. Thus, in addition to accuracy, ease of interpretation of data-interpretation results is imperative to asset managers.
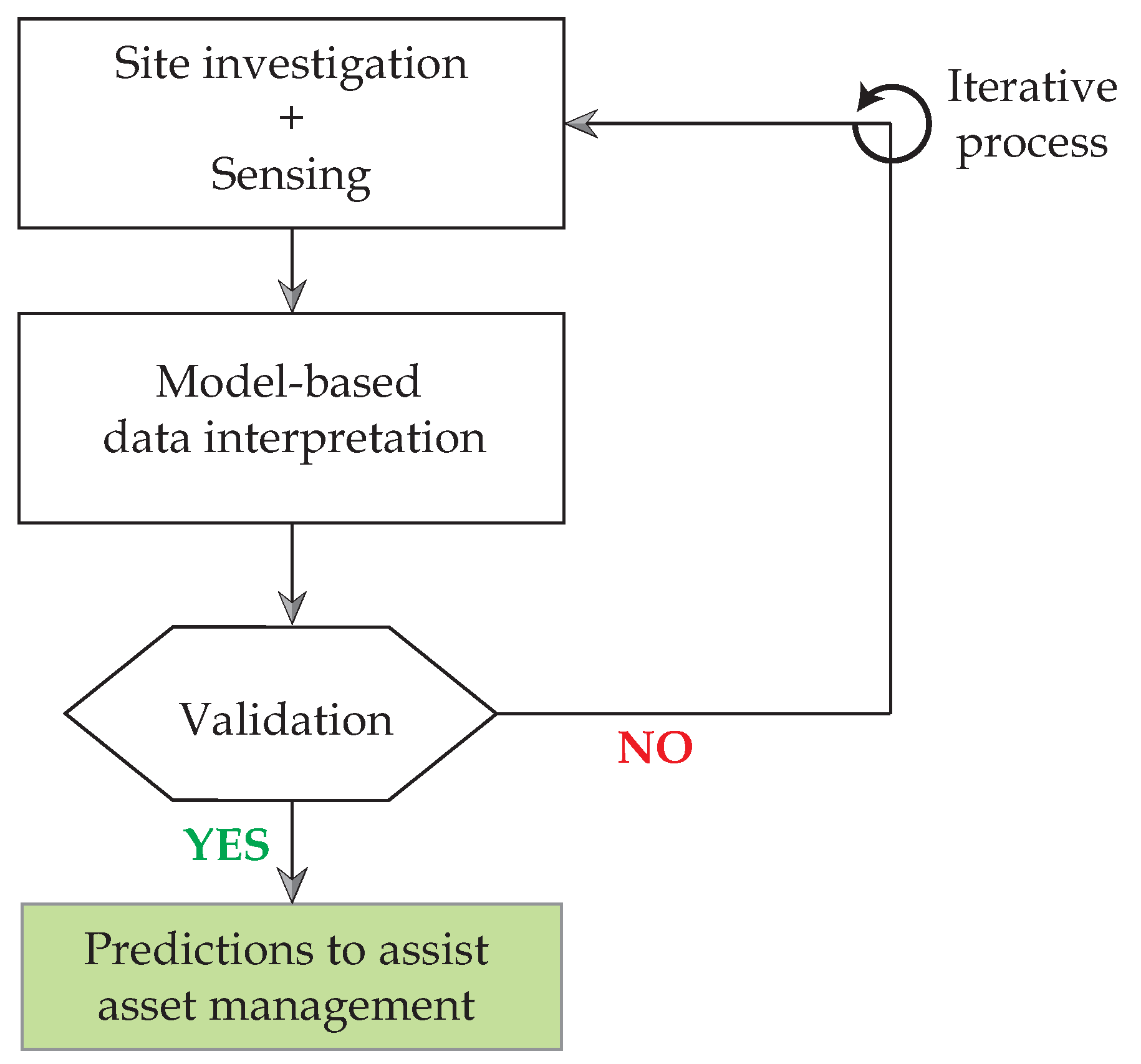
In
Figure 1, typical steps involved in using model-based data-interpretation is presented. The sequence shown in the flowchart is general and a sequence-free framework for more specific asset management tasks was presented by Pasquier and Smith [
33]. In this paper, the steps involving model-based data-interpretation and validation are discussed.
In
Figure 1, site investigations help collect data useful for modeling and understanding sources of uncertainty. The task of sensing involves collecting data pertaining to structural response during either a load test or in-service conditions.
The task of model-based data-interpretation in
Figure 1 consists of quantification of uncertainties, determination of a model class for identification and use of measurement data to update the values of parameters defined by the model class. Interpretation of measurement data may be carried out using various methodologies and some of these are described in
Section 2.1.
A key task that is generally absent in most applications of model-based data interpretation is validation before making predictions. The validation task, subsequent to data interpretation (see
Figure 1), has been recommended to be carried out using a leave-one-out cross-validation strategy in this paper. This is explained in
Section 2.2.
Data interpretation, as shown in
Figure 1, is iterative, especially as new information becomes available over the service life of the structure. New information takes the form of new measurements, improved understanding of uncertainties, improved understanding leading to a new model class, etc. Lack of validation of data-interpretation results may also necessitate iterations. Therefore, methodologies for data interpretation should be amenable to new information and flexible to changes.
In
Section 2.1, data-interpretation methodologies that are available in the literature are described. These methodologies make implicit assumptions regarding estimation and quantification of uncertainties affecting structural identification. Methodologies also differ in the sampling strategies used to obtain appropriate solution(s). Accuracy of these methodologies in interpreting measurement data is dependant on the validity of assumptions. A leave-one-out cross-validation method to assess accuracy and precision of data-interpretation is explained in
Section 2.2. In this paper, a comparison of data-interpretation methodologies based on iterative applications is presented. The objective of these comparisons and validation checks are to help engineers select a suitable methodology to interpret measurements using physics-based models.
2.1. Background of Data-Interpretation Methods
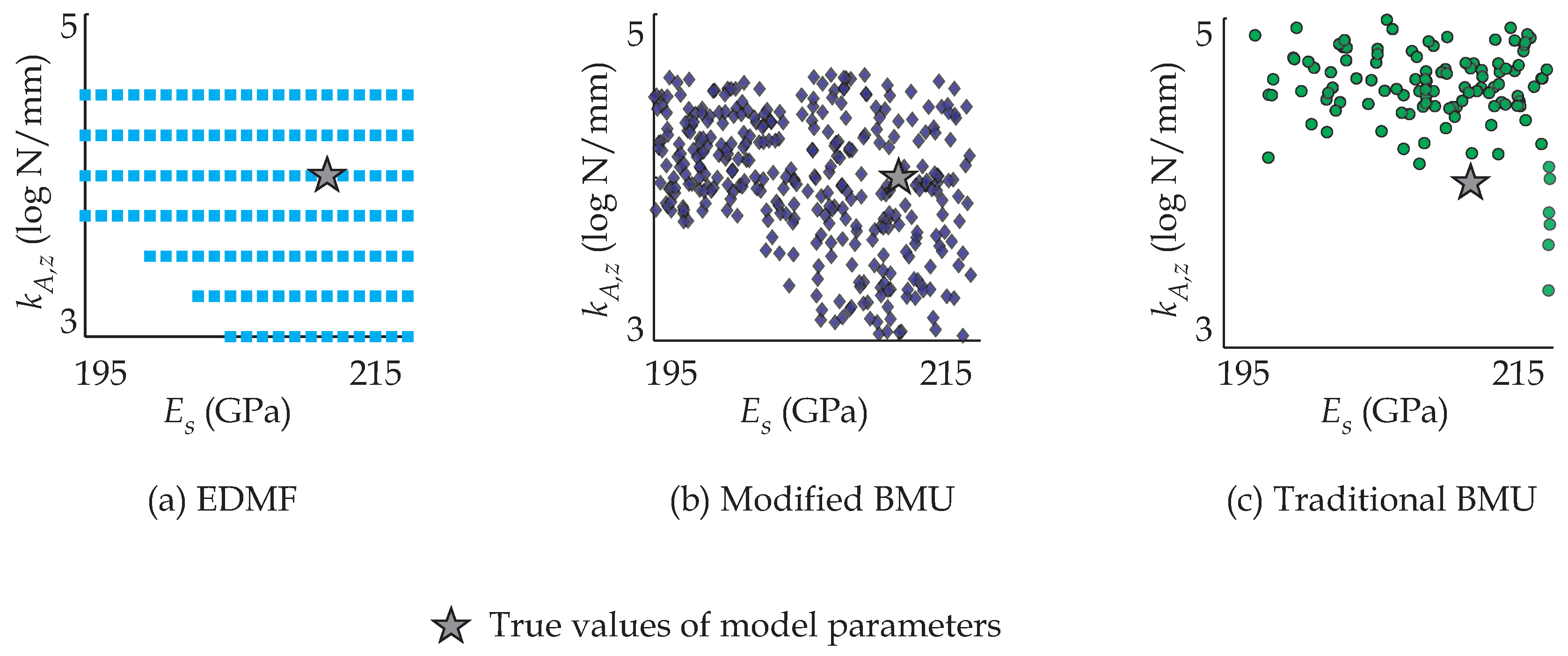
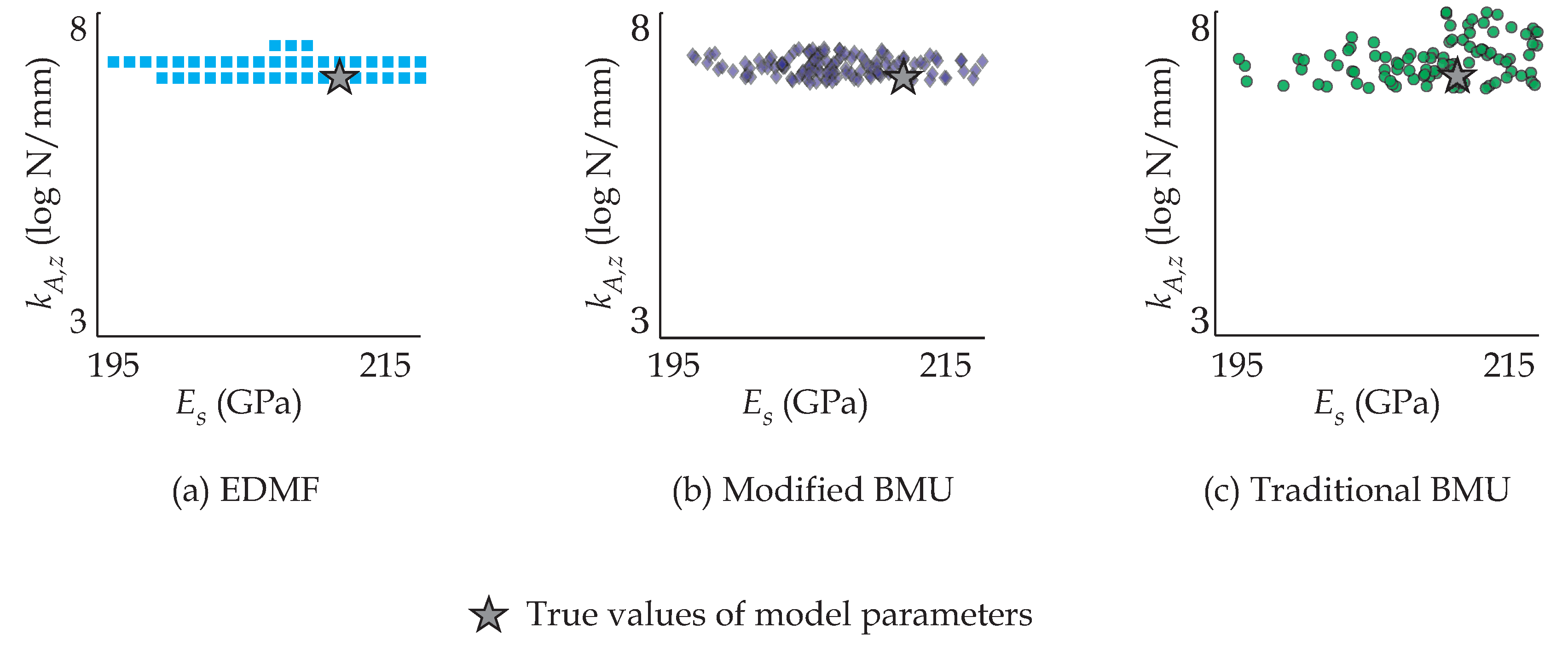
In this paper, four data-interpretation methodologies are compared with respect to their ability to provide accurate identification and incorporate new information in an iterative manner. In the following, the four methodologies are briefly introduced and their inherent assumptions are discussed.
2.1.1. Residual Minimization
In residual minimization, a structural model is calibrated by determining model-parameter values that minimize the error between model predictions and measurements. A typical objective function for residual minimization is shown in Equation (
1).
In Equation (
1),
is the optimum model-parameter set obtained using measurements and
is the residual obtained between the model response,
, and measurement,
, at measurement location
i.
Predictions with models updated using residual minimization are limited to the domain of data used for calibration [
56]. Therefore, calibrated model-parameter values may only be suitable for predictions that involve interpolation [
56] and not for extrapolation (predictions outside the domain of data used for calibration) [
19,
20].
2.1.2. Traditional Bayesian Model Updating
Bayesian model updating (BMU) is a popular probabilistic data-interpretation methodology [
24,
57,
58] based on Bayes’ theorem. In BMU, prior information of model parameters,
, is conditionally updated using a likelihood function
to obtain a posterior distribution of model parameters,
, as shown in Equation (
2).
In Equation (
2),
is the normalization constant.
is the prior distribution of model parameters, which indicates prior available knowledge regarding parameter values. The likelihood function,
, is the probability of observing the measurement data,
y, for a specific set of model-parameter values,
. The most commonly used likelihood function is a
-norm-based Gaussian probability-distribution function (PDF), as shown in Equation (
3).
In Equation (
3),
is a covariance matrix that consists of variances and correlation coefficients of uncertainties related to each measured location. In most applications of BMU, uncertainties at measurement locations are assumed to be independent zero-mean Gaussian distributions [
59,
60,
61,
62,
63,
64,
65,
66]. In addition, the variance in uncertainty,
, is assumed to be the same for all measurement locations. This leads the covariance matrix to be a diagonal matrix, with all non-zero terms being equal. However, the assumption of a
-norm-based Gaussian distribution for uncertainty [
67] and uncorrelated error [
28] is rarely satisfied and may lead to a biased updated probability distribution [
29,
30,
32].
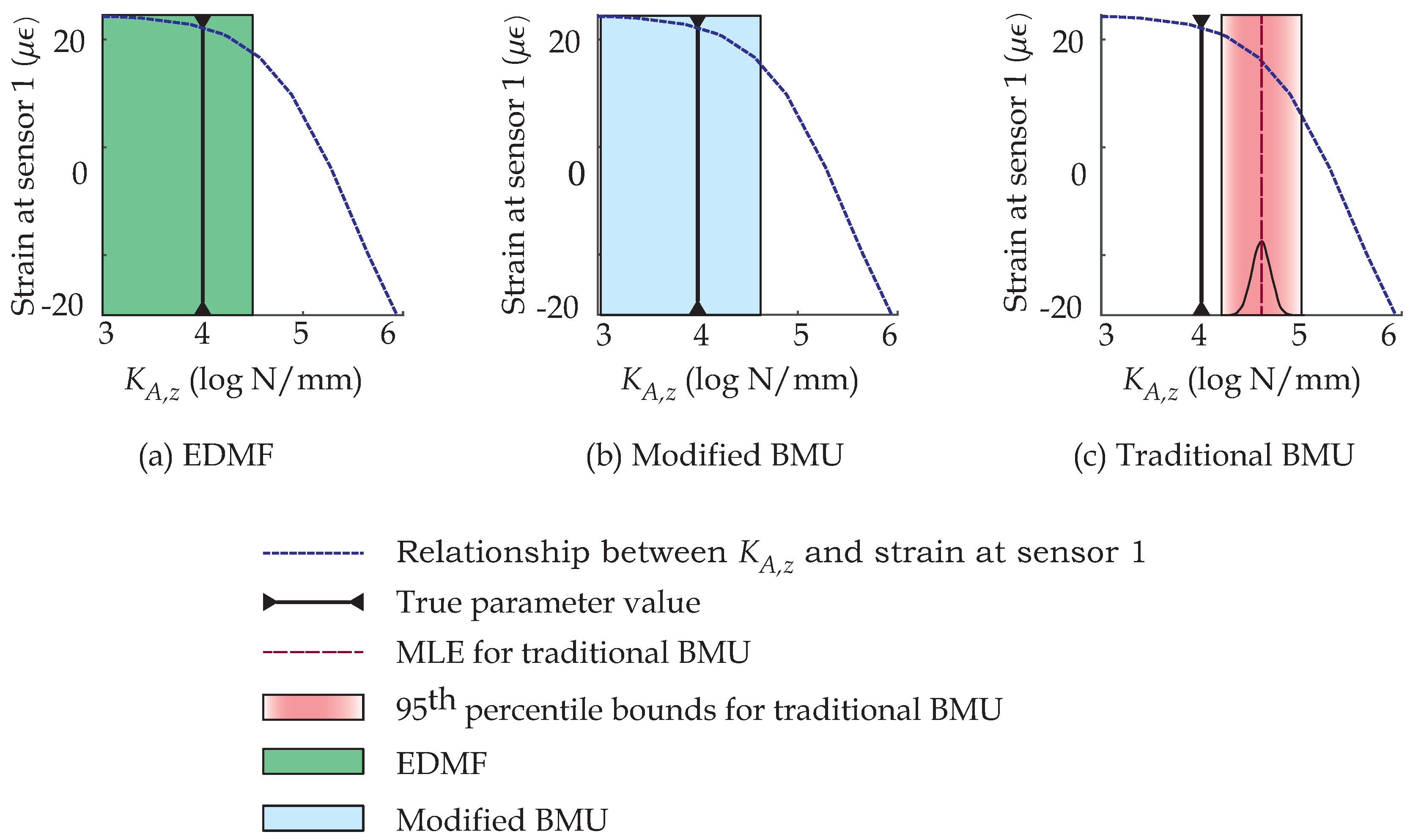
2.1.3. Error-Domain Model Falsification
Error-domain model falsification (EDMF) is a data-interpretation methodology developed by Goulet and Smith [
29]. EDMF is based on the assertion by Popper [
68] that models cannot be validated by data; they can only be falsified. Model instances (instances of model-parameter values) are falsified based on information from measurements. Model instances that are not falsified form a candidate set, which is a subset of all possible parameter values based on the prior model parameter PDFs.
Generally, civil infrastructure are designed using conservative and simplified models. As a result, engineering models possess significant model bias from sources such as simplification of loading conditions, geometrical properties, material properties and boundary conditions. Extent of these uncertainties can only be estimated using engineering heuristics and usually takes the form of bounds.
Let
be the modeling uncertainty and
the measurement uncertainty, both at a measurement location
q. Let the structure be represented by a physics-based model,
. The true response of the structure at a measurement location is given by Equation (
4).
In Equation (
4),
is the model response at a measurement location
q for the real values of the model parameters,
.
is the measured response of the structure at measurement location
q. Rearranging the terms of Equation (
4), a relationship among model response,
, measurement,
, and uncertainties,
and
, at location
q is obtained, as shown by Equation (
5).
In Equation (
5), the residual between model response,
, and measurement,
, at a sensor location,
q, is equal to the combined model and measurement uncertainty. Engineers make design decisions based on predefined target reliability. Using the target reliability,
, for identification, the criteria for falsification, thresholds
and
, are computed using Equation (
6).
In Equation (
6),
is the PDF of combined uncertainty at measurement location
q and
is the target reliability of identification. Thresholds,
and
, correspond to the shortest interval providing a probability equal to target reliability,
. In Equation (
6), the term
is the Šidák correction [
69], which accounts for
m independent measurements used in identification of model parameters. In EDMF, compatibility of model predictions with measurements at each sensor location is considered as a hypothesis, which can have false positives and negatives. Inclusion of false positives as a candidate instance decreases precision of model updating, while falsely rejecting a model instance could potentially lead to falsification of true parameter values. Šidák correction controls the error rate such that the possibility of rejecting the true parameter values is lower than
.
EDMF is traditionally carried out using grid sampling. In grid sampling, samples from prior distribution of model parameters, , are drawn. If samples are drawn from the prior distribution of each parameter, then these samples constitute a grid, which is called the initial model set (IMS). For samples drawn from parameters, the total number of model instances in the IMS is .
Residual between model responses,
, and measurements,
y, are compared with the thresholds,
and
. If the residual between model response and measurements lies within the thresholds for all measurement locations, then the model instance is accepted. This criteria for falsification is shown in Equation (
7).
If predictions for a model instance,
, does not satisfy Equation (
7) for even one measurement location, then that model instance is falsified. All candidate model instances are considered equally likely and, thus, assigned a uniform probability density. Candidate models are used for making further predictions using the physics-based model with reduced parametric uncertainty [
30]. The EDMF methodology has been applied to more than 20 full-scale systems since 1998 [
4]. Recent applications include: model identification [
70]; leak detection [
71,
72]; wind simulation [
73]; fatigue life evaluation [
74,
75,
76]; measurement-system design [
77,
78,
79,
80]; post-earthquake assessment [
34,
81]; damage localization in tensegrity structures [
82]; and occupant localization [
83].
EDMF when compared with BMU and residual minimization has been shown to provide accurate identification due to its robustness to correlation assumptions and explicit estimation of model bias based on engineering heuristics [
29,
30,
31,
32]. Although grid sampling carries some advantages with respect to practical applications and parallel computing, grid sampling remains computationally expensive [
53].
2.1.4. Modified Bayesian Model Updating
To alleviate shortcomings of traditional BMU (see
Section 2.1.2), a box-car likelihood function is utilized for modified BMU, which is more robust to incomplete knowledge of uncertainties and correlations than standard
-norm-based Gaussian likelihood functions. The box-car likelihood function is developed using an
-norm-based Gaussian likelihood function [
67], which is defined as shown in Equation (
8).
In Equation (
8), parameters of the likelihood function,
and
, are determined using Equations (
9) and (
10).
In Equations (
9) and (
10),
and
are the thresholds computed for EDMF using Equation (
6) for a target reliability of identification
. Modified BMU using such a box-car likelihood distribution has been shown to provide results similar to those obtained using EDMF [
31,
32].
2.2. Practical Challenges Associated with Model-Based Data Interpretation
As stated before, data interpretation is an iterative task that requires exploring results and re-evaluating results in light of new information regarding uncertainties or new measurements. In addition, the task of data-interpretation may have to be repeated when identification results are found to be inaccurate due to a wrong model class. Assessing accuracy is a challenge as knowledge of true parameter values is unavailable. Accuracy can be approximated with cross-validation methods [
84]. While enabling accuracy estimation, such validation strategies are limited to the domain of data used for identification. Moreover, when these methods indicate that structural identification is inaccurate, diagnostics are required to re-assess the assumptions made during identification.
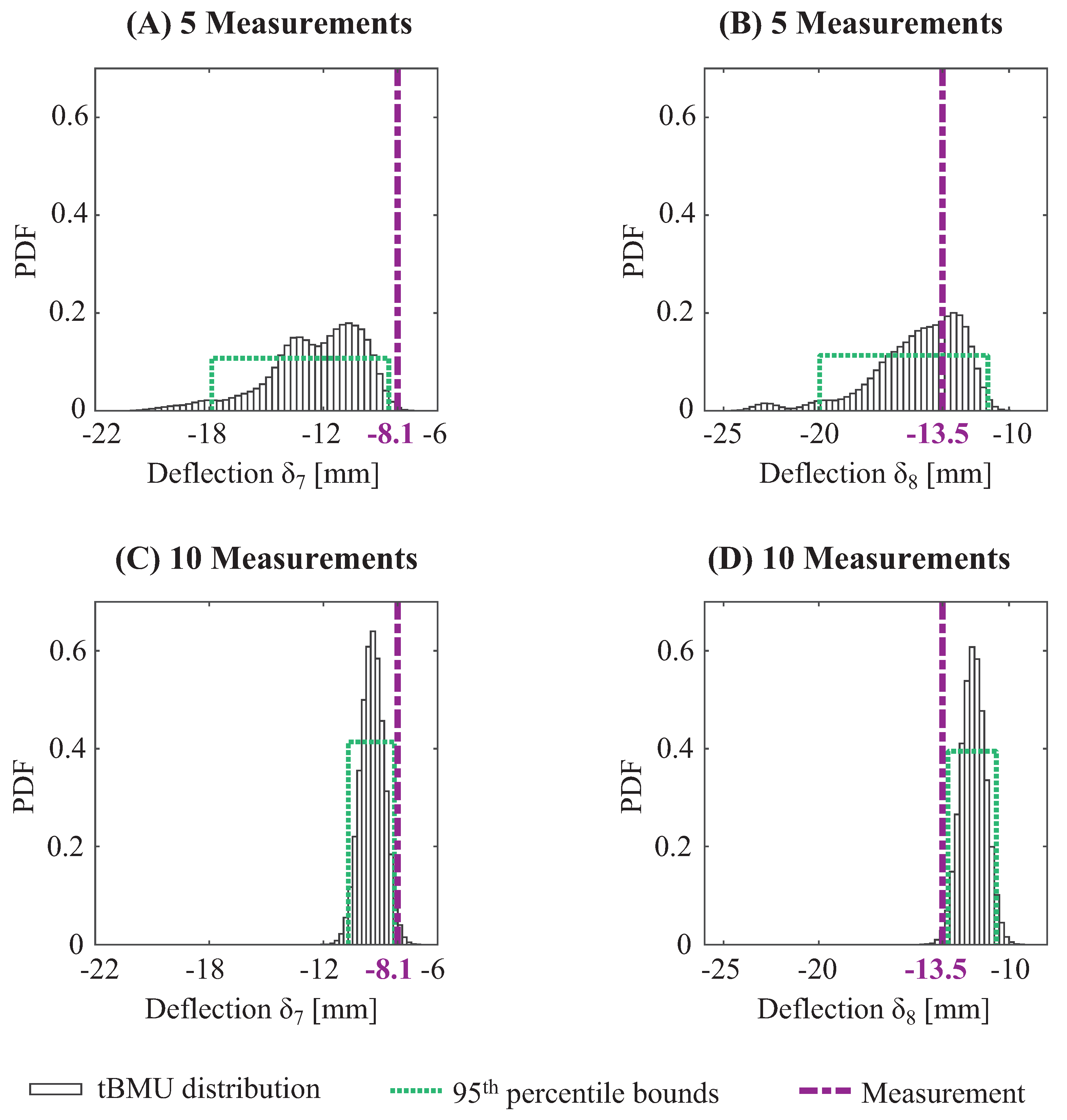
Cross validation of structural-identification results can be conducted using several techniques, such as leave-one-out, hold-out and k-fold. Hold-out and k-fold cross-validation require large measurement datasets for identification and validation. In structural identification of civil infrastructure, measurements are typically scarce with few sensors that provide information about structural behavior. Thus, leave-one-out cross-validation is preferred over other strategies for validating model-updating results.
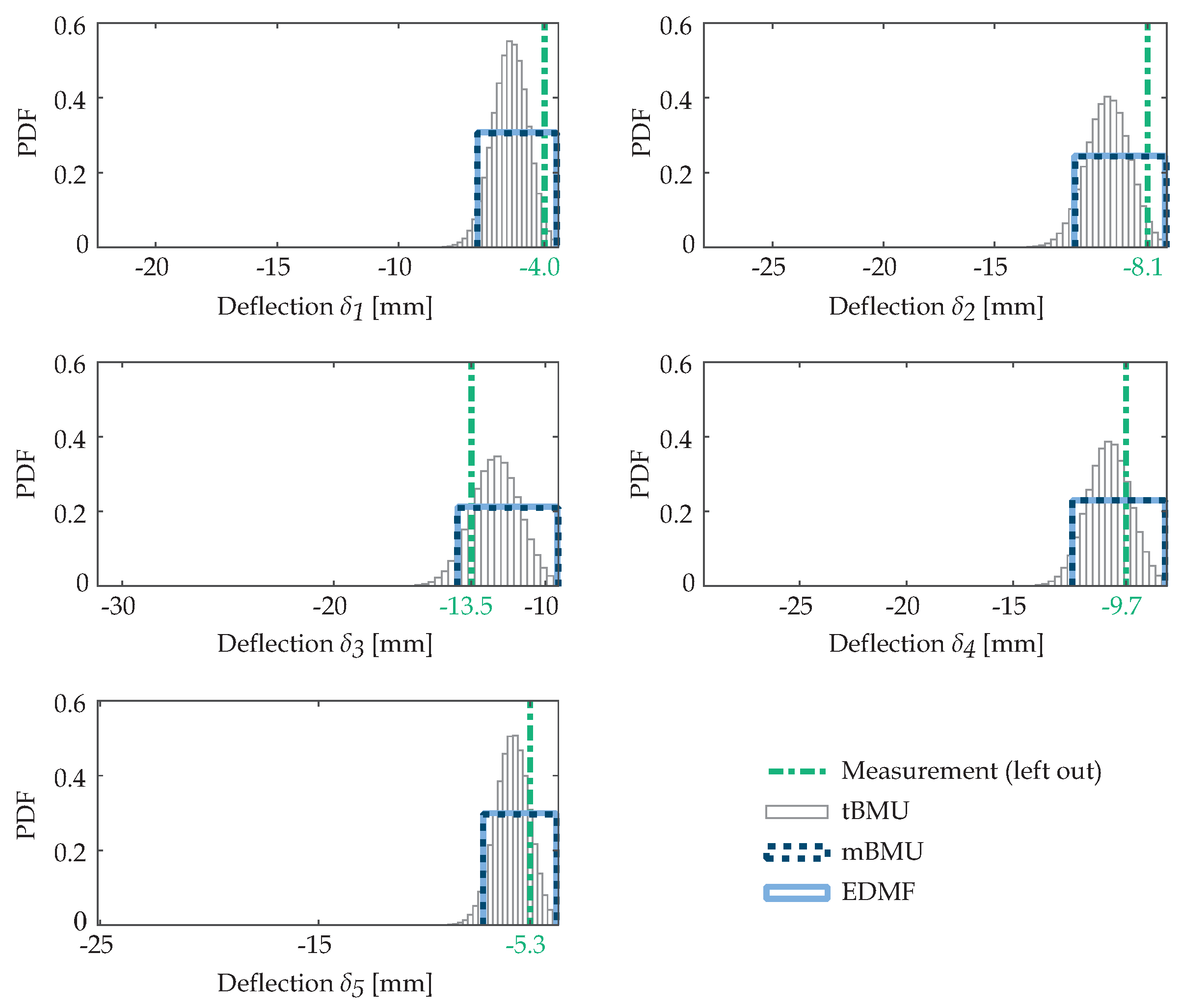
In leave-one-out cross validation, observation from one sensor is omitted (left-out) and structural identification is carried out using all remaining measurements. Updated model-parameter values are then used to predict the model response at the omitted sensor. If the omitted measurement is compatible with updated model predictions, then structural identification is concluded to be accurate for that sensor location. This procedure is repeated by omitting each sensor separately in order to assess accuracy at all measurement locations.
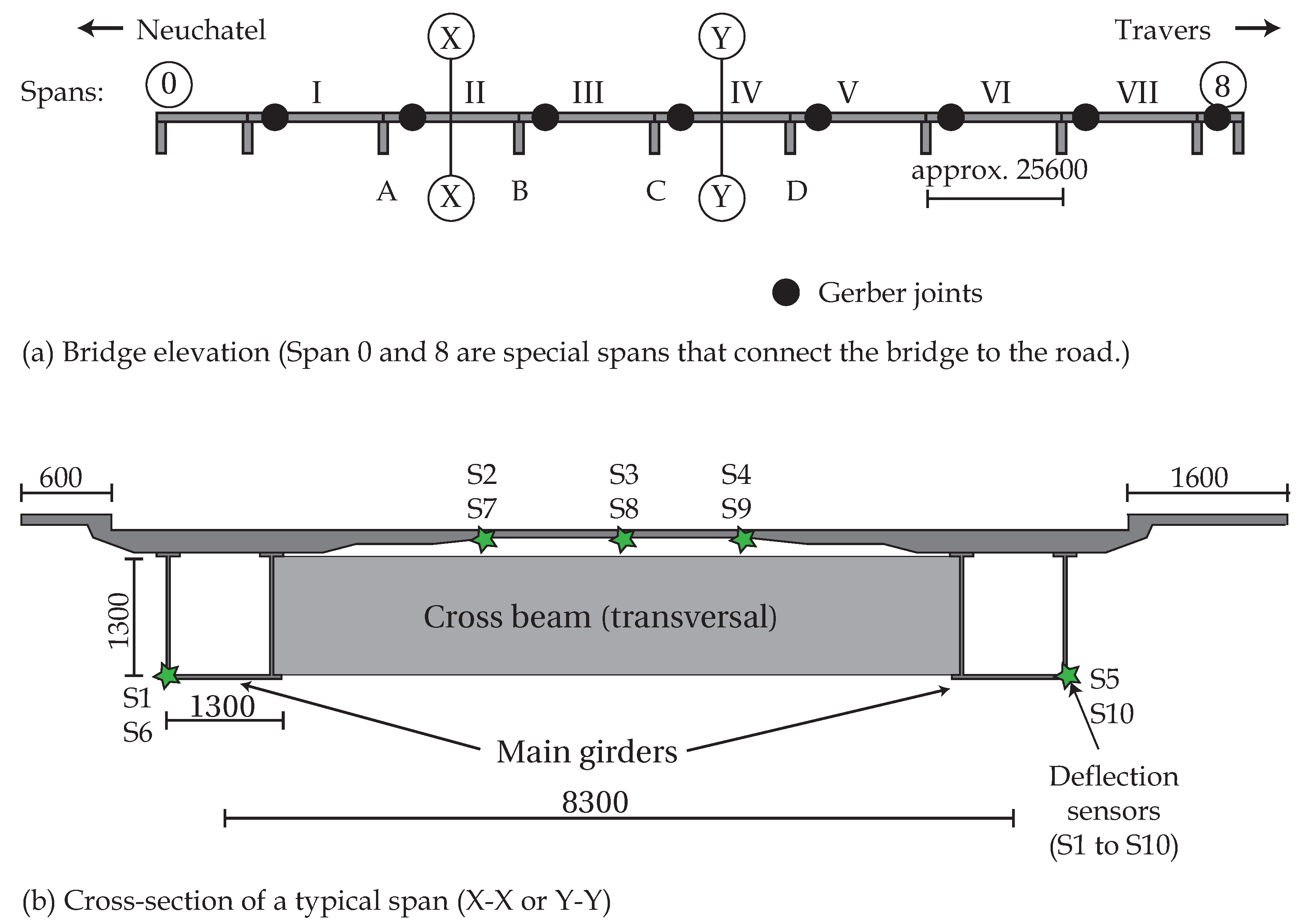
Consider that
measurements are acquired during a load test. These measurements are used for updating a physics-based model of the structure,
, which has parameters
, where
is the number of parameters. Prior to model updating, the initial prediction at a sensor location
j is given by Equation (
11).
In Equation (
11),
is the model prediction at sensor
j for model parameters
and
is the model error from sources such as parameters not considered in the parameter vector
, uncertainty in load and its position. The model-prediction distribution including model error before model updating is
.
Let measurement from sensor
j be excluded from model updating of parameters
to perform leave-one-out cross-validation. The Sidâk correction for determining the threshold bounds, leaving one sensor out, is
. Model parameters,
, are updated to obtain candidate model parameters,
. Model updating is performed using the four methodologies described in the previous sections. The following equations apply directly to EDMF and modified BMU. For traditional BMU, they can be calculated based on the 95th-percentile bound of the prediction distribution. Updated parameters,
, are provided as input to the physics-based model,
, to predict the model response at the omitted sensor,
j, as shown in Equation (
12).
In Equation (
12),
is the distribution of updated model predictions at sensor location
j. Depending on the uncertainties and relationships between model parameters and response, the prediction distributions obtained using Equations (
11) and (
12) are irregular. They are assumed to have uniform distributions based on the principle of maximum entropy. When bounds of the updated distribution of model predictions include the measured value, which has been left out for model updating, then identification is considered to be accurate.
Using leave-one-out cross validation, precision of structural identification can be quantified in addition to accuracy. Precision is a measure of variability either in updated model-parameter distributions or model predictions. Using leave-one-out cross-validation precision is estimated using the error between the updated model-prediction distributions and corresponding measurements. The model-prediction distribution at sensor
j before and after model updating is given by Equations (
11) and (
12). The measurement at this sensor location is
. The prediction error is the residual between model predictions and measurement. The prediction error distribution at sensor
j, before and after model updating are uniform and their ranges are given by Equations (
13) and (
14).
In Equations (
13) and (
14),
and
are ranges of prediction-error distributions relative to the measurement at sensor
j before and after model updating. For
cases of leave-one-out cross-validation,
prediction-error ranges before and after model updating are obtained. Considering prediction-error ranges for all cases of leave-one-out cross-validation before and after model updating, the precision index,
, is defined as shown in Equation (
15).
In Equation (
15),
and
are the mean of prediction-error ranges, before and after model updating, over all cases of sensors left out. Precision,
, represents reduction in prediction error after model updating and ranges from 0 to 1. Precision,
, equal to zero implies no gain in information from model updating. In such situations,
is equal to
, implying that on average over all cases of leave-one-out cross-validation, no reduction in prediction uncertainty is obtained. Precision index,
, equal to one implies perfect model updating wherein updated parameter and consequently the prediction distributions have zero variability.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
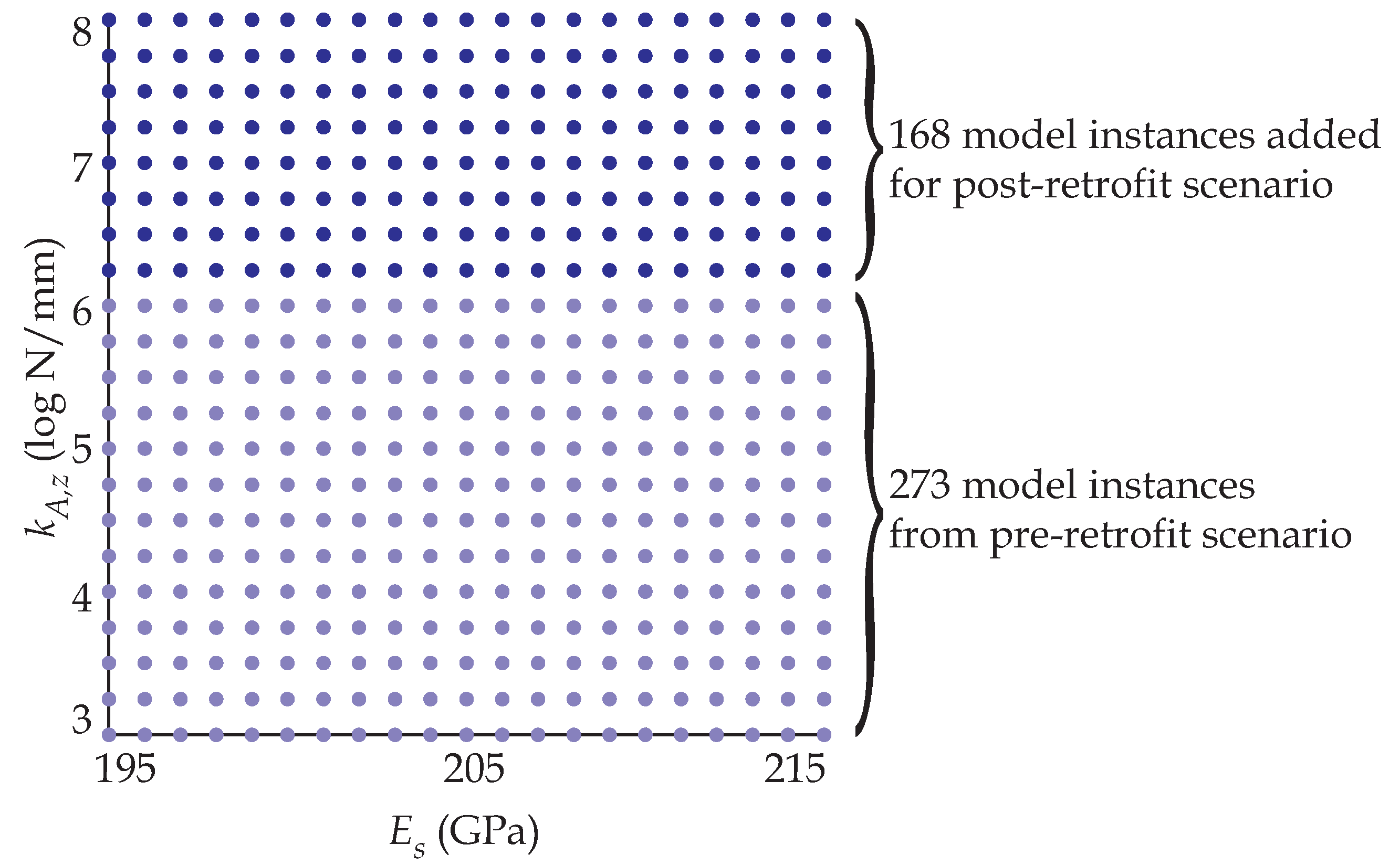{kind=link}
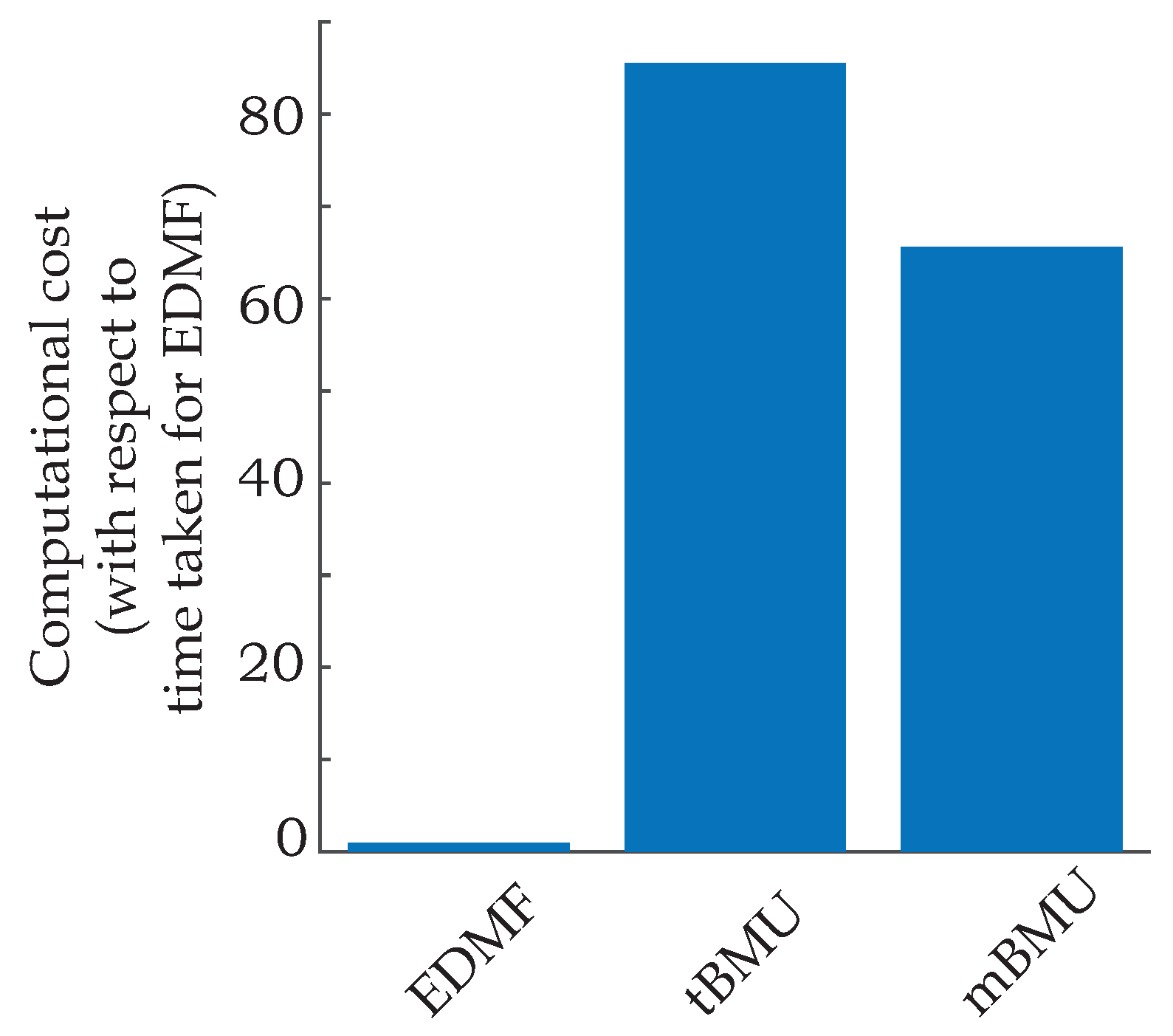{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}