
Structural Compressed Panel VAR with Stochastic Volatility: A Robust Bayesian Model Averaging Procedure


Abstract
:1. Introduction
2. Econometric Model
2.1. Model Estimation
2.2. Multivariate ROB Procedure
2.3. Model Features
- is not relevant and then discarded from the system (absence of the 4- covariate in the model), but it shows some (potential) interactions with .
- does not depend on and .
- .
- No conditional effect of and on given . More precisely, there are no linear dependence of on and in the presence of .
- and .
- and then .
3. Prior Specification Strategy and Posterior Distributions
4. Empirical Application
4.1. Data Description and Results
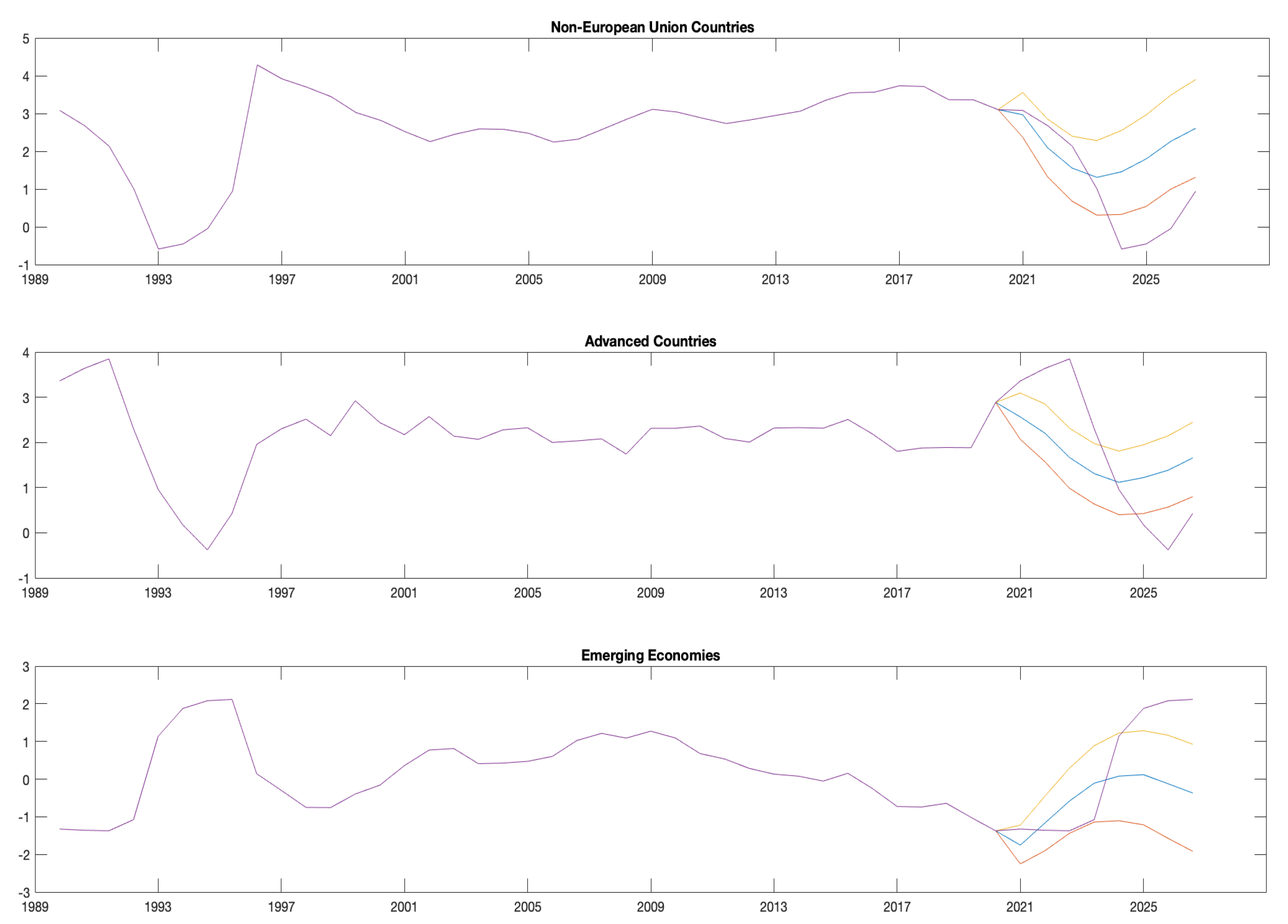
4.2. Forecasting Results and Policy Issues
5. Simulated Experiment and Forecasting Accuracy
- *
- SBCPVAR model for and :where stands for ‘simulated’ and the 120 supposed variables are split for and equally (60 supposed predictors for each composed vector). Thus, the (simulated) estimation sample amounts, without restrictions, to 900,000 regression parameters, with ·.
- *
- SPBVAR-MTV model:where the 120 supposed variables are split for , , , and equally (30 supposed predictors for each vector). In this context, , with and denoting the (simulated) time-varying log-volatilities stacked for i, with .
- *
- BCVAR model:where contains matrices of coefficients concerning (simulated) lagged outcomes and elements of obtained by following a triangular decomposition, refers to the randomly projection matrix shrinking the parameter space, is a vector containing the observable (simulated) outcomes observed at time t and , and denotes the (simulated) standard deviations of the volatilities associated to the vector 8, with .
- *
- FAVAR model:where follows a VAR(l) process, denotes the matrix of coefficients concerning (simulated) lagged outcomes, refers to the vector of lagged (simulated) outcomes, and , with .
6. Concluding Remarks
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | In econometrics, predetermined variables denote covariates uncorrelated with contemporaneous errors, but not for their past and future values. |
| 2 | These can be easily added in a straightforward fashion with a vector of intercepts and an identity matrix of size in the vector . In the empirical and simulated applications, time-varying coefficients that multiply constant terms are added anyway. |
| 3 | In Bayesian analysis, posterior concistency ensures that the posterior probability (PMP) concentrates on the true model. |
| 4 | Austria (AU), Belgium (BE), Finland (FI), France (FR), Germany (DE), Ireland (IR), Italy (IT), Portugal (PT), and Spain (ES). |
| 5 | Czech Republic (CZ), Estonia (ES), Greece (GR), Hungary (HU), Latvia (LV), Lithuania (LT), Poland (PO), Slovak Republic (SK), and Slovenia (SV). |
| 6 | China (CH), Japan (JP), Korea (KO), United Kingdom (GB), and United States (US). |
| 7 | It is worth noting that the ongoing triggering events in the world due to the Russo-Ukrainian War are not included in the analysis but evaluated through conditional density forecasts. |
| 8 | and do not need to be described through the superscript ‘’ corresponding to randomly projections and country indexes (i), respectively. |
| 9 |
References
- Andrews, Donald W. K. 1991a. Asymptotic normality of series estimators for nonparametric and semiparametric regression models. Econometrica 59: 307–45. [Google Scholar] [CrossRef]
- Andrews, Donald W. K. 1991b. Heteroskedasticity and autocorrelation consistent covariance matrix estimation. Econometrica 59: 817–58. [Google Scholar] [CrossRef]
- Banbura, Marta, Domenico Giannone, and Lucrezia Reichlin. 2010. Large bayesian vector autoregressions. Journal of Applied Econometrics 25: 71–92. [Google Scholar] [CrossRef]
- Bernanke, Ben S., Jean Boivin, and Piotr Eliasz. 2005. Measuring monetary policy: A factor augmented vector autoregressive (favar) approach. The Quarterly Journal of Economics 120: 387–422. [Google Scholar]
- Canova, Fabio, and Fernando J. Pérez Forero. 2015. Estimating overidentified, nonrecursive, time-varying coefficients structural vector autoregressions. Quantitative Economics 6: 359–84. [Google Scholar] [CrossRef] [Green Version]
- Canova, Fabio, and Matteo Ciccarelli. 2009. Estimating multicountry var models. International Economic Review 50: 929–59. [Google Scholar] [CrossRef] [Green Version]
- Canova, Fabio, and Matteo Ciccarelli. 2016. Panel vector autoregressive models: A survey. Advances in Econometrics 32: 205–46. [Google Scholar]
- Carriero, Andrea, George Kapetanios, and Massimiliano Marcellino. 2009. Forecasting exchange rates with a large bayesian var. International Journal of Forecasting 25: 400–17. [Google Scholar] [CrossRef] [Green Version]
- Carriero, Andrea, Todd E. Clark, and Massimiliano Marcellino. 2015a. Bayesian vars: Specification choices and forecast accuracy. Journal of Applied Econometrics 30: 46–73. [Google Scholar] [CrossRef]
- Carriero, Andrea, Todd E. Clark, and Massimiliano Marcellino. 2015b. Large Vector Autoregressions with Asymmetric Priors and Time Varying Volatilities. Working Paper. Brisbane: School of Economics and Finance, vol. 759, pp. 1–34. Available online: http://hdl.handle.net/10419/130773 (accessed on 1 July 2022).
- Carriero, Andrea, Todd E. Clark, and Massimiliano Marcellino. 2016. Common drifting volatility in large bayesian vars. Journal of Business and Economic Statistics 34: 375–90. [Google Scholar] [CrossRef]
- Carriero, Andrea, Todd E. Clark, and Massimiliano Marcellino. 2019. Large bayesian vector autoregressions with stochastic volatility and non-conjugate priors. Journal of Econometrics 212: 137–54. [Google Scholar] [CrossRef]
- Christoffersen, Peter F., and Francis X. Diebold. 1998. Cointegration and long-horizon forecasting. Journal of Business and Economic Statistics 16: 450–58. [Google Scholar]
- Ciccarelli, Matteo, Eva Ortega, and Maria T. Valderrama. 2018. Commonalities and cross-country spillovers in macroeconomic-financial linkages. Journal of Macroeconomics 16: 231–75. [Google Scholar] [CrossRef]
- Clark, Todd E. 2011. Real-time density forecasts from bayesian vector autoregressions with stochastic volatility. Journal of Business and Economic Statistics 29: 327–41. [Google Scholar] [CrossRef]
- Clark, Todd E., and Francesco Ravazzolo. 2015. Macroeconomic forecasting performance under alternative specifications of time-varying volatility. Journal of Applied Econometrics 30: 551–75. [Google Scholar] [CrossRef]
- Cogley, Timothy, and Thomas J. Sargent. 2005. Drifts and volatilities: Monetary policy and outcomes in the post wwii u.s. Review of Economic Dynamics 8: 262–302. [Google Scholar] [CrossRef] [Green Version]
- Cogley, Timothy, Sergei Morozov, and Thomas J. Sargent. 2005. Bayesian fan charts for uk inflation: Forecasting and sources of uncertainty in an evolving monetary system. Journal of Economic Dynamics and Control 29: 1893–925. [Google Scholar] [CrossRef] [Green Version]
- Cuaresma, Jesús Crespo, Martin Feldkircher, and Florian Huber. 2016. Forecasting with global vector autoregressive models: A bayesian approach. Journal of Applied Econometrics 31: 1371–91. [Google Scholar] [CrossRef]
- Curcio, Domenico, Rosa Cocozza, and Antonio Pacifico. 2020. Do global markets imply common fear? Rivista Bancaria—Minerva Bancaria 2020: 1–24. [Google Scholar]
- D’Agostino, Antonello, Luca Gambetti, and Domenico Giannone. 2013. Macroeconomic forecasting and structural change. Journal of Applied Econometrics 28: 82–101. [Google Scholar] [CrossRef] [Green Version]
- Dées, Stéphane, Filippo Di Mauro, M. Hashem Pesaran, and L. Vanessa Smith. 2007. Exploring the international linkages of the euro area: A global var analysis. Journal of Applied Econometrics 22: 1–38. [Google Scholar] [CrossRef] [Green Version]
- Dovern, Jonas, Martin Feldkircher, and Florian Huber. 2016. Does joint modelling of the world economy pay off? evaluating global forecasts from a bayesian gvar. Journal of Economic Dynamics and Control 70: 86–100. [Google Scholar] [CrossRef] [Green Version]
- Feldkircher, Martin, and Florian Huber. 2016. The international transmission of us shocks—Evidence from bayesian global vector autoregressions. European Economic Review 81: 167–88. [Google Scholar] [CrossRef]
- Gelfand, Alan E., and Dipak K. Dey. 1994. Bayesian model choice: Asymptotics and exact calculations. Journal of the Royal Statistical Society: Series B 56: 501–14. [Google Scholar]
- George, Edward I., Dongchu Sun, and Shawn Ni. 2008. Bayesian stochastic search for var model restrictions. Journal of Econometrics 142: 553–80. [Google Scholar] [CrossRef] [Green Version]
- Giannone, Domenico, Michele Lenza, and Giorgio E. Primiceri. 2015. Prior selection for vector autoregressions. The Review of Economics and Statistics 97: 436–51. [Google Scholar] [CrossRef] [Green Version]
- Götz, Thomas, and Erik Haustein. 2018. Bayesian compression for mixed frequency vector autoregressions: A forecast study for germany. SSRN, 1–36. [Google Scholar] [CrossRef]
- Guhaniyogi, Rajarshi, and David B. Dunson. 2015. Bayesian compressed regression. Journal of the American Statistical Association 110: 1500–14. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 1992. Tests for parameter instability in regressions with i(1) processes. Journal of Business and Economic Statistics 10: 321–35. [Google Scholar]
- Huber, Florian. 2016. Density forecasting using bayesian global vector autoregressions with stochastic volatility. International Journal of Forecasting 32: 818–37. [Google Scholar] [CrossRef]
- Jacquier, Eric, Nicholas G. Polson, and Peter E. Rossi. 1994. Bayesian analysis of stochastic volatility. Journal of Business and Economic Statistics 12: 371–417. [Google Scholar]
- Kadiyala, Rao K., and Sune Karlsson. 1997. Numerical methods for estimation and inference in bayesian var models. Journal of Applied Econometrics 12: 99–132. [Google Scholar] [CrossRef]
- Koop, Gary. 2013. Forecasting with medium and large bayesian vars. Journal of Applied Econometrics 28: 177–203. [Google Scholar] [CrossRef] [Green Version]
- Koop, Gary, and Dimitris Korobilis. 2009. Bayesian multivariate time series methods for empirical macroeconomics. Foundations and Trends in Econometrics 3: 267–358. [Google Scholar] [CrossRef]
- Koop, Gary, and Dimitris Korobilis. 2013. Large time-varying parameter vars. Journal of Econometrics 177: 185–98. [Google Scholar] [CrossRef] [Green Version]
- Koop, Gary, and Dimitris Korobilis. 2016. Model uncertainty in panel vector autoregressive models. European Economic Review 81: 115–31. [Google Scholar] [CrossRef] [Green Version]
- Koop, Gary, Dimitris Korobilis, and Davide Pettenuzzo. 2019. Bayesian compressed vector autoregressions. Journal of Econometrics 210: 135–54. [Google Scholar] [CrossRef] [Green Version]
- Korobilis, Dimitris. 2016. Prior selection for panel vector autoregressions. Computational Statistics and Data Analysis 101: 110–20. [Google Scholar] [CrossRef] [Green Version]
- Madigan, David, and Adrian E. Raftery. 1994. Model selection and accounting for model uncertainty in graphical models using occam’s window. Journal of American Statistical Association 89: 1535–46. [Google Scholar] [CrossRef]
- Madigan, David, Jeremy York, and Denis Allard. 1995. Bayesian graphical models for discrete data. International Statistical Review 63: 215–32. [Google Scholar] [CrossRef] [Green Version]
- Mullainathan, Sendhil, and Jann Spiess. 2017. Machine learning: An applied econometric approach. Journal of Economic Perspectives 31: 87–106. [Google Scholar] [CrossRef] [Green Version]
- Pacifico, Antonio. 2019. Structural panel bayesian var model to deal with model misspecification and unobserved heterogeneity problems. Econometrics 7: 8. [Google Scholar] [CrossRef] [Green Version]
- Pacifico, Antonio. 2020a. Fiscal implications, misspecified dynamics, and international spillover effects across europe: A time-varying multicountry analysis. International Journal of Statistics and Economics 21: 18–40. [Google Scholar]
- Pacifico, Antonio. 2020b. Robust open bayesian analysis: Overfitting, model uncertainty, and endogeneity issues in multiple regression models. Econometric Reviews 40: 148–76. [Google Scholar] [CrossRef]
- Pacifico, Antonio. 2021. Structural panel bayesian var with multivariate time-varying volatility to jointly deal with structural changes, policy regime shifts, and endogeneity issues. Econometrics 9: 20. [Google Scholar] [CrossRef]
- Pesaran, M. Hashem, Til Schuermann, and Vanessa L. Smith. 2009. Forecasting economic and financial variables with global vars. International Journal of Forecasting 25: 642–75. [Google Scholar] [CrossRef] [Green Version]
- Pesaran, M. Hashem, Til Schuermann, and Scott M. Weiner. 2004. Modeling regional interdependencies using a global error-correcting macroeconometric model. Journal of Business and Economic Statistics 22: 129–62. [Google Scholar] [CrossRef]
- Primiceri, Giorgio E. 2005. Time varying structural vector autoregressions and monetary policy. Review of Economic Studies 72: 821–52. [Google Scholar] [CrossRef]
- Quintos, Carmela E., and Peter C. B. Phillips. 1993. Parameter constancy in cointegrating regressions. Empirical Economics 18: 675–706. [Google Scholar] [CrossRef]
- Raftery, Adrian E., David Madigan, and Chris T. Volinsky. 1995. Accounting for model uncertainty in survival analysis improves predictive performance. Bayesian Statistics 6: 323–49. [Google Scholar]
- Raftery, Adrian E., David Madigan, and Jennifer A. Hoeting. 1997. Bayesian model averaging for linear regression models. Journal of American Statistical Association 92: 179–91. [Google Scholar] [CrossRef]
- Sofer, Tamar, Lee Dicker, and Xihong Lin. 2014. Variable selection for high dimensional multivariate outcomes. Statistica Sinica 24: 1633–54. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taveeapiradeecharoen, Paponpat, and Nattapol Aunsri. 2020. A time-varying bayesian compressed vector autoregression for macroeconomic forecasting. IEEE Access 8: 192777–86. [Google Scholar]
- Taveeapiradeecharoen, Paponpat, Chamnongthai Kosin, and Nattapol Aunsri. 2019. Bayesian compressed vector autoregression for financial time-series analysis and forecasting. IEEE Access 7: 16777–86. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Idx. | Predictor | Label | Unit | PIP(%) | CPS |
|---|---|---|---|---|---|
| Economic Status | |||||
| 1 | per capita, PPP | dlgdp | logarithm (current US$) | 75.74 | |
| 2 | Employment in Industry | empin | total pop. (%) | ||
| 3 | Employment in Services | empse | total pop. (%) | 63.13 | |
| 4 | Final Consumption Expenditure | fexp | % GDP | ||
| 5 | Gen. Gov. Final Cons. Expenditure | fexp | % GDP | 37.72 | |
| 6 | GDP per capita Growth | gdpg | quarterly (%) | 82.31 | |
| 7 | Labour Force | labtot | logarithm (total) | 43.62 | |
| 8 | Total Debt Service | totdeb | export goods & services (%) | ||
| 9 | Trade in Services | tradess | % GDP | ||
| Socioeconomic–demographic Statistics | |||||
| 10 | Dom. Gen. Gov. Health Expenditure | gghe | % GDP | 43.31 | |
| 11 | Population Growth | popg | quarterly (%) | 36.02 | |
| 12 | Fertility Rate | frate | births (total) | ||
| 13 | Gov. Expenditure on Education | exedu | % GDP | 37.17 | |
| 14 | High-technology Exports | hitech | manuf. exports (%) | ||
| 15 | Urban Population Growth | urbag | quarterly (%) | 30.94 | |
| 16 | Households Final Cons. Expenditure | hfexp | % GDP | 23.74 | |
| 17 | Wage and Salaried Workers | wage | total employment (%) | 73.28 | |
| Macroeconomic–Financial Indicators | |||||
| 18 | Exports of Goods and Services | exp | % GDP | ||
| 19 | Imports of Goods and Services | imp | % GDP | ||
| 20 | External debt stocks | exdeb | logarithm (current US$) | ||
| 21 | Inflation Rate | inf | quarterly (%) | 44.16 | |
| 22 | Bank Capital | bcap | asset ratio (%) | ||
| 23 | Bank Liquid Reserves | blres | asset ratio (%) | ||
| 24 | Foreign Direct Investment | fdi | % GDP | 45.61 | |
| 25 | GNI Growth | gni | quarterly (%) | 67.31 | |
| 26 | Gross Fixed Capital Formation | gfcf | % GDP | 57.62 | |
| 27 | Net Financial Flows, Bilateral | bfin | logarithm (current US$) | ||
| 28 | Net Financial Flows, Multilateral | mfin | logarithm (current US$) | ||
| 29 | Trade | trade | % GDP | 38.13 | |
| 30 | Unemployment Change | unem | total labour force (%) | 73.64 | |
| 31 | Gross Savings | gsav | % GDP | 23.51 | |
| 32 | Net Financial Account | bop | logarithm (current US$) | 28.13 | |
| 33 | Net Foreign Assets | netfa | logarithm (current US$) | ||
| 34 | Credit Growth | credit | % GDP | 54.41 | |
| - | GDP per capita, PPP | lgdp | logarithm (current US$) | - | - |
| Forecast | FAVAR | SPBVAR-MTV | BCVAR | ||
|---|---|---|---|---|---|
| 1.053 | 1.046 | 0.931 ** | 0.932 ** | 0.904 *** | |
| 1.037 | 1.021 | 0.939 * | 0.929 ** | 0.898 *** | |
| 1.028 | 1.019 | 0.957 | 0.965 | 0.913 ** | |
| 1.025 | 1.013 | 0.974 | 0.981 | 0.927 ** | |
| 1.010 | 1.004 | 0.981 | 0.998 | 0.908 *** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pacifico, A. Structural Compressed Panel VAR with Stochastic Volatility: A Robust Bayesian Model Averaging Procedure. Econometrics 2022, 10, 28. https://doi.org/10.3390/econometrics10030028
Pacifico A. Structural Compressed Panel VAR with Stochastic Volatility: A Robust Bayesian Model Averaging Procedure. Econometrics. 2022; 10(3):28. https://doi.org/10.3390/econometrics10030028
Chicago/Turabian StylePacifico, Antonio. 2022. "Structural Compressed Panel VAR with Stochastic Volatility: A Robust Bayesian Model Averaging Procedure" Econometrics 10, no. 3: 28. https://doi.org/10.3390/econometrics10030028
APA StylePacifico, A. (2022). Structural Compressed Panel VAR with Stochastic Volatility: A Robust Bayesian Model Averaging Procedure. Econometrics, 10(3), 28. https://doi.org/10.3390/econometrics10030028