Confidence Distributions for FIC Scores


Abstract
:1. Introduction and Summary
2. Basic Setup and the FIC
2.1. The I.I.D. Setup
2.2. Extension to Regression Models
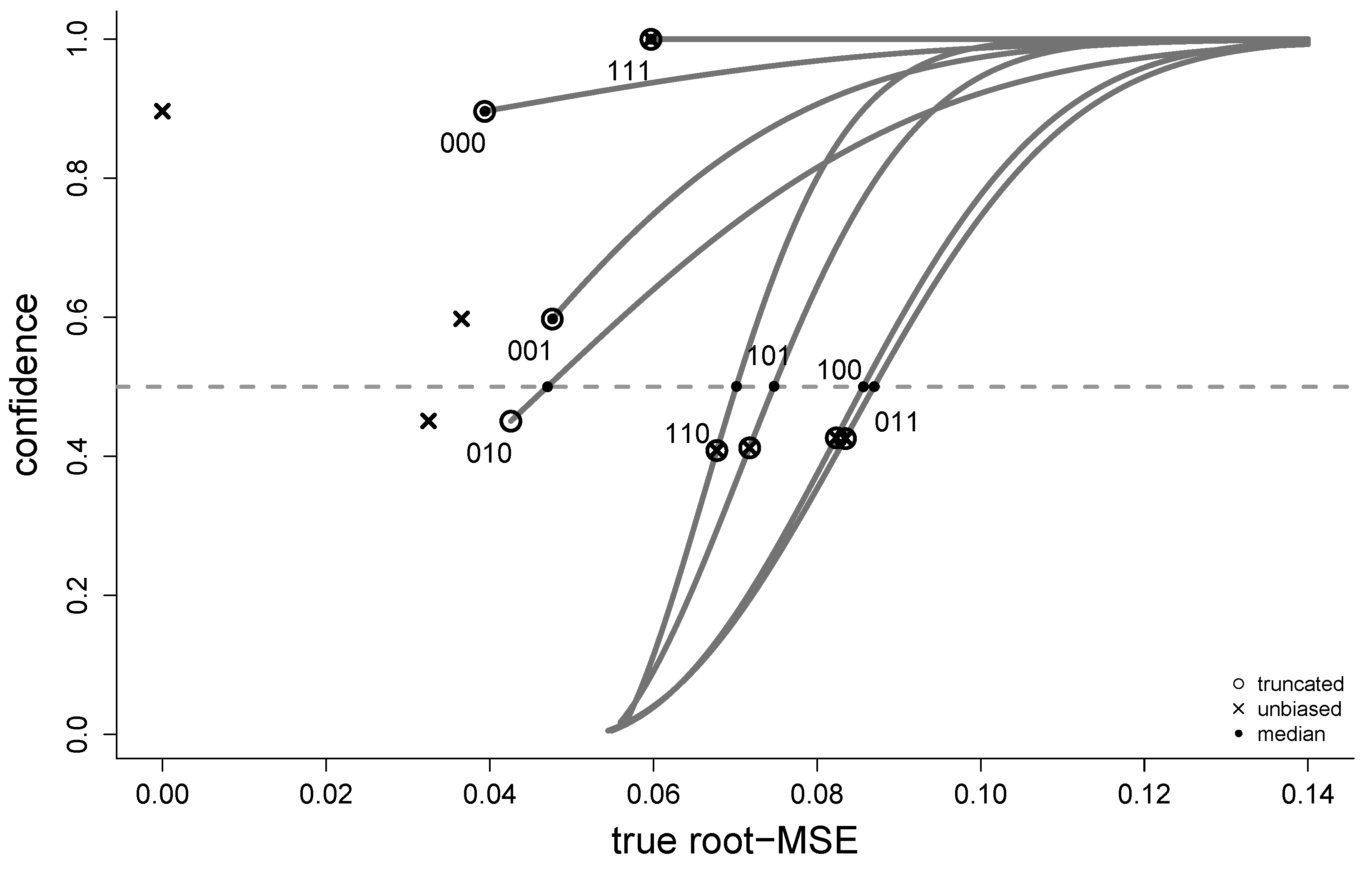
3. Confidence Distributions for FIC Scores
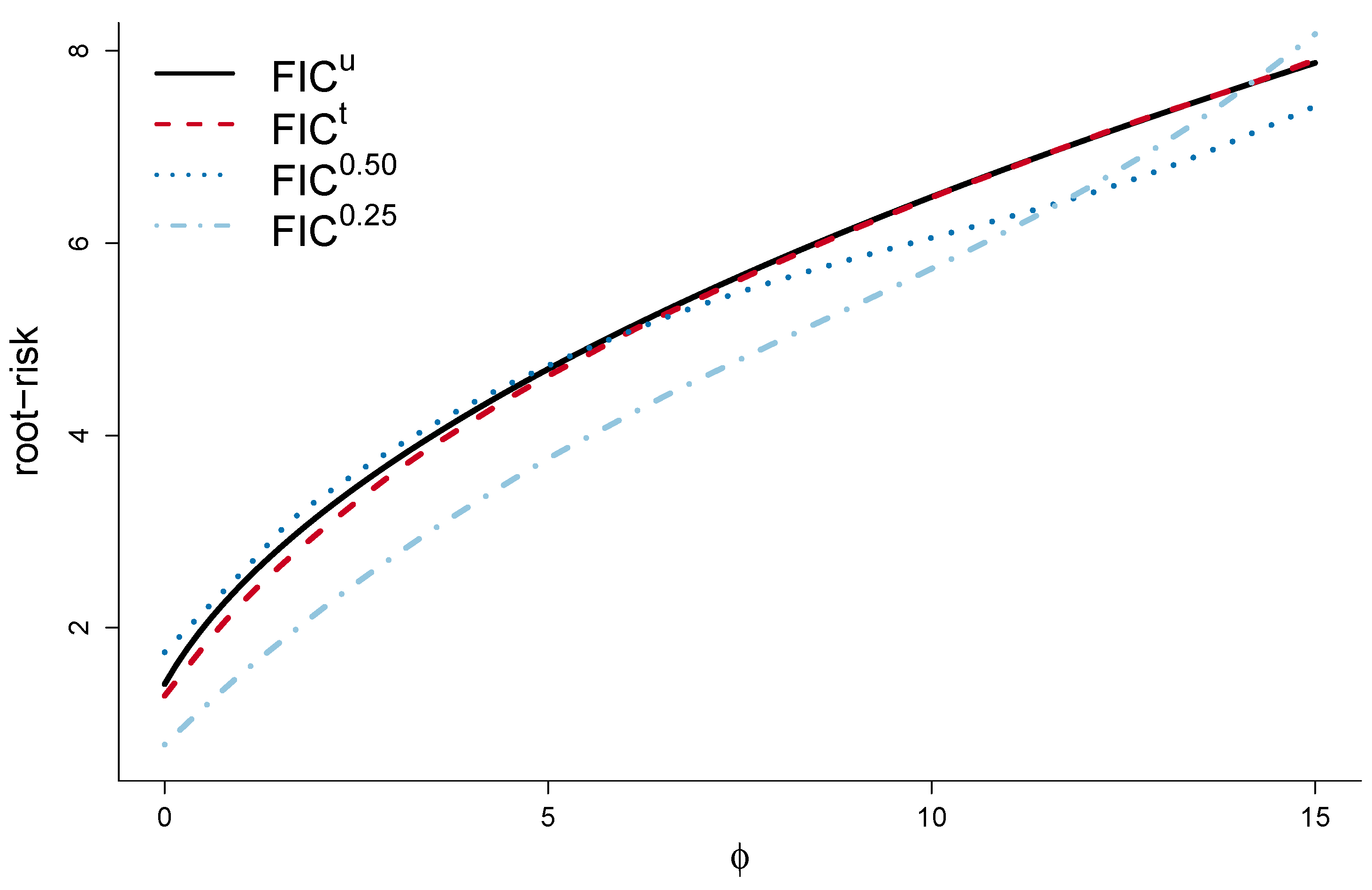
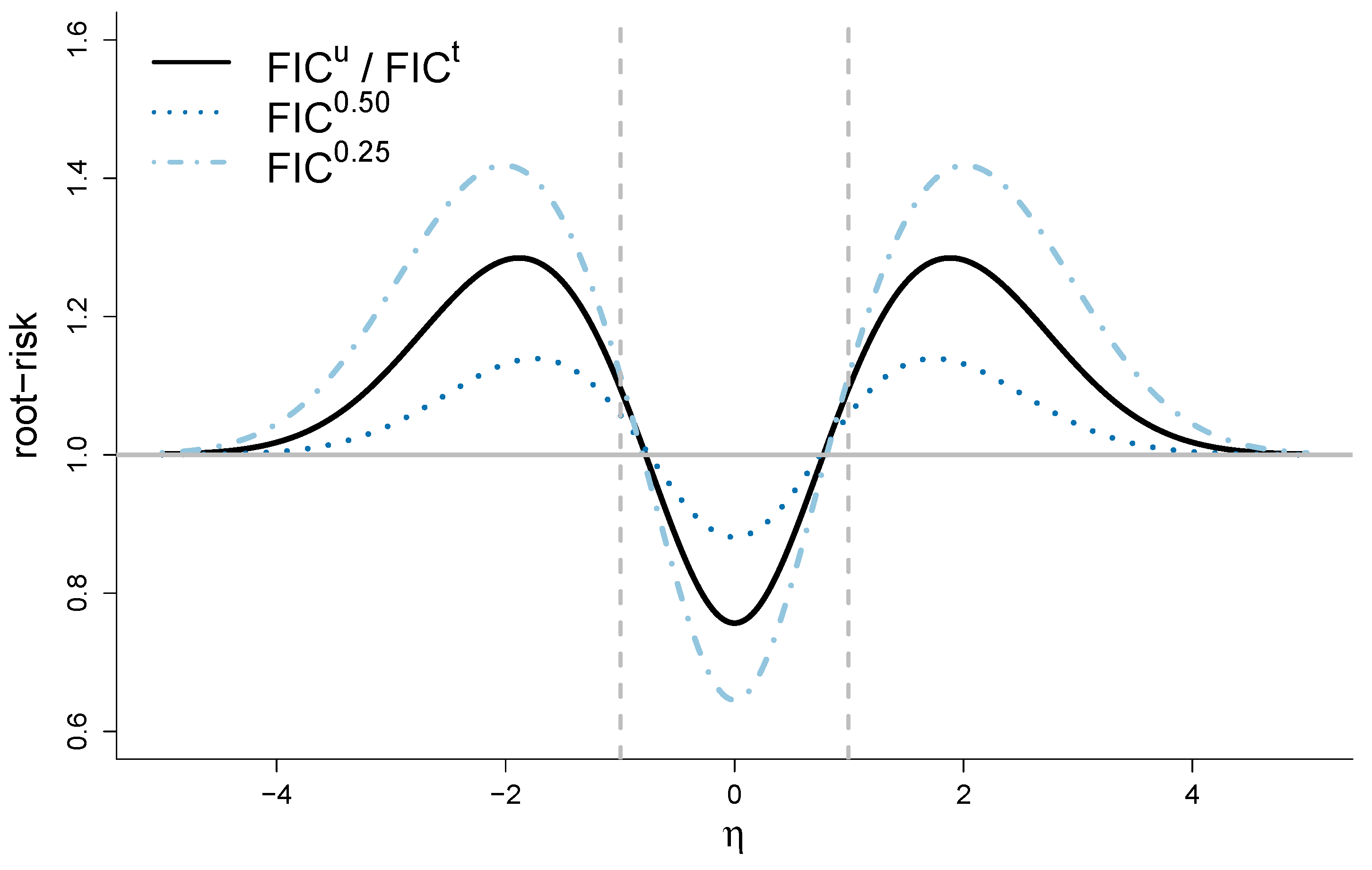
4. Median-FIC and Quantile-FIC
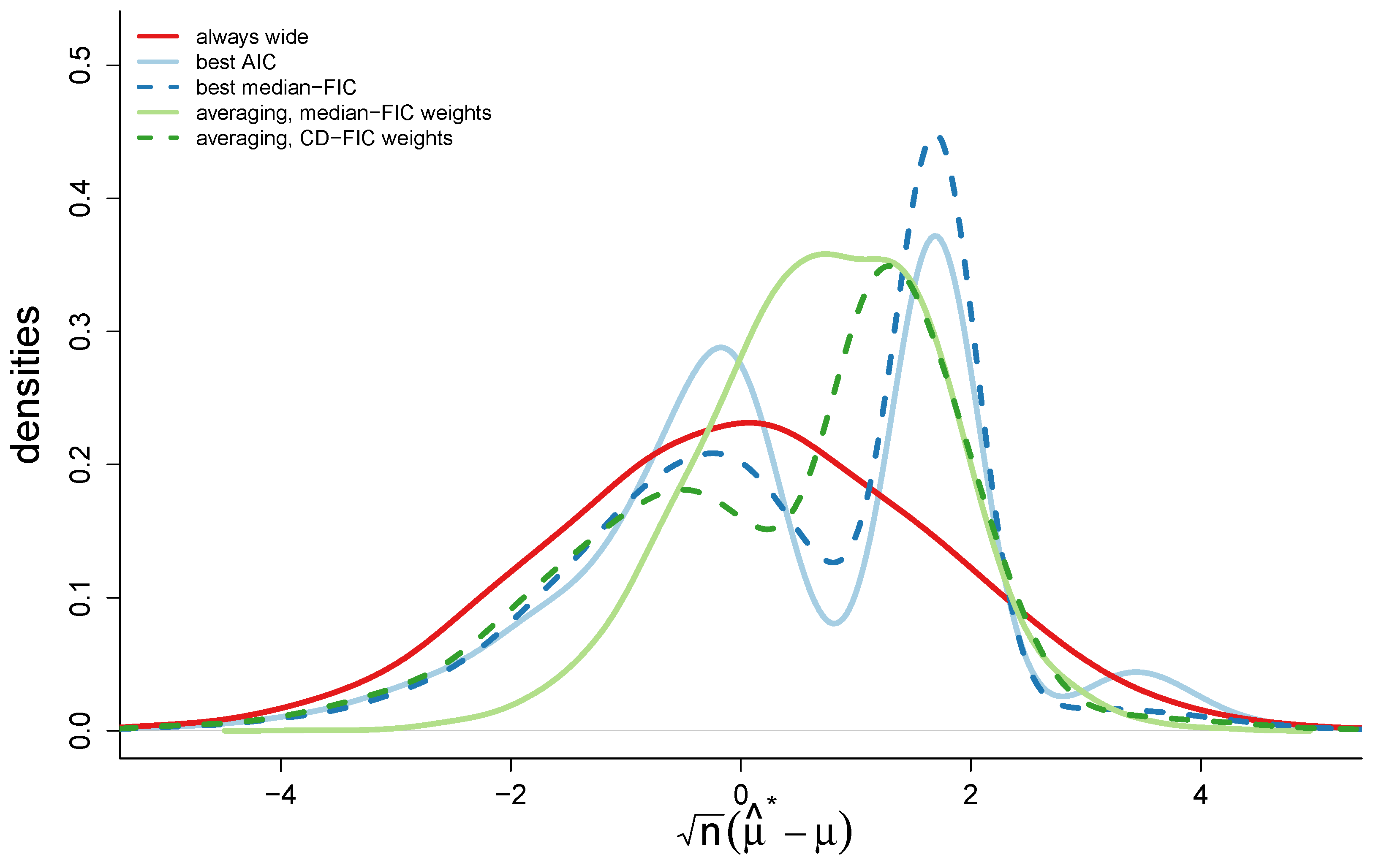
5. Model Averaging
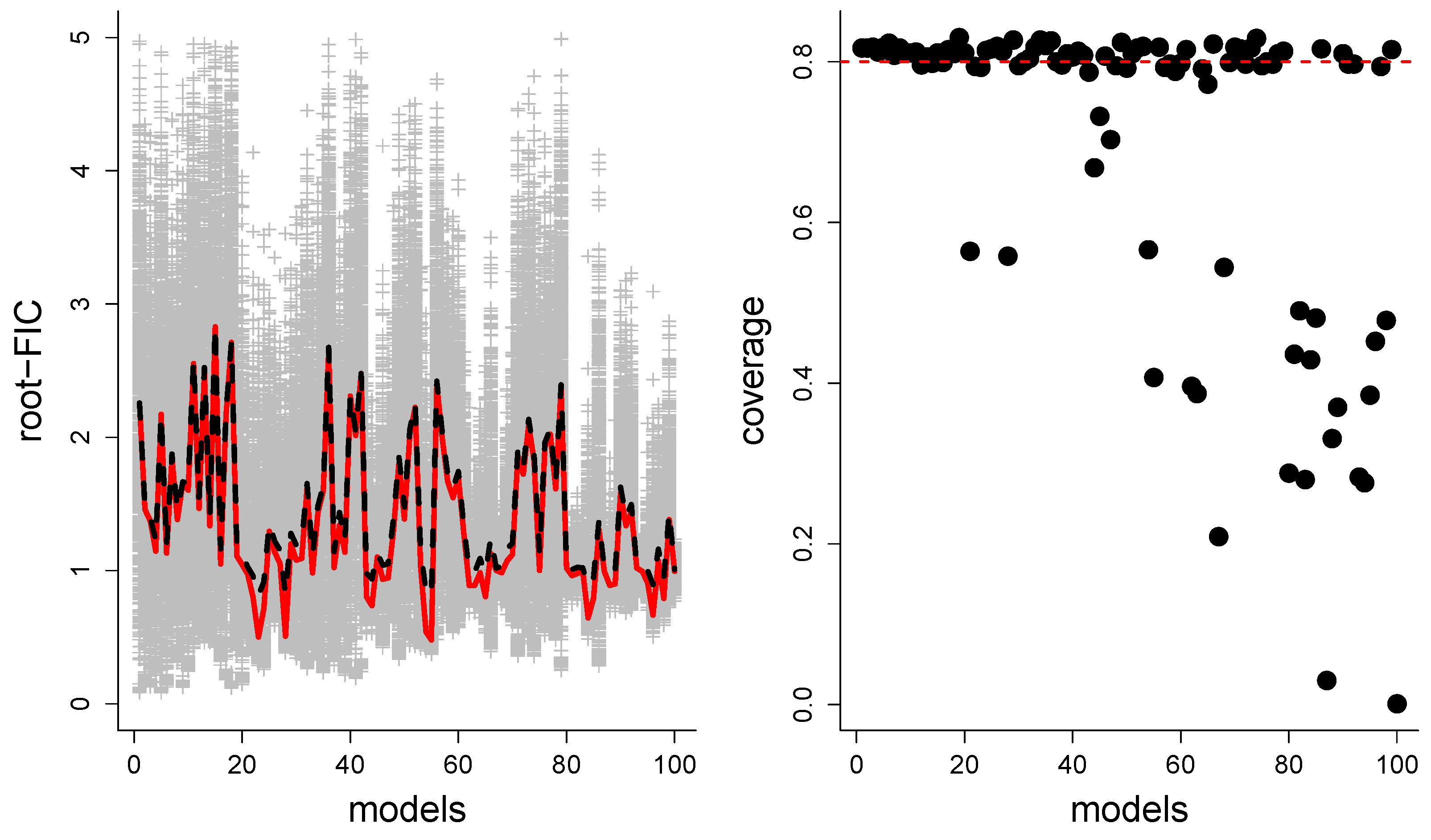
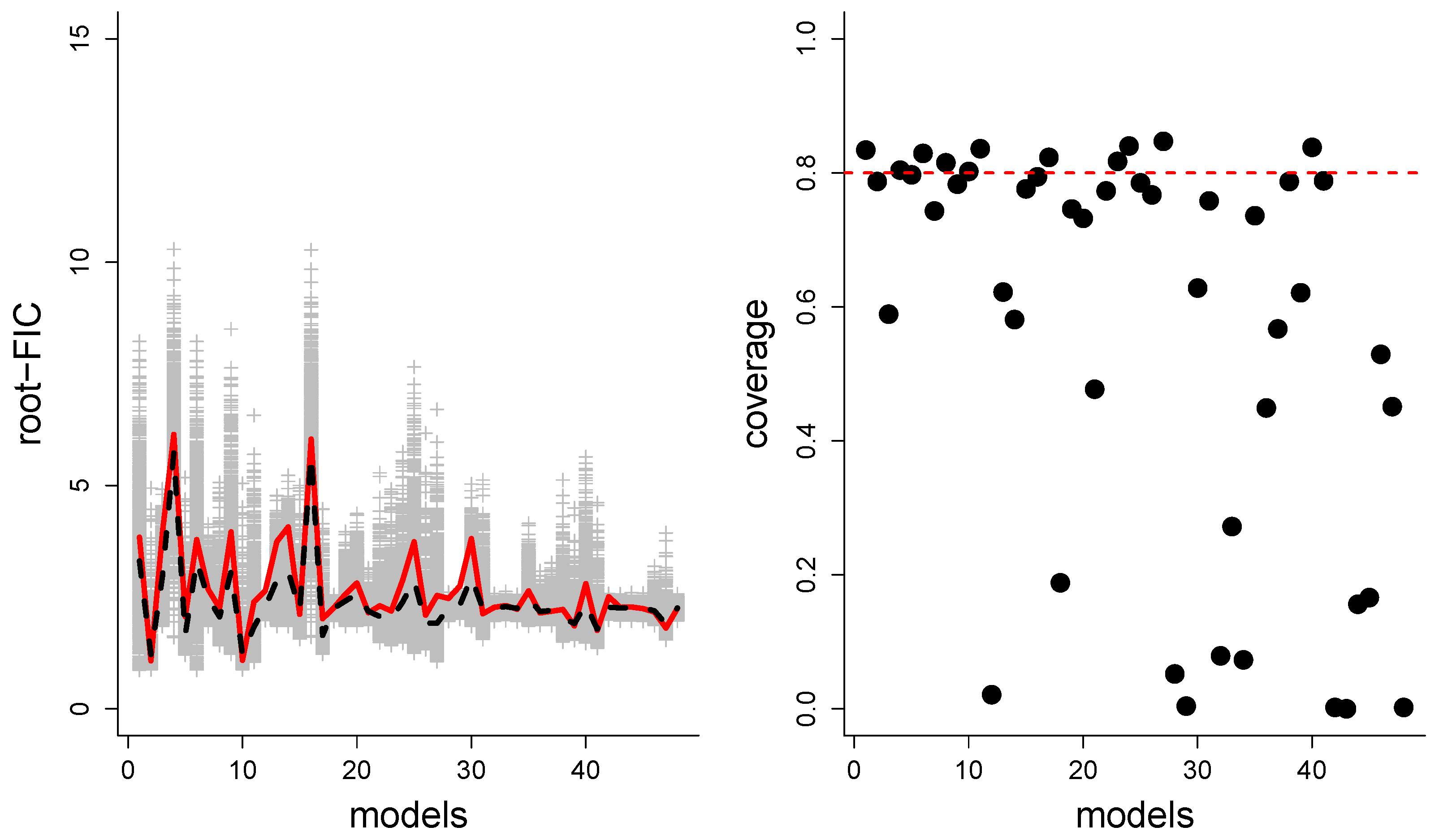
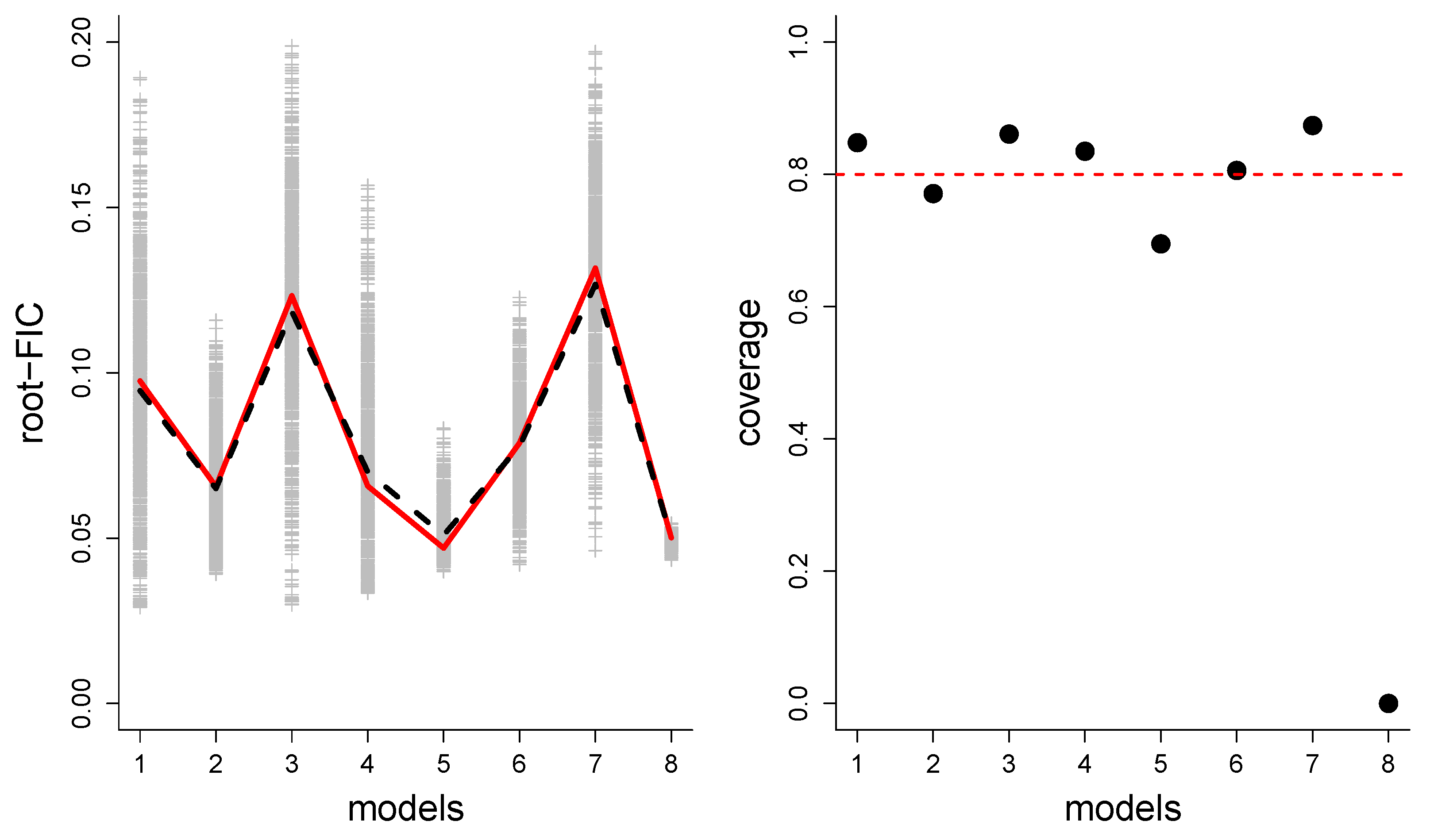
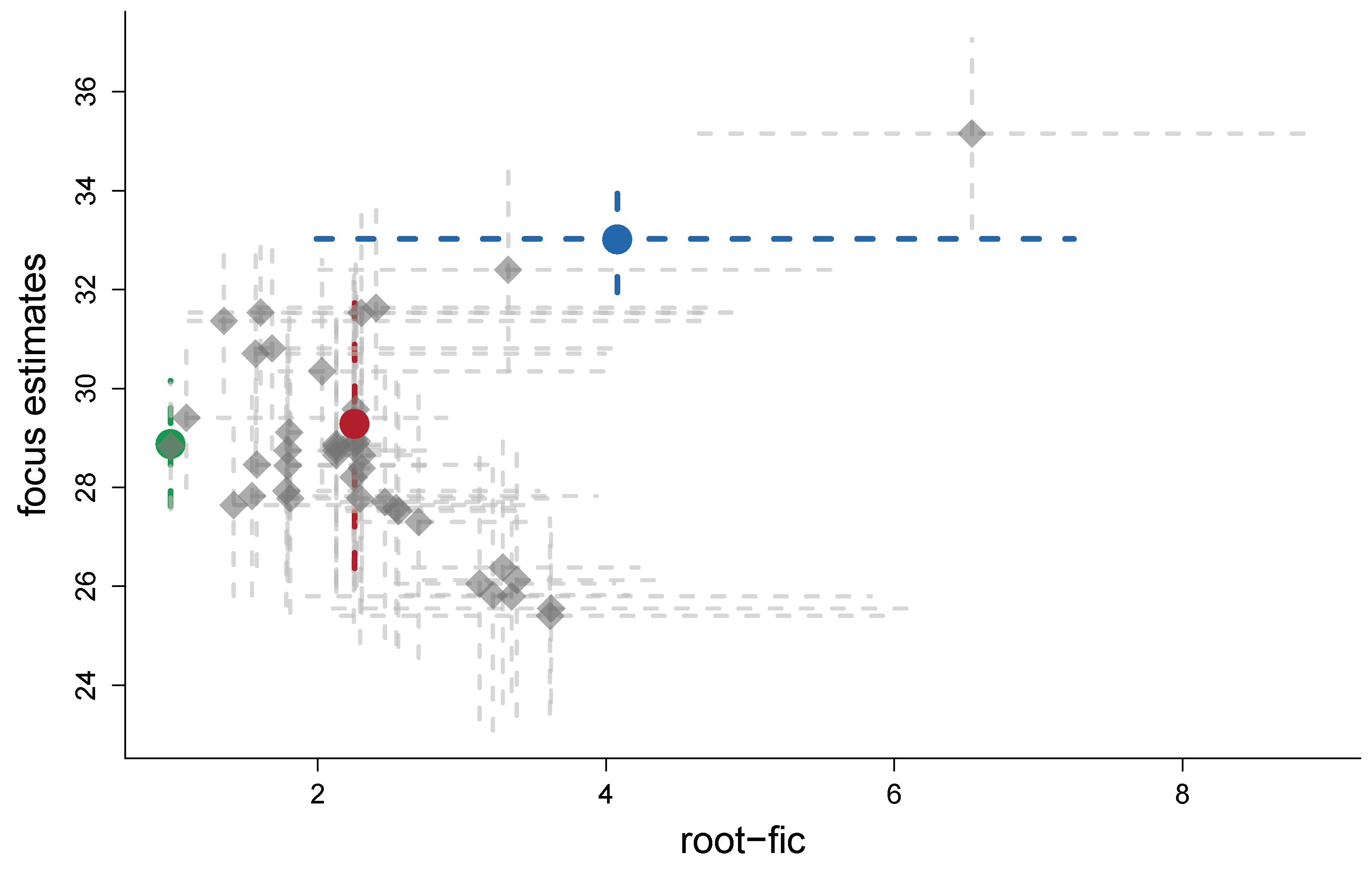
6. Performance Aspects for the Different Versions of FIC
- (a)
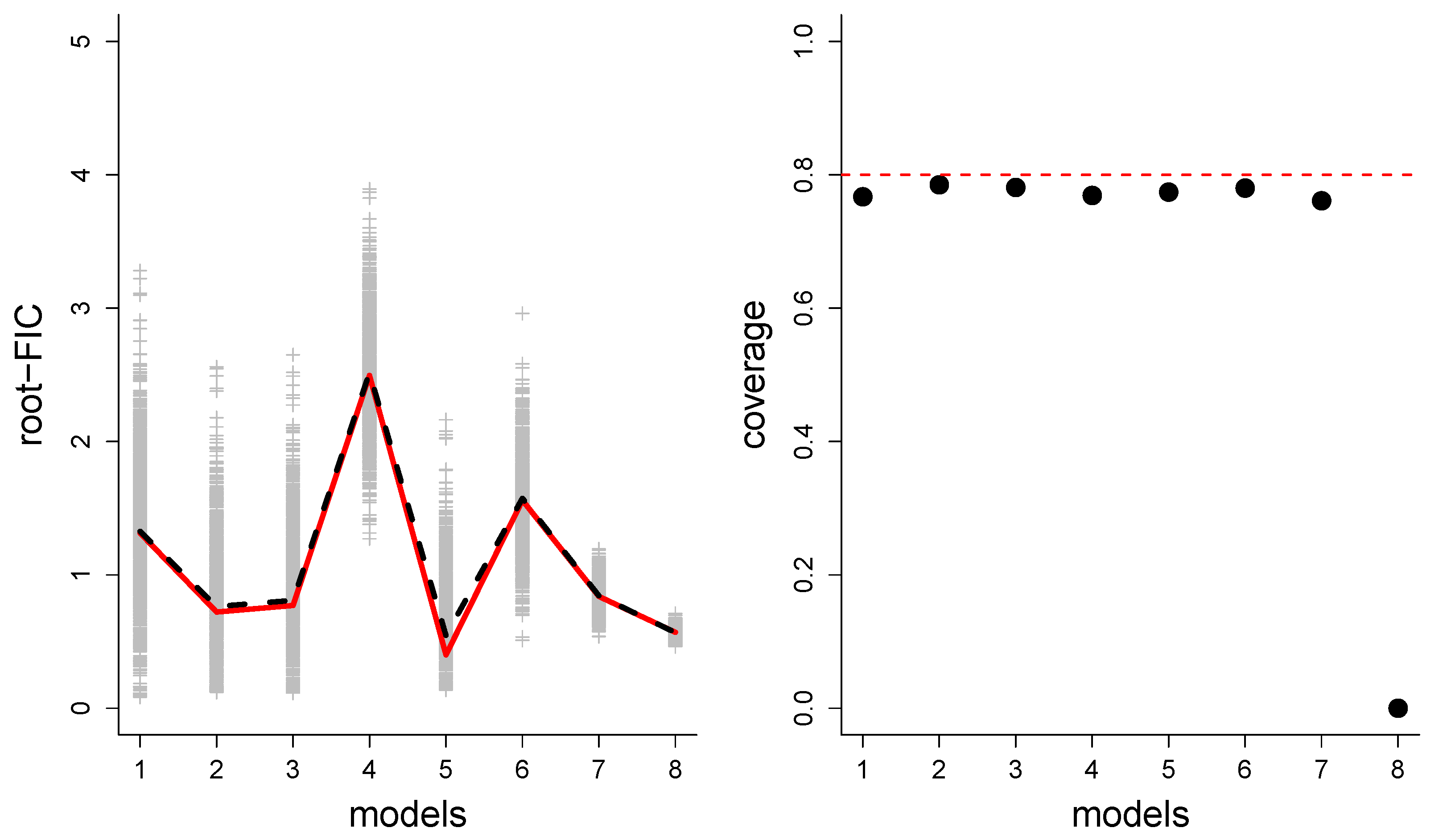
- How good is the root-FIC score, as an estimator of the rmse?
- (b)
- How well-working is the implied FIC scheme for finding the underlying best model, e.g., as a function of increasing sample size?
- (c)
- (d)
- How well-working are the (approximate) CDs regarding coverage properties; do confidence intervals of the type contain the true 80% of the time?
6.1. FIC for Estimating MSE
6.2. Narrow vs. Wide
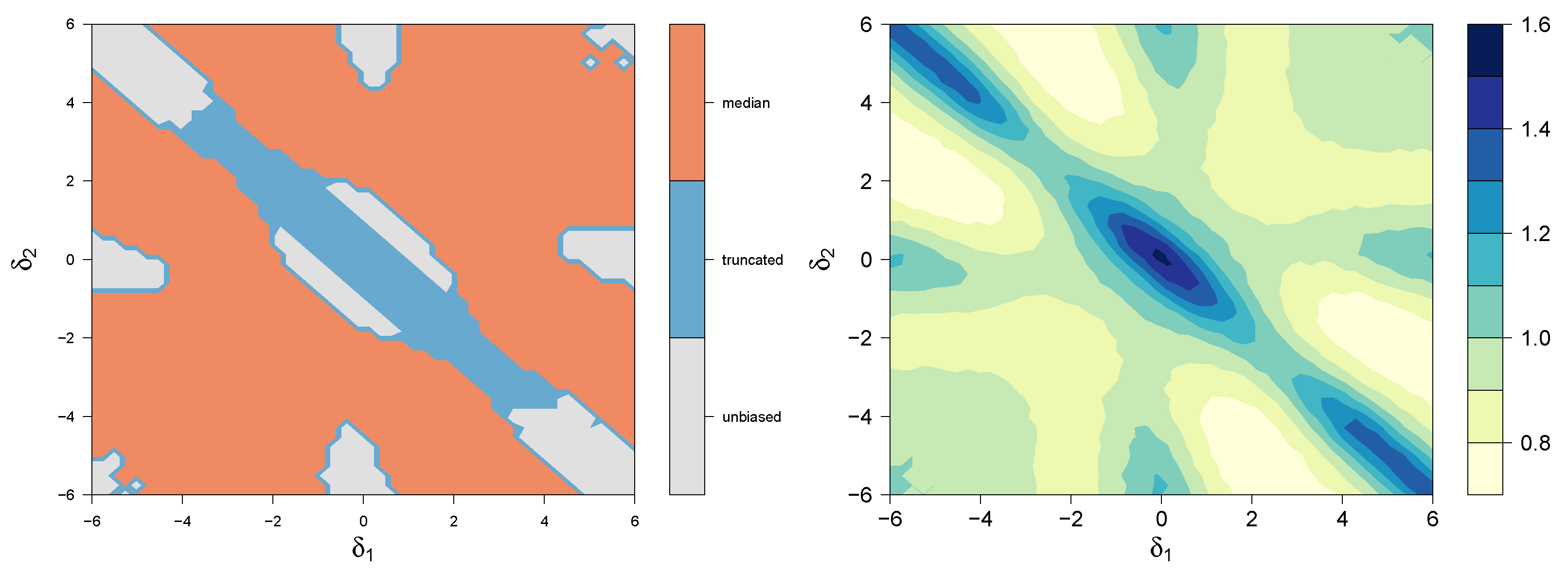
6.3. Three FIC Schemes with Q = 2
7. Finite-Sample Performance Evaluations
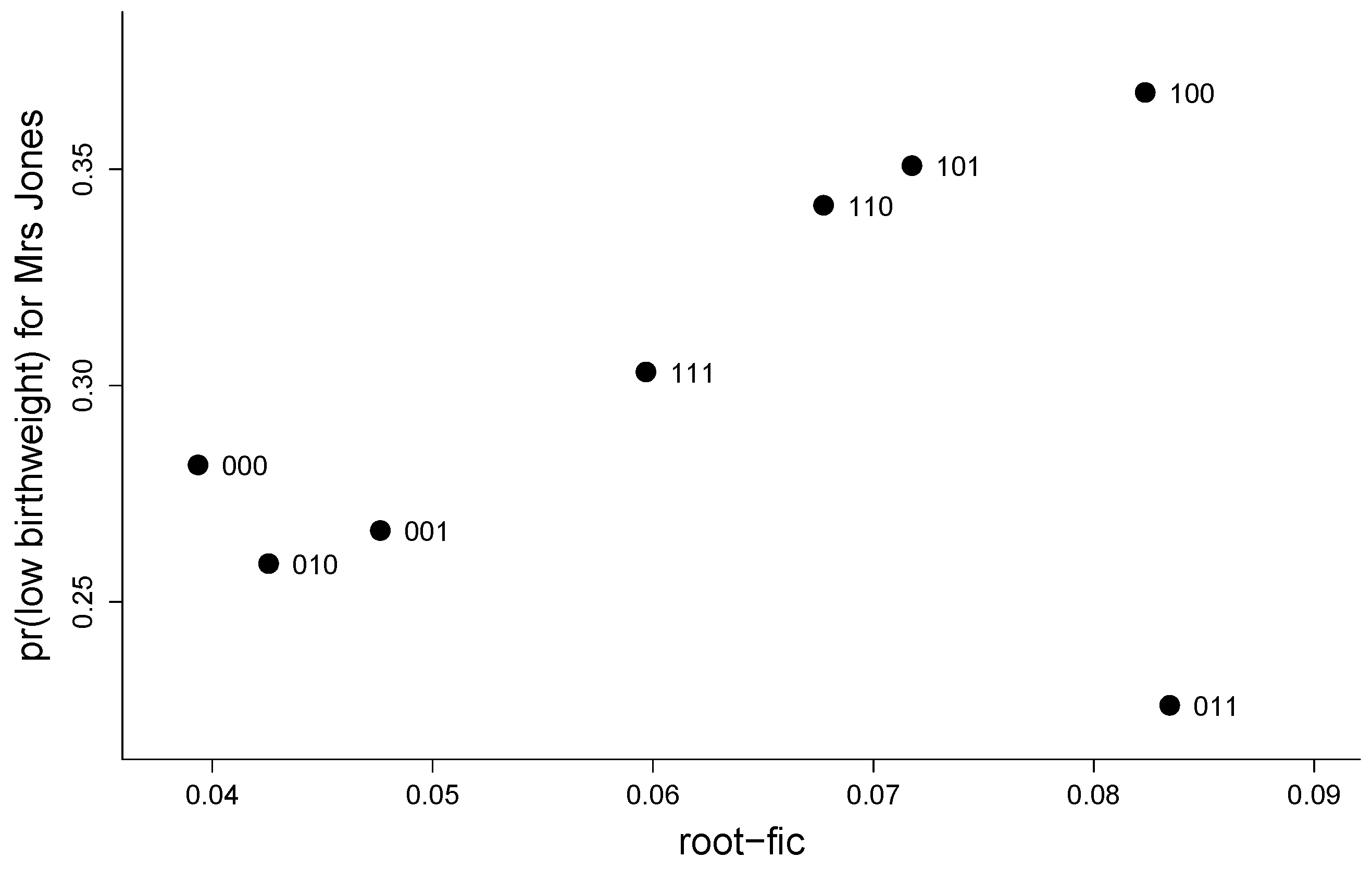
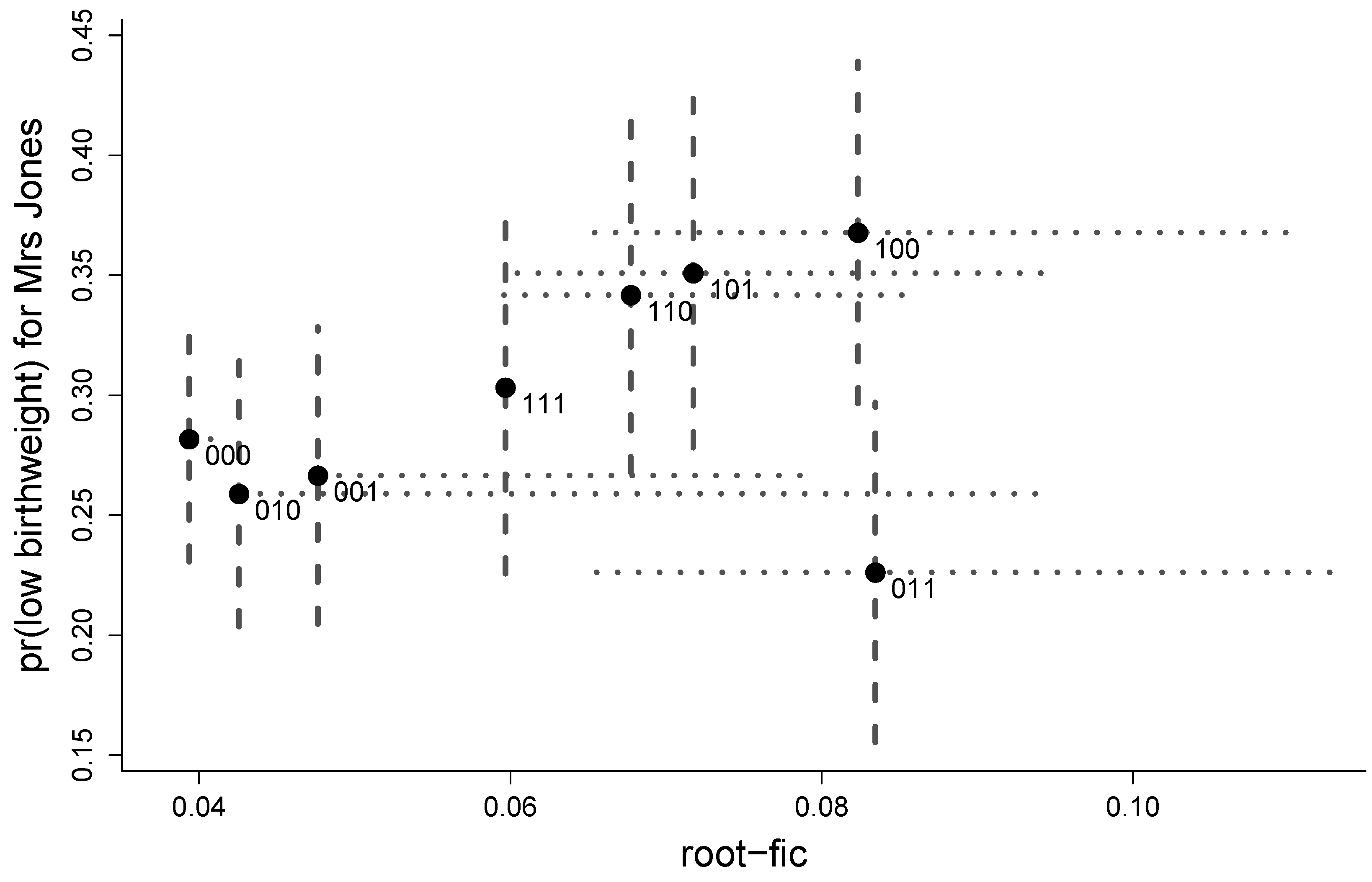
8. Illustration: Birds on 73 British and Irish Islands
9. Discussion
10. Concluding Remarks
11. FIC and CD–FIC Formulae for General Regression Models
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Behl, Peter, Holger Dette, Manuel Frondel, and Harald Tauchmann. 2012. Choice is suffering: A focused information criterion for model selection. Economic Modelling 29: 817–22. [Google Scholar] [CrossRef] [Green Version]
- Brownlees, Christian, and Giampiero Gallo. 2008. On variable selection for volatility forecasting: The role of focused selection criteria. Journal of Financial Econometrics 6: 513–39. [Google Scholar] [CrossRef]
- Chan, Felix, Laurent Pauwels, and Sylvia Soltyk. 2020. Frequentist averaging. In Macroeconomic Forecasting in the Era of Big Data. Berlin: Springer Verlag, pp. 329–57. [Google Scholar]
- Claeskens, Gerda, Christophe Croux, and Johan Van Kerckhoven. 2007. Prediction focused model selection for autoregressive models. The Australian and New Zealand Journal of Statistics 49: 359–79. [Google Scholar] [CrossRef]
- Claeskens, Gerda, Céline Cunen, and Nils Lid Hjort. 2019. Model selection via Focused Information Criteria for complex data in ecology and evolution. Frontiers in Ecology and Evolution 7: 415–28. [Google Scholar] [CrossRef] [Green Version]
- Claeskens, Gerda, and Nils Lid Hjort. 2003. The focused information criterion [with discussion and a rejoinder]. Journal of the American Statistical Association 98: 900–16. [Google Scholar] [CrossRef]
- Claeskens, Gerda, and Nils Lid Hjort. 2008. Model Selection and Model Averaging. Cambridge: Cambridge University Press. [Google Scholar]
- Cunen, Céline, Nils Lid Hjort, and Håvard Mokleiv Nygård. 2020. Statistical sightings of better angels. Journal of Peace Research 57: 221–34. [Google Scholar] [CrossRef] [Green Version]
- Cunen, Céline, Lars Walløe, and Nils Lid Hjort. 2020. Focused model selection for linear mixed models, with an application to whale ecology. Annals of Applied Statistics. forthcoming. [Google Scholar] [CrossRef]
- Efron, Bradley. 2014. Estimation and accuracy after model selection [with discussion contributions and a rejoinder]. Journal of the American Statistical Association 110: 991–1007. [Google Scholar] [CrossRef] [Green Version]
- Fletcher, David, Peter W. Dillingham, and Jiaxu Zeng. 2019. Model-averaged confidence distributions. Environmental and Ecological Statistics 46: 367–84. [Google Scholar] [CrossRef]
- Gueuning, Thomas, and Gerda Claeskens. 2018. A high-dimensional focused information criterion. Scandinavian Journal of Statistics 45: 34–61. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 2007. Least squares model averaging. Econometrica 75: 1175–89. [Google Scholar] [CrossRef] [Green Version]
- Hermansen, Gudmund Horn, Nils Lid Hjort, and Olav S. Kjesbu. 2016. Recent advances in statistical methodology applied to the Hjort liver index time series (1859-2012) and associated influential factors. Canadian Journal of Fisheries and Aquatic Sciences 73: 279–95. [Google Scholar] [CrossRef] [Green Version]
- Hjort, Nils Lid. 2008. Focused information criteria for the linear hazard regression model. In Statistical Models and Methods for Biomedical and Technical Systems. Edited by F. Vonta, M. Nikulin, N. Limnios and C. Huber-Carol. Boston: Birkhäuser, pp. 487–502. [Google Scholar]
- Hjort, Nils Lid. 2014. Discussion of Efron’s ‘Estimation and accuracy after model selection’. Journal of the American Statistical Association 110: 1017–20. [Google Scholar] [CrossRef]
- Hjort, Nils Lid. 2020. The Focused Relative Risk Information Criterion for Variable Selection in Linear Regression. Technical Report. Oslo: Department of Mathematics, University of Oslo. [Google Scholar]
- Hjort, Nils Lid, and Gerda Claeskens. 2003a. Frequentist model average estimators [with discussion and a rejoinder]. Journal of the American Statistical Association 98: 879–99. [Google Scholar] [CrossRef] [Green Version]
- Hjort, Nils Lid, and Gerda Claeskens. 2003b. Rejoinder to the discussion of ‘frequentist model average estimators’ and ‘the focused information criterion’. Journal of the American Statistical Association 98: 938–45. [Google Scholar] [CrossRef]
- Hjort, Nils Lid, and Gerda Claeskens. 2006. Focused information criteria and model averaging for the Cox hazard regression model. Journal of the American Statistical Association 101: 1449–64. [Google Scholar] [CrossRef]
- Hjort, Nils Lid, and Tore Schweder. 2018. Confidence distributions and related themes: Introduction to the special issue. Journal of Statistical Planning and Inference 195: 1–13. [Google Scholar] [CrossRef]
- Hoeting, Jennifer A., David Madigan, Adrian E. Raftery, and Chris T. Volinsky. 1999. Bayesian model averaging: A tutorial. Statistical Science 14: 382–401. [Google Scholar]
- Jackson, Christopher, and Gerda Claeskens. 2019. fic: Focused Information Criteria for Model Comparison, R package version 1.0.0; Available online: rdrr.io/cran/fic/ (accessed on 29 November 2019).
- Jullum, Martin, and Nils Lid Hjort. 2017. Parametric of nonparametric: The FIC approach. Statitica Sinica 27: 951–81. [Google Scholar] [CrossRef] [Green Version]
- Jullum, Martin, and Nils Lid Hjort. 2019. What price semiparametric Cox regression? Lifetime Data Analysis 25: 406–38. [Google Scholar] [CrossRef] [Green Version]
- Kabaila, Paul, Alan H. Welsh, and Christeen Wijethunga. 2019. Finite sample properties of confidence intervals centered on a model averaged estimator. Journal of Statistical Planning and Inference 207: 10–26. [Google Scholar] [CrossRef] [Green Version]
- Ko, Vinnie, Nils Lid Hjort, and Ingrid Hobæk Haff. 2019. Focused information criteria for copulae. Scandinavian Journal of Statistics 46: 1117–40. [Google Scholar] [CrossRef]
- Liang, Hua, Guohua Zou, Alan T. K. Wan, and Xinyu Zhang. 2011. Optimal weight choice for frequentist model average estimators. Journal of the American Statistical Association 106: 1053–66. [Google Scholar] [CrossRef]
- Magnus, Jan R., Owen Powell, and Patricia Prüfer. 2009. A comparison of two model averaging techniques with an application to growth empirics. Journal of Econometrics 154: 139–53. [Google Scholar] [CrossRef] [Green Version]
- Reed, Timothy. 1981. The number of breeding landbird species on British islands. The Journal of Animal Ecology 50: 613–24. [Google Scholar] [CrossRef]
- Schweder, Tore, and Nils Lid Hjort. 2016. Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions. Cambridge: Cambridge University Press. [Google Scholar]
- Wang, Haiying, Xinyu Zhang, and Guohua Zou. 2009. Frequentist model averaging estimation: A review. Journal of Systems Science and Complexity 22: 732–48. [Google Scholar] [CrossRef]
- Zhang, Xinyu, and Hua Liang. 2011. Focused information criterion and model averaging for generalized additive partial linear models. Annals of Statistics 39: 174–200. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Xinyu, Alan T. K. Wan, and Sherry Z. Zhou. 2012. Focused information criteria, model selection, and model averaging in a tobit model with a nonzero threshold. Journal of Business & Economic Statistics 30: 131–42. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| in-or-out | Stdev | Bias | Root-FIC | Rank | ||
|---|---|---|---|---|---|---|
| 1 | 0 0 0 | 0.282 | 0.039 | 0.000 | 0.039 | 1 |
| 2 | 1 0 0 | 0.368 | 0.055 | 0.061 | 0.082 | 7 |
| 3 | 0 1 0 | 0.259 | 0.042 | 0.000 | 0.042 | 2 |
| 4 | 0 0 1 | 0.267 | 0.048 | 0.000 | 0.048 | 3 |
| 5 | 1 1 0 | 0.342 | 0.057 | 0.037 | 0.068 | 5 |
| 6 | 1 0 1 | 0.351 | 0.056 | 0.045 | 0.072 | 6 |
| 7 | 0 1 1 | 0.226 | 0.054 | 0.063 | 0.083 | 8 |
| 8 | 1 1 1 | 0.303 | 0.060 | 0.000 | 0.060 | 4 |
| (1) winning % | 5.5 | 6.1 | 18.1 | 0 | 32.0 | 0 | 0 | 38.3 |
| (4) winning % | 6.1 | 10.3 | 0.1 | 20.8 | 41.3 | 0.5 | 0 | 20.9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cunen, C.; Hjort, N.L. Confidence Distributions for FIC Scores. Econometrics 2020, 8, 27. https://doi.org/10.3390/econometrics8030027
Cunen C, Hjort NL. Confidence Distributions for FIC Scores. Econometrics. 2020; 8(3):27. https://doi.org/10.3390/econometrics8030027
Chicago/Turabian StyleCunen, Céline, and Nils Lid Hjort. 2020. "Confidence Distributions for FIC Scores" Econometrics 8, no. 3: 27. https://doi.org/10.3390/econometrics8030027
APA StyleCunen, C., & Hjort, N. L. (2020). Confidence Distributions for FIC Scores. Econometrics, 8(3), 27. https://doi.org/10.3390/econometrics8030027